Lecture 17: Analytical Modeling of Parallel Programs: Scalability CSCE 569 Parallel Computing
|
|
|
- Cordelia Porter
- 5 years ago
- Views:
Transcription
1 Lecture 17: Analytical Modeling of Parallel Programs: Scalability CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan 1
2 Topic Overview Introduction Performance Metrics for Parallel Systems Execution Time, Overhead, Speedup, Efficiency, Cost Amdahl s Law Scalability of Parallel Systems Isoefficiency Metric of Scalability Minimum Execution Time and Minimum Cost-Optimal Execution Time Asymptotic Analysis of Parallel Programs Other Scalability Metrics Scaled speedup, Serial fraction 2
3 Speedup and Efficiency 3
4 Amdahl s Law Speedup 4

5 Scalability of Parallel Systems Scalability: The patterns of speedup How the performance of a parallel application changes as the number of processors is increased Scaling: performance improves steadily Not scaling: performance does not improve or becomes worse
6 Scalability of Parallel Systems Two different types of scaling with regards to the problem size Strong Scaling Total problem size stays the same as the number of processors increases Weak Scaling The problem size increases at the same rate as the number of processors, keeping the amount of work per processor the same Strong scaling is generally more useful and more difficult to achieve than weak scaling
7 Strong Scaling 7
8 Weak Scaling of Parallel Systems Extrapolate performance From small problems and small systems à larger problems on larger configurations 3 parallel algorithms for computing an n-point FFT on 64 PEs Inferences from small datasets or small machines can be misleading 8
 Overhead increases as")
 and Keeping the number of PEs")
9 Scaling Characteristics of Parallel Programs: Increase problem size Efficiency: Parallel overhead: T o = p T P T S è E = T S / (T S + T o ) Overhead increases as p increase Problem size: Given problem size, T S remains constant Efficiency increases if The problem size increases (T s ) and Keeping the number of PEs constant. 9
10 Example: Adding n Numbers on p PEs Addition = 1 time unit; communication = 1 time unit Speedup tends to saturate and efficiency drops 10

11 Scaling Characteristics of Parallel Programs: Increase problem size and increase # PEs Overhead T o = ƒ (T s, p), i.e. problem size and p In many cases, T o grows sublinearly with respect to T s Efficiency: Decreases as we increase p -> T 0 Increases as we increase problem size (Ts) Keep efficiency constant Increase problem sizes and proportionally increasing the number of PEs Scalable parallel systems 12
12 Isoefficiency Metric of Scalability Rate at which the problem size (T s ) must increase per additional PE (T 0 ) to keep the efficiency fixed The scalability of the system The slower this rate, the better scalability Rate == 0: strong scaling. The same problem (same size) scales when increasing number of PEs To formalize this rate, we define The problem size W = the asymptotic number of operations associated with the best serial algorithm to solve the problem. The serial execution time, T s 14


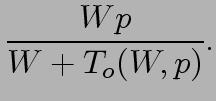

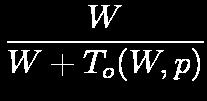
13 Isoefficiency Metric of Scalability Parallel overhead: T o (W,p), again, W ~= T s Parallel execution time: Speedup: Efficiency 15


")



14 Isoefficiency Metric of Scalability To maintain constant efficiency (between 0 and 1) K = E / (1 E) is a constant related to the desired efficiency Ratio T o / W should be maintained at a constant value. 16
 - Φ (p) To maintain constant efficiency, how much to increase the problem size if adding one more PE?")
15 Isoefficiency Metric of Scalability W = Φ (p) such that efficiency is constant W = Φ (p) is called the isoefficiency function Read as: what is the problem size when we have p PEs to maintain constant efficiency? W p+1 W p = Φ (p+1) - Φ (p) To maintain constant efficiency, how much to increase the problem size if adding one more PE? isoefficiency function determines the ease With which a parallel system maintain a constant efficiency Hence achieve speedups increasing in proportion to # PEs 17
16 Isoefficiency Example 1 Adding n numbers using p PEs Parallel overhead: T o = 2p log p W = KT 0 (W,p), substitute T 0 W = K *2*p*log p K *2*p*log p is the isoefficiency function The asymptotic isoefficiency function for this parallel system is Θ(p*log p) To have the same efficiency on p processors as on p problem size n must increase by (p log p ) / (p log p) when increasing PEs from p to p 18
17 by (p log p ) / (p log p) Examples If p = 8, p = 16 16*log16/(8*log8) = 16*4/(8*3) = 8/3 = M on 8 cores 10*2.67M on 16 cores 19
18 Cost-Optimality and Isoefficiency A parallel system is cost-optimal if and only if Parallel cost == total work Efficiency = 1 From this, we have: i.e. work dominates overhead If we have an isoefficiency function f(p) The relation W = Ω(f(p)) must be satisfied to ensure the costoptimality of a parallel system as it is scaled up 21
19 Topic Overview Introduction Performance Metrics for Parallel Systems Execution Time, Overhead, Speedup, Efficiency, Cost Amdahl s Law Scalability of Parallel Systems Isoefficiency Metric of Scalability Minimum Execution Time Asymptotic Analysis of Parallel Programs Other Scalability Metrics Scaled speedup, Serial fraction 25


20 Minimum Execution Time Often, we are interested in the minimum time to solution To determine the minimum exe time T P min for a given W Differentiating the expression for T P w.r.t. p and equate it to 0 = 0 If p 0 is the value of p as determined by this equation T P (p 0 ) is the minimum parallel time 26
21 Minimum Execution Time: Example Adding n numbers Parallel execution time: Compute the derivative: = Set the derivative = 0, solve for p: The corresponding exe time: = Note that at this point, the formulation is not cost-optimal. 27
22 Topic Overview Introduction Performance Metrics for Parallel Systems Execution Time, Overhead, Speedup, Efficiency, Cost Amdahl s Law Scalability of Parallel Systems Isoefficiency Metric of Scalability Minimum Execution Time Asymptotic Analysis of Parallel Programs Other Scalability Metrics Scaled speedup, Serial fraction 30
23 Asymptotic Analysis of Parallel Programs Sorting a list of n numbers. The fastest serial programs: Θ(n log n). Four parallel algorithms, A1, A2, A3, and A4 31
24 Asymptotic Analysis of Parallel Programs Sorting a list of n numbers. If metric is speed (T P ), algorithm A1 is the best, followed by A3, A4, and A2 In terms of efficiency (E), A2 and A4 are the best, followed by A3 and A1. In terms of cost(pt p ), algorithms A2 and A4 are cost optimal, A1 and A3 are not. It is important to identify the analysis objectives and to use appropriate metrics! 32
25 Topic Overview Introduction Performance Metrics for Parallel Systems Execution Time, Overhead, Speedup, Efficiency, Cost Amdahl s Law Scalability of Parallel Systems Isoefficiency Metric of Scalability Minimum Execution Time Asymptotic Analysis of Parallel Programs Other Scalability Metrics Scaled speedup, Serial fraction 33




26 Scaled Speedup: Example n x n matrix multiplication The serial execution time: t c n 3. The parallel execution time: Speedup: 39


27 Scaled Speedup: Example (continued) Consider memory-constrained scaled speedup. We have memory complexity m= Θ(n 2 ) = Θ(p), or n 2 =c x p. At this growth rate, scaled speedup S is given by: Note that this is scalable. 40


28 Scaled Speedup: Example (continued) Consider time-constrained scaled speedup. We have T P = O(1) = O(n 3 / p), or n 3 =c x p. Time-constrained speedup S is given by: Memory constrained scaling yields better performance. 41
29 References Adapted from slides Principles of Parallel Algorithm Design by Ananth Grama Analytical Modeling of Parallel Systems, Chapter 5 in Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar, Introduction to Parallel Computing'', Addison Wesley, Grama, Ananth Y.; Gupta, A.; Kumar, V., "Isoefficiency: measuring the scalability of parallel algorithms and architectures," in Parallel & Distributed Technology: Systems & Applications, IEEE, vol.1, no.3, pp.12-21, Aug. 1993, doi: / , =242438&isnumber=
Analytical Modeling of Parallel Systems
 Analytical Modeling of Parallel Systems Chieh-Sen (Jason) Huang Department of Applied Mathematics National Sun Yat-sen University Thank Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar for providing
Analytical Modeling of Parallel Systems Chieh-Sen (Jason) Huang Department of Applied Mathematics National Sun Yat-sen University Thank Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar for providing
Analytical Modeling of Parallel Programs. S. Oliveira
 Analytical Modeling of Parallel Programs S. Oliveira Fall 2005 1 Scalability of Parallel Systems Efficiency of a parallel program E = S/P = T s /PT p Using the parallel overhead expression E = 1/(1 + T
Analytical Modeling of Parallel Programs S. Oliveira Fall 2005 1 Scalability of Parallel Systems Efficiency of a parallel program E = S/P = T s /PT p Using the parallel overhead expression E = 1/(1 + T
Analytical Modeling of Parallel Programs (Chapter 5) Alexandre David
 Alexandre David") Analytical Modeling of Parallel Programs (Chapter 5) Alexandre David 1.2.05 1 Topic Overview Sources of overhead in parallel programs. Performance metrics for parallel systems. Effect of granularity on
Analytical Modeling of Parallel Programs (Chapter 5) Alexandre David 1.2.05 1 Topic Overview Sources of overhead in parallel programs. Performance metrics for parallel systems. Effect of granularity on
Recap from the previous lecture on Analytical Modeling
 COSC 637 Parallel Computation Analytical Modeling of Parallel Programs (II) Edgar Gabriel Fall 20 Recap from the previous lecture on Analytical Modeling Speedup: S p = T s / T p (p) Efficiency E = S p
COSC 637 Parallel Computation Analytical Modeling of Parallel Programs (II) Edgar Gabriel Fall 20 Recap from the previous lecture on Analytical Modeling Speedup: S p = T s / T p (p) Efficiency E = S p
Performance Evaluation of Codes. Performance Metrics
 CS6230 Performance Evaluation of Codes Performance Metrics Aim to understanding the algorithmic issues in obtaining high performance from large scale parallel computers Topics for Conisderation General
CS6230 Performance Evaluation of Codes Performance Metrics Aim to understanding the algorithmic issues in obtaining high performance from large scale parallel computers Topics for Conisderation General
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #19 3/28/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 From last class PRAM
EE/CSCI 451: Parallel and Distributed Computation Lecture #19 3/28/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 From last class PRAM
Performance and Scalability. Lars Karlsson
 Performance and Scalability Lars Karlsson Outline Complexity analysis Runtime, speedup, efficiency Amdahl s Law and scalability Cost and overhead Cost optimality Iso-efficiency function Case study: matrix
Performance and Scalability Lars Karlsson Outline Complexity analysis Runtime, speedup, efficiency Amdahl s Law and scalability Cost and overhead Cost optimality Iso-efficiency function Case study: matrix
Parallel Performance Theory - 1
 Parallel Performance Theory - 1 Parallel Computing CIS 410/510 Department of Computer and Information Science Outline q Performance scalability q Analytical performance measures q Amdahl s law and Gustafson-Barsis
Parallel Performance Theory - 1 Parallel Computing CIS 410/510 Department of Computer and Information Science Outline q Performance scalability q Analytical performance measures q Amdahl s law and Gustafson-Barsis
Parallel Program Performance Analysis
 Parallel Program Performance Analysis Chris Kauffman CS 499: Spring 2016 GMU Logistics Today Final details of HW2 interviews HW2 timings HW2 Questions Parallel Performance Theory Special Office Hours Mon
Parallel Program Performance Analysis Chris Kauffman CS 499: Spring 2016 GMU Logistics Today Final details of HW2 interviews HW2 timings HW2 Questions Parallel Performance Theory Special Office Hours Mon
Notation. Bounds on Speedup. Parallel Processing. CS575 Parallel Processing
 Parallel Processing CS575 Parallel Processing Lecture five: Efficiency Wim Bohm, Colorado State University Some material from Speedup vs Efficiency in Parallel Systems - Eager, Zahorjan and Lazowska IEEE
Parallel Processing CS575 Parallel Processing Lecture five: Efficiency Wim Bohm, Colorado State University Some material from Speedup vs Efficiency in Parallel Systems - Eager, Zahorjan and Lazowska IEEE
Parallel Algorithms for Forward and Back Substitution in Direct Solution of Sparse Linear Systems
 Parallel Algorithms for Forward and Back Substitution in Direct Solution of Sparse Linear Systems ANSHUL GUPTA IBM T.J.WATSON RESEARCH CENTER YORKTOWN HEIGHTS, NY 109 ANSHUL@WATSON.IBM.COM VIPIN KUMAR
Parallel Algorithms for Forward and Back Substitution in Direct Solution of Sparse Linear Systems ANSHUL GUPTA IBM T.J.WATSON RESEARCH CENTER YORKTOWN HEIGHTS, NY 109 ANSHUL@WATSON.IBM.COM VIPIN KUMAR
Parallel programming using MPI. Analysis and optimization. Bhupender Thakur, Jim Lupo, Le Yan, Alex Pacheco
 Parallel programming using MPI Analysis and optimization Bhupender Thakur, Jim Lupo, Le Yan, Alex Pacheco Outline l Parallel programming: Basic definitions l Choosing right algorithms: Optimal serial and
Parallel programming using MPI Analysis and optimization Bhupender Thakur, Jim Lupo, Le Yan, Alex Pacheco Outline l Parallel programming: Basic definitions l Choosing right algorithms: Optimal serial and
Parallel Performance Theory
 AMS 250: An Introduction to High Performance Computing Parallel Performance Theory Shawfeng Dong shaw@ucsc.edu (831) 502-7743 Applied Mathematics & Statistics University of California, Santa Cruz Outline
AMS 250: An Introduction to High Performance Computing Parallel Performance Theory Shawfeng Dong shaw@ucsc.edu (831) 502-7743 Applied Mathematics & Statistics University of California, Santa Cruz Outline
Analysis of execution time for parallel algorithm to dertmine if it is worth the effort to code and debug in parallel
 Performance Analysis Introduction Analysis of execution time for arallel algorithm to dertmine if it is worth the effort to code and debug in arallel Understanding barriers to high erformance and redict
Performance Analysis Introduction Analysis of execution time for arallel algorithm to dertmine if it is worth the effort to code and debug in arallel Understanding barriers to high erformance and redict
A Note on Parallel Algorithmic Speedup Bounds
 arxiv:1104.4078v1 [cs.dc] 20 Apr 2011 A Note on Parallel Algorithmic Speedup Bounds Neil J. Gunther February 8, 2011 Abstract A parallel program can be represented as a directed acyclic graph. An important
arxiv:1104.4078v1 [cs.dc] 20 Apr 2011 A Note on Parallel Algorithmic Speedup Bounds Neil J. Gunther February 8, 2011 Abstract A parallel program can be represented as a directed acyclic graph. An important
Parallel Numerical Algorithms
 Parallel Numerical Algorithms Chapter 13 Prof. Michael T. Heath Department of Computer Science University of Illinois at Urbana-Champaign CS 554 / CSE 512 Michael T. Heath Parallel Numerical Algorithms
Parallel Numerical Algorithms Chapter 13 Prof. Michael T. Heath Department of Computer Science University of Illinois at Urbana-Champaign CS 554 / CSE 512 Michael T. Heath Parallel Numerical Algorithms
Analyzing the Error Bounds of Multipole-Based
 Page 1 of 12 Analyzing the Error Bounds of Multipole-Based Treecodes Vivek Sarin, Ananth Grama, and Ahmed Sameh Department of Computer Sciences Purdue University W. Lafayette, IN 47906 Email: Sarin, Grama,
Page 1 of 12 Analyzing the Error Bounds of Multipole-Based Treecodes Vivek Sarin, Ananth Grama, and Ahmed Sameh Department of Computer Sciences Purdue University W. Lafayette, IN 47906 Email: Sarin, Grama,
MICROPROCESSOR REPORT. THE INSIDER S GUIDE TO MICROPROCESSOR HARDWARE
 MICROPROCESSOR www.mpronline.com REPORT THE INSIDER S GUIDE TO MICROPROCESSOR HARDWARE ENERGY COROLLARIES TO AMDAHL S LAW Analyzing the Interactions Between Parallel Execution and Energy Consumption By
MICROPROCESSOR www.mpronline.com REPORT THE INSIDER S GUIDE TO MICROPROCESSOR HARDWARE ENERGY COROLLARIES TO AMDAHL S LAW Analyzing the Interactions Between Parallel Execution and Energy Consumption By
CS 700: Quantitative Methods & Experimental Design in Computer Science
 CS 700: Quantitative Methods & Experimental Design in Computer Science Sanjeev Setia Dept of Computer Science George Mason University Logistics Grade: 35% project, 25% Homework assignments 20% midterm,
CS 700: Quantitative Methods & Experimental Design in Computer Science Sanjeev Setia Dept of Computer Science George Mason University Logistics Grade: 35% project, 25% Homework assignments 20% midterm,
Introduction to Algorithms 6.046J/18.401J
 Introduction to Algorithms 6.046J/8.40J Lecture Prof. Piotr Indyk Welcome to Introduction to Algorithms, Spring 08 Handouts. Course Information. Calendar 3. Signup sheet (PLEASE return at the end of this
Introduction to Algorithms 6.046J/8.40J Lecture Prof. Piotr Indyk Welcome to Introduction to Algorithms, Spring 08 Handouts. Course Information. Calendar 3. Signup sheet (PLEASE return at the end of this
Review: From problem to parallel algorithm
 Review: From problem to parallel algorithm Mathematical formulations of interesting problems abound Poisson s equation Sources: Electrostatics, gravity, fluid flow, image processing (!) Numerical solution:
Review: From problem to parallel algorithm Mathematical formulations of interesting problems abound Poisson s equation Sources: Electrostatics, gravity, fluid flow, image processing (!) Numerical solution:
Multipole-Based Preconditioners for Sparse Linear Systems.
 Multipole-Based Preconditioners for Sparse Linear Systems. Ananth Grama Purdue University. Supported by the National Science Foundation. Overview Summary of Contributions Generalized Stokes Problem Solenoidal
Multipole-Based Preconditioners for Sparse Linear Systems. Ananth Grama Purdue University. Supported by the National Science Foundation. Overview Summary of Contributions Generalized Stokes Problem Solenoidal
(a) (b) (c) (d) (e) (f) (g)
 (b) (c) (d) (e) (f) (g)") t s =1000 t w =1 t s =1000 t w =50 t s =50000 t w =10 (a) (b) (c) t s =1000 t w =1 t s =1000 t w =50 t s =50000 t w =10 (d) (e) (f) Figure 2: Scalability plots of the system for eigenvalue computation
t s =1000 t w =1 t s =1000 t w =50 t s =50000 t w =10 (a) (b) (c) t s =1000 t w =1 t s =1000 t w =50 t s =50000 t w =10 (d) (e) (f) Figure 2: Scalability plots of the system for eigenvalue computation
MPI Implementations for Solving Dot - Product on Heterogeneous Platforms
 MPI Implementations for Solving Dot - Product on Heterogeneous Platforms Panagiotis D. Michailidis and Konstantinos G. Margaritis Abstract This paper is focused on designing two parallel dot product implementations
MPI Implementations for Solving Dot - Product on Heterogeneous Platforms Panagiotis D. Michailidis and Konstantinos G. Margaritis Abstract This paper is focused on designing two parallel dot product implementations
Models: Amdahl s Law, PRAM, α-β Tal Ben-Nun
 spcl.inf.ethz.ch @spcl_eth Models: Amdahl s Law, PRAM, α-β Tal Ben-Nun Design of Parallel and High-Performance Computing Fall 2017 DPHPC Overview cache coherency memory models 2 Speedup An application
spcl.inf.ethz.ch @spcl_eth Models: Amdahl s Law, PRAM, α-β Tal Ben-Nun Design of Parallel and High-Performance Computing Fall 2017 DPHPC Overview cache coherency memory models 2 Speedup An application
Review for the Midterm Exam
 Review for the Midterm Exam 1 Three Questions of the Computational Science Prelim scaled speedup network topologies work stealing 2 The in-class Spring 2012 Midterm Exam pleasingly parallel computations
Review for the Midterm Exam 1 Three Questions of the Computational Science Prelim scaled speedup network topologies work stealing 2 The in-class Spring 2012 Midterm Exam pleasingly parallel computations
= ( 1 P + S V P) 1. Speedup T S /T V p
 1. Speedup T S /T V p") Numerical Simulation - Homework Solutions 2013 1. Amdahl s law. (28%) Consider parallel processing with common memory. The number of parallel processor is 254. Explain why Amdahl s law for this situation
Numerical Simulation - Homework Solutions 2013 1. Amdahl s law. (28%) Consider parallel processing with common memory. The number of parallel processor is 254. Explain why Amdahl s law for this situation
Fast, Parallel Algorithm for Multiplying Polynomials with Integer Coefficients
 , July 4-6, 01, London, UK Fast, Parallel Algorithm for Multiplying Polynomials with Integer Coefficients Andrzej Chmielowiec Abstract This paper aims to develop and analyze an effective parallel algorithm
, July 4-6, 01, London, UK Fast, Parallel Algorithm for Multiplying Polynomials with Integer Coefficients Andrzej Chmielowiec Abstract This paper aims to develop and analyze an effective parallel algorithm
Lecture 2: Metrics to Evaluate Systems
 Lecture 2: Metrics to Evaluate Systems Topics: Metrics: power, reliability, cost, benchmark suites, performance equation, summarizing performance with AM, GM, HM Sign up for the class mailing list! Video
Lecture 2: Metrics to Evaluate Systems Topics: Metrics: power, reliability, cost, benchmark suites, performance equation, summarizing performance with AM, GM, HM Sign up for the class mailing list! Video
FORSCHUNGSZENTRUM JÜLICH GmbH Zentralinstitut für Angewandte Mathematik D Jülich, Tel. (02461)
") FORSCHUNGSZENTRUM JÜLICH GmbH Zentralinstitut für Angewandte Mathematik D-52425 Jülich, Tel. (02461) 61-6402 Interner Bericht Isoefficiency Analysis of Parallel QMR-Like Iterative Methods and its Implications
FORSCHUNGSZENTRUM JÜLICH GmbH Zentralinstitut für Angewandte Mathematik D-52425 Jülich, Tel. (02461) 61-6402 Interner Bericht Isoefficiency Analysis of Parallel QMR-Like Iterative Methods and its Implications
Algorithms. What is an algorithm?
 What is an algorithm? What is an algorithm? Informally, an algorithm is a well-defined finite set of rules that specifies a sequential series of elementary operations to be applied to some data called
What is an algorithm? What is an algorithm? Informally, an algorithm is a well-defined finite set of rules that specifies a sequential series of elementary operations to be applied to some data called
Scalability Metrics for Parallel Molecular Dynamics
 Scalability Metrics for arallel Molecular Dynamics arallel Efficiency We define the efficiency of a parallel program running on processors to solve a problem of size W Let T(W, ) be the execution time
Scalability Metrics for arallel Molecular Dynamics arallel Efficiency We define the efficiency of a parallel program running on processors to solve a problem of size W Let T(W, ) be the execution time
P E R E N C O - C H R I S T M A S P A R T Y
 L E T T I C E L E T T I C E I S A F A M I L Y R U N C O M P A N Y S P A N N I N G T W O G E N E R A T I O N S A N D T H R E E D E C A D E S. B A S E D I N L O N D O N, W E H A V E T H E P E R F E C T R
L E T T I C E L E T T I C E I S A F A M I L Y R U N C O M P A N Y S P A N N I N G T W O G E N E R A T I O N S A N D T H R E E D E C A D E S. B A S E D I N L O N D O N, W E H A V E T H E P E R F E C T R
CHAPTER 6 : LITERATURE REVIEW
 CHAPTER 6 : LITERATURE REVIEW Chapter : LITERATURE REVIEW 77 M E A S U R I N G T H E E F F I C I E N C Y O F D E C I S I O N M A K I N G U N I T S A B S T R A C T A n o n l i n e a r ( n o n c o n v e
CHAPTER 6 : LITERATURE REVIEW Chapter : LITERATURE REVIEW 77 M E A S U R I N G T H E E F F I C I E N C Y O F D E C I S I O N M A K I N G U N I T S A B S T R A C T A n o n l i n e a r ( n o n c o n v e
Lecture 22: Multithreaded Algorithms CSCI Algorithms I. Andrew Rosenberg
 Lecture 22: Multithreaded Algorithms CSCI 700 - Algorithms I Andrew Rosenberg Last Time Open Addressing Hashing Today Multithreading Two Styles of Threading Shared Memory Every thread can access the same
Lecture 22: Multithreaded Algorithms CSCI 700 - Algorithms I Andrew Rosenberg Last Time Open Addressing Hashing Today Multithreading Two Styles of Threading Shared Memory Every thread can access the same
Welcome to MCS 572. content and organization expectations of the course. definition and classification
 Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
On The Energy Complexity of Parallel Algorithms
 On The Energy Complexity of Parallel Algorithms Vijay Anand Korthikanti Department of Computer Science University of Illinois at Urbana Champaign vkortho2@illinois.edu Gul Agha Department of Computer Science
On The Energy Complexity of Parallel Algorithms Vijay Anand Korthikanti Department of Computer Science University of Illinois at Urbana Champaign vkortho2@illinois.edu Gul Agha Department of Computer Science
hal , version 1-27 Mar 2014
 Author manuscript, published in "2nd Multidisciplinary International Conference on Scheduling : Theory and Applications (MISTA 2005), New York, NY. : United States (2005)" 2 More formally, we denote by
Author manuscript, published in "2nd Multidisciplinary International Conference on Scheduling : Theory and Applications (MISTA 2005), New York, NY. : United States (2005)" 2 More formally, we denote by
Sakurai-Sugiura algorithm based eigenvalue solver for Siesta. Georg Huhs
 Sakurai-Sugiura algorithm based eigenvalue solver for Siesta Georg Huhs Motivation Timing analysis for one SCF-loop iteration: left: CNT/Graphene, right: DNA Siesta Specifics High fraction of EVs needed
Sakurai-Sugiura algorithm based eigenvalue solver for Siesta Georg Huhs Motivation Timing analysis for one SCF-loop iteration: left: CNT/Graphene, right: DNA Siesta Specifics High fraction of EVs needed
T i t l e o f t h e w o r k : L a M a r e a Y o k o h a m a. A r t i s t : M a r i a n o P e n s o t t i ( P l a y w r i g h t, D i r e c t o r )
") v e r. E N G O u t l i n e T i t l e o f t h e w o r k : L a M a r e a Y o k o h a m a A r t i s t : M a r i a n o P e n s o t t i ( P l a y w r i g h t, D i r e c t o r ) C o n t e n t s : T h i s w o
v e r. E N G O u t l i n e T i t l e o f t h e w o r k : L a M a r e a Y o k o h a m a A r t i s t : M a r i a n o P e n s o t t i ( P l a y w r i g h t, D i r e c t o r ) C o n t e n t s : T h i s w o
CS 4407 Algorithms Lecture 3: Iterative and Divide and Conquer Algorithms
 CS 4407 Algorithms Lecture 3: Iterative and Divide and Conquer Algorithms Prof. Gregory Provan Department of Computer Science University College Cork 1 Lecture Outline CS 4407, Algorithms Growth Functions
CS 4407 Algorithms Lecture 3: Iterative and Divide and Conquer Algorithms Prof. Gregory Provan Department of Computer Science University College Cork 1 Lecture Outline CS 4407, Algorithms Growth Functions
Goals for Performance Lecture
 Goals for Performance Lecture Understand performance, speedup, throughput, latency Relationship between cycle time, cycles/instruction (CPI), number of instructions (the performance equation) Amdahl s
Goals for Performance Lecture Understand performance, speedup, throughput, latency Relationship between cycle time, cycles/instruction (CPI), number of instructions (the performance equation) Amdahl s
PERFORMANCE METRICS. Mahdi Nazm Bojnordi. CS/ECE 6810: Computer Architecture. Assistant Professor School of Computing University of Utah
 PERFORMANCE METRICS Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Jan. 17 th : Homework 1 release (due on Jan.
PERFORMANCE METRICS Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Jan. 17 th : Homework 1 release (due on Jan.
Parallelization of the Dirac operator. Pushan Majumdar. Indian Association for the Cultivation of Sciences, Jadavpur, Kolkata
 Parallelization of the Dirac operator Pushan Majumdar Indian Association for the Cultivation of Sciences, Jadavpur, Kolkata Outline Introduction Algorithms Parallelization Comparison of performances Conclusions
Parallelization of the Dirac operator Pushan Majumdar Indian Association for the Cultivation of Sciences, Jadavpur, Kolkata Outline Introduction Algorithms Parallelization Comparison of performances Conclusions
Plain Polynomial Arithmetic on GPU
 Plain Polynomial Arithmetic on GPU Sardar Anisul Haque, Marc Moreno Maza University of Western Ontario, Canada E-mail: shaque4@uwo.ca, moreno@csd.uwo.ca Abstract. As for serial code on CPUs, parallel code
Plain Polynomial Arithmetic on GPU Sardar Anisul Haque, Marc Moreno Maza University of Western Ontario, Canada E-mail: shaque4@uwo.ca, moreno@csd.uwo.ca Abstract. As for serial code on CPUs, parallel code
Cpt S 223. School of EECS, WSU
 Algorithm Analysis 1 Purpose Why bother analyzing code; isn t getting it to work enough? Estimate time and memory in the average case and worst case Identify bottlenecks, i.e., where to reduce time Compare
Algorithm Analysis 1 Purpose Why bother analyzing code; isn t getting it to work enough? Estimate time and memory in the average case and worst case Identify bottlenecks, i.e., where to reduce time Compare
Performance of Computers. Performance of Computers. Defining Performance. Forecast
 Performance of Computers Which computer is fastest? Not so simple scientific simulation - FP performance program development - Integer performance commercial work - I/O Performance of Computers Want to
Performance of Computers Which computer is fastest? Not so simple scientific simulation - FP performance program development - Integer performance commercial work - I/O Performance of Computers Want to
Applications of Mathematical Economics
 Applications of Mathematical Economics Michael Curran Trinity College Dublin Overview Introduction. Data Preparation Filters. Dynamic Stochastic General Equilibrium Models: Sunspots and Blanchard-Kahn
Applications of Mathematical Economics Michael Curran Trinity College Dublin Overview Introduction. Data Preparation Filters. Dynamic Stochastic General Equilibrium Models: Sunspots and Blanchard-Kahn
A Comparison of Parallel Solvers for Diagonally. Dominant and General Narrow-Banded Linear. Systems II.
 A Comparison of Parallel Solvers for Diagonally Dominant and General Narrow-Banded Linear Systems II Peter Arbenz 1, Andrew Cleary 2, Jack Dongarra 3, and Markus Hegland 4 1 Institute of Scientic Computing,
A Comparison of Parallel Solvers for Diagonally Dominant and General Narrow-Banded Linear Systems II Peter Arbenz 1, Andrew Cleary 2, Jack Dongarra 3, and Markus Hegland 4 1 Institute of Scientic Computing,
Analysis of Algorithms [Reading: CLRS 2.2, 3] Laura Toma, csci2200, Bowdoin College
![Analysis of Algorithms [Reading: CLRS 2.2, 3] Laura Toma, csci2200, Bowdoin College](/thumbs/79/78926994.jpg "Analysis of Algorithms [Reading: CLRS 2.2, 3] Laura Toma, csci2200, Bowdoin College") Analysis of Algorithms [Reading: CLRS 2.2, 3] Laura Toma, csci2200, Bowdoin College Why analysis? We want to predict how the algorithm will behave (e.g. running time) on arbitrary inputs, and how it will
Analysis of Algorithms [Reading: CLRS 2.2, 3] Laura Toma, csci2200, Bowdoin College Why analysis? We want to predict how the algorithm will behave (e.g. running time) on arbitrary inputs, and how it will
Algorithms for Collective Communication. Design and Analysis of Parallel Algorithms
 Algorithms for Collective Communication Design and Analysis of Parallel Algorithms Source A. Grama, A. Gupta, G. Karypis, and V. Kumar. Introduction to Parallel Computing, Chapter 4, 2003. Outline One-to-all
Algorithms for Collective Communication Design and Analysis of Parallel Algorithms Source A. Grama, A. Gupta, G. Karypis, and V. Kumar. Introduction to Parallel Computing, Chapter 4, 2003. Outline One-to-all
ENEE350 Lecture Notes-Weeks 14 and 15
 Pipelining & Amdahl s Law ENEE350 Lecture Notes-Weeks 14 and 15 Pipelining is a method of processing in which a problem is divided into a number of sub problems and solved and the solu8ons of the sub problems
Pipelining & Amdahl s Law ENEE350 Lecture Notes-Weeks 14 and 15 Pipelining is a method of processing in which a problem is divided into a number of sub problems and solved and the solu8ons of the sub problems
Improvements for Implicit Linear Equation Solvers
 Improvements for Implicit Linear Equation Solvers Roger Grimes, Bob Lucas, Clement Weisbecker Livermore Software Technology Corporation Abstract Solving large sparse linear systems of equations is often
Improvements for Implicit Linear Equation Solvers Roger Grimes, Bob Lucas, Clement Weisbecker Livermore Software Technology Corporation Abstract Solving large sparse linear systems of equations is often
QR Decomposition in a Multicore Environment
 QR Decomposition in a Multicore Environment Omar Ahsan University of Maryland-College Park Advised by Professor Howard Elman College Park, MD oha@cs.umd.edu ABSTRACT In this study we examine performance
QR Decomposition in a Multicore Environment Omar Ahsan University of Maryland-College Park Advised by Professor Howard Elman College Park, MD oha@cs.umd.edu ABSTRACT In this study we examine performance
A Many-Core Machine Model for Designing Algorithms with Minimum Parallelism Overheads
 A Many-Core Machine Model for Designing Algorithms with Minimum Parallelism Overheads Sardar Anisul HAQUE a, Marc MORENO MAZA a,b and Ning XIE a a Department of Computer Science, University of Western
A Many-Core Machine Model for Designing Algorithms with Minimum Parallelism Overheads Sardar Anisul HAQUE a, Marc MORENO MAZA a,b and Ning XIE a a Department of Computer Science, University of Western
CSE332: Data Structures & Parallelism Lecture 2: Algorithm Analysis. Ruth Anderson Winter 2018
 CSE332: Data Structures & Parallelism Lecture 2: Algorithm Analysis Ruth Anderson Winter 2018 Today Algorithm Analysis What do we care about? How to compare two algorithms Analyzing Code Asymptotic Analysis
CSE332: Data Structures & Parallelism Lecture 2: Algorithm Analysis Ruth Anderson Winter 2018 Today Algorithm Analysis What do we care about? How to compare two algorithms Analyzing Code Asymptotic Analysis
Topic 17. Analysis of Algorithms
 Topic 17 Analysis of Algorithms Analysis of Algorithms- Review Efficiency of an algorithm can be measured in terms of : Time complexity: a measure of the amount of time required to execute an algorithm
Topic 17 Analysis of Algorithms Analysis of Algorithms- Review Efficiency of an algorithm can be measured in terms of : Time complexity: a measure of the amount of time required to execute an algorithm
Dense Arithmetic over Finite Fields with CUMODP
 Dense Arithmetic over Finite Fields with CUMODP Sardar Anisul Haque 1 Xin Li 2 Farnam Mansouri 1 Marc Moreno Maza 1 Wei Pan 3 Ning Xie 1 1 University of Western Ontario, Canada 2 Universidad Carlos III,
Dense Arithmetic over Finite Fields with CUMODP Sardar Anisul Haque 1 Xin Li 2 Farnam Mansouri 1 Marc Moreno Maza 1 Wei Pan 3 Ning Xie 1 1 University of Western Ontario, Canada 2 Universidad Carlos III,
CSE332: Data Structures & Parallelism Lecture 2: Algorithm Analysis. Ruth Anderson Winter 2018
 CSE332: Data Structures & Parallelism Lecture 2: Algorithm Analysis Ruth Anderson Winter 2018 Today Algorithm Analysis What do we care about? How to compare two algorithms Analyzing Code Asymptotic Analysis
CSE332: Data Structures & Parallelism Lecture 2: Algorithm Analysis Ruth Anderson Winter 2018 Today Algorithm Analysis What do we care about? How to compare two algorithms Analyzing Code Asymptotic Analysis
CS 4407 Algorithms Lecture 2: Iterative and Divide and Conquer Algorithms
 CS 4407 Algorithms Lecture 2: Iterative and Divide and Conquer Algorithms Prof. Gregory Provan Department of Computer Science University College Cork 1 Lecture Outline CS 4407, Algorithms Growth Functions
CS 4407 Algorithms Lecture 2: Iterative and Divide and Conquer Algorithms Prof. Gregory Provan Department of Computer Science University College Cork 1 Lecture Outline CS 4407, Algorithms Growth Functions
CSE332: Data Structures & Parallelism Lecture 2: Algorithm Analysis. Ruth Anderson Winter 2019
 CSE332: Data Structures & Parallelism Lecture 2: Algorithm Analysis Ruth Anderson Winter 2019 Today Algorithm Analysis What do we care about? How to compare two algorithms Analyzing Code Asymptotic Analysis
CSE332: Data Structures & Parallelism Lecture 2: Algorithm Analysis Ruth Anderson Winter 2019 Today Algorithm Analysis What do we care about? How to compare two algorithms Analyzing Code Asymptotic Analysis
CSCI Final Project Report A Parallel Implementation of Viterbi s Decoding Algorithm
 CSCI 1760 - Final Project Report A Parallel Implementation of Viterbi s Decoding Algorithm Shay Mozes Brown University shay@cs.brown.edu Abstract. This report describes parallel Java implementations of
CSCI 1760 - Final Project Report A Parallel Implementation of Viterbi s Decoding Algorithm Shay Mozes Brown University shay@cs.brown.edu Abstract. This report describes parallel Java implementations of
Copyright 2000, Kevin Wayne 1
 Chapter 2 2.1 Computational Tractability Basics of Algorithm Analysis "For me, great algorithms are the poetry of computation. Just like verse, they can be terse, allusive, dense, and even mysterious.
Chapter 2 2.1 Computational Tractability Basics of Algorithm Analysis "For me, great algorithms are the poetry of computation. Just like verse, they can be terse, allusive, dense, and even mysterious.
Extending Parallel Scalability of LAMMPS and Multiscale Reactive Molecular Simulations
 September 18, 2012 Extending Parallel Scalability of LAMMPS and Multiscale Reactive Molecular Simulations Yuxing Peng, Chris Knight, Philip Blood, Lonnie Crosby, and Gregory A. Voth Outline Proton Solvation
September 18, 2012 Extending Parallel Scalability of LAMMPS and Multiscale Reactive Molecular Simulations Yuxing Peng, Chris Knight, Philip Blood, Lonnie Crosby, and Gregory A. Voth Outline Proton Solvation
Sorting. Chapter 11. CSE 2011 Prof. J. Elder Last Updated: :11 AM
 Sorting Chapter 11-1 - Sorting Ø We have seen the advantage of sorted data representations for a number of applications q Sparse vectors q Maps q Dictionaries Ø Here we consider the problem of how to efficiently
Sorting Chapter 11-1 - Sorting Ø We have seen the advantage of sorted data representations for a number of applications q Sparse vectors q Maps q Dictionaries Ø Here we consider the problem of how to efficiently
Lecture 27: Hardware Acceleration. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 27: Hardware Acceleration James C. Hoe Department of ECE Carnegie Mellon niversity 18 447 S18 L27 S1, James C. Hoe, CM/ECE/CALCM, 2018 18 447 S18 L27 S2, James C. Hoe, CM/ECE/CALCM, 2018
18 447 Lecture 27: Hardware Acceleration James C. Hoe Department of ECE Carnegie Mellon niversity 18 447 S18 L27 S1, James C. Hoe, CM/ECE/CALCM, 2018 18 447 S18 L27 S2, James C. Hoe, CM/ECE/CALCM, 2018
Optimization of a parallel 3d-FFT with non-blocking collective operations
 Optimization of a parallel 3d-FFT with non-blocking collective operations Chair of Computer Architecture Technical University of Chemnitz Département de Physique Théorique et Appliquée Commissariat à l
Optimization of a parallel 3d-FFT with non-blocking collective operations Chair of Computer Architecture Technical University of Chemnitz Département de Physique Théorique et Appliquée Commissariat à l
Enhancing Scalability of Sparse Direct Methods
 Journal of Physics: Conference Series 78 (007) 0 doi:0.088/7-6596/78//0 Enhancing Scalability of Sparse Direct Methods X.S. Li, J. Demmel, L. Grigori, M. Gu, J. Xia 5, S. Jardin 6, C. Sovinec 7, L.-Q.
Journal of Physics: Conference Series 78 (007) 0 doi:0.088/7-6596/78//0 Enhancing Scalability of Sparse Direct Methods X.S. Li, J. Demmel, L. Grigori, M. Gu, J. Xia 5, S. Jardin 6, C. Sovinec 7, L.-Q.
Chapter 5. Digital Design and Computer Architecture, 2 nd Edition. David Money Harris and Sarah L. Harris. Chapter 5 <1>
 Chapter 5 Digital Design and Computer Architecture, 2 nd Edition David Money Harris and Sarah L. Harris Chapter 5 Chapter 5 :: Topics Introduction Arithmetic Circuits umber Systems Sequential Building
Chapter 5 Digital Design and Computer Architecture, 2 nd Edition David Money Harris and Sarah L. Harris Chapter 5 Chapter 5 :: Topics Introduction Arithmetic Circuits umber Systems Sequential Building
Multiprocessor Scheduling of Age Constraint Processes
 Multiprocessor Scheduling of Age Constraint Processes Lars Lundberg Department of Computer Science, University of Karlskrona/Ronneby, Soft Center, S-372 25 Ronneby, Sweden, email: Lars.Lundberg@ide.hk-r.se
Multiprocessor Scheduling of Age Constraint Processes Lars Lundberg Department of Computer Science, University of Karlskrona/Ronneby, Soft Center, S-372 25 Ronneby, Sweden, email: Lars.Lundberg@ide.hk-r.se
Parallel algorithms for three-dimensional parabolic and pseudoparabolic problems with different boundary conditions
 382 Nonlinear Analysis: Modelling and Control, 204, Vol. 9, No. 3, 382 395 http://dx.doi.org/0.5388/na.204.3.5 Parallel algorithms for three-dimensional parabolic and pseudoparabolic problems with different
382 Nonlinear Analysis: Modelling and Control, 204, Vol. 9, No. 3, 382 395 http://dx.doi.org/0.5388/na.204.3.5 Parallel algorithms for three-dimensional parabolic and pseudoparabolic problems with different
CSE 548: Analysis of Algorithms. Lecture 12 ( Analyzing Parallel Algorithms )
") CSE 548: Analysis of Algorithms Lecture 12 ( Analyzing Parallel Algorithms ) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Fall 2017 Why Parallelism? Moore s Law Source: Wikipedia
CSE 548: Analysis of Algorithms Lecture 12 ( Analyzing Parallel Algorithms ) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Fall 2017 Why Parallelism? Moore s Law Source: Wikipedia
ECE250: Algorithms and Data Structures Analyzing and Designing Algorithms
 ECE50: Algorithms and Data Structures Analyzing and Designing Algorithms Ladan Tahvildari, PEng, SMIEEE Associate Professor Software Technologies Applied Research (STAR) Group Dept. of Elect. & Comp. Eng.
ECE50: Algorithms and Data Structures Analyzing and Designing Algorithms Ladan Tahvildari, PEng, SMIEEE Associate Professor Software Technologies Applied Research (STAR) Group Dept. of Elect. & Comp. Eng.
Finite-State Model Checking
 EECS 219C: Computer-Aided Verification Intro. to Model Checking: Models and Properties Sanjit A. Seshia EECS, UC Berkeley Finite-State Model Checking G(p X q) Temporal logic q p FSM Model Checker Yes,
EECS 219C: Computer-Aided Verification Intro. to Model Checking: Models and Properties Sanjit A. Seshia EECS, UC Berkeley Finite-State Model Checking G(p X q) Temporal logic q p FSM Model Checker Yes,
Scalability is Quantifiable
 Scalability is Quantifiable Universal Scalability Law Baron Schwartz - November 2017 Logistics & Stuff Slides will be posted :) Ask questions anytime! Founder of VividCortex Wrote High Performance MySQL
Scalability is Quantifiable Universal Scalability Law Baron Schwartz - November 2017 Logistics & Stuff Slides will be posted :) Ask questions anytime! Founder of VividCortex Wrote High Performance MySQL
NCU EE -- DSP VLSI Design. Tsung-Han Tsai 1
 NCU EE -- DSP VLSI Design. Tsung-Han Tsai 1 Multi-processor vs. Multi-computer architecture µp vs. DSP RISC vs. DSP RISC Reduced-instruction-set Register-to-register operation Higher throughput by using
NCU EE -- DSP VLSI Design. Tsung-Han Tsai 1 Multi-processor vs. Multi-computer architecture µp vs. DSP RISC vs. DSP RISC Reduced-instruction-set Register-to-register operation Higher throughput by using
Large Integer Multiplication on Hypercubes. Barry S. Fagin Thayer School of Engineering Dartmouth College Hanover, NH
 Large Integer Multiplication on Hypercubes Barry S. Fagin Thayer School of Engineering Dartmouth College Hanover, NH 03755 barry.fagin@dartmouth.edu Large Integer Multiplication 1 B. Fagin ABSTRACT Previous
Large Integer Multiplication on Hypercubes Barry S. Fagin Thayer School of Engineering Dartmouth College Hanover, NH 03755 barry.fagin@dartmouth.edu Large Integer Multiplication 1 B. Fagin ABSTRACT Previous
Computer Architecture
 Lecture 2: Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture CPU Evolution What is? 2 Outline Measurements and metrics : Performance, Cost, Dependability, Power Guidelines
Lecture 2: Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture CPU Evolution What is? 2 Outline Measurements and metrics : Performance, Cost, Dependability, Power Guidelines
CA-SVM: Communication-Avoiding Support Vector Machines on Distributed System
 CA-SVM: Communication-Avoiding Support Vector Machines on Distributed System Yang You 1, James Demmel 1, Kent Czechowski 2, Le Song 2, Richard Vuduc 2 UC Berkeley 1, Georgia Tech 2 Yang You (Speaker) James
CA-SVM: Communication-Avoiding Support Vector Machines on Distributed System Yang You 1, James Demmel 1, Kent Czechowski 2, Le Song 2, Richard Vuduc 2 UC Berkeley 1, Georgia Tech 2 Yang You (Speaker) James
Parallel PIPS-SBB Multi-level parallelism for 2-stage SMIPS. Lluís-Miquel Munguia, Geoffrey M. Oxberry, Deepak Rajan, Yuji Shinano
 Parallel PIPS-SBB Multi-level parallelism for 2-stage SMIPS Lluís-Miquel Munguia, Geoffrey M. Oxberry, Deepak Rajan, Yuji Shinano ... Our contribution PIPS-PSBB*: Multi-level parallelism for Stochastic
Parallel PIPS-SBB Multi-level parallelism for 2-stage SMIPS Lluís-Miquel Munguia, Geoffrey M. Oxberry, Deepak Rajan, Yuji Shinano ... Our contribution PIPS-PSBB*: Multi-level parallelism for Stochastic
CS Data Structures and Algorithm Analysis
 CS 483 - Data Structures and Algorithm Analysis Lecture II: Chapter 2 R. Paul Wiegand George Mason University, Department of Computer Science February 1, 2006 Outline 1 Analysis Framework 2 Asymptotic
CS 483 - Data Structures and Algorithm Analysis Lecture II: Chapter 2 R. Paul Wiegand George Mason University, Department of Computer Science February 1, 2006 Outline 1 Analysis Framework 2 Asymptotic
EE382 Processor Design Winter 1999 Chapter 2 Lectures Clocking and Pipelining
 Slide 1 EE382 Processor Design Winter 1999 Chapter 2 Lectures Clocking and Pipelining Slide 2 Topics Clocking Clock Parameters Latch Types Requirements for reliable clocking Pipelining Optimal pipelining
Slide 1 EE382 Processor Design Winter 1999 Chapter 2 Lectures Clocking and Pipelining Slide 2 Topics Clocking Clock Parameters Latch Types Requirements for reliable clocking Pipelining Optimal pipelining
Environment (Parallelizing Query Optimization)
") Advanced d Query Optimization i i Techniques in a Parallel Computing Environment (Parallelizing Query Optimization) Wook-Shin Han*, Wooseong Kwak, Jinsoo Lee Guy M. Lohman, Volker Markl Kyungpook National
Advanced d Query Optimization i i Techniques in a Parallel Computing Environment (Parallelizing Query Optimization) Wook-Shin Han*, Wooseong Kwak, Jinsoo Lee Guy M. Lohman, Volker Markl Kyungpook National
Program Performance Metrics
 Program Performance Metrics he parallel run time (par) is the time from the moment when computation starts to the moment when the last processor finished his execution he speedup (S) is defined as the
Program Performance Metrics he parallel run time (par) is the time from the moment when computation starts to the moment when the last processor finished his execution he speedup (S) is defined as the
Carlo Cavazzoni, HPC department, CINECA
 Large Scale Parallelism Carlo Cavazzoni, HPC department, CINECA Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have a mixed architecture + accelerators
Large Scale Parallelism Carlo Cavazzoni, HPC department, CINECA Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have a mixed architecture + accelerators
BeiHang Short Course, Part 7: HW Acceleration: It s about Performance, Energy and Power
 BeiHang Short Course, Part 7: HW Acceleration: It s about Performance, Energy and Power James C. Hoe Department of ECE Carnegie Mellon niversity Eric S. Chung, et al., Single chip Heterogeneous Computing:
BeiHang Short Course, Part 7: HW Acceleration: It s about Performance, Energy and Power James C. Hoe Department of ECE Carnegie Mellon niversity Eric S. Chung, et al., Single chip Heterogeneous Computing:
Lecture 5: Performance and Efficiency. James C. Hoe Department of ECE Carnegie Mellon University
 18 643 Lecture 5: Performance and Efficiency James C. Hoe Department of ECE Carnegie Mellon University 18 643 F17 L05 S1, James C. Hoe, CMU/ECE/CALCM, 2017 18 643 F17 L05 S2, James C. Hoe, CMU/ECE/CALCM,
18 643 Lecture 5: Performance and Efficiency James C. Hoe Department of ECE Carnegie Mellon University 18 643 F17 L05 S1, James C. Hoe, CMU/ECE/CALCM, 2017 18 643 F17 L05 S2, James C. Hoe, CMU/ECE/CALCM,
Solution of Linear Systems
 Solution of Linear Systems Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico May 12, 2016 CPD (DEI / IST) Parallel and Distributed Computing
Solution of Linear Systems Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico May 12, 2016 CPD (DEI / IST) Parallel and Distributed Computing
TR A Comparison of the Performance of SaP::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems
 for Solving Dense Banded Linear Systems") TR-0-07 A Comparison of the Performance of ::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems Ang Li, Omkar Deshmukh, Radu Serban, Dan Negrut May, 0 Abstract ::GPU is a
TR-0-07 A Comparison of the Performance of ::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems Ang Li, Omkar Deshmukh, Radu Serban, Dan Negrut May, 0 Abstract ::GPU is a
Communication-avoiding LU and QR factorizations for multicore architectures
 Communication-avoiding LU and QR factorizations for multicore architectures DONFACK Simplice INRIA Saclay Joint work with Laura Grigori INRIA Saclay Alok Kumar Gupta BCCS,Norway-5075 16th April 2010 Communication-avoiding
Communication-avoiding LU and QR factorizations for multicore architectures DONFACK Simplice INRIA Saclay Joint work with Laura Grigori INRIA Saclay Alok Kumar Gupta BCCS,Norway-5075 16th April 2010 Communication-avoiding
DMP. Deterministic Shared Memory Multiprocessing. Presenter: Wu, Weiyi Yale University
 DMP Deterministic Shared Memory Multiprocessing 1 Presenter: Wu, Weiyi Yale University Outline What is determinism? How to make execution deterministic? What s the overhead of determinism? 2 What Is Determinism?
DMP Deterministic Shared Memory Multiprocessing 1 Presenter: Wu, Weiyi Yale University Outline What is determinism? How to make execution deterministic? What s the overhead of determinism? 2 What Is Determinism?
Embedded Systems Design: Optimization Challenges. Paul Pop Embedded Systems Lab (ESLAB) Linköping University, Sweden
 Linköping University, Sweden") of /4 4 Embedded Systems Design: Optimization Challenges Paul Pop Embedded Systems Lab (ESLAB) Linköping University, Sweden Outline! Embedded systems " Example area: automotive electronics " Embedded systems
of /4 4 Embedded Systems Design: Optimization Challenges Paul Pop Embedded Systems Lab (ESLAB) Linköping University, Sweden Outline! Embedded systems " Example area: automotive electronics " Embedded systems
Electrical system elements aggregation for parallel computing in real-time digital simulators
 Computer Applications in Electrical Engineering Electrical system elements aggregation for parallel computing in real-time digital simulators Sławomir Cieślik University of Technology and Life Sciences
Computer Applications in Electrical Engineering Electrical system elements aggregation for parallel computing in real-time digital simulators Sławomir Cieślik University of Technology and Life Sciences
IN these past decades, the performance advances
 IEEE TRANSACTIONS ON COMUTERS, VOL. *, NO. *, * * The Reliability all for Exascale Supercomputing Xuejun Yang, Member, IEEE, Zhiyuan ang, Jingling Xue, Senior Member, IEEE, and Yun Zhou Abstract Reliability
IEEE TRANSACTIONS ON COMUTERS, VOL. *, NO. *, * * The Reliability all for Exascale Supercomputing Xuejun Yang, Member, IEEE, Zhiyuan ang, Jingling Xue, Senior Member, IEEE, and Yun Zhou Abstract Reliability
Algorithms and Their Complexity
 CSCE 222 Discrete Structures for Computing David Kebo Houngninou Algorithms and Their Complexity Chapter 3 Algorithm An algorithm is a finite sequence of steps that solves a problem. Computational complexity
CSCE 222 Discrete Structures for Computing David Kebo Houngninou Algorithms and Their Complexity Chapter 3 Algorithm An algorithm is a finite sequence of steps that solves a problem. Computational complexity
Using a CUDA-Accelerated PGAS Model on a GPU Cluster for Bioinformatics
 Using a CUDA-Accelerated PGAS Model on a GPU Cluster for Bioinformatics Jorge González-Domínguez Parallel and Distributed Architectures Group Johannes Gutenberg University of Mainz, Germany j.gonzalez@uni-mainz.de
Using a CUDA-Accelerated PGAS Model on a GPU Cluster for Bioinformatics Jorge González-Domínguez Parallel and Distributed Architectures Group Johannes Gutenberg University of Mainz, Germany j.gonzalez@uni-mainz.de
Euler-Lagrange's equations in several variables
 Euler-Lagrange's equations in several variables So far we have studied one variable and its derivative Let us now consider L2:1 More:1 Taylor: 226-227 (This proof is slightly more general than Taylor's.)
Euler-Lagrange's equations in several variables So far we have studied one variable and its derivative Let us now consider L2:1 More:1 Taylor: 226-227 (This proof is slightly more general than Taylor's.)
D-Wave: real quantum computer?
 D-Wave: real quantum computer? M. Johnson et al., "Quantum annealing with manufactured spins", Nature 473, 194-198 (2011) S. Boixo et al., "Evidence for quantum annealing wiht more than one hundred qubits",
D-Wave: real quantum computer? M. Johnson et al., "Quantum annealing with manufactured spins", Nature 473, 194-198 (2011) S. Boixo et al., "Evidence for quantum annealing wiht more than one hundred qubits",
Ways to make neural networks generalize better
 Ways to make neural networks generalize better Seminar in Deep Learning University of Tartu 04 / 10 / 2014 Pihel Saatmann Topics Overview of ways to improve generalization Limiting the size of the weights
Ways to make neural networks generalize better Seminar in Deep Learning University of Tartu 04 / 10 / 2014 Pihel Saatmann Topics Overview of ways to improve generalization Limiting the size of the weights
Measurement & Performance
 Measurement & Performance Timers Performance measures Time-based metrics Rate-based metrics Benchmarking Amdahl s law Topics 2 Page The Nature of Time real (i.e. wall clock) time = User Time: time spent
Measurement & Performance Timers Performance measures Time-based metrics Rate-based metrics Benchmarking Amdahl s law Topics 2 Page The Nature of Time real (i.e. wall clock) time = User Time: time spent