Scalable MCMC for the horseshoe prior
|
|
|
- Derek Daniels
- 5 years ago
- Views:
Transcription
1 Scalable MCMC for the horseshoe prior Anirban Bhattacharya Department of Statistics, Texas A&M University Joint work with James Johndrow and Paolo Orenstein September 7, 2018 Cornell Day of Statistics 2018 Department of Statistical Science, Cornell University
2 Introduction Original motivation: develop scalable MCMC algorithms for large (N, p) regression with continuous shrinkage priors For example, the horseshoe prior of Carvalho et al. (2010) One-group alternative to traditional two-group (spike-and-slab) priors (George & McCulloch, 1997; Scott & Berger, 2010; Rockova & George, 2014) Interesting in their own right - many attractive theoretical properties Lack of algorithms that scale to large (N, p) problems
3 Approximations in MCMC Our proposed algorithm introduces certain approximations at each MCMC step - substantial computational advantages How to quantify the effect of such approximations? Perturbation theory for MCMC algorithms (Alquier et al. 2014, Rudolf & Schweizer (2018), Johndrow & Mattingley (2018)...) A new general result + bounds on approximation error for our algorithm
4 Bayesian shrinkage: motivation and background
5 Global-local shrinkage priors Consider a Gaussian linear model z = W β + ε, ε N(0, σ 2 I N ) where W is N p, with N, p both possibly large The basic form of the prior is β j σ, ξ, η ind N(0, σ 2 ξ 1 η 1 j ) The η 1/2 j are the local scales and ξ 1/2 the global scale A popular choice for π(ξ, η) is the Horseshoe η 1/2 j ind. Cauchy + (0, 1), ξ 1/2 Cauchy + (0, 1)
6 Global-local shrinkage priors The basic form of the prior is β j σ, ξ, η ind N(0, σ 2 ξ 1 η 1 j ) The η 1/2 j are the local scales and ξ 1/2 the global scale Only global scale ridge type shrinkage Local scales help adapt to sparsity The global scale ξ 1/2 controls how many β j are signals, and η 1/2 j control their identities
7 Continuous shrinkage via one group models Comparsion of priors: central region Laplace Cauchy Horseshoe DL 1/ Comparsion of priors: tails 0.03 Laplace Cauchy Horseshoe DL 1/
8 Properties Minimax optimal posterior concentration (van der Pas et al. (2014); Ghosh & Chakraborty (2015); van der Pas et al. (2016a,b); Chakraborty, B., Mallick (2017) etc) der Pas et al. (2016b)) and frequentist coverage of credible sets (van No result on MCMC convergence (e.g., geometric ergodicity) to best of our knowledge; because of polynomial tails?
.")
9 Example Simulation with N = 2, 000 and p = 20, 000: first 50 β j (rest are zero). Posterior medians, 95 percent credible intervals, along with the truth.
10 Computational challenges
11 MCMC review We need to compute the posterior expectation, and would like to have access to marginals for β We won t get this from optimization (not a convex problem anyway), instead we do MCMC Basic idea of MCMC: construct a Markov transition kernel P with invariant measure the posterior, i.e. µp = µ where µ is the posterior measure Then approximate µϕ n 1 ϕ(x)µ(dx) n 1 ϕ(x k ) k=0 for X k νp k 1
12 Computational cost What is the computational cost? Two factors 1. The cost of taking one step with P 2. How long the Markov chain needs to be to make approximation good
13 Computational cost per step Perform various matrix operations - multiplication, solving linear systems, Cholesky etc
14 Length of path required How long of a Markov chain do we need to approximate the posterior well? Informally, the higher the autocorrelations, the longer the path we will need Another performance metric: effective sample size, the equivalent number of independent samples (larger is better)
15 Computational cost What is the computational cost? Two factors 1. The cost of taking one step with P 2. How long the Markov chain needs to be to make approximation good For the horseshoe, both of these present challenges Linear algebra with large matrices High autocorrelation
16 Algorithmic developments
17 Gibbs sampling for the Horseshoe The full horseshoe hierarchical structure is z β, σ 2, ξ, η N(W β, σ 2 I ) β j σ 2, ξ, η iid N(0, σ 2 ξ 1 η 1 j ) ξ 1/2 Cauchy + (0, 1) η 1/2 j Cauchy + (0, 1) σ 2 InvGamma(a/2, b/2) Typical computational approach: blocked Gibbs sampling (Polson et al (2012)) η β, σ 2, ξ, z ξ β, σ 2, η, z (β, σ 2 ) η, ξ, z
18 Mixing issues The algorithm is known to exhibit poor mixing for ξ (Polson et al. (2012))
19 Mixing issues This algorithm is known to exhibit poor mixing for ξ (Polson et al (2012))
20 Remedy: Johndrow, Orenstein, B. (2018+) Our approach: blocking (β, σ 2, ξ) η, z η (β, σ 2, ξ), z The first step is done by sampling ξ η, z σ 2 η, ξ, z β η, σ 2, ξ, z
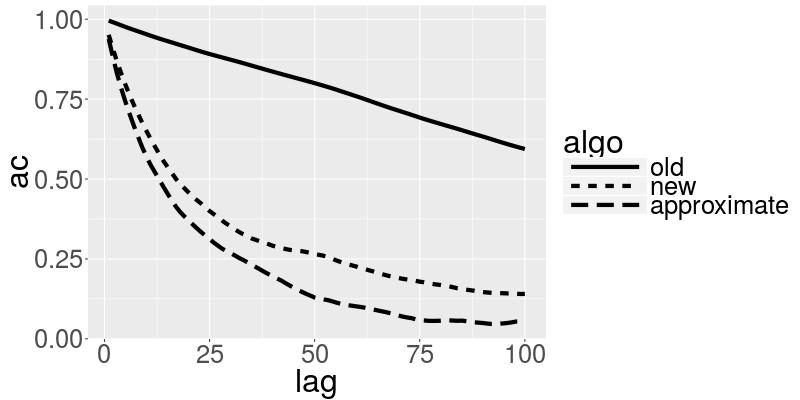
21 Results: Autocorrelations for ξ
22 Geometric ergodicity Theorem. The blocked sampler above is geometrically ergodic. Specifically, let x = (η, ξ, σ 2, β) and P the transition kernel. Also, let µ be the invariant measure, i.e., the posterior. We show: 1. Foster Lyapunov condition. There exists a function V : X [0, ) and constants 0 < γ < 1 and K > 0 such that (PV )(x) V (y)p(x, dy) γv (x) + K. 2. Minorization. For every R > 0 there exists α (0, 1) (depending on R) such that such that sup P(x, ) P(y, ) TV 2(1 α) x,y S(R) where S(R) = {x : V (x) < R}.
23 Geometric ergodicity Theorem. Let x = (η, ξ, σ 2, β) and P the transition kernel. Also, let µ be the invariant measure, i.e., the posterior. Together, (1) and (2) imply, ϕ(y)(p(x, ) µ)(dy) Cᾱ n V (x). sup ϕ <1+V
24 Our exact algorithm Blocking significantly improves mixing, plus provably geometrically ergodic. But what about the cost-per-step?
25 Cost-per-iteration Let s focus on the update of β: ( (W β σ 2, ξ, η, z N W + (ξ 1 D) 1) 1 W z, σ 2( W T W + (ξ 1 D) 1) 1) where D = diag(η 1 j ). Usual Cholesky based sampler (Rue, 2001) for N(Q 1 b, Q 1 ) requires O(p 3 ) computation for non-sparse Q. Highly prohibitive O(p 3 ) complexity per iteration when p N.
