Outline. Overview CNTK introduction. Educational resources Conclusions. Symbolic loop Batch scheduling Data parallel training
|
|
|
- Muriel McBride
- 6 years ago
- Views:
Transcription

1


2
3 Outline Overview CNTK introduction Symbolic loop Batch scheduling Data parallel training Educational resources Conclusions
4 Outline Overview CNTK introduction Symbolic loop Batch scheduling Data parallel training Educational resources Conclusions




5 Deep Learning at Services Skype Translator Cortana Bing HoloLens Research

6 24% 14%
7 ImageNet: 2015 ResNet 28.2 ImageNet Classification top-5 error (%) ILSVRC 2010 NEC America ILSVRC 2011 Xerox ILSVRC 2012 AlexNet ILSVRC 2013 Clarifi ILSVRC 2014 VGG ILSVRC 2014 GoogleNet ILSVRC 2015 ResNet had all 5 entries being the 1-st places in 2015: ImageNet classification, ImageNet localization, ImageNet detection, COCO detection, and COCO segmentation

8 Services




9

10
 Task: given a retail image, find same product on competitor websites (to compare price).")
11 Image Similarity Goal: given query image, find similar images. Customer: Anonymous ISV (Azure Partner) Task: given a retail image, find same product on competitor websites (to compare price). Existing solution: solely based on mining text information from the websites of Target, Macy, etc. Customer asked for individual similarity measure (e.g. texture, neck style, etc).
12 Bing / Bing Ads

13 Translator Power point-plug in for translating speech to subtitles

14 Youtube Link

15 Customer Support Agent
16
17
18
19


20
 in 2012, Computational Network On GitHub since Jan 2016 under MIT license Python support since Oct 2016 (beta), rebranded as External contributions e.g.")
21 (CNTK) s open-source deep-learning toolkit Created by Speech researchers (Dong Yu et al.) in 2012, Computational Network On GitHub since Jan 2016 under MIT license Python support since Oct 2016 (beta), rebranded as External contributions e.g. from MIT, Stanford and Nvidia Over 80% internal DL workload runs CNTK 1st-class on Linux and Windows, docker support Python, C++, C#, Java, Keras Internal == External
22 CTNK Speed Benchmarking by HKBU, Version 8 Single Tesla K80 GPU, CUDA: 8.0 CUDNN: v5.1 Caffe: 1.0rc5(39f28e4) CNTK: 2.0 Beta10(1ae666d) MXNet: 0.93(32dc3a2) TensorFlow: 1.0(4ac9c09) Torch: 7(748f5e3) Caffe CNTK MxNet TensorFlow Torch FCN5 (1024) ms ms ms ms ms AlexNet (256) ms ms ms ms ms ResNet (32) ms ms ms ms ms LSTM (256) (v7 benchmark) ms (44.917ms) ms ( ms) - ( ms) ms ( ms)
23 CNTK is production-ready: State-of-the-art accuracy, efficient, and scales to multi-gpu/multi-server speed comparison (samples/second), higher = better [note: December 2015] Achieved with 1-bit gradient quantization algorithm Theano only supports 1 GPU CNTK Theano TensorFlow Torch 7 Caffe 1 GPU 1 x 4 GPUs 2 x 4 GPUs (8 GPUs)
 AlexNet training batch size 128, Grad Bit = 32, Dual socket E5-2699v4 CPUs")
24 images / sec MICROSOFT COGNITIVE TOOLKIT First Deep Learning Framework Fully Optimized for Pascal Delivering Near-Linear Multi-GPU Scaling AlexNet Performance 14,000 12,000 10,000 13, x Faster v. CPU Server 8,000 7,600 6,000 4,000 2,000 2,400 3, Dual Socket CPU Server 1x P100 2x P100 4x P100 DGX-1 (8x P100) AlexNet training batch size 128, Grad Bit = 32, Dual socket E5-2699v4 CPUs (total 44 cores) CNTK 2.0b3 (to be released) includes cudnn 5.1.8, NCCL 1.6.1, NVLink enabled




25 Superior performance

26 CNTK Scalability ResNet50 on DGX-1, tested by Nvidia, Dec. 2016
27 CNTK Other Advantages Python and C++ API Mostly implemented in C++ Low level + high level Python API Extensibility User functions and learners in pure Python Readers Distributed, highly efficient built-in data readers Internal == External
28 CNTK Other Advantages Keras interoperability With CNTK backend Try models trained with TF/Theano with CNTK (vice versa) Demo RL with DQN Binary evaluation 10x speed-up in model execution
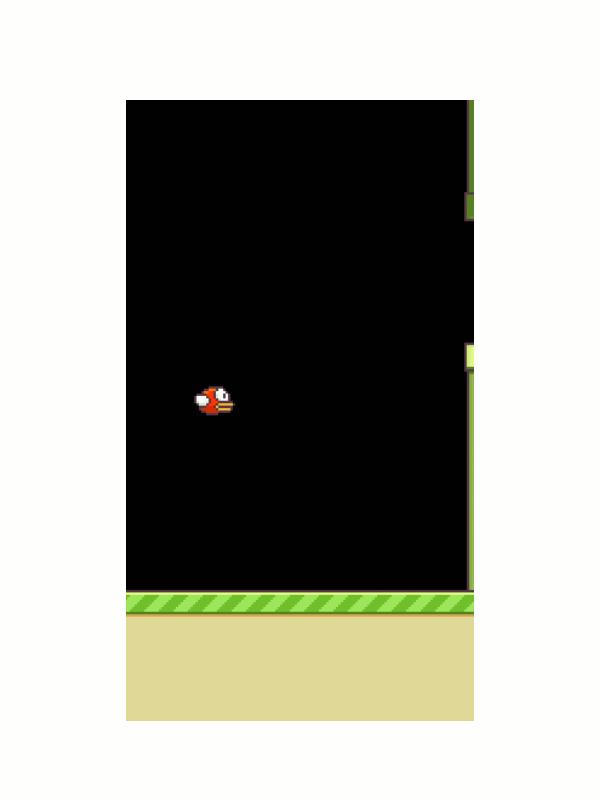

29 Reinforcement Learning with Flappy Bird

30 Binary evaluation Conv-Net Binary Conv-Net
31 Outline Overview CNTK introduction Symbolic loop Batch scheduling Data parallel training Educational resources Conclusions
32 What is CNTK? CNTK expresses (nearly) arbitrary neural networks by composing simple building blocks into complex computational networks, supporting relevant network types and applications.
33 What is CNTK? Example: 2-hidden layer feed-forward NN h 1 = s(w 1 x + b 1 ) h1 = sigmoid W1 + b1) h 2 = s(w 2 h 1 + b 2 ) h2 = sigmoid W2 + b2) P = softmax(w out h 2 + b out ) P = softmax Wout + bout) with input x R M and one-hot label L R M and cross-entropy training criterion ce = L T log P ce = cross_entropy (L, P) = max Scorpus ce
34 What is CNTK? Example: 2-hidden layer feed-forward NN h 1 = s(w 1 x + b 1 ) h1 = sigmoid W1 + b1) h 2 = s(w 2 h 1 + b 2 ) h2 = sigmoid W2 + b2) P = softmax(w out h 2 + b out ) P = softmax Wout + bout) with input x R M and one-hot label y R J and cross-entropy training criterion ce = y T log P ce = cross_entropy (L, P) = max Scorpus ce
35 What is CNTK? example: 2-hidden layer feed-forward NN h 1 = s(w 1 x + b 1 ) h1 = sigmoid W1 + b1) h 2 = s(w 2 h 1 + b 2 ) h2 = sigmoid W2 + b2) P = softmax(w out h 2 + b out ) P = softmax Wout + bout) with input x R M and one-hot label y R J and cross-entropy training criterion ce = y T log P ce = cross_entropy (P, y) = max Scorpus ce
36 What is CNTK? h1 = sigmoid W1 + b1) h2 = sigmoid W2 + b2) P = softmax Wout + bout) ce = cross_entropy (P, y)
37 What is CNTK? b out W out b 2 W 2 ce cross_entropy P softmax + h 2 s + h 1 s h1 = sigmoid W1 + b1) h2 = sigmoid W2 + b2) P = softmax Wout + bout) ce = cross_entropy (P, y) b 1 W 1 + x y
38 What is CNTK? b out W out b 2 W 2 ce cross_entropy P softmax + h 2 s + h 1 s Nodes: functions (primitives) Can be composed into reusable composites Edges: values Incl. tensors, sparse Automatic differentiation F / in = F / out out / in Deferred computation execution engine Editable, clonable b 1 W 1 + x y LEGO-like composability allows CNTK to support wide range of networks & applications
39 CNTK Unique Features Symbolic loops over sequences with dynamic scheduling Turn graph into parallel program through minibatching Unique parallel training algorithms (1-bit SGD, Block Momentum)
40 Symbolic Loops over Sequential Data Extend our example to a recurrent network (RNN) h 1 (t) = s(w 1 x(t) + H 1 h 1 (t-1) + b 1 ) h1 = W1 + past_value(h1) + b1) h 2 (t) = s(w 2 h 1 (t) + H 2 h 2 (t-1) + b 2 ) h2 = W2 + H2 + b2) P(t) = softmax(w out h 2 (t) + b out ) P = Wout + bout) ce(t) = L T (t) log P(t) ce = cross_entropy(p, L) = max Scorpus ce(t) no explicit notion of time
41 Symbolic Loops over Sequential Data Extend our example to a recurrent network (RNN) h 1 (t) = s(w 1 x(t) + R 1 h 1 (t-1) + b 1 ) h1 = W1 + R1 + b1) h 2 (t) = s(w 2 h 1 (t) + R 2 h 2 (t-1) + b 2 ) h2 = W2 + R2 + b2) P(t) = softmax(w out h 2 (t) + b out ) P = Wout + bout) ce(t) = L T (t) log P(t) ce = cross_entropy(p, L) = max Scorpus ce(t)
42 Symbolic Loops over Sequential Data Extend our example to a recurrent network (RNN) h 1 (t) = s(w 1 x(t) + R 1 h 1 (t-1) + b 1 ) h1 = W1 + R1 + b1) h 2 (t) = s(w 2 h 1 (t) + R 2 h 2 (t-1) + b 2 ) h2 = W2 + R2 + b2) P(t) = softmax(w out h 2 (t) + b out ) P = Wout + bout) ce(t) = L T (t) log P(t) ce = cross_entropy(p, L) = max Scorpus ce(t) compare to id (Irvine Dataflow): [Arvind et al., TR114a, Dept ISC, UC Irvine, Dec 1978; Executing a Program on the MIT Tagged-Token Dataflow Architecture, def ip(a: Sequence[tensor], b: Sequence[tensor]): s0 = 0 s_ = ForwardDeclaration() s = past_value(s_, initial_value=s0) + a * b s_.resolve_to(s) s = last(s) return s
43 Symbolic Loops over Sequential Data b out W out b 2 W 2 b 1 W 1 ce cross_entropy P softmax + h 2 s + h 1 s + + x z -1 + R 2 z -1 R 1 y h1 = W1 + R1 + b1) h2 = W2 + R2 + b2) P = Wout + bout) ce = cross_entropy(p, L) CNTK automatically unrolls cycles at execution time cycles are detected with Tarjan s algorithm only nodes in cycles efficient and composable cf. TensorFlow: [ lstm = rnn_cell.basiclstmcell(lstm_size) state = tf.zeros([batch_size, lstm.state_size] probabilities = [] loss = 0.0 for current_batch_of_words in words_in_dataset: output, state = lstm(current_batch_of_words, state) logits = tf.matmul(output, softmax_w) + softmax_b probabilities.append(tf.nn.softmax(logits)) loss += loss_function(probabilities, target_words)
44 parallel sequences Batch-Scheduling of Variable-Length Sequences Minibatches containing sequences of different lengths are automatically packed and padded time steps computed in parallel sequence 1 sequence 2 sequence 3 sequence 3 sequence 7 padding sequence 5 sequence 6 CNTK handles the special cases: past_value operation correctly resets state and gradient at sequence boundaries non-recurrent operations just pretend there is no padding ( garbage-in/garbage-out ) sequence reductions
45 parallel sequences Batch-Scheduling of Variable-Length Sequences Minibatches containing sequences of different lengths are automatically packed and padded time steps computed in parallel sequence 1 sequence 2 sequence 3 padding schedule into the same slot, it may come for free! sequence 4 sequence 7 sequence 5 sequence 6 CNTK handles the special cases: past_value operation correctly resets state and gradient at sequence boundaries non-recurrent operations just pretend there is no padding ( garbage-in/garbage-out ) sequence reductions
46 parallel sequences Batch-Scheduling of Variable-Length Sequences Minibatches containing sequences of different lengths are automatically packed and padded time steps computed in parallel sequence 1 sequence 2 sequence 3 sequence 4 sequence 7 padding Fully transparent batching Recurrent CNTK unrolls, handles sequence boundaries Non-recurrent operations parallel Sequence reductions mask sequence 5 sequence 6
47 Data-Parallel Training Degrees of parallelism: Within-vector parallelization: vectorized Across independent samples: batching Across GPUs: async PCIe device-to-device transfers Across servers: MPI etc., NVidia NCCL Parallelization options: Data-parallel Model-parallel Layer-parallel
48 Data-Parallel Training Data-parallelism: distribute minibatch over workers, all-reduce partial gradients node 1 node 2 node 3 S all-reduce
49 Data-Parallel Training Data-parallelism: distribute minibatch over workers, all-reduce partial gradients node 1 node 2 node 3
50 Data-Parallel Training Data-parallelism: distribute minibatch over workers, all-reduce partial gradients node 1 node 2 node 3 ring algorithm O(2 (K-1)/K M) O(1) w.r.t. K
51 Data-Parallel Training Data-parallelism: distribute minibatch over workers, all-reduce partial gradients O(1) enough? Example: DNN, MB size 1024, 160M model parameters compute per MB: 1/7 second communication per MB: 1/9 second (640M over 6 GB/s) can t even parallelize to 2 GPUs: communication cost already dominates! How about doing it asynchronously? HogWild! [-], DistBelief ASGD [Dean et al., 2012] Helps with latency and jitter, could hide some communication cost with pipeline Does not change the problem fundamentally
52 Data-Parallel Training How to reduce communication cost: communicate less each time 1-bit SGD: [F. Seide, H. Fu, J. Droppo, G. Li, D. Yu: 1-Bit Stochastic Gradient Descent... Distributed Training of Speech DNNs, Interspeech 2014] Quantize gradients to 1 bit per value Trick: carry over quantization error to next minibatch 1-bit quantized with residual node 1 node 2 node 3 1-bit quantized with residual
53 Data-Parallel Training How to reduce communication cost: communicate less each time 1-bit SGD: [F. Seide, H. Fu, J. Droppo, G. Li, D. Yu: 1-Bit Stochastic Gradient Descent...Distributed Training of Speech DNNs, Interspeech 2014] quantize gradients to 1 bit per value trick: carry over quantization error to next minibatch communicate less often Automatic MB sizing [F. Seide, H. Fu, J. Droppo, G. Li, D. Yu: ON Parallelizability of Stochastic Gradient Descent..., ICASSP 2014] Block momentum [K. Chen, Q. Huo: Scalable training of deep learning machines by incremental block training, ICASSP 2016] Very recent, very effective parallelization method Combines model averaging with error-residual idea
54 Outline Overview CNTK introduction Symbolic loop Batch scheduling Data parallel training Educational resources Conclusions

55 Where to begin? Tutorials:

56

57 Where to begin? Azure Notebooks: Try for free pre-hosted
58
59

60
61 Outline Overview CNTK introduction Symbolic loop Batch scheduling Data parallel training Educational resources Conclusions
62 Conclusions CNTK: fast, scalable, and extensible CNTK Unique features: Symbolic loop Batch scheduling Data parallel training Educational resources Azure Notebooks with CNTK (at no cost) EdX Deep Learning Explained course
63 Thanks!
64


65

66 Power point-plug in for Translating
67 Data Partition Partition randomly training dataset D into S minibatches D = {B i i = 1,2,, S} Group every τ mini-batches to form a split Group every N splits to form a data block Training dataset D consists of M data blocks S = M N τ Training dataset is processed block-by-block Incremental Block Training (IBT)
68 Intra-Block Parallel Optimization (IBPO) Select randomly an unprocessed data block denoted as D t Distribute N splits of D t to N parallel workers Starting from an initial model denoted as W init (t), each worker optimizes its local model independently by 1-sweep mini-batch SGD with momentum trick Average N optimized local models to get W(t)
69 Blockwise Model-Update Filtering (BMUF) Generate model-update resulting from data block D t : G t = W t W init t Calculate global model-update: Δ t = η t Δ t 1 + ς t G t ς t : Block Learning Rate (BLR) η t : Block Momentum (BM) When ς t = 1 and η t = 0 MA Update global model W t = W t 1 + Δ t Generate initial model for next data block Classical Block Momentum (CBM) W init t + 1 = W t Nesterov Block Momentum (NBM) W init t + 1 = W t + η t+1 Δ t
70 Iteration Repeat IBPO and BMUF until all data blocks are processed So-called one sweep Re-partition training set for a new sweep, repeat the above step Repeat the above step until a stopping criterion is satisfied Obtain the final global model W final
71 WER(%) WER(%) Benchmark Result of Parallel Training on CNTK Training data: 2,670-hour speech from real traffics of VS, SMD, and Cortana About 16 and 20 days to train DNN and LSTM on 1-GPU, respectively bit-average 1bit-peak BMUF-average BMUF-peak 1bit/BMUF Speedup Factors in LSTM Training GPUs 8 GPUs 16 GPUs 32 GPUs 64 GPUs Credit: Yongqiang Wang, Kai Chen, Qiang Huo WER of CE-trained DNN with different # of GPUs bit BMUF # of GPUs WER of CE-trained LSTM with different # of GPUs bit 10.6 BMUF # of GPUs
72 Results Achievement Almost linear speedup without degradation of model quality Verified for training DNN, CNN, LSTM up to 64 GPUs for speech recognition, image classification, OCR, and click prediction tasks Released in CNTK as a critical differentiator Used for enterprise scale production data loads Production tools in other companies such as iflytek and Alibaba
73
74

75
CNTK Microsoft s Open Source Deep Learning Toolkit. Taifeng Wang Lead Researcher, Microsoft Research Asia 2016 GTC China
 CNTK Microsoft s Open Source Deep Learning Toolkit Taifeng Wang Lead Researcher, Microsoft Research Asia 2016 GTC China Deep learning in Microsoft Cognitive Services https://how-old.net http://www.captionbot.ai
CNTK Microsoft s Open Source Deep Learning Toolkit Taifeng Wang Lead Researcher, Microsoft Research Asia 2016 GTC China Deep learning in Microsoft Cognitive Services https://how-old.net http://www.captionbot.ai
Roadmap. Task and history System overview and results Human versus machine Cognitive Toolkit (CNTK) Summary and outlook. Microsoft Cognitive Toolkit
 Summary and outlook. Microsoft Cognitive Toolkit") Roadmap Task and history System overview and results Human versus machine (CNTK) Summary and outlook Introduction: Task and History 4 The Human Parity Experiment Conversational telephone speech has been
Roadmap Task and history System overview and results Human versus machine (CNTK) Summary and outlook Introduction: Task and History 4 The Human Parity Experiment Conversational telephone speech has been
Tao Mei, Senior Researcher Cha Zhang, Principal Applied Science Manager Microsoft AI & Research
 Tao Mei, Senior Researcher Cha Zhang, Principal Applied Science Manager Microsoft AI & Research Agenda Introduction for Cognitive Toolkit (Cha) CNTK overview CNTK for image/video tasks Break Intelligent
Tao Mei, Senior Researcher Cha Zhang, Principal Applied Science Manager Microsoft AI & Research Agenda Introduction for Cognitive Toolkit (Cha) CNTK overview CNTK for image/video tasks Break Intelligent
Faster Machine Learning via Low-Precision Communication & Computation. Dan Alistarh (IST Austria & ETH Zurich), Hantian Zhang (ETH Zurich)
, Hantian Zhang (ETH Zurich)") Faster Machine Learning via Low-Precision Communication & Computation Dan Alistarh (IST Austria & ETH Zurich), Hantian Zhang (ETH Zurich) 2 How many bits do you need to represent a single number in machine
Faster Machine Learning via Low-Precision Communication & Computation Dan Alistarh (IST Austria & ETH Zurich), Hantian Zhang (ETH Zurich) 2 How many bits do you need to represent a single number in machine
Distributed Machine Learning: A Brief Overview. Dan Alistarh IST Austria
 Distributed Machine Learning: A Brief Overview Dan Alistarh IST Austria Background The Machine Learning Cambrian Explosion Key Factors: 1. Large s: Millions of labelled images, thousands of hours of speech
Distributed Machine Learning: A Brief Overview Dan Alistarh IST Austria Background The Machine Learning Cambrian Explosion Key Factors: 1. Large s: Millions of labelled images, thousands of hours of speech
A Practitioner s Guide to MXNet
 1/34 A Practitioner s Guide to MXNet Xingjian Shi Hong Kong University of Science and Technology (HKUST) HKUST CSE Seminar, March 31st, 2017 2/34 Outline 1 Introduction Deep Learning Basics MXNet Highlights
1/34 A Practitioner s Guide to MXNet Xingjian Shi Hong Kong University of Science and Technology (HKUST) HKUST CSE Seminar, March 31st, 2017 2/34 Outline 1 Introduction Deep Learning Basics MXNet Highlights
Deep Learning intro and hands-on tutorial
 Deep Learning intro and hands-on tutorial Π passalis@csd.auth.gr Ε. ώ Π ώ. Π ΠΘ 1 / 53 Deep Learning 2 / 53 Δ Έ ( ) ω π μ, ώπ ώ π ω (,...), π ώ π π π π ω ω ώπ ώ π, (biologically plausible) Δ π ώώ π ώ Ε
Deep Learning intro and hands-on tutorial Π passalis@csd.auth.gr Ε. ώ Π ώ. Π ΠΘ 1 / 53 Deep Learning 2 / 53 Δ Έ ( ) ω π μ, ώπ ώ π ω (,...), π ώ π π π π ω ω ώπ ώ π, (biologically plausible) Δ π ώώ π ώ Ε
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Pytorch Tutorial. Xiaoyong Yuan, Xiyao Ma 2018/01
 (Li Lab) National Science Foundation Center for Big Learning (CBL) Department of Electrical and Computer Engineering (ECE) Department of Computer & Information Science & Engineering (CISE) Pytorch Tutorial
(Li Lab) National Science Foundation Center for Big Learning (CBL) Department of Electrical and Computer Engineering (ECE) Department of Computer & Information Science & Engineering (CISE) Pytorch Tutorial
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Network Architecture
 Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis
 T. BEN-NUN, T. HOEFLER Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis https://www.arxiv.org/abs/1802.09941 What is Deep Learning good for? Digit Recognition Object
T. BEN-NUN, T. HOEFLER Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis https://www.arxiv.org/abs/1802.09941 What is Deep Learning good for? Digit Recognition Object
Google s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
 Google s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation Y. Wu, M. Schuster, Z. Chen, Q.V. Le, M. Norouzi, et al. Google arxiv:1609.08144v2 Reviewed by : Bill
Google s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation Y. Wu, M. Schuster, Z. Chen, Q.V. Le, M. Norouzi, et al. Google arxiv:1609.08144v2 Reviewed by : Bill
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Introduction to Neural Networks
 Introduction to Neural Networks Philipp Koehn 3 October 207 Linear Models We used before weighted linear combination of feature values h j and weights λ j score(λ, d i ) = j λ j h j (d i ) Such models
Introduction to Neural Networks Philipp Koehn 3 October 207 Linear Models We used before weighted linear combination of feature values h j and weights λ j score(λ, d i ) = j λ j h j (d i ) Such models
T. HOEFLER
 T HOEFLER Demystifying Parallel and Distributed Deep Learning - An In-Depth Concurrency Analysis Keynote at the 6 th Accelerated Data Analytics and Computing Workshop (ADAC 18) https://wwwarxivorg/abs/1829941
T HOEFLER Demystifying Parallel and Distributed Deep Learning - An In-Depth Concurrency Analysis Keynote at the 6 th Accelerated Data Analytics and Computing Workshop (ADAC 18) https://wwwarxivorg/abs/1829941
Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions
 2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
Deep learning attracts lots of attention.
 Deep Learning Deep learning attracts lots of attention. I believe you have seen lots of exciting results before. Deep learning trends at Google. Source: SIGMOD/Jeff Dean Ups and downs of Deep Learning
Deep Learning Deep learning attracts lots of attention. I believe you have seen lots of exciting results before. Deep learning trends at Google. Source: SIGMOD/Jeff Dean Ups and downs of Deep Learning
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
arxiv: v3 [cs.lg] 14 Jan 2018
![arxiv: v3 [cs.lg] 14 Jan 2018](/thumbs/92/109503708.jpg "arxiv: v3 [cs.lg] 14 Jan 2018") A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation Gang Chen Department of Computer Science and Engineering, SUNY at Buffalo arxiv:1610.02583v3 [cs.lg] 14 Jan 2018 1 abstract We describe
Neural Networks. Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016
 Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Fast, Cheap and Deep Scaling machine learning
 Fast, Cheap and Deep Scaling machine learning SFW Alexander Smola CMU Machine Learning and github.com/dmlc Many thanks to Mu Li Dave Andersen Chris Dyer Li Zhou Ziqi Liu Manzil Zaheer Qicong Chen Amr Ahmed
Fast, Cheap and Deep Scaling machine learning SFW Alexander Smola CMU Machine Learning and github.com/dmlc Many thanks to Mu Li Dave Andersen Chris Dyer Li Zhou Ziqi Liu Manzil Zaheer Qicong Chen Amr Ahmed
Binary Convolutional Neural Network on RRAM
 Binary Convolutional Neural Network on RRAM Tianqi Tang, Lixue Xia, Boxun Li, Yu Wang, Huazhong Yang Dept. of E.E, Tsinghua National Laboratory for Information Science and Technology (TNList) Tsinghua
Binary Convolutional Neural Network on RRAM Tianqi Tang, Lixue Xia, Boxun Li, Yu Wang, Huazhong Yang Dept. of E.E, Tsinghua National Laboratory for Information Science and Technology (TNList) Tsinghua
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Recurrent Neural Networks. COMP-550 Oct 5, 2017
 Recurrent Neural Networks COMP-550 Oct 5, 2017 Outline Introduction to neural networks and deep learning Feedforward neural networks Recurrent neural networks 2 Classification Review y = f( x) output label
Recurrent Neural Networks COMP-550 Oct 5, 2017 Outline Introduction to neural networks and deep learning Feedforward neural networks Recurrent neural networks 2 Classification Review y = f( x) output label
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Lecture 2
 Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Deep Residual. Variations
 Deep Residual Network and Its Variations Diyu Yang (Originally prepared by Kaiming He from Microsoft Research) Advantages of Depth Degradation Problem Possible Causes? Vanishing/Exploding Gradients. Overfitting
Deep Residual Network and Its Variations Diyu Yang (Originally prepared by Kaiming He from Microsoft Research) Advantages of Depth Degradation Problem Possible Causes? Vanishing/Exploding Gradients. Overfitting
A Tutorial On Backward Propagation Through Time (BPTT) In The Gated Recurrent Unit (GRU) RNN
 In The Gated Recurrent Unit (GRU) RNN") A Tutorial On Backward Propagation Through Time (BPTT In The Gated Recurrent Unit (GRU RNN Minchen Li Department of Computer Science The University of British Columbia minchenl@cs.ubc.ca Abstract In this
A Tutorial On Backward Propagation Through Time (BPTT In The Gated Recurrent Unit (GRU RNN Minchen Li Department of Computer Science The University of British Columbia minchenl@cs.ubc.ca Abstract In this
DANIEL WILSON AND BEN CONKLIN. Integrating AI with Foundation Intelligence for Actionable Intelligence
 DANIEL WILSON AND BEN CONKLIN Integrating AI with Foundation Intelligence for Actionable Intelligence INTEGRATING AI WITH FOUNDATION INTELLIGENCE FOR ACTIONABLE INTELLIGENCE in an arms race for artificial
DANIEL WILSON AND BEN CONKLIN Integrating AI with Foundation Intelligence for Actionable Intelligence INTEGRATING AI WITH FOUNDATION INTELLIGENCE FOR ACTIONABLE INTELLIGENCE in an arms race for artificial
ECE521 W17 Tutorial 1. Renjie Liao & Min Bai
 ECE521 W17 Tutorial 1 Renjie Liao & Min Bai Schedule Linear Algebra Review Matrices, vectors Basic operations Introduction to TensorFlow NumPy Computational Graphs Basic Examples Linear Algebra Review
ECE521 W17 Tutorial 1 Renjie Liao & Min Bai Schedule Linear Algebra Review Matrices, vectors Basic operations Introduction to TensorFlow NumPy Computational Graphs Basic Examples Linear Algebra Review
Machine Learning for Signal Processing Neural Networks Continue. Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016
 Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Slide Set 6: Neural Networks and Deep Learning January 2018 Heikki Huttunen heikki.huttunen@tut.fi Department of Signal Processing Tampere University of Technology
PATTERN RECOGNITION AND MACHINE LEARNING Slide Set 6: Neural Networks and Deep Learning January 2018 Heikki Huttunen heikki.huttunen@tut.fi Department of Signal Processing Tampere University of Technology
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
TensorFlow: A Framework for Scalable Machine Learning
 TensorFlow: A Framework for Scalable Machine Learning You probably Outline want to know... What is TensorFlow? Why did we create TensorFlow? How does Tensorflow Work? Example: Linear Regression Example:
TensorFlow: A Framework for Scalable Machine Learning You probably Outline want to know... What is TensorFlow? Why did we create TensorFlow? How does Tensorflow Work? Example: Linear Regression Example:
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
COMPARING FIXED AND ADAPTIVE COMPUTATION TIME FOR RE-
 Workshop track - ICLR COMPARING FIXED AND ADAPTIVE COMPUTATION TIME FOR RE- CURRENT NEURAL NETWORKS Daniel Fojo, Víctor Campos, Xavier Giró-i-Nieto Universitat Politècnica de Catalunya, Barcelona Supercomputing
Workshop track - ICLR COMPARING FIXED AND ADAPTIVE COMPUTATION TIME FOR RE- CURRENT NEURAL NETWORKS Daniel Fojo, Víctor Campos, Xavier Giró-i-Nieto Universitat Politècnica de Catalunya, Barcelona Supercomputing
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Deep Learning: Pre- Requisites. Understanding gradient descent, autodiff, and softmax
 Deep Learning: Pre- Requisites Understanding gradient descent, autodiff, and softmax Gradient Descent autodiff Gradient descent requires knowledge of, well, the gradient from your cost function (MSE) Mathematically
Deep Learning: Pre- Requisites Understanding gradient descent, autodiff, and softmax Gradient Descent autodiff Gradient descent requires knowledge of, well, the gradient from your cost function (MSE) Mathematically
NLP Homework: Dependency Parsing with Feed-Forward Neural Network
 NLP Homework: Dependency Parsing with Feed-Forward Neural Network Submission Deadline: Monday Dec. 11th, 5 pm 1 Background on Dependency Parsing Dependency trees are one of the main representations used
NLP Homework: Dependency Parsing with Feed-Forward Neural Network Submission Deadline: Monday Dec. 11th, 5 pm 1 Background on Dependency Parsing Dependency trees are one of the main representations used
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
MIXED PRECISION TRAINING ON VOLTA GPUS
 MIXED PRECISION TRAINING ON VOLTA GPUS Boris Ginsburg, Paulius Micikevicius, Oleksii Kuchaiev, Sergei Nikolaev bginsburg, pauliusm, okuchaiev, snikolaev@nvidia.com 10/17/2017 ACKNOWLEDGMENTS Michael Houston,
MIXED PRECISION TRAINING ON VOLTA GPUS Boris Ginsburg, Paulius Micikevicius, Oleksii Kuchaiev, Sergei Nikolaev bginsburg, pauliusm, okuchaiev, snikolaev@nvidia.com 10/17/2017 ACKNOWLEDGMENTS Michael Houston,
Speaker Representation and Verification Part II. by Vasileios Vasilakakis
 Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning. Hung-yi Lee 李宏毅
 Deep Learning Hung-yi Lee 李宏毅 Deep learning attracts lots of attention. I believe you have seen lots of exciting results before. Deep learning trends at Google. Source: SIGMOD 206/Jeff Dean 958: Perceptron
Deep Learning Hung-yi Lee 李宏毅 Deep learning attracts lots of attention. I believe you have seen lots of exciting results before. Deep learning trends at Google. Source: SIGMOD 206/Jeff Dean 958: Perceptron
Introduction to Machine Learning (67577)
") Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Source localization in an ocean waveguide using supervised machine learning
 Source localization in an ocean waveguide using supervised machine learning Haiqiang Niu, Emma Reeves, and Peter Gerstoft Scripps Institution of Oceanography, UC San Diego Part I Localization on Noise09
Source localization in an ocean waveguide using supervised machine learning Haiqiang Niu, Emma Reeves, and Peter Gerstoft Scripps Institution of Oceanography, UC San Diego Part I Localization on Noise09
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Deep Learning (CNNs)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation
 Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation Dr. Yanjun Qi Department of Computer Science University of Virginia Tutorial @ ACM BCB-2018 8/29/18 Yanjun Qi / UVA
Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation Dr. Yanjun Qi Department of Computer Science University of Virginia Tutorial @ ACM BCB-2018 8/29/18 Yanjun Qi / UVA
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Tutorial on: Optimization I. (from a deep learning perspective) Jimmy Ba
 Jimmy Ba") Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Identifying QCD transition using Deep Learning
 Identifying QCD transition using Deep Learning Kai Zhou Long-Gang Pang, Nan Su, Hannah Peterson, Horst Stoecker, Xin-Nian Wang Collaborators: arxiv:1612.04262 Outline 2 What is deep learning? Artificial
Identifying QCD transition using Deep Learning Kai Zhou Long-Gang Pang, Nan Su, Hannah Peterson, Horst Stoecker, Xin-Nian Wang Collaborators: arxiv:1612.04262 Outline 2 What is deep learning? Artificial
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Parallel and Distributed Stochastic Learning -Towards Scalable Learning for Big Data Intelligence
 Parallel and Distributed Stochastic Learning -Towards Scalable Learning for Big Data Intelligence oé LAMDA Group H ŒÆOŽÅ Æ EâX ^ #EâI[ : liwujun@nju.edu.cn Dec 10, 2016 Wu-Jun Li (http://cs.nju.edu.cn/lwj)
Parallel and Distributed Stochastic Learning -Towards Scalable Learning for Big Data Intelligence oé LAMDA Group H ŒÆOŽÅ Æ EâX ^ #EâI[ : liwujun@nju.edu.cn Dec 10, 2016 Wu-Jun Li (http://cs.nju.edu.cn/lwj)
Neural Architectures for Image, Language, and Speech Processing
 Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
INF 5860 Machine learning for image classification. Lecture 5 : Introduction to TensorFlow Tollef Jahren February 14, 2018
 INF 5860 Machine learning for image classification Lecture 5 : Introduction to TensorFlow Tollef Jahren February 14, 2018 OUTLINE Deep learning frameworks TensorFlow TensorFlow graphs TensorFlow session
INF 5860 Machine learning for image classification Lecture 5 : Introduction to TensorFlow Tollef Jahren February 14, 2018 OUTLINE Deep learning frameworks TensorFlow TensorFlow graphs TensorFlow session
HIGH PERFORMANCE CTC TRAINING FOR END-TO-END SPEECH RECOGNITION ON GPU
 April 4-7, 2016 Silicon Valley HIGH PERFORMANCE CTC TRAINING FOR END-TO-END SPEECH RECOGNITION ON GPU Minmin Sun, NVIDIA minmins@nvidia.com April 5th Brief Introduction of CTC AGENDA Alpha/Beta Matrix
April 4-7, 2016 Silicon Valley HIGH PERFORMANCE CTC TRAINING FOR END-TO-END SPEECH RECOGNITION ON GPU Minmin Sun, NVIDIA minmins@nvidia.com April 5th Brief Introduction of CTC AGENDA Alpha/Beta Matrix
Quantum Artificial Intelligence and Machine Learning: The Path to Enterprise Deployments. Randall Correll. +1 (703) Palo Alto, CA
 Palo Alto, CA") Quantum Artificial Intelligence and Machine : The Path to Enterprise Deployments Randall Correll randall.correll@qcware.com +1 (703) 867-2395 Palo Alto, CA 1 Bundled software and services Professional
Quantum Artificial Intelligence and Machine : The Path to Enterprise Deployments Randall Correll randall.correll@qcware.com +1 (703) 867-2395 Palo Alto, CA 1 Bundled software and services Professional
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Asaf Bar Zvi Adi Hayat. Semantic Segmentation
 Asaf Bar Zvi Adi Hayat Semantic Segmentation Today s Topics Fully Convolutional Networks (FCN) (CVPR 2015) Conditional Random Fields as Recurrent Neural Networks (ICCV 2015) Gaussian Conditional random
Asaf Bar Zvi Adi Hayat Semantic Segmentation Today s Topics Fully Convolutional Networks (FCN) (CVPR 2015) Conditional Random Fields as Recurrent Neural Networks (ICCV 2015) Gaussian Conditional random
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets)
") COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
Memory-Augmented Attention Model for Scene Text Recognition
 Memory-Augmented Attention Model for Scene Text Recognition Cong Wang 1,2, Fei Yin 1,2, Cheng-Lin Liu 1,2,3 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences
Memory-Augmented Attention Model for Scene Text Recognition Cong Wang 1,2, Fei Yin 1,2, Cheng-Lin Liu 1,2,3 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences
Notes on Back Propagation in 4 Lines
 Notes on Back Propagation in 4 Lines Lili Mou moull12@sei.pku.edu.cn March, 2015 Congratulations! You are reading the clearest explanation of forward and backward propagation I have ever seen. In this
Notes on Back Propagation in 4 Lines Lili Mou moull12@sei.pku.edu.cn March, 2015 Congratulations! You are reading the clearest explanation of forward and backward propagation I have ever seen. In this
Task-Oriented Dialogue System (Young, 2000)
") 2 Review Task-Oriented Dialogue System (Young, 2000) 3 http://rsta.royalsocietypublishing.org/content/358/1769/1389.short Speech Signal Speech Recognition Hypothesis are there any action movies to see
2 Review Task-Oriented Dialogue System (Young, 2000) 3 http://rsta.royalsocietypublishing.org/content/358/1769/1389.short Speech Signal Speech Recognition Hypothesis are there any action movies to see
More on Neural Networks
 More on Neural Networks Yujia Yan Fall 2018 Outline Linear Regression y = Wx + b (1) Linear Regression y = Wx + b (1) Polynomial Regression y = Wφ(x) + b (2) where φ(x) gives the polynomial basis, e.g.,
More on Neural Networks Yujia Yan Fall 2018 Outline Linear Regression y = Wx + b (1) Linear Regression y = Wx + b (1) Polynomial Regression y = Wφ(x) + b (2) where φ(x) gives the polynomial basis, e.g.,
Recurrent Neural Networks Deep Learning Lecture 5. Efstratios Gavves
 Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Non-Linearity. CS 188: Artificial Intelligence. Non-Linear Separators. Non-Linear Separators. Deep Learning I
 Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
Introduction to Neural Networks
 Introduction to Neural Networks Philipp Koehn 4 April 205 Linear Models We used before weighted linear combination of feature values h j and weights λ j score(λ, d i ) = j λ j h j (d i ) Such models can
Introduction to Neural Networks Philipp Koehn 4 April 205 Linear Models We used before weighted linear combination of feature values h j and weights λ j score(λ, d i ) = j λ j h j (d i ) Such models can
Tasks ADAS. Self Driving. Non-machine Learning. Traditional MLP. Machine-Learning based method. Supervised CNN. Methods. Deep-Learning based
 UNDERSTANDING CNN ADAS Tasks Self Driving Localizati on Perception Planning/ Control Driver state Vehicle Diagnosis Smart factory Methods Traditional Deep-Learning based Non-machine Learning Machine-Learning
UNDERSTANDING CNN ADAS Tasks Self Driving Localizati on Perception Planning/ Control Driver state Vehicle Diagnosis Smart factory Methods Traditional Deep-Learning based Non-machine Learning Machine-Learning
Value-aware Quantization for Training and Inference of Neural Networks
 Value-aware Quantization for Training and Inference of Neural Networks Eunhyeok Park 1, Sungjoo Yoo 1, and Peter Vajda 2 1 Department of Computer Science and Engineering Seoul National University {eunhyeok.park,sungjoo.yoo}@gmail.com
Value-aware Quantization for Training and Inference of Neural Networks Eunhyeok Park 1, Sungjoo Yoo 1, and Peter Vajda 2 1 Department of Computer Science and Engineering Seoul National University {eunhyeok.park,sungjoo.yoo}@gmail.com
>TensorFlow and deep learning_
 >TensorFlow and deep learning_ without a PhD deep Science! #Tensorflow deep Code... @martin_gorner Hello World: handwritten digits classification - MNIST? MNIST = Mixed National Institute of Standards
>TensorFlow and deep learning_ without a PhD deep Science! #Tensorflow deep Code... @martin_gorner Hello World: handwritten digits classification - MNIST? MNIST = Mixed National Institute of Standards
Deep Learning Architectures and Algorithms
 Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Advanced Training Techniques. Prajit Ramachandran
 Advanced Training Techniques Prajit Ramachandran Outline Optimization Regularization Initialization Optimization Optimization Outline Gradient Descent Momentum RMSProp Adam Distributed SGD Gradient Noise
Advanced Training Techniques Prajit Ramachandran Outline Optimization Regularization Initialization Optimization Optimization Outline Gradient Descent Momentum RMSProp Adam Distributed SGD Gradient Noise
Scaling Deep Learning Algorithms on Extreme Scale Architectures
 Scaling Deep Learning Algorithms on Extreme Scale Architectures ABHINAV VISHNU Team Lead, Scalable Machine Learning, Pacific Northwest National Laboratory MVAPICH User Group (MUG) 2017 1 The rise of Deep
Scaling Deep Learning Algorithms on Extreme Scale Architectures ABHINAV VISHNU Team Lead, Scalable Machine Learning, Pacific Northwest National Laboratory MVAPICH User Group (MUG) 2017 1 The rise of Deep
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Stochastic gradient descent; Classification
 Stochastic gradient descent; Classification Steve Renals Machine Learning Practical MLP Lecture 2 28 September 2016 MLP Lecture 2 Stochastic gradient descent; Classification 1 Single Layer Networks MLP
Stochastic gradient descent; Classification Steve Renals Machine Learning Practical MLP Lecture 2 28 September 2016 MLP Lecture 2 Stochastic gradient descent; Classification 1 Single Layer Networks MLP
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)
: Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Machine Learning. Boris
 Machine Learning Boris Nadion boris@astrails.com @borisnadion @borisnadion boris@astrails.com astrails http://astrails.com awesome web and mobile apps since 2005 terms AI (artificial intelligence)
Machine Learning Boris Nadion boris@astrails.com @borisnadion @borisnadion boris@astrails.com astrails http://astrails.com awesome web and mobile apps since 2005 terms AI (artificial intelligence)
Supporting Information
 Supporting Information Convolutional Embedding of Attributed Molecular Graphs for Physical Property Prediction Connor W. Coley a, Regina Barzilay b, William H. Green a, Tommi S. Jaakkola b, Klavs F. Jensen
Supporting Information Convolutional Embedding of Attributed Molecular Graphs for Physical Property Prediction Connor W. Coley a, Regina Barzilay b, William H. Green a, Tommi S. Jaakkola b, Klavs F. Jensen
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions