Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
|
|
|
- Matilda Edwards
- 5 years ago
- Views:
Transcription



1 Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima J. Nocedal with N. Keskar Northwestern University D. Mudigere INTEL P. Tang INTEL M. Smelyanskiy INTEL 1
2 Initial Remarks SGD (and variants) is the method of choice Take another look at batch methods for training DNN Because they have the potential to parallelize Widely accepted that batch methods overfit Revisit this in the non-convex case of DNN with multiple minimizers o o o Performed an exploration using ADAM where gradient sample increased from stochastic to batch regime Ran methods until no measurable progress is made in training Does the batch method converge to shallower minimizer? 2
3 Testing Accuracy is lost with increase in batch size ADAM optimizer: 256 (small batch) v/s 10% (large batch) This behavior has been observed by others Testing Accuracy Studied 6 network configurations 3
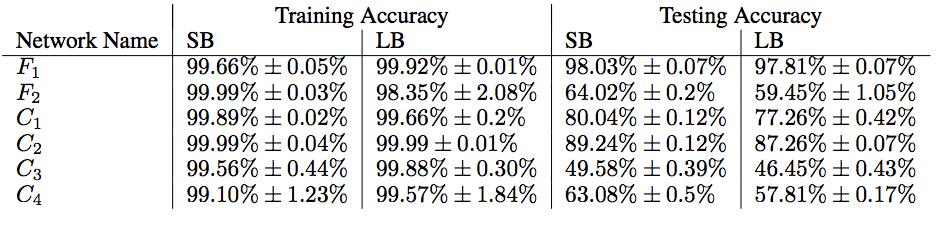
4 Training and Testing Accuracy SB: small batch LB: large batch No Problems in Training! 4
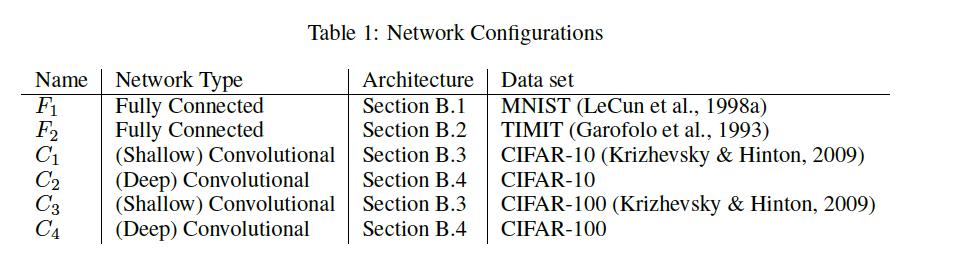
5 Network configurations 5
6 Early stopping would not help large batch methods Testing error for large batch method Batch methods somehow do not employ information improperly To be described mathematically in this context! 6
7 Methods converge to different types of minimizers Next: plot the geometry of the loss function along the line joining the small batch solution and large batch solution Plot the true loss and test functions Goodfellow et al 7
8 What is going on? Gradient method over-fits We need to back-up: Define setting of supervised training Le Convolutional neural net CIFAR-10 LeCun, private communication Small batch solution SG: mini-batch of size 256 large batch solution Batch: 10% of training set 8
9 Accuracy: correct classification SG solution Batch solution 9
10 Combined 10
11 We observe this over and over Has this been observed by others? Hochreiter and Schmidhuber. Flat minima
12 What are Sharp and Wide Minima? Volume. Free Energy. Robust Solution. Instead we use Given a parameter w * and a box B of width ε centered at w *, we define the sharpness of w * as max w B f (w * + w) f (w * ) 1+ f (w * ) 1. Maximum sensitivity 2. Observed sharp solutions are wide in most of the space 3. Computed with an optimization solver (inexactly) 4. Verified through random sampling 5. Also minimized/samples in random subspaces. 12
13 Sharpness: small batch solution SB large batch solution LB Small batch solution large batch solution 13
14 Sampling in a subsapce 14
15 Sharp and Wide Minima: an illusion? 1. It is tempting to conclude that convergence to sharp minima explains why batch methods do not generalize well 2. Perturbation analysis in parameter space refers to training problem 3. But geometry of loss function depends on the basis used in parameter space. One can alter it in various ways without changing prediction capability 4. Dinh et al 2017 Sharp Minima can generalize: 5. construct two identical predictors; one 6. sharp minimum; the other not 7. Neyshabur et al: Path-SGD (2015) 8. Chaudhari et al. Entropy-sgd: Biasing gradient 9. descent into wide valleys α w αw 15
16 Nevertheless our observations require an explanation 1. Sharpness grows as batch optimization iteration progresses 2. Controlled experiments: start with SGD and swtich to batch: can get trapped in sharp minima. 16
17 Remarks Ø Ø Ø Ø Ø Ø Convergence to sharp/wide minima seems to be persistent Plausible: due to effect of noise in SGD and the fact that steplength is selected to give good testing error (noise adjustment) But it is not clear how to properly define sharp/wide minima so that they relate to generalization We need a mathematical explanation of the generalization properties of batch methods in the context of DNNs (not convex case) And convergence of the optimization on training functions A batch method with good generalization properties could make use of parallel platforms 17
Stochastic Optimization Methods for Machine Learning. Jorge Nocedal
 Stochastic Optimization Methods for Machine Learning Jorge Nocedal Northwestern University SIAM CSE, March 2017 1 Collaborators Richard Byrd R. Bollagragada N. Keskar University of Colorado Northwestern
Stochastic Optimization Methods for Machine Learning Jorge Nocedal Northwestern University SIAM CSE, March 2017 1 Collaborators Richard Byrd R. Bollagragada N. Keskar University of Colorado Northwestern
Sub-Sampled Newton Methods for Machine Learning. Jorge Nocedal
 Sub-Sampled Newton Methods for Machine Learning Jorge Nocedal Northwestern University Goldman Lecture, Sept 2016 1 Collaborators Raghu Bollapragada Northwestern University Richard Byrd University of Colorado
Sub-Sampled Newton Methods for Machine Learning Jorge Nocedal Northwestern University Goldman Lecture, Sept 2016 1 Collaborators Raghu Bollapragada Northwestern University Richard Byrd University of Colorado
Deep Neural Networks: From Flat Minima to Numerically Nonvacuous Generalization Bounds via PAC-Bayes
 Deep Neural Networks: From Flat Minima to Numerically Nonvacuous Generalization Bounds via PAC-Bayes Daniel M. Roy University of Toronto; Vector Institute Joint work with Gintarė K. Džiugaitė University
Deep Neural Networks: From Flat Minima to Numerically Nonvacuous Generalization Bounds via PAC-Bayes Daniel M. Roy University of Toronto; Vector Institute Joint work with Gintarė K. Džiugaitė University
Nonlinear Optimization Methods for Machine Learning
 Nonlinear Optimization Methods for Machine Learning Jorge Nocedal Northwestern University University of California, Davis, Sept 2018 1 Introduction We don t really know, do we? a) Deep neural networks
Nonlinear Optimization Methods for Machine Learning Jorge Nocedal Northwestern University University of California, Davis, Sept 2018 1 Introduction We don t really know, do we? a) Deep neural networks
Theory of Deep Learning IIb: Optimization Properties of SGD
 CBMM Memo No. 72 December 27, 217 Theory of Deep Learning IIb: Optimization Properties of SGD by Chiyuan Zhang 1 Qianli Liao 1 Alexander Rakhlin 2 Brando Miranda 1 Noah Golowich 1 Tomaso Poggio 1 1 Center
CBMM Memo No. 72 December 27, 217 Theory of Deep Learning IIb: Optimization Properties of SGD by Chiyuan Zhang 1 Qianli Liao 1 Alexander Rakhlin 2 Brando Miranda 1 Noah Golowich 1 Tomaso Poggio 1 1 Center
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent
 CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
IPAM Summer School Optimization methods for machine learning. Jorge Nocedal
 IPAM Summer School 2012 Tutorial on Optimization methods for machine learning Jorge Nocedal Northwestern University Overview 1. We discuss some characteristics of optimization problems arising in deep
IPAM Summer School 2012 Tutorial on Optimization methods for machine learning Jorge Nocedal Northwestern University Overview 1. We discuss some characteristics of optimization problems arising in deep
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Don t Decay the Learning Rate, Increase the Batch Size. Samuel L. Smith, Pieter-Jan Kindermans, Quoc V. Le December 9 th 2017
 Don t Decay the Learning Rate, Increase the Batch Size Samuel L. Smith, Pieter-Jan Kindermans, Quoc V. Le December 9 th 2017 slsmith@ Google Brain Three related questions: What properties control generalization?
Don t Decay the Learning Rate, Increase the Batch Size Samuel L. Smith, Pieter-Jan Kindermans, Quoc V. Le December 9 th 2017 slsmith@ Google Brain Three related questions: What properties control generalization?
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Stochastic Optimization Algorithms Beyond SG
 Stochastic Optimization Algorithms Beyond SG Frank E. Curtis 1, Lehigh University involving joint work with Léon Bottou, Facebook AI Research Jorge Nocedal, Northwestern University Optimization Methods
Stochastic Optimization Algorithms Beyond SG Frank E. Curtis 1, Lehigh University involving joint work with Léon Bottou, Facebook AI Research Jorge Nocedal, Northwestern University Optimization Methods
Advanced computational methods X Selected Topics: SGD
 Advanced computational methods X071521-Selected Topics: SGD. In this lecture, we look at the stochastic gradient descent (SGD) method 1 An illustrating example The MNIST is a simple dataset of variety
Advanced computational methods X071521-Selected Topics: SGD. In this lecture, we look at the stochastic gradient descent (SGD) method 1 An illustrating example The MNIST is a simple dataset of variety
THERE ARE MANY CONSISTENT EXPLANATIONS OF UNLABELED DATA: WHY YOU SHOULD AVERAGE
 THERE ARE MANY CONSISTENT EXPLANATIONS OF UNLABELED DATA: WHY YOU SHOULD AVERAGE Anonymous authors Paper under double-blind review Abstract Presently the most successful approaches to semi-supervised learning
THERE ARE MANY CONSISTENT EXPLANATIONS OF UNLABELED DATA: WHY YOU SHOULD AVERAGE Anonymous authors Paper under double-blind review Abstract Presently the most successful approaches to semi-supervised learning
Unraveling the mysteries of stochastic gradient descent on deep neural networks
 Unraveling the mysteries of stochastic gradient descent on deep neural networks Pratik Chaudhari UCLA VISION LAB 1 The question measures disagreement of predictions with ground truth Cat Dog... x = argmin
Unraveling the mysteries of stochastic gradient descent on deep neural networks Pratik Chaudhari UCLA VISION LAB 1 The question measures disagreement of predictions with ground truth Cat Dog... x = argmin
CS260: Machine Learning Algorithms
 CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
Deep Learning & Artificial Intelligence WS 2018/2019
 Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Deep Relaxation: PDEs for optimizing Deep Neural Networks
 Deep Relaxation: PDEs for optimizing Deep Neural Networks IPAM Mean Field Games August 30, 2017 Adam Oberman (McGill) Thanks to the Simons Foundation (grant 395980) and the hospitality of the UCLA math
Deep Relaxation: PDEs for optimizing Deep Neural Networks IPAM Mean Field Games August 30, 2017 Adam Oberman (McGill) Thanks to the Simons Foundation (grant 395980) and the hospitality of the UCLA math
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
OPTIMIZATION METHODS IN DEEP LEARNING
 Tutorial outline OPTIMIZATION METHODS IN DEEP LEARNING Based on Deep Learning, chapter 8 by Ian Goodfellow, Yoshua Bengio and Aaron Courville Presented By Nadav Bhonker Optimization vs Learning Surrogate
Tutorial outline OPTIMIZATION METHODS IN DEEP LEARNING Based on Deep Learning, chapter 8 by Ian Goodfellow, Yoshua Bengio and Aaron Courville Presented By Nadav Bhonker Optimization vs Learning Surrogate
An Evolving Gradient Resampling Method for Machine Learning. Jorge Nocedal
 An Evolving Gradient Resampling Method for Machine Learning Jorge Nocedal Northwestern University NIPS, Montreal 2015 1 Collaborators Figen Oztoprak Stefan Solntsev Richard Byrd 2 Outline 1. How to improve
An Evolving Gradient Resampling Method for Machine Learning Jorge Nocedal Northwestern University NIPS, Montreal 2015 1 Collaborators Figen Oztoprak Stefan Solntsev Richard Byrd 2 Outline 1. How to improve
Training Neural Networks Practical Issues
 Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Stochastic Gradient Descent
 Stochastic Gradient Descent Weihang Chen, Xingchen Chen, Jinxiu Liang, Cheng Xu, Zehao Chen and Donglin He March 26, 2017 Outline What is Stochastic Gradient Descent Comparison between BGD and SGD Analysis
Stochastic Gradient Descent Weihang Chen, Xingchen Chen, Jinxiu Liang, Cheng Xu, Zehao Chen and Donglin He March 26, 2017 Outline What is Stochastic Gradient Descent Comparison between BGD and SGD Analysis
A picture of the energy landscape of! deep neural networks
 A picture of the energy landscape of! deep neural networks Pratik Chaudhari December 15, 2017 UCLA VISION LAB 1 Dy (x; w) = (w p (w p 1 (... (w 1 x))...)) w = argmin w (x,y ) 2 D kx 1 {y =i } log Dy i
A picture of the energy landscape of! deep neural networks Pratik Chaudhari December 15, 2017 UCLA VISION LAB 1 Dy (x; w) = (w p (w p 1 (... (w 1 x))...)) w = argmin w (x,y ) 2 D kx 1 {y =i } log Dy i
GRADIENT DESCENT. CSE 559A: Computer Vision GRADIENT DESCENT GRADIENT DESCENT [0, 1] Pr(y = 1) w T x. 1 f (x; θ) = 1 f (x; θ) = exp( w T x)
![GRADIENT DESCENT. CSE 559A: Computer Vision GRADIENT DESCENT GRADIENT DESCENT [0, 1] Pr(y = 1) w T x. 1 f (x; θ) = 1 f (x; θ) = exp( w T x)](/thumbs/81/84408888.jpg "GRADIENT DESCENT. CSE 559A: Computer Vision GRADIENT DESCENT GRADIENT DESCENT [0, 1] Pr(y = 1) w T x. 1 f (x; θ) = 1 f (x; θ) = exp( w T x)") 0 x x x CSE 559A: Computer Vision For Binary Classification: [0, ] f (x; ) = σ( x) = exp( x) + exp( x) Output is interpreted as probability Pr(y = ) x are the log-odds. Fall 207: -R: :30-pm @ Lopata 0
0 x x x CSE 559A: Computer Vision For Binary Classification: [0, ] f (x; ) = σ( x) = exp( x) + exp( x) Output is interpreted as probability Pr(y = ) x are the log-odds. Fall 207: -R: :30-pm @ Lopata 0
Overview of gradient descent optimization algorithms. HYUNG IL KOO Based on
 Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Theory of Deep Learning III: the non-overfitting puzzle
 CBMM Memo No. 073 January 30, 2018 Theory of Deep Learning III: the non-overfitting puzzle by T. Poggio, K. Kawaguchi, Q. Liao, B. Miranda, L. Rosasco with X. Boix, J. Hidary, H. Mhaskar, Center for Brains,
CBMM Memo No. 073 January 30, 2018 Theory of Deep Learning III: the non-overfitting puzzle by T. Poggio, K. Kawaguchi, Q. Liao, B. Miranda, L. Rosasco with X. Boix, J. Hidary, H. Mhaskar, Center for Brains,
Theory of Deep Learning III: explaining the non-overfitting puzzle
 CBMM Memo No. 073 January 17, 2018 arxiv:1801.00173v2 [cs.lg] 16 Jan 2018 Theory of Deep Learning III: explaining the non-overfitting puzzle by T. Poggio, K. Kawaguchi, Q. Liao, B. Miranda, L. Rosasco
CBMM Memo No. 073 January 17, 2018 arxiv:1801.00173v2 [cs.lg] 16 Jan 2018 Theory of Deep Learning III: explaining the non-overfitting puzzle by T. Poggio, K. Kawaguchi, Q. Liao, B. Miranda, L. Rosasco
arxiv: v2 [cs.lg] 28 Nov 2017
![arxiv: v2 [cs.lg] 28 Nov 2017](/thumbs/93/113246853.jpg "arxiv: v2 [cs.lg] 28 Nov 2017") Towards Understanding Generalization of Deep Learning: Perspective of Loss Landscapes arxiv:1706.239v2 [cs.lg] 28 ov 17 Lei Wu School of Mathematics, Peking University Beijing, China leiwu@pku.edu.cn Zhanxing
Towards Understanding Generalization of Deep Learning: Perspective of Loss Landscapes arxiv:1706.239v2 [cs.lg] 28 ov 17 Lei Wu School of Mathematics, Peking University Beijing, China leiwu@pku.edu.cn Zhanxing
Normalization Techniques in Training of Deep Neural Networks
 Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Machine Learning CS 4900/5900. Lecture 03. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
On stochas*c gradient descent, flatness and generaliza*on Yoshua Bengio
 On stochas*c gradient descent, flatness and generaliza*on Yoshua Bengio July 14, 2018 ICML 2018 Workshop on nonconvex op=miza=on Disentangling optimization and generalization The tradi=onal ML picture is
On stochas*c gradient descent, flatness and generaliza*on Yoshua Bengio July 14, 2018 ICML 2018 Workshop on nonconvex op=miza=on Disentangling optimization and generalization The tradi=onal ML picture is
Theory of Deep Learning III: Generalization Properties of SGD
 . CBMM Memo No. 67 April 4, 217 Theory of Deep Learning III: Generalization Properties of SGD by Chiyuan Zhang 1 Qianli Liao 1 Alexander Rakhlin 2 Karthik Sridharan 3 Brando Miranda 1 Noah Golowich 1 Tomaso
. CBMM Memo No. 67 April 4, 217 Theory of Deep Learning III: Generalization Properties of SGD by Chiyuan Zhang 1 Qianli Liao 1 Alexander Rakhlin 2 Karthik Sridharan 3 Brando Miranda 1 Noah Golowich 1 Tomaso
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Neural Networks: Optimization & Regularization
 Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
CSC321 Lecture 8: Optimization
 CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
arxiv: v2 [stat.ml] 1 Jan 2018
![arxiv: v2 [stat.ml] 1 Jan 2018](/thumbs/81/83373862.jpg "arxiv: v2 [stat.ml] 1 Jan 2018") Train longer, generalize better: closing the generalization gap in large batch training of neural networks arxiv:1705.08741v2 [stat.ml] 1 Jan 2018 Elad Hoffer, Itay Hubara, Daniel Soudry Technion - Israel
Train longer, generalize better: closing the generalization gap in large batch training of neural networks arxiv:1705.08741v2 [stat.ml] 1 Jan 2018 Elad Hoffer, Itay Hubara, Daniel Soudry Technion - Israel
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
 Empirical Analysis of the Hessian of Over-Parametrized Neural Networks Levent Sagun Courant Institute, NYU sagun@cims.nyu.edu Utku Evci Computer Science Department, NYU ue225@nyu.edu V. Uğur Güney ugurguney@gmail.com
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks Levent Sagun Courant Institute, NYU sagun@cims.nyu.edu Utku Evci Computer Science Department, NYU ue225@nyu.edu V. Uğur Güney ugurguney@gmail.com
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Linear Regression. Aarti Singh. Machine Learning / Sept 27, 2010
 Linear Regression Aarti Singh Machine Learning 10-701/15-781 Sept 27, 2010 Discrete to Continuous Labels Classification Sports Science News Anemic cell Healthy cell Regression X = Document Y = Topic X
Linear Regression Aarti Singh Machine Learning 10-701/15-781 Sept 27, 2010 Discrete to Continuous Labels Classification Sports Science News Anemic cell Healthy cell Regression X = Document Y = Topic X
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Deep Residual. Variations
 Deep Residual Network and Its Variations Diyu Yang (Originally prepared by Kaiming He from Microsoft Research) Advantages of Depth Degradation Problem Possible Causes? Vanishing/Exploding Gradients. Overfitting
Deep Residual Network and Its Variations Diyu Yang (Originally prepared by Kaiming He from Microsoft Research) Advantages of Depth Degradation Problem Possible Causes? Vanishing/Exploding Gradients. Overfitting
Second-Order Methods for Stochastic Optimization
 Second-Order Methods for Stochastic Optimization Frank E. Curtis, Lehigh University involving joint work with Léon Bottou, Facebook AI Research Jorge Nocedal, Northwestern University Optimization Methods
Second-Order Methods for Stochastic Optimization Frank E. Curtis, Lehigh University involving joint work with Léon Bottou, Facebook AI Research Jorge Nocedal, Northwestern University Optimization Methods
CSC321 Lecture 9: Generalization
 CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 26 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 26 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
Overparametrization for Landscape Design in Non-convex Optimization
 Overparametrization for Landscape Design in Non-convex Optimization Jason D. Lee University of Southern California September 19, 2018 The State of Non-Convex Optimization Practical observation: Empirically,
Overparametrization for Landscape Design in Non-convex Optimization Jason D. Lee University of Southern California September 19, 2018 The State of Non-Convex Optimization Practical observation: Empirically,
Lecture 6 Optimization for Deep Neural Networks
 Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Optimization for Training I. First-Order Methods Training algorithm
 Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
arxiv: v2 [cs.lg] 16 Aug 2018
![arxiv: v2 [cs.lg] 16 Aug 2018](/thumbs/87/96786714.jpg "arxiv: v2 [cs.lg] 16 Aug 2018") An Alternative View: When Does SGD Escape Local Minima? arxiv:180.06175v [cs.lg] 16 Aug 018 Robert Kleinberg Department of Computer Science Cornell University rdk@cs.cornell.edu Yang Yuan Department of
An Alternative View: When Does SGD Escape Local Minima? arxiv:180.06175v [cs.lg] 16 Aug 018 Robert Kleinberg Department of Computer Science Cornell University rdk@cs.cornell.edu Yang Yuan Department of
Machine Learning. Lecture 2: Linear regression. Feng Li. https://funglee.github.io
 Machine Learning Lecture 2: Linear regression Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2017 Supervised Learning Regression: Predict
Machine Learning Lecture 2: Linear regression Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2017 Supervised Learning Regression: Predict
CSC321 Lecture 7: Optimization
 CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
Improving L-BFGS Initialization for Trust-Region Methods in Deep Learning
 Improving L-BFGS Initialization for Trust-Region Methods in Deep Learning Jacob Rafati http://rafati.net jrafatiheravi@ucmerced.edu Ph.D. Candidate, Electrical Engineering and Computer Science University
Improving L-BFGS Initialization for Trust-Region Methods in Deep Learning Jacob Rafati http://rafati.net jrafatiheravi@ucmerced.edu Ph.D. Candidate, Electrical Engineering and Computer Science University
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
what can deep learning learn from linear regression? Benjamin Recht University of California, Berkeley
 what can deep learning learn from linear regression? Benjamin Recht University of California, Berkeley Collaborators Joint work with Samy Bengio, Moritz Hardt, Michael Jordan, Jason Lee, Max Simchowitz,
what can deep learning learn from linear regression? Benjamin Recht University of California, Berkeley Collaborators Joint work with Samy Bengio, Moritz Hardt, Michael Jordan, Jason Lee, Max Simchowitz,
CSC321 Lecture 9: Generalization
 CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 27 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
CSC321 Lecture 9: Generalization Roger Grosse Roger Grosse CSC321 Lecture 9: Generalization 1 / 27 Overview We ve focused so far on how to optimize neural nets how to get them to make good predictions
Optimization and Gradient Descent
 Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Theory IIIb: Generalization in Deep Networks
 CBMM Memo No. 90 June 29, 2018 Theory IIIb: Generalization in Deep Networks Tomaso Poggio 1, Qianli Liao 1, Brando Miranda 1, Andrzej Banburski 1, Xavier Boix 1 and Jack Hidary 2 1 Center for Brains, Minds,
CBMM Memo No. 90 June 29, 2018 Theory IIIb: Generalization in Deep Networks Tomaso Poggio 1, Qianli Liao 1, Brando Miranda 1, Andrzej Banburski 1, Xavier Boix 1 and Jack Hidary 2 1 Center for Brains, Minds,
Tips for Deep Learning
 Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Tips for Deep Learning Recipe of Deep Learning Step : define a set of function Step : goodness of function Step 3: pick the best function NO Overfitting! NO YES Good Results on Testing Data? YES Good Results
Linear Regression. CSL603 - Fall 2017 Narayanan C Krishnan
 Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Gradient-Based Learning. Sargur N. Srihari
 Gradient-Based Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Gradient-Based Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Simple Techniques for Improving SGD. CS6787 Lecture 2 Fall 2017
 Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
RegML 2018 Class 8 Deep learning
 RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
J. Sadeghi E. Patelli M. de Angelis
 J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Tutorial on: Optimization I. (from a deep learning perspective) Jimmy Ba
 Jimmy Ba") Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Nonlinear Models. Numerical Methods for Deep Learning. Lars Ruthotto. Departments of Mathematics and Computer Science, Emory University.
 Nonlinear Models Numerical Methods for Deep Learning Lars Ruthotto Departments of Mathematics and Computer Science, Emory University Intro 1 Course Overview Intro 2 Course Overview Lecture 1: Linear Models
Nonlinear Models Numerical Methods for Deep Learning Lars Ruthotto Departments of Mathematics and Computer Science, Emory University Intro 1 Course Overview Intro 2 Course Overview Lecture 1: Linear Models
Non-Linearity. CS 188: Artificial Intelligence. Non-Linear Separators. Non-Linear Separators. Deep Learning I
 Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Deep Learning Lecture 2
 Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data
 Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data DD2424 March 23, 2017 Binary classification problem given labelled training data Have labelled training examples? Given
Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data DD2424 March 23, 2017 Binary classification problem given labelled training data Have labelled training examples? Given
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent
 Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent 1 Xi-Lin Li, lixilinx@gmail.com arxiv:1606.04449v2 [stat.ml] 8 Dec 2016 Abstract This paper studies the performance of
Recurrent Neural Network Training with Preconditioned Stochastic Gradient Descent 1 Xi-Lin Li, lixilinx@gmail.com arxiv:1606.04449v2 [stat.ml] 8 Dec 2016 Abstract This paper studies the performance of
Non-Convex Optimization. CS6787 Lecture 7 Fall 2017
 Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Stochastic Variance Reduction for Nonconvex Optimization. Barnabás Póczos
 1 Stochastic Variance Reduction for Nonconvex Optimization Barnabás Póczos Contents 2 Stochastic Variance Reduction for Nonconvex Optimization Joint work with Sashank Reddi, Ahmed Hefny, Suvrit Sra, and
1 Stochastic Variance Reduction for Nonconvex Optimization Barnabás Póczos Contents 2 Stochastic Variance Reduction for Nonconvex Optimization Joint work with Sashank Reddi, Ahmed Hefny, Suvrit Sra, and
Stochastic Gradient Descent. CS 584: Big Data Analytics
 Stochastic Gradient Descent CS 584: Big Data Analytics Gradient Descent Recap Simplest and extremely popular Main Idea: take a step proportional to the negative of the gradient Easy to implement Each iteration
Stochastic Gradient Descent CS 584: Big Data Analytics Gradient Descent Recap Simplest and extremely popular Main Idea: take a step proportional to the negative of the gradient Easy to implement Each iteration
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
Implicit Optimization Bias
 Implicit Optimization Bias as a key to Understanding Deep Learning Nati Srebro (TTIC) Based on joint work with Behnam Neyshabur (TTIC IAS), Ryota Tomioka (TTIC MSR), Srinadh Bhojanapalli, Suriya Gunasekar,
Implicit Optimization Bias as a key to Understanding Deep Learning Nati Srebro (TTIC) Based on joint work with Behnam Neyshabur (TTIC IAS), Ryota Tomioka (TTIC MSR), Srinadh Bhojanapalli, Suriya Gunasekar,
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Least Mean Squares Regression. Machine Learning Fall 2018
 Least Mean Squares Regression Machine Learning Fall 2018 1 Where are we? Least Squares Method for regression Examples The LMS objective Gradient descent Incremental/stochastic gradient descent Exercises
Least Mean Squares Regression Machine Learning Fall 2018 1 Where are we? Least Squares Method for regression Examples The LMS objective Gradient descent Incremental/stochastic gradient descent Exercises
Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions
 2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
Least Mean Squares Regression
 Least Mean Squares Regression Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture Overview Linear classifiers What functions do linear classifiers express? Least Squares Method
Least Mean Squares Regression Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture Overview Linear classifiers What functions do linear classifiers express? Least Squares Method
Pattern Classification
 Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Machine Learning (CSE 446): Backpropagation
: Backpropagation") Machine Learning (CSE 446): Backpropagation Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 8, 2017 1 / 32 Neuron-Inspired Classifiers correct output y n L n loss hidden units
Machine Learning (CSE 446): Backpropagation Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 8, 2017 1 / 32 Neuron-Inspired Classifiers correct output y n L n loss hidden units
Mini-Course 1: SGD Escapes Saddle Points
 Mini-Course 1: SGD Escapes Saddle Points Yang Yuan Computer Science Department Cornell University Gradient Descent (GD) Task: min x f (x) GD does iterative updates x t+1 = x t η t f (x t ) Gradient Descent
Mini-Course 1: SGD Escapes Saddle Points Yang Yuan Computer Science Department Cornell University Gradient Descent (GD) Task: min x f (x) GD does iterative updates x t+1 = x t η t f (x t ) Gradient Descent
Energy Landscapes of Deep Networks
 Energy Landscapes of Deep Networks Pratik Chaudhari February 29, 2016 References Auffinger, A., Arous, G. B., & Černý, J. (2013). Random matrices and complexity of spin glasses. arxiv:1003.1129.# Choromanska,
Energy Landscapes of Deep Networks Pratik Chaudhari February 29, 2016 References Auffinger, A., Arous, G. B., & Černý, J. (2013). Random matrices and complexity of spin glasses. arxiv:1003.1129.# Choromanska,
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic