Parallelization of the Dirac operator. Pushan Majumdar. Indian Association for the Cultivation of Sciences, Jadavpur, Kolkata
|
|
|
- Tyrone Bertram McDowell
- 6 years ago
- Views:
Transcription
1 Parallelization of the Dirac operator Pushan Majumdar Indian Association for the Cultivation of Sciences, Jadavpur, Kolkata
2 Outline Introduction Algorithms Parallelization Comparison of performances Conclusions
3 The use of QCD to describe the strong force was motivated by a whole series of experimental and theoretical discoveries made in the 1960 s and 70 s. successful classification of particles by the quark model multiplicities of certain high-energy strong interactions. QCD is a non-abelian gauge theory with gauge group SU(3). The matter fields describe quarks, which are spin 1/2 objects transforming under the fundamental representation of SU(3). The QCD lagrangian is : S = ψd/ (A)ψ + F 2 (A). Till date QCD is our best candidate theory for describing strong interactions.
4 Observables in non-abelian gauge theories where S = ψd/ (A)ψ + F 2 (A). O = Z 1 DAD ψdψ O e S (1) S is quartic in A. Functional integral cannot be done analytically. Two options : 1) Expand e S as a series in g. 2) Estimate the integral numerically. (1) works for small values of g and leads to perturbative QCD. (2) is fully non-perturbative, but requires a discretization for implementation. This leads to lattice gauge theory. The value of g depends upon the energy with which you probe the system
5 Wilson s LGT : Discretization maintaining gauge invariance. finite lattice spacing : UV cut off finite lattice size : IR cut off Periodic boundary conditions to avoid end effects T 4 topology. Finally one must extrapolate to zero lattice spacing.
 Not possible to do exactly use sampling")
6 dimension of the integral : 4 N 4 domain of integration : manifold of the group SU(3) Not possible to do exactly use sampling techniques
7 Molecular Dynamics Euclidean path integral for quantum theory Partition function for classical statistical mechanical system in 4 space dimensions. Dynamics in simulation time. O can (β) thermodynamic limit [ O micro ] E=Ē(β) ergodic lim T 1 T T 0 dτ O(φ i(τ)) Canonical ensemble average microcanonical ensemble average at E = Ē(β) (equilibrium temperature) Time average over classical trajectories. d 2 φ i dτ 2 = S[φ] φ i (configuration φ has energy Ē).
8 Complexity of motion in higher dimension Quantum fluctuations in original theory O = 1 Z Dφ O[φ]e S[β,φ] (Original theory) O = 1 Z DφDπ O[φ]e 1 2 i π2 i S[β,φ] (with auxiliary field π). Equations of motion: H 4 dim = 1 2 πi 2 i + S[β, φ] φ i = H[φ, π] H[φ, π] ; π i = π i φ i Problems: Not ergodic. Not possible to take the thermodynamic limit.
9 Hybrid Algorithms Langevin dynamics + Molecular Dynamics Uses MD to move fast through configuration space, but choice of momenta from a random distribution (Langevin step) makes it ergodic. Implementation: (i) Choose {φ i } in some arbitrary way. (ii) Choose {π i } from some Gaussian (random) ensemble. P {π i } = ( i 1 2π ) e 1 2 i π2 i. (iii) Evaluate π i (1) = π i (1 + ɛ/2) (iv) Iterate the MD equations for a few steps and store φ i (n). (To be used as φ i (1) for the next MD update.) (v) Go back to step (ii) and repeat. Systematic error introduced by finite time step remains.
10 Hybrid Monte Carlo Hybrid algorithm + Metropolis accept/reject step. Implementation: (0) Start with a configuration {φ 1 i, π1 i }. (i)-(iv) Do the first 4 steps as in the Hybrid algorithm to get to {φ N i, πn i } after N MD steps. (v) Accept the configuration {φ N i, πn i } with probability p acc = min { 1, exp( H[φN i, πn i ] exp( H[φ 1 i, π1 i ] (vi) If {φ N i, πn i } is not accepted keep {φ1 i, π1 i } and choose new momenta. Otherwise make {φ N i, πn i } the new {φ1 i, π1 i } and choose new momenta. This algorithm satisfies detailed balance (necessary for equilibrium distribution) and eliminates error due to finite time step. }
11 Equilibration β = 5.2, a m = 0.03 from top to bottom: mean plaquette ; # of CG iterations for accept/reject step ; min(re(λ)) λ: eigenvalue of Dirac operator., topological charge ν The lower two rows values have been determined only for every 5th configuration.
12 Hybrid Monte Carlo - Parallelization Generate the Gaussian noise (random momenta) Cheap. Integrate the Hamiltonian equations of motion. Integration done using the leap-frog integration scheme. Improved integration schemes viz. Sexton-Weingarten, Omelyan etc. exist. Expensive. Target for parallelization. Accept/Reject step : Corrects for numerical errors introduced during integration of the equations of motion.
13 Example : Lattice gauge theory Degrees of freedom : SU(3) matrices & complex vector fields. For two flavours of mass degenerate quarks : H = 1 2 trp2 + Gauge Action(U) + φ (M M) 1 (U)φ where M is a matrix representation of the Dirac operator and U s are SU(3) matrices. Hamiltonian equations of motion update p s and U s. φ is held constant during the molecular dynamics. Equations of motion are : U = i p U and H/ t = 0
14 The conjugate gradient algorithm Most expensive part of calculation is evaluation of t φ (M M) 1 φ which requires the evaluation of (M M) 1 φ at every molecular dynamics step. For a hermitian matrix A, the inversion is best done by conjugate gradient. If we want to evaluate x = A 1 b, we can as well solve the linear system Ax = b or minimize the quadratic form Ax b.
15 Let {p n } be a sequence of conjugate vectors. ( p i, Ap j = 0) Then {p n } forms a basis in R n. Let the system Ax = b be solved by x = α i p i. Then α i = p i, b p i, Ap i Requires repeated application of A on p i and then dot products between various vectors. Objective : Try to parallelize the matrix-vector multiplication A p Two options : OpenMP & MPI
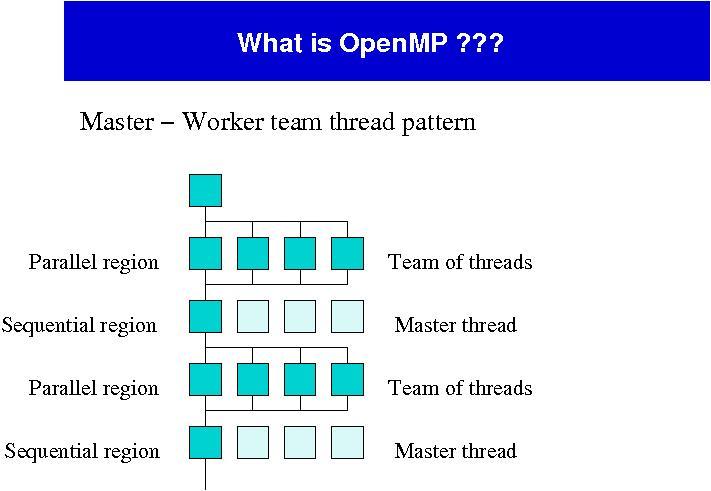
16
17 OpenMP concentrates on parallelizing loops. Compiler needs to be told which loops can be safely parallelized. Evaluation of b = Da!$OMP PARALLEL DO do isb = 1,nsite do idb = 1,4 do icb = 1,3 b(icb,idb,isb) = diag*a(icb,idb,isb) end do end do end do!$omp END PARALLEL DO
18 !$OMP PARALLEL DO PRIVATE(isb,ida,ica,idb,icb,idir,isap,isam,uu, & & uudag) SHARED(a,b) do isb = 1,nsite do idir=1,4 isap=neib(idir,isb) isam=neib(-idir,isb) call uextract(uu,idir,isb) call udagextract(uudag,idir,isam) internal loop over colour & dirac indices (ida,ica,idb,icb) b(icb,idb,isb) = b(icb,idb,isb) & & -gp(idb,ida,idir)*uu(icb,ica)*a(ica,ida,isap) & & -gm(idb,ida,idir)*uudag(icb,ica)*a(ica,ida,isam) enddo enddo!$omp END PARALLEL DO
19 Pros: Simple Data layout and decomposition is handled automatically by directives. Unified code for both serial and parallel applications Original (serial) code statements need not, in general, be modified when parallelized with OpenMP.
20 Cons: Currently only runs efficiently in shared-memory multiprocessor platforms Requires a compiler that supports OpenMP. Scalability is limited by memory architecture. Reliable error handling is missing.
21 What is MPI? A standard protocol for passing messages between parallel processors. Small: Require only six library functions to write any parallel code. Large: There are more than 200 functions in MPI-2. It uses communicator a handle to identify a set of processes and topology for different pattern of communication. A communicator is a collection of processes that can send messages to each other. Can be called by Fortran, C or C++ codes. Small MPI: MPI_Init MPI_Comm_size MPI_Comm_rank MPI_Send MPI_Recv MPI_Finalize
22 program hmc_main use paramod use params implicit none integer i, ierr, numprocs include "mpif.h" call MPI_INIT( ierr ) call MPI_COMM_RANK( MPI_COMM_WORLD, rank, ierr ) call MPI_COMM_SIZE( MPI_COMM_WORLD, numprocs, ierr ) print *, "Process ", rank, " of ", numprocs, " is alive" call init_once call do_hmc_wilson call MPI_FINALIZE(ierr) end program hmc_main mpirun -n 8./executable < input > out &
23 subroutine ddagonvec(b,a)! Evaluates b = D a. base=rank*nsub do isb = 1,nsub loop over colour and dirac indices (icb,idb) b(icb,idb,isb) = diag*a(icb,idb,isb+base) end do do isb = base+1,base+nsub do idir=1,4 isap=neib(idir,isb) isam=neib(-idir,isb) call uextract(uu,idir,isb) call udagextract(uudag,idir,isam) loop over internal colour & dirac indices (ida,ica,idb,icb) b(icb,idb,isb-base) = b(icb,idb,isb-base) & & -gp(idb,ida,idir)*uu(icb,ica)*a(ica,ida,isap) & & -gm(idb,ida,idir)*uudag(icb,ica)*a(ica,ida,isam) enddo enddo return end subroutine ddagonvec
24 subroutine matvec_wilson_ddagd(vec,res) use lattsize use paramod include "mpif.h" implicit none complex(8), dimension(blocksize*nsite), intent(in) :: vec complex(8), dimension(blocksize*nsite) :: vec1 complex(8), dimension(blocksize*nsite), intent(out) :: res complex(8), dimension(blocksize*nsub) :: res_loc1,res_loc2 integer :: ierr call donvec(res_loc1,vec) call MPI_ALLGATHER(res_loc1,blocksize*nsub,MPI_DOUBLE_COMPLEX, & vec1,blocksize*nsub,mpi_double_complex,mpi_comm_world,ierr) call ddagonvec(res_loc2,vec1) call MPI_ALLGATHER(res_loc2,blocksize*nsub,MPI_DOUBLE_COMPLEX, & res,blocksize*nsub,mpi_double_complex,mpi_comm_world,ierr) end subroutine matvec_wilson_ddagd
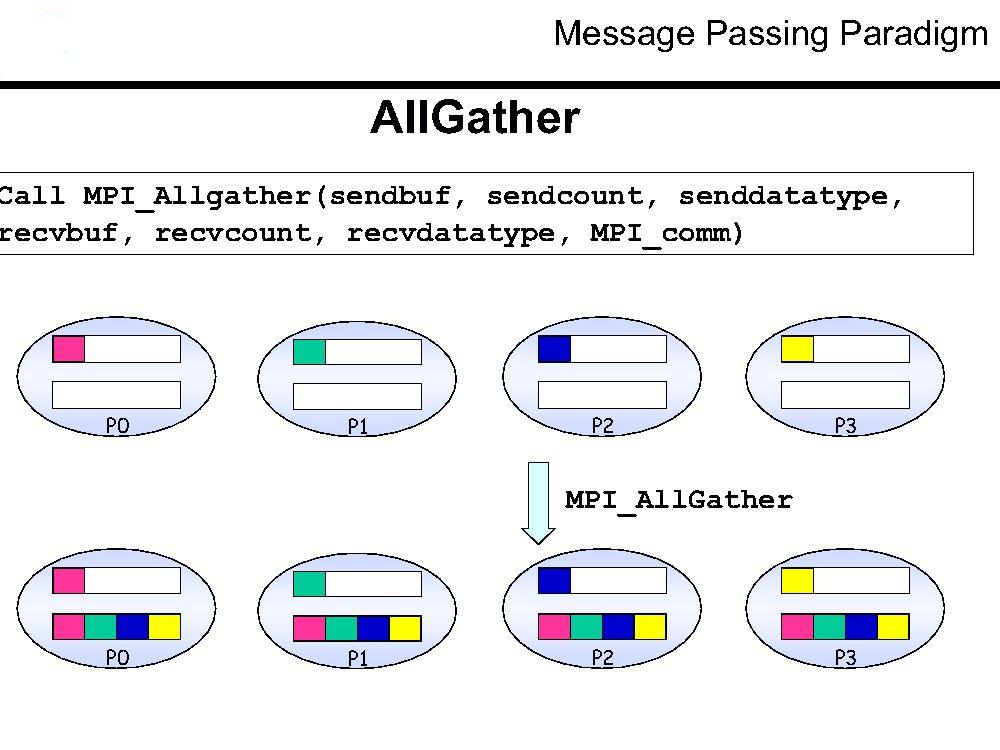
25
26
27
28 Performance comparisons Amdahl s Law: S = 1 f + (1 f)/p S: Speed up factor over serial code f: Fraction of code that is serial P: Number of precesses If f = 0.1, then even if P, S 10. Similarly if f = 0.2 then S 5.
29 Tests were performed on a IBM p-590 which has 32 cores and 64 GB memory. Each core can handle 2 threads giving 64 logical CPU s. Compiler used was threadsafe IBM fortran compiler xlf90. Lattice OpenMP MPI no. of threads no. of processes All timings are for 5 full MD trajectories + Accept/Reject step. Conjugate Gradient tolerance was kept at Each MD trajectory involved 50 integration steps with a time step of 0.02.
30 Typical inversion time OMP Lattice Serial 2 threads 4 threads 8 threads 16 threads / / / / / / / /16 MPI Lattice Serial 2 procs 4 procs 8 procs 16 procs Typical force calculation time OMP Lattice Serial 2 threads 4 threads 8 threads 16 threads /2 4.28/4 2.95/8 3.23/ /2 9.43/ / /16 MPI Lattice Serial 2 procs 4 procs 8 procs 16 procs Reference: (16/12) 5 = (16/12) 4 = 3.16
31
32
33 Conclusions Both MPI and OpenMP parallelizations show a speedup by about a factor four using 16 processes. Applying Amdahl s law we see that our parallelization is about 85% The overhead for MPI is higher than OpenMP. OpenMP can scale upto 64 or at most 128 processors. But this is extremely costly. A 32 core IBM p590 (2.2GHz PPC) costs > Rs. 2 crores.
34 Memory is an issue for these kinds of machines. Again the limit is either 64 GB or at most 128 GB. Wilson Dirac operator with Wilson gauge action on a 16 4 lattice takes up close to 300 MB of memory. A 64 4 lattice will require =76.8 GB of memory. With OpenMP one has to be careful about synchronization. A variable may suffer unwanted updates by threads. Use PRIVATE & SHARED declarations to avoid such problems. With OpenMP coding is easier. Unlike MPI where parallelization has to be done globally, here parallelization can be done incrementally loop by loop.
35 Main advantage of MPI is that it can scale to thousands of processors. So it does not suffer from the Memory constraints. If memory is not a problem and you have enough independent runs to do which uses up all your independent nodes, then use OpenMP. If not you will have to use MPI. Thank you
arxiv: v1 [hep-lat] 10 Jul 2012
![arxiv: v1 [hep-lat] 10 Jul 2012](/thumbs/90/103025692.jpg "arxiv: v1 [hep-lat] 10 Jul 2012") Hybrid Monte Carlo with Wilson Dirac operator on the Fermi GPU Abhijit Chakrabarty Electra Design Automation, SDF Building, SaltLake Sec-V, Kolkata - 700091. Pushan Majumdar Dept. of Theoretical Physics,
Hybrid Monte Carlo with Wilson Dirac operator on the Fermi GPU Abhijit Chakrabarty Electra Design Automation, SDF Building, SaltLake Sec-V, Kolkata - 700091. Pushan Majumdar Dept. of Theoretical Physics,
Polynomial Filtered Hybrid Monte Carlo
 Polynomial Filtered Hybrid Monte Carlo Waseem Kamleh and Michael J. Peardon CSSM & U NIVERSITY OF A DELAIDE QCDNA VII, July 4th 6th, 2012 Introduction Generating large, light quark dynamical gauge field
Polynomial Filtered Hybrid Monte Carlo Waseem Kamleh and Michael J. Peardon CSSM & U NIVERSITY OF A DELAIDE QCDNA VII, July 4th 6th, 2012 Introduction Generating large, light quark dynamical gauge field
Performance Analysis of Lattice QCD Application with APGAS Programming Model
 Performance Analysis of Lattice QCD Application with APGAS Programming Model Koichi Shirahata 1, Jun Doi 2, Mikio Takeuchi 2 1: Tokyo Institute of Technology 2: IBM Research - Tokyo Programming Models
Performance Analysis of Lattice QCD Application with APGAS Programming Model Koichi Shirahata 1, Jun Doi 2, Mikio Takeuchi 2 1: Tokyo Institute of Technology 2: IBM Research - Tokyo Programming Models
Claude Tadonki. MINES ParisTech PSL Research University Centre de Recherche Informatique
 Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Numerical Time Integration in Hybrid Monte Carlo Schemes for Lattice Quantum Chromo Dynamics
 Numerical Time Integration in Hybrid Monte Carlo Schemes for Lattice Quantum Chromo Dynamics M. Günther and M. Wandelt Bergische Universität Wuppertal IMACM Dortmund, March 12, 2018 Contents Lattice QCD
Numerical Time Integration in Hybrid Monte Carlo Schemes for Lattice Quantum Chromo Dynamics M. Günther and M. Wandelt Bergische Universität Wuppertal IMACM Dortmund, March 12, 2018 Contents Lattice QCD
Lecture 24 - MPI ECE 459: Programming for Performance
 ECE 459: Programming for Performance Jon Eyolfson March 9, 2012 What is MPI? Messaging Passing Interface A language-independent communation protocol for parallel computers Run the same code on a number
ECE 459: Programming for Performance Jon Eyolfson March 9, 2012 What is MPI? Messaging Passing Interface A language-independent communation protocol for parallel computers Run the same code on a number
Model Order Reduction via Matlab Parallel Computing Toolbox. Istanbul Technical University
 Model Order Reduction via Matlab Parallel Computing Toolbox E. Fatih Yetkin & Hasan Dağ Istanbul Technical University Computational Science & Engineering Department September 21, 2009 E. Fatih Yetkin (Istanbul
Model Order Reduction via Matlab Parallel Computing Toolbox E. Fatih Yetkin & Hasan Dağ Istanbul Technical University Computational Science & Engineering Department September 21, 2009 E. Fatih Yetkin (Istanbul
Domain Wall Fermion Simulations with the Exact One-Flavor Algorithm
 Domain Wall Fermion Simulations with the Exact One-Flavor Algorithm David Murphy Columbia University The 34th International Symposium on Lattice Field Theory (Southampton, UK) July 27th, 2016 D. Murphy
Domain Wall Fermion Simulations with the Exact One-Flavor Algorithm David Murphy Columbia University The 34th International Symposium on Lattice Field Theory (Southampton, UK) July 27th, 2016 D. Murphy
Introduction to lattice QCD simulations
 Introduction to lattice QCD simulations Hideo Matsufuru High Energy Accelerator Research Organization (KEK), Oho 1-1, Tsukuba 305-0801, Japan Email: hideo.matsufuru@kek.jp WWW: http://www.rcnp.osaka-u.ac.jp/
Introduction to lattice QCD simulations Hideo Matsufuru High Energy Accelerator Research Organization (KEK), Oho 1-1, Tsukuba 305-0801, Japan Email: hideo.matsufuru@kek.jp WWW: http://www.rcnp.osaka-u.ac.jp/
Case Study: Quantum Chromodynamics
 Case Study: Quantum Chromodynamics Michael Clark Harvard University with R. Babich, K. Barros, R. Brower, J. Chen and C. Rebbi Outline Primer to QCD QCD on a GPU Mixed Precision Solvers Multigrid solver
Case Study: Quantum Chromodynamics Michael Clark Harvard University with R. Babich, K. Barros, R. Brower, J. Chen and C. Rebbi Outline Primer to QCD QCD on a GPU Mixed Precision Solvers Multigrid solver
QCD on the lattice - an introduction
 QCD on the lattice - an introduction Mike Peardon School of Mathematics, Trinity College Dublin Currently on sabbatical leave at JLab HUGS 2008 - Jefferson Lab, June 3, 2008 Mike Peardon (TCD) QCD on the
QCD on the lattice - an introduction Mike Peardon School of Mathematics, Trinity College Dublin Currently on sabbatical leave at JLab HUGS 2008 - Jefferson Lab, June 3, 2008 Mike Peardon (TCD) QCD on the
Introductory MPI June 2008
 7: http://people.sc.fsu.edu/ jburkardt/presentations/ fdi 2008 lecture7.pdf... John Information Technology Department Virginia Tech... FDI Summer Track V: Parallel Programming 10-12 June 2008 MPI: Why,
7: http://people.sc.fsu.edu/ jburkardt/presentations/ fdi 2008 lecture7.pdf... John Information Technology Department Virginia Tech... FDI Summer Track V: Parallel Programming 10-12 June 2008 MPI: Why,
CEE 618 Scientific Parallel Computing (Lecture 7): OpenMP (con td) and Matrix Multiplication
: OpenMP (con td) and Matrix Multiplication") 1 / 26 CEE 618 Scientific Parallel Computing (Lecture 7): OpenMP (con td) and Matrix Multiplication Albert S. Kim Department of Civil and Environmental Engineering University of Hawai i at Manoa 2540 Dole
1 / 26 CEE 618 Scientific Parallel Computing (Lecture 7): OpenMP (con td) and Matrix Multiplication Albert S. Kim Department of Civil and Environmental Engineering University of Hawai i at Manoa 2540 Dole
Tuning And Understanding MILC Performance In Cray XK6 GPU Clusters. Mike Showerman, Guochun Shi Steven Gottlieb
 Tuning And Understanding MILC Performance In Cray XK6 GPU Clusters Mike Showerman, Guochun Shi Steven Gottlieb Outline Background Lattice QCD and MILC GPU and Cray XK6 node architecture Implementation
Tuning And Understanding MILC Performance In Cray XK6 GPU Clusters Mike Showerman, Guochun Shi Steven Gottlieb Outline Background Lattice QCD and MILC GPU and Cray XK6 node architecture Implementation
Renormalization Group: non perturbative aspects and applications in statistical and solid state physics.
 Renormalization Group: non perturbative aspects and applications in statistical and solid state physics. Bertrand Delamotte Saclay, march 3, 2009 Introduction Field theory: - infinitely many degrees of
Renormalization Group: non perturbative aspects and applications in statistical and solid state physics. Bertrand Delamotte Saclay, march 3, 2009 Introduction Field theory: - infinitely many degrees of
11 Parallel programming models
 237 // Program Design 10.3 Assessing parallel programs 11 Parallel programming models Many different models for expressing parallelism in programming languages Actor model Erlang Scala Coordination languages
237 // Program Design 10.3 Assessing parallel programs 11 Parallel programming models Many different models for expressing parallelism in programming languages Actor model Erlang Scala Coordination languages
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing
 TMA4280 Introduction to Supercomputing") The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF February 9. 2018 1 Recap: Parallelism with MPI An MPI execution is started on a set of processes P with: mpirun -n N
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF February 9. 2018 1 Recap: Parallelism with MPI An MPI execution is started on a set of processes P with: mpirun -n N
Lattice Quantum Chromodynamics on the MIC architectures
 Lattice Quantum Chromodynamics on the MIC architectures Piotr Korcyl Universität Regensburg Intel MIC Programming Workshop @ LRZ 28 June 2017 Piotr Korcyl Lattice Quantum Chromodynamics on the MIC 1/ 25
Lattice Quantum Chromodynamics on the MIC architectures Piotr Korcyl Universität Regensburg Intel MIC Programming Workshop @ LRZ 28 June 2017 Piotr Korcyl Lattice Quantum Chromodynamics on the MIC 1/ 25
Lecture 4: Linear Algebra 1
 Lecture 4: Linear Algebra 1 Sourendu Gupta TIFR Graduate School Computational Physics 1 February 12, 2010 c : Sourendu Gupta (TIFR) Lecture 4: Linear Algebra 1 CP 1 1 / 26 Outline 1 Linear problems Motivation
Lecture 4: Linear Algebra 1 Sourendu Gupta TIFR Graduate School Computational Physics 1 February 12, 2010 c : Sourendu Gupta (TIFR) Lecture 4: Linear Algebra 1 CP 1 1 / 26 Outline 1 Linear problems Motivation
Parallel Transposition of Sparse Data Structures
 Parallel Transposition of Sparse Data Structures Hao Wang, Weifeng Liu, Kaixi Hou, Wu-chun Feng Department of Computer Science, Virginia Tech Niels Bohr Institute, University of Copenhagen Scientific Computing
Parallel Transposition of Sparse Data Structures Hao Wang, Weifeng Liu, Kaixi Hou, Wu-chun Feng Department of Computer Science, Virginia Tech Niels Bohr Institute, University of Copenhagen Scientific Computing
Excited states of the QCD flux tube
 Excited states of the QCD flux tube Bastian Brandt Forschungsseminar Quantenfeldtheorie 19.11.2007 Contents 1 Why flux tubes? 2 Flux tubes and Wilson loops 3 Effective stringtheories Nambu-Goto Lüscher-Weisz
Excited states of the QCD flux tube Bastian Brandt Forschungsseminar Quantenfeldtheorie 19.11.2007 Contents 1 Why flux tubes? 2 Flux tubes and Wilson loops 3 Effective stringtheories Nambu-Goto Lüscher-Weisz
arxiv: v1 [hep-lat] 7 Oct 2010
![arxiv: v1 [hep-lat] 7 Oct 2010](/thumbs/79/80346009.jpg "arxiv: v1 [hep-lat] 7 Oct 2010") arxiv:.486v [hep-lat] 7 Oct 2 Nuno Cardoso CFTP, Instituto Superior Técnico E-mail: nunocardoso@cftp.ist.utl.pt Pedro Bicudo CFTP, Instituto Superior Técnico E-mail: bicudo@ist.utl.pt We discuss the CUDA
arxiv:.486v [hep-lat] 7 Oct 2 Nuno Cardoso CFTP, Instituto Superior Técnico E-mail: nunocardoso@cftp.ist.utl.pt Pedro Bicudo CFTP, Instituto Superior Técnico E-mail: bicudo@ist.utl.pt We discuss the CUDA
Finite Temperature Field Theory
 Finite Temperature Field Theory Dietrich Bödeker, Universität Bielefeld 1. Thermodynamics (better: thermo-statics) (a) Imaginary time formalism (b) free energy: scalar particles, resummation i. pedestrian
Finite Temperature Field Theory Dietrich Bödeker, Universität Bielefeld 1. Thermodynamics (better: thermo-statics) (a) Imaginary time formalism (b) free energy: scalar particles, resummation i. pedestrian
Trivially parallel computing
 Parallel Computing After briefly discussing the often neglected, but in praxis frequently encountered, issue of trivially parallel computing, we turn to parallel computing with information exchange. Our
Parallel Computing After briefly discussing the often neglected, but in praxis frequently encountered, issue of trivially parallel computing, we turn to parallel computing with information exchange. Our
High-performance processing and development with Madagascar. July 24, 2010 Madagascar development team
 High-performance processing and development with Madagascar July 24, 2010 Madagascar development team Outline 1 HPC terminology and frameworks 2 Utilizing data parallelism 3 HPC development with Madagascar
High-performance processing and development with Madagascar July 24, 2010 Madagascar development team Outline 1 HPC terminology and frameworks 2 Utilizing data parallelism 3 HPC development with Madagascar
CEE 618 Scientific Parallel Computing (Lecture 4): Message-Passing Interface (MPI)
: Message-Passing Interface (MPI)") 1 / 48 CEE 618 Scientific Parallel Computing (Lecture 4): Message-Passing Interface (MPI) Albert S. Kim Department of Civil and Environmental Engineering University of Hawai i at Manoa 2540 Dole Street,
1 / 48 CEE 618 Scientific Parallel Computing (Lecture 4): Message-Passing Interface (MPI) Albert S. Kim Department of Civil and Environmental Engineering University of Hawai i at Manoa 2540 Dole Street,
Testing a Fourier Accelerated Hybrid Monte Carlo Algorithm
 Syracuse University SURFACE Physics College of Arts and Sciences 12-17-2001 Testing a Fourier Accelerated Hybrid Monte Carlo Algorithm Simon Catterall Syracuse University Sergey Karamov Syracuse University
Syracuse University SURFACE Physics College of Arts and Sciences 12-17-2001 Testing a Fourier Accelerated Hybrid Monte Carlo Algorithm Simon Catterall Syracuse University Sergey Karamov Syracuse University
Finite Chemical Potential in N t = 6 QCD
 Finite Chemical Potential in N t = 6 QCD Rajiv Gavai and Sourendu Gupta ILGTI: TIFR Lattice 2008, Williamsburg July 15, 2008 Rajiv Gavai and Sourendu Gupta ILGTI: TIFRLattice Finite Chemical 2008, Williamsburg
Finite Chemical Potential in N t = 6 QCD Rajiv Gavai and Sourendu Gupta ILGTI: TIFR Lattice 2008, Williamsburg July 15, 2008 Rajiv Gavai and Sourendu Gupta ILGTI: TIFRLattice Finite Chemical 2008, Williamsburg
lattice QCD and the hadron spectrum Jozef Dudek ODU/JLab
 lattice QCD and the hadron spectrum Jozef Dudek ODU/JLab a black box? QCD lattice QCD observables (scattering amplitudes?) in these lectures, hope to give you a look inside the box 2 these lectures how
lattice QCD and the hadron spectrum Jozef Dudek ODU/JLab a black box? QCD lattice QCD observables (scattering amplitudes?) in these lectures, hope to give you a look inside the box 2 these lectures how
PETSc for Python. Lisandro Dalcin
 PETSc for Python http://petsc4py.googlecode.com Lisandro Dalcin dalcinl@gmail.com Centro Internacional de Métodos Computacionales en Ingeniería Consejo Nacional de Investigaciones Científicas y Técnicas
PETSc for Python http://petsc4py.googlecode.com Lisandro Dalcin dalcinl@gmail.com Centro Internacional de Métodos Computacionales en Ingeniería Consejo Nacional de Investigaciones Científicas y Técnicas
A Numerical QCD Hello World
 A Numerical QCD Hello World Bálint Thomas Jefferson National Accelerator Facility Newport News, VA, USA INT Summer School On Lattice QCD, 2007 What is involved in a Lattice Calculation What is a lattice
A Numerical QCD Hello World Bálint Thomas Jefferson National Accelerator Facility Newport News, VA, USA INT Summer School On Lattice QCD, 2007 What is involved in a Lattice Calculation What is a lattice
Monte Carlo. Lecture 15 4/9/18. Harvard SEAS AP 275 Atomistic Modeling of Materials Boris Kozinsky
 Monte Carlo Lecture 15 4/9/18 1 Sampling with dynamics In Molecular Dynamics we simulate evolution of a system over time according to Newton s equations, conserving energy Averages (thermodynamic properties)
Monte Carlo Lecture 15 4/9/18 1 Sampling with dynamics In Molecular Dynamics we simulate evolution of a system over time according to Newton s equations, conserving energy Averages (thermodynamic properties)
Inverse problems. High-order optimization and parallel computing. Lecture 7
 Inverse problems High-order optimization and parallel computing Nikolai Piskunov 2014 Lecture 7 Non-linear least square fit The (conjugate) gradient search has one important problem which often occurs
Inverse problems High-order optimization and parallel computing Nikolai Piskunov 2014 Lecture 7 Non-linear least square fit The (conjugate) gradient search has one important problem which often occurs
What is Classical Molecular Dynamics?
 What is Classical Molecular Dynamics? Simulation of explicit particles (atoms, ions,... ) Particles interact via relatively simple analytical potential functions Newton s equations of motion are integrated
What is Classical Molecular Dynamics? Simulation of explicit particles (atoms, ions,... ) Particles interact via relatively simple analytical potential functions Newton s equations of motion are integrated
Large-scale Electronic Structure Simulations with MVAPICH2 on Intel Knights Landing Manycore Processors
 Large-scale Electronic Structure Simulations with MVAPICH2 on Intel Knights Landing Manycore Processors Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr) Principal Researcher / Korea Institute of Science and Technology
Large-scale Electronic Structure Simulations with MVAPICH2 on Intel Knights Landing Manycore Processors Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr) Principal Researcher / Korea Institute of Science and Technology
Treecodes for Cosmology Thomas Quinn University of Washington N-Body Shop
 Treecodes for Cosmology Thomas Quinn University of Washington N-Body Shop Outline Motivation Multipole Expansions Tree Algorithms Periodic Boundaries Time integration Gravitational Softening SPH Parallel
Treecodes for Cosmology Thomas Quinn University of Washington N-Body Shop Outline Motivation Multipole Expansions Tree Algorithms Periodic Boundaries Time integration Gravitational Softening SPH Parallel
MCRG Flow for the Nonlinear Sigma Model
 Raphael Flore,, Björn Wellegehausen, Andreas Wipf 23.03.2012 So you want to quantize gravity... RG Approach to QFT all information stored in correlation functions φ(x 0 )... φ(x n ) = N Dφ φ(x 0 )... φ(x
Raphael Flore,, Björn Wellegehausen, Andreas Wipf 23.03.2012 So you want to quantize gravity... RG Approach to QFT all information stored in correlation functions φ(x 0 )... φ(x n ) = N Dφ φ(x 0 )... φ(x
Principles of Equilibrium Statistical Mechanics
 Debashish Chowdhury, Dietrich Stauffer Principles of Equilibrium Statistical Mechanics WILEY-VCH Weinheim New York Chichester Brisbane Singapore Toronto Table of Contents Part I: THERMOSTATICS 1 1 BASIC
Debashish Chowdhury, Dietrich Stauffer Principles of Equilibrium Statistical Mechanics WILEY-VCH Weinheim New York Chichester Brisbane Singapore Toronto Table of Contents Part I: THERMOSTATICS 1 1 BASIC
arxiv:hep-lat/ v1 6 Oct 2000
 1 Scalar and Tensor Glueballs on Asymmetric Coarse Lattices C. Liu a, a Department of Physics, Peking University, Beijing 100871, P. R. China arxiv:hep-lat/0010007v1 6 Oct 2000 Scalar and tensor glueball
1 Scalar and Tensor Glueballs on Asymmetric Coarse Lattices C. Liu a, a Department of Physics, Peking University, Beijing 100871, P. R. China arxiv:hep-lat/0010007v1 6 Oct 2000 Scalar and tensor glueball
Extending Parallel Scalability of LAMMPS and Multiscale Reactive Molecular Simulations
 September 18, 2012 Extending Parallel Scalability of LAMMPS and Multiscale Reactive Molecular Simulations Yuxing Peng, Chris Knight, Philip Blood, Lonnie Crosby, and Gregory A. Voth Outline Proton Solvation
September 18, 2012 Extending Parallel Scalability of LAMMPS and Multiscale Reactive Molecular Simulations Yuxing Peng, Chris Knight, Philip Blood, Lonnie Crosby, and Gregory A. Voth Outline Proton Solvation
Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems
 Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems Ichitaro Yamazaki University of Tennessee, Knoxville Xiaoye Sherry Li Lawrence Berkeley National Laboratory MS49: Sparse
Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems Ichitaro Yamazaki University of Tennessee, Knoxville Xiaoye Sherry Li Lawrence Berkeley National Laboratory MS49: Sparse
A Robustness Optimization of SRAM Dynamic Stability by Sensitivity-based Reachability Analysis
 ASP-DAC 2014 A Robustness Optimization of SRAM Dynamic Stability by Sensitivity-based Reachability Analysis Yang Song, Sai Manoj P. D. and Hao Yu School of Electrical and Electronic Engineering, Nanyang
ASP-DAC 2014 A Robustness Optimization of SRAM Dynamic Stability by Sensitivity-based Reachability Analysis Yang Song, Sai Manoj P. D. and Hao Yu School of Electrical and Electronic Engineering, Nanyang
Parallelization of Multilevel Preconditioners Constructed from Inverse-Based ILUs on Shared-Memory Multiprocessors
 Parallelization of Multilevel Preconditioners Constructed from Inverse-Based ILUs on Shared-Memory Multiprocessors J.I. Aliaga 1 M. Bollhöfer 2 A.F. Martín 1 E.S. Quintana-Ortí 1 1 Deparment of Computer
Parallelization of Multilevel Preconditioners Constructed from Inverse-Based ILUs on Shared-Memory Multiprocessors J.I. Aliaga 1 M. Bollhöfer 2 A.F. Martín 1 E.S. Quintana-Ortí 1 1 Deparment of Computer
NATIONAL UNIVERSITY OF SINGAPORE PC5215 NUMERICAL RECIPES WITH APPLICATIONS. (Semester I: AY ) Time Allowed: 2 Hours
 Time Allowed: 2 Hours") NATIONAL UNIVERSITY OF SINGAPORE PC5215 NUMERICAL RECIPES WITH APPLICATIONS (Semester I: AY 2014-15) Time Allowed: 2 Hours INSTRUCTIONS TO CANDIDATES 1. Please write your student number only. 2. This examination
NATIONAL UNIVERSITY OF SINGAPORE PC5215 NUMERICAL RECIPES WITH APPLICATIONS (Semester I: AY 2014-15) Time Allowed: 2 Hours INSTRUCTIONS TO CANDIDATES 1. Please write your student number only. 2. This examination
lattice QCD and the hadron spectrum Jozef Dudek ODU/JLab
 lattice QCD and the hadron spectrum Jozef Dudek ODU/JLab the light meson spectrum relatively simple models of hadrons: bound states of constituent quarks and antiquarks the quark model empirical meson
lattice QCD and the hadron spectrum Jozef Dudek ODU/JLab the light meson spectrum relatively simple models of hadrons: bound states of constituent quarks and antiquarks the quark model empirical meson
Panorama des modèles et outils de programmation parallèle
 Panorama des modèles et outils de programmation parallèle Sylvain HENRY sylvain.henry@inria.fr University of Bordeaux - LaBRI - Inria - ENSEIRB April 19th, 2013 1/45 Outline Introduction Accelerators &
Panorama des modèles et outils de programmation parallèle Sylvain HENRY sylvain.henry@inria.fr University of Bordeaux - LaBRI - Inria - ENSEIRB April 19th, 2013 1/45 Outline Introduction Accelerators &
Zacros. Software Package Development: Pushing the Frontiers of Kinetic Monte Carlo Simulation in Catalysis
 Zacros Software Package Development: Pushing the Frontiers of Kinetic Monte Carlo Simulation in Catalysis Jens H Nielsen, Mayeul D'Avezac, James Hetherington & Michail Stamatakis Introduction to Zacros
Zacros Software Package Development: Pushing the Frontiers of Kinetic Monte Carlo Simulation in Catalysis Jens H Nielsen, Mayeul D'Avezac, James Hetherington & Michail Stamatakis Introduction to Zacros
Effective Field Theory
 Effective Field Theory Iain Stewart MIT The 19 th Taiwan Spring School on Particles and Fields April, 2006 Physics compartmentalized Quantum Field Theory String Theory? General Relativity short distance
Effective Field Theory Iain Stewart MIT The 19 th Taiwan Spring School on Particles and Fields April, 2006 Physics compartmentalized Quantum Field Theory String Theory? General Relativity short distance
ERLANGEN REGIONAL COMPUTING CENTER
 ERLANGEN REGIONAL COMPUTING CENTER Making Sense of Performance Numbers Georg Hager Erlangen Regional Computing Center (RRZE) Friedrich-Alexander-Universität Erlangen-Nürnberg OpenMPCon 2018 Barcelona,
ERLANGEN REGIONAL COMPUTING CENTER Making Sense of Performance Numbers Georg Hager Erlangen Regional Computing Center (RRZE) Friedrich-Alexander-Universität Erlangen-Nürnberg OpenMPCon 2018 Barcelona,
6. Auxiliary field continuous time quantum Monte Carlo
 6. Auxiliary field continuous time quantum Monte Carlo The purpose of the auxiliary field continuous time quantum Monte Carlo method 1 is to calculate the full Greens function of the Anderson impurity
6. Auxiliary field continuous time quantum Monte Carlo The purpose of the auxiliary field continuous time quantum Monte Carlo method 1 is to calculate the full Greens function of the Anderson impurity
The Fermion Bag Approach
 The Fermion Bag Approach Anyi Li Duke University In collaboration with Shailesh Chandrasekharan 1 Motivation Monte Carlo simulation Sign problem Fermion sign problem Solutions to the sign problem Fermion
The Fermion Bag Approach Anyi Li Duke University In collaboration with Shailesh Chandrasekharan 1 Motivation Monte Carlo simulation Sign problem Fermion sign problem Solutions to the sign problem Fermion
CRYSTAL in parallel: replicated and distributed (MPP) data. Why parallel?
 data. Why parallel?") CRYSTAL in parallel: replicated and distributed (MPP) data Roberto Orlando Dipartimento di Chimica Università di Torino Via Pietro Giuria 5, 10125 Torino (Italy) roberto.orlando@unito.it 1 Why parallel?
CRYSTAL in parallel: replicated and distributed (MPP) data Roberto Orlando Dipartimento di Chimica Università di Torino Via Pietro Giuria 5, 10125 Torino (Italy) roberto.orlando@unito.it 1 Why parallel?
and B. Taglienti (b) (a): Dipartimento di Fisica and Infn, Universita di Cagliari (c): Dipartimento di Fisica and Infn, Universita di Roma La Sapienza
 (a): Dipartimento di Fisica and Infn, Universita di Cagliari (c): Dipartimento di Fisica and Infn, Universita di Roma La Sapienza") Glue Ball Masses and the Chameleon Gauge E. Marinari (a),m.l.paciello (b),g.parisi (c) and B. Taglienti (b) (a): Dipartimento di Fisica and Infn, Universita di Cagliari Via Ospedale 72, 09100 Cagliari
Glue Ball Masses and the Chameleon Gauge E. Marinari (a),m.l.paciello (b),g.parisi (c) and B. Taglienti (b) (a): Dipartimento di Fisica and Infn, Universita di Cagliari Via Ospedale 72, 09100 Cagliari
An Efficient FETI Implementation on Distributed Shared Memory Machines with Independent Numbers of Subdomains and Processors
 Contemporary Mathematics Volume 218, 1998 B 0-8218-0988-1-03024-7 An Efficient FETI Implementation on Distributed Shared Memory Machines with Independent Numbers of Subdomains and Processors Michel Lesoinne
Contemporary Mathematics Volume 218, 1998 B 0-8218-0988-1-03024-7 An Efficient FETI Implementation on Distributed Shared Memory Machines with Independent Numbers of Subdomains and Processors Michel Lesoinne
A Parallel Implementation of the. Yuan-Jye Jason Wu y. September 2, Abstract. The GTH algorithm is a very accurate direct method for nding
 A Parallel Implementation of the Block-GTH algorithm Yuan-Jye Jason Wu y September 2, 1994 Abstract The GTH algorithm is a very accurate direct method for nding the stationary distribution of a nite-state,
A Parallel Implementation of the Block-GTH algorithm Yuan-Jye Jason Wu y September 2, 1994 Abstract The GTH algorithm is a very accurate direct method for nding the stationary distribution of a nite-state,
Restricted Spin Set Lattice Models A route to Topological Order
 Restricted Spin Set Lattice Models A route to Topological Order R. Zach Lamberty with Stefanos Papanikolaou and Christopher L. Henley Supported by NSF grant DMR-1005466 and an NSF GRF APS March Meeting
Restricted Spin Set Lattice Models A route to Topological Order R. Zach Lamberty with Stefanos Papanikolaou and Christopher L. Henley Supported by NSF grant DMR-1005466 and an NSF GRF APS March Meeting
NATIONAL UNIVERSITY OF SINGAPORE PC5215 NUMERICAL RECIPES WITH APPLICATIONS. (Semester I: AY ) Time Allowed: 2 Hours
 Time Allowed: 2 Hours") NATIONAL UNIVERSITY OF SINGAPORE PC55 NUMERICAL RECIPES WITH APPLICATIONS (Semester I: AY 0-) Time Allowed: Hours INSTRUCTIONS TO CANDIDATES. This examination paper contains FIVE questions and comprises
NATIONAL UNIVERSITY OF SINGAPORE PC55 NUMERICAL RECIPES WITH APPLICATIONS (Semester I: AY 0-) Time Allowed: Hours INSTRUCTIONS TO CANDIDATES. This examination paper contains FIVE questions and comprises
Finite-temperature Field Theory
 Finite-temperature Field Theory Aleksi Vuorinen CERN Initial Conditions in Heavy Ion Collisions Goa, India, September 2008 Outline Further tools for equilibrium thermodynamics Gauge symmetry Faddeev-Popov
Finite-temperature Field Theory Aleksi Vuorinen CERN Initial Conditions in Heavy Ion Collisions Goa, India, September 2008 Outline Further tools for equilibrium thermodynamics Gauge symmetry Faddeev-Popov
 Fortran program + Partial data layout specifications Data Layout Assistant.. regular problems. dynamic remapping allowed Invoked only a few times Not part of the compiler Can use expensive techniques HPF
Fortran program + Partial data layout specifications Data Layout Assistant.. regular problems. dynamic remapping allowed Invoked only a few times Not part of the compiler Can use expensive techniques HPF
Parallel programming using MPI. Analysis and optimization. Bhupender Thakur, Jim Lupo, Le Yan, Alex Pacheco
 Parallel programming using MPI Analysis and optimization Bhupender Thakur, Jim Lupo, Le Yan, Alex Pacheco Outline l Parallel programming: Basic definitions l Choosing right algorithms: Optimal serial and
Parallel programming using MPI Analysis and optimization Bhupender Thakur, Jim Lupo, Le Yan, Alex Pacheco Outline l Parallel programming: Basic definitions l Choosing right algorithms: Optimal serial and
Mixed action simulations: approaching physical quark masses
 Mixed action simulations: approaching physical quark masses Stefan Krieg NIC Forschungszentrum Jülich, Wuppertal University in collaboration with S. Durr, Z. Fodor, C. Hoelbling, S. Katz, T. Kurth, L.
Mixed action simulations: approaching physical quark masses Stefan Krieg NIC Forschungszentrum Jülich, Wuppertal University in collaboration with S. Durr, Z. Fodor, C. Hoelbling, S. Katz, T. Kurth, L.
Multi-Length Scale Matrix Computations and Applications in Quantum Mechanical Simulations
 Multi-Length Scale Matrix Computations and Applications in Quantum Mechanical Simulations Zhaojun Bai http://www.cs.ucdavis.edu/ bai joint work with Wenbin Chen, Roger Lee, Richard Scalettar, Ichitaro
Multi-Length Scale Matrix Computations and Applications in Quantum Mechanical Simulations Zhaojun Bai http://www.cs.ucdavis.edu/ bai joint work with Wenbin Chen, Roger Lee, Richard Scalettar, Ichitaro
Symmetric Pivoting in ScaLAPACK Craig Lucas University of Manchester Cray User Group 8 May 2006, Lugano
 Symmetric Pivoting in ScaLAPACK Craig Lucas University of Manchester Cray User Group 8 May 2006, Lugano Introduction Introduction We wanted to parallelize a serial algorithm for the pivoted Cholesky factorization
Symmetric Pivoting in ScaLAPACK Craig Lucas University of Manchester Cray User Group 8 May 2006, Lugano Introduction Introduction We wanted to parallelize a serial algorithm for the pivoted Cholesky factorization
Maxwell s equations. based on S-54. electric field charge density. current density
 Maxwell s equations based on S-54 Our next task is to find a quantum field theory description of spin-1 particles, e.g. photons. Classical electrodynamics is governed by Maxwell s equations: electric field
Maxwell s equations based on S-54 Our next task is to find a quantum field theory description of spin-1 particles, e.g. photons. Classical electrodynamics is governed by Maxwell s equations: electric field
Monte Carlo studies of the spontaneous rotational symmetry breaking in dimensionally reduced super Yang-Mills models
 Monte Carlo studies of the spontaneous rotational symmetry breaking in dimensionally reduced super Yang-Mills models K. N. Anagnostopoulos 1 T. Azuma 2 J. Nishimura 3 1 Department of Physics, National
Monte Carlo studies of the spontaneous rotational symmetry breaking in dimensionally reduced super Yang-Mills models K. N. Anagnostopoulos 1 T. Azuma 2 J. Nishimura 3 1 Department of Physics, National
Lattice Gauge Theory: A Non-Perturbative Approach to QCD
 Lattice Gauge Theory: A Non-Perturbative Approach to QCD Michael Dine Department of Physics University of California, Santa Cruz May 2011 Non-Perturbative Tools in Quantum Field Theory Limited: 1 Semi-classical
Lattice Gauge Theory: A Non-Perturbative Approach to QCD Michael Dine Department of Physics University of California, Santa Cruz May 2011 Non-Perturbative Tools in Quantum Field Theory Limited: 1 Semi-classical
Maxwell s equations. electric field charge density. current density
 Maxwell s equations based on S-54 Our next task is to find a quantum field theory description of spin-1 particles, e.g. photons. Classical electrodynamics is governed by Maxwell s equations: electric field
Maxwell s equations based on S-54 Our next task is to find a quantum field theory description of spin-1 particles, e.g. photons. Classical electrodynamics is governed by Maxwell s equations: electric field
Hamiltonian approach to Yang- Mills Theories in 2+1 Dimensions: Glueball and Meson Mass Spectra
 Hamiltonian approach to Yang- Mills Theories in 2+1 Dimensions: Glueball and Meson Mass Spectra Aleksandr Yelnikov Virginia Tech based on hep-th/0512200 hep-th/0604060 with Rob Leigh and Djordje Minic
Hamiltonian approach to Yang- Mills Theories in 2+1 Dimensions: Glueball and Meson Mass Spectra Aleksandr Yelnikov Virginia Tech based on hep-th/0512200 hep-th/0604060 with Rob Leigh and Djordje Minic
Massively parallel semi-lagrangian solution of the 6d Vlasov-Poisson problem
 Massively parallel semi-lagrangian solution of the 6d Vlasov-Poisson problem Katharina Kormann 1 Klaus Reuter 2 Markus Rampp 2 Eric Sonnendrücker 1 1 Max Planck Institut für Plasmaphysik 2 Max Planck Computing
Massively parallel semi-lagrangian solution of the 6d Vlasov-Poisson problem Katharina Kormann 1 Klaus Reuter 2 Markus Rampp 2 Eric Sonnendrücker 1 1 Max Planck Institut für Plasmaphysik 2 Max Planck Computing
Parallelization Strategies for Density Matrix Renormalization Group algorithms on Shared-Memory Systems
 Parallelization Strategies for Density Matrix Renormalization Group algorithms on Shared-Memory Systems G. Hager HPC Services, Computing Center Erlangen, Germany E. Jeckelmann Theoretical Physics, Univ.
Parallelization Strategies for Density Matrix Renormalization Group algorithms on Shared-Memory Systems G. Hager HPC Services, Computing Center Erlangen, Germany E. Jeckelmann Theoretical Physics, Univ.
arxiv: v1 [hep-lat] 28 Aug 2014 Karthee Sivalingam
![arxiv: v1 [hep-lat] 28 Aug 2014 Karthee Sivalingam](/thumbs/83/87153979.jpg "arxiv: v1 [hep-lat] 28 Aug 2014 Karthee Sivalingam") Clover Action for Blue Gene-Q and Iterative solvers for DWF arxiv:18.687v1 [hep-lat] 8 Aug 1 Department of Meteorology, University of Reading, Reading, UK E-mail: K.Sivalingam@reading.ac.uk P.A. Boyle
Clover Action for Blue Gene-Q and Iterative solvers for DWF arxiv:18.687v1 [hep-lat] 8 Aug 1 Department of Meteorology, University of Reading, Reading, UK E-mail: K.Sivalingam@reading.ac.uk P.A. Boyle
Random Walks A&T and F&S 3.1.2
 Random Walks A&T 110-123 and F&S 3.1.2 As we explained last time, it is very difficult to sample directly a general probability distribution. - If we sample from another distribution, the overlap will
Random Walks A&T 110-123 and F&S 3.1.2 As we explained last time, it is very difficult to sample directly a general probability distribution. - If we sample from another distribution, the overlap will
COMBINED EXPLICIT-IMPLICIT TAYLOR SERIES METHODS
 COMBINED EXPLICIT-IMPLICIT TAYLOR SERIES METHODS S.N. Dimova 1, I.G. Hristov 1, a, R.D. Hristova 1, I V. Puzynin 2, T.P. Puzynina 2, Z.A. Sharipov 2, b, N.G. Shegunov 1, Z.K. Tukhliev 2 1 Sofia University,
COMBINED EXPLICIT-IMPLICIT TAYLOR SERIES METHODS S.N. Dimova 1, I.G. Hristov 1, a, R.D. Hristova 1, I V. Puzynin 2, T.P. Puzynina 2, Z.A. Sharipov 2, b, N.G. Shegunov 1, Z.K. Tukhliev 2 1 Sofia University,
The Blue Gene/P at Jülich Case Study & Optimization. W.Frings, Forschungszentrum Jülich,
 The Blue Gene/P at Jülich Case Study & Optimization W.Frings, Forschungszentrum Jülich, 26.08.2008 Jugene Case-Studies: Overview Case Study: PEPC Case Study: racoon Case Study: QCD CPU0CPU3 CPU1CPU2 2
The Blue Gene/P at Jülich Case Study & Optimization W.Frings, Forschungszentrum Jülich, 26.08.2008 Jugene Case-Studies: Overview Case Study: PEPC Case Study: racoon Case Study: QCD CPU0CPU3 CPU1CPU2 2
Advanced sampling. fluids of strongly orientation-dependent interactions (e.g., dipoles, hydrogen bonds)
") Advanced sampling ChE210D Today's lecture: methods for facilitating equilibration and sampling in complex, frustrated, or slow-evolving systems Difficult-to-simulate systems Practically speaking, one is
Advanced sampling ChE210D Today's lecture: methods for facilitating equilibration and sampling in complex, frustrated, or slow-evolving systems Difficult-to-simulate systems Practically speaking, one is
A Lattice Study of the Glueball Spectrum
 Commun. Theor. Phys. (Beijing, China) 35 (2001) pp. 288 292 c International Academic Publishers Vol. 35, No. 3, March 15, 2001 A Lattice Study of the Glueball Spectrum LIU Chuan Department of Physics,
Commun. Theor. Phys. (Beijing, China) 35 (2001) pp. 288 292 c International Academic Publishers Vol. 35, No. 3, March 15, 2001 A Lattice Study of the Glueball Spectrum LIU Chuan Department of Physics,
Review of lattice EFT methods and connections to lattice QCD
 Review of lattice EFT methods and connections to lattice QCD Dean Lee Michigan State University uclear Lattice EFT Collaboration Multi-Hadron Systems from Lattice QCD Institute for uclear Theory Feburary
Review of lattice EFT methods and connections to lattice QCD Dean Lee Michigan State University uclear Lattice EFT Collaboration Multi-Hadron Systems from Lattice QCD Institute for uclear Theory Feburary
Parallel Eigensolver Performance on High Performance Computers
 Parallel Eigensolver Performance on High Performance Computers Andrew Sunderland Advanced Research Computing Group STFC Daresbury Laboratory CUG 2008 Helsinki 1 Summary (Briefly) Introduce parallel diagonalization
Parallel Eigensolver Performance on High Performance Computers Andrew Sunderland Advanced Research Computing Group STFC Daresbury Laboratory CUG 2008 Helsinki 1 Summary (Briefly) Introduce parallel diagonalization
4th year Project demo presentation
 4th year Project demo presentation Colm Ó héigeartaigh CASE4-99387212 coheig-case4@computing.dcu.ie 4th year Project demo presentation p. 1/23 Table of Contents An Introduction to Quantum Computing The
4th year Project demo presentation Colm Ó héigeartaigh CASE4-99387212 coheig-case4@computing.dcu.ie 4th year Project demo presentation p. 1/23 Table of Contents An Introduction to Quantum Computing The
Understanding Molecular Simulation 2009 Monte Carlo and Molecular Dynamics in different ensembles. Srikanth Sastry
 JNCASR August 20, 21 2009 Understanding Molecular Simulation 2009 Monte Carlo and Molecular Dynamics in different ensembles Srikanth Sastry Jawaharlal Nehru Centre for Advanced Scientific Research, Bangalore
JNCASR August 20, 21 2009 Understanding Molecular Simulation 2009 Monte Carlo and Molecular Dynamics in different ensembles Srikanth Sastry Jawaharlal Nehru Centre for Advanced Scientific Research, Bangalore
Hamiltonian approach to Yang- Mills Theories in 2+1 Dimensions: Glueball and Meson Mass Spectra
 Hamiltonian approach to Yang- Mills Theories in 2+1 Dimensions: Glueball and Meson Mass Spectra Aleksandr Yelnikov Virginia Tech based on hep-th/0512200 hep-th/0604060 with Rob Leigh and Djordje Minic
Hamiltonian approach to Yang- Mills Theories in 2+1 Dimensions: Glueball and Meson Mass Spectra Aleksandr Yelnikov Virginia Tech based on hep-th/0512200 hep-th/0604060 with Rob Leigh and Djordje Minic
Solving the Inverse Toeplitz Eigenproblem Using ScaLAPACK and MPI *
 Solving the Inverse Toeplitz Eigenproblem Using ScaLAPACK and MPI * J.M. Badía and A.M. Vidal Dpto. Informática., Univ Jaume I. 07, Castellón, Spain. badia@inf.uji.es Dpto. Sistemas Informáticos y Computación.
Solving the Inverse Toeplitz Eigenproblem Using ScaLAPACK and MPI * J.M. Badía and A.M. Vidal Dpto. Informática., Univ Jaume I. 07, Castellón, Spain. badia@inf.uji.es Dpto. Sistemas Informáticos y Computación.
Contents. Preface... xi. Introduction...
 Contents Preface... xi Introduction... xv Chapter 1. Computer Architectures... 1 1.1. Different types of parallelism... 1 1.1.1. Overlap, concurrency and parallelism... 1 1.1.2. Temporal and spatial parallelism
Contents Preface... xi Introduction... xv Chapter 1. Computer Architectures... 1 1.1. Different types of parallelism... 1 1.1.1. Overlap, concurrency and parallelism... 1 1.1.2. Temporal and spatial parallelism
Factoring large integers using parallel Quadratic Sieve
 Factoring large integers using parallel Quadratic Sieve Olof Åsbrink d95-oas@nada.kth.se Joel Brynielsson joel@nada.kth.se 14th April 2 Abstract Integer factorization is a well studied topic. Parts of
Factoring large integers using parallel Quadratic Sieve Olof Åsbrink d95-oas@nada.kth.se Joel Brynielsson joel@nada.kth.se 14th April 2 Abstract Integer factorization is a well studied topic. Parts of
Path Integrals. Andreas Wipf Theoretisch-Physikalisches-Institut Friedrich-Schiller-Universität, Max Wien Platz Jena
 Path Integrals Andreas Wipf Theoretisch-Physikalisches-Institut Friedrich-Schiller-Universität, Max Wien Platz 1 07743 Jena 5. Auflage WS 2008/09 1. Auflage, SS 1991 (ETH-Zürich) I ask readers to report
Path Integrals Andreas Wipf Theoretisch-Physikalisches-Institut Friedrich-Schiller-Universität, Max Wien Platz 1 07743 Jena 5. Auflage WS 2008/09 1. Auflage, SS 1991 (ETH-Zürich) I ask readers to report
Cactus Tools for Petascale Computing
 Cactus Tools for Petascale Computing Erik Schnetter Reno, November 2007 Gamma Ray Bursts ~10 7 km He Protoneutron Star Accretion Collapse to a Black Hole Jet Formation and Sustainment Fe-group nuclei Si
Cactus Tools for Petascale Computing Erik Schnetter Reno, November 2007 Gamma Ray Bursts ~10 7 km He Protoneutron Star Accretion Collapse to a Black Hole Jet Formation and Sustainment Fe-group nuclei Si
PRECONDITIONING IN THE PARALLEL BLOCK-JACOBI SVD ALGORITHM
 Proceedings of ALGORITMY 25 pp. 22 211 PRECONDITIONING IN THE PARALLEL BLOCK-JACOBI SVD ALGORITHM GABRIEL OKŠA AND MARIÁN VAJTERŠIC Abstract. One way, how to speed up the computation of the singular value
Proceedings of ALGORITMY 25 pp. 22 211 PRECONDITIONING IN THE PARALLEL BLOCK-JACOBI SVD ALGORITHM GABRIEL OKŠA AND MARIÁN VAJTERŠIC Abstract. One way, how to speed up the computation of the singular value
Sparse BLAS-3 Reduction
 Sparse BLAS-3 Reduction to Banded Upper Triangular (Spar3Bnd) Gary Howell, HPC/OIT NC State University gary howell@ncsu.edu Sparse BLAS-3 Reduction p.1/27 Acknowledgements James Demmel, Gene Golub, Franc
Sparse BLAS-3 Reduction to Banded Upper Triangular (Spar3Bnd) Gary Howell, HPC/OIT NC State University gary howell@ncsu.edu Sparse BLAS-3 Reduction p.1/27 Acknowledgements James Demmel, Gene Golub, Franc
Algorithm for Sparse Approximate Inverse Preconditioners in the Conjugate Gradient Method
 Algorithm for Sparse Approximate Inverse Preconditioners in the Conjugate Gradient Method Ilya B. Labutin A.A. Trofimuk Institute of Petroleum Geology and Geophysics SB RAS, 3, acad. Koptyug Ave., Novosibirsk
Algorithm for Sparse Approximate Inverse Preconditioners in the Conjugate Gradient Method Ilya B. Labutin A.A. Trofimuk Institute of Petroleum Geology and Geophysics SB RAS, 3, acad. Koptyug Ave., Novosibirsk
openq*d simulation code for QCD+QED
 LATTICE 2017 Granada openq*d simulation code for QCD+QED Agostino Patella CERN & Plymouth University on behalf of the software-development team of the RC collaboration: Isabel Campos (IFCA, IFT), Patrick
LATTICE 2017 Granada openq*d simulation code for QCD+QED Agostino Patella CERN & Plymouth University on behalf of the software-development team of the RC collaboration: Isabel Campos (IFCA, IFT), Patrick
arxiv: v1 [hep-lat] 2 May 2012
![arxiv: v1 [hep-lat] 2 May 2012](/thumbs/79/79469396.jpg "arxiv: v1 [hep-lat] 2 May 2012") A CG Method for Multiple Right Hand Sides and Multiple Shifts in Lattice QCD Calculations arxiv:1205.0359v1 [hep-lat] 2 May 2012 Fachbereich C, Mathematik und Naturwissenschaften, Bergische Universität
A CG Method for Multiple Right Hand Sides and Multiple Shifts in Lattice QCD Calculations arxiv:1205.0359v1 [hep-lat] 2 May 2012 Fachbereich C, Mathematik und Naturwissenschaften, Bergische Universität
Accelerating Quantum Chromodynamics Calculations with GPUs
 Accelerating Quantum Chromodynamics Calculations with GPUs Guochun Shi, Steven Gottlieb, Aaron Torok, Volodymyr Kindratenko NCSA & Indiana University National Center for Supercomputing Applications University
Accelerating Quantum Chromodynamics Calculations with GPUs Guochun Shi, Steven Gottlieb, Aaron Torok, Volodymyr Kindratenko NCSA & Indiana University National Center for Supercomputing Applications University
The symmetries of QCD (and consequences)
") The symmetries of QCD (and consequences) Sinéad M. Ryan Trinity College Dublin Quantum Universe Symposium, Groningen, March 2018 Understand nature in terms of fundamental building blocks The Rumsfeld
The symmetries of QCD (and consequences) Sinéad M. Ryan Trinity College Dublin Quantum Universe Symposium, Groningen, March 2018 Understand nature in terms of fundamental building blocks The Rumsfeld
Efficient implementation of the overlap operator on multi-gpus
 Efficient implementation of the overlap operator on multi-gpus Andrei Alexandru Mike Lujan, Craig Pelissier, Ben Gamari, Frank Lee SAAHPC 2011 - University of Tennessee Outline Motivation Overlap operator
Efficient implementation of the overlap operator on multi-gpus Andrei Alexandru Mike Lujan, Craig Pelissier, Ben Gamari, Frank Lee SAAHPC 2011 - University of Tennessee Outline Motivation Overlap operator
Perm State University Research-Education Center Parallel and Distributed Computing
 Perm State University Research-Education Center Parallel and Distributed Computing A 25-minute Talk (S4493) at the GPU Technology Conference (GTC) 2014 MARCH 24-27, 2014 SAN JOSE, CA GPU-accelerated modeling
Perm State University Research-Education Center Parallel and Distributed Computing A 25-minute Talk (S4493) at the GPU Technology Conference (GTC) 2014 MARCH 24-27, 2014 SAN JOSE, CA GPU-accelerated modeling
PhD in Theoretical Particle Physics Academic Year 2017/2018
 July 10, 017 SISSA Entrance Examination PhD in Theoretical Particle Physics Academic Year 017/018 S olve two among the four problems presented. Problem I Consider a quantum harmonic oscillator in one spatial
July 10, 017 SISSA Entrance Examination PhD in Theoretical Particle Physics Academic Year 017/018 S olve two among the four problems presented. Problem I Consider a quantum harmonic oscillator in one spatial
Chemical composition of the decaying glasma
 Chemical composition of the decaying glasma Tuomas Lappi BNL tvv@quark.phy.bnl.gov with F. Gelis and K. Kajantie Strangeness in Quark Matter, UCLA, March 2006 Abstract I will present results of a nonperturbative
Chemical composition of the decaying glasma Tuomas Lappi BNL tvv@quark.phy.bnl.gov with F. Gelis and K. Kajantie Strangeness in Quark Matter, UCLA, March 2006 Abstract I will present results of a nonperturbative
Page rank computation HPC course project a.y
 Page rank computation HPC course project a.y. 2015-16 Compute efficient and scalable Pagerank MPI, Multithreading, SSE 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and
Page rank computation HPC course project a.y. 2015-16 Compute efficient and scalable Pagerank MPI, Multithreading, SSE 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and
Molecular Dynamics. What to choose in an integrator The Verlet algorithm Boundary Conditions in Space and time Reading Assignment: F&S Chapter 4
 Molecular Dynamics What to choose in an integrator The Verlet algorithm Boundary Conditions in Space and time Reading Assignment: F&S Chapter 4 MSE485/PHY466/CSE485 1 The Molecular Dynamics (MD) method
Molecular Dynamics What to choose in an integrator The Verlet algorithm Boundary Conditions in Space and time Reading Assignment: F&S Chapter 4 MSE485/PHY466/CSE485 1 The Molecular Dynamics (MD) method
Massively scalable computing method to tackle large eigenvalue problems for nanoelectronics modeling
 2019 Intel extreme Performance Users Group (IXPUG) meeting Massively scalable computing method to tackle large eigenvalue problems for nanoelectronics modeling Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr)
2019 Intel extreme Performance Users Group (IXPUG) meeting Massively scalable computing method to tackle large eigenvalue problems for nanoelectronics modeling Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr)