p L yi z n m x N n xi
|
|
|
- Alexandra Burke
- 6 years ago
- Views:
Transcription
1 y i z n x n N x i
2 Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference
3 Books statistical perspective Graphical Models, S. Lauritzen (1996) An Introduction to Bayesian Networks, F. Jensen (1996) Expert Systems and Probabilistic Network Models, Castillo et al. (1997) Probabilistic Reasoning in Intelligent Systems, J. Pearl (1998) Probabilistic Expert Systems, Cowell et al., (1999) Bayesian Networks and Decision Graphs, F. Jensen (2001) Learning Bayesian Networks, R. Neapolitan (2004)
4 Books learning perspective Learning in Graphical Models, M. I. Jordan, Ed.,(1998) Graphical Models for Machine Learning and Digital Communication, B. Frey (1998) Graphical Models, M. I. Jordan (TBD) Information Theory, Inference, and Learning Algorithms, D. J. C. MacKay (2003) Also

5 Pattern Recognition and Machine Learning Springer (2005) 600 pages, hardback, four colour, low price Graduate-level text book Worked solutions to all 250 exercises Complete lectures on www Matlab software: Netlab, and companion text with Ian Nabney (Springer 2006)
6 Probabilistic Graphical Models Graphical representations of probability distributions new insights into existing models motivation for new models graph based algorithms for calculation and computation
7 Probability Theory Sum rule Product rule From these we have Bayes theorem with normalization
8 Directed Graphs: Decomposition Consider an arbitrary joint distribution By successive application of the product rule x y z
9 Directed Acyclic Graphs Joint distribution where denotes the parents of x 2 x 1 x 3 x 4 x 5 x 6 x 7 No directed cycles
10 Examples of Directed Graphs Hidden Markov models Kalman filters Factor analysis Probabilistic principal component analysis Independent component analysis Mixtures of Gaussians Transformed component analysis Probabilistic expert systems Sigmoid belief networks Hierarchical mixtures of experts Etc, etc,
11 Undirected Graphs Provided then joint distribution is product of non-negative functions over the cliques of the graph where are the clique potentials, and Z is a normalization constant w x y z
12 Conditioning on Evidence Variables may be hidden (latent) or visible (observed) visible hidden Latent variables may have a specific interpretation, or may be introduced to permit a richer class of distribution
13 Importance of Ordering Battery Fuel gauge Fuel Start Engine turns over Fuel gauge Engine turns over Start Battery Fuel
14 Causality Directed graphs can express causal relationships Often we observe child variables and wish to infer the posterior distribution of parent variables Example: x cancer x cancer y blood test y blood test Note: inferring causal structure from data is subtle
15 Conditional Independence independent of given if, for all values of, Phil Dawid s notation Equivalently Conditional independence crucial in practical applications since we can rarely work with a general joint distribution
16 Markov Properties Can we determine the conditional independence properties of a distribution directly from its graph? undirected graphs: easy directed graphs: one subtlety
17 Undirected Graphs Conditional independence given by graph separation!
18 Graphs as Filters p( x) DF? Factorization and conditional independence give identical families of distributions
19 Directed Markov Properties: Example 1 Joint distribution over 3 variables specified by the graph a c b Note the missing edge from to Node c is head-to-tail with respect to the path Joint distribution
20 Directed Markov Properties: Example 1 Suppose we condition on node a c b Hence Note that if is not observed we have Informally: observation of blocks the path from to
21 Directed Markov Properties: Example 2 3-node graph c a b Joint distribution Node is tail-to-tail with respect to the path Again, note missing edge fromto
22 Directed Markov Properties: Example 2 Now condition on node We have Hence a c b Again, if is not observed Informally: observation of blocks the path from to
23 Directed Markov Properties: Example 3 Node is head-to-head with respect to the path a b Joint distribution c Note missing edge from to If is not observed we have and hence
24 Directed Markov Properties: Example 3 Suppose we condition on node a b Hence c Informally: unobserved head-to-head node blocks the path from to once is observed the path is unblocked Note: observation of any descendent of also unblocks the path
25 Explaining Away Illustration: pixel colour in an image lighting colour surface colour image colour
26 d-separation Conditional independence if, and only if, all possible paths are blocked. Examples: f f a a e b e b c c (i) (ii)
27 Markov Blankets
28 Directed versus Undirected w x y x y z z D U P
29 Example: State Space Models Hidden Markov model Kalman filter
30 Example: Bayesian SSM
31 Example: Factorial SSM Multiple hidden sequences
32 Example: Markov Random Field Typical application: image region labelling y i x i
33 Example: Conditional Random Field y y y y x i
34 Summary of Factorization Properties Directed graphs conditional independence from d-separation test Undirected graphs conditional independence from graph separation
35 Inference Simple example: Bayes theorem x x y y
36 Message Passing Example x 1 x 2 x L-1 x L Find marginal for a particular node for -state nodes, cost is exponential in length of chain but, we can exploit the graphical structure (conditional independences)
37 Message Passing Joint distribution Exchange sums and products
38 Message Passing Express as product of messages m ( x i ) m ( x i ) x i 1 x i x i 1 Recursive evaluation of messages Find by normalizing
39 Belief Propagation Extension to general tree-structured graphs At each node: form product of incoming messages and local evidence marginalize to give outgoing message one message in each direction across every link also called the sum-product algorithm x i Fails if there are loops
40 Max-product Algorithm Goal: find define then Message passing algorithm with sum replaced by max Generalization of Viterbi algorithm for HMMs
41 Example: Hidden Markov Model Inference involves one forward and one backward pass Computational cost grows linearly with length of chain Similarly for the Kalman filter
42 Junction Tree Algorithm An efficient exact algorithm for a general graph applies to both directed and undirected graphs compile original graph into a tree of cliques then perform message passing on this tree Problem: cost is exponential in size of largest clique many interesting models have intractably large cliques
43 Loopy Belief Propagation Apply belief propagation directly to general graph need to keep iterating might not converge State-of-the-art performance in error-correcting codes
44 Junction Tree Algorithm Key steps: 1. Moralize 2. Absorb evidence 3. Triangulate 4. Construct junction tree of cliques 5. Pass messages to achieve consistency
45 Moralization There are algorithms which work with the original directed graph, but these turn out to be special cases of the junction tree algorithm In the JT algorithm we first convert the directed graph into an undirected graph directed and undirected graphs are then treated using the same approach Suppose we are given a directed graph with a conditionals and we wish to find a representation as an undirected graph
46 Moralization (cont d) The conditionals are obvious candidates as clique potentials, but we need to ensure that each node belongs in the same clique as its parents This is achieved by adding, for each node, links connecting together all of the parents
47 Moralization (cont d) Moralization therefore consists of the following steps: 1. For each node in the graph, add an edge between all parents of the node and then convert directed edges to undirected edges 2. Initialize the clique potentials of the moral graph to 1 3. For each local conditional probability choose a clique C such that C contains both and pa i and multiply by Note that this undirected graph automatically has a normalization factor
48 Moralization (cont d) By adding links we have discarded some conditional independencies However, any conditional independencies in the moral graph also hold for the original directed graph, so if we solve the inference problem for the moral graph we will solve it also for the directed graph
49 Absorbing Evidence The nodes can be grouped into visible V for, which we have particular observed values, and hidden H We are interested in the conditional (posterior) probability Absorb evidence simply by altering the clique potentials to be zero for any configuration inconsistent with
50 Absorbing Evidence (cont d) We can view as an un-normalized version of and hence an un-normalized version of
51 Local Consistency As it stands, the graph correctly represents the (unnormalized) joint distribution but the clique potentials do not have an interpretation as marginal probabilities Our goal is to update the clique potentials so that they acquire a local probabilistic interpretation while preserving the global distribution
52 Local Consistency (cont d) Note that we cannot simply have with as can be seen by considering the three node graph where
53 Local Consistency (cont d) Instead we consider a more general representation for undirected graphs including separator sets
54 Local Consistency (cont d) Starting from our un-normalized representation of in terms of products of clique potentials, we can introduce separator potentials initially set to unity Note that nodes can appear in more than one clique, and we require that these be consistent for all marginals Achieving consistency is central to the junction tree algorithm
55 Local Consistency (cont d) Consider the elemental problem of achieving consistency between a pair of cliques V and W, with separator set S Initially
56 Local Consistency (cont d) First construct a message at clique V and pass to W Since is unchanged, and so the joint distribution is invariant
57 Local Consistency (cont d) Next pass a message back from W to V using the same update rule Here is unchanged and so, and again the joint distribution is unchanged The marginals are now correct for both of the cliques and also for the separator
58 Local Consistency (cont d) Example: return to the earlier three node graph Initially the clique potentials are and, and the separator potential The first message pass gives the following update which are the correct marginals In this case the second message is vacuous
59 Local Consistency (cont d) Now suppose that node is observed so that Absorbing the evidence by setting for Summing over A gives Updating the potential gives
60 Local Consistency (cont d) Hence the potentials after the first message pass are Again the reverse message is vacuous Note that the resulting clique and separator marginals require normalization (a local operation)
61 Global Consistency How can we extend our two-clique procedure to ensure consistency across the whole graph? We construct a clique tree by considering a spanning tree linking all of the cliques which is maximal with respect to the cardinality of the intersection sets Next we construct and pass messages using the following protocol: a clique can send a message to a neighbouring clique only when it has received messages from all of its neighbours
62 Global Consistency (cont d) In practice this can be achieved by designating one clique as root and then (i) collecting evidence by passing messages from the leaves to the root (ii) distributing evidence by propagating outwards from the root to the leaves
63 One Last Issue The algorithm discussed so far is not quite sufficient to guarantee consistency for an arbitrary graph Consider the four node graph here, together with a maximal spanning clique tree Node C appears in two places - no guarantee that local consistency for will result in global consistency
64 One Last Issue (cont d) The problem is resolved if the tree of cliques is a junction tree, i.e. if for every pair of cliques V and W all cliques on the (unique) path from V to W contain V W (running intersection property) As a by-product we are also guaranteed that the (now consistent) clique potentials are indeed marginals
65 One Last Issue (cont d) How do we ensure that the maximal spanning tree of cliques will be a junction tree? Result: a graph has a junction tree if, and only if, it is triangulated, i.e. there are no chordless cycles of four or more nodes in the graph Example of a graph and its triangulated counterpart
66 Summary of Junction Tree Algorithm Key steps: 1. Moralize 2.Absorb evidence 3. Triangulate 4.Construct junction tree 5.Pass messages to achieve consistency
67 Example of JT Algorithm Original directed graph
68 Example of JT Algorithm (cont d) Moralization
69 Example of JT Algorithm (cont d) Undirected graph
70 Example of JT Algorithm (cont d) Triangulation
71 Example of JT Algorithm (cont d) Junction tree
72 Inference and Learning Data set Likelihood function (independent observations) Maximize (log) likelihood Predictive distribution
73 Regularized Maximum Likelihood Prior, posterior MAP (maximum posterior) Predictive distribution Not really Bayesian
74 Bayesian Learning Key idea is to marginalize over unknown parameters, rather than make point estimates avoids severe over-fitting of ML and MAP allows direct model comparison Parameters are now latent variables Bayesian learning is an inference problem!
75 Bayesian Learning
76 Bayesian Learning
77 The Exponential Family Many distributions can be written in the form Includes: Gaussian Dirichlet Gamma Multi-nomial Wishart Bernoulli Building blocks in graphs to give rich probabilistic models
78 Illustration: the Gaussian Use precision (inverse variance) In standard form
79 Maximum Likelihood Likelihood function (independent observations) Depends on data via sufficient statistics of fixed dimension
80 Conjugate Priors Prior has same functional form as likelihood Hence posterior is of the form Can interpret prior as effective observations of value Examples: Gaussian for the mean of a Gaussian Gaussian-Wishart for mean and precision of Gaussian Dirichlet for the parameters of a discrete distribution
81 EM and Variational Inference Roadmap: mixtures of Gaussians EM (informal derivation) lower bound viewpoint EM revisited variational inference
82 The Gaussian Distribution Multivariate Gaussian mean covariance Maximum likelihood
83 Gaussian Mixtures Linear super-position of Gaussians Normalization and positivity require
 0 0 0.5 1 (b)")
84 Example: Mixture of 3 Gaussians (a) (b)
85 Maximum Likelihood for the GMM Log likelihood function Sum over components appears inside the log no closed form ML solution
86 EM Algorithm Informal Derivation
87 EM Algorithm Informal Derivation M step equations
88 EM Algorithm Informal Derivation E step equation
89 Responsibilities Can interpret the mixing coefficients as prior probabilities Corresponding posterior probabilities (responsibilities)
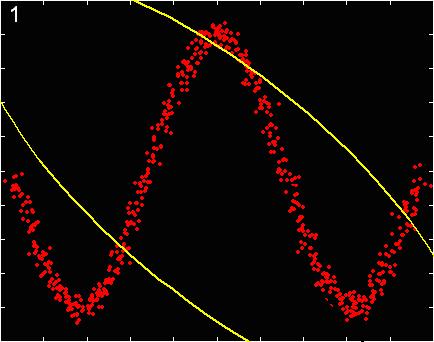
 Duration of eruption")
90 Old Faithful Data Set Time between eruptions (minutes) Duration of eruption (minutes)
91
92
93
94
95
96
97 Over-fitting in Gaussian Mixture Models Infinities in likelihood function when a component collapses onto a data point: with Also, maximum likelihood cannot determine the number of components
98 Latent Variable View of EM To sample from a Gaussian mixture: first pick one of the components with probability then draw a sample from that component repeat these two steps for each new data point (a)
99 Latent Variable View of EM Goal is to solve the inverse problem: given a data set, find Suppose we knew the colours maximum likelihood would involve fitting each component to the corresponding cluster Problem: the colours are latent (hidden) variables
100 Incomplete and Complete Data (a) complete (b) incomplete
101 Latent Variable Viewpoint Binary latent variables describing which component generated each data point Z X Example: 3 components and 5 data points
102 Latent Variable Viewpoint Conditional distribution of observed variable Z Prior distribution of latent variables X Marginalizing over the latent variables we obtain
103 Graphical Representation of GMM z n x n N
104 Latent Variable View of EM Suppose we knew the values for the latent variables maximize the complete-data log likelihood trivial closed-form solution: fit each component to the corresponding set of data points
105 Latent Variable View of EM Problem: we don t know the values of the latent variables Instead maximize the expected value of the completedata log likelihood Make use of Gives the EM algorithm In summary: maximize the log of the joint distribution of latent and observed variables, averaged w.r.t. the posterior distribution of the latent variables
106 Posterior Probabilities (colour coded) (b) (a)
107 Lower Bound on Model Evidence For arbitrary where Maximizing over would give the true posterior
108 Variational Lower Bound
109 EM: Variational Viewpoint (cont d) If we maximize with respect to a free-form distribution we obtain which is the true posterior distribution The lower bound then becomes which, as a function of is the expected complete-data log likelihood (up to an additive constant)
110 Initial Configuration
111 E-step
112 M-step
113 KL Divergence
114 KL Divergence
115
116
117 Bayesian Learning Introduce prior distributions over parameters Equivalent to graph with additional hidden variables Learning becomes inference on the expanded graph No distinction between variables and parameters
118 Bayesian Mixture of Gaussians Parameters and latent variables appear on equal footing Conjugate priors z n x n N

119
120 Explaining Away
121 Lower Bound on Model Evidence For arbitrary where Maximizing over would give the true posterior
122 Variational Lower Bound
123 Variational Inference KL divergence vanishes when equals By definition the exact posterior is intractable We therefore restrict attention to a family of distributions that are both sufficiently simple to be tractable sufficiently flexible to give a good approximation to the true posterior One approach is to use a parametric family
124 Factorized Approximation Here we consider factorized distributions No further assumptions are required!
125 Factorized Approximation
126 Factorized Approximation Optimal solution for one factor, keeping the remainder fixed coupled solutions so initialize then cyclically update message passing view (Winn and Bishop, 2004 to appear in JMLR)
127 1 x x 1 (a) 1
128 1 x x 1 (b) 1
129 Illustration: Univariate Gaussian Likelihood function Conjugate prior Factorized variational distribution
130 Initial Configuration 2 (a) τ µ 1
131 After Updating 2 (b) τ µ 1
132 After Updating 2 (c) τ µ 1
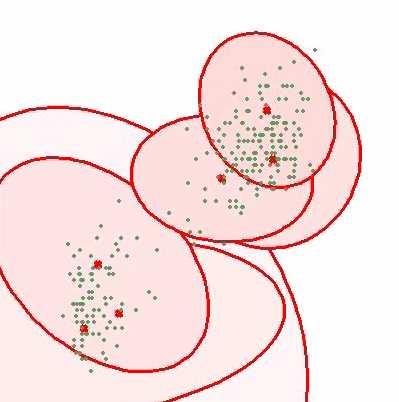
133 Converged Solution 2 (d) τ µ 1
134 Bayesian Model Complexity Consider multiple models Prior probabilities Observed data set Posterior probabilities If prior probabilities equal, models are ranked by their evidence
135 Lower Bound Can also be evaluated Useful for maths/code verification Also useful for model comparison:
136 Variational Mixture of Gaussians Assume factorized posterior distribution No other approximations needed!
137 Variational Equations for GMM
138 Lower Bound for GMM
139 Bound vs. K for Old Faithful Data
140 Bayesian Model Complexity
141
142 Sparse Bayes for Gaussian Mixture Corduneanu and Bishop (2001) Start with large value of treat mixing coefficients as parameters maximize marginal likelihood prunes out excess components
143

144
145 Conventional PCA Minimize sum-of-squares reconstruction error Solution given by of eigen-spectrum of data covariance x 2 x n u 1 ~ xn x 1
146 Probabilistic PCA Tipping and Bishop (1998) Generative latent variable model Maximum likelihood solution given by eigenspectrum x 2 w { z x 1
147 EM for PCA 2 (a)
148 EM for PCA 2 (b)
149 EM for PCA 2 (c)
150 EM for PCA 2 (d)
151 EM for PCA 2 (e)
152 EM for PCA 2 (f)
153 EM for PCA 2 (g)
 Gaussian prior")


154 Bayesian PCA Bishop (1998) Gaussian prior over columns of Automatic relevance determination (ARD) z n N W x n ML PCA Bayesian PCA
155 Bayesian Mixture of BPCA Models Bishop and Winn (2000) W m s n z nm x n N m M
156
157 VIBES Variational Inference for Bayesian Networks Winn and Bishop (1999, 2003, 2004) A general inference engine using variational methods VIBES available from:
158 VIBES (cont d) A key observation is that in the general solution the update for a particular node (or group of nodes) depends only on other nodes in the Markov blanket Permits a local message-passing implementation which is independent of the particular graph structure
")
159 VIBES (cont d)
")

160 VIBES (cont d)
161 VIBES (cont d)
162 Structured Variational Inference Example: factorial HMM
163 Variational Approximation
164 Viewgraphs and papers:
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Chris Bishop s PRML Ch. 8: Graphical Models
 Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
ECE521 Tutorial 11. Topic Review. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides. ECE521 Tutorial 11 / 4
 ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Variational Message Passing. By John Winn, Christopher M. Bishop Presented by Andy Miller
 Variational Message Passing By John Winn, Christopher M. Bishop Presented by Andy Miller Overview Background Variational Inference Conjugate-Exponential Models Variational Message Passing Messages Univariate
Variational Message Passing By John Winn, Christopher M. Bishop Presented by Andy Miller Overview Background Variational Inference Conjugate-Exponential Models Variational Message Passing Messages Univariate
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2014
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Graphical Models 359
 8 Graphical Models Probabilities play a central role in modern pattern recognition. We have seen in Chapter 1 that probability theory can be expressed in terms of two simple equations corresponding to
8 Graphical Models Probabilities play a central role in modern pattern recognition. We have seen in Chapter 1 that probability theory can be expressed in terms of two simple equations corresponding to
Probabilistic Graphical Models (I)
") Probabilistic Graphical Models (I) Hongxin Zhang zhx@cad.zju.edu.cn State Key Lab of CAD&CG, ZJU 2015-03-31 Probabilistic Graphical Models Modeling many real-world problems => a large number of random
Probabilistic Graphical Models (I) Hongxin Zhang zhx@cad.zju.edu.cn State Key Lab of CAD&CG, ZJU 2015-03-31 Probabilistic Graphical Models Modeling many real-world problems => a large number of random
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
6.867 Machine learning, lecture 23 (Jaakkola)
") Lecture topics: Markov Random Fields Probabilistic inference Markov Random Fields We will briefly go over undirected graphical models or Markov Random Fields (MRFs) as they will be needed in the context
Lecture topics: Markov Random Fields Probabilistic inference Markov Random Fields We will briefly go over undirected graphical models or Markov Random Fields (MRFs) as they will be needed in the context
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Machine Learning Lecture 14
 Many slides adapted from B. Schiele, S. Roth, Z. Gharahmani Machine Learning Lecture 14 Undirected Graphical Models & Inference 23.06.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de
Many slides adapted from B. Schiele, S. Roth, Z. Gharahmani Machine Learning Lecture 14 Undirected Graphical Models & Inference 23.06.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Part I. C. M. Bishop PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS
 Part I C. M. Bishop PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS Probabilistic Graphical Models Graphical representation of a probabilistic model Each variable corresponds to a
Part I C. M. Bishop PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS Probabilistic Graphical Models Graphical representation of a probabilistic model Each variable corresponds to a
9 Forward-backward algorithm, sum-product on factor graphs
 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 9 Forward-backward algorithm, sum-product on factor graphs The previous
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 9 Forward-backward algorithm, sum-product on factor graphs The previous
Message Passing and Junction Tree Algorithms. Kayhan Batmanghelich
 Message Passing and Junction Tree Algorithms Kayhan Batmanghelich 1 Review 2 Review 3 Great Ideas in ML: Message Passing Each soldier receives reports from all branches of tree 3 here 7 here 1 of me 11
Message Passing and Junction Tree Algorithms Kayhan Batmanghelich 1 Review 2 Review 3 Great Ideas in ML: Message Passing Each soldier receives reports from all branches of tree 3 here 7 here 1 of me 11
Bayesian Machine Learning - Lecture 7
 Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Graphical Models and Kernel Methods
 Graphical Models and Kernel Methods Jerry Zhu Department of Computer Sciences University of Wisconsin Madison, USA MLSS June 17, 2014 1 / 123 Outline Graphical Models Probabilistic Inference Directed vs.
Graphical Models and Kernel Methods Jerry Zhu Department of Computer Sciences University of Wisconsin Madison, USA MLSS June 17, 2014 1 / 123 Outline Graphical Models Probabilistic Inference Directed vs.
CS 2750: Machine Learning. Bayesian Networks. Prof. Adriana Kovashka University of Pittsburgh March 14, 2016
 CS 2750: Machine Learning Bayesian Networks Prof. Adriana Kovashka University of Pittsburgh March 14, 2016 Plan for today and next week Today and next time: Bayesian networks (Bishop Sec. 8.1) Conditional
CS 2750: Machine Learning Bayesian Networks Prof. Adriana Kovashka University of Pittsburgh March 14, 2016 Plan for today and next week Today and next time: Bayesian networks (Bishop Sec. 8.1) Conditional
Expectation Maximization
 Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Statistical Approaches to Learning and Discovery
 Statistical Approaches to Learning and Discovery Graphical Models Zoubin Ghahramani & Teddy Seidenfeld zoubin@cs.cmu.edu & teddy@stat.cmu.edu CALD / CS / Statistics / Philosophy Carnegie Mellon University
Statistical Approaches to Learning and Discovery Graphical Models Zoubin Ghahramani & Teddy Seidenfeld zoubin@cs.cmu.edu & teddy@stat.cmu.edu CALD / CS / Statistics / Philosophy Carnegie Mellon University
VIBES: A Variational Inference Engine for Bayesian Networks
 VIBES: A Variational Inference Engine for Bayesian Networks Christopher M. Bishop Microsoft Research Cambridge, CB3 0FB, U.K. research.microsoft.com/ cmbishop David Spiegelhalter MRC Biostatistics Unit
VIBES: A Variational Inference Engine for Bayesian Networks Christopher M. Bishop Microsoft Research Cambridge, CB3 0FB, U.K. research.microsoft.com/ cmbishop David Spiegelhalter MRC Biostatistics Unit
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Variational Inference (11/04/13)
") STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
Probabilistic Graphical Models: Representation and Inference
 Probabilistic Graphical Models: Representation and Inference Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Andrew Moore 1 Overview
Probabilistic Graphical Models: Representation and Inference Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Andrew Moore 1 Overview
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Mixtures of Gaussians. Sargur Srihari
 Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Machine Learning 4771
 Machine Learning 4771 Instructor: Tony Jebara Topic 16 Undirected Graphs Undirected Separation Inferring Marginals & Conditionals Moralization Junction Trees Triangulation Undirected Graphs Separation
Machine Learning 4771 Instructor: Tony Jebara Topic 16 Undirected Graphs Undirected Separation Inferring Marginals & Conditionals Moralization Junction Trees Triangulation Undirected Graphs Separation
Probabilistic Graphical Models Homework 2: Due February 24, 2014 at 4 pm
 Probabilistic Graphical Models 10-708 Homework 2: Due February 24, 2014 at 4 pm Directions. This homework assignment covers the material presented in Lectures 4-8. You must complete all four problems to
Probabilistic Graphical Models 10-708 Homework 2: Due February 24, 2014 at 4 pm Directions. This homework assignment covers the material presented in Lectures 4-8. You must complete all four problems to
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Chapter 16. Structured Probabilistic Models for Deep Learning
 Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Variational Principal Components
 Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection
 CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
Probabilistic and Bayesian Machine Learning
 Probabilistic and Bayesian Machine Learning Day 4: Expectation and Belief Propagation Yee Whye Teh ywteh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London http://www.gatsby.ucl.ac.uk/
Probabilistic and Bayesian Machine Learning Day 4: Expectation and Belief Propagation Yee Whye Teh ywteh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London http://www.gatsby.ucl.ac.uk/
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Belief Update in CLG Bayesian Networks With Lazy Propagation
 Belief Update in CLG Bayesian Networks With Lazy Propagation Anders L Madsen HUGIN Expert A/S Gasværksvej 5 9000 Aalborg, Denmark Anders.L.Madsen@hugin.com Abstract In recent years Bayesian networks (BNs)
Belief Update in CLG Bayesian Networks With Lazy Propagation Anders L Madsen HUGIN Expert A/S Gasværksvej 5 9000 Aalborg, Denmark Anders.L.Madsen@hugin.com Abstract In recent years Bayesian networks (BNs)
Conditional Independence
 Conditional Independence Sargur Srihari srihari@cedar.buffalo.edu 1 Conditional Independence Topics 1. What is Conditional Independence? Factorization of probability distribution into marginals 2. Why
Conditional Independence Sargur Srihari srihari@cedar.buffalo.edu 1 Conditional Independence Topics 1. What is Conditional Independence? Factorization of probability distribution into marginals 2. Why
Machine Learning Summer School
 Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 9 Undirected Models CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due next Wednesday (Nov 4) in class Start early!!! Project milestones due Monday (Nov 9)
Probabilistic Graphical Models Lecture 9 Undirected Models CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due next Wednesday (Nov 4) in class Start early!!! Project milestones due Monday (Nov 9)
Inference in Bayesian Networks
 Andrea Passerini passerini@disi.unitn.it Machine Learning Inference in graphical models Description Assume we have evidence e on the state of a subset of variables E in the model (i.e. Bayesian Network)
Andrea Passerini passerini@disi.unitn.it Machine Learning Inference in graphical models Description Assume we have evidence e on the state of a subset of variables E in the model (i.e. Bayesian Network)
Lecture 6: Graphical Models: Learning
 Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
Variational Scoring of Graphical Model Structures
 Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Lecture 15. Probabilistic Models on Graph
 Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Probabilistic Graphical Models. Guest Lecture by Narges Razavian Machine Learning Class April
 Probabilistic Graphical Models Guest Lecture by Narges Razavian Machine Learning Class April 14 2017 Today What is probabilistic graphical model and why it is useful? Bayesian Networks Basic Inference
Probabilistic Graphical Models Guest Lecture by Narges Razavian Machine Learning Class April 14 2017 Today What is probabilistic graphical model and why it is useful? Bayesian Networks Basic Inference
Machine Learning Overview
 Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
Exact Inference I. Mark Peot. In this lecture we will look at issues associated with exact inference. = =
 Exact Inference I Mark Peot In this lecture we will look at issues associated with exact inference 10 Queries The objective of probabilistic inference is to compute a joint distribution of a set of query
Exact Inference I Mark Peot In this lecture we will look at issues associated with exact inference 10 Queries The objective of probabilistic inference is to compute a joint distribution of a set of query
PROBABILITY DISTRIBUTIONS. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
Basic Sampling Methods
 Basic Sampling Methods Sargur Srihari srihari@cedar.buffalo.edu 1 1. Motivation Topics Intractability in ML How sampling can help 2. Ancestral Sampling Using BNs 3. Transforming a Uniform Distribution
Basic Sampling Methods Sargur Srihari srihari@cedar.buffalo.edu 1 1. Motivation Topics Intractability in ML How sampling can help 2. Ancestral Sampling Using BNs 3. Transforming a Uniform Distribution
Introduction to Graphical Models
 Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
Intelligent Systems:
 Intelligent Systems: Undirected Graphical models (Factor Graphs) (2 lectures) Carsten Rother 15/01/2015 Intelligent Systems: Probabilistic Inference in DGM and UGM Roadmap for next two lectures Definition
Intelligent Systems: Undirected Graphical models (Factor Graphs) (2 lectures) Carsten Rother 15/01/2015 Intelligent Systems: Probabilistic Inference in DGM and UGM Roadmap for next two lectures Definition
Lecture 17: May 29, 2002
 EE596 Pat. Recog. II: Introduction to Graphical Models University of Washington Spring 2000 Dept. of Electrical Engineering Lecture 17: May 29, 2002 Lecturer: Jeff ilmes Scribe: Kurt Partridge, Salvador
EE596 Pat. Recog. II: Introduction to Graphical Models University of Washington Spring 2000 Dept. of Electrical Engineering Lecture 17: May 29, 2002 Lecturer: Jeff ilmes Scribe: Kurt Partridge, Salvador
27 : Distributed Monte Carlo Markov Chain. 1 Recap of MCMC and Naive Parallel Gibbs Sampling
 10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Introduction to Probabilistic Graphical Models
 Introduction to Probabilistic Graphical Models Sargur Srihari srihari@cedar.buffalo.edu 1 Topics 1. What are probabilistic graphical models (PGMs) 2. Use of PGMs Engineering and AI 3. Directionality in
Introduction to Probabilistic Graphical Models Sargur Srihari srihari@cedar.buffalo.edu 1 Topics 1. What are probabilistic graphical models (PGMs) 2. Use of PGMs Engineering and AI 3. Directionality in
6.047 / Computational Biology: Genomes, Networks, Evolution Fall 2008
 MIT OpenCourseWare http://ocw.mit.edu 6.047 / 6.878 Computational Biology: Genomes, Networks, Evolution Fall 2008 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
MIT OpenCourseWare http://ocw.mit.edu 6.047 / 6.878 Computational Biology: Genomes, Networks, Evolution Fall 2008 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
Lecture 21: Spectral Learning for Graphical Models
 10-708: Probabilistic Graphical Models 10-708, Spring 2016 Lecture 21: Spectral Learning for Graphical Models Lecturer: Eric P. Xing Scribes: Maruan Al-Shedivat, Wei-Cheng Chang, Frederick Liu 1 Motivation
10-708: Probabilistic Graphical Models 10-708, Spring 2016 Lecture 21: Spectral Learning for Graphical Models Lecturer: Eric P. Xing Scribes: Maruan Al-Shedivat, Wei-Cheng Chang, Frederick Liu 1 Motivation
NPFL108 Bayesian inference. Introduction. Filip Jurčíček. Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic
 NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
Introduction to Probabilistic Graphical Models
 Introduction to Probabilistic Graphical Models Kyu-Baek Hwang and Byoung-Tak Zhang Biointelligence Lab School of Computer Science and Engineering Seoul National University Seoul 151-742 Korea E-mail: kbhwang@bi.snu.ac.kr
Introduction to Probabilistic Graphical Models Kyu-Baek Hwang and Byoung-Tak Zhang Biointelligence Lab School of Computer Science and Engineering Seoul National University Seoul 151-742 Korea E-mail: kbhwang@bi.snu.ac.kr
Lecture 10. Announcement. Mixture Models II. Topics of This Lecture. This Lecture: Advanced Machine Learning. Recap: GMMs as Latent Variable Models
 Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
The Particle Filter. PD Dr. Rudolph Triebel Computer Vision Group. Machine Learning for Computer Vision
 The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
An Introduction to Bayesian Machine Learning
 1 An Introduction to Bayesian Machine Learning José Miguel Hernández-Lobato Department of Engineering, Cambridge University April 8, 2013 2 What is Machine Learning? The design of computational systems
1 An Introduction to Bayesian Machine Learning José Miguel Hernández-Lobato Department of Engineering, Cambridge University April 8, 2013 2 What is Machine Learning? The design of computational systems
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science Algorithms For Inference Fall 2014
 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 Problem Set 3 Issued: Thursday, September 25, 2014 Due: Thursday,
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 Problem Set 3 Issued: Thursday, September 25, 2014 Due: Thursday,
bound on the likelihood through the use of a simpler variational approximating distribution. A lower bound is particularly useful since maximization o
 Category: Algorithms and Architectures. Address correspondence to rst author. Preferred Presentation: oral. Variational Belief Networks for Approximate Inference Wim Wiegerinck David Barber Stichting Neurale
Category: Algorithms and Architectures. Address correspondence to rst author. Preferred Presentation: oral. Variational Belief Networks for Approximate Inference Wim Wiegerinck David Barber Stichting Neurale
Directed and Undirected Graphical Models
 Directed and Undirected Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Machine Learning: Neural Networks and Advanced Models (AA2) Last Lecture Refresher Lecture Plan Directed
Directed and Undirected Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Machine Learning: Neural Networks and Advanced Models (AA2) Last Lecture Refresher Lecture Plan Directed
13 : Variational Inference: Loopy Belief Propagation and Mean Field
 10-708: Probabilistic Graphical Models 10-708, Spring 2012 13 : Variational Inference: Loopy Belief Propagation and Mean Field Lecturer: Eric P. Xing Scribes: Peter Schulam and William Wang 1 Introduction
10-708: Probabilistic Graphical Models 10-708, Spring 2012 13 : Variational Inference: Loopy Belief Propagation and Mean Field Lecturer: Eric P. Xing Scribes: Peter Schulam and William Wang 1 Introduction
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Directed Graphical Models
 CS 2750: Machine Learning Directed Graphical Models Prof. Adriana Kovashka University of Pittsburgh March 28, 2017 Graphical Models If no assumption of independence is made, must estimate an exponential
CS 2750: Machine Learning Directed Graphical Models Prof. Adriana Kovashka University of Pittsburgh March 28, 2017 Graphical Models If no assumption of independence is made, must estimate an exponential
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 8: Bayesian Networks
 Lecture 8: Bayesian Networks Bayesian Networks Inference in Bayesian Networks COMP-652 and ECSE 608, Lecture 8 - January 31, 2017 1 Bayes nets P(E) E=1 E=0 0.005 0.995 E B P(B) B=1 B=0 0.01 0.99 E=0 E=1
Lecture 8: Bayesian Networks Bayesian Networks Inference in Bayesian Networks COMP-652 and ECSE 608, Lecture 8 - January 31, 2017 1 Bayes nets P(E) E=1 E=0 0.005 0.995 E B P(B) B=1 B=0 0.01 0.99 E=0 E=1
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Variational Message Passing
 Journal of Machine Learning Research 5 (2004)?-? Submitted 2/04; Published?/04 Variational Message Passing John Winn and Christopher M. Bishop Microsoft Research Cambridge Roger Needham Building 7 J. J.
Journal of Machine Learning Research 5 (2004)?-? Submitted 2/04; Published?/04 Variational Message Passing John Winn and Christopher M. Bishop Microsoft Research Cambridge Roger Needham Building 7 J. J.
Probabilistic Time Series Classification
 Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
A Brief Introduction to Graphical Models. Presenter: Yijuan Lu November 12,2004
 A Brief Introduction to Graphical Models Presenter: Yijuan Lu November 12,2004 References Introduction to Graphical Models, Kevin Murphy, Technical Report, May 2001 Learning in Graphical Models, Michael
A Brief Introduction to Graphical Models Presenter: Yijuan Lu November 12,2004 References Introduction to Graphical Models, Kevin Murphy, Technical Report, May 2001 Learning in Graphical Models, Michael
Generative and Discriminative Approaches to Graphical Models CMSC Topics in AI
 Generative and Discriminative Approaches to Graphical Models CMSC 35900 Topics in AI Lecture 2 Yasemin Altun January 26, 2007 Review of Inference on Graphical Models Elimination algorithm finds single
Generative and Discriminative Approaches to Graphical Models CMSC 35900 Topics in AI Lecture 2 Yasemin Altun January 26, 2007 Review of Inference on Graphical Models Elimination algorithm finds single
Directed Probabilistic Graphical Models CMSC 678 UMBC
 Directed Probabilistic Graphical Models CMSC 678 UMBC Announcement 1: Assignment 3 Due Wednesday April 11 th, 11:59 AM Any questions? Announcement 2: Progress Report on Project Due Monday April 16 th,
Directed Probabilistic Graphical Models CMSC 678 UMBC Announcement 1: Assignment 3 Due Wednesday April 11 th, 11:59 AM Any questions? Announcement 2: Progress Report on Project Due Monday April 16 th,
Hidden Markov Models. Aarti Singh Slides courtesy: Eric Xing. Machine Learning / Nov 8, 2010
 Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models
 A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models Jeff A. Bilmes (bilmes@cs.berkeley.edu) International Computer Science Institute
A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models Jeff A. Bilmes (bilmes@cs.berkeley.edu) International Computer Science Institute
Junction Tree, BP and Variational Methods
 Junction Tree, BP and Variational Methods Adrian Weller MLSALT4 Lecture Feb 21, 2018 With thanks to David Sontag (MIT) and Tony Jebara (Columbia) for use of many slides and illustrations For more information,
Junction Tree, BP and Variational Methods Adrian Weller MLSALT4 Lecture Feb 21, 2018 With thanks to David Sontag (MIT) and Tony Jebara (Columbia) for use of many slides and illustrations For more information,
Probabilistic Graphical Models
 2016 Robert Nowak Probabilistic Graphical Models 1 Introduction We have focused mainly on linear models for signals, in particular the subspace model x = Uθ, where U is a n k matrix and θ R k is a vector
2016 Robert Nowak Probabilistic Graphical Models 1 Introduction We have focused mainly on linear models for signals, in particular the subspace model x = Uθ, where U is a n k matrix and θ R k is a vector
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Bayesian Networks BY: MOHAMAD ALSABBAGH
 Bayesian Networks BY: MOHAMAD ALSABBAGH Outlines Introduction Bayes Rule Bayesian Networks (BN) Representation Size of a Bayesian Network Inference via BN BN Learning Dynamic BN Introduction Conditional
Bayesian Networks BY: MOHAMAD ALSABBAGH Outlines Introduction Bayes Rule Bayesian Networks (BN) Representation Size of a Bayesian Network Inference via BN BN Learning Dynamic BN Introduction Conditional
Introduction to Probabilistic Graphical Models: Exercises
 Introduction to Probabilistic Graphical Models: Exercises Cédric Archambeau Xerox Research Centre Europe cedric.archambeau@xrce.xerox.com Pascal Bootcamp Marseille, France, July 2010 Exercise 1: basics
Introduction to Probabilistic Graphical Models: Exercises Cédric Archambeau Xerox Research Centre Europe cedric.archambeau@xrce.xerox.com Pascal Bootcamp Marseille, France, July 2010 Exercise 1: basics
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian