Modern Methods of Statistical Learning sf2935 Lecture 5: Logistic Regression T.K
|
|
|
- Janis Georgiana Evans
- 5 years ago
- Views:
Transcription
1 Lecture 5: Logistic Regression T.K

2 Overview of the Lecture
3 Your Learning Outcomes Discriminative v.s. Generative Odds, Odds Ratio, Logit function, Logistic function Logistic regression definition likelihood function: perfect linear classifier as special case maximum likelihood estimate best prediction and linear perceptron Accuracy, Precision, Sensitivity, Specificity
4 The setting: Y is a binary r.v.. x is its covariant, predictor or explanatory variable. x can be continuous, categorical. We cannot model the assocication of Y to x by a direct linear regression, Y = α + βx + e where e is, e.g., N (0, σ 2 ). Y = Bacterial Meningitis or Acute Viral Meningitis. x =cerebrospinal fluid total protein count.
5 Logistic regression Let x i X R p, y i Y = {+1, 1} 1, X = (X 1,..., X p ) T, a vector. Y is r.v. with two values, 1 and 1. We consider the problem of modelling the probability P (Y = 1 X). The model will be called logistic regression. 1 We could use Y = {+1, 0}
6 Supervised Learning Let x i X R p, y i Y = {+1, 1}, i = 1,... n be n pairs of examples of a binary target concept. Then is the training set. S = {(x 1, y 1 ),..., (x n, y n )} Training logistic regression using S, prediction of Y using x X and logistic regression. P (Y = 1 X) We need some additional concepts.
7 Supervised Learning; Supervised Classification Modelling of P (Y = 1 X) This is known as the discriminative approach to supervised classification (with binary alternatives). The generative approach: Model P (X Y = 1) and P (Y = 1) and use Bayes, formula to find P (Y = 1 X). The discriminative approach models P (X Y = 1) and P (Y = 1) and implicitly. There is an Appendix showing how a certain generative model of binary classification can be transformed to a logistic regression.
8 Generative: Class Data Discriminative: Data Class
9 Part I: Concepts Odds, Odds Ratio Logit function Logistic function a.k.a Sigmoid function
10 Odds The odds of a statement (event e.t.c) A is calculated as the probability p(a) of observing A divided by the probability of not observing A: odds of A = p(a) 1 p(a) E.g., in humans an average of 51 boys are born in every 1000 births, the odds of a randomly chosen delivery being boy are: odds of a boy = = 1.04 The odds of a certain thing happening are infinite.
11 An Aside: Posterior Odds The posterior probability p(h E ) of H given the evidence E: posterior odds of H = p(h E ) 1 p(h E ) If there are only two alternative hypotheses, H and not-h, then posterior odds of H = p(h E ) p(not-h E ) by Bayes formula = p(e H) p(h) p(e not-h) p(not-h). = likelihood ratio prior odds
12 Odds ratio The odds ratio ψ is the ratio of odds from two different conditions or populations. ψ = odds of A 1 odds of A 2 = p(a 1 ) 1 p(a 1 ) p(a 2 ) 1 p(a 2 )
13 Bernoulli Distribution again Consider r.v. Y with values 0, 1, 0 < p < 1 and y = 1 y = 0 f (y) p 1 p Y Be(p) = Bin(1, p).
14 Bernoulli Distribution again We write this as and y = 1 y = 0 f (y) p 1 p f (y) = p y (1 p) 1 y = e ln( p 1 p )y+ln(1 p)
15 The function logit(p) The logarithmic odds of success is called the logit of p ( ) p logit(p) = ln 1 p f (y) = e ln( p 1 p )y+ln(1 p) = e logit(p)y+ln(1 p)
16 The function logit(p) and its inverse ( ) p logit(p) = log 1 p If θ = logit(p), then the inverse function is p = logit 1 (θ) = eθ 1 + e θ
17 The logit(p) and its inverse The function ( ) p logit(p) = log, 0 < p < 1 1 p p = logit 1 (θ) = σ(θ) = eθ 1 + e θ = e θ 1, < θ <, 1 + e θ is called the logistic function or sigmoid. Note that σ(0) = 1 2.
18 Logistic function a.k.a. sigmoid In biology the logistic function refers to change in size of a species population. In artifical neural networks it is a network output function (sigmoid). In statistics it is the canonical link function for the Bernoulli distribution (c.f. above).
19 The logit(p) and the logistic function Sats The logit function ( ) p θ = logit(p) = log, 0 < p < 1 1 p and the logistic function p = σ(θ) = are inverse functions to each other. 1, < θ <, 1 + e θ
20 The logit(p) and the logistic function ( ) p 1 θ = logit(p) = log, 0 < p < 1 p = σ(θ) =, < θ <, 1 p 1 + e θ
21 Part II: Logistic Regression A regression function log odds of Y a regression function How to generate Y, logistic noise
22 Let β = (β 0, β 1, β 2,..., β p ) be (p + 1) 1 vector and X = (1, X 1, X 2,..., X p ) be a (p + 1) 1 -vector of (predictor) variables. We set, as in multiple regression, β T X = β 0 + β 1 X 1 + β 2 X β p X p Then G (X) = σ(β T X) = T X e = e β βt X 1 + e βt X
23 Logistic regression The predictor variables (X 1, X 2,..., X p ) can be binary, ordinal, categorical or continuous. In the examples below they are mostly continuous.
24 e βt X G (X) = σ(β T X) = 1 + e βt X By construction 0 < G (X) < 1. Then logit is well defined and logit(g (X)) = ln G (X) 1 G (X) = βt X = β 0 + β 1 X 1 + β 2 X β p X p.
25 Logistic regression Let now Y be a binary random variable such that { 1 with probability G (X) Y = 1 with probability 1 G (X) Definition If the logit of G (X) (or log odds of Y ) is logit(g (X)) = ln G (X) 1 G (X) = β 0 + β 1 X 1 + β 2 X β p X p, then we say that Y follows a logistic regression w.r.t. the predictor variables X = (1, X 1, X 2,..., X p ).
26 Logistic regression For fixed β we have the hyperplane D(β) = {X β T X = 0} For any X D(β), G (X) = σ(0) = 1 2 and Y = { 1 with probability with probability 1 2
27 An Aside: Deciban We might use (suggestion by Alan Turing for logarithm of posterior odds) e(y X) = 10 log 10 G (X) 1 G (X) and call it the evidence for Y given X. Turing called this deciban. The unit of evidence is then decibel (db). 1 db change in evidence is the smallest increment in of plausibility that is perceptible for our intuition.
28 Logistic regression: genetic epidemiology Logistic regression { success with probability G (X) Y = failure with probability 1 G (X) logit(g (X)) = ln G (X) 1 G (X) = β 0 + β 1 X 1 + β 2 X β p X p. is extensively applied in medical research, where success may mean the occurrence of a disease or death due to a disease, and X 1, X 2,..., X p are environmental and genetic riskfactors. Woodward, M. : Epidemiology: study design and data analysis, 2013, CRC Press.
29 Logistic regression: genetic epidemiology Suppose we have two populations, where X i = x 1 in first population and X i = x 2 in the second population, all other predictors are equal in the two populations. Then a medical geneticist finds it useful to calculate the logarithm of the odds ratio ln ψ = ln p 1 1 p 1 ln = β i (x 1 x 2 ) p 2 1 p 2 or ψ = e β i (x 1 x 2 )
30 EGAT Study (from Woodward) Smoker at entry Cardiovascular death during follow-up Yes No Total Yes No Total
31 EGAT Study (from Woodward) Logistic regression logit = x was fitted with x = 1 for smokers and x = 0 for non-smokers. Then the odds ratio is The log odds for smokers is ψ = e β(x 1 x 2 ) = e (1 0) = = giving odds= For non-smokers the odds are
32 EGAT Study (from Woodward) The risk for cardiovascular death for smokers is 1 = e For nonsmokers 1 = e
33 Logistic regression e βt X P(Y = 1 X) = G (X) = σ(β T X) = 1 + e βt X 1 P(Y = 1 X) = 1 G (X) = e = e β βt X 1 + e βt X = e βt X. Hence a unit change in X i corresponds to e β i change in odds and β i change in logodds. T X
34 ɛ is a r.v., ɛ Logistic(0, 1) means that the cumulative distribution function (CDF) of the logistic distribution is the logistic function: P (ɛ x) = 1 = σ(x) 1 + e x
35 A generative model We need the following regression model Y = β T X + ɛ where β T X = β 0 + β 1 X 1 + β 2 X β p X p and ɛ Logistic(0, 1), i.e. the variable Y can be written directly in terms of the linear predictor function and an additive random error variable. The logistic distribution (?) is the probability distribution the random error.
36 Logistic distribution ɛ is a r.v., ɛ Logistic(0, 1) means that the cumulative distribution function (CDF) of the logistic distribution is the logistic function: P (ɛ x) = 1 = σ(x) 1 + e x I.e. ɛ Logistic(0, 1), if the probability density function is d dx σ(x) = e x (1 + e x ) 2.
37 Simulating ɛ Logistic(0, 1) This is simple: simulate p 1,..., p n from the uniform distribution on (0, 1) and then do ɛ i = logit(p i ), i = 1,..., n. In the figure we plot the empirical distribution function of ɛ i for n =
38 A piece of probability ɛ Logistic(0, 1), what is P ( ɛ x)? P ( ɛ x) = P (ɛ x) = 1 P (ɛ x) = 1 σ( x) = e x = ex 1 + e x = e x = P (ɛ x). ɛ Logistic(0, 1) ɛ Logistic(0, 1).
39 Generating model and/or how to simulate Take a continuous latent variable Y (latent= an unobserved random variable) that is given as follows: Y = β T X + ɛ where β T X = β 0 + β 1 X 1 + β 2 X β p X p and ɛ Logistic(0, 1).
40 Define the response Y as the indicator for whether the latent variable is positive: { 1 if Y > 0 i.e. ε < β T X, Y = 1 otherwise. Then Y follows a logistic regression w.r.t. X. We need only to verify that 1 P(Y = 1 X) = 1 + e. βt X
41 P(Y = 1 X) = P(Y > 0 X) (1) = P(β T X + ε > 0) (2) = P(ε > β T X) (3) = P( ε < β T X) (4) = P(ε < β T X) (5) = σ(β T X) (6) 1 = (7) 1 + e βt X where we used in (4) -(5) that the logistic distribution is symmetric (and continuous), as learned above, Pr ( ε x) = Pr (ε x).
42 Part III: Logistic Regression Simulated Data Some Probit Analysis Maximum Likelihood
43 Simulate ɛ, compute Y = β T X + ɛ with known β and levels of X. Compute { 1 if Y > 0 i.e. ε < β T X, Y = 0 otherwise.
44 Maximum likelihood We have data S = {(X 1, y 1 ),..., (X n, y n )} Next the labels are coded as +1 +1, 1 0. The likelihood function is L (β) def = l i=1 G (X i ) y i (1 G (X i )) 1 y i.
45 Maximum likelihood Some simple manipulation gives that ln L (β) = n i=1 ( )) y i β T X i ln (1 + e βt X i There is no closed form solution to the minimization of ln L (β). The function is twice continuously differentiable, convex and even strictly convex if the data is not linearly separable (c.f., sf2935 Lecture 1). There are standard optimization algorithms for minimization of functions with these properties.
46 Model validation: the χ 2 -test Let us look at following data on dose pesticide and death. We can write the data for males as Dose (µg) Die Survive
47 Model validation: the χ 2 -test Using the ML-estimates α = and β = we can calculate the probability of death for the dose x = 1 as 1 = e and then the expected frequency of death at x = 1 is = In the same way we can calculate the probabilities of death and survival for the other doses x.
48 Model validation: the χ 2 -test We use the chi-square goodness-of-fit test statistic Q Q = r (observed freq i expected freq i ) 2 r (x = i np i ) i=1 expected freq 2. i i=1 np i where r is the number of groups in the grouped data. It can be shown that Q is approximatively χ 2 (r/2 2)- distributed (chi square with r/2 2 degrees of freedom) under the (null) hypothesis that the probabilities of death and survival are as given by the estimated model. The reduction with two degrees of freedom is for the fact that we have estimated two parameters.
49 Model validation: the χ 2 -test Q = r (observed freq i expected freq i ) 2 r (x = i np i ) i=1 expected freq 2. i i=1 np i E.g., n 2 = 4 and n p 2 = 20 P(Y = 1 x = 2) = e α 2 β
50 Model validation: the χ 2 -test We get Q = 12 (observed freq i expected freq i ) 2 i=1 expected freq i ( )2 ( )2 = = The p-value is P (Q 4.24) = where Q is χ 2 (6 2)- distributed. Hence we do not reject the logistic regression model 2. 2 Here the expected frequency of 0 taken as 0.01 in the textbook cited.
51 Part IV: More on Maximum Likelihood Likelihood function rewritten Training: an algorithm for computing the Maximum Likelihood Estimate Linear Separability and Regularization
52 Part V: Logistic Regression Special case: β T X = β 0 + β 1 x. Likelihood Maximum Likelihood
53 We consider the model: β T X = β 0 + β 1 x. P(Y = 1 x) = σ(β T X) = e (β 0+β 1 x)
54 Notation: P(Y = y x) = σ(β T X) y (1 σ(β T X) 1 y = { σ(β T X) if y = 1 1 σ(β T X) if y = 0
55 Data (x i, y i ) n i=1, likelihood function with the notation above L (β 0, β 1 ) = P(Y = y 1 x 1 ) P(Y = y 2 x 2 ) P(Y = y n x n ) = σ(β T X 1 ) y 1 (1 σ(β T X 1 ) 1 y1 σ(β T X n ) y n (1 σ(β T X n ) 1 y n = A B A = σ(β T X 1 ) y1 σ(β T X 2 ) y2 σ(β T X n ) y n B = (1 σ(β T X 1 ) 1 y 1 (1 σ(β T X 2 ) 1 y2 (1 σ(β T X n ) 1 y n
56 = n i=1 + ln L (β 0, β 1 ) = ln A + ln B n i=1 = n y l ln σ(β T X i ) i=1 (1 y i ) ln(1 σ(β T X i )) ln(1 σ(β T X i )) + n i=1 σ(β T X i ) y l ln 1 σ(β T X i )
57 ( ln(1 σ(β T X i )) = ln 1 ( e (β 0+β 1 x) = ln 1 + e (β 0+β 1 x i ) ( ) 1 = ln 1 + e β 0+β 1 = x i ) = ln (e β 0+β 1 x i ) e (β 0+β 1 x i ) )
58 logodds σ(β T X i ) ln 1 σ(β T X i ) = β 0 + β 1 x i
59 In summary: ln L (β 0, β 1 ) = n i=1 y i (β 0 + β 1 x i ) n i=1 ) ln (e β 0+β 1 x i
60 = n i=1 β 1 ln L (β 0, β 1 ) y i x i n i=1 ) ln (e β 0+β 1 x i β 1 ) ln (e β 0+β 1 x i β 1 = e β 0+β 1 x i x i 1 + e β 0+β 1 x i = P(Y = 1 x i ) x i.
61 ln L (β 0, β 1 ) = 0 β 1 n (y i x i P(Y = 1 x i ) x i ) = 0. i=1 In the same manner we can also find n ln L (β 0, β 1 ) = β 0 (y i P(Y = 1 x i )) = 0 i=1 These two equations have no closed form solution w.r.t. β 0 and β 1.
62 Newton-Raphson for MLE: a one-parameter case For one parameter θ, set f (θ) = ln L(θ). We are searching for the solution of Newton-Raphson method f (θ) = d f (θ) = 0. dθ θ new = θ old + f ( θ old ) where a good initial value is desired. f (θ old ),
63 Newton-Raphson for logistic MLE ( β new 0 β new 1 ) = ( β old 0 β old 1 ) ( + H 1 (β old 0, β old β 1 ) 0 ln L ( β old 0, ) βold 1 β 1 ln L ( β old 0, ) βold 1 ). where H 1 (β old (next slide) 0, βold 1 ) is the matrix inverse of the 2 2 matrix
64 Newton-Raphson for logistic MLE H(β old 0, β old 1 ) = 2 β 2 0 ln L ( β old 0, ) βold 1 2 β 1 β 0 ln L ( β old 0, βold 1 ) 2 β 0 β 1 ln L ( β old 2 β 2 1 0, βold 1 ln L ( β old 0, βold 1 ) ) = n i=1 P (Y = 1 x i ) (1 P(Y = 1 x i ) n i=1 P (Y = 1 x i ) (1 P(Y = 1 x i ) right)cdotx i n i=1 P (Y = 1 x i ) (1 P (Y = 1 x i )) x i n i=1 P (Y = 1 x i ) (1 P(Y = 1 x i )) x 2 i
65
66 The trick applied to rewriting the logistic probability σ(t) = e t Let us recode y {+1, 1}. Then we get ( ) P (y X) = σ y β T X
67 Logistic Regression: a check y {+1, 1}. P (+1 X) = σ(t) = e t 1 ( ) 1 + e = σ +1β T X. βt X 1 P ( 1 X) = 1 P (+1 X) = e βt X = e βt X 1 + e βt X = e βt X 1 + e = 1 ( ) βt X e βt X + 1 = σ 1β T X.
68 Logistic Regression: Likelihood of β A training set The likelihood function of β is ( ) P (y X; β) = σ y β T X S = {(X 1, y 1 ),..., (X n, y n )} L (β) def = n i=1 P (y l X l ; β)
69 Logistic Regression: -log likelihood of β The negative log likelihood l (β) def = ln L (β) = n = ln P (y l X l ; β) i=1 n ) = ln σ (y i β T X i i=1 = n ln i=1 = n ln i=1 [ e y i β T X i ] [1 + e y i β T X i ]
70 Logistic Regression: ML (1) Let us recall that l (β) = n ] ln [1 + e y i β T X i i=1 β = (β 0, β 1, β 2,..., β p ). Then ] ln [1 + e y i β T X i e y i(β T X i) = y i β e y i β T X i = y i σ( y i β T X i ) = y i (1 P (y i X; β))
71 Logistic Regression: ML (2) l (β) = n ] ln [1 + e y i β T X i i=1 β = (β 0, β 1, β 2,..., β p ). ] ln [1 + e y i β T X i e y i(β T X i) = y i X i β k 1 + e y i β T X i = y i X i σ( y i β T X i ) = y i X i (1 P (y i X; β))
72 Logistic Regression: ML (3) l (β) = β = (β 0, β 1, β 2,..., β p ). n ] ln [1 + e y i β T X i i=1 ] ln [1 + e y i β T X i = y i (1 P (y i X; β)) β 0 ] ln [1 + e y i β T X i = y i X i (1 P (y i X; β)) β k
73 Logistic Regression: ML (3) Update ] ln [1 + e y i β T X i = y i (1 P (y i X; β)) β 0 ] ln [1 + e y i β T X i = y i X i (1 P (y i X; β)) β k Parameters can then be updated by selecting training samples at random and moving the parameters in the opposite direction of the partial derivatives (stochastic gradient algorithm).
74 Logistic Regression: ML (4) Update Parameters can then be updated by selecting training samples at random and moving the parameters in the opposite direction of the partial derivatives β 0 β 0 + ηy i (1 P (y i X; β)) β β + ηy i X i (1 P (y i X; β))
75 Logistic Regression: ML (5) Update β 0 β 0 + ηy i (1 P (y i X; β)) β β + ηy i X i (1 P (y i X; β)). Resembles strongly of the perceptron algorithm, with on-line updates driven by mistakes. The difference here is that the updates are made in proportion to the probability of making a mistake. We give no proof of convergence.
76 Properties of ML Assume that the training examples S = {(X 1, y 1 ),..., (X n, y n )} is linearly separable (c.f., Lecture I). In this case we know (previous lecture) that the are values of β such that y i β T X i > 0 for all training examples. Then the likelihood function L (β) = n i=1 ) σ (y i β T X i = n i= e y i β T X i is strictly increasing as a function of y i β T X i. Hence we can scale up 3 the parameters β and make them larger and larger. Thus the maximum likelihood estimated values increase to infinity for a perfect linear classifier. 3 Scaling freedom of Lecture I
77 ML & Regularizer To avoid linear separability due to small training sets we minimize the regularizer + the negative loglikelihood function or λ 2 βt β + n i=1 ] ln [1 + e y i β T X i where λ is a parameter that measures the strength of regularization.
78 More on ML n ) l (β) = ln σ (y i β T X i i=1 Then we recall that X = (1, X 1, X 2,..., X p ). Thus l β F (β) = y i X i σ( y i β T X i ). i=1 This follows by the preceding, or expressing the preceding in vector notation β βt X = β XT β = X Thus if we set the gradient βf (β) = 0 (= a column vector of p + 1 zeros) we get n y i X i σ( y i β T X i ) = 0 i=1
79 The ML estimate β will satisfy 0 = 0 = n y i σ( y i βt Xi )X i i=1 n y i (1 P(y i βt Xi )X i i=1
80 The section above is partially based on: T.S. Jaakkola: course material for Machine Learning, Fall 2006, MIT, T.S. Jaakkola & D. Haussler (1998): Exploiting generative models in discriminative classifiers. T.S. Jaakkola & D. Haussler (1999): Probabilistic kernel regression models. Proceedings of the Seventh International Workshop on Artificial Intelligence and Statistics.
81 Part IV: Prediction Prediction & Perceptron Crossvalidation
82 When we insert β back to P (y X) we have ( P (y X) = σ y β T ) X or ) P (Y = 1 X) = σ ( βt X
83 Logistic Regression as Perceptron We can drop the notations P and β for ease ( of writing. ) For given X the task is to maximize P (y X) = σ y β T X. There are only two values y = ±1 to choose among. There are two cases to consider. 1) t = β T X > 0. Then if y = +1, and y = 1 y t < 0 < yt e y t < e yt e yt < e y t i.e. 1 + e yt < 1 + e y t e y t < e yt P (y X) = σ (yt) > σ (y t) = P (y X)
84 Logistic Regression as Perceptron 2) t = β T X < 0. If y = +1, and y = 1, then yt < y t and it follows in the same way as above that P (y X) > P (y X) Hence: the maximum probability is assumed by y that has the same sign as β T X.
85 Logistic Regression as Perceptron Given β, the best probability predictor of Y, denoted by Ŷ, for given X is ) Ŷ = sign ( β T X This is recognized as the input-output map of a perceptron, c.f., Lecture I. The training of logistic regression is not, however, done by the perceptron algorithm.
86 Model validation: Cross-validation A way to check a model s suitability is to assess the model against a set of data (testing set) that was not used to create the model: this is called cross-validation. This is a holdout model assessment method.
87 Cross validation We have a training set of l pairs Y {0, 1} and the corresponding values of the predictors. S = {(X 1, y 1 ),..., (X n, y n )} and use this to estimate β by β = β(s), e.g., by ML. We must have another set of data, testing set, of holdout samples T = {( X t 1, y1) t (,..., X t m, ym t )} Having found β we should apply the optimal predictor P (y X t l ) on T, and compare the prediction to yj t for all j. Note that in this β = β(s)
88 Cross-validation: categories of error prediction of -1 when the holdout sample has a -1 (True Negatives, the number of which is TN) prediction of -1 when the holdout sample has a 1 (False Negatives, the number of which is FN) prediction of 1 when the holdout sample has a -1 (False Positives, the number of which is FP) prediction of 1 when the holdout sample has a 1 (True Positives, the number of which is TP)
89 Evaluation of logistic regression (and other) models False Positives = FP, True Positives = TP False Negatives = FN, True Negatives= TN Y = +1 Y = 1 Ŷ = +1 TP FP Ŷ = 1 FN TN
90 Cross-validation In machine learning & medical research one often encounters one or several of the following criteria of evaluating a classifier: TP+TN Accuracy = TP+FP+FN+TN =fraction of observations with correct predicted classification Precision = PositivePredictiveValue = predicted positives that are correct TP TP TP+FP =Fraction of Recall = Sensitivity = TP+FN =fraction of observations that are actually 1 with a correct predicted classification TN Specificity = TN+FP =fraction of observations that are actually -1 with a correct predicted classification
91 Simulated Data The same as above: With the true generative model log(p/(1 p)) = x + ɛ, we simulate 2000 pairs of test data. We predict Y in the test set using α = 3.21, β = found from the training data. The results are: Accuracy = Precision= Recall=Sensitivity= Specificity= Negative Predictive value=
92 Error rates with statistics names Let N=TN+FP, P=FN+TP. FP/N = type I error = = 1 Specificity TP/P= 1-type II error = =power =sensitivity=recall
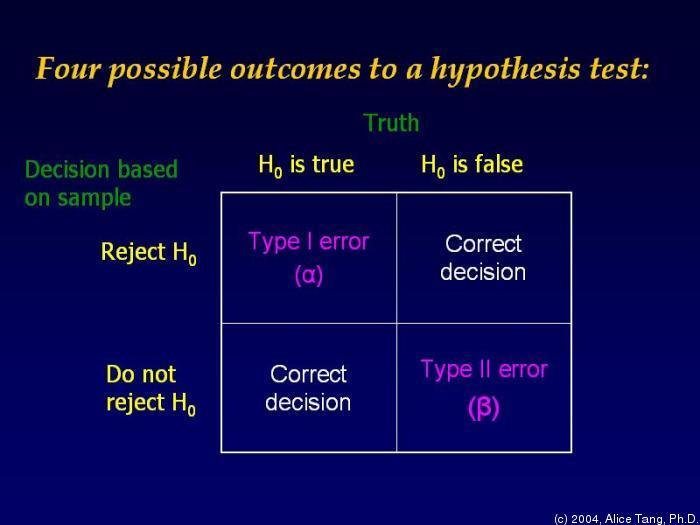
93 Hypothesis testing
94 Hypothesis testing
Logistisk regression T.K.
 Föreläsning 13: Logistisk regression T.K. 05.12.2017 Your Learning Outcomes Odds, Odds Ratio, Logit function, Logistic function Logistic regression definition likelihood function: maximum likelihood estimate
Föreläsning 13: Logistisk regression T.K. 05.12.2017 Your Learning Outcomes Odds, Odds Ratio, Logit function, Logistic function Logistic regression definition likelihood function: maximum likelihood estimate
> DEPARTMENT OF MATHEMATICS AND COMPUTER SCIENCE GRAVIS 2016 BASEL. Logistic Regression. Pattern Recognition 2016 Sandro Schönborn University of Basel
 Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods.
 Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Linear Models in Machine Learning
 CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
Logistic Regression. Will Monroe CS 109. Lecture Notes #22 August 14, 2017
 1 Will Monroe CS 109 Logistic Regression Lecture Notes #22 August 14, 2017 Based on a chapter by Chris Piech Logistic regression is a classification algorithm1 that works by trying to learn a function
1 Will Monroe CS 109 Logistic Regression Lecture Notes #22 August 14, 2017 Based on a chapter by Chris Piech Logistic regression is a classification algorithm1 that works by trying to learn a function
Lecture 2 Machine Learning Review
 Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Machine Learning Linear Classification. Prof. Matteo Matteucci
 Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Machine Learning. Lecture 3: Logistic Regression. Feng Li.
 Machine Learning Lecture 3: Logistic Regression Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2016 Logistic Regression Classification
Machine Learning Lecture 3: Logistic Regression Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2016 Logistic Regression Classification
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION
 SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
CPSC 340: Machine Learning and Data Mining. MLE and MAP Fall 2017
 CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
Logistic Regression. Sargur N. Srihari. University at Buffalo, State University of New York USA
 Logistic Regression Sargur N. University at Buffalo, State University of New York USA Topics in Linear Classification using Probabilistic Discriminative Models Generative vs Discriminative 1. Fixed basis
Logistic Regression Sargur N. University at Buffalo, State University of New York USA Topics in Linear Classification using Probabilistic Discriminative Models Generative vs Discriminative 1. Fixed basis
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Lecture #11: Classification & Logistic Regression
 Lecture #11: Classification & Logistic Regression CS 109A, STAT 121A, AC 209A: Data Science Weiwei Pan, Pavlos Protopapas, Kevin Rader Fall 2016 Harvard University 1 Announcements Midterm: will be graded
Lecture #11: Classification & Logistic Regression CS 109A, STAT 121A, AC 209A: Data Science Weiwei Pan, Pavlos Protopapas, Kevin Rader Fall 2016 Harvard University 1 Announcements Midterm: will be graded
Classification Based on Probability
 Logistic Regression These slides were assembled by Byron Boots, with only minor modifications from Eric Eaton s slides and grateful acknowledgement to the many others who made their course materials freely
Logistic Regression These slides were assembled by Byron Boots, with only minor modifications from Eric Eaton s slides and grateful acknowledgement to the many others who made their course materials freely
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Linear Regression Models P8111
 Linear Regression Models P8111 Lecture 25 Jeff Goldsmith April 26, 2016 1 of 37 Today s Lecture Logistic regression / GLMs Model framework Interpretation Estimation 2 of 37 Linear regression Course started
Linear Regression Models P8111 Lecture 25 Jeff Goldsmith April 26, 2016 1 of 37 Today s Lecture Logistic regression / GLMs Model framework Interpretation Estimation 2 of 37 Linear regression Course started
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
BANA 7046 Data Mining I Lecture 4. Logistic Regression and Classications 1
 BANA 7046 Data Mining I Lecture 4. Logistic Regression and Classications 1 Shaobo Li University of Cincinnati 1 Partially based on Hastie, et al. (2009) ESL, and James, et al. (2013) ISLR Data Mining I
BANA 7046 Data Mining I Lecture 4. Logistic Regression and Classications 1 Shaobo Li University of Cincinnati 1 Partially based on Hastie, et al. (2009) ESL, and James, et al. (2013) ISLR Data Mining I
Lecture 01: Introduction
 Lecture 01: Introduction Dipankar Bandyopadhyay, Ph.D. BMTRY 711: Analysis of Categorical Data Spring 2011 Division of Biostatistics and Epidemiology Medical University of South Carolina Lecture 01: Introduction
Lecture 01: Introduction Dipankar Bandyopadhyay, Ph.D. BMTRY 711: Analysis of Categorical Data Spring 2011 Division of Biostatistics and Epidemiology Medical University of South Carolina Lecture 01: Introduction
σ(a) = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =
 = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =") Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Machine Learning and Data Mining. Linear classification. Kalev Kask
 Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
ECLT 5810 Linear Regression and Logistic Regression for Classification. Prof. Wai Lam
 ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Rapid Introduction to Machine Learning/ Deep Learning
 Rapid Introduction to Machine Learning/ Deep Learning Hyeong In Choi Seoul National University 1/62 Lecture 1b Logistic regression & neural network October 2, 2015 2/62 Table of contents 1 1 Bird s-eye
Rapid Introduction to Machine Learning/ Deep Learning Hyeong In Choi Seoul National University 1/62 Lecture 1b Logistic regression & neural network October 2, 2015 2/62 Table of contents 1 1 Bird s-eye
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Gradient-Based Learning. Sargur N. Srihari
 Gradient-Based Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Gradient-Based Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
ECLT 5810 Linear Regression and Logistic Regression for Classification. Prof. Wai Lam
 ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
ECLT 5810 Linear Regression and Logistic Regression for Classification Prof. Wai Lam Linear Regression Models Least Squares Input vectors is an attribute / feature / predictor (independent variable) The
Logistic Regression. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Logistic Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Logistic Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Outline. Supervised Learning. Hong Chang. Institute of Computing Technology, Chinese Academy of Sciences. Machine Learning Methods (Fall 2012)
") Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Math for Machine Learning Open Doors to Data Science and Artificial Intelligence. Richard Han
 Math for Machine Learning Open Doors to Data Science and Artificial Intelligence Richard Han Copyright 05 Richard Han All rights reserved. CONTENTS PREFACE... - INTRODUCTION... LINEAR REGRESSION... 4 LINEAR
Math for Machine Learning Open Doors to Data Science and Artificial Intelligence Richard Han Copyright 05 Richard Han All rights reserved. CONTENTS PREFACE... - INTRODUCTION... LINEAR REGRESSION... 4 LINEAR
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Association studies and regression
 Association studies and regression CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar Association studies and regression 1 / 104 Administration
Association studies and regression CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar Association studies and regression 1 / 104 Administration
Machine Learning. Bayesian Regression & Classification. Marc Toussaint U Stuttgart
 Machine Learning Bayesian Regression & Classification learning as inference, Bayesian Kernel Ridge regression & Gaussian Processes, Bayesian Kernel Logistic Regression & GP classification, Bayesian Neural
Machine Learning Bayesian Regression & Classification learning as inference, Bayesian Kernel Ridge regression & Gaussian Processes, Bayesian Kernel Logistic Regression & GP classification, Bayesian Neural
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
LINEAR MODELS FOR CLASSIFICATION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
22s:152 Applied Linear Regression. Example: Study on lead levels in children. Ch. 14 (sec. 1) and Ch. 15 (sec. 1 & 4): Logistic Regression
 and Ch. 15 (sec. 1 & 4): Logistic Regression") 22s:52 Applied Linear Regression Ch. 4 (sec. and Ch. 5 (sec. & 4: Logistic Regression Logistic Regression When the response variable is a binary variable, such as 0 or live or die fail or succeed then
22s:52 Applied Linear Regression Ch. 4 (sec. and Ch. 5 (sec. & 4: Logistic Regression Logistic Regression When the response variable is a binary variable, such as 0 or live or die fail or succeed then
Linear Models for Classification
 Catherine Lee Anderson figures courtesy of Christopher M. Bishop Department of Computer Science University of Nebraska at Lincoln CSCE 970: Pattern Recognition and Machine Learning Congradulations!!!!
Catherine Lee Anderson figures courtesy of Christopher M. Bishop Department of Computer Science University of Nebraska at Lincoln CSCE 970: Pattern Recognition and Machine Learning Congradulations!!!!
Notes on Noise Contrastive Estimation (NCE)
") Notes on Noise Contrastive Estimation NCE) David Meyer dmm@{-4-5.net,uoregon.edu,...} March 0, 207 Introduction In this note we follow the notation used in [2]. Suppose X x, x 2,, x Td ) is a sample of
Notes on Noise Contrastive Estimation NCE) David Meyer dmm@{-4-5.net,uoregon.edu,...} March 0, 207 Introduction In this note we follow the notation used in [2]. Suppose X x, x 2,, x Td ) is a sample of
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 8 Feb. 12, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
1 Machine Learning Concepts (16 points)
") CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Classification. Chapter Introduction. 6.2 The Bayes classifier
 Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Chapter 6 Classification 6.1 Introduction Often encountered in applications is the situation where the response variable Y takes values in a finite set of labels. For example, the response Y could encode
Beyond GLM and likelihood
 Stat 6620: Applied Linear Models Department of Statistics Western Michigan University Statistics curriculum Core knowledge (modeling and estimation) Math stat 1 (probability, distributions, convergence
Stat 6620: Applied Linear Models Department of Statistics Western Michigan University Statistics curriculum Core knowledge (modeling and estimation) Math stat 1 (probability, distributions, convergence
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Linear Regression (9/11/13)
") STA561: Probabilistic machine learning Linear Regression (9/11/13) Lecturer: Barbara Engelhardt Scribes: Zachary Abzug, Mike Gloudemans, Zhuosheng Gu, Zhao Song 1 Why use linear regression? Figure 1: Scatter
STA561: Probabilistic machine learning Linear Regression (9/11/13) Lecturer: Barbara Engelhardt Scribes: Zachary Abzug, Mike Gloudemans, Zhuosheng Gu, Zhao Song 1 Why use linear regression? Figure 1: Scatter
Evaluation. Andrea Passerini Machine Learning. Evaluation
 Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
HOMEWORK #4: LOGISTIC REGRESSION
 HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2018 Due: Friday, February 23rd, 2018, 11:55 PM Submit code and report via EEE Dropbox You should submit a
HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2018 Due: Friday, February 23rd, 2018, 11:55 PM Submit code and report via EEE Dropbox You should submit a
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Bayesian Learning. Tobias Scheffer, Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Generalized Linear Models and Exponential Families
 Generalized Linear Models and Exponential Families David M. Blei COS424 Princeton University April 12, 2012 Generalized Linear Models x n y n β Linear regression and logistic regression are both linear
Generalized Linear Models and Exponential Families David M. Blei COS424 Princeton University April 12, 2012 Generalized Linear Models x n y n β Linear regression and logistic regression are both linear
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Data-analysis and Retrieval Ordinal Classification
 Data-analysis and Retrieval Ordinal Classification Ad Feelders Universiteit Utrecht Data-analysis and Retrieval 1 / 30 Strongly disagree Ordinal Classification 1 2 3 4 5 0% (0) 10.5% (2) 21.1% (4) 42.1%
Data-analysis and Retrieval Ordinal Classification Ad Feelders Universiteit Utrecht Data-analysis and Retrieval 1 / 30 Strongly disagree Ordinal Classification 1 2 3 4 5 0% (0) 10.5% (2) 21.1% (4) 42.1%
Performance Evaluation and Comparison
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Cross Validation and Resampling 3 Interval Estimation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Cross Validation and Resampling 3 Interval Estimation
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Class 4: Classification. Quaid Morris February 11 th, 2011 ML4Bio
 Class 4: Classification Quaid Morris February 11 th, 211 ML4Bio Overview Basic concepts in classification: overfitting, cross-validation, evaluation. Linear Discriminant Analysis and Quadratic Discriminant
Class 4: Classification Quaid Morris February 11 th, 211 ML4Bio Overview Basic concepts in classification: overfitting, cross-validation, evaluation. Linear Discriminant Analysis and Quadratic Discriminant
Machine Learning. Linear Models. Fabio Vandin October 10, 2017
 Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Logistic Regression. Seungjin Choi
 Logistic Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Logistic Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Empirical Risk Minimization
 Empirical Risk Minimization Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Introduction PAC learning ERM in practice 2 General setting Data X the input space and Y the output space
Empirical Risk Minimization Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Introduction PAC learning ERM in practice 2 General setting Data X the input space and Y the output space
Final Overview. Introduction to ML. Marek Petrik 4/25/2017
 Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
6.867 Machine learning: lecture 2. Tommi S. Jaakkola MIT CSAIL
 6.867 Machine learning: lecture 2 Tommi S. Jaakkola MIT CSAIL tommi@csail.mit.edu Topics The learning problem hypothesis class, estimation algorithm loss and estimation criterion sampling, empirical and
6.867 Machine learning: lecture 2 Tommi S. Jaakkola MIT CSAIL tommi@csail.mit.edu Topics The learning problem hypothesis class, estimation algorithm loss and estimation criterion sampling, empirical and
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
Evaluation requires to define performance measures to be optimized
 Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
Machine Learning for NLP
 Machine Learning for NLP Uppsala University Department of Linguistics and Philology Slides borrowed from Ryan McDonald, Google Research Machine Learning for NLP 1(50) Introduction Linear Classifiers Classifiers
Machine Learning for NLP Uppsala University Department of Linguistics and Philology Slides borrowed from Ryan McDonald, Google Research Machine Learning for NLP 1(50) Introduction Linear Classifiers Classifiers
Introduction to Machine Learning. Introduction to ML - TAU 2016/7 1
 Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
LOGISTIC REGRESSION Joseph M. Hilbe
 LOGISTIC REGRESSION Joseph M. Hilbe Arizona State University Logistic regression is the most common method used to model binary response data. When the response is binary, it typically takes the form of
LOGISTIC REGRESSION Joseph M. Hilbe Arizona State University Logistic regression is the most common method used to model binary response data. When the response is binary, it typically takes the form of
Linear Classifiers. Michael Collins. January 18, 2012
 Linear Classifiers Michael Collins January 18, 2012 Today s Lecture Binary classification problems Linear classifiers The perceptron algorithm Classification Problems: An Example Goal: build a system that
Linear Classifiers Michael Collins January 18, 2012 Today s Lecture Binary classification problems Linear classifiers The perceptron algorithm Classification Problems: An Example Goal: build a system that
Introduction to Bayesian Learning. Machine Learning Fall 2018
 Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
Generative Learning. INFO-4604, Applied Machine Learning University of Colorado Boulder. November 29, 2018 Prof. Michael Paul
 Generative Learning INFO-4604, Applied Machine Learning University of Colorado Boulder November 29, 2018 Prof. Michael Paul Generative vs Discriminative The classification algorithms we have seen so far
Generative Learning INFO-4604, Applied Machine Learning University of Colorado Boulder November 29, 2018 Prof. Michael Paul Generative vs Discriminative The classification algorithms we have seen so far
Machine Learning. Lecture 04: Logistic and Softmax Regression. Nevin L. Zhang
 Machine Learning Lecture 04: Logistic and Softmax Regression Nevin L. Zhang lzhang@cse.ust.hk Department of Computer Science and Engineering The Hong Kong University of Science and Technology This set
Machine Learning Lecture 04: Logistic and Softmax Regression Nevin L. Zhang lzhang@cse.ust.hk Department of Computer Science and Engineering The Hong Kong University of Science and Technology This set
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
Probability and Information Theory. Sargur N. Srihari
 Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining MLE and MAP Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due tonight. Assignment 5: Will be released
CPSC 340: Machine Learning and Data Mining MLE and MAP Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due tonight. Assignment 5: Will be released
Lecture 3 - Linear and Logistic Regression
 3 - Linear and Logistic Regression-1 Machine Learning Course Lecture 3 - Linear and Logistic Regression Lecturer: Haim Permuter Scribe: Ziv Aharoni Throughout this lecture we talk about how to use regression
3 - Linear and Logistic Regression-1 Machine Learning Course Lecture 3 - Linear and Logistic Regression Lecturer: Haim Permuter Scribe: Ziv Aharoni Throughout this lecture we talk about how to use regression
Linear Classification. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
Lecture 4: Types of errors. Bayesian regression models. Logistic regression
 Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Introduction to Machine Learning
 1, DATA11002 Introduction to Machine Learning Lecturer: Teemu Roos TAs: Ville Hyvönen and Janne Leppä-aho Department of Computer Science University of Helsinki (based in part on material by Patrik Hoyer
1, DATA11002 Introduction to Machine Learning Lecturer: Teemu Roos TAs: Ville Hyvönen and Janne Leppä-aho Department of Computer Science University of Helsinki (based in part on material by Patrik Hoyer
Lecture Slides for INTRODUCTION TO. Machine Learning. ETHEM ALPAYDIN The MIT Press,
 Lecture Slides for INTRODUCTION TO Machine Learning ETHEM ALPAYDIN The MIT Press, 2004 alpaydin@boun.edu.tr http://www.cmpe.boun.edu.tr/~ethem/i2ml CHAPTER 14: Assessing and Comparing Classification Algorithms
Lecture Slides for INTRODUCTION TO Machine Learning ETHEM ALPAYDIN The MIT Press, 2004 alpaydin@boun.edu.tr http://www.cmpe.boun.edu.tr/~ethem/i2ml CHAPTER 14: Assessing and Comparing Classification Algorithms
Normal distribution We have a random sample from N(m, υ). The sample mean is Ȳ and the corrected sum of squares is S yy. After some simplification,
. The sample mean is Ȳ and the corrected sum of squares is S yy. After some simplification,") Likelihood Let P (D H) be the probability an experiment produces data D, given hypothesis H. Usually H is regarded as fixed and D variable. Before the experiment, the data D are unknown, and the probability
Likelihood Let P (D H) be the probability an experiment produces data D, given hypothesis H. Usually H is regarded as fixed and D variable. Before the experiment, the data D are unknown, and the probability
Chapter 20: Logistic regression for binary response variables
 Chapter 20: Logistic regression for binary response variables In 1846, the Donner and Reed families left Illinois for California by covered wagon (87 people, 20 wagons). They attempted a new and untried
Chapter 20: Logistic regression for binary response variables In 1846, the Donner and Reed families left Illinois for California by covered wagon (87 people, 20 wagons). They attempted a new and untried
HOMEWORK #4: LOGISTIC REGRESSION
 HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2019 Due: 11am Monday, February 25th, 2019 Submit scan of plots/written responses to Gradebook; submit your
HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2019 Due: 11am Monday, February 25th, 2019 Submit scan of plots/written responses to Gradebook; submit your
Logistic regression and linear classifiers COMS 4771
 Logistic regression and linear classifiers COMS 4771 1. Prediction functions (again) Learning prediction functions IID model for supervised learning: (X 1, Y 1),..., (X n, Y n), (X, Y ) are iid random
Logistic regression and linear classifiers COMS 4771 1. Prediction functions (again) Learning prediction functions IID model for supervised learning: (X 1, Y 1),..., (X n, Y n), (X, Y ) are iid random
Bayesian Learning (II)
") Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet.
 or two-page (one side) crib sheet.") CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please