Distirbutional robustness, regularizing variance, and adversaries
|
|
|
- Philip Roberts
- 5 years ago
- Views:
Transcription
1 Distirbutional robustness, regularizing variance, and adversaries John Duchi Based on joint work with Hongseok Namkoong and Aman Sinha Stanford University November 2017
2 Motivation We do not want machine-learned systems to fail when they get in the real world
3 Challenge one: Curly fries
4 Challenge one: Curly fries Who doesn t like curly fries?
5 Challenge two: changes in environment Learning to drive in California
6 Challenge two: changes in environment Learning to drive in California Driving in Ann Arbor
7 Challenge three: adversaries [Goodfellow et al. 15]
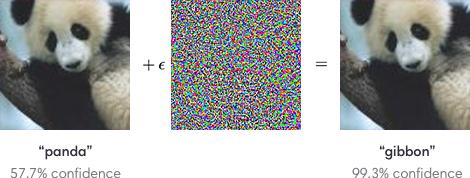
8 Challenge three: adversaries [Goodfellow et al. 15] Paraphrased Quote: We could put a transparent film on a stop sign, essentially imperceptible to a human, and a computer would see the stop sign as air (Dan Boneh)
9 Stochastic optimization problems minimize R(θ) := E P0 [l(θ; Z)] = l(θ; z)dp 0 (z) subject to θ Θ. Empirical risk minimization: Often, solve θ n = argmin θ Θ R n (θ) := 1 n n l(θ; Z i ) i=1
10 Stochastic optimization problems minimize R(θ) := E P0 [l(θ; Z)] = l(θ; z)dp 0 (z) subject to θ Θ. Data/randomness is Z Loss function θ l(θ; z) Parameter space Θ is a nonempty closed (convex) set Empirical risk minimization: Often, solve θ n = argmin θ Θ R n (θ) := 1 n n l(θ; Z i ) i=1
11 Stochastic optimization problems minimize R(θ) := E P0 [l(θ; Z)] = l(θ; z)dp 0 (z) subject to θ Θ. Data/randomness is Z Loss function θ l(θ; z) Parameter space Θ is a nonempty closed (convex) set iid Observe data Z i P0, i = 1,..., n Empirical risk minimization: Often, solve θ n = argmin θ Θ R n (θ) := 1 n n l(θ; Z i ) i=1
12 Distributional robustness R(θ) = E P0 [l(θ; Z)]
13 Distributional robustness R(θ, P) := sup E P [l(θ; Z)] P P
14 Distributional robustness R(θ, P) := sup E P [l(θ; Z)] P P Uncertainty set P is set of possible distributions/worlds Different choices of uncertainty yield different behaviors Some sample-based uncertainty sets P certify future performance
15 Distributional robustness R(θ, P) := sup E P [l(θ; Z)] P P Uncertainty set P is set of possible distributions/worlds Different choices of uncertainty yield different behaviors Some sample-based uncertainty sets P certify future performance Much work in optimization literature: [Delage & Ye 10, Ben-Tal et al. 13, Bertsimas et al. 14, Lam & Zhou 15, Gotoh et al. 15]
16 Distributional robustness R(θ, P) := sup E P [l(θ; Z)] P P Uncertainty set P is set of possible distributions/worlds Different choices of uncertainty yield different behaviors Some sample-based uncertainty sets P certify future performance Much work in optimization literature: [Delage & Ye 10, Ben-Tal et al. 13, Bertsimas et al. 14, Lam & Zhou 15, Gotoh et al. 15] Rest of this talk: Two vignettes showing some aspects of this approach
17 Vignette one: regularization by variance
18 Vignette one: regularization by variance Any learning algorithm has bias (approximation error) and variance (estimation error)
19 Vignette one: regularization by variance Any learning algorithm has bias (approximation error) and variance (estimation error) From empirical Bernstein s inequality, with probability 1 δ 2Var Pn (l(θ; X)) R(θ) R n (θ) + }{{} bias } n {{ } variance + C log 1 δ n
20 Vignette one: regularization by variance Any learning algorithm has bias (approximation error) and variance (estimation error) From empirical Bernstein s inequality, with probability 1 δ 2Var Pn (l(θ; X)) R(θ) R n (θ) + }{{} bias } n {{ } variance + C log 1 δ n Goal: Trade between these automatically and optimally by solving θ var argmin θ Θ R 2Var n (θ) + Pn (l(θ; X)) n.
21 Optimizing for bias and variance Good idea: Directly minimize bias + variance, certify optimality!
22 Optimizing for bias and variance Good idea: Directly minimize bias + variance, certify optimality! Minor issue: variance is wildly non-convex Figure: Variance of l(θ, X) = θ X
23 Robust ERM Goal: minimize θ Θ R(θ) = E P0 [l(θ; X)]
24 Robust ERM Goal: minimize θ Θ Solve empirical risk minimization problem R(θ) = E P0 [l(θ; X)] minimize θ Θ n i=1 1 n l(θ; X i)
25 Robust ERM Goal: minimize θ Θ R(θ) = E P0 [l(θ; X)] Solve sample average optimization problem minimize θ Θ n i=1 1 n l(θ; X i)
26 Robust ERM Goal: minimize θ Θ R(θ) = E P0 [l(θ; X)] Instead, solve distributionally robust optimization (RO) problem minimize θ Θ sup p P n,ρ n p i l(θ; X i ) i=1 where P n,ρ is some appropriately chosen set of vectors
27 Robust ERM Goal: minimize θ Θ R(θ) = E P0 [l(θ; X)] Instead, solve distributionally robust optimization (RO) problem minimize θ Θ sup p P n,ρ n p i l(θ; X i ) i=1 where P n,ρ is some appropriately chosen set of vectors This bit of talk: Give a principled statistical approach to choosing P n,ρ and give stochastic optimality certificates for RO.
