Probability and Estimation. Alan Moses
|
|
|
- Clarissa Chambers
- 5 years ago
- Views:
Transcription
1 Probability and Estimation Alan Moses
2 Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic. Describes events (e.g., coin toss is heads) In practice, all observed data can be thought of as an event (e.g., expression level of p53 is ) Probability theory is a mathematical way of understanding (and predicting) the stochastic variability
3 Why did probability theory originate?
4 laws of probability Say X is a random variable and P(X=A) is the probability of event A, (often written simply as P(X) ) Σ A P(X=A) = 1 Say Y is another random variable, P(X=A,Y=32.7) is the joint probability of events A and 32.7 (often written simply as P(X,Y)) Σ Σ Y X P(X,Y) = 1 If X and Y are independent, the joint distribution can be factored or Σ X P(X=A, Y=32.7) = P(X=A)P(Y=32.7) P(X) = 1 or P(X,Y) = P(X)P(Y)
5 More laws of probability More generally, if X 1 X N are a series of independent random variables, i=n P(X 1 X N ) = Π P(X i ) i=1 P(X=A Y=32.7) is the conditional probability of event A given that event 32.7 already happened P(X=A, Y=32.7) = P(X=A Y=32.7)P(Y=32.7) or P(X,Y) = P(X Y)P(Y)
6 Exercises: Proove Bayes theorem: P(X Y) = P(Y X) Solve: Σ X Σ Y P(X Y) =??? P(X Y) =??? P(X) P(Y) Show that the Poisson is correctly normalized, if P(X λ) is the Poisson pdf X= Σ X=0 P(X λ) = 1
7 Probabilistic models In biology, the Truth is usually unknown and very complicated We only will consider the data we have and our ability to make a model of it We don t think about whether our model is True or Correct, but only how well it fits the data We accept that a better model will always be possible Realistic (=complicated) models need more data that simple ones, so we usually try to choose a simple on
8 Probabilistic models Probability distributions are mathematical objects that include several functions. pdf (probability distribution function) cdf (cumulative distribution function) Probability generating function Moment generating function Distributions can be characterized by their moments (1 st and 2 nd moments are mean and variance ) What distribution describes my data? Continuous vs. discrete vs. ordinal distributions
 = f P(X=0) = 1 - f Binomial describes the number of positive outcomes in a series of N Bernoulli trials i=n say Y = Σ X i i=1 Y is another random variable, whose distribution is P(Y f,n) = ( N")
9 Bernoulli, binomial, multinomial Major family of distributions for discrete events Bernoulli describes binary outcomes (heads/tails) in a single trial, based on a single parameter, say f P(X f) P(X=1) = f P(X=0) = 1 - f Binomial describes the number of positive outcomes in a series of N Bernoulli trials i=n say Y = Σ X i i=1 Y is another random variable, whose distribution is P(Y f,n) = ( N ) Y f Y (1 - f ) N - Y Let s derive the Binomial pdf
10 Moments 1 st moment is the mean or expectation E[X] = Σ P(X=A)A or A E[X] = 2 nd moment is the variance V[X] = P(X)(X E[X]) 2 = E[(X E[X]) 2 ] Σ X Σ P(X)X X What are the mean and variance of the Bernoulli?
11 Multivariate generalization What if there are more than 2 possibilities? Multinomial is the generalization of the binomial to the case of more than 2 possibilities. E.g., for DNA. The sequence ACGT might be written as: X 1 = (1, 0, 0, 0) X 2 = (0, 1, 0, 0) X 3 = (0, 0, 1, 0) X 4 = (0, 0, 0, 1) A distribution P(X f) now needs f = (f A, f C, f G, f T ) dimensions are not independent, this can be quantified by correlation or covariance
12 Gaussian/Normal Major distribution for continuous events Gaussian describes the probability of observing real numbers between - and, in terms of two parameters, µ, σ 1 P(X µ,σ) = 2πσ 2 P(X µ,σ) dx = 1 Because of the very special Gaussian integral e (X µ) 2 2σ 2 May be due to Laplace in 1782

13 Why the Gaussian? What s so normal about it? Why do so many measurements in the real world follow such an obscure mathematical formula? E.g., Binomial converges to a Gaussian as N becomes large N=20 f=0.5 Why are random errors usually Gaussian?
14 Gaussian distribution has very special moments 1 st moment is the mean or expectation E[X] = P(X µ,σ) X X dx = µ 2 nd moment is the variance V[X] = P(X µ,σ) X (X µ) 2 dx = σ 2 For this reason, the parameters of the Gaussian are named mean and standard deviation.
15 Moments of continuous distributions In general, the mean and variance are functions of the parameters of the distribution, but not necessarily simple ones E.g., Gumbel or Extreme Value Distribution (used for for BLAST statistics) has pdf P(X µ,σ) = 1 σ µ X e σ e µ X σ E[X] = µ + σγ, where γ = (= Euler s constant) V[X] = π 2 σ 2 6
16 Multivariate Gaussian Now each observation is a vector, say X 1 = (1.3, 4,6) The mean is a vector, µ = (µ 1, µ 2 ) The variance is a matrix Σ = V 11 V 12 V 12 V 22 The diagonal elements are the variances in each dimension The off diagonal elements are the covariances which summarize the dependence between the dimensions
17 Multivariate Gaussian
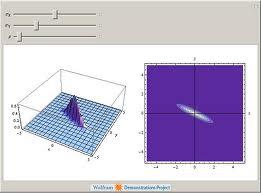
18 Multivariate Gaussian
19 Parameter estimation Given some data, and some probabilistic model, how do I infer the parameters? The technical name for this is estimation. Several methods exist, each yielding estimators Least squares methods (NWLS, MMSE) Maximum likelihood (ML) Maximum a posteriori probability (MAP) How are estimators evaluated? consistency bias efficiency
20 Likelihood and MLEs Likelihood is the probability of the data (say X) given certain parameters (say θ) L = P(X θ) Maximum likelihood estimation says: choose θ, so that the data is most probable. L = 0 θ In practice there are many ways to maximize the likelihood.
21 Example of ML estimation Data: X i P(X i µ=6.5, σ=1.5) L = P(X θ) = P(X 1 X N θ) i=5 = Π P(X i µ=6.5, σ=1.5) = 6.39 x 10-5 i=1 L Mean, µ
22 Example of ML estimation In practice, we almost always use the log likelihood, which becomes a very large negative number when there is a lot of data Mean, µ Log(L)

23 Log(L) Example of ML estimation
24 ML Estimation In general, the likelihood is a function of multiple variables, so the derivatives with respect to all of these should be zero at a maximum In the example of the Gaussian, we have two parameters, so that L = 0 µ and L = 0 σ In general, finding MLEs means solving a set of coupled equations, which usually have to be solved numerically for complex models.
25 MLEs for the Gaussian 1 1 µ ML = Σ X V ML = Σ (X - µ ML ) 2 N X The Gaussian is the symmetric continuous distribution that has as its centre a parameter given by what we consider the average. The MLE for the for variance of the Gaussian is like the squared error from the mean, but is actually a biased (but still consistent!?) estimator N X
26 Let s derive the MLEs for the Binomial distribution
27 Properties of MLEs MLEs are asymptotically normal The mean of the MLE is the parameter you are trying to estimate, i.e., E[θ ML ]=θ The variance of the MLE is given by: V[θ ML ] = 2 E[- logl θ ML ] -1 2 θ Often written as V[θ ML ] = I -1, where the E[ ] is called the Fisher Information
28 Likelihood and MLEs In general, the likelihood function might be too complicated to calculate the MLEs analytically MLEs can still be obtained by maximizing the likelihood using numerical methods. Greedy: Gradient Ascent, Newton s Method Sampling methods: Gibbs, Metropolis The likelihood could have multiple maxima that make optimization difficult The more parameters the likelihood has, the more difficult the optimization problem
29 MAP estimation We can then write the posterior probability of the model, given some data. We can compute the posterior using Bayes theorem Where posterior = P(θ X) posterior = P(X θ) P(X) = Σ θ MAP estimate says: maximize the posterior P(θ) is a prior distribution P(θ) P(X) P(X θ)p(θ) = L Don t usually need to integrate over all the parameters weighting the likelihood by prior beliefs P(θ) P(X)
30 Bayesian methods Do we really need estimators for all parameters? Nuisance parameters Instead, use the whole posterior distribution Use its moments, quantiles, etc. Integrate the function (e.g., squared error) that you care about over the posterior directly E.g., mean of the posterior distribution: E[θ ] = Σ P(θ X)θ 1 1 θ Now we do need to integrate over the prior distribution
31 Conjugate priors special mathematically convenient prior distributions that make integrations possible/easier Priors are distributions on the parameters. Often use exotic distributions rarely needed for real data The parameters of these distributions are called hyperparameters and also have to be estimated or integrated away E.g., for a Bernouli, the parameter is a continuous value between 0 and 1 (the prior is a Beta) E.g., for a Gaussian, the prior on the mean is a Gaussian, but the prior on the standard deviation (which is always >0) is exotic (inverse Gamma?)
Computational Perception. Bayesian Inference
 Computational Perception 15-485/785 January 24, 2008 Bayesian Inference The process of probabilistic inference 1. define model of problem 2. derive posterior distributions and estimators 3. estimate parameters
Computational Perception 15-485/785 January 24, 2008 Bayesian Inference The process of probabilistic inference 1. define model of problem 2. derive posterior distributions and estimators 3. estimate parameters
Review of Probabilities and Basic Statistics
 Alex Smola Barnabas Poczos TA: Ina Fiterau 4 th year PhD student MLD Review of Probabilities and Basic Statistics 10-701 Recitations 1/25/2013 Recitation 1: Statistics Intro 1 Overview Introduction to
Alex Smola Barnabas Poczos TA: Ina Fiterau 4 th year PhD student MLD Review of Probabilities and Basic Statistics 10-701 Recitations 1/25/2013 Recitation 1: Statistics Intro 1 Overview Introduction to
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
PMR Learning as Inference
 Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Bayesian Inference and MCMC
 Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
Computational Cognitive Science
 Computational Cognitive Science Lecture 8: Frank Keller School of Informatics University of Edinburgh keller@inf.ed.ac.uk Based on slides by Sharon Goldwater October 14, 2016 Frank Keller Computational
Computational Cognitive Science Lecture 8: Frank Keller School of Informatics University of Edinburgh keller@inf.ed.ac.uk Based on slides by Sharon Goldwater October 14, 2016 Frank Keller Computational
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Aarti Singh. Lecture 2, January 13, Reading: Bishop: Chap 1,2. Slides courtesy: Eric Xing, Andrew Moore, Tom Mitchell
 Machine Learning 0-70/5 70/5-78, 78, Spring 00 Probability 0 Aarti Singh Lecture, January 3, 00 f(x) µ x Reading: Bishop: Chap, Slides courtesy: Eric Xing, Andrew Moore, Tom Mitchell Announcements Homework
Machine Learning 0-70/5 70/5-78, 78, Spring 00 Probability 0 Aarti Singh Lecture, January 3, 00 f(x) µ x Reading: Bishop: Chap, Slides courtesy: Eric Xing, Andrew Moore, Tom Mitchell Announcements Homework
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
Estimation of reliability parameters from Experimental data (Parte 2) Prof. Enrico Zio
 Prof. Enrico Zio") Estimation of reliability parameters from Experimental data (Parte 2) This lecture Life test (t 1,t 2,...,t n ) Estimate θ of f T t θ For example: λ of f T (t)= λe - λt Classical approach (frequentist
Estimation of reliability parameters from Experimental data (Parte 2) This lecture Life test (t 1,t 2,...,t n ) Estimate θ of f T t θ For example: λ of f T (t)= λe - λt Classical approach (frequentist
CS 361: Probability & Statistics
 October 17, 2017 CS 361: Probability & Statistics Inference Maximum likelihood: drawbacks A couple of things might trip up max likelihood estimation: 1) Finding the maximum of some functions can be quite
October 17, 2017 CS 361: Probability & Statistics Inference Maximum likelihood: drawbacks A couple of things might trip up max likelihood estimation: 1) Finding the maximum of some functions can be quite
Linear Models A linear model is defined by the expression
 Linear Models A linear model is defined by the expression x = F β + ɛ. where x = (x 1, x 2,..., x n ) is vector of size n usually known as the response vector. β = (β 1, β 2,..., β p ) is the transpose
Linear Models A linear model is defined by the expression x = F β + ɛ. where x = (x 1, x 2,..., x n ) is vector of size n usually known as the response vector. β = (β 1, β 2,..., β p ) is the transpose
Machine Learning CMPT 726 Simon Fraser University. Binomial Parameter Estimation
 Machine Learning CMPT 726 Simon Fraser University Binomial Parameter Estimation Outline Maximum Likelihood Estimation Smoothed Frequencies, Laplace Correction. Bayesian Approach. Conjugate Prior. Uniform
Machine Learning CMPT 726 Simon Fraser University Binomial Parameter Estimation Outline Maximum Likelihood Estimation Smoothed Frequencies, Laplace Correction. Bayesian Approach. Conjugate Prior. Uniform
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Introduction to Machine Learning
 Introduction to Machine Learning Generative Models Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Introduction to Machine Learning Generative Models Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Intro to Probability. Andrei Barbu
 Intro to Probability Andrei Barbu Some problems Some problems A means to capture uncertainty Some problems A means to capture uncertainty You have data from two sources, are they different? Some problems
Intro to Probability Andrei Barbu Some problems Some problems A means to capture uncertainty Some problems A means to capture uncertainty You have data from two sources, are they different? Some problems
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
COS513 LECTURE 8 STATISTICAL CONCEPTS
 COS513 LECTURE 8 STATISTICAL CONCEPTS NIKOLAI SLAVOV AND ANKUR PARIKH 1. MAKING MEANINGFUL STATEMENTS FROM JOINT PROBABILITY DISTRIBUTIONS. A graphical model (GM) represents a family of probability distributions
COS513 LECTURE 8 STATISTICAL CONCEPTS NIKOLAI SLAVOV AND ANKUR PARIKH 1. MAKING MEANINGFUL STATEMENTS FROM JOINT PROBABILITY DISTRIBUTIONS. A graphical model (GM) represents a family of probability distributions
Fundamentals. CS 281A: Statistical Learning Theory. Yangqing Jia. August, Based on tutorial slides by Lester Mackey and Ariel Kleiner
 Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
Bayesian Inference. STA 121: Regression Analysis Artin Armagan
 Bayesian Inference STA 121: Regression Analysis Artin Armagan Bayes Rule...s! Reverend Thomas Bayes Posterior Prior p(θ y) = p(y θ)p(θ)/p(y) Likelihood - Sampling Distribution Normalizing Constant: p(y
Bayesian Inference STA 121: Regression Analysis Artin Armagan Bayes Rule...s! Reverend Thomas Bayes Posterior Prior p(θ y) = p(y θ)p(θ)/p(y) Likelihood - Sampling Distribution Normalizing Constant: p(y
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian RL Seminar. Chris Mansley September 9, 2008
 Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Discrete Binary Distributions
 Discrete Binary Distributions Carl Edward Rasmussen November th, 26 Carl Edward Rasmussen Discrete Binary Distributions November th, 26 / 5 Key concepts Bernoulli: probabilities over binary variables Binomial:
Discrete Binary Distributions Carl Edward Rasmussen November th, 26 Carl Edward Rasmussen Discrete Binary Distributions November th, 26 / 5 Key concepts Bernoulli: probabilities over binary variables Binomial:
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
Time Series and Dynamic Models
 Time Series and Dynamic Models Section 1 Intro to Bayesian Inference Carlos M. Carvalho The University of Texas at Austin 1 Outline 1 1. Foundations of Bayesian Statistics 2. Bayesian Estimation 3. The
Time Series and Dynamic Models Section 1 Intro to Bayesian Inference Carlos M. Carvalho The University of Texas at Austin 1 Outline 1 1. Foundations of Bayesian Statistics 2. Bayesian Estimation 3. The
Lecture 2: Priors and Conjugacy
 Lecture 2: Priors and Conjugacy Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 6, 2014 Some nice courses Fred A. Hamprecht (Heidelberg U.) https://www.youtube.com/watch?v=j66rrnzzkow Michael I.
Lecture 2: Priors and Conjugacy Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 6, 2014 Some nice courses Fred A. Hamprecht (Heidelberg U.) https://www.youtube.com/watch?v=j66rrnzzkow Michael I.
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probabilistic Machine Learning
 Probabilistic Machine Learning Bayesian Nets, MCMC, and more Marek Petrik 4/18/2017 Based on: P. Murphy, K. (2012). Machine Learning: A Probabilistic Perspective. Chapter 10. Conditional Independence Independent
Probabilistic Machine Learning Bayesian Nets, MCMC, and more Marek Petrik 4/18/2017 Based on: P. Murphy, K. (2012). Machine Learning: A Probabilistic Perspective. Chapter 10. Conditional Independence Independent
Probability. Machine Learning and Pattern Recognition. Chris Williams. School of Informatics, University of Edinburgh. August 2014
 Probability Machine Learning and Pattern Recognition Chris Williams School of Informatics, University of Edinburgh August 2014 (All of the slides in this course have been adapted from previous versions
Probability Machine Learning and Pattern Recognition Chris Williams School of Informatics, University of Edinburgh August 2014 (All of the slides in this course have been adapted from previous versions
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
NPFL108 Bayesian inference. Introduction. Filip Jurčíček. Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic
 NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
Introduction to Machine Learning
 Introduction to Machine Learning Bayesian Classification Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Introduction to Machine Learning Bayesian Classification Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2
 Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak
 Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak 1 Introduction. Random variables During the course we are interested in reasoning about considered phenomenon. In other words,
Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak 1 Introduction. Random variables During the course we are interested in reasoning about considered phenomenon. In other words,
DS-GA 1002 Lecture notes 11 Fall Bayesian statistics
 DS-GA 100 Lecture notes 11 Fall 016 Bayesian statistics In the frequentist paradigm we model the data as realizations from a distribution that depends on deterministic parameters. In contrast, in Bayesian
DS-GA 100 Lecture notes 11 Fall 016 Bayesian statistics In the frequentist paradigm we model the data as realizations from a distribution that depends on deterministic parameters. In contrast, in Bayesian
Probability Theory and Simulation Methods
 Feb 28th, 2018 Lecture 10: Random variables Countdown to midterm (March 21st): 28 days Week 1 Chapter 1: Axioms of probability Week 2 Chapter 3: Conditional probability and independence Week 4 Chapters
Feb 28th, 2018 Lecture 10: Random variables Countdown to midterm (March 21st): 28 days Week 1 Chapter 1: Axioms of probability Week 2 Chapter 3: Conditional probability and independence Week 4 Chapters
Stat 5101 Lecture Notes
 Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Introduc)on to Bayesian Methods
on to Bayesian Methods") Introduc)on to Bayesian Methods Bayes Rule py x)px) = px! y) = px y)py) py x) = px y)py) px) px) =! px! y) = px y)py) y py x) = py x) =! y "! y px y)py) px y)py) px y)py) px y)py)dy Bayes Rule py x) =
Introduc)on to Bayesian Methods Bayes Rule py x)px) = px! y) = px y)py) py x) = px y)py) px) px) =! px! y) = px y)py) y py x) = py x) =! y "! y px y)py) px y)py) px y)py) px y)py)dy Bayes Rule py x) =
Introduction to Machine Learning
 Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB
Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB
A.I. in health informatics lecture 2 clinical reasoning & probabilistic inference, I. kevin small & byron wallace
 A.I. in health informatics lecture 2 clinical reasoning & probabilistic inference, I kevin small & byron wallace today a review of probability random variables, maximum likelihood, etc. crucial for clinical
A.I. in health informatics lecture 2 clinical reasoning & probabilistic inference, I kevin small & byron wallace today a review of probability random variables, maximum likelihood, etc. crucial for clinical
Computational Cognitive Science
 Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
MA/ST 810 Mathematical-Statistical Modeling and Analysis of Complex Systems
 MA/ST 810 Mathematical-Statistical Modeling and Analysis of Complex Systems Review of Basic Probability The fundamentals, random variables, probability distributions Probability mass/density functions
MA/ST 810 Mathematical-Statistical Modeling and Analysis of Complex Systems Review of Basic Probability The fundamentals, random variables, probability distributions Probability mass/density functions
Bayesian Methods: Naïve Bayes
 Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory
 Bayesian Inference Statistical Decison Theory") Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Statistical Inference Parametric Inference Maximum Likelihood Inference Exponential Families Expectation Maximization (EM) Bayesian Inference Statistical Decison Theory IP, José Bioucas Dias, IST, 2007
Patterns of Scalable Bayesian Inference Background (Session 1)
") Patterns of Scalable Bayesian Inference Background (Session 1) Jerónimo Arenas-García Universidad Carlos III de Madrid jeronimo.arenas@gmail.com June 14, 2017 1 / 15 Motivation. Bayesian Learning principles
Patterns of Scalable Bayesian Inference Background (Session 1) Jerónimo Arenas-García Universidad Carlos III de Madrid jeronimo.arenas@gmail.com June 14, 2017 1 / 15 Motivation. Bayesian Learning principles
6.867 Machine Learning
 6.867 Machine Learning Problem set 1 Due Thursday, September 19, in class What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
6.867 Machine Learning Problem set 1 Due Thursday, September 19, in class What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
The Exciting Guide To Probability Distributions Part 2. Jamie Frost v1.1
 The Exciting Guide To Probability Distributions Part 2 Jamie Frost v. Contents Part 2 A revisit of the multinomial distribution The Dirichlet Distribution The Beta Distribution Conjugate Priors The Gamma
The Exciting Guide To Probability Distributions Part 2 Jamie Frost v. Contents Part 2 A revisit of the multinomial distribution The Dirichlet Distribution The Beta Distribution Conjugate Priors The Gamma
6.867 Machine Learning
 6.867 Machine Learning Problem set 1 Solutions Thursday, September 19 What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
6.867 Machine Learning Problem set 1 Solutions Thursday, September 19 What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove.
Probability Theory for Machine Learning. Chris Cremer September 2015
 Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Quick Tour of Basic Probability Theory and Linear Algebra
 Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra CS224w: Social and Information Network Analysis Fall 2011 Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra Outline Definitions
Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra CS224w: Social and Information Network Analysis Fall 2011 Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra Outline Definitions
Chapter 3: Maximum-Likelihood & Bayesian Parameter Estimation (part 1)
") HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
Introduction to Machine Learning
 Outline Introduction to Machine Learning Bayesian Classification Varun Chandola March 8, 017 1. {circular,large,light,smooth,thick}, malignant. {circular,large,light,irregular,thick}, malignant 3. {oval,large,dark,smooth,thin},
Outline Introduction to Machine Learning Bayesian Classification Varun Chandola March 8, 017 1. {circular,large,light,smooth,thick}, malignant. {circular,large,light,irregular,thick}, malignant 3. {oval,large,dark,smooth,thin},
CS 361: Probability & Statistics
 March 14, 2018 CS 361: Probability & Statistics Inference The prior From Bayes rule, we know that we can express our function of interest as Likelihood Prior Posterior The right hand side contains the
March 14, 2018 CS 361: Probability & Statistics Inference The prior From Bayes rule, we know that we can express our function of interest as Likelihood Prior Posterior The right hand side contains the
Pattern Recognition and Machine Learning. Bishop Chapter 2: Probability Distributions
 Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Statistical Methods in Particle Physics
 Statistical Methods in Particle Physics Lecture 3 October 29, 2012 Silvia Masciocchi, GSI Darmstadt s.masciocchi@gsi.de Winter Semester 2012 / 13 Outline Reminder: Probability density function Cumulative
Statistical Methods in Particle Physics Lecture 3 October 29, 2012 Silvia Masciocchi, GSI Darmstadt s.masciocchi@gsi.de Winter Semester 2012 / 13 Outline Reminder: Probability density function Cumulative
Basics on Probability. Jingrui He 09/11/2007
 Basics on Probability Jingrui He 09/11/2007 Coin Flips You flip a coin Head with probability 0.5 You flip 100 coins How many heads would you expect Coin Flips cont. You flip a coin Head with probability
Basics on Probability Jingrui He 09/11/2007 Coin Flips You flip a coin Head with probability 0.5 You flip 100 coins How many heads would you expect Coin Flips cont. You flip a coin Head with probability
Bayesian Regression Linear and Logistic Regression
 When we want more than point estimates Bayesian Regression Linear and Logistic Regression Nicole Beckage Ordinary Least Squares Regression and Lasso Regression return only point estimates But what if we
When we want more than point estimates Bayesian Regression Linear and Logistic Regression Nicole Beckage Ordinary Least Squares Regression and Lasso Regression return only point estimates But what if we
Machine Learning 4771
 Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Lecture 2: Conjugate priors
 (Spring ʼ) Lecture : Conjugate priors Julia Hockenmaier juliahmr@illinois.edu Siebel Center http://www.cs.uiuc.edu/class/sp/cs98jhm The binomial distribution If p is the probability of heads, the probability
(Spring ʼ) Lecture : Conjugate priors Julia Hockenmaier juliahmr@illinois.edu Siebel Center http://www.cs.uiuc.edu/class/sp/cs98jhm The binomial distribution If p is the probability of heads, the probability
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Machine Learning using Bayesian Approaches
 Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
10. Exchangeability and hierarchical models Objective. Recommended reading
 10. Exchangeability and hierarchical models Objective Introduce exchangeability and its relation to Bayesian hierarchical models. Show how to fit such models using fully and empirical Bayesian methods.
10. Exchangeability and hierarchical models Objective Introduce exchangeability and its relation to Bayesian hierarchical models. Show how to fit such models using fully and empirical Bayesian methods.
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Brandon C. Kelly (Harvard Smithsonian Center for Astrophysics)
") Brandon C. Kelly (Harvard Smithsonian Center for Astrophysics) Probability quantifies randomness and uncertainty How do I estimate the normalization and logarithmic slope of a X ray continuum, assuming
Brandon C. Kelly (Harvard Smithsonian Center for Astrophysics) Probability quantifies randomness and uncertainty How do I estimate the normalization and logarithmic slope of a X ray continuum, assuming
Lecture 11: Probability Distributions and Parameter Estimation
 Intelligent Data Analysis and Probabilistic Inference Lecture 11: Probability Distributions and Parameter Estimation Recommended reading: Bishop: Chapters 1.2, 2.1 2.3.4, Appendix B Duncan Gillies and
Intelligent Data Analysis and Probabilistic Inference Lecture 11: Probability Distributions and Parameter Estimation Recommended reading: Bishop: Chapters 1.2, 2.1 2.3.4, Appendix B Duncan Gillies and
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Exponential Families
 Exponential Families David M. Blei 1 Introduction We discuss the exponential family, a very flexible family of distributions. Most distributions that you have heard of are in the exponential family. Bernoulli,
Exponential Families David M. Blei 1 Introduction We discuss the exponential family, a very flexible family of distributions. Most distributions that you have heard of are in the exponential family. Bernoulli,
Midterm Examination. STA 215: Statistical Inference. Due Wednesday, 2006 Mar 8, 1:15 pm
 Midterm Examination STA 215: Statistical Inference Due Wednesday, 2006 Mar 8, 1:15 pm This is an open-book take-home examination. You may work on it during any consecutive 24-hour period you like; please
Midterm Examination STA 215: Statistical Inference Due Wednesday, 2006 Mar 8, 1:15 pm This is an open-book take-home examination. You may work on it during any consecutive 24-hour period you like; please
A primer on Bayesian statistics, with an application to mortality rate estimation
 A primer on Bayesian statistics, with an application to mortality rate estimation Peter off University of Washington Outline Subjective probability Practical aspects Application to mortality rate estimation
A primer on Bayesian statistics, with an application to mortality rate estimation Peter off University of Washington Outline Subjective probability Practical aspects Application to mortality rate estimation
Point Estimation. Vibhav Gogate The University of Texas at Dallas
 Point Estimation Vibhav Gogate The University of Texas at Dallas Some slides courtesy of Carlos Guestrin, Chris Bishop, Dan Weld and Luke Zettlemoyer. Basics: Expectation and Variance Binary Variables
Point Estimation Vibhav Gogate The University of Texas at Dallas Some slides courtesy of Carlos Guestrin, Chris Bishop, Dan Weld and Luke Zettlemoyer. Basics: Expectation and Variance Binary Variables
ECE521 W17 Tutorial 6. Min Bai and Yuhuai (Tony) Wu
 Wu") ECE521 W17 Tutorial 6 Min Bai and Yuhuai (Tony) Wu Agenda knn and PCA Bayesian Inference k-means Technique for clustering Unsupervised pattern and grouping discovery Class prediction Outlier detection
ECE521 W17 Tutorial 6 Min Bai and Yuhuai (Tony) Wu Agenda knn and PCA Bayesian Inference k-means Technique for clustering Unsupervised pattern and grouping discovery Class prediction Outlier detection
Mathematical statistics
 October 4 th, 2018 Lecture 12: Information Where are we? Week 1 Week 2 Week 4 Week 7 Week 10 Week 14 Probability reviews Chapter 6: Statistics and Sampling Distributions Chapter 7: Point Estimation Chapter
October 4 th, 2018 Lecture 12: Information Where are we? Week 1 Week 2 Week 4 Week 7 Week 10 Week 14 Probability reviews Chapter 6: Statistics and Sampling Distributions Chapter 7: Point Estimation Chapter
EIE6207: Maximum-Likelihood and Bayesian Estimation
 EIE6207: Maximum-Likelihood and Bayesian Estimation Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak
EIE6207: Maximum-Likelihood and Bayesian Estimation Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak
Statistics: Learning models from data
 DS-GA 1002 Lecture notes 5 October 19, 2015 Statistics: Learning models from data Learning models from data that are assumed to be generated probabilistically from a certain unknown distribution is a crucial
DS-GA 1002 Lecture notes 5 October 19, 2015 Statistics: Learning models from data Learning models from data that are assumed to be generated probabilistically from a certain unknown distribution is a crucial
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Accouncements. You should turn in a PDF and a python file(s) Figure for problem 9 should be in the PDF
 Figure for problem 9 should be in the PDF") Accouncements You should turn in a PDF and a python file(s) Figure for problem 9 should be in the PDF Please do not zip these files and submit (unless there are >5 files) 1 Bayesian Methods Machine Learning
Accouncements You should turn in a PDF and a python file(s) Figure for problem 9 should be in the PDF Please do not zip these files and submit (unless there are >5 files) 1 Bayesian Methods Machine Learning
Gaussian processes and bayesian optimization Stanisław Jastrzębski. kudkudak.github.io kudkudak
 Gaussian processes and bayesian optimization Stanisław Jastrzębski kudkudak.github.io kudkudak Plan Goal: talk about modern hyperparameter optimization algorithms Bayes reminder: equivalent linear regression
Gaussian processes and bayesian optimization Stanisław Jastrzębski kudkudak.github.io kudkudak Plan Goal: talk about modern hyperparameter optimization algorithms Bayes reminder: equivalent linear regression
Introduction to Machine Learning
 What does this mean? Outline Contents Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola December 26, 2017 1 Introduction to Probability 1 2 Random Variables 3 3 Bayes
What does this mean? Outline Contents Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola December 26, 2017 1 Introduction to Probability 1 2 Random Variables 3 3 Bayes
Introduction to Applied Bayesian Modeling. ICPSR Day 4
 Introduction to Applied Bayesian Modeling ICPSR Day 4 Simple Priors Remember Bayes Law: Where P(A) is the prior probability of A Simple prior Recall the test for disease example where we specified the
Introduction to Applied Bayesian Modeling ICPSR Day 4 Simple Priors Remember Bayes Law: Where P(A) is the prior probability of A Simple prior Recall the test for disease example where we specified the
CS540 Machine learning L9 Bayesian statistics
 CS540 Machine learning L9 Bayesian statistics 1 Last time Naïve Bayes Beta-Bernoulli 2 Outline Bayesian concept learning Beta-Bernoulli model (review) Dirichlet-multinomial model Credible intervals 3 Bayesian
CS540 Machine learning L9 Bayesian statistics 1 Last time Naïve Bayes Beta-Bernoulli 2 Outline Bayesian concept learning Beta-Bernoulli model (review) Dirichlet-multinomial model Credible intervals 3 Bayesian
Naïve Bayes. Jia-Bin Huang. Virginia Tech Spring 2019 ECE-5424G / CS-5824
 Naïve Bayes Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 out today. Please start early! Office hours Chen: Wed 4pm-5pm Shih-Yang: Fri 3pm-4pm Location: Whittemore 266
Naïve Bayes Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 out today. Please start early! Office hours Chen: Wed 4pm-5pm Shih-Yang: Fri 3pm-4pm Location: Whittemore 266
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
CS 630 Basic Probability and Information Theory. Tim Campbell
 CS 630 Basic Probability and Information Theory Tim Campbell 21 January 2003 Probability Theory Probability Theory is the study of how best to predict outcomes of events. An experiment (or trial or event)
CS 630 Basic Probability and Information Theory Tim Campbell 21 January 2003 Probability Theory Probability Theory is the study of how best to predict outcomes of events. An experiment (or trial or event)
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining MLE and MAP Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due tonight. Assignment 5: Will be released
CPSC 340: Machine Learning and Data Mining MLE and MAP Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due tonight. Assignment 5: Will be released
Data Analysis and Uncertainty Part 2: Estimation
 Data Analysis and Uncertainty Part 2: Estimation Instructor: Sargur N. University at Buffalo The State University of New York srihari@cedar.buffalo.edu 1 Topics in Estimation 1. Estimation 2. Desirable
Data Analysis and Uncertainty Part 2: Estimation Instructor: Sargur N. University at Buffalo The State University of New York srihari@cedar.buffalo.edu 1 Topics in Estimation 1. Estimation 2. Desirable
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, 2013
 Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Conjugate Priors, Uninformative Priors
 Conjugate Priors, Uninformative Priors Nasim Zolaktaf UBC Machine Learning Reading Group January 2016 Outline Exponential Families Conjugacy Conjugate priors Mixture of conjugate prior Uninformative priors
Conjugate Priors, Uninformative Priors Nasim Zolaktaf UBC Machine Learning Reading Group January 2016 Outline Exponential Families Conjugacy Conjugate priors Mixture of conjugate prior Uninformative priors
Introduction to Probability and Statistics (Continued)
") Introduction to Probability and Statistics (Continued) Prof. icholas Zabaras Center for Informatics and Computational Science https://cics.nd.edu/ University of otre Dame otre Dame, Indiana, USA Email:
Introduction to Probability and Statistics (Continued) Prof. icholas Zabaras Center for Informatics and Computational Science https://cics.nd.edu/ University of otre Dame otre Dame, Indiana, USA Email:
The binomial model. Assume a uniform prior distribution on p(θ). Write the pdf for this distribution.
. Write the pdf for this distribution.") The binomial model Example. After suspicious performance in the weekly soccer match, 37 mathematical sciences students, staff, and faculty were tested for the use of performance enhancing analytics. Let
The binomial model Example. After suspicious performance in the weekly soccer match, 37 mathematical sciences students, staff, and faculty were tested for the use of performance enhancing analytics. Let
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference
 COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation. EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016
 Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016 EPSY 905: Intro to Bayesian and MCMC Today s Class An
Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation EPSY 905: Multivariate Analysis Spring 2016 Lecture #10: April 6, 2016 EPSY 905: Intro to Bayesian and MCMC Today s Class An
STAT J535: Chapter 5: Classes of Bayesian Priors
 STAT J535: Chapter 5: Classes of Bayesian Priors David B. Hitchcock E-Mail: hitchcock@stat.sc.edu Spring 2012 The Bayesian Prior A prior distribution must be specified in a Bayesian analysis. The choice
STAT J535: Chapter 5: Classes of Bayesian Priors David B. Hitchcock E-Mail: hitchcock@stat.sc.edu Spring 2012 The Bayesian Prior A prior distribution must be specified in a Bayesian analysis. The choice
Probability and Information Theory. Sargur N. Srihari
 Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Bayesian inference. Fredrik Ronquist and Peter Beerli. October 3, 2007
 Bayesian inference Fredrik Ronquist and Peter Beerli October 3, 2007 1 Introduction The last few decades has seen a growing interest in Bayesian inference, an alternative approach to statistical inference.
Bayesian inference Fredrik Ronquist and Peter Beerli October 3, 2007 1 Introduction The last few decades has seen a growing interest in Bayesian inference, an alternative approach to statistical inference.
Overview of Course. Nevin L. Zhang (HKUST) Bayesian Networks Fall / 58
 Bayesian Networks Fall / 58") Overview of Course So far, we have studied The concept of Bayesian network Independence and Separation in Bayesian networks Inference in Bayesian networks The rest of the course: Data analysis using Bayesian
Overview of Course So far, we have studied The concept of Bayesian network Independence and Separation in Bayesian networks Inference in Bayesian networks The rest of the course: Data analysis using Bayesian
Bayesian Methods. David S. Rosenberg. New York University. March 20, 2018
 Bayesian Methods David S. Rosenberg New York University March 20, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 March 20, 2018 1 / 38 Contents 1 Classical Statistics 2 Bayesian
Bayesian Methods David S. Rosenberg New York University March 20, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 March 20, 2018 1 / 38 Contents 1 Classical Statistics 2 Bayesian