Automating variational inference for statistics and data mining
|
|
|
- Marilynn Melinda Lee
- 5 years ago
- Views:
Transcription
1 Automating variational inference for statistics and data mining Tom Minka Machine Learning and Perception Group Microsoft Research Cambridge
2 A common situation You have a dataset Some models in mind Want to fit many different models to the data 2
3 Model-based psychometrics y ij ~ f ( y α, β, θ ) i j Subjects i = 1,...,N Questions j = 1,...,J = subject effect α i = question effect β j θ = other parameters 3
4 The problem Inference code is difficult to write As a result: Only a few models can be tried Code runs too slow for real datasets Only use models with available code How to get out of this dilemma? 4
5 Infer.NET: An inference compiler You specify a statistical model It produces efficient code to fit the model to data Multiple inference algorithms available: Variational message passing Expectation propagation Gibbs sampling (coming soon) User extensible
6 Infer.NET: An inference compiler A compiler, not an application Model can be written in any.net language (C++, C#, Python, Basic, ) Can use data structures, functions of the parent language (jagged arrays, if statements, ) Generated inference code can be embedded in a larger program Freely available at:
7 Papers using Infer.NET Benjamin Livshits, Aditya V. Nori, Sriram K. Rajamani, Anindya Banerjee, Merlin: Specification Inference for Explicit Information Flow Problems, Prog. Language Design and Implementation, 2009 Vincent Y. F. Tan, John Winn, Angela Simpson, Adnan Custovic, Immune System Modeling with Infer.NET, IEEE International Conference on e- Science, 2008 David Stern, Ralf Herbrich, Thore Graepel, Matchbox: Large Scale Online Bayesian Recommendations, WWW 2009 Kuang Chen, Harr Chen, Neil Conway, Joseph M. Hellerstein, Tapan S. Parikh, Usher: Improving Data Quality With Dynamic Forms, ICTD
8 Variational Bayesian inference True posterior is approximated by a simpler distribution (Gaussian, Gamma, Beta, ) Point-estimate plus uncertainty Halfway between maximum-likelihood and sampling 8
9 Variational Bayesian inference Let variables be x 1,..., x V For each x, v pick an approximating family (Gaussian, Gamma, Beta, ) Find the joint distribution that minimizes the divergence KL ( q( x) p( x data )) q ( x) = q( x v ) v q( x v ) 9
10 Variational Bayesian inference Well-suited to large datasets, sequential processing (in style of Kalman filter) Provides Bayesian model score 10
11 Implementation Convert model into factor graph Pass messages on the graph until convergence p ( y x) = p( y1 x1, x2 ) p( y2 x1, x2 ) t1 t2 11
12 Further reading C. Bishop, Pattern Recognition and Machine Learning. Springer, T. Minka, Divergence measures and message passing, Microsoft Tech. Rep., T. Minka & J. Winn, Gates, NIPS M.J. Beal & Z. Ghahramani, The Variational Bayesian EM Algorithm for Incomplete Data: with Application to Scoring Graphical Model Structures, Bayesian Statistics 7,
13 Example: Cognitive Diagnosis Models (DINA,NIDA) B. W. Junker and K. Sijtsma, Cognitive Assessment Models with Few Assumptions, and Connections with Nonparametric Item Response Theory, Applied Psychological Measurement 25: (2001) 13
14 = 1 if student i answered question j correctly (observed) y ij if question j requires skill k (known) q jk = 1 if student i has skill k (latent) hasskill = 1 ik hasskill ik ~ Bernoulli ( pskill k ) DINA model: K+2J parameters hasskills ij = hasskill p( y ij = 1) = (1 slip q jk hasskills NIDA model: K+2K parameters k j ) q ik ij guess 1 hasskills j ij exhibitssk ill ik = (1 slip k ) hasskill ik guess 1 hasskill k ik p( y ij = 1) = k exhibitssk ill q ik jk 14
15 15 Graphical model
16 Prior work Junker & Sijtsma (2001), Anozie & Junker (2003) found that MCMC was effective but slow to converge Ayers, Nugent & Dean (2008) proposed clustering as fast alternative to DINA model What about variational inference? 16
17 DINA,NIDA models in Infer.NET Each model is approx 50 lines of code Tested on synthetic data generated from the models 100 students, 100 questions, 10 skills Random question-skill matrix Each question required at least 2 skills Infer.NET used Expectation Propagation (EP) with Beta distributions for parameter posteriors Variational Message Passing gave similar results on DINA, couldn t be applied to NIDA 17
