Q-Learning in Continuous State Action Spaces
|
|
|
- Sandra Shields
- 6 years ago
- Views:
Transcription
1 Q-Learning in Continuous State Action Spaces Alex Irpan December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental Results 7 6 Further Work 10 7 Conclusion 11 1 Introduction Recent results combining Q-learning with deep neural nets have achieved surprising result. The highest profile success story comes from Google DeepMind s paper on learning how to play Atari games from raw pixel input [1]. However, their approach applies best to problems with a small discrete action space, which is not ideal for many problems. This presents some potential methods for Q-learning in continuous state action spaces. 2 Background A Markov Decision Process (MDP) is a tuple (S, A, P, R, γ, H). S is the state space, A is the action space, P is the transition dynamics which represents P r(s t+1 s, a). R represents the reward when taking action a in state s. For now, we assume R is constant given s, a, and successor state s. γ (0, 1] is the discount factor. Commonly, exponential discounting is used, meaning the reward at time step t is multiplied by γ t. H is the horizon, and describes how 1
2 many time steps the agent has to act. This can either be finite or infinite; in the infinite horizon case we require γ < 1. Collectively, these are called the dynamics of the MDP. As suggested by the name, an MDP is memoryless, and the next state depends only on the current state and action. More formally, s t+1 s 1, a 1,..., s t 1, a t 1 s t, a t A policy π returns the action an agent should take from a given state. The goal is to learn the policy that maximizes expected reward (henceforth called the optimal policy and denoted by π. In many scenarios, the dynamics are only partially known. In these settings, we need to learn estimates of the dynamics, which makes the problem significantly more difficult. Reinforcement learning algorithms (often abbreviated as RL) are a broad class of algorithms for solving these problems. At a high level, these algorithms are structured as the following. 1. Initialize parameters of the policy randomly 2. Sample the state action space, observing transitions (s t, a t, r t, s t+1 ) (reward and next state for taking action s t in state s t.) 3. Update parameters according to these samples in a way that increases reward of the new policy. Repeat. We present some traditional RL algorithms before describing their modifications. For more details, see [2]. 3 Q-Learning In the following, we often refer to episodes from a policy. An episode is a sequence (s 0, a 0, s 1, a 1, ) of the states and actions the agent observes. An episode continues until we either run out of time or hit a terminal state. Let V π (s) be the value function, the expected reward when following policy π from state s. The Q-function Q π (s, a) is the expected reward for taking action a from s, then following policy π for the rest of the episode. It can be defined as Q π (s, a) = E s [R(s, a) + γv π (s )] = E s [R(s, a) + γq(s, π(s ))] Q-learning is a reinforcement learning algorithm that learns the Q-function. To derive the approach used, first consider the optimal value and Q-functions. The optimal value function is V (s) = V π (s), and the optimal Q-function is Q (s, a) = Q π (s, a). Because MDPs are memoryless, we have V (s) = max Q (s, a) a In other words, the optimal action a is the one such that the reward for taking action a and acting optimally afterwards is maximized. Substituting into the 2
3 Q-function, this gives Q (s, a) = E s [R(s, a) + γ max a Q (s, a )] From this, we can derive the core operator of Q-learning, the Bellman backup operator. Going forward, we assume Q-functions are defined by a parameter vector θ, with notation Q θ (s, a). On each iteration of Q-learning, we have a parameter estimate θ (n). From the current estimated Q(s, a), generate a policy π n. One common choice is ɛ-greedy, defined as { random with probability ɛ π n (s) = argmax a Q θ (n)(s, a) otherwise After trying action a from state s, we observe reward R and next state s. After seeing this sample (s, a, R, s ), we want the Q-function to satisfy Q θ (s, a) = R + γ max a Q θ (s, a ) Use a quadratic loss function to describe the error. Update θ by l (n) (θ) = 1 ((R + γ max Q 2 θ (n)(s, a )) Q θ (s, a)) 2 a θ (n+1) min θ l (n) (θ (n) ) Note every iteration has a slightly different loss function. Computing max a Q θ (s, a) is difficult if θ is a parameter of the loss function, so we instead maximize with respect to known parameter θ (n), and use a more accurate loss function each iteration. The Bellman backup can be interpreted as a one step lookahead. R + γ max a Q θ (n)(s, a) is the value for taking action a, then acting optimally based on the current estimate of θ. Thus, the loss depends on the sample and the value exactly one timestep in the future. Q-learning is guaranteed to converge when Q is represented by a S A array. Once parametrized, these theoretical guarantees go away, but unfortunately this is necessary to make problems computationally tractable. For the approach used in the project, the parameters θ are the parameters of a neural net. The minimum θ can be computed by running gradient descent for enough iterations, but instead we run only one update. θ (n+1) θ (n) η θ l (n) (θ (n) ) where η is a step size. Expanding the gradient gives θ (n+1) θ (n) η(r + γ max a Q θ (n)(s, a ) Q θ (s, a)) θ Q θ (s, a) 3
4 This approach is more common, and can be interpreted as either avoiding overfitting to one sample or adding a penalty term for moving too far from θ (n). It can also be motivated by noting that samples received depend on the accuracy of θ, so updating θ earlier should give a more accurate loss function (at the cost of more variance.) The great strength of reinforcement learning is that it is online and model free. The agent can learn even when it has no information on how the environment behaves, and can do so by directly taking actions in the environment instead of in simultation. This gives these algorithms incredible generality. However, this generality comes at significant cost. Often, reinforcement learning requires many samples to converge to a good policy. RL also struggles with exploration-exploitation trade-offs, the problem of choosing whether to repeatedly take a known good action or whether to explore an unknown action that could be better. In recent years, reinforcement learning has received a revival of interest because of the advancements in deep learning. Often called deep reinforcment learning, this approach uses a deep neural net to model Q-functions. The neural net takes state as input, and outputs A values, corresponding to the estimated Q-values for each action. Neural net Q-functions still have the same issues as the rest of RL, but more uniquely training a large neural net requires even more samples and even more training time. 4 Q-Learning In Continuous Spaces Q-learning in continuous spaces becomes significantly trickier, since many approaches for Q-learning assume a discrete action space. The simplest way to get around this is to apply discretization. For an action from a continuous range, divide it into N buckets. Apply Q-learning to this approximated MDP with a discrete action space. When getting samples, act in the true continuous MDP. Dividing a two dimensional action space into 9 discrete actions As N increases, the discretization gets more accurate. However, this introduces new problems. Suppose the MDP action space is multidimensional. If the action space is d-dimensional, and each dimension is discretized into N buckets, there are N d actions. For even small dimensional problems, this quickly limits how large N can be. For neural net Q-functions, this is especially problematic 4

5 because the final layer needs to have N d outputs, which makes the number of parameters grow exponentially. A representation for when N = 3, d = 3. The final layer needs 27 outputs. To deal with the problem, we add indepedence assumptions. More specifically, we assume the dimensions of the action space are mutually independent. Suppose the Q-function is the additive sum of basis functions that are defined only over one of the action dimensions. Q(s, a) = i Q i (s, a(i)) Then, the value for an action only requires storing the d values for each Q i (s, a(i)), giving N d outputs total. 5
, max a Q(s, a), and Q(s, a). Computing Q(s, a) is easy from the definition.")
6 The representation with independence assumptions. The 9 outputs are split into three blocks of 3, for the three dimensions of the action space. To motivate why an additive Q-function is good, consider the Q-learning update. This requires evaluating Q(s, a), max a Q(s, a), and Q(s, a). Computing Q(s, a) is easy from the definition. For the other two, max a Q(s, a) = max a Q i (s, a(i)) = i i max a(i) Q i(s, a(i)) Q(s, a) = i Q i (s, a(i)) = i Q i (s, a(i)) The additive nature makes everything in the update computable from just the basis functions. Much like directed graphical models, this allows us to implicitly represent the joint action space with a set of smaller spaces, and this representation allows us to run Q-learning without ever needing to explicitly expand out all N d possible actions. Note also that the independence assumption arises naturally - the value for the component a(i) can be maximized independently of the value for a(j). Work by Guestrin et. al. showed that the Q-function can be represented by a graph, where edges denote dependence and lack of edges denote conditional independence [3]. Computing the maximum can be done with an analogue of variable elimination. 6
7 Adding this independence assumption may not be accurate, and in fact for many problems it seems very unlikely it would be. However, parametrized Q- functions are already quite lossy, so it seemed interesting to see if the increased loss from adding unsupported independences could be balanced out by the faster computation. 5 Experimental Results For the continuous problem, I have tried running experiments in LQR, because the problem is both small and the dimension can be made arbitrarily large. Unfortunately, I have yet to get Q-learning working in even the one-dimensional case, which makes it hard to run experimenets in higher dimensions. This section will be devoted to analyzing a more discrete problem. In the Atari domain, the states are the pixels displayed on the screen. The actions are the 18 actions corresponding to a choice of each of the following. Left, neutral, or right on the control stick. Up, neutral, or down on the control stick. Press, do not press the button. The reward is the score gained after taking the given action. As a control, the experiment starts with the neural net architecture from Google DeepMind. This is a convolutional neural net that ends in a final fully connected layer with 18 outputs, the Q-values for the 18 actions. (They actually use a variant called DQN. This variant stores a replay buffer of the most recent actions, and samples data from the replay buffer instead of using just the most recent action.) In the factored version, everything is the same except for the final layer, which is replaced with the = 8 outputs needed for the three dimensions. The evaluation, max, and gradient are also changed to match the derivations above. All hyperparameters are unchanged. Both approaches were tested on the Atari game Asteroids. The reason for choosing this game is that in the factored representation, there is an assumption that every action in the joint action space in meaningful. For some games like Breakout, only a small subset of the 18 actions actually make sense. Results are summarized in the following three graphs. Joint refers to the control, where the final layer has 18 outputs. Factored refers to the factored representation. Each epoch is sample actions, divided into several episodes. An episode is one run of the policy, starting from the start state and stopping when the player loses their last life. Loss is averaged across each episode, while mean episode length and average reward are averaged across epochs. 7
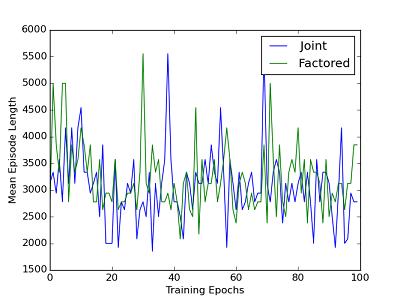
8 8
9 The average loss appears to stay roughly constant over time, but for Q- learning this is not necessarily bad. Recall the loss function changes every time θ changes. Decreasing loss may mean the algorithm plateaus, or it may mean the rate of improvement is constant. In this case, it unfortunately seems like the former is true. The mean episode length does not increase, much like the control. However, the average reward is immediately much higher than the neural net with the joint action space. Note however that average reward is immediately much better than the control algorithm. On inspecting a sample episode by the factored agent, its ability to dodge asteroids is qualitatively the same as the control. However, it shoots much more often, earning it more points. This is backed up by the mean episode length being around the same for both approaches. If the improved performance was just from computational speedup, an improvement of this order of magnitude sounds too good to be true. The different loss curves suggests that the algorithm setup is simply more conducive to this specific problem. In the game of Asteroids, shooting is almost always a good move. In the control algorithm, the shooting decision is spread out over the 9 separate actions describing how the ship should move while shooting. In the factored algorithm, the shooting decision depends on only the 2 actions for that dimension of the action space. The observed reward on shooting is concentrated on just the one output node, which lets it propagate back faster. Although this domain is a bad example for demonstrating computational speedup, it does suggest that explicitly diving the action space can sometimes give better performance on its own. 9
, outputting a distribution over actions given the state.")
10 6 Further Work There are other RL approaches that may benefit from applying conditional independence. One promising approach is policy gradient methods. In these methods we learn a stochastic policy π(a s), outputting a distribution over actions given the state. A stochastic policy lets us make a smooth update towards improving the policy, allowing us to learn policies directly. Let a trajectory τ = (s 0, a 0, s 1, a 1, ) be the states and actions seen in one episode. Let θ be the parameters for π. The trajectory depends on the policy, so we can define the following. l(θ) = E τ πθ [R(τ)] Through some manipulation, we can show the gradient is [ ] θ l(τ) = E R(τ) t θ log π(a t s t ) See [4] for the derivation. This expectation is still hard to compute exactly, but as an estimate we can sample n trajectories and take the average. Doing gradient ascent will adjust θ towards improved expected reward. The action distribution can be represented by a directed graphical model like this one, where each action node depends on the state node. Each action dimension is conditioned on the state and optionally other action dimensions. Let π i be the conditional probability at node i. This gives π(a s) = i π i (a(i) parents(i), s) 10
11 To run policy gradient, we need to sample actions a and evaluate θ log π(a t s t ). Since the graphical model is a DAG, sampling can be done by choosing the component for the root node, then removing assigned nodes. For the gradient, θ log π(a s) = i θ log π i (a(i) parents(i), s) which is computable directly from the conditional probabilities. However, this policy gradient approach is still based on discretizing the continuous action space. It seems that there should be a better approach that exploits the continuous structure. One approach that looks interesting is the wire fitting method [5]. In this approach, the inference algorithm takes state s, and outputs pairs (q i, ai ). The Q-function is then interpolated by these pairs. i Q(s, a) = w iq i (s) i w, where w i 1/ dist(a, a i ) i These pairs are called wires because they guide the Q-function. The algorithm is designed such that the wire locations can change based on the state, and those locations depend on the samples received so far. Intuitively, the discretization approach assumes the Q-function has about the same complexity across the entire action space. If the Q-function is complex in a small region (if the Q-function rises and falls many times in that region), then discretization will not model that Q-function well. The other benefit is that because there is a computable Q-function for an arbitrary continuous action, we can directly sample actions from the continuous space, instead of sampling actions from the discretized space. One approach for turning the Q-function into a policy is to find the maximal action, then add Gaussian noise to the action. 7 Conclusion Although I unfortunately did not get the approach to work in a continuous problem, the experiments I did do suggests there are merits to this idea, and there are some interesting alternate approaches that are worth trying out. References [1] Mnih, Volodymyr, et al. Human-level control through deep reinforcement learning. Nature (2015): s [2] Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. Vol. 1. No. 1. Cambridge: MIT press, [3] Guestrin, Carlos, et al. Efficient solution algorithms for factored MDPs. Journal of Artificial Intelligence Research (2003):
12 [4] Jan Peters (2010) Policy gradient methods. Scholarpedia, 5(11):3698. [5] Gaskett, Chris, David Wettergreen, and Alexander Zelinsky. Q-learning in continuous state and action spaces. Australian Joint Conference on Artificial Intelligence
(Deep) Reinforcement Learning
 Reinforcement Learning") Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
INF 5860 Machine learning for image classification. Lecture 14: Reinforcement learning May 9, 2018
 Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
1 Introduction 2. 4 Q-Learning The Q-value The Temporal Difference The whole Q-Learning process... 5
 Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
Human-level control through deep reinforcement. Liia Butler
 Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Introduction to Reinforcement Learning
 CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
Trust Region Policy Optimization
 Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Deep Reinforcement Learning
 Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 50 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 50 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Approximation Methods in Reinforcement Learning
 2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
David Silver, Google DeepMind
 Tutorial: Deep Reinforcement Learning David Silver, Google DeepMind Outline Introduction to Deep Learning Introduction to Reinforcement Learning Value-Based Deep RL Policy-Based Deep RL Model-Based Deep
Tutorial: Deep Reinforcement Learning David Silver, Google DeepMind Outline Introduction to Deep Learning Introduction to Reinforcement Learning Value-Based Deep RL Policy-Based Deep RL Model-Based Deep
15-780: ReinforcementLearning
 15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
, and rewards and transition matrices as shown below:
 CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
Markov Decision Processes and Solving Finite Problems. February 8, 2017
 Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Q-learning. Tambet Matiisen
 Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Reinforcement Learning. Spring 2018 Defining MDPs, Planning
 Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Lecture 10 - Planning under Uncertainty (III)
") Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
Learning Control for Air Hockey Striking using Deep Reinforcement Learning
 Learning Control for Air Hockey Striking using Deep Reinforcement Learning Ayal Taitler, Nahum Shimkin Faculty of Electrical Engineering Technion - Israel Institute of Technology May 8, 2017 A. Taitler,
Learning Control for Air Hockey Striking using Deep Reinforcement Learning Ayal Taitler, Nahum Shimkin Faculty of Electrical Engineering Technion - Israel Institute of Technology May 8, 2017 A. Taitler,
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016)
") Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016) Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology October 11, 2016 Outline
Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016) Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology October 11, 2016 Outline
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation
 Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 9: Policy Gradient II 1
 Lecture 9: Policy Gradient II 1 Emma Brunskill CS234 Reinforcement Learning. Winter 2019 Additional reading: Sutton and Barto 2018 Chp. 13 1 With many slides from or derived from David Silver and John
Lecture 9: Policy Gradient II 1 Emma Brunskill CS234 Reinforcement Learning. Winter 2019 Additional reading: Sutton and Barto 2018 Chp. 13 1 With many slides from or derived from David Silver and John
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Lecture 9: Policy Gradient II (Post lecture) 2
 2") Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Approximate Q-Learning. Dan Weld / University of Washington
 Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Internet Monetization
 Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
Temporal Difference. Learning KENNETH TRAN. Principal Research Engineer, MSR AI
 Temporal Difference Learning KENNETH TRAN Principal Research Engineer, MSR AI Temporal Difference Learning Policy Evaluation Intro to model-free learning Monte Carlo Learning Temporal Difference Learning
Temporal Difference Learning KENNETH TRAN Principal Research Engineer, MSR AI Temporal Difference Learning Policy Evaluation Intro to model-free learning Monte Carlo Learning Temporal Difference Learning
Temporal difference learning
 Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
MDP Preliminaries. Nan Jiang. February 10, 2019
 MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
Reinforcement Learning
 Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
CS230: Lecture 9 Deep Reinforcement Learning
 CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
Administration. CSCI567 Machine Learning (Fall 2018) Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.
 Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.") Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning
 REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
Artificial Intelligence
 Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Reinforcement Learning Active Learning
 Reinforcement Learning Active Learning Alan Fern * Based in part on slides by Daniel Weld 1 Active Reinforcement Learning So far, we ve assumed agent has a policy We just learned how good it is Now, suppose
Reinforcement Learning Active Learning Alan Fern * Based in part on slides by Daniel Weld 1 Active Reinforcement Learning So far, we ve assumed agent has a policy We just learned how good it is Now, suppose
Reinforcement Learning
 Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Variance Reduction for Policy Gradient Methods. March 13, 2017
 Variance Reduction for Policy Gradient Methods March 13, 2017 Reward Shaping Reward Shaping Reward Shaping Reward shaping: r(s, a, s ) = r(s, a, s ) + γφ(s ) Φ(s) for arbitrary potential Φ Theorem: r admits
Variance Reduction for Policy Gradient Methods March 13, 2017 Reward Shaping Reward Shaping Reward Shaping Reward shaping: r(s, a, s ) = r(s, a, s ) + γφ(s ) Φ(s) for arbitrary potential Φ Theorem: r admits
Reinforcement Learning and Control
 CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
ARTIFICIAL INTELLIGENCE. Reinforcement learning
 INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Machine Learning I Reinforcement Learning
 Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Reinforcement Learning with Function Approximation. Joseph Christian G. Noel
 Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Final Exam December 12, 2017
 Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms *
 Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
Machine Learning. Reinforcement learning. Hamid Beigy. Sharif University of Technology. Fall 1396
 Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
Reinforcement Learning Part 2
 Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Multiagent (Deep) Reinforcement Learning
 Reinforcement Learning") Multiagent (Deep) Reinforcement Learning MARTIN PILÁT (MARTIN.PILAT@MFF.CUNI.CZ) Reinforcement learning The agent needs to learn to perform tasks in environment No prior knowledge about the effects of
Multiagent (Deep) Reinforcement Learning MARTIN PILÁT (MARTIN.PILAT@MFF.CUNI.CZ) Reinforcement learning The agent needs to learn to perform tasks in environment No prior knowledge about the effects of
Deep reinforcement learning. Dialogue Systems Group, Cambridge University Engineering Department
 Deep reinforcement learning Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 25 In this lecture... Introduction to deep reinforcement learning Value-based Deep RL Deep
Deep reinforcement learning Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 25 In this lecture... Introduction to deep reinforcement learning Value-based Deep RL Deep
Decision Theory: Markov Decision Processes
 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13. Decision Making. Abdeslam Boularias. Wednesday, December 7, 2016
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Lecture 23: Reinforcement Learning
 Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Learning in Zero-Sum Team Markov Games using Factored Value Functions
 Learning in Zero-Sum Team Markov Games using Factored Value Functions Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 27708 mgl@cs.duke.edu Ronald Parr Department of Computer
Learning in Zero-Sum Team Markov Games using Factored Value Functions Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 27708 mgl@cs.duke.edu Ronald Parr Department of Computer
Deep Reinforcement Learning: Policy Gradients and Q-Learning
 Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan
 COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
Reinforcement Learning
 Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Reinforcement Learning and Deep Reinforcement Learning
 Reinforcement Learning and Deep Reinforcement Learning Ashis Kumer Biswas, Ph.D. ashis.biswas@ucdenver.edu Deep Learning November 5, 2018 1 / 64 Outlines 1 Principles of Reinforcement Learning 2 The Q
Reinforcement Learning and Deep Reinforcement Learning Ashis Kumer Biswas, Ph.D. ashis.biswas@ucdenver.edu Deep Learning November 5, 2018 1 / 64 Outlines 1 Principles of Reinforcement Learning 2 The Q
CS 570: Machine Learning Seminar. Fall 2016
 CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
Deep Reinforcement Learning SISL. Jeremy Morton (jmorton2) November 7, Stanford Intelligent Systems Laboratory
 November 7, Stanford Intelligent Systems Laboratory") Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Final Exam December 12, 2017
 Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Policy Gradient Reinforcement Learning for Robotics
 Policy Gradient Reinforcement Learning for Robotics Michael C. Koval mkoval@cs.rutgers.edu Michael L. Littman mlittman@cs.rutgers.edu May 9, 211 1 Introduction Learning in an environment with a continuous
Policy Gradient Reinforcement Learning for Robotics Michael C. Koval mkoval@cs.rutgers.edu Michael L. Littman mlittman@cs.rutgers.edu May 9, 211 1 Introduction Learning in an environment with a continuous
Policy Gradient Methods. February 13, 2017
 Policy Gradient Methods February 13, 2017 Policy Optimization Problems maximize E π [expression] π Fixed-horizon episodic: T 1 Average-cost: lim T 1 T r t T 1 r t Infinite-horizon discounted: γt r t Variable-length
Policy Gradient Methods February 13, 2017 Policy Optimization Problems maximize E π [expression] π Fixed-horizon episodic: T 1 Average-cost: lim T 1 T r t T 1 r t Infinite-horizon discounted: γt r t Variable-length
Markov Decision Processes
 Markov Decision Processes Noel Welsh 11 November 2010 Noel Welsh () Markov Decision Processes 11 November 2010 1 / 30 Annoucements Applicant visitor day seeks robot demonstrators for exciting half hour
Markov Decision Processes Noel Welsh 11 November 2010 Noel Welsh () Markov Decision Processes 11 November 2010 1 / 30 Annoucements Applicant visitor day seeks robot demonstrators for exciting half hour
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement. Function Approximation. Learning with KATJA HOFMANN. Researcher, MSR Cambridge
 Reinforcement Learning with Function Approximation KATJA HOFMANN Researcher, MSR Cambridge Representation and Generalization in RL Focus on training stability Learning generalizable value functions Navigating
Reinforcement Learning with Function Approximation KATJA HOFMANN Researcher, MSR Cambridge Representation and Generalization in RL Focus on training stability Learning generalizable value functions Navigating
16.410/413 Principles of Autonomy and Decision Making
 16.410/413 Principles of Autonomy and Decision Making Lecture 23: Markov Decision Processes Policy Iteration Emilio Frazzoli Aeronautics and Astronautics Massachusetts Institute of Technology December
16.410/413 Principles of Autonomy and Decision Making Lecture 23: Markov Decision Processes Policy Iteration Emilio Frazzoli Aeronautics and Astronautics Massachusetts Institute of Technology December
Notes on Reinforcement Learning
 1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
Lecture 3: The Reinforcement Learning Problem
 Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
Reinforcement Learning. Introduction
 Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Reinforcement Learning for NLP
 Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Reinforcement Learning
 Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning
 Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
An Adaptive Clustering Method for Model-free Reinforcement Learning
 An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
Optimization of a Sequential Decision Making Problem for a Rare Disease Diagnostic Application.
 Optimization of a Sequential Decision Making Problem for a Rare Disease Diagnostic Application. Rémi Besson with Erwan Le Pennec and Stéphanie Allassonnière École Polytechnique - 09/07/2018 Prenatal Ultrasound
Optimization of a Sequential Decision Making Problem for a Rare Disease Diagnostic Application. Rémi Besson with Erwan Le Pennec and Stéphanie Allassonnière École Polytechnique - 09/07/2018 Prenatal Ultrasound
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
Notes on Tabular Methods
 Notes on Tabular ethods Nan Jiang September 28, 208 Overview of the methods. Tabular certainty-equivalence Certainty-equivalence is a model-based RL algorithm, that is, it first estimates an DP model from
Notes on Tabular ethods Nan Jiang September 28, 208 Overview of the methods. Tabular certainty-equivalence Certainty-equivalence is a model-based RL algorithm, that is, it first estimates an DP model from
Lecture 3: Markov Decision Processes
 Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
The exam is closed book, closed calculator, and closed notes except your one-page crib sheet.
 CS 188 Spring 2017 Introduction to Artificial Intelligence Midterm V2 You have approximately 80 minutes. The exam is closed book, closed calculator, and closed notes except your one-page crib sheet. Mark
CS 188 Spring 2017 Introduction to Artificial Intelligence Midterm V2 You have approximately 80 minutes. The exam is closed book, closed calculator, and closed notes except your one-page crib sheet. Mark
Reinforcement Learning II
 Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Today s Outline. Recap: MDPs. Bellman Equations. Q-Value Iteration. Bellman Backup 5/7/2012. CSE 473: Artificial Intelligence Reinforcement Learning
 CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
Active Policy Iteration: Efficient Exploration through Active Learning for Value Function Approximation in Reinforcement Learning
 Active Policy Iteration: fficient xploration through Active Learning for Value Function Approximation in Reinforcement Learning Takayuki Akiyama, Hirotaka Hachiya, and Masashi Sugiyama Department of Computer
Active Policy Iteration: fficient xploration through Active Learning for Value Function Approximation in Reinforcement Learning Takayuki Akiyama, Hirotaka Hachiya, and Masashi Sugiyama Department of Computer
The Reinforcement Learning Problem
 The Reinforcement Learning Problem Slides based on the book Reinforcement Learning by Sutton and Barto Formalizing Reinforcement Learning Formally, the agent and environment interact at each of a sequence
The Reinforcement Learning Problem Slides based on the book Reinforcement Learning by Sutton and Barto Formalizing Reinforcement Learning Formally, the agent and environment interact at each of a sequence
15-889e Policy Search: Gradient Methods Emma Brunskill. All slides from David Silver (with EB adding minor modificafons), unless otherwise noted
, unless otherwise noted") 15-889e Policy Search: Gradient Methods Emma Brunskill All slides from David Silver (with EB adding minor modificafons), unless otherwise noted Outline 1 Introduction 2 Finite Difference Policy Gradient
15-889e Policy Search: Gradient Methods Emma Brunskill All slides from David Silver (with EB adding minor modificafons), unless otherwise noted Outline 1 Introduction 2 Finite Difference Policy Gradient
Q-Learning for Markov Decision Processes*
 McGill University ECSE 506: Term Project Q-Learning for Markov Decision Processes* Authors: Khoa Phan khoa.phan@mail.mcgill.ca Sandeep Manjanna sandeep.manjanna@mail.mcgill.ca (*Based on: Convergence of
McGill University ECSE 506: Term Project Q-Learning for Markov Decision Processes* Authors: Khoa Phan khoa.phan@mail.mcgill.ca Sandeep Manjanna sandeep.manjanna@mail.mcgill.ca (*Based on: Convergence of
Reinforcement Learning
 Reinforcement Learning RL in continuous MDPs March April, 2015 Large/Continuous MDPs Large/Continuous state space Tabular representation cannot be used Large/Continuous action space Maximization over action
Reinforcement Learning RL in continuous MDPs March April, 2015 Large/Continuous MDPs Large/Continuous state space Tabular representation cannot be used Large/Continuous action space Maximization over action
Reinforcement Learning
 1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
Reinforcement Learning. George Konidaris
 Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom