Multiclass Multilabel Classification with More Classes than Examples
|
|
|
- Barbara Patrick
- 5 years ago
- Views:
Transcription

1 Multiclass Multilabel Classification with More Classes than Examples Ohad Shamir Weizmann Institute of Science Joint work with Ofer Dekel, MSR NIPS 2015 Extreme Classification Workshop
2 Extreme Multiclass Multilabel Problems Label set is a folksonomy (a.k.a. collaborative tagging or social tagging)

3

4

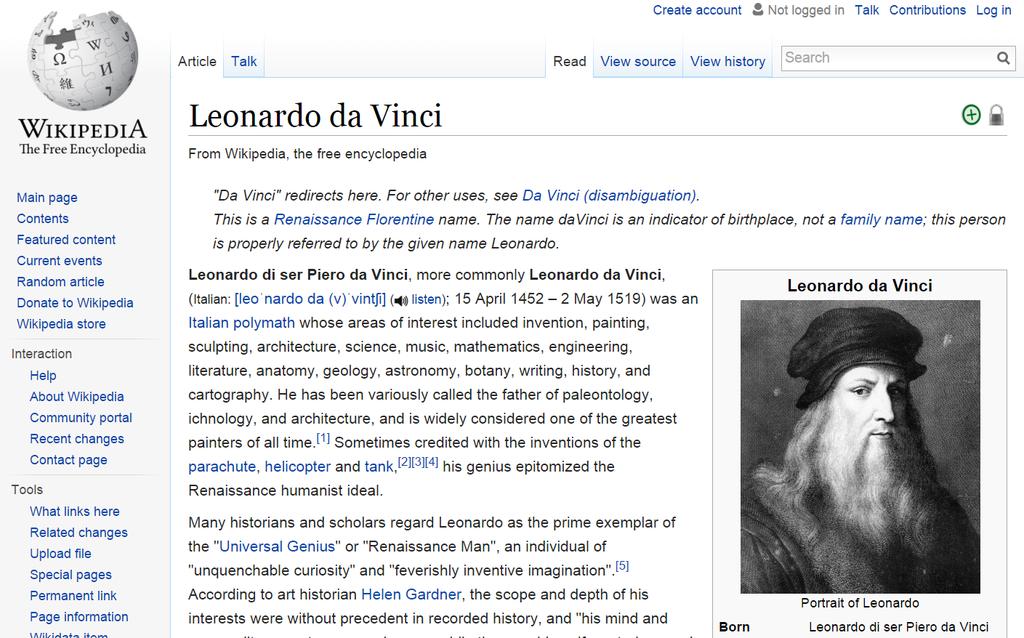
5 Categories 1452 births / 1519 deaths / 15 th century in science / ambassadors of the republic of Florence / Ballistic experts / Fabulists / giftedness / mathematics and culture / Italian inventors / Members of the Guild of Saint Luke / Tuscan painters / people persecuted under antihomosexuality laws...
6 Problem Definition Multiclass multilabel classification m training examples, k categories m, k together Possibly even k > m Goal: Categorize unseen instances
7 Extreme Multiclass Supervised learning starts with binary classification (k=2) and extends to multiclass learning Theory: VC dimension Natarajan dimension Algorithms: binary multiclass Usually, assume k = O 1 Some exceptions Hierarchy with prior knowledge on relationships not always available Additional assumptions (e.g. talk by Marius earlier)

 Labels: All Wikipedia")
8 Application Classify the web based on Wikipedia categories Training set: All Wikipedia pages (m = ) Labels: All Wikipedia categories (k = )
9 Challenges Statistical problem: Can t get a large (or even moderate) sample from each class. Computational problem: Many classification algorithms will choke on millions of labels
10 Propagating Labels on the Click-Graph queries web pages A bipartite graph derived from search engine logs: clicks encoded as weighted edges Wikipedia pages are labeled web pages Labels propagate along edges to other pages
11 Example da Vinci passes multiple labels to Among them Renaissance artists good 1452 births bad Observation: 1452 births induces many false-positives (FP): best to remove it altogether from classifier output (FP TN, TP FN)
12 Simple Label Pruning Approach 1. Split dataset to training and validation set 2. Use training set to build an initial classifier h pre (e.g. by propagating labels over click-graph) 3. Apply h pre to validation set, count FP and TP 4. j 1,, k, remove label j if FP j > 1 γ TP j γ Defines a new pruned classifier h post
13 Simple Label Pruning Approach Explicitly minimizes empirical risk with respect to the γ-weighted loss: k j=1 l h x, y = γ I h j x = 1, y j = γ I h j x = 0, y j = 1 FP (false positive) FN (false negative)
14 Main Question Would this actually reduce the risk? E x,y l h post x, y < E x,y l h pre x, y - positive
15 Baseline Approach Prove that uniformly for all labels j FP j TP j FP j TP j Pr(label j and not predicted) Pr(label j and predicted) Problem: m, k together. Many classes only have a handful of examples
16 Uniform Convergence Approach Algorithm implicitly chooses a hypothesis from a certain hypothesis class Pruning rules on top of fixed predictor h pre Prove uniform convergence by bounding VC dimension / Rademacher complexity Conclude that if empirical risk decreases, the risk decreases as well
17 Uniform Convergence Fails Unfortunately, no uniform convergence and even no algorithm/data-dependent convergence! k E R h post R h post Pr j pruned TP j FP j j=1 k = j=1 Pr FP j > TP j TP j FP j Weak correlation in m k regime
18 A Less Obvious Approach Prove directly that risk decreases Important (but mild) assumption: Each example labeled by s labels Step 1: Risk of h post is concentrated. For all ε, Pr R h post ER h post
19 A Less Obvious Approach Part 2: Enough to prove R h pre ER h post > 0 Assuming for γ = 1 2 for simplicity, can be shown that R h pre ER h post > pos O FP j + TP j j 1/2 m where w 1/2 = j w j 2
20 A Less Obvious Approach For probability vector, Part 2: Enough to prove R h pre always ER at most h post k > 0 FP j TP j Assuming for γ = 1 for simplicity, Smaller can the be shown more nonuniform is the distribution that 2 R h pre ER h post j:fp j TP j > pos O FP j + TP j j 1/2 m where w 1/2 = j w j 2
21 Wikipedia Power-Law: r = 1.6
22 Wikipedia Power-Law: r = 1.6 R h pre ER h post > pos O k 0.4 m
23 Experiment Click graph on the entire web (based on search engine logs)



24 Experiment Categories from Wikipedia pages propagated twice through graph




25 Experiment Train/test split of Wikipedia pages How good are propagated categories from training set in predicting categories at test set pages?
26 Experiment
27 Another less obvious approach = = k j=1 k j=1 R h pre ER h post Pr j pruned FP j TP j Pr FP j > TP j FP j TP j Weak but positive correlation, even if only few examples per label For large k, sum will tend to be positive
28 Different Application: Crowdsourcing (Dekel and S., 2009)

29 Different Application: Crowdsourcing (Dekel and S., 2009)

30 Different Application: Crowdsourcing (Dekel and S., 2009)

31 Different Application: Crowdsourcing (Dekel and S., 2009)
32 Different Application: Crowdsourcing How can we improve crowdsourced data? Standard approach: Repeated labeling, but expensive A bootstrap approach: Learn predictor from data of all workers Throw away examples labeled by workers disagreeing a lot with the predictor Re-train on remaining examples Works! (Under certain assumptions) Challenge: Workers often labels only a handful of examples
33 Different Application: Crowdsourcing # examples/worker might be small, but many workers...
34 Different Application: Crowdsourcing # examples/worker might be small, but many workers...
35 Different Application: Crowdsourcing # examples/worker might be small, but many workers...
36 Conclusions # classes violates assumptions of most multiclass analyses Often based on generalizations of binary classification Possible approach Avoid standard analysis Extreme X can be a blessing rather than a curse Other applications? More complex learning algorithms (e.g. substitution)?
37 Thanks!
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION
 SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
Classification, Linear Models, Naïve Bayes
 Classification, Linear Models, Naïve Bayes CMSC 470 Marine Carpuat Slides credit: Dan Jurafsky & James Martin, Jacob Eisenstein Today Text classification problems and their evaluation Linear classifiers
Classification, Linear Models, Naïve Bayes CMSC 470 Marine Carpuat Slides credit: Dan Jurafsky & James Martin, Jacob Eisenstein Today Text classification problems and their evaluation Linear classifiers
Generalization, Overfitting, and Model Selection
 Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Introduction and Models
 CSE522, Winter 2011, Learning Theory Lecture 1 and 2-01/04/2011, 01/06/2011 Lecturer: Ofer Dekel Introduction and Models Scribe: Jessica Chang Machine learning algorithms have emerged as the dominant and
CSE522, Winter 2011, Learning Theory Lecture 1 and 2-01/04/2011, 01/06/2011 Lecturer: Ofer Dekel Introduction and Models Scribe: Jessica Chang Machine learning algorithms have emerged as the dominant and
Evaluation. Andrea Passerini Machine Learning. Evaluation
 Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
Deconstructing Data Science
 Deconstructing Data Science David Bamman, UC Berkeley Info 290 Lecture 3: Classification overview Jan 24, 2017 Auditors Send me an email to get access to bcourses (announcements, readings, etc.) Classification
Deconstructing Data Science David Bamman, UC Berkeley Info 290 Lecture 3: Classification overview Jan 24, 2017 Auditors Send me an email to get access to bcourses (announcements, readings, etc.) Classification
Evaluation requires to define performance measures to be optimized
 Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
Hypothesis Evaluation
 Hypothesis Evaluation Machine Learning Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Hypothesis Evaluation Fall 1395 1 / 31 Table of contents 1 Introduction
Hypothesis Evaluation Machine Learning Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Hypothesis Evaluation Fall 1395 1 / 31 Table of contents 1 Introduction
Generalization and Overfitting
 Generalization and Overfitting Model Selection Maria-Florina (Nina) Balcan February 24th, 2016 PAC/SLT models for Supervised Learning Data Source Distribution D on X Learning Algorithm Expert / Oracle
Generalization and Overfitting Model Selection Maria-Florina (Nina) Balcan February 24th, 2016 PAC/SLT models for Supervised Learning Data Source Distribution D on X Learning Algorithm Expert / Oracle
Generalization, Overfitting, and Model Selection
 Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification MariaFlorina (Nina) Balcan 10/05/2016 Reminders Midterm Exam Mon, Oct. 10th Midterm Review Session
Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification MariaFlorina (Nina) Balcan 10/05/2016 Reminders Midterm Exam Mon, Oct. 10th Midterm Review Session
Model Accuracy Measures
 Model Accuracy Measures Master in Bioinformatics UPF 2017-2018 Eduardo Eyras Computational Genomics Pompeu Fabra University - ICREA Barcelona, Spain Variables What we can measure (attributes) Hypotheses
Model Accuracy Measures Master in Bioinformatics UPF 2017-2018 Eduardo Eyras Computational Genomics Pompeu Fabra University - ICREA Barcelona, Spain Variables What we can measure (attributes) Hypotheses
Ensemble Methods. NLP ML Web! Fall 2013! Andrew Rosenberg! TA/Grader: David Guy Brizan
 Ensemble Methods NLP ML Web! Fall 2013! Andrew Rosenberg! TA/Grader: David Guy Brizan How do you make a decision? What do you want for lunch today?! What did you have last night?! What are your favorite
Ensemble Methods NLP ML Web! Fall 2013! Andrew Rosenberg! TA/Grader: David Guy Brizan How do you make a decision? What do you want for lunch today?! What did you have last night?! What are your favorite
A first model of learning
 A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) We observe the data where each Suppose we are given an ensemble of possible hypotheses / classifiers
A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) We observe the data where each Suppose we are given an ensemble of possible hypotheses / classifiers
Does Unlabeled Data Help?
 Does Unlabeled Data Help? Worst-case Analysis of the Sample Complexity of Semi-supervised Learning. Ben-David, Lu and Pal; COLT, 2008. Presentation by Ashish Rastogi Courant Machine Learning Seminar. Outline
Does Unlabeled Data Help? Worst-case Analysis of the Sample Complexity of Semi-supervised Learning. Ben-David, Lu and Pal; COLT, 2008. Presentation by Ashish Rastogi Courant Machine Learning Seminar. Outline
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Least Squares Classification
 Least Squares Classification Stephen Boyd EE103 Stanford University November 4, 2017 Outline Classification Least squares classification Multi-class classifiers Classification 2 Classification data fitting
Least Squares Classification Stephen Boyd EE103 Stanford University November 4, 2017 Outline Classification Least squares classification Multi-class classifiers Classification 2 Classification data fitting
Methods and Criteria for Model Selection. CS57300 Data Mining Fall Instructor: Bruno Ribeiro
 Methods and Criteria for Model Selection CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Introduce classifier evaluation criteria } Introduce Bias x Variance duality } Model Assessment }
Methods and Criteria for Model Selection CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Introduce classifier evaluation criteria } Introduce Bias x Variance duality } Model Assessment }
Large-Margin Thresholded Ensembles for Ordinal Regression
 Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin (accepted by ALT 06, joint work with Ling Li) Learning Systems Group, Caltech Workshop Talk in MLSS 2006, Taipei, Taiwan, 07/25/2006
Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin (accepted by ALT 06, joint work with Ling Li) Learning Systems Group, Caltech Workshop Talk in MLSS 2006, Taipei, Taiwan, 07/25/2006
Class 4: Classification. Quaid Morris February 11 th, 2011 ML4Bio
 Class 4: Classification Quaid Morris February 11 th, 211 ML4Bio Overview Basic concepts in classification: overfitting, cross-validation, evaluation. Linear Discriminant Analysis and Quadratic Discriminant
Class 4: Classification Quaid Morris February 11 th, 211 ML4Bio Overview Basic concepts in classification: overfitting, cross-validation, evaluation. Linear Discriminant Analysis and Quadratic Discriminant
PAC Learning Introduction to Machine Learning. Matt Gormley Lecture 14 March 5, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University PAC Learning Matt Gormley Lecture 14 March 5, 2018 1 ML Big Picture Learning Paradigms:
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University PAC Learning Matt Gormley Lecture 14 March 5, 2018 1 ML Big Picture Learning Paradigms:
Information, Learning and Falsification
 Information, Learning and Falsification David Balduzzi December 17, 2011 Max Planck Institute for Intelligent Systems Tübingen, Germany Three main theories of information: Algorithmic information. Description.
Information, Learning and Falsification David Balduzzi December 17, 2011 Max Planck Institute for Intelligent Systems Tübingen, Germany Three main theories of information: Algorithmic information. Description.
The Naïve Bayes Classifier. Machine Learning Fall 2017
 The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy. Denny Zhou Qiang Liu John Platt Chris Meek
 Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy Denny Zhou Qiang Liu John Platt Chris Meek 2 Crowds vs experts labeling: strength Time saving Money saving Big labeled data More data
Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy Denny Zhou Qiang Liu John Platt Chris Meek 2 Crowds vs experts labeling: strength Time saving Money saving Big labeled data More data
Machine Learning. Linear Models. Fabio Vandin October 10, 2017
 Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
PAC-Bayesian Learning and Domain Adaptation
 PAC-Bayesian Learning and Domain Adaptation Pascal Germain 1 François Laviolette 1 Amaury Habrard 2 Emilie Morvant 3 1 GRAAL Machine Learning Research Group Département d informatique et de génie logiciel
PAC-Bayesian Learning and Domain Adaptation Pascal Germain 1 François Laviolette 1 Amaury Habrard 2 Emilie Morvant 3 1 GRAAL Machine Learning Research Group Département d informatique et de génie logiciel
Improving Quality of Crowdsourced Labels via Probabilistic Matrix Factorization
 Human Computation AAAI Technical Report WS-12-08 Improving Quality of Crowdsourced Labels via Probabilistic Matrix Factorization Hyun Joon Jung School of Information University of Texas at Austin hyunjoon@utexas.edu
Human Computation AAAI Technical Report WS-12-08 Improving Quality of Crowdsourced Labels via Probabilistic Matrix Factorization Hyun Joon Jung School of Information University of Texas at Austin hyunjoon@utexas.edu
Support Vector Machines.
 Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Decision Support. Dr. Johan Hagelbäck.
 Decision Support Dr. Johan Hagelbäck johan.hagelback@lnu.se http://aiguy.org Decision Support One of the earliest AI problems was decision support The first solution to this problem was expert systems
Decision Support Dr. Johan Hagelbäck johan.hagelback@lnu.se http://aiguy.org Decision Support One of the earliest AI problems was decision support The first solution to this problem was expert systems
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Modern Methods of Statistical Learning sf2935 Lecture 5: Logistic Regression T.K
 Lecture 5: Logistic Regression T.K. 10.11.2016 Overview of the Lecture Your Learning Outcomes Discriminative v.s. Generative Odds, Odds Ratio, Logit function, Logistic function Logistic regression definition
Lecture 5: Logistic Regression T.K. 10.11.2016 Overview of the Lecture Your Learning Outcomes Discriminative v.s. Generative Odds, Odds Ratio, Logit function, Logistic function Logistic regression definition
Linear Classifiers IV
 Universität Potsdam Institut für Informatik Lehrstuhl Linear Classifiers IV Blaine Nelson, Tobias Scheffer Contents Classification Problem Bayesian Classifier Decision Linear Classifiers, MAP Models Logistic
Universität Potsdam Institut für Informatik Lehrstuhl Linear Classifiers IV Blaine Nelson, Tobias Scheffer Contents Classification Problem Bayesian Classifier Decision Linear Classifiers, MAP Models Logistic
Machine Learning for Structured Prediction
 Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Notes on the framework of Ando and Zhang (2005) 1 Beyond learning good functions: learning good spaces
 1 Beyond learning good functions: learning good spaces") Notes on the framework of Ando and Zhang (2005 Karl Stratos 1 Beyond learning good functions: learning good spaces 1.1 A single binary classification problem Let X denote the problem domain. Suppose we
Notes on the framework of Ando and Zhang (2005 Karl Stratos 1 Beyond learning good functions: learning good spaces 1.1 A single binary classification problem Let X denote the problem domain. Suppose we
IFT Lecture 7 Elements of statistical learning theory
 IFT 6085 - Lecture 7 Elements of statistical learning theory This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s): Brady Neal and
IFT 6085 - Lecture 7 Elements of statistical learning theory This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s): Brady Neal and
Pointwise Exact Bootstrap Distributions of Cost Curves
 Pointwise Exact Bootstrap Distributions of Cost Curves Charles Dugas and David Gadoury University of Montréal 25th ICML Helsinki July 2008 Dugas, Gadoury (U Montréal) Cost curves July 8, 2008 1 / 24 Outline
Pointwise Exact Bootstrap Distributions of Cost Curves Charles Dugas and David Gadoury University of Montréal 25th ICML Helsinki July 2008 Dugas, Gadoury (U Montréal) Cost curves July 8, 2008 1 / 24 Outline
Foundations of Machine Learning
 Introduction to ML Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu page 1 Logistics Prerequisites: basics in linear algebra, probability, and analysis of algorithms. Workload: about
Introduction to ML Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu page 1 Logistics Prerequisites: basics in linear algebra, probability, and analysis of algorithms. Workload: about
Intro. ANN & Fuzzy Systems. Lecture 15. Pattern Classification (I): Statistical Formulation
: Statistical Formulation") Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH
 HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH Hoang Trang 1, Tran Hoang Loc 1 1 Ho Chi Minh City University of Technology-VNU HCM, Ho Chi
HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH Hoang Trang 1, Tran Hoang Loc 1 1 Ho Chi Minh City University of Technology-VNU HCM, Ho Chi
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Performance Evaluation and Comparison
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Cross Validation and Resampling 3 Interval Estimation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Cross Validation and Resampling 3 Interval Estimation
