Lecture 5: GMM Acoustic Modeling and Feature Extraction
|
|
|
- Miranda Lucas
- 5 years ago
- Views:
Transcription
1 CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 5: GMM Acoustic Modeling and Feature Extraction Original slides by Dan Jurafsky
2 Outline for Today Acoustic Model Acoustic likelihood for each state using Gaussians and Mixtures of Gaussians Where a state is progressively: CI Subphone (3ish per phone) Context Dependent (CD) phone (=triphones) State-tying of CD phone MFCC feature extraction Handling variation MLLR adaptation MAP adaptation (On your own)
3 Vector quantization: Discrete observations feature value 2 for state j feature value 1 for state j Slide from John-Paul Hosum
4 VQ We ll define a Codebook, which lists for each symbol A prototype vector, or codeword If we had 256 classes ( 8-bit VQ ), A codebook with 256 prototype vectors Given an incoming feature vector, we compare it to each of the 256 prototype vectors We pick whichever one is closest (by some distance metric) And replace the input vector by the index of this prototype vector
5 Vector Quantization Create a training set of feature vectors Cluster them into a small number of classes Represent each class by a discrete symbol For each class v k, we can compute the probability that it is generated by a given HMM state using Baum-Welch
6 Vector quantization: Discrete observations feature value 2 for state j feature value 1 for state j b j (v k ) = number of vectors with codebook index k in state j number of vectors in state j 14 1 = = 56 4 Slide from John-Paul Hosum
7 Directly Modeling Continuous Observations Gaussians Univariate Gaussians Baum-Welch for univariate Gaussians Multivariate Gaussians Baum-Welch for multivariate Gausians Gaussian Mixture Models (GMMs) Baum-Welch for GMMs
8 Better than VQ VQ is insufficient for real ASR Instead: Assume the possible values of the observation feature vector o t are normally distributed. Represent the observation likelihood function b j (o t ) as a Gaussian with mean µ j and variance s j 2 f (x µ,σ) = 1 σ 2π exp( (x µ)2 2σ 2 )
9 Gaussians are parameterized by mean and variance
10 Gaussians for Acoustic Modeling P(o q): A Gaussian parameterized by mean and variance: Different means P(o q) is highest here at mean P(o q) P(o q) low here, far from mean o
11 Using a (univariate) Gaussian as an acoustic likelihood estimator Let s suppose our observation was a single real-valued feature (instead of 39D vector) Then if we had learned a Gaussian over the distribution of values of this feature We could compute the likelihood of any given observation o t as follows:
12 Training a Univariate Gaussian A (single) Gaussian is characterized by a mean and a variance Imagine that we had some training data in which each state was labeled We could just compute the mean and variance from the data: µ i = 1 T T o t s.t. o t is state i t=1 σ i 2 = 1 T T (o t µ i ) 2 s.t. q t is state i t=1
13 Training Univariate Gaussians But we don t know which observation was produced by which state! What we want: to assign each observation vector o t to every possible state i, prorated by the probability the the HMM was in state i at time t. The probability of being in state i at time t is γ t (i)!! µ i = T t=1 T t=1 γ t (i)o t γ t (i) σ 2 i = T t=1 γ t (i)(o t µ i ) 2 T t=1 γ t (i)
14 Multivariate Gaussians Instead of a single mean µ and variance s: f (x µ,σ) = 1 σ 2π exp( (x µ)2 2σ 2 ) Vector of observations x modeled by vector of means µ and covariance matrix S f (x µ,σ) = 1 (2π) D / 2 Σ exp % 1 1/ 2 2 (x ( ' µ)t Σ 1 (x µ) * & )
15 Multivariate Gaussians Defining µ and S µ = E(x) [ ] Σ = E (x µ)(x µ) T So the i-jth element of S is: [ ] σ ij 2 = E (x i µ i )(x j µ j )
![Gaussian Intuitions: Size of S µ = [0 0] µ = [0 0] µ = [0 0] S = I S = 0.](/docs-images/86/94793304/images/16-0.jpg "6I S = 2I As S becomes larger, Gaussian becomes more spread out; as S becomes smaller, Gaussian more compressed")
16 Gaussian Intuitions: Size of S µ = [0 0] µ = [0 0] µ = [0 0] S = I S = 0.6I S = 2I As S becomes larger, Gaussian becomes more spread out; as S becomes smaller, Gaussian more compressed From Andrew Ng s lecture notes for CS229
17 From Chen, Picheny et al lecture slides
![[1 0] [.](/docs-images/86/94793304/images/18-0.jpg "6 0] [0 1] [ 0 2] Different")
18 [1 0] [.6 0] [0 1] [ 0 2] Different variances in different dimensions

19 Gaussian Intuitions: Off-diagonal As we increase the off-diagonal entries, more correlation between value of x and value of y Text and figures from Andrew Ng s lecture notes for CS229
20 Gaussian Intuitions: off-diagonal As we increase the off-diagonal entries, more correlation between value of x and value of y Text and figures from Andrew Ng s lecture notes for CS229
21 Gaussian Intuitions: off-diagonal and diagonal Decreasing non-diagonal entries (#1-2) Increasing variance of one dimension in diagonal (#3) Text and figures from Andrew Ng s lecture notes for CS229
22 In two dimensions From Chen, Picheny et al lecture slides
23 But: assume diagonal covariance I.e., assume that the features in the feature vector are uncorrelated This isn t true for FFT features, but is true for MFCC features, as we will see later. Computation and storage much cheaper if diagonal covariance. I.e. only diagonal entries are non-zero Diagonal contains the variance of each dimension s ii 2 So this means we consider the variance of each acoustic feature (dimension) separately
24 But we re not there yet Single Gaussian may do a bad job of modeling distribution in any dimension: Solution: Mixtures of Gaussians Figure from Chen, Picheney et al slides
25 Mixture of Gaussians to model a function %&* %&) %&( %&' %&! %&" %&# %&$ %!!!"!#!$ % $ # "!
26 GMMs Summary: each state has a likelihood function parameterized by: M Mixture weights M Mean Vectors of dimensionality D Either M Covariance Matrices of DxD Or more likely M Diagonal Covariance Matrices of DxD which is equivalent to M Variance Vectors of dimensionality D

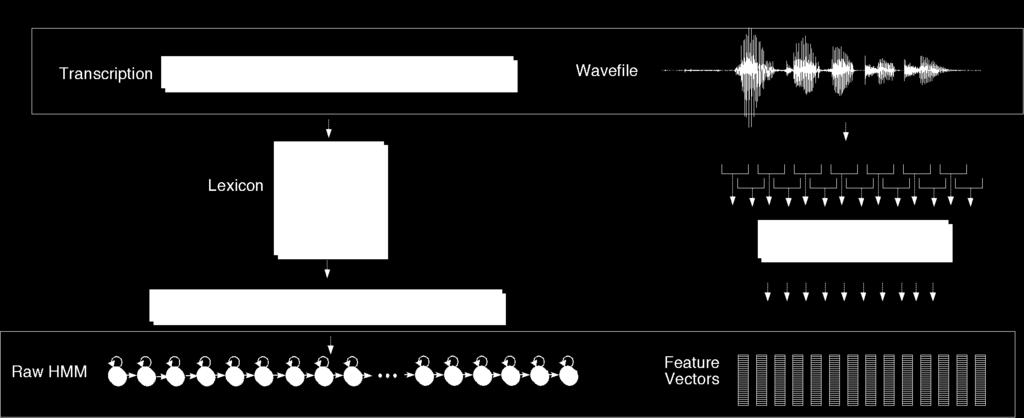
27 Embedded Training
28 Initialization: Flat start Transition probabilities: set to zero any that you want to be structurally zero Set the rest to identical values Likelihoods: initialize µ and s of each state to global mean and variance of all training data
29 Embedded Training Given: phoneset, lexicon, transcribed wavefiles Build a whole sentence HMM for each sentence Initialize A probs to 0.5, or to zero Initialize B probs to global mean and variance Run multiple iterations of Baum Welch During each iteration, we compute forward and backward probabilities Use them to re-estimate A and B Run Baum-Welch until convergence.
30 Viterbi training Baum-Welch training says: We need to know what state we were in, to accumulate counts of a given output symbol o t We ll compute γ i (t), the probability of being in state i at time t, by using forward-backward to sum over all possible paths that might have been in state i and output o t. Viterbi training says: Instead of summing over all possible paths, just take the single most likely path Use the Viterbi algorithm to compute this Viterbi path Via forced alignment
31 Forced Alignment Computing the Viterbi path over the training data is called forced alignment Because we know which word string to assign to each observation sequence. We just don t know the state sequence. So we use a ij to constrain the path to go through the correct words And otherwise do normal Viterbi Result: state sequence!
32 Viterbi training equations Viterbi Baum-Welch a ˆ ij = n ij n i For all pairs of emitting states, 1 <= i, j <= N b ˆ (v ) = n j (s.t.o = v ) t k j k n j γ γ Where n ij is number of frames with transition from i to j in best path And n j is number of frames where state j is occupied
33 Outline for Today Acoustic Model Acoustic likelihood for each state using Gaussians and Mixtures of Gaussians Where a state is progressively: CI Subphone (3ish per phone) Context Dependent (CD) phone (=triphones) State-tying of CD phone MFCC feature extraction Handling variation MLLR adaptation MAP adaptation (On your own)

34 Phonetic context: different eh s w eh d y eh l b eh n
35 Modeling phonetic context The strongest factor affecting phonetic variability is the neighboring phone How to model that in HMMs? Idea: have phone models which are specific to context. Instead of Context-Independent (CI) phones We ll have Context-Dependent (CD) phones
36 CD phones: triphones Triphones Each triphone captures facts about preceding and following phone Monophone: p, t, k Triphone: iy-p+aa a-b+c means phone b, preceding by phone a, followed by phone c
37 Need with triphone models
38 Word-Boundary Modeling Word-Internal Context-Dependent Models OUR LIST : SIL AA+R AA-R L+IH L-IH+S IH-S+T S-T Cross-Word Context-Dependent Models OUR LIST : SIL-AA+R AA-R+L R-L+IH L-IH+S IH-S+T S-T+SIL Dealing with cross-words makes decoding harder!
39 Implications of Cross-Word Triphones Possible triphones: 50x50x50=125,000 How many triphone types actually occur? 20K word WSJ Task, numbers from Young et al Cross-word models: need 55,000 triphones But in training data only 18,500 triphones occur! Need to generalize models

40 Modeling phonetic context: some contexts look similar w iy r iy m iy n iy
41 Solution: State Tying Young, Odell, Woodland 1994 Decision-Tree based clustering of triphone states States which are clustered together will share their Gaussians We call this state tying, since these states are tied together to the same Gaussian.

42 Young et al state tying
43 State tying/clustering How do we decide which triphones to cluster together? Use phonetic features (or broad phonetic classes ) Stop Nasal Fricative Sibilant Vowel Lateral
44 Decision tree for clustering triphones for tying

45 Decision tree for clustering triphones for tying
*!\" +:-.;)3&6.23&3453&6*.#3.#0!453&6* #$!\"%& #$!")
 *$!\"%) <<<.")
46 State Tying: Young, Odell, Woodland ,-./01!&.23&3453&6. *!&')6.718**!1& 2396)*!" +:-.;)3&6.23&3453&6*.#3.#0!453&6* #$!"%& #$!"%&' ($!"%) *$!"%) <<<. +>-.;)8*#60.1&9.#!6. #0!453&6* #$!"%& #$!"%&' ($!"%) *$!"%) <<<. 7BB* #$!"%& #$!"%&' ($!"%) *$!"%) <<<.
47 Summary: Acoustic Modeling for LVCSR Increasingly sophisticated models For each state: Gaussians Multivariate Gaussians Mixtures of Multivariate Gaussians Where a state is progressively: CI Phone CI Subphone (3ish per phone) CD phone (=triphones) State-tying of CD phone Neural network acoustic models after all of the above Viterbi training
48 Summary: ASR Architecture Five easy pieces: ASR Noisy Channel architecture Feature Extraction: 39 MFCC features Acoustic Model: Gaussians for computing p(o q) Lexicon/Pronunciation Model HMM: what phones can follow each other Language Model N-grams for computing p(wi wi-1) Decoder Viterbi algorithm: dynamic programming for combining all these to get word sequence from speech! 64
49 Outline for Today Acoustic Model Acoustic likelihood for each state using Gaussians and Mixtures of Gaussians Where a state is progressively: CI Subphone (3ish per phone) Context Dependent (CD) phone (=triphones) State-tying of CD phone MFCC feature extraction Handling variation MLLR adaptation MAP adaptation (On your own)
50 Discrete Representation of Signal Represent continuous signal into discrete form. Image from Bryan Pellom

51 Sampling Original signal in red: If measure at green dots, will see a lower frequency wave and miss the correct higher frequency one!
52 WAV format Many formats, trade-offs in compression, quality Nice sound manipulation tool: Sox convert speech formats
53 MFCC Mel-Frequency Cepstral Coefficient (MFCC) Most widely used spectral representation in ASR
54 MFCC Mel-Frequency Cepstral Coefficient (MFCC) Most widely used spectral representation in ASR

55 Windowing Image from Bryan Pellom
56 MFCC
57 Discrete Fourier Transform computing a spectrum A 25 ms Hamming-windowed signal from [iy] And its spectrum as computed by DFT (plus other smoothing) Time (s) Sound pressure level (db/hz) Frequency (Hz)
58 MFCC
59 Mel-scale Human hearing is not equally sensitive to all frequency bands Less sensitive at higher frequencies, roughly > 1000 Hz I.e. human perception of frequency is non-linear:
60 Mel Filter Bank Processing Mel Filter bank Roughly uniformly spaced before 1 khz logarithmic scale after 1 khz

61 Mel-filter Bank Processing Apply the bank of Mel-scaled filters to the spectrum Each filter output is the sum of its filtered spectral components
62 MFCC
63 Log energy computation Compute the logarithm of the square magnitude of the output of Mel-filter bank
64 MFCC
65 The Cepstrum One way to think about this Separating the source and filter Speech waveform is created by A glottal source waveform Passes through a vocal tract which because of its shape has a particular filtering characteristic Remember articulatory facts from lecture 2: The vocal cord vibrations create harmonics The mouth is an amplifier Depending on shape of oral cavity, some harmonics are amplified more than others
66 George Miller figure
67 We care about the filter not the source Most characteristics of the source F0 Details of glottal pulse Don t matter for phone detection What we care about is the filter The exact position of the articulators in the oral tract So we want a way to separate these And use only the filter function
68 The Cepstrum The spectrum of the log of the spectrum Spectrum Log spectrum Spectrum of log spectrum
69 Another advantage of the Cepstrum DCT produces highly uncorrelated features If we use only the diagonal covariance matrix for our Gaussian mixture models, we can only handle uncorrelated features. In general we ll just use the first 12 cepstral coefficients (we don t want the later ones which have e.g. the F0 spike)
70 MFCC
71 Delta features Speech signal is not constant slope of formants, change from stop burst to release So in addition to the cepstral features Need to model changes in the cepstral features over time. delta features double delta (acceleration) features
72 Delta and double-delta Derivative: in order to obtain temporal information
73 Typical MFCC features Window size: 25ms Window shift: 10ms Pre-emphasis coefficient: 0.97 MFCC: 12 MFCC (mel frequency cepstral coefficients) 1 energy feature 12 delta MFCC features 12 double-delta MFCC features 1 delta energy feature 1 double-delta energy feature Total 39-dimensional features
74 Why is MFCC so popular? Efficient to compute Incorporates a perceptual Mel frequency scale Separates the source and filter IDFT(DCT) decorrelates the features Necessary for diagonal assumption in HMM modeling There are alternatives like PLP Choice matters less for neural network acoustic models (in future lectures)
75 Outline for Today Acoustic Model Acoustic likelihood for each state using Gaussians and Mixtures of Gaussians Where a state is progressively: CI Subphone (3ish per phone) CD phone (=triphones) State-tying of CD phone MFCC feature extraction Handling variation MLLR adaptation MAP adaptation (On your own)
76 Acoustic Model Adaptation Shift the means and variances of Gaussians to better match the input feature distribution Maximum Likelihood Linear Regression (MLLR) Maximum A Posteriori (MAP) Adaptation For both speaker adaptation and environment adaptation Widely used!
77 Maximum Likelihood Linear Regression (MLLR) Leggetter, C.J. and P. Woodland Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models. Computer Speech and Language 9:2, Given: a trained AM a small adaptation dataset from a new speaker Learn new values for the Gaussian mean vectors Not by just training on the new data (too small) But by learning a linear transform which moves the means.
78 Maximum Likelihood Linear Regression (MLLR) Estimates a linear transform matrix (W) and bias vector (w) to transform HMM model means: µ new = W r µ old + ω r Transform estimated to maximize the likelihood of the adaptation data Slide from Bryan Pellom
79 MLLR New equation for output likelihood b j (o t ) = 1 (2π) n / 2 Σ j exp & 1 1/ 2 2 (o ) ( t (Wµ j + ω)) Σ j 1 (o t (Wµ j + ω)) T + ' *
80 MLLR Q: Why is estimating a linear transform from adaptation data different than just training on the data? A: Even from a very small amount of data we can learn 1 single transform for all triphones! So small number of parameters. A2: If we have enough data, we could learn more transforms (but still less than the number of triphones). One per phone (~50) is often done.
81 MLLR: Learning Given a small labeled adaptation set (a couple sentences) a trained AM Do forward-backward alignment on adaptation set to compute state occupation probabilities γ j (t). W can now be computed by solving a system of simultaneous equations involving γ j (t)
82 MLLR performance on baby task (RM) (Leggetter and Woodland 1995) Only 3 sentences! 11 seconds of speech!
83 MLLR doesn t need supervised adaptation set!
84 Slide from Bryan Pellom
85 Slide from Bryan Pellom after Huang et al
86 Summary MLLR: works on small amounts of adaptation data MAP: Maximum A Posterior Adaptation Works well on large adaptation sets Acoustic adaptation techniques are quite successful at dealing with speaker variability If we can get 10 seconds with the speaker.
The Noisy Channel Model. Statistical NLP Spring Mel Freq. Cepstral Coefficients. Frame Extraction ... Lecture 10: Acoustic Models
 Statistical NLP Spring 2009 The Noisy Channel Model Lecture 10: Acoustic Models Dan Klein UC Berkeley Search through space of all possible sentences. Pick the one that is most probable given the waveform.
Statistical NLP Spring 2009 The Noisy Channel Model Lecture 10: Acoustic Models Dan Klein UC Berkeley Search through space of all possible sentences. Pick the one that is most probable given the waveform.
Statistical NLP Spring The Noisy Channel Model
 Statistical NLP Spring 2009 Lecture 10: Acoustic Models Dan Klein UC Berkeley The Noisy Channel Model Search through space of all possible sentences. Pick the one that is most probable given the waveform.
Statistical NLP Spring 2009 Lecture 10: Acoustic Models Dan Klein UC Berkeley The Noisy Channel Model Search through space of all possible sentences. Pick the one that is most probable given the waveform.
The Noisy Channel Model. CS 294-5: Statistical Natural Language Processing. Speech Recognition Architecture. Digitizing Speech
 CS 294-5: Statistical Natural Language Processing The Noisy Channel Model Speech Recognition II Lecture 21: 11/29/05 Search through space of all possible sentences. Pick the one that is most probable given
CS 294-5: Statistical Natural Language Processing The Noisy Channel Model Speech Recognition II Lecture 21: 11/29/05 Search through space of all possible sentences. Pick the one that is most probable given
Statistical NLP Spring Digitizing Speech
 Statistical NLP Spring 2008 Lecture 10: Acoustic Models Dan Klein UC Berkeley Digitizing Speech 1 Frame Extraction A frame (25 ms wide) extracted every 10 ms 25 ms 10ms... a 1 a 2 a 3 Figure from Simon
Statistical NLP Spring 2008 Lecture 10: Acoustic Models Dan Klein UC Berkeley Digitizing Speech 1 Frame Extraction A frame (25 ms wide) extracted every 10 ms 25 ms 10ms... a 1 a 2 a 3 Figure from Simon
Digitizing Speech. Statistical NLP Spring Frame Extraction. Gaussian Emissions. Vector Quantization. HMMs for Continuous Observations? ...
 Statistical NLP Spring 2008 Digitizing Speech Lecture 10: Acoustic Models Dan Klein UC Berkeley Frame Extraction A frame (25 ms wide extracted every 10 ms 25 ms 10ms... a 1 a 2 a 3 Figure from Simon Arnfield
Statistical NLP Spring 2008 Digitizing Speech Lecture 10: Acoustic Models Dan Klein UC Berkeley Frame Extraction A frame (25 ms wide extracted every 10 ms 25 ms 10ms... a 1 a 2 a 3 Figure from Simon Arnfield
The Noisy Channel Model. Statistical NLP Spring Mel Freq. Cepstral Coefficients. Frame Extraction ... Lecture 9: Acoustic Models
 Statistical NLP Spring 2010 The Noisy Channel Model Lecture 9: Acoustic Models Dan Klein UC Berkeley Acoustic model: HMMs over word positions with mixtures of Gaussians as emissions Language model: Distributions
Statistical NLP Spring 2010 The Noisy Channel Model Lecture 9: Acoustic Models Dan Klein UC Berkeley Acoustic model: HMMs over word positions with mixtures of Gaussians as emissions Language model: Distributions
Speech and Language Processing. Chapter 9 of SLP Automatic Speech Recognition (II)
") Speech and Language Processing Chapter 9 of SLP Automatic Speech Recognition (II) Outline for ASR ASR Architecture The Noisy Channel Model Five easy pieces of an ASR system 1) Language Model 2) Lexicon/Pronunciation
Speech and Language Processing Chapter 9 of SLP Automatic Speech Recognition (II) Outline for ASR ASR Architecture The Noisy Channel Model Five easy pieces of an ASR system 1) Language Model 2) Lexicon/Pronunciation
CS 136 Lecture 5 Acoustic modeling Phoneme modeling
 + September 9, 2016 Professor Meteer CS 136 Lecture 5 Acoustic modeling Phoneme modeling Thanks to Dan Jurafsky for these slides + Directly Modeling Continuous Observations n Gaussians n Univariate Gaussians
+ September 9, 2016 Professor Meteer CS 136 Lecture 5 Acoustic modeling Phoneme modeling Thanks to Dan Jurafsky for these slides + Directly Modeling Continuous Observations n Gaussians n Univariate Gaussians
CS 136a Lecture 7 Speech Recognition Architecture: Training models with the Forward backward algorithm
 + September13, 2016 Professor Meteer CS 136a Lecture 7 Speech Recognition Architecture: Training models with the Forward backward algorithm Thanks to Dan Jurafsky for these slides + ASR components n Feature
+ September13, 2016 Professor Meteer CS 136a Lecture 7 Speech Recognition Architecture: Training models with the Forward backward algorithm Thanks to Dan Jurafsky for these slides + ASR components n Feature
Lecture 3: ASR: HMMs, Forward, Viterbi
 Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Speech Recognition. CS 294-5: Statistical Natural Language Processing. State-of-the-Art: Recognition. ASR for Dialog Systems.
 CS 294-5: Statistical Natural Language Processing Speech Recognition Lecture 20: 11/22/05 Slides directly from Dan Jurafsky, indirectly many others Speech Recognition Overview: Demo Phonetics Articulatory
CS 294-5: Statistical Natural Language Processing Speech Recognition Lecture 20: 11/22/05 Slides directly from Dan Jurafsky, indirectly many others Speech Recognition Overview: Demo Phonetics Articulatory
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (CS753) Lecture 12: Acoustic Feature Extraction for ASR Instructor: Preethi Jyothi Feb 13, 2017 Speech Signal Analysis Generate discrete samples A frame Need to focus on short
Automatic Speech Recognition (CS753) Lecture 12: Acoustic Feature Extraction for ASR Instructor: Preethi Jyothi Feb 13, 2017 Speech Signal Analysis Generate discrete samples A frame Need to focus on short
University of Cambridge. MPhil in Computer Speech Text & Internet Technology. Module: Speech Processing II. Lecture 2: Hidden Markov Models I
 University of Cambridge MPhil in Computer Speech Text & Internet Technology Module: Speech Processing II Lecture 2: Hidden Markov Models I o o o o o 1 2 3 4 T 1 b 2 () a 12 2 a 3 a 4 5 34 a 23 b () b ()
University of Cambridge MPhil in Computer Speech Text & Internet Technology Module: Speech Processing II Lecture 2: Hidden Markov Models I o o o o o 1 2 3 4 T 1 b 2 () a 12 2 a 3 a 4 5 34 a 23 b () b ()
Hidden Markov Models and Gaussian Mixture Models
 Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 23&27 January 2014 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 23&27 January 2014 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Chapter 9 Automatic Speech Recognition DRAFT
 P R E L I M I N A R Y P R O O F S. Unpublished Work c 2008 by Pearson Education, Inc. To be published by Pearson Prentice Hall, Pearson Education, Inc., Upper Saddle River, New Jersey. All rights reserved.
P R E L I M I N A R Y P R O O F S. Unpublished Work c 2008 by Pearson Education, Inc. To be published by Pearson Prentice Hall, Pearson Education, Inc., Upper Saddle River, New Jersey. All rights reserved.
Signal Modeling Techniques in Speech Recognition. Hassan A. Kingravi
 Signal Modeling Techniques in Speech Recognition Hassan A. Kingravi Outline Introduction Spectral Shaping Spectral Analysis Parameter Transforms Statistical Modeling Discussion Conclusions 1: Introduction
Signal Modeling Techniques in Speech Recognition Hassan A. Kingravi Outline Introduction Spectral Shaping Spectral Analysis Parameter Transforms Statistical Modeling Discussion Conclusions 1: Introduction
Estimation of Cepstral Coefficients for Robust Speech Recognition
 Estimation of Cepstral Coefficients for Robust Speech Recognition by Kevin M. Indrebo, B.S., M.S. A Dissertation submitted to the Faculty of the Graduate School, Marquette University, in Partial Fulfillment
Estimation of Cepstral Coefficients for Robust Speech Recognition by Kevin M. Indrebo, B.S., M.S. A Dissertation submitted to the Faculty of the Graduate School, Marquette University, in Partial Fulfillment
Reformulating the HMM as a trajectory model by imposing explicit relationship between static and dynamic features
 Reformulating the HMM as a trajectory model by imposing explicit relationship between static and dynamic features Heiga ZEN (Byung Ha CHUN) Nagoya Inst. of Tech., Japan Overview. Research backgrounds 2.
Reformulating the HMM as a trajectory model by imposing explicit relationship between static and dynamic features Heiga ZEN (Byung Ha CHUN) Nagoya Inst. of Tech., Japan Overview. Research backgrounds 2.
Hidden Markov Models and Gaussian Mixture Models
 Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 25&29 January 2018 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 25&29 January 2018 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Hidden Markov Model and Speech Recognition
 1 Dec,2006 Outline Introduction 1 Introduction 2 3 4 5 Introduction What is Speech Recognition? Understanding what is being said Mapping speech data to textual information Speech Recognition is indeed
1 Dec,2006 Outline Introduction 1 Introduction 2 3 4 5 Introduction What is Speech Recognition? Understanding what is being said Mapping speech data to textual information Speech Recognition is indeed
Experiments with a Gaussian Merging-Splitting Algorithm for HMM Training for Speech Recognition
 Experiments with a Gaussian Merging-Splitting Algorithm for HMM Training for Speech Recognition ABSTRACT It is well known that the expectation-maximization (EM) algorithm, commonly used to estimate hidden
Experiments with a Gaussian Merging-Splitting Algorithm for HMM Training for Speech Recognition ABSTRACT It is well known that the expectation-maximization (EM) algorithm, commonly used to estimate hidden
10. Hidden Markov Models (HMM) for Speech Processing. (some slides taken from Glass and Zue course)
 for Speech Processing. (some slides taken from Glass and Zue course)") 10. Hidden Markov Models (HMM) for Speech Processing (some slides taken from Glass and Zue course) Definition of an HMM The HMM are powerful statistical methods to characterize the observed samples of
10. Hidden Markov Models (HMM) for Speech Processing (some slides taken from Glass and Zue course) Definition of an HMM The HMM are powerful statistical methods to characterize the observed samples of
Hidden Markov Modelling
 Hidden Markov Modelling Introduction Problem formulation Forward-Backward algorithm Viterbi search Baum-Welch parameter estimation Other considerations Multiple observation sequences Phone-based models
Hidden Markov Modelling Introduction Problem formulation Forward-Backward algorithm Viterbi search Baum-Welch parameter estimation Other considerations Multiple observation sequences Phone-based models
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (CS753) Lecture 21: Speaker Adaptation Instructor: Preethi Jyothi Oct 23, 2017 Speaker variations Major cause of variability in speech is the differences between speakers Speaking
Automatic Speech Recognition (CS753) Lecture 21: Speaker Adaptation Instructor: Preethi Jyothi Oct 23, 2017 Speaker variations Major cause of variability in speech is the differences between speakers Speaking
Feature extraction 2
 Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Feature extraction 2 Dr Philip Jackson Linear prediction Perceptual linear prediction Comparison of feature methods
Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Feature extraction 2 Dr Philip Jackson Linear prediction Perceptual linear prediction Comparison of feature methods
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Speech Signal Representations
 Speech Signal Representations Berlin Chen 2003 References: 1. X. Huang et. al., Spoken Language Processing, Chapters 5, 6 2. J. R. Deller et. al., Discrete-Time Processing of Speech Signals, Chapters 4-6
Speech Signal Representations Berlin Chen 2003 References: 1. X. Huang et. al., Spoken Language Processing, Chapters 5, 6 2. J. R. Deller et. al., Discrete-Time Processing of Speech Signals, Chapters 4-6
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (CS753) Lecture 6: Hidden Markov Models (Part II) Instructor: Preethi Jyothi Aug 10, 2017 Recall: Computing Likelihood Problem 1 (Likelihood): Given an HMM l =(A, B) and an
Automatic Speech Recognition (CS753) Lecture 6: Hidden Markov Models (Part II) Instructor: Preethi Jyothi Aug 10, 2017 Recall: Computing Likelihood Problem 1 (Likelihood): Given an HMM l =(A, B) and an
On the Influence of the Delta Coefficients in a HMM-based Speech Recognition System
 On the Influence of the Delta Coefficients in a HMM-based Speech Recognition System Fabrice Lefèvre, Claude Montacié and Marie-José Caraty Laboratoire d'informatique de Paris VI 4, place Jussieu 755 PARIS
On the Influence of the Delta Coefficients in a HMM-based Speech Recognition System Fabrice Lefèvre, Claude Montacié and Marie-José Caraty Laboratoire d'informatique de Paris VI 4, place Jussieu 755 PARIS
Lecture 9: Speech Recognition. Recognizing Speech
 EE E68: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 3 4 Recognizing Speech Feature Calculation Sequence Recognition Hidden Markov Models Dan Ellis http://www.ee.columbia.edu/~dpwe/e68/
EE E68: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 3 4 Recognizing Speech Feature Calculation Sequence Recognition Hidden Markov Models Dan Ellis http://www.ee.columbia.edu/~dpwe/e68/
Lecture 9: Speech Recognition
 EE E682: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 2 3 4 Recognizing Speech Feature Calculation Sequence Recognition Hidden Markov Models Dan Ellis
EE E682: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 2 3 4 Recognizing Speech Feature Calculation Sequence Recognition Hidden Markov Models Dan Ellis
Engineering Part IIB: Module 4F11 Speech and Language Processing Lectures 4/5 : Speech Recognition Basics
 Engineering Part IIB: Module 4F11 Speech and Language Processing Lectures 4/5 : Speech Recognition Basics Phil Woodland: pcw@eng.cam.ac.uk Lent 2013 Engineering Part IIB: Module 4F11 What is Speech Recognition?
Engineering Part IIB: Module 4F11 Speech and Language Processing Lectures 4/5 : Speech Recognition Basics Phil Woodland: pcw@eng.cam.ac.uk Lent 2013 Engineering Part IIB: Module 4F11 What is Speech Recognition?
Robust Speaker Identification
 Robust Speaker Identification by Smarajit Bose Interdisciplinary Statistical Research Unit Indian Statistical Institute, Kolkata Joint work with Amita Pal and Ayanendranath Basu Overview } } } } } } }
Robust Speaker Identification by Smarajit Bose Interdisciplinary Statistical Research Unit Indian Statistical Institute, Kolkata Joint work with Amita Pal and Ayanendranath Basu Overview } } } } } } }
Deep Learning for Speech Recognition. Hung-yi Lee
 Deep Learning for Speech Recognition Hung-yi Lee Outline Conventional Speech Recognition How to use Deep Learning in acoustic modeling? Why Deep Learning? Speaker Adaptation Multi-task Deep Learning New
Deep Learning for Speech Recognition Hung-yi Lee Outline Conventional Speech Recognition How to use Deep Learning in acoustic modeling? Why Deep Learning? Speaker Adaptation Multi-task Deep Learning New
Temporal Modeling and Basic Speech Recognition
 UNIVERSITY ILLINOIS @ URBANA-CHAMPAIGN OF CS 498PS Audio Computing Lab Temporal Modeling and Basic Speech Recognition Paris Smaragdis paris@illinois.edu paris.cs.illinois.edu Today s lecture Recognizing
UNIVERSITY ILLINOIS @ URBANA-CHAMPAIGN OF CS 498PS Audio Computing Lab Temporal Modeling and Basic Speech Recognition Paris Smaragdis paris@illinois.edu paris.cs.illinois.edu Today s lecture Recognizing
Discriminative models for speech recognition
 Discriminative models for speech recognition Anton Ragni Peterhouse University of Cambridge A thesis submitted for the degree of Doctor of Philosophy 2013 Declaration This dissertation is the result of
Discriminative models for speech recognition Anton Ragni Peterhouse University of Cambridge A thesis submitted for the degree of Doctor of Philosophy 2013 Declaration This dissertation is the result of
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
ON THE USE OF MLP-DISTANCE TO ESTIMATE POSTERIOR PROBABILITIES BY KNN FOR SPEECH RECOGNITION
 Zaragoza Del 8 al 1 de Noviembre de 26 ON THE USE OF MLP-DISTANCE TO ESTIMATE POSTERIOR PROBABILITIES BY KNN FOR SPEECH RECOGNITION Ana I. García Moral, Carmen Peláez Moreno EPS-Universidad Carlos III
Zaragoza Del 8 al 1 de Noviembre de 26 ON THE USE OF MLP-DISTANCE TO ESTIMATE POSTERIOR PROBABILITIES BY KNN FOR SPEECH RECOGNITION Ana I. García Moral, Carmen Peláez Moreno EPS-Universidad Carlos III
CS 188: Artificial Intelligence Fall 2011
 CS 188: Artificial Intelligence Fall 2011 Lecture 20: HMMs / Speech / ML 11/8/2011 Dan Klein UC Berkeley Today HMMs Demo bonanza! Most likely explanation queries Speech recognition A massive HMM! Details
CS 188: Artificial Intelligence Fall 2011 Lecture 20: HMMs / Speech / ML 11/8/2011 Dan Klein UC Berkeley Today HMMs Demo bonanza! Most likely explanation queries Speech recognition A massive HMM! Details
Machine Learning for Data Science (CS4786) Lecture 12
 Lecture 12") Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Hidden Markov Models
 Hidden Markov Models Dr Philip Jackson Centre for Vision, Speech & Signal Processing University of Surrey, UK 1 3 2 http://www.ee.surrey.ac.uk/personal/p.jackson/isspr/ Outline 1. Recognizing patterns
Hidden Markov Models Dr Philip Jackson Centre for Vision, Speech & Signal Processing University of Surrey, UK 1 3 2 http://www.ee.surrey.ac.uk/personal/p.jackson/isspr/ Outline 1. Recognizing patterns
Augmented Statistical Models for Speech Recognition
 Augmented Statistical Models for Speech Recognition Mark Gales & Martin Layton 31 August 2005 Trajectory Models For Speech Processing Workshop Overview Dependency Modelling in Speech Recognition: latent
Augmented Statistical Models for Speech Recognition Mark Gales & Martin Layton 31 August 2005 Trajectory Models For Speech Processing Workshop Overview Dependency Modelling in Speech Recognition: latent
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (CS753) Lecture 8: Tied state HMMs + DNNs in ASR Instructor: Preethi Jyothi Aug 17, 2017 Final Project Landscape Voice conversion using GANs Musical Note Extraction Keystroke
Automatic Speech Recognition (CS753) Lecture 8: Tied state HMMs + DNNs in ASR Instructor: Preethi Jyothi Aug 17, 2017 Final Project Landscape Voice conversion using GANs Musical Note Extraction Keystroke
GMM Vector Quantization on the Modeling of DHMM for Arabic Isolated Word Recognition System
 GMM Vector Quantization on the Modeling of DHMM for Arabic Isolated Word Recognition System Snani Cherifa 1, Ramdani Messaoud 1, Zermi Narima 1, Bourouba Houcine 2 1 Laboratoire d Automatique et Signaux
GMM Vector Quantization on the Modeling of DHMM for Arabic Isolated Word Recognition System Snani Cherifa 1, Ramdani Messaoud 1, Zermi Narima 1, Bourouba Houcine 2 1 Laboratoire d Automatique et Signaux
SPEECH RECOGNITION USING TIME DOMAIN FEATURES FROM PHASE SPACE RECONSTRUCTIONS
 SPEECH RECOGNITION USING TIME DOMAIN FEATURES FROM PHASE SPACE RECONSTRUCTIONS by Jinjin Ye, B.S. A THESIS SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL IN PARTIAL FULFILLMENT OF THE REQUIREMENTS for
SPEECH RECOGNITION USING TIME DOMAIN FEATURES FROM PHASE SPACE RECONSTRUCTIONS by Jinjin Ye, B.S. A THESIS SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL IN PARTIAL FULFILLMENT OF THE REQUIREMENTS for
Deep Learning for Automatic Speech Recognition Part I
 Deep Learning for Automatic Speech Recognition Part I Xiaodong Cui IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Fall, 2018 Outline A brief history of automatic speech recognition Speech
Deep Learning for Automatic Speech Recognition Part I Xiaodong Cui IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Fall, 2018 Outline A brief history of automatic speech recognition Speech
Hidden Markov Models. Aarti Singh Slides courtesy: Eric Xing. Machine Learning / Nov 8, 2010
 Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Linear Prediction 1 / 41
 Linear Prediction 1 / 41 A map of speech signal processing Natural signals Models Artificial signals Inference Speech synthesis Hidden Markov Inference Homomorphic processing Dereverberation, Deconvolution
Linear Prediction 1 / 41 A map of speech signal processing Natural signals Models Artificial signals Inference Speech synthesis Hidden Markov Inference Homomorphic processing Dereverberation, Deconvolution
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Hidden Markov Models. By Parisa Abedi. Slides courtesy: Eric Xing
 Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Dept. of Linguistics, Indiana University Fall 2009
 1 / 14 Markov L645 Dept. of Linguistics, Indiana University Fall 2009 2 / 14 Markov (1) (review) Markov A Markov Model consists of: a finite set of statesω={s 1,...,s n }; an signal alphabetσ={σ 1,...,σ
1 / 14 Markov L645 Dept. of Linguistics, Indiana University Fall 2009 2 / 14 Markov (1) (review) Markov A Markov Model consists of: a finite set of statesω={s 1,...,s n }; an signal alphabetσ={σ 1,...,σ
Lecture 3: Pattern Classification
 EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
L7: Linear prediction of speech
 L7: Linear prediction of speech Introduction Linear prediction Finding the linear prediction coefficients Alternative representations This lecture is based on [Dutoit and Marques, 2009, ch1; Taylor, 2009,
L7: Linear prediction of speech Introduction Linear prediction Finding the linear prediction coefficients Alternative representations This lecture is based on [Dutoit and Marques, 2009, ch1; Taylor, 2009,
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch. COMP-599 Oct 1, 2015
 Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Lecture 3. Gaussian Mixture Models and Introduction to HMM s. Michael Picheny, Bhuvana Ramabhadran, Stanley F. Chen, Markus Nussbaum-Thom
 Lecture 3 Gaussian Mixture Models and Introduction to HMM s Michael Picheny, Bhuvana Ramabhadran, Stanley F. Chen, Markus Nussbaum-Thom Watson Group IBM T.J. Watson Research Center Yorktown Heights, New
Lecture 3 Gaussian Mixture Models and Introduction to HMM s Michael Picheny, Bhuvana Ramabhadran, Stanley F. Chen, Markus Nussbaum-Thom Watson Group IBM T.J. Watson Research Center Yorktown Heights, New
Hidden Markov Models
 Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Using Sub-Phonemic Units for HMM Based Phone Recognition
 Jarle Bauck Hamar Using Sub-Phonemic Units for HMM Based Phone Recognition Thesis for the degree of Philosophiae Doctor Trondheim, June 2013 Norwegian University of Science and Technology Faculty of Information
Jarle Bauck Hamar Using Sub-Phonemic Units for HMM Based Phone Recognition Thesis for the degree of Philosophiae Doctor Trondheim, June 2013 Norwegian University of Science and Technology Faculty of Information
HIDDEN MARKOV MODELS IN SPEECH RECOGNITION
 HIDDEN MARKOV MODELS IN SPEECH RECOGNITION Wayne Ward Carnegie Mellon University Pittsburgh, PA 1 Acknowledgements Much of this talk is derived from the paper "An Introduction to Hidden Markov Models",
HIDDEN MARKOV MODELS IN SPEECH RECOGNITION Wayne Ward Carnegie Mellon University Pittsburgh, PA 1 Acknowledgements Much of this talk is derived from the paper "An Introduction to Hidden Markov Models",
Acoustic Modeling for Speech Recognition
 Acoustic Modeling for Speech Recognition Berlin Chen 2004 References:. X. Huang et. al. Spoken Language Processing. Chapter 8 2. S. Young. The HTK Book (HTK Version 3.2) Introduction For the given acoustic
Acoustic Modeling for Speech Recognition Berlin Chen 2004 References:. X. Huang et. al. Spoken Language Processing. Chapter 8 2. S. Young. The HTK Book (HTK Version 3.2) Introduction For the given acoustic
T Automatic Speech Recognition: From Theory to Practice
 Automatic Speech Recognition: From Theory to Practice http://www.cis.hut.fi/opinnot// September 20, 2004 Prof. Bryan Pellom Department of Computer Science Center for Spoken Language Research University
Automatic Speech Recognition: From Theory to Practice http://www.cis.hut.fi/opinnot// September 20, 2004 Prof. Bryan Pellom Department of Computer Science Center for Spoken Language Research University
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Robust Speech Recognition in the Presence of Additive Noise. Svein Gunnar Storebakken Pettersen
 Robust Speech Recognition in the Presence of Additive Noise Svein Gunnar Storebakken Pettersen A Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree of PHILOSOPHIAE DOCTOR
Robust Speech Recognition in the Presence of Additive Noise Svein Gunnar Storebakken Pettersen A Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree of PHILOSOPHIAE DOCTOR
Design and Implementation of Speech Recognition Systems
 Design and Implementation of Speech Recognition Systems Spring 2013 Class 7: Templates to HMMs 13 Feb 2013 1 Recap Thus far, we have looked at dynamic programming for string matching, And derived DTW from
Design and Implementation of Speech Recognition Systems Spring 2013 Class 7: Templates to HMMs 13 Feb 2013 1 Recap Thus far, we have looked at dynamic programming for string matching, And derived DTW from
Covariance Matrix Enhancement Approach to Train Robust Gaussian Mixture Models of Speech Data
 Covariance Matrix Enhancement Approach to Train Robust Gaussian Mixture Models of Speech Data Jan Vaněk, Lukáš Machlica, Josef V. Psutka, Josef Psutka University of West Bohemia in Pilsen, Univerzitní
Covariance Matrix Enhancement Approach to Train Robust Gaussian Mixture Models of Speech Data Jan Vaněk, Lukáš Machlica, Josef V. Psutka, Josef Psutka University of West Bohemia in Pilsen, Univerzitní
Speech Recognition HMM
 Speech Recognition HMM Jan Černocký, Valentina Hubeika {cernocky ihubeika}@fit.vutbr.cz FIT BUT Brno Speech Recognition HMM Jan Černocký, Valentina Hubeika, DCGM FIT BUT Brno 1/38 Agenda Recap variability
Speech Recognition HMM Jan Černocký, Valentina Hubeika {cernocky ihubeika}@fit.vutbr.cz FIT BUT Brno Speech Recognition HMM Jan Černocký, Valentina Hubeika, DCGM FIT BUT Brno 1/38 Agenda Recap variability
Machine Learning for natural language processing
 Machine Learning for natural language processing Hidden Markov Models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 33 Introduction So far, we have classified texts/observations
Machine Learning for natural language processing Hidden Markov Models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 33 Introduction So far, we have classified texts/observations
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
Feature extraction 1
 Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Feature extraction 1 Dr Philip Jackson Cepstral analysis - Real & complex cepstra - Homomorphic decomposition Filter
Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Feature extraction 1 Dr Philip Jackson Cepstral analysis - Real & complex cepstra - Homomorphic decomposition Filter
An Introduction to Bioinformatics Algorithms Hidden Markov Models
 Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
ISOLATED WORD RECOGNITION FOR ENGLISH LANGUAGE USING LPC,VQ AND HMM
 ISOLATED WORD RECOGNITION FOR ENGLISH LANGUAGE USING LPC,VQ AND HMM Mayukh Bhaowal and Kunal Chawla (Students)Indian Institute of Information Technology, Allahabad, India Abstract: Key words: Speech recognition
ISOLATED WORD RECOGNITION FOR ENGLISH LANGUAGE USING LPC,VQ AND HMM Mayukh Bhaowal and Kunal Chawla (Students)Indian Institute of Information Technology, Allahabad, India Abstract: Key words: Speech recognition
Jorge Silva and Shrikanth Narayanan, Senior Member, IEEE. 1 is the probability measure induced by the probability density function
 890 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Average Divergence Distance as a Statistical Discrimination Measure for Hidden Markov Models Jorge Silva and Shrikanth
890 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Average Divergence Distance as a Statistical Discrimination Measure for Hidden Markov Models Jorge Silva and Shrikanth
COMP 546, Winter 2018 lecture 19 - sound 2
 Sound waves Last lecture we considered sound to be a pressure function I(X, Y, Z, t). However, sound is not just any function of those four variables. Rather, sound obeys the wave equation: 2 I(X, Y, Z,
Sound waves Last lecture we considered sound to be a pressure function I(X, Y, Z, t). However, sound is not just any function of those four variables. Rather, sound obeys the wave equation: 2 I(X, Y, Z,
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
Comparing linear and non-linear transformation of speech
 Comparing linear and non-linear transformation of speech Larbi Mesbahi, Vincent Barreaud and Olivier Boeffard IRISA / ENSSAT - University of Rennes 1 6, rue de Kerampont, Lannion, France {lmesbahi, vincent.barreaud,
Comparing linear and non-linear transformation of speech Larbi Mesbahi, Vincent Barreaud and Olivier Boeffard IRISA / ENSSAT - University of Rennes 1 6, rue de Kerampont, Lannion, France {lmesbahi, vincent.barreaud,
Chapter 9. Linear Predictive Analysis of Speech Signals 语音信号的线性预测分析
 Chapter 9 Linear Predictive Analysis of Speech Signals 语音信号的线性预测分析 1 LPC Methods LPC methods are the most widely used in speech coding, speech synthesis, speech recognition, speaker recognition and verification
Chapter 9 Linear Predictive Analysis of Speech Signals 语音信号的线性预测分析 1 LPC Methods LPC methods are the most widely used in speech coding, speech synthesis, speech recognition, speaker recognition and verification
Pair Hidden Markov Models
 Pair Hidden Markov Models Scribe: Rishi Bedi Lecturer: Serafim Batzoglou January 29, 2015 1 Recap of HMMs alphabet: Σ = {b 1,...b M } set of states: Q = {1,..., K} transition probabilities: A = [a ij ]
Pair Hidden Markov Models Scribe: Rishi Bedi Lecturer: Serafim Batzoglou January 29, 2015 1 Recap of HMMs alphabet: Σ = {b 1,...b M } set of states: Q = {1,..., K} transition probabilities: A = [a ij ]
Statistical Sequence Recognition and Training: An Introduction to HMMs
 Statistical Sequence Recognition and Training: An Introduction to HMMs EECS 225D Nikki Mirghafori nikki@icsi.berkeley.edu March 7, 2005 Credit: many of the HMM slides have been borrowed and adapted, with
Statistical Sequence Recognition and Training: An Introduction to HMMs EECS 225D Nikki Mirghafori nikki@icsi.berkeley.edu March 7, 2005 Credit: many of the HMM slides have been borrowed and adapted, with
CISC 889 Bioinformatics (Spring 2004) Hidden Markov Models (II)
 Hidden Markov Models (II)") CISC 889 Bioinformatics (Spring 24) Hidden Markov Models (II) a. Likelihood: forward algorithm b. Decoding: Viterbi algorithm c. Model building: Baum-Welch algorithm Viterbi training Hidden Markov models
CISC 889 Bioinformatics (Spring 24) Hidden Markov Models (II) a. Likelihood: forward algorithm b. Decoding: Viterbi algorithm c. Model building: Baum-Welch algorithm Viterbi training Hidden Markov models
Around the Speaker De-Identification (Speaker diarization for de-identification ++) Itshak Lapidot Moez Ajili Jean-Francois Bonastre
 Itshak Lapidot Moez Ajili Jean-Francois Bonastre") Around the Speaker De-Identification (Speaker diarization for de-identification ++) Itshak Lapidot Moez Ajili Jean-Francois Bonastre The 2 Parts HDM based diarization System The homogeneity measure 2 Outline
Around the Speaker De-Identification (Speaker diarization for de-identification ++) Itshak Lapidot Moez Ajili Jean-Francois Bonastre The 2 Parts HDM based diarization System The homogeneity measure 2 Outline
EECS E6870: Lecture 4: Hidden Markov Models
 EECS E6870: Lecture 4: Hidden Markov Models Stanley F. Chen, Michael A. Picheny and Bhuvana Ramabhadran IBM T. J. Watson Research Center Yorktown Heights, NY 10549 stanchen@us.ibm.com, picheny@us.ibm.com,
EECS E6870: Lecture 4: Hidden Markov Models Stanley F. Chen, Michael A. Picheny and Bhuvana Ramabhadran IBM T. J. Watson Research Center Yorktown Heights, NY 10549 stanchen@us.ibm.com, picheny@us.ibm.com,
Hidden Markov Models
 CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
Recap: HMM. ANLP Lecture 9: Algorithms for HMMs. More general notation. Recap: HMM. Elements of HMM: Sharon Goldwater 4 Oct 2018.
 Recap: HMM ANLP Lecture 9: Algorithms for HMMs Sharon Goldwater 4 Oct 2018 Elements of HMM: Set of states (tags) Output alphabet (word types) Start state (beginning of sentence) State transition probabilities
Recap: HMM ANLP Lecture 9: Algorithms for HMMs Sharon Goldwater 4 Oct 2018 Elements of HMM: Set of states (tags) Output alphabet (word types) Start state (beginning of sentence) State transition probabilities
Semi-Supervised Learning of Speech Sounds
 Aren Jansen Partha Niyogi Department of Computer Science Interspeech 2007 Objectives 1 Present a manifold learning algorithm based on locality preserving projections for semi-supervised phone classification
Aren Jansen Partha Niyogi Department of Computer Science Interspeech 2007 Objectives 1 Present a manifold learning algorithm based on locality preserving projections for semi-supervised phone classification
Lecture 7: Feature Extraction
 Lecture 7: Feature Extraction Kai Yu SpeechLab Department of Computer Science & Engineering Shanghai Jiao Tong University Autumn 2014 Kai Yu Lecture 7: Feature Extraction SJTU Speech Lab 1 / 28 Table of
Lecture 7: Feature Extraction Kai Yu SpeechLab Department of Computer Science & Engineering Shanghai Jiao Tong University Autumn 2014 Kai Yu Lecture 7: Feature Extraction SJTU Speech Lab 1 / 28 Table of
TinySR. Peter Schmidt-Nielsen. August 27, 2014
 TinySR Peter Schmidt-Nielsen August 27, 2014 Abstract TinySR is a light weight real-time small vocabulary speech recognizer written entirely in portable C. The library fits in a single file (plus header),
TinySR Peter Schmidt-Nielsen August 27, 2014 Abstract TinySR is a light weight real-time small vocabulary speech recognizer written entirely in portable C. The library fits in a single file (plus header),
Hidden Markov Models
 Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Speech Recognition. Department of Computer Science & Information Engineering National Taiwan Normal University. References:
 Acoustic Modeling for Speech Recognition Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References:. X. Huang et. al. Spoken Language age Processing.
Acoustic Modeling for Speech Recognition Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References:. X. Huang et. al. Spoken Language age Processing.
CHAPTER 8 Viterbi Decoding of Convolutional Codes
 MIT 6.02 DRAFT Lecture Notes Fall 2011 (Last update: October 9, 2011) Comments, questions or bug reports? Please contact hari at mit.edu CHAPTER 8 Viterbi Decoding of Convolutional Codes This chapter describes
MIT 6.02 DRAFT Lecture Notes Fall 2011 (Last update: October 9, 2011) Comments, questions or bug reports? Please contact hari at mit.edu CHAPTER 8 Viterbi Decoding of Convolutional Codes This chapter describes
An Evolutionary Programming Based Algorithm for HMM training
 An Evolutionary Programming Based Algorithm for HMM training Ewa Figielska,Wlodzimierz Kasprzak Institute of Control and Computation Engineering, Warsaw University of Technology ul. Nowowiejska 15/19,
An Evolutionary Programming Based Algorithm for HMM training Ewa Figielska,Wlodzimierz Kasprzak Institute of Control and Computation Engineering, Warsaw University of Technology ul. Nowowiejska 15/19,
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Sound 2: frequency analysis
 COMP 546 Lecture 19 Sound 2: frequency analysis Tues. March 27, 2018 1 Speed of Sound Sound travels at about 340 m/s, or 34 cm/ ms. (This depends on temperature and other factors) 2 Wave equation Pressure
COMP 546 Lecture 19 Sound 2: frequency analysis Tues. March 27, 2018 1 Speed of Sound Sound travels at about 340 m/s, or 34 cm/ ms. (This depends on temperature and other factors) 2 Wave equation Pressure
Hidden Markov models
 Hidden Markov models Charles Elkan November 26, 2012 Important: These lecture notes are based on notes written by Lawrence Saul. Also, these typeset notes lack illustrations. See the classroom lectures
Hidden Markov models Charles Elkan November 26, 2012 Important: These lecture notes are based on notes written by Lawrence Saul. Also, these typeset notes lack illustrations. See the classroom lectures
ELEN E Topics in Signal Processing Topic: Speech Recognition Lecture 9
 ELEN E6884 - Topics in Signal Processing Topic: Speech Recognition Lecture 9 Stanley F. Chen, Ellen Eide, and Michael A. Picheny IBM T.J. Watson Research Center Yorktown Heights, NY, USA stanchen@us.ibm.com,
ELEN E6884 - Topics in Signal Processing Topic: Speech Recognition Lecture 9 Stanley F. Chen, Ellen Eide, and Michael A. Picheny IBM T.J. Watson Research Center Yorktown Heights, NY, USA stanchen@us.ibm.com,
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging
 Tagging") ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Lecture 3: Pattern Classification. Pattern classification
 EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and