Point Estimation. Vibhav Gogate The University of Texas at Dallas
|
|
|
- Megan Poole
- 5 years ago
- Views:
Transcription
1 Point Estimation Vibhav Gogate The University of Texas at Dallas Some slides courtesy of Carlos Guestrin, Chris Bishop, Dan Weld and Luke Zettlemoyer.
2 Basics: Expectation and Variance
 Coin flipping:")

3 Binary Variables (1) Coin flipping: heads=1, tails=0 Bernoulli Distribution



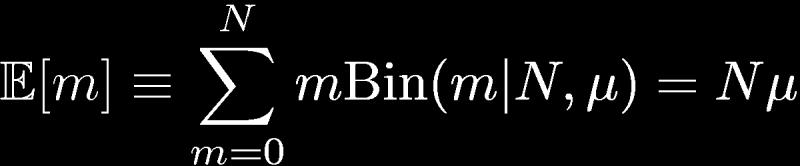
4 Binary Variables (2) N coin flips: Binomial Distribution
5 Your first consulting job Billionaire in Dallas asks: He says: I have thumbtack, if I flip it, what s the probability it will fall with the nail up? You say: Please flip it a few times: You say: The probability is: P(H) = 3/5 He says: Why??? You say: Because
6 Thumbtack Binomial Distribution P(Heads) =, P(Tails) = 1- Flips are i.i.d.: Independent events Identically distributed according to Binomial distribution Sequence D of H Heads and T Tails
7 Maximum Likelihood Estimation Data: Observed set D of H Heads and T Tails Hypothesis: Binomial distribution Learning: finding is an optimization problem What s the objective function? MLE: Choose to maximize probability of D
8 Your first parameter learning algorithm Set derivative to zero, and solve!
9 At each point, the derivative is the slope of a line that is tangent to the curve. Note: derivative is positive where green, negative where red, and zero where black. Source: Wikipedia.com
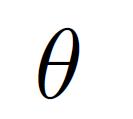
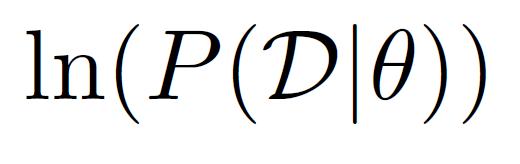
10 Data
11 But, how many flips do I need? Billionaire says: I flipped 3 heads and 2 tails. You say: = 3/5, I can prove it! He says: What if I flipped 30 heads and 20 tails? You say: Same answer, I can prove it! He says: What s better? You say: Umm The more the merrier??? He says: Is this why I am paying you the big bucks??? You say: I will give you a theoretical bound.
12 Prob. of Mistake A bound (from Hoeffding s inequality) For N = H + T, and Let * be the true parameter, for any >0: Exponential Decay! N
13 PAC Learning PAC: Probably Approximate Correct Billionaire says: I want to know the thumbtack, within = 0.1, with probability of mistake, <= How many flips? Or, how big do I set N? Interesting! Lets look at some numbers! = 0.1, =0.05
14 What if I have prior beliefs? Billionaire says: Wait, I know that the thumbtack is close to What can you do for me now? You say: I can learn it the Bayesian way Rather than estimating a single, we obtain a distribution over possible values of In the beginning Observe flips e.g.: {tails, tails} After observations

15 Bayesian Learning Use Bayes rule: Data Likelihood Prior Posterior Normalization Or equivalently: Also, for uniform priors: reduces to MLE objective
16 Bayesian Learning for Thumbtacks Likelihood function is Binomial: What about prior? Represent expert knowledge Simple posterior form Conjugate priors: Closed-form representation of posterior For Binomial, conjugate prior is Beta distribution
")
 b 1 du, a>0, b>0 Γ a = u a 1")
17 Beta Distribution Distribution over. B a, b = Γ(a + b) Γ(a)Γ(b) 1 0 B a, b = u a 1 (1 u) b 1 du, a>0, b>0 Γ a = u a 1 e a du 0
18 Beta Distribution
19 Beta prior distribution P( ) Likelihood function: Posterior: = θ α H +β H 1 (1 θ) α T +β T 1
20 Posterior Distribution Prior: Data: H heads and T tails Posterior distribution:
21 Bayesian Posterior Inference Posterior distribution: Bayesian inference: No longer single parameter For any specific f, the function of interest Compute the expected value of f Integral is often hard to compute
22 MAP: Maximum a Posteriori Approximation As more data is observed, Beta is more certain MAP: use most likely parameter to approximate the expectation
23 MAP for Beta distribution MAP: use most likely parameter: Beta prior equivalent to extra thumbtack flips As N, prior is forgotten But, for small sample size, prior is important!

24 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do for me? You say: Let me tell you about Gaussians
25 Learning a Gaussian Collect a bunch of data Hopefully, i.i.d. samples e.g., exam scores Learn parameters Mean: μ Variance: σ X i =i Exam Score
26 MLE for Gaussian: Prob. of i.i.d. samples D={x 1,,x N }: Log-likelihood of data:
27 Your second learning algorithm: MLE for mean of a Gaussian What s MLE for mean?
28 MLE for variance Again, set derivative to zero:
29 MLE: Learning Gaussian parameters BTW. MLE for the variance of a Gaussian is biased Expected result of estimation is not true parameter! Unbiased variance estimator:
Point Estimation. Maximum likelihood estimation for a binomial distribution. CSE 446: Machine Learning
 Point Estimation Emily Fox University of Washington January 6, 2017 Maximum likelihood estimation for a binomial distribution 1 Your first consulting job A bored Seattle billionaire asks you a question:
Point Estimation Emily Fox University of Washington January 6, 2017 Maximum likelihood estimation for a binomial distribution 1 Your first consulting job A bored Seattle billionaire asks you a question:
Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2
 Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, What about continuous variables?
 Linear Regression Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2014 1 What about continuous variables? n Billionaire says: If I am measuring a continuous variable, what
Linear Regression Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2014 1 What about continuous variables? n Billionaire says: If I am measuring a continuous variable, what
Introduc)on to Bayesian methods (con)nued) - Lecture 16
on to Bayesian methods (con)nued) - Lecture 16") Introduc)on to Bayesian methods (con)nued) - Lecture 16 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, Dan Klein, and Vibhav Gogate Outline of lectures Review of
Introduc)on to Bayesian methods (con)nued) - Lecture 16 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, Dan Klein, and Vibhav Gogate Outline of lectures Review of
Machine Learning CSE546 Sham Kakade University of Washington. Oct 4, What about continuous variables?
 Linear Regression Machine Learning CSE546 Sham Kakade University of Washington Oct 4, 2016 1 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do
Linear Regression Machine Learning CSE546 Sham Kakade University of Washington Oct 4, 2016 1 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do
Accouncements. You should turn in a PDF and a python file(s) Figure for problem 9 should be in the PDF
 Figure for problem 9 should be in the PDF") Accouncements You should turn in a PDF and a python file(s) Figure for problem 9 should be in the PDF Please do not zip these files and submit (unless there are >5 files) 1 Bayesian Methods Machine Learning
Accouncements You should turn in a PDF and a python file(s) Figure for problem 9 should be in the PDF Please do not zip these files and submit (unless there are >5 files) 1 Bayesian Methods Machine Learning
Gaussians Linear Regression Bias-Variance Tradeoff
 Readings listed in class website Gaussians Linear Regression Bias-Variance Tradeoff Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University January 22 nd, 2007 Maximum Likelihood Estimation
Readings listed in class website Gaussians Linear Regression Bias-Variance Tradeoff Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University January 22 nd, 2007 Maximum Likelihood Estimation
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, 2013
 Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Bayesian Methods: Naïve Bayes
 Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Parametric Models: from data to models
 Parametric Models: from data to models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Jan 22, 2018 Recall: Model-based ML DATA MODEL LEARNING MODEL MODEL INFERENCE KNOWLEDGE Learning:
Parametric Models: from data to models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Jan 22, 2018 Recall: Model-based ML DATA MODEL LEARNING MODEL MODEL INFERENCE KNOWLEDGE Learning:
Naïve Bayes Lecture 17
 Naïve Bayes Lecture 17 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, Dan Klein, and Mehryar Mohri Bayesian Learning Use Bayes rule! Data Likelihood Prior Posterior
Naïve Bayes Lecture 17 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, Dan Klein, and Mehryar Mohri Bayesian Learning Use Bayes rule! Data Likelihood Prior Posterior
Machine Learning CMPT 726 Simon Fraser University. Binomial Parameter Estimation
 Machine Learning CMPT 726 Simon Fraser University Binomial Parameter Estimation Outline Maximum Likelihood Estimation Smoothed Frequencies, Laplace Correction. Bayesian Approach. Conjugate Prior. Uniform
Machine Learning CMPT 726 Simon Fraser University Binomial Parameter Estimation Outline Maximum Likelihood Estimation Smoothed Frequencies, Laplace Correction. Bayesian Approach. Conjugate Prior. Uniform
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Hypothesis testing Machine Learning CSE546 Kevin Jamieson University of Washington October 30, 2018 2018 Kevin Jamieson 2 Anomaly detection You are
Announcements Proposals graded Kevin Jamieson 2018 1 Hypothesis testing Machine Learning CSE546 Kevin Jamieson University of Washington October 30, 2018 2018 Kevin Jamieson 2 Anomaly detection You are
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Learning P-maps Param. Learning
 Readings: K&F: 3.3, 3.4, 16.1, 16.2, 16.3, 16.4 Learning P-maps Param. Learning Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 24 th, 2008 10-708 Carlos Guestrin 2006-2008
Readings: K&F: 3.3, 3.4, 16.1, 16.2, 16.3, 16.4 Learning P-maps Param. Learning Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 24 th, 2008 10-708 Carlos Guestrin 2006-2008
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
CS 361: Probability & Statistics
 October 17, 2017 CS 361: Probability & Statistics Inference Maximum likelihood: drawbacks A couple of things might trip up max likelihood estimation: 1) Finding the maximum of some functions can be quite
October 17, 2017 CS 361: Probability & Statistics Inference Maximum likelihood: drawbacks A couple of things might trip up max likelihood estimation: 1) Finding the maximum of some functions can be quite
CS 361: Probability & Statistics
 March 14, 2018 CS 361: Probability & Statistics Inference The prior From Bayes rule, we know that we can express our function of interest as Likelihood Prior Posterior The right hand side contains the
March 14, 2018 CS 361: Probability & Statistics Inference The prior From Bayes rule, we know that we can express our function of interest as Likelihood Prior Posterior The right hand side contains the
INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP
 INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP Personal Healthcare Revolution Electronic health records (CFH) Personal genomics (DeCode, Navigenics, 23andMe) X-prize: first $10k human genome technology
INTRODUCTION TO BAYESIAN INFERENCE PART 2 CHRIS BISHOP Personal Healthcare Revolution Electronic health records (CFH) Personal genomics (DeCode, Navigenics, 23andMe) X-prize: first $10k human genome technology
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
BN Semantics 3 Now it s personal! Parameter Learning 1
 Readings: K&F: 3.4, 14.1, 14.2 BN Semantics 3 Now it s personal! Parameter Learning 1 Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 22 nd, 2006 1 Building BNs from independence
Readings: K&F: 3.4, 14.1, 14.2 BN Semantics 3 Now it s personal! Parameter Learning 1 Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 22 nd, 2006 1 Building BNs from independence
Introduction to Bayesian Learning. Machine Learning Fall 2018
 Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Introduction to Machine Learning
 Introduction to Machine Learning Generative Models Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Introduction to Machine Learning Generative Models Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Machine Learning CSE546
 http://www.cs.washington.edu/education/courses/cse546/17au/ Machine Learning CSE546 Kevin Jamieson University of Washington September 28, 2017 1 You may also like ML uses past data to make personalized
http://www.cs.washington.edu/education/courses/cse546/17au/ Machine Learning CSE546 Kevin Jamieson University of Washington September 28, 2017 1 You may also like ML uses past data to make personalized
Readings: K&F: 16.3, 16.4, Graphical Models Carlos Guestrin Carnegie Mellon University October 6 th, 2008
 Readings: K&F: 16.3, 16.4, 17.3 Bayesian Param. Learning Bayesian Structure Learning Graphical Models 10708 Carlos Guestrin Carnegie Mellon University October 6 th, 2008 10-708 Carlos Guestrin 2006-2008
Readings: K&F: 16.3, 16.4, 17.3 Bayesian Param. Learning Bayesian Structure Learning Graphical Models 10708 Carlos Guestrin Carnegie Mellon University October 6 th, 2008 10-708 Carlos Guestrin 2006-2008
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
Bayesian Methods. David S. Rosenberg. New York University. March 20, 2018
 Bayesian Methods David S. Rosenberg New York University March 20, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 March 20, 2018 1 / 38 Contents 1 Classical Statistics 2 Bayesian
Bayesian Methods David S. Rosenberg New York University March 20, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 March 20, 2018 1 / 38 Contents 1 Classical Statistics 2 Bayesian
PROBABILITY DISTRIBUTIONS. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
Bayesian Learning (II)
") Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Bayesian Inference and MCMC
 Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
Expectation Maximization Algorithm
 Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Estimation of reliability parameters from Experimental data (Parte 2) Prof. Enrico Zio
 Prof. Enrico Zio") Estimation of reliability parameters from Experimental data (Parte 2) This lecture Life test (t 1,t 2,...,t n ) Estimate θ of f T t θ For example: λ of f T (t)= λe - λt Classical approach (frequentist
Estimation of reliability parameters from Experimental data (Parte 2) This lecture Life test (t 1,t 2,...,t n ) Estimate θ of f T t θ For example: λ of f T (t)= λe - λt Classical approach (frequentist
Machine Learning CSE546
 https://www.cs.washington.edu/education/courses/cse546/18au/ Machine Learning CSE546 Kevin Jamieson University of Washington September 27, 2018 1 Traditional algorithms Social media mentions of Cats vs.
https://www.cs.washington.edu/education/courses/cse546/18au/ Machine Learning CSE546 Kevin Jamieson University of Washington September 27, 2018 1 Traditional algorithms Social media mentions of Cats vs.
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference
 COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
Lecture 11: Probability Distributions and Parameter Estimation
 Intelligent Data Analysis and Probabilistic Inference Lecture 11: Probability Distributions and Parameter Estimation Recommended reading: Bishop: Chapters 1.2, 2.1 2.3.4, Appendix B Duncan Gillies and
Intelligent Data Analysis and Probabilistic Inference Lecture 11: Probability Distributions and Parameter Estimation Recommended reading: Bishop: Chapters 1.2, 2.1 2.3.4, Appendix B Duncan Gillies and
DS-GA 1002 Lecture notes 11 Fall Bayesian statistics
 DS-GA 100 Lecture notes 11 Fall 016 Bayesian statistics In the frequentist paradigm we model the data as realizations from a distribution that depends on deterministic parameters. In contrast, in Bayesian
DS-GA 100 Lecture notes 11 Fall 016 Bayesian statistics In the frequentist paradigm we model the data as realizations from a distribution that depends on deterministic parameters. In contrast, in Bayesian
Logistic Regression. Vibhav Gogate The University of Texas at Dallas. Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld.
 Logistic Regression Vibhav Gogate The University of Texas at Dallas Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld. Generative vs. Discriminative Classifiers Want to Learn: h:x Y X features
Logistic Regression Vibhav Gogate The University of Texas at Dallas Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld. Generative vs. Discriminative Classifiers Want to Learn: h:x Y X features
Computational Cognitive Science
 Computational Cognitive Science Lecture 8: Frank Keller School of Informatics University of Edinburgh keller@inf.ed.ac.uk Based on slides by Sharon Goldwater October 14, 2016 Frank Keller Computational
Computational Cognitive Science Lecture 8: Frank Keller School of Informatics University of Edinburgh keller@inf.ed.ac.uk Based on slides by Sharon Goldwater October 14, 2016 Frank Keller Computational
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
CLASS NOTES Models, Algorithms and Data: Introduction to computing 2018
 CLASS NOTES Models, Algorithms and Data: Introduction to computing 208 Petros Koumoutsakos, Jens Honore Walther (Last update: June, 208) IMPORTANT DISCLAIMERS. REFERENCES: Much of the material (ideas,
CLASS NOTES Models, Algorithms and Data: Introduction to computing 208 Petros Koumoutsakos, Jens Honore Walther (Last update: June, 208) IMPORTANT DISCLAIMERS. REFERENCES: Much of the material (ideas,
Bayesian RL Seminar. Chris Mansley September 9, 2008
 Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Lecture 2: Conjugate priors
 (Spring ʼ) Lecture : Conjugate priors Julia Hockenmaier juliahmr@illinois.edu Siebel Center http://www.cs.uiuc.edu/class/sp/cs98jhm The binomial distribution If p is the probability of heads, the probability
(Spring ʼ) Lecture : Conjugate priors Julia Hockenmaier juliahmr@illinois.edu Siebel Center http://www.cs.uiuc.edu/class/sp/cs98jhm The binomial distribution If p is the probability of heads, the probability
Discrete Binary Distributions
 Discrete Binary Distributions Carl Edward Rasmussen November th, 26 Carl Edward Rasmussen Discrete Binary Distributions November th, 26 / 5 Key concepts Bernoulli: probabilities over binary variables Binomial:
Discrete Binary Distributions Carl Edward Rasmussen November th, 26 Carl Edward Rasmussen Discrete Binary Distributions November th, 26 / 5 Key concepts Bernoulli: probabilities over binary variables Binomial:
Which coin will I use? Which coin will I use? Logistics. Statistical Learning. Topics. 573 Topics. Coin Flip. Coin Flip
 Logistics Statistical Learning CSE 57 Team Meetings Midterm Open book, notes Studying See AIMA exercises Daniel S. Weld Daniel S. Weld Supervised Learning 57 Topics Logic-Based Reinforcement Learning Planning
Logistics Statistical Learning CSE 57 Team Meetings Midterm Open book, notes Studying See AIMA exercises Daniel S. Weld Daniel S. Weld Supervised Learning 57 Topics Logic-Based Reinforcement Learning Planning
Last Time. Today. Bayesian Learning. The Distributions We Love. CSE 446 Gaussian Naïve Bayes & Logistic Regression
 CSE 446 Gaussian Naïve Bayes & Logistic Regression Winter 22 Dan Weld Learning Gaussians Naïve Bayes Last Time Gaussians Naïve Bayes Logistic Regression Today Some slides from Carlos Guestrin, Luke Zettlemoyer
CSE 446 Gaussian Naïve Bayes & Logistic Regression Winter 22 Dan Weld Learning Gaussians Naïve Bayes Last Time Gaussians Naïve Bayes Logistic Regression Today Some slides from Carlos Guestrin, Luke Zettlemoyer
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
Page Max. Possible Points Total 100
 Math 3215 Exam 2 Summer 2014 Instructor: Sal Barone Name: GT username: 1. No books or notes are allowed. 2. You may use ONLY NON-GRAPHING and NON-PROGRAMABLE scientific calculators. All other electronic
Math 3215 Exam 2 Summer 2014 Instructor: Sal Barone Name: GT username: 1. No books or notes are allowed. 2. You may use ONLY NON-GRAPHING and NON-PROGRAMABLE scientific calculators. All other electronic
Probability and Estimation. Alan Moses
 Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Computational Cognitive Science
 Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Naïve Bayes. Jia-Bin Huang. Virginia Tech Spring 2019 ECE-5424G / CS-5824
 Naïve Bayes Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 out today. Please start early! Office hours Chen: Wed 4pm-5pm Shih-Yang: Fri 3pm-4pm Location: Whittemore 266
Naïve Bayes Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 out today. Please start early! Office hours Chen: Wed 4pm-5pm Shih-Yang: Fri 3pm-4pm Location: Whittemore 266
Quantitative Introduction ro Risk and Uncertainty in Business Module 5: Hypothesis Testing
 Quantitative Introduction ro Risk and Uncertainty in Business Module 5: Hypothesis Testing M. Vidyasagar Cecil & Ida Green Chair The University of Texas at Dallas Email: M.Vidyasagar@utdallas.edu October