26 (Partial) Remedy In B., Chakraborty, Mallick (2016), we propose an alternative exact sampler with O(N 2 p) complexity. (i) Sample u N(0, ξ 1 D) and f N(0, I N ) indep. (ii) Set v = Wu + f (iii) Solve M ξ v = (z/σ v) where M ξ = I N + ξ 1 WDW (iv) Set β = σ(u + ξ 1 DW v ) (iii) is the costliest step taking max{o(n 2 p), O(N 3 )} steps. Significant savings when p N.
27 Cost-per-iteration However, still O(N 2 p) computation. N can be in the order of tens of thousands in GWAS studies. The remaining bottleneck is only in calculating M ξ = I N + ξ 1 WDW which is needed by the updates for β, σ 2, and ξ
28 Approximations in MCMC
29 Approximation Horseshoe is designed to shrink most coordinates of β toward zero... So most of the ξ 1 η 1 j will typically be tiny at any iteration Idea: Choose a small threshold δ, approximate M ξ by M ξ,δ = I N + ξ 1 W S D S W S, S = {j : ξ 1 η 1 j > δ} where W S is the submatrix consisting of columns in the set S, etc Carefully replace all calculations involving M ξ with M ξ,δ Reduces cost per step to Ns 2 Np, where s = S Note: this is different from setting some β j = 0 at each scan
30 Perturabtion bounds A general strategy to reduce cost per step: approximate P by P ɛ Question: is for X ɛ k νpk ɛ? n 1 µϕ n 1 ϕ(xk ɛ ) k=0 Answer: yes, if (along with other verifiable conditions) sup P(x, ) P ɛ (x, ) TV x is small, i.e., uniform total variation control between the exact and approximate chains.
31 Approximation error condition We show that our approximation achieves sup P(x, ) P ɛ (x, ) 2 TV δ W 2[ 4N( z 2 /b 0 ) + 9 ] + O(δ 2 ) x for any fixed threshold δ (0, 1).
![Approximation error condition We show that this approximation achieves sup P(x, ) P ɛ (x, ) 2 TV δ W 2[ 4N( z 2 /b 0 ) + 9 ] + O(δ 2 ) x for any fixed threshold δ.](/docs-images/92/110906858/images/32-0.jpg "Practically: we put δ = 10 4 and have observed no advantages from smaller values.")
32 Approximation error condition We show that this approximation achieves sup P(x, ) P ɛ (x, ) 2 TV δ W 2[ 4N( z 2 /b 0 ) + 9 ] + O(δ 2 ) x for any fixed threshold δ. Practically: we put δ = 10 4 and have observed no advantages from smaller values. Don t have a result in Wasserstein, but can numerically compute pathwise Wasserstein-2 and get
33 Simulation studies The results that follow use a common simulation structure w i iid Np (0, Σ) z i N(w i β, 4) { 2 (j/4 9/4) j < 24 β j = 0 j > 23, So there are always small and large signals, and true nulls We consider both Σ = I (independent design) and Σ ij = 0.9 i j (correlated design)
34 Effective sample size Recall effective sample size n e, a measure of the number of independent samples your Markov path is worth If n e = n then your MCMC is giving essentially independent samples (like vanilla Monte Carlo) If n e n then your MCMC has very high autocorrelations, need very long path to get good approximation to posterior

35 Mixing as p increases Effective sample sizes are essentially independent of p, even when the design matrix is highly correlated

36 Mixing as N increases Effective sample sizes are essentially independent of N, even when the design matrix is highly correlated
37 Effective samples per second Recall effective sample size n e, a measure of the number of independent samples your Markov path is worth So if t is computation time in seconds, effective samples per second n e /t is an empirical measurement of overall computational efficiency

38 Results: Effective samples per second The approximate algorithm is fifty times more efficient when N = 2, 000 and p = 20, 000

39 Results: Accuracy The old algorithm often failed to identify components of β with bimodal marginals This coveys uncertainty about whether β j is a true signal, which is one of the nice features of taking a Bayesian approach to multiple testing

40 Accuracy The old algorithm actually failed to converge in some cases, a result of numerical truncation rules used to control underflow
41 Scaling to a small GWAS dataset We consider a GWAS dataset consisting of p = 98, 385 from N = 2, 267 inbred maize lines in the USDA Ames, IA seed bank The phenotype is growing degree days to silking, which is basically a measurement of how fast the maize bears fruit, controlling for temperature Our goal is only to demonstrate that our algorithm can handle this application GWAS data obtained from Professors Xiaolei Liu and Xiang Zhou.
 not being very sparse (s 2000")
42 Application to GWAS Ran 30,000 iterations in about 4 hours, despite the signals (apparently) not being very sparse (s 2000 typically)

43 Inference: marginals for β j with largest posterior means Lasso solution indicated in red, horseshoe estimated posterior mean in blue
44 Conclusion Computational cost for MCMC shouldn t massively differ from alternatives designed for the same problem But making the algorithm fast takes work, often problem-specific More thrust on computing posteriors that we know have nice properties
45 References Carvalho, C., Polson, N. & Scott, J. (2010). The horseshoe estimator for sparse signals. Biometrika Bhattacharya, A., Chakraborty, A., Mallick, B. (2016). Fast sampling with Gaussian scale-mixture priors in high-dimensional regression. Biometrika arxiv preprint arxiv: Johndrow, J. E., Orenstein, P., & Bhattacharya, A. (2018). Scalable MCMC for Bayes Shrinkage Priors. arxiv preprint arxiv: Johndrow, J. E., & Mattingly, J. C. (2017). Error bounds for Approximations of Markov chains. arxiv preprint arxiv:
46 Thank You
47 Performance in p n settings
48 Data generation Replicated simulation study with horseshoe prior (Carvalho et al. (2010) n = 200 & p = True β 0 has 5 non-zero entries and σ = 1.5 Two signal strengths: (i) weak - β 0S = ±(0.75, 1, 1.25, 1.5, 1.75) T (ii) moderate - β 0S = ±(1.5, 1.75, 2, 2.25, 2.5) T Two types of design matrix: (i) Independent - X j i.i.d. N(0, I p ) (ii) compound symmetry - X j i.i.d. N(0, Σ), Σ jj = δ jj Summary over 100 datasets
49 Weak signal case β^ β 0 1 β^ β 0 2 Xβ^ Xβ 0 2 HS_me HS_m MCP SCAD HS_me HS_m MCP SCAD HS_me HS_m MCP SCAD HS_me HS_m MCP SCAD HS_me HS_m MCP SCAD HS_me HS_m MCP SCAD Estimation performance: Boxplots of l 1, l 2 and prediction error across 100 simulation replicates. HS me and HS m are posterior point wise median and mean for the horeshoe prior. Top row: Independent covariates, Bottom row: Compound symmetry
50 Moderate signal case β^ β 0 1 β^ β 0 2 Xβ^ Xβ 0 2 HS_me HS_m MCP SCAD HS_me HS_m MCP SCAD HS_me HS_m MCP SCAD HS_me HS_m MCP SCAD HS_me HS_m MCP SCAD HS_me HS_m MCP SCAD Estimation performance: Boxplots of l 1, l 2 and prediction error across 100 simulation replicates. HS me and HS m are posterior point wise median and mean for the horeshoe prior. Top row: Independent covariates, Bottom row: Compound symmetry
51 Frequentist coverage of 95% credible intervals Frequentist coverages (%) and 100 lengths of point wise 95% intervals. Average coverages and lengths are reported after averaging across all signal variables (rows 1 and 2) and noise variables (rows 3 and 4). Subscripts denote 100 standard errors for coverages. LASSO and SS respectively stand for the methods in van de Geer et al. (2014) and Javanmard & Montanari (2014). The intervals for the horseshoe (HS) are the symmetric posterior credible intervals.
