Supervised Hierarchical Pitman-Yor Process for Natural Scene Segmentation
|
|
|
- Silas McLaughlin
- 6 years ago
- Views:
Transcription
1 Supervised Hierarchical Pitman-Yor Process for Natural Scene Segmentation Alex Shyr UC Berkeley Trevor Darrell ICSI, UC Berkeley Michael Jordan UC Berkeley Raquel Urtasun TTI Chicago Abstract From conventional wisdom and empirical studies of annotated data, it has been shown that visual statistics such as object frequencies and segment sizes follow power law distributions. Using these two as prior distributions, the hierarchical Pitman-Yor process has been proposed for the scene segmentation task. In this paper, we add label information into the previously unsupervised model. Our approach exploits the labelled data by adding constraints on the parameter space during the variational learning phase. We evaluate our formulation on the LabelMe natural scene dataset, and show the effectiveness of our approach.. Introduction The problem of image segmentation and grouping remains one of the important challenges in computer vision, as segmenting a scene into semantic categories is one of the key steps towards scene understanding. As evidenced by the PASCAL VOC challenge [7], segmentation is still an unsolved problem - the accuracy of existing approaches is still insufficient for integration into real-world applications, e.g., robotics. In the past few years, approaches based on Markov random fields (MRF) have been popular for segmentation [3] [] [5]. In these approaches, the image is modelled as an undirected graphical model, with nodes being pixels and/or superpixels. Node potentials are defined in terms of the local evidence, and edge potentials are defined to encourage smoothness in the segmentation. The resulting inference problem is either solved by graph-cuts [4] or messagepassing algorithms [9]. While very effective for certain tasks, these probabilistic models do not reflect the underlying statistics of natural images. Recent studies show that a wide range of natural image statistics are distributed according to heavy-tailed distributions. This problem has been noticed not only for segmentation, but also for optical flow (denoising) [25], intrinsic images [33] and layer extraction []. Moreover, long range dependencies are difficult to capture with MRFs. The gpb method of [7] computes long-range interactions by building an affinity matrix from local cues via the Pb response[8] and computing gradients of the corresponding eigenvectors. These gradients are then combined with local feature gradients to obtain the final gpb function. [2] applies the oriented watershed transform (OWT) of the gpb response to form regions, and subsequently construct the ultrametric contour map (UCM), defining a hierarchical segmentation. We adopt the gpb function as a basic boundary model, and we demonstrate in our experiments that a probabilistic model with a prior which succinctly describes segment statistics achieves better performance than the OWT-UCM model. Sudderth and Jordan [3] proposed an unsupervised probabilistic model for segmentation that is based on the Hierarchical Pitman-Yor process (), which is a nonparametric Bayesian prior over infinite partitions. The process is a generalization of the hierarchical Dirichlet processes (HDP), with heavier-tailed power law prior distributions. Confirming the findings of Sudderth et al., we show that the distribution over the size of natural segments as well as the frequencies that objects appear in an image follow a power law distribution. Long range dependencies are introduced in their framework via thresholded Gaussian processes. Their approach, however, is unsupervised, and does not leverage the ever growing abundance of annotations and ground truth data, e.g., LabelMe. As a consequence, the inferred segmentations are not always accurate and have room for improvement. In this paper we propose a novel supervised discriminative Hierarchical Pitman-Yor process () approach to segmentation. In particular, we frame the learning as a regularized constrained optimization problem, where we maximize a variational lower bound on the log likelihood while imposing the inferred labels at the segment and object levels agree with the ground truth annotations. We borrow intuitions from the literature of cutting plane and subgradient optimization methods, and derive an efficient method to train the. At every step of the algorithm the most violated constraint is introduced into the optimization via Lagrange multipliers. While we leverage the additional annotations, we also inherit the nice properties of [3]; more specifically, we are able to capture long range dependencies 228
2 via thresholded Gaussian process, and we retain the natural power-law priors. We demonstrate the effectiveness of our approach in a dataset composed of 8 different types of scenes and object categories taken from the LabelMe dataset [26]. Our approach outperforms normalized cuts [28], the Ultrametric Contour Map approach of [2], as well as the unsupervised [3]. In the remainder of the paper we first review the related work. We then introduce the process, derive our supervised formulation, show empirical results, and conclude with avenues of future research. 2. Related Work Markov Random Fields (MRFs) have become a popular approach to segmentation, as demonstrated by the large body of work [3,, 5]. In these approaches the image is modeled as an undirected graphical model at the level of pixels and/or superpixels. Node potentials describe local evidence and edge potentials usually encourage smoothness for neighboring pixels/superpixels with the same label. Several approaches to inference have been proposed for the MRF, such as graph cuts [4] and belief propagation [9]. One particular form of MRF that directly defines a discriminative distribution of the latent states is the Conditional Random Field (CRF) [29]. Inference is made easier since the conditional probabilities of the latent labels given the observations are modelled directly. Another way that supervision is used is through the fusing of contextual information [5]. Context can be added in the form of global constraints which usually specify class-cooccurrence and/or conditional dependence in the form of clique structure. While effective for segmentation, MRFs have been shown to be inadequate for modelling the visual statistics of natural scenes [27]. In this paper, we build on top of the Hierarchical Pitman-Yor processes, which accurately model the power law prior distributions, such as the distributions over the number of objects per image as well as that of the size of natural segments. Recently, [5, 6] show that segmentation can be framed as a two step process. First, candidate segments which can be part of an object are identified - [5] employs a graph-cut optimization framework, while [6] uses a CRF model. The segmentation problem is then formulated as a ranking problem over the candidate segments, which involves computing segment-level features such as segment area, perimeter and shape statistics. Sudderth and Jordan [3] proposed an unsupervised approach to image segmentation that models segments of visual scenes with a hierarchical Pitman-Yor process (). Thresholded Gaussian process are utilized to capture spatial coherence among regions. Moreover, this captures longrange dependences among the observations, which are diffi- Figure : Graphical model of the Hierarchical Pitman-Yor Process (), applied to natural scene segmentation [3]. Each observation x is assigned to layer z, an indicator variable. The assignment depends on the thresholded GPs u jt and layer probabilities v jt, which are generated from the PY stick-breaking prior GEM(α a, α b ). Each layer is assigned to class c jt, another indicator variable, which follow the PY prior GEM(γ a, γ b ) where w k are the stick lengths. Each class has an associated appearance model θ k. cult to achieve with MRFs. In this paper we propose a novel supervised process framework for segmentation, and show that the use of annotations significantly improves the performance over the unsupervised. Discriminative nonparametric Bayesian models have been proposed in the context of latent variable models, e.g., Latent Dirichlet Allocation (LDA) [3, 4]. These approaches modify the graphical model, by adding either a generative distribution of the label given the latent state [3] or a discriminative distribution of the latent state given the label [4]. However, it is not easy to pick a suitable distribution, such as generalized linear models (GLM). There is also the question of how much discriminative power the modified likelihood can exert on the latent states. Unlike these approaches, we propose to maximize a variational lower bound on the log likelihood while imposing the inferred label assignments coincide with the ground truth annotations. We derive an efficient method to train the model. In contrast to other supervised approaches to nonparametric Bayesian models, our discriminative approach makes use of supervised data directly resulting in significant performance improvements over the unsupervised model. 3. A Review of Unsupervised Processes We now describe the hierarchical Pitman-Yor () model for visual scenes [3], which is a generalization of the hierarchical Dirichlet process (HDP)[3]. In the next section we will introduce our new supervised 2282
3 model. The Pitman-Yor process [22], denoted by φ GEM(γ a, γ b ), places a prior distribution over partitions with hyperparameters γ a, γ b satisfying γ a < and γ b > γ a. It can be defined using the stick-breaking construction as k k φ k = w k ( w l ) = w k ( φ l ), l= l= with w k Beta( γ a, γ b + kγ a ). () The {φ k } are the partition probabilities, while the {w k } are the stick lengths. Note that we recover a Dirichlet process, specified by a single concentration parameter γ b, when γ a =. When γ a >, the partition probabilities follow a power-law distribution with a heavy tail. While the PY process is a prior on infinite partitions, only a finite subset of partitions will have positive probabilities greater than a threshold ɛ. Hence, the PY process implicitly imposes a prior on the number of partitions. In the model, two Pitman-Yor process priors are placed over the distributions of global class categories and segment proportions. Fig. shows the directed graphical model. Each image is segmented into superpixels, which are from now on treated as the observed data units x. Each data point is then assigned to a layer with probability P [z = t z t,..., ] = P [u jti < Φ (v jt )] = v jt, where we have introduced a zero mean Gaussian process (GP) u jt for each layer t. These thresholded GPs completely determine the layer assignment of each superpixel, with the assignment rule being z = min{t u jti < Φ (v jt )}. (2) Each layer is associated with a global object class c jt with an appearance model θ k. The emission probability is then p(x z = t, c jt = k, θ) = Mult(x θ k ). (3) with θ = {θ, } To place PY priors on the distributions over global class categories and segment proportions, the class assignments c jt are sampled from φ GEM(γ a, γ b ), which is the stick-breaking prior described above, with w k the stick length. Similarly, the layer assignment probabilities v jt are sampled from π GEM(α a, α b ). 4. Supervised Hierarchical Pitman-Yor Model In this section we present our supervised hierarchical Pitman-Yor process model for image segmentation. We first derive our variational learning approach and show how to incorporate supervision by solving a constrained optimization problem. We then derive a cutting plane method to efficiently learn the model. Following [3], we train the model with a mean field variational approximation. A completely factorized variational posterior is introduced as follows q(u, v, c, w, θ) = J j= t= K q(w k ω k )q(θ k η k ) k= N T j q(v jt ν jt )q(c jt κ jt ) q(u jti µ jti ), i= where the distributions are, with v jt = Φ (v jt ), q(θ k η k ) = Dir(η k ) q(c j κ j ) = Mult(c j κ j ) q(w k ω k,a, ω k,b ) = Beta(w k ω k,a, ω k,b ) q( v jt ν jt, δ jt ) = N( v jt ν jt, δ jt ) q(u jti µ jti, λ jti ) = N(u jti µ jti, λ jti ). We truncate the variational posterior by setting q(v jt = ) = and q(w K = ) =. We then train the model by optimizing the lower bound on the marginal likelihood log p(x α, γ, ρ) H(q) + E q[log p(x, z, u, v, c, w, θ α, γ, ρ)] = E q[log p(x, z, u, v, c, w, θ α, γ, ρ)] E q[log q(u, v, c, w, θ)] L This is equivalent to minimizing the KL-divergence between p and q. The optimization is done through a combination of closed-form updates and gradient descent. Inference in the unsupervised model produce layerlevel and class-level segmentations using the variational marginals arg max t P q (z = t) and arg max k P q (c jt = k), where t νjt µjti νjτ µjτi P q(z = t) = Φ( ) ( Φ( )) δjt + λ jti δjτ + λ jτi P q(c jt = k) = κ jtk = exp{ i,l τ= x,l P q(z = t) E q log η k,l + k E q log ω k,l}, k = with E q log η k,l = Ψ(η k,l ) Ψ( l η k,l) and E q log ω k,l = Ψ(ω k,t) Ψ(ω k,t + ω k,b) from the Dirichlet posterior assumption. The last equation stems from the closed-form update for κ jtk. Let A be the set of annotations. We are provided with two types of annotations: { } A = (a s, a c ) a s {,..., T }, a c {,..., K} where a s : segment-level annotation, and a c : class-level annotation. Segment-level annotations describe the layer assignment of each observation, while class-level annotation describes the class assignment of each layer. Note that we have imposed an absolute ordering on the layers, due to the stick-breaking 2283
4 construction of the layer model; in practice, we sort the different layers in decreasing order of their sizes. We apply supervision constrains that are added to the variational program. Learning the supervised can then be formulated as the following maximization problem max s.t. L (j, i) A, P q(z = a s ) max P t q(z = t) (j, i) A, P q(c ja s = a c ) max P q(c ja s k = k) with respect to µ jti, λ jti, ν jt and δ jt. Note that the above probabilities have been defined perviously in terms of these variables. We transform the above optimization problem into a single objective by adding slack variables max L (i,j) A (Cs ζ s + C c ζ c ) s.t. (j, i) A, P q(z = a s ) + ζ s max t P q(z = t) (j, i) A, P q(c ja s = a c ) + ζ c max k P q(c ja s = k) The Lagrangian l can then be defined as l = L C s (max P q(z = t) P q(z = a s )) C c (i,j) A (i,j) A t (max P q(c ja s = k) P q(c ja s = a c )) k Maximizing the Lagrangian defines the optimization problem we solve to learn the discriminative model. The coefficients C s and C c determine the relative weighting the model puts on minimizing the KL divergence and minimizing the segmentation error. Learning: In the unsupervised model gradient descent is carried out independently for each image and layer. With the segment-level and class-level constraints, the layers and images are now dependent, complicating the optimization. Since adding all constraints to the optimization is computationally expensive, we derive a cutting plane type algorithm that selects, during each iteration, the most violated constraint and adds it to the optimization. We now explain the learning process in detail (see also Table ). First, we initialize the appearance model multinomial parameters, setting them according to the class-level annotations. Note that it is possible that our truncated value for the number of classes, K, is less than the number of global class categories. We first sort the classes in descending frequency, and lump the truncated classes into a background class. For classes that have not been observed in the training data, we randomly sample their appearance model from the background class, which may exhibit extensive intraclass variability. We then initialize all the other variational posteriors. Within each image, we first train the variational parameters in the unsupervised fashion via gradient descent on Algorithm : for each k = observed, non-background class Set η k = j,i {ac =k}x j,i j,i {ac =k} for each k = unobserved class Initialize η k randomly from background class Initialize table assignments Initialize class assignments κ jt from a c Initialize µ jti, λ jti, ν jt, δ jt for each image j = to J Run unsupervised training for each i = to N j Set assign(i) = P q (min{t u jti < Φ (v jt )} = t) Set M = getoptimalpermutation(assign, a s ) Permute layers according to M Construct new confusion matrix C end Do while s t C(s, t) stabilizes: Set s, t = arg max s t C(s, t) Set k = arg max k P q (c j,s = k) Set I = {i P q (z = t ) < P q (z = s )} Set I = {i I P q (c j,s = a c ) < P q(c j,s = k )} Set L s = {i I }(P q (z = t ) P q (z = s )) Set L c = {i I }(P q (c j,s = k ) P q (c j,s = a c )) Run gradient descent with L C s L s C c L c function getoptimalpermutation(assign, assign gt) Construct confusion matrix C: for n = Range(assign) for m = Range(assign gt) C(n, m) = {(i, j) assign(i) = n, assign gt(j) = m} Run Hungarian algorithm with weight matrix C return matching M Table : Discriminative () learning algorithm using Gradient Descent the objective L. Next, we permute the layers to minimize the number of violated constraints. This is necessary since we imposed an absolute ordering on the layers. The problem of computing the optimal permutation can be formulated as a bipartite matching on a graph where the nodes are the assignment labels and the edge weights are the number of agreements in the layer assignments - or more simply, the confusion matrix. The intuition behind this reformulation is that a permutation is an independent edge set (or a matching) since each assignment id can only be permuted to one other id, and vice versa. The matching is carried out with the Hungarian algorithm [2]. Once the layers are properly permuted, we iteratively identify the pair of layers with the most violated constraints, as motivated by the cutting-plane method in []. This corresponds to finding the largest off-diagonal entry in the new confusion matrix. Given this pair of layers, we find the set of observations which violate these segment-level constraints, as well as the subset of observations which violate 2284
5 Log log plot of Segment Size Distribution PY(5, 4.8) EmpiricalDistribution Log log plot of Class Distribution PY(, ) EmpiricalDistribution.9 Average over all categories 2 Density Segment Sizes Density Class Counts (a) Segment Sizes (b) Class Frequencies (c) Figure 2: (a,b) Power-law Empirical Distributions across all categories and their fitted Pitman-Yor processes. (c) Performance in terms of as a function of the number of training examples aggregated across categories the class-level constraints. We now perform gradient descent on these sets of nodes, using the subgradient method suggested in [23] which approximates f(x) max f(x) max x x S, where S is the set of subgradients of max f(x). We proceed until there are no more violated constraints. In practice, however, this is never accomplished; hence, we iterate until the number of violated constraints stabilizes. Modeling Spatial Dependencies: We employ a few mechanisms to capture spatial dependencies. First, a bottom-up approach preprocess the data into superpixels [8, 9, 24, 2, 6], over-segmenting each image into locally consistent regions. In our experiments, we use TurboPixels [6]. Recall that in the model, each layer is associated with a zero mean GP over u jt. If the GPs have diagonal covariance functions, the model is spatially independent. More general covariances can encode affinities among pairs of data features. In particular, for an image j, we employ a covariance that incorporates intervening contour cues based on the gp b detector [2], W j (x i, x i ) = exp{ x i x i 2 }( gp b (x i, x i )) σ gpb, 2σ 2 sp where σ sp and σ gpb are constants, x i is the centroid of the i- th superpixel and gp b (x i, x i ) is the maximal gp b response along the line between the two superpixels centroids. To induce sparsity, we also included a neighborhood parameter, ɛ n ; the covariance entry is zero if the corresponding superpixel centroids are more than ɛ n pixels apart; otherwise, the value is the same as above. Since W j is a covariance matrix, it is required to be positive semi-definite (PSD). To ensure that the covariance is PSD, we compute the eigendecomposition of W j and retain only the eigenvalues that are at least ɛ eig times the maximal eigenvalue. This is done for robustness and computational reasons (the feature dimension becomes smaller). 5. Experimental Evaluation We validate our approach on the natural scene dataset of [2, 3], which is a subset of the LabelMe [26] database. The dataset consists of eight categories and a total of 2,688 images, each comprising a number of manually segmented polygons with a semantic text label. For all experiments, we use σ sp = 3, σ gpb =, ɛ n = 2, and ɛ eig =., which are estimated via cross-validation. Each image is first preprocessed into roughly, superpixels. We use a local texton histogram quantized to 64 bins and a color histogram quantized to bins as features. For each image, the segments are sorted in decreasing order, with the largest segment assigned to be layer. The segment label for each superpixel is then computed as the majority segment id among the encompassing pixels. The class label is taken to be the most frequent unigram, accounting for plurals and ignoring labels marked as occluded. The empirical distributions of the segment sizes (in terms of superpixels) and class counts are shown in Fig. 2. The asymptotic linearity in the loglog plot is evidence of a power law distribution; fitted Pitman-Yor priors are shown. A single and model is trained for each category. In our experiments, we set the number of global classes K to be (across all scene categories); we bundle the truncated classes into a background class. For computation reasons, we set the number of segments T to be the same as the number of global classes. The crucial classlevel PY hyperparameters γ a, γ b are set to their fitted values ( and respectively). Similarly, the segment-level PY hyperparameters α a, α b are set to the globally fitted values (5 and 4.8). The segmentation is computed as the class with the maximal posterior probability of assignment. Results are reported with respect to the ground truth (manual segmentation) in terms of two metrics: the Rand index [32] and the Pascal score. The Rand index measures the similarity between two data clustering schemes. Given two cluster assignments X and Y, it is defined as 2285
 = # Agreements between X,Y All possible pairs The Pascal score, on the other hand, measures the number of correctly labelled segments.")
 can be formulated as a bipartite matching problem, as explained in the previous section (see Table ).")
6 () (Pascal Score) Figure 3: Performance across the 8 categories for our approach and the baselines. Best viewed in color. RandIndex(X, Y ) = # Agreements between X,Y All possible pairs The Pascal score, on the other hand, measures the number of correctly labelled segments. Note that the Rand index does not require a particular assignment permutation, while the Pascal score depends on the permutation. The problem of computing the optimal Pascal score (with the optimal permutation) can be formulated as a bipartite matching problem, as explained in the previous section (see Table ). We compare our supervised model () with the unsupervised model, as well as Normalized Cuts (Ncut) and the thresholded Oriented Watershed Transform - Ultrametric Contour Map (OWT-UCM) [2]. The unsupervised model is initialized with the same parameters as the. The Ncut baseline is performed on the covariance matrix used in our thresholded Gaussian processes, which makes use of the discriminative gpb detector as well as an Euclidean smoothness metric. For each image, we compute Ncut assuming the number of clusters is the number of segments in the ground truth annotation. The OWT-UCM baseline is built on top of the state-of-the-art gpb contour detector; given a threshold value, closed regions can be obtained by computing the connected components in the image. Since we do not know the optimal threshold a priori, we run three OWT-UCM baselines, with the threshold being 5, and 5. The results across the 8 categories are shown in Fig. 3, in terms of the Rand index and the Pascal score respectively. Our supervised approach improves the performance of the unsupervised model while reducing the variance. Across all categories, our model achieves a Rand index of 848 ±.696 and a Pascal score of 25 ±.686. In terms of the averaged over all categories, our method achieves an improvement of 36 over the closest competitor with a p-value of.223, which is statistically significant at the 5% level. We also evaluate the Rand index performance as a function of the number of training examples. Fig. 2(c) depicts the Rand index averaged among all categories, while Fig. 4 depicts the index for each individual category. The OWT- UCM baseline is chosen to be the best one out of the three thresholded versions. Our model converges to the asymptotic performance more quickly, while incurring a smaller variance with fewer training data. Finally, we show segmentation outputs from the different models in Fig Conclusion We have proposed a novel supervised Discriminative Hierarchical Pitman-Yor () model, and demonstrated its effectiveness on a natural scene dataset with manual human annotations. Our approach outperforms several baselines, notably the unsupervised model and the OWT-UCM algorithm. Moreover, we have formulated a new constrained optimization framework for nonparametric Bayesian models which can directly and discriminatively train the likelihood distribution, while incorporating the power law priors that are appropriate for generating the visual statistics in natural scenes. In the future we plan to investigate other ways of introducing annotations. References [] N. Apostoloff and A. Fitzgibbon. Bayesian video matting using learnt image priors. In CVPR, [2] P. Arbelaez, M. Maire, C. Fowlkes, and J. Malik. From contours to regions: An empirical evaluation. In CVPR, , 2282, 2285, 2286 [3] D. Blei and J. Mcauliffe. Supervised topic models. In NIPS, [4] Y. Boykov and V. Kolmogorov. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. PAMI, 26, , 2282 [5] J. Carreira and C. Sminchisescu. Constrained parametric min-cuts for automatic object segmentation. In CVPR, [6] I. Endres and D. Hoiem. Category independent object proposals. In ECCV, [7] M. Everingham, L. V. Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. IJCV, 88, [8] P. Felzenszwalb and D. Huttenlocher. Efficient graph-based image segmentation. IJCV, 59, [9] P. Felzenszwalb and D. Huttenlocher. Efficient belief propagatino for early vision. IJCV, 4, , 2282 [] T. Joachims, T. Finley, and C.-N. J. Yu. Cutting-plane training of structural svms. Machine Learning, 77, Various co-authors of this work have been supported in part by awards from the US DOD and DARPA, including contract W9NF--2-59, by NSF awards IIS and IIS-89984, and by Toyota and Google. 2286
7 Category: coast Category: forest Category: highway Category: insidecity (Coast) (Forest) (Highway) (Insidecity) Category: mountain Category: opencountry Category: street Category: tallbuilding (Mountain) (Opencountry) (Street) (TallBuilding) Figure 4: as a function of the number of training examples for the different categories. [] P. Kohli, M. Pawan, K. Philip, and H. S. Torr. p 3 & beyond: Solving energies with higher order cliques. In CVPR, , 2282 [2] H. W. Kuhn. The hungarian method for the assignment problem. In 5 Years of Integer Programming , pages [3] M. P. Kumar, P. H. S. Torr, and A. Zisserman. Obj cut. In CVPR, , 2282 [4] S. Lacoste-julien, F. Sha, and M. I. Jordan. Disclda: Discriminative learning for dimensionality reduction and classification. In NIPS, [5] L. Ladicky, C. Russell, P. Kohli, and P. Torr. Graph cut based inference with co-occurrence statistics. In ECCV, , 2282 [6] A. Levinstein, A. Stere, K. Kutulakos, D. Fleet, S. Dickinson, and K. Siddiqi. Turbopixels: Fast superpixels using geometric flows. PAMI, 3, [7] M. Maire, P. Arbelaez, C. Fowlkes, and J. Malik. Using contours to detect and localize junctions in natural images. In CVPR, [8] D. R. Martin, C. C. Fowlkes, and J. Malik. Learning to detect natural image boundaries using local brightness, color, and texture cues. PAMI, 26, [9] A. Moore, S. Prince, J. Warrell, U. Mohammed, and G. Jones. Superpixel lattices. In CVPR, [2] G. Mori, X. Ren, A. Efros, and J. Malik. Recovering human body configurations: Combining segmentation and recognition. In CVPR, [2] A. Oliva and A. Torralba. Modeling the shape of the scene: A holistic representation of the spatial envelope. IJCV, 42, [22] J. Pitman and M. Yor. The two-parameter poissondirichlet distribution derived from a stable subordinator. Annals of Probability, 25, [23] N. Ratliff, A. Bagnell, and M. Zinkevich. Subgradient methods for maximum margin structured learning. In Workshop on Learning in Structured Outputs Spaces at ICML, [24] X. Ren and J. Malik. Learning a classification model for segmentation. In ICCV, [25] S. Roth and M. J. Black. On the spatial statistics of optical flow. In ICCV, [26] B. C. Russell, A. Torralba, K. P. Murphy, and W. T. Freeman. Labelme: a database and web-based tool for image annotation. IJCV, 77, , 2285 [27] U. Schmidt, Q. Gao, and S. Roth. A generative perspective on mrfs in low-level vision. In CVPR, [28] J. Shi and J. Malik. Normalized cuts and image segmentation. PAMI, 22, [29] J. Shotton, J. Winn, C. Rother, and A. Criminisi. Textonboost: Joint appearance, shape and context modeling for multi-class object recognition and segmentation. In ECCV, [3] E. Sudderth and M. Jordan. Shared segmentation of natural scenes using dependent pitman-yor processes. In NIPS, , 2282, 2283, 2285 [3] Y. W. Teh, M. I. Jordan, M. J. Beal, and D. M. Blei. Hierarchical dirichlet processes. Journal of the American Statistical Association,, [32] R. Unnikrishnan, C. Pantofaru, and M. Hebert. Toward objective evaluation of image segmentation algorithms. PAMI, 29, [33] Y. Weiss. Deriving intrinsic images from image sequences. In ICCV,
")
")
")

























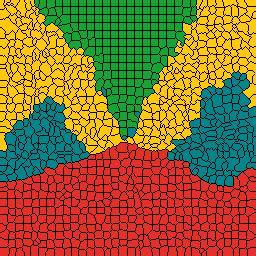






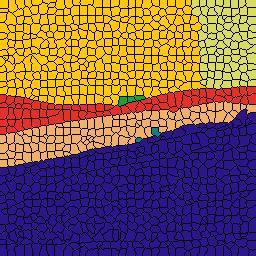
















8 (a) Raw Image (b) Ground Truth (c) model (d) model (e) N-cut (f) OWT-UCM(5) (g) OWT-UCM() (h) OWT-UCM(5) Figure 5: Segmentation results for categories coast, forest, highway, insidecity, mountain, opencountry, street, tallbuilding. The different colors represent different segments. The superpixel boundaries are also displayed for rows (b)-(e). Best viewed in color. 2288
Shared Segmentation of Natural Scenes. Dependent Pitman-Yor Processes
 Shared Segmentation of Natural Scenes using Dependent Pitman-Yor Processes Erik Sudderth & Michael Jordan University of California, Berkeley Parsing Visual Scenes sky skyscraper sky dome buildings trees
Shared Segmentation of Natural Scenes using Dependent Pitman-Yor Processes Erik Sudderth & Michael Jordan University of California, Berkeley Parsing Visual Scenes sky skyscraper sky dome buildings trees
Spatial Bayesian Nonparametrics for Natural Image Segmentation
 Spatial Bayesian Nonparametrics for Natural Image Segmentation Erik Sudderth Brown University Joint work with Michael Jordan University of California Soumya Ghosh Brown University Parsing Visual Scenes
Spatial Bayesian Nonparametrics for Natural Image Segmentation Erik Sudderth Brown University Joint work with Michael Jordan University of California Soumya Ghosh Brown University Parsing Visual Scenes
Fantope Regularization in Metric Learning
 Fantope Regularization in Metric Learning CVPR 2014 Marc T. Law (LIP6, UPMC), Nicolas Thome (LIP6 - UPMC Sorbonne Universités), Matthieu Cord (LIP6 - UPMC Sorbonne Universités), Paris, France Introduction
Fantope Regularization in Metric Learning CVPR 2014 Marc T. Law (LIP6, UPMC), Nicolas Thome (LIP6 - UPMC Sorbonne Universités), Matthieu Cord (LIP6 - UPMC Sorbonne Universités), Paris, France Introduction
Kernel Density Topic Models: Visual Topics Without Visual Words
 Kernel Density Topic Models: Visual Topics Without Visual Words Konstantinos Rematas K.U. Leuven ESAT-iMinds krematas@esat.kuleuven.be Mario Fritz Max Planck Institute for Informatics mfrtiz@mpi-inf.mpg.de
Kernel Density Topic Models: Visual Topics Without Visual Words Konstantinos Rematas K.U. Leuven ESAT-iMinds krematas@esat.kuleuven.be Mario Fritz Max Planck Institute for Informatics mfrtiz@mpi-inf.mpg.de
Asaf Bar Zvi Adi Hayat. Semantic Segmentation
 Asaf Bar Zvi Adi Hayat Semantic Segmentation Today s Topics Fully Convolutional Networks (FCN) (CVPR 2015) Conditional Random Fields as Recurrent Neural Networks (ICCV 2015) Gaussian Conditional random
Asaf Bar Zvi Adi Hayat Semantic Segmentation Today s Topics Fully Convolutional Networks (FCN) (CVPR 2015) Conditional Random Fields as Recurrent Neural Networks (ICCV 2015) Gaussian Conditional random
Distinguish between different types of scenes. Matching human perception Understanding the environment
 Scene Recognition Adriana Kovashka UTCS, PhD student Problem Statement Distinguish between different types of scenes Applications Matching human perception Understanding the environment Indexing of images
Scene Recognition Adriana Kovashka UTCS, PhD student Problem Statement Distinguish between different types of scenes Applications Matching human perception Understanding the environment Indexing of images
Lecture 15. Probabilistic Models on Graph
 Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
ECE 6504: Advanced Topics in Machine Learning Probabilistic Graphical Models and Large-Scale Learning
 ECE 6504: Advanced Topics in Machine Learning Probabilistic Graphical Models and Large-Scale Learning Topics Markov Random Fields: Representation Conditional Random Fields Log-Linear Models Readings: KF
ECE 6504: Advanced Topics in Machine Learning Probabilistic Graphical Models and Large-Scale Learning Topics Markov Random Fields: Representation Conditional Random Fields Log-Linear Models Readings: KF
Undirected graphical models
 Undirected graphical models Semantics of probabilistic models over undirected graphs Parameters of undirected models Example applications COMP-652 and ECSE-608, February 16, 2017 1 Undirected graphical
Undirected graphical models Semantics of probabilistic models over undirected graphs Parameters of undirected models Example applications COMP-652 and ECSE-608, February 16, 2017 1 Undirected graphical
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Bayesian Nonparametrics for Speech and Signal Processing
 Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Graphical Object Models for Detection and Tracking
 Graphical Object Models for Detection and Tracking (ls@cs.brown.edu) Department of Computer Science Brown University Joined work with: -Ying Zhu, Siemens Corporate Research, Princeton, NJ -DorinComaniciu,
Graphical Object Models for Detection and Tracking (ls@cs.brown.edu) Department of Computer Science Brown University Joined work with: -Ying Zhu, Siemens Corporate Research, Princeton, NJ -DorinComaniciu,
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
A Generative Perspective on MRFs in Low-Level Vision Supplemental Material
 A Generative Perspective on MRFs in Low-Level Vision Supplemental Material Uwe Schmidt Qi Gao Stefan Roth Department of Computer Science, TU Darmstadt 1. Derivations 1.1. Sampling the Prior We first rewrite
A Generative Perspective on MRFs in Low-Level Vision Supplemental Material Uwe Schmidt Qi Gao Stefan Roth Department of Computer Science, TU Darmstadt 1. Derivations 1.1. Sampling the Prior We first rewrite
Global Scene Representations. Tilke Judd
 Global Scene Representations Tilke Judd Papers Oliva and Torralba [2001] Fei Fei and Perona [2005] Labzebnik, Schmid and Ponce [2006] Commonalities Goal: Recognize natural scene categories Extract features
Global Scene Representations Tilke Judd Papers Oliva and Torralba [2001] Fei Fei and Perona [2005] Labzebnik, Schmid and Ponce [2006] Commonalities Goal: Recognize natural scene categories Extract features
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Dynamic Data Modeling, Recognition, and Synthesis. Rui Zhao Thesis Defense Advisor: Professor Qiang Ji
 Dynamic Data Modeling, Recognition, and Synthesis Rui Zhao Thesis Defense Advisor: Professor Qiang Ji Contents Introduction Related Work Dynamic Data Modeling & Analysis Temporal localization Insufficient
Dynamic Data Modeling, Recognition, and Synthesis Rui Zhao Thesis Defense Advisor: Professor Qiang Ji Contents Introduction Related Work Dynamic Data Modeling & Analysis Temporal localization Insufficient
Acoustic Unit Discovery (AUD) Models. Leda Sarı
 Models. Leda Sarı") Acoustic Unit Discovery (AUD) Models Leda Sarı Lucas Ondel and Lukáš Burget A summary of AUD experiments from JHU Frederick Jelinek Summer Workshop 2016 lsari2@illinois.edu November 07, 2016 1 / 23 The
Acoustic Unit Discovery (AUD) Models Leda Sarı Lucas Ondel and Lukáš Burget A summary of AUD experiments from JHU Frederick Jelinek Summer Workshop 2016 lsari2@illinois.edu November 07, 2016 1 / 23 The
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
CS 664 Segmentation (2) Daniel Huttenlocher
 Daniel Huttenlocher") CS 664 Segmentation (2) Daniel Huttenlocher Recap Last time covered perceptual organization more broadly, focused in on pixel-wise segmentation Covered local graph-based methods such as MST and Felzenszwalb-Huttenlocher
CS 664 Segmentation (2) Daniel Huttenlocher Recap Last time covered perceptual organization more broadly, focused in on pixel-wise segmentation Covered local graph-based methods such as MST and Felzenszwalb-Huttenlocher
Making the Right Moves: Guiding Alpha-Expansion using Local Primal-Dual Gaps
 Making the Right Moves: Guiding Alpha-Expansion using Local Primal-Dual Gaps Dhruv Batra TTI Chicago dbatra@ttic.edu Pushmeet Kohli Microsoft Research Cambridge pkohli@microsoft.com Abstract 5 This paper
Making the Right Moves: Guiding Alpha-Expansion using Local Primal-Dual Gaps Dhruv Batra TTI Chicago dbatra@ttic.edu Pushmeet Kohli Microsoft Research Cambridge pkohli@microsoft.com Abstract 5 This paper
Variational Inference (11/04/13)
") STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
Diversity Regularization of Latent Variable Models: Theory, Algorithm and Applications
 Diversity Regularization of Latent Variable Models: Theory, Algorithm and Applications Pengtao Xie, Machine Learning Department, Carnegie Mellon University 1. Background Latent Variable Models (LVMs) are
Diversity Regularization of Latent Variable Models: Theory, Algorithm and Applications Pengtao Xie, Machine Learning Department, Carnegie Mellon University 1. Background Latent Variable Models (LVMs) are
Probabilistic Graphical Models: MRFs and CRFs. CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov
 Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Conditional Random Field
 Introduction Linear-Chain General Specific Implementations Conclusions Corso di Elaborazione del Linguaggio Naturale Pisa, May, 2011 Introduction Linear-Chain General Specific Implementations Conclusions
Introduction Linear-Chain General Specific Implementations Conclusions Corso di Elaborazione del Linguaggio Naturale Pisa, May, 2011 Introduction Linear-Chain General Specific Implementations Conclusions
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Unsupervised Activity Perception by Hierarchical Bayesian Models
 Unsupervised Activity Perception by Hierarchical Bayesian Models Xiaogang Wang Xiaoxu Ma Eric Grimson Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge,
Unsupervised Activity Perception by Hierarchical Bayesian Models Xiaogang Wang Xiaoxu Ma Eric Grimson Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge,
Unsupervised Activity Perception in Crowded and Complicated Scenes Using Hierarchical Bayesian Models
 SUBMISSION TO IEEE TRANS. ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 1 Unsupervised Activity Perception in Crowded and Complicated Scenes Using Hierarchical Bayesian Models Xiaogang Wang, Xiaoxu Ma,
SUBMISSION TO IEEE TRANS. ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 1 Unsupervised Activity Perception in Crowded and Complicated Scenes Using Hierarchical Bayesian Models Xiaogang Wang, Xiaoxu Ma,
Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials
 Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials by Phillip Krahenbuhl and Vladlen Koltun Presented by Adam Stambler Multi-class image segmentation Assign a class label to each
Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials by Phillip Krahenbuhl and Vladlen Koltun Presented by Adam Stambler Multi-class image segmentation Assign a class label to each
Segmentation Using Superpixels: A Bipartite Graph Partitioning Approach
 Segmentation Using Superpixels: A Bipartite Graph Partitioning Approach Zhenguo Li Xiao-Ming Wu Shih-Fu Chang Dept. of Electrical Engineering, Columbia University, New York {zgli,xmwu,sfchang}@ee.columbia.edu
Segmentation Using Superpixels: A Bipartite Graph Partitioning Approach Zhenguo Li Xiao-Ming Wu Shih-Fu Chang Dept. of Electrical Engineering, Columbia University, New York {zgli,xmwu,sfchang}@ee.columbia.edu
Unsupervised Activity Perception in Crowded and Complicated Scenes Using Hierarchical Bayesian Models
 SUBMISSION TO IEEE TRANS. ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 1 Unsupervised Activity Perception in Crowded and Complicated Scenes Using Hierarchical Bayesian Models Xiaogang Wang, Xiaoxu Ma,
SUBMISSION TO IEEE TRANS. ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 1 Unsupervised Activity Perception in Crowded and Complicated Scenes Using Hierarchical Bayesian Models Xiaogang Wang, Xiaoxu Ma,
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Integrating Local Classifiers through Nonlinear Dynamics on Label Graphs with an Application to Image Segmentation
 Integrating Local Classifiers through Nonlinear Dynamics on Label Graphs with an Application to Image Segmentation Yutian Chen Andrew Gelfand Charless C. Fowlkes Max Welling Bren School of Information
Integrating Local Classifiers through Nonlinear Dynamics on Label Graphs with an Application to Image Segmentation Yutian Chen Andrew Gelfand Charless C. Fowlkes Max Welling Bren School of Information
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Learning Spectral Graph Segmentation
 Learning Spectral Graph Segmentation AISTATS 2005 Timothée Cour Jianbo Shi Nicolas Gogin Computer and Information Science Department University of Pennsylvania Computer Science Ecole Polytechnique Graph-based
Learning Spectral Graph Segmentation AISTATS 2005 Timothée Cour Jianbo Shi Nicolas Gogin Computer and Information Science Department University of Pennsylvania Computer Science Ecole Polytechnique Graph-based
Chris Bishop s PRML Ch. 8: Graphical Models
 Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Intelligent Systems:
 Intelligent Systems: Undirected Graphical models (Factor Graphs) (2 lectures) Carsten Rother 15/01/2015 Intelligent Systems: Probabilistic Inference in DGM and UGM Roadmap for next two lectures Definition
Intelligent Systems: Undirected Graphical models (Factor Graphs) (2 lectures) Carsten Rother 15/01/2015 Intelligent Systems: Probabilistic Inference in DGM and UGM Roadmap for next two lectures Definition
Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text
 Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text Yi Zhang Machine Learning Department Carnegie Mellon University yizhang1@cs.cmu.edu Jeff Schneider The Robotics Institute
Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text Yi Zhang Machine Learning Department Carnegie Mellon University yizhang1@cs.cmu.edu Jeff Schneider The Robotics Institute
Image segmentation combining Markov Random Fields and Dirichlet Processes
 Image segmentation combining Markov Random Fields and Dirichlet Processes Jessica SODJO IMS, Groupe Signal Image, Talence Encadrants : A. Giremus, J.-F. Giovannelli, F. Caron, N. Dobigeon Jessica SODJO
Image segmentation combining Markov Random Fields and Dirichlet Processes Jessica SODJO IMS, Groupe Signal Image, Talence Encadrants : A. Giremus, J.-F. Giovannelli, F. Caron, N. Dobigeon Jessica SODJO
Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model
 Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model (& discussion on the GPLVM tech. report by Prof. N. Lawrence, 06) Andreas Damianou Department of Neuro- and Computer Science,
Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model (& discussion on the GPLVM tech. report by Prof. N. Lawrence, 06) Andreas Damianou Department of Neuro- and Computer Science,
Combining Generative and Discriminative Methods for Pixel Classification with Multi-Conditional Learning
 Combining Generative and Discriminative Methods for Pixel Classification with Multi-Conditional Learning B. Michael Kelm Interdisciplinary Center for Scientific Computing University of Heidelberg michael.kelm@iwr.uni-heidelberg.de
Combining Generative and Discriminative Methods for Pixel Classification with Multi-Conditional Learning B. Michael Kelm Interdisciplinary Center for Scientific Computing University of Heidelberg michael.kelm@iwr.uni-heidelberg.de
13 : Variational Inference: Loopy Belief Propagation and Mean Field
 10-708: Probabilistic Graphical Models 10-708, Spring 2012 13 : Variational Inference: Loopy Belief Propagation and Mean Field Lecturer: Eric P. Xing Scribes: Peter Schulam and William Wang 1 Introduction
10-708: Probabilistic Graphical Models 10-708, Spring 2012 13 : Variational Inference: Loopy Belief Propagation and Mean Field Lecturer: Eric P. Xing Scribes: Peter Schulam and William Wang 1 Introduction
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Probabilistic Time Series Classification
 Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
CSC 412 (Lecture 4): Undirected Graphical Models
: Undirected Graphical Models") CSC 412 (Lecture 4): Undirected Graphical Models Raquel Urtasun University of Toronto Feb 2, 2016 R Urtasun (UofT) CSC 412 Feb 2, 2016 1 / 37 Today Undirected Graphical Models: Semantics of the graph:
CSC 412 (Lecture 4): Undirected Graphical Models Raquel Urtasun University of Toronto Feb 2, 2016 R Urtasun (UofT) CSC 412 Feb 2, 2016 1 / 37 Today Undirected Graphical Models: Semantics of the graph:
6.047 / Computational Biology: Genomes, Networks, Evolution Fall 2008
 MIT OpenCourseWare http://ocw.mit.edu 6.047 / 6.878 Computational Biology: Genomes, etworks, Evolution Fall 2008 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
MIT OpenCourseWare http://ocw.mit.edu 6.047 / 6.878 Computational Biology: Genomes, etworks, Evolution Fall 2008 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
Modeling Mutual Context of Object and Human Pose in Human-Object Interaction Activities
 Modeling Mutual Context of Object and Human Pose in Human-Object Interaction Activities Bangpeng Yao and Li Fei-Fei Computer Science Department, Stanford University {bangpeng,feifeili}@cs.stanford.edu
Modeling Mutual Context of Object and Human Pose in Human-Object Interaction Activities Bangpeng Yao and Li Fei-Fei Computer Science Department, Stanford University {bangpeng,feifeili}@cs.stanford.edu
An Introduction to Bayesian Machine Learning
 1 An Introduction to Bayesian Machine Learning José Miguel Hernández-Lobato Department of Engineering, Cambridge University April 8, 2013 2 What is Machine Learning? The design of computational systems
1 An Introduction to Bayesian Machine Learning José Miguel Hernández-Lobato Department of Engineering, Cambridge University April 8, 2013 2 What is Machine Learning? The design of computational systems
Riemannian Metric Learning for Symmetric Positive Definite Matrices
 CMSC 88J: Linear Subspaces and Manifolds for Computer Vision and Machine Learning Riemannian Metric Learning for Symmetric Positive Definite Matrices Raviteja Vemulapalli Guide: Professor David W. Jacobs
CMSC 88J: Linear Subspaces and Manifolds for Computer Vision and Machine Learning Riemannian Metric Learning for Symmetric Positive Definite Matrices Raviteja Vemulapalli Guide: Professor David W. Jacobs
Learning Tetris. 1 Tetris. February 3, 2009
 Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Unsupervised Learning with Permuted Data
 Unsupervised Learning with Permuted Data Sergey Kirshner skirshne@ics.uci.edu Sridevi Parise sparise@ics.uci.edu Padhraic Smyth smyth@ics.uci.edu School of Information and Computer Science, University
Unsupervised Learning with Permuted Data Sergey Kirshner skirshne@ics.uci.edu Sridevi Parise sparise@ics.uci.edu Padhraic Smyth smyth@ics.uci.edu School of Information and Computer Science, University
Supplementary Material for Superpixel Sampling Networks
 Supplementary Material for Superpixel Sampling Networks Varun Jampani 1, Deqing Sun 1, Ming-Yu Liu 1, Ming-Hsuan Yang 1,2, Jan Kautz 1 1 NVIDIA 2 UC Merced {vjampani,deqings,mingyul,jkautz}@nvidia.com,
Supplementary Material for Superpixel Sampling Networks Varun Jampani 1, Deqing Sun 1, Ming-Yu Liu 1, Ming-Hsuan Yang 1,2, Jan Kautz 1 1 NVIDIA 2 UC Merced {vjampani,deqings,mingyul,jkautz}@nvidia.com,
SPECTRAL CLUSTERING AND KERNEL PRINCIPAL COMPONENT ANALYSIS ARE PURSUING GOOD PROJECTIONS
 SPECTRAL CLUSTERING AND KERNEL PRINCIPAL COMPONENT ANALYSIS ARE PURSUING GOOD PROJECTIONS VIKAS CHANDRAKANT RAYKAR DECEMBER 5, 24 Abstract. We interpret spectral clustering algorithms in the light of unsupervised
SPECTRAL CLUSTERING AND KERNEL PRINCIPAL COMPONENT ANALYSIS ARE PURSUING GOOD PROJECTIONS VIKAS CHANDRAKANT RAYKAR DECEMBER 5, 24 Abstract. We interpret spectral clustering algorithms in the light of unsupervised
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Self-Tuning Semantic Image Segmentation
 Self-Tuning Semantic Image Segmentation Sergey Milyaev 1,2, Olga Barinova 2 1 Voronezh State University sergey.milyaev@gmail.com 2 Lomonosov Moscow State University obarinova@graphics.cs.msu.su Abstract.
Self-Tuning Semantic Image Segmentation Sergey Milyaev 1,2, Olga Barinova 2 1 Voronezh State University sergey.milyaev@gmail.com 2 Lomonosov Moscow State University obarinova@graphics.cs.msu.su Abstract.
Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures
 17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
Lecture 13 Visual recognition
 Lecture 13 Visual recognition Announcements Silvio Savarese Lecture 13-20-Feb-14 Lecture 13 Visual recognition Object classification bag of words models Discriminative methods Generative methods Object
Lecture 13 Visual recognition Announcements Silvio Savarese Lecture 13-20-Feb-14 Lecture 13 Visual recognition Object classification bag of words models Discriminative methods Generative methods Object
Chapter 16. Structured Probabilistic Models for Deep Learning
 Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Hidden CRFs for Human Activity Classification from RGBD Data
 H Hidden s for Human from RGBD Data Avi Singh & Ankit Goyal IIT-Kanpur CS679: Machine Learning for Computer Vision April 13, 215 Overview H 1 2 3 H 4 5 6 7 Statement H Input An RGBD video with a human
H Hidden s for Human from RGBD Data Avi Singh & Ankit Goyal IIT-Kanpur CS679: Machine Learning for Computer Vision April 13, 215 Overview H 1 2 3 H 4 5 6 7 Statement H Input An RGBD video with a human
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
10 : HMM and CRF. 1 Case Study: Supervised Part-of-Speech Tagging
 10-708: Probabilistic Graphical Models 10-708, Spring 2018 10 : HMM and CRF Lecturer: Kayhan Batmanghelich Scribes: Ben Lengerich, Michael Kleyman 1 Case Study: Supervised Part-of-Speech Tagging We will
10-708: Probabilistic Graphical Models 10-708, Spring 2018 10 : HMM and CRF Lecturer: Kayhan Batmanghelich Scribes: Ben Lengerich, Michael Kleyman 1 Case Study: Supervised Part-of-Speech Tagging We will
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project
 Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
Probabilistic Graphical Models
 2016 Robert Nowak Probabilistic Graphical Models 1 Introduction We have focused mainly on linear models for signals, in particular the subspace model x = Uθ, where U is a n k matrix and θ R k is a vector
2016 Robert Nowak Probabilistic Graphical Models 1 Introduction We have focused mainly on linear models for signals, in particular the subspace model x = Uθ, where U is a n k matrix and θ R k is a vector
Markov Networks. l Like Bayes Nets. l Graphical model that describes joint probability distribution using tables (AKA potentials)
") Markov Networks l Like Bayes Nets l Graphical model that describes joint probability distribution using tables (AKA potentials) l Nodes are random variables l Labels are outcomes over the variables Markov
Markov Networks l Like Bayes Nets l Graphical model that describes joint probability distribution using tables (AKA potentials) l Nodes are random variables l Labels are outcomes over the variables Markov
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 9: Expectation Maximiation (EM) Algorithm, Learning in Undirected Graphical Models Some figures courtesy
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 9: Expectation Maximiation (EM) Algorithm, Learning in Undirected Graphical Models Some figures courtesy
Undirected Graphical Models: Markov Random Fields
 Undirected Graphical Models: Markov Random Fields 40-956 Advanced Topics in AI: Probabilistic Graphical Models Sharif University of Technology Soleymani Spring 2015 Markov Random Field Structure: undirected
Undirected Graphical Models: Markov Random Fields 40-956 Advanced Topics in AI: Probabilistic Graphical Models Sharif University of Technology Soleymani Spring 2015 Markov Random Field Structure: undirected
Sparse Gaussian conditional random fields
 Sparse Gaussian conditional random fields Matt Wytock, J. ico Kolter School of Computer Science Carnegie Mellon University Pittsburgh, PA 53 {mwytock, zkolter}@cs.cmu.edu Abstract We propose sparse Gaussian
Sparse Gaussian conditional random fields Matt Wytock, J. ico Kolter School of Computer Science Carnegie Mellon University Pittsburgh, PA 53 {mwytock, zkolter}@cs.cmu.edu Abstract We propose sparse Gaussian
Latent Dirichlet Allocation Introduction/Overview
 Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Hierarchical Dirichlet Processes with Random Effects
 Hierarchical Dirichlet Processes with Random Effects Seyoung Kim Department of Computer Science University of California, Irvine Irvine, CA 92697-34 sykim@ics.uci.edu Padhraic Smyth Department of Computer
Hierarchical Dirichlet Processes with Random Effects Seyoung Kim Department of Computer Science University of California, Irvine Irvine, CA 92697-34 sykim@ics.uci.edu Padhraic Smyth Department of Computer
Deep Poisson Factorization Machines: a factor analysis model for mapping behaviors in journalist ecosystem
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Spectral Clustering. Spectral Clustering? Two Moons Data. Spectral Clustering Algorithm: Bipartioning. Spectral methods
 Spectral Clustering Seungjin Choi Department of Computer Science POSTECH, Korea seungjin@postech.ac.kr 1 Spectral methods Spectral Clustering? Methods using eigenvectors of some matrices Involve eigen-decomposition
Spectral Clustering Seungjin Choi Department of Computer Science POSTECH, Korea seungjin@postech.ac.kr 1 Spectral methods Spectral Clustering? Methods using eigenvectors of some matrices Involve eigen-decomposition
Unsupervised Image Segmentation Using Comparative Reasoning and Random Walks
 Unsupervised Image Segmentation Using Comparative Reasoning and Random Walks Anuva Kulkarni Carnegie Mellon University Filipe Condessa Carnegie Mellon, IST-University of Lisbon Jelena Kovacevic Carnegie
Unsupervised Image Segmentation Using Comparative Reasoning and Random Walks Anuva Kulkarni Carnegie Mellon University Filipe Condessa Carnegie Mellon, IST-University of Lisbon Jelena Kovacevic Carnegie
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc.
 Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Markov Networks. l Like Bayes Nets. l Graph model that describes joint probability distribution using tables (AKA potentials)
") Markov Networks l Like Bayes Nets l Graph model that describes joint probability distribution using tables (AKA potentials) l Nodes are random variables l Labels are outcomes over the variables Markov
Markov Networks l Like Bayes Nets l Graph model that describes joint probability distribution using tables (AKA potentials) l Nodes are random variables l Labels are outcomes over the variables Markov
Diagram Structure Recognition by Bayesian Conditional Random Fields
 Diagram Structure Recognition by Bayesian Conditional Random Fields Yuan Qi MIT CSAIL 32 Vassar Street Cambridge, MA, 0239, USA alanqi@csail.mit.edu Martin Szummer Microsoft Research 7 J J Thomson Avenue
Diagram Structure Recognition by Bayesian Conditional Random Fields Yuan Qi MIT CSAIL 32 Vassar Street Cambridge, MA, 0239, USA alanqi@csail.mit.edu Martin Szummer Microsoft Research 7 J J Thomson Avenue
PMR Learning as Inference
 Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Classical Predictive Models
 Laplace Max-margin Markov Networks Recent Advances in Learning SPARSE Structured I/O Models: models, algorithms, and applications Eric Xing epxing@cs.cmu.edu Machine Learning Dept./Language Technology
Laplace Max-margin Markov Networks Recent Advances in Learning SPARSE Structured I/O Models: models, algorithms, and applications Eric Xing epxing@cs.cmu.edu Machine Learning Dept./Language Technology
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
EEL 851: Biometrics. An Overview of Statistical Pattern Recognition EEL 851 1
 EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
Gaussian processes. Chuong B. Do (updated by Honglak Lee) November 22, 2008
 November 22, 2008") Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Transformation of Markov Random Fields for Marginal Distribution Estimation
 Transformation of Markov Random Fields for Marginal Distribution Estimation Masaki Saito Takayuki Okatani Tohoku University, Japan {msaito, okatani}@vision.is.tohoku.ac.jp Abstract This paper presents
Transformation of Markov Random Fields for Marginal Distribution Estimation Masaki Saito Takayuki Okatani Tohoku University, Japan {msaito, okatani}@vision.is.tohoku.ac.jp Abstract This paper presents
Learning MN Parameters with Alternative Objective Functions. Sargur Srihari
 Learning MN Parameters with Alternative Objective Functions Sargur srihari@cedar.buffalo.edu 1 Topics Max Likelihood & Contrastive Objectives Contrastive Objective Learning Methods Pseudo-likelihood Gradient
Learning MN Parameters with Alternative Objective Functions Sargur srihari@cedar.buffalo.edu 1 Topics Max Likelihood & Contrastive Objectives Contrastive Objective Learning Methods Pseudo-likelihood Gradient
Graph Cut based Inference with Co-occurrence Statistics
 Graph Cut based Inference with Co-occurrence Statistics Lubor Ladicky 1,3, Chris Russell 1,3, Pushmeet Kohli 2, and Philip H.S. Torr 1 1 Oxford Brookes 2 Microsoft Research Abstract. Markov and Conditional
Graph Cut based Inference with Co-occurrence Statistics Lubor Ladicky 1,3, Chris Russell 1,3, Pushmeet Kohli 2, and Philip H.S. Torr 1 1 Oxford Brookes 2 Microsoft Research Abstract. Markov and Conditional
Bayesian Nonparametrics
 Bayesian Nonparametrics Lorenzo Rosasco 9.520 Class 18 April 11, 2011 About this class Goal To give an overview of some of the basic concepts in Bayesian Nonparametrics. In particular, to discuss Dirichelet
Bayesian Nonparametrics Lorenzo Rosasco 9.520 Class 18 April 11, 2011 About this class Goal To give an overview of some of the basic concepts in Bayesian Nonparametrics. In particular, to discuss Dirichelet
LOCALITY PRESERVING HASHING. Electrical Engineering and Computer Science University of California, Merced Merced, CA 95344, USA
 LOCALITY PRESERVING HASHING Yi-Hsuan Tsai Ming-Hsuan Yang Electrical Engineering and Computer Science University of California, Merced Merced, CA 95344, USA ABSTRACT The spectral hashing algorithm relaxes
LOCALITY PRESERVING HASHING Yi-Hsuan Tsai Ming-Hsuan Yang Electrical Engineering and Computer Science University of California, Merced Merced, CA 95344, USA ABSTRACT The spectral hashing algorithm relaxes
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Dan Oneaţă 1 Introduction Probabilistic Latent Semantic Analysis (plsa) is a technique from the category of topic models. Its main goal is to model cooccurrence information
Probabilistic Latent Semantic Analysis Dan Oneaţă 1 Introduction Probabilistic Latent Semantic Analysis (plsa) is a technique from the category of topic models. Its main goal is to model cooccurrence information
Detecting Humans via Their Pose
 Detecting Humans via Their Pose Alessandro Bissacco Computer Science Department University of California, Los Angeles Los Angeles, CA 90095 bissacco@cs.ucla.edu Ming-Hsuan Yang Honda Research Institute
Detecting Humans via Their Pose Alessandro Bissacco Computer Science Department University of California, Los Angeles Los Angeles, CA 90095 bissacco@cs.ucla.edu Ming-Hsuan Yang Honda Research Institute
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Document and Topic Models: plsa and LDA
 Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Gaussian Models
 Gaussian Models ddebarr@uw.edu 2016-04-28 Agenda Introduction Gaussian Discriminant Analysis Inference Linear Gaussian Systems The Wishart Distribution Inferring Parameters Introduction Gaussian Density
Gaussian Models ddebarr@uw.edu 2016-04-28 Agenda Introduction Gaussian Discriminant Analysis Inference Linear Gaussian Systems The Wishart Distribution Inferring Parameters Introduction Gaussian Density
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Feedback Loop between High Level Semantics and Low Level Vision
 Feedback Loop between High Level Semantics and Low Level Vision Varun K. Nagaraja Vlad I. Morariu Larry S. Davis {varun,morariu,lsd}@umiacs.umd.edu University of Maryland, College Park, MD, USA. Abstract.
Feedback Loop between High Level Semantics and Low Level Vision Varun K. Nagaraja Vlad I. Morariu Larry S. Davis {varun,morariu,lsd}@umiacs.umd.edu University of Maryland, College Park, MD, USA. Abstract.
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For