Quantitative Introduction ro Risk and Uncertainty in Business Module 5: Hypothesis Testing M. Vidyasagar Cecil & Ida Green Chair The University of Texas at Dallas Email: M.Vidyasagar@utdallas.edu October
(1) Introduction to Bayesian statistics
 Introduction to Bayesian statistics") Spring, 2018 A motivating example Student 1 will write down a number and then flip a coin If the flip is heads, they will honestly tell student 2 if the number is even or odd If the flip is tails, they
Spring, 2018 A motivating example Student 1 will write down a number and then flip a coin If the flip is heads, they will honestly tell student 2 if the number is even or odd If the flip is tails, they
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 22, 2011 Today: MLE and MAP Bayes Classifiers Naïve Bayes Readings: Mitchell: Naïve Bayes and Logistic
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 22, 2011 Today: MLE and MAP Bayes Classifiers Naïve Bayes Readings: Mitchell: Naïve Bayes and Logistic
ECE521 Tutorial 11. Topic Review. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides. ECE521 Tutorial 11 / 4
 ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
Bayesian statistics. DS GA 1002 Statistical and Mathematical Models. Carlos Fernandez-Granda
 Bayesian statistics DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall15 Carlos Fernandez-Granda Frequentist vs Bayesian statistics In frequentist statistics
Bayesian statistics DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall15 Carlos Fernandez-Granda Frequentist vs Bayesian statistics In frequentist statistics
Learning Theory. Machine Learning CSE546 Carlos Guestrin University of Washington. November 25, Carlos Guestrin
 Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
A Brief Review of Probability, Bayesian Statistics, and Information Theory
 A Brief Review of Probability, Bayesian Statistics, and Information Theory Brendan Frey Electrical and Computer Engineering University of Toronto frey@psi.toronto.edu http://www.psi.toronto.edu A system
A Brief Review of Probability, Bayesian Statistics, and Information Theory Brendan Frey Electrical and Computer Engineering University of Toronto frey@psi.toronto.edu http://www.psi.toronto.edu A system
Computational Perception. Bayesian Inference
 Computational Perception 15-485/785 January 24, 2008 Bayesian Inference The process of probabilistic inference 1. define model of problem 2. derive posterior distributions and estimators 3. estimate parameters
Computational Perception 15-485/785 January 24, 2008 Bayesian Inference The process of probabilistic inference 1. define model of problem 2. derive posterior distributions and estimators 3. estimate parameters
Maximum-Likelihood Estimation: Basic Ideas
 Sociology 740 John Fox Lecture Notes Maximum-Likelihood Estimation: Basic Ideas Copyright 2014 by John Fox Maximum-Likelihood Estimation: Basic Ideas 1 I The method of maximum likelihood provides estimators
Sociology 740 John Fox Lecture Notes Maximum-Likelihood Estimation: Basic Ideas Copyright 2014 by John Fox Maximum-Likelihood Estimation: Basic Ideas 1 I The method of maximum likelihood provides estimators
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Empirical Bayes, Hierarchical Bayes Mark Schmidt University of British Columbia Winter 2017 Admin Assignment 5: Due April 10. Project description on Piazza. Final details coming
CPSC 540: Machine Learning Empirical Bayes, Hierarchical Bayes Mark Schmidt University of British Columbia Winter 2017 Admin Assignment 5: Due April 10. Project description on Piazza. Final details coming
Introduction to Machine Learning. Lecture 2
 Introduction to Machine Learning Lecturer: Eran Halperin Lecture 2 Fall Semester Scribe: Yishay Mansour Some of the material was not presented in class (and is marked with a side line) and is given for
Introduction to Machine Learning Lecturer: Eran Halperin Lecture 2 Fall Semester Scribe: Yishay Mansour Some of the material was not presented in class (and is marked with a side line) and is given for
Compute f(x θ)f(θ) dθ
f(θ) dθ") Bayesian Updating: Continuous Priors 18.05 Spring 2014 b a Compute f(x θ)f(θ) dθ January 1, 2017 1 /26 Beta distribution Beta(a, b) has density (a + b 1)! f (θ) = θ a 1 (1 θ) b 1 (a 1)!(b 1)! http://mathlets.org/mathlets/beta-distribution/
Bayesian Updating: Continuous Priors 18.05 Spring 2014 b a Compute f(x θ)f(θ) dθ January 1, 2017 1 /26 Beta distribution Beta(a, b) has density (a + b 1)! f (θ) = θ a 1 (1 θ) b 1 (a 1)!(b 1)! http://mathlets.org/mathlets/beta-distribution/
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
Why Bayesian? Rigorous approach to address statistical estimation problems. The Bayesian philosophy is mature and powerful.
 Why Bayesian? Rigorous approach to address statistical estimation problems. The Bayesian philosophy is mature and powerful. Even if you aren t Bayesian, you can define an uninformative prior and everything
Why Bayesian? Rigorous approach to address statistical estimation problems. The Bayesian philosophy is mature and powerful. Even if you aren t Bayesian, you can define an uninformative prior and everything
CS 6140: Machine Learning Spring What We Learned Last Week. Survey 2/26/16. VS. Model
 Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Assignment
Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Assignment
CS 6140: Machine Learning Spring 2016
 CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa?on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis?cs Assignment
CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa?on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis?cs Assignment
Naïve Bayes. Vibhav Gogate The University of Texas at Dallas
 Naïve Bayes Vibhav Gogate The University of Texas at Dallas Supervised Learning of Classifiers Find f Given: Training set {(x i, y i ) i = 1 n} Find: A good approximation to f : X Y Examples: what are
Naïve Bayes Vibhav Gogate The University of Texas at Dallas Supervised Learning of Classifiers Find f Given: Training set {(x i, y i ) i = 1 n} Find: A good approximation to f : X Y Examples: what are
Non-parametric Methods
 Non-parametric Methods Machine Learning Alireza Ghane Non-Parametric Methods Alireza Ghane / Torsten Möller 1 Outline Machine Learning: What, Why, and How? Curve Fitting: (e.g.) Regression and Model Selection
Non-parametric Methods Machine Learning Alireza Ghane Non-Parametric Methods Alireza Ghane / Torsten Möller 1 Outline Machine Learning: What, Why, and How? Curve Fitting: (e.g.) Regression and Model Selection
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Statistics: Learning models from data
 DS-GA 1002 Lecture notes 5 October 19, 2015 Statistics: Learning models from data Learning models from data that are assumed to be generated probabilistically from a certain unknown distribution is a crucial
DS-GA 1002 Lecture notes 5 October 19, 2015 Statistics: Learning models from data Learning models from data that are assumed to be generated probabilistically from a certain unknown distribution is a crucial
Parameter Learning With Binary Variables
 With Binary Variables University of Nebraska Lincoln CSCE 970 Pattern Recognition Outline Outline 1 Learning a Single Parameter 2 More on the Beta Density Function 3 Computing a Probability Interval Outline
With Binary Variables University of Nebraska Lincoln CSCE 970 Pattern Recognition Outline Outline 1 Learning a Single Parameter 2 More on the Beta Density Function 3 Computing a Probability Interval Outline
ECE521 W17 Tutorial 6. Min Bai and Yuhuai (Tony) Wu
 Wu") ECE521 W17 Tutorial 6 Min Bai and Yuhuai (Tony) Wu Agenda knn and PCA Bayesian Inference k-means Technique for clustering Unsupervised pattern and grouping discovery Class prediction Outlier detection
ECE521 W17 Tutorial 6 Min Bai and Yuhuai (Tony) Wu Agenda knn and PCA Bayesian Inference k-means Technique for clustering Unsupervised pattern and grouping discovery Class prediction Outlier detection
Probability Theory for Machine Learning. Chris Cremer September 2015
 Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Machine Learning
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 13, 2011 Today: The Big Picture Overfitting Review: probability Readings: Decision trees, overfiting
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 13, 2011 Today: The Big Picture Overfitting Review: probability Readings: Decision trees, overfiting
Lecture 8: Maximum Likelihood Estimation (MLE) (cont d.) Maximum a posteriori (MAP) estimation Naïve Bayes Classifier
 (cont d.) Maximum a posteriori (MAP) estimation Naïve Bayes Classifier") Lecture 8: Maximum Likelihood Estimation (MLE) (cont d.) Maximum a posteriori (MAP) estimation Naïve Bayes Classifier Aykut Erdem March 2016 Hacettepe University Flipping a Coin Last time Flipping a Coin
Lecture 8: Maximum Likelihood Estimation (MLE) (cont d.) Maximum a posteriori (MAP) estimation Naïve Bayes Classifier Aykut Erdem March 2016 Hacettepe University Flipping a Coin Last time Flipping a Coin
Inconsistency of Bayesian inference when the model is wrong, and how to repair it
 Inconsistency of Bayesian inference when the model is wrong, and how to repair it Peter Grünwald Thijs van Ommen Centrum Wiskunde & Informatica, Amsterdam Universiteit Leiden June 3, 2015 Outline 1 Introduction
Inconsistency of Bayesian inference when the model is wrong, and how to repair it Peter Grünwald Thijs van Ommen Centrum Wiskunde & Informatica, Amsterdam Universiteit Leiden June 3, 2015 Outline 1 Introduction
Today. Statistical Learning. Coin Flip. Coin Flip. Experiment 1: Heads. Experiment 1: Heads. Which coin will I use? Which coin will I use?
 Today Statistical Learning Parameter Estimation: Maximum Likelihood (ML) Maximum A Posteriori (MAP) Bayesian Continuous case Learning Parameters for a Bayesian Network Naive Bayes Maximum Likelihood estimates
Today Statistical Learning Parameter Estimation: Maximum Likelihood (ML) Maximum A Posteriori (MAP) Bayesian Continuous case Learning Parameters for a Bayesian Network Naive Bayes Maximum Likelihood estimates
Learning Theory. Aar$ Singh and Barnabas Poczos. Machine Learning / Apr 17, Slides courtesy: Carlos Guestrin
 Learning Theory Aar$ Singh and Barnabas Poczos Machine Learning 10-701/15-781 Apr 17, 2014 Slides courtesy: Carlos Guestrin Learning Theory We have explored many ways of learning from data But How good
Learning Theory Aar$ Singh and Barnabas Poczos Machine Learning 10-701/15-781 Apr 17, 2014 Slides courtesy: Carlos Guestrin Learning Theory We have explored many ways of learning from data But How good
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Exam 2 Practice Questions, 18.05, Spring 2014
 Exam 2 Practice Questions, 18.05, Spring 2014 Note: This is a set of practice problems for exam 2. The actual exam will be much shorter. Within each section we ve arranged the problems roughly in order
Exam 2 Practice Questions, 18.05, Spring 2014 Note: This is a set of practice problems for exam 2. The actual exam will be much shorter. Within each section we ve arranged the problems roughly in order
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning
 Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
DS-GA 1003: Machine Learning and Computational Statistics Homework 7: Bayesian Modeling
 DS-GA 1003: Machine Learning and Computational Statistics Homework 7: Bayesian Modeling Due: Tuesday, May 10, 2016, at 6pm (Submit via NYU Classes) Instructions: Your answers to the questions below, including
DS-GA 1003: Machine Learning and Computational Statistics Homework 7: Bayesian Modeling Due: Tuesday, May 10, 2016, at 6pm (Submit via NYU Classes) Instructions: Your answers to the questions below, including
PMR Learning as Inference
 Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Day 5: Generative models, structured classification
 Day 5: Generative models, structured classification Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 22 June 2018 Linear regression
Day 5: Generative models, structured classification Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 22 June 2018 Linear regression
Midterm Examination. STA 215: Statistical Inference. Due Wednesday, 2006 Mar 8, 1:15 pm
 Midterm Examination STA 215: Statistical Inference Due Wednesday, 2006 Mar 8, 1:15 pm This is an open-book take-home examination. You may work on it during any consecutive 24-hour period you like; please
Midterm Examination STA 215: Statistical Inference Due Wednesday, 2006 Mar 8, 1:15 pm This is an open-book take-home examination. You may work on it during any consecutive 24-hour period you like; please
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 143 Part IV
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 143 Part IV
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
Machine Learning
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
CSE 473: Artificial Intelligence Autumn Topics
 CSE 473: Artificial Intelligence Autumn 2014 Bayesian Networks Learning II Dan Weld Slides adapted from Jack Breese, Dan Klein, Daphne Koller, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 473 Topics
CSE 473: Artificial Intelligence Autumn 2014 Bayesian Networks Learning II Dan Weld Slides adapted from Jack Breese, Dan Klein, Daphne Koller, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 473 Topics
Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory
 Bayesian Inference Statistical Decison Theory") Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007