Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
|
|
|
- Richard Cameron
- 5 years ago
- Views:
Transcription
1 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer
2 Introduction So far we were mostly concerned with supervised learning: we predicted one or several target variables based on information on one or several input variables If applicable, supervised learning is often the best solution and powerful models such as Neural Networks and SVMs are available But there are cases where supervised learning is not applicable: when there is not one target variable of interest but many, or when in each data point different variables might be available or missing Typical example: medical domain with many kinds of diseases, symptoms, and context information: for a given patient little is known and one is interested in the prediction of many possible diseases Bayesian networks can deal with these challenges, which is the reason for their popularity in probabilistic reasoning and machine learning 2
3
4
5 Bayes Nets Deterministic rule-based systems were the dominating approach during the first phase of AI. A major problem was that deterministic rules cannot deal with uncertainty and ambiguity Probability was rejected since a naive representation would require 2 M parameters; how should all these numbers be specified? In Bayes nets one constructs a high-dimensional probability distribution based on a set of local probabilistic rules Bayes nets are closely related to a causal world model Bayes Nets started as a small community and then developed to one of the main approaches in AI They also have a great influence on machine learning 3
6
7 Definition of a Bayes Net The random variables in a domain are displayed as nodes (vertices) Directed links (arcs, edges) represent direct (causal) dependencies between parent node and child node Quantification of the dependency: For nodes without parents one specifies a priori probabilities P (A = i) i For nodes with parents, one specifies conditional probabilities. E.g., for two parents P (A = i B = j, C = k) i, j, k 4
8 Joint Probability Distribution A Bayes net specifies a probability distribution in the form M P (X 1,... X M ) = P (X i par(x i )) i=1 where par(x i ) is the set of parent nodes. This set can be zero. 5
9 Factorization of Probability Distributions Let s start with the factorization of a probability distribution (see review on Probability Theory) P (X 1,... X M ) = M i=1 P (X i X 1,..., X i 1 ) This decomposition can be done with an arbitrary ordering of variables; each variable is conditioned on all predecessor variables The dependencies can be simplified if a variable does not depend on all of its predecessors with P (X i X 1,..., X i 1 ) = P (X i par(x i )) par(x i ) X 1,..., X i 1 6
10 Causal Ordering When the ordering of the variables corresponds to a causal ordering, we obtain a causal probabilistic network A decomposition obeying the causal ordering typically yields a representation with the smallest number of parent variables Deterministic and probabilistic causality: it might be that the underlying true model is deterministic causal. The probabilistic model leaves out many influential factors. The assumption is that the un-modeled factors should only significantly influence individual nodes (and thus appear as noise), but NOT pairs or larger sets of variables (which would induce dependencies)! 7
11 Design of a Bayes Net The expert needs to be clear about the important variables in the domain The expert must indicate direct causal dependencies by specifying the directed link in the net The expert needs to quantify the causal dependencies: define the conditional probability tables 8
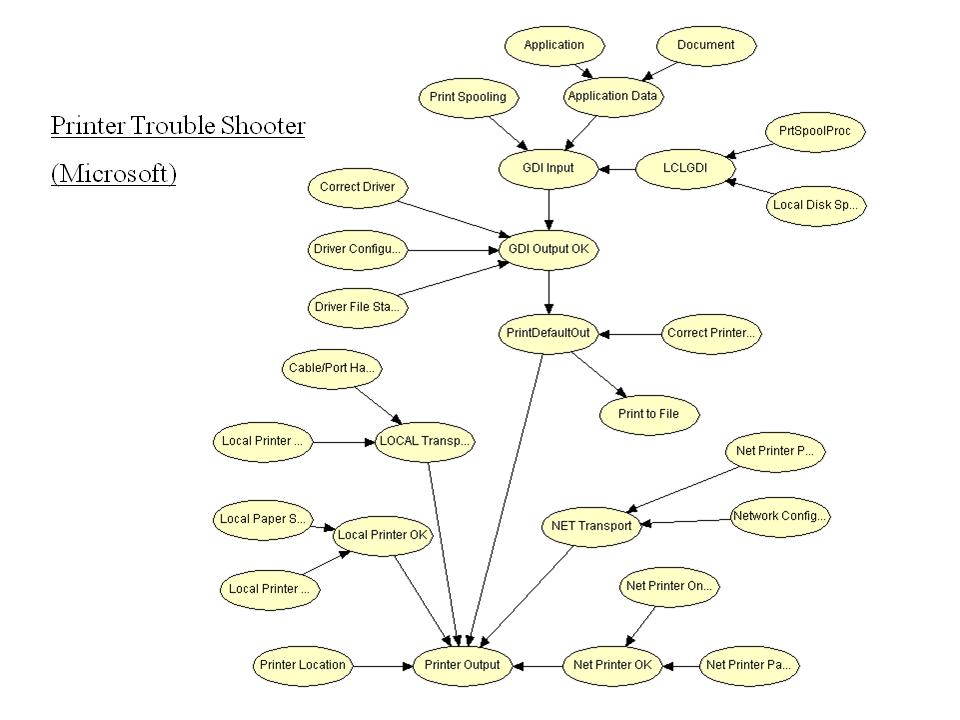
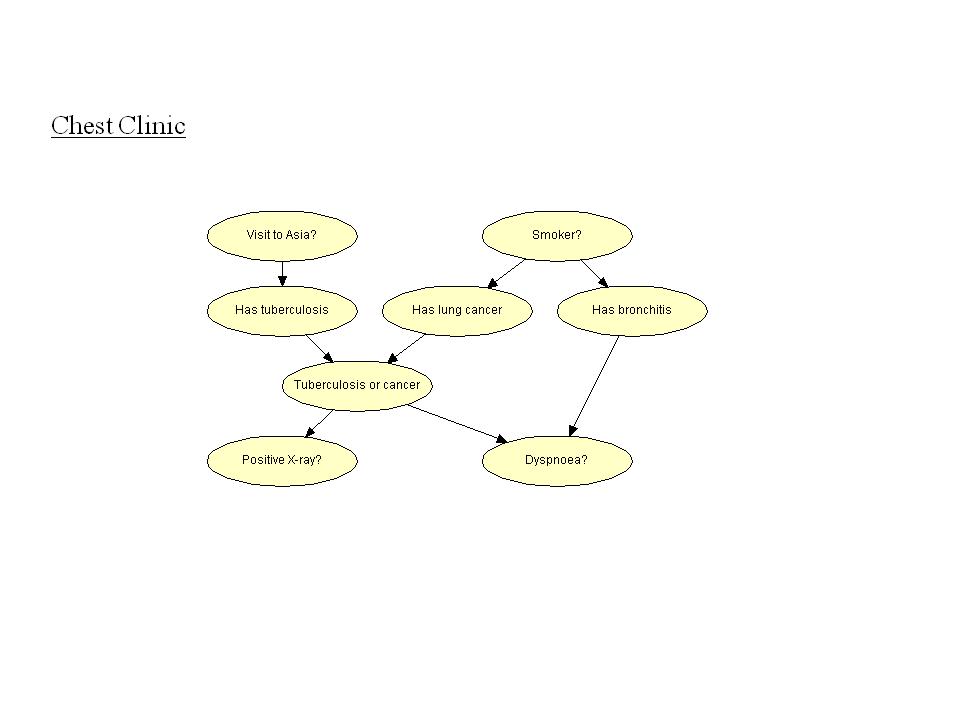
12 Propositional Level and Template Level Note that the Holmes Network contains propositional Boolean variables such as Alarm or Burglary. Also, the Alarm Network might only be applicable to a particular clinic. Thus the Holmes Network and the Alarm Network are examples of propositional Bayesian networks In contrast the Chest Clinic example and the Printer Trouble Shooter example are applicable to any patient, resp. to any printer. Thus here the Bayes net defines a template 9
13 Inference The most important important operation is inference: given that the state a set of random variables is known, what is the probability distribution of one or several of the remaining variables Let X be the set of random variables. Let X m X be the set of known (measured) variables and let X q X \X m be the variable of interest and let X r = X \(X m X q ) be the set of remaining variables 10
14 Inference: Marginalization and Conditioning In the simplest inference approach one proceeds as follows : We calculate the probability distribution of the known variables and the query variable via marginalization P (X q, X m ) = X r P (X 1,... X M ) The normalization is calculated as P (X m ) = X q P (X q, X m ) Calculation of the conditional probability distributions P (X q X m ) = P (Xq, X m ) P (X m ) 11
15
16
17
18
19
20
21
22
23 Inference in Bayes nets without Cycles in Undirected Net By construction there are no cycles in the directed net; the structure of a Bayesian net is a directed acyclic graph (DAG) But there might be cycles when one ignores the directions Let s first consider the simpler case without cycles in the undirected graph; the structure of the the Bayes net is a poly-tree: there is at most one directed path between two nodes 12
24
25 Marginalization The marginalization can be computationally expensive: the sum contains exponentially many terms; for binary variables 2 X r The goal is now to exploit the structure of the net to calculate the marginalization efficient 13
26 Example: Markov Chain Consider the Markov chain of length M with binary variables where the first variable X 1 and the last variable X M are known We can apply the iterative formula for propagating information on X 1 down the chain π(x i ) = P (X i X 1 ) = X i 1 P (X i, X i 1 X 1 ) = X i 1 P (X i X i 1 )P (X i 1 X 1 ) We can apply the iterative formula for propagating information on X M up the chain λ(x i ) = P (X M X i ) = X i+1 P (X M, X i+1 X i ) = X i+1 P (X i+1 X i )P (X M X i+1 ) 14
27 Posterior Probability Then we can calculate for any X i P (X i = 1 X 1, X M ) = P (X i = 1, X 1, X M ) P (X i = 1, X 1, X M ) + P (X i = 0, X 1, X M ) = P (X 1 )P (X i = 1 X 1 )P (X i = 1 X M ) P (X 1 )P (X i = 1 X 1 )P (X i = 1 X M ) + P (X 1 )P (X i = 0 X 1 )P (X i = 0 X M ) = π(x i = 1)λ(X i = 1) π(x i = 1)λ(X i = 1) + π(x i = 0)λ(X i = 0) 15
28
29 Propagation in Polytrees Inference in polytrees can be performed in a similar (but more complex) way π and λ propagation is generalized to polytrees 16
30
31 Max-Propagation With similar efficiency, one can calculate the maximum likely configuration (Maxproduct Rule) X r max = arg max X r P (X r, X m ) 17
32 Hidden Markov Models Hidden Markov Models (HMMs) are the basis of modern speech recognition systems. An HMM is a Bayesian network with latent variables States corresponds to phonemes; measurements correspond to the acoustic spectrum The HMM contains the transition probability between states P (X i X i 1 ) and emission probabilities P (Y X). To find the most likely sequence of states, the Viterbi Algorithm is employed, which is identical to the Max-Prop Algorithm 18
33
34 Loopy Belief Propagation: Belief Propagation in Bayes Nets with Loops When there a loops in the undirected Bayes net, belief propagation is not applicable: There cannot be a local message passing rule since information arriving at a node from different paths can be correlated Loopy Belief Propagation the application of belief propagation to Bayes nets with cycles (although strictly not correct) The local update rules are applied until convergence is achieved (which is not always the case) Loopy Belief Propagation is applied in Probabilistic Relational Models which are typically large Bayes nets describing domains where relationships are important, e.g., friend of 19
35 Loopy Belief Propagation in Decoding Most interesting and surprising: Turbo codes and Low-Density Parity-Check (LDPC) Codes use Loopy Belief Propagation for decoding. Both become very close to the Shannon limit and require long code words and thus produce delays. Thus they are not useful for interactive communication but for broadcasting of information (mobile communication) and in space applications (NASA) 20
36 Junction tree algorithm: Correct Inference Most (non-)commercial Bayes nets contain the junction tree algorithm which realizes correct probabilistic inference The junction tree algorithm combined variables such that the resulting net has no loops The junction tree can be inefficient when the combines variables have many states 21
37 Junction tree algorithm: Basic Idea By combining variables to form a new super variable, one can remove the loops In the example, we see a loop in the network. The nodes Mary and Susan have each two states. The super variable Mary-Susan has 4 states. 22
38
39
40 Design of a Bayes Net The expert needs to be clear about the important variables in the domain The expert must indicate direct causal dependencies by specifying the directed link in the net The expert needs to quantify the causal dependencies: define the conditional probability tables This can be challenging if a node has many parents: if a binary node has n binary parents, then the expert needs to specify 2 n numbers! To simplify this task one often makes simplifying assumptions; the best-known one is the Noisy-Or Assumption 23
41 Noisy-Or Let X {0, 1} be a binary node with binary parents U 1,..., U n Let q i be the probability, that X = 0 (symptom), when U i = 1 (disease) and all other (diseases) U j = 0; this means, that c i = 1 q i is the influence of a single parent (disease) on X (the symptom) Then one assumes, P (X = 0 U 1,..., U n ) = n i=1 q U i i, or equivalently, n P (X = 1 U 1,..., U n ) = 1 This means that if several diseases are present that can cause the symptom, then the probability of the symptom increases (if compared to the probabilities for the single disease i=1 q U i i 24
42 Maximum Likelihood Learning with Complete Data We assume that all nodes in the Bayesian net have been observed for N instances (e.g., N patients) ML-parameter estimation simply means counting Let θ i,j,k be defines as θ i,j,k = P (X i = k par(x i ) = j) This means that θ i,j,k is the probability that X i is in state k, when its parents are in the state j (we assume that the states of the parents can be enumerated in a systematic way) Then the ML estimate is θ ML i,j,k = N i,j,k k N i,j,k Here, N i,j,k is the number of samples in which X i = k and par(x i ) = j 25
43 MAP-estimate for Integrating Prior Knowledge Often counts are very small and a ML-estimate has high variance One simply specifies efficient counts (counts from virtual data) which then can be treated as real counts Let α i,j,k 0 be virtual counts for N i,j,k One obtains the maximum a posteriori (MAP) estimate as i,j,k = α i,j,k + N i,j,k k (α i,j,k + N i,j,k ) θ MAP 26
44 Missing Data The problem of missing data is an important issue in statistical modeling In the simplest case, one can assume that data are missing at random Data is not missing at random, if for example, I analyse the wealth distribution in a city and rich people tend to refuse to report their income For some models the EM (Expectation Maximization)-algorithm can be applied and leads to ML or MAP estimates Consider a particular data point l. In the E-step we calculate the probability for marginal probabilities of interest given the known information in that data point d l and given the current estimates of the parameters ˆθ, using belief proagation or the junction tree algorithm. Then we get E(N i,j,k ) = N l=1 P (X i = k, par(x i ) = j d l, ˆθ) 27
45 Note that if the parent and child nodes are known then P (X i = k, par(x i ) = j d l, ˆθ) is either zero or one, otherwise a number between zero and one Based on the E-step, we get in the M-step ˆθ ML i,j,k = E(N i,j,k) k E(N i,j,k) E-Step and M-Step are iterated until convergence. One can show that EM does not decrease the likelihood in each step; EM might converge to local optima, even if there might only be a global optimum for the model with complete data
