Hybrid Dirichlet processes for functional data
|
|
|
- Franklin Alexander
- 5 years ago
- Views:
Transcription
1 Hybrid Dirichlet processes for functional data Sonia Petrone Università Bocconi, Milano Joint work with Michele Guindani - U.T. MD Anderson Cancer Center, Houston and Alan Gelfand - Duke University, USA Cambridge, August 2007
2 Outline the problem: inference for functional data with individual heterogeneity Mixture of Gaussian processes finite mixtures : DP k functional Dirichlet process mixtures problem: as many clusters as the sample size... global random partition Hybrid DP processes local random effects and clustering dependent local random partitions Examples: simulated data brain images
3 The problem Functional data: in principle, data are realizations of a random curve (stochastic process) Y = (Y (x), x D) We observe replicates of the curve at coordinates (x 1,..., x m ) Y i = (Y i (x 1 ),..., Y i (x m )), i = 1,..., n Problem: Bayesian inference for functional data in presence of random effects and heterogeneity
4 examples time series regression curves Y i (x), x 0 (x time) Y i (x), x D R p (x covariates)... Dunson s tutorial, Cox s talk,... spatial data Y i (x), x D R 2 (x spatial coordinate) motivating example: brain RMI images for patient i, i = 1,..., n Y (x)=level of gray at coordinate x




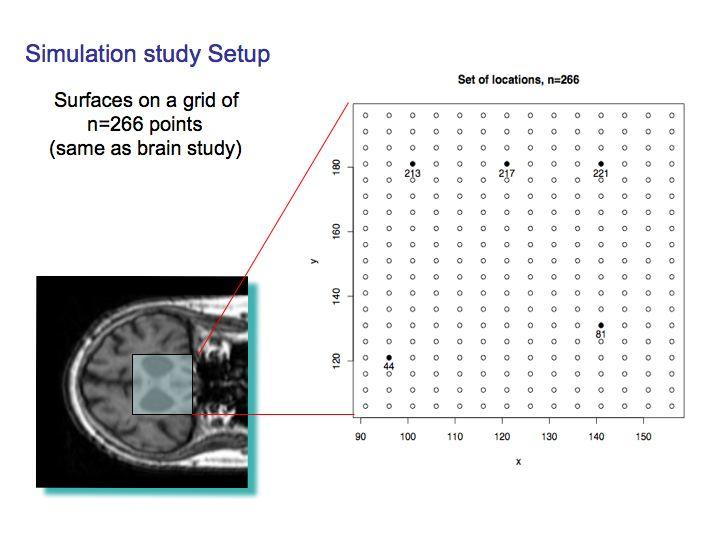
5 Figure: Sections of MRI brain images showing the effect of the Alzheimer s disease on the amygdalar-hippocampal complex
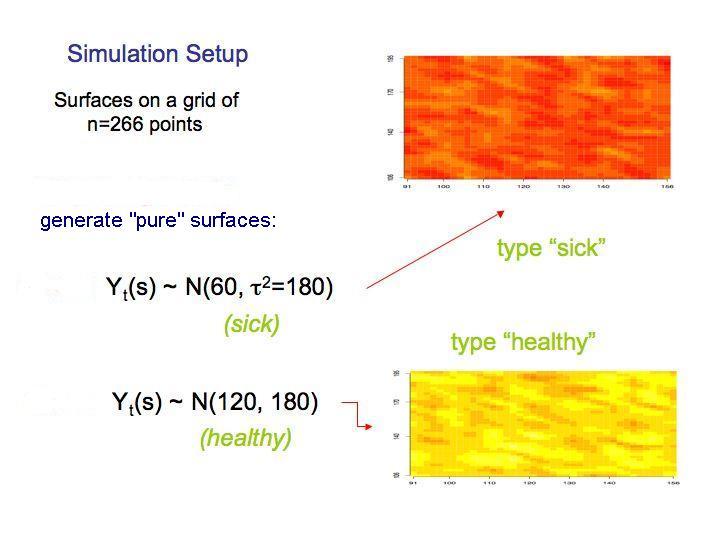
6 The basic model The basic model assumes that the curves are realizations of a stochastic process Y i = {Y i (x), x D}, D R d, In particular, conditionally on the unknown parameters, Y i is a Gaussian process. or Y i (x) = θ(x) + ɛ i, i = 1,..., n, x D Y i (x) = z(x) β + θ(x) + ɛ i, i = 1,..., n z(x) β θ(x) ɛ i mean regressive term functional behavior, forgotten covariates... i.i.d pure noise term, ɛ i N(0, τ 2 )
7 Gaussian process Y i = (Y (x), x D), i = 1,..., n. Assume: Y i θ, τ i.i.d GP(θ, τ( )), a Gaussian process with mean function θ = (θ(x), x D) and simple covariance function τ(x, x) = τ 2, τ(x, x ) = 0 θ G 0 = GP(θ 0, σ(, )) a Gaussian process with covariance function expressing the functional dependence, e.g. σ(x, x ) = σ 2 exp( φ x x ); (other approaches: θ(x) modeled by basis-functions expansions with random coefficients).
8 Mixtures of Gaussian processes For modeling random effects, use a hierarchical model that is Y i (x) = θ i (x) + ɛ i, x D Y i θ i indep GP(θ i ; τ) θ i G i.i.d G G random prob measure on R D π. We have a mixture of Gaussian processes: Y i G i.i.d GP(θ, τ)dg(θ),. The finite dimensionals are mixtures of multivariate Normals.
9 Data are observed at coordinates (x 1,..., x n ): Y i = (Y i (x 1 ),..., Y i (x m )), and let θ i = (θ(x 1 ),..., θ(x m )). Y i θ i indep N m (θ i ; τ 2 I m ) θ i G x1,...,x m i.i.d G x1,...,x m G x1,...,x m π x1,...,x m, so that i.i.d Y i G x1,...,x m N m (θ, τ 2 I m )dg x1,...,x m (θ) Dependent priors on the mixing distributions G x1,...,x m, consistently for any m and (x 1,..., x m ) * π prior on G (prob. measure on R D ) functional prior ** π x1,...,x m corresponding prior on the finite-dimensional d.f. s G x1,...,x m (on R m )
10 Species sampling priors (Pitman, 1996) G = k p j δ θ j, k j=1 (proper s.s.p.) θ 1, θ 2,... i.i.d. G 0, non-atomic species in the population. p j proportion of species j. Describe the sampling of new species in an environment. It is characterized by the predictive structure. (θ i, i 1) exchangeable with de Finetti measure G iff θ 1 G 0 d θ n+1 θ 1,..., θ n, D n = d p j(n n)δ θ j + p d+1 (N n)g 0 where D n = number of distinct values (observed species) among θ 1,..., θ n N n = (N 1,n, N 2,n,..., N Dn,n) =number of elements of (θ 1,..., θ n) which j=1 belongs to the first, second,..., D nth species.
11 Random partitions A partition of the data into clusters or species is described by the configurations of the ties. A discrete prior on G implies a probability measure on the random partition. The allocation of the data into the different clusters is determined by the predictive rule for the θ i s. Note that, for functional data, the θ i are random curves
12 Examples: finite mixtures functional finite-dimensional DP: G fdp k ((α 1,k,..., α k,k ), G 0) G = k j=1 p jδ θ, k < j where θ 1, θ 2,... i.i.d G 0, independent on (p 1,..., p k ) Dir(α 1,k,..., α k,k ) (often, a symmetric Dirichlet Dir(α/k,..., α/k)). This is the usual prior for finite mixture models, but note that here the θ j are random curves, i.i.d. from G 0 on R D. Then k G x1,...,x m = p jδ θ j (x 1 ),...,θ j (xm) j=1 with the θ j = (θ j (x 1),..., θ j(x m)) s i.i.d. G 0,x1,...,x m, are dependent DP k processes.
13 Dirichlet process G functional Dirichlet process fdp (α k, G 0 ) G = j=1 p j δ θ, j (p j, j 1) GEM(α), θ j s i.i.d. G 0. Again, the usual DP, but here the support points are random curves. (The finite dimensionals G x1,...,x m are DDP). Under conditions, DP k DP. Theorem (Ishwaran+Zarepour, 2002) If max(α 1,..., α k ) 0 and k j=1 α j α, 0 < α < for k, the DP k ((α 1,..., α k ), G 0 ) converges weakly to a DP (αg 0 ).
14 Mixtures for functional data Y i = (Y i (x), x D), t = 1, 2,... random curves on D R p, observed on finite sets of coordinates. Heterogeneity among replications is described by a hierarchical model Y i θ i, τ θ i indep GP(θ i, τ) i.i.d G G π Allocation of the curves into clusters is determined by the species sampling of the individual parameters (curves) θ i. With a DP prior θ n+1 θ 1,..., θ n θ 1 G 0 α α + n G 0 + d j=1 n j α + n δ θ. j
15 Random partitions A discrete prior on G implies a probability measure on the random partition. BUT for functional data, this might produce too many clusters! A new species is envisaged even if the curve differs from the previous ones only at some coordinates...
16
17
18 toy example simulated data t= 3 t= 6 t= 9 t= 12 t= 15 t= 18 t= 21 t= 24 t= 27 t= 30 t= 33 t= 36 t= 39 t= 42 t= 45 t= 48 A DP prior would suggest as many clusters as the sample size! it can give a good fit but somehow misses the clustering purposes of the model
19 Dependent local partitions The DP k and the DP imply global random partitions. In other terms, the DP k or the DP model global evolution of the curves. More general notions of species might be natural. In the brain images example, we think of sick or healthy brains. But only some portions of the brain are affected by the desease. We want to allow hybrid species, where portions of the curve might belong to one species and others to a different one. This give rise to local clustering and dependent local random partitions
20
21
22 Hybrid species sampling priors We want to model local clustering where a curve can have some portions belonging to a group and other parts belonging to a different group. G 0 random probability measure on R m. Consider a sample θ 1,..., θ k from G 0. These are interpreted as pure species. Then define a random d.f. G as G = k j 1 =1 k j m=1 p(j 1,..., j m )δ θ 1,j1,...,θ m,jm G is discrete and selects hybrid species obtained by mixing the components of the θj vectors, with random probabilities p(j 1,..., j m ).
23 Hybrid Dirichlet processes hybrid DP k G = k j 1 =1 k j m=1 p(j 1,..., j m )δ θ 1,j1,...,θ m,jm where k < and p is a random prob. function on {1,..., k} m with p = (p(j 1,..., j m ), j i = 1,..., k) Dirichlet(αq k ). hybrid DP k = and p is a random prob. measure on {1, 2,...} m p DP (αq). Functional hdp k and hdp k If P G is a random probability measure on R D, define analogously functional hybrid DP k or DP.
24 Functional hybrid DP A probability measure G on R D is characterized by the consistent collection of finite-dimensional distributions {G x1,...,x m }. A prior π for a random prob measure on R D can be defined by saying how it selects a collection of finite-dimensional d.f. s {G x1,...,x m }, consistently. A functional hdp prior selects θ 1, θ 2,... i.i.d. from G 0 on R D pure species and a probability measure p on (1, 2,..., k) D, k and forms G x1,...,x m = k j 1 =1 k p x1,...,x m (j 1,..., j m)δ θ j1 (x 1 ),...,θ jm (xm) j m=1 for any choice of (x 1,..., x m). Note that the θ j s are i.i.d. from G 0,x1,...,x m. Since the {p x1,...,x m } and {G 0,x1,...,x m } are consistent, one can easily check that the {G 0,x1,...,x m } are consistent so define a probability measure G on R D.
25 Mixture models For the mixture of Gaussian processes model, or its finite dimensional version i.i.d Y i G x1,...,x m, τ N m (θ, τ 2 I m )dg x1,...,x m (θ) G x1,...,x m π x1,...,x m we can compare a DP k or DP prior with hybrid DP priors. The different clustering behavior is better understood by reformulating the model in terms of hidden factors.
26 DP mixtures: constant hidden factor The DP prior for the mixing distribution implies a constant hidden factor Z with values in {1, 2,...}, which acts globally on the entire curve, that is, θ i = θ j if Z i = j; Y i Z i = j, θ 1,..., θ n, τ 2 N(y i θ j, τ 2 I m ) Z 1,..., Z n p i.i.d p on(1, 2,...), (p 1, p 2,...) GEM(α) θ j i.i.d G 0.

27 The constant latent factor implies the global allocation of the curves Suppose Z = 3 implies θ i = θ 3, a yellow surface
28 hybrid DP mixtures: hidden process The hybrid DP prior implies a hidden process Z = (Z(x), x D) with values in {1,..., k} D, describing local random effects on each coordinate of the curve. Let Z i = (Z i (x 1 ),..., Z i (x m )) be the values of the latent process at coordinates (x 1,..., x m ). Z i is a vector of local labels θ i = θ (Z i ) = (θ j 1 (x 1 ),..., θ j m (x m )) if Z i = (j 1,..., j m ) A mixture model with mixing distribution G x1,...,x m = k j 1 =1 k j m=1 p x1,...,x m (j 1,..., j m )δ θ j1 (x 1 ),...,θ jm (xm) implies a vector of labels Z i with conditional distribution p x1,...,x m on (1,..., k) m.
29 The hybrid DP k mixture can be written in terms of Z(x) as Y i Z i, θ 1,..., θ k, τ 2 N m (θ (Z i ), τ 2 I m ), where θ (Z i ) = (θ j 1 (x 1 ),..., θ j m (x m )) if Z i = (j 1,..., j m ); Z 1,..., Z n p x1,...,x m p x1,...,x m where p x1,...,x m is the finite dimensional probability function of the conditional law p of the process Z; p x1,...,x m Dirichlet(α k q x1,...,x m ) and the θ j s are i.i.d. G 0,x 1,...,x m.
30 The hidden process Z allows local selection
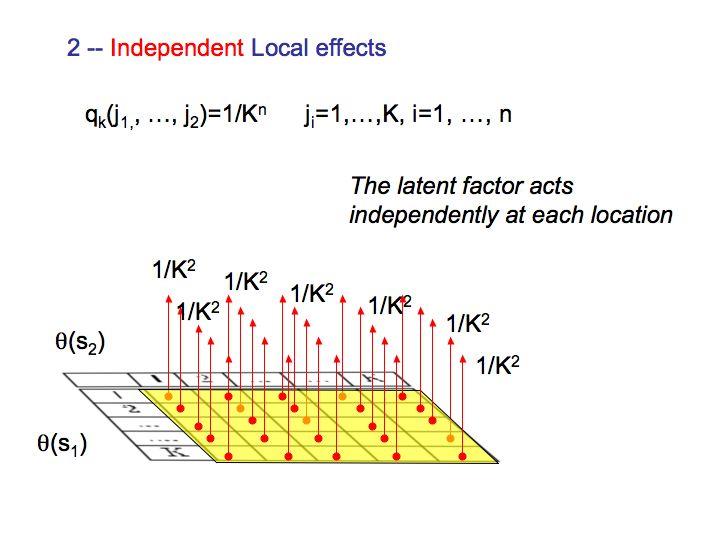
31 Examples Let m = 2, and fix coordinates (x 1, x 2 ). Then P r(z(x 1 ) = i, Z(x 2 ) = j) = E(P r(z(x 1 ) = i, Z(x 2 ) = j p) = q(i, j), i, j = 1,..., k. 1. Constant latent factor. If q(i, j) = 1/k if i = j and zero otherwise, then the latent process Z is constant. The hfdp k reduces to a fdp k, which implies a global effect of the latent factor. 2. Independent local effects. If q(i, j) = 1/k 2, the latent factor acts independently at each coordinate of the curve.
32
33
34 Ex: general dependence, uniform marginals In finite mixtures, often one uses a symmetric Dirichlet(α/k,..., α/k). In our context, this means that the probability measure q on {1,..., k} D must have uniform marginals. 3. Discrete process with uniform marginals. A general process Z with values in {1,..., k} D and uniform marginals can be obtained by considering the copula of a continuous stochastic process and then discretizing it.
35 example: copula specification Let H x1,...,x m be the finite dim. distribution of a process with values in [0, 1] D, e.g. the copula of a Gaussian process. Take m = 2 here. Partition [0, 1] 2 into subsquares C k,j1,j 2 = ( j 1 1, j 1 k k ] (j 2 1 k, j 2 k ], j i = 1,..., k, i = 1, 2, Then let q x1,x 2 (i, j) = H(C k,j1,j 2 ), j i = 1,..., k, i = 1, 2. The marginals of q k are uniform on {1,..., k} and the dependence structure of H is reflected in the joint distribution q.

36
37 Some properties limits of finite mixtures In some applications, finite mixtures are more appropriate; the number of components might be known or be part of the decision problem (e.g., in multiple testing, one envisages k = 2 groups). The common prior in finite mixture models is a DP k. However, the behavior of the model for moderate or large k can be quite different from that shown for small k (Ishwaran and Zarepour, 2002). In fact, it depends on the limiting behavior of the DP k Under conditions, the DP k DP. What about the limiting behavior of hybrid DP k?
38 weak limit of the DP k Theorem (Ishwaran+Zarepour, 2002) If max(α 1,..., α k ) 0 and k j=1 α j α, 0 < α < for k, the DP k ((α 1,..., α k ), G 0 ) converges weakly to a DP (αg 0 ). The idea of the proof is as follows. Under the stated conditions, the ordered Dirichlet weights (Kingman, 1975) (p (1),..., p (k) ) d (p 1, p 2,...) Poisson-Dirichlet G = k j=1 pjδ θ j =d k i=1 p (i)δ θ i, since the support points θ j are i.i.d. G 0, thus G converges in distribution to G = j=1 p j δ θ j, which is a DP (αg 0) (Ferguson 1973,Pitman...).
39 Weak limit of hybrid DP k We have to take a different approach. 1 G hdp k (α k q k, G 0) = d mixture of DP DP (α k Q k )dµ k (Q k ), where Q k is a weighted empirical d.f. of the θ j i.i.d. G 0 Q k = Q k (θ 1, θ 2,...) = Analogous for the hdp prior. k j 1 =1 k q k (j 1,..., j m)δ θ 1,j1,...,θ m,jm j m=1 2 Suppose α k α. The limit of the hdp k depends on the limit of Q k. If Q k d Q, a non random prob measure on R m, then hdp k (α k q k, G 0) Q If Q is random, with prob law Q, then hdp k (α k q k, G 0) DP (αq)dµ(q).
40 examples 1. DP k. If q k (j 1,..., j m ) = q j,k if j 1 = = j m = j, j = 1,..., k = 0 otherwise, the hdp k reduces to a DP k. Q k is a weighted empirical d.f. of the θj s, j = 1,..., k. If α k α, 0 < α < and max(q k,1,..., q k,k ) 0, then Q k d G 0. Thus, the DP k DP (αg 0 ).
41 examples 2. Independence case. If then q k (j 1,..., j m ) = 1 k m, j 1,..., j m = 1,..., k, Q k = k j 1 =1 k j m=1 1 k m δ θ 1,j 1,...,θ m,jm is the product of the marginal empirical distributions of θ 1,..., θ k and it converges in distribution to k j=1 G 0,i. Then hdp k (α k q k, G 0 ) DP (α k j=1 G 0,i). If q k is a mixture of 1 and 2, hdp k DP (α (ag 0 + b m j=1 G 0,i)), a DP with a mixture base measure.
42 4. hdp limit If the sequence of probability measures q k converges in total variation to a measure q on {1, 2,...} m for k, then Q k converges in total variation to the random probability measure Q = j 1 =1 j m=1 q(j 1,..., j m )δ θ 1,j1,...,θ m,jm. Then the hdp k (α k q k, G 0 ) converges to the mixture of Dirichlet processes DP (αq )dµ(q ), which is a hdp (αq, G 0 ).
43 Examples spatial data The data are observations of different surfaces on a (regular) grid of coordinates: Y i = (Y i (x 1 ),..., Y i (x m )), i = 1,..., n. A model for spatial data is Y 1,..., Y n µ, θ 1,..., θ n τ 2 θ 1,..., θ n G x1,...,x m n N(y i µ + θ i, τ 2 I m ) i=1 i.i.d where G expresses the spatial dependence, G x1,...,x m G x1,...,x m π x1,...,x m
44 We compare two choices for π x1,...,x m (a) a DP k ((α 1,..., α k ), G 0,x1,...,x m ) where G 0,x1,...,x m = N m (0, σ 2 R m (φ)), the correlation matrix R m (φ) having element (i, j) = exp( φ x i x j ). (b) a hdp k (α k q, G 0,x1,...,x m ) where q is assigned via the copula construction, with H being the copula of a N m (0, γ 2 R m (φ )). We assign a prior on the hyperparameters (µ, τ 2, σ 2, φ, φ ) while we fix α = 1 and γ = 1.
45 Example Simulated data The simulated data are a toy version of the brain RMI data. We generated n = 48 surfaces on a regular grid of points, as noisy realizations of hybrids of two base processes (θ j N m(µ j, σ 2 R(φ)), µ 1 = 60, µ 2 = 120, σ = 3 and φ = 0.5). Aim: compare the global clustering obtained by the mixture model with a DP k prior and the local clustering provided by the hybrid DP k prior.
46 Simulated data t= 3 t= 6 t= 9 t= 12 t= 15 t= 18 t= 21 t= 24 t= 27 t= 30 t= 33 t= 36 t= 39 t= 42 t= 45 t= 48
47 Simulated data For giving a good fit, the DP k and the DP need k n. The hybrid DP k gives a good fit for k = 2. t= 3 t= 13 t= 23 t= 33 Obs DPk (k=2) hdpk (k=2) DPk (k=10) hdpk (k=10) Figure: Image plots of the simulated data (first row) and the posterior predictive means, respectively for the DP k and the hdp k, with k = 2 and k = 10, for some replicates i = 3, 13, 23, 33.
48 The hdp k mixture model provides dependent local partitions of individuals, for each location x How describing efficiently the posterior distribution on the random partitions? For a fixed location x, through the number d n (x) of species at location x, and the size of the groups the values θ j (x) which characterize the observed species the composition of the groups.
49 posterior for d n (x) location location # species # species Figure: Posterior number of clusters at two locations x 213 and x 45 under a hdp k (k = 10)
50 posterior for the groups parameters hdp_k species location DP_k species Figure: Boxplots of the ordered values of θ (x 45 ) corresponding to d(x 45 ) = 4, for the hdp k and DP k (k = 10)

51 Example Brain images.
52 Finite mixtures (k = 2) t= 2 t= 6 t= 12 t= 17 Obs DPk (k=2) hdpk (k=2) Figure: Image plots of observations and posterior predictive means for the DP k and hdp k (k = 2) for some individuals ((i = 2, 6, 12, 17))
53 multiple comparison For multiple comparison, one might consider posterior probability maps (Müller et al.(2004; 2007) for more formal Bayesian decision rules) t=2 t= Figure: Posterior probability maps of pixel impairment (we consider a pixel impaired if p(θ t (s) = min k (θk (s)) data) > 0.7 ) for two individuals.
54 Finite mixtures (k = 10) location location # species # species Figure: Posterior number of clusters at two locations x 122 and x 220 under a hdp k (k = 10).
55 Finite mixtures (k = 10) hdp_k DP_k location species species Figure: Boxplots of the ordered values of θ (x 220 ) corresponding to d(x 220 ) = 6, for the hdp k and DP k (k = 10).
56 Summary We have studied a class of hybrid species priors for Bayesian inference with functional data with local random effects. DP mixtures only describe global random effects while for multivariate or functional data, new issues of dependent local partitions arise. Notions/applications in other areas: * Hidden processes (Green+Richardson (2001), Fernandez+Green (2002),..) * Population genetics: model partial or local evolution for arrays of genes or functions? (Ruggiero, Spano..) * multiple testing *... Computations are challenging. Monte Carlo methods needed, for complex, high dimensional state space.
Bayesian Nonparametrics: Dirichlet Process
 Bayesian Nonparametrics: Dirichlet Process Yee Whye Teh Gatsby Computational Neuroscience Unit, UCL http://www.gatsby.ucl.ac.uk/~ywteh/teaching/npbayes2012 Dirichlet Process Cornerstone of modern Bayesian
Bayesian Nonparametrics: Dirichlet Process Yee Whye Teh Gatsby Computational Neuroscience Unit, UCL http://www.gatsby.ucl.ac.uk/~ywteh/teaching/npbayes2012 Dirichlet Process Cornerstone of modern Bayesian
THE DIRICHLET LABELING PROCESS FOR CLUSTERING FUNCTIONAL DATA
 THE DIRICHET ABEING PROCESS FOR CUSTERING FUNCTIONA DATA Xuanong Nguyen & Alan E. Gelfand University of Michigan & Duke University Abstract: We consider problems involving functional data where we have
THE DIRICHET ABEING PROCESS FOR CUSTERING FUNCTIONA DATA Xuanong Nguyen & Alan E. Gelfand University of Michigan & Duke University Abstract: We consider problems involving functional data where we have
Non-parametric Clustering with Dirichlet Processes
 Non-parametric Clustering with Dirichlet Processes Timothy Burns SUNY at Buffalo Mar. 31 2009 T. Burns (SUNY at Buffalo) Non-parametric Clustering with Dirichlet Processes Mar. 31 2009 1 / 24 Introduction
Non-parametric Clustering with Dirichlet Processes Timothy Burns SUNY at Buffalo Mar. 31 2009 T. Burns (SUNY at Buffalo) Non-parametric Clustering with Dirichlet Processes Mar. 31 2009 1 / 24 Introduction
STAT Advanced Bayesian Inference
 1 / 32 STAT 625 - Advanced Bayesian Inference Meng Li Department of Statistics Jan 23, 218 The Dirichlet distribution 2 / 32 θ Dirichlet(a 1,...,a k ) with density p(θ 1,θ 2,...,θ k ) = k j=1 Γ(a j) Γ(
1 / 32 STAT 625 - Advanced Bayesian Inference Meng Li Department of Statistics Jan 23, 218 The Dirichlet distribution 2 / 32 θ Dirichlet(a 1,...,a k ) with density p(θ 1,θ 2,...,θ k ) = k j=1 Γ(a j) Γ(
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Bayesian Statistics. Debdeep Pati Florida State University. April 3, 2017
 Bayesian Statistics Debdeep Pati Florida State University April 3, 2017 Finite mixture model The finite mixture of normals can be equivalently expressed as y i N(µ Si ; τ 1 S i ), S i k π h δ h h=1 δ h
Bayesian Statistics Debdeep Pati Florida State University April 3, 2017 Finite mixture model The finite mixture of normals can be equivalently expressed as y i N(µ Si ; τ 1 S i ), S i k π h δ h h=1 δ h
Dirichlet Processes: Tutorial and Practical Course
 Dirichlet Processes: Tutorial and Practical Course (updated) Yee Whye Teh Gatsby Computational Neuroscience Unit University College London August 2007 / MLSS Yee Whye Teh (Gatsby) DP August 2007 / MLSS
Dirichlet Processes: Tutorial and Practical Course (updated) Yee Whye Teh Gatsby Computational Neuroscience Unit University College London August 2007 / MLSS Yee Whye Teh (Gatsby) DP August 2007 / MLSS
Bayesian Nonparametric Autoregressive Models via Latent Variable Representation
 Bayesian Nonparametric Autoregressive Models via Latent Variable Representation Maria De Iorio Yale-NUS College Dept of Statistical Science, University College London Collaborators: Lifeng Ye (UCL, London,
Bayesian Nonparametric Autoregressive Models via Latent Variable Representation Maria De Iorio Yale-NUS College Dept of Statistical Science, University College London Collaborators: Lifeng Ye (UCL, London,
A Brief Overview of Nonparametric Bayesian Models
 A Brief Overview of Nonparametric Bayesian Models Eurandom Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin Also at Machine
A Brief Overview of Nonparametric Bayesian Models Eurandom Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin Also at Machine
On the posterior structure of NRMI
 On the posterior structure of NRMI Igor Prünster University of Turin, Collegio Carlo Alberto and ICER Joint work with L.F. James and A. Lijoi Isaac Newton Institute, BNR Programme, 8th August 2007 Outline
On the posterior structure of NRMI Igor Prünster University of Turin, Collegio Carlo Alberto and ICER Joint work with L.F. James and A. Lijoi Isaac Newton Institute, BNR Programme, 8th August 2007 Outline
Bayesian Nonparametric Regression through Mixture Models
 Bayesian Nonparametric Regression through Mixture Models Sara Wade Bocconi University Advisor: Sonia Petrone October 7, 2013 Outline 1 Introduction 2 Enriched Dirichlet Process 3 EDP Mixtures for Regression
Bayesian Nonparametric Regression through Mixture Models Sara Wade Bocconi University Advisor: Sonia Petrone October 7, 2013 Outline 1 Introduction 2 Enriched Dirichlet Process 3 EDP Mixtures for Regression
Spatial Bayesian Nonparametrics for Natural Image Segmentation
 Spatial Bayesian Nonparametrics for Natural Image Segmentation Erik Sudderth Brown University Joint work with Michael Jordan University of California Soumya Ghosh Brown University Parsing Visual Scenes
Spatial Bayesian Nonparametrics for Natural Image Segmentation Erik Sudderth Brown University Joint work with Michael Jordan University of California Soumya Ghosh Brown University Parsing Visual Scenes
Bayesian nonparametrics
 Bayesian nonparametrics 1 Some preliminaries 1.1 de Finetti s theorem We will start our discussion with this foundational theorem. We will assume throughout all variables are defined on the probability
Bayesian nonparametrics 1 Some preliminaries 1.1 de Finetti s theorem We will start our discussion with this foundational theorem. We will assume throughout all variables are defined on the probability
THE DIRICHLET LABELING PROCESS FOR CLUSTERING FUNCTIONAL DATA
 THE DIRICHET ABEING PROCESS FOR CUSTERING FUNCTIONA DATA Xuanong Nguyen & Alan E. Gelfand University of Michigan & Duke University Abstract: We consider problems involving functional data where we have
THE DIRICHET ABEING PROCESS FOR CUSTERING FUNCTIONA DATA Xuanong Nguyen & Alan E. Gelfand University of Michigan & Duke University Abstract: We consider problems involving functional data where we have
Bayesian Nonparametrics for Speech and Signal Processing
 Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Foundations of Nonparametric Bayesian Methods
 1 / 27 Foundations of Nonparametric Bayesian Methods Part II: Models on the Simplex Peter Orbanz http://mlg.eng.cam.ac.uk/porbanz/npb-tutorial.html 2 / 27 Tutorial Overview Part I: Basics Part II: Models
1 / 27 Foundations of Nonparametric Bayesian Methods Part II: Models on the Simplex Peter Orbanz http://mlg.eng.cam.ac.uk/porbanz/npb-tutorial.html 2 / 27 Tutorial Overview Part I: Basics Part II: Models
Integrated Non-Factorized Variational Inference
 Integrated Non-Factorized Variational Inference Shaobo Han, Xuejun Liao and Lawrence Carin Duke University February 27, 2014 S. Han et al. Integrated Non-Factorized Variational Inference February 27, 2014
Integrated Non-Factorized Variational Inference Shaobo Han, Xuejun Liao and Lawrence Carin Duke University February 27, 2014 S. Han et al. Integrated Non-Factorized Variational Inference February 27, 2014
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Lecture: Gaussian Process Regression. STAT 6474 Instructor: Hongxiao Zhu
 Lecture: Gaussian Process Regression STAT 6474 Instructor: Hongxiao Zhu Motivation Reference: Marc Deisenroth s tutorial on Robot Learning. 2 Fast Learning for Autonomous Robots with Gaussian Processes
Lecture: Gaussian Process Regression STAT 6474 Instructor: Hongxiao Zhu Motivation Reference: Marc Deisenroth s tutorial on Robot Learning. 2 Fast Learning for Autonomous Robots with Gaussian Processes
Chapter 2. Data Analysis
 Chapter 2 Data Analysis 2.1. Density Estimation and Survival Analysis The most straightforward application of BNP priors for statistical inference is in density estimation problems. Consider the generic
Chapter 2 Data Analysis 2.1. Density Estimation and Survival Analysis The most straightforward application of BNP priors for statistical inference is in density estimation problems. Consider the generic
Nonparametric Bayesian Methods - Lecture I
 Nonparametric Bayesian Methods - Lecture I Harry van Zanten Korteweg-de Vries Institute for Mathematics CRiSM Masterclass, April 4-6, 2016 Overview of the lectures I Intro to nonparametric Bayesian statistics
Nonparametric Bayesian Methods - Lecture I Harry van Zanten Korteweg-de Vries Institute for Mathematics CRiSM Masterclass, April 4-6, 2016 Overview of the lectures I Intro to nonparametric Bayesian statistics
Bayesian Nonparametrics: Models Based on the Dirichlet Process
 Bayesian Nonparametrics: Models Based on the Dirichlet Process Alessandro Panella Department of Computer Science University of Illinois at Chicago Machine Learning Seminar Series February 18, 2013 Alessandro
Bayesian Nonparametrics: Models Based on the Dirichlet Process Alessandro Panella Department of Computer Science University of Illinois at Chicago Machine Learning Seminar Series February 18, 2013 Alessandro
False Discovery Control in Spatial Multiple Testing
 False Discovery Control in Spatial Multiple Testing WSun 1,BReich 2,TCai 3, M Guindani 4, and A. Schwartzman 2 WNAR, June, 2012 1 University of Southern California 2 North Carolina State University 3 University
False Discovery Control in Spatial Multiple Testing WSun 1,BReich 2,TCai 3, M Guindani 4, and A. Schwartzman 2 WNAR, June, 2012 1 University of Southern California 2 North Carolina State University 3 University
Modeling conditional distributions with mixture models: Theory and Inference
 Modeling conditional distributions with mixture models: Theory and Inference John Geweke University of Iowa, USA Journal of Applied Econometrics Invited Lecture Università di Venezia Italia June 2, 2005
Modeling conditional distributions with mixture models: Theory and Inference John Geweke University of Iowa, USA Journal of Applied Econometrics Invited Lecture Università di Venezia Italia June 2, 2005
Nonparametric Bayesian modeling for dynamic ordinal regression relationships
 Nonparametric Bayesian modeling for dynamic ordinal regression relationships Athanasios Kottas Department of Applied Mathematics and Statistics, University of California, Santa Cruz Joint work with Maria
Nonparametric Bayesian modeling for dynamic ordinal regression relationships Athanasios Kottas Department of Applied Mathematics and Statistics, University of California, Santa Cruz Joint work with Maria
STAT 518 Intro Student Presentation
 STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
GAUSSIAN PROCESS REGRESSION
 GAUSSIAN PROCESS REGRESSION CSE 515T Spring 2015 1. BACKGROUND The kernel trick again... The Kernel Trick Consider again the linear regression model: y(x) = φ(x) w + ε, with prior p(w) = N (w; 0, Σ). The
GAUSSIAN PROCESS REGRESSION CSE 515T Spring 2015 1. BACKGROUND The kernel trick again... The Kernel Trick Consider again the linear regression model: y(x) = φ(x) w + ε, with prior p(w) = N (w; 0, Σ). The
Nonparametric Mixed Membership Models
 5 Nonparametric Mixed Membership Models Daniel Heinz Department of Mathematics and Statistics, Loyola University of Maryland, Baltimore, MD 21210, USA CONTENTS 5.1 Introduction................................................................................
5 Nonparametric Mixed Membership Models Daniel Heinz Department of Mathematics and Statistics, Loyola University of Maryland, Baltimore, MD 21210, USA CONTENTS 5.1 Introduction................................................................................
Markov Chain Monte Carlo (MCMC)
") Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Log Gaussian Cox Processes. Chi Group Meeting February 23, 2016
 Log Gaussian Cox Processes Chi Group Meeting February 23, 2016 Outline Typical motivating application Introduction to LGCP model Brief overview of inference Applications in my work just getting started
Log Gaussian Cox Processes Chi Group Meeting February 23, 2016 Outline Typical motivating application Introduction to LGCP model Brief overview of inference Applications in my work just getting started
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
A short introduction to INLA and R-INLA
 A short introduction to INLA and R-INLA Integrated Nested Laplace Approximation Thomas Opitz, BioSP, INRA Avignon Workshop: Theory and practice of INLA and SPDE November 7, 2018 2/21 Plan for this talk
A short introduction to INLA and R-INLA Integrated Nested Laplace Approximation Thomas Opitz, BioSP, INRA Avignon Workshop: Theory and practice of INLA and SPDE November 7, 2018 2/21 Plan for this talk
Flexible Regression Modeling using Bayesian Nonparametric Mixtures
 Flexible Regression Modeling using Bayesian Nonparametric Mixtures Athanasios Kottas Department of Applied Mathematics and Statistics University of California, Santa Cruz Department of Statistics Brigham
Flexible Regression Modeling using Bayesian Nonparametric Mixtures Athanasios Kottas Department of Applied Mathematics and Statistics University of California, Santa Cruz Department of Statistics Brigham
Truncation error of a superposed gamma process in a decreasing order representation
 Truncation error of a superposed gamma process in a decreasing order representation B julyan.arbel@inria.fr Í www.julyanarbel.com Inria, Mistis, Grenoble, France Joint work with Igor Pru nster (Bocconi
Truncation error of a superposed gamma process in a decreasing order representation B julyan.arbel@inria.fr Í www.julyanarbel.com Inria, Mistis, Grenoble, France Joint work with Igor Pru nster (Bocconi
Bayesian Nonparametrics
 Bayesian Nonparametrics Peter Orbanz Columbia University PARAMETERS AND PATTERNS Parameters P(X θ) = Probability[data pattern] 3 2 1 0 1 2 3 5 0 5 Inference idea data = underlying pattern + independent
Bayesian Nonparametrics Peter Orbanz Columbia University PARAMETERS AND PATTERNS Parameters P(X θ) = Probability[data pattern] 3 2 1 0 1 2 3 5 0 5 Inference idea data = underlying pattern + independent
Image segmentation combining Markov Random Fields and Dirichlet Processes
 Image segmentation combining Markov Random Fields and Dirichlet Processes Jessica SODJO IMS, Groupe Signal Image, Talence Encadrants : A. Giremus, J.-F. Giovannelli, F. Caron, N. Dobigeon Jessica SODJO
Image segmentation combining Markov Random Fields and Dirichlet Processes Jessica SODJO IMS, Groupe Signal Image, Talence Encadrants : A. Giremus, J.-F. Giovannelli, F. Caron, N. Dobigeon Jessica SODJO
Bayesian spatial hierarchical modeling for temperature extremes
 Bayesian spatial hierarchical modeling for temperature extremes Indriati Bisono Dr. Andrew Robinson Dr. Aloke Phatak Mathematics and Statistics Department The University of Melbourne Maths, Informatics
Bayesian spatial hierarchical modeling for temperature extremes Indriati Bisono Dr. Andrew Robinson Dr. Aloke Phatak Mathematics and Statistics Department The University of Melbourne Maths, Informatics
On the Support of MacEachern s Dependent Dirichlet Processes and Extensions
 Bayesian Analysis (2012) 7, Number 2, pp. 277 310 On the Support of MacEachern s Dependent Dirichlet Processes and Extensions Andrés F. Barrientos, Alejandro Jara and Fernando A. Quintana Abstract. We
Bayesian Analysis (2012) 7, Number 2, pp. 277 310 On the Support of MacEachern s Dependent Dirichlet Processes and Extensions Andrés F. Barrientos, Alejandro Jara and Fernando A. Quintana Abstract. We
Practical Bayesian Optimization of Machine Learning. Learning Algorithms
 Practical Bayesian Optimization of Machine Learning Algorithms CS 294 University of California, Berkeley Tuesday, April 20, 2016 Motivation Machine Learning Algorithms (MLA s) have hyperparameters that
Practical Bayesian Optimization of Machine Learning Algorithms CS 294 University of California, Berkeley Tuesday, April 20, 2016 Motivation Machine Learning Algorithms (MLA s) have hyperparameters that
Variational Principal Components
 Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
Chapter 4 Dynamic Bayesian Networks Fall Jin Gu, Michael Zhang
 Chapter 4 Dynamic Bayesian Networks 2016 Fall Jin Gu, Michael Zhang Reviews: BN Representation Basic steps for BN representations Define variables Define the preliminary relations between variables Check
Chapter 4 Dynamic Bayesian Networks 2016 Fall Jin Gu, Michael Zhang Reviews: BN Representation Basic steps for BN representations Define variables Define the preliminary relations between variables Check
Bayesian Nonparametrics
 Bayesian Nonparametrics Lorenzo Rosasco 9.520 Class 18 April 11, 2011 About this class Goal To give an overview of some of the basic concepts in Bayesian Nonparametrics. In particular, to discuss Dirichelet
Bayesian Nonparametrics Lorenzo Rosasco 9.520 Class 18 April 11, 2011 About this class Goal To give an overview of some of the basic concepts in Bayesian Nonparametrics. In particular, to discuss Dirichelet
Lecture 3a: Dirichlet processes
 Lecture 3a: Dirichlet processes Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced Topics
Lecture 3a: Dirichlet processes Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced Topics
Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures
 17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
Normalized kernel-weighted random measures
 Normalized kernel-weighted random measures Jim Griffin University of Kent 1 August 27 Outline 1 Introduction 2 Ornstein-Uhlenbeck DP 3 Generalisations Bayesian Density Regression We observe data (x 1,
Normalized kernel-weighted random measures Jim Griffin University of Kent 1 August 27 Outline 1 Introduction 2 Ornstein-Uhlenbeck DP 3 Generalisations Bayesian Density Regression We observe data (x 1,
Bayesian Modeling of Conditional Distributions
 Bayesian Modeling of Conditional Distributions John Geweke University of Iowa Indiana University Department of Economics February 27, 2007 Outline Motivation Model description Methods of inference Earnings
Bayesian Modeling of Conditional Distributions John Geweke University of Iowa Indiana University Department of Economics February 27, 2007 Outline Motivation Model description Methods of inference Earnings
Lecture 16-17: Bayesian Nonparametrics I. STAT 6474 Instructor: Hongxiao Zhu
 Lecture 16-17: Bayesian Nonparametrics I STAT 6474 Instructor: Hongxiao Zhu Plan for today Why Bayesian Nonparametrics? Dirichlet Distribution and Dirichlet Processes. 2 Parameter and Patterns Reference:
Lecture 16-17: Bayesian Nonparametrics I STAT 6474 Instructor: Hongxiao Zhu Plan for today Why Bayesian Nonparametrics? Dirichlet Distribution and Dirichlet Processes. 2 Parameter and Patterns Reference:
Density Modeling and Clustering Using Dirichlet Diffusion Trees
 p. 1/3 Density Modeling and Clustering Using Dirichlet Diffusion Trees Radford M. Neal Bayesian Statistics 7, 2003, pp. 619-629. Presenter: Ivo D. Shterev p. 2/3 Outline Motivation. Data points generation.
p. 1/3 Density Modeling and Clustering Using Dirichlet Diffusion Trees Radford M. Neal Bayesian Statistics 7, 2003, pp. 619-629. Presenter: Ivo D. Shterev p. 2/3 Outline Motivation. Data points generation.
Contents. Part I: Fundamentals of Bayesian Inference 1
 Contents Preface xiii Part I: Fundamentals of Bayesian Inference 1 1 Probability and inference 3 1.1 The three steps of Bayesian data analysis 3 1.2 General notation for statistical inference 4 1.3 Bayesian
Contents Preface xiii Part I: Fundamentals of Bayesian Inference 1 1 Probability and inference 3 1.1 The three steps of Bayesian data analysis 3 1.2 General notation for statistical inference 4 1.3 Bayesian
Chris Bishop s PRML Ch. 8: Graphical Models
 Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
PMR Learning as Inference
 Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Scaling up Bayesian Inference
 Scaling up Bayesian Inference David Dunson Departments of Statistical Science, Mathematics & ECE, Duke University May 1, 2017 Outline Motivation & background EP-MCMC amcmc Discussion Motivation & background
Scaling up Bayesian Inference David Dunson Departments of Statistical Science, Mathematics & ECE, Duke University May 1, 2017 Outline Motivation & background EP-MCMC amcmc Discussion Motivation & background
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Improper mixtures and Bayes s theorem
 and Bayes s theorem and Han Han Department of Statistics University of Chicago DASF-III conference Toronto, March 2010 Outline Bayes s theorem 1 Bayes s theorem 2 Bayes s theorem Non-Bayesian model: Domain
and Bayes s theorem and Han Han Department of Statistics University of Chicago DASF-III conference Toronto, March 2010 Outline Bayes s theorem 1 Bayes s theorem 2 Bayes s theorem Non-Bayesian model: Domain
Dependent hierarchical processes for multi armed bandits
 Dependent hierarchical processes for multi armed bandits Federico Camerlenghi University of Bologna, BIDSA & Collegio Carlo Alberto First Italian meeting on Probability and Mathematical Statistics, Torino
Dependent hierarchical processes for multi armed bandits Federico Camerlenghi University of Bologna, BIDSA & Collegio Carlo Alberto First Italian meeting on Probability and Mathematical Statistics, Torino
Bayesian Nonparametric Models
 Bayesian Nonparametric Models David M. Blei Columbia University December 15, 2015 Introduction We have been looking at models that posit latent structure in high dimensional data. We use the posterior
Bayesian Nonparametric Models David M. Blei Columbia University December 15, 2015 Introduction We have been looking at models that posit latent structure in high dimensional data. We use the posterior
Bayesian Nonparametrics: some contributions to construction and properties of prior distributions
 Bayesian Nonparametrics: some contributions to construction and properties of prior distributions Annalisa Cerquetti Collegio Nuovo, University of Pavia, Italy Interview Day, CETL Lectureship in Statistics,
Bayesian Nonparametrics: some contributions to construction and properties of prior distributions Annalisa Cerquetti Collegio Nuovo, University of Pavia, Italy Interview Day, CETL Lectureship in Statistics,
COS513 LECTURE 8 STATISTICAL CONCEPTS
 COS513 LECTURE 8 STATISTICAL CONCEPTS NIKOLAI SLAVOV AND ANKUR PARIKH 1. MAKING MEANINGFUL STATEMENTS FROM JOINT PROBABILITY DISTRIBUTIONS. A graphical model (GM) represents a family of probability distributions
COS513 LECTURE 8 STATISTICAL CONCEPTS NIKOLAI SLAVOV AND ANKUR PARIKH 1. MAKING MEANINGFUL STATEMENTS FROM JOINT PROBABILITY DISTRIBUTIONS. A graphical model (GM) represents a family of probability distributions
Exchangeability. Peter Orbanz. Columbia University
 Exchangeability Peter Orbanz Columbia University PARAMETERS AND PATTERNS Parameters P(X θ) = Probability[data pattern] 3 2 1 0 1 2 3 5 0 5 Inference idea data = underlying pattern + independent noise Peter
Exchangeability Peter Orbanz Columbia University PARAMETERS AND PATTERNS Parameters P(X θ) = Probability[data pattern] 3 2 1 0 1 2 3 5 0 5 Inference idea data = underlying pattern + independent noise Peter
On prediction and density estimation Peter McCullagh University of Chicago December 2004
 On prediction and density estimation Peter McCullagh University of Chicago December 2004 Summary Having observed the initial segment of a random sequence, subsequent values may be predicted by calculating
On prediction and density estimation Peter McCullagh University of Chicago December 2004 Summary Having observed the initial segment of a random sequence, subsequent values may be predicted by calculating
Non-parametric Bayesian Methods
 Non-parametric Bayesian Methods Uncertainty in Artificial Intelligence Tutorial July 25 Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London, UK Center for Automated Learning
Non-parametric Bayesian Methods Uncertainty in Artificial Intelligence Tutorial July 25 Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London, UK Center for Automated Learning
A Fully Nonparametric Modeling Approach to. BNP Binary Regression
 A Fully Nonparametric Modeling Approach to Binary Regression Maria Department of Applied Mathematics and Statistics University of California, Santa Cruz SBIES, April 27-28, 2012 Outline 1 2 3 Simulation
A Fully Nonparametric Modeling Approach to Binary Regression Maria Department of Applied Mathematics and Statistics University of California, Santa Cruz SBIES, April 27-28, 2012 Outline 1 2 3 Simulation
Bayesian Inference for Dirichlet-Multinomials
 Bayesian Inference for Dirichlet-Multinomials Mark Johnson Macquarie University Sydney, Australia MLSS Summer School 1 / 50 Random variables and distributed according to notation A probability distribution
Bayesian Inference for Dirichlet-Multinomials Mark Johnson Macquarie University Sydney, Australia MLSS Summer School 1 / 50 Random variables and distributed according to notation A probability distribution
Colouring and breaking sticks, pairwise coincidence losses, and clustering expression profiles
 Colouring and breaking sticks, pairwise coincidence losses, and clustering expression profiles Peter Green and John Lau University of Bristol P.J.Green@bristol.ac.uk Isaac Newton Institute, 11 December
Colouring and breaking sticks, pairwise coincidence losses, and clustering expression profiles Peter Green and John Lau University of Bristol P.J.Green@bristol.ac.uk Isaac Newton Institute, 11 December
Dirichlet Processes and other non-parametric Bayesian models
 Dirichlet Processes and other non-parametric Bayesian models Zoubin Ghahramani http://learning.eng.cam.ac.uk/zoubin/ zoubin@cs.cmu.edu Statistical Machine Learning CMU 10-702 / 36-702 Spring 2008 Model
Dirichlet Processes and other non-parametric Bayesian models Zoubin Ghahramani http://learning.eng.cam.ac.uk/zoubin/ zoubin@cs.cmu.edu Statistical Machine Learning CMU 10-702 / 36-702 Spring 2008 Model
A Simple Proof of the Stick-Breaking Construction of the Dirichlet Process
 A Simple Proof of the Stick-Breaking Construction of the Dirichlet Process John Paisley Department of Computer Science Princeton University, Princeton, NJ jpaisley@princeton.edu Abstract We give a simple
A Simple Proof of the Stick-Breaking Construction of the Dirichlet Process John Paisley Department of Computer Science Princeton University, Princeton, NJ jpaisley@princeton.edu Abstract We give a simple
A Bayesian Nonparametric Model for Predicting Disease Status Using Longitudinal Profiles
 A Bayesian Nonparametric Model for Predicting Disease Status Using Longitudinal Profiles Jeremy Gaskins Department of Bioinformatics & Biostatistics University of Louisville Joint work with Claudio Fuentes
A Bayesian Nonparametric Model for Predicting Disease Status Using Longitudinal Profiles Jeremy Gaskins Department of Bioinformatics & Biostatistics University of Louisville Joint work with Claudio Fuentes
Advanced Machine Learning
 Advanced Machine Learning Nonparametric Bayesian Models --Learning/Reasoning in Open Possible Worlds Eric Xing Lecture 7, August 4, 2009 Reading: Eric Xing Eric Xing @ CMU, 2006-2009 Clustering Eric Xing
Advanced Machine Learning Nonparametric Bayesian Models --Learning/Reasoning in Open Possible Worlds Eric Xing Lecture 7, August 4, 2009 Reading: Eric Xing Eric Xing @ CMU, 2006-2009 Clustering Eric Xing
Bayesian non-parametric model to longitudinally predict churn
 Bayesian non-parametric model to longitudinally predict churn Bruno Scarpa Università di Padova Conference of European Statistics Stakeholders Methodologists, Producers and Users of European Statistics
Bayesian non-parametric model to longitudinally predict churn Bruno Scarpa Università di Padova Conference of European Statistics Stakeholders Methodologists, Producers and Users of European Statistics
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Dirichlet Process. Yee Whye Teh, University College London
 Dirichlet Process Yee Whye Teh, University College London Related keywords: Bayesian nonparametrics, stochastic processes, clustering, infinite mixture model, Blackwell-MacQueen urn scheme, Chinese restaurant
Dirichlet Process Yee Whye Teh, University College London Related keywords: Bayesian nonparametrics, stochastic processes, clustering, infinite mixture model, Blackwell-MacQueen urn scheme, Chinese restaurant
Gaussian processes for inference in stochastic differential equations
 Gaussian processes for inference in stochastic differential equations Manfred Opper, AI group, TU Berlin November 6, 2017 Manfred Opper, AI group, TU Berlin (TU Berlin) inference in SDE November 6, 2017
Gaussian processes for inference in stochastic differential equations Manfred Opper, AI group, TU Berlin November 6, 2017 Manfred Opper, AI group, TU Berlin (TU Berlin) inference in SDE November 6, 2017
A Nonparametric Model for Stationary Time Series
 A Nonparametric Model for Stationary Time Series Isadora Antoniano-Villalobos Bocconi University, Milan, Italy. isadora.antoniano@unibocconi.it Stephen G. Walker University of Texas at Austin, USA. s.g.walker@math.utexas.edu
A Nonparametric Model for Stationary Time Series Isadora Antoniano-Villalobos Bocconi University, Milan, Italy. isadora.antoniano@unibocconi.it Stephen G. Walker University of Texas at Austin, USA. s.g.walker@math.utexas.edu
On Simulations form the Two-Parameter. Poisson-Dirichlet Process and the Normalized. Inverse-Gaussian Process
 On Simulations form the Two-Parameter arxiv:1209.5359v1 [stat.co] 24 Sep 2012 Poisson-Dirichlet Process and the Normalized Inverse-Gaussian Process Luai Al Labadi and Mahmoud Zarepour May 8, 2018 ABSTRACT
On Simulations form the Two-Parameter arxiv:1209.5359v1 [stat.co] 24 Sep 2012 Poisson-Dirichlet Process and the Normalized Inverse-Gaussian Process Luai Al Labadi and Mahmoud Zarepour May 8, 2018 ABSTRACT
Bayesian Nonparametric Inference Methods for Mean Residual Life Functions
 Bayesian Nonparametric Inference Methods for Mean Residual Life Functions Valerie Poynor Department of Applied Mathematics and Statistics, University of California, Santa Cruz April 28, 212 1/3 Outline
Bayesian Nonparametric Inference Methods for Mean Residual Life Functions Valerie Poynor Department of Applied Mathematics and Statistics, University of California, Santa Cruz April 28, 212 1/3 Outline
Nonparametric Bayes tensor factorizations for big data
 Nonparametric Bayes tensor factorizations for big data David Dunson Department of Statistical Science, Duke University Funded from NIH R01-ES017240, R01-ES017436 & DARPA N66001-09-C-2082 Motivation Conditional
Nonparametric Bayes tensor factorizations for big data David Dunson Department of Statistical Science, Duke University Funded from NIH R01-ES017240, R01-ES017436 & DARPA N66001-09-C-2082 Motivation Conditional
CS 540: Machine Learning Lecture 2: Review of Probability & Statistics
 CS 540: Machine Learning Lecture 2: Review of Probability & Statistics AD January 2008 AD () January 2008 1 / 35 Outline Probability theory (PRML, Section 1.2) Statistics (PRML, Sections 2.1-2.4) AD ()
CS 540: Machine Learning Lecture 2: Review of Probability & Statistics AD January 2008 AD () January 2008 1 / 35 Outline Probability theory (PRML, Section 1.2) Statistics (PRML, Sections 2.1-2.4) AD ()
Gaussian processes. Chuong B. Do (updated by Honglak Lee) November 22, 2008
 November 22, 2008") Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Particle Learning for General Mixtures
 Particle Learning for General Mixtures Hedibert Freitas Lopes 1 Booth School of Business University of Chicago Dipartimento di Scienze delle Decisioni Università Bocconi, Milano 1 Joint work with Nicholas
Particle Learning for General Mixtures Hedibert Freitas Lopes 1 Booth School of Business University of Chicago Dipartimento di Scienze delle Decisioni Università Bocconi, Milano 1 Joint work with Nicholas
Dependent mixture models: clustering and borrowing information
 ISSN 2279-9362 Dependent mixture models: clustering and borrowing information Antonio Lijoi Bernardo Nipoti Igor Pruenster No. 32 June 213 www.carloalberto.org/research/working-papers 213 by Antonio Lijoi,
ISSN 2279-9362 Dependent mixture models: clustering and borrowing information Antonio Lijoi Bernardo Nipoti Igor Pruenster No. 32 June 213 www.carloalberto.org/research/working-papers 213 by Antonio Lijoi,
Default Priors and Effcient Posterior Computation in Bayesian
 Default Priors and Effcient Posterior Computation in Bayesian Factor Analysis January 16, 2010 Presented by Eric Wang, Duke University Background and Motivation A Brief Review of Parameter Expansion Literature
Default Priors and Effcient Posterior Computation in Bayesian Factor Analysis January 16, 2010 Presented by Eric Wang, Duke University Background and Motivation A Brief Review of Parameter Expansion Literature
Asymptotics for posterior hazards
 Asymptotics for posterior hazards Pierpaolo De Blasi University of Turin 10th August 2007, BNR Workshop, Isaac Newton Intitute, Cambridge, UK Joint work with Giovanni Peccati (Université Paris VI) and
Asymptotics for posterior hazards Pierpaolo De Blasi University of Turin 10th August 2007, BNR Workshop, Isaac Newton Intitute, Cambridge, UK Joint work with Giovanni Peccati (Université Paris VI) and
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Stochastic Processes, Kernel Regression, Infinite Mixture Models
 Stochastic Processes, Kernel Regression, Infinite Mixture Models Gabriel Huang (TA for Simon Lacoste-Julien) IFT 6269 : Probabilistic Graphical Models - Fall 2018 Stochastic Process = Random Function 2
Stochastic Processes, Kernel Regression, Infinite Mixture Models Gabriel Huang (TA for Simon Lacoste-Julien) IFT 6269 : Probabilistic Graphical Models - Fall 2018 Stochastic Process = Random Function 2
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
A comparative review of variable selection techniques for covariate dependent Dirichlet process mixture models
 A comparative review of variable selection techniques for covariate dependent Dirichlet process mixture models William Barcella 1, Maria De Iorio 1 and Gianluca Baio 1 1 Department of Statistical Science,
A comparative review of variable selection techniques for covariate dependent Dirichlet process mixture models William Barcella 1, Maria De Iorio 1 and Gianluca Baio 1 1 Department of Statistical Science,
Monte Carlo conditioning on a sufficient statistic
 Seminar, UC Davis, 24 April 2008 p. 1/22 Monte Carlo conditioning on a sufficient statistic Bo Henry Lindqvist Norwegian University of Science and Technology, Trondheim Joint work with Gunnar Taraldsen,
Seminar, UC Davis, 24 April 2008 p. 1/22 Monte Carlo conditioning on a sufficient statistic Bo Henry Lindqvist Norwegian University of Science and Technology, Trondheim Joint work with Gunnar Taraldsen,
ICML Scalable Bayesian Inference on Point processes. with Gaussian Processes. Yves-Laurent Kom Samo & Stephen Roberts
 ICML 2015 Scalable Nonparametric Bayesian Inference on Point Processes with Gaussian Processes Machine Learning Research Group and Oxford-Man Institute University of Oxford July 8, 2015 Point Processes
ICML 2015 Scalable Nonparametric Bayesian Inference on Point Processes with Gaussian Processes Machine Learning Research Group and Oxford-Man Institute University of Oxford July 8, 2015 Point Processes
Principles of Bayesian Inference
 Principles of Bayesian Inference Sudipto Banerjee and Andrew O. Finley 2 Biostatistics, School of Public Health, University of Minnesota, Minneapolis, Minnesota, U.S.A. 2 Department of Forestry & Department
Principles of Bayesian Inference Sudipto Banerjee and Andrew O. Finley 2 Biostatistics, School of Public Health, University of Minnesota, Minneapolis, Minnesota, U.S.A. 2 Department of Forestry & Department
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Disease mapping with Gaussian processes
 EUROHEIS2 Kuopio, Finland 17-18 August 2010 Aki Vehtari (former Helsinki University of Technology) Department of Biomedical Engineering and Computational Science (BECS) Acknowledgments Researchers - Jarno
EUROHEIS2 Kuopio, Finland 17-18 August 2010 Aki Vehtari (former Helsinki University of Technology) Department of Biomedical Engineering and Computational Science (BECS) Acknowledgments Researchers - Jarno
Bayesian PalaeoClimate Reconstruction from proxies:
 Bayesian PalaeoClimate Reconstruction from proxies: Framework Bayesian modelling of space-time processes General Circulation Models Space time stochastic process C = {C(x,t) = Multivariate climate at all
Bayesian PalaeoClimate Reconstruction from proxies: Framework Bayesian modelling of space-time processes General Circulation Models Space time stochastic process C = {C(x,t) = Multivariate climate at all
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
3 Comparison with Other Dummy Variable Methods
 Stats 300C: Theory of Statistics Spring 2018 Lecture 11 April 25, 2018 Prof. Emmanuel Candès Scribe: Emmanuel Candès, Michael Celentano, Zijun Gao, Shuangning Li 1 Outline Agenda: Knockoffs 1. Introduction
Stats 300C: Theory of Statistics Spring 2018 Lecture 11 April 25, 2018 Prof. Emmanuel Candès Scribe: Emmanuel Candès, Michael Celentano, Zijun Gao, Shuangning Li 1 Outline Agenda: Knockoffs 1. Introduction
Stat 542: Item Response Theory Modeling Using The Extended Rank Likelihood
 Stat 542: Item Response Theory Modeling Using The Extended Rank Likelihood Jonathan Gruhl March 18, 2010 1 Introduction Researchers commonly apply item response theory (IRT) models to binary and ordinal
Stat 542: Item Response Theory Modeling Using The Extended Rank Likelihood Jonathan Gruhl March 18, 2010 1 Introduction Researchers commonly apply item response theory (IRT) models to binary and ordinal
CSC 2541: Bayesian Methods for Machine Learning
 CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 4 Problem: Density Estimation We have observed data, y 1,..., y n, drawn independently from some unknown
CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 4 Problem: Density Estimation We have observed data, y 1,..., y n, drawn independently from some unknown
Study Notes on the Latent Dirichlet Allocation
 Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Generative Models and Stochastic Algorithms for Population Average Estimation and Image Analysis
 Generative Models and Stochastic Algorithms for Population Average Estimation and Image Analysis Stéphanie Allassonnière CIS, JHU July, 15th 28 Context : Computational Anatomy Context and motivations :
Generative Models and Stochastic Algorithms for Population Average Estimation and Image Analysis Stéphanie Allassonnière CIS, JHU July, 15th 28 Context : Computational Anatomy Context and motivations :
CS281B / Stat 241B : Statistical Learning Theory Lecture: #22 on 19 Apr Dirichlet Process I
 X i Ν CS281B / Stat 241B : Statistical Learning Theory Lecture: #22 on 19 Apr 2004 Dirichlet Process I Lecturer: Prof. Michael Jordan Scribe: Daniel Schonberg dschonbe@eecs.berkeley.edu 22.1 Dirichlet
X i Ν CS281B / Stat 241B : Statistical Learning Theory Lecture: #22 on 19 Apr 2004 Dirichlet Process I Lecturer: Prof. Michael Jordan Scribe: Daniel Schonberg dschonbe@eecs.berkeley.edu 22.1 Dirichlet
USEFUL PROPERTIES OF THE MULTIVARIATE NORMAL*
 USEFUL PROPERTIES OF THE MULTIVARIATE NORMAL* 3 Conditionals and marginals For Bayesian analysis it is very useful to understand how to write joint, marginal, and conditional distributions for the multivariate
USEFUL PROPERTIES OF THE MULTIVARIATE NORMAL* 3 Conditionals and marginals For Bayesian analysis it is very useful to understand how to write joint, marginal, and conditional distributions for the multivariate