VIME: Variational Information Maximizing Exploration
|
|
|
- Cory Goodwin
- 5 years ago
- Views:
Transcription
1 1 VIME: Variational Information Maximizing Exploration Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel Reviewed by Zhao Song January 13, 2017
2 1 Exploration in Reinforcement Learning The exploration-exploitation dilemma: Exploration: The agent experiments with novel strategies that may improve returns in the long run; Exploitation: The agent maximizes rewards through behavior that is known to be successful. This paper focuses on the exploration.
3 2 Exploration in Reinforcement Learning (cont.) Typical strategies in exploration: Bayesian RL and PAC-MDP methods - Theoretical guarantees - Not scalable - Continuous control Heuristic exploration - Data inefficient
4 3 Notations Finite-horizon discounted Markov decision process (M D P): S R n : the state set A R m : the action set P : S A S R 0 : the transition probability r : S A R: the reward function γ (0, 1]: the discount factor T : the horizon
5 4 Curiosity-driven Exploration Basic idea: Seeking out state-action regions relatively unexplored [Schmidhuber 1991] Environment dynamics modeled as p(s t+1 s t, a t ; θ) Taking actions that maximize the reduction in uncertainty about the dynamics [ H(Θ ξt, a t ) H(Θ s t+1, ξ t, a t ) ] t where ξ t = {s 1, a 1,..., s t } corresponds to the history up to time t Interpretation using mutual information between s t+1 and Θ [ I(s t+1 ; Θ ξ t, a t ) = E st+1 P( ξ t,a t){d KL p(θ ξt, a t, s t+1 ) p(θ ξ t ) ] } }{{} Information Gain
6 5 Curiosity-driven Exploration (cont.) Explicitly maxmizing mutual information intractable An approximate approach with RL - Taking action a t π α (s t ) - Sampling s t+1 P( s t, a t ) - Obtaining the new reward r (s t, a t, s t+1 ) = r(s t, a t ) + ηd KL [ p(θ ξt, a t, s t+1 ) p(θ ξ t ) ] where η R + is a hyperparameter

7 The VIME Algorithm 6
8 7 Variational Bayes Posterior via Bayes rule where p(θ ξ t, a t, s t+1 ) = p(θ ξ t) p(s t+1 ξ t, a t ; θ) p(s t+1 ξ t, a t ) p(s t+1 ξ t, a t ) = Approximating p(θ D) with q(θ; φ) The total reward is then approximated as Θ p(s t+1 ξ t, a t ; θ) p(θ ξ t )dθ r (s t, a t, s t+1 ) = r(s t, a t ) + ηd KL [ q(θ φt+1 ) q(θ φ t ) ]
9 8 Neural Networks Implementation The Bayesian nerual network (BNN) [Blundell et al. 2015] Modeling p(s t+1 s t, a t ; θ) The weight distribution parameterized by φ Θ q(θ; φ) = N (θ i µ i, σi 2 ) i=1 Feedforward network structure and ReLU nonlinearity between hidden layers Trained by maximizing the variational lower bound using Backprop L[q(θ; φ), D] = E θ q( ;φ) [log p(d θ)] D KL [q(θ; φ) p(θ)]
10 9 Efficient Computation of Information Gain Approximated with D KL [q(θ; φ + λ φ ) q(θ; φ)] 1 Newton s method - Step φ = H 1 (l) φ l ( q(θ; φ), s t ) - Diagonal Hessian 2 Taylor expansion - Only the second-order term left - D KL [q(θ; φ + λ φ ) q(θ; φ)] 1 2 λ2 φ l T H 1 φ l
11 10 Experiments Setup Continous control problems Policies learned by TRPO [Schulman et al. 2015] Performance measured in terms of average return
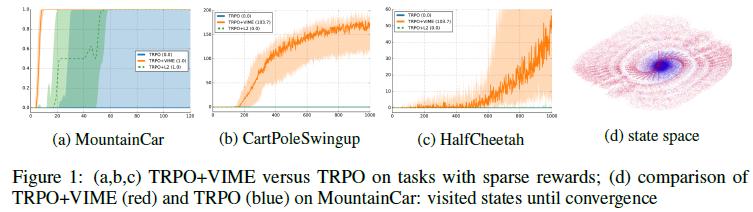
12 Experimental Results 11

13 Experimental Results (cont.) 12

14 Experimental Results (cont.) 13
15 14 References I Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight Uncertainty in Neural Network. : Proceedings of The 32nd International Conference on Machine Learning Jürgen Schmidhuber. Curious Model-Building Control Systems. : Proceedings of International Joint Conference on Neural Networks. Citeseer John Schulman, Sergey Levine, Philipp Moritz, Michael Jordan, and Pieter Abbeel. Trust Region Policy Optimization. : Proceedings of the 32nd International Conference on Machine Learning (ICML-15)
arxiv: v1 [cs.lg] 31 May 2016
![arxiv: v1 [cs.lg] 31 May 2016](/thumbs/89/100528417.jpg "arxiv: v1 [cs.lg] 31 May 2016") Curiosity-driven Exploration in Deep Reinforcement Learning via Bayesian Neural Networks arxiv:165.9674v1 [cs.lg] 31 May 216 Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel
Curiosity-driven Exploration in Deep Reinforcement Learning via Bayesian Neural Networks arxiv:165.9674v1 [cs.lg] 31 May 216 Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel
arxiv: v4 [cs.lg] 27 Jan 2017
![arxiv: v4 [cs.lg] 27 Jan 2017](/thumbs/78/77483835.jpg "arxiv: v4 [cs.lg] 27 Jan 2017") VIME: Variational Information Maximizing Exploration arxiv:1605.09674v4 [cs.lg] 27 Jan 2017 Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel UC Berkeley, Department of Electrical
VIME: Variational Information Maximizing Exploration arxiv:1605.09674v4 [cs.lg] 27 Jan 2017 Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel UC Berkeley, Department of Electrical
Advanced Policy Gradient Methods: Natural Gradient, TRPO, and More. March 8, 2017
 Advanced Policy Gradient Methods: Natural Gradient, TRPO, and More March 8, 2017 Defining a Loss Function for RL Let η(π) denote the expected return of π [ ] η(π) = E s0 ρ 0,a t π( s t) γ t r t We collect
Advanced Policy Gradient Methods: Natural Gradient, TRPO, and More March 8, 2017 Defining a Loss Function for RL Let η(π) denote the expected return of π [ ] η(π) = E s0 ρ 0,a t π( s t) γ t r t We collect
Behavior Policy Gradient Supplemental Material
 Behavior Policy Gradient Supplemental Material Josiah P. Hanna 1 Philip S. Thomas 2 3 Peter Stone 1 Scott Niekum 1 A. Proof of Theorem 1 In Appendix A, we give the full derivation of our primary theoretical
Behavior Policy Gradient Supplemental Material Josiah P. Hanna 1 Philip S. Thomas 2 3 Peter Stone 1 Scott Niekum 1 A. Proof of Theorem 1 In Appendix A, we give the full derivation of our primary theoretical
Trust Region Policy Optimization
 Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Noisy Natural Gradient as Variational Inference
 Noisy Natural Gradient as Variational Inference Guodong Zhang Shengyang Sun David Duvenaud Roger Grosse University of Toronto Vector Institute {gdzhang, ssy, duvenaud, rgrosse}@cs.toronto.edu Abstract
Noisy Natural Gradient as Variational Inference Guodong Zhang Shengyang Sun David Duvenaud Roger Grosse University of Toronto Vector Institute {gdzhang, ssy, duvenaud, rgrosse}@cs.toronto.edu Abstract
Combine Monte Carlo with Exhaustive Search: Effective Variational Inference and Policy Gradient Reinforcement Learning
 Combine Monte Carlo with Exhaustive Search: Effective Variational Inference and Policy Gradient Reinforcement Learning Michalis K. Titsias Department of Informatics Athens University of Economics and Business
Combine Monte Carlo with Exhaustive Search: Effective Variational Inference and Policy Gradient Reinforcement Learning Michalis K. Titsias Department of Informatics Athens University of Economics and Business
Variational Deep Q Network
 Variational Deep Q Network Yunhao Tang Department of IEOR Columbia University yt2541@columbia.edu Alp Kucukelbir Department of Computer Science Columbia University alp@cs.columbia.edu Abstract We propose
Variational Deep Q Network Yunhao Tang Department of IEOR Columbia University yt2541@columbia.edu Alp Kucukelbir Department of Computer Science Columbia University alp@cs.columbia.edu Abstract We propose
Exploration. 2015/10/12 John Schulman
 Exploration 2015/10/12 John Schulman What is the exploration problem? Given a long-lived agent (or long-running learning algorithm), how to balance exploration and exploitation to maximize long-term rewards
Exploration 2015/10/12 John Schulman What is the exploration problem? Given a long-lived agent (or long-running learning algorithm), how to balance exploration and exploitation to maximize long-term rewards
Combining PPO and Evolutionary Strategies for Better Policy Search
 Combining PPO and Evolutionary Strategies for Better Policy Search Jennifer She 1 Abstract A good policy search algorithm needs to strike a balance between being able to explore candidate policies and
Combining PPO and Evolutionary Strategies for Better Policy Search Jennifer She 1 Abstract A good policy search algorithm needs to strike a balance between being able to explore candidate policies and
Probabilistic Mixture of Model-Agnostic Meta-Learners
 Probabilistic Mixture of Model-Agnostic Meta-Learners Prasanna Sattigeri psattig@us.ibm.com Soumya Ghosh ghoshso@us.ibm.com Abhishe Kumar abhishe@inductivebias.net Karthieyan Natesan Ramamurthy natesa@us.ibm.com
Probabilistic Mixture of Model-Agnostic Meta-Learners Prasanna Sattigeri psattig@us.ibm.com Soumya Ghosh ghoshso@us.ibm.com Abhishe Kumar abhishe@inductivebias.net Karthieyan Natesan Ramamurthy natesa@us.ibm.com
Gradient Estimation Using Stochastic Computation Graphs
 Gradient Estimation Using Stochastic Computation Graphs Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology May 9, 2017 Outline Stochastic Gradient Estimation
Gradient Estimation Using Stochastic Computation Graphs Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology May 9, 2017 Outline Stochastic Gradient Estimation
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms *
 Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
σ(a) = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =
 = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =") Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
An Information Theoretic Interpretation of Variational Inference based on the MDL Principle and the Bits-Back Coding Scheme
 An Information Theoretic Interpretation of Variational Inference based on the MDL Principle and the Bits-Back Coding Scheme Ghassen Jerfel April 2017 As we will see during this talk, the Bayesian and information-theoretic
An Information Theoretic Interpretation of Variational Inference based on the MDL Principle and the Bits-Back Coding Scheme Ghassen Jerfel April 2017 As we will see during this talk, the Bayesian and information-theoretic
Reinforcement Learning
 Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Deep Reinforcement Learning
 Deep Reinforcement Learning John Schulman 1 MLSS, May 2016, Cadiz 1 Berkeley Artificial Intelligence Research Lab Agenda Introduction and Overview Markov Decision Processes Reinforcement Learning via Black-Box
Deep Reinforcement Learning John Schulman 1 MLSS, May 2016, Cadiz 1 Berkeley Artificial Intelligence Research Lab Agenda Introduction and Overview Markov Decision Processes Reinforcement Learning via Black-Box
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning. Hanna Kurniawati
 COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
Lecture 9: Policy Gradient II 1
 Lecture 9: Policy Gradient II 1 Emma Brunskill CS234 Reinforcement Learning. Winter 2019 Additional reading: Sutton and Barto 2018 Chp. 13 1 With many slides from or derived from David Silver and John
Lecture 9: Policy Gradient II 1 Emma Brunskill CS234 Reinforcement Learning. Winter 2019 Additional reading: Sutton and Barto 2018 Chp. 13 1 With many slides from or derived from David Silver and John
Decision Theory: Markov Decision Processes
 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Reinforcement Learning for NLP
 Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Deep Reinforcement Learning: Policy Gradients and Q-Learning
 Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Artificial Intelligence & Sequential Decision Problems
 Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
arxiv: v2 [cs.lg] 7 Mar 2018
![arxiv: v2 [cs.lg] 7 Mar 2018](/thumbs/76/73786584.jpg "arxiv: v2 [cs.lg] 7 Mar 2018") Comparing Deep Reinforcement Learning and Evolutionary Methods in Continuous Control arxiv:1712.00006v2 [cs.lg] 7 Mar 2018 Shangtong Zhang 1, Osmar R. Zaiane 2 12 Dept. of Computing Science, University
Comparing Deep Reinforcement Learning and Evolutionary Methods in Continuous Control arxiv:1712.00006v2 [cs.lg] 7 Mar 2018 Shangtong Zhang 1, Osmar R. Zaiane 2 12 Dept. of Computing Science, University
Noisy Natural Gradient as Variational Inference
 Guodong Zhang * 1 2 Shengyang Sun * 1 2 David Duvenaud 1 2 Roger Grosse 1 2 Abstract Variational Bayesian neural nets combine the flexibility of deep learning with Bayesian uncertainty estimation. Unfortunately,
Guodong Zhang * 1 2 Shengyang Sun * 1 2 David Duvenaud 1 2 Roger Grosse 1 2 Abstract Variational Bayesian neural nets combine the flexibility of deep learning with Bayesian uncertainty estimation. Unfortunately,
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
Efficient Learning in Linearly Solvable MDP Models
 Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence Efficient Learning in Linearly Solvable MDP Models Ang Li Department of Computer Science, University of Minnesota
Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence Efficient Learning in Linearly Solvable MDP Models Ang Li Department of Computer Science, University of Minnesota
Reinforcement Learning as Variational Inference: Two Recent Approaches
 Reinforcement Learning as Variational Inference: Two Recent Approaches Rohith Kuditipudi Duke University 11 August 2017 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing
Reinforcement Learning as Variational Inference: Two Recent Approaches Rohith Kuditipudi Duke University 11 August 2017 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing
Stein Variational Policy Gradient
 Stein Variational Policy Gradient Yang Liu UIUC liu301@illinois.edu Prajit Ramachandran UIUC prajitram@gmail.com Qiang Liu Dartmouth qiang.liu@dartmouth.edu Jian Peng UIUC jianpeng@illinois.edu Abstract
Stein Variational Policy Gradient Yang Liu UIUC liu301@illinois.edu Prajit Ramachandran UIUC prajitram@gmail.com Qiang Liu Dartmouth qiang.liu@dartmouth.edu Jian Peng UIUC jianpeng@illinois.edu Abstract
Bayesian Policy Gradients via Alpha Divergence Dropout Inference
 Bayesian Policy Gradients via Alpha Divergence Dropout Inference Peter Henderson* Thang Doan* Riashat Islam David Meger * Equal contributors McGill University peter.henderson@mail.mcgill.ca thang.doan@mail.mcgill.ca
Bayesian Policy Gradients via Alpha Divergence Dropout Inference Peter Henderson* Thang Doan* Riashat Islam David Meger * Equal contributors McGill University peter.henderson@mail.mcgill.ca thang.doan@mail.mcgill.ca
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
 Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel & Sergey Levine Department of Electrical Engineering and Computer
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel & Sergey Levine Department of Electrical Engineering and Computer
Planning by Probabilistic Inference
 Planning by Probabilistic Inference Hagai Attias Microsoft Research 1 Microsoft Way Redmond, WA 98052 Abstract This paper presents and demonstrates a new approach to the problem of planning under uncertainty.
Planning by Probabilistic Inference Hagai Attias Microsoft Research 1 Microsoft Way Redmond, WA 98052 Abstract This paper presents and demonstrates a new approach to the problem of planning under uncertainty.
Recurrent Latent Variable Networks for Session-Based Recommendation
 Recurrent Latent Variable Networks for Session-Based Recommendation Panayiotis Christodoulou Cyprus University of Technology paa.christodoulou@edu.cut.ac.cy 27/8/2017 Panayiotis Christodoulou (C.U.T.)
Recurrent Latent Variable Networks for Session-Based Recommendation Panayiotis Christodoulou Cyprus University of Technology paa.christodoulou@edu.cut.ac.cy 27/8/2017 Panayiotis Christodoulou (C.U.T.)
Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning
 Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning Christos Dimitrakakis Informatics Institute, University of Amsterdam, Amsterdam, The Netherlands
Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning Christos Dimitrakakis Informatics Institute, University of Amsterdam, Amsterdam, The Netherlands
Reinforcement Learning: An Introduction
 Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Bayesian Semi-supervised Learning with Deep Generative Models
 Bayesian Semi-supervised Learning with Deep Generative Models Jonathan Gordon Department of Engineering Cambridge University jg801@cam.ac.uk José Miguel Hernández-Lobato Department of Engineering Cambridge
Bayesian Semi-supervised Learning with Deep Generative Models Jonathan Gordon Department of Engineering Cambridge University jg801@cam.ac.uk José Miguel Hernández-Lobato Department of Engineering Cambridge
Neural network ensembles and variational inference revisited
 1st Symposium on Advances in Approximate Bayesian Inference, 2018 1 11 Neural network ensembles and variational inference revisited Marcin B. Tomczak marcin@prowler.io PROWLER.io Office, 72 Hills Road,
1st Symposium on Advances in Approximate Bayesian Inference, 2018 1 11 Neural network ensembles and variational inference revisited Marcin B. Tomczak marcin@prowler.io PROWLER.io Office, 72 Hills Road,
Machine Learning I Continuous Reinforcement Learning
 Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Crowdsourcing & Optimal Budget Allocation in Crowd Labeling
 Crowdsourcing & Optimal Budget Allocation in Crowd Labeling Madhav Mohandas, Richard Zhu, Vincent Zhuang May 5, 2016 Table of Contents 1. Intro to Crowdsourcing 2. The Problem 3. Knowledge Gradient Algorithm
Crowdsourcing & Optimal Budget Allocation in Crowd Labeling Madhav Mohandas, Richard Zhu, Vincent Zhuang May 5, 2016 Table of Contents 1. Intro to Crowdsourcing 2. The Problem 3. Knowledge Gradient Algorithm
Administration. CSCI567 Machine Learning (Fall 2018) Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.
 Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.") Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
CSC 2541: Bayesian Methods for Machine Learning
 CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 10 Alternatives to Monte Carlo Computation Since about 1990, Markov chain Monte Carlo has been the dominant
CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 10 Alternatives to Monte Carlo Computation Since about 1990, Markov chain Monte Carlo has been the dominant
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning
 REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
Multiagent (Deep) Reinforcement Learning
 Reinforcement Learning") Multiagent (Deep) Reinforcement Learning MARTIN PILÁT (MARTIN.PILAT@MFF.CUNI.CZ) Reinforcement learning The agent needs to learn to perform tasks in environment No prior knowledge about the effects of
Multiagent (Deep) Reinforcement Learning MARTIN PILÁT (MARTIN.PILAT@MFF.CUNI.CZ) Reinforcement learning The agent needs to learn to perform tasks in environment No prior knowledge about the effects of
Lecture 9: Policy Gradient II (Post lecture) 2
 2") Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016)
") Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016) Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology October 11, 2016 Outline
Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016) Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology October 11, 2016 Outline
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Learning Dexterity Matthias Plappert SEPTEMBER 6, 2018
 Learning Dexterity Matthias Plappert SEPTEMBER 6, 2018 OpenAI OpenAI is a non-profit AI research company, discovering and enacting the path to safe artificial general intelligence. OpenAI OpenAI is a non-profit
Learning Dexterity Matthias Plappert SEPTEMBER 6, 2018 OpenAI OpenAI is a non-profit AI research company, discovering and enacting the path to safe artificial general intelligence. OpenAI OpenAI is a non-profit
MDP Preliminaries. Nan Jiang. February 10, 2019
 MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
Bayesian Regression Linear and Logistic Regression
 When we want more than point estimates Bayesian Regression Linear and Logistic Regression Nicole Beckage Ordinary Least Squares Regression and Lasso Regression return only point estimates But what if we
When we want more than point estimates Bayesian Regression Linear and Logistic Regression Nicole Beckage Ordinary Least Squares Regression and Lasso Regression return only point estimates But what if we
Reinforcement Learning
 Reinforcement Learning From the basics to Deep RL Olivier Sigaud ISIR, UPMC + INRIA http://people.isir.upmc.fr/sigaud September 14, 2017 1 / 54 Introduction Outline Some quick background about discrete
Reinforcement Learning From the basics to Deep RL Olivier Sigaud ISIR, UPMC + INRIA http://people.isir.upmc.fr/sigaud September 14, 2017 1 / 54 Introduction Outline Some quick background about discrete
Active Learning of MDP models
 Active Learning of MDP models Mauricio Araya-López, Olivier Buffet, Vincent Thomas, and François Charpillet Nancy Université / INRIA LORIA Campus Scientifique BP 239 54506 Vandoeuvre-lès-Nancy Cedex France
Active Learning of MDP models Mauricio Araya-López, Olivier Buffet, Vincent Thomas, and François Charpillet Nancy Université / INRIA LORIA Campus Scientifique BP 239 54506 Vandoeuvre-lès-Nancy Cedex France
Be able to define the following terms and answer basic questions about them:
 CS440/ECE448 Section Q Fall 2017 Final Review Be able to define the following terms and answer basic questions about them: Probability o Random variables, axioms of probability o Joint, marginal, conditional
CS440/ECE448 Section Q Fall 2017 Final Review Be able to define the following terms and answer basic questions about them: Probability o Random variables, axioms of probability o Joint, marginal, conditional
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Lecture 7: CS395T Numerical Optimization for Graphics and AI Trust Region Methods
 Lecture 7: CS395T Numerical Optimization for Graphics and AI Trust Region Methods Qixing Huang The University of Texas at Austin huangqx@cs.utexas.edu 1 Disclaimer This note is adapted from Section 4 of
Lecture 7: CS395T Numerical Optimization for Graphics and AI Trust Region Methods Qixing Huang The University of Texas at Austin huangqx@cs.utexas.edu 1 Disclaimer This note is adapted from Section 4 of
Q-learning. Tambet Matiisen
 Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning via Policy Optimization
 Reinforcement Learning via Policy Optimization Hanxiao Liu November 22, 2017 1 / 27 Reinforcement Learning Policy a π(s) 2 / 27 Example - Mario 3 / 27 Example - ChatBot 4 / 27 Applications - Video Games
Reinforcement Learning via Policy Optimization Hanxiao Liu November 22, 2017 1 / 27 Reinforcement Learning Policy a π(s) 2 / 27 Example - Mario 3 / 27 Example - ChatBot 4 / 27 Applications - Video Games
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
CS230: Lecture 9 Deep Reinforcement Learning
 CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
arxiv: v3 [cs.ai] 22 Feb 2018
![arxiv: v3 [cs.ai] 22 Feb 2018](/thumbs/80/80503071.jpg "arxiv: v3 [cs.ai] 22 Feb 2018") TRUST-PCL: AN OFF-POLICY TRUST REGION METHOD FOR CONTINUOUS CONTROL Ofir Nachum, Mohammad Norouzi, Kelvin Xu, & Dale Schuurmans {ofirnachum,mnorouzi,kelvinxx,schuurmans}@google.com Google Brain ABSTRACT
TRUST-PCL: AN OFF-POLICY TRUST REGION METHOD FOR CONTINUOUS CONTROL Ofir Nachum, Mohammad Norouzi, Kelvin Xu, & Dale Schuurmans {ofirnachum,mnorouzi,kelvinxx,schuurmans}@google.com Google Brain ABSTRACT
Sampling diverse neural networks for exploration in reinforcement learning
 Sampling diverse neural networks for exploration in reinforcement learning Maxime Wabartha School of Computer Science McGill University maxime.wabartha@mail.mcgill.ca Vincent François-Lavet School of Computer
Sampling diverse neural networks for exploration in reinforcement learning Maxime Wabartha School of Computer Science McGill University maxime.wabartha@mail.mcgill.ca Vincent François-Lavet School of Computer
Algorithms for Variational Learning of Mixture of Gaussians
 Algorithms for Variational Learning of Mixture of Gaussians Instructors: Tapani Raiko and Antti Honkela Bayes Group Adaptive Informatics Research Center 28.08.2008 Variational Bayesian Inference Mixture
Algorithms for Variational Learning of Mixture of Gaussians Instructors: Tapani Raiko and Antti Honkela Bayes Group Adaptive Informatics Research Center 28.08.2008 Variational Bayesian Inference Mixture
Preference Elicitation for Sequential Decision Problems
 Preference Elicitation for Sequential Decision Problems Kevin Regan University of Toronto Introduction 2 Motivation Focus: Computational approaches to sequential decision making under uncertainty These
Preference Elicitation for Sequential Decision Problems Kevin Regan University of Toronto Introduction 2 Motivation Focus: Computational approaches to sequential decision making under uncertainty These
Nonparametric Inference for Auto-Encoding Variational Bayes
 Nonparametric Inference for Auto-Encoding Variational Bayes Erik Bodin * Iman Malik * Carl Henrik Ek * Neill D. F. Campbell * University of Bristol University of Bath Variational approximations are an
Nonparametric Inference for Auto-Encoding Variational Bayes Erik Bodin * Iman Malik * Carl Henrik Ek * Neill D. F. Campbell * University of Bristol University of Bath Variational approximations are an
Learning Exploration/Exploitation Strategies for Single Trajectory Reinforcement Learning
 JMLR: Workshop and Conference Proceedings vol:1 8, 2012 10th European Workshop on Reinforcement Learning Learning Exploration/Exploitation Strategies for Single Trajectory Reinforcement Learning Michael
JMLR: Workshop and Conference Proceedings vol:1 8, 2012 10th European Workshop on Reinforcement Learning Learning Exploration/Exploitation Strategies for Single Trajectory Reinforcement Learning Michael
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Constraint-Space Projection Direct Policy Search
 Constraint-Space Projection Direct Policy Search Constraint-Space Projection Direct Policy Search Riad Akrour 1 riad@robot-learning.de Jan Peters 1,2 jan@robot-learning.de Gerhard Neumann 1,2 geri@robot-learning.de
Constraint-Space Projection Direct Policy Search Constraint-Space Projection Direct Policy Search Riad Akrour 1 riad@robot-learning.de Jan Peters 1,2 jan@robot-learning.de Gerhard Neumann 1,2 geri@robot-learning.de
Scalable Non-linear Beta Process Factor Analysis
 Scalable Non-linear Beta Process Factor Analysis Kai Fan Duke University kai.fan@stat.duke.edu Katherine Heller Duke University kheller@stat.duke.com Abstract We propose a non-linear extension of the factor
Scalable Non-linear Beta Process Factor Analysis Kai Fan Duke University kai.fan@stat.duke.edu Katherine Heller Duke University kheller@stat.duke.com Abstract We propose a non-linear extension of the factor
arxiv: v4 [stat.ml] 15 Jun 2018
![arxiv: v4 [stat.ml] 15 Jun 2018](/thumbs/87/96966065.jpg "arxiv: v4 [stat.ml] 15 Jun 2018") for Efficient and Risk-sensitive Learning Stefan Depeweg 1 2 José Miguel Hernández-Lobato 3 Finale Doshi-Velez 4 Steffen Udluft 1 arxiv:1710.07283v4 [stat.ml] 15 Jun 2018 Abstract Bayesian neural networks
for Efficient and Risk-sensitive Learning Stefan Depeweg 1 2 José Miguel Hernández-Lobato 3 Finale Doshi-Velez 4 Steffen Udluft 1 arxiv:1710.07283v4 [stat.ml] 15 Jun 2018 Abstract Bayesian neural networks
Exercises, II part Exercises, II part
 Inference: 12 Jul 2012 Consider the following Joint Probability Table for the three binary random variables A, B, C. Compute the following queries: 1 P(C A=T,B=T) 2 P(C A=T) P(A, B, C) A B C 0.108 T T
Inference: 12 Jul 2012 Consider the following Joint Probability Table for the three binary random variables A, B, C. Compute the following queries: 1 P(C A=T,B=T) 2 P(C A=T) P(A, B, C) A B C 0.108 T T
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Bayesian reinforcement learning and partially observable Markov decision processes November 6, / 24
 and partially observable Markov decision processes Christos Dimitrakakis EPFL November 6, 2013 Bayesian reinforcement learning and partially observable Markov decision processes November 6, 2013 1 / 24
and partially observable Markov decision processes Christos Dimitrakakis EPFL November 6, 2013 Bayesian reinforcement learning and partially observable Markov decision processes November 6, 2013 1 / 24
Deep Q-Learning with Recurrent Neural Networks
 Deep Q-Learning with Recurrent Neural Networks Clare Chen cchen9@stanford.edu Vincent Ying vincenthying@stanford.edu Dillon Laird dalaird@cs.stanford.edu Abstract Deep reinforcement learning models have
Deep Q-Learning with Recurrent Neural Networks Clare Chen cchen9@stanford.edu Vincent Ying vincenthying@stanford.edu Dillon Laird dalaird@cs.stanford.edu Abstract Deep reinforcement learning models have
Markov decision processes
 CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
Proximal Policy Optimization (PPO)
") Proximal Policy Optimization (PPO) default reinforcement learning algorithm at OpenAI Policy Gradient On-policy Off-policy Add constraint DeepMind https://youtu.be/gn4nrcc9twq OpenAI https://blog.openai.com/o
Proximal Policy Optimization (PPO) default reinforcement learning algorithm at OpenAI Policy Gradient On-policy Off-policy Add constraint DeepMind https://youtu.be/gn4nrcc9twq OpenAI https://blog.openai.com/o
, and rewards and transition matrices as shown below:
 CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
Deep Reinforcement Learning SISL. Jeremy Morton (jmorton2) November 7, Stanford Intelligent Systems Laboratory
 November 7, Stanford Intelligent Systems Laboratory") Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Model Selection for Gaussian Processes
 Institute for Adaptive and Neural Computation School of Informatics,, UK December 26 Outline GP basics Model selection: covariance functions and parameterizations Criteria for model selection Marginal
Institute for Adaptive and Neural Computation School of Informatics,, UK December 26 Outline GP basics Model selection: covariance functions and parameterizations Criteria for model selection Marginal
CS 598 Statistical Reinforcement Learning. Nan Jiang
 CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
Reinforcement Learning as Classification Leveraging Modern Classifiers
 Reinforcement Learning as Classification Leveraging Modern Classifiers Michail G. Lagoudakis and Ronald Parr Department of Computer Science Duke University Durham, NC 27708 Machine Learning Reductions
Reinforcement Learning as Classification Leveraging Modern Classifiers Michail G. Lagoudakis and Ronald Parr Department of Computer Science Duke University Durham, NC 27708 Machine Learning Reductions
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
Predictive Processing in Planning:
 Predictive Processing in Planning: Choice Behavior as Active Bayesian Inference Philipp Schwartenbeck Wellcome Trust Centre for Human Neuroimaging, UCL The Promise of Predictive Processing: A Critical
Predictive Processing in Planning: Choice Behavior as Active Bayesian Inference Philipp Schwartenbeck Wellcome Trust Centre for Human Neuroimaging, UCL The Promise of Predictive Processing: A Critical
Inverse Optimal Control
 Inverse Optimal Control Oleg Arenz Technische Universität Darmstadt o.arenz@gmx.de Abstract In Reinforcement Learning, an agent learns a policy that maximizes a given reward function. However, providing
Inverse Optimal Control Oleg Arenz Technische Universität Darmstadt o.arenz@gmx.de Abstract In Reinforcement Learning, an agent learns a policy that maximizes a given reward function. However, providing
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Comparing Deep Reinforcement Learning and Evolutionary Methods in Continuous Control
 Comparing Deep Reinforcement Learning and Evolutionary Methods in Continuous Control Shangtong Zhang Dept. of Computing Science University of Alberta shangtong.zhang@ualberta.ca Osmar R. Zaiane Dept. of
Comparing Deep Reinforcement Learning and Evolutionary Methods in Continuous Control Shangtong Zhang Dept. of Computing Science University of Alberta shangtong.zhang@ualberta.ca Osmar R. Zaiane Dept. of
Forward Actor-Critic for Nonlinear Function Approximation in Reinforcement Learning
 Forward Actor-Critic for Nonlinear Function Approximation in Reinforcement Learning Vivek Veeriah Dept. of Computing Science University of Alberta Edmonton, Canada vivekveeriah@ualberta.ca Harm van Seijen
Forward Actor-Critic for Nonlinear Function Approximation in Reinforcement Learning Vivek Veeriah Dept. of Computing Science University of Alberta Edmonton, Canada vivekveeriah@ualberta.ca Harm van Seijen
Bayesian Neural Networks
 Vikram Mullachery mv333@nyu.edu Bayesian Neural Networks Aniruddh Khera ak5146@nyu.edu Amir Husain ah3548@nyu.edu Abstract This paper describes, and discusses Bayesian Neural Network (BNN). The paper showcases
Vikram Mullachery mv333@nyu.edu Bayesian Neural Networks Aniruddh Khera ak5146@nyu.edu Amir Husain ah3548@nyu.edu Abstract This paper describes, and discusses Bayesian Neural Network (BNN). The paper showcases
Development of a Deep Recurrent Neural Network Controller for Flight Applications
 Development of a Deep Recurrent Neural Network Controller for Flight Applications American Control Conference (ACC) May 26, 2017 Scott A. Nivison Pramod P. Khargonekar Department of Electrical and Computer
Development of a Deep Recurrent Neural Network Controller for Flight Applications American Control Conference (ACC) May 26, 2017 Scott A. Nivison Pramod P. Khargonekar Department of Electrical and Computer
Variance Reduction for Policy Gradient Methods. March 13, 2017
 Variance Reduction for Policy Gradient Methods March 13, 2017 Reward Shaping Reward Shaping Reward Shaping Reward shaping: r(s, a, s ) = r(s, a, s ) + γφ(s ) Φ(s) for arbitrary potential Φ Theorem: r admits
Variance Reduction for Policy Gradient Methods March 13, 2017 Reward Shaping Reward Shaping Reward Shaping Reward shaping: r(s, a, s ) = r(s, a, s ) + γφ(s ) Φ(s) for arbitrary potential Φ Theorem: r admits
Lecture 8: Policy Gradient I 2
 Lecture 8: Policy Gradient I 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver and John Schulman
Lecture 8: Policy Gradient I 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver and John Schulman
Implicit Incremental Natural Actor Critic
 Implicit Incremental Natural Actor Critic Ryo Iwaki and Minoru Asada Osaka University, -1, Yamadaoka, Suita city, Osaka, Japan {ryo.iwaki,asada}@ams.eng.osaka-u.ac.jp Abstract. The natural policy gradient
Implicit Incremental Natural Actor Critic Ryo Iwaki and Minoru Asada Osaka University, -1, Yamadaoka, Suita city, Osaka, Japan {ryo.iwaki,asada}@ams.eng.osaka-u.ac.jp Abstract. The natural policy gradient
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Reinforcement Learning. George Konidaris
 Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
arxiv: v1 [cs.ne] 4 Dec 2015
![arxiv: v1 [cs.ne] 4 Dec 2015](/thumbs/74/70189552.jpg "arxiv: v1 [cs.ne] 4 Dec 2015") Q-Networks for Binary Vector Actions arxiv:1512.01332v1 [cs.ne] 4 Dec 2015 Naoto Yoshida Tohoku University Aramaki Aza Aoba 6-6-01 Sendai 980-8579, Miyagi, Japan naotoyoshida@pfsl.mech.tohoku.ac.jp Abstract
Q-Networks for Binary Vector Actions arxiv:1512.01332v1 [cs.ne] 4 Dec 2015 Naoto Yoshida Tohoku University Aramaki Aza Aoba 6-6-01 Sendai 980-8579, Miyagi, Japan naotoyoshida@pfsl.mech.tohoku.ac.jp Abstract