46 EM-Learning with the HMM and the Kalman Filter HMMs are trained using the so-called Baum-Welch-Algorithm. This is exactly an EM algorithm Offline Versions of the Kalman filter can also be performed via EM 28
47 Alternatives for the E-step The E-step is really an inference step Here, also approximate inference can be used (loopy-belief propagation, MCMC, Gibbs, mean-field) 29
48 Beyond Table Representations For learning the conditional probabilities, many approaches have been employed Decision Trees, Neural networks, log-linear models,... 30
49 Structural Learning in Bayes Nets One can also consider learning the structure of a Bayes net and maybe even discover causality In structural learning, several points need to be considered There are models that are structural equivalent. For example in a net with only two variables A and B one might show that there is statistical correlation between the two variables, but it is impossible to decide if A B or A B. Colliders (nodes where arrow-head meet) can make directions identifiable If C is highly correlated with A and B and A and B are also highly correlated, it might be clear from the data that C depends on both A and B but difficult to decide if it only depends on A or only depends on B In general, the structure of the Bayes model and its parameters model the joint distribution of all the variables under consideration 31
50 Recall that the way the data was collected can also have influence: I will get a different distribution if I consider data from the general population and data collected from patients visiting a specialists in a rich neighborhood
51 Structure Learning via Greedy Search In the most common approaches one defines a cost function and looks for the structure that is optimal under the cost function. One has to deal with many local optima Greedy Search: One starts with an initial network (fully connected, empty)and makes local changes (removal of directed link, adding a link, reversing direction of a link,...) and accepts the change, when the cost function improves Greedy search can be started from different initial conditions Alternatives: Simulated Annealing, Genetic Algorithms 32
52 Cost Functions As a cost function one might use a cross-validation set Often BIC (Bayesian Information Criterion) is used: 1 N log L M 2N log N (M is the number of parameters; N is the number of data points) Recall, that Bayesian model selection is based on P (D M). With complete data we get, P (D M) = N i=1 j Γ(α i,j ) Γ(α i,j + N i,j ) k Γ(α i,j,k + N i,j,k ) Γ(α i,j,k ) where α i,j = k α i,j,k and N i,j = k N i,j,k and where Γ( ) is the gamma function 33
53
54 Constrained-Based Methods for Structural Learning One performs statistical independence tests and uses those tests to decide on network structure For the example in the V-structure in the image (1), M and S are marginally mutually independent but they might become dependent given J. J is dependent on both M and S In the other structure (2), (3), (4), S and M are dependent when J is unknown. But now M and S become independent given that J is known! The structure with the collider (1) can be identified. The structures (2), (3), (4) are all structurally equivalent 34
55
56 Causal Interpretation of Structure and Parameters One has to be very cautious with a causal interpretation of a learned model One assumption is that the world under consideration is causal Another assumption is that all relevant information in part of the model. (See discussion on confounders in the lecture on causality) Sometimes temporal information is available which constraints the direction of links (Granger causality) 35
57 Evaluation of Causal Effect Under the assumption that the model is causal and reflects reality (either designed form an expert or learned from data) Remove all links to the causal node Manipulate the causal node and observe effect on the other nodes by normal inference If of interest: condition on other nodes, which are not causally influenced by the causal node (stratification) Comment: this is exactly what is going on in randomized clinical studies. It can also be concluded from the causal probabilistic network 36
58
59
60
61 Concluding Remarks Bayesian networks are used as expert systems in medical domains The underlying theory can be used to derive the likelihood of complex models (e.g., HMMs) Markov Nets are related to Bayesian networks and use undirected edges; they typical do not have a causal interpretation Bayes nets and Markov nets are the most important representatives of the class of graphical models In the lecture we focussed on nets with discrete variables. Also commonly studied are nets with continous variables and Gaussian distributions 37
62
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2014
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks. Motivation
 Bayesian Networks Computer Sciences 760 Spring 2014 http://pages.cs.wisc.edu/~dpage/cs760/ Motivation Assume we have five Boolean variables,,,, The joint probability is,,,, How many state configurations
Bayesian Networks Computer Sciences 760 Spring 2014 http://pages.cs.wisc.edu/~dpage/cs760/ Motivation Assume we have five Boolean variables,,,, The joint probability is,,,, How many state configurations
Bayesian Networks BY: MOHAMAD ALSABBAGH
 Bayesian Networks BY: MOHAMAD ALSABBAGH Outlines Introduction Bayes Rule Bayesian Networks (BN) Representation Size of a Bayesian Network Inference via BN BN Learning Dynamic BN Introduction Conditional
Bayesian Networks BY: MOHAMAD ALSABBAGH Outlines Introduction Bayes Rule Bayesian Networks (BN) Representation Size of a Bayesian Network Inference via BN BN Learning Dynamic BN Introduction Conditional
p L yi z n m x N n xi
 y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
Bayesian Networks Inference with Probabilistic Graphical Models
 4190.408 2016-Spring Bayesian Networks Inference with Probabilistic Graphical Models Byoung-Tak Zhang intelligence Lab Seoul National University 4190.408 Artificial (2016-Spring) 1 Machine Learning? Learning
4190.408 2016-Spring Bayesian Networks Inference with Probabilistic Graphical Models Byoung-Tak Zhang intelligence Lab Seoul National University 4190.408 Artificial (2016-Spring) 1 Machine Learning? Learning
Graphical Models and Kernel Methods
 Graphical Models and Kernel Methods Jerry Zhu Department of Computer Sciences University of Wisconsin Madison, USA MLSS June 17, 2014 1 / 123 Outline Graphical Models Probabilistic Inference Directed vs.
Graphical Models and Kernel Methods Jerry Zhu Department of Computer Sciences University of Wisconsin Madison, USA MLSS June 17, 2014 1 / 123 Outline Graphical Models Probabilistic Inference Directed vs.
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Machine Learning Summer School
 Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Lecture 6: Graphical Models: Learning
 Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
CS 2750: Machine Learning. Bayesian Networks. Prof. Adriana Kovashka University of Pittsburgh March 14, 2016
 CS 2750: Machine Learning Bayesian Networks Prof. Adriana Kovashka University of Pittsburgh March 14, 2016 Plan for today and next week Today and next time: Bayesian networks (Bishop Sec. 8.1) Conditional
CS 2750: Machine Learning Bayesian Networks Prof. Adriana Kovashka University of Pittsburgh March 14, 2016 Plan for today and next week Today and next time: Bayesian networks (Bishop Sec. 8.1) Conditional
Learning Bayesian Networks (part 1) Goals for the lecture
 Goals for the lecture") Learning Bayesian Networks (part 1) Mark Craven and David Page Computer Scices 760 Spring 2018 www.biostat.wisc.edu/~craven/cs760/ Some ohe slides in these lectures have been adapted/borrowed from materials
Learning Bayesian Networks (part 1) Mark Craven and David Page Computer Scices 760 Spring 2018 www.biostat.wisc.edu/~craven/cs760/ Some ohe slides in these lectures have been adapted/borrowed from materials
9 Forward-backward algorithm, sum-product on factor graphs
 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 9 Forward-backward algorithm, sum-product on factor graphs The previous
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 9 Forward-backward algorithm, sum-product on factor graphs The previous
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Probabilistic Graphical Models. Guest Lecture by Narges Razavian Machine Learning Class April
 Probabilistic Graphical Models Guest Lecture by Narges Razavian Machine Learning Class April 14 2017 Today What is probabilistic graphical model and why it is useful? Bayesian Networks Basic Inference
Probabilistic Graphical Models Guest Lecture by Narges Razavian Machine Learning Class April 14 2017 Today What is probabilistic graphical model and why it is useful? Bayesian Networks Basic Inference
A Brief Introduction to Graphical Models. Presenter: Yijuan Lu November 12,2004
 A Brief Introduction to Graphical Models Presenter: Yijuan Lu November 12,2004 References Introduction to Graphical Models, Kevin Murphy, Technical Report, May 2001 Learning in Graphical Models, Michael
A Brief Introduction to Graphical Models Presenter: Yijuan Lu November 12,2004 References Introduction to Graphical Models, Kevin Murphy, Technical Report, May 2001 Learning in Graphical Models, Michael
Probabilistic Machine Learning
 Probabilistic Machine Learning Bayesian Nets, MCMC, and more Marek Petrik 4/18/2017 Based on: P. Murphy, K. (2012). Machine Learning: A Probabilistic Perspective. Chapter 10. Conditional Independence Independent
Probabilistic Machine Learning Bayesian Nets, MCMC, and more Marek Petrik 4/18/2017 Based on: P. Murphy, K. (2012). Machine Learning: A Probabilistic Perspective. Chapter 10. Conditional Independence Independent
Introduction to Bayesian Learning
 Course Information Introduction Introduction to Bayesian Learning Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Apprendimento Automatico: Fondamenti - A.A. 2016/2017 Outline
Course Information Introduction Introduction to Bayesian Learning Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Apprendimento Automatico: Fondamenti - A.A. 2016/2017 Outline
Lecture 5: Bayesian Network
 Lecture 5: Bayesian Network Topics of this lecture What is a Bayesian network? A simple example Formal definition of BN A slightly difficult example Learning of BN An example of learning Important topics
Lecture 5: Bayesian Network Topics of this lecture What is a Bayesian network? A simple example Formal definition of BN A slightly difficult example Learning of BN An example of learning Important topics
EE562 ARTIFICIAL INTELLIGENCE FOR ENGINEERS
 EE562 ARTIFICIAL INTELLIGENCE FOR ENGINEERS Lecture 16, 6/1/2005 University of Washington, Department of Electrical Engineering Spring 2005 Instructor: Professor Jeff A. Bilmes Uncertainty & Bayesian Networks
EE562 ARTIFICIAL INTELLIGENCE FOR ENGINEERS Lecture 16, 6/1/2005 University of Washington, Department of Electrical Engineering Spring 2005 Instructor: Professor Jeff A. Bilmes Uncertainty & Bayesian Networks
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Lecture 8: Bayesian Networks
 Lecture 8: Bayesian Networks Bayesian Networks Inference in Bayesian Networks COMP-652 and ECSE 608, Lecture 8 - January 31, 2017 1 Bayes nets P(E) E=1 E=0 0.005 0.995 E B P(B) B=1 B=0 0.01 0.99 E=0 E=1
Lecture 8: Bayesian Networks Bayesian Networks Inference in Bayesian Networks COMP-652 and ECSE 608, Lecture 8 - January 31, 2017 1 Bayes nets P(E) E=1 E=0 0.005 0.995 E B P(B) B=1 B=0 0.01 0.99 E=0 E=1
PROBABILISTIC REASONING SYSTEMS
 PROBABILISTIC REASONING SYSTEMS In which we explain how to build reasoning systems that use network models to reason with uncertainty according to the laws of probability theory. Outline Knowledge in uncertain
PROBABILISTIC REASONING SYSTEMS In which we explain how to build reasoning systems that use network models to reason with uncertainty according to the laws of probability theory. Outline Knowledge in uncertain
Algorithmisches Lernen/Machine Learning
 Algorithmisches Lernen/Machine Learning Part 1: Stefan Wermter Introduction Connectionist Learning (e.g. Neural Networks) Decision-Trees, Genetic Algorithms Part 2: Norman Hendrich Support-Vector Machines
Algorithmisches Lernen/Machine Learning Part 1: Stefan Wermter Introduction Connectionist Learning (e.g. Neural Networks) Decision-Trees, Genetic Algorithms Part 2: Norman Hendrich Support-Vector Machines
Lecture 15. Probabilistic Models on Graph
 Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Chris Bishop s PRML Ch. 8: Graphical Models
 Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
Probabilistic Graphical Models (I)
") Probabilistic Graphical Models (I) Hongxin Zhang zhx@cad.zju.edu.cn State Key Lab of CAD&CG, ZJU 2015-03-31 Probabilistic Graphical Models Modeling many real-world problems => a large number of random
Probabilistic Graphical Models (I) Hongxin Zhang zhx@cad.zju.edu.cn State Key Lab of CAD&CG, ZJU 2015-03-31 Probabilistic Graphical Models Modeling many real-world problems => a large number of random
Directed Graphical Models
 CS 2750: Machine Learning Directed Graphical Models Prof. Adriana Kovashka University of Pittsburgh March 28, 2017 Graphical Models If no assumption of independence is made, must estimate an exponential
CS 2750: Machine Learning Directed Graphical Models Prof. Adriana Kovashka University of Pittsburgh March 28, 2017 Graphical Models If no assumption of independence is made, must estimate an exponential
Probabilistic Graphical Models Homework 2: Due February 24, 2014 at 4 pm
 Probabilistic Graphical Models 10-708 Homework 2: Due February 24, 2014 at 4 pm Directions. This homework assignment covers the material presented in Lectures 4-8. You must complete all four problems to
Probabilistic Graphical Models 10-708 Homework 2: Due February 24, 2014 at 4 pm Directions. This homework assignment covers the material presented in Lectures 4-8. You must complete all four problems to
ECE521 Tutorial 11. Topic Review. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides. ECE521 Tutorial 11 / 4
 ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
2 : Directed GMs: Bayesian Networks
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 2 : Directed GMs: Bayesian Networks Lecturer: Eric P. Xing Scribes: Jayanth Koushik, Hiroaki Hayashi, Christian Perez Topic: Directed GMs 1 Types
10-708: Probabilistic Graphical Models 10-708, Spring 2017 2 : Directed GMs: Bayesian Networks Lecturer: Eric P. Xing Scribes: Jayanth Koushik, Hiroaki Hayashi, Christian Perez Topic: Directed GMs 1 Types
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Modeling and reasoning with uncertainty
 CS 2710 Foundations of AI Lecture 18 Modeling and reasoning with uncertainty Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square KB systems. Medical example. We want to build a KB system for the diagnosis
CS 2710 Foundations of AI Lecture 18 Modeling and reasoning with uncertainty Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square KB systems. Medical example. We want to build a KB system for the diagnosis
Soft Computing. Lecture Notes on Machine Learning. Matteo Matteucci.
 Soft Computing Lecture Notes on Machine Learning Matteo Matteucci matteucci@elet.polimi.it Department of Electronics and Information Politecnico di Milano Matteo Matteucci c Lecture Notes on Machine Learning
Soft Computing Lecture Notes on Machine Learning Matteo Matteucci matteucci@elet.polimi.it Department of Electronics and Information Politecnico di Milano Matteo Matteucci c Lecture Notes on Machine Learning
Review: Bayesian learning and inference
 Review: Bayesian learning and inference Suppose the agent has to make decisions about the value of an unobserved query variable X based on the values of an observed evidence variable E Inference problem:
Review: Bayesian learning and inference Suppose the agent has to make decisions about the value of an unobserved query variable X based on the values of an observed evidence variable E Inference problem:
6.867 Machine learning, lecture 23 (Jaakkola)
") Lecture topics: Markov Random Fields Probabilistic inference Markov Random Fields We will briefly go over undirected graphical models or Markov Random Fields (MRFs) as they will be needed in the context
Lecture topics: Markov Random Fields Probabilistic inference Markov Random Fields We will briefly go over undirected graphical models or Markov Random Fields (MRFs) as they will be needed in the context
CSCE 478/878 Lecture 6: Bayesian Learning
 Bayesian Methods Not all hypotheses are created equal (even if they are all consistent with the training data) Outline CSCE 478/878 Lecture 6: Bayesian Learning Stephen D. Scott (Adapted from Tom Mitchell
Bayesian Methods Not all hypotheses are created equal (even if they are all consistent with the training data) Outline CSCE 478/878 Lecture 6: Bayesian Learning Stephen D. Scott (Adapted from Tom Mitchell
Bayesian Inference. Definitions from Probability: Naive Bayes Classifiers: Advantages and Disadvantages of Naive Bayes Classifiers:
 Bayesian Inference The purpose of this document is to review belief networks and naive Bayes classifiers. Definitions from Probability: Belief networks: Naive Bayes Classifiers: Advantages and Disadvantages
Bayesian Inference The purpose of this document is to review belief networks and naive Bayes classifiers. Definitions from Probability: Belief networks: Naive Bayes Classifiers: Advantages and Disadvantages
Probabilistic Graphical Models
 2016 Robert Nowak Probabilistic Graphical Models 1 Introduction We have focused mainly on linear models for signals, in particular the subspace model x = Uθ, where U is a n k matrix and θ R k is a vector
2016 Robert Nowak Probabilistic Graphical Models 1 Introduction We have focused mainly on linear models for signals, in particular the subspace model x = Uθ, where U is a n k matrix and θ R k is a vector
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Inference in Bayesian Networks
 Andrea Passerini passerini@disi.unitn.it Machine Learning Inference in graphical models Description Assume we have evidence e on the state of a subset of variables E in the model (i.e. Bayesian Network)
Andrea Passerini passerini@disi.unitn.it Machine Learning Inference in graphical models Description Assume we have evidence e on the state of a subset of variables E in the model (i.e. Bayesian Network)
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Classification: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu September 21, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
CS6220: DATA MINING TECHNIQUES Matrix Data: Classification: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu September 21, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
Dynamic Approaches: The Hidden Markov Model
 Dynamic Approaches: The Hidden Markov Model Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Machine Learning: Neural Networks and Advanced Models (AA2) Inference as Message
Dynamic Approaches: The Hidden Markov Model Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Machine Learning: Neural Networks and Advanced Models (AA2) Inference as Message
Learning in Bayesian Networks
 Learning in Bayesian Networks Florian Markowetz Max-Planck-Institute for Molecular Genetics Computational Molecular Biology Berlin Berlin: 20.06.2002 1 Overview 1. Bayesian Networks Stochastic Networks
Learning in Bayesian Networks Florian Markowetz Max-Planck-Institute for Molecular Genetics Computational Molecular Biology Berlin Berlin: 20.06.2002 1 Overview 1. Bayesian Networks Stochastic Networks
Hidden Markov Models. By Parisa Abedi. Slides courtesy: Eric Xing
 Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
MODULE -4 BAYEIAN LEARNING
 MODULE -4 BAYEIAN LEARNING CONTENT Introduction Bayes theorem Bayes theorem and concept learning Maximum likelihood and Least Squared Error Hypothesis Maximum likelihood Hypotheses for predicting probabilities
MODULE -4 BAYEIAN LEARNING CONTENT Introduction Bayes theorem Bayes theorem and concept learning Maximum likelihood and Least Squared Error Hypothesis Maximum likelihood Hypotheses for predicting probabilities
Part I. C. M. Bishop PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS
 Part I C. M. Bishop PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS Probabilistic Graphical Models Graphical representation of a probabilistic model Each variable corresponds to a
Part I C. M. Bishop PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS Probabilistic Graphical Models Graphical representation of a probabilistic model Each variable corresponds to a
Linear Dynamical Systems (Kalman filter)
") Linear Dynamical Systems (Kalman filter) (a) Overview of HMMs (b) From HMMs to Linear Dynamical Systems (LDS) 1 Markov Chains with Discrete Random Variables x 1 x 2 x 3 x T Let s assume we have discrete
Linear Dynamical Systems (Kalman filter) (a) Overview of HMMs (b) From HMMs to Linear Dynamical Systems (LDS) 1 Markov Chains with Discrete Random Variables x 1 x 2 x 3 x T Let s assume we have discrete
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Why do we care? Measurements. Handling uncertainty over time: predicting, estimating, recognizing, learning. Dealing with time
 Handling uncertainty over time: predicting, estimating, recognizing, learning Chris Atkeson 2004 Why do we care? Speech recognition makes use of dependence of words and phonemes across time. Knowing where
Handling uncertainty over time: predicting, estimating, recognizing, learning Chris Atkeson 2004 Why do we care? Speech recognition makes use of dependence of words and phonemes across time. Knowing where
Outline. Spring It Introduction Representation. Markov Random Field. Conclusion. Conditional Independence Inference: Variable elimination
 Probabilistic Graphical Models COMP 790-90 Seminar Spring 2011 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Outline It Introduction ti Representation Bayesian network Conditional Independence Inference:
Probabilistic Graphical Models COMP 790-90 Seminar Spring 2011 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Outline It Introduction ti Representation Bayesian network Conditional Independence Inference:
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Chapter 8&9: Classification: Part 3 Instructor: Yizhou Sun yzsun@ccs.neu.edu March 12, 2013 Midterm Report Grade Distribution 90-100 10 80-89 16 70-79 8 60-69 4
CS6220: DATA MINING TECHNIQUES Chapter 8&9: Classification: Part 3 Instructor: Yizhou Sun yzsun@ccs.neu.edu March 12, 2013 Midterm Report Grade Distribution 90-100 10 80-89 16 70-79 8 60-69 4
Probabilistic Reasoning. (Mostly using Bayesian Networks)
") Probabilistic Reasoning (Mostly using Bayesian Networks) Introduction: Why probabilistic reasoning? The world is not deterministic. (Usually because information is limited.) Ways of coping with uncertainty
Probabilistic Reasoning (Mostly using Bayesian Networks) Introduction: Why probabilistic reasoning? The world is not deterministic. (Usually because information is limited.) Ways of coping with uncertainty
Introduction to Probabilistic Graphical Models
 Introduction to Probabilistic Graphical Models Kyu-Baek Hwang and Byoung-Tak Zhang Biointelligence Lab School of Computer Science and Engineering Seoul National University Seoul 151-742 Korea E-mail: kbhwang@bi.snu.ac.kr
Introduction to Probabilistic Graphical Models Kyu-Baek Hwang and Byoung-Tak Zhang Biointelligence Lab School of Computer Science and Engineering Seoul National University Seoul 151-742 Korea E-mail: kbhwang@bi.snu.ac.kr
Probabilistic Graphical Networks: Definitions and Basic Results
 This document gives a cursory overview of Probabilistic Graphical Networks. The material has been gleaned from different sources. I make no claim to original authorship of this material. Bayesian Graphical
This document gives a cursory overview of Probabilistic Graphical Networks. The material has been gleaned from different sources. I make no claim to original authorship of this material. Bayesian Graphical
Recall from last time: Conditional probabilities. Lecture 2: Belief (Bayesian) networks. Bayes ball. Example (continued) Example: Inference problem
 networks. Bayes ball. Example (continued) Example: Inference problem") Recall from last time: Conditional probabilities Our probabilistic models will compute and manipulate conditional probabilities. Given two random variables X, Y, we denote by Lecture 2: Belief (Bayesian)
Recall from last time: Conditional probabilities Our probabilistic models will compute and manipulate conditional probabilities. Given two random variables X, Y, we denote by Lecture 2: Belief (Bayesian)
Hidden Markov models
 Hidden Markov models Charles Elkan November 26, 2012 Important: These lecture notes are based on notes written by Lawrence Saul. Also, these typeset notes lack illustrations. See the classroom lectures
Hidden Markov models Charles Elkan November 26, 2012 Important: These lecture notes are based on notes written by Lawrence Saul. Also, these typeset notes lack illustrations. See the classroom lectures
Approximate Inference
 Approximate Inference Simulation has a name: sampling Sampling is a hot topic in machine learning, and it s really simple Basic idea: Draw N samples from a sampling distribution S Compute an approximate
Approximate Inference Simulation has a name: sampling Sampling is a hot topic in machine learning, and it s really simple Basic idea: Draw N samples from a sampling distribution S Compute an approximate
Hidden Markov Models. Aarti Singh Slides courtesy: Eric Xing. Machine Learning / Nov 8, 2010
 Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Machine Learning Lecture 14
 Many slides adapted from B. Schiele, S. Roth, Z. Gharahmani Machine Learning Lecture 14 Undirected Graphical Models & Inference 23.06.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de
Many slides adapted from B. Schiele, S. Roth, Z. Gharahmani Machine Learning Lecture 14 Undirected Graphical Models & Inference 23.06.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de
Markov Networks. l Like Bayes Nets. l Graph model that describes joint probability distribution using tables (AKA potentials)
") Markov Networks l Like Bayes Nets l Graph model that describes joint probability distribution using tables (AKA potentials) l Nodes are random variables l Labels are outcomes over the variables Markov
Markov Networks l Like Bayes Nets l Graph model that describes joint probability distribution using tables (AKA potentials) l Nodes are random variables l Labels are outcomes over the variables Markov
Bayesian Networks. Characteristics of Learning BN Models. Bayesian Learning. An Example
 Bayesian Networks Characteristics of Learning BN Models (All hail Judea Pearl) (some hail Greg Cooper) Benefits Handle incomplete data Can model causal chains of relationships Combine domain knowledge
Bayesian Networks Characteristics of Learning BN Models (All hail Judea Pearl) (some hail Greg Cooper) Benefits Handle incomplete data Can model causal chains of relationships Combine domain knowledge
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Using first-order logic, formalize the following knowledge:
 Probabilistic Artificial Intelligence Final Exam Feb 2, 2016 Time limit: 120 minutes Number of pages: 19 Total points: 100 You can use the back of the pages if you run out of space. Collaboration on the
Probabilistic Artificial Intelligence Final Exam Feb 2, 2016 Time limit: 120 minutes Number of pages: 19 Total points: 100 You can use the back of the pages if you run out of space. Collaboration on the
Bayes Networks 6.872/HST.950
 Bayes Networks 6.872/HST.950 What Probabilistic Models Should We Use? Full joint distribution Completely expressive Hugely data-hungry Exponential computational complexity Naive Bayes (full conditional
Bayes Networks 6.872/HST.950 What Probabilistic Models Should We Use? Full joint distribution Completely expressive Hugely data-hungry Exponential computational complexity Naive Bayes (full conditional
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Directed Probabilistic Graphical Models CMSC 678 UMBC
 Directed Probabilistic Graphical Models CMSC 678 UMBC Announcement 1: Assignment 3 Due Wednesday April 11 th, 11:59 AM Any questions? Announcement 2: Progress Report on Project Due Monday April 16 th,
Directed Probabilistic Graphical Models CMSC 678 UMBC Announcement 1: Assignment 3 Due Wednesday April 11 th, 11:59 AM Any questions? Announcement 2: Progress Report on Project Due Monday April 16 th,
The Origin of Deep Learning. Lili Mou Jan, 2015
 The Origin of Deep Learning Lili Mou Jan, 2015 Acknowledgment Most of the materials come from G. E. Hinton s online course. Outline Introduction Preliminary Boltzmann Machines and RBMs Deep Belief Nets
The Origin of Deep Learning Lili Mou Jan, 2015 Acknowledgment Most of the materials come from G. E. Hinton s online course. Outline Introduction Preliminary Boltzmann Machines and RBMs Deep Belief Nets
Machine Learning 4771
 Machine Learning 4771 Instructor: Tony Jebara Topic 16 Undirected Graphs Undirected Separation Inferring Marginals & Conditionals Moralization Junction Trees Triangulation Undirected Graphs Separation
Machine Learning 4771 Instructor: Tony Jebara Topic 16 Undirected Graphs Undirected Separation Inferring Marginals & Conditionals Moralization Junction Trees Triangulation Undirected Graphs Separation
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Statistical Approaches to Learning and Discovery
 Statistical Approaches to Learning and Discovery Graphical Models Zoubin Ghahramani & Teddy Seidenfeld zoubin@cs.cmu.edu & teddy@stat.cmu.edu CALD / CS / Statistics / Philosophy Carnegie Mellon University
Statistical Approaches to Learning and Discovery Graphical Models Zoubin Ghahramani & Teddy Seidenfeld zoubin@cs.cmu.edu & teddy@stat.cmu.edu CALD / CS / Statistics / Philosophy Carnegie Mellon University
Directed and Undirected Graphical Models
 Directed and Undirected Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Machine Learning: Neural Networks and Advanced Models (AA2) Last Lecture Refresher Lecture Plan Directed
Directed and Undirected Davide Bacciu Dipartimento di Informatica Università di Pisa bacciu@di.unipi.it Machine Learning: Neural Networks and Advanced Models (AA2) Last Lecture Refresher Lecture Plan Directed
Variational Scoring of Graphical Model Structures
 Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Probabilistic Classification
 Bayesian Networks Probabilistic Classification Goal: Gather Labeled Training Data Build/Learn a Probability Model Use the model to infer class labels for unlabeled data points Example: Spam Filtering...
Bayesian Networks Probabilistic Classification Goal: Gather Labeled Training Data Build/Learn a Probability Model Use the model to infer class labels for unlabeled data points Example: Spam Filtering...
Inference and estimation in probabilistic time series models
 1 Inference and estimation in probabilistic time series models David Barber, A Taylan Cemgil and Silvia Chiappa 11 Time series The term time series refers to data that can be represented as a sequence
1 Inference and estimation in probabilistic time series models David Barber, A Taylan Cemgil and Silvia Chiappa 11 Time series The term time series refers to data that can be represented as a sequence
Probabilistic Graphical Models: Representation and Inference
 Probabilistic Graphical Models: Representation and Inference Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Andrew Moore 1 Overview
Probabilistic Graphical Models: Representation and Inference Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Andrew Moore 1 Overview
Chapter 16. Structured Probabilistic Models for Deep Learning
 Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
CS 188: Artificial Intelligence. Bayes Nets
 CS 188: Artificial Intelligence Probabilistic Inference: Enumeration, Variable Elimination, Sampling Pieter Abbeel UC Berkeley Many slides over this course adapted from Dan Klein, Stuart Russell, Andrew
CS 188: Artificial Intelligence Probabilistic Inference: Enumeration, Variable Elimination, Sampling Pieter Abbeel UC Berkeley Many slides over this course adapted from Dan Klein, Stuart Russell, Andrew
Basic math for biology
 Basic math for biology Lei Li Florida State University, Feb 6, 2002 The EM algorithm: setup Parametric models: {P θ }. Data: full data (Y, X); partial data Y. Missing data: X. Likelihood and maximum likelihood
Basic math for biology Lei Li Florida State University, Feb 6, 2002 The EM algorithm: setup Parametric models: {P θ }. Data: full data (Y, X); partial data Y. Missing data: X. Likelihood and maximum likelihood
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Directed and Undirected Graphical Models
 Directed and Undirected Graphical Models Adrian Weller MLSALT4 Lecture Feb 26, 2016 With thanks to David Sontag (NYU) and Tony Jebara (Columbia) for use of many slides and illustrations For more information,
Directed and Undirected Graphical Models Adrian Weller MLSALT4 Lecture Feb 26, 2016 With thanks to David Sontag (NYU) and Tony Jebara (Columbia) for use of many slides and illustrations For more information,
PILCO: A Model-Based and Data-Efficient Approach to Policy Search
 PILCO: A Model-Based and Data-Efficient Approach to Policy Search (M.P. Deisenroth and C.E. Rasmussen) CSC2541 November 4, 2016 PILCO Graphical Model PILCO Probabilistic Inference for Learning COntrol
PILCO: A Model-Based and Data-Efficient Approach to Policy Search (M.P. Deisenroth and C.E. Rasmussen) CSC2541 November 4, 2016 PILCO Graphical Model PILCO Probabilistic Inference for Learning COntrol
Introduction to Artificial Intelligence. Unit # 11
 Introduction to Artificial Intelligence Unit # 11 1 Course Outline Overview of Artificial Intelligence State Space Representation Search Techniques Machine Learning Logic Probabilistic Reasoning/Bayesian
Introduction to Artificial Intelligence Unit # 11 1 Course Outline Overview of Artificial Intelligence State Space Representation Search Techniques Machine Learning Logic Probabilistic Reasoning/Bayesian
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection
 CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
Directed Graphical Models or Bayesian Networks
 Directed Graphical Models or Bayesian Networks Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Bayesian Networks One of the most exciting recent advancements in statistical AI Compact
Directed Graphical Models or Bayesian Networks Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Bayesian Networks One of the most exciting recent advancements in statistical AI Compact
13 : Variational Inference: Loopy Belief Propagation and Mean Field
 10-708: Probabilistic Graphical Models 10-708, Spring 2012 13 : Variational Inference: Loopy Belief Propagation and Mean Field Lecturer: Eric P. Xing Scribes: Peter Schulam and William Wang 1 Introduction
10-708: Probabilistic Graphical Models 10-708, Spring 2012 13 : Variational Inference: Loopy Belief Propagation and Mean Field Lecturer: Eric P. Xing Scribes: Peter Schulam and William Wang 1 Introduction
Markov Networks. l Like Bayes Nets. l Graphical model that describes joint probability distribution using tables (AKA potentials)
") Markov Networks l Like Bayes Nets l Graphical model that describes joint probability distribution using tables (AKA potentials) l Nodes are random variables l Labels are outcomes over the variables Markov
Markov Networks l Like Bayes Nets l Graphical model that describes joint probability distribution using tables (AKA potentials) l Nodes are random variables l Labels are outcomes over the variables Markov
COMS 4771 Probabilistic Reasoning via Graphical Models. Nakul Verma
 COMS 4771 Probabilistic Reasoning via Graphical Models Nakul Verma Last time Dimensionality Reduction Linear vs non-linear Dimensionality Reduction Principal Component Analysis (PCA) Non-linear methods
COMS 4771 Probabilistic Reasoning via Graphical Models Nakul Verma Last time Dimensionality Reduction Linear vs non-linear Dimensionality Reduction Principal Component Analysis (PCA) Non-linear methods
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Notes on Machine Learning for and
 Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Choosing Hypotheses Generally want the most probable hypothesis given the training data Maximum a posteriori
Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Choosing Hypotheses Generally want the most probable hypothesis given the training data Maximum a posteriori
Extensions of Bayesian Networks. Outline. Bayesian Network. Reasoning under Uncertainty. Features of Bayesian Networks.
 Extensions of Bayesian Networks Outline Ethan Howe, James Lenfestey, Tom Temple Intro to Dynamic Bayesian Nets (Tom Exact inference in DBNs with demo (Ethan Approximate inference and learning (Tom Probabilistic
Extensions of Bayesian Networks Outline Ethan Howe, James Lenfestey, Tom Temple Intro to Dynamic Bayesian Nets (Tom Exact inference in DBNs with demo (Ethan Approximate inference and learning (Tom Probabilistic
Bayesian belief networks
 CS 2001 Lecture 1 Bayesian belief networks Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square 4-8845 Milos research interests Artificial Intelligence Planning, reasoning and optimization in the presence
CS 2001 Lecture 1 Bayesian belief networks Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square 4-8845 Milos research interests Artificial Intelligence Planning, reasoning and optimization in the presence
Hidden Markov Models
 CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each