European Workshop on Reinforcement Learning A POMDP Tutorial. Joelle Pineau. McGill University
|
|
|
- Pamela Lawson
- 6 years ago
- Views:
Transcription
1 European Workshop on Reinforcement Learning 2013 A POMDP Tutorial Joelle Pineau McGill University (With many slides & pictures from Mauricio Araya-Lopez and others.) August 2013

2 Sequential decision-making under uncertainty



3 Sequential decision-making under uncertainty
4 Partially Observable MDP POMDP defined by n-tuple <S, A, Z, T, O, R>, where <S, A, T, R> are same as in an MDP. States are hidden Observations (Z) Observation function O(s,a,z) := Pr(z s, a) Hidden S 0... T T S t 1 S t S t+1 r t r t+1 Visible... O O O Z t 1 A t Z t A t+1 Z t+1
5 Belief-MDP (Astrom, 1965) Belief-state, b t : Probability distribution over states, is a sufficient statistic of history {a 0, z 0, a t, z t }. Hidden S 0... T T S t 1 S t S t+1 Karl Åström r t r t+1 The belief simplex Visible... O O O A t+1 Z t 1 A t Z t Z t+1 2 states Belief b 0... b t 1 τ b t τ b t+1 3 states 4 states
6 Belief-MDP (Astrom, 1965) Belief MDP: S, A, Z,T,O, R! ", A,!, ", b 0 Hidden S 0 Transition function:! (b, a, b') Expected reward:... "!(b, a) = b(s)r(s, a) s!s T T S t 1 S t S t+1 r t r t+1 Karl Åström The belief simplex Visible... O O O A t+1 Z t 1 A t Z t Z t+1 2 states Belief b 0... b t 1 τ b t τ b t+1 3 states 4 states
7 Belief-MDP (Astrom, 1965) Belief update: Bayes Rule! Value fn: Bellman s equation! Policy: π : b a Hidden S 0... T T S t 1 S t S t+1 Karl Åström r t r t+1 The belief simplex Visible... O O O A t+1 Z t 1 A t Z t Z t+1 2 states Belief b 0... b t 1 τ b t τ b t+1 3 states 4 states
 is therefore")

 = b(s)r(s, a) s!")
8 Early POMDP solution methods Observe: Reward function is linear V t* (b) is therefore piecewise linear and convex. Set of hyper-planes, named α-vectors, represent value function V(b) = max! # b!!" "!(b, a) = b(s)r(s, a) s!s Edward Sondik (a) (b) (c) value value value 0 b 1 0 b 1 0 b 1
9 V (b) α V (b) α Early POMDP solution methods ρ(b, a) = b(s)r(s, a) s a) = " b(s)r(s, a) Observe: Reward function is linear! (b, (b) s!s V ρ(b, a) = b(s)r(s, a) t s Vt*(b) is therefore piecewise linear and convex. Vt (b) V (b) = max α b α Γ Set of hyper-planes, named α-vectors, represent value V (b) = max α b function V (b) = max! # b!!" α Γ Edward Sondik


10 Solving small information-gathering problems From Mauricio Araya-Lopez, JFPDA 2013.


11 Approximate belief discretization methods Apply Bellman over a discretization of the belief space. Various methods to select discretization (regular, adaptive). Polynomial-time approximate algorithm. William Lovejoy Bounded error that depends on the grid resolution. Ronen Brafman Milos Hauskrecht
12 Gridworld POMDPs Solved!





 b 1 b 0 b a,z a,z 2")
13 Point-based value iteration (Pineau et al., 2003) Select a small set of reachable belief points. Perform Bellman updates at those points, keeping value & gradient. Anytime and polynomial algorithm. Bounded error depends on density of points. V(b) b 1 b 0 b a,z a,z 2 cision-making under uncertainty 15 P(s 1 ) Joelle Pi


14 POMDPs with thousands of states SOLVED!

15 Harder problem: Robocup Rescue Simulation Highly dynamic environment. Approx. 30 agents of 6 types Partially observable state. Real-time constraints on agents response time. Agents face unknown instances of the environment. From Sébastien Paquet et al., 2005
16 Online planning Offline: Policy Construction Policy Execution Online:





 Chaib-draa,")
17 Online search for POMDP solutions Build an AND/OR tree of the reachable belief states, from the current belief b 0 :" " Approaches:" Branch-and-bound Heuristic search Monte-Carlo Tree Search " (Paquet, Tobin & (Ross, Pineau, (McAllester & Singh, 1999) (Silver & Veness, 2010) Chaib-draa, 2005) Paquet, Chaib-draa, 2008)

18 Are we done yet? Pocman problem: S =10 56, A =4, Z =


19 There is no simulator for this!
20 Learning POMDPs from data Expectation-maximization» Online nested EM (Liu, Liao & Carin, 2013)» Model-free RL as mixture learning (Vlassis & Toussaint, 2009) History-based methods» U-Tree (McCallum, 1996)» MC-AIXI (Veness, Ng, Hutter, Uther & Silver, 2011) Predictive state representations» PSRs (Littman, Sutton, Singh, 2002)» TPSRs (Boots & Gordon, 2010)» Compressed PSRs (Hamilton, Fard & Pineau, 2013) Bayesian learning» Bayes-Adaptive POMDP (Ross, Chaib-draa & Pineau, 2007)» Infinite POMDP (Doshi-Velez, 2009)
21 Compressed Predictive State Representations (CPSRs) Goal: Efficiently learn a model of a dynamical system using time-series data, when you have: large discrete observation spaces; partial observability; sparsity.
22 The PSR systems dynamics matrix

23 Sparsity Assume that only a subset of tests is possible given any history h i. Sparse structure can be exploited using random projections.
24 Algorithm CPSR Algorithm Obtain compressed estimates for sub-matrices of D, ΦP T,H, ΦP T,o l,h s, and P H by sampling time series data. Estimate ΦP T,H in compressed space by adding φ i to column j each time t i observed after h i (Likewise for ΦP T,o l,hs). Compute CPSR model: c 0 = Φ ˆP(τ ) C o = ΦP T,o l,h(φp T,H ) + c =(ΦP T,H ) + ˆP H State definition and necessary equations c 0 serves as initial prediction vector (i.e. state vector). Update state vector after seeing observation with c t+1 = C oc t C C o c t Predict k-steps into the future using P(o j t+k h t)=b C o j (C ) k 1 C t where C = o i O C o i.
25 Theory overview Error of the CPSR parameters With probability no less than 1 δ we have: C o (ΦP Q,h ) ΦP Q,o,h ρ(x) d( H, Q, d, L o, σ 2 o, δ/d) Error propagation The total propagated error for T steps is bounded by (c T 1)/(c 1). Projection size A projection size of d = O(k log Q ) suffices in a majority of systems.
 15 10 5 0 CPSR TPSR Prediction Error 0.012 0.01 0.008 0.006 0.")
26 GridWorld Results TPSR runtime (minutes) CPSR TPSR Prediction Error CPSR Steps Ahead to Predict

27 Poc-Man Results CPSR All Tests TPSR Single Length Tests Prediction Error
28 Learning POMDPs from data Expectation-maximization» Online nested EM (Liu, Liao & Carin, 2013)» Model-free RL as mixture learning (Vlassis & Toussaint, 2009) History-based methods» U-Tree (McCallum, 1996)» MC-AIXI (Veness, Ng, Hutter, Uther & Silver, 2011) Predictive state representations» PSRs (Littman, Sutton, Singh, 2002)» TPSRs (Boots & Gordon, 2010)» Compressed PSRs (Hamilton, Fard & Pineau, 2013) Bayesian learning» Bayes-Adaptive POMDP (Ross, Chaib-draa & Pineau, 2007)» Infinite POMDP (Doshi-Velez, 2009)
29 Bayesian learning: POMDPS Estimate POMDP model parameters using Bayesian inference: T: Estimate a posterior ϕ a ss on the incidence of transitions s a s. O: Estimate a posterior ψ a sz on the incidence of observations s a z. R: Assume for now this is known (straight-forward extension.) Goal: Maximize expected return under partial observability of (s, ϕ, ψ). This is also a POMDP problem: S : physical state (s S) + information state (ϕ, ψ) T : describes probability of update (s, ϕ, ψ) a (s, ϕ, ψ ) O : describes probability of observing count increment.

30 Bayes-Adaptive POMDPs [Ross et al. JMLR 11] Learning = Tracking the hyper-state A solution to this problem is an optimal plan to act and learn!
31 Bayes-Adaptive POMDPs: Belief tracking Assume S, A, Z are discrete. Model ϕ, ψ using Dirichlet distributions. Initial hyper-belief: b 0 (s, ϕ, ψ ) = b 0 (s) I(ϕ=ϕ 0 ) I(ψ=ψ 0 ) where b 0 (s) is the initial belief over original state space I( ) is the indicator function (ϕ 0, ψ 0 ) are the initial counts (prior on T, O) Updating b t defines a mixture of Dirichlets, with O( S t+1 ) components. In practice, approximate with a particle filter.
 2. K most probable hyper-states (MP) 3.")
32 Bayes-Adaptive POMDPs: Belief tracking Different ways of approximating b t (s, φ, ψ) via particle filtering: 1. Monte-Carlo sampling (MC) 2. K most probable hyper-states (MP) 3. Risk-sensitive filtering with weighted distance metric:
 motion behaviors. Learn ϕ 1 ~ Dir( α 11,, α K 1 ), ϕ 2 ~ Dir( α 12,, α K 2 ), a motion model of each person.")
33 Bayes-Adaptive POMDPs: Preliminary results Follow domain: A robot must follow one of two individuals in a 2D open area. Their identity is not observable. They have different (unknown) motion behaviors. Learn ϕ 1 ~ Dir( α 11,, α K 1 ), ϕ 2 ~ Dir( α 12,, α K 2 ), a motion model of each person. Bayesian POMDP results: Learning is achieved, if you track the important hyper-beliefs.

34 Bayes-Adaptive POMDPs: Planning Receding horizon control to estimate the value of each action at current belief, b t. Usually consider a short horizon of reachable beliefs. Use pruning and heuristics to reach longer planning horizons.
35 Bayes-Adaptive POMDPs: Preliminary results RockSample domain [Smith&Simmons, 2004]: A robot must move around its environment in order to gather samples of good rocks, while avoiding bad rocks. Learn ψ ~ Dir( α 11,, α d 1 ), the accuracy of the rock quality sensor. Results: Again, learning is achieved, converging to the optimal solution. In this case, most probable particle selection is better.
36 Case study #1: Dialogue management Estimate O(s,a,z) using Bayes-adaptive POMDP. [Png & Pineau ICASSP 11] Reduce number of parameters to learn via hand-coded symmetry. Consider both a good prior (ψ=0.8) and a weak prior (ψ=0.6) Empirical returns show good learning. Using domain-knowledge to constrain the structure is more useful than having accurate priors. Can we infer this structure from data?
 A A = A Z = S T (s, G, θ G, a, s, G, θ G ) = Pr(s s, G, θ G, a) Pr(G, θ G G, θ G, s, a, s ) Approximate posterior Pr( G a h ) using a particle")
37 Case study #2: Learning a factored model Consider a factored model, where both the graph structure and transition parameters are unknown. [Ross & Pineau. UAI 08] Bayesian POMDP framework: S = S x (G, θ G ) A A = A Z = S T (s, G, θ G, a, s, G, θ G ) = Pr(s s, G, θ G, a) Pr(G, θ G G, θ G, s, a, s ) Approximate posterior Pr( G a h ) using a particle filter. Guestrin et al. JAIR 03 Maintain exact posterior Pr( θ G G a ) using Dirichlet distributions. Solve the planning problem using online forward search.
38 Case study #2: Learning a factored model Network administration domain [Guestrin et al. JAIR 03]» Two-part densely connected network.» Each node is a machine (on/off state).» Actions: reboot any machine, do nothing. Bayesian RL results: Learning the structure and parameters simultaneously improves performance.
39 Case study #3: Multitasking SLAM SLAM = Simultaneous Localization and Mapping» One of the key problems in robotics.» Usually solved with techniques such as EM. [Guez & Pineau. ICRA 10] Active SLAM = Simultaneous Planning, Localization, and Mapping» Can be cast as a POMDP problem.» Often, greedy exploration techniques perform best. Multitasking SLAM = Active SLAM + other simultaneous task e.g. target following / avoidance
40 Case study #3: Multitasking SLAM The image cannot be displayed. Your computer may not have enough memory to open the image, or the image may have been corrupted. Restart your computer, and then open the file again. If the red x still appears, you may have to delete the image and then insert it again.
41 Case study #3: Multitasking SLAM Decision-theoretic framework: State space: S = X x M x P X = set of possible trajectories taken M = set of possible maps P = set of additional planning states Actions: A = D x θ D = forward displacement θ = angular displacement Observations: Z = L x U L = laser range-finder measurements U = odometry reading Learning (state estimation): Approximated using a Rao-Blackwellized particle filter. Planning: Online forward search + Deterministic motion planning algorithm (e.g. RRTs) to allow deep search.

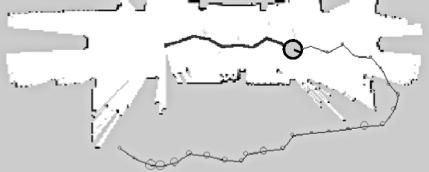


42 Case study #3: Multitasking SLAM Target following experiment:
43 Beyond the standard POMDP framework Policy search for POMDPs (Hansen, 1998; Meuleau et al. 1999; Ng&Jordan, 2000; Aberdeen&Baxter, 2002; Braziunas&Boutilier, 2004) Continuous POMDPs (Porta et al. 2006; Erez&Smart 2010; Deisenroth&Peters 2012) Factored POMDPs (Boutilier&Poole, 1996; McAllester&Singh, 1999; Guestrin et al., 2001) Hierarchical POMDPs (Pineau et al. 2001; Hansen&Zhou, 2003; Theocharous et al., 2004; Foka et al. 2005; Toussaint et al. 2008; Sridharan et al. 2008) Dec-POMDPs (Emery-Montemerlo et al. 2004; Szer et al. 2005; Oliehoek et al. 2008; Seuken&Zilberstein, 2007; Amato et al., 2009; Kumar&Zilberstein 2010; Spaan et al. 2011) Mixed Observability POMDPs (Ong et al., RSS 2005) ρpomdps (Araya et al., NIPS 2010)
Bayes-Adaptive POMDPs 1
 Bayes-Adaptive POMDPs 1 Stéphane Ross, Brahim Chaib-draa and Joelle Pineau SOCS-TR-007.6 School of Computer Science McGill University Montreal, Qc, Canada Department of Computer Science and Software Engineering
Bayes-Adaptive POMDPs 1 Stéphane Ross, Brahim Chaib-draa and Joelle Pineau SOCS-TR-007.6 School of Computer Science McGill University Montreal, Qc, Canada Department of Computer Science and Software Engineering
RL 14: POMDPs continued
 RL 14: POMDPs continued Michael Herrmann University of Edinburgh, School of Informatics 06/03/2015 POMDPs: Points to remember Belief states are probability distributions over states Even if computationally
RL 14: POMDPs continued Michael Herrmann University of Edinburgh, School of Informatics 06/03/2015 POMDPs: Points to remember Belief states are probability distributions over states Even if computationally
Artificial Intelligence
 Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Optimally Solving Dec-POMDPs as Continuous-State MDPs
 Optimally Solving Dec-POMDPs as Continuous-State MDPs Jilles Dibangoye (1), Chris Amato (2), Olivier Buffet (1) and François Charpillet (1) (1) Inria, Université de Lorraine France (2) MIT, CSAIL USA IJCAI
Optimally Solving Dec-POMDPs as Continuous-State MDPs Jilles Dibangoye (1), Chris Amato (2), Olivier Buffet (1) and François Charpillet (1) (1) Inria, Université de Lorraine France (2) MIT, CSAIL USA IJCAI
Modelling Sparse Dynamical Systems with Compressed Predictive State Representations
 with Compressed Predictive State Representations William L. Hamilton whamil3@cs.mcgill.ca Reasoning and Learning Laboratory, School of Computer Science, McGill University, Montreal, QC, Canada Mahdi Milani
with Compressed Predictive State Representations William L. Hamilton whamil3@cs.mcgill.ca Reasoning and Learning Laboratory, School of Computer Science, McGill University, Montreal, QC, Canada Mahdi Milani
Partially Observable Markov Decision Processes (POMDPs)
") Partially Observable Markov Decision Processes (POMDPs) Geoff Hollinger Sequential Decision Making in Robotics Spring, 2011 *Some media from Reid Simmons, Trey Smith, Tony Cassandra, Michael Littman, and
Partially Observable Markov Decision Processes (POMDPs) Geoff Hollinger Sequential Decision Making in Robotics Spring, 2011 *Some media from Reid Simmons, Trey Smith, Tony Cassandra, Michael Littman, and
Bayesian Reinforcement Learning in Continuous POMDPs with Application to Robot Navigation
 2008 IEEE International Conference on Robotics and Automation Pasadena, CA, USA, May 19-23, 2008 Bayesian Reinforcement Learning in Continuous POMDPs with Application to Robot Navigation Stéphane Ross
2008 IEEE International Conference on Robotics and Automation Pasadena, CA, USA, May 19-23, 2008 Bayesian Reinforcement Learning in Continuous POMDPs with Application to Robot Navigation Stéphane Ross
On Prediction and Planning in Partially Observable Markov Decision Processes with Large Observation Sets
 On Prediction and Planning in Partially Observable Markov Decision Processes with Large Observation Sets Pablo Samuel Castro pcastr@cs.mcgill.ca McGill University Joint work with: Doina Precup and Prakash
On Prediction and Planning in Partially Observable Markov Decision Processes with Large Observation Sets Pablo Samuel Castro pcastr@cs.mcgill.ca McGill University Joint work with: Doina Precup and Prakash
Bayes-Adaptive POMDPs: Toward an Optimal Policy for Learning POMDPs with Parameter Uncertainty
 Bayes-Adaptive POMDPs: Toward an Optimal Policy for Learning POMDPs with Parameter Uncertainty Stéphane Ross School of Computer Science McGill University, Montreal (Qc), Canada, H3A 2A7 stephane.ross@mail.mcgill.ca
Bayes-Adaptive POMDPs: Toward an Optimal Policy for Learning POMDPs with Parameter Uncertainty Stéphane Ross School of Computer Science McGill University, Montreal (Qc), Canada, H3A 2A7 stephane.ross@mail.mcgill.ca
A Bayesian Approach for Learning and Planning in Partially Observable Markov Decision Processes
 Journal of Machine Learning Research 12 (2011) 1729-1770 Submitted 10/08; Revised 11/10; Published 5/11 A Bayesian Approach for Learning and Planning in Partially Observable Markov Decision Processes Stéphane
Journal of Machine Learning Research 12 (2011) 1729-1770 Submitted 10/08; Revised 11/10; Published 5/11 A Bayesian Approach for Learning and Planning in Partially Observable Markov Decision Processes Stéphane
Information Gathering and Reward Exploitation of Subgoals for P
 Information Gathering and Reward Exploitation of Subgoals for POMDPs Hang Ma and Joelle Pineau McGill University AAAI January 27, 2015 http://www.cs.washington.edu/ai/mobile_robotics/mcl/animations/global-floor.gif
Information Gathering and Reward Exploitation of Subgoals for POMDPs Hang Ma and Joelle Pineau McGill University AAAI January 27, 2015 http://www.cs.washington.edu/ai/mobile_robotics/mcl/animations/global-floor.gif
RL 14: Simplifications of POMDPs
 RL 14: Simplifications of POMDPs Michael Herrmann University of Edinburgh, School of Informatics 04/03/2016 POMDPs: Points to remember Belief states are probability distributions over states Even if computationally
RL 14: Simplifications of POMDPs Michael Herrmann University of Edinburgh, School of Informatics 04/03/2016 POMDPs: Points to remember Belief states are probability distributions over states Even if computationally
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Today s Outline. Recap: MDPs. Bellman Equations. Q-Value Iteration. Bellman Backup 5/7/2012. CSE 473: Artificial Intelligence Reinforcement Learning
 CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
arxiv: v2 [cs.ai] 20 Dec 2014
![arxiv: v2 [cs.ai] 20 Dec 2014](/thumbs/72/67421392.jpg "arxiv: v2 [cs.ai] 20 Dec 2014") Scalable Planning and Learning for Multiagent POMDPs: Extended Version arxiv:1404.1140v2 [cs.ai] 20 Dec 2014 Christopher Amato CSAIL, MIT Cambridge, MA 02139 camato@csail.mit.edu Frans A. Oliehoek Informatics
Scalable Planning and Learning for Multiagent POMDPs: Extended Version arxiv:1404.1140v2 [cs.ai] 20 Dec 2014 Christopher Amato CSAIL, MIT Cambridge, MA 02139 camato@csail.mit.edu Frans A. Oliehoek Informatics
Partially Observable Markov Decision Processes (POMDPs) Pieter Abbeel UC Berkeley EECS
 Pieter Abbeel UC Berkeley EECS") Partially Observable Markov Decision Processes (POMDPs) Pieter Abbeel UC Berkeley EECS Many slides adapted from Jur van den Berg Outline POMDPs Separation Principle / Certainty Equivalence Locally Optimal
Partially Observable Markov Decision Processes (POMDPs) Pieter Abbeel UC Berkeley EECS Many slides adapted from Jur van den Berg Outline POMDPs Separation Principle / Certainty Equivalence Locally Optimal
Kalman Based Temporal Difference Neural Network for Policy Generation under Uncertainty (KBTDNN)
") Kalman Based Temporal Difference Neural Network for Policy Generation under Uncertainty (KBTDNN) Alp Sardag and H.Levent Akin Bogazici University Department of Computer Engineering 34342 Bebek, Istanbul,
Kalman Based Temporal Difference Neural Network for Policy Generation under Uncertainty (KBTDNN) Alp Sardag and H.Levent Akin Bogazici University Department of Computer Engineering 34342 Bebek, Istanbul,
Factored State Spaces 3/2/178
 Factored State Spaces 3/2/178 Converting POMDPs to MDPs In a POMDP: Action + observation updates beliefs Value is a function of beliefs. Instead we can view this as an MDP where: There is a state for every
Factored State Spaces 3/2/178 Converting POMDPs to MDPs In a POMDP: Action + observation updates beliefs Value is a function of beliefs. Instead we can view this as an MDP where: There is a state for every
Dialogue as a Decision Making Process
 Dialogue as a Decision Making Process Nicholas Roy Challenges of Autonomy in the Real World Wide range of sensors Noisy sensors World dynamics Adaptability Incomplete information Robustness under uncertainty
Dialogue as a Decision Making Process Nicholas Roy Challenges of Autonomy in the Real World Wide range of sensors Noisy sensors World dynamics Adaptability Incomplete information Robustness under uncertainty
Decentralized Decision Making!
 Decentralized Decision Making! in Partially Observable, Uncertain Worlds Shlomo Zilberstein Department of Computer Science University of Massachusetts Amherst Joint work with Martin Allen, Christopher
Decentralized Decision Making! in Partially Observable, Uncertain Worlds Shlomo Zilberstein Department of Computer Science University of Massachusetts Amherst Joint work with Martin Allen, Christopher
Planning by Probabilistic Inference
 Planning by Probabilistic Inference Hagai Attias Microsoft Research 1 Microsoft Way Redmond, WA 98052 Abstract This paper presents and demonstrates a new approach to the problem of planning under uncertainty.
Planning by Probabilistic Inference Hagai Attias Microsoft Research 1 Microsoft Way Redmond, WA 98052 Abstract This paper presents and demonstrates a new approach to the problem of planning under uncertainty.
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes
 CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
Scalable and Efficient Bayes-Adaptive Reinforcement Learning Based on Monte-Carlo Tree Search
 Journal of Artificial Intelligence Research 48 (2013) 841-883 Submitted 06/13; published 11/13 Scalable and Efficient Bayes-Adaptive Reinforcement Learning Based on Monte-Carlo Tree Search Arthur Guez
Journal of Artificial Intelligence Research 48 (2013) 841-883 Submitted 06/13; published 11/13 Scalable and Efficient Bayes-Adaptive Reinforcement Learning Based on Monte-Carlo Tree Search Arthur Guez
Approximate Universal Artificial Intelligence
 Approximate Universal Artificial Intelligence A Monte-Carlo AIXI Approximation Joel Veness Kee Siong Ng Marcus Hutter David Silver University of New South Wales National ICT Australia The Australian National
Approximate Universal Artificial Intelligence A Monte-Carlo AIXI Approximation Joel Veness Kee Siong Ng Marcus Hutter David Silver University of New South Wales National ICT Australia The Australian National
Active Learning of MDP models
 Active Learning of MDP models Mauricio Araya-López, Olivier Buffet, Vincent Thomas, and François Charpillet Nancy Université / INRIA LORIA Campus Scientifique BP 239 54506 Vandoeuvre-lès-Nancy Cedex France
Active Learning of MDP models Mauricio Araya-López, Olivier Buffet, Vincent Thomas, and François Charpillet Nancy Université / INRIA LORIA Campus Scientifique BP 239 54506 Vandoeuvre-lès-Nancy Cedex France
Optimally Solving Dec-POMDPs as Continuous-State MDPs
 Optimally Solving Dec-POMDPs as Continuous-State MDPs Jilles Steeve Dibangoye Inria / Université de Lorraine Nancy, France jilles.dibangoye@inria.fr Christopher Amato CSAIL / MIT Cambridge, MA, USA camato@csail.mit.edu
Optimally Solving Dec-POMDPs as Continuous-State MDPs Jilles Steeve Dibangoye Inria / Université de Lorraine Nancy, France jilles.dibangoye@inria.fr Christopher Amato CSAIL / MIT Cambridge, MA, USA camato@csail.mit.edu
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning
 REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
Probabilistic inference for computing optimal policies in MDPs
 Probabilistic inference for computing optimal policies in MDPs Marc Toussaint Amos Storkey School of Informatics, University of Edinburgh Edinburgh EH1 2QL, Scotland, UK mtoussai@inf.ed.ac.uk, amos@storkey.org
Probabilistic inference for computing optimal policies in MDPs Marc Toussaint Amos Storkey School of Informatics, University of Edinburgh Edinburgh EH1 2QL, Scotland, UK mtoussai@inf.ed.ac.uk, amos@storkey.org
CMU Lecture 12: Reinforcement Learning. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
Symbolic Perseus: a Generic POMDP Algorithm with Application to Dynamic Pricing with Demand Learning
 Symbolic Perseus: a Generic POMDP Algorithm with Application to Dynamic Pricing with Demand Learning Pascal Poupart (University of Waterloo) INFORMS 2009 1 Outline Dynamic Pricing as a POMDP Symbolic Perseus
Symbolic Perseus: a Generic POMDP Algorithm with Application to Dynamic Pricing with Demand Learning Pascal Poupart (University of Waterloo) INFORMS 2009 1 Outline Dynamic Pricing as a POMDP Symbolic Perseus
, and rewards and transition matrices as shown below:
 CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
Learning for Multiagent Decentralized Control in Large Partially Observable Stochastic Environments
 Learning for Multiagent Decentralized Control in Large Partially Observable Stochastic Environments Miao Liu Laboratory for Information and Decision Systems Cambridge, MA 02139 miaoliu@mit.edu Christopher
Learning for Multiagent Decentralized Control in Large Partially Observable Stochastic Environments Miao Liu Laboratory for Information and Decision Systems Cambridge, MA 02139 miaoliu@mit.edu Christopher
Decision-theoretic approaches to planning, coordination and communication in multiagent systems
 Decision-theoretic approaches to planning, coordination and communication in multiagent systems Matthijs Spaan Frans Oliehoek 2 Stefan Witwicki 3 Delft University of Technology 2 U. of Liverpool & U. of
Decision-theoretic approaches to planning, coordination and communication in multiagent systems Matthijs Spaan Frans Oliehoek 2 Stefan Witwicki 3 Delft University of Technology 2 U. of Liverpool & U. of
Finite-State Controllers Based on Mealy Machines for Centralized and Decentralized POMDPs
 Finite-State Controllers Based on Mealy Machines for Centralized and Decentralized POMDPs Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu
Finite-State Controllers Based on Mealy Machines for Centralized and Decentralized POMDPs Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu
Partially Observable Markov Decision Processes (POMDPs)
") Partially Observable Markov Decision Processes (POMDPs) Sachin Patil Guest Lecture: CS287 Advanced Robotics Slides adapted from Pieter Abbeel, Alex Lee Outline Introduction to POMDPs Locally Optimal Solutions
Partially Observable Markov Decision Processes (POMDPs) Sachin Patil Guest Lecture: CS287 Advanced Robotics Slides adapted from Pieter Abbeel, Alex Lee Outline Introduction to POMDPs Locally Optimal Solutions
Reinforcement Learning
 Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
An Analytic Solution to Discrete Bayesian Reinforcement Learning
 An Analytic Solution to Discrete Bayesian Reinforcement Learning Pascal Poupart (U of Waterloo) Nikos Vlassis (U of Amsterdam) Jesse Hoey (U of Toronto) Kevin Regan (U of Waterloo) 1 Motivation Automated
An Analytic Solution to Discrete Bayesian Reinforcement Learning Pascal Poupart (U of Waterloo) Nikos Vlassis (U of Amsterdam) Jesse Hoey (U of Toronto) Kevin Regan (U of Waterloo) 1 Motivation Automated
Lecture 3: Markov Decision Processes
 Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
Learning in POMDPs with Monte Carlo Tree Search
 Sammie Katt 1 Frans A. Oliehoek 2 Christopher Amato 1 Abstract The POMDP is a powerful framework for reasoning under outcome and information uncertainty, but constructing an accurate POMDP model is difficult.
Sammie Katt 1 Frans A. Oliehoek 2 Christopher Amato 1 Abstract The POMDP is a powerful framework for reasoning under outcome and information uncertainty, but constructing an accurate POMDP model is difficult.
Bayes Adaptive Reinforcement Learning versus Off-line Prior-based Policy Search: an Empirical Comparison
 Bayes Adaptive Reinforcement Learning versus Off-line Prior-based Policy Search: an Empirical Comparison Michaël Castronovo University of Liège, Institut Montefiore, B28, B-4000 Liège, BELGIUM Damien Ernst
Bayes Adaptive Reinforcement Learning versus Off-line Prior-based Policy Search: an Empirical Comparison Michaël Castronovo University of Liège, Institut Montefiore, B28, B-4000 Liège, BELGIUM Damien Ernst
Learning in non-stationary Partially Observable Markov Decision Processes
 Learning in non-stationary Partially Observable Markov Decision Processes Robin JAULMES, Joelle PINEAU, Doina PRECUP McGill University, School of Computer Science, 3480 University St., Montreal, QC, Canada,
Learning in non-stationary Partially Observable Markov Decision Processes Robin JAULMES, Joelle PINEAU, Doina PRECUP McGill University, School of Computer Science, 3480 University St., Montreal, QC, Canada,
Region-Based Dynamic Programming for Partially Observable Markov Decision Processes
 Region-Based Dynamic Programming for Partially Observable Markov Decision Processes Zhengzhu Feng Department of Computer Science University of Massachusetts Amherst, MA 01003 fengzz@cs.umass.edu Abstract
Region-Based Dynamic Programming for Partially Observable Markov Decision Processes Zhengzhu Feng Department of Computer Science University of Massachusetts Amherst, MA 01003 fengzz@cs.umass.edu Abstract
Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning
 Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning Christos Dimitrakakis Informatics Institute, University of Amsterdam, Amsterdam, The Netherlands
Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning Christos Dimitrakakis Informatics Institute, University of Amsterdam, Amsterdam, The Netherlands
Multi-task Reinforcement Learning in Partially Observable Stochastic Environments
 Journal of Machine Learning Research Submitted 0/2009 Multi-task Reinforcement Learning in Partially Observable Stochastic Environments Hui Li Xuejun Liao Lawrence Carin Department of Electrical and Computer
Journal of Machine Learning Research Submitted 0/2009 Multi-task Reinforcement Learning in Partially Observable Stochastic Environments Hui Li Xuejun Liao Lawrence Carin Department of Electrical and Computer
Producing Efficient Error-bounded Solutions for Transition Independent Decentralized MDPs
 Producing Efficient Error-bounded Solutions for Transition Independent Decentralized MDPs Jilles S. Dibangoye INRIA Loria, Campus Scientifique Vandœuvre-lès-Nancy, France jilles.dibangoye@inria.fr Christopher
Producing Efficient Error-bounded Solutions for Transition Independent Decentralized MDPs Jilles S. Dibangoye INRIA Loria, Campus Scientifique Vandœuvre-lès-Nancy, France jilles.dibangoye@inria.fr Christopher
CSEP 573: Artificial Intelligence
 CSEP 573: Artificial Intelligence Hidden Markov Models Luke Zettlemoyer Many slides over the course adapted from either Dan Klein, Stuart Russell, Andrew Moore, Ali Farhadi, or Dan Weld 1 Outline Probabilistic
CSEP 573: Artificial Intelligence Hidden Markov Models Luke Zettlemoyer Many slides over the course adapted from either Dan Klein, Stuart Russell, Andrew Moore, Ali Farhadi, or Dan Weld 1 Outline Probabilistic
Dialogue management: Parametric approaches to policy optimisation. Dialogue Systems Group, Cambridge University Engineering Department
 Dialogue management: Parametric approaches to policy optimisation Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 30 Dialogue optimisation as a reinforcement learning
Dialogue management: Parametric approaches to policy optimisation Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 30 Dialogue optimisation as a reinforcement learning
Mobile Robot Localization
 Mobile Robot Localization 1 The Problem of Robot Localization Given a map of the environment, how can a robot determine its pose (planar coordinates + orientation)? Two sources of uncertainty: - observations
Mobile Robot Localization 1 The Problem of Robot Localization Given a map of the environment, how can a robot determine its pose (planar coordinates + orientation)? Two sources of uncertainty: - observations
Probabilistic robot planning under model uncertainty: an active learning approach
 Probabilistic robot planning under model uncertainty: an active learning approach Robin JAULMES, Joelle PINEAU and Doina PRECUP School of Computer Science McGill University Montreal, QC CANADA H3A 2A7
Probabilistic robot planning under model uncertainty: an active learning approach Robin JAULMES, Joelle PINEAU and Doina PRECUP School of Computer Science McGill University Montreal, QC CANADA H3A 2A7
Approximate Universal Artificial Intelligence
 Approximate Universal Artificial Intelligence A Monte-Carlo AIXI Approximation Joel Veness Kee Siong Ng Marcus Hutter Dave Silver UNSW / NICTA / ANU / UoA September 8, 2010 General Reinforcement Learning
Approximate Universal Artificial Intelligence A Monte-Carlo AIXI Approximation Joel Veness Kee Siong Ng Marcus Hutter Dave Silver UNSW / NICTA / ANU / UoA September 8, 2010 General Reinforcement Learning
Heuristic Search Value Iteration for POMDPs
 520 SMITH & SIMMONS UAI 2004 Heuristic Search Value Iteration for POMDPs Trey Smith and Reid Simmons Robotics Institute, Carnegie Mellon University {trey,reids}@ri.cmu.edu Abstract We present a novel POMDP
520 SMITH & SIMMONS UAI 2004 Heuristic Search Value Iteration for POMDPs Trey Smith and Reid Simmons Robotics Institute, Carnegie Mellon University {trey,reids}@ri.cmu.edu Abstract We present a novel POMDP
Machine Learning I Reinforcement Learning
 Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms *
 Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
University of Alberta
 University of Alberta NEW REPRESENTATIONS AND APPROXIMATIONS FOR SEQUENTIAL DECISION MAKING UNDER UNCERTAINTY by Tao Wang A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment
University of Alberta NEW REPRESENTATIONS AND APPROXIMATIONS FOR SEQUENTIAL DECISION MAKING UNDER UNCERTAINTY by Tao Wang A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment
Machine Learning Summer School
 Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation
 Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 6: Graphical Models: Learning
 Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Importance Sampling for Online Planning under Uncertainty
 APPEARED IN Proc. Int. Workshop on the Algorithmic Foundations of Robotics (WAFR), 016 Importance Sampling for Online Planning under Uncertainty Yuanfu Luo, Haoyu Bai, David Hsu, and Wee Sun Lee National
APPEARED IN Proc. Int. Workshop on the Algorithmic Foundations of Robotics (WAFR), 016 Importance Sampling for Online Planning under Uncertainty Yuanfu Luo, Haoyu Bai, David Hsu, and Wee Sun Lee National
Point Based Value Iteration with Optimal Belief Compression for Dec-POMDPs
 Point Based Value Iteration with Optimal Belief Compression for Dec-POMDPs Liam MacDermed College of Computing Georgia Institute of Technology Atlanta, GA 30332 liam@cc.gatech.edu Charles L. Isbell College
Point Based Value Iteration with Optimal Belief Compression for Dec-POMDPs Liam MacDermed College of Computing Georgia Institute of Technology Atlanta, GA 30332 liam@cc.gatech.edu Charles L. Isbell College
Final Exam December 12, 2017
 Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Reinforcement Learning in Partially Observable Multiagent Settings: Monte Carlo Exploring Policies
 Reinforcement earning in Partially Observable Multiagent Settings: Monte Carlo Exploring Policies Presenter: Roi Ceren THINC ab, University of Georgia roi@ceren.net Prashant Doshi THINC ab, University
Reinforcement earning in Partially Observable Multiagent Settings: Monte Carlo Exploring Policies Presenter: Roi Ceren THINC ab, University of Georgia roi@ceren.net Prashant Doshi THINC ab, University
Towards Faster Planning with Continuous Resources in Stochastic Domains
 Towards Faster Planning with Continuous Resources in Stochastic Domains Janusz Marecki and Milind Tambe Computer Science Department University of Southern California 941 W 37th Place, Los Angeles, CA 989
Towards Faster Planning with Continuous Resources in Stochastic Domains Janusz Marecki and Milind Tambe Computer Science Department University of Southern California 941 W 37th Place, Los Angeles, CA 989
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning. Hanna Kurniawati
 COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
Topics of Active Research in Reinforcement Learning Relevant to Spoken Dialogue Systems
 Topics of Active Research in Reinforcement Learning Relevant to Spoken Dialogue Systems Pascal Poupart David R. Cheriton School of Computer Science University of Waterloo 1 Outline Review Markov Models
Topics of Active Research in Reinforcement Learning Relevant to Spoken Dialogue Systems Pascal Poupart David R. Cheriton School of Computer Science University of Waterloo 1 Outline Review Markov Models
Efficient Maximization in Solving POMDPs
 Efficient Maximization in Solving POMDPs Zhengzhu Feng Computer Science Department University of Massachusetts Amherst, MA 01003 fengzz@cs.umass.edu Shlomo Zilberstein Computer Science Department University
Efficient Maximization in Solving POMDPs Zhengzhu Feng Computer Science Department University of Massachusetts Amherst, MA 01003 fengzz@cs.umass.edu Shlomo Zilberstein Computer Science Department University
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Lecture 12: Probability 3/2/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Announcements P3 due on Monday (3/7) at 4:59pm W3 going out
CS 188: Artificial Intelligence Spring 2011 Lecture 12: Probability 3/2/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Announcements P3 due on Monday (3/7) at 4:59pm W3 going out
Markov decision processes
 CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
Decayed Markov Chain Monte Carlo for Interactive POMDPs
 Decayed Markov Chain Monte Carlo for Interactive POMDPs Yanlin Han Piotr Gmytrasiewicz Department of Computer Science University of Illinois at Chicago Chicago, IL 60607 {yhan37,piotr}@uic.edu Abstract
Decayed Markov Chain Monte Carlo for Interactive POMDPs Yanlin Han Piotr Gmytrasiewicz Department of Computer Science University of Illinois at Chicago Chicago, IL 60607 {yhan37,piotr}@uic.edu Abstract
Reinforcement Learning: An Introduction
 Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
arxiv: v1 [cs.ai] 14 Nov 2018
![arxiv: v1 [cs.ai] 14 Nov 2018](/thumbs/94/119187341.jpg "arxiv: v1 [cs.ai] 14 Nov 2018") Bayesian Reinforcement Learning in Factored POMDPs arxiv:1811.05612v1 [cs.ai] 14 Nov 2018 ABSTRACT Sammie Katt Northeastern University Bayesian approaches provide a principled solution to the explorationexploitation
Bayesian Reinforcement Learning in Factored POMDPs arxiv:1811.05612v1 [cs.ai] 14 Nov 2018 ABSTRACT Sammie Katt Northeastern University Bayesian approaches provide a principled solution to the explorationexploitation
Outline. CSE 573: Artificial Intelligence Autumn Agent. Partial Observability. Markov Decision Process (MDP) 10/31/2012
 10/31/2012") CSE 573: Artificial Intelligence Autumn 2012 Reasoning about Uncertainty & Hidden Markov Models Daniel Weld Many slides adapted from Dan Klein, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 Outline
CSE 573: Artificial Intelligence Autumn 2012 Reasoning about Uncertainty & Hidden Markov Models Daniel Weld Many slides adapted from Dan Klein, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 Outline
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Optimal and Approximate Q-value Functions for Decentralized POMDPs
 Journal of Artificial Intelligence Research 32 (2008) 289 353 Submitted 09/07; published 05/08 Optimal and Approximate Q-value Functions for Decentralized POMDPs Frans A. Oliehoek Intelligent Systems Lab
Journal of Artificial Intelligence Research 32 (2008) 289 353 Submitted 09/07; published 05/08 Optimal and Approximate Q-value Functions for Decentralized POMDPs Frans A. Oliehoek Intelligent Systems Lab
Final Exam December 12, 2017
 Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Autonomous Helicopter Flight via Reinforcement Learning
 Autonomous Helicopter Flight via Reinforcement Learning Authors: Andrew Y. Ng, H. Jin Kim, Michael I. Jordan, Shankar Sastry Presenters: Shiv Ballianda, Jerrolyn Hebert, Shuiwang Ji, Kenley Malveaux, Huy
Autonomous Helicopter Flight via Reinforcement Learning Authors: Andrew Y. Ng, H. Jin Kim, Michael I. Jordan, Shankar Sastry Presenters: Shiv Ballianda, Jerrolyn Hebert, Shuiwang Ji, Kenley Malveaux, Huy
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Reinforcement Learning as Classification Leveraging Modern Classifiers
 Reinforcement Learning as Classification Leveraging Modern Classifiers Michail G. Lagoudakis and Ronald Parr Department of Computer Science Duke University Durham, NC 27708 Machine Learning Reductions
Reinforcement Learning as Classification Leveraging Modern Classifiers Michail G. Lagoudakis and Ronald Parr Department of Computer Science Duke University Durham, NC 27708 Machine Learning Reductions
Online Expectation Maximization for Reinforcement Learning in POMDPs
 Online Expectation Maximization for Reinforcement Learning in POMDPs Miao Liu, Xuejun Liao, Lawrence Carin {miao.liu, xjliao, lcarin}@duke.edu Duke University, Durham, NC 27708, USA Abstract We present
Online Expectation Maximization for Reinforcement Learning in POMDPs Miao Liu, Xuejun Liao, Lawrence Carin {miao.liu, xjliao, lcarin}@duke.edu Duke University, Durham, NC 27708, USA Abstract We present
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Part 2
 Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Efficient Learning in Linearly Solvable MDP Models
 Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence Efficient Learning in Linearly Solvable MDP Models Ang Li Department of Computer Science, University of Minnesota
Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence Efficient Learning in Linearly Solvable MDP Models Ang Li Department of Computer Science, University of Minnesota
Tutorial on Optimization for PartiallyObserved Markov Decision. Processes
 Tutorial on Optimization for PartiallyObserved Markov Decision Processes Salvatore Candido Dept. of Electrical and Computer Engineering University of Illinois Probability Theory Prerequisites A random
Tutorial on Optimization for PartiallyObserved Markov Decision Processes Salvatore Candido Dept. of Electrical and Computer Engineering University of Illinois Probability Theory Prerequisites A random
Optimizing Memory-Bounded Controllers for Decentralized POMDPs
 Optimizing Memory-Bounded Controllers for Decentralized POMDPs Christopher Amato, Daniel S. Bernstein and Shlomo Zilberstein Department of Computer Science University of Massachusetts Amherst, MA 01003
Optimizing Memory-Bounded Controllers for Decentralized POMDPs Christopher Amato, Daniel S. Bernstein and Shlomo Zilberstein Department of Computer Science University of Massachusetts Amherst, MA 01003
State Space Compression with Predictive Representations
 State Space Compression with Predictive Representations Abdeslam Boularias Laval University Quebec GK 7P4, Canada Masoumeh Izadi McGill University Montreal H3A A3, Canada Brahim Chaib-draa Laval University
State Space Compression with Predictive Representations Abdeslam Boularias Laval University Quebec GK 7P4, Canada Masoumeh Izadi McGill University Montreal H3A A3, Canada Brahim Chaib-draa Laval University
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13. Decision Making. Abdeslam Boularias. Wednesday, December 7, 2016
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Lecture 10 - Planning under Uncertainty (III)
") Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
Reinforcement Learning. Spring 2018 Defining MDPs, Planning
 Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Partially observable Markov decision processes. Department of Computer Science, Czech Technical University in Prague
 Partially observable Markov decision processes Jiří Kléma Department of Computer Science, Czech Technical University in Prague https://cw.fel.cvut.cz/wiki/courses/b4b36zui/prednasky pagenda Previous lecture:
Partially observable Markov decision processes Jiří Kléma Department of Computer Science, Czech Technical University in Prague https://cw.fel.cvut.cz/wiki/courses/b4b36zui/prednasky pagenda Previous lecture:
Expectation-Maximization methods for solving (PO)MDPs and optimal control problems
MDPs and optimal control problems") Chapter 1 Expectation-Maximization methods for solving (PO)MDPs and optimal control problems Marc Toussaint 1, Amos Storkey 2 and Stefan Harmeling 3 As this book demonstrates, the development of efficient
Chapter 1 Expectation-Maximization methods for solving (PO)MDPs and optimal control problems Marc Toussaint 1, Amos Storkey 2 and Stefan Harmeling 3 As this book demonstrates, the development of efficient
Accelerated Vector Pruning for Optimal POMDP Solvers
 Accelerated Vector Pruning for Optimal POMDP Solvers Erwin Walraven and Matthijs T. J. Spaan Delft University of Technology Mekelweg 4, 2628 CD Delft, The Netherlands Abstract Partially Observable Markov
Accelerated Vector Pruning for Optimal POMDP Solvers Erwin Walraven and Matthijs T. J. Spaan Delft University of Technology Mekelweg 4, 2628 CD Delft, The Netherlands Abstract Partially Observable Markov
ARTIFICIAL INTELLIGENCE. Reinforcement learning
 INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Reinforcement Learning
 Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Machine Learning I Continuous Reinforcement Learning
 Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
School of Informatics, University of Edinburgh
 T E H U N I V E R S I T Y O H F R G School of Informatics, University of Edinburgh E D I N B U Institute for Adaptive and Neural Computation Probabilistic inference for solving (PO)MDPs by Marc Toussaint,
T E H U N I V E R S I T Y O H F R G School of Informatics, University of Edinburgh E D I N B U Institute for Adaptive and Neural Computation Probabilistic inference for solving (PO)MDPs by Marc Toussaint,