18 Comparison to BUGS EP results compared to 20,000 samples from BUGS For estimating posterior means, EP is as accurate as 10,000 samples, for same cost as 100 samples i.e. 100x faster 18


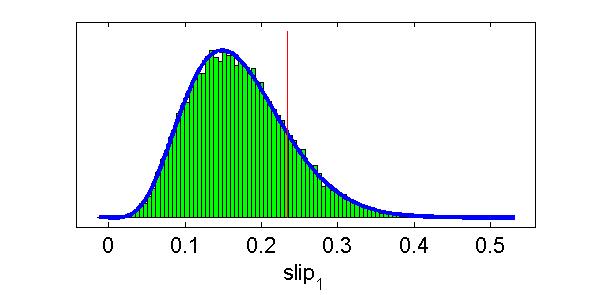
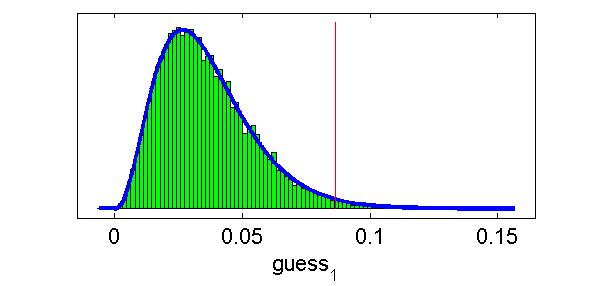
19 DINA model on DINA data 19

20 NIDA model on NIDA data 20
21 21 Model selection
22 Code for DINA model using (Variable.ForEach(student)) { using (Variable.ForEach(question)) { VariableArray<bool> hasskills = Variable.Subarray(hasSkill[student], skillsrequiredforquestion[question]); Variable<bool> hasallskills = Variable.AllTrue(hasSkills); using (Variable.If(hasAllSkills)) { responses[student][question] =!Variable.Bernoulli(slip[question]); } using (Variable.IfNot(hasAllSkills)) { responses[student][question] = Variable.Bernoulli(guess[question]); } } } 22
23 Code for NIDA model using (Variable.ForEach(skillForQuestion)) { using (Variable.If(hasSkills[skillForQuestion])) { showsskill[skillforquestion] =!Variable.Bernoulli(slipSkill[skillForQuestion]); } using (Variable.IfNot(hasSkills[skillForQuestion])) { showsskill[skillforquestion] = Variable.Bernoulli(guessSkill[skillForQuestion]); } } responses[student][question] = Variable.AllTrue(showsSkill); 23
24 Example: Latent class models for diary data F. Rijmen and K. Vansteelandt and P. De Boeck, Latent class models for diary method data: parameter estimation by local computations, Psychometrika, 73, (2008) 24
25 Diary data Patients assess their emotional state over time (Rijmen et al 2008, PMKA) y itj = 1 if subject i at time t feels emotion j (observed) Basic Hidden Markov model: z it { 1,..., S} is hidden state of subject i at time t (latent) S 2 JS 25
26 Prior work Rijmen et al (2008) used maximum-likelihood estimation of HMM parameters model selection was an open issue Which model gets highest score from variational Bayes? 26
27 HMM in Infer.NET Model is approx 70 lines of code Can vary: number of latent classes (S) whether states are independent or Markov 27
28 Hierarchical HMM Real data has more structure than HMM 32 subjects were observed over 7 days, having 9 observations per day Basic HMM treated each day independently Rijmen et al (2008) proposed switching between different HMMs on different days (hierarchical HMM) more model selection issues 28
29 Hierarchical HMM in Infer.NET Model is approx 100 lines of code Can additionally vary: number of HMMs (1,3,5,7,9) whether days are independent or Markov whether transition params depend on day whether observation params depend on day Best model among 400 combinations (2 hours using VMP): 5 HMMs, each having 5 latent states Observation params depend on day, but transition params do not 29
30 Summary Infer.NET allowed 4 custom models to be implemented in a short amount of time Resulting code was efficient enough to process large datasets, compare many models Variational inference is potential replacement for sampling in DINA,NIDA models 30
31 Acknowledgements Rest of Infer.NET team: John Winn, John Guiver, Anitha Kannan Beth Ayers, Brian Junker (DINA,NIDA models) Frank Rijmen (Diary data) 31
Probabilistic Programming with Infer.NET. John Bronskill University of Cambridge 19 th October 2017
 Probabilistic Programming with Infer.NET John Bronskill University of Cambridge 19 th October 2017 The Promise of Probabilistic Programming We want to do for machine learning what the advent of high-level
Probabilistic Programming with Infer.NET John Bronskill University of Cambridge 19 th October 2017 The Promise of Probabilistic Programming We want to do for machine learning what the advent of high-level
Graphical Models Chris Bishop
 Graphical Models Chris Bishop Microsoft Research Cambridge Machine Learning Summer School 2013, Tübingen http://research.microsoft.com/~cmbishop Chapter 8: Graphical Models (PDF download) http://research.microsoft.com/~cmbishop
Graphical Models Chris Bishop Microsoft Research Cambridge Machine Learning Summer School 2013, Tübingen http://research.microsoft.com/~cmbishop Chapter 8: Graphical Models (PDF download) http://research.microsoft.com/~cmbishop
Large-scale Ordinal Collaborative Filtering
 Large-scale Ordinal Collaborative Filtering Ulrich Paquet, Blaise Thomson, and Ole Winther Microsoft Research Cambridge, University of Cambridge, Technical University of Denmark ulripa@microsoft.com,brmt2@cam.ac.uk,owi@imm.dtu.dk
Large-scale Ordinal Collaborative Filtering Ulrich Paquet, Blaise Thomson, and Ole Winther Microsoft Research Cambridge, University of Cambridge, Technical University of Denmark ulripa@microsoft.com,brmt2@cam.ac.uk,owi@imm.dtu.dk
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Machine Learning Summer School
 Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Dynamic Probabilistic Models for Latent Feature Propagation in Social Networks
 Dynamic Probabilistic Models for Latent Feature Propagation in Social Networks Creighton Heaukulani and Zoubin Ghahramani University of Cambridge TU Denmark, June 2013 1 A Network Dynamic network data
Dynamic Probabilistic Models for Latent Feature Propagation in Social Networks Creighton Heaukulani and Zoubin Ghahramani University of Cambridge TU Denmark, June 2013 1 A Network Dynamic network data
p L yi z n m x N n xi
 y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
MODEL-LEARNER PATTERN
 Andy Gordon (MSR and University of Edinburgh) Joint work with Mihhail Aizatulin (OU), Johannes Borgström (Uppsala), Guillaume Claret (MSR), Thore Graepel (MSR), Aditya Nori (MSR), Sriram Rajamani (MSR),
Andy Gordon (MSR and University of Edinburgh) Joint work with Mihhail Aizatulin (OU), Johannes Borgström (Uppsala), Guillaume Claret (MSR), Thore Graepel (MSR), Aditya Nori (MSR), Sriram Rajamani (MSR),
Lecture 6: Graphical Models: Learning
 Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Part 1: Expectation Propagation
 Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Bayesian Inference Course, WTCN, UCL, March 2013
 Bayesian Course, WTCN, UCL, March 2013 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information
Bayesian Course, WTCN, UCL, March 2013 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
A Simulation Study to Compare CAT Strategies for Cognitive Diagnosis
 A Simulation Study to Compare CAT Strategies for Cognitive Diagnosis Xueli Xu Department of Statistics,University of Illinois Hua-Hua Chang Department of Educational Psychology,University of Texas Jeff
A Simulation Study to Compare CAT Strategies for Cognitive Diagnosis Xueli Xu Department of Statistics,University of Illinois Hua-Hua Chang Department of Educational Psychology,University of Texas Jeff
ECE521 Lecture 19 HMM cont. Inference in HMM
 ECE521 Lecture 19 HMM cont. Inference in HMM Outline Hidden Markov models Model definitions and notations Inference in HMMs Learning in HMMs 2 Formally, a hidden Markov model defines a generative process
ECE521 Lecture 19 HMM cont. Inference in HMM Outline Hidden Markov models Model definitions and notations Inference in HMMs Learning in HMMs 2 Formally, a hidden Markov model defines a generative process
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Variational Scoring of Graphical Model Structures
 Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Bayesian Networks BY: MOHAMAD ALSABBAGH
 Bayesian Networks BY: MOHAMAD ALSABBAGH Outlines Introduction Bayes Rule Bayesian Networks (BN) Representation Size of a Bayesian Network Inference via BN BN Learning Dynamic BN Introduction Conditional
Bayesian Networks BY: MOHAMAD ALSABBAGH Outlines Introduction Bayes Rule Bayesian Networks (BN) Representation Size of a Bayesian Network Inference via BN BN Learning Dynamic BN Introduction Conditional
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
Expectation Propagation for Approximate Bayesian Inference
 Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Approximate Inference in Practice Microsoft s Xbox TrueSkill TM
 1 Approximate Inference in Practice Microsoft s Xbox TrueSkill TM Daniel Hernández-Lobato Universidad Autónoma de Madrid 2014 2 Outline 1 Introduction 2 The Probabilistic Model 3 Approximate Inference
1 Approximate Inference in Practice Microsoft s Xbox TrueSkill TM Daniel Hernández-Lobato Universidad Autónoma de Madrid 2014 2 Outline 1 Introduction 2 The Probabilistic Model 3 Approximate Inference
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Probabilistic Machine Learning
 Probabilistic Machine Learning Bayesian Nets, MCMC, and more Marek Petrik 4/18/2017 Based on: P. Murphy, K. (2012). Machine Learning: A Probabilistic Perspective. Chapter 10. Conditional Independence Independent
Probabilistic Machine Learning Bayesian Nets, MCMC, and more Marek Petrik 4/18/2017 Based on: P. Murphy, K. (2012). Machine Learning: A Probabilistic Perspective. Chapter 10. Conditional Independence Independent
36-463/663: Hierarchical Linear Models
 36-463/663: Hierarchical Linear Models Taste of MCMC / Bayes for 3 or more levels Brian Junker 132E Baker Hall brian@stat.cmu.edu 1 Outline Practical Bayes Mastery Learning Example A brief taste of JAGS
36-463/663: Hierarchical Linear Models Taste of MCMC / Bayes for 3 or more levels Brian Junker 132E Baker Hall brian@stat.cmu.edu 1 Outline Practical Bayes Mastery Learning Example A brief taste of JAGS
Bayesian nonparametric models for bipartite graphs
 Bayesian nonparametric models for bipartite graphs François Caron Department of Statistics, Oxford Statistics Colloquium, Harvard University November 11, 2013 F. Caron 1 / 27 Bipartite networks Readers/Customers
Bayesian nonparametric models for bipartite graphs François Caron Department of Statistics, Oxford Statistics Colloquium, Harvard University November 11, 2013 F. Caron 1 / 27 Bipartite networks Readers/Customers
Advanced Machine Learning
 Advanced Machine Learning Nonparametric Bayesian Models --Learning/Reasoning in Open Possible Worlds Eric Xing Lecture 7, August 4, 2009 Reading: Eric Xing Eric Xing @ CMU, 2006-2009 Clustering Eric Xing
Advanced Machine Learning Nonparametric Bayesian Models --Learning/Reasoning in Open Possible Worlds Eric Xing Lecture 7, August 4, 2009 Reading: Eric Xing Eric Xing @ CMU, 2006-2009 Clustering Eric Xing
Bayesian Learning in Undirected Graphical Models
 Bayesian Learning in Undirected Graphical Models Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London, UK http://www.gatsby.ucl.ac.uk/ Work with: Iain Murray and Hyun-Chul
Bayesian Learning in Undirected Graphical Models Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London, UK http://www.gatsby.ucl.ac.uk/ Work with: Iain Murray and Hyun-Chul
Variational Message Passing. By John Winn, Christopher M. Bishop Presented by Andy Miller
 Variational Message Passing By John Winn, Christopher M. Bishop Presented by Andy Miller Overview Background Variational Inference Conjugate-Exponential Models Variational Message Passing Messages Univariate
Variational Message Passing By John Winn, Christopher M. Bishop Presented by Andy Miller Overview Background Variational Inference Conjugate-Exponential Models Variational Message Passing Messages Univariate
Bayesian Learning in Undirected Graphical Models
 Bayesian Learning in Undirected Graphical Models Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London, UK http://www.gatsby.ucl.ac.uk/ and Center for Automated Learning and
Bayesian Learning in Undirected Graphical Models Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London, UK http://www.gatsby.ucl.ac.uk/ and Center for Automated Learning and
Bayesian Networks in Educational Assessment Tutorial
 Bayesian Networks in Educational Assessment Tutorial Session V: Refining Bayes Nets with Data Russell Almond, Bob Mislevy, David Williamson and Duanli Yan Unpublished work 2002-2014 ETS 1 Agenda SESSION
Bayesian Networks in Educational Assessment Tutorial Session V: Refining Bayes Nets with Data Russell Almond, Bob Mislevy, David Williamson and Duanli Yan Unpublished work 2002-2014 ETS 1 Agenda SESSION
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA Contents in latter part Linear Dynamical Systems What is different from HMM? Kalman filter Its strength and limitation Particle Filter
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA Contents in latter part Linear Dynamical Systems What is different from HMM? Kalman filter Its strength and limitation Particle Filter
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
NPFL108 Bayesian inference. Introduction. Filip Jurčíček. Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic
 NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
Scaling Neighbourhood Methods
 Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
Tutorial on Probabilistic Programming with PyMC3
 185.A83 Machine Learning for Health Informatics 2017S, VU, 2.0 h, 3.0 ECTS Tutorial 02-04.04.2017 Tutorial on Probabilistic Programming with PyMC3 florian.endel@tuwien.ac.at http://hci-kdd.org/machine-learning-for-health-informatics-course
185.A83 Machine Learning for Health Informatics 2017S, VU, 2.0 h, 3.0 ECTS Tutorial 02-04.04.2017 Tutorial on Probabilistic Programming with PyMC3 florian.endel@tuwien.ac.at http://hci-kdd.org/machine-learning-for-health-informatics-course
Bayesian Networks. instructor: Matteo Pozzi. x 1. x 2. x 3 x 4. x 5. x 6. x 7. x 8. x 9. Lec : Urban Systems Modeling
 12735: Urban Systems Modeling Lec. 09 Bayesian Networks instructor: Matteo Pozzi x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 1 outline example of applications how to shape a problem as a BN complexity of the inference
12735: Urban Systems Modeling Lec. 09 Bayesian Networks instructor: Matteo Pozzi x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 1 outline example of applications how to shape a problem as a BN complexity of the inference
Course 495: Advanced Statistical Machine Learning/Pattern Recognition
 Course 495: Advanced Statistical Machine Learning/Pattern Recognition Lecturer: Stefanos Zafeiriou Goal (Lectures): To present discrete and continuous valued probabilistic linear dynamical systems (HMMs
Course 495: Advanced Statistical Machine Learning/Pattern Recognition Lecturer: Stefanos Zafeiriou Goal (Lectures): To present discrete and continuous valued probabilistic linear dynamical systems (HMMs
A Brief Overview of Nonparametric Bayesian Models
 A Brief Overview of Nonparametric Bayesian Models Eurandom Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin Also at Machine
A Brief Overview of Nonparametric Bayesian Models Eurandom Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin Also at Machine
Model Comparison. Course on Bayesian Inference, WTCN, UCL, February Model Comparison. Bayes rule for models. Linear Models. AIC and BIC.
 Course on Bayesian Inference, WTCN, UCL, February 2013 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented
Course on Bayesian Inference, WTCN, UCL, February 2013 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented
27 : Distributed Monte Carlo Markov Chain. 1 Recap of MCMC and Naive Parallel Gibbs Sampling
 10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
An Overview of Edward: A Probabilistic Programming System. Dustin Tran Columbia University
 An Overview of Edward: A Probabilistic Programming System Dustin Tran Columbia University Alp Kucukelbir Eugene Brevdo Andrew Gelman Adji Dieng Maja Rudolph David Blei Dawen Liang Matt Hoffman Kevin Murphy
An Overview of Edward: A Probabilistic Programming System Dustin Tran Columbia University Alp Kucukelbir Eugene Brevdo Andrew Gelman Adji Dieng Maja Rudolph David Blei Dawen Liang Matt Hoffman Kevin Murphy
Hidden Markov Models. Aarti Singh Slides courtesy: Eric Xing. Machine Learning / Nov 8, 2010
 Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Bayesian Hidden Markov Models and Extensions
 Bayesian Hidden Markov Models and Extensions Zoubin Ghahramani Department of Engineering University of Cambridge joint work with Matt Beal, Jurgen van Gael, Yunus Saatci, Tom Stepleton, Yee Whye Teh Modeling
Bayesian Hidden Markov Models and Extensions Zoubin Ghahramani Department of Engineering University of Cambridge joint work with Matt Beal, Jurgen van Gael, Yunus Saatci, Tom Stepleton, Yee Whye Teh Modeling
Variational Learning : From exponential families to multilinear systems
 Variational Learning : From exponential families to multilinear systems Ananth Ranganathan th February 005 Abstract This note aims to give a general overview of variational inference on graphical models.
Variational Learning : From exponential families to multilinear systems Ananth Ranganathan th February 005 Abstract This note aims to give a general overview of variational inference on graphical models.
Gentle Introduction to Infinite Gaussian Mixture Modeling
 Gentle Introduction to Infinite Gaussian Mixture Modeling with an application in neuroscience By Frank Wood Rasmussen, NIPS 1999 Neuroscience Application: Spike Sorting Important in neuroscience and for
Gentle Introduction to Infinite Gaussian Mixture Modeling with an application in neuroscience By Frank Wood Rasmussen, NIPS 1999 Neuroscience Application: Spike Sorting Important in neuroscience and for
VIBES: A Variational Inference Engine for Bayesian Networks
 VIBES: A Variational Inference Engine for Bayesian Networks Christopher M. Bishop Microsoft Research Cambridge, CB3 0FB, U.K. research.microsoft.com/ cmbishop David Spiegelhalter MRC Biostatistics Unit
VIBES: A Variational Inference Engine for Bayesian Networks Christopher M. Bishop Microsoft Research Cambridge, CB3 0FB, U.K. research.microsoft.com/ cmbishop David Spiegelhalter MRC Biostatistics Unit
Hidden Markov Models. Terminology, Representation and Basic Problems
 Hidden Markov Models Terminology, Representation and Basic Problems Data analysis? Machine learning? In bioinformatics, we analyze a lot of (sequential) data (biological sequences) to learn unknown parameters
Hidden Markov Models Terminology, Representation and Basic Problems Data analysis? Machine learning? In bioinformatics, we analyze a lot of (sequential) data (biological sequences) to learn unknown parameters
6.867 Machine learning, lecture 23 (Jaakkola)
") Lecture topics: Markov Random Fields Probabilistic inference Markov Random Fields We will briefly go over undirected graphical models or Markov Random Fields (MRFs) as they will be needed in the context
Lecture topics: Markov Random Fields Probabilistic inference Markov Random Fields We will briefly go over undirected graphical models or Markov Random Fields (MRFs) as they will be needed in the context
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
A Comparison of Two MCMC Algorithms for Hierarchical Mixture Models
 A Comparison of Two MCMC Algorithms for Hierarchical Mixture Models Russell Almond Florida State University College of Education Educational Psychology and Learning Systems ralmond@fsu.edu BMAW 2014 1
A Comparison of Two MCMC Algorithms for Hierarchical Mixture Models Russell Almond Florida State University College of Education Educational Psychology and Learning Systems ralmond@fsu.edu BMAW 2014 1
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Does the Wake-sleep Algorithm Produce Good Density Estimators?
 Does the Wake-sleep Algorithm Produce Good Density Estimators? Brendan J. Frey, Geoffrey E. Hinton Peter Dayan Department of Computer Science Department of Brain and Cognitive Sciences University of Toronto
Does the Wake-sleep Algorithm Produce Good Density Estimators? Brendan J. Frey, Geoffrey E. Hinton Peter Dayan Department of Computer Science Department of Brain and Cognitive Sciences University of Toronto
Expectation Propagation in Dynamical Systems
 Expectation Propagation in Dynamical Systems Marc Peter Deisenroth Joint Work with Shakir Mohamed (UBC) August 10, 2012 Marc Deisenroth (TU Darmstadt) EP in Dynamical Systems 1 Motivation Figure : Complex
Expectation Propagation in Dynamical Systems Marc Peter Deisenroth Joint Work with Shakir Mohamed (UBC) August 10, 2012 Marc Deisenroth (TU Darmstadt) EP in Dynamical Systems 1 Motivation Figure : Complex
Hidden Markov Models. By Parisa Abedi. Slides courtesy: Eric Xing
 Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Message Passing Algorithms for Dirichlet Diffusion Trees
 Message Passing Algorithms for Dirichlet Diffusion Trees David A. Knowles, University of Cambridge Jurgen Van Gael, Microsoft Research Cambridge Zoubin Ghahramani, University of Cambridge May 6, 2011 Abstract
Message Passing Algorithms for Dirichlet Diffusion Trees David A. Knowles, University of Cambridge Jurgen Van Gael, Microsoft Research Cambridge Zoubin Ghahramani, University of Cambridge May 6, 2011 Abstract
Variational Principal Components
 Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
ECE521 Tutorial 11. Topic Review. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides. ECE521 Tutorial 11 / 4
 ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Latent Variable Models and EM Algorithm
 SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2014
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Understanding Covariance Estimates in Expectation Propagation
 Understanding Covariance Estimates in Expectation Propagation William Stephenson Department of EECS Massachusetts Institute of Technology Cambridge, MA 019 wtstephe@csail.mit.edu Tamara Broderick Department
Understanding Covariance Estimates in Expectation Propagation William Stephenson Department of EECS Massachusetts Institute of Technology Cambridge, MA 019 wtstephe@csail.mit.edu Tamara Broderick Department
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection
 CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
10708 Graphical Models: Homework 2
 10708 Graphical Models: Homework 2 Due Monday, March 18, beginning of class Feburary 27, 2013 Instructions: There are five questions (one for extra credit) on this assignment. There is a problem involves
10708 Graphical Models: Homework 2 Due Monday, March 18, beginning of class Feburary 27, 2013 Instructions: There are five questions (one for extra credit) on this assignment. There is a problem involves
Equivalency of the DINA Model and a Constrained General Diagnostic Model
 Research Report ETS RR 11-37 Equivalency of the DINA Model and a Constrained General Diagnostic Model Matthias von Davier September 2011 Equivalency of the DINA Model and a Constrained General Diagnostic
Research Report ETS RR 11-37 Equivalency of the DINA Model and a Constrained General Diagnostic Model Matthias von Davier September 2011 Equivalency of the DINA Model and a Constrained General Diagnostic
Bayesian Machine Learning - Lecture 7
 Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
The Particle Filter. PD Dr. Rudolph Triebel Computer Vision Group. Machine Learning for Computer Vision
 The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
An Introduction to Bayesian Machine Learning
 1 An Introduction to Bayesian Machine Learning José Miguel Hernández-Lobato Department of Engineering, Cambridge University April 8, 2013 2 What is Machine Learning? The design of computational systems
1 An Introduction to Bayesian Machine Learning José Miguel Hernández-Lobato Department of Engineering, Cambridge University April 8, 2013 2 What is Machine Learning? The design of computational systems
CPSC 540: Machine Learning
 CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
Another Walkthrough of Variational Bayes. Bevan Jones Machine Learning Reading Group Macquarie University
 Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis
Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis
Inference in Explicit Duration Hidden Markov Models
 Inference in Explicit Duration Hidden Markov Models Frank Wood Joint work with Chris Wiggins, Mike Dewar Columbia University November, 2011 Wood (Columbia University) EDHMM Inference November, 2011 1 /
Inference in Explicit Duration Hidden Markov Models Frank Wood Joint work with Chris Wiggins, Mike Dewar Columbia University November, 2011 Wood (Columbia University) EDHMM Inference November, 2011 1 /
Expectation propagation as a way of life
 Expectation propagation as a way of life Yingzhen Li Department of Engineering Feb. 2014 Yingzhen Li (Department of Engineering) Expectation propagation as a way of life Feb. 2014 1 / 9 Reference This
Expectation propagation as a way of life Yingzhen Li Department of Engineering Feb. 2014 Yingzhen Li (Department of Engineering) Expectation propagation as a way of life Feb. 2014 1 / 9 Reference This
Restricted Boltzmann Machines for Collaborative Filtering
 Restricted Boltzmann Machines for Collaborative Filtering Authors: Ruslan Salakhutdinov Andriy Mnih Geoffrey Hinton Benjamin Schwehn Presentation by: Ioan Stanculescu 1 Overview The Netflix prize problem
Restricted Boltzmann Machines for Collaborative Filtering Authors: Ruslan Salakhutdinov Andriy Mnih Geoffrey Hinton Benjamin Schwehn Presentation by: Ioan Stanculescu 1 Overview The Netflix prize problem
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Bayesian Nonparametrics for Speech and Signal Processing
 Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Recall: Modeling Time Series. CSE 586, Spring 2015 Computer Vision II. Hidden Markov Model and Kalman Filter. Modeling Time Series
 Recall: Modeling Time Series CSE 586, Spring 2015 Computer Vision II Hidden Markov Model and Kalman Filter State-Space Model: You have a Markov chain of latent (unobserved) states Each state generates
Recall: Modeling Time Series CSE 586, Spring 2015 Computer Vision II Hidden Markov Model and Kalman Filter State-Space Model: You have a Markov chain of latent (unobserved) states Each state generates
Stochastic Variational Inference
 Stochastic Variational Inference David M. Blei Princeton University (DRAFT: DO NOT CITE) December 8, 2011 We derive a stochastic optimization algorithm for mean field variational inference, which we call
Stochastic Variational Inference David M. Blei Princeton University (DRAFT: DO NOT CITE) December 8, 2011 We derive a stochastic optimization algorithm for mean field variational inference, which we call
STRUCTURAL BIOINFORMATICS I. Fall 2015
 STRUCTURAL BIOINFORMATICS I Fall 2015 Info Course Number - Classification: Biology 5411 Class Schedule: Monday 5:30-7:50 PM, SERC Room 456 (4 th floor) Instructors: Vincenzo Carnevale - SERC, Room 704C;
STRUCTURAL BIOINFORMATICS I Fall 2015 Info Course Number - Classification: Biology 5411 Class Schedule: Monday 5:30-7:50 PM, SERC Room 456 (4 th floor) Instructors: Vincenzo Carnevale - SERC, Room 704C;
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Center for Advanced Studies in Measurement and Assessment. CASMA Research Report. Hierarchical Cognitive Diagnostic Analysis: Simulation Study
 Center for Advanced Studies in Measurement and Assessment CASMA Research Report Number 38 Hierarchical Cognitive Diagnostic Analysis: Simulation Study Yu-Lan Su, Won-Chan Lee, & Kyong Mi Choi Dec 2013
Center for Advanced Studies in Measurement and Assessment CASMA Research Report Number 38 Hierarchical Cognitive Diagnostic Analysis: Simulation Study Yu-Lan Su, Won-Chan Lee, & Kyong Mi Choi Dec 2013
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Sequential Monte Carlo Methods for Bayesian Computation
 Sequential Monte Carlo Methods for Bayesian Computation A. Doucet Kyoto Sept. 2012 A. Doucet (MLSS Sept. 2012) Sept. 2012 1 / 136 Motivating Example 1: Generic Bayesian Model Let X be a vector parameter
Sequential Monte Carlo Methods for Bayesian Computation A. Doucet Kyoto Sept. 2012 A. Doucet (MLSS Sept. 2012) Sept. 2012 1 / 136 Motivating Example 1: Generic Bayesian Model Let X be a vector parameter
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Probabilistic and Bayesian Machine Learning
 Probabilistic and Bayesian Machine Learning Day 4: Expectation and Belief Propagation Yee Whye Teh ywteh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London http://www.gatsby.ucl.ac.uk/
Probabilistic and Bayesian Machine Learning Day 4: Expectation and Belief Propagation Yee Whye Teh ywteh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London http://www.gatsby.ucl.ac.uk/
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Machine Learning for Data Science (CS4786) Lecture 24
 Lecture 24") Machine Learning for Data Science (CS4786) Lecture 24 HMM Particle Filter Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2017fa/ Rejection Sampling Rejection Sampling Sample variables from joint
Machine Learning for Data Science (CS4786) Lecture 24 HMM Particle Filter Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2017fa/ Rejection Sampling Rejection Sampling Sample variables from joint
Power EP. Thomas Minka Microsoft Research Ltd., Cambridge, UK MSR-TR , October 4, Abstract
 Power EP Thomas Minka Microsoft Research Ltd., Cambridge, UK MSR-TR-2004-149, October 4, 2004 Abstract This note describes power EP, an etension of Epectation Propagation (EP) that makes the computations
Power EP Thomas Minka Microsoft Research Ltd., Cambridge, UK MSR-TR-2004-149, October 4, 2004 Abstract This note describes power EP, an etension of Epectation Propagation (EP) that makes the computations
Bayesian Nonparametrics
 Bayesian Nonparametrics Peter Orbanz Columbia University PARAMETERS AND PATTERNS Parameters P(X θ) = Probability[data pattern] 3 2 1 0 1 2 3 5 0 5 Inference idea data = underlying pattern + independent
Bayesian Nonparametrics Peter Orbanz Columbia University PARAMETERS AND PATTERNS Parameters P(X θ) = Probability[data pattern] 3 2 1 0 1 2 3 5 0 5 Inference idea data = underlying pattern + independent
Online Algorithms for Sum-Product
 Online Algorithms for Sum-Product Networks with Continuous Variables Priyank Jaini Ph.D. Seminar Consistent/Robust Tensor Decomposition And Spectral Learning Offline Bayesian Learning ADF, EP, SGD, oem
Online Algorithms for Sum-Product Networks with Continuous Variables Priyank Jaini Ph.D. Seminar Consistent/Robust Tensor Decomposition And Spectral Learning Offline Bayesian Learning ADF, EP, SGD, oem
2 : Directed GMs: Bayesian Networks
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 2 : Directed GMs: Bayesian Networks Lecturer: Eric P. Xing Scribes: Jayanth Koushik, Hiroaki Hayashi, Christian Perez Topic: Directed GMs 1 Types
10-708: Probabilistic Graphical Models 10-708, Spring 2017 2 : Directed GMs: Bayesian Networks Lecturer: Eric P. Xing Scribes: Jayanth Koushik, Hiroaki Hayashi, Christian Perez Topic: Directed GMs 1 Types