Bayesian Nonparametrics
|
|
|
- Barnard Tracy Bryan
- 6 years ago
- Views:
Transcription
1 Bayesian Nonparametrics Lorenzo Rosasco Class 18 April 11, 2011
2 About this class Goal To give an overview of some of the basic concepts in Bayesian Nonparametrics. In particular, to discuss Dirichelet processes and their several characterizations and properties.
3 Plan Parametrics, nonparametrics and priors A reminder on distributions Dirichelet processes Definition Stick Breaking Pólya Urn Scheme and Chinese processes
4 References and Acknowledgments This lecture heavily draws (sometimes literally) from the list of references below, which we suggest as further readings. Figures are taken either from Sudderth PhD thesis or Teh Tutorial. Main references/sources: See also: Yee Whye Teh, Tutorial in the Machine Learning Summer School, and his notes Dirichelet Processes. Erik Sudderth, PhD Thesis. Gosh and Ramamoorthi, Bayesian Nonparametrics, (book). Zoubin Ghahramani, Tutorial ICML. Michael Jordan, Nips Tutorial. Rasmussen, Williams, Gaussian Processes for Machine Learning, (book). Ferguson, paper in Annals of Statistics. Sethuraman, paper in Statistica Sinica. Berlinet, Thomas-Agnan, RKHS in Probability and Statistics, (book). Thanks to Dan, Rus and Charlie for various discussions.
5 Parametrics vs Nonparametrics We can illustrate the difference between the two approaches considering the following prototype problems. 1 function estimation 2 density estimation
6 (Parametric) Function Estimation Data, S = (X, Y ) = (x i, y i ) n i=1 Model, y i = f θ (x i ) + ɛ i, e.g. f θ (x) = θ, x and ɛ N (0, σ 2 ), σ > 0. prior θ P(θ) posterior P(θ X, Y ) = prediction P(y x, X, Y ) = P(θ)P(Y X, θ) P(Y X) P(y x, θ)p(θ X, Y )dθ
7 (Parametric) Density Estimation Data, S = (x i ) n i=1 Model, x i F θ prior θ P(θ) posterior prediction P(θ X) = P(θ)P(X θ) P(X) P(x X) = P(x θ)p(θ X)dθ
8 Nonparametrics: a Working Definition In the above models the number of parameters available for learning is fixed a priori. Ideally the more data we have, the more parameters we would like to explore. This is in essence the idea underlying nonparametric models.
9 The Right to a Prior A finite sequence is exchangeable if its distribution does not change under permutation of the indices. A sequence is infinitely exchangeable if any finite subsequence is exchangeable. De Finetti s Theorem If the random variables (x i ) i=1 are infinitely exchangeable, then there exists some space Θ and a corresponding distribution p(θ), such that the joint distribution of n observations is given by: n P(x 1,..., x n ) = P(θ) P(x i θ)dθ. Θ i=1
10 Question The previous classical result is often advocated as a justification for considering (possibly infinite dimensional) priors. Can we find computationally efficient nonparametric models? We already met one when we considered the Bayesian interpretation of regularization...
11 Reminder: Stochastic Processes Stochastic Process A family (X t ) : (Ω, P) R, t T, of random variables over some index set T. Note that: X t (ω), ω Ω, is a number, X t ( ) is a random variable, X ( ) (ω) : T R is a function and is called sample path.
12 Gaussian Processes GP(f 0, K ), Gaussian Process (GP) with mean f 0 and covariance function K A family (G x ) x X of random variables over X such that: for any x 1,..., x n in X, G x1,..., G xn is a multivariate Gaussian. We can define the mean f 0 : X R of the GP from the mean f 0 (x 1 ),..., f 0 (x n ) and the covariance function K : X X R settting K (x i, x j ) equal to the corresponding entries of covariance matrix. Then K is symm., pos. def. function. A sample path of the GP can be thought of as a random function f GP(f 0, K ).
13 (Nonparametric) Function Estimation Data, S = (X, Y ) = (x i, y i ) n i=1 Model, y i = f (x i ) + ɛ i prior f GP(f 0, K ) posterior P(f X, Y ) = prediction P(y x, X, Y ) = P(f )P(Y X, f ) P(Y X) P(y x, f )P(f X, Y )df We have seen that the last equation can be computed in closed form.
14 (Nonparametric) Density Estimation Dirichelet Processes (DP) will give us a way to build nonparametric priors for density estimation. Data, S = (x i ) n i=1 Model, x i F prior F DP(α, H) posterior prediction P(F X) = P(F)P(X F) P(X) P(x X) = P(x F)P(F X)dF
15 Plan Parametrics, nonparametrics and priors A reminder on distributions Dirichelet processes Definition Stick Breaking Pólya Urn Scheme and Chinese processes
16 Dirichelet Distribution It is a distribution over the K-dimensional simplex S K, i.e. x R K such that K i=1 x i = 1 and x i 0 for all i. The Dirichelet distribution is given by P(x) = P(x 1,..., x K ) = Γ( K i=1 αi ) K i=1 Γ(αi ) K (x i ) αi 1 where α = (α 1,..., α K ) is a parameter vector and Γ is the Gamma function. We write x Dir(α), i.e. x 1,..., x K Dir(α 1,..., α K ). i=1


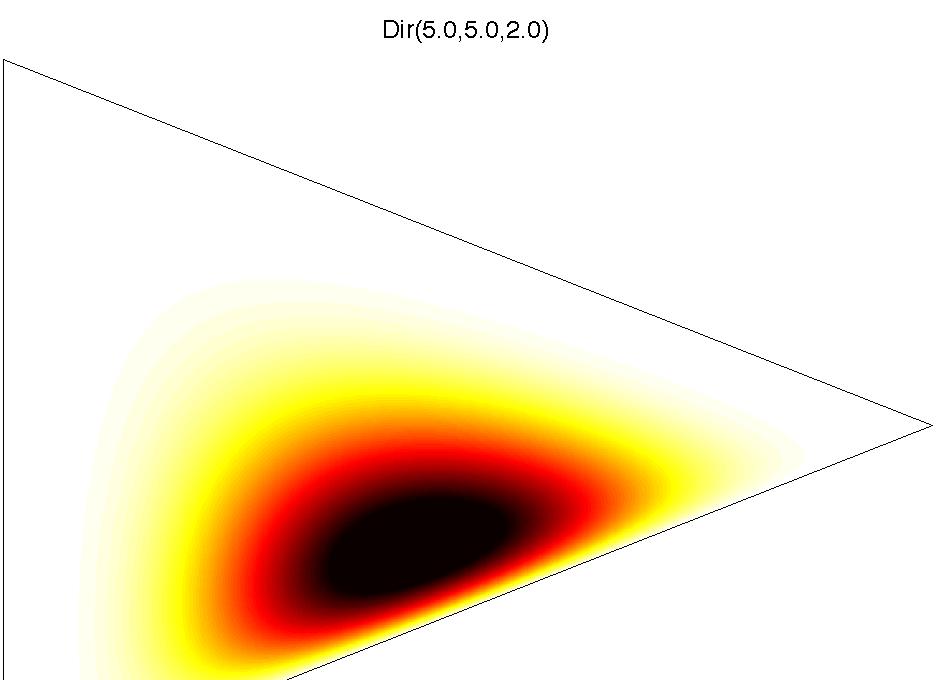
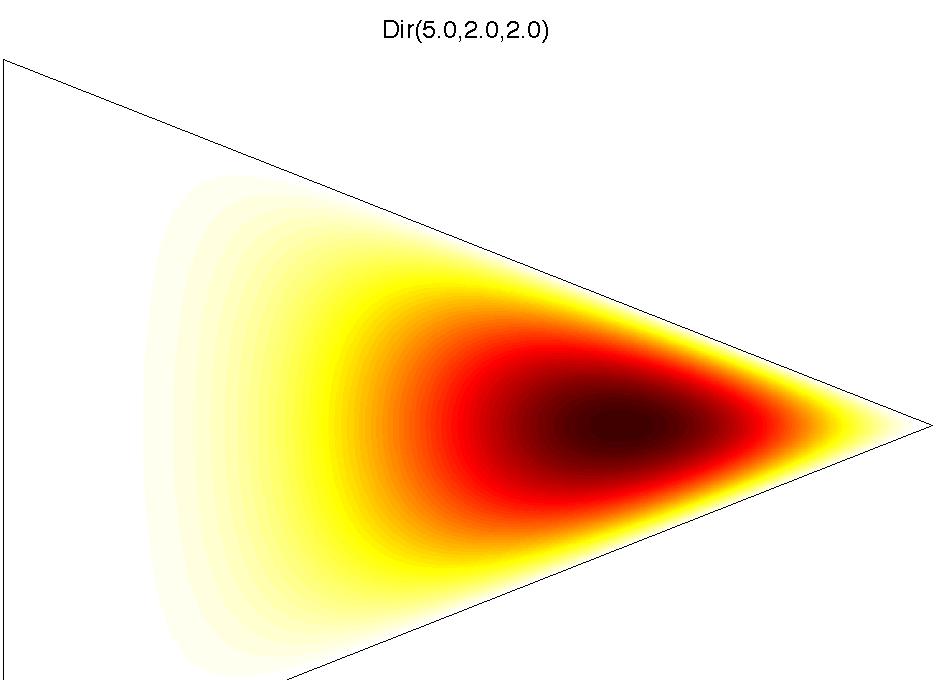
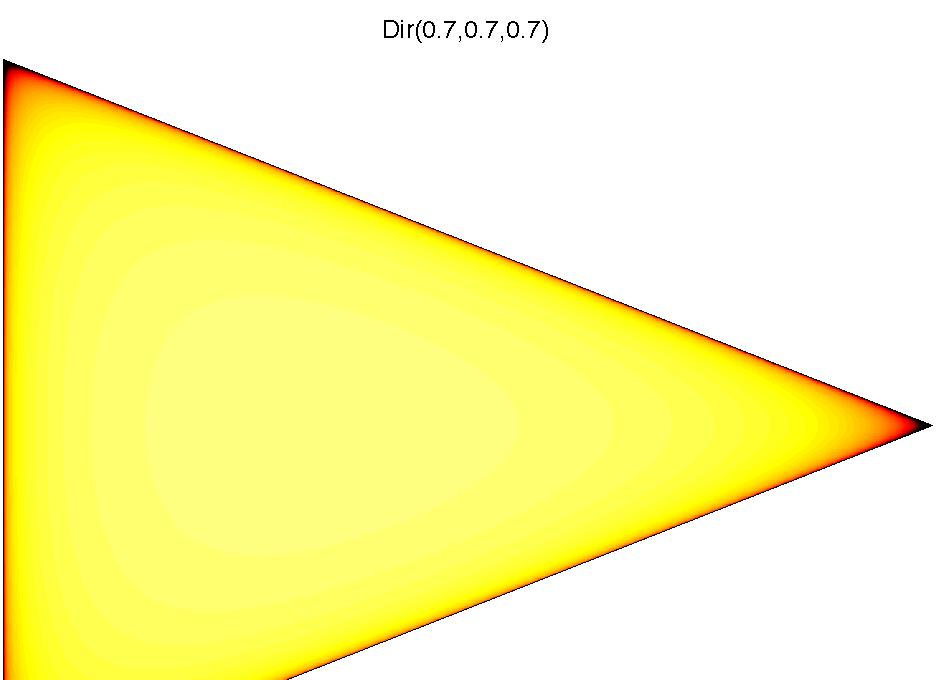

17 Dirichelet Dirichlet Distribution Processes Examples of Dirichlet distributions. university-log Yee Whye Teh (Gatsby) DP August 2007 / MLSS 28 / 80
18 Reminder: Gamma Function and Beta Distribution The Gamma function γ(z) = 0 t z 1 e t dt. It is possible to prove that Γ(z + 1) = zγ(z). Beta Distribution Special case of the Dirichelet distribution given by K = 2. P(x α, β) = Γ(α + β) Γ(α) + Γ(β) x (α 1) (1 x) (β 1) Note that here x [0, 1] whereas for the Dirichelet distribution we would have x = (x 1, x 2 ) with x 1, x 2 > 0 and x 1 + x 2 = 1.

 2 1.5 p(! \",#) 2 1.5 1 1 0.5 0.")

19 Beta Distribution " = 1, # = 1 " = 2, # = 2 " = 5, # = 3 " = 4, # = " = 1.0, # = 1.0 " = 1.0, # = 3.0 " = 1.0, # = 0.3 " = 0.3, # = p(! ",#) p(! ",#) ! ! For large parameters the distribution is unimodal. For small parameters it favors biased binomial distributions.! 2! 2
20 Properties of the Dirichelet Distribution Note that the K -simplex S K can be seen as the space of probabilities of a discrete (categorical) random variable with K possible values. Let α 0 = K i=1 αi. Expectation Variance Covariance E[x i ] = αi α 0. V[x i ] = αi (α 0 α i ) α 2 0 (α 0 + 1). Cov(x i, x j ) = α i α j α 2 0 (α 0 + 1).
21 Properties of the Dirichelet Distribution Aggregation: let (x 1,..., x K ) Dir(α 1,..., α K ) then (x 1 + x 2,..., x K ) Dir(α 1 + α 2,..., α K ). More generally, aggregation of any subset of the categories produces a Dirichelet distribution with parameters summed as above. The marginal distribution of any single component of a Dirichelet distribution follows a beta distribution.
22 Conjugate Priors Let X F and F P( α) = P α. P(F X, α) = P(F, α)p(x F, α) P(X, α) We say that P(F, α) is a conjugate prior for the likelihood P(X F, α) if, for any X and α, the posterior distribution P(F X, α) is in the same family of the prior. Moreover in this case the prior and the posterior distributions are then called conjugate distributions. The Dirichelet distribution is conjugate to the multinomial distribution
23 Multinomial Distribution Let X have values in {1,..., K }. Given π 1,..., π K define the probability mass function, multinomial distribution P(X π 1,..., π K ) = K i=1 π δ i (X) i. Given n observations the total probability of all possible sequences of length n taking those values is P(x 1,..., x n π 1,..., π K ) = n! K i=1 C i! K i=1 π C i i, where C i = n j=1 δ i(x j ) (C i is the number of observations with value i). For K = 2 this is just the binomial distribution.
24 Conjugate Posteriors and Predictions Given n observations S = x 1,..., x n from a multinomial distribution P( θ) with a Dirichelet prior P(θ α) we have P(θ S, α) P(θ α)p(s θ) K (θ i ) (α i +C i 1) Dir(α 1 + C 1,..., α K + C K ) i=1 where C i is the number of observations with value i.
25 Plan Parametrics, nonparametrics and priors A reminder on distributions Dirichelet processes Definition Stick Breaking Pólya Urn Scheme and Chinese processes
26 Dirichelet Processes Given a space X we denote with F a distribution on X and with F(X) the set of all possible distributions on X. Informal Description A Dirichelet process (DP) will be a distribution over F(X). A sample from a DP can be seen as a (random) probability distribution on X.
27 Dirichelet Processes (cont.) A partition of X is a collection of subsets B 1,..., B N is such that, if B i B j =, i j and N i=1 B i = X. Definition (Existence Theorem) Let α > 0 and H a probability distribution on X. One can prove that there exists a unique distribution DP(α, H) on F(X) such that, if F DP(α, H) and B 1,..., B N is a partition of X then (F(B 1 ),..., F(B N )) Dir(αH(B 1 ),..., αh(b N )). The above result is proved (Ferguson 73) using Kolmogorov s Consistency theorem (Kolmogorov 33).

28 Dirichelet Processes Illustrated Sec Dirichlet Processes 97 T 1 T 2 T 3 ~ T 1 ~ T 4 ~ T 5 ~ T 2 ~ T 3 Figure Dirichlet processes induce Dirichlet distributions on every finite, measurable partition. Left: An example base measure H on a bounded, two dimensional space Θ (darker regions have higher probability). Center: A partition with K = 3 cells. The weight that a random measure G DP(α,H) assigns to these cells follows a Dirichlet distribution (see eq. (2.166)). We shade each cell T k according to its mean E[G(T k)] = H(T k). Right: Another partition with K = 5 cells. The consistency of G implies, for example, that (G(T 1)+G(T 2)) and G( e T 1) follow identical beta distributions.
29 Dirichelet Processes (cont.) The previous definition is the one giving the name to the process. It is in fact also possible to show that a Dirichelet process corresponds to a stochastic process where the sample paths are probability distributions on X.
30 Properties of Dirichelet Processes Hereafter F DP(α, H) and A is a measurable set in X. Expectation: E[F(A)] = αh(a). Variance: V[F(A)] = H(A)(1 H(A)) α+1
31 Properties of Dirichelet Processes (cont.) Posterior and Conjugacy: let x F and consider a fixed partition B 1,..., B N, then P(F(B 1 ),..., F(B N ) x B k ) = Dir(αH(B 1 ),..., αh(b k ) + 1,..., αh(b N )). It is possible to prove that if S = (x 1,..., x n ) F, and F DP(α, H), then ( ( )) 1 n P(F S, α, H) = DP α + n, αh + δ xi n + α i=1
32 Plan Parametrics, nonparametrics and priors A reminder on distributions Dirichelet processes Definition Stick Breaking Pólya Urn Scheme and Chinese processes
33 A Qualitative Reasoning From the form of the posterior we have that ( E(F (A) S, α, H) = 1 αh(a) + n + α If α < and n one can argue that ) n δ xi (A). i=1 E(F(A) S, α, H) = π i δ xi (A) i=1 where (π i ) i=1 is the sequence corresponding to the limit lim n C i /n of the empirical frequencies of the observations (x i ) i=1. If the posterior concentrates about its mean the above reasoning suggests that the obtained distribution is discrete.
34 Stick Breaking Construction Explicit construction of a DP. Let α > 0, (π i ) i=1 such that i 1 i 1 π i = β i (1 β j ) = β i (1 π j ) j=1 where β i Beta(1, α), for all i. Let H be a distribution on X and define where θ i H, for all i. F = π i δ θi i=1 j=1
35 Stick Breaking Construction (cont.) it is possible to prove (Sethuraman 94) that the previous construction returns a DP and conversely a Dirichelet process is discrete almost surely.
36 Stick Breaking Construction: Interpretation Sec Dirichlet Processes 101 β 1 π 1 π β β 1 1 β 2! k ! k β3 π 3 π 4 1 β3 β 4 1 β 4 β k k ! k 0.2! k 0.2 π k k α =1 α =5 Figure Sequential stick breaking construction of the infinite set of mixture weights π GEM(α) corresponding to a measure G DP(α,H). Left: The first weight π 1 Beta(1, α). Each subsequent weight π k (red) is some random proportion β k (blue) of the remaining, unbroken stick of probability mass. Right: The first K = 20 weights generated by four random stick breaking constructions (two with α = 1, two with α = 5). Note that the weights π k do not monotonically decrease. The weights π partition a unit-length stick in an infinite set: the i-th weight is a random proportion β i of the stick remaining after sampling the first i 1 weights. discrete parameters {θ k } k=1. For a given α and dataset size N, there are strong bounds on the accuracy of particular finite truncations of this stick breaking process [147], which are often used in approximate computational methods [29, 147, 148, 289]. Several other stick breaking processes have been proposed which sample the proportions β from different distributions [147, 148, 233]. For example, the two parameter
37 The Role of the Strength Parameter Note that E[β i ] = 1/(1 + α). for small α, the first few components will have all the mass. for large α, F approaches the distribution H assigning uniform weights to the samples θ i.
38 Plan Parametrics, nonparametrics and priors A reminder on distributions Dirichelet processes Definition Stick Breaking Pólya Urn Scheme and Chinese processes
39 Pólya Urn Scheme The observation that a sample from a DP is discrete allows to simplify the form of the prediction distribution, ( E(F(A) S, α, H) = 1 αh(a) + n + α ) K N i δ xi (A). where N i are the number of observations with value i. In fact, It is possible to prove (Blackwell and MacQueen 94) that if the base measure has a density h, then ( P(x S, α, H) = 1 αh(x ) + n + α i=1 ) K N i δ xi (x ). i=1
40 Chinese Restaurant Processes The previous prediction distribution gives a distribution over partitions. Pitman and Dubins called it Chinese Restaurant Processes (CRP) inspired by the seemingly infinite seating capacity of restaurants in San Francisco s Chinatown.
41 Chinese Restaurant Processes (cont.) There is an infinite (countable) set of tables. First customer sits in the first table. Customer n sits at table k with probability n k α + n + 1, where n k is the number of customers at table k. Customer n sits at table k + 1 with probability α α + n + 1.
42 Number of Clusters and Strength Parameter It is possible to prove (Antoniak 77??) that the number of clusters K grows as α log n as we increase the number of observations n.
43 Dirichelet Process Mixture The clustering effect in DP arises from assuming that there are multiple observations having the same values. This is hardly the case in practice. Dirichelet Process Mixture (DPM) The above observation suggests to consider the following model, F DP(α, H), θ i F and x i G( θ i ). Usually G is a distribution in the exponential family and H = H(λ) a corresponding conjugate prior.
44 Dirichelet Process Mixture CRP give another representation of the DPM. Let z i denote the unique cluster associated to x i, then z i π and x i G(θ zi ). If we marginalize the indicator variables z i s we obtain an infinite mixture model P(x π, θ 1, θ 2,... ) = π i f (x θ i ) i=1
45 Dirichelet Process and Model Selection Rather than choosing a finite number of components K, the DP use the stick breaking construction to adapt the number of clusters to the data. The complexity of the model is controlled by the strength parameter α.
46 Conclusions DP provide a framework for nonparametric inference. Different characterizations shed light on different properties. DP mixtures allow to adapt the number of components to the number of samples......but the complexity of the model is controlled by the strength parameter α. Neither the posterior distribution nor the prediction distribution can be found analytically approximate inference is needed- see next class.
47 What about Generalizatoin Bounds? Note that ideally X F and F DP(α, H ) for some α, H and we can compute the posterior P = P(F X, α, H ). In practice we have only samples S = (x 1,..., x n ) F and have to choose α, H to compute P n = P(F S, α, H). [Consistency] Does P n approximate P (in some suitable sense)? [Model Selection] How should we choose α (and H)?
Dirichlet Processes: Tutorial and Practical Course
 Dirichlet Processes: Tutorial and Practical Course (updated) Yee Whye Teh Gatsby Computational Neuroscience Unit University College London August 2007 / MLSS Yee Whye Teh (Gatsby) DP August 2007 / MLSS
Dirichlet Processes: Tutorial and Practical Course (updated) Yee Whye Teh Gatsby Computational Neuroscience Unit University College London August 2007 / MLSS Yee Whye Teh (Gatsby) DP August 2007 / MLSS
Lecture 3a: Dirichlet processes
 Lecture 3a: Dirichlet processes Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced Topics
Lecture 3a: Dirichlet processes Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced Topics
Bayesian Nonparametrics: Dirichlet Process
 Bayesian Nonparametrics: Dirichlet Process Yee Whye Teh Gatsby Computational Neuroscience Unit, UCL http://www.gatsby.ucl.ac.uk/~ywteh/teaching/npbayes2012 Dirichlet Process Cornerstone of modern Bayesian
Bayesian Nonparametrics: Dirichlet Process Yee Whye Teh Gatsby Computational Neuroscience Unit, UCL http://www.gatsby.ucl.ac.uk/~ywteh/teaching/npbayes2012 Dirichlet Process Cornerstone of modern Bayesian
Bayesian Nonparametrics: Models Based on the Dirichlet Process
 Bayesian Nonparametrics: Models Based on the Dirichlet Process Alessandro Panella Department of Computer Science University of Illinois at Chicago Machine Learning Seminar Series February 18, 2013 Alessandro
Bayesian Nonparametrics: Models Based on the Dirichlet Process Alessandro Panella Department of Computer Science University of Illinois at Chicago Machine Learning Seminar Series February 18, 2013 Alessandro
A Brief Overview of Nonparametric Bayesian Models
 A Brief Overview of Nonparametric Bayesian Models Eurandom Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin Also at Machine
A Brief Overview of Nonparametric Bayesian Models Eurandom Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin Also at Machine
CS281B / Stat 241B : Statistical Learning Theory Lecture: #22 on 19 Apr Dirichlet Process I
 X i Ν CS281B / Stat 241B : Statistical Learning Theory Lecture: #22 on 19 Apr 2004 Dirichlet Process I Lecturer: Prof. Michael Jordan Scribe: Daniel Schonberg dschonbe@eecs.berkeley.edu 22.1 Dirichlet
X i Ν CS281B / Stat 241B : Statistical Learning Theory Lecture: #22 on 19 Apr 2004 Dirichlet Process I Lecturer: Prof. Michael Jordan Scribe: Daniel Schonberg dschonbe@eecs.berkeley.edu 22.1 Dirichlet
Dirichlet Process. Yee Whye Teh, University College London
 Dirichlet Process Yee Whye Teh, University College London Related keywords: Bayesian nonparametrics, stochastic processes, clustering, infinite mixture model, Blackwell-MacQueen urn scheme, Chinese restaurant
Dirichlet Process Yee Whye Teh, University College London Related keywords: Bayesian nonparametrics, stochastic processes, clustering, infinite mixture model, Blackwell-MacQueen urn scheme, Chinese restaurant
Lecture 16-17: Bayesian Nonparametrics I. STAT 6474 Instructor: Hongxiao Zhu
 Lecture 16-17: Bayesian Nonparametrics I STAT 6474 Instructor: Hongxiao Zhu Plan for today Why Bayesian Nonparametrics? Dirichlet Distribution and Dirichlet Processes. 2 Parameter and Patterns Reference:
Lecture 16-17: Bayesian Nonparametrics I STAT 6474 Instructor: Hongxiao Zhu Plan for today Why Bayesian Nonparametrics? Dirichlet Distribution and Dirichlet Processes. 2 Parameter and Patterns Reference:
Non-parametric Clustering with Dirichlet Processes
 Non-parametric Clustering with Dirichlet Processes Timothy Burns SUNY at Buffalo Mar. 31 2009 T. Burns (SUNY at Buffalo) Non-parametric Clustering with Dirichlet Processes Mar. 31 2009 1 / 24 Introduction
Non-parametric Clustering with Dirichlet Processes Timothy Burns SUNY at Buffalo Mar. 31 2009 T. Burns (SUNY at Buffalo) Non-parametric Clustering with Dirichlet Processes Mar. 31 2009 1 / 24 Introduction
Foundations of Nonparametric Bayesian Methods
 1 / 27 Foundations of Nonparametric Bayesian Methods Part II: Models on the Simplex Peter Orbanz http://mlg.eng.cam.ac.uk/porbanz/npb-tutorial.html 2 / 27 Tutorial Overview Part I: Basics Part II: Models
1 / 27 Foundations of Nonparametric Bayesian Methods Part II: Models on the Simplex Peter Orbanz http://mlg.eng.cam.ac.uk/porbanz/npb-tutorial.html 2 / 27 Tutorial Overview Part I: Basics Part II: Models
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
STAT Advanced Bayesian Inference
 1 / 32 STAT 625 - Advanced Bayesian Inference Meng Li Department of Statistics Jan 23, 218 The Dirichlet distribution 2 / 32 θ Dirichlet(a 1,...,a k ) with density p(θ 1,θ 2,...,θ k ) = k j=1 Γ(a j) Γ(
1 / 32 STAT 625 - Advanced Bayesian Inference Meng Li Department of Statistics Jan 23, 218 The Dirichlet distribution 2 / 32 θ Dirichlet(a 1,...,a k ) with density p(θ 1,θ 2,...,θ k ) = k j=1 Γ(a j) Γ(
Bayesian nonparametrics
 Bayesian nonparametrics 1 Some preliminaries 1.1 de Finetti s theorem We will start our discussion with this foundational theorem. We will assume throughout all variables are defined on the probability
Bayesian nonparametrics 1 Some preliminaries 1.1 de Finetti s theorem We will start our discussion with this foundational theorem. We will assume throughout all variables are defined on the probability
Dirichlet Processes and other non-parametric Bayesian models
 Dirichlet Processes and other non-parametric Bayesian models Zoubin Ghahramani http://learning.eng.cam.ac.uk/zoubin/ zoubin@cs.cmu.edu Statistical Machine Learning CMU 10-702 / 36-702 Spring 2008 Model
Dirichlet Processes and other non-parametric Bayesian models Zoubin Ghahramani http://learning.eng.cam.ac.uk/zoubin/ zoubin@cs.cmu.edu Statistical Machine Learning CMU 10-702 / 36-702 Spring 2008 Model
Bayesian Nonparametrics for Speech and Signal Processing
 Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Stochastic Processes, Kernel Regression, Infinite Mixture Models
 Stochastic Processes, Kernel Regression, Infinite Mixture Models Gabriel Huang (TA for Simon Lacoste-Julien) IFT 6269 : Probabilistic Graphical Models - Fall 2018 Stochastic Process = Random Function 2
Stochastic Processes, Kernel Regression, Infinite Mixture Models Gabriel Huang (TA for Simon Lacoste-Julien) IFT 6269 : Probabilistic Graphical Models - Fall 2018 Stochastic Process = Random Function 2
Non-parametric Bayesian Methods
 Non-parametric Bayesian Methods Uncertainty in Artificial Intelligence Tutorial July 25 Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London, UK Center for Automated Learning
Non-parametric Bayesian Methods Uncertainty in Artificial Intelligence Tutorial July 25 Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London, UK Center for Automated Learning
Infinite latent feature models and the Indian Buffet Process
 p.1 Infinite latent feature models and the Indian Buffet Process Tom Griffiths Cognitive and Linguistic Sciences Brown University Joint work with Zoubin Ghahramani p.2 Beyond latent classes Unsupervised
p.1 Infinite latent feature models and the Indian Buffet Process Tom Griffiths Cognitive and Linguistic Sciences Brown University Joint work with Zoubin Ghahramani p.2 Beyond latent classes Unsupervised
The Indian Buffet Process: An Introduction and Review
 Journal of Machine Learning Research 12 (2011) 1185-1224 Submitted 3/10; Revised 3/11; Published 4/11 The Indian Buffet Process: An Introduction and Review Thomas L. Griffiths Department of Psychology
Journal of Machine Learning Research 12 (2011) 1185-1224 Submitted 3/10; Revised 3/11; Published 4/11 The Indian Buffet Process: An Introduction and Review Thomas L. Griffiths Department of Psychology
Bayesian nonparametric latent feature models
 Bayesian nonparametric latent feature models François Caron UBC October 2, 2007 / MLRG François Caron (UBC) Bayes. nonparametric latent feature models October 2, 2007 / MLRG 1 / 29 Overview 1 Introduction
Bayesian nonparametric latent feature models François Caron UBC October 2, 2007 / MLRG François Caron (UBC) Bayes. nonparametric latent feature models October 2, 2007 / MLRG 1 / 29 Overview 1 Introduction
Probabilistic modeling of NLP
 Structured Bayesian Nonparametric Models with Variational Inference ACL Tutorial Prague, Czech Republic June 24, 2007 Percy Liang and Dan Klein Probabilistic modeling of NLP Document clustering Topic modeling
Structured Bayesian Nonparametric Models with Variational Inference ACL Tutorial Prague, Czech Republic June 24, 2007 Percy Liang and Dan Klein Probabilistic modeling of NLP Document clustering Topic modeling
Bayesian Nonparametric Models
 Bayesian Nonparametric Models David M. Blei Columbia University December 15, 2015 Introduction We have been looking at models that posit latent structure in high dimensional data. We use the posterior
Bayesian Nonparametric Models David M. Blei Columbia University December 15, 2015 Introduction We have been looking at models that posit latent structure in high dimensional data. We use the posterior
A Simple Proof of the Stick-Breaking Construction of the Dirichlet Process
 A Simple Proof of the Stick-Breaking Construction of the Dirichlet Process John Paisley Department of Computer Science Princeton University, Princeton, NJ jpaisley@princeton.edu Abstract We give a simple
A Simple Proof of the Stick-Breaking Construction of the Dirichlet Process John Paisley Department of Computer Science Princeton University, Princeton, NJ jpaisley@princeton.edu Abstract We give a simple
Lecturer: David Blei Lecture #3 Scribes: Jordan Boyd-Graber and Francisco Pereira October 1, 2007
 COS 597C: Bayesian Nonparametrics Lecturer: David Blei Lecture # Scribes: Jordan Boyd-Graber and Francisco Pereira October, 7 Gibbs Sampling with a DP First, let s recapitulate the model that we re using.
COS 597C: Bayesian Nonparametrics Lecturer: David Blei Lecture # Scribes: Jordan Boyd-Graber and Francisco Pereira October, 7 Gibbs Sampling with a DP First, let s recapitulate the model that we re using.
Haupthseminar: Machine Learning. Chinese Restaurant Process, Indian Buffet Process
 Haupthseminar: Machine Learning Chinese Restaurant Process, Indian Buffet Process Agenda Motivation Chinese Restaurant Process- CRP Dirichlet Process Interlude on CRP Infinite and CRP mixture model Estimation
Haupthseminar: Machine Learning Chinese Restaurant Process, Indian Buffet Process Agenda Motivation Chinese Restaurant Process- CRP Dirichlet Process Interlude on CRP Infinite and CRP mixture model Estimation
Outline. Binomial, Multinomial, Normal, Beta, Dirichlet. Posterior mean, MAP, credible interval, posterior distribution
 Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Nonparametric Bayesian Methods - Lecture I
 Nonparametric Bayesian Methods - Lecture I Harry van Zanten Korteweg-de Vries Institute for Mathematics CRiSM Masterclass, April 4-6, 2016 Overview of the lectures I Intro to nonparametric Bayesian statistics
Nonparametric Bayesian Methods - Lecture I Harry van Zanten Korteweg-de Vries Institute for Mathematics CRiSM Masterclass, April 4-6, 2016 Overview of the lectures I Intro to nonparametric Bayesian statistics
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Gentle Introduction to Infinite Gaussian Mixture Modeling
 Gentle Introduction to Infinite Gaussian Mixture Modeling with an application in neuroscience By Frank Wood Rasmussen, NIPS 1999 Neuroscience Application: Spike Sorting Important in neuroscience and for
Gentle Introduction to Infinite Gaussian Mixture Modeling with an application in neuroscience By Frank Wood Rasmussen, NIPS 1999 Neuroscience Application: Spike Sorting Important in neuroscience and for
A Process over all Stationary Covariance Kernels
 A Process over all Stationary Covariance Kernels Andrew Gordon Wilson June 9, 0 Abstract I define a process over all stationary covariance kernels. I show how one might be able to perform inference that
A Process over all Stationary Covariance Kernels Andrew Gordon Wilson June 9, 0 Abstract I define a process over all stationary covariance kernels. I show how one might be able to perform inference that
Nonparametric Mixed Membership Models
 5 Nonparametric Mixed Membership Models Daniel Heinz Department of Mathematics and Statistics, Loyola University of Maryland, Baltimore, MD 21210, USA CONTENTS 5.1 Introduction................................................................................
5 Nonparametric Mixed Membership Models Daniel Heinz Department of Mathematics and Statistics, Loyola University of Maryland, Baltimore, MD 21210, USA CONTENTS 5.1 Introduction................................................................................
Applied Nonparametric Bayes
 Applied Nonparametric Bayes Michael I. Jordan Department of Electrical Engineering and Computer Science Department of Statistics University of California, Berkeley http://www.cs.berkeley.edu/ jordan Acknowledgments:
Applied Nonparametric Bayes Michael I. Jordan Department of Electrical Engineering and Computer Science Department of Statistics University of California, Berkeley http://www.cs.berkeley.edu/ jordan Acknowledgments:
Bayesian non parametric approaches: an introduction
 Introduction Latent class models Latent feature models Conclusion & Perspectives Bayesian non parametric approaches: an introduction Pierre CHAINAIS Bordeaux - nov. 2012 Trajectory 1 Bayesian non parametric
Introduction Latent class models Latent feature models Conclusion & Perspectives Bayesian non parametric approaches: an introduction Pierre CHAINAIS Bordeaux - nov. 2012 Trajectory 1 Bayesian non parametric
Probability Background
 CS76 Spring 0 Advanced Machine Learning robability Background Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu robability Meure A sample space Ω is the set of all possible outcomes. Elements ω Ω are called sample
CS76 Spring 0 Advanced Machine Learning robability Background Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu robability Meure A sample space Ω is the set of all possible outcomes. Elements ω Ω are called sample
Hierarchical Models, Nested Models and Completely Random Measures
 See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/238729763 Hierarchical Models, Nested Models and Completely Random Measures Article March 2012
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/238729763 Hierarchical Models, Nested Models and Completely Random Measures Article March 2012
19 : Bayesian Nonparametrics: The Indian Buffet Process. 1 Latent Variable Models and the Indian Buffet Process
 10-708: Probabilistic Graphical Models, Spring 2015 19 : Bayesian Nonparametrics: The Indian Buffet Process Lecturer: Avinava Dubey Scribes: Rishav Das, Adam Brodie, and Hemank Lamba 1 Latent Variable
10-708: Probabilistic Graphical Models, Spring 2015 19 : Bayesian Nonparametrics: The Indian Buffet Process Lecturer: Avinava Dubey Scribes: Rishav Das, Adam Brodie, and Hemank Lamba 1 Latent Variable
Learning Bayesian network : Given structure and completely observed data
 Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
Learning Bayesian network : Given structure and completely observed data Probabilistic Graphical Models Sharif University of Technology Spring 2017 Soleymani Learning problem Target: true distribution
CSCI 5822 Probabilistic Model of Human and Machine Learning. Mike Mozer University of Colorado
 CSCI 5822 Probabilistic Model of Human and Machine Learning Mike Mozer University of Colorado Topics Language modeling Hierarchical processes Pitman-Yor processes Based on work of Teh (2006), A hierarchical
CSCI 5822 Probabilistic Model of Human and Machine Learning Mike Mozer University of Colorado Topics Language modeling Hierarchical processes Pitman-Yor processes Based on work of Teh (2006), A hierarchical
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Infinite Latent Feature Models and the Indian Buffet Process
 Infinite Latent Feature Models and the Indian Buffet Process Thomas L. Griffiths Cognitive and Linguistic Sciences Brown University, Providence RI 292 tom griffiths@brown.edu Zoubin Ghahramani Gatsby Computational
Infinite Latent Feature Models and the Indian Buffet Process Thomas L. Griffiths Cognitive and Linguistic Sciences Brown University, Providence RI 292 tom griffiths@brown.edu Zoubin Ghahramani Gatsby Computational
Lecture 10. Announcement. Mixture Models II. Topics of This Lecture. This Lecture: Advanced Machine Learning. Recap: GMMs as Latent Variable Models
 Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Sharing Clusters Among Related Groups: Hierarchical Dirichlet Processes
 Sharing Clusters Among Related Groups: Hierarchical Dirichlet Processes Yee Whye Teh (1), Michael I. Jordan (1,2), Matthew J. Beal (3) and David M. Blei (1) (1) Computer Science Div., (2) Dept. of Statistics
Sharing Clusters Among Related Groups: Hierarchical Dirichlet Processes Yee Whye Teh (1), Michael I. Jordan (1,2), Matthew J. Beal (3) and David M. Blei (1) (1) Computer Science Div., (2) Dept. of Statistics
GAUSSIAN PROCESS REGRESSION
 GAUSSIAN PROCESS REGRESSION CSE 515T Spring 2015 1. BACKGROUND The kernel trick again... The Kernel Trick Consider again the linear regression model: y(x) = φ(x) w + ε, with prior p(w) = N (w; 0, Σ). The
GAUSSIAN PROCESS REGRESSION CSE 515T Spring 2015 1. BACKGROUND The kernel trick again... The Kernel Trick Consider again the linear regression model: y(x) = φ(x) w + ε, with prior p(w) = N (w; 0, Σ). The
Nonparameteric Regression:
 Nonparameteric Regression: Nadaraya-Watson Kernel Regression & Gaussian Process Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Nonparameteric Regression: Nadaraya-Watson Kernel Regression & Gaussian Process Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Hierarchical Bayesian Languge Model Based on Pitman-Yor Processes. Yee Whye Teh
 Hierarchical Bayesian Languge Model Based on Pitman-Yor Processes Yee Whye Teh Probabilistic model of language n-gram model Utility i-1 P(word i word i-n+1 ) Typically, trigram model (n=3) e.g., speech,
Hierarchical Bayesian Languge Model Based on Pitman-Yor Processes Yee Whye Teh Probabilistic model of language n-gram model Utility i-1 P(word i word i-n+1 ) Typically, trigram model (n=3) e.g., speech,
Probabilistic Graphical Models
 School of Computer Science Probabilistic Graphical Models Infinite Feature Models: The Indian Buffet Process Eric Xing Lecture 21, April 2, 214 Acknowledgement: slides first drafted by Sinead Williamson
School of Computer Science Probabilistic Graphical Models Infinite Feature Models: The Indian Buffet Process Eric Xing Lecture 21, April 2, 214 Acknowledgement: slides first drafted by Sinead Williamson
Lecture 1: Bayesian Framework Basics
 Lecture 1: Bayesian Framework Basics Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de April 21, 2014 What is this course about? Building Bayesian machine learning models Performing the inference of
Lecture 1: Bayesian Framework Basics Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de April 21, 2014 What is this course about? Building Bayesian machine learning models Performing the inference of
Bayesian Statistics. Debdeep Pati Florida State University. April 3, 2017
 Bayesian Statistics Debdeep Pati Florida State University April 3, 2017 Finite mixture model The finite mixture of normals can be equivalently expressed as y i N(µ Si ; τ 1 S i ), S i k π h δ h h=1 δ h
Bayesian Statistics Debdeep Pati Florida State University April 3, 2017 Finite mixture model The finite mixture of normals can be equivalently expressed as y i N(µ Si ; τ 1 S i ), S i k π h δ h h=1 δ h
Non-parametric Bayesian Methods for Structured Topic Models
 Non-parametric Bayesian Methods for Structured Topic Models Lan Du October, 2012 A thesis submitted for the degree of Doctor of Philosophy of the Australian National University To my wife, Jiejuan Wang,
Non-parametric Bayesian Methods for Structured Topic Models Lan Du October, 2012 A thesis submitted for the degree of Doctor of Philosophy of the Australian National University To my wife, Jiejuan Wang,
Tree-Based Inference for Dirichlet Process Mixtures
 Yang Xu Machine Learning Department School of Computer Science Carnegie Mellon University Pittsburgh, USA Katherine A. Heller Department of Engineering University of Cambridge Cambridge, UK Zoubin Ghahramani
Yang Xu Machine Learning Department School of Computer Science Carnegie Mellon University Pittsburgh, USA Katherine A. Heller Department of Engineering University of Cambridge Cambridge, UK Zoubin Ghahramani
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Hierarchical Dirichlet Processes
 Hierarchical Dirichlet Processes Yee Whye Teh, Michael I. Jordan, Matthew J. Beal and David M. Blei Computer Science Div., Dept. of Statistics Dept. of Computer Science University of California at Berkeley
Hierarchical Dirichlet Processes Yee Whye Teh, Michael I. Jordan, Matthew J. Beal and David M. Blei Computer Science Div., Dept. of Statistics Dept. of Computer Science University of California at Berkeley
CPSC 540: Machine Learning
 CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
Spatial Bayesian Nonparametrics for Natural Image Segmentation
 Spatial Bayesian Nonparametrics for Natural Image Segmentation Erik Sudderth Brown University Joint work with Michael Jordan University of California Soumya Ghosh Brown University Parsing Visual Scenes
Spatial Bayesian Nonparametrics for Natural Image Segmentation Erik Sudderth Brown University Joint work with Michael Jordan University of California Soumya Ghosh Brown University Parsing Visual Scenes
Construction of Dependent Dirichlet Processes based on Poisson Processes
 1 / 31 Construction of Dependent Dirichlet Processes based on Poisson Processes Dahua Lin Eric Grimson John Fisher CSAIL MIT NIPS 2010 Outstanding Student Paper Award Presented by Shouyuan Chen Outline
1 / 31 Construction of Dependent Dirichlet Processes based on Poisson Processes Dahua Lin Eric Grimson John Fisher CSAIL MIT NIPS 2010 Outstanding Student Paper Award Presented by Shouyuan Chen Outline
arxiv: v1 [cs.lg] 22 Jun 2009
![arxiv: v1 [cs.lg] 22 Jun 2009](/thumbs/76/73986991.jpg "arxiv: v1 [cs.lg] 22 Jun 2009") Bayesian two-sample tests arxiv:0906.4032v1 [cs.lg] 22 Jun 2009 Karsten M. Borgwardt 1 and Zoubin Ghahramani 2 1 Max-Planck-Institutes Tübingen, 2 University of Cambridge June 22, 2009 Abstract In this
Bayesian two-sample tests arxiv:0906.4032v1 [cs.lg] 22 Jun 2009 Karsten M. Borgwardt 1 and Zoubin Ghahramani 2 1 Max-Planck-Institutes Tübingen, 2 University of Cambridge June 22, 2009 Abstract In this
Bayesian Mixture Modeling of Significant P Values: A Meta-Analytic Method to Estimate the Degree of Contamination from H 0 : Supplemental Material
 Bayesian Mixture Modeling of Significant P Values: A Meta-Analytic Method to Estimate the Degree of Contamination from H 0 : Supplemental Material Quentin Frederik Gronau 1, Monique Duizer 1, Marjan Bakker
Bayesian Mixture Modeling of Significant P Values: A Meta-Analytic Method to Estimate the Degree of Contamination from H 0 : Supplemental Material Quentin Frederik Gronau 1, Monique Duizer 1, Marjan Bakker
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Spatial Normalized Gamma Process
 Spatial Normalized Gamma Process Vinayak Rao Yee Whye Teh Presented at NIPS 2009 Discussion and Slides by Eric Wang June 23, 2010 Outline Introduction Motivation The Gamma Process Spatial Normalized Gamma
Spatial Normalized Gamma Process Vinayak Rao Yee Whye Teh Presented at NIPS 2009 Discussion and Slides by Eric Wang June 23, 2010 Outline Introduction Motivation The Gamma Process Spatial Normalized Gamma
Patterns of Scalable Bayesian Inference Background (Session 1)
") Patterns of Scalable Bayesian Inference Background (Session 1) Jerónimo Arenas-García Universidad Carlos III de Madrid jeronimo.arenas@gmail.com June 14, 2017 1 / 15 Motivation. Bayesian Learning principles
Patterns of Scalable Bayesian Inference Background (Session 1) Jerónimo Arenas-García Universidad Carlos III de Madrid jeronimo.arenas@gmail.com June 14, 2017 1 / 15 Motivation. Bayesian Learning principles
Lecture 6: Graphical Models: Learning
 Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Dirichlet Enhanced Latent Semantic Analysis
 Dirichlet Enhanced Latent Semantic Analysis Kai Yu Siemens Corporate Technology D-81730 Munich, Germany Kai.Yu@siemens.com Shipeng Yu Institute for Computer Science University of Munich D-80538 Munich,
Dirichlet Enhanced Latent Semantic Analysis Kai Yu Siemens Corporate Technology D-81730 Munich, Germany Kai.Yu@siemens.com Shipeng Yu Institute for Computer Science University of Munich D-80538 Munich,
Introduction to the Dirichlet Distribution and Related Processes
 Introduction to the Dirichlet Distribution and Related Processes Bela A. Frigyik, Amol Kapila, and Maya R. Gupta Department of Electrical Engineering University of Washington Seattle, WA 9895 {gupta}@ee.washington.edu
Introduction to the Dirichlet Distribution and Related Processes Bela A. Frigyik, Amol Kapila, and Maya R. Gupta Department of Electrical Engineering University of Washington Seattle, WA 9895 {gupta}@ee.washington.edu
Machine Learning Summer School
 Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
ICML Scalable Bayesian Inference on Point processes. with Gaussian Processes. Yves-Laurent Kom Samo & Stephen Roberts
 ICML 2015 Scalable Nonparametric Bayesian Inference on Point Processes with Gaussian Processes Machine Learning Research Group and Oxford-Man Institute University of Oxford July 8, 2015 Point Processes
ICML 2015 Scalable Nonparametric Bayesian Inference on Point Processes with Gaussian Processes Machine Learning Research Group and Oxford-Man Institute University of Oxford July 8, 2015 Point Processes
Infinite-State Markov-switching for Dynamic. Volatility Models : Web Appendix
 Infinite-State Markov-switching for Dynamic Volatility Models : Web Appendix Arnaud Dufays 1 Centre de Recherche en Economie et Statistique March 19, 2014 1 Comparison of the two MS-GARCH approximations
Infinite-State Markov-switching for Dynamic Volatility Models : Web Appendix Arnaud Dufays 1 Centre de Recherche en Economie et Statistique March 19, 2014 1 Comparison of the two MS-GARCH approximations
Colouring and breaking sticks, pairwise coincidence losses, and clustering expression profiles
 Colouring and breaking sticks, pairwise coincidence losses, and clustering expression profiles Peter Green and John Lau University of Bristol P.J.Green@bristol.ac.uk Isaac Newton Institute, 11 December
Colouring and breaking sticks, pairwise coincidence losses, and clustering expression profiles Peter Green and John Lau University of Bristol P.J.Green@bristol.ac.uk Isaac Newton Institute, 11 December
CSC 2541: Bayesian Methods for Machine Learning
 CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 4 Problem: Density Estimation We have observed data, y 1,..., y n, drawn independently from some unknown
CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 4 Problem: Density Estimation We have observed data, y 1,..., y n, drawn independently from some unknown
arxiv: v1 [stat.ml] 20 Nov 2012
![arxiv: v1 [stat.ml] 20 Nov 2012](/thumbs/76/73739913.jpg "arxiv: v1 [stat.ml] 20 Nov 2012") A survey of non-exchangeable priors for Bayesian nonparametric models arxiv:1211.4798v1 [stat.ml] 20 Nov 2012 Nicholas J. Foti 1 and Sinead Williamson 2 1 Department of Computer Science, Dartmouth College
A survey of non-exchangeable priors for Bayesian nonparametric models arxiv:1211.4798v1 [stat.ml] 20 Nov 2012 Nicholas J. Foti 1 and Sinead Williamson 2 1 Department of Computer Science, Dartmouth College
Bayesian Hidden Markov Models and Extensions
 Bayesian Hidden Markov Models and Extensions Zoubin Ghahramani Department of Engineering University of Cambridge joint work with Matt Beal, Jurgen van Gael, Yunus Saatci, Tom Stepleton, Yee Whye Teh Modeling
Bayesian Hidden Markov Models and Extensions Zoubin Ghahramani Department of Engineering University of Cambridge joint work with Matt Beal, Jurgen van Gael, Yunus Saatci, Tom Stepleton, Yee Whye Teh Modeling
Exchangeability. Peter Orbanz. Columbia University
 Exchangeability Peter Orbanz Columbia University PARAMETERS AND PATTERNS Parameters P(X θ) = Probability[data pattern] 3 2 1 0 1 2 3 5 0 5 Inference idea data = underlying pattern + independent noise Peter
Exchangeability Peter Orbanz Columbia University PARAMETERS AND PATTERNS Parameters P(X θ) = Probability[data pattern] 3 2 1 0 1 2 3 5 0 5 Inference idea data = underlying pattern + independent noise Peter
Motif representation using position weight matrix
 Motif representation using position weight matrix Xiaohui Xie University of California, Irvine Motif representation using position weight matrix p.1/31 Position weight matrix Position weight matrix representation
Motif representation using position weight matrix Xiaohui Xie University of California, Irvine Motif representation using position weight matrix p.1/31 Position weight matrix Position weight matrix representation
Lecture 2: From Linear Regression to Kalman Filter and Beyond
 Lecture 2: From Linear Regression to Kalman Filter and Beyond January 18, 2017 Contents 1 Batch and Recursive Estimation 2 Towards Bayesian Filtering 3 Kalman Filter and Bayesian Filtering and Smoothing
Lecture 2: From Linear Regression to Kalman Filter and Beyond January 18, 2017 Contents 1 Batch and Recursive Estimation 2 Towards Bayesian Filtering 3 Kalman Filter and Bayesian Filtering and Smoothing
Advanced Machine Learning
 Advanced Machine Learning Nonparametric Bayesian Models --Learning/Reasoning in Open Possible Worlds Eric Xing Lecture 7, August 4, 2009 Reading: Eric Xing Eric Xing @ CMU, 2006-2009 Clustering Eric Xing
Advanced Machine Learning Nonparametric Bayesian Models --Learning/Reasoning in Open Possible Worlds Eric Xing Lecture 7, August 4, 2009 Reading: Eric Xing Eric Xing @ CMU, 2006-2009 Clustering Eric Xing
Truncation error of a superposed gamma process in a decreasing order representation
 Truncation error of a superposed gamma process in a decreasing order representation B julyan.arbel@inria.fr Í www.julyanarbel.com Inria, Mistis, Grenoble, France Joint work with Igor Pru nster (Bocconi
Truncation error of a superposed gamma process in a decreasing order representation B julyan.arbel@inria.fr Í www.julyanarbel.com Inria, Mistis, Grenoble, France Joint work with Igor Pru nster (Bocconi
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Bayesian nonparametric latent feature models
 Bayesian nonparametric latent feature models Indian Buffet process, beta process, and related models François Caron Department of Statistics, Oxford Applied Bayesian Statistics Summer School Como, Italy
Bayesian nonparametric latent feature models Indian Buffet process, beta process, and related models François Caron Department of Statistics, Oxford Applied Bayesian Statistics Summer School Como, Italy
Review of Probabilities and Basic Statistics
 Alex Smola Barnabas Poczos TA: Ina Fiterau 4 th year PhD student MLD Review of Probabilities and Basic Statistics 10-701 Recitations 1/25/2013 Recitation 1: Statistics Intro 1 Overview Introduction to
Alex Smola Barnabas Poczos TA: Ina Fiterau 4 th year PhD student MLD Review of Probabilities and Basic Statistics 10-701 Recitations 1/25/2013 Recitation 1: Statistics Intro 1 Overview Introduction to
Bayesian nonparametric estimation of finite population quantities in absence of design information on nonsampled units
 Bayesian nonparametric estimation of finite population quantities in absence of design information on nonsampled units Sahar Z Zangeneh Robert W. Keener Roderick J.A. Little Abstract In Probability proportional
Bayesian nonparametric estimation of finite population quantities in absence of design information on nonsampled units Sahar Z Zangeneh Robert W. Keener Roderick J.A. Little Abstract In Probability proportional
Overview of Course. Nevin L. Zhang (HKUST) Bayesian Networks Fall / 58
 Bayesian Networks Fall / 58") Overview of Course So far, we have studied The concept of Bayesian network Independence and Separation in Bayesian networks Inference in Bayesian networks The rest of the course: Data analysis using Bayesian
Overview of Course So far, we have studied The concept of Bayesian network Independence and Separation in Bayesian networks Inference in Bayesian networks The rest of the course: Data analysis using Bayesian
arxiv: v2 [stat.ml] 4 Aug 2011
![arxiv: v2 [stat.ml] 4 Aug 2011](/thumbs/87/95597257.jpg "arxiv: v2 [stat.ml] 4 Aug 2011") A Tutorial on Bayesian Nonparametric Models Samuel J. Gershman 1 and David M. Blei 2 1 Department of Psychology and Neuroscience Institute, Princeton University 2 Department of Computer Science, Princeton
A Tutorial on Bayesian Nonparametric Models Samuel J. Gershman 1 and David M. Blei 2 1 Department of Psychology and Neuroscience Institute, Princeton University 2 Department of Computer Science, Princeton
Chapter 8 PROBABILISTIC MODELS FOR TEXT MINING. Yizhou Sun Department of Computer Science University of Illinois at Urbana-Champaign
 Chapter 8 PROBABILISTIC MODELS FOR TEXT MINING Yizhou Sun Department of Computer Science University of Illinois at Urbana-Champaign sun22@illinois.edu Hongbo Deng Department of Computer Science University
Chapter 8 PROBABILISTIC MODELS FOR TEXT MINING Yizhou Sun Department of Computer Science University of Illinois at Urbana-Champaign sun22@illinois.edu Hongbo Deng Department of Computer Science University
An Introduction to Bayesian Nonparametric Modelling
 An Introduction to Bayesian Nonparametric Modelling Yee Whye Teh Gatsby Computational Neuroscience Unit University College London October, 2009 / Toronto Outline Some Examples of Parametric Models Bayesian
An Introduction to Bayesian Nonparametric Modelling Yee Whye Teh Gatsby Computational Neuroscience Unit University College London October, 2009 / Toronto Outline Some Examples of Parametric Models Bayesian
Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model
 Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model (& discussion on the GPLVM tech. report by Prof. N. Lawrence, 06) Andreas Damianou Department of Neuro- and Computer Science,
Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model (& discussion on the GPLVM tech. report by Prof. N. Lawrence, 06) Andreas Damianou Department of Neuro- and Computer Science,
Image segmentation combining Markov Random Fields and Dirichlet Processes
 Image segmentation combining Markov Random Fields and Dirichlet Processes Jessica SODJO IMS, Groupe Signal Image, Talence Encadrants : A. Giremus, J.-F. Giovannelli, F. Caron, N. Dobigeon Jessica SODJO
Image segmentation combining Markov Random Fields and Dirichlet Processes Jessica SODJO IMS, Groupe Signal Image, Talence Encadrants : A. Giremus, J.-F. Giovannelli, F. Caron, N. Dobigeon Jessica SODJO
Probabilistic & Unsupervised Learning
 Probabilistic & Unsupervised Learning Gaussian Processes Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College London
Probabilistic & Unsupervised Learning Gaussian Processes Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College London
TWO MODELS INVOLVING BAYESIAN NONPARAMETRIC TECHNIQUES
 TWO MODELS INVOLVING BAYESIAN NONPARAMETRIC TECHNIQUES By SUBHAJIT SENGUPTA A DISSERTATION PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE
TWO MODELS INVOLVING BAYESIAN NONPARAMETRIC TECHNIQUES By SUBHAJIT SENGUPTA A DISSERTATION PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE
Nonparmeteric Bayes & Gaussian Processes. Baback Moghaddam Machine Learning Group
 Nonparmeteric Bayes & Gaussian Processes Baback Moghaddam baback@jpl.nasa.gov Machine Learning Group Outline Bayesian Inference Hierarchical Models Model Selection Parametric vs. Nonparametric Gaussian
Nonparmeteric Bayes & Gaussian Processes Baback Moghaddam baback@jpl.nasa.gov Machine Learning Group Outline Bayesian Inference Hierarchical Models Model Selection Parametric vs. Nonparametric Gaussian
Factor Analysis and Indian Buffet Process
 Factor Analysis and Indian Buffet Process Lecture 4 Peixian Chen pchenac@cse.ust.hk Department of Computer Science and Engineering Hong Kong University of Science and Technology March 25, 2013 Peixian
Factor Analysis and Indian Buffet Process Lecture 4 Peixian Chen pchenac@cse.ust.hk Department of Computer Science and Engineering Hong Kong University of Science and Technology March 25, 2013 Peixian
An Introduction to Bayesian Machine Learning
 1 An Introduction to Bayesian Machine Learning José Miguel Hernández-Lobato Department of Engineering, Cambridge University April 8, 2013 2 What is Machine Learning? The design of computational systems
1 An Introduction to Bayesian Machine Learning José Miguel Hernández-Lobato Department of Engineering, Cambridge University April 8, 2013 2 What is Machine Learning? The design of computational systems
Collapsed Variational Dirichlet Process Mixture Models
 Collapsed Variational Dirichlet Process Mixture Models Kenichi Kurihara Dept. of Computer Science Tokyo Institute of Technology, Japan kurihara@mi.cs.titech.ac.jp Max Welling Dept. of Computer Science
Collapsed Variational Dirichlet Process Mixture Models Kenichi Kurihara Dept. of Computer Science Tokyo Institute of Technology, Japan kurihara@mi.cs.titech.ac.jp Max Welling Dept. of Computer Science
COS513 LECTURE 8 STATISTICAL CONCEPTS
 COS513 LECTURE 8 STATISTICAL CONCEPTS NIKOLAI SLAVOV AND ANKUR PARIKH 1. MAKING MEANINGFUL STATEMENTS FROM JOINT PROBABILITY DISTRIBUTIONS. A graphical model (GM) represents a family of probability distributions
COS513 LECTURE 8 STATISTICAL CONCEPTS NIKOLAI SLAVOV AND ANKUR PARIKH 1. MAKING MEANINGFUL STATEMENTS FROM JOINT PROBABILITY DISTRIBUTIONS. A graphical model (GM) represents a family of probability distributions
CMPS 242: Project Report
 CMPS 242: Project Report RadhaKrishna Vuppala Univ. of California, Santa Cruz vrk@soe.ucsc.edu Abstract The classification procedures impose certain models on the data and when the assumption match the
CMPS 242: Project Report RadhaKrishna Vuppala Univ. of California, Santa Cruz vrk@soe.ucsc.edu Abstract The classification procedures impose certain models on the data and when the assumption match the
Nonparametric Probabilistic Modelling
 Nonparametric Probabilistic Modelling Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Signal processing and inference
Nonparametric Probabilistic Modelling Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Signal processing and inference
Nonparametric Bayesian Models for Sparse Matrices and Covariances
 Nonparametric Bayesian Models for Sparse Matrices and Covariances Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Bayes
Nonparametric Bayesian Models for Sparse Matrices and Covariances Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Bayes
Lecture 2: From Linear Regression to Kalman Filter and Beyond
 Lecture 2: From Linear Regression to Kalman Filter and Beyond Department of Biomedical Engineering and Computational Science Aalto University January 26, 2012 Contents 1 Batch and Recursive Estimation
Lecture 2: From Linear Regression to Kalman Filter and Beyond Department of Biomedical Engineering and Computational Science Aalto University January 26, 2012 Contents 1 Batch and Recursive Estimation
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College