Introduction to Convolutional Neural Networks (CNNs)
|
|
|
- Isabella Burke
- 5 years ago
- Views:
Transcription
1 Introduction to Convolutional Neural Networks (CNNs) Department of Transdisciplinary Studies Seoul National University, Korea Jan Many slides are from Fei-Fei Raquel Toronto, and Marc Aurelio

2 Traditional Pattern Recognition
3 Hierarchical Compositionality (DEEP)
 cascades of nonlinear transformations End-to-end learning (no human")
4 Deep Learning What is deep learning? Nothing new! (Many) cascades of nonlinear transformations End-to-end learning (no human intervention / no fixed features)
 Learning Examples")
5 Shallow(?) Learning Examples - Supervised

6 Deep Learning Examples - Supervised
7 Artificial Neural Networks (ANN) Biologically inspired models
8 Variants of ANNs

9 A Brief History of ANNs source of image: VUNO Inc.
10 A Brief History of ANNs First Generation: 1957 Perceptron: Rosenblatt, 1957 Adaline: Widrow and Hoff, 1960
11 A Brief History of ANNs First Generation: 1957 Perceptron: Rosenblatt, 1957 Adaline: Widrow and Hoff, 1960 Second Generation: 1986 MLP with BP: Rumelhart
12 A Brief History of ANNs Third Generation: 2006 RBM: Hinton and Salkhutdinov Reinvigorated research in Deep Learning
13 Classification problems Given inputs x, and outputs t { 1, 1} Find a hyperplane that divides the space into half (binary classification) y = sign(w T x + w 0 ) SVM tries to maximize the margin.
 y = sign(w T x + b) SVM tries to maximize the")
14 Classification problems Given inputs x, and outputs t { 1, 1} Find a hyperplane that divides the space into half (binary classification) y = sign(w T x + b) SVM tries to maximize the margin.
15 Nonlinear predictors How can we make our classifier more powerful?
16 Nonlinear predictors How can we make our classifier more powerful? Compute nonlinear functions of the input y = F(x, w)
17 Nonlinear predictors How can we make our classifier more powerful? Compute nonlinear functions of the input y = F(x, w) Two types of widely used approaches
18 Nonlinear predictors How can we make our classifier more powerful? Compute nonlinear functions of the input y = F(x, w) Two types of widely used approaches Kernel Trick: Fixed functions and optimize linear parameters on nonlinear mappings φ(x) y = sign(w T φ(x) + b)
19 Nonlinear predictors How can we make our classifier more powerful? Compute nonlinear functions of the input y = F(x, w) Two types of widely used approaches Kernel Trick: Fixed functions and optimize linear parameters on nonlinear mappings φ(x) y = sign(w T φ(x) + b) Deep Learning: Learn parametric nonlinear functions y = F(x, w) = (h 2 (w T 2 h 1 (w T 1 x + b 1 ) + b 2 ) h 1,2 : activation function at layer 1 or 2
")
20 Neural Networks Deep learning uses composite of simpler functions, e.g., ReLU, sigmoid, tanh, max Note: a composite of linear functions is linear! Example: 2 layer NNet (Convention: input and output layers are not taken as a layer)
21 Neural Networks Deep learning uses composite of simpler functions, e.g., ReLU, sigmoid, tanh, max Note: a composite of linear functions is linear! Example: 2 layer NNet (Convention: input and output layers are not taken as a layer) x is the input y is the output h i is the i-th hidden layer output W i is the set of parameters of the i-th layer
22 Nonlinearity - Activation function A singlue neuron can be used as a binary linear classifier Regularization has the interpretation of gradual forgetting Classical NNs used sigmoid or tanh function as an activation function. sigmoid: σ(x) = 1 1+e x tanh: tanh(x) = ex e x e x +e x
23 Sigmoid function Squashes numbers to range [0,1] Historically popular since they have nice interpretation as a saturating firing rate of a neuron
24 Sigmoid function Squashes numbers to range [0,1] Historically popular since they have nice interpretation as a saturating firing rate of a neuron 2 BIG problems: 1 Saturated neurons kill the gradients (cannot backprop further) Major bottleneck for the conventional NNs: not able to train more than 2 or 3 layers 2 Sigmoid outputs are not zero-centered Restriction on the gradient directions
25 ReLU: Rectified Linear Unit f (x) = max(0, x) Does not saturate Computationally very efficient Converges much faster than sigmoid/tanh in practice (e.g. 6x)
 One annoying problem Dead neurons")
26 ReLU: Rectified Linear Unit f (x) = max(0, x) Does not saturate Computationally very efficient Converges much faster than sigmoid/tanh in practice (e.g. 6x) One annoying problem Dead neurons
27 ReLU: Rectified Linear Unit f (x) = max(0, x) Does not saturate Computationally very efficient Converges much faster than sigmoid/tanh in practice (e.g. 6x) One annoying problem Dead neurons Solution: leaky ReLU (small slope for negative input) Never dies. However, almost the same performance in practice.

28 Why ReLU? Piecewise linear tiling: mapping is locally linear Montufar et al. On the number of linear regions of DNNs, arxiv 2014
29 Forward Pass: Evaluating the function Forward propagation: compute the output y given the input x Fully connected layer Nonlinearity comes from ReLU Do it in a compositional way x h 1 h 2 y

30 Alternative graphical representation Slide from M. Ranzato

31 Why many layers? Hierarchically distributed representations Lee et al. Convolutional DBN s ICML 2009

32 Why many layers? Hierarchically distributed representations Lee et al. Convolutional DBN s ICML 2009
33 Training We want to estimate the parameters, biases and hyper-parameters (e.g., number of layers, number of neurons) for good predictions. Collect a training set of input-output pairs {x i, t i } N i=1. Encode the output with 1-K encoding t = [0,, 1,, 0].
34 Training We want to estimate the parameters, biases and hyper-parameters (e.g., number of layers, number of neurons) for good predictions. Collect a training set of input-output pairs {x i, t i } N i=1. Encode the output with 1-K encoding t = [0,, 1,, 0]. Define a loss per training example and minimize the empirical loss L(w) = 1 N l(w, x i, t i ) + R(w) N i=1 N : number of training examples R: regularizer w: set of all parameters
35 Loss functions L(w) = 1 N N l(w, x i, t i ) + R(w) i=1 Softmax (Probability of class k given input): p(c k = 1 x) = exp(y k ) Cj=1 exp(y j )
36 Loss functions L(w) = 1 N N l(w, x i, t i ) + R(w) i=1 Softmax (Probability of class k given input): p(c k = 1 x) = exp(y k ) Cj=1 exp(y j ) Cross entropy (most popular loss function for classification): l(w, x, t) = C t (k) log p(c k x) k=1
37 Loss functions L(w) = 1 N N l(w, x i, t i ) + R(w) i=1 Softmax (Probability of class k given input): p(c k = 1 x) = exp(y k ) Cj=1 exp(y j ) Cross entropy (most popular loss function for classification): l(w, x, t) = C t (k) log p(c k x) k=1 Gradient descent to train the network w = argmin L(w) w
38 Backpropagation Efficient way of computing gradient (Chain rule) Partial derivatives and gradients f (x, y) = xy f x = y df (x) f (x + h) f (x) = lim dx h 0 h f y = x df (x) f (x + h) = f (x) + h dx
39 Backpropagation Efficient way of computing gradient (Chain rule) Partial derivatives and gradients f (x, y) = xy f x = y df (x) f (x + h) f (x) = lim dx h 0 h f y = x Example: x = 4, y = 3 f (x, y) = 12 f x = 3 f x = 4 df (x) f (x + h) = f (x) + h dx [ f f = x, f ] y
40 Backpropagation Efficient way of computing gradient (Chain rule) Partial derivatives and gradients f (x, y) = xy f x = y df (x) f (x + h) f (x) = lim dx h 0 h f y = x Example: x = 4, y = 3 f (x, y) = 12 f x = 3 f x = 4 df (x) f (x + h) = f (x) + h dx [ f f = x, f ] y Question: If I increase x by h, how would the output f change?
41 Backpropagation Compound expressions with graphics (example from F.F. Li) q = x + y f = qz f q q x = 1, q x = 1 = z, f z = q Chain rule: f x = f q q x
42 Backpropagation: Another Example
43 Backpropagation: Another Example
44 Backpropagation: Another Example
45 Backpropagation: Another Example
46 Backpropagation: Another Example
47 Backpropagation: Another Example
48 Backpropagation: Another Example
49 Backpropagation: Key Idea
50 Backpropagation: Patterns in BP Add: gradient distributor Max: gradient router Mul: gradient switcher
51 Learning via Gradient Descent Gradient descent to train the network w = argmin w 1 N At each iteration, we need to compute N l(w, x i, t i ) + R(w) i=1 w n+1 = w n γ n L(w n ) Use the backward pass to compute L(w n ) efficiently Recall that the backward pass requires the forward pass first
52 Dealing with Big Data At each iteration, we need to compute w n+1 = w n γ n L(w n ) with L(w n ) = 1 N N l(w n, x i, t i ) + R(w n ) i=1 Too expensive when having millions of training examples
53 Dealing with Big Data At each iteration, we need to compute with L(w n ) = 1 N w n+1 = w n γ n L(w n ) N l(w n, x i, t i ) + R(w n ) i=1 Too expensive when having millions of training examples Instead, approximate the gradient with a mini-batch (subset of examples: 100 1,000) - called stochastic gradient descent 1 N N i=1 l(w n, x i, t i ) 1 S l(w n, x i, t i ) i S
54 SGD with momentum Stochastic Gradient Descent update with w n+1 = w n γ n L(w n ) L(w n ) = 1 S We can use momentum l(w n, x i, t i ) i S w w γ κ + L We can also decay learning rate γ as iterations goes on

55 Fully Connected Layer

56 Locally Connected Layer

57 Locally Connected Layer

58 Convolutional Neural Networks Idea: statistics are similar at different locations (Lecun 1998) Connect each hidden unit to a small input patch and share the weight across space This is called convolution layer and the network is a convolutional neural network
 Volumetric")
59 Convolutional Neural Networks Number of filters (neurons) is considered as a new dimension (depth) Volumetric representation
60 Convolutional Neural Networks Number of filters (neurons) is considered as a new dimension (depth) Volumetric representation
61 Convolutional Neural Networks CNNs are just neural nets BUT: 1. Local connectivity

62 Convolutional Neural Networks image: 32x32x3 volume CNNs are just neural nets BUT: 1. Local connectivity before: fully connected: 32x32x3 weights now: one neuron will connect to, e.g., 5x5x3 chunk (receptive field) and only have 5x5x3 weights connectivity is: local in space (5x5 instead of 32x32) but full in depth (all 3 depth channels)
63 Convolutional Neural Networks CNNs are just neural nets BUT: 1. Local connectivity

64 Convolutional Neural Networks CNNs are just neural nets BUT: 1. Local connectivity Multiple neurons all looking at the same region of the input volume, stacked along depth.
65 Convolutional Neural Networks CNNs are just neural nets BUT: 2. Weight sharing

66 Convolutional Neural Networks CNNs are just neural nets BUT: 2. Weight sharing Weights are shared across different locations Each depth slice is called one feature map
67 Convolutional Neural Networks
68 Convolutional Neural Networks
69 Convolutional Neural Networks
70 Convolutional Neural Networks
71 Convolutional Neural Networks
72 Convolutional Neural Networks
73 Convolutional Layer: Summary Input volume of size [W1 x H1 x D1] using K neurons with receptive fields F x F and applying them at strides of S gives Output volume: [W2, H2, D2] W2 = (W1-F)/S+1, H2 = (H1-F)/S+1, D2 = K
")
74 Feature (Filter) Visualization


75 Pooling In CNNs, Conv layers are often followed by Pool layers Pooling layer: makes the representations smaller and more manageable without losing too much information Increased receptive field Most common: MAX pooling Others: average, L2 pooling
76 Improving Generalization Weight sharing (Reduce the number of parameters) Data augmentation (e.g., jittering, noise injection, tranformations) Dropout [Hinton et al.]: randomly drop units (along with their connections) from the neural network during training. Use for the fully connected layers only Regularization: Weight decay (L2, L1) Sparsity in the hidden units Multi-task learning Transfer learning
 from the neural network during")
77 Improving Generalization Dropout [Hinton et al.]: randomly drop units (along with their connections) from the neural network during training. Use for the fully connected layers only

78 Optimality Common knowledge: for non-convex problems, training does not work because we get stuck to local minima
79 Optimality Common knowledge: for non-convex problems, training does not work because we get stuck to local minima Not true!!! If the size of the network is large enough, local descent can reach a global minimizer from any initialization Haeffele, Vidal. Global Optimality in Tensor Factorization, Deep Learning and Beyond, arxiv 15
![ConvNets Typical ConvNet: Image [Conv - ReLU]](/docs-images/90/103240377/images/80-2.jpg "(Pool) [Conv - ReLU] (Pool) FC (fully-connected)")
80 ConvNets Typical ConvNet: Image [Conv - ReLU] (Pool) [Conv - ReLU] (Pool) FC (fully-connected) Softmax


81 ConvNets - Flavours Lenet5 (Yann Lecun 1998) Alexnet (Alex Krizhevsky et. al., 2012)
82 ConvNets - Flavours ZFnet: Clarifai (Matt Zeiler and Rob Fergus, 2013) Googlenet (Google, 2014)
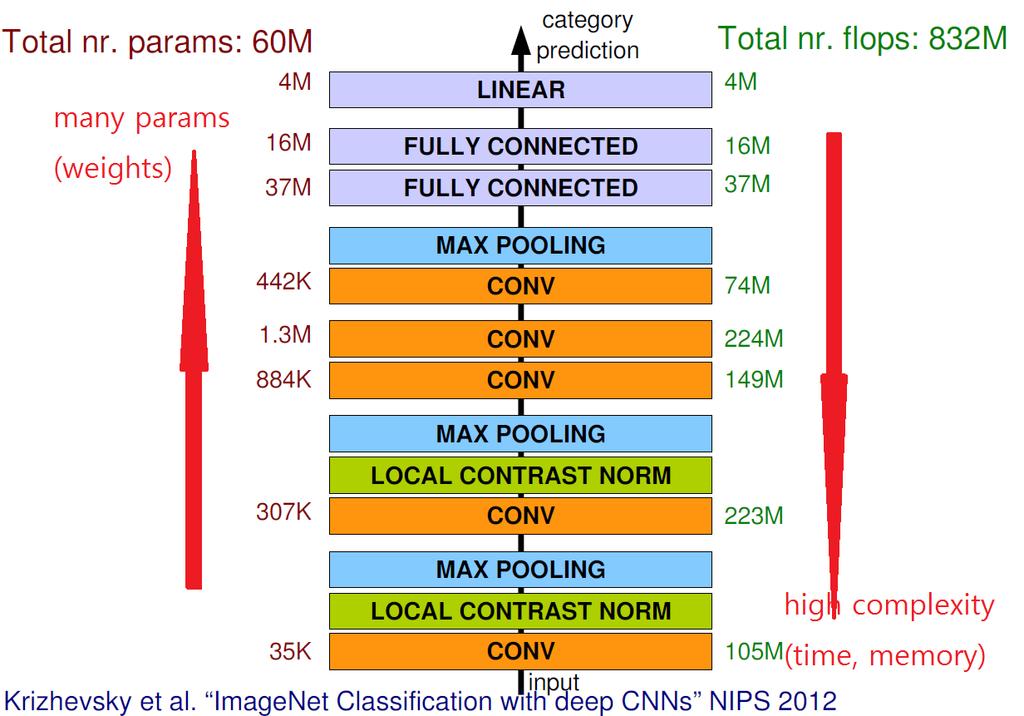
83 Complexity (Alexnet)
84 Recent Trend Human: 5.1% (Karpathy), Baidu cheating ( ) %
85 Recent Trend
86 Recent Trend
87 Conclusions Deep Learning = learning hierarhical models. ConvNets are the most successful example. Leverage large labeled datasets. Optimization Don t we get stuck in local minima? No, they are all the same! In large scale applications, local minima are even less of an issue. Scaling GPUs Distributed framework (Google) Better optimization techniques Generalization on small datasets (curse of dimensionality): data augmentation weight decay dropout unsupervised learning multi-task learning
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Neural Networks: A brief touch Yuejie Chi Department of Electrical and Computer Engineering Spring 2018 1/41 Outline
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Lecture 35: Optimization and Neural Nets
 Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
CS 1674: Intro to Computer Vision. Final Review. Prof. Adriana Kovashka University of Pittsburgh December 7, 2016
 CS 1674: Intro to Computer Vision Final Review Prof. Adriana Kovashka University of Pittsburgh December 7, 2016 Final info Format: multiple-choice, true/false, fill in the blank, short answers, apply an
CS 1674: Intro to Computer Vision Final Review Prof. Adriana Kovashka University of Pittsburgh December 7, 2016 Final info Format: multiple-choice, true/false, fill in the blank, short answers, apply an
Training Neural Networks Practical Issues
 Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)
: Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Neural Networks. Learning and Computer Vision Prof. Olga Veksler CS9840. Lecture 10
 CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard Outline Short Intro Perceptron ( layer NN) Multilayer
CS9840 Learning and Computer Vision Prof. Olga Veksler Lecture 0 Neural Networks Many slides are from Andrew NG, Yann LeCun, Geoffry Hinton, Abin - Roozgard Outline Short Intro Perceptron ( layer NN) Multilayer
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Machine Learning for Signal Processing Neural Networks Continue. Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016
 Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Lecture 7 Convolutional Neural Networks
 Lecture 7 Convolutional Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 17, 2017 We saw before: ŷ x 1 x 2 x 3 x 4 A series of matrix multiplications:
Lecture 7 Convolutional Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 17, 2017 We saw before: ŷ x 1 x 2 x 3 x 4 A series of matrix multiplications:
Introduction to Convolutional Neural Networks 2018 / 02 / 23
 Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Deep Feedforward Networks. Seung-Hoon Na Chonbuk National University
 Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Based on the original slides of Hung-yi Lee Google Trends Deep learning obtains many exciting results. Can contribute to new Smart Services in the Context of the Internet of Things (IoT). IoT Services
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Deep Learning (CNNs)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Convolutional Neural Networks. Srikumar Ramalingam
 Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN)
") EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN) TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent
EVERYTHING YOU NEED TO KNOW TO BUILD YOUR FIRST CONVOLUTIONAL NEURAL NETWORK (CNN) TARGETED PIECES OF KNOWLEDGE Linear regression Activation function Multi-Layers Perceptron (MLP) Stochastic Gradient Descent
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Maxout Networks. Hien Quoc Dang
 Maxout Networks Hien Quoc Dang Outline Introduction Maxout Networks Description A Universal Approximator & Proof Experiments with Maxout Why does Maxout work? Conclusion 10/12/13 Hien Quoc Dang Machine
Maxout Networks Hien Quoc Dang Outline Introduction Maxout Networks Description A Universal Approximator & Proof Experiments with Maxout Why does Maxout work? Conclusion 10/12/13 Hien Quoc Dang Machine
Convolutional Neural Network Architecture
 Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Bayesian Networks (Part I)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part I) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part I) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Introduction to (Convolutional) Neural Networks
 Neural Networks") Introduction to (Convolutional) Neural Networks Philipp Grohs Summer School DL and Vis, Sept 2018 Syllabus 1 Motivation and Definition 2 Universal Approximation 3 Backpropagation 4 Stochastic Gradient
Introduction to (Convolutional) Neural Networks Philipp Grohs Summer School DL and Vis, Sept 2018 Syllabus 1 Motivation and Definition 2 Universal Approximation 3 Backpropagation 4 Stochastic Gradient
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Artificial Neural Networks. Historical description
 Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
Artificial Neural Networks Historical description Victor G. Lopez 1 / 23 Artificial Neural Networks (ANN) An artificial neural network is a computational model that attempts to emulate the functions of
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Machine Learning (67577)
") Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Introduction to Machine Learning (67577) Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Deep Learning Shai Shalev-Shwartz (Hebrew U) IML Deep Learning Neural Networks
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Lecture 2: Learning with neural networks
 Lecture 2: Learning with neural networks Deep Learning @ UvA LEARNING WITH NEURAL NETWORKS - PAGE 1 Lecture Overview o Machine Learning Paradigm for Neural Networks o The Backpropagation algorithm for
Lecture 2: Learning with neural networks Deep Learning @ UvA LEARNING WITH NEURAL NETWORKS - PAGE 1 Lecture Overview o Machine Learning Paradigm for Neural Networks o The Backpropagation algorithm for
Machine Learning Lecture 14
 Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
arxiv: v1 [cs.cv] 11 May 2015 Abstract
![arxiv: v1 [cs.cv] 11 May 2015 Abstract](/thumbs/80/80674557.jpg "arxiv: v1 [cs.cv] 11 May 2015 Abstract") Training Deeper Convolutional Networks with Deep Supervision Liwei Wang Computer Science Dept UIUC lwang97@illinois.edu Chen-Yu Lee ECE Dept UCSD chl260@ucsd.edu Zhuowen Tu CogSci Dept UCSD ztu0@ucsd.edu
Training Deeper Convolutional Networks with Deep Supervision Liwei Wang Computer Science Dept UIUC lwang97@illinois.edu Chen-Yu Lee ECE Dept UCSD chl260@ucsd.edu Zhuowen Tu CogSci Dept UCSD ztu0@ucsd.edu
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
A summary of Deep Learning without Poor Local Minima
 A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Demystifying deep learning. Artificial Intelligence Group Department of Computer Science and Technology, University of Cambridge, UK
 Demystifying deep learning Petar Veličković Artificial Intelligence Group Department of Computer Science and Technology, University of Cambridge, UK London Data Science Summit 20 October 2017 Introduction
Demystifying deep learning Petar Veličković Artificial Intelligence Group Department of Computer Science and Technology, University of Cambridge, UK London Data Science Summit 20 October 2017 Introduction
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Backpropagation Introduction to Machine Learning. Matt Gormley Lecture 12 Feb 23, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
Deep Learning Lecture 2
 Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Fall 2016 Machine Learning CMPSCI 689 Deep Learning Lecture 2 Sridhar Mahadevan Autonomous Learning Lab UMass Amherst COLLEGE Outline of lecture New type of units Convolutional units, Rectified linear
Introduction to Deep Learning
 Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2015 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2015 1 / 39 Outline 1 Universality of Neural Networks
Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2015 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2015 1 / 39 Outline 1 Universality of Neural Networks
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
CS60010: Deep Learning
 CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
Deep Neural Networks
 Deep Neural Networks DT2118 Speech and Speaker Recognition Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 45 Outline State-to-Output Probability Model Artificial Neural Networks Perceptron Multi
Deep Neural Networks DT2118 Speech and Speaker Recognition Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 45 Outline State-to-Output Probability Model Artificial Neural Networks Perceptron Multi
Introduction Biologically Motivated Crude Model Backpropagation
 Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
Introduction Biologically Motivated Crude Model Backpropagation 1 McCulloch-Pitts Neurons In 1943 Warren S. McCulloch, a neuroscientist, and Walter Pitts, a logician, published A logical calculus of the
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
1 Machine Learning Concepts (16 points)
") CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
Understanding Neural Networks : Part I
 TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
TensorFlow Workshop 2018 Understanding Neural Networks Part I : Artificial Neurons and Network Optimization Nick Winovich Department of Mathematics Purdue University July 2018 Outline 1 Neural Networks
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Lecture given by Daniel Khashabi Slides were created
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Lecture given by Daniel Khashabi Slides were created
UNSUPERVISED LEARNING
 UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Feed-forward Networks Network Training Error Backpropagation Applications. Neural Networks. Oliver Schulte - CMPT 726. Bishop PRML Ch.
 Neural Networks Oliver Schulte - CMPT 726 Bishop PRML Ch. 5 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will
Neural Networks Oliver Schulte - CMPT 726 Bishop PRML Ch. 5 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will
Handwritten Indic Character Recognition using Capsule Networks
 Handwritten Indic Character Recognition using Capsule Networks Bodhisatwa Mandal,Suvam Dubey, Swarnendu Ghosh, RiteshSarkhel, Nibaran Das Dept. of CSE, Jadavpur University, Kolkata, 700032, WB, India.
Handwritten Indic Character Recognition using Capsule Networks Bodhisatwa Mandal,Suvam Dubey, Swarnendu Ghosh, RiteshSarkhel, Nibaran Das Dept. of CSE, Jadavpur University, Kolkata, 700032, WB, India.
DeepLearning on FPGAs
 DeepLearning on FPGAs Introduction to Deep Learning Sebastian Buschäger Technische Universität Dortmund - Fakultät Informatik - Lehrstuhl 8 October 21, 2017 1 Recap Computer Science Approach Technical
DeepLearning on FPGAs Introduction to Deep Learning Sebastian Buschäger Technische Universität Dortmund - Fakultät Informatik - Lehrstuhl 8 October 21, 2017 1 Recap Computer Science Approach Technical
Neural Networks Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav
 Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Neural Networks 30.11.2015 Lecturer: J. Matas Authors: J. Matas, B. Flach, O. Drbohlav 1 Talk Outline Perceptron Combining neurons to a network Neural network, processing input to an output Learning Cost
Machine Learning Lecture 12
 Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Neural Networks. Lecture 2. Rob Fergus
 Neural Networks Lecture 2 Rob Fergus Overview Individual neuron Non-linearities (RELU, tanh, sigmoid) Single layer model Multiple layer models Theoretical discussion: representational power Examples shown
Neural Networks Lecture 2 Rob Fergus Overview Individual neuron Non-linearities (RELU, tanh, sigmoid) Single layer model Multiple layer models Theoretical discussion: representational power Examples shown
Ch.6 Deep Feedforward Networks (2/3)
") Ch.6 Deep Feedforward Networks (2/3) 16. 10. 17. (Mon.) System Software Lab., Dept. of Mechanical & Information Eng. Woonggy Kim 1 Contents 6.3. Hidden Units 6.3.1. Rectified Linear Units and Their Generalizations
Ch.6 Deep Feedforward Networks (2/3) 16. 10. 17. (Mon.) System Software Lab., Dept. of Mechanical & Information Eng. Woonggy Kim 1 Contents 6.3. Hidden Units 6.3.1. Rectified Linear Units and Their Generalizations
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Deep Learning Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein, Pieter Abbeel, Anca Dragan for CS188 Intro to AI at UC Berkeley.
CS 343: Artificial Intelligence Deep Learning Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein, Pieter Abbeel, Anca Dragan for CS188 Intro to AI at UC Berkeley.
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