28 Empirical likelihood and robustness Idea: Optimize over uncertainty set of possible distributions, { P n,ρ := Distributions P such that D(P P n ) ρ } n for some ρ > 0, where D(P Q) = (p/q 1) 2 q
29 Empirical likelihood and robustness Idea: Optimize over uncertainty set of possible distributions, { P n,ρ := Distributions P such that D(P P n ) ρ } n for some ρ > 0, where D(P Q) = (p/q 1) 2 q Define (and optimize) empirical likelihood upper confidence bound R n (θ, P n,ρ ) := max P P n,ρ E P [l(θ, X)] = max p P n,ρ n p i l(θ, X i ) i=1
30 Empirical likelihood and robustness Idea: Optimize over uncertainty set of possible distributions, { P n,ρ := Distributions P such that D(P P n ) ρ } n for some ρ > 0, where D(P Q) = (p/q 1) 2 q Define (and optimize) empirical likelihood upper confidence bound R n (θ, P n,ρ ) := max P P n,ρ E P [l(θ, X)] = max p P n,ρ Nice properties: Convex optimization problem n p i l(θ, X i ) i=1 Efficient solution methods [D. & Namkoong NIPS 16]
31 Robust Optimization = Variance Regularization Theorem (D. & Namkoong) Assume that l is bounded over the space of decision vectors θ. Then R n (θ; P n,ρ ) = R 2ρVar n (θ) + Pn (l(θ; X)) + O(ρ/n). n
32 Robust Optimization = Variance Regularization Theorem (D. & Namkoong) Assume that l is bounded over the space of decision vectors θ. Then R n (θ; P n,ρ ) = R 2ρVar n (θ) + Pn (l(θ; X)) + O(ρ/n). n Choose θ rob to minimize robust empirical risk R n (θ, P n,ρ ) := max P P n,ρ E P [l(θ, X)] = max p P n,ρ n p i l(θ, X i ). i=1
33 Optimal bias variance tradeoff Choose θ rob to minimize robust empirical risk { R n ( θ rob, P n,ρ ) = min max E P [l(θ; X)] : D χ θ Θ P P 2 (P P ) n ρ }. n n
34 Optimal bias variance tradeoff Choose θ rob to minimize robust empirical risk { R n ( θ rob, P n,ρ ) = min max E P [l(θ; X)] : D χ θ Θ P P 2 (P P ) n ρ }. n n Assume that Θ R d compact with radius R and l(θ; X) is M-Lipschitz.
35 Optimal bias variance tradeoff Choose θ rob to minimize robust empirical risk { R n ( θ rob, P n,ρ ) = min max E P [l(θ; X)] : D χ θ Θ P P 2 (P P ) n ρ }. n n Assume that Θ R d compact with radius R and l(θ; X) is M-Lipschitz. Theorem (D. & Namkoong 17) Let ρ = log 1 δ + d log n. Then with probability at least 1 δ, R( θ rob ) R n ( θ rob, P n,ρ ) }{{} optimality certificate + cmr n ρ { } 2ρVar(l(θ, ξ)) min R(θ) cmr θ Θ n n ρ }{{} optimal tradeoff for some universal constant c > 0.
36 Experiment: Reuters Corpus (multi-label) Problem: Classify documents as a subset of the 4 categories: { } Corporate, Economics, Government, Markets
37 Experiment: Reuters Corpus (multi-label) Problem: Classify documents as a subset of the 4 categories: { } Corporate, Economics, Government, Markets Data: pairs x R d represents document, y { 1, 1} 4 where y j = 1 indicating x belongs j-th category.
38 Experiment: Reuters Corpus (multi-label) Problem: Classify documents as a subset of the 4 categories: { } Corporate, Economics, Government, Markets Data: pairs x R d represents document, y { 1, 1} 4 where y j = 1 indicating x belongs j-th category. Loss l(θ j, (x, y)) = log(1 + e yx θ j ) for each j = 1,..., 4 and Θ = { θ R d : θ }.
39 Experiment: Reuters Corpus (multi-label) Problem: Classify documents as a subset of the 4 categories: { } Corporate, Economics, Government, Markets Data: pairs x R d represents document, y { 1, 1} 4 where y j = 1 indicating x belongs j-th category. Loss l(θ j, (x, y)) = log(1 + e yx θ j ) for each j = 1,..., 4 and Θ = { θ R d : θ }. d = 47, 236, n = 804, fold cross-validation.
40 Experiment: Reuters Corpus (multi-label) Problem: Classify documents as a subset of the 4 categories: { } Corporate, Economics, Government, Markets Data: pairs x R d represents document, y { 1, 1} 4 where y j = 1 indicating x belongs j-th category. Loss l(θ j, (x, y)) = log(1 + e yx θ j ) for each j = 1,..., 4 and Θ = { θ R d : θ }. d = 47, 236, n = 804, fold cross-validation. Table: Reuters Number of Examples Corporate Economics Government Markets 381, , , ,820
41 Experiment: Reuters Corpus (multi-label) Table: Reuters Corpus (%) Precision Recall Corporate Economics ρ train test train test train test train test erm
42 Experiment: Reuters Corpus (multi-label) Figure: Recall on rare category (Economics) train test 0.78 Recall (Economics) ERM ρ
43 Experiment: Reuters Corpus (multi-label) Figure: Average logistic risk and confidence bound risk train risk test robust train Risk ERM ρ
44 Vignette two: Wasserstein robustness We do not want machine-learned systems to fail when they get in the real world
45 Vignette two: Wasserstein robustness We do not want machine-learned systems to fail when they get in the real world It is irresponsible to release systems into the world whose robustness we do not understand
46 Challenges
47 A type of robustess Robust optimization: instead of l, look at robust loss l ɛ (θ; z) := sup l(θ; z + ) ɛ
48 A type of robustess Robust optimization: instead of l, look at robust loss l ɛ (θ; z) := sup l(θ; z + ) ɛ Adversarial attacks and defenses with heuristics and more advanced ideas [Goodfellow et al. 15, Jia and Liang 17, Papernot et al. 16, Madry et al. 17]
49 A type of robustess Robust optimization: instead of l, look at robust loss l ɛ (θ; z) := sup l(θ; z + ) ɛ Adversarial attacks and defenses with heuristics and more advanced ideas [Goodfellow et al. 15, Jia and Liang 17, Papernot et al. 16, Madry et al. 17] Minor issue: Usually this is NP-hard Further issue: In neural network, f θ (x) = θ T 1 σ relu (θ T 2 σ relu ( )) and is is NP-hard to compute sup l(f θ (x + ))
50 Distributional robustness Question: How can we figure out how to change distribution right way to get robustness?
51 Distributional robustness Question: How can we figure out how to change distribution right way to get robustness? Let c : Z Z R + be some cost function, and define Wasserstein distance W c (P, Q) := inf c(z 1, z 2 )dm(z 1, z 2 ) M { } = sup f(z)(dp (z) dq(z)) f(x) f(z) c(x, z) f where M has P and Q as its marginal distributions
52 Wasserstein robustness Look at distributionally robust risk R(θ, P) := sup {E P [l(θ; Z)] P P} P
53 Wasserstein robustness Look at distributionally robust risk defined for ρ 0 R(θ, ρ) := sup {E P [l(θ; Z)] s.t. W c (P, P 0 ) ρ} P
54 Wasserstein robustness Look at distributionally robust risk defined for ρ 0 R(θ, ρ) := sup {E P [l(θ; Z)] s.t. W c (P, P 0 ) ρ} P Allows changing support to harder distributions Studied in robust optimization literature [Shafieezadeh-Abadeh et al. 15, Esfahani & Kuhn 15, Blanchet and Murthy 16] Minor issue: Often still NP-hard
55 A first idea (Simple) insight: If l(θ, z) is smooth in θ and z, then life gets a bit easier
56 A first idea (Simple) insight: If l(θ, z) is smooth in θ and z, then life gets a bit easier The function { l λ (θ; z) := sup l(θ; z + ) λ } is efficient to compute (and differentiable, etc.) for large enough λ
57 Duality and robustness Theorem (D., Namkoong, Sinha) Let P 0 be any distribution on Z and c : Z Z R + be any function. Then { { sup E P [l(θ; Z)] = inf sup l(θ; z ) λc(z, z) } } dp 0 (z) + λρ W c(p,p 0 ) ρ λ 0 z = inf λ 0 {E P 0 [l λ (θ; Z)] + λρ}.
58 Duality and robustness Theorem (D., Namkoong, Sinha) Let P 0 be any distribution on Z and c : Z Z R + be any function. Then { { sup E P [l(θ; Z)] = inf sup l(θ; z ) λc(z, z) } } dp 0 (z) + λρ W c(p,p 0 ) ρ λ 0 z = inf λ 0 {E P 0 [l λ (θ; Z)] + λρ}. Idea: Ignore that infimum, pick a large enough λ, and solve minimize θ E P0 [l λ (θ; Z)]
59 Stochastic gradient algorithm Repeat: minimize θ 1. Draw Z k iid P { E P0 [l λ (θ; Z)] = E P0 [sup l(θ; Z + ) λ }] Compute (approximate) maximizer 3. Update where α k is a stepsize Ẑ k argmax z { l(θ; z) λ 2 z Z k 2 2 θ k+1 := θ k α k θ l(θ k ; Ẑk) }
60 Stochastic gradient algorithm Repeat: minimize θ 1. Draw Z k iid P { E P0 [l λ (θ; Z)] = E P0 [sup l(θ; Z + ) λ }] Compute (approximate) maximizer 3. Update where α k is a stepsize Ẑ k argmax z { l(θ; z) λ 2 z Z k 2 2 θ k+1 := θ k α k θ l(θ k ; Ẑk) Theorem(ish): This converges with all the typical convergence properties }
61 A certificate of robustness A desiderata: We would like to certify that any learned θ has robustness properties
62 A certificate of robustness A desiderata: We would like to certify that any learned θ has robustness properties Theorem (D., Namkoong, Sinha 17) With high probability, for all θ Θ and uniformly in ρ, 1 n n i=1 { sup l(θ; Z i + ) λ } λρ sup {E P [l(θ; Z)]} O(1) P :W (P,P 0 ) ρ n
63 A certificate of robustness A desiderata: We would like to certify that any learned θ has robustness properties Theorem (D., Namkoong, Sinha 17) With high probability, for all θ Θ 1 n n i=1 { sup l(θ; Z i + ) λ } λŵ (θ) sup {E P [l(θ; Z)]} O(1) P :W (P,P 0 ) Ŵ n (θ) Empirical estimate: get an approximate divergence Ŵ (θ) := 1 2n n Ẑi(θ) Z i (θ) i=1 where Ẑi = argmax z {l(θ; z) λ 2 z Z i 2 2 } 2 2
64 Digging into neural networks Typically predict with f θ (x) = θ 1 σ relu (θ 2 σ relu ( )) where σ relu (t) = min{1, (t) + }
65 Digging into neural networks Typically predict with f θ (x) = θ 1 σ relu (θ 2 σ relu ( )) where σ relu (t) = min{1, (t) + } Replace σ relu with (t) 2 + 2ɛ if t ɛ σ smooth (t) = t + ɛ 2 if ɛ t 1 ɛ (1 t)2 + 2ɛ + 1 if t t ɛ

66 Simple Visualization y = sign( x 2 2)
67 Experimental results: adversarial classification MNIST dataset with 3 convolutional layers, fully connected softmax top layer
68 Experimental results: adversarial classification MNIST dataset with 3 convolutional layers, fully connected softmax top layer

69 Reading tea leaves
70 Reinforcement learning?
71 References H. Namkoong and J. C. Duchi. Stochastic gradient methods for distributionally robust optimization with f-divergences. In Advances in Neural Information Processing Systems 29, 2016 H. Namkoong and J. C. Duchi. Variance regularization with convex objectives. In Advances in Neural Information Processing Systems 30, 2017 A. Sinha, H. Namkoong, and J. C. Duchi. Certifiable distributional robustness with principled adversarial training. arxiv: [stat.ml], 2017
Optimal Transport Methods in Operations Research and Statistics
 Optimal Transport Methods in Operations Research and Statistics Jose Blanchet (based on work with F. He, Y. Kang, K. Murthy, F. Zhang). Stanford University (Management Science and Engineering), and Columbia
Optimal Transport Methods in Operations Research and Statistics Jose Blanchet (based on work with F. He, Y. Kang, K. Murthy, F. Zhang). Stanford University (Management Science and Engineering), and Columbia
Distributionally Robust Stochastic Optimization with Wasserstein Distance
 Distributionally Robust Stochastic Optimization with Wasserstein Distance Rui Gao DOS Seminar, Oct 2016 Joint work with Anton Kleywegt School of Industrial and Systems Engineering Georgia Tech What is
Distributionally Robust Stochastic Optimization with Wasserstein Distance Rui Gao DOS Seminar, Oct 2016 Joint work with Anton Kleywegt School of Industrial and Systems Engineering Georgia Tech What is
Machine Learning Basics Lecture 2: Linear Classification. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 2: Linear Classification Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d.
Machine Learning Basics Lecture 2: Linear Classification Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d.
arxiv: v4 [stat.ml] 1 May 2018
![arxiv: v4 [stat.ml] 1 May 2018](/thumbs/86/93345979.jpg "arxiv: v4 [stat.ml] 1 May 2018") Certifying Some Distributional Robustness with Principled Adversarial Training arxiv:1710.10571v4 [stat.ml] 1 May 2018 Aman Sinha *1 Hongseok Namkoong 2 John C. Duchi 1,3 Departments of 1 Electrical Engineering,
Certifying Some Distributional Robustness with Principled Adversarial Training arxiv:1710.10571v4 [stat.ml] 1 May 2018 Aman Sinha *1 Hongseok Namkoong 2 John C. Duchi 1,3 Departments of 1 Electrical Engineering,
Optimal Transport in Risk Analysis
 Optimal Transport in Risk Analysis Jose Blanchet (based on work with Y. Kang and K. Murthy) Stanford University (Management Science and Engineering), and Columbia University (Department of Statistics and
Optimal Transport in Risk Analysis Jose Blanchet (based on work with Y. Kang and K. Murthy) Stanford University (Management Science and Engineering), and Columbia University (Department of Statistics and
Class 2 & 3 Overfitting & Regularization
 Class 2 & 3 Overfitting & Regularization Carlo Ciliberto Department of Computer Science, UCL October 18, 2017 Last Class The goal of Statistical Learning Theory is to find a good estimator f n : X Y, approximating
Class 2 & 3 Overfitting & Regularization Carlo Ciliberto Department of Computer Science, UCL October 18, 2017 Last Class The goal of Statistical Learning Theory is to find a good estimator f n : X Y, approximating
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Importance Reweighting Using Adversarial-Collaborative Training
 Importance Reweighting Using Adversarial-Collaborative Training Yifan Wu yw4@andrew.cmu.edu Tianshu Ren tren@andrew.cmu.edu Lidan Mu lmu@andrew.cmu.edu Abstract We consider the problem of reweighting a
Importance Reweighting Using Adversarial-Collaborative Training Yifan Wu yw4@andrew.cmu.edu Tianshu Ren tren@andrew.cmu.edu Lidan Mu lmu@andrew.cmu.edu Abstract We consider the problem of reweighting a
Machine Learning. Linear Models. Fabio Vandin October 10, 2017
 Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Statistical Approaches to Learning and Discovery. Week 4: Decision Theory and Risk Minimization. February 3, 2003
 Statistical Approaches to Learning and Discovery Week 4: Decision Theory and Risk Minimization February 3, 2003 Recall From Last Time Bayesian expected loss is ρ(π, a) = E π [L(θ, a)] = L(θ, a) df π (θ)
Statistical Approaches to Learning and Discovery Week 4: Decision Theory and Risk Minimization February 3, 2003 Recall From Last Time Bayesian expected loss is ρ(π, a) = E π [L(θ, a)] = L(θ, a) df π (θ)
Machine Learning Basics Lecture 4: SVM I. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Qualifying Exam in Machine Learning
 Qualifying Exam in Machine Learning October 20, 2009 Instructions: Answer two out of the three questions in Part 1. In addition, answer two out of three questions in two additional parts (choose two parts
Qualifying Exam in Machine Learning October 20, 2009 Instructions: Answer two out of the three questions in Part 1. In addition, answer two out of three questions in two additional parts (choose two parts
Reward-modulated inference
 Buck Shlegeris Matthew Alger COMP3740, 2014 Outline Supervised, unsupervised, and reinforcement learning Neural nets RMI Results with RMI Types of machine learning supervised unsupervised reinforcement
Buck Shlegeris Matthew Alger COMP3740, 2014 Outline Supervised, unsupervised, and reinforcement learning Neural nets RMI Results with RMI Types of machine learning supervised unsupervised reinforcement
CS229 Supplemental Lecture notes
 CS229 Supplemental Lecture notes John Duchi Binary classification In binary classification problems, the target y can take on at only two values. In this set of notes, we show how to model this problem
CS229 Supplemental Lecture notes John Duchi Binary classification In binary classification problems, the target y can take on at only two values. In this set of notes, we show how to model this problem
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Machine Learning And Applications: Supervised Learning-SVM
 Machine Learning And Applications: Supervised Learning-SVM Raphaël Bournhonesque École Normale Supérieure de Lyon, Lyon, France raphael.bournhonesque@ens-lyon.fr 1 Supervised vs unsupervised learning Machine
Machine Learning And Applications: Supervised Learning-SVM Raphaël Bournhonesque École Normale Supérieure de Lyon, Lyon, France raphael.bournhonesque@ens-lyon.fr 1 Supervised vs unsupervised learning Machine
Generalization theory
 Generalization theory Daniel Hsu Columbia TRIPODS Bootcamp 1 Motivation 2 Support vector machines X = R d, Y = { 1, +1}. Return solution ŵ R d to following optimization problem: λ min w R d 2 w 2 2 + 1
Generalization theory Daniel Hsu Columbia TRIPODS Bootcamp 1 Motivation 2 Support vector machines X = R d, Y = { 1, +1}. Return solution ŵ R d to following optimization problem: λ min w R d 2 w 2 2 + 1
Lecture 2: Statistical Decision Theory (Part I)
") Lecture 2: Statistical Decision Theory (Part I) Hao Helen Zhang Hao Helen Zhang Lecture 2: Statistical Decision Theory (Part I) 1 / 35 Outline of This Note Part I: Statistics Decision Theory (from Statistical
Lecture 2: Statistical Decision Theory (Part I) Hao Helen Zhang Hao Helen Zhang Lecture 2: Statistical Decision Theory (Part I) 1 / 35 Outline of This Note Part I: Statistics Decision Theory (from Statistical
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Information theoretic perspectives on learning algorithms
 Information theoretic perspectives on learning algorithms Varun Jog University of Wisconsin - Madison Departments of ECE and Mathematics Shannon Channel Hangout! May 8, 2018 Jointly with Adrian Tovar-Lopez
Information theoretic perspectives on learning algorithms Varun Jog University of Wisconsin - Madison Departments of ECE and Mathematics Shannon Channel Hangout! May 8, 2018 Jointly with Adrian Tovar-Lopez
Does Distributionally Robust Supervised Learning Give Robust Classifiers?
 Weihua Hu 2 Gang Niu 2 Issei Sato 2 Masashi Sugiyama 2 Abstract Distributionally Robust Supervised Learning (DRSL) is necessary for building reliable machine learning systems. When machine learning is
Weihua Hu 2 Gang Niu 2 Issei Sato 2 Masashi Sugiyama 2 Abstract Distributionally Robust Supervised Learning (DRSL) is necessary for building reliable machine learning systems. When machine learning is
Lecture 3 January 28
 EECS 28B / STAT 24B: Advanced Topics in Statistical LearningSpring 2009 Lecture 3 January 28 Lecturer: Pradeep Ravikumar Scribe: Timothy J. Wheeler Note: These lecture notes are still rough, and have only
EECS 28B / STAT 24B: Advanced Topics in Statistical LearningSpring 2009 Lecture 3 January 28 Lecturer: Pradeep Ravikumar Scribe: Timothy J. Wheeler Note: These lecture notes are still rough, and have only
Empirical Risk Minimization
 Empirical Risk Minimization Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Introduction PAC learning ERM in practice 2 General setting Data X the input space and Y the output space
Empirical Risk Minimization Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Introduction PAC learning ERM in practice 2 General setting Data X the input space and Y the output space
Nishant Gurnani. GAN Reading Group. April 14th, / 107
 Nishant Gurnani GAN Reading Group April 14th, 2017 1 / 107 Why are these Papers Important? 2 / 107 Why are these Papers Important? Recently a large number of GAN frameworks have been proposed - BGAN, LSGAN,
Nishant Gurnani GAN Reading Group April 14th, 2017 1 / 107 Why are these Papers Important? 2 / 107 Why are these Papers Important? Recently a large number of GAN frameworks have been proposed - BGAN, LSGAN,
Stochastic optimization in Hilbert spaces
 Stochastic optimization in Hilbert spaces Aymeric Dieuleveut Aymeric Dieuleveut Stochastic optimization Hilbert spaces 1 / 48 Outline Learning vs Statistics Aymeric Dieuleveut Stochastic optimization Hilbert
Stochastic optimization in Hilbert spaces Aymeric Dieuleveut Aymeric Dieuleveut Stochastic optimization Hilbert spaces 1 / 48 Outline Learning vs Statistics Aymeric Dieuleveut Stochastic optimization Hilbert
Quantifying Stochastic Model Errors via Robust Optimization
 Quantifying Stochastic Model Errors via Robust Optimization IPAM Workshop on Uncertainty Quantification for Multiscale Stochastic Systems and Applications Jan 19, 2016 Henry Lam Industrial & Operations
Quantifying Stochastic Model Errors via Robust Optimization IPAM Workshop on Uncertainty Quantification for Multiscale Stochastic Systems and Applications Jan 19, 2016 Henry Lam Industrial & Operations
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning
 SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistics 300B Winter 2018 Final Exam Due 24 Hours after receiving it
 Statistics 300B Winter 08 Final Exam Due 4 Hours after receiving it Directions: This test is open book and open internet, but must be done without consulting other students. Any consultation of other students
Statistics 300B Winter 08 Final Exam Due 4 Hours after receiving it Directions: This test is open book and open internet, but must be done without consulting other students. Any consultation of other students
Day 5: Generative models, structured classification
 Day 5: Generative models, structured classification Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 22 June 2018 Linear regression
Day 5: Generative models, structured classification Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 22 June 2018 Linear regression
Computational and Statistical Learning Theory
 Computational and Statistical Learning Theory TTIC 31120 Prof. Nati Srebro Lecture 17: Stochastic Optimization Part II: Realizable vs Agnostic Rates Part III: Nearest Neighbor Classification Stochastic
Computational and Statistical Learning Theory TTIC 31120 Prof. Nati Srebro Lecture 17: Stochastic Optimization Part II: Realizable vs Agnostic Rates Part III: Nearest Neighbor Classification Stochastic
Provable Non-Convex Min-Max Optimization
 Provable Non-Convex Min-Max Optimization Mingrui Liu, Hassan Rafique, Qihang Lin, Tianbao Yang Department of Computer Science, The University of Iowa, Iowa City, IA, 52242 Department of Mathematics, The
Provable Non-Convex Min-Max Optimization Mingrui Liu, Hassan Rafique, Qihang Lin, Tianbao Yang Department of Computer Science, The University of Iowa, Iowa City, IA, 52242 Department of Mathematics, The
Lecture 35: December The fundamental statistical distances
 36-705: Intermediate Statistics Fall 207 Lecturer: Siva Balakrishnan Lecture 35: December 4 Today we will discuss distances and metrics between distributions that are useful in statistics. I will be lose
36-705: Intermediate Statistics Fall 207 Lecturer: Siva Balakrishnan Lecture 35: December 4 Today we will discuss distances and metrics between distributions that are useful in statistics. I will be lose
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Variations of Logistic Regression with Stochastic Gradient Descent
 Variations of Logistic Regression with Stochastic Gradient Descent Panqu Wang(pawang@ucsd.edu) Phuc Xuan Nguyen(pxn002@ucsd.edu) January 26, 2012 Abstract In this paper, we extend the traditional logistic
Variations of Logistic Regression with Stochastic Gradient Descent Panqu Wang(pawang@ucsd.edu) Phuc Xuan Nguyen(pxn002@ucsd.edu) January 26, 2012 Abstract In this paper, we extend the traditional logistic
Logistic Regression Trained with Different Loss Functions. Discussion
 Logistic Regression Trained with Different Loss Functions Discussion CS640 Notations We restrict our discussions to the binary case. g(z) = g (z) = g(z) z h w (x) = g(wx) = + e z = g(z)( g(z)) + e wx =
Logistic Regression Trained with Different Loss Functions Discussion CS640 Notations We restrict our discussions to the binary case. g(z) = g (z) = g(z) z h w (x) = g(wx) = + e z = g(z)( g(z)) + e wx =
Robustness in GANs and in Black-box Optimization
 Robustness in GANs and in Black-box Optimization Stefanie Jegelka MIT CSAIL joint work with Zhi Xu, Chengtao Li, Ilija Bogunovic, Jonathan Scarlett and Volkan Cevher Robustness in ML noise Generator Critic
Robustness in GANs and in Black-box Optimization Stefanie Jegelka MIT CSAIL joint work with Zhi Xu, Chengtao Li, Ilija Bogunovic, Jonathan Scarlett and Volkan Cevher Robustness in ML noise Generator Critic
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Algorithmic Stability and Generalization Christoph Lampert
 Algorithmic Stability and Generalization Christoph Lampert November 28, 2018 1 / 32 IST Austria (Institute of Science and Technology Austria) institute for basic research opened in 2009 located in outskirts
Algorithmic Stability and Generalization Christoph Lampert November 28, 2018 1 / 32 IST Austria (Institute of Science and Technology Austria) institute for basic research opened in 2009 located in outskirts
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Selected Topics in Optimization. Some slides borrowed from
 Selected Topics in Optimization Some slides borrowed from http://www.stat.cmu.edu/~ryantibs/convexopt/ Overview Optimization problems are almost everywhere in statistics and machine learning. Input Model
Selected Topics in Optimization Some slides borrowed from http://www.stat.cmu.edu/~ryantibs/convexopt/ Overview Optimization problems are almost everywhere in statistics and machine learning. Input Model
Chapter ML:II (continued)
") Chapter ML:II (continued) II. Machine Learning Basics Regression Concept Learning: Search in Hypothesis Space Concept Learning: Search in Version Space Measuring Performance ML:II-96 Basics STEIN/LETTMANN
Chapter ML:II (continued) II. Machine Learning Basics Regression Concept Learning: Search in Hypothesis Space Concept Learning: Search in Version Space Measuring Performance ML:II-96 Basics STEIN/LETTMANN
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Midterm exam CS 189/289, Fall 2015
 Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Machine Learning Basics Lecture 7: Multiclass Classification. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 7: Multiclass Classification Princeton University COS 495 Instructor: Yingyu Liang Example: image classification indoor Indoor outdoor Example: image classification (multiclass)
Machine Learning Basics Lecture 7: Multiclass Classification Princeton University COS 495 Instructor: Yingyu Liang Example: image classification indoor Indoor outdoor Example: image classification (multiclass)
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 8 Feb. 12, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
Probabilistic Graphical Models & Applications
 Probabilistic Graphical Models & Applications Learning of Graphical Models Bjoern Andres and Bernt Schiele Max Planck Institute for Informatics The slides of today s lecture are authored by and shown with
Probabilistic Graphical Models & Applications Learning of Graphical Models Bjoern Andres and Bernt Schiele Max Planck Institute for Informatics The slides of today s lecture are authored by and shown with
Lecture 4: Training a Classifier
 Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
1 Machine Learning Concepts (16 points)
") CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
Introduction to Logistic Regression and Support Vector Machine
 Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron
 CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
Introduction to Machine Learning. Lecture 2
 Introduction to Machine Learning Lecturer: Eran Halperin Lecture 2 Fall Semester Scribe: Yishay Mansour Some of the material was not presented in class (and is marked with a side line) and is given for
Introduction to Machine Learning Lecturer: Eran Halperin Lecture 2 Fall Semester Scribe: Yishay Mansour Some of the material was not presented in class (and is marked with a side line) and is given for
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Dan Roth 461C, 3401 Walnut
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
Statistical Machine Learning Hilary Term 2018
 Statistical Machine Learning Hilary Term 2018 Pier Francesco Palamara Department of Statistics University of Oxford Slide credits and other course material can be found at: http://www.stats.ox.ac.uk/~palamara/sml18.html
Statistical Machine Learning Hilary Term 2018 Pier Francesco Palamara Department of Statistics University of Oxford Slide credits and other course material can be found at: http://www.stats.ox.ac.uk/~palamara/sml18.html
Accelerating Stochastic Optimization
 Accelerating Stochastic Optimization Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem and Mobileye Master Class at Tel-Aviv, Tel-Aviv University, November 2014 Shalev-Shwartz
Accelerating Stochastic Optimization Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem and Mobileye Master Class at Tel-Aviv, Tel-Aviv University, November 2014 Shalev-Shwartz
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
CS229T/STATS231: Statistical Learning Theory. Lecturer: Tengyu Ma Lecture 11 Scribe: Jongho Kim, Jamie Kang October 29th, 2018
 CS229T/STATS231: Statistical Learning Theory Lecturer: Tengyu Ma Lecture 11 Scribe: Jongho Kim, Jamie Kang October 29th, 2018 1 Overview This lecture mainly covers Recall the statistical theory of GANs
CS229T/STATS231: Statistical Learning Theory Lecturer: Tengyu Ma Lecture 11 Scribe: Jongho Kim, Jamie Kang October 29th, 2018 1 Overview This lecture mainly covers Recall the statistical theory of GANs
Topics we covered. Machine Learning. Statistics. Optimization. Systems! Basics of probability Tail bounds Density Estimation Exponential Families
 Midterm Review Topics we covered Machine Learning Optimization Basics of optimization Convexity Unconstrained: GD, SGD Constrained: Lagrange, KKT Duality Linear Methods Perceptrons Support Vector Machines
Midterm Review Topics we covered Machine Learning Optimization Basics of optimization Convexity Unconstrained: GD, SGD Constrained: Lagrange, KKT Duality Linear Methods Perceptrons Support Vector Machines
Generalization, Overfitting, and Model Selection
 Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Distributionally Robust Convex Optimization
 Distributionally Robust Convex Optimization Wolfram Wiesemann 1, Daniel Kuhn 1, and Melvyn Sim 2 1 Department of Computing, Imperial College London, United Kingdom 2 Department of Decision Sciences, National
Distributionally Robust Convex Optimization Wolfram Wiesemann 1, Daniel Kuhn 1, and Melvyn Sim 2 1 Department of Computing, Imperial College London, United Kingdom 2 Department of Decision Sciences, National
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
An Introduction to Statistical Machine Learning - Theoretical Aspects -
 An Introduction to Statistical Machine Learning - Theoretical Aspects - Samy Bengio bengio@idiap.ch Dalle Molle Institute for Perceptual Artificial Intelligence (IDIAP) CP 592, rue du Simplon 4 1920 Martigny,
An Introduction to Statistical Machine Learning - Theoretical Aspects - Samy Bengio bengio@idiap.ch Dalle Molle Institute for Perceptual Artificial Intelligence (IDIAP) CP 592, rue du Simplon 4 1920 Martigny,
The connection of dropout and Bayesian statistics
 The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
Contents. 1 Introduction. 1.1 History of Optimization ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016
 ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016 LECTURERS: NAMAN AGARWAL AND BRIAN BULLINS SCRIBE: KIRAN VODRAHALLI Contents 1 Introduction 1 1.1 History of Optimization.....................................
ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016 LECTURERS: NAMAN AGARWAL AND BRIAN BULLINS SCRIBE: KIRAN VODRAHALLI Contents 1 Introduction 1 1.1 History of Optimization.....................................
Decision Tree Learning Lecture 2
 Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
I D I A P. Online Policy Adaptation for Ensemble Classifiers R E S E A R C H R E P O R T. Samy Bengio b. Christos Dimitrakakis a IDIAP RR 03-69
 R E S E A R C H R E P O R T Online Policy Adaptation for Ensemble Classifiers Christos Dimitrakakis a IDIAP RR 03-69 Samy Bengio b I D I A P December 2003 D a l l e M o l l e I n s t i t u t e for Perceptual
R E S E A R C H R E P O R T Online Policy Adaptation for Ensemble Classifiers Christos Dimitrakakis a IDIAP RR 03-69 Samy Bengio b I D I A P December 2003 D a l l e M o l l e I n s t i t u t e for Perceptual
Support Vector Machines. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Model Selection and Geometry
 Model Selection and Geometry Pascal Massart Université Paris-Sud, Orsay Leipzig, February Purpose of the talk! Concentration of measure plays a fundamental role in the theory of model selection! Model
Model Selection and Geometry Pascal Massart Université Paris-Sud, Orsay Leipzig, February Purpose of the talk! Concentration of measure plays a fundamental role in the theory of model selection! Model
Stochastic Optimization Algorithms Beyond SG
 Stochastic Optimization Algorithms Beyond SG Frank E. Curtis 1, Lehigh University involving joint work with Léon Bottou, Facebook AI Research Jorge Nocedal, Northwestern University Optimization Methods
Stochastic Optimization Algorithms Beyond SG Frank E. Curtis 1, Lehigh University involving joint work with Léon Bottou, Facebook AI Research Jorge Nocedal, Northwestern University Optimization Methods
Machine Learning 4771
 Machine Learning 477 Instructor: Tony Jebara Topic 5 Generalization Guarantees VC-Dimension Nearest Neighbor Classification (infinite VC dimension) Structural Risk Minimization Support Vector Machines
Machine Learning 477 Instructor: Tony Jebara Topic 5 Generalization Guarantees VC-Dimension Nearest Neighbor Classification (infinite VC dimension) Structural Risk Minimization Support Vector Machines
Deep Neural Networks: From Flat Minima to Numerically Nonvacuous Generalization Bounds via PAC-Bayes
 Deep Neural Networks: From Flat Minima to Numerically Nonvacuous Generalization Bounds via PAC-Bayes Daniel M. Roy University of Toronto; Vector Institute Joint work with Gintarė K. Džiugaitė University
Deep Neural Networks: From Flat Minima to Numerically Nonvacuous Generalization Bounds via PAC-Bayes Daniel M. Roy University of Toronto; Vector Institute Joint work with Gintarė K. Džiugaitė University
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Machine Learning. Regularization and Feature Selection. Fabio Vandin November 13, 2017
 Machine Learning Regularization and Feature Selection Fabio Vandin November 13, 2017 1 Learning Model A: learning algorithm for a machine learning task S: m i.i.d. pairs z i = (x i, y i ), i = 1,..., m,
Machine Learning Regularization and Feature Selection Fabio Vandin November 13, 2017 1 Learning Model A: learning algorithm for a machine learning task S: m i.i.d. pairs z i = (x i, y i ), i = 1,..., m,
Machine Learning. Regression-Based Classification & Gaussian Discriminant Analysis. Manfred Huber
 Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
Lecture 11. Linear Soft Margin Support Vector Machines
 CS142: Machine Learning Spring 2017 Lecture 11 Instructor: Pedro Felzenszwalb Scribes: Dan Xiang, Tyler Dae Devlin Linear Soft Margin Support Vector Machines We continue our discussion of linear soft margin
CS142: Machine Learning Spring 2017 Lecture 11 Instructor: Pedro Felzenszwalb Scribes: Dan Xiang, Tyler Dae Devlin Linear Soft Margin Support Vector Machines We continue our discussion of linear soft margin
Least Squares Regression
 E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 17. Bayesian inference; Bayesian regression Training == optimisation (?) Stages of learning & inference: Formulate model Regression
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 17. Bayesian inference; Bayesian regression Training == optimisation (?) Stages of learning & inference: Formulate model Regression
Understanding Generalization Error: Bounds and Decompositions
 CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
Linear Classifiers and the Perceptron
 Linear Classifiers and the Perceptron William Cohen February 4, 2008 1 Linear classifiers Let s assume that every instance is an n-dimensional vector of real numbers x R n, and there are only two possible
Linear Classifiers and the Perceptron William Cohen February 4, 2008 1 Linear classifiers Let s assume that every instance is an n-dimensional vector of real numbers x R n, and there are only two possible
CS60021: Scalable Data Mining. Large Scale Machine Learning
 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 CS60021: Scalable Data Mining Large Scale Machine Learning Sourangshu Bhattacharya Example: Spam filtering Instance
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 CS60021: Scalable Data Mining Large Scale Machine Learning Sourangshu Bhattacharya Example: Spam filtering Instance
Machine Learning Basics
 Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
From Binary to Multiclass Classification. CS 6961: Structured Prediction Spring 2018
 From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
COS513: FOUNDATIONS OF PROBABILISTIC MODELS LECTURE 9: LINEAR REGRESSION
 COS513: FOUNDATIONS OF PROBABILISTIC MODELS LECTURE 9: LINEAR REGRESSION SEAN GERRISH AND CHONG WANG 1. WAYS OF ORGANIZING MODELS In probabilistic modeling, there are several ways of organizing models:
COS513: FOUNDATIONS OF PROBABILISTIC MODELS LECTURE 9: LINEAR REGRESSION SEAN GERRISH AND CHONG WANG 1. WAYS OF ORGANIZING MODELS In probabilistic modeling, there are several ways of organizing models:
Neural Networks: Optimization & Regularization
 Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Linear Models in Machine Learning
 CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
Computational Oracle Inequalities for Large Scale Model Selection Problems
 for Large Scale Model Selection Problems University of California at Berkeley Queensland University of Technology ETH Zürich, September 2011 Joint work with Alekh Agarwal, John Duchi and Clément Levrard.
for Large Scale Model Selection Problems University of California at Berkeley Queensland University of Technology ETH Zürich, September 2011 Joint work with Alekh Agarwal, John Duchi and Clément Levrard.
Adversarially Robust Optimization and Generalization
 Adversarially Robust Optimization and Generalization Ludwig Schmidt MIT UC Berkeley Based on joint works with Logan ngstrom (MIT), Aleksander Madry (MIT), Aleksandar Makelov (MIT), Dimitris Tsipras (MIT),
Adversarially Robust Optimization and Generalization Ludwig Schmidt MIT UC Berkeley Based on joint works with Logan ngstrom (MIT), Aleksander Madry (MIT), Aleksandar Makelov (MIT), Dimitris Tsipras (MIT),