52 Variable selection by postprocessing Q(β) = 1 p 2 X ˆβ X β µ j β j, µ j = ˆβ j 2. j=1
53 Variable selection performance SAVS: Variable selection by post-processing the posterior mean from the HS prior. Plot of Mathew s correlation coefficient (MCC) over 1000 simulations for various methods. MCC values closer to 1 indicate better variable selection performance.
Package horseshoe. November 8, 2016
 Title Implementation of the Horseshoe Prior Version 0.1.0 Package horseshoe November 8, 2016 Description Contains functions for applying the horseshoe prior to highdimensional linear regression, yielding
Title Implementation of the Horseshoe Prior Version 0.1.0 Package horseshoe November 8, 2016 Description Contains functions for applying the horseshoe prior to highdimensional linear regression, yielding
Or How to select variables Using Bayesian LASSO
 Or How to select variables Using Bayesian LASSO x 1 x 2 x 3 x 4 Or How to select variables Using Bayesian LASSO x 1 x 2 x 3 x 4 Or How to select variables Using Bayesian LASSO On Bayesian Variable Selection
Or How to select variables Using Bayesian LASSO x 1 x 2 x 3 x 4 Or How to select variables Using Bayesian LASSO x 1 x 2 x 3 x 4 Or How to select variables Using Bayesian LASSO On Bayesian Variable Selection
BAGUS: Bayesian Regularization for Graphical Models with Unequal Shrinkage
 BAGUS: Bayesian Regularization for Graphical Models with Unequal Shrinkage Lingrui Gan, Naveen N. Narisetty, Feng Liang Department of Statistics University of Illinois at Urbana-Champaign Problem Statement
BAGUS: Bayesian Regularization for Graphical Models with Unequal Shrinkage Lingrui Gan, Naveen N. Narisetty, Feng Liang Department of Statistics University of Illinois at Urbana-Champaign Problem Statement
Geometric ergodicity of the Bayesian lasso
 Geometric ergodicity of the Bayesian lasso Kshiti Khare and James P. Hobert Department of Statistics University of Florida June 3 Abstract Consider the standard linear model y = X +, where the components
Geometric ergodicity of the Bayesian lasso Kshiti Khare and James P. Hobert Department of Statistics University of Florida June 3 Abstract Consider the standard linear model y = X +, where the components
Bayesian Sparse Linear Regression with Unknown Symmetric Error
 Bayesian Sparse Linear Regression with Unknown Symmetric Error Minwoo Chae 1 Joint work with Lizhen Lin 2 David B. Dunson 3 1 Department of Mathematics, The University of Texas at Austin 2 Department of
Bayesian Sparse Linear Regression with Unknown Symmetric Error Minwoo Chae 1 Joint work with Lizhen Lin 2 David B. Dunson 3 1 Department of Mathematics, The University of Texas at Austin 2 Department of
Bayesian Grouped Horseshoe Regression with Application to Additive Models
 Bayesian Grouped Horseshoe Regression with Application to Additive Models Zemei Xu 1,2, Daniel F. Schmidt 1, Enes Makalic 1, Guoqi Qian 2, John L. Hopper 1 1 Centre for Epidemiology and Biostatistics,
Bayesian Grouped Horseshoe Regression with Application to Additive Models Zemei Xu 1,2, Daniel F. Schmidt 1, Enes Makalic 1, Guoqi Qian 2, John L. Hopper 1 1 Centre for Epidemiology and Biostatistics,
Bayesian linear regression
 Bayesian linear regression Linear regression is the basis of most statistical modeling. The model is Y i = X T i β + ε i, where Y i is the continuous response X i = (X i1,..., X ip ) T is the corresponding
Bayesian linear regression Linear regression is the basis of most statistical modeling. The model is Y i = X T i β + ε i, where Y i is the continuous response X i = (X i1,..., X ip ) T is the corresponding
Consistent high-dimensional Bayesian variable selection via penalized credible regions
 Consistent high-dimensional Bayesian variable selection via penalized credible regions Howard Bondell bondell@stat.ncsu.edu Joint work with Brian Reich Howard Bondell p. 1 Outline High-Dimensional Variable
Consistent high-dimensional Bayesian variable selection via penalized credible regions Howard Bondell bondell@stat.ncsu.edu Joint work with Brian Reich Howard Bondell p. 1 Outline High-Dimensional Variable
Bayesian Regression Linear and Logistic Regression
 When we want more than point estimates Bayesian Regression Linear and Logistic Regression Nicole Beckage Ordinary Least Squares Regression and Lasso Regression return only point estimates But what if we
When we want more than point estimates Bayesian Regression Linear and Logistic Regression Nicole Beckage Ordinary Least Squares Regression and Lasso Regression return only point estimates But what if we
Nearest Neighbor Gaussian Processes for Large Spatial Data
 Nearest Neighbor Gaussian Processes for Large Spatial Data Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public Health, Johns
Nearest Neighbor Gaussian Processes for Large Spatial Data Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public Health, Johns
Scaling up Bayesian Inference
 Scaling up Bayesian Inference David Dunson Departments of Statistical Science, Mathematics & ECE, Duke University May 1, 2017 Outline Motivation & background EP-MCMC amcmc Discussion Motivation & background
Scaling up Bayesian Inference David Dunson Departments of Statistical Science, Mathematics & ECE, Duke University May 1, 2017 Outline Motivation & background EP-MCMC amcmc Discussion Motivation & background
Partial factor modeling: predictor-dependent shrinkage for linear regression
 modeling: predictor-dependent shrinkage for linear Richard Hahn, Carlos Carvalho and Sayan Mukherjee JASA 2013 Review by Esther Salazar Duke University December, 2013 Factor framework The factor framework
modeling: predictor-dependent shrinkage for linear Richard Hahn, Carlos Carvalho and Sayan Mukherjee JASA 2013 Review by Esther Salazar Duke University December, 2013 Factor framework The factor framework
Markov Chain Monte Carlo methods
 Markov Chain Monte Carlo methods By Oleg Makhnin 1 Introduction a b c M = d e f g h i 0 f(x)dx 1.1 Motivation 1.1.1 Just here Supresses numbering 1.1.2 After this 1.2 Literature 2 Method 2.1 New math As
Markov Chain Monte Carlo methods By Oleg Makhnin 1 Introduction a b c M = d e f g h i 0 f(x)dx 1.1 Motivation 1.1.1 Just here Supresses numbering 1.1.2 After this 1.2 Literature 2 Method 2.1 New math As
Bayesian methods in economics and finance
 1/26 Bayesian methods in economics and finance Linear regression: Bayesian model selection and sparsity priors Linear Regression 2/26 Linear regression Model for relationship between (several) independent
1/26 Bayesian methods in economics and finance Linear regression: Bayesian model selection and sparsity priors Linear Regression 2/26 Linear regression Model for relationship between (several) independent
Approximating high-dimensional posteriors with nuisance parameters via integrated rotated Gaussian approximation (IRGA)
") Approximating high-dimensional posteriors with nuisance parameters via integrated rotated Gaussian approximation (IRGA) Willem van den Boom Department of Statistics and Applied Probability National University
Approximating high-dimensional posteriors with nuisance parameters via integrated rotated Gaussian approximation (IRGA) Willem van den Boom Department of Statistics and Applied Probability National University
CPSC 540: Machine Learning
 CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
Bayesian Grouped Horseshoe Regression with Application to Additive Models
 Bayesian Grouped Horseshoe Regression with Application to Additive Models Zemei Xu, Daniel F. Schmidt, Enes Makalic, Guoqi Qian, and John L. Hopper Centre for Epidemiology and Biostatistics, Melbourne
Bayesian Grouped Horseshoe Regression with Application to Additive Models Zemei Xu, Daniel F. Schmidt, Enes Makalic, Guoqi Qian, and John L. Hopper Centre for Epidemiology and Biostatistics, Melbourne
Markov Chain Monte Carlo (MCMC)
") Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Markov Chain Monte Carlo (MCMC Dependent Sampling Suppose we wish to sample from a density π, and we can evaluate π as a function but have no means to directly generate a sample. Rejection sampling can
Bayesian variable selection and classification with control of predictive values
 Bayesian variable selection and classification with control of predictive values Eleni Vradi 1, Thomas Jaki 2, Richardus Vonk 1, Werner Brannath 3 1 Bayer AG, Germany, 2 Lancaster University, UK, 3 University
Bayesian variable selection and classification with control of predictive values Eleni Vradi 1, Thomas Jaki 2, Richardus Vonk 1, Werner Brannath 3 1 Bayer AG, Germany, 2 Lancaster University, UK, 3 University
On Bayesian Computation
 On Bayesian Computation Michael I. Jordan with Elaine Angelino, Maxim Rabinovich, Martin Wainwright and Yun Yang Previous Work: Information Constraints on Inference Minimize the minimax risk under constraints
On Bayesian Computation Michael I. Jordan with Elaine Angelino, Maxim Rabinovich, Martin Wainwright and Yun Yang Previous Work: Information Constraints on Inference Minimize the minimax risk under constraints
arxiv: v3 [stat.co] 15 Oct 2018
![arxiv: v3 [stat.co] 15 Oct 2018](/thumbs/90/103925709.jpg "arxiv: v3 [stat.co] 15 Oct 2018") arxiv:1705.00841v3 [stat.co] 15 Oct 2018 Bayes Shrinkage at GWAS scale: Convergence and Approximation Theory of a Scalable MCMC Algorithm for the Horseshoe Prior James E. Johndrow, Paulo Orenstein and
arxiv:1705.00841v3 [stat.co] 15 Oct 2018 Bayes Shrinkage at GWAS scale: Convergence and Approximation Theory of a Scalable MCMC Algorithm for the Horseshoe Prior James E. Johndrow, Paulo Orenstein and
A MCMC Approach for Learning the Structure of Gaussian Acyclic Directed Mixed Graphs
 A MCMC Approach for Learning the Structure of Gaussian Acyclic Directed Mixed Graphs Ricardo Silva Abstract Graphical models are widely used to encode conditional independence constraints and causal assumptions,
A MCMC Approach for Learning the Structure of Gaussian Acyclic Directed Mixed Graphs Ricardo Silva Abstract Graphical models are widely used to encode conditional independence constraints and causal assumptions,
MCMC for big data. Geir Storvik. BigInsight lunch - May Geir Storvik MCMC for big data BigInsight lunch - May / 17
 MCMC for big data Geir Storvik BigInsight lunch - May 2 2018 Geir Storvik MCMC for big data BigInsight lunch - May 2 2018 1 / 17 Outline Why ordinary MCMC is not scalable Different approaches for making
MCMC for big data Geir Storvik BigInsight lunch - May 2 2018 Geir Storvik MCMC for big data BigInsight lunch - May 2 2018 1 / 17 Outline Why ordinary MCMC is not scalable Different approaches for making
Sparse Linear Models (10/7/13)
") STA56: Probabilistic machine learning Sparse Linear Models (0/7/) Lecturer: Barbara Engelhardt Scribes: Jiaji Huang, Xin Jiang, Albert Oh Sparsity Sparsity has been a hot topic in statistics and machine
STA56: Probabilistic machine learning Sparse Linear Models (0/7/) Lecturer: Barbara Engelhardt Scribes: Jiaji Huang, Xin Jiang, Albert Oh Sparsity Sparsity has been a hot topic in statistics and machine
Default Priors and Effcient Posterior Computation in Bayesian
 Default Priors and Effcient Posterior Computation in Bayesian Factor Analysis January 16, 2010 Presented by Eric Wang, Duke University Background and Motivation A Brief Review of Parameter Expansion Literature
Default Priors and Effcient Posterior Computation in Bayesian Factor Analysis January 16, 2010 Presented by Eric Wang, Duke University Background and Motivation A Brief Review of Parameter Expansion Literature
Estimating Sparse High Dimensional Linear Models using Global-Local Shrinkage
 Estimating Sparse High Dimensional Linear Models using Global-Local Shrinkage Daniel F. Schmidt Centre for Biostatistics and Epidemiology The University of Melbourne Monash University May 11, 2017 Outline
Estimating Sparse High Dimensional Linear Models using Global-Local Shrinkage Daniel F. Schmidt Centre for Biostatistics and Epidemiology The University of Melbourne Monash University May 11, 2017 Outline
Bayesian Linear Regression
 Bayesian Linear Regression Sudipto Banerjee 1 Biostatistics, School of Public Health, University of Minnesota, Minneapolis, Minnesota, U.S.A. September 15, 2010 1 Linear regression models: a Bayesian perspective
Bayesian Linear Regression Sudipto Banerjee 1 Biostatistics, School of Public Health, University of Minnesota, Minneapolis, Minnesota, U.S.A. September 15, 2010 1 Linear regression models: a Bayesian perspective
Analysis Methods for Supersaturated Design: Some Comparisons
 Journal of Data Science 1(2003), 249-260 Analysis Methods for Supersaturated Design: Some Comparisons Runze Li 1 and Dennis K. J. Lin 2 The Pennsylvania State University Abstract: Supersaturated designs
Journal of Data Science 1(2003), 249-260 Analysis Methods for Supersaturated Design: Some Comparisons Runze Li 1 and Dennis K. J. Lin 2 The Pennsylvania State University Abstract: Supersaturated designs
Efficient sampling for Gaussian linear regression with arbitrary priors
 Efficient sampling for Gaussian linear regression with arbitrary priors P. Richard Hahn Arizona State University and Jingyu He Booth School of Business, University of Chicago and Hedibert F. Lopes INSPER
Efficient sampling for Gaussian linear regression with arbitrary priors P. Richard Hahn Arizona State University and Jingyu He Booth School of Business, University of Chicago and Hedibert F. Lopes INSPER
VCMC: Variational Consensus Monte Carlo
 VCMC: Variational Consensus Monte Carlo Maxim Rabinovich, Elaine Angelino, Michael I. Jordan Berkeley Vision and Learning Center September 22, 2015 probabilistic models! sky fog bridge water grass object
VCMC: Variational Consensus Monte Carlo Maxim Rabinovich, Elaine Angelino, Michael I. Jordan Berkeley Vision and Learning Center September 22, 2015 probabilistic models! sky fog bridge water grass object
(5) Multi-parameter models - Gibbs sampling. ST440/540: Applied Bayesian Analysis
 Multi-parameter models - Gibbs sampling. ST440/540: Applied Bayesian Analysis") Summarizing a posterior Given the data and prior the posterior is determined Summarizing the posterior gives parameter estimates, intervals, and hypothesis tests Most of these computations are integrals
Summarizing a posterior Given the data and prior the posterior is determined Summarizing the posterior gives parameter estimates, intervals, and hypothesis tests Most of these computations are integrals
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Sparse Recovery using L1 minimization - algorithms Yuejie Chi Department of Electrical and Computer Engineering Spring
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Sparse Recovery using L1 minimization - algorithms Yuejie Chi Department of Electrical and Computer Engineering Spring
Coupled Hidden Markov Models: Computational Challenges
 .. Coupled Hidden Markov Models: Computational Challenges Louis J. M. Aslett and Chris C. Holmes i-like Research Group University of Oxford Warwick Algorithms Seminar 7 th March 2014 ... Hidden Markov
.. Coupled Hidden Markov Models: Computational Challenges Louis J. M. Aslett and Chris C. Holmes i-like Research Group University of Oxford Warwick Algorithms Seminar 7 th March 2014 ... Hidden Markov
MCMC Sampling for Bayesian Inference using L1-type Priors
 MÜNSTER MCMC Sampling for Bayesian Inference using L1-type Priors (what I do whenever the ill-posedness of EEG/MEG is just not frustrating enough!) AG Imaging Seminar Felix Lucka 26.06.2012 , MÜNSTER Sampling
MÜNSTER MCMC Sampling for Bayesian Inference using L1-type Priors (what I do whenever the ill-posedness of EEG/MEG is just not frustrating enough!) AG Imaging Seminar Felix Lucka 26.06.2012 , MÜNSTER Sampling
University of Toronto Department of Statistics
 Norm Comparisons for Data Augmentation by James P. Hobert Department of Statistics University of Florida and Jeffrey S. Rosenthal Department of Statistics University of Toronto Technical Report No. 0704
Norm Comparisons for Data Augmentation by James P. Hobert Department of Statistics University of Florida and Jeffrey S. Rosenthal Department of Statistics University of Toronto Technical Report No. 0704
Bayesian Estimation of Input Output Tables for Russia
 Bayesian Estimation of Input Output Tables for Russia Oleg Lugovoy (EDF, RANE) Andrey Polbin (RANE) Vladimir Potashnikov (RANE) WIOD Conference April 24, 2012 Groningen Outline Motivation Objectives Bayesian
Bayesian Estimation of Input Output Tables for Russia Oleg Lugovoy (EDF, RANE) Andrey Polbin (RANE) Vladimir Potashnikov (RANE) WIOD Conference April 24, 2012 Groningen Outline Motivation Objectives Bayesian
sparse and low-rank tensor recovery Cubic-Sketching
 Sparse and Low-Ran Tensor Recovery via Cubic-Setching Guang Cheng Department of Statistics Purdue University www.science.purdue.edu/bigdata CCAM@Purdue Math Oct. 27, 2017 Joint wor with Botao Hao and Anru
Sparse and Low-Ran Tensor Recovery via Cubic-Setching Guang Cheng Department of Statistics Purdue University www.science.purdue.edu/bigdata CCAM@Purdue Math Oct. 27, 2017 Joint wor with Botao Hao and Anru
MCMC algorithms for fitting Bayesian models
 MCMC algorithms for fitting Bayesian models p. 1/1 MCMC algorithms for fitting Bayesian models Sudipto Banerjee sudiptob@biostat.umn.edu University of Minnesota MCMC algorithms for fitting Bayesian models
MCMC algorithms for fitting Bayesian models p. 1/1 MCMC algorithms for fitting Bayesian models Sudipto Banerjee sudiptob@biostat.umn.edu University of Minnesota MCMC algorithms for fitting Bayesian models
20: Gaussian Processes
 10-708: Probabilistic Graphical Models 10-708, Spring 2016 20: Gaussian Processes Lecturer: Andrew Gordon Wilson Scribes: Sai Ganesh Bandiatmakuri 1 Discussion about ML Here we discuss an introduction
10-708: Probabilistic Graphical Models 10-708, Spring 2016 20: Gaussian Processes Lecturer: Andrew Gordon Wilson Scribes: Sai Ganesh Bandiatmakuri 1 Discussion about ML Here we discuss an introduction
Making rating curves - the Bayesian approach
 Making rating curves - the Bayesian approach Rating curves what is wanted? A best estimate of the relationship between stage and discharge at a given place in a river. The relationship should be on the
Making rating curves - the Bayesian approach Rating curves what is wanted? A best estimate of the relationship between stage and discharge at a given place in a river. The relationship should be on the
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
arxiv: v2 [stat.me] 16 Aug 2018
![arxiv: v2 [stat.me] 16 Aug 2018](/thumbs/85/91334133.jpg "arxiv: v2 [stat.me] 16 Aug 2018") arxiv:1807.06539v [stat.me] 16 Aug 018 On the Beta Prime Prior for Scale Parameters in High-Dimensional Bayesian Regression Models Ray Bai Malay Ghosh August 0, 018 Abstract We study high-dimensional Bayesian
arxiv:1807.06539v [stat.me] 16 Aug 018 On the Beta Prime Prior for Scale Parameters in High-Dimensional Bayesian Regression Models Ray Bai Malay Ghosh August 0, 018 Abstract We study high-dimensional Bayesian
Bayesian Variable Selection Under Collinearity
 Bayesian Variable Selection Under Collinearity Joyee Ghosh Andrew E. Ghattas. June 3, 2014 Abstract In this article we provide some guidelines to practitioners who use Bayesian variable selection for linear
Bayesian Variable Selection Under Collinearity Joyee Ghosh Andrew E. Ghattas. June 3, 2014 Abstract In this article we provide some guidelines to practitioners who use Bayesian variable selection for linear
Bayes: All uncertainty is described using probability.
 Bayes: All uncertainty is described using probability. Let w be the data and θ be any unknown quantities. Likelihood. The probability model π(w θ) has θ fixed and w varying. The likelihood L(θ; w) is π(w
Bayes: All uncertainty is described using probability. Let w be the data and θ be any unknown quantities. Likelihood. The probability model π(w θ) has θ fixed and w varying. The likelihood L(θ; w) is π(w
Part 8: GLMs and Hierarchical LMs and GLMs
 Part 8: GLMs and Hierarchical LMs and GLMs 1 Example: Song sparrow reproductive success Arcese et al., (1992) provide data on a sample from a population of 52 female song sparrows studied over the course
Part 8: GLMs and Hierarchical LMs and GLMs 1 Example: Song sparrow reproductive success Arcese et al., (1992) provide data on a sample from a population of 52 female song sparrows studied over the course
Statistical Inference
 Statistical Inference Liu Yang Florida State University October 27, 2016 Liu Yang, Libo Wang (Florida State University) Statistical Inference October 27, 2016 1 / 27 Outline The Bayesian Lasso Trevor Park
Statistical Inference Liu Yang Florida State University October 27, 2016 Liu Yang, Libo Wang (Florida State University) Statistical Inference October 27, 2016 1 / 27 Outline The Bayesian Lasso Trevor Park
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Stochastic Proximal Gradient Algorithm
 Stochastic Institut Mines-Télécom / Telecom ParisTech / Laboratoire Traitement et Communication de l Information Joint work with: Y. Atchade, Ann Arbor, USA, G. Fort LTCI/Télécom Paristech and the kind
Stochastic Institut Mines-Télécom / Telecom ParisTech / Laboratoire Traitement et Communication de l Information Joint work with: Y. Atchade, Ann Arbor, USA, G. Fort LTCI/Télécom Paristech and the kind
Bayesian shrinkage approach in variable selection for mixed
 Bayesian shrinkage approach in variable selection for mixed effects s GGI Statistics Conference, Florence, 2015 Bayesian Variable Selection June 22-26, 2015 Outline 1 Introduction 2 3 4 Outline Introduction
Bayesian shrinkage approach in variable selection for mixed effects s GGI Statistics Conference, Florence, 2015 Bayesian Variable Selection June 22-26, 2015 Outline 1 Introduction 2 3 4 Outline Introduction
Computational statistics
 Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
Package IGG. R topics documented: April 9, 2018
 Package IGG April 9, 2018 Type Package Title Inverse Gamma-Gamma Version 1.0 Date 2018-04-04 Author Ray Bai, Malay Ghosh Maintainer Ray Bai Description Implements Bayesian linear regression,
Package IGG April 9, 2018 Type Package Title Inverse Gamma-Gamma Version 1.0 Date 2018-04-04 Author Ray Bai, Malay Ghosh Maintainer Ray Bai Description Implements Bayesian linear regression,
MCMC: Markov Chain Monte Carlo
 I529: Machine Learning in Bioinformatics (Spring 2013) MCMC: Markov Chain Monte Carlo Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2013 Contents Review of Markov
I529: Machine Learning in Bioinformatics (Spring 2013) MCMC: Markov Chain Monte Carlo Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2013 Contents Review of Markov
STAT 518 Intro Student Presentation
 STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
Nonconvex penalties: Signal-to-noise ratio and algorithms
 Nonconvex penalties: Signal-to-noise ratio and algorithms Patrick Breheny March 21 Patrick Breheny High-Dimensional Data Analysis (BIOS 7600) 1/22 Introduction In today s lecture, we will return to nonconvex
Nonconvex penalties: Signal-to-noise ratio and algorithms Patrick Breheny March 21 Patrick Breheny High-Dimensional Data Analysis (BIOS 7600) 1/22 Introduction In today s lecture, we will return to nonconvex
Bayesian Regularization
 Bayesian Regularization Aad van der Vaart Vrije Universiteit Amsterdam International Congress of Mathematicians Hyderabad, August 2010 Contents Introduction Abstract result Gaussian process priors Co-authors
Bayesian Regularization Aad van der Vaart Vrije Universiteit Amsterdam International Congress of Mathematicians Hyderabad, August 2010 Contents Introduction Abstract result Gaussian process priors Co-authors
Web Appendix for Hierarchical Adaptive Regression Kernels for Regression with Functional Predictors by D. B. Woodard, C. Crainiceanu, and D.