Bagging. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL 8.7
 Bagging Ryan Tibshirani Data Mining: 36-462/36-662 April 23 2013 Optional reading: ISL 8.2, ESL 8.7 1 Reminder: classification trees Our task is to predict the class label y {1,... K} given a feature vector
Bagging Ryan Tibshirani Data Mining: 36-462/36-662 April 23 2013 Optional reading: ISL 8.2, ESL 8.7 1 Reminder: classification trees Our task is to predict the class label y {1,... K} given a feature vector
Final Exam, Machine Learning, Spring 2009
 Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Incentive Compatible Regression Learning
 Incentive Compatible Regression Learning Ofer Dekel 1 Felix Fischer 2 Ariel D. Procaccia 1 1 School of Computer Science and Engineering The Hebrew University of Jerusalem 2 Institut für Informatik Ludwig-Maximilians-Universität
Incentive Compatible Regression Learning Ofer Dekel 1 Felix Fischer 2 Ariel D. Procaccia 1 1 School of Computer Science and Engineering The Hebrew University of Jerusalem 2 Institut für Informatik Ludwig-Maximilians-Universität
CptS 570 Machine Learning School of EECS Washington State University. CptS Machine Learning 1
 CptS 570 Machine Learning School of EECS Washington State University CptS 570 - Machine Learning 1 IEEE Expert, October 1996 CptS 570 - Machine Learning 2 Given sample S from all possible examples D Learner
CptS 570 Machine Learning School of EECS Washington State University CptS 570 - Machine Learning 1 IEEE Expert, October 1996 CptS 570 - Machine Learning 2 Given sample S from all possible examples D Learner
EECS 349:Machine Learning Bryan Pardo
 EECS 349:Machine Learning Bryan Pardo Topic 2: Decision Trees (Includes content provided by: Russel & Norvig, D. Downie, P. Domingos) 1 General Learning Task There is a set of possible examples Each example
EECS 349:Machine Learning Bryan Pardo Topic 2: Decision Trees (Includes content provided by: Russel & Norvig, D. Downie, P. Domingos) 1 General Learning Task There is a set of possible examples Each example
Machine Learning Basics Lecture 7: Multiclass Classification. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 7: Multiclass Classification Princeton University COS 495 Instructor: Yingyu Liang Example: image classification indoor Indoor outdoor Example: image classification (multiclass)
Machine Learning Basics Lecture 7: Multiclass Classification Princeton University COS 495 Instructor: Yingyu Liang Example: image classification indoor Indoor outdoor Example: image classification (multiclass)
Introduction to Supervised Learning. Performance Evaluation
 Introduction to Supervised Learning Performance Evaluation Marcelo S. Lauretto Escola de Artes, Ciências e Humanidades, Universidade de São Paulo marcelolauretto@usp.br Lima - Peru Performance Evaluation
Introduction to Supervised Learning Performance Evaluation Marcelo S. Lauretto Escola de Artes, Ciências e Humanidades, Universidade de São Paulo marcelolauretto@usp.br Lima - Peru Performance Evaluation
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Machine Learning. Linear Models. Fabio Vandin October 10, 2017
 Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Surrogate regret bounds for generalized classification performance metrics
 Surrogate regret bounds for generalized classification performance metrics Wojciech Kotłowski Krzysztof Dembczyński Poznań University of Technology PL-SIGML, Częstochowa, 14.04.2016 1 / 36 Motivation 2
Surrogate regret bounds for generalized classification performance metrics Wojciech Kotłowski Krzysztof Dembczyński Poznań University of Technology PL-SIGML, Częstochowa, 14.04.2016 1 / 36 Motivation 2
Learning from the Wisdom of Crowds by Minimax Entropy. Denny Zhou, John Platt, Sumit Basu and Yi Mao Microsoft Research, Redmond, WA
 Learning from the Wisdom of Crowds by Minimax Entropy Denny Zhou, John Platt, Sumit Basu and Yi Mao Microsoft Research, Redmond, WA Outline 1. Introduction 2. Minimax entropy principle 3. Future work and
Learning from the Wisdom of Crowds by Minimax Entropy Denny Zhou, John Platt, Sumit Basu and Yi Mao Microsoft Research, Redmond, WA Outline 1. Introduction 2. Minimax entropy principle 3. Future work and
day month year documentname/initials 1
 ECE471-571 Pattern Recognition Lecture 13 Decision Tree Hairong Qi, Gonzalez Family Professor Electrical Engineering and Computer Science University of Tennessee, Knoxville http://www.eecs.utk.edu/faculty/qi
ECE471-571 Pattern Recognition Lecture 13 Decision Tree Hairong Qi, Gonzalez Family Professor Electrical Engineering and Computer Science University of Tennessee, Knoxville http://www.eecs.utk.edu/faculty/qi
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 3 We are given a set of training examples, consisting of input-output pairs (x,y), where: 1. x is an item of the type we want to evaluate. 2. y is the value of some
Jeffrey D. Ullman Stanford University 3 We are given a set of training examples, consisting of input-output pairs (x,y), where: 1. x is an item of the type we want to evaluate. 2. y is the value of some
Online Passive-Aggressive Algorithms. Tirgul 11
 Online Passive-Aggressive Algorithms Tirgul 11 Multi-Label Classification 2 Multilabel Problem: Example Mapping Apps to smart folders: Assign an installed app to one or more folders Candy Crush Saga 3
Online Passive-Aggressive Algorithms Tirgul 11 Multi-Label Classification 2 Multilabel Problem: Example Mapping Apps to smart folders: Assign an installed app to one or more folders Candy Crush Saga 3
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Active learning. Sanjoy Dasgupta. University of California, San Diego
 Active learning Sanjoy Dasgupta University of California, San Diego Exploiting unlabeled data A lot of unlabeled data is plentiful and cheap, eg. documents off the web speech samples images and video But
Active learning Sanjoy Dasgupta University of California, San Diego Exploiting unlabeled data A lot of unlabeled data is plentiful and cheap, eg. documents off the web speech samples images and video But
Learning Theory. Machine Learning CSE546 Carlos Guestrin University of Washington. November 25, Carlos Guestrin
 Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
CS434a/541a: Pattern Recognition Prof. Olga Veksler. Lecture 3
 CS434a/541a: attern Recognition rof. Olga Veksler Lecture 3 1 Announcements Link to error data in the book Reading assignment Assignment 1 handed out, due Oct. 4 lease send me an email with your name and
CS434a/541a: attern Recognition rof. Olga Veksler Lecture 3 1 Announcements Link to error data in the book Reading assignment Assignment 1 handed out, due Oct. 4 lease send me an email with your name and
Classification of Ordinal Data Using Neural Networks
 Classification of Ordinal Data Using Neural Networks Joaquim Pinto da Costa and Jaime S. Cardoso 2 Faculdade Ciências Universidade Porto, Porto, Portugal jpcosta@fc.up.pt 2 Faculdade Engenharia Universidade
Classification of Ordinal Data Using Neural Networks Joaquim Pinto da Costa and Jaime S. Cardoso 2 Faculdade Ciências Universidade Porto, Porto, Portugal jpcosta@fc.up.pt 2 Faculdade Engenharia Universidade
Models, Data, Learning Problems
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Models, Data, Learning Problems Tobias Scheffer Overview Types of learning problems: Supervised Learning (Classification, Regression,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Models, Data, Learning Problems Tobias Scheffer Overview Types of learning problems: Supervised Learning (Classification, Regression,
Regret Analysis for Performance Metrics in Multi-Label Classification The Case of Hamming and Subset Zero-One Loss
 Regret Analysis for Performance Metrics in Multi-Label Classification The Case of Hamming and Subset Zero-One Loss Krzysztof Dembczyński 1, Willem Waegeman 2, Weiwei Cheng 1, and Eyke Hüllermeier 1 1 Knowledge
Regret Analysis for Performance Metrics in Multi-Label Classification The Case of Hamming and Subset Zero-One Loss Krzysztof Dembczyński 1, Willem Waegeman 2, Weiwei Cheng 1, and Eyke Hüllermeier 1 1 Knowledge
Performance Evaluation
 Performance Evaluation David S. Rosenberg Bloomberg ML EDU October 26, 2017 David S. Rosenberg (Bloomberg ML EDU) October 26, 2017 1 / 36 Baseline Models David S. Rosenberg (Bloomberg ML EDU) October 26,
Performance Evaluation David S. Rosenberg Bloomberg ML EDU October 26, 2017 David S. Rosenberg (Bloomberg ML EDU) October 26, 2017 1 / 36 Baseline Models David S. Rosenberg (Bloomberg ML EDU) October 26,
Classifier performance evaluation
 Classifier performance evaluation Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics 166 36 Prague 6, Jugoslávských partyzánu 1580/3, Czech Republic
Classifier performance evaluation Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics 166 36 Prague 6, Jugoslávských partyzánu 1580/3, Czech Republic
Bias Correction in Classification Tree Construction ICML 2001
 Bias Correction in Classification Tree Construction ICML 21 Alin Dobra Johannes Gehrke Department of Computer Science Cornell University December 15, 21 Classification Tree Construction Outlook Temp. Humidity
Bias Correction in Classification Tree Construction ICML 21 Alin Dobra Johannes Gehrke Department of Computer Science Cornell University December 15, 21 Classification Tree Construction Outlook Temp. Humidity
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 23. Decision Trees Barnabás Póczos Contents Decision Trees: Definition + Motivation Algorithm for Learning Decision Trees Entropy, Mutual Information, Information
Introduction to Machine Learning CMU-10701 23. Decision Trees Barnabás Póczos Contents Decision Trees: Definition + Motivation Algorithm for Learning Decision Trees Entropy, Mutual Information, Information
Domain-Adversarial Neural Networks
 Domain-Adversarial Neural Networks Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand Département d informatique et de génie logiciel, Université Laval, Québec, Canada Département
Domain-Adversarial Neural Networks Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand Département d informatique et de génie logiciel, Université Laval, Québec, Canada Département
CLASSIFICATION NAIVE BAYES. NIKOLA MILIKIĆ UROŠ KRČADINAC
 CLASSIFICATION NAIVE BAYES NIKOLA MILIKIĆ nikola.milikic@fon.bg.ac.rs UROŠ KRČADINAC uros@krcadinac.com WHAT IS CLASSIFICATION? A supervised learning task of determining the class of an instance; it is
CLASSIFICATION NAIVE BAYES NIKOLA MILIKIĆ nikola.milikic@fon.bg.ac.rs UROŠ KRČADINAC uros@krcadinac.com WHAT IS CLASSIFICATION? A supervised learning task of determining the class of an instance; it is
More Smoothing, Tuning, and Evaluation
 More Smoothing, Tuning, and Evaluation Nathan Schneider (slides adapted from Henry Thompson, Alex Lascarides, Chris Dyer, Noah Smith, et al.) ENLP 21 September 2016 1 Review: 2 Naïve Bayes Classifier w
More Smoothing, Tuning, and Evaluation Nathan Schneider (slides adapted from Henry Thompson, Alex Lascarides, Chris Dyer, Noah Smith, et al.) ENLP 21 September 2016 1 Review: 2 Naïve Bayes Classifier w
6.867 Machine learning: lecture 2. Tommi S. Jaakkola MIT CSAIL
 6.867 Machine learning: lecture 2 Tommi S. Jaakkola MIT CSAIL tommi@csail.mit.edu Topics The learning problem hypothesis class, estimation algorithm loss and estimation criterion sampling, empirical and
6.867 Machine learning: lecture 2 Tommi S. Jaakkola MIT CSAIL tommi@csail.mit.edu Topics The learning problem hypothesis class, estimation algorithm loss and estimation criterion sampling, empirical and
Given a feature in I 1, how to find the best match in I 2?
 Feature Matching 1 Feature matching Given a feature in I 1, how to find the best match in I 2? 1. Define distance function that compares two descriptors 2. Test all the features in I 2, find the one with
Feature Matching 1 Feature matching Given a feature in I 1, how to find the best match in I 2? 1. Define distance function that compares two descriptors 2. Test all the features in I 2, find the one with
Stephen Scott.
 1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
Large-Margin Thresholded Ensembles for Ordinal Regression
 Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin and Ling Li Learning Systems Group, California Institute of Technology, U.S.A. Conf. on Algorithmic Learning Theory, October 9,
Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin and Ling Li Learning Systems Group, California Institute of Technology, U.S.A. Conf. on Algorithmic Learning Theory, October 9,
Recap from previous lecture
 Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Performance Metrics for Machine Learning. Sargur N. Srihari
 Performance Metrics for Machine Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Performance Metrics 2. Default Baseline Models 3. Determining whether to gather more data 4. Selecting hyperparamaters
Performance Metrics for Machine Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Performance Metrics 2. Default Baseline Models 3. Determining whether to gather more data 4. Selecting hyperparamaters
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
COMP9444: Neural Networks. Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization
 : Neural Networks Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization 11s2 VC-dimension and PAC-learning 1 How good a classifier does a learner produce? Training error is the precentage
: Neural Networks Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization 11s2 VC-dimension and PAC-learning 1 How good a classifier does a learner produce? Training error is the precentage
Part of the slides are adapted from Ziko Kolter
 Part of the slides are adapted from Ziko Kolter OUTLINE 1 Supervised learning: classification........................................................ 2 2 Non-linear regression/classification, overfitting,
Part of the slides are adapted from Ziko Kolter OUTLINE 1 Supervised learning: classification........................................................ 2 2 Non-linear regression/classification, overfitting,
Bayesian Decision Theory
 Introduction to Pattern Recognition [ Part 4 ] Mahdi Vasighi Remarks It is quite common to assume that the data in each class are adequately described by a Gaussian distribution. Bayesian classifier is
Introduction to Pattern Recognition [ Part 4 ] Mahdi Vasighi Remarks It is quite common to assume that the data in each class are adequately described by a Gaussian distribution. Bayesian classifier is
Decision Tree Learning Lecture 2
 Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Decision trees COMS 4771
 Decision trees COMS 4771 1. Prediction functions (again) Learning prediction functions IID model for supervised learning: (X 1, Y 1),..., (X n, Y n), (X, Y ) are iid random pairs (i.e., labeled examples).
Decision trees COMS 4771 1. Prediction functions (again) Learning prediction functions IID model for supervised learning: (X 1, Y 1),..., (X n, Y n), (X, Y ) are iid random pairs (i.e., labeled examples).
Binary Classification, Multi-label Classification and Ranking: A Decision-theoretic Approach
 Binary Classification, Multi-label Classification and Ranking: A Decision-theoretic Approach Krzysztof Dembczyński and Wojciech Kot lowski Intelligent Decision Support Systems Laboratory (IDSS) Poznań
Binary Classification, Multi-label Classification and Ranking: A Decision-theoretic Approach Krzysztof Dembczyński and Wojciech Kot lowski Intelligent Decision Support Systems Laboratory (IDSS) Poznań
Q1 (12 points): Chap 4 Exercise 3 (a) to (f) (2 points each)
: Chap 4 Exercise 3 (a) to (f) (2 points each)") Q1 (1 points): Chap 4 Exercise 3 (a) to (f) ( points each) Given a table Table 1 Dataset for Exercise 3 Instance a 1 a a 3 Target Class 1 T T 1.0 + T T 6.0 + 3 T F 5.0-4 F F 4.0 + 5 F T 7.0-6 F T 3.0-7
Q1 (1 points): Chap 4 Exercise 3 (a) to (f) ( points each) Given a table Table 1 Dataset for Exercise 3 Instance a 1 a a 3 Target Class 1 T T 1.0 + T T 6.0 + 3 T F 5.0-4 F F 4.0 + 5 F T 7.0-6 F T 3.0-7
Introduction to Machine Learning. Introduction to ML - TAU 2016/7 1
 Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 27, 2015 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 27, 2015 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
DECISION TREE LEARNING. [read Chapter 3] [recommended exercises 3.1, 3.4]
![DECISION TREE LEARNING. [read Chapter 3] [recommended exercises 3.1, 3.4]](/thumbs/78/78784288.jpg "DECISION TREE LEARNING. [read Chapter 3] [recommended exercises 3.1, 3.4]") 1 DECISION TREE LEARNING [read Chapter 3] [recommended exercises 3.1, 3.4] Decision tree representation ID3 learning algorithm Entropy, Information gain Overfitting Decision Tree 2 Representation: Tree-structured
1 DECISION TREE LEARNING [read Chapter 3] [recommended exercises 3.1, 3.4] Decision tree representation ID3 learning algorithm Entropy, Information gain Overfitting Decision Tree 2 Representation: Tree-structured
Lecture Slides for INTRODUCTION TO. Machine Learning. ETHEM ALPAYDIN The MIT Press,
 Lecture Slides for INTRODUCTION TO Machine Learning ETHEM ALPAYDIN The MIT Press, 2004 alpaydin@boun.edu.tr http://www.cmpe.boun.edu.tr/~ethem/i2ml CHAPTER 14: Assessing and Comparing Classification Algorithms
Lecture Slides for INTRODUCTION TO Machine Learning ETHEM ALPAYDIN The MIT Press, 2004 alpaydin@boun.edu.tr http://www.cmpe.boun.edu.tr/~ethem/i2ml CHAPTER 14: Assessing and Comparing Classification Algorithms
Failures of Gradient-Based Deep Learning
 Failures of Gradient-Based Deep Learning Shai Shalev-Shwartz, Shaked Shammah, Ohad Shamir The Hebrew University and Mobileye Representation Learning Workshop Simons Institute, Berkeley, 2017 Shai Shalev-Shwartz
Failures of Gradient-Based Deep Learning Shai Shalev-Shwartz, Shaked Shammah, Ohad Shamir The Hebrew University and Mobileye Representation Learning Workshop Simons Institute, Berkeley, 2017 Shai Shalev-Shwartz
.. Cal Poly CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. for each element of the dataset we are given its class label.
 .. Cal Poly CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Definitions Data. Consider a set A = {A 1,...,A n } of attributes, and an additional
.. Cal Poly CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Definitions Data. Consider a set A = {A 1,...,A n } of attributes, and an additional
Smart Home Health Analytics Information Systems University of Maryland Baltimore County
 Smart Home Health Analytics Information Systems University of Maryland Baltimore County 1 IEEE Expert, October 1996 2 Given sample S from all possible examples D Learner L learns hypothesis h based on
Smart Home Health Analytics Information Systems University of Maryland Baltimore County 1 IEEE Expert, October 1996 2 Given sample S from all possible examples D Learner L learns hypothesis h based on
Learning From Crowds. Presented by: Bei Peng 03/24/15
 Learning From Crowds Presented by: Bei Peng 03/24/15 1 Supervised Learning Given labeled training data, learn to generalize well on unseen data Binary classification ( ) Multi-class classification ( y
Learning From Crowds Presented by: Bei Peng 03/24/15 1 Supervised Learning Given labeled training data, learn to generalize well on unseen data Binary classification ( ) Multi-class classification ( y
Evaluating Classifiers. Lecture 2 Instructor: Max Welling
 Evaluating Classifiers Lecture 2 Instructor: Max Welling Evaluation of Results How do you report classification error? How certain are you about the error you claim? How do you compare two algorithms?
Evaluating Classifiers Lecture 2 Instructor: Max Welling Evaluation of Results How do you report classification error? How certain are you about the error you claim? How do you compare two algorithms?
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 18, 2016 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 18, 2016 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
Metric Embedding of Task-Specific Similarity. joint work with Trevor Darrell (MIT)
") Metric Embedding of Task-Specific Similarity Greg Shakhnarovich Brown University joint work with Trevor Darrell (MIT) August 9, 2006 Task-specific similarity A toy example: Task-specific similarity A toy
Metric Embedding of Task-Specific Similarity Greg Shakhnarovich Brown University joint work with Trevor Darrell (MIT) August 9, 2006 Task-specific similarity A toy example: Task-specific similarity A toy
Adaptive Crowdsourcing via EM with Prior
 Adaptive Crowdsourcing via EM with Prior Peter Maginnis and Tanmay Gupta May, 205 In this work, we make two primary contributions: derivation of the EM update for the shifted and rescaled beta prior and
Adaptive Crowdsourcing via EM with Prior Peter Maginnis and Tanmay Gupta May, 205 In this work, we make two primary contributions: derivation of the EM update for the shifted and rescaled beta prior and
Machine Learning for natural language processing
 Machine Learning for natural language processing Classification: Naive Bayes Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 20 Introduction Classification = supervised method for
Machine Learning for natural language processing Classification: Naive Bayes Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 20 Introduction Classification = supervised method for
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning
 SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
Variance Reduction and Ensemble Methods
 Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis