CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes
|
|
|
- Randolf Gilbert
- 5 years ago
- Views:
Transcription
1 CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division
2 Markov Decision Processes (MDPs) A popular model for sequential decision problems; Specified by A set of possible world states s 2 S A set of possible actions a 2 A A real-valued reward function R(s) A transition model T(s, a, s ) given by P(s s,a) Assumes fully observable environment with a Markovian transition model: P(S t+1 =s S t =s t, A t =a t, S t-1 =s t-1, A t-1 =a t-1, ) = P(S t+1 =s S t =s t, A t =a t ) Example: Maze Robot
3 Finite MDP Example: Recycling Robot At each step, robot has to decide whether it should (1) actively search for a can, (2) wait for someone to bring it a can, or (3) go to home base and recharge. Searching is better but runs down the battery; if runs out of power while searching, has to be rescued (which is bad). Decisions made on basis of current energy level: high, low. Reward = number of cans collected
4 Recycling Robot MDP S = fhigh; lowg A(high) = fsearch; waitg A(low) = fsearch; wait; rechargeg R search = expected # of cans while searching R wait = expected # of cans while waiting R search > R wait
5 Value Functions The value of a state is the expected return starting from that state; depends on the agent s policy State-value function of policy ¼ " 1 # X V ¼ (s) = E ¼ [R t js t = s] = E ¼ k r t+k+1 js t = s k=0 The value of taking an action in a state under policy p is the expected return starting from that state, taking that action, and thereafter following p : Action-value function for policy ¼ " 1 # X Q ¼ (s; a) = E ¼ [R t js t = s; a t = a] = E ¼ k r t+k+1 js t = s; a t = a k=0
6 Bellman Equation for V p Basic Idea: Bellman equation V ¼ (s) = E ¼ [R t js t = s] " 1 # X = E ¼ k r t+k+1 js t = s k=0 = E ¼ "r t+1 + = X a = X a R t = r t+1 + r t r t+3 + = r t+1 + (r t+2 + r t+3 + ) = r t+1 + R t+1 # 1X k r t+k+2 js t = s k=0 ¼(s; a) X T (s; a; s 0 ) s 0 " " 1 ## X R(s; a; s 0 ) + E ¼ k r t+k+2 js t+1 = s 0 k=0 ¼(s; a) X T (s; a; s 0 ) R(s; a; s 0 ) + V ¼ (s 0 ) s 0
7 More on Bellman Equation V ¼ (s) = X a ¼(s; a) X T(s; a; s 0 ) [R(s; a; s 0 ) + V ¼ (s 0 )] s 0 In fact, it is a set of linear equations for each state s; is a unique solution to this system of equations V ¼ Backup diagrams V ¼ Q ¼
8 MDP Example: Gridworld Actions: north, south, east, west; deterministic If would take agent off the grid: no move but reward = 1 Other actions produce reward = 0, except actions that move agent out of special states A and B as shown State-value function for equiprobable random policy; = 0:9
9 MDP Example: Golf State is ball location Reward of 1 for each stroke until the ball is in the hole Actions: putt (use putter) driver (use driver) putt succeeds anywhere on the green Value of a state?
10 Optimal Value Functions For finite MDPs, policies can be partially ordered: ¼ < ¼ 0 if and only if V ¼ (s) V ¼0 (s) for all s 2 S There are always one or more policies that are better than or equal to all the others. These are the optimal policies. We denote them all p * Optimal policies share the same optimal state-value function: V (s) = max V ¼ (s) for all s 2 S ¼ Optimal policies also share the same optimal action-value function: Q (s; a) = max Q ¼ (s; a) for all s 2 S and a 2 A(s) ¼ Expected return for executing action a in state s and then following an optimal policy
11 Optimal Action-Value Function for Golf We can hit the ball farther with driver than with putter, but with less accuracy Q*(s, driver) gives the value or using driver first, then using whichever actions are best
12 Bellman Optimality Equation for V* The value of a state under an optimal policy must equal the expected return for the best action from that state: V (s) = max a2a(s) Q (s; a) The backup diagram: = max E[r t+1 + V (s t+1 )js t = s; a t = a] a2a(s) X = max T(s; a; s 0 )[R(s; a; s 0 ) + V (s 0 )] a2a(s) s 0 V is the unique solution to the system of nonlinear equations
13 Bellman Optimality Equation for Q* Q (s; a) = E[r t+1 + max Q (s t+1 ; a 0 )js t = s; a t = a] a 0 = X T (s; a; s 0 )[R(s; a; s 0 ) + max Q (s 0 ; a 0 )] a 0 s 0 The backup diagram: Q is the unique solution to the system of nonlinear equations
14 Policies: Solution to MDPs p: S! A p(s) : recommended action for state s Following a policy p: (1) Determine the current state s (2) Execute action p(s) (3) Goto step 1 Evaluating p: How good is a policy p in a state s? Total sum of the rewards obtained can be infinite Finite horizon vs. Infinite horizon Additive rewards vs. Discounted rewards V ¼ ([s 0 ;s 1 ;s 2 ;:::]) = R(s 0 ) +R(s 1 ) +R(s 2 ) +::: V ¼ ([s 0 ; s 1 ; s 2 ; : : :]) = R(s 0 ) + R(s 1 ) + 2 R(s 2 ) + : : : Optimal policy:
15 Optimal Policy from V* Any policy that is greedy with respect to policy Therefore, given optimal actions V Example: Gridworld V is an optimal, one-step-ahead search produces the long-term
16 Optimal Policy from Q* Q Given, the agent does not even have to do a one-stepahead search: ¼ (s) = argmax Q (s; a) a2a(s)
17 Solving the Bellman Optimality Equation Finding an optimal policy by solving the Bellman Optimality Equation requires the following: accurate knowledge of environment dynamics; we have enough space and time to do the computation; the Markov Property How much space and time do we need? Polynomial in number of states (via dynamic programming methods) BUT, number of states can be huge (e.g., backgammon has about 1020 states) We usually have to settle for approximations Many RL methods (next week) can be understood as approximately solving the Bellman Optimality Equation But for this lecture, we assume we can solve without approximation
18 Value Iteration Algorithm Suppose that we know the utility of optimal policy It should satisfy Bellman X equation: V ¼ (s) = R(s) + max T(s; a; s 0 )V ¼ (s 0 ) a s 0 Then the optimal " policy can be derived by # ¼ (s) = arg max Iterative algorithm for solving X the Bellman equation V i+1 (s) Ã R(s) + max T(s; a; s 0 )V i (s 0 ) [Bellman update] a s 0 As i! 1 a R(s) + X T(s; a; s 0 )V ¼ (s 0 ) s 0, V i+1 converges to the utility of optimal policy Proof sketch: (1) prove that it converges to a vector (2) prove that vector satisfies the Bellman equation

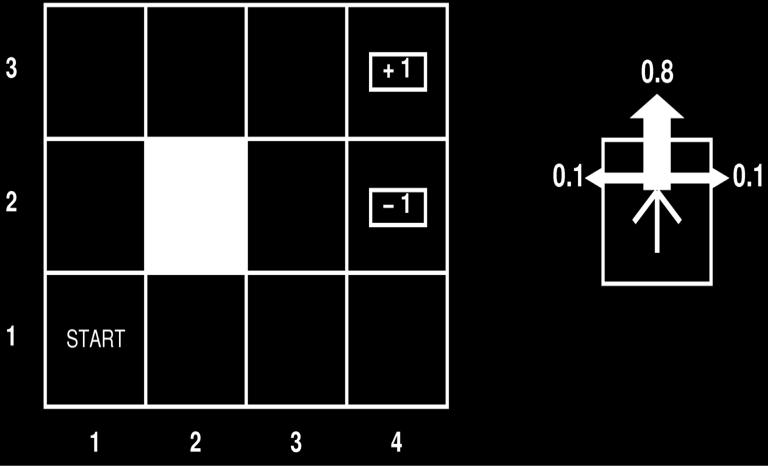
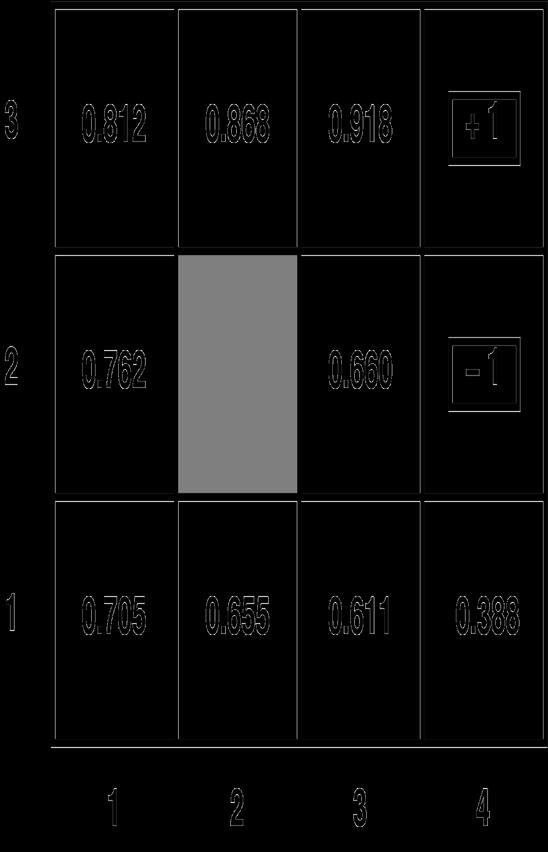

19 Value Iteration Example?
20 Policy Iteration Algorithm From value iteration, let p i+1 (s) be the policy from the i-th Bellman update: " # ¼ i+1 (s) Ã arg max a R(s) + X T(s; a; s 0 )V i (s 0 ) s 0 p i+1 can be seen as improvement to current guess of optimal policy from inaccurate guess of value V i of following policy p i Idea: improvement will be more accurate if V i is more accurate! Policy Iteration Policy Evaluation: given a policy p, calculate V i = V pi (solving a set of linear equations) Policy Improvement: Calculate a new MEU policy p i+1, using one-step look-ahead based on V i (See above) If policy evaluation can be done very quickly, policy iteration is typically faster than value iteration
21 Summary Markov decision processes (MDPs): a popular model for sequential decision making problems under uncertainty Strong assumption Polynomial time computation of an optimal policy using dynamic programming However, if state space is too large, dynamic programming is impractical Application to dialogue management State space? Action space? Transition probabilities? Rewards? Next week: we will look at RL solutions Read Singh, Litman, Kearns, and Walker, Optimizing Dialogue Management with Reinforcement Learning: Experiments with the NJFun System, Journal of Artificial Intelligence Research, 2002
Reading Response: Due Wednesday. R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1
 Reading Response: Due Wednesday R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Another Example Get to the top of the hill as quickly as possible. reward = 1 for each step where
Reading Response: Due Wednesday R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Another Example Get to the top of the hill as quickly as possible. reward = 1 for each step where
Lecture 3: The Reinforcement Learning Problem
 Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
ARTIFICIAL INTELLIGENCE. Reinforcement learning
 INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Course basics. CSE 190: Reinforcement Learning: An Introduction. Last Time. Course goals. The website for the class is linked off my homepage.
 Course basics CSE 190: Reinforcement Learning: An Introduction The website for the class is linked off my homepage. Grades will be based on programming assignments, homeworks, and class participation.
Course basics CSE 190: Reinforcement Learning: An Introduction The website for the class is linked off my homepage. Grades will be based on programming assignments, homeworks, and class participation.
Reinforcement Learning
 Reinforcement Learning 1 Reinforcement Learning Mainly based on Reinforcement Learning An Introduction by Richard Sutton and Andrew Barto Slides are mainly based on the course material provided by the
Reinforcement Learning 1 Reinforcement Learning Mainly based on Reinforcement Learning An Introduction by Richard Sutton and Andrew Barto Slides are mainly based on the course material provided by the
Reinforcement Learning. Up until now we have been
 Reinforcement Learning Slides by Rich Sutton Mods by Dan Lizotte Refer to Reinforcement Learning: An Introduction by Sutton and Barto Alpaydin Chapter 16 Up until now we have been Supervised Learning Classifying,
Reinforcement Learning Slides by Rich Sutton Mods by Dan Lizotte Refer to Reinforcement Learning: An Introduction by Sutton and Barto Alpaydin Chapter 16 Up until now we have been Supervised Learning Classifying,
CMU Lecture 11: Markov Decision Processes II. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 11: Markov Decision Processes II Teacher: Gianni A. Di Caro RECAP: DEFINING MDPS Markov decision processes: o Set of states S o Start state s 0 o Set of actions A o Transitions P(s s,a)
CMU 15-781 Lecture 11: Markov Decision Processes II Teacher: Gianni A. Di Caro RECAP: DEFINING MDPS Markov decision processes: o Set of states S o Start state s 0 o Set of actions A o Transitions P(s s,a)
The Markov Decision Process (MDP) model
 model") Decision Making in Robots and Autonomous Agents The Markov Decision Process (MDP) model Subramanian Ramamoorthy School of Informatics 25 January, 2013 In the MAB Model We were in a single casino and the
Decision Making in Robots and Autonomous Agents The Markov Decision Process (MDP) model Subramanian Ramamoorthy School of Informatics 25 January, 2013 In the MAB Model We were in a single casino and the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13. Decision Making. Abdeslam Boularias. Wednesday, December 7, 2016
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Introduction to Reinforcement Learning. Part 6: Core Theory II: Bellman Equations and Dynamic Programming
 Introduction to Reinforcement Learning Part 6: Core Theory II: Bellman Equations and Dynamic Programming Bellman Equations Recursive relationships among values that can be used to compute values The tree
Introduction to Reinforcement Learning Part 6: Core Theory II: Bellman Equations and Dynamic Programming Bellman Equations Recursive relationships among values that can be used to compute values The tree
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Decision Theory: Markov Decision Processes
 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Reinforcement Learning (1)
") Reinforcement Learning 1 Reinforcement Learning (1) Machine Learning 64-360, Part II Norman Hendrich University of Hamburg, Dept. of Informatics Vogt-Kölln-Str. 30, D-22527 Hamburg hendrich@informatik.uni-hamburg.de
Reinforcement Learning 1 Reinforcement Learning (1) Machine Learning 64-360, Part II Norman Hendrich University of Hamburg, Dept. of Informatics Vogt-Kölln-Str. 30, D-22527 Hamburg hendrich@informatik.uni-hamburg.de
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Some AI Planning Problems
 Course Logistics CS533: Intelligent Agents and Decision Making M, W, F: 1:00 1:50 Instructor: Alan Fern (KEC2071) Office hours: by appointment (see me after class or send email) Emailing me: include CS533
Course Logistics CS533: Intelligent Agents and Decision Making M, W, F: 1:00 1:50 Instructor: Alan Fern (KEC2071) Office hours: by appointment (see me after class or send email) Emailing me: include CS533
Reinforcement Learning. Introduction
 Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
CS 7180: Behavioral Modeling and Decisionmaking
 CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
Planning in Markov Decision Processes
 Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Planning in Markov Decision Processes Lecture 3, CMU 10703 Katerina Fragkiadaki Markov Decision Process (MDP) A Markov
Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Planning in Markov Decision Processes Lecture 3, CMU 10703 Katerina Fragkiadaki Markov Decision Process (MDP) A Markov
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Factored State Spaces 3/2/178
 Factored State Spaces 3/2/178 Converting POMDPs to MDPs In a POMDP: Action + observation updates beliefs Value is a function of beliefs. Instead we can view this as an MDP where: There is a state for every
Factored State Spaces 3/2/178 Converting POMDPs to MDPs In a POMDP: Action + observation updates beliefs Value is a function of beliefs. Instead we can view this as an MDP where: There is a state for every
Introduction to Reinforcement Learning
 CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Markov decision processes
 CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
Real Time Value Iteration and the State-Action Value Function
 MS&E338 Reinforcement Learning Lecture 3-4/9/18 Real Time Value Iteration and the State-Action Value Function Lecturer: Ben Van Roy Scribe: Apoorva Sharma and Tong Mu 1 Review Last time we left off discussing
MS&E338 Reinforcement Learning Lecture 3-4/9/18 Real Time Value Iteration and the State-Action Value Function Lecturer: Ben Van Roy Scribe: Apoorva Sharma and Tong Mu 1 Review Last time we left off discussing
Reinforcement Learning and Control
 CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
, and rewards and transition matrices as shown below:
 CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
Sequential decision making under uncertainty. Department of Computer Science, Czech Technical University in Prague
 Sequential decision making under uncertainty Jiří Kléma Department of Computer Science, Czech Technical University in Prague https://cw.fel.cvut.cz/wiki/courses/b4b36zui/prednasky pagenda Previous lecture:
Sequential decision making under uncertainty Jiří Kléma Department of Computer Science, Czech Technical University in Prague https://cw.fel.cvut.cz/wiki/courses/b4b36zui/prednasky pagenda Previous lecture:
Markov Decision Processes Chapter 17. Mausam
 Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
Probabilistic Planning. George Konidaris
 Probabilistic Planning George Konidaris gdk@cs.brown.edu Fall 2017 The Planning Problem Finding a sequence of actions to achieve some goal. Plans It s great when a plan just works but the world doesn t
Probabilistic Planning George Konidaris gdk@cs.brown.edu Fall 2017 The Planning Problem Finding a sequence of actions to achieve some goal. Plans It s great when a plan just works but the world doesn t
Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan
 COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
Introduction to Reinforcement Learning Part 1: Markov Decision Processes
 Introduction to Reinforcement Learning Part 1: Markov Decision Processes Rowan McAllister Reinforcement Learning Reading Group 8 April 2015 Note I ve created these slides whilst following Algorithms for
Introduction to Reinforcement Learning Part 1: Markov Decision Processes Rowan McAllister Reinforcement Learning Reading Group 8 April 2015 Note I ve created these slides whilst following Algorithms for
Reinforcement Learning: An Introduction
 Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer.
 This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
Markov decision processes (MDP) CS 416 Artificial Intelligence. Iterative solution of Bellman equations. Building an optimal policy.
 CS 416 Artificial Intelligence. Iterative solution of Bellman equations. Building an optimal policy.") Page 1 Markov decision processes (MDP) CS 416 Artificial Intelligence Lecture 21 Making Complex Decisions Chapter 17 Initial State S 0 Transition Model T (s, a, s ) How does Markov apply here? Uncertainty
Page 1 Markov decision processes (MDP) CS 416 Artificial Intelligence Lecture 21 Making Complex Decisions Chapter 17 Initial State S 0 Transition Model T (s, a, s ) How does Markov apply here? Uncertainty
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
Today s Outline. Recap: MDPs. Bellman Equations. Q-Value Iteration. Bellman Backup 5/7/2012. CSE 473: Artificial Intelligence Reinforcement Learning
 CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
Markov Decision Processes Chapter 17. Mausam
 Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
Reinforcement Learning Active Learning
 Reinforcement Learning Active Learning Alan Fern * Based in part on slides by Daniel Weld 1 Active Reinforcement Learning So far, we ve assumed agent has a policy We just learned how good it is Now, suppose
Reinforcement Learning Active Learning Alan Fern * Based in part on slides by Daniel Weld 1 Active Reinforcement Learning So far, we ve assumed agent has a policy We just learned how good it is Now, suppose
MS&E338 Reinforcement Learning Lecture 1 - April 2, Introduction
 MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
Internet Monetization
 Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
Reinforcement Learning
 Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Reinforcement Learning. George Konidaris
 Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Reinforcement Learning II
 Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement learning
 Reinforcement learning Stuart Russell, UC Berkeley Stuart Russell, UC Berkeley 1 Outline Sequential decision making Dynamic programming algorithms Reinforcement learning algorithms temporal difference
Reinforcement learning Stuart Russell, UC Berkeley Stuart Russell, UC Berkeley 1 Outline Sequential decision making Dynamic programming algorithms Reinforcement learning algorithms temporal difference
16.4 Multiattribute Utility Functions
 285 Normalized utilities The scale of utilities reaches from the best possible prize u to the worst possible catastrophe u Normalized utilities use a scale with u = 0 and u = 1 Utilities of intermediate
285 Normalized utilities The scale of utilities reaches from the best possible prize u to the worst possible catastrophe u Normalized utilities use a scale with u = 0 and u = 1 Utilities of intermediate
Reinforcement Learning
 1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
A Gentle Introduction to Reinforcement Learning
 A Gentle Introduction to Reinforcement Learning Alexander Jung 2018 1 Introduction and Motivation Consider the cleaning robot Rumba which has to clean the office room B329. In order to keep things simple,
A Gentle Introduction to Reinforcement Learning Alexander Jung 2018 1 Introduction and Motivation Consider the cleaning robot Rumba which has to clean the office room B329. In order to keep things simple,
Hidden Markov Models (HMM) and Support Vector Machine (SVM)
 and Support Vector Machine (SVM)") Hidden Markov Models (HMM) and Support Vector Machine (SVM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1 Hidden Markov Models (HMM)
Hidden Markov Models (HMM) and Support Vector Machine (SVM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1 Hidden Markov Models (HMM)
Machine Learning I Reinforcement Learning
 Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Administration. CSCI567 Machine Learning (Fall 2018) Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.
 Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.") Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
An Introduction to Markov Decision Processes. MDP Tutorial - 1
 An Introduction to Markov Decision Processes Bob Givan Purdue University Ron Parr Duke University MDP Tutorial - 1 Outline Markov Decision Processes defined (Bob) Objective functions Policies Finding Optimal
An Introduction to Markov Decision Processes Bob Givan Purdue University Ron Parr Duke University MDP Tutorial - 1 Outline Markov Decision Processes defined (Bob) Objective functions Policies Finding Optimal
Markov Decision Processes and Solving Finite Problems. February 8, 2017
 Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Reinforcement Learning
 CS7/CS7 Fall 005 Supervised Learning: Training examples: (x,y) Direct feedback y for each input x Sequence of decisions with eventual feedback No teacher that critiques individual actions Learn to act
CS7/CS7 Fall 005 Supervised Learning: Training examples: (x,y) Direct feedback y for each input x Sequence of decisions with eventual feedback No teacher that critiques individual actions Learn to act
15-780: Graduate Artificial Intelligence. Reinforcement learning (RL)
") 15-780: Graduate Artificial Intelligence Reinforcement learning (RL) From MDPs to RL We still use the same Markov model with rewards and actions But there are a few differences: 1. We do not assume we
15-780: Graduate Artificial Intelligence Reinforcement learning (RL) From MDPs to RL We still use the same Markov model with rewards and actions But there are a few differences: 1. We do not assume we
CS 287: Advanced Robotics Fall Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study
 CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Assignment #1 Roll-out: nice example paper: X.
CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Assignment #1 Roll-out: nice example paper: X.
Reinforcement Learning and Deep Reinforcement Learning
 Reinforcement Learning and Deep Reinforcement Learning Ashis Kumer Biswas, Ph.D. ashis.biswas@ucdenver.edu Deep Learning November 5, 2018 1 / 64 Outlines 1 Principles of Reinforcement Learning 2 The Q
Reinforcement Learning and Deep Reinforcement Learning Ashis Kumer Biswas, Ph.D. ashis.biswas@ucdenver.edu Deep Learning November 5, 2018 1 / 64 Outlines 1 Principles of Reinforcement Learning 2 The Q
Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]
![Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]](/thumbs/94/119187228.jpg "Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]") Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
Machine Learning. Reinforcement learning. Hamid Beigy. Sharif University of Technology. Fall 1396
 Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
Final Exam December 12, 2017
 Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Discrete planning (an introduction)
") Sistemi Intelligenti Corso di Laurea in Informatica, A.A. 2017-2018 Università degli Studi di Milano Discrete planning (an introduction) Nicola Basilico Dipartimento di Informatica Via Comelico 39/41-20135
Sistemi Intelligenti Corso di Laurea in Informatica, A.A. 2017-2018 Università degli Studi di Milano Discrete planning (an introduction) Nicola Basilico Dipartimento di Informatica Via Comelico 39/41-20135
Markov Decision Processes Infinite Horizon Problems
 Markov Decision Processes Infinite Horizon Problems Alan Fern * * Based in part on slides by Craig Boutilier and Daniel Weld 1 What is a solution to an MDP? MDP Planning Problem: Input: an MDP (S,A,R,T)
Markov Decision Processes Infinite Horizon Problems Alan Fern * * Based in part on slides by Craig Boutilier and Daniel Weld 1 What is a solution to an MDP? MDP Planning Problem: Input: an MDP (S,A,R,T)
Artificial Intelligence
 Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Reinforcement Learning
 Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
CMU Lecture 12: Reinforcement Learning. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
Artificial Intelligence & Sequential Decision Problems
 Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Markov Decision Processes (and a small amount of reinforcement learning)
") Markov Decision Processes (and a small amount of reinforcement learning) Slides adapted from: Brian Williams, MIT Manuela Veloso, Andrew Moore, Reid Simmons, & Tom Mitchell, CMU Nicholas Roy 16.4/13 Session
Markov Decision Processes (and a small amount of reinforcement learning) Slides adapted from: Brian Williams, MIT Manuela Veloso, Andrew Moore, Reid Simmons, & Tom Mitchell, CMU Nicholas Roy 16.4/13 Session
An Adaptive Clustering Method for Model-free Reinforcement Learning
 An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
Preference Elicitation for Sequential Decision Problems
 Preference Elicitation for Sequential Decision Problems Kevin Regan University of Toronto Introduction 2 Motivation Focus: Computational approaches to sequential decision making under uncertainty These
Preference Elicitation for Sequential Decision Problems Kevin Regan University of Toronto Introduction 2 Motivation Focus: Computational approaches to sequential decision making under uncertainty These
Sequential decision making under uncertainty. Department of Computer Science, Czech Technical University in Prague
 Sequential decision making under uncertainty Jiří Kléma Department of Computer Science, Czech Technical University in Prague /doku.php/courses/a4b33zui/start pagenda Previous lecture: individual rational
Sequential decision making under uncertainty Jiří Kléma Department of Computer Science, Czech Technical University in Prague /doku.php/courses/a4b33zui/start pagenda Previous lecture: individual rational
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning. Hanna Kurniawati
 COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
INF 5860 Machine learning for image classification. Lecture 14: Reinforcement learning May 9, 2018
 Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation
 Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
CSE250A Fall 12: Discussion Week 9
 CSE250A Fall 12: Discussion Week 9 Aditya Menon (akmenon@ucsd.edu) December 4, 2012 1 Schedule for today Recap of Markov Decision Processes. Examples: slot machines and maze traversal. Planning and learning.
CSE250A Fall 12: Discussion Week 9 Aditya Menon (akmenon@ucsd.edu) December 4, 2012 1 Schedule for today Recap of Markov Decision Processes. Examples: slot machines and maze traversal. Planning and learning.
2534 Lecture 4: Sequential Decisions and Markov Decision Processes
 2534 Lecture 4: Sequential Decisions and Markov Decision Processes Briefly: preference elicitation (last week s readings) Utility Elicitation as a Classification Problem. Chajewska, U., L. Getoor, J. Norman,Y.
2534 Lecture 4: Sequential Decisions and Markov Decision Processes Briefly: preference elicitation (last week s readings) Utility Elicitation as a Classification Problem. Chajewska, U., L. Getoor, J. Norman,Y.
Lecture 23: Reinforcement Learning
 Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Final Exam December 12, 2017
 Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Lecture 25: Learning 4. Victor R. Lesser. CMPSCI 683 Fall 2010
 Lecture 25: Learning 4 Victor R. Lesser CMPSCI 683 Fall 2010 Final Exam Information Final EXAM on Th 12/16 at 4:00pm in Lederle Grad Res Ctr Rm A301 2 Hours but obviously you can leave early! Open Book
Lecture 25: Learning 4 Victor R. Lesser CMPSCI 683 Fall 2010 Final Exam Information Final EXAM on Th 12/16 at 4:00pm in Lederle Grad Res Ctr Rm A301 2 Hours but obviously you can leave early! Open Book
CS 570: Machine Learning Seminar. Fall 2016
 CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
Partially Observable Markov Decision Processes (POMDPs)
") Partially Observable Markov Decision Processes (POMDPs) Geoff Hollinger Sequential Decision Making in Robotics Spring, 2011 *Some media from Reid Simmons, Trey Smith, Tony Cassandra, Michael Littman, and
Partially Observable Markov Decision Processes (POMDPs) Geoff Hollinger Sequential Decision Making in Robotics Spring, 2011 *Some media from Reid Simmons, Trey Smith, Tony Cassandra, Michael Littman, and
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Reinforcement Learning
 Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
1. (3 pts) In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max a
 In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max a") 3 MDP (2 points). (3 pts) In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max a s P (s s, a)u(s ) where R(s) is the reward associated with being in state s. Suppose now
3 MDP (2 points). (3 pts) In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max a s P (s s, a)u(s ) where R(s) is the reward associated with being in state s. Suppose now
Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms
 Artificial Intelligence Review manuscript No. (will be inserted by the editor) Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms Mostafa D. Awheda Howard M. Schwartz Received:
Artificial Intelligence Review manuscript No. (will be inserted by the editor) Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms Mostafa D. Awheda Howard M. Schwartz Received:
Introduction to Markov Decision Processes
 Introduction to Markov Decision Processes Fall - 2013 Alborz Geramifard Research Scientist at Amazon.com *This work was done during my postdoc at MIT. 1 Motivation Understand the customer s need in a sequence
Introduction to Markov Decision Processes Fall - 2013 Alborz Geramifard Research Scientist at Amazon.com *This work was done during my postdoc at MIT. 1 Motivation Understand the customer s need in a sequence
CS 4100 // artificial intelligence. Recap/midterm review!
 CS 4100 // artificial intelligence instructor: byron wallace Recap/midterm review! Attribution: many of these slides are modified versions of those distributed with the UC Berkeley CS188 materials Thanks
CS 4100 // artificial intelligence instructor: byron wallace Recap/midterm review! Attribution: many of these slides are modified versions of those distributed with the UC Berkeley CS188 materials Thanks
CS 598 Statistical Reinforcement Learning. Nan Jiang
 CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
Active Policy Iteration: Efficient Exploration through Active Learning for Value Function Approximation in Reinforcement Learning
 Active Policy Iteration: fficient xploration through Active Learning for Value Function Approximation in Reinforcement Learning Takayuki Akiyama, Hirotaka Hachiya, and Masashi Sugiyama Department of Computer
Active Policy Iteration: fficient xploration through Active Learning for Value Function Approximation in Reinforcement Learning Takayuki Akiyama, Hirotaka Hachiya, and Masashi Sugiyama Department of Computer