 Web Appendix for Hierarchical Adaptive Regression Kernels for Regression with Functional Predictors by D. B. Woodard, C. Crainiceanu, and D. Ruppert A. EMPIRICAL ESTIMATE OF THE KERNEL MIXTURE Here we
Web Appendix for Hierarchical Adaptive Regression Kernels for Regression with Functional Predictors by D. B. Woodard, C. Crainiceanu, and D. Ruppert A. EMPIRICAL ESTIMATE OF THE KERNEL MIXTURE Here we
Integrated Non-Factorized Variational Inference
 Integrated Non-Factorized Variational Inference Shaobo Han, Xuejun Liao and Lawrence Carin Duke University February 27, 2014 S. Han et al. Integrated Non-Factorized Variational Inference February 27, 2014
Integrated Non-Factorized Variational Inference Shaobo Han, Xuejun Liao and Lawrence Carin Duke University February 27, 2014 S. Han et al. Integrated Non-Factorized Variational Inference February 27, 2014
Review. DS GA 1002 Statistical and Mathematical Models. Carlos Fernandez-Granda
 Review DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall16 Carlos Fernandez-Granda Probability and statistics Probability: Framework for dealing with
Review DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall16 Carlos Fernandez-Granda Probability and statistics Probability: Framework for dealing with
Spatially Adaptive Smoothing Splines
 Spatially Adaptive Smoothing Splines Paul Speckman University of Missouri-Columbia speckman@statmissouriedu September 11, 23 Banff 9/7/3 Ordinary Simple Spline Smoothing Observe y i = f(t i ) + ε i, =
Spatially Adaptive Smoothing Splines Paul Speckman University of Missouri-Columbia speckman@statmissouriedu September 11, 23 Banff 9/7/3 Ordinary Simple Spline Smoothing Observe y i = f(t i ) + ε i, =
Fitting Narrow Emission Lines in X-ray Spectra
 Outline Fitting Narrow Emission Lines in X-ray Spectra Taeyoung Park Department of Statistics, University of Pittsburgh October 11, 2007 Outline of Presentation Outline This talk has three components:
Outline Fitting Narrow Emission Lines in X-ray Spectra Taeyoung Park Department of Statistics, University of Pittsburgh October 11, 2007 Outline of Presentation Outline This talk has three components:
Probabilistic machine learning group, Aalto University Bayesian theory and methods, approximative integration, model
 Aki Vehtari, Aalto University, Finland Probabilistic machine learning group, Aalto University http://research.cs.aalto.fi/pml/ Bayesian theory and methods, approximative integration, model assessment and
Aki Vehtari, Aalto University, Finland Probabilistic machine learning group, Aalto University http://research.cs.aalto.fi/pml/ Bayesian theory and methods, approximative integration, model assessment and
Comparing Non-informative Priors for Estimation and Prediction in Spatial Models
 Environmentrics 00, 1 12 DOI: 10.1002/env.XXXX Comparing Non-informative Priors for Estimation and Prediction in Spatial Models Regina Wu a and Cari G. Kaufman a Summary: Fitting a Bayesian model to spatial
Environmentrics 00, 1 12 DOI: 10.1002/env.XXXX Comparing Non-informative Priors for Estimation and Prediction in Spatial Models Regina Wu a and Cari G. Kaufman a Summary: Fitting a Bayesian model to spatial
arxiv: v1 [stat.me] 6 Jul 2017
![arxiv: v1 [stat.me] 6 Jul 2017](/thumbs/89/98510504.jpg "arxiv: v1 [stat.me] 6 Jul 2017") Sparsity information and regularization in the horseshoe and other shrinkage priors arxiv:77.694v [stat.me] 6 Jul 7 Juho Piironen and Aki Vehtari Helsinki Institute for Information Technology, HIIT Department
Sparsity information and regularization in the horseshoe and other shrinkage priors arxiv:77.694v [stat.me] 6 Jul 7 Juho Piironen and Aki Vehtari Helsinki Institute for Information Technology, HIIT Department
ST 740: Markov Chain Monte Carlo
 ST 740: Markov Chain Monte Carlo Alyson Wilson Department of Statistics North Carolina State University October 14, 2012 A. Wilson (NCSU Stsatistics) MCMC October 14, 2012 1 / 20 Convergence Diagnostics:
ST 740: Markov Chain Monte Carlo Alyson Wilson Department of Statistics North Carolina State University October 14, 2012 A. Wilson (NCSU Stsatistics) MCMC October 14, 2012 1 / 20 Convergence Diagnostics:
Principles of Bayesian Inference
 Principles of Bayesian Inference Sudipto Banerjee University of Minnesota July 20th, 2008 1 Bayesian Principles Classical statistics: model parameters are fixed and unknown. A Bayesian thinks of parameters
Principles of Bayesian Inference Sudipto Banerjee University of Minnesota July 20th, 2008 1 Bayesian Principles Classical statistics: model parameters are fixed and unknown. A Bayesian thinks of parameters
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Markov Chain Monte Carlo methods
 Markov Chain Monte Carlo methods Tomas McKelvey and Lennart Svensson Signal Processing Group Department of Signals and Systems Chalmers University of Technology, Sweden November 26, 2012 Today s learning
Markov Chain Monte Carlo methods Tomas McKelvey and Lennart Svensson Signal Processing Group Department of Signals and Systems Chalmers University of Technology, Sweden November 26, 2012 Today s learning
Advanced Statistical Methods. Lecture 6
 Advanced Statistical Methods Lecture 6 Convergence distribution of M.-H. MCMC We denote the PDF estimated by the MCMC as. It has the property Convergence distribution After some time, the distribution
Advanced Statistical Methods Lecture 6 Convergence distribution of M.-H. MCMC We denote the PDF estimated by the MCMC as. It has the property Convergence distribution After some time, the distribution
STAT 499/962 Topics in Statistics Bayesian Inference and Decision Theory Jan 2018, Handout 01
 STAT 499/962 Topics in Statistics Bayesian Inference and Decision Theory Jan 2018, Handout 01 Nasser Sadeghkhani a.sadeghkhani@queensu.ca There are two main schools to statistical inference: 1-frequentist
STAT 499/962 Topics in Statistics Bayesian Inference and Decision Theory Jan 2018, Handout 01 Nasser Sadeghkhani a.sadeghkhani@queensu.ca There are two main schools to statistical inference: 1-frequentist
A new Hierarchical Bayes approach to ensemble-variational data assimilation
 A new Hierarchical Bayes approach to ensemble-variational data assimilation Michael Tsyrulnikov and Alexander Rakitko HydroMetCenter of Russia College Park, 20 Oct 2014 Michael Tsyrulnikov and Alexander
A new Hierarchical Bayes approach to ensemble-variational data assimilation Michael Tsyrulnikov and Alexander Rakitko HydroMetCenter of Russia College Park, 20 Oct 2014 Michael Tsyrulnikov and Alexander
arxiv: v1 [stat.co] 2 Nov 2017
![arxiv: v1 [stat.co] 2 Nov 2017](/thumbs/86/93943752.jpg "arxiv: v1 [stat.co] 2 Nov 2017") Binary Bouncy Particle Sampler arxiv:1711.922v1 [stat.co] 2 Nov 217 Ari Pakman Department of Statistics Center for Theoretical Neuroscience Grossman Center for the Statistics of Mind Columbia University
Binary Bouncy Particle Sampler arxiv:1711.922v1 [stat.co] 2 Nov 217 Ari Pakman Department of Statistics Center for Theoretical Neuroscience Grossman Center for the Statistics of Mind Columbia University
Horseshoe, Lasso and Related Shrinkage Methods
 Readings Chapter 15 Christensen Merlise Clyde October 15, 2015 Bayesian Lasso Park & Casella (JASA 2008) and Hans (Biometrika 2010) propose Bayesian versions of the Lasso Bayesian Lasso Park & Casella
Readings Chapter 15 Christensen Merlise Clyde October 15, 2015 Bayesian Lasso Park & Casella (JASA 2008) and Hans (Biometrika 2010) propose Bayesian versions of the Lasso Bayesian Lasso Park & Casella
Discussion of Predictive Density Combinations with Dynamic Learning for Large Data Sets in Economics and Finance
 Discussion of Predictive Density Combinations with Dynamic Learning for Large Data Sets in Economics and Finance by Casarin, Grassi, Ravazzolo, Herman K. van Dijk Dimitris Korobilis University of Essex,
Discussion of Predictive Density Combinations with Dynamic Learning for Large Data Sets in Economics and Finance by Casarin, Grassi, Ravazzolo, Herman K. van Dijk Dimitris Korobilis University of Essex,
Chris Fraley and Daniel Percival. August 22, 2008, revised May 14, 2010
 Model-Averaged l 1 Regularization using Markov Chain Monte Carlo Model Composition Technical Report No. 541 Department of Statistics, University of Washington Chris Fraley and Daniel Percival August 22,
Model-Averaged l 1 Regularization using Markov Chain Monte Carlo Model Composition Technical Report No. 541 Department of Statistics, University of Washington Chris Fraley and Daniel Percival August 22,
A Note on the comparison of Nearest Neighbor Gaussian Process (NNGP) based models
 based models") A Note on the comparison of Nearest Neighbor Gaussian Process (NNGP) based models arxiv:1811.03735v1 [math.st] 9 Nov 2018 Lu Zhang UCLA Department of Biostatistics Lu.Zhang@ucla.edu Sudipto Banerjee UCLA
A Note on the comparison of Nearest Neighbor Gaussian Process (NNGP) based models arxiv:1811.03735v1 [math.st] 9 Nov 2018 Lu Zhang UCLA Department of Biostatistics Lu.Zhang@ucla.edu Sudipto Banerjee UCLA
Sparsity Regularization
 Sparsity Regularization Bangti Jin Course Inverse Problems & Imaging 1 / 41 Outline 1 Motivation: sparsity? 2 Mathematical preliminaries 3 l 1 solvers 2 / 41 problem setup finite-dimensional formulation
Sparsity Regularization Bangti Jin Course Inverse Problems & Imaging 1 / 41 Outline 1 Motivation: sparsity? 2 Mathematical preliminaries 3 l 1 solvers 2 / 41 problem setup finite-dimensional formulation
Markov Chain Monte Carlo
 Markov Chain Monte Carlo Recall: To compute the expectation E ( h(y ) ) we use the approximation E(h(Y )) 1 n n h(y ) t=1 with Y (1),..., Y (n) h(y). Thus our aim is to sample Y (1),..., Y (n) from f(y).
Markov Chain Monte Carlo Recall: To compute the expectation E ( h(y ) ) we use the approximation E(h(Y )) 1 n n h(y ) t=1 with Y (1),..., Y (n) h(y). Thus our aim is to sample Y (1),..., Y (n) from f(y).
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
SAMPLING ALGORITHMS. In general. Inference in Bayesian models
 SAMPLING ALGORITHMS SAMPLING ALGORITHMS In general A sampling algorithm is an algorithm that outputs samples x 1, x 2,... from a given distribution P or density p. Sampling algorithms can for example be
SAMPLING ALGORITHMS SAMPLING ALGORITHMS In general A sampling algorithm is an algorithm that outputs samples x 1, x 2,... from a given distribution P or density p. Sampling algorithms can for example be
arxiv: v3 [stat.me] 10 Aug 2018
![arxiv: v3 [stat.me] 10 Aug 2018](/thumbs/89/100000591.jpg "arxiv: v3 [stat.me] 10 Aug 2018") Lasso Meets Horseshoe: A Survey arxiv:1706.10179v3 [stat.me] 10 Aug 2018 Anindya Bhadra 250 N. University St., West Lafayette, IN 47907. e-mail: bhadra@purdue.edu Jyotishka Datta 1 University of Arkansas,
Lasso Meets Horseshoe: A Survey arxiv:1706.10179v3 [stat.me] 10 Aug 2018 Anindya Bhadra 250 N. University St., West Lafayette, IN 47907. e-mail: bhadra@purdue.edu Jyotishka Datta 1 University of Arkansas,
CSC 2541: Bayesian Methods for Machine Learning
 CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 3 More Markov Chain Monte Carlo Methods The Metropolis algorithm isn t the only way to do MCMC. We ll
CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 3 More Markov Chain Monte Carlo Methods The Metropolis algorithm isn t the only way to do MCMC. We ll
Handling Sparsity via the Horseshoe
 Handling Sparsity via the Carlos M. Carvalho Booth School of Business The University of Chicago Chicago, IL 60637 Nicholas G. Polson Booth School of Business The University of Chicago Chicago, IL 60637
Handling Sparsity via the Carlos M. Carvalho Booth School of Business The University of Chicago Chicago, IL 60637 Nicholas G. Polson Booth School of Business The University of Chicago Chicago, IL 60637
An introduction to adaptive MCMC
 An introduction to adaptive MCMC Gareth Roberts MIRAW Day on Monte Carlo methods March 2011 Mainly joint work with Jeff Rosenthal. http://www2.warwick.ac.uk/fac/sci/statistics/crism/ Conferences and workshops
An introduction to adaptive MCMC Gareth Roberts MIRAW Day on Monte Carlo methods March 2011 Mainly joint work with Jeff Rosenthal. http://www2.warwick.ac.uk/fac/sci/statistics/crism/ Conferences and workshops
Ergodicity in data assimilation methods
 Ergodicity in data assimilation methods David Kelly Andy Majda Xin Tong Courant Institute New York University New York NY www.dtbkelly.com April 15, 2016 ETH Zurich David Kelly (CIMS) Data assimilation
Ergodicity in data assimilation methods David Kelly Andy Majda Xin Tong Courant Institute New York University New York NY www.dtbkelly.com April 15, 2016 ETH Zurich David Kelly (CIMS) Data assimilation
A New Combined Approach for Inference in High-Dimensional Regression Models with Correlated Variables
 A New Combined Approach for Inference in High-Dimensional Regression Models with Correlated Variables Niharika Gauraha and Swapan Parui Indian Statistical Institute Abstract. We consider the problem of
A New Combined Approach for Inference in High-Dimensional Regression Models with Correlated Variables Niharika Gauraha and Swapan Parui Indian Statistical Institute Abstract. We consider the problem of
Variance prior forms for high-dimensional Bayesian variable selection
 Bayesian Analysis (0000) 00, Number 0, pp. 1 Variance prior forms for high-dimensional Bayesian variable selection Gemma E. Moran, Veronika Ročková and Edward I. George Abstract. Consider the problem of
Bayesian Analysis (0000) 00, Number 0, pp. 1 Variance prior forms for high-dimensional Bayesian variable selection Gemma E. Moran, Veronika Ročková and Edward I. George Abstract. Consider the problem of
Stat 451 Lecture Notes Markov Chain Monte Carlo. Ryan Martin UIC
 Stat 451 Lecture Notes 07 12 Markov Chain Monte Carlo Ryan Martin UIC www.math.uic.edu/~rgmartin 1 Based on Chapters 8 9 in Givens & Hoeting, Chapters 25 27 in Lange 2 Updated: April 4, 2016 1 / 42 Outline
Stat 451 Lecture Notes 07 12 Markov Chain Monte Carlo Ryan Martin UIC www.math.uic.edu/~rgmartin 1 Based on Chapters 8 9 in Givens & Hoeting, Chapters 25 27 in Lange 2 Updated: April 4, 2016 1 / 42 Outline
Bi-level feature selection with applications to genetic association
 Bi-level feature selection with applications to genetic association studies October 15, 2008 Motivation In many applications, biological features possess a grouping structure Categorical variables may
Bi-level feature selection with applications to genetic association studies October 15, 2008 Motivation In many applications, biological features possess a grouping structure Categorical variables may
An Extended BIC for Model Selection
 An Extended BIC for Model Selection at the JSM meeting 2007 - Salt Lake City Surajit Ray Boston University (Dept of Mathematics and Statistics) Joint work with James Berger, Duke University; Susie Bayarri,
An Extended BIC for Model Selection at the JSM meeting 2007 - Salt Lake City Surajit Ray Boston University (Dept of Mathematics and Statistics) Joint work with James Berger, Duke University; Susie Bayarri,
Bayesian Inference in GLMs. Frequentists typically base inferences on MLEs, asymptotic confidence
 Bayesian Inference in GLMs Frequentists typically base inferences on MLEs, asymptotic confidence limits, and log-likelihood ratio tests Bayesians base inferences on the posterior distribution of the unknowns
Bayesian Inference in GLMs Frequentists typically base inferences on MLEs, asymptotic confidence limits, and log-likelihood ratio tests Bayesians base inferences on the posterior distribution of the unknowns
Package basad. November 20, 2017
 Package basad November 20, 2017 Type Package Title Bayesian Variable Selection with Shrinking and Diffusing Priors Version 0.2.0 Date 2017-11-15 Author Qingyan Xiang , Naveen Narisetty
Package basad November 20, 2017 Type Package Title Bayesian Variable Selection with Shrinking and Diffusing Priors Version 0.2.0 Date 2017-11-15 Author Qingyan Xiang , Naveen Narisetty
Large-scale Collaborative Prediction Using a Nonparametric Random Effects Model
 Large-scale Collaborative Prediction Using a Nonparametric Random Effects Model Kai Yu Joint work with John Lafferty and Shenghuo Zhu NEC Laboratories America, Carnegie Mellon University First Prev Page
Large-scale Collaborative Prediction Using a Nonparametric Random Effects Model Kai Yu Joint work with John Lafferty and Shenghuo Zhu NEC Laboratories America, Carnegie Mellon University First Prev Page
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Bayesian Statistics in High Dimensions
 Bayesian Statistics in High Dimensions Lecture 2: Sparsity Aad van der Vaart Universiteit Leiden, Netherlands 47th John H. Barrett Memorial Lectures, Knoxville, Tenessee, May 2017 Contents Sparsity Bayesian
Bayesian Statistics in High Dimensions Lecture 2: Sparsity Aad van der Vaart Universiteit Leiden, Netherlands 47th John H. Barrett Memorial Lectures, Knoxville, Tenessee, May 2017 Contents Sparsity Bayesian
Bayesian model selection in graphs by using BDgraph package
 Bayesian model selection in graphs by using BDgraph package A. Mohammadi and E. Wit March 26, 2013 MOTIVATION Flow cytometry data with 11 proteins from Sachs et al. (2005) RESULT FOR CELL SIGNALING DATA
Bayesian model selection in graphs by using BDgraph package A. Mohammadi and E. Wit March 26, 2013 MOTIVATION Flow cytometry data with 11 proteins from Sachs et al. (2005) RESULT FOR CELL SIGNALING DATA
High-dimensional Ordinary Least-squares Projection for Screening Variables
 1 / 38 High-dimensional Ordinary Least-squares Projection for Screening Variables Chenlei Leng Joint with Xiangyu Wang (Duke) Conference on Nonparametric Statistics for Big Data and Celebration to Honor
1 / 38 High-dimensional Ordinary Least-squares Projection for Screening Variables Chenlei Leng Joint with Xiangyu Wang (Duke) Conference on Nonparametric Statistics for Big Data and Celebration to Honor
Likelihood-free MCMC
 Bayesian inference for stable distributions with applications in finance Department of Mathematics University of Leicester September 2, 2011 MSc project final presentation Outline 1 2 3 4 Classical Monte
Bayesian inference for stable distributions with applications in finance Department of Mathematics University of Leicester September 2, 2011 MSc project final presentation Outline 1 2 3 4 Classical Monte
Hastings-within-Gibbs Algorithm: Introduction and Application on Hierarchical Model
 UNIVERSITY OF TEXAS AT SAN ANTONIO Hastings-within-Gibbs Algorithm: Introduction and Application on Hierarchical Model Liang Jing April 2010 1 1 ABSTRACT In this paper, common MCMC algorithms are introduced
UNIVERSITY OF TEXAS AT SAN ANTONIO Hastings-within-Gibbs Algorithm: Introduction and Application on Hierarchical Model Liang Jing April 2010 1 1 ABSTRACT In this paper, common MCMC algorithms are introduced
L 0 methods. H.J. Kappen Donders Institute for Neuroscience Radboud University, Nijmegen, the Netherlands. December 5, 2011.
 L methods H.J. Kappen Donders Institute for Neuroscience Radboud University, Nijmegen, the Netherlands December 5, 2 Bert Kappen Outline George McCullochs model The Variational Garrote Bert Kappen L methods
L methods H.J. Kappen Donders Institute for Neuroscience Radboud University, Nijmegen, the Netherlands December 5, 2 Bert Kappen Outline George McCullochs model The Variational Garrote Bert Kappen L methods
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov