Learning Dexterity Matthias Plappert SEPTEMBER 6, 2018
|
|
|
- Winfred Carr
- 5 years ago
- Views:
Transcription
1 Learning Dexterity Matthias Plappert SEPTEMBER 6, 2018
2 OpenAI OpenAI is a non-profit AI research company, discovering and enacting the path to safe artificial general intelligence.
3 OpenAI OpenAI is a non-profit AI research company, discovering and enacting the path to safe artificial general intelligence.
4 OpenAI OpenAI is a non-profit AI research company, discovering and enacting the path to safe artificial general intelligence.
5 OpenAI OpenAI is a non-profit AI research company, discovering and enacting the path to safe artificial general intelligence.

6 OpenAI Charter Broadly Distributed Benefits Long-Term Safety Technical Leadership Cooperative Orientation Full text available on our blog:
7 Learning Dexterity





8




9
10


11 Reinforcement Learning GO (ALPHAGO ZERO) DOTA 2 (OPENAI FIVE)
 Rajeswaran et al.")
12 Reinforcement Learning for Robotics (1) Rajeswaran et al. (2017)
13 Reinforcement Learning for Robotics (2) Kumar et al. (2016)
 Levine et al.")
14 Reinforcement Learning for Robotics (3) Levine et al. (2018)


15 Sim2Real Simulated environment Simulated environment for training Simulated environment for training Simulated environments for training for training Transfer Real robot hardware
16 Transfer
17 Transfer
18 Task & Setup

19

20
21
22 Shadow Dexterous Hand
23 PhaseSpace tracking
24 Top RGB camera Right RGB camera Left RGB camera

25 Challenges Reinforcement learning for the real world High-dimensional control Noisy and partial observations Manipulating more than one object
26 Reinforcement Learning + Domain Randomization
27 Reinforcement Learning
28 Reinforcement Learning (1) Action at Agent Environment State st+1 and reward rt
29 Reinforcement Learning (2) Formalize as Markov decision process M = (S, A, P, ρ, r)
30 Reinforcement Learning (2) Formalize as Markov decision process Set of states M = (S, A, P, ρ, r)
31 Reinforcement Learning (2) Formalize as Markov decision process Set of states M = (S, A, P, ρ, r) Set of actions
32 Reinforcement Learning (2) Formalize as Markov decision process Set of states Transition probabilities: s t+1 P(, s t, a t ) M = (S, A, P, ρ, r) Set of actions
33 Reinforcement Learning (2) Formalize as Markov decision process Set of states Transition probabilities: s t+1 P(, s t, a t ) M = (S, A, P, ρ, r) Set of actions Initial state distribution: s 0 ρ( )
34 Reinforcement Learning (2) Formalize as Markov decision process Transition probabilities: s t+1 P(, s t, a t ) Set of states Reward function: r : S A M = (S, A, P, ρ, r) Set of actions Initial state distribution: s 0 ρ( )
35 Reinforcement Learning (2) Formalize as Markov decision process Transition probabilities: s t+1 P(, s t, a t ) Set of states Reward function: r : S A M = (S, A, P, ρ, r) Set of actions Initial state distribution: s 0 ρ( ) Agent uses a policy to select actions: a t π( s t )
36 Reinforcement Learning (3) Let τ denote a trajectory with s 0 ρ( ), a t π( s t ), s t+1 P( s t, a t )
37 Reinforcement Learning (3) Let τ denote a trajectory with s 0 ρ( ), a t π( s t ), s t+1 P( s t, a t ) The discounted return is then defined as: R(τ) := t γ t r(s t, a t ) γ [0,1)
38 Reinforcement Learning (3) Let τ denote a trajectory with s 0 ρ( ), a t π( s t ), s t+1 P( s t, a t ) The discounted return is then defined as: R(τ) := t γ t r(s t, a t ) γ [0,1) We wish to find a policy that maximizes the expected discounted return: π* := arg max E τ [R(τ)] π
39 Reinforcement Learning (4) Depending on the assumptions, many methods exist to find optimal policies. Examples are: Dynamic programming Policy gradient methods Q learning This talk will focus on policy gradient methods Policy gradients are model-free, i.e. we do not know the transition distribution
40 Policy Gradients (1) Let s assume a parameterized policy πθ, where θ is some parameter vector
41 Policy Gradients (1) Let s assume a parameterized policy πθ, where θ is some parameter vector Our optimization objective then is: J(θ) := E τ [R(τ)]
42 Policy Gradients (1) Let s assume a parameterized policy πθ, where θ is some parameter vector Our optimization objective then is: has a dependency on θ through τ J(θ) := E τ [R(τ)] has no dependency on θ
43 Policy Gradients (1) Let s assume a parameterized policy πθ, where θ is some parameter vector Our optimization objective then is: has a dependency on θ through τ J(θ) := E τ [R(τ)] has no dependency on θ Simple idea: Let s compute the gradient w.r.t. θ and do gradient ascent
44 Policy Gradients (2) Goal: Compute the gradient θ J(θ) = θ E τ [R(τ)]
45 Policy Gradients (2) Goal: Compute the gradient θ J(θ) = θ E τ [R(τ)] Expanding the expectation and rearranging we get: θ J(θ) = θ [ R(τ)p(τ)dτ ]
46 Policy Gradients (2) Goal: Compute the gradient θ J(θ) = θ E τ [R(τ)] Expanding the expectation and rearranging we get: θ J(θ) = θ [ R(τ)p(τ)dτ ] = R(τ) θ p(τ)dτ
47 Policy Gradients (3) θ J(θ) = R(τ) θ p(τ)dτ Goal: Compute
48 Policy Gradients (3) θ J(θ) = R(τ) θ p(τ)dτ Goal: Compute
49 Policy Gradients (3) Goal: Compute θ J(θ) = R(τ) θ p(τ)dτ Use the "log derivative trick": log p(τ) = 1 θ p(τ) θ p(τ) θ p(τ) = log p(τ)p(τ) θ
50 Policy Gradients (3) Goal: Compute θ J(θ) = R(τ) θ p(τ)dτ Use the "log derivative trick": log p(τ) = 1 θ p(τ) θ p(τ) θ p(τ) = log p(τ)p(τ) θ... and plug back in to obtain: θ J(θ) = R(τ) θ log p(τ)p(τ)dτ
51 Policy Gradients (3) Goal: Compute θ J(θ) = R(τ) θ p(τ)dτ Use the "log derivative trick": log p(τ) = 1 θ p(τ) θ p(τ) θ p(τ) = log p(τ)p(τ) θ... and plug back in to obtain: θ J(θ) = R(τ) θ log p(τ)p(τ)dτ = E τ [R(τ) θ log p(τ)]
52 Policy Gradients (4) Goal: Compute θ log p(τ)
53 Policy Gradients (4) Goal: Compute θ log p(τ) Probability of a trajectory τ is: p(τ) = ρ(s 0 ) t P(s t+1 s t, a t )π θ (a t s t )
54 Policy Gradients (4) Goal: Compute θ log p(τ) Probability of a trajectory τ is: p(τ) = ρ(s 0 ) t P(s t+1 s t, a t )π θ (a t s t ) log p(τ) = log ρ(s 0 ) + t log P(s t+1 s t, a t ) + log π θ (a t s t )
55 Policy Gradients (4) Goal: Compute θ log p(τ) Probability of a trajectory τ is: p(τ) = ρ(s 0 ) t P(s t+1 s t, a t )π θ (a t s t ) log p(τ) = log ρ(s 0 ) + t log P(s t+1 s t, a t ) + log π θ (a t s t ) Taking the gradient: θ log p(τ) = t θ log π θ (a t s t )
56 Policy Gradients (5) Putting it all together: θ J(θ) = θ E τ [R(τ)]
57 Policy Gradients (5) Putting it all together: θ J(θ) = θ E τ [R(τ)] = R(τ) θ p(τ)dτ
58 Policy Gradients (5) Putting it all together: θ J(θ) = θ E τ [R(τ)] = R(τ) θ p(τ)dτ = E τ [R(τ) θ log p(τ)]
59 Policy Gradients (5) Putting it all together: θ J(θ) = θ E τ [R(τ)] = R(τ) θ p(τ)dτ = E τ [R(τ) θ log p(τ)] = E τ [ R(τ) t θ log π θ (a t s t ) ]
60 Policy Gradients (5) Putting it all together: θ J(θ) = θ E τ [R(τ)] = R(τ) θ p(τ)dτ = E τ [R(τ) θ log p(τ)] = E τ [ R(τ) t θ log π θ (a t s t ) ] Last missing piece: Computing the expectation
61 Policy Gradients (6) Goal: Compute expectation of: θ J(θ) = E τ [ R(τ) t θ log π θ (a t s t ) ]
62 Policy Gradients (6) Goal: Compute expectation of: θ J(θ) = E τ [ R(τ) t θ log π θ (a t s t ) ] Can be estimated using Monte Carlo sampling, which corresponds to rolling out the policy multiple times to collect N trajectories: τ (1), τ (2),, τ (N)
63 Policy Gradients (6) Goal: Compute expectation of: θ J(θ) = E τ [ R(τ) t θ log π θ (a t s t ) ] Can be estimated using Monte Carlo sampling, which corresponds to rolling out the policy multiple times to collect N trajectories: τ (1), τ (2),, τ (N) Our final estimate of the policy gradient is thus: N θ J(θ) 1 N n=1 [ R(τ(n) ) t θ log π θ (a (n) t s (n) t ) ]
64 Policy Gradients (7) 1. Initialize θ arbitrarily 2. Repeat 1. Collect N trajectories τ (1), τ (2),, τ (N) 2. Estimate gradient: N g 1 N n=1 [ R(τ(n) ) t θ log π θ (a (n) t s (n) t ) ] 3. Update parameters: θ θ + α g
65 Proximal Policy Optimization Vanilla policy gradient algorithm simple but has several shortcomings We use Proximal Policy Optimization (PPO) in all our experiments (Schulman et al., 2017) Underlaying idea is exactly the same but uses Baselines for variance reduction with generalized advantage estimation Importance sampling to use slightly off-policy data Clipping to improve stability
66 Reward Function r t = d t d t+1, where d t and d t+1 denote the rotation angle between the desired and current orientation before and after the transition On success: +5 On drop: -20
67 Policy Architecture Action Distribution finger joint positions LSTM Fully-connected ReLU Normalization fingertip positions object pose Noisy Observation Goal
68 Distributed Training with Rapid Parameters Worker Optimizer 6,000 CPU cores 8 GPUs
69 Transfer
70 Transfer
71 Domain Randomization
 Sadeghi & Levine")
72 Domain Randomization (1) Sadeghi & Levine (2017)


73 Domain Randomization (2) Tobin et al. (2017)

74

75 Vision Randomizations
76 Vision Architecture ReLU Object Position Object Rotation Concat SSM SSM SSM ResNet ResNet ResNet Pool Pool Pool Conv Conv Conv Camera 1 Camera 2 Camera 3
 Peng et al. (2018)")
77 Physics Randomizations (1) Peng et al. (2018)
78 Physics Randomizations (2) object dimensions object and robot link masses surface friction coefficients robot joint damping coefficients actuator force gains joint limits gravity vector
79 Full System Recap
80
81
82 Results
83 Page Title

84 Learned Strategies




85 Learned Grasps Tip Palmar Tripo Quadpo Power 5-finger Precision
86 Quantitative Results
87 Quantitative Results
88 Quantitative Results
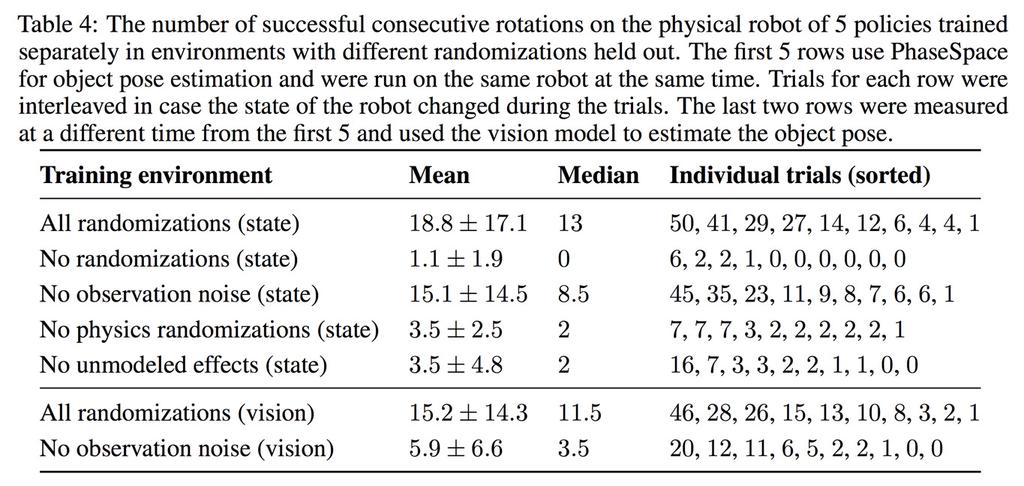
89 Ablation of Randomizations

90 Training Time

91 Effect of Memory
92 Surprises Tactile sensing is not necessary to manipulate real-world objects Randomizations developed for one object generalize to others with similar properties With physical robots, good systems engineering is as important as good algorithms
93 Challenges Ahead Less manual tuning in domain randomization Make use of demonstrations Faster learning in real world


94 Blog Post Pre-print

95 Thank You Visit openai.com for more information. ON TWITTER
96 References Levine et al. "Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection." The International Journal of Robotics Research (2018): Peng et al. "Sim-to-real transfer of robotic control with dynamics randomization." arxiv preprint arxiv: (2017). Tobin et al. "Domain randomization for transferring deep neural networks from simulation to the real world." Intelligent Robots and Systems (IROS), 2017 IEEE/RSJ International Conference on. IEEE, Rajeswaran et al. "Learning complex dexterous manipulation with deep reinforcement learning and demonstrations." arxiv preprint arxiv: (2017). Kumar, Vikash, Emanuel Todorov, and Sergey Levine. "Optimal control with learned local models: Application to dexterous manipulation." Robotics and Automation (ICRA), 2016 IEEE International Conference on. IEEE, Schulman et al. "Proximal policy optimization algorithms." arxiv preprint arxiv: (2017). Sadeghi & Levine. "CAD2RL: Real single-image flight without a single real image." arxiv preprint arxiv: (2016).
Trust Region Policy Optimization
 Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Reinforcement Learning via Policy Optimization
 Reinforcement Learning via Policy Optimization Hanxiao Liu November 22, 2017 1 / 27 Reinforcement Learning Policy a π(s) 2 / 27 Example - Mario 3 / 27 Example - ChatBot 4 / 27 Applications - Video Games
Reinforcement Learning via Policy Optimization Hanxiao Liu November 22, 2017 1 / 27 Reinforcement Learning Policy a π(s) 2 / 27 Example - Mario 3 / 27 Example - ChatBot 4 / 27 Applications - Video Games
Reinforcement Learning
 Reinforcement Learning Policy gradients Daniel Hennes 26.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Policy based reinforcement learning So far we approximated the action value
Reinforcement Learning Policy gradients Daniel Hennes 26.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Policy based reinforcement learning So far we approximated the action value
Deep Reinforcement Learning: Policy Gradients and Q-Learning
 Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
CS230: Lecture 9 Deep Reinforcement Learning
 CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
Reinforcement Learning
 Reinforcement Learning Policy Search: Actor-Critic and Gradient Policy search Mario Martin CS-UPC May 28, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 28, 2018 / 63 Goal of this lecture So far
Reinforcement Learning Policy Search: Actor-Critic and Gradient Policy search Mario Martin CS-UPC May 28, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 28, 2018 / 63 Goal of this lecture So far
Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms *
 Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
INF 5860 Machine learning for image classification. Lecture 14: Reinforcement learning May 9, 2018
 Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Lecture 8: Policy Gradient I 2
 Lecture 8: Policy Gradient I 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver and John Schulman
Lecture 8: Policy Gradient I 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver and John Schulman
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
1 Introduction 2. 4 Q-Learning The Q-value The Temporal Difference The whole Q-Learning process... 5
 Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Policy Gradient Methods. February 13, 2017
 Policy Gradient Methods February 13, 2017 Policy Optimization Problems maximize E π [expression] π Fixed-horizon episodic: T 1 Average-cost: lim T 1 T r t T 1 r t Infinite-horizon discounted: γt r t Variable-length
Policy Gradient Methods February 13, 2017 Policy Optimization Problems maximize E π [expression] π Fixed-horizon episodic: T 1 Average-cost: lim T 1 T r t T 1 r t Infinite-horizon discounted: γt r t Variable-length
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning
 REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
Combining PPO and Evolutionary Strategies for Better Policy Search
 Combining PPO and Evolutionary Strategies for Better Policy Search Jennifer She 1 Abstract A good policy search algorithm needs to strike a balance between being able to explore candidate policies and
Combining PPO and Evolutionary Strategies for Better Policy Search Jennifer She 1 Abstract A good policy search algorithm needs to strike a balance between being able to explore candidate policies and
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Introduction of Reinforcement Learning
 Introduction of Reinforcement Learning Deep Reinforcement Learning Reference Textbook: Reinforcement Learning: An Introduction http://incompleteideas.net/sutton/book/the-book.html Lectures of David Silver
Introduction of Reinforcement Learning Deep Reinforcement Learning Reference Textbook: Reinforcement Learning: An Introduction http://incompleteideas.net/sutton/book/the-book.html Lectures of David Silver
Lecture 6: CS395T Numerical Optimization for Graphics and AI Line Search Applications
 Lecture 6: CS395T Numerical Optimization for Graphics and AI Line Search Applications Qixing Huang The University of Texas at Austin huangqx@cs.utexas.edu 1 Disclaimer This note is adapted from Section
Lecture 6: CS395T Numerical Optimization for Graphics and AI Line Search Applications Qixing Huang The University of Texas at Austin huangqx@cs.utexas.edu 1 Disclaimer This note is adapted from Section
Towards Generalization and Simplicity in Continuous Control
 Towards Generalization and Simplicity in Continuous Control Aravind Rajeswaran, Kendall Lowrey, Emanuel Todorov, Sham Kakade Paul Allen School of Computer Science University of Washington Seattle { aravraj,
Towards Generalization and Simplicity in Continuous Control Aravind Rajeswaran, Kendall Lowrey, Emanuel Todorov, Sham Kakade Paul Allen School of Computer Science University of Washington Seattle { aravraj,
Development of a Deep Recurrent Neural Network Controller for Flight Applications
 Development of a Deep Recurrent Neural Network Controller for Flight Applications American Control Conference (ACC) May 26, 2017 Scott A. Nivison Pramod P. Khargonekar Department of Electrical and Computer
Development of a Deep Recurrent Neural Network Controller for Flight Applications American Control Conference (ACC) May 26, 2017 Scott A. Nivison Pramod P. Khargonekar Department of Electrical and Computer
Reinforcement Learning, Neural Networks and PI Control Applied to a Heating Coil
 Reinforcement Learning, Neural Networks and PI Control Applied to a Heating Coil Charles W. Anderson 1, Douglas C. Hittle 2, Alon D. Katz 2, and R. Matt Kretchmar 1 1 Department of Computer Science Colorado
Reinforcement Learning, Neural Networks and PI Control Applied to a Heating Coil Charles W. Anderson 1, Douglas C. Hittle 2, Alon D. Katz 2, and R. Matt Kretchmar 1 1 Department of Computer Science Colorado
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Decision Theory: Markov Decision Processes
 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Reinforcement Learning
 Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Variance Reduction for Policy Gradient Methods. March 13, 2017
 Variance Reduction for Policy Gradient Methods March 13, 2017 Reward Shaping Reward Shaping Reward Shaping Reward shaping: r(s, a, s ) = r(s, a, s ) + γφ(s ) Φ(s) for arbitrary potential Φ Theorem: r admits
Variance Reduction for Policy Gradient Methods March 13, 2017 Reward Shaping Reward Shaping Reward Shaping Reward shaping: r(s, a, s ) = r(s, a, s ) + γφ(s ) Φ(s) for arbitrary potential Φ Theorem: r admits
Deep Reinforcement Learning SISL. Jeremy Morton (jmorton2) November 7, Stanford Intelligent Systems Laboratory
 November 7, Stanford Intelligent Systems Laboratory") Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Lecture 9: Policy Gradient II (Post lecture) 2
 2") Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Learning Control for Air Hockey Striking using Deep Reinforcement Learning
 Learning Control for Air Hockey Striking using Deep Reinforcement Learning Ayal Taitler, Nahum Shimkin Faculty of Electrical Engineering Technion - Israel Institute of Technology May 8, 2017 A. Taitler,
Learning Control for Air Hockey Striking using Deep Reinforcement Learning Ayal Taitler, Nahum Shimkin Faculty of Electrical Engineering Technion - Israel Institute of Technology May 8, 2017 A. Taitler,
Notes on policy gradients and the log derivative trick for reinforcement learning
 Notes on policy gradients and the log derivative trick for reinforcement learning David Meyer dmm@{1-4-5.net,uoregon.edu,brocade.com,...} June 3, 2016 1 Introduction The log derivative trick 1 is a widely
Notes on policy gradients and the log derivative trick for reinforcement learning David Meyer dmm@{1-4-5.net,uoregon.edu,brocade.com,...} June 3, 2016 1 Introduction The log derivative trick 1 is a widely
Reinforcement Learning
 Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
Lecture 9: Policy Gradient II 1
 Lecture 9: Policy Gradient II 1 Emma Brunskill CS234 Reinforcement Learning. Winter 2019 Additional reading: Sutton and Barto 2018 Chp. 13 1 With many slides from or derived from David Silver and John
Lecture 9: Policy Gradient II 1 Emma Brunskill CS234 Reinforcement Learning. Winter 2019 Additional reading: Sutton and Barto 2018 Chp. 13 1 With many slides from or derived from David Silver and John
Deep Reinforcement Learning via Policy Optimization
 Deep Reinforcement Learning via Policy Optimization John Schulman July 3, 2017 Introduction Deep Reinforcement Learning: What to Learn? Policies (select next action) Deep Reinforcement Learning: What to
Deep Reinforcement Learning via Policy Optimization John Schulman July 3, 2017 Introduction Deep Reinforcement Learning: What to Learn? Policies (select next action) Deep Reinforcement Learning: What to
ELEC-E8119 Robotics: Manipulation, Decision Making and Learning Policy gradient approaches. Ville Kyrki
 ELEC-E8119 Robotics: Manipulation, Decision Making and Learning Policy gradient approaches Ville Kyrki 9.10.2017 Today Direct policy learning via policy gradient. Learning goals Understand basis and limitations
ELEC-E8119 Robotics: Manipulation, Decision Making and Learning Policy gradient approaches Ville Kyrki 9.10.2017 Today Direct policy learning via policy gradient. Learning goals Understand basis and limitations
Advanced Policy Gradient Methods: Natural Gradient, TRPO, and More. March 8, 2017
 Advanced Policy Gradient Methods: Natural Gradient, TRPO, and More March 8, 2017 Defining a Loss Function for RL Let η(π) denote the expected return of π [ ] η(π) = E s0 ρ 0,a t π( s t) γ t r t We collect
Advanced Policy Gradient Methods: Natural Gradient, TRPO, and More March 8, 2017 Defining a Loss Function for RL Let η(π) denote the expected return of π [ ] η(π) = E s0 ρ 0,a t π( s t) γ t r t We collect
Visual meta-learning for planning and control
 Visual meta-learning for planning and control Seminar on Current Works in Computer Vision @ Chair of Pattern Recognition and Image Processing. Samuel Roth Winter Semester 2018/19 Albert-Ludwigs-Universität
Visual meta-learning for planning and control Seminar on Current Works in Computer Vision @ Chair of Pattern Recognition and Image Processing. Samuel Roth Winter Semester 2018/19 Albert-Ludwigs-Universität
Proximal Policy Optimization (PPO)
") Proximal Policy Optimization (PPO) default reinforcement learning algorithm at OpenAI Policy Gradient On-policy Off-policy Add constraint DeepMind https://youtu.be/gn4nrcc9twq OpenAI https://blog.openai.com/o
Proximal Policy Optimization (PPO) default reinforcement learning algorithm at OpenAI Policy Gradient On-policy Off-policy Add constraint DeepMind https://youtu.be/gn4nrcc9twq OpenAI https://blog.openai.com/o
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
VIME: Variational Information Maximizing Exploration
 1 VIME: Variational Information Maximizing Exploration Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel Reviewed by Zhao Song January 13, 2017 1 Exploration in Reinforcement
1 VIME: Variational Information Maximizing Exploration Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel Reviewed by Zhao Song January 13, 2017 1 Exploration in Reinforcement
Towards Generalization and Simplicity in Continuous Control
 Towards Generalization and Simplicity in Continuous Control Aravind Rajeswaran Kendall Lowrey Emanuel Todorov Sham Kakade University of Washington Seattle { aravraj, klowrey, todorov, sham } @ cs.washington.edu
Towards Generalization and Simplicity in Continuous Control Aravind Rajeswaran Kendall Lowrey Emanuel Todorov Sham Kakade University of Washington Seattle { aravraj, klowrey, todorov, sham } @ cs.washington.edu
Driving a car with low dimensional input features
 December 2016 Driving a car with low dimensional input features Jean-Claude Manoli jcma@stanford.edu Abstract The aim of this project is to train a Deep Q-Network to drive a car on a race track using only
December 2016 Driving a car with low dimensional input features Jean-Claude Manoli jcma@stanford.edu Abstract The aim of this project is to train a Deep Q-Network to drive a car on a race track using only
CS Deep Reinforcement Learning HW2: Policy Gradients due September 19th 2018, 11:59 pm
 CS294-112 Deep Reinforcement Learning HW2: Policy Gradients due September 19th 2018, 11:59 pm 1 Introduction The goal of this assignment is to experiment with policy gradient and its variants, including
CS294-112 Deep Reinforcement Learning HW2: Policy Gradients due September 19th 2018, 11:59 pm 1 Introduction The goal of this assignment is to experiment with policy gradient and its variants, including
Reinforcement Learning Part 2
 Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Markov decision processes
 CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Deep Reinforcement Learning. Scratching the surface
 Deep Reinforcement Learning Scratching the surface Deep Reinforcement Learning Scenario of Reinforcement Learning Observation State Agent Action Change the environment Don t do that Reward Environment
Deep Reinforcement Learning Scratching the surface Deep Reinforcement Learning Scenario of Reinforcement Learning Observation State Agent Action Change the environment Don t do that Reward Environment
Artificial Intelligence & Sequential Decision Problems
 Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Lecture 8: Policy Gradient
 Lecture 8: Policy Gradient Hado van Hasselt Outline 1 Introduction 2 Finite Difference Policy Gradient 3 Monte-Carlo Policy Gradient 4 Actor-Critic Policy Gradient Introduction Vapnik s rule Never solve
Lecture 8: Policy Gradient Hado van Hasselt Outline 1 Introduction 2 Finite Difference Policy Gradient 3 Monte-Carlo Policy Gradient 4 Actor-Critic Policy Gradient Introduction Vapnik s rule Never solve
Prof. Dr. Ann Nowé. Artificial Intelligence Lab ai.vub.ac.be
 REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer.
 This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
Lecture 10 - Planning under Uncertainty (III)
") Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
arxiv: v1 [cs.lg] 13 Dec 2013
![arxiv: v1 [cs.lg] 13 Dec 2013](/thumbs/71/66147318.jpg "arxiv: v1 [cs.lg] 13 Dec 2013") Efficient Baseline-free Sampling in Parameter Exploring Policy Gradients: Super Symmetric PGPE Frank Sehnke Zentrum für Sonnenenergie- und Wasserstoff-Forschung, Industriestr. 6, Stuttgart, BW 70565 Germany
Efficient Baseline-free Sampling in Parameter Exploring Policy Gradients: Super Symmetric PGPE Frank Sehnke Zentrum für Sonnenenergie- und Wasserstoff-Forschung, Industriestr. 6, Stuttgart, BW 70565 Germany
Human-level control through deep reinforcement. Liia Butler
 Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
arxiv: v1 [cs.lg] 20 Jun 2018
![arxiv: v1 [cs.lg] 20 Jun 2018](/thumbs/91/106639826.jpg "arxiv: v1 [cs.lg] 20 Jun 2018") RUDDER: Return Decomposition for Delayed Rewards arxiv:1806.07857v1 [cs.lg 20 Jun 2018 Jose A. Arjona-Medina Michael Gillhofer Michael Widrich Thomas Unterthiner Sepp Hochreiter LIT AI Lab Institute for
RUDDER: Return Decomposition for Delayed Rewards arxiv:1806.07857v1 [cs.lg 20 Jun 2018 Jose A. Arjona-Medina Michael Gillhofer Michael Widrich Thomas Unterthiner Sepp Hochreiter LIT AI Lab Institute for
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
An Introduction to Reinforcement Learning
 An Introduction to Reinforcement Learning Shivaram Kalyanakrishnan shivaram@cse.iitb.ac.in Department of Computer Science and Engineering Indian Institute of Technology Bombay April 2018 What is Reinforcement
An Introduction to Reinforcement Learning Shivaram Kalyanakrishnan shivaram@cse.iitb.ac.in Department of Computer Science and Engineering Indian Institute of Technology Bombay April 2018 What is Reinforcement
Identifying and Solving an Unknown Acrobot System
 Identifying and Solving an Unknown Acrobot System Clement Gehring and Xinkun Nie Abstract Identifying dynamical parameters is a challenging and important part of solving dynamical systems. For this project,
Identifying and Solving an Unknown Acrobot System Clement Gehring and Xinkun Nie Abstract Identifying dynamical parameters is a challenging and important part of solving dynamical systems. For this project,
arxiv: v2 [cs.lg] 20 Mar 2018
![arxiv: v2 [cs.lg] 20 Mar 2018](/thumbs/86/93359448.jpg "arxiv: v2 [cs.lg] 20 Mar 2018") Towards Generalization and Simplicity in Continuous Control arxiv:1703.02660v2 [cs.lg] 20 Mar 2018 Aravind Rajeswaran Kendall Lowrey Emanuel Todorov Sham Kakade University of Washington Seattle { aravraj,
Towards Generalization and Simplicity in Continuous Control arxiv:1703.02660v2 [cs.lg] 20 Mar 2018 Aravind Rajeswaran Kendall Lowrey Emanuel Todorov Sham Kakade University of Washington Seattle { aravraj,
Policy Gradient Reinforcement Learning for Robotics
 Policy Gradient Reinforcement Learning for Robotics Michael C. Koval mkoval@cs.rutgers.edu Michael L. Littman mlittman@cs.rutgers.edu May 9, 211 1 Introduction Learning in an environment with a continuous
Policy Gradient Reinforcement Learning for Robotics Michael C. Koval mkoval@cs.rutgers.edu Michael L. Littman mlittman@cs.rutgers.edu May 9, 211 1 Introduction Learning in an environment with a continuous
Deep Reinforcement Learning
 Deep Reinforcement Learning John Schulman 1 MLSS, May 2016, Cadiz 1 Berkeley Artificial Intelligence Research Lab Agenda Introduction and Overview Markov Decision Processes Reinforcement Learning via Black-Box
Deep Reinforcement Learning John Schulman 1 MLSS, May 2016, Cadiz 1 Berkeley Artificial Intelligence Research Lab Agenda Introduction and Overview Markov Decision Processes Reinforcement Learning via Black-Box
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Lecture 23: Reinforcement Learning
 Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Reinforcement Learning as Classification Leveraging Modern Classifiers
 Reinforcement Learning as Classification Leveraging Modern Classifiers Michail G. Lagoudakis and Ronald Parr Department of Computer Science Duke University Durham, NC 27708 Machine Learning Reductions
Reinforcement Learning as Classification Leveraging Modern Classifiers Michail G. Lagoudakis and Ronald Parr Department of Computer Science Duke University Durham, NC 27708 Machine Learning Reductions
Deep Reinforcement Learning. STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017
 Deep Reinforcement Learning STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017 Outline Introduction to Reinforcement Learning AlphaGo (Deep RL for Computer Go)
Deep Reinforcement Learning STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017 Outline Introduction to Reinforcement Learning AlphaGo (Deep RL for Computer Go)
Bayesian Deep Learning
 Bayesian Deep Learning Mohammad Emtiyaz Khan AIP (RIKEN), Tokyo http://emtiyaz.github.io emtiyaz.khan@riken.jp June 06, 2018 Mohammad Emtiyaz Khan 2018 1 What will you learn? Why is Bayesian inference
Bayesian Deep Learning Mohammad Emtiyaz Khan AIP (RIKEN), Tokyo http://emtiyaz.github.io emtiyaz.khan@riken.jp June 06, 2018 Mohammad Emtiyaz Khan 2018 1 What will you learn? Why is Bayesian inference
Notes on Reinforcement Learning
 1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
Reinforcement Learning and Deep Reinforcement Learning
 Reinforcement Learning and Deep Reinforcement Learning Ashis Kumer Biswas, Ph.D. ashis.biswas@ucdenver.edu Deep Learning November 5, 2018 1 / 64 Outlines 1 Principles of Reinforcement Learning 2 The Q
Reinforcement Learning and Deep Reinforcement Learning Ashis Kumer Biswas, Ph.D. ashis.biswas@ucdenver.edu Deep Learning November 5, 2018 1 / 64 Outlines 1 Principles of Reinforcement Learning 2 The Q
Machine Learning I Continuous Reinforcement Learning
 Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Markov Decision Processes and Solving Finite Problems. February 8, 2017
 Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Optimal Control. McGill COMP 765 Oct 3 rd, 2017
 Optimal Control McGill COMP 765 Oct 3 rd, 2017 Classical Control Quiz Question 1: Can a PID controller be used to balance an inverted pendulum: A) That starts upright? B) That must be swung-up (perhaps
Optimal Control McGill COMP 765 Oct 3 rd, 2017 Classical Control Quiz Question 1: Can a PID controller be used to balance an inverted pendulum: A) That starts upright? B) That must be swung-up (perhaps
CONCEPT LEARNING WITH ENERGY-BASED MODELS
 CONCEPT LEARNING WITH ENERGY-BASED MODELS Igor Mordatch OpenAI San Francisco mordatch@openai.com 1 OVERVIEW Many hallmarks of human intelligence, such as generalizing from limited experience, abstract
CONCEPT LEARNING WITH ENERGY-BASED MODELS Igor Mordatch OpenAI San Francisco mordatch@openai.com 1 OVERVIEW Many hallmarks of human intelligence, such as generalizing from limited experience, abstract
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Dialogue management: Parametric approaches to policy optimisation. Dialogue Systems Group, Cambridge University Engineering Department
 Dialogue management: Parametric approaches to policy optimisation Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 30 Dialogue optimisation as a reinforcement learning
Dialogue management: Parametric approaches to policy optimisation Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 30 Dialogue optimisation as a reinforcement learning
Discrete Latent Variable Models
 Discrete Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 14 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 14 1 / 29 Summary Major themes in the course
Discrete Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 14 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 14 1 / 29 Summary Major themes in the course
Partially Observable Markov Decision Processes (POMDPs)
") Partially Observable Markov Decision Processes (POMDPs) Sachin Patil Guest Lecture: CS287 Advanced Robotics Slides adapted from Pieter Abbeel, Alex Lee Outline Introduction to POMDPs Locally Optimal Solutions
Partially Observable Markov Decision Processes (POMDPs) Sachin Patil Guest Lecture: CS287 Advanced Robotics Slides adapted from Pieter Abbeel, Alex Lee Outline Introduction to POMDPs Locally Optimal Solutions
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Active Policy Iteration: Efficient Exploration through Active Learning for Value Function Approximation in Reinforcement Learning
 Active Policy Iteration: fficient xploration through Active Learning for Value Function Approximation in Reinforcement Learning Takayuki Akiyama, Hirotaka Hachiya, and Masashi Sugiyama Department of Computer
Active Policy Iteration: fficient xploration through Active Learning for Value Function Approximation in Reinforcement Learning Takayuki Akiyama, Hirotaka Hachiya, and Masashi Sugiyama Department of Computer
CS 570: Machine Learning Seminar. Fall 2016
 CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Multi-Batch Experience Replay for Fast Convergence of Continuous Action Control
 1 Multi-Batch Experience Replay for Fast Convergence of Continuous Action Control Seungyul Han and Youngchul Sung Abstract arxiv:1710.04423v1 [cs.lg] 12 Oct 2017 Policy gradient methods for direct policy
1 Multi-Batch Experience Replay for Fast Convergence of Continuous Action Control Seungyul Han and Youngchul Sung Abstract arxiv:1710.04423v1 [cs.lg] 12 Oct 2017 Policy gradient methods for direct policy
Learning Tetris. 1 Tetris. February 3, 2009
 Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
15-889e Policy Search: Gradient Methods Emma Brunskill. All slides from David Silver (with EB adding minor modificafons), unless otherwise noted
, unless otherwise noted") 15-889e Policy Search: Gradient Methods Emma Brunskill All slides from David Silver (with EB adding minor modificafons), unless otherwise noted Outline 1 Introduction 2 Finite Difference Policy Gradient
15-889e Policy Search: Gradient Methods Emma Brunskill All slides from David Silver (with EB adding minor modificafons), unless otherwise noted Outline 1 Introduction 2 Finite Difference Policy Gradient
Reinforcement Learning for NLP
 Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Reinforcement learning an introduction
 Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
16.410/413 Principles of Autonomy and Decision Making
 16.410/413 Principles of Autonomy and Decision Making Lecture 23: Markov Decision Processes Policy Iteration Emilio Frazzoli Aeronautics and Astronautics Massachusetts Institute of Technology December
16.410/413 Principles of Autonomy and Decision Making Lecture 23: Markov Decision Processes Policy Iteration Emilio Frazzoli Aeronautics and Astronautics Massachusetts Institute of Technology December
Autonomous Helicopter Flight via Reinforcement Learning
 Autonomous Helicopter Flight via Reinforcement Learning Authors: Andrew Y. Ng, H. Jin Kim, Michael I. Jordan, Shankar Sastry Presenters: Shiv Ballianda, Jerrolyn Hebert, Shuiwang Ji, Kenley Malveaux, Huy
Autonomous Helicopter Flight via Reinforcement Learning Authors: Andrew Y. Ng, H. Jin Kim, Michael I. Jordan, Shankar Sastry Presenters: Shiv Ballianda, Jerrolyn Hebert, Shuiwang Ji, Kenley Malveaux, Huy
ARTIFICIAL INTELLIGENCE. Reinforcement learning
 INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
arxiv: v1 [cs.lg] 13 Dec 2018
![arxiv: v1 [cs.lg] 13 Dec 2018](/thumbs/92/108315530.jpg "arxiv: v1 [cs.lg] 13 Dec 2018") Soft Actor-Critic Algorithms and Applications Tuomas Haarnoja Aurick Zhou Kristian Hartikainen George Tucker arxiv:1812.05905v1 [cs.lg] 13 Dec 2018 Sehoon Ha Jie Tan Vikash Kumar Henry Zhu Abhishek Gupta
Soft Actor-Critic Algorithms and Applications Tuomas Haarnoja Aurick Zhou Kristian Hartikainen George Tucker arxiv:1812.05905v1 [cs.lg] 13 Dec 2018 Sehoon Ha Jie Tan Vikash Kumar Henry Zhu Abhishek Gupta
MS&E338 Reinforcement Learning Lecture 1 - April 2, Introduction
 MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
Q-learning. Tambet Matiisen
 Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Reinforcement Learning
 Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
arxiv: v1 [stat.ml] 6 Nov 2018
![arxiv: v1 [stat.ml] 6 Nov 2018](/thumbs/90/101223289.jpg "arxiv: v1 [stat.ml] 6 Nov 2018") Are Deep Policy Gradient Algorithms Truly Policy Gradient Algorithms? Andrew Ilyas 1, Logan Engstrom 1, Shibani Santurkar 1, Dimitris Tsipras 1, Firdaus Janoos 2, Larry Rudolph 1,2, and Aleksander Mądry
Are Deep Policy Gradient Algorithms Truly Policy Gradient Algorithms? Andrew Ilyas 1, Logan Engstrom 1, Shibani Santurkar 1, Dimitris Tsipras 1, Firdaus Janoos 2, Larry Rudolph 1,2, and Aleksander Mądry
Introduction to Convolutional Neural Networks 2018 / 02 / 23
 Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
An Adaptive Clustering Method for Model-free Reinforcement Learning
 An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
CS343 Artificial Intelligence
 CS343 Artificial Intelligence Prof: Department of Computer Science The University of Texas at Austin Good Afternoon, Colleagues Good Afternoon, Colleagues Are there any questions? Logistics Problems with
CS343 Artificial Intelligence Prof: Department of Computer Science The University of Texas at Austin Good Afternoon, Colleagues Good Afternoon, Colleagues Are there any questions? Logistics Problems with