Crowdsourcing & Optimal Budget Allocation in Crowd Labeling
|
|
|
- Alan Hopkins
- 5 years ago
- Views:
Transcription
1 Crowdsourcing & Optimal Budget Allocation in Crowd Labeling Madhav Mohandas, Richard Zhu, Vincent Zhuang May 5, 2016
2 Table of Contents 1. Intro to Crowdsourcing 2. The Problem 3. Knowledge Gradient Algorithm 4. Experiments
3 1 Intro to Crowdsourcing 2 The Problem 3 Knowledge Gradient Algorithm 4 Experiments
4 Active learning Semi-supervised learning! Learner makes queries and receives outputs, choosing which examples to learn from Effective when labels are expensive or difficult to obtain Examples: Streaming-based active learning (IWAL, last Thursday) Near-Optimal Bayesian Active Learning for Decision Making (NOBAL, this Tuesday) Fundamental assumption: oracle or perfect labeler Abstract away the process of actually obtaining data
5 Crowdsourcing In real life, no oracle exists Both passive/active learning require labeled data Data is naturally unlabeled Obtaining accurate labels is difficult and expensive Getting expert annotations is often infeasible
6 Crowdsourcing Query labels from the crowd (e.g. Amazon Mechanical Turk) Introduces further challenges Workers are unreliable... Maximize overall accuracy with the knowledge that workers are unreliable

7 Intro to Crowdsourcing Examples Object labeling The Problem Knowledge Gradient Algorithm Experiments
8 Crowdsourcing issues Low-paid labeling ( $0.01 / instance, $1 - $5 / hour) usually very noisy Get an instance labeled several times by different workers Infer the true label by some clever aggregation of labels (oftentimes domain-specific techniques) How do you accurately estimate labeling difficulty for a given instance?
9 Varying label quality How can we deal with varying quality of crowdsourced labels in algorithms? Use redundancy and aggregation Naive: Majority voting heuristic (error-prone, all annotators are not equal) 2nd level: Generative probabilistic models, inference (EM algorithm) Modern day: Variational inference approaches Belief propagation (BP) Mean field (MF) Efficient and possess strong optimality guarantees
10 Budget Allocation vs. Active Learning Both amenable to crowdsourcing, but seek to answer very different questions: Active learning: how many samples does it take for our algorithm to produce a good model? Budget allocation: given a fixed budget, how do we allocate it so that we get the best data/model possible?
11 Budget Allocation Problem Budget requires you to decide whether to spend more on ambiguous instances, or instead save money and label other instances. Balance exploration (labeling other instances) and exploitation (continue labeling ambiguous instances) Previous work on crowdsourcing addressed parts independently This paper addresses both budget allocation (selection of instances) and the label aggregation (inference of true label) in a general framework
12 Where we re going Bayesian statistics setup Problem formulated finite-horizon Markov Decision Process Optimal budget allocation π obtained using DP Computationally intractable! State space exp(t ) Introduce efficient approximate algorithm - optimistic knowledge gradient Experiments and applications
13 1 Intro to Crowdsourcing 2 The Problem 3 Knowledge Gradient Algorithm 4 Experiments
14 Problem Setting Binary labeling task K coins (instances) with true labels Z i { 1, 1}, 1 i K Positive set: H = {i : Z i = 1} Goal is to predict true label of each instance using labels generated by crowd members
15 Problem Setting All workers are identical and noiseless (perfectly reliable) Accuracy of the worker label only depends on the inherent difficulty of categorizing the instance Ambiguity of instance i parameterized by θ i [0, 1] Equivalently, θ i is the fraction of workers that will label instance i as +1 (ensemble average) In coin-flipping interpretation, θ i is bias of the coin Assume soft-label is consistent with true label, i.e. Z i = 1 θ i 0.5




16 Problem Setting Interpretation of θ i. Adult +1, not adult 1:
17 Budget Allocation Challenge Total budget of T Costs 1 unit to get a worker to label some instance i How to spend money in a way that maximizes overall accuracy?
18 Budget Allocation Challenge Can formulate as a finite horizon decision process: At each timestep 0 t T 1, choose an instance i t A = {1,..., K } to label, and receive label y it. (Budget Allocation Phase) After final step make inference of true label, estimate positive set H and gain reward H H + H c (H ) c. (Label Aggregation Phase) Best prediction strategy is majority vote (proof in paper), since all workers are assumed to be identical. This assumption relaxed later on Goal: determine optimal (adaptive) budget allocation policy π to label instances
19 Simple Example Here we assume no prior knowledge about the θ i s What instance should we label next?
20 Simple Example Consider instance 1. If we label instance 1, majority vote guarantees us to predict Ẑi +1. No improvement in expected accuracy, regardless of whether θ i > 0.5 or θ i < 0.5
21 Simple Example Consider instance 2. If θ 2 >.5, then true label for instance 2 will be 1 Current expected accuracy:.5 If received label is 1 (P(y 2 = 1) = θ 2 ), accuracy will be 1. If received label is -1, accuracy will be 0. So, expected accuracy after receiving label is θ 2. Improvement is θ 2.5 > 0
22 Simple Example Consider instance 2. If θ 2 <.5, then true label for instance 2 will be 1 Current expected accuracy:.5 If received label is 1 (P(y 2 = 1) = θ 2 ), accuracy will be 0. If received label is -1, accuracy will be 1. So, expected accuracy after receiving label is 1 θ 2. Improvement is 0.5 θ 2 > 0
23 Simple Example Consider instance 3. If θ 3 >.5, then true label for instance 3 will be +1 Current expected accuracy: 1 If received label is 1 (P(y 3 = 1) = θ 3 ), accuracy will be 1. If received label is -1, accuracy will be 0.5 So, expected accuracy after receiving label is θ (1 θ 3 ). Improvement is 0.5(θ 3 1) < 0
24 Simple Example Consider instance 3. If θ 3 <.5, then true label for instance 3 will be 1 Current expected accuracy: 0 If received label is 1 (P(y 3 = 1) = θ 3 ), accuracy will be 0. If received label is -1, accuracy will be 0.5 So, expected accuracy after receiving label is 0.5(1 θ 3 ). Improvement is 0.5(1 θ 3 ) > 0
25 Simple Example Expected increase in accuracy for instance i is a function of the true value of θ i No optimal choice in frequentist setting!

26 Simple Example Boundary Decisi
27 Simple Example Originally made no assumptions on distributions of θ i But if we assume θ i are sampled from some prior distribution, we can compute the expected value of this improvement Optimal choice exists in Bayesian setting!
28 Bayesian Modeling K coin-flipping problem! The label y it { 1, 1} must follow y it Bernoulli(θ it ) We assumed all workers to be identical, so y it depends only on θ it Prior to any labels being collected, we assume that θ i Unif (0, 1) = Beta(1, 1) Define a t i /bt i as 1+ the number of positive/negative labels we have gathered for instance i before time t. a 0 i = b 0 i = 1
29 Bayesian Modeling Define state of the decision process at (the start of) timestep t as S t = {ai t, bt i }K i=1 (K x 2 matrix) If we request a label for instance i t in state S t, our state will be updated according to: e it is a K x 1 vector with 1 at the i t -th entry and 0 at all other entries
30 Bayesian Modeling Recall: y i Bernoulli(θ i ) θ i Unif (0, 1) So: P(θ i S t ) = P(St θ i ) P(θ i ) P(S t ) P(S t θ i ) P(θ i ) θ at i 1 i (1 θ i ) bt i 1 = Beta(ai t, bt i )
31 Bayesian Modeling Given state S t and instance choice i t, can transition to two different states S t+1 according to:
32 Markov Decision Process Starting to sound like a MDP: State: S t, Action: instance i t to label Next state is determined completely from previous state and action, according to transition probabilities Must develop notion of reward of taking action i t in state S t
33 Reward function Define: P t i = P(θ i.5 S t i ) = P(θ i.5 a t i, bt i ) h(x) = max(x, 1 x) Then: h(pi t ) = expected accuracy of the prediction (majority vote) for the label of instance i at time t
34 Reward function R(S t, i t ) = E(h(P t+1 i t ) h(p t i t ) S t, i t ) Reward for choosing action i t in state S t is the expected gain in accuracy of classifying instance i after receiving y it.
35 Value function V t0 (S t 0 ) = sup π E π ( T 1 t=t 0 R(S t, i t ))
36 Value function V (S t 0 ) = sup π E π ( T 1 t=t 0 R(S t, i t ))
37 Value function V (S t 0 ) = sup π T 1 E π ( R(S t, i t )) t=t 0 If we know the value of every state, optimal policy follows Can derive value function using dynamic programming
38 Dynamic programming Downside: Number of possible states S t grows exponentially in t. (State is reachable at time t if K i=1 (at i + b t i ) (a0 i + b 0 i ) = t) Will develop computationally efficient approximate algorithm Notation: R(S t, i t ) = R(a t i t, b t i t ) R(a t i t, b t i t ) = p 1 R 1 (a t i t, b t i t ) + p 2 R 2 (a t i t, b t i t ) R 1 /R 2 is the reward if the received label y it is 1/ 1 p 1 and p 2 are the transition probabilities
39 1 Intro to Crowdsourcing 2 The Problem 3 Knowledge Gradient Algorithm 4 Experiments
40 MAB Approximation Reformulate as finite-horizon Bayesian MAB problem: Arms are K instances Rewards R 1, R 2 are provided i.i.d from a fixed set of Bernoulli distributions Bandit algorithms offer approximate solutions in the finite horizon e.g. Gittins index
41 Our ideal algorithm Ideally, we want an approximation algorithm that is: computationally efficient Gittins index is either O(T 3 ) or O(T 6 ), depending on if we want the exact index or not consistent i.e. obtains 100% accuracy a.s. as T
42 Knowledge Gradient Recall that we have two possible rewards for any given instance at each iteration: R 1 (a, b) = h(i(a + 1, b)) h(i(a, b)) R 2 (a, b) = h(i(a, b + 1)) h(i(a, b)) Greedily picks instance with largest expected reward: ( i t = arg max R(ai t, bt i ) = i What happens if there is a tie? Deterministic KG: pick smallest i Randomized KG: pick randomly ) at i ai t + bi t R 1 (ai t, bt i ) + bt i ai t + bi t R 2 (ai t, bt i )
43 Behavior of KG Deterministic KG is inconsistent Randomized KG performs badly empirically (behaves similarly to uniform sampling)
44 Optimistic Knowledge Gradient Optimistic KG greedily selects largest optimistic reward [ i t = arg max R + (a i, b i ) = max (R 1 (a i, b i ), R 2 (a i, b i )) ] i Runtime O(KT ) Consistent!
45 Algorithm 1: Init T and prior parameters {a 0 i, b0 i }K i=1 2: for t = 0,..., T 1 do 3: Select the next instance i t to label according to [ i t = arg max R + (a i, b i ) = max (R 1 (a i, b i ), R 2 (a i, b i )) ] i 4: Acquire label y i { 1, 1} 5: if y it = 1 then 6: a t+1 i t = ai t t + 1, b t+1 i t = bi t t 7: else 8: a t+1 i t = ai t t, b t+1 i t = bi t t + 1 9: end if 10: end for
46 Consistency Theorem Assuming that a 0 i and b 0 i are positive integers, the optimistic KG is a consistent policy, i.e. as T goes to infinity, the accuracy will be 100% (i.e. H T = H ) almost surely.
47 Properties of R Can write out R, R + explicitly using Beta distribution. For example, if a > b, then R + (a, b) = R 1 (a, b) = 0.5a+b ab(a,b). Lemma 1 R(a, b) is symmetric, i.e. R + (a, b) = R + (b, a) 2 lim a R + (a, a) = 0 3 For any fixed a 1, R + (a + k, a k) = R + (a k, a + k) is monotonically decreasing in k for k = 0,..., a 1 4 When a b, for any fixed b, R + (a, b) is monotonically decreasing in a. By the symmetry of R + (a, b), when b a, for any fixed a, R + (a, b) is monotonically decreasing in b.
48 Every instance labelled infinitely many times as T! Let I(ω) be set of all instances labelled only finitely many times for some infinite sample path ω Must exist some T after which no instances in I will be labelled For any instance j / I, R + (a j, b j ) 0 (from lemma) Optimistic KG will select an instance in I next, contradiction!
49 Let η i (T ) = a T i + b T i be number of times instance i has been picked before step T. Since each instance will be labelled infinitely many times as T, by the Strong Law of Large Numbers, ai T bi T lim T η i (T ) = 2θ i 1
50 Recall that accuracy Acc(T ) is defined as 1 K H H + H c (H ) c where H T = {i : a T i b T i } and H = {i : θ i 0.5}. Then: ( ) Pr lim Acc(T ) = 1 {θ i} K i=1 T ( ) 1 =Pr lim T K H H + H c (H ) c = 1 {θ i } K i=1 ( ) ai T bi T Pr lim = 2θ 1 {θ i } K i=1 T η i (T ) =1
51 Take expectation over all θ 0.5, since {θ i θ i = 0.5} has measure zero: Pr (Acc(T ) = 1) [ ( )] Pr lim Acc(T ) = 1 {θ i} K i=1 T =E {θi :θ i 0.5} K i=1 =E {θi :θ i 0.5} K i=1[1] = 1
52 Recap Basic intuition: Optimistic KG adequately explores all instances Given enough samples, we converge to the true θ s
53 Worker Reliability Suppose we have M unreliable workers Let ρ j be the probability of worker j getting the same label as a perfectly reliable noiseless worker and Z ij be the label we receive from worker j on instance i Then we can parameterize the probability by ρ and θ: Pr(Z ij = 1) = ρ j θ i + (1 ρ j )(1 θ i ) Assume Beta prior for ρ as well
54 Note that the posterior is no longer a product of beta distributions Assume posterior factorizes (conditional independence): p(θ i, ρ j Z ij = z) p(θ i Z ij = z)p(ρ j Z ij = z) Beta(a i (z), b i (z))beta(c j (z), d j (z)) Must find a i (z), b i (z), c j (z), d j (z) using variational approximation (moment matching on marginals)
55 Extensions features: apply Bayesian updates onto weights multiclass labelling: Dirichlet prior
56 1 Intro to Crowdsourcing 2 The Problem 3 Knowledge Gradient Algorithm 4 Experiments
57 Experiments First, consider identical, noiseless workers K = 21 instances, (θ 1, θ 2, θ 3...θ K ) = (0,.05,.1,...1) Averaged over 20 runs In general, more ambiguous instances get labeled more, but most ambiguous instance may not get most labels As budget grows, algorithm considers increasingly ambiguous instances
58 Experiments Now add M = 59 workers with: (ρ 1...ρ M ) = (.1...,.995) As the budget increases, more reliable workers get more assignments.
59 Experiments How robust is Opt-KG under incorrect assumption of prior for θ?
60 Experiments
61 Experiments How does the accuracy of Opt-KG compare to the following algorithms: Uniform: Uniform sampling KG(Random): Randomized knowledge gradient (Frazier et al., 2008) Gittins-Inf: Gittins-indexed based policy for solivng infinite-horizon MAB problem with reward discounted by δ (Xie and Frazier, 2013) NLU: The new labeling uncertainty method (Ipeirotis et al., 2013)
62 Experiments Simulated Setting: Identical and noiseless workers K = 50 instances, with each θ i Beta(1, 1), θ i Beta(.5,.5), θ i Beta(4, 1) Results show average of 20 runs on independently generated sets of {θ i } K i=1
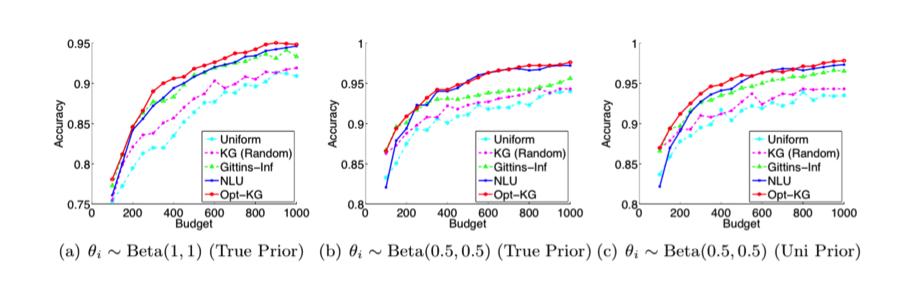
63 Experiments
64 Experiments Test using real data set for recognizing textual entailment (RTE) RTE task: Given ordered pair of sentences (s 1, s 2 ) Return 1 if s 2 can be inferred from s 1 Example: s 1 : If you help the needy, God will reward you. s 2 : Giving money to a poor man has good consequences.
65 Experiments Data set: 800 instances (sentence pairs) Each instance labeled by 10 different workers 164 different workers First, consider homogeneous noiseless workers Results show average of 20 independent trials for each policy
66 Experiments
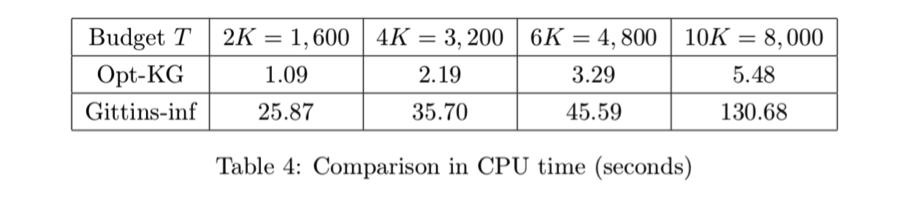
67 Experiments
68 Experiments Now incorporate worker reliabilities: ρ j Beta(4, 1) (i.e. workers behave reliably 80% of the time).
69 References Chen, Xi, Qihang Lin, and Dengyong Zhou. Optimistic knowledge gradient policy for optimal budget allocation in crowdsourcing. Proceedings of the 30th International Conference on Machine Learning (ICML-13)
Appendix. Machine Learning Department, Carnegie Mellon University, Pittsburgh, PA 15213, USA Qihang Lin
 Xi Chen xichen@cscmuedu Machine Learning Department, Carnegie Mellon University, Pittsburgh, PA 53, USA Qihang Lin qihangl@andrewcmuedu Tepper School of Business, Carnegie Mellon University, Pittsburgh,
Xi Chen xichen@cscmuedu Machine Learning Department, Carnegie Mellon University, Pittsburgh, PA 53, USA Qihang Lin qihangl@andrewcmuedu Tepper School of Business, Carnegie Mellon University, Pittsburgh,
Bandit-Based Task Assignment for Heterogeneous Crowdsourcing
 Neural Computation, vol.27, no., pp.2447 2475, 205. Bandit-Based Task Assignment for Heterogeneous Crowdsourcing Hao Zhang Department of Computer Science, Tokyo Institute of Technology, Japan Yao Ma Department
Neural Computation, vol.27, no., pp.2447 2475, 205. Bandit-Based Task Assignment for Heterogeneous Crowdsourcing Hao Zhang Department of Computer Science, Tokyo Institute of Technology, Japan Yao Ma Department
Bandit models: a tutorial
 Gdt COS, December 3rd, 2015 Multi-Armed Bandit model: general setting K arms: for a {1,..., K}, (X a,t ) t N is a stochastic process. (unknown distributions) Bandit game: a each round t, an agent chooses
Gdt COS, December 3rd, 2015 Multi-Armed Bandit model: general setting K arms: for a {1,..., K}, (X a,t ) t N is a stochastic process. (unknown distributions) Bandit game: a each round t, an agent chooses
Artificial Intelligence
 Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Multi-armed bandit models: a tutorial
 Multi-armed bandit models: a tutorial CERMICS seminar, March 30th, 2016 Multi-Armed Bandit model: general setting K arms: for a {1,..., K}, (X a,t ) t N is a stochastic process. (unknown distributions)
Multi-armed bandit models: a tutorial CERMICS seminar, March 30th, 2016 Multi-Armed Bandit model: general setting K arms: for a {1,..., K}, (X a,t ) t N is a stochastic process. (unknown distributions)
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Budget-Optimal Task Allocation for Reliable Crowdsourcing Systems
 Budget-Optimal Task Allocation for Reliable Crowdsourcing Systems Sewoong Oh Massachusetts Institute of Technology joint work with David R. Karger and Devavrat Shah September 28, 2011 1 / 13 Crowdsourcing
Budget-Optimal Task Allocation for Reliable Crowdsourcing Systems Sewoong Oh Massachusetts Institute of Technology joint work with David R. Karger and Devavrat Shah September 28, 2011 1 / 13 Crowdsourcing
Multi-Armed Bandit: Learning in Dynamic Systems with Unknown Models
 c Qing Zhao, UC Davis. Talk at Xidian Univ., September, 2011. 1 Multi-Armed Bandit: Learning in Dynamic Systems with Unknown Models Qing Zhao Department of Electrical and Computer Engineering University
c Qing Zhao, UC Davis. Talk at Xidian Univ., September, 2011. 1 Multi-Armed Bandit: Learning in Dynamic Systems with Unknown Models Qing Zhao Department of Electrical and Computer Engineering University
Practical Agnostic Active Learning
 Practical Agnostic Active Learning Alina Beygelzimer Yahoo Research based on joint work with Sanjoy Dasgupta, Daniel Hsu, John Langford, Francesco Orabona, Chicheng Zhang, and Tong Zhang * * introductory
Practical Agnostic Active Learning Alina Beygelzimer Yahoo Research based on joint work with Sanjoy Dasgupta, Daniel Hsu, John Langford, Francesco Orabona, Chicheng Zhang, and Tong Zhang * * introductory
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning. Hanna Kurniawati
 COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
1 MDP Value Iteration Algorithm
 CS 0. - Active Learning Problem Set Handed out: 4 Jan 009 Due: 9 Jan 009 MDP Value Iteration Algorithm. Implement the value iteration algorithm given in the lecture. That is, solve Bellman s equation using
CS 0. - Active Learning Problem Set Handed out: 4 Jan 009 Due: 9 Jan 009 MDP Value Iteration Algorithm. Implement the value iteration algorithm given in the lecture. That is, solve Bellman s equation using
Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy. Denny Zhou Qiang Liu John Platt Chris Meek
 Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy Denny Zhou Qiang Liu John Platt Chris Meek 2 Crowds vs experts labeling: strength Time saving Money saving Big labeled data More data
Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy Denny Zhou Qiang Liu John Platt Chris Meek 2 Crowds vs experts labeling: strength Time saving Money saving Big labeled data More data
16.4 Multiattribute Utility Functions
 285 Normalized utilities The scale of utilities reaches from the best possible prize u to the worst possible catastrophe u Normalized utilities use a scale with u = 0 and u = 1 Utilities of intermediate
285 Normalized utilities The scale of utilities reaches from the best possible prize u to the worst possible catastrophe u Normalized utilities use a scale with u = 0 and u = 1 Utilities of intermediate
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
CS 7180: Behavioral Modeling and Decisionmaking
 CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
A Bayesian Concept Learning Approach to Crowdsourcing
 A Bayesian Concept Learning Approach to Crowdsourcing Paolo Viappiani Dept. of Computer Science Aalborg University Sandra Zilles, Howard J. Hamilton Dept. of Computer Science University of Regina Craig
A Bayesian Concept Learning Approach to Crowdsourcing Paolo Viappiani Dept. of Computer Science Aalborg University Sandra Zilles, Howard J. Hamilton Dept. of Computer Science University of Regina Craig
Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning
 Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning Christos Dimitrakakis Informatics Institute, University of Amsterdam, Amsterdam, The Netherlands
Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning Christos Dimitrakakis Informatics Institute, University of Amsterdam, Amsterdam, The Netherlands
Bayesian Decision Process for Cost-Efficient Dynamic Ranking via Crowdsourcing
 Journal of Machine Learning Research 17 (016) 1-40 Submitted /16; Published 11/16 Bayesian Decision Process for Cost-Efficient Dynamic Ranking via Crowdsourcing Xi Chen Stern School of Business New York
Journal of Machine Learning Research 17 (016) 1-40 Submitted /16; Published 11/16 Bayesian Decision Process for Cost-Efficient Dynamic Ranking via Crowdsourcing Xi Chen Stern School of Business New York
Active Learning and Optimized Information Gathering
 Active Learning and Optimized Information Gathering Lecture 7 Learning Theory CS 101.2 Andreas Krause Announcements Project proposal: Due tomorrow 1/27 Homework 1: Due Thursday 1/29 Any time is ok. Office
Active Learning and Optimized Information Gathering Lecture 7 Learning Theory CS 101.2 Andreas Krause Announcements Project proposal: Due tomorrow 1/27 Homework 1: Due Thursday 1/29 Any time is ok. Office
Reinforcement Learning
 Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Learning Tetris. 1 Tetris. February 3, 2009
 Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
VIME: Variational Information Maximizing Exploration
 1 VIME: Variational Information Maximizing Exploration Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel Reviewed by Zhao Song January 13, 2017 1 Exploration in Reinforcement
1 VIME: Variational Information Maximizing Exploration Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel Reviewed by Zhao Song January 13, 2017 1 Exploration in Reinforcement
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Uncertainty & Probabilities & Bandits Daniel Hennes 16.11.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Uncertainty Probability
Grundlagen der Künstlichen Intelligenz Uncertainty & Probabilities & Bandits Daniel Hennes 16.11.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Uncertainty Probability
MDP Preliminaries. Nan Jiang. February 10, 2019
 MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
Computational Cognitive Science
 Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
Discrete Mathematics and Probability Theory Fall 2015 Lecture 21
 CS 70 Discrete Mathematics and Probability Theory Fall 205 Lecture 2 Inference In this note we revisit the problem of inference: Given some data or observations from the world, what can we infer about
CS 70 Discrete Mathematics and Probability Theory Fall 205 Lecture 2 Inference In this note we revisit the problem of inference: Given some data or observations from the world, what can we infer about
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Artificial Intelligence & Sequential Decision Problems
 Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring /
 Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Does Unlabeled Data Help?
 Does Unlabeled Data Help? Worst-case Analysis of the Sample Complexity of Semi-supervised Learning. Ben-David, Lu and Pal; COLT, 2008. Presentation by Ashish Rastogi Courant Machine Learning Seminar. Outline
Does Unlabeled Data Help? Worst-case Analysis of the Sample Complexity of Semi-supervised Learning. Ben-David, Lu and Pal; COLT, 2008. Presentation by Ashish Rastogi Courant Machine Learning Seminar. Outline
Final Exam, Spring 2006
 070 Final Exam, Spring 2006. Write your name and your email address below. Name: Andrew account: 2. There should be 22 numbered pages in this exam (including this cover sheet). 3. You may use any and all
070 Final Exam, Spring 2006. Write your name and your email address below. Name: Andrew account: 2. There should be 22 numbered pages in this exam (including this cover sheet). 3. You may use any and all
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Be able to define the following terms and answer basic questions about them:
 CS440/ECE448 Section Q Fall 2017 Final Review Be able to define the following terms and answer basic questions about them: Probability o Random variables, axioms of probability o Joint, marginal, conditional
CS440/ECE448 Section Q Fall 2017 Final Review Be able to define the following terms and answer basic questions about them: Probability o Random variables, axioms of probability o Joint, marginal, conditional
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
DS-GA 1002 Lecture notes 11 Fall Bayesian statistics
 DS-GA 100 Lecture notes 11 Fall 016 Bayesian statistics In the frequentist paradigm we model the data as realizations from a distribution that depends on deterministic parameters. In contrast, in Bayesian
DS-GA 100 Lecture notes 11 Fall 016 Bayesian statistics In the frequentist paradigm we model the data as realizations from a distribution that depends on deterministic parameters. In contrast, in Bayesian
How can a Machine Learn: Passive, Active, and Teaching
 How can a Machine Learn: Passive, Active, and Teaching Xiaojin Zhu jerryzhu@cs.wisc.edu Department of Computer Sciences University of Wisconsin-Madison NLP&CC 2013 Zhu (Univ. Wisconsin-Madison) How can
How can a Machine Learn: Passive, Active, and Teaching Xiaojin Zhu jerryzhu@cs.wisc.edu Department of Computer Sciences University of Wisconsin-Madison NLP&CC 2013 Zhu (Univ. Wisconsin-Madison) How can
arxiv: v3 [cs.lg] 25 Aug 2017
![arxiv: v3 [cs.lg] 25 Aug 2017](/thumbs/84/89382803.jpg "arxiv: v3 [cs.lg] 25 Aug 2017") Achieving Budget-optimality with Adaptive Schemes in Crowdsourcing Ashish Khetan and Sewoong Oh arxiv:602.0348v3 [cs.lg] 25 Aug 207 Abstract Crowdsourcing platforms provide marketplaces where task requesters
Achieving Budget-optimality with Adaptive Schemes in Crowdsourcing Ashish Khetan and Sewoong Oh arxiv:602.0348v3 [cs.lg] 25 Aug 207 Abstract Crowdsourcing platforms provide marketplaces where task requesters
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
, and rewards and transition matrices as shown below:
 CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Click Prediction and Preference Ranking of RSS Feeds
 Click Prediction and Preference Ranking of RSS Feeds 1 Introduction December 11, 2009 Steven Wu RSS (Really Simple Syndication) is a family of data formats used to publish frequently updated works. RSS
Click Prediction and Preference Ranking of RSS Feeds 1 Introduction December 11, 2009 Steven Wu RSS (Really Simple Syndication) is a family of data formats used to publish frequently updated works. RSS
Statistics: Learning models from data
 DS-GA 1002 Lecture notes 5 October 19, 2015 Statistics: Learning models from data Learning models from data that are assumed to be generated probabilistically from a certain unknown distribution is a crucial
DS-GA 1002 Lecture notes 5 October 19, 2015 Statistics: Learning models from data Learning models from data that are assumed to be generated probabilistically from a certain unknown distribution is a crucial
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2014
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
CS 446 Machine Learning Fall 2016 Nov 01, Bayesian Learning
 CS 446 Machine Learning Fall 206 Nov 0, 206 Bayesian Learning Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes Overview Bayesian Learning Naive Bayes Logistic Regression Bayesian Learning So far, we
CS 446 Machine Learning Fall 206 Nov 0, 206 Bayesian Learning Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes Overview Bayesian Learning Naive Bayes Logistic Regression Bayesian Learning So far, we
1 [15 points] Search Strategies
![1 [15 points] Search Strategies](/thumbs/94/120795649.jpg "1 [15 points] Search Strategies") Probabilistic Foundations of Artificial Intelligence Final Exam Date: 29 January 2013 Time limit: 120 minutes Number of pages: 12 You can use the back of the pages if you run out of space. strictly forbidden.
Probabilistic Foundations of Artificial Intelligence Final Exam Date: 29 January 2013 Time limit: 120 minutes Number of pages: 12 You can use the back of the pages if you run out of space. strictly forbidden.
Stratégies bayésiennes et fréquentistes dans un modèle de bandit
 Stratégies bayésiennes et fréquentistes dans un modèle de bandit thèse effectuée à Telecom ParisTech, co-dirigée par Olivier Cappé, Aurélien Garivier et Rémi Munos Journées MAS, Grenoble, 30 août 2016
Stratégies bayésiennes et fréquentistes dans un modèle de bandit thèse effectuée à Telecom ParisTech, co-dirigée par Olivier Cappé, Aurélien Garivier et Rémi Munos Journées MAS, Grenoble, 30 août 2016
Clustering bi-partite networks using collapsed latent block models
 Clustering bi-partite networks using collapsed latent block models Jason Wyse, Nial Friel & Pierre Latouche Insight at UCD Laboratoire SAMM, Université Paris 1 Mail: jason.wyse@ucd.ie Insight Latent Space
Clustering bi-partite networks using collapsed latent block models Jason Wyse, Nial Friel & Pierre Latouche Insight at UCD Laboratoire SAMM, Université Paris 1 Mail: jason.wyse@ucd.ie Insight Latent Space
an introduction to bayesian inference
 with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Learning From Crowds. Presented by: Bei Peng 03/24/15
 Learning From Crowds Presented by: Bei Peng 03/24/15 1 Supervised Learning Given labeled training data, learn to generalize well on unseen data Binary classification ( ) Multi-class classification ( y
Learning From Crowds Presented by: Bei Peng 03/24/15 1 Supervised Learning Given labeled training data, learn to generalize well on unseen data Binary classification ( ) Multi-class classification ( y
Using first-order logic, formalize the following knowledge:
 Probabilistic Artificial Intelligence Final Exam Feb 2, 2016 Time limit: 120 minutes Number of pages: 19 Total points: 100 You can use the back of the pages if you run out of space. Collaboration on the
Probabilistic Artificial Intelligence Final Exam Feb 2, 2016 Time limit: 120 minutes Number of pages: 19 Total points: 100 You can use the back of the pages if you run out of space. Collaboration on the
Atutorialonactivelearning
 Atutorialonactivelearning Sanjoy Dasgupta 1 John Langford 2 UC San Diego 1 Yahoo Labs 2 Exploiting unlabeled data Alotofunlabeleddataisplentifulandcheap,eg. documents off the web speech samples images
Atutorialonactivelearning Sanjoy Dasgupta 1 John Langford 2 UC San Diego 1 Yahoo Labs 2 Exploiting unlabeled data Alotofunlabeleddataisplentifulandcheap,eg. documents off the web speech samples images
Trust Region Policy Optimization
 Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Be able to define the following terms and answer basic questions about them:
 CS440/ECE448 Fall 2016 Final Review Be able to define the following terms and answer basic questions about them: Probability o Random variables o Axioms of probability o Joint, marginal, conditional probability
CS440/ECE448 Fall 2016 Final Review Be able to define the following terms and answer basic questions about them: Probability o Random variables o Axioms of probability o Joint, marginal, conditional probability
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Active and Semi-supervised Kernel Classification
 Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
Crowdsourcing via Tensor Augmentation and Completion (TAC)
") Crowdsourcing via Tensor Augmentation and Completion (TAC) Presenter: Yao Zhou joint work with: Dr. Jingrui He - 1 - Roadmap Background Related work Crowdsourcing based on TAC Experimental results Conclusion
Crowdsourcing via Tensor Augmentation and Completion (TAC) Presenter: Yao Zhou joint work with: Dr. Jingrui He - 1 - Roadmap Background Related work Crowdsourcing based on TAC Experimental results Conclusion
Notes on Machine Learning for and
 Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Choosing Hypotheses Generally want the most probable hypothesis given the training data Maximum a posteriori
Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Choosing Hypotheses Generally want the most probable hypothesis given the training data Maximum a posteriori
Probability Theory Review
 Probability Theory Review Brendan O Connor 10-601 Recitation Sept 11 & 12, 2012 1 Mathematical Tools for Machine Learning Probability Theory Linear Algebra Calculus Wikipedia is great reference 2 Probability
Probability Theory Review Brendan O Connor 10-601 Recitation Sept 11 & 12, 2012 1 Mathematical Tools for Machine Learning Probability Theory Linear Algebra Calculus Wikipedia is great reference 2 Probability
Distributed Optimization. Song Chong EE, KAIST
 Distributed Optimization Song Chong EE, KAIST songchong@kaist.edu Dynamic Programming for Path Planning A path-planning problem consists of a weighted directed graph with a set of n nodes N, directed links
Distributed Optimization Song Chong EE, KAIST songchong@kaist.edu Dynamic Programming for Path Planning A path-planning problem consists of a weighted directed graph with a set of n nodes N, directed links
An Analytic Solution to Discrete Bayesian Reinforcement Learning
 An Analytic Solution to Discrete Bayesian Reinforcement Learning Pascal Poupart (U of Waterloo) Nikos Vlassis (U of Amsterdam) Jesse Hoey (U of Toronto) Kevin Regan (U of Waterloo) 1 Motivation Automated
An Analytic Solution to Discrete Bayesian Reinforcement Learning Pascal Poupart (U of Waterloo) Nikos Vlassis (U of Amsterdam) Jesse Hoey (U of Toronto) Kevin Regan (U of Waterloo) 1 Motivation Automated
Hypothesis Testing. Part I. James J. Heckman University of Chicago. Econ 312 This draft, April 20, 2006
 Hypothesis Testing Part I James J. Heckman University of Chicago Econ 312 This draft, April 20, 2006 1 1 A Brief Review of Hypothesis Testing and Its Uses values and pure significance tests (R.A. Fisher)
Hypothesis Testing Part I James J. Heckman University of Chicago Econ 312 This draft, April 20, 2006 1 1 A Brief Review of Hypothesis Testing and Its Uses values and pure significance tests (R.A. Fisher)
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Active Learning of MDP models
 Active Learning of MDP models Mauricio Araya-López, Olivier Buffet, Vincent Thomas, and François Charpillet Nancy Université / INRIA LORIA Campus Scientifique BP 239 54506 Vandoeuvre-lès-Nancy Cedex France
Active Learning of MDP models Mauricio Araya-López, Olivier Buffet, Vincent Thomas, and François Charpillet Nancy Université / INRIA LORIA Campus Scientifique BP 239 54506 Vandoeuvre-lès-Nancy Cedex France
Bayesian Contextual Multi-armed Bandits
 Bayesian Contextual Multi-armed Bandits Xiaoting Zhao Joint Work with Peter I. Frazier School of Operations Research and Information Engineering Cornell University October 22, 2012 1 / 33 Outline 1 Motivating
Bayesian Contextual Multi-armed Bandits Xiaoting Zhao Joint Work with Peter I. Frazier School of Operations Research and Information Engineering Cornell University October 22, 2012 1 / 33 Outline 1 Motivating
CHAPTER 2 Estimating Probabilities
 CHAPTER 2 Estimating Probabilities Machine Learning Copyright c 2017. Tom M. Mitchell. All rights reserved. *DRAFT OF September 16, 2017* *PLEASE DO NOT DISTRIBUTE WITHOUT AUTHOR S PERMISSION* This is
CHAPTER 2 Estimating Probabilities Machine Learning Copyright c 2017. Tom M. Mitchell. All rights reserved. *DRAFT OF September 16, 2017* *PLEASE DO NOT DISTRIBUTE WITHOUT AUTHOR S PERMISSION* This is
Introduction to Machine Learning
 Outline Introduction to Machine Learning Bayesian Classification Varun Chandola March 8, 017 1. {circular,large,light,smooth,thick}, malignant. {circular,large,light,irregular,thick}, malignant 3. {oval,large,dark,smooth,thin},
Outline Introduction to Machine Learning Bayesian Classification Varun Chandola March 8, 017 1. {circular,large,light,smooth,thick}, malignant. {circular,large,light,irregular,thick}, malignant 3. {oval,large,dark,smooth,thin},
Planning by Probabilistic Inference
 Planning by Probabilistic Inference Hagai Attias Microsoft Research 1 Microsoft Way Redmond, WA 98052 Abstract This paper presents and demonstrates a new approach to the problem of planning under uncertainty.
Planning by Probabilistic Inference Hagai Attias Microsoft Research 1 Microsoft Way Redmond, WA 98052 Abstract This paper presents and demonstrates a new approach to the problem of planning under uncertainty.
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
CSE250A Fall 12: Discussion Week 9
 CSE250A Fall 12: Discussion Week 9 Aditya Menon (akmenon@ucsd.edu) December 4, 2012 1 Schedule for today Recap of Markov Decision Processes. Examples: slot machines and maze traversal. Planning and learning.
CSE250A Fall 12: Discussion Week 9 Aditya Menon (akmenon@ucsd.edu) December 4, 2012 1 Schedule for today Recap of Markov Decision Processes. Examples: slot machines and maze traversal. Planning and learning.
Notes from Week 9: Multi-Armed Bandit Problems II. 1 Information-theoretic lower bounds for multiarmed
 CS 683 Learning, Games, and Electronic Markets Spring 007 Notes from Week 9: Multi-Armed Bandit Problems II Instructor: Robert Kleinberg 6-30 Mar 007 1 Information-theoretic lower bounds for multiarmed
CS 683 Learning, Games, and Electronic Markets Spring 007 Notes from Week 9: Multi-Armed Bandit Problems II Instructor: Robert Kleinberg 6-30 Mar 007 1 Information-theoretic lower bounds for multiarmed
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning as Classification Leveraging Modern Classifiers
 Reinforcement Learning as Classification Leveraging Modern Classifiers Michail G. Lagoudakis and Ronald Parr Department of Computer Science Duke University Durham, NC 27708 Machine Learning Reductions
Reinforcement Learning as Classification Leveraging Modern Classifiers Michail G. Lagoudakis and Ronald Parr Department of Computer Science Duke University Durham, NC 27708 Machine Learning Reductions
Computational and Statistical Learning Theory
 Computational and Statistical Learning Theory TTIC 31120 Prof. Nati Srebro Lecture 17: Stochastic Optimization Part II: Realizable vs Agnostic Rates Part III: Nearest Neighbor Classification Stochastic
Computational and Statistical Learning Theory TTIC 31120 Prof. Nati Srebro Lecture 17: Stochastic Optimization Part II: Realizable vs Agnostic Rates Part III: Nearest Neighbor Classification Stochastic
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Notes on Markov Networks
 Notes on Markov Networks Lili Mou moull12@sei.pku.edu.cn December, 2014 This note covers basic topics in Markov networks. We mainly talk about the formal definition, Gibbs sampling for inference, and maximum
Notes on Markov Networks Lili Mou moull12@sei.pku.edu.cn December, 2014 This note covers basic topics in Markov networks. We mainly talk about the formal definition, Gibbs sampling for inference, and maximum
Elements of Reinforcement Learning
 Elements of Reinforcement Learning Policy: way learning algorithm behaves (mapping from state to action) Reward function: Mapping of state action pair to reward or cost Value function: long term reward,
Elements of Reinforcement Learning Policy: way learning algorithm behaves (mapping from state to action) Reward function: Mapping of state action pair to reward or cost Value function: long term reward,
Adaptive Crowdsourcing via EM with Prior
 Adaptive Crowdsourcing via EM with Prior Peter Maginnis and Tanmay Gupta May, 205 In this work, we make two primary contributions: derivation of the EM update for the shifted and rescaled beta prior and
Adaptive Crowdsourcing via EM with Prior Peter Maginnis and Tanmay Gupta May, 205 In this work, we make two primary contributions: derivation of the EM update for the shifted and rescaled beta prior and
Online Learning and Sequential Decision Making
 Online Learning and Sequential Decision Making Emilie Kaufmann CNRS & CRIStAL, Inria SequeL, emilie.kaufmann@univ-lille.fr Research School, ENS Lyon, Novembre 12-13th 2018 Emilie Kaufmann Sequential Decision
Online Learning and Sequential Decision Making Emilie Kaufmann CNRS & CRIStAL, Inria SequeL, emilie.kaufmann@univ-lille.fr Research School, ENS Lyon, Novembre 12-13th 2018 Emilie Kaufmann Sequential Decision
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
arxiv: v4 [cs.lg] 22 Jul 2014
![arxiv: v4 [cs.lg] 22 Jul 2014](/thumbs/75/72909820.jpg "arxiv: v4 [cs.lg] 22 Jul 2014") Learning to Optimize Via Information-Directed Sampling Daniel Russo and Benjamin Van Roy July 23, 2014 arxiv:1403.5556v4 cs.lg] 22 Jul 2014 Abstract We propose information-directed sampling a new algorithm
Learning to Optimize Via Information-Directed Sampling Daniel Russo and Benjamin Van Roy July 23, 2014 arxiv:1403.5556v4 cs.lg] 22 Jul 2014 Abstract We propose information-directed sampling a new algorithm
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Machine Learning. Linear Models. Fabio Vandin October 10, 2017
 Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
An Empirical Algorithm for Relative Value Iteration for Average-cost MDPs
 2015 IEEE 54th Annual Conference on Decision and Control CDC December 15-18, 2015. Osaka, Japan An Empirical Algorithm for Relative Value Iteration for Average-cost MDPs Abhishek Gupta Rahul Jain Peter
2015 IEEE 54th Annual Conference on Decision and Control CDC December 15-18, 2015. Osaka, Japan An Empirical Algorithm for Relative Value Iteration for Average-cost MDPs Abhishek Gupta Rahul Jain Peter
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
Bayesian Methods. David S. Rosenberg. New York University. March 20, 2018
 Bayesian Methods David S. Rosenberg New York University March 20, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 March 20, 2018 1 / 38 Contents 1 Classical Statistics 2 Bayesian
Bayesian Methods David S. Rosenberg New York University March 20, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 March 20, 2018 1 / 38 Contents 1 Classical Statistics 2 Bayesian
Thompson Sampling for the non-stationary Corrupt Multi-Armed Bandit
 European Worshop on Reinforcement Learning 14 (2018 October 2018, Lille, France. Thompson Sampling for the non-stationary Corrupt Multi-Armed Bandit Réda Alami Orange Labs 2 Avenue Pierre Marzin 22300,
European Worshop on Reinforcement Learning 14 (2018 October 2018, Lille, France. Thompson Sampling for the non-stationary Corrupt Multi-Armed Bandit Réda Alami Orange Labs 2 Avenue Pierre Marzin 22300,
Decision Theory: Markov Decision Processes
 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Algorithmisches Lernen/Machine Learning
 Algorithmisches Lernen/Machine Learning Part 1: Stefan Wermter Introduction Connectionist Learning (e.g. Neural Networks) Decision-Trees, Genetic Algorithms Part 2: Norman Hendrich Support-Vector Machines
Algorithmisches Lernen/Machine Learning Part 1: Stefan Wermter Introduction Connectionist Learning (e.g. Neural Networks) Decision-Trees, Genetic Algorithms Part 2: Norman Hendrich Support-Vector Machines