Recent Advances in Bayesian Inference Techniques
|
|
|
- Alexina Henderson
- 5 years ago
- Views:
Transcription
1 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004
2 Abstract Bayesian methods offer significant advantages over many conventional techniques such as maximum likelihood. However, their practicality has traditionally been limited by the computational cost of implementing them, which has often been done using Monte Carlo methods. In recent years, however, the applicability of Bayesian methods has been greatly extended through the development of fast analytical techniques such as variational inference. In this talk I will give a tutorial introduction to variational methods and will demonstrate their applicability in both supervised and unsupervised learning domains. I will also discuss techniques for automating variational inference, allowing rapid prototyping and testing of new probabilistic models.
3 Overview What is Bayesian Inference? Variational methods Example 1: uni-variate Gaussian Example 2: mixture of Gaussians Example 3: sparse kernel machines (RVM) Example 4: latent Dirichlet allocation Automatic variational inference
4 Maximum Likelihood Parametric model Data set (i.i.d.) where Likelihood function Maximize (log) likelihood Predictive distribution
5 Regularized Maximum Likelihood Prior, posterior MAP (maximum posterior) Predictive distribution For example, if data model is Gaussian with unknown mean and if prior over mean is Gaussian which is least squares with quadratic regularizer
6 Bayesian Inference Key idea is to marginalize over unknown parameters, rather than make point estimates avoids severe over-fitting of ML/MAP allows direct model comparison Most interesting probabilistic models also have hidden (latent) variables we should marginalize over these too Such integrations (summations) are generally intractable Traditional approach: Markov chain Monte Carlo computationally very expensive limited to small data sets
7 This Talk Variational methods extend the practicality of Bayesian inference to medium sized data sets
8 Data Set Size Problem 1: learn the function for from 100 (slightly) noisy examples data set is computationally small but statistically large Problem 2: learn to recognize 1,000 everyday objects from 5,000,000 natural images data set is computationally large but statistically small Bayesian inference computationally more demanding than ML or MAP significant benefit for statistically small data sets
9 Model Complexity A central issue in statistical inference is the choice of model complexity: too simple poor predictions too complex poor predictions (and slow on test) Maximum likelihood always favours more complex models over-fitting It is usual to resort to cross-validation computationally expensive limited to one or two complexity parameters Bayesian inference can determine model complexity from training data even with many complexity parameters Still a good idea to test final model on independent data
10 Variational Inference Goal: approximate posterior by a simpler distribution for which marginalization is tractable Posterior related to joint by marginal likelihood also a key quantity for model comparison
11 Variational Inference For an arbitrary we have where Kullback-Leibler divergence satisfies
12 Variational Inference Choose to maximize the lower bound KL( qp ) L( q ) ln pd ( )
13 Variational Inference Free-form optimization over would give the true posterior distribution but this is intractable by definition One approach would be to consider a parametric family of distributions and choose the best member Here we consider factorized approximations with free-form optimization of the factors A few lines of algebra shows that the optimum factors are These are coupled so we need to iterate
14 1 x x 1 (a) 1
15 Lower Bound Can also be evaluated Useful for maths + code verification Also useful for model comparison and hence
16 Example 1: Simple Gaussian Likelihood function mean Conjugate priors precision (inverse variance) Factorized variational distribution
17 Variational Posterior Distribution where
18 Initial Configuration 2 (a) τ µ 1
19 After Updating 2 (b) τ µ 1
20 After Updating 2 (c) τ µ 1
21 Converged Solution 2 (d) τ µ 1
22 Applications of Variational Inference Hidden Markov models (MacKay) Neural networks (Hinton) Bayesian PCA (Bishop) Independent Component Analysis (Attias) Mixtures of Gaussians (Attias; Ghahramani and Beal) Mixtures of Bayesian PCA (Bishop and Winn) Flexible video sprites (Frey et al.) Audio-video fusion for tracking (Attias et al.) Latent Dirichlet Allocation (Jordan et al.) Relevance Vector Machine (Tipping and Bishop) Object recognition in images (Li et al.)
23 Example 2: Gaussian Mixture Model Linear superposition of Gaussians Conventional maximum likelihood solution using EM: E-step: evaluate responsibilities
24 Gaussian Mixture Model M-step: re-estimate parameters Problems: singularities how to choose K?
25 Bayesian Mixture of Gaussians Conjugate priors for the parameters: Dirichlet prior for mixing coefficients normal-wishart prior for means and precisions where the Wishart distribution is given by
26 Graphical Representation Parameters and latent variables appear on equal footing z n x n N
27 Variational Mixture of Gaussians Assume factorized posterior distribution No other assumptions! Gives optimal solution in the form where is a Dirichlet, and is a Normal- Wishart; is multinomial
28 Sufficient Statistics Similar computational cost to maximum likelihood EM No singularities! Predictive distribution is mixture of Student-t distributions
29 Variational Equations for GMM
30 Old Faithful Data Set Time between eruptions (minutes) Duration of eruption (minutes)
31 Bound vs. K for Old Faithful Data
32 Bayesian Model Complexity p ( D K ) D 0 D
33 Sparse Gaussian Mixtures Instead of comparing different values of K, start with a large value and prune out excess components Achieved by treating mixing coefficients as parameters, and maximizing marginal likelihood (Corduneanu and Bishop, AI Stats 2001) Gives simple re-estimation equations for the mixing coefficients interleave with variational updates
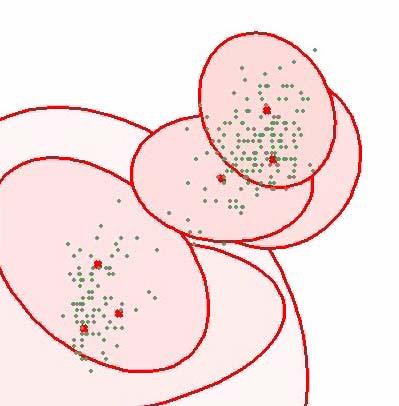
34

35
36 Example 3: RVM Relevance Vector Machine (Tipping, 1999) Bayesian alternative to support vector machine (SVM) Limitations of the SVM: two classes large number of kernels (in spite of sparsity) kernels must satisfy Mercer criterion cross-validation to set parameters C (and ε) decisions at outputs instead of probabilities
37 Relevance Vector Machine Linear model as for SVM Input vectors and targets Regression Classification
38 Relevance Vector Machine Gaussian prior for with hyper-parameters Hyper-priors over (and if regression) A high proportion of are driven to large values in the posterior distribution, and corresponding are driven to zero, giving a sparse model
39 Relevance Vector Machine Graphical model representation (regression) For classification use sigmoid (or softmax for multi-class) outputs and omit noise node
40 Relevance Vector Machine Regression: synthetic data Truth VRVM
41 Relevance Vector Machine Regression: synthetic data log 10 α mean weight value
42 Relevance Vector Machine Classification: SVM
43 Relevance Vector Machine Classification: VRVM
44 Relevance Vector Machine Results on Ripley regression data (Bayes error rate 8%) Model SVM VRVM Error 10.6% 9.2% No. kernels 38 4 Results on classification benchmark data Errors Kernels SVM GP RVM SVM GP RVM Pima Indians U.S.P.S. 4.4% - 5.1%
45 Relevance Vector Machine Properties comparable error rates to SVM on new data no cross-validation to set comlexity parameters applicable to wide choice of basis function multi-class classification probabilistic outputs dramatically fewer kernels (by an order of magnitude) but, slower to train than SVM
46 Fast RVM Training Tipping and Faul (2003) Analytic treatment of each hyper-parameter in turn Applied to 250,000 image patches (face/non-face) Recently applied to regression with 10 6 data points

47 Face Detection

48 Face Detection

49 Face Detection
50 Face Detection
51 Face Detection
52 Example 4: Latent Dirichlet Allocation Blei, Jordan and Ng (2003) Generative model of documents (but broadly applicable e.g. collaborative filtering, image retrieval, bioinformatics) Generative model: choose choose topic choose word z w N M
53 Latent Dirichlet Allocation Variational approximation Data set: 15,000 documents 90,000 terms 2.1 million words Model: 100 factors 9 million parameters MCMC totally infeasible for this problem
54 Automatic Variational Inference Currently for each new model we have to 1. derive the variational update equations 2. write application-specific code to find the solution Each can be time consuming and error prone Can we build a general-purpose inference engine which automates these procedures?
55 VIBES Variational Inference for Bayesian Networks Bishop and Winn (1999, 2004) A general inference engine using variational methods Analogous to BUGS for MCMC VIBES is available on the web
56 VIBES (cont d) A key observation is that in the general solution the update for a particular node (or group of nodes) depends only on other nodes in the Markov blanket Permits a local message-passing framework which is independent of the particular graph structure
")
57 VIBES (cont d)
")

58 VIBES (cont d)
59 VIBES (cont d)
60 New Book Pattern Recognition and Machine Learning Springer (2005) 600 pages, hardback, four colour, maximum $75 Graduate level text book Worked solutions to all 250 exercises Complete lectures on www Companion software text with Ian Nabney Matlab software on www
61 Conclusions Variational inference: a broad class of new semianalytical algorithms for Bayesian inference Applicable to much larger data sets than MCMC Can be automated for rapid prototyping
62 Viewgraphs and tutorials available from: research.microsoft.com/~cmbishop
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
p L yi z n m x N n xi
 y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
VIBES: A Variational Inference Engine for Bayesian Networks
 VIBES: A Variational Inference Engine for Bayesian Networks Christopher M. Bishop Microsoft Research Cambridge, CB3 0FB, U.K. research.microsoft.com/ cmbishop David Spiegelhalter MRC Biostatistics Unit
VIBES: A Variational Inference Engine for Bayesian Networks Christopher M. Bishop Microsoft Research Cambridge, CB3 0FB, U.K. research.microsoft.com/ cmbishop David Spiegelhalter MRC Biostatistics Unit
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Variational Principal Components
 Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures
 17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Bayesian Inference: Principles and Practice 3. Sparse Bayesian Models and the Relevance Vector Machine
 Bayesian Inference: Principles and Practice 3. Sparse Bayesian Models and the Relevance Vector Machine Mike Tipping Gaussian prior Marginal prior: single α Independent α Cambridge, UK Lecture 3: Overview
Bayesian Inference: Principles and Practice 3. Sparse Bayesian Models and the Relevance Vector Machine Mike Tipping Gaussian prior Marginal prior: single α Independent α Cambridge, UK Lecture 3: Overview
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Curve Fitting Re-visited, Bishop1.2.5
 Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Variational Message Passing. By John Winn, Christopher M. Bishop Presented by Andy Miller
 Variational Message Passing By John Winn, Christopher M. Bishop Presented by Andy Miller Overview Background Variational Inference Conjugate-Exponential Models Variational Message Passing Messages Univariate
Variational Message Passing By John Winn, Christopher M. Bishop Presented by Andy Miller Overview Background Variational Inference Conjugate-Exponential Models Variational Message Passing Messages Univariate
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Machine Learning Overview
 Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Relevance Vector Machines
 LUT February 21, 2011 Support Vector Machines Model / Regression Marginal Likelihood Regression Relevance vector machines Exercise Support Vector Machines The relevance vector machine (RVM) is a bayesian
LUT February 21, 2011 Support Vector Machines Model / Regression Marginal Likelihood Regression Relevance vector machines Exercise Support Vector Machines The relevance vector machine (RVM) is a bayesian
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
Variational Scoring of Graphical Model Structures
 Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection
 CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
Study Notes on the Latent Dirichlet Allocation
 Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Latent Dirichlet Allocation Introduction/Overview
 Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Probabilistic Graphical Models for Image Analysis - Lecture 1
 Probabilistic Graphical Models for Image Analysis - Lecture 1 Alexey Gronskiy, Stefan Bauer 21 September 2018 Max Planck ETH Center for Learning Systems Overview 1. Motivation - Why Graphical Models 2.
Probabilistic Graphical Models for Image Analysis - Lecture 1 Alexey Gronskiy, Stefan Bauer 21 September 2018 Max Planck ETH Center for Learning Systems Overview 1. Motivation - Why Graphical Models 2.
PROBABILITY DISTRIBUTIONS. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
PROBABILITY DISTRIBUTIONS Credits 2 These slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Parametric Distributions 3 Basic building blocks: Need to determine given Representation:
Part 1: Expectation Propagation
 Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Variational Methods in Bayesian Deconvolution
 PHYSTAT, SLAC, Stanford, California, September 8-, Variational Methods in Bayesian Deconvolution K. Zarb Adami Cavendish Laboratory, University of Cambridge, UK This paper gives an introduction to the
PHYSTAT, SLAC, Stanford, California, September 8-, Variational Methods in Bayesian Deconvolution K. Zarb Adami Cavendish Laboratory, University of Cambridge, UK This paper gives an introduction to the
Lecture: Gaussian Process Regression. STAT 6474 Instructor: Hongxiao Zhu
 Lecture: Gaussian Process Regression STAT 6474 Instructor: Hongxiao Zhu Motivation Reference: Marc Deisenroth s tutorial on Robot Learning. 2 Fast Learning for Autonomous Robots with Gaussian Processes
Lecture: Gaussian Process Regression STAT 6474 Instructor: Hongxiao Zhu Motivation Reference: Marc Deisenroth s tutorial on Robot Learning. 2 Fast Learning for Autonomous Robots with Gaussian Processes
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
NPFL108 Bayesian inference. Introduction. Filip Jurčíček. Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic
 NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
NPFL108 Bayesian inference Introduction Filip Jurčíček Institute of Formal and Applied Linguistics Charles University in Prague Czech Republic Home page: http://ufal.mff.cuni.cz/~jurcicek Version: 21/02/2014
Lecture 6: Graphical Models: Learning
 Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Expectation Maximization
 Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Machine Learning Summer School
 Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Lecture 10. Announcement. Mixture Models II. Topics of This Lecture. This Lecture: Advanced Machine Learning. Recap: GMMs as Latent Variable Models
 Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Expectation Propagation for Approximate Bayesian Inference
 Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Bayesian Hidden Markov Models and Extensions
 Bayesian Hidden Markov Models and Extensions Zoubin Ghahramani Department of Engineering University of Cambridge joint work with Matt Beal, Jurgen van Gael, Yunus Saatci, Tom Stepleton, Yee Whye Teh Modeling
Bayesian Hidden Markov Models and Extensions Zoubin Ghahramani Department of Engineering University of Cambridge joint work with Matt Beal, Jurgen van Gael, Yunus Saatci, Tom Stepleton, Yee Whye Teh Modeling
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
PILCO: A Model-Based and Data-Efficient Approach to Policy Search
 PILCO: A Model-Based and Data-Efficient Approach to Policy Search (M.P. Deisenroth and C.E. Rasmussen) CSC2541 November 4, 2016 PILCO Graphical Model PILCO Probabilistic Inference for Learning COntrol
PILCO: A Model-Based and Data-Efficient Approach to Policy Search (M.P. Deisenroth and C.E. Rasmussen) CSC2541 November 4, 2016 PILCO Graphical Model PILCO Probabilistic Inference for Learning COntrol
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
COURSE INTRODUCTION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 COURSE INTRODUCTION COMPUTATIONAL MODELING OF VISUAL PERCEPTION 2 The goal of this course is to provide a framework and computational tools for modeling visual inference, motivated by interesting examples
COURSE INTRODUCTION COMPUTATIONAL MODELING OF VISUAL PERCEPTION 2 The goal of this course is to provide a framework and computational tools for modeling visual inference, motivated by interesting examples
CSci 8980: Advanced Topics in Graphical Models Gaussian Processes
 CSci 8980: Advanced Topics in Graphical Models Gaussian Processes Instructor: Arindam Banerjee November 15, 2007 Gaussian Processes Outline Gaussian Processes Outline Parametric Bayesian Regression Gaussian
CSci 8980: Advanced Topics in Graphical Models Gaussian Processes Instructor: Arindam Banerjee November 15, 2007 Gaussian Processes Outline Gaussian Processes Outline Parametric Bayesian Regression Gaussian
The Variational Gaussian Approximation Revisited
 The Variational Gaussian Approximation Revisited Manfred Opper Cédric Archambeau March 16, 2009 Abstract The variational approximation of posterior distributions by multivariate Gaussians has been much
The Variational Gaussian Approximation Revisited Manfred Opper Cédric Archambeau March 16, 2009 Abstract The variational approximation of posterior distributions by multivariate Gaussians has been much
ECE285/SIO209, Machine learning for physical applications, Spring 2017
 ECE285/SIO209, Machine learning for physical applications, Spring 2017 Peter Gerstoft, 534-7768, gerstoft@ucsd.edu We meet Wednesday from 5 to 6:20pm in Spies Hall 330 Text Bishop Grading A or maybe S
ECE285/SIO209, Machine learning for physical applications, Spring 2017 Peter Gerstoft, 534-7768, gerstoft@ucsd.edu We meet Wednesday from 5 to 6:20pm in Spies Hall 330 Text Bishop Grading A or maybe S
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Least Absolute Shrinkage is Equivalent to Quadratic Penalization
 Least Absolute Shrinkage is Equivalent to Quadratic Penalization Yves Grandvalet Heudiasyc, UMR CNRS 6599, Université de Technologie de Compiègne, BP 20.529, 60205 Compiègne Cedex, France Yves.Grandvalet@hds.utc.fr
Least Absolute Shrinkage is Equivalent to Quadratic Penalization Yves Grandvalet Heudiasyc, UMR CNRS 6599, Université de Technologie de Compiègne, BP 20.529, 60205 Compiègne Cedex, France Yves.Grandvalet@hds.utc.fr
Large-scale Ordinal Collaborative Filtering
 Large-scale Ordinal Collaborative Filtering Ulrich Paquet, Blaise Thomson, and Ole Winther Microsoft Research Cambridge, University of Cambridge, Technical University of Denmark ulripa@microsoft.com,brmt2@cam.ac.uk,owi@imm.dtu.dk
Large-scale Ordinal Collaborative Filtering Ulrich Paquet, Blaise Thomson, and Ole Winther Microsoft Research Cambridge, University of Cambridge, Technical University of Denmark ulripa@microsoft.com,brmt2@cam.ac.uk,owi@imm.dtu.dk
The Expectation-Maximization Algorithm
 1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
Sparse Bayesian Logistic Regression with Hierarchical Prior and Variational Inference
 Sparse Bayesian Logistic Regression with Hierarchical Prior and Variational Inference Shunsuke Horii Waseda University s.horii@aoni.waseda.jp Abstract In this paper, we present a hierarchical model which
Sparse Bayesian Logistic Regression with Hierarchical Prior and Variational Inference Shunsuke Horii Waseda University s.horii@aoni.waseda.jp Abstract In this paper, we present a hierarchical model which
Latent Dirichlet Allocation (LDA)
") Latent Dirichlet Allocation (LDA) A review of topic modeling and customer interactions application 3/11/2015 1 Agenda Agenda Items 1 What is topic modeling? Intro Text Mining & Pre-Processing Natural Language
Latent Dirichlet Allocation (LDA) A review of topic modeling and customer interactions application 3/11/2015 1 Agenda Agenda Items 1 What is topic modeling? Intro Text Mining & Pre-Processing Natural Language
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
Machine Learning. Probabilistic KNN.
 Machine Learning. Mark Girolami girolami@dcs.gla.ac.uk Department of Computing Science University of Glasgow June 21, 2007 p. 1/3 KNN is a remarkably simple algorithm with proven error-rates June 21, 2007
Machine Learning. Mark Girolami girolami@dcs.gla.ac.uk Department of Computing Science University of Glasgow June 21, 2007 p. 1/3 KNN is a remarkably simple algorithm with proven error-rates June 21, 2007
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding
 Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2014
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Sparse Gaussian Markov Random Field Mixtures for Anomaly Detection
 Sparse Gaussian Markov Random Field Mixtures for Anomaly Detection Tsuyoshi Idé ( Ide-san ), Ankush Khandelwal*, Jayant Kalagnanam IBM Research, T. J. Watson Research Center (*Currently with University
Sparse Gaussian Markov Random Field Mixtures for Anomaly Detection Tsuyoshi Idé ( Ide-san ), Ankush Khandelwal*, Jayant Kalagnanam IBM Research, T. J. Watson Research Center (*Currently with University
Variational Inference. Sargur Srihari
 Variational Inference Sargur srihari@cedar.buffalo.edu 1 Plan of discussion We first describe inference with PGMs and the intractability of exact inference Then give a taxonomy of inference algorithms
Variational Inference Sargur srihari@cedar.buffalo.edu 1 Plan of discussion We first describe inference with PGMs and the intractability of exact inference Then give a taxonomy of inference algorithms
Bayesian Inference Course, WTCN, UCL, March 2013
 Bayesian Course, WTCN, UCL, March 2013 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information
Bayesian Course, WTCN, UCL, March 2013 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information
Bayesian Networks Inference with Probabilistic Graphical Models
 4190.408 2016-Spring Bayesian Networks Inference with Probabilistic Graphical Models Byoung-Tak Zhang intelligence Lab Seoul National University 4190.408 Artificial (2016-Spring) 1 Machine Learning? Learning
4190.408 2016-Spring Bayesian Networks Inference with Probabilistic Graphical Models Byoung-Tak Zhang intelligence Lab Seoul National University 4190.408 Artificial (2016-Spring) 1 Machine Learning? Learning
an introduction to bayesian inference
 with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
Generative models for missing value completion
 Generative models for missing value completion Kousuke Ariga Department of Computer Science and Engineering University of Washington Seattle, WA 98105 koar8470@cs.washington.edu Abstract Deep generative
Generative models for missing value completion Kousuke Ariga Department of Computer Science and Engineering University of Washington Seattle, WA 98105 koar8470@cs.washington.edu Abstract Deep generative
Bayesian Mixtures of Bernoulli Distributions
 Bayesian Mixtures of Bernoulli Distributions Laurens van der Maaten Department of Computer Science and Engineering University of California, San Diego Introduction The mixture of Bernoulli distributions
Bayesian Mixtures of Bernoulli Distributions Laurens van der Maaten Department of Computer Science and Engineering University of California, San Diego Introduction The mixture of Bernoulli distributions
GWAS V: Gaussian processes
 GWAS V: Gaussian processes Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS V: Gaussian processes Summer 2011
GWAS V: Gaussian processes Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS V: Gaussian processes Summer 2011
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
Expectation Propagation in Dynamical Systems
 Expectation Propagation in Dynamical Systems Marc Peter Deisenroth Joint Work with Shakir Mohamed (UBC) August 10, 2012 Marc Deisenroth (TU Darmstadt) EP in Dynamical Systems 1 Motivation Figure : Complex
Expectation Propagation in Dynamical Systems Marc Peter Deisenroth Joint Work with Shakir Mohamed (UBC) August 10, 2012 Marc Deisenroth (TU Darmstadt) EP in Dynamical Systems 1 Motivation Figure : Complex
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 9: Expectation Maximiation (EM) Algorithm, Learning in Undirected Graphical Models Some figures courtesy
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 9: Expectation Maximiation (EM) Algorithm, Learning in Undirected Graphical Models Some figures courtesy
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Stochastic Variational Inference
 Stochastic Variational Inference David M. Blei Princeton University (DRAFT: DO NOT CITE) December 8, 2011 We derive a stochastic optimization algorithm for mean field variational inference, which we call
Stochastic Variational Inference David M. Blei Princeton University (DRAFT: DO NOT CITE) December 8, 2011 We derive a stochastic optimization algorithm for mean field variational inference, which we call
STAT 518 Intro Student Presentation
 STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
Replicated Softmax: an Undirected Topic Model. Stephen Turner
 Replicated Softmax: an Undirected Topic Model Stephen Turner 1. Introduction 2. Replicated Softmax: A Generative Model of Word Counts 3. Evaluating Replicated Softmax as a Generative Model 4. Experimental
Replicated Softmax: an Undirected Topic Model Stephen Turner 1. Introduction 2. Replicated Softmax: A Generative Model of Word Counts 3. Evaluating Replicated Softmax as a Generative Model 4. Experimental
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Machine Learning using Bayesian Approaches
 Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Neutron inverse kinetics via Gaussian Processes
 Neutron inverse kinetics via Gaussian Processes P. Picca Politecnico di Torino, Torino, Italy R. Furfaro University of Arizona, Tucson, Arizona Outline Introduction Review of inverse kinetics techniques
Neutron inverse kinetics via Gaussian Processes P. Picca Politecnico di Torino, Torino, Italy R. Furfaro University of Arizona, Tucson, Arizona Outline Introduction Review of inverse kinetics techniques
Variational Bayesian Logistic Regression
 Variational Bayesian Logistic Regression Sargur N. University at Buffalo, State University of New York USA Topics in Linear Models for Classification Overview 1. Discriminant Functions 2. Probabilistic
Variational Bayesian Logistic Regression Sargur N. University at Buffalo, State University of New York USA Topics in Linear Models for Classification Overview 1. Discriminant Functions 2. Probabilistic
Variational Message Passing
 Journal of Machine Learning Research 5 (2004)?-? Submitted 2/04; Published?/04 Variational Message Passing John Winn and Christopher M. Bishop Microsoft Research Cambridge Roger Needham Building 7 J. J.
Journal of Machine Learning Research 5 (2004)?-? Submitted 2/04; Published?/04 Variational Message Passing John Winn and Christopher M. Bishop Microsoft Research Cambridge Roger Needham Building 7 J. J.
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Overview of Statistical Tools. Statistical Inference. Bayesian Framework. Modeling. Very simple case. Things are usually more complicated
 Fall 3 Computer Vision Overview of Statistical Tools Statistical Inference Haibin Ling Observation inference Decision Prior knowledge http://www.dabi.temple.edu/~hbling/teaching/3f_5543/index.html Bayesian
Fall 3 Computer Vision Overview of Statistical Tools Statistical Inference Haibin Ling Observation inference Decision Prior knowledge http://www.dabi.temple.edu/~hbling/teaching/3f_5543/index.html Bayesian
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations