ARTIFICIAL INTELLIGENCE. Reinforcement learning
|
|
|
- Baldric Hudson
- 5 years ago
- Views:
Transcription

1 INFOB2KI Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from
2 Outline Reinforcement learning basics Relation with MDPs Model-based and model-free learning Exploitation vs. exploration (Approximate Q-learning) 2
3 Reinforcement learning RL methods are employed to address two related problems: the Prediction Problem and the Control Problem. Prediction: learn value function for a (fixed) policy and use that to predict reward for future actions. Control: learn, by interacting with the environment, a policy which maximizes the reward when traveling through state space obtain an optimal policy which allows for action planning and optimal control. 3
4 Examples of Reinforcement Learning Robocup Soccer Teams (Stone & Veloso, Reidmiller et al.) World s best player of simulated soccer, 1999; Runner-up 2000 Inventory Management (Van Roy, Bertsekas, Lee & Tsitsiklis) 10-15% improvement over industry standard methods Dynamic Channel Assignment (Singh & Bertsekas, Nie & Haykin) World's best assigner of radio channels to mobile telephone calls Elevator Control (Crites & Barto) (Probably) world's best down-peak elevator controller Many Robots navigation, bi-pedal walking, grasping, switching between skills... Games: TD-Gammon, Jellyfish (Tesauro, Dahl), AlphaGo (Deepmind) World's best backgammon & Go players (Alpha Go: 5
5 Key Features of RL Agent learns by interacting with environment Agent learns from the consequences of its actions, rather than from being explicitly taught, by receiving a reinforcement signal Because of chance, agent has to try things repeatedly Agent makes mistakes, even if it learns intelligently (regret) Agent selects its actions based on its past experiences (exploitation) and also on new choices (exploration) trial and error learning Possibly sacrifices short-term gains for larger long-term gains 6
6 Reinforcement Learning: idea Agent State: s Reward: r Actions: a Environment Basic idea: Receive feedback in the form of rewards Agent s return in long run is defined by the reward function Must (learn to) act so as to maximize expected return All learning is based on observed samples of outcomes! 8

7 The Agent-Environment Interface Agent: Interacts with environment at time t Observes state at step t: s t S Produces action at step t: a t A(s t ) Gets resulting reward: r t 1 R And resulting next state: s t 1 0, 1, 2,... r t +1 s t +1 r t +2 s t +2 r t +3 s t s t a t a t +1 a t +2 a t +3 9
8 RL as MDP The best studied case is when RL can be formulated as a (finite) Markov Decision Process (MDP), i.e. we assume: A (finite) set of states s S A set of actions (per state) A A model T(s,a,s ) A reward function R(s,a,s ) Markov assumption Still looking for a policy (s) New twist: we don t know T or R! I.e. we don t know which states are good or what the actions do Must actually try actions and states out to learn 11
. Actions are chosen based on current energy level (states): high, low.")
9 An Example: Recycling robot At each step, robot has to decide whether it should (1) actively search for a can, (2) wait for someone to bring it a can, or (3) go to home base and recharge. Searching is better but runs down the battery; if it runs out of power while searching, it has to be rescued (which is bad). Actions are chosen based on current energy level (states): high, low. Reward = number of cans collected 12

10 Recycling Robot MDP S high, low A(high) search, wait A(low) search, wait, recharge R R search wait expected no. of cans while searching expected no. of cans while waiting R search R wait 13
11 MDPs and RL Known MDP: Offline Solution, no learning Goal Compute V π Compute V*, * Technique Policy evaluation Value / policy iteration Unknown MDP: Model-Based Unknown MDP: Model-Free Goal Technique Compute V*, * VI/PI on approximated MDP Goal Technique Compute V π Direct evaluation TD-learning Compute Q*, * Q-learning 14
12 Model-Based Learning Model-Based Idea: Learn an approximate model based on experiences Solve for values, as if the learned model were correct Step 1: Learn empirical MDP model Count outcomes s for each s, a Normalize to give an estimate of Discover each when we experience (s, a, s ) Step 2: Solve the learned MDP For example, use value iteration, as before: 15
13 Model-Free Learning Model-Free idea: Directly learn (approximate) state values, based on experiences Methods (a.o.): I. Direct evaluation II. Temporal difference learning III. Q-learning Passive: use fixed policy Active: off-policy Remember: this is NOT offline planning! You actually take actions in the world. 16

14 I: Direct Evaluation Goal: Compute V(s) under given Idea: Average reward to go of visits 1. First act according to for several episodes/epochs 2. Afterwards, for every state s and every time t that s is visited: determine the rewards r t r subsequently received in epoch 3. Sample for s at time t = sum of discounted future rewards sample = R t s = r t + γr t+1 s (R s = r ) given experience tuples <s, (s), r t, s > 4. Average samples over all visits of s Note: this is the simplest Monte Carlo method 17
15 Example: Direct Evaluation Input: Policy A B C D E States Assume: = 1 Observed Episodes (Training) Episode 1 Episode 2 B, east, -1, C C, east, -1, D D, exit, +10, B, east, -1, C C, east, -1, D D, exit, +10, Episode 3 Episode 4 E, north, -1, C C, east, -1, D D, exit, +10, E, north, -1, C C, east, -1, A A, exit, -10, Output Values -10 A B C D E -2 18
16 Properties of Direct Evaluation Benefits: easy to understand doesn t require any knowledge of T, R eventually computes the correct average values, using just sample transitions Drawbacks: wastes information about state connections each state must be learned separately takes a long time to learn Output Values -10 A B C D E -2 If B and E both go to C under this policy, how can their values be different? 20
17 II: Temporal Difference Learning Goal: Compute V(s) under given Big idea: update after every experience! Likely outcomes will contribute updates more often s Temporal difference learning of values s (s) 1. Initialize each V(s) with some value 2. Observe experience tuple <s, (s), r, s > 3. Use observation in rough estimate of long-term reward V(s) sample s = r + γ V π (s ) 4. Update V(s) by moving values slightly towards estimate: V π (s) V π (s) + α (sample s V π (s)) where 0 α 1 is the learning rate. 21
18 Example: TD- Learning Input: Policy A A B C D B C D E E States Assume: init Each V(s) can be initialised with an arbitrary value. Reward function is unknown; but perhaps we do know that we receive a reward of 8 after ending up in D this can be exploited. = 1, α = 1/2 22
19 Example: TD- Learning Input: Policy A A Experience <s,π(s),r,s > B, east, -2, C 0 0 sample(b): 2 + γ 0 = 2 B C D B C D E E States Assume: = 1, α = 1/ init Update V π (B): 1 α 0 + α sample(b) V π (s) V π (s) + α (sample s V π (s)) = (1 α)v π (s) + α sample s = (1 α)v π (s) + α(r + γ V π (s )) 23
: 2 + γ 8 = 6 Update V π (C): 1 α 0 + α sample(c)")
20 Example: TD- Learning Input: Policy A A 0 Experienced <s,π(s),r,s > C, east, -2, D 0 0 B C D B C D E E States Assume: = 1, α = 1/ init sample(c): 2 + γ 8 = 6 Update V π (C): 1 α 0 + α sample(c) 24
21 Properties of TD Value Learning Benefits: Model free Bellman updates: connections between states used Updates upon each action Drawback: Values are learnt per policy Good for policy evaluation Long way from establishing optimal policy (Note that same holds for Direct evaluation) 25
")
22 26 Golf example: how valuable is a state? State is ball location Reward of 1 for each stroke until the ball is in the hole Actions: putt (use putter) driver (use driver) putt succeeds anywhere on the green Value of a state??
 has value Q(s,a): Q *")
 = optimal action from state s")
23 Optimal quantities revisited State s has value V(s): V * (s) = expected reward starting in s and acting optimally a state s q-state (s,a) has value Q(s,a): Q * (s,a) = expected reward having taken action a from state s and (thereafter) acting optimally q-state The optimal policy: * (s) = optimal action from state s state s
24 Bellman equation revisited Recall the Bellman equation for the optimal value function: V * ( s) max T ( s, a, s') a s' * * R( s, a, s') V ( s') maxq ( s, a) a Now, since also Q * V * ( s') maxq a' ( s', a'), we have that * ( s, a) T ( s, a, s') R( s, a, s') max Q ( s', a' ) a' s' The optimal policy now directly (no look-ahead) follows with argmax: * * ( s) arg maxq a * ( s, a) 28

25 Gridworld: V and Q values Noise = 0.2 Discount γ = 0.9 Living reward R(s) = 0 Optimal policy? 29
26 III: Q-Learning Idea: do Q-value updates to each q-state (like VI): But: can t compute this update without knowing T, R Instead: incorporate estimates as we go (like TD) 1. Initialize Q(s,a) = 0 for each s,a pair 2. Select action a and observe experience <s, a, r, s > 3. Use observation in rough estimate of Q(s, a): sample( s, a) r max a' Q( s', a') 4. Update Q(s,a) by moving values slightly towards estimate: Q( s, a) Q( s, a) sample( s, a) Q( s, a) (1 ) Q( s, a) sample( s, a) 30
 gives the value or using driver first, then using whichever actions are best 31")
27 Optimal Q -Function for Golf We can hit the ball farther with driver than with putter, but with less accuracy Q(s,driver) gives the value or using driver first, then using whichever actions are best 31
28 Updating Q -values: example Current Q(s,a) indicated; experience <s 1,a right, 0,s 2 > sample( s1, aright ) r max Q( s2 a', a') max{63,81,100} γ = 0.9 α = 1 90 Q( s1, aright ) (1 ) Q( s1, aright ) sample( s1, a (1 ) right ) 32
 Q Amazing result: Q-learning converges to optimal policy -- even if you re acting suboptimally!")
29 Q-Learning Properties I Q-learning is off-policy learning if rewards 0 then Q -values 0 and non-decreasing with each update If each (s,a) pair is visited infinitely often, the process convergences to true (optimal) Q Amazing result: Q-learning converges to optimal policy -- even if you re acting suboptimally! Basically, in the limit, it doesn t matter how you select actions (!) 33
30 Q-Learning Properties II Caveats: You have to explore enough You have to eventually make the learning rate α small enough but not decrease it too quickly 34


31 Exploration vs. Exploitation Multi-armed bandit: each machine provides a random reward from a distribution specific to that machine. Which machine should you play, and how many times? 35
32 Exploration vs Exploitation The policy indicates the exploration strategy: which action to take in which state Standard Q-learning uses Q-values associated with best action: pure exploitation, using what it already knows We can add randomness for true exploration: sometimes try to learn something new by picking a random action (e.g. -greedy) The exploration-exploitation trade-off is highly influenced by context: online or offline? 36
33 Q-learning to crawl 37

34 Approximate Q-Learning 38


35 Generalizing Across States Basic Q-Learning keeps a table of all q-values In realistic situations, we cannot possibly learn about every single state! Too many states to visit them all in training Too many states to hold the q-tables in memory Instead, we want to generalize: Learn about some small number of training states from experience Generalize that experience to new, similar situations This is a fundamental idea in machine learning! 39
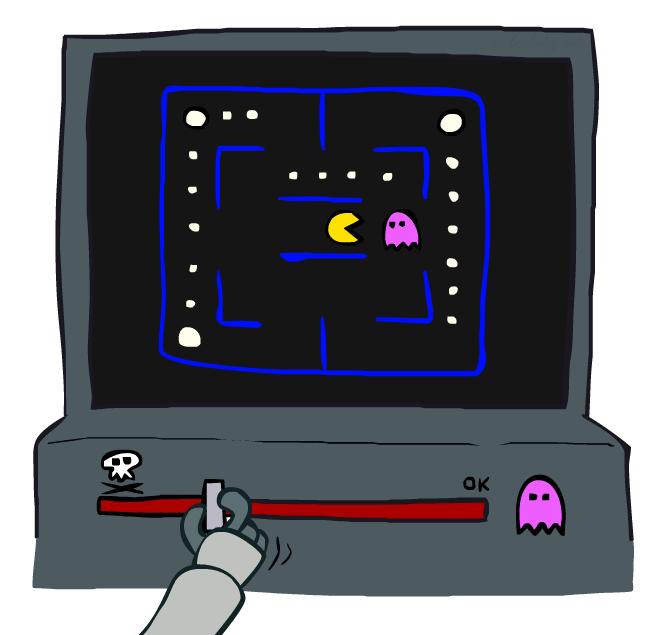
36 Example: Pacman Let s say we discover through experience that this state is bad: In naïve Q-learning, we know nothing about this state: Or even this one! 40
 that capture important properties of the state Example features:")
 etc. Is it the exact state on this slide? Can also describe a q-state (s, a) with features (e.g.")
37 Feature-Based Representations Solution: describe a state using a vector of features (properties) Features are functions from states to real numbers (often 0/1) that capture important properties of the state Example features: Distance to closest ghost Distance to closest dot Number of ghosts 1 / (dist to dot) 2 Is Pacman in a tunnel? (0/1) etc. Is it the exact state on this slide? Can also describe a q-state (s, a) with features (e.g. action moves closer to food) 41
38 Linear Value Functions Using a feature representation, we can write a Q or V function for any state using a few weights: Advantage: our experience is summed up in a few powerful numbers Disadvantage: states may share features but actually be very different in value! 42
39 Approximate Q-Learning In Q-learning, use difference between current Q(s,a) and new sample to update weights of active features: transition = <s,a,r,s > sample before (exact Q): now: approximate Q with w updates Intuitive interpretation: if something unexpectedly bad happens, blame the features that were on: disprefer all states with that state s features 43
40 Example: Q-Pacman (no noise) 44
41 Summary Reinforcement learning: learn from experience, not from a teacher Reinforcement learning problem can be cast as MDP with unknown T and R Model-based RL: estimate R and T from experience Model-free RL: estimate V(s) or Q(s,a) from experience Latter can be done actively, using Q-learning, and gives optimal policy Large state-spaces: use approximate Q-learning with domain-specific features 46
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
Reading Response: Due Wednesday. R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1
 Reading Response: Due Wednesday R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Another Example Get to the top of the hill as quickly as possible. reward = 1 for each step where
Reading Response: Due Wednesday R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Another Example Get to the top of the hill as quickly as possible. reward = 1 for each step where
Lecture 3: The Reinforcement Learning Problem
 Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Reinforcement Learning. Up until now we have been
 Reinforcement Learning Slides by Rich Sutton Mods by Dan Lizotte Refer to Reinforcement Learning: An Introduction by Sutton and Barto Alpaydin Chapter 16 Up until now we have been Supervised Learning Classifying,
Reinforcement Learning Slides by Rich Sutton Mods by Dan Lizotte Refer to Reinforcement Learning: An Introduction by Sutton and Barto Alpaydin Chapter 16 Up until now we have been Supervised Learning Classifying,
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes
 CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
Reinforcement Learning
 Reinforcement Learning 1 Reinforcement Learning Mainly based on Reinforcement Learning An Introduction by Richard Sutton and Andrew Barto Slides are mainly based on the course material provided by the
Reinforcement Learning 1 Reinforcement Learning Mainly based on Reinforcement Learning An Introduction by Richard Sutton and Andrew Barto Slides are mainly based on the course material provided by the
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Reinforcement Learning Instructor: Fabrice Popineau [These slides adapted from Stuart Russell, Dan Klein and Pieter Abbeel @ai.berkeley.edu] Reinforcement Learning Double
CS 188: Artificial Intelligence Reinforcement Learning Instructor: Fabrice Popineau [These slides adapted from Stuart Russell, Dan Klein and Pieter Abbeel @ai.berkeley.edu] Reinforcement Learning Double
Course basics. CSE 190: Reinforcement Learning: An Introduction. Last Time. Course goals. The website for the class is linked off my homepage.
 Course basics CSE 190: Reinforcement Learning: An Introduction The website for the class is linked off my homepage. Grades will be based on programming assignments, homeworks, and class participation.
Course basics CSE 190: Reinforcement Learning: An Introduction The website for the class is linked off my homepage. Grades will be based on programming assignments, homeworks, and class participation.
Today s Outline. Recap: MDPs. Bellman Equations. Q-Value Iteration. Bellman Backup 5/7/2012. CSE 473: Artificial Intelligence Reinforcement Learning
 CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
Lecture 23: Reinforcement Learning
 Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Reinforcement Learning (1)
") Reinforcement Learning 1 Reinforcement Learning (1) Machine Learning 64-360, Part II Norman Hendrich University of Hamburg, Dept. of Informatics Vogt-Kölln-Str. 30, D-22527 Hamburg hendrich@informatik.uni-hamburg.de
Reinforcement Learning 1 Reinforcement Learning (1) Machine Learning 64-360, Part II Norman Hendrich University of Hamburg, Dept. of Informatics Vogt-Kölln-Str. 30, D-22527 Hamburg hendrich@informatik.uni-hamburg.de
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
CMU Lecture 12: Reinforcement Learning. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
Prof. Dr. Ann Nowé. Artificial Intelligence Lab ai.vub.ac.be
 REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
Machine Learning. Reinforcement learning. Hamid Beigy. Sharif University of Technology. Fall 1396
 Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Lecture 12: Probability 3/2/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Announcements P3 due on Monday (3/7) at 4:59pm W3 going out
CS 188: Artificial Intelligence Spring 2011 Lecture 12: Probability 3/2/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Announcements P3 due on Monday (3/7) at 4:59pm W3 going out
Machine Learning. Machine Learning: Jordan Boyd-Graber University of Maryland REINFORCEMENT LEARNING. Slides adapted from Tom Mitchell and Peter Abeel
 Machine Learning Machine Learning: Jordan Boyd-Graber University of Maryland REINFORCEMENT LEARNING Slides adapted from Tom Mitchell and Peter Abeel Machine Learning: Jordan Boyd-Graber UMD Machine Learning
Machine Learning Machine Learning: Jordan Boyd-Graber University of Maryland REINFORCEMENT LEARNING Slides adapted from Tom Mitchell and Peter Abeel Machine Learning: Jordan Boyd-Graber UMD Machine Learning
Reinforcement learning an introduction
 Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Administration. CSCI567 Machine Learning (Fall 2018) Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.
 Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.") Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Reinforcement Learning
 1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
Reinforcement Learning
 CS7/CS7 Fall 005 Supervised Learning: Training examples: (x,y) Direct feedback y for each input x Sequence of decisions with eventual feedback No teacher that critiques individual actions Learn to act
CS7/CS7 Fall 005 Supervised Learning: Training examples: (x,y) Direct feedback y for each input x Sequence of decisions with eventual feedback No teacher that critiques individual actions Learn to act
Approximate Q-Learning. Dan Weld / University of Washington
 Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Reinforcement Learning. Spring 2018 Defining MDPs, Planning
 Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning
 Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Reinforcement Learning. George Konidaris
 Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
The Markov Decision Process (MDP) model
 model") Decision Making in Robots and Autonomous Agents The Markov Decision Process (MDP) model Subramanian Ramamoorthy School of Informatics 25 January, 2013 In the MAB Model We were in a single casino and the
Decision Making in Robots and Autonomous Agents The Markov Decision Process (MDP) model Subramanian Ramamoorthy School of Informatics 25 January, 2013 In the MAB Model We were in a single casino and the
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Reinforcement Learning
 Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Reinforcement Learning II
 Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Machine Learning I Reinforcement Learning
 Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
15-780: ReinforcementLearning
 15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation
 Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
CS 570: Machine Learning Seminar. Fall 2016
 CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13. Decision Making. Abdeslam Boularias. Wednesday, December 7, 2016
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Reinforcement Learning Wrap-up
 Reinforcement Learning Wrap-up Slides courtesy of Dan Klein and Pieter Abbeel University of California, Berkeley [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Reinforcement Learning Wrap-up Slides courtesy of Dan Klein and Pieter Abbeel University of California, Berkeley [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Deep Reinforcement Learning. STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017
 Deep Reinforcement Learning STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017 Outline Introduction to Reinforcement Learning AlphaGo (Deep RL for Computer Go)
Deep Reinforcement Learning STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017 Outline Introduction to Reinforcement Learning AlphaGo (Deep RL for Computer Go)
Lecture 25: Learning 4. Victor R. Lesser. CMPSCI 683 Fall 2010
 Lecture 25: Learning 4 Victor R. Lesser CMPSCI 683 Fall 2010 Final Exam Information Final EXAM on Th 12/16 at 4:00pm in Lederle Grad Res Ctr Rm A301 2 Hours but obviously you can leave early! Open Book
Lecture 25: Learning 4 Victor R. Lesser CMPSCI 683 Fall 2010 Final Exam Information Final EXAM on Th 12/16 at 4:00pm in Lederle Grad Res Ctr Rm A301 2 Hours but obviously you can leave early! Open Book
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
Reinforcement Learning: An Introduction
 Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Reinforcement Learning Active Learning
 Reinforcement Learning Active Learning Alan Fern * Based in part on slides by Daniel Weld 1 Active Reinforcement Learning So far, we ve assumed agent has a policy We just learned how good it is Now, suppose
Reinforcement Learning Active Learning Alan Fern * Based in part on slides by Daniel Weld 1 Active Reinforcement Learning So far, we ve assumed agent has a policy We just learned how good it is Now, suppose
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
CMU Lecture 11: Markov Decision Processes II. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 11: Markov Decision Processes II Teacher: Gianni A. Di Caro RECAP: DEFINING MDPS Markov decision processes: o Set of states S o Start state s 0 o Set of actions A o Transitions P(s s,a)
CMU 15-781 Lecture 11: Markov Decision Processes II Teacher: Gianni A. Di Caro RECAP: DEFINING MDPS Markov decision processes: o Set of states S o Start state s 0 o Set of actions A o Transitions P(s s,a)
Temporal Difference. Learning KENNETH TRAN. Principal Research Engineer, MSR AI
 Temporal Difference Learning KENNETH TRAN Principal Research Engineer, MSR AI Temporal Difference Learning Policy Evaluation Intro to model-free learning Monte Carlo Learning Temporal Difference Learning
Temporal Difference Learning KENNETH TRAN Principal Research Engineer, MSR AI Temporal Difference Learning Policy Evaluation Intro to model-free learning Monte Carlo Learning Temporal Difference Learning
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
15-780: Graduate Artificial Intelligence. Reinforcement learning (RL)
") 15-780: Graduate Artificial Intelligence Reinforcement learning (RL) From MDPs to RL We still use the same Markov model with rewards and actions But there are a few differences: 1. We do not assume we
15-780: Graduate Artificial Intelligence Reinforcement learning (RL) From MDPs to RL We still use the same Markov model with rewards and actions But there are a few differences: 1. We do not assume we
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
Reinforcement Learning
 Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo MLR, University of Stuttgart
Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo MLR, University of Stuttgart
Q-learning. Tambet Matiisen
 Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Probabilistic Planning. George Konidaris
 Probabilistic Planning George Konidaris gdk@cs.brown.edu Fall 2017 The Planning Problem Finding a sequence of actions to achieve some goal. Plans It s great when a plan just works but the world doesn t
Probabilistic Planning George Konidaris gdk@cs.brown.edu Fall 2017 The Planning Problem Finding a sequence of actions to achieve some goal. Plans It s great when a plan just works but the world doesn t
Reinforcement Learning and Control
 CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
Reinforcement Learning. Summer 2017 Defining MDPs, Planning
 Reinforcement Learning Summer 2017 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Summer 2017 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Open Theoretical Questions in Reinforcement Learning
 Open Theoretical Questions in Reinforcement Learning Richard S. Sutton AT&T Labs, Florham Park, NJ 07932, USA, sutton@research.att.com, www.cs.umass.edu/~rich Reinforcement learning (RL) concerns the problem
Open Theoretical Questions in Reinforcement Learning Richard S. Sutton AT&T Labs, Florham Park, NJ 07932, USA, sutton@research.att.com, www.cs.umass.edu/~rich Reinforcement learning (RL) concerns the problem
Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]
![Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]](/thumbs/94/119187228.jpg "Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]") Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
An Introduction to Reinforcement Learning
 An Introduction to Reinforcement Learning Shivaram Kalyanakrishnan shivaram@cse.iitb.ac.in Department of Computer Science and Engineering Indian Institute of Technology Bombay April 2018 What is Reinforcement
An Introduction to Reinforcement Learning Shivaram Kalyanakrishnan shivaram@cse.iitb.ac.in Department of Computer Science and Engineering Indian Institute of Technology Bombay April 2018 What is Reinforcement
Chapter 7: Eligibility Traces. R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1
 Chapter 7: Eligibility Traces R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Midterm Mean = 77.33 Median = 82 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction
Chapter 7: Eligibility Traces R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Midterm Mean = 77.33 Median = 82 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction
Introduction to Reinforcement Learning
 CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning. Hanna Kurniawati
 COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Reinforcement Learning with Function Approximation. Joseph Christian G. Noel
 Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Elements of Reinforcement Learning
 Elements of Reinforcement Learning Policy: way learning algorithm behaves (mapping from state to action) Reward function: Mapping of state action pair to reward or cost Value function: long term reward,
Elements of Reinforcement Learning Policy: way learning algorithm behaves (mapping from state to action) Reward function: Mapping of state action pair to reward or cost Value function: long term reward,
Temporal difference learning
 Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
6 Reinforcement Learning
 6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
Reinforcement learning
 Reinforcement learning Stuart Russell, UC Berkeley Stuart Russell, UC Berkeley 1 Outline Sequential decision making Dynamic programming algorithms Reinforcement learning algorithms temporal difference
Reinforcement learning Stuart Russell, UC Berkeley Stuart Russell, UC Berkeley 1 Outline Sequential decision making Dynamic programming algorithms Reinforcement learning algorithms temporal difference
Factored State Spaces 3/2/178
 Factored State Spaces 3/2/178 Converting POMDPs to MDPs In a POMDP: Action + observation updates beliefs Value is a function of beliefs. Instead we can view this as an MDP where: There is a state for every
Factored State Spaces 3/2/178 Converting POMDPs to MDPs In a POMDP: Action + observation updates beliefs Value is a function of beliefs. Instead we can view this as an MDP where: There is a state for every
MS&E338 Reinforcement Learning Lecture 1 - April 2, Introduction
 MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
Reinforcement Learning
 Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
CS230: Lecture 9 Deep Reinforcement Learning
 CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
Reinforcement Learning
 Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
RL 3: Reinforcement Learning
 RL 3: Reinforcement Learning Q-Learning Michael Herrmann University of Edinburgh, School of Informatics 20/01/2015 Last time: Multi-Armed Bandits (10 Points to remember) MAB applications do exist (e.g.
RL 3: Reinforcement Learning Q-Learning Michael Herrmann University of Edinburgh, School of Informatics 20/01/2015 Last time: Multi-Armed Bandits (10 Points to remember) MAB applications do exist (e.g.
An Adaptive Clustering Method for Model-free Reinforcement Learning
 An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
Reinforcement learning
 Reinforcement learning Based on [Kaelbling et al., 1996, Bertsekas, 2000] Bert Kappen Reinforcement learning Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error
Reinforcement learning Based on [Kaelbling et al., 1996, Bertsekas, 2000] Bert Kappen Reinforcement learning Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error
15-889e Policy Search: Gradient Methods Emma Brunskill. All slides from David Silver (with EB adding minor modificafons), unless otherwise noted
, unless otherwise noted") 15-889e Policy Search: Gradient Methods Emma Brunskill All slides from David Silver (with EB adding minor modificafons), unless otherwise noted Outline 1 Introduction 2 Finite Difference Policy Gradient
15-889e Policy Search: Gradient Methods Emma Brunskill All slides from David Silver (with EB adding minor modificafons), unless otherwise noted Outline 1 Introduction 2 Finite Difference Policy Gradient
Introduction to Reinforcement Learning. Part 5: Temporal-Difference Learning
 Introduction to Reinforcement Learning Part 5: emporal-difference Learning What everybody should know about emporal-difference (D) learning Used to learn value functions without human input Learns a guess
Introduction to Reinforcement Learning Part 5: emporal-difference Learning What everybody should know about emporal-difference (D) learning Used to learn value functions without human input Learns a guess
Notes on Reinforcement Learning
 1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
The Book: Where we are and where we re going. CSE 190: Reinforcement Learning: An Introduction. Chapter 7: Eligibility Traces. Simple Monte Carlo
 CSE 190: Reinforcement Learning: An Introduction Chapter 7: Eligibility races Acknowledgment: A good number of these slides are cribbed from Rich Sutton he Book: Where we are and where we re going Part
CSE 190: Reinforcement Learning: An Introduction Chapter 7: Eligibility races Acknowledgment: A good number of these slides are cribbed from Rich Sutton he Book: Where we are and where we re going Part
CSE 573. Markov Decision Processes: Heuristic Search & Real-Time Dynamic Programming. Slides adapted from Andrey Kolobov and Mausam
 CSE 573 Markov Decision Processes: Heuristic Search & Real-Time Dynamic Programming Slides adapted from Andrey Kolobov and Mausam 1 Stochastic Shortest-Path MDPs: Motivation Assume the agent pays cost
CSE 573 Markov Decision Processes: Heuristic Search & Real-Time Dynamic Programming Slides adapted from Andrey Kolobov and Mausam 1 Stochastic Shortest-Path MDPs: Motivation Assume the agent pays cost
CS 598 Statistical Reinforcement Learning. Nan Jiang
 CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
INF 5860 Machine learning for image classification. Lecture 14: Reinforcement learning May 9, 2018
 Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Temporal Difference Learning & Policy Iteration
 Temporal Difference Learning & Policy Iteration Advanced Topics in Reinforcement Learning Seminar WS 15/16 ±0 ±0 +1 by Tobias Joppen 03.11.2015 Fachbereich Informatik Knowledge Engineering Group Prof.
Temporal Difference Learning & Policy Iteration Advanced Topics in Reinforcement Learning Seminar WS 15/16 ±0 ±0 +1 by Tobias Joppen 03.11.2015 Fachbereich Informatik Knowledge Engineering Group Prof.
Real Time Value Iteration and the State-Action Value Function
 MS&E338 Reinforcement Learning Lecture 3-4/9/18 Real Time Value Iteration and the State-Action Value Function Lecturer: Ben Van Roy Scribe: Apoorva Sharma and Tong Mu 1 Review Last time we left off discussing
MS&E338 Reinforcement Learning Lecture 3-4/9/18 Real Time Value Iteration and the State-Action Value Function Lecturer: Ben Van Roy Scribe: Apoorva Sharma and Tong Mu 1 Review Last time we left off discussing
Reinforcement Learning Part 2
 Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Markov Decision Processes
 Markov Decision Processes Noel Welsh 11 November 2010 Noel Welsh () Markov Decision Processes 11 November 2010 1 / 30 Annoucements Applicant visitor day seeks robot demonstrators for exciting half hour
Markov Decision Processes Noel Welsh 11 November 2010 Noel Welsh () Markov Decision Processes 11 November 2010 1 / 30 Annoucements Applicant visitor day seeks robot demonstrators for exciting half hour
CS 4100 // artificial intelligence. Recap/midterm review!
 CS 4100 // artificial intelligence instructor: byron wallace Recap/midterm review! Attribution: many of these slides are modified versions of those distributed with the UC Berkeley CS188 materials Thanks
CS 4100 // artificial intelligence instructor: byron wallace Recap/midterm review! Attribution: many of these slides are modified versions of those distributed with the UC Berkeley CS188 materials Thanks
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
A Gentle Introduction to Reinforcement Learning
 A Gentle Introduction to Reinforcement Learning Alexander Jung 2018 1 Introduction and Motivation Consider the cleaning robot Rumba which has to clean the office room B329. In order to keep things simple,
A Gentle Introduction to Reinforcement Learning Alexander Jung 2018 1 Introduction and Motivation Consider the cleaning robot Rumba which has to clean the office room B329. In order to keep things simple,
1 Introduction 2. 4 Q-Learning The Q-value The Temporal Difference The whole Q-Learning process... 5
 Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Dual Memory Model for Using Pre-Existing Knowledge in Reinforcement Learning Tasks
 Dual Memory Model for Using Pre-Existing Knowledge in Reinforcement Learning Tasks Kary Främling Helsinki University of Technology, PL 55, FI-25 TKK, Finland Kary.Framling@hut.fi Abstract. Reinforcement
Dual Memory Model for Using Pre-Existing Knowledge in Reinforcement Learning Tasks Kary Främling Helsinki University of Technology, PL 55, FI-25 TKK, Finland Kary.Framling@hut.fi Abstract. Reinforcement
CS 287: Advanced Robotics Fall Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study
 CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Assignment #1 Roll-out: nice example paper: X.
CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Assignment #1 Roll-out: nice example paper: X.
Reinforcement Learning. Introduction
 Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control