Automatic Speech Recognition (CS753)
|
|
|
- Dina White
- 5 years ago
- Views:
Transcription
 Lecture 6: Hidden")

1 Automatic Speech Recognition (CS753) Lecture 6: Hidden Markov Models (Part II) Instructor: Preethi Jyothi Aug 10, 2017
2 Recall: Computing Likelihood Problem 1 (Likelihood): Given an HMM l =(A, B) and an observation sequence O, determine the likelihood P(O l). Problem 2 (Decoding): Given an observation sequence O and an HMM l = (A,B), discover the best hidden state sequence Q. Problem 3 (Learning): Given an observation sequence O and the set of states in the HMM, learn the HMM parameters A and B. Computing Likelihood: Given an HMM l =(A,B) and an observation sequence O, determine the likelihood P(O l). Use the Forward Algorithm
3 Recall: Decoding best state sequence Problem 1 (Likelihood): Given an HMM l =(A, B) and an observation sequence O, determine the likelihood P(O l). Problem 2 (Decoding): Given an observation sequence O and an HMM l = (A,B), discover the best hidden state sequence Q. Problem 3 (Learning): Given an observation sequence O and the set of states in the HMM, learn the HMM parameters A and B. Decoding: Given as input an HMM l =(A,B) and a sequence of observations O = o 1,o 2,...,o T, find the most probable sequence of states Q = q 1 q 2 q 3...q T. Use the Viterbi Algorithm
4 Learning HMM Parameters Problem 1 (Likelihood): Given an HMM l =(A, B) and an observation sequence O, determine the likelihood P(O l). Problem 2 (Decoding): Given an observation sequence O and an HMM l = (A,B), discover the best hidden state sequence Q. Problem 3 (Learning): Given an observation sequence O and the set of states in the HMM, learn the HMM parameters A and B. Learning: Given an observation sequence O and the set of possible states in the HMM, learn the HMM parameters A and B. Standard algorithm for HMM training: Forward-backward or Baum-Welch algorithm Before moving on to Baum-Welch, what is the Expectation Maximization algorithm?
5 EM Algorithm: Fitting Parameters to Data Parameter θ determines Pr(x, z; θ) where x is observed and z is hidden Observed data: i.i.d samples xi, i=1,, N Goal: Find arg max L( ) Initial parameters: θ 0 where L( ) = NX i=1 log Pr(x i ; ) Iteratively compute θ l as follows: NX X Q(, ` 1 )= i=1 z Pr(z x i ; ` 1 ) log Pr(x i,z; ) ` = arg max Q(, ` 1 ) Estimate θ l cannot get worse over iterations because for all θ: L( ) L( ` 1 ) Q(, ` 1 ) Q( ` 1, ` 1 ) EM is guaranteed to converge to a local optimum [Wu83]
6 Coin example to illustrate EM Coin 1 Coin 2 Coin 3 ρ1 = Pr(H) ρ2 = Pr(H) ρ3 = Pr(H) Repeat: Toss Coin 1 privately if it shows H: Toss Coin 2 twice else Toss Coin 3 twice The following sequence is observed: HH, TT, HH, TT, HH How do you estimate ρ1, ρ2 and ρ3?
7 Coin example to illustrate EM Recall, for partially observed data, the likelihood is given by: L( ) = NX log Pr(x i ; ) = NX log X z Pr(x i,z; ) i=1 i=1 where, for the coin example: each observation x i X = {HH,HT,TH,TT} the hidden variable z Z = {H,T}
8 Coin example to illustrate EM Recall, for partially observed data, the likelihood is given by: L( ) = NX log Pr(x i ; ) = NX log X z Pr(x i,z; ) i=1 i=1 Pr(x, z; ) =Pr(x z; )Pr(z; ) where Pr(z; ) = Pr(x z; ) = Coin 1 ρ1 = Pr(H) ( 1 if z =H Coin 2 Coin 3 ρ2 =Pr(H) 1 1 if z =T ( h 2(1 2 ) t if z =H h 3(1 3 ) t if z =T ρ3 = Pr(H) h : number of heads, t : number of tails
9 Coin example to illustrate EM Our observed data is: {HH, TT, HH, TT, HH} Let s use EM to estimate θ = (ρ1, ρ2, ρ3) [EM Iteration, E-step] Compute quantities involved in Q(, ` 1 )= NX i=1 X where γ(z, x) = Pr(z x ;θ l -1 ) Suppose θ l -1 is ρ1 = 0.3, ρ2 = 0.4, ρ3 = 0.6: What is γ(h, HH)? What is γ(h, TT)? z (z,x i ) log Pr(x i,z; ) i.e., compute γ(z, x i ) for all z and all i = 0.16 = 0.49
10 Coin example to illustrate EM Our observed data is: {HH, TT, HH, TT, HH} Let s use EM to estimate θ = (ρ1, ρ2, ρ3) [EM Iteration, M-step] Find θ which maximises Q(, ` 1 )= NX X i=1 z (z,x i ) log Pr(x i,z; ) 1 = 2 = P N i=1 (H,x i) N P N i=1 (H,x i)h i P N i=1 (H,x i)(h i + t i ) 3 = P N i=1 (T,x i)h i P N i=1 (T,x i)(h i + t i )
11 Coin example to illustrate EM ε/1 This was a very simple HMM (with observations from 2 states) ε/ρ1 H/ρ2 H T/1-ρ2 State remains the same after the first transition ε/1-ρ1 T ε/1 γ estimated the distribution of this state H/ρ3 T/1-ρ3 More generally, will need the distribution of the state at each time step EM for general HMMs: Baum-Welch algorithm (1972) predates the general formulation of EM (1977)
12 Baum-Welch Algorithm as EM Observed data: N sequences, x i = (x i1,, x it i), i=1 N where x it R d Parameters θ : transition matrix A, observation probabilities B [EM Iteration, E-step] Compute quantities involved in Q(θ,θ l -1 ) γi,t (j) = Pr(z t = j x i ;θ l -1 ) ξ i,t (j,k) = Pr(z t-1 = j, z t = k x i ;θ l -1 )
13 Baum-Welch Algorithm as EM Observed data: N sequences, x i = (x i1,, x it i), i=1 N where x it R d Parameters θ : transition matrix A, observation probabilities B [EM Iteration, M-step] Find θ which maximises Q(θ,θ l -1 ) A j,k = B j,v = P N P Ti i=1 t=2 i,t(j, k) P N P Ti P i=1 t=2 k 0 i,t (j, k 0 ) P N P i=1 t:x it =v i,t(j) P N P Ti i=1 t=1 i,t(j)
14 Gaussian Observation Model So far we considered HMMs with discrete outputs In acoustic models, HMMs output real valued vectors Hence, observation probabilities are defined using probability density functions A widely used model: Gaussian distribution N (x µ, 2 )= 1 p e (x µ)2 HMM emission/observation probabilities bj(x) = N(x µj, σj 2 ) where µj is the mean associated with state j and σj 2 is its variance. For multivariate Gaussians, bj(x) = N(x µj, Σj) where Σ is the covariance associated with state j
15 BW for Gaussian Observation Model Observed data: N sequences, x i = (x i1,, x it i), i=1 N where x it R d Parameters θ : transition matrix A, observation prob. B = {(µj,σj)} for all j [EM Iteration, M-step] Find θ which maximises Q(θ,θ l -1 ) A same as with discrete outputs P N P Ti i=1 t=1 i,t(j)x it µ j = P N P Ti i=1 t=1 i,t(j) j = P N i=1 P Ti t=1 i,t(j)(x it µ j )(x it µ j ) T P N i=1 P Ti t=1 i,t(j)
16 Gaussian Mixture Model A single Gaussian observation model assumes that the observed acoustic feature vectors are unimodal
17 Unimodal μ= 0, μ= 0, μ= 0, μ= 2, 2 σ = 0.2, 2 σ = 1.0, 2 σ = 5.0, 2 σ = 0.5, x) 0.6 φ μ,σ 2( x
18 Gaussian Mixture Model A single Gaussian observation model assumes that the observed acoustic feature vectors are unimodal More generally, we use a mixture of Gaussians to model multiple modes in the data

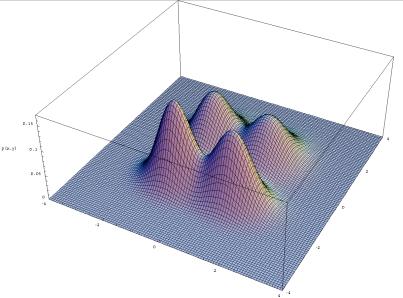
19 Mixture Models
20 Gaussian Mixture Model A single Gaussian observation model assumes that the observed acoustic feature vectors are unimodal More generally, we use a mixture of Gaussians to model multiple modes in the data Instead of bj(x) = N(x µj, Σj) in the single Gaussian case, bj(x) now becomes: b j (x) = MX m=1 c jm N (x µ jm, jm ) where cjm is the mixing probability for Gaussian component m of state j MX m=1 c jm =1, c jm 0
21 BW for Gaussian Mixture Model Observed data: N sequences, x i = (x i1,, x it i), i=1 N where x it R d Parameters θ : transition matrix A, observation prob. B = {(µjm,σjm,cjm)} for all j,m [EM Iteration, M-step] Find θ which maximises Q(θ,θ l -1 ) P N P Ti i=1 t=1 i,t(j, m)x it µ jm = P N P Ti i=1 t=1 i,t(j, m) P N P Ti i=1 t=1 i,t(j, m)(x it µ jm )(x it µ jm ) T jm = P N P Ti i=1 t=1 i,t(j, m) P N P Ti i=1 t=1 i,t(j, m) c jm = P N P Ti i=1 t=1 i,t(j) γi,t(j)=pr(qt=j xi) Mixing probabilities
22 ASR Framework: Acoustic Models Acoustic Features Acoustic Models H Triphones Context Transducer Monophones Pronunciation Model Words Language Model Acoustic models are estimated using training data: {x i, y i }, i=1 N where x i corresponds to a sequence of acoustic feature vectors and y i corresponds to a sequence of words Word Sequence For each x i, y i, a composite HMM is constructed using the HMMs that correspond to the triphone sequence in y i Hello world sil hh ah l ow w er l d sil sil sil/hh/ah hh/ah/l ah/l/ow l/ow/w er/w/l l/er/d er/l/d l/d/sil sil
23 ASR Framework: Acoustic Models Acoustic Features Acoustic Models H Triphones Context Transducer Monophones Pronunciation Model Words Language Model Acoustic models are estimated using training data: {x i, y i }, i=1 N where x i corresponds to a sequence of acoustic feature vectors and y i corresponds to a sequence of words Word Sequence For each x i, y i, a composite HMM is constructed using the HMMs that correspond to the triphone sequence in y i Parameters of these composite HMMs are the parameters of the constituent triphone HMMs. These parameters are fit to the acoustic data {x i }, i=1 N using the Baum-Welch algorithm (EM)
24 Baum Welch: In summary [Every EM Iteration] Compute θ = { Ajk, (µjm,σjm,cjm) } for all j,k,m A j,k = P N P Ti i=1 t=2 i,t(j, k) P N P Ti P i=1 t=2 k 0 i,t (j, k 0 ) P N P Ti i=1 t=1 i,t(j, m)x it µ jm = P N P Ti i=1 t=1 i,t(j, m) jm = P N i=1 P Ti t=1 i,t(j, m)(x it µ jm )(x it µ jm ) T P N P Ti i=1 t=1 i,t(j, m) P N P Ti i=1 t=1 i,t(j, m) c jm = P N P Ti i=1 t=1 i,t(j) How do we efficiently compute these quantities? Next class!
Hidden Markov Models and Gaussian Mixture Models
 Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 23&27 January 2014 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 23&27 January 2014 ASR Lectures 4&5 Hidden Markov Models and Gaussian
CS 136a Lecture 7 Speech Recognition Architecture: Training models with the Forward backward algorithm
 + September13, 2016 Professor Meteer CS 136a Lecture 7 Speech Recognition Architecture: Training models with the Forward backward algorithm Thanks to Dan Jurafsky for these slides + ASR components n Feature
+ September13, 2016 Professor Meteer CS 136a Lecture 7 Speech Recognition Architecture: Training models with the Forward backward algorithm Thanks to Dan Jurafsky for these slides + ASR components n Feature
HIDDEN MARKOV MODELS IN SPEECH RECOGNITION
 HIDDEN MARKOV MODELS IN SPEECH RECOGNITION Wayne Ward Carnegie Mellon University Pittsburgh, PA 1 Acknowledgements Much of this talk is derived from the paper "An Introduction to Hidden Markov Models",
HIDDEN MARKOV MODELS IN SPEECH RECOGNITION Wayne Ward Carnegie Mellon University Pittsburgh, PA 1 Acknowledgements Much of this talk is derived from the paper "An Introduction to Hidden Markov Models",
Statistical NLP Spring Digitizing Speech
 Statistical NLP Spring 2008 Lecture 10: Acoustic Models Dan Klein UC Berkeley Digitizing Speech 1 Frame Extraction A frame (25 ms wide) extracted every 10 ms 25 ms 10ms... a 1 a 2 a 3 Figure from Simon
Statistical NLP Spring 2008 Lecture 10: Acoustic Models Dan Klein UC Berkeley Digitizing Speech 1 Frame Extraction A frame (25 ms wide) extracted every 10 ms 25 ms 10ms... a 1 a 2 a 3 Figure from Simon
Digitizing Speech. Statistical NLP Spring Frame Extraction. Gaussian Emissions. Vector Quantization. HMMs for Continuous Observations? ...
 Statistical NLP Spring 2008 Digitizing Speech Lecture 10: Acoustic Models Dan Klein UC Berkeley Frame Extraction A frame (25 ms wide extracted every 10 ms 25 ms 10ms... a 1 a 2 a 3 Figure from Simon Arnfield
Statistical NLP Spring 2008 Digitizing Speech Lecture 10: Acoustic Models Dan Klein UC Berkeley Frame Extraction A frame (25 ms wide extracted every 10 ms 25 ms 10ms... a 1 a 2 a 3 Figure from Simon Arnfield
Statistical Sequence Recognition and Training: An Introduction to HMMs
 Statistical Sequence Recognition and Training: An Introduction to HMMs EECS 225D Nikki Mirghafori nikki@icsi.berkeley.edu March 7, 2005 Credit: many of the HMM slides have been borrowed and adapted, with
Statistical Sequence Recognition and Training: An Introduction to HMMs EECS 225D Nikki Mirghafori nikki@icsi.berkeley.edu March 7, 2005 Credit: many of the HMM slides have been borrowed and adapted, with
University of Cambridge. MPhil in Computer Speech Text & Internet Technology. Module: Speech Processing II. Lecture 2: Hidden Markov Models I
 University of Cambridge MPhil in Computer Speech Text & Internet Technology Module: Speech Processing II Lecture 2: Hidden Markov Models I o o o o o 1 2 3 4 T 1 b 2 () a 12 2 a 3 a 4 5 34 a 23 b () b ()
University of Cambridge MPhil in Computer Speech Text & Internet Technology Module: Speech Processing II Lecture 2: Hidden Markov Models I o o o o o 1 2 3 4 T 1 b 2 () a 12 2 a 3 a 4 5 34 a 23 b () b ()
The Noisy Channel Model. Statistical NLP Spring Mel Freq. Cepstral Coefficients. Frame Extraction ... Lecture 10: Acoustic Models
 Statistical NLP Spring 2009 The Noisy Channel Model Lecture 10: Acoustic Models Dan Klein UC Berkeley Search through space of all possible sentences. Pick the one that is most probable given the waveform.
Statistical NLP Spring 2009 The Noisy Channel Model Lecture 10: Acoustic Models Dan Klein UC Berkeley Search through space of all possible sentences. Pick the one that is most probable given the waveform.
Statistical NLP Spring The Noisy Channel Model
 Statistical NLP Spring 2009 Lecture 10: Acoustic Models Dan Klein UC Berkeley The Noisy Channel Model Search through space of all possible sentences. Pick the one that is most probable given the waveform.
Statistical NLP Spring 2009 Lecture 10: Acoustic Models Dan Klein UC Berkeley The Noisy Channel Model Search through space of all possible sentences. Pick the one that is most probable given the waveform.
Hidden Markov Models and Gaussian Mixture Models
 Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 25&29 January 2018 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 25&29 January 2018 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Hidden Markov Modelling
 Hidden Markov Modelling Introduction Problem formulation Forward-Backward algorithm Viterbi search Baum-Welch parameter estimation Other considerations Multiple observation sequences Phone-based models
Hidden Markov Modelling Introduction Problem formulation Forward-Backward algorithm Viterbi search Baum-Welch parameter estimation Other considerations Multiple observation sequences Phone-based models
EECS E6870: Lecture 4: Hidden Markov Models
 EECS E6870: Lecture 4: Hidden Markov Models Stanley F. Chen, Michael A. Picheny and Bhuvana Ramabhadran IBM T. J. Watson Research Center Yorktown Heights, NY 10549 stanchen@us.ibm.com, picheny@us.ibm.com,
EECS E6870: Lecture 4: Hidden Markov Models Stanley F. Chen, Michael A. Picheny and Bhuvana Ramabhadran IBM T. J. Watson Research Center Yorktown Heights, NY 10549 stanchen@us.ibm.com, picheny@us.ibm.com,
Hidden Markov Model. Ying Wu. Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208
 Hidden Markov Model Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/19 Outline Example: Hidden Coin Tossing Hidden
Hidden Markov Model Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/19 Outline Example: Hidden Coin Tossing Hidden
Hidden Markov Models. Aarti Singh Slides courtesy: Eric Xing. Machine Learning / Nov 8, 2010
 Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
] Automatic Speech Recognition (CS753)
![] Automatic Speech Recognition (CS753)](/thumbs/79/79577735.jpg "] Automatic Speech Recognition (CS753)") ] Automatic Speech Recognition (CS753) Lecture 17: Discriminative Training for HMMs Instructor: Preethi Jyothi Sep 28, 2017 Discriminative Training Recall: MLE for HMMs Maximum likelihood estimation (MLE)
] Automatic Speech Recognition (CS753) Lecture 17: Discriminative Training for HMMs Instructor: Preethi Jyothi Sep 28, 2017 Discriminative Training Recall: MLE for HMMs Maximum likelihood estimation (MLE)
Hidden Markov Models. By Parisa Abedi. Slides courtesy: Eric Xing
 Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Hidden Markov Models
 CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (CS753) Lecture 21: Speaker Adaptation Instructor: Preethi Jyothi Oct 23, 2017 Speaker variations Major cause of variability in speech is the differences between speakers Speaking
Automatic Speech Recognition (CS753) Lecture 21: Speaker Adaptation Instructor: Preethi Jyothi Oct 23, 2017 Speaker variations Major cause of variability in speech is the differences between speakers Speaking
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Speech and Language Processing. Chapter 9 of SLP Automatic Speech Recognition (II)
") Speech and Language Processing Chapter 9 of SLP Automatic Speech Recognition (II) Outline for ASR ASR Architecture The Noisy Channel Model Five easy pieces of an ASR system 1) Language Model 2) Lexicon/Pronunciation
Speech and Language Processing Chapter 9 of SLP Automatic Speech Recognition (II) Outline for ASR ASR Architecture The Noisy Channel Model Five easy pieces of an ASR system 1) Language Model 2) Lexicon/Pronunciation
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (S753) Lecture 5: idden Markov s (Part I) Instructor: Preethi Jyothi August 7, 2017 Recap: WFSTs applied to ASR WFST-based ASR System Indices s Triphones ontext Transducer
Automatic Speech Recognition (S753) Lecture 5: idden Markov s (Part I) Instructor: Preethi Jyothi August 7, 2017 Recap: WFSTs applied to ASR WFST-based ASR System Indices s Triphones ontext Transducer
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
The Noisy Channel Model. Statistical NLP Spring Mel Freq. Cepstral Coefficients. Frame Extraction ... Lecture 9: Acoustic Models
 Statistical NLP Spring 2010 The Noisy Channel Model Lecture 9: Acoustic Models Dan Klein UC Berkeley Acoustic model: HMMs over word positions with mixtures of Gaussians as emissions Language model: Distributions
Statistical NLP Spring 2010 The Noisy Channel Model Lecture 9: Acoustic Models Dan Klein UC Berkeley Acoustic model: HMMs over word positions with mixtures of Gaussians as emissions Language model: Distributions
Parametric Models Part III: Hidden Markov Models
 Parametric Models Part III: Hidden Markov Models Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2014 CS 551, Spring 2014 c 2014, Selim Aksoy (Bilkent
Parametric Models Part III: Hidden Markov Models Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2014 CS 551, Spring 2014 c 2014, Selim Aksoy (Bilkent
Note Set 5: Hidden Markov Models
 Note Set 5: Hidden Markov Models Probabilistic Learning: Theory and Algorithms, CS 274A, Winter 2016 1 Hidden Markov Models (HMMs) 1.1 Introduction Consider observed data vectors x t that are d-dimensional
Note Set 5: Hidden Markov Models Probabilistic Learning: Theory and Algorithms, CS 274A, Winter 2016 1 Hidden Markov Models (HMMs) 1.1 Introduction Consider observed data vectors x t that are d-dimensional
Lecture 5: GMM Acoustic Modeling and Feature Extraction
 CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 5: GMM Acoustic Modeling and Feature Extraction Original slides by Dan Jurafsky Outline for Today Acoustic
CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 5: GMM Acoustic Modeling and Feature Extraction Original slides by Dan Jurafsky Outline for Today Acoustic
Weighted Finite-State Transducers in Computational Biology
 Weighted Finite-State Transducers in Computational Biology Mehryar Mohri Courant Institute of Mathematical Sciences mohri@cims.nyu.edu Joint work with Corinna Cortes (Google Research). 1 This Tutorial
Weighted Finite-State Transducers in Computational Biology Mehryar Mohri Courant Institute of Mathematical Sciences mohri@cims.nyu.edu Joint work with Corinna Cortes (Google Research). 1 This Tutorial
Lecture 9. Intro to Hidden Markov Models (finish up)
") Lecture 9 Intro to Hidden Markov Models (finish up) Review Structure Number of states Q 1.. Q N M output symbols Parameters: Transition probability matrix a ij Emission probabilities b i (a), which is
Lecture 9 Intro to Hidden Markov Models (finish up) Review Structure Number of states Q 1.. Q N M output symbols Parameters: Transition probability matrix a ij Emission probabilities b i (a), which is
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Multiscale Systems Engineering Research Group
 Hidden Markov Model Prof. Yan Wang Woodruff School of Mechanical Engineering Georgia Institute of echnology Atlanta, GA 30332, U.S.A. yan.wang@me.gatech.edu Learning Objectives o familiarize the hidden
Hidden Markov Model Prof. Yan Wang Woodruff School of Mechanical Engineering Georgia Institute of echnology Atlanta, GA 30332, U.S.A. yan.wang@me.gatech.edu Learning Objectives o familiarize the hidden
Linear Dynamical Systems (Kalman filter)
") Linear Dynamical Systems (Kalman filter) (a) Overview of HMMs (b) From HMMs to Linear Dynamical Systems (LDS) 1 Markov Chains with Discrete Random Variables x 1 x 2 x 3 x T Let s assume we have discrete
Linear Dynamical Systems (Kalman filter) (a) Overview of HMMs (b) From HMMs to Linear Dynamical Systems (LDS) 1 Markov Chains with Discrete Random Variables x 1 x 2 x 3 x T Let s assume we have discrete
CS838-1 Advanced NLP: Hidden Markov Models
 CS838-1 Advanced NLP: Hidden Markov Models Xiaojin Zhu 2007 Send comments to jerryzhu@cs.wisc.edu 1 Part of Speech Tagging Tag each word in a sentence with its part-of-speech, e.g., The/AT representative/nn
CS838-1 Advanced NLP: Hidden Markov Models Xiaojin Zhu 2007 Send comments to jerryzhu@cs.wisc.edu 1 Part of Speech Tagging Tag each word in a sentence with its part-of-speech, e.g., The/AT representative/nn
Machine Learning for natural language processing
 Machine Learning for natural language processing Hidden Markov Models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 33 Introduction So far, we have classified texts/observations
Machine Learning for natural language processing Hidden Markov Models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 33 Introduction So far, we have classified texts/observations
Hidden Markov Model and Speech Recognition
 1 Dec,2006 Outline Introduction 1 Introduction 2 3 4 5 Introduction What is Speech Recognition? Understanding what is being said Mapping speech data to textual information Speech Recognition is indeed
1 Dec,2006 Outline Introduction 1 Introduction 2 3 4 5 Introduction What is Speech Recognition? Understanding what is being said Mapping speech data to textual information Speech Recognition is indeed
CS 136 Lecture 5 Acoustic modeling Phoneme modeling
 + September 9, 2016 Professor Meteer CS 136 Lecture 5 Acoustic modeling Phoneme modeling Thanks to Dan Jurafsky for these slides + Directly Modeling Continuous Observations n Gaussians n Univariate Gaussians
+ September 9, 2016 Professor Meteer CS 136 Lecture 5 Acoustic modeling Phoneme modeling Thanks to Dan Jurafsky for these slides + Directly Modeling Continuous Observations n Gaussians n Univariate Gaussians
The Noisy Channel Model. CS 294-5: Statistical Natural Language Processing. Speech Recognition Architecture. Digitizing Speech
 CS 294-5: Statistical Natural Language Processing The Noisy Channel Model Speech Recognition II Lecture 21: 11/29/05 Search through space of all possible sentences. Pick the one that is most probable given
CS 294-5: Statistical Natural Language Processing The Noisy Channel Model Speech Recognition II Lecture 21: 11/29/05 Search through space of all possible sentences. Pick the one that is most probable given
Hidden Markov Models (HMMs)
") Hidden Markov Models (HMMs) Reading Assignments R. Duda, P. Hart, and D. Stork, Pattern Classification, John-Wiley, 2nd edition, 2001 (section 3.10, hard-copy). L. Rabiner, "A tutorial on HMMs and selected
Hidden Markov Models (HMMs) Reading Assignments R. Duda, P. Hart, and D. Stork, Pattern Classification, John-Wiley, 2nd edition, 2001 (section 3.10, hard-copy). L. Rabiner, "A tutorial on HMMs and selected
Lecture 3: ASR: HMMs, Forward, Viterbi
 Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
An Introduction to Bioinformatics Algorithms Hidden Markov Models
 Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (CS753) Lecture 8: Tied state HMMs + DNNs in ASR Instructor: Preethi Jyothi Aug 17, 2017 Final Project Landscape Voice conversion using GANs Musical Note Extraction Keystroke
Automatic Speech Recognition (CS753) Lecture 8: Tied state HMMs + DNNs in ASR Instructor: Preethi Jyothi Aug 17, 2017 Final Project Landscape Voice conversion using GANs Musical Note Extraction Keystroke
A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models
 A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models Jeff A. Bilmes (bilmes@cs.berkeley.edu) International Computer Science Institute
A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models Jeff A. Bilmes (bilmes@cs.berkeley.edu) International Computer Science Institute
Sparse Models for Speech Recognition
 Sparse Models for Speech Recognition Weibin Zhang and Pascale Fung Human Language Technology Center Hong Kong University of Science and Technology Outline Introduction to speech recognition Motivations
Sparse Models for Speech Recognition Weibin Zhang and Pascale Fung Human Language Technology Center Hong Kong University of Science and Technology Outline Introduction to speech recognition Motivations
Speech Recognition Lecture 8: Expectation-Maximization Algorithm, Hidden Markov Models.
 Speech Recognition Lecture 8: Expectation-Maximization Algorithm, Hidden Markov Models. Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.com This Lecture Expectation-Maximization (EM)
Speech Recognition Lecture 8: Expectation-Maximization Algorithm, Hidden Markov Models. Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.com This Lecture Expectation-Maximization (EM)
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
Hidden Markov Models in Language Processing
 Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Hidden Markov Models
 Hidden Markov Models CI/CI(CS) UE, SS 2015 Christian Knoll Signal Processing and Speech Communication Laboratory Graz University of Technology June 23, 2015 CI/CI(CS) SS 2015 June 23, 2015 Slide 1/26 Content
Hidden Markov Models CI/CI(CS) UE, SS 2015 Christian Knoll Signal Processing and Speech Communication Laboratory Graz University of Technology June 23, 2015 CI/CI(CS) SS 2015 June 23, 2015 Slide 1/26 Content
Expectation Maximization (EM)
") Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
L23: hidden Markov models
 L23: hidden Markov models Discrete Markov processes Hidden Markov models Forward and Backward procedures The Viterbi algorithm This lecture is based on [Rabiner and Juang, 1993] Introduction to Speech
L23: hidden Markov models Discrete Markov processes Hidden Markov models Forward and Backward procedures The Viterbi algorithm This lecture is based on [Rabiner and Juang, 1993] Introduction to Speech
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Reformulating the HMM as a trajectory model by imposing explicit relationship between static and dynamic features
 Reformulating the HMM as a trajectory model by imposing explicit relationship between static and dynamic features Heiga ZEN (Byung Ha CHUN) Nagoya Inst. of Tech., Japan Overview. Research backgrounds 2.
Reformulating the HMM as a trajectory model by imposing explicit relationship between static and dynamic features Heiga ZEN (Byung Ha CHUN) Nagoya Inst. of Tech., Japan Overview. Research backgrounds 2.
Hidden Markov Models. x 1 x 2 x 3 x K
 Hidden Markov Models 1 1 1 1 2 2 2 2 K K K K x 1 x 2 x 3 x K HiSeq X & NextSeq Viterbi, Forward, Backward VITERBI FORWARD BACKWARD Initialization: V 0 (0) = 1 V k (0) = 0, for all k > 0 Initialization:
Hidden Markov Models 1 1 1 1 2 2 2 2 K K K K x 1 x 2 x 3 x K HiSeq X & NextSeq Viterbi, Forward, Backward VITERBI FORWARD BACKWARD Initialization: V 0 (0) = 1 V k (0) = 0, for all k > 0 Initialization:
Hidden Markov Models
 Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Hidden Markov Models Part 2: Algorithms
 Hidden Markov Models Part 2: Algorithms CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Hidden Markov Model An HMM consists of:
Hidden Markov Models Part 2: Algorithms CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Hidden Markov Model An HMM consists of:
Expectation Maximization (EM)
") Expectation Maximization (EM) The Expectation Maximization (EM) algorithm is one approach to unsupervised, semi-supervised, or lightly supervised learning. In this kind of learning either no labels are
Expectation Maximization (EM) The Expectation Maximization (EM) algorithm is one approach to unsupervised, semi-supervised, or lightly supervised learning. In this kind of learning either no labels are
Recap: HMM. ANLP Lecture 9: Algorithms for HMMs. More general notation. Recap: HMM. Elements of HMM: Sharon Goldwater 4 Oct 2018.
 Recap: HMM ANLP Lecture 9: Algorithms for HMMs Sharon Goldwater 4 Oct 2018 Elements of HMM: Set of states (tags) Output alphabet (word types) Start state (beginning of sentence) State transition probabilities
Recap: HMM ANLP Lecture 9: Algorithms for HMMs Sharon Goldwater 4 Oct 2018 Elements of HMM: Set of states (tags) Output alphabet (word types) Start state (beginning of sentence) State transition probabilities
Lecture 11: Hidden Markov Models
 Lecture 11: Hidden Markov Models Cognitive Systems - Machine Learning Cognitive Systems, Applied Computer Science, Bamberg University slides by Dr. Philip Jackson Centre for Vision, Speech & Signal Processing
Lecture 11: Hidden Markov Models Cognitive Systems - Machine Learning Cognitive Systems, Applied Computer Science, Bamberg University slides by Dr. Philip Jackson Centre for Vision, Speech & Signal Processing
Hidden Markov Models Hamid R. Rabiee
 Hidden Markov Models Hamid R. Rabiee 1 Hidden Markov Models (HMMs) In the previous slides, we have seen that in many cases the underlying behavior of nature could be modeled as a Markov process. However
Hidden Markov Models Hamid R. Rabiee 1 Hidden Markov Models (HMMs) In the previous slides, we have seen that in many cases the underlying behavior of nature could be modeled as a Markov process. However
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data Statistical Machine Learning from Data Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne (EPFL),
Samy Bengio Statistical Machine Learning from Data Statistical Machine Learning from Data Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne (EPFL),
Hidden Markov Models
 Hidden Markov Models Lecture Notes Speech Communication 2, SS 2004 Erhard Rank/Franz Pernkopf Signal Processing and Speech Communication Laboratory Graz University of Technology Inffeldgasse 16c, A-8010
Hidden Markov Models Lecture Notes Speech Communication 2, SS 2004 Erhard Rank/Franz Pernkopf Signal Processing and Speech Communication Laboratory Graz University of Technology Inffeldgasse 16c, A-8010
10. Hidden Markov Models (HMM) for Speech Processing. (some slides taken from Glass and Zue course)
 for Speech Processing. (some slides taken from Glass and Zue course)") 10. Hidden Markov Models (HMM) for Speech Processing (some slides taken from Glass and Zue course) Definition of an HMM The HMM are powerful statistical methods to characterize the observed samples of
10. Hidden Markov Models (HMM) for Speech Processing (some slides taken from Glass and Zue course) Definition of an HMM The HMM are powerful statistical methods to characterize the observed samples of
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Hidden Markov Models The three basic HMM problems (note: change in notation) Mitch Marcus CSE 391
 Mitch Marcus CSE 391") Hidden Markov Models The three basic HMM problems (note: change in notation) Mitch Marcus CSE 391 Parameters of an HMM States: A set of states S=s 1, s n Transition probabilities: A= a 1,1, a 1,2,, a n,n
Hidden Markov Models The three basic HMM problems (note: change in notation) Mitch Marcus CSE 391 Parameters of an HMM States: A set of states S=s 1, s n Transition probabilities: A= a 1,1, a 1,2,, a n,n
Human Mobility Pattern Prediction Algorithm using Mobile Device Location and Time Data
 Human Mobility Pattern Prediction Algorithm using Mobile Device Location and Time Data 0. Notations Myungjun Choi, Yonghyun Ro, Han Lee N = number of states in the model T = length of observation sequence
Human Mobility Pattern Prediction Algorithm using Mobile Device Location and Time Data 0. Notations Myungjun Choi, Yonghyun Ro, Han Lee N = number of states in the model T = length of observation sequence
p(d θ ) l(θ ) 1.2 x x x
 l(θ ) 1.2 x x x") p(d θ ).2 x 0-7 0.8 x 0-7 0.4 x 0-7 l(θ ) -20-40 -60-80 -00 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ θ x FIGURE 3.. The top graph shows several training points in one dimension, known or assumed to
p(d θ ).2 x 0-7 0.8 x 0-7 0.4 x 0-7 l(θ ) -20-40 -60-80 -00 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ θ x FIGURE 3.. The top graph shows several training points in one dimension, known or assumed to
Hidden Markov Models
 Hidden Markov Models Dr Philip Jackson Centre for Vision, Speech & Signal Processing University of Surrey, UK 1 3 2 http://www.ee.surrey.ac.uk/personal/p.jackson/isspr/ Outline 1. Recognizing patterns
Hidden Markov Models Dr Philip Jackson Centre for Vision, Speech & Signal Processing University of Surrey, UK 1 3 2 http://www.ee.surrey.ac.uk/personal/p.jackson/isspr/ Outline 1. Recognizing patterns
Hidden Markov Models. x 1 x 2 x 3 x K
 Hidden Markov Models 1 1 1 1 2 2 2 2 K K K K x 1 x 2 x 3 x K Viterbi, Forward, Backward VITERBI FORWARD BACKWARD Initialization: V 0 (0) = 1 V k (0) = 0, for all k > 0 Initialization: f 0 (0) = 1 f k (0)
Hidden Markov Models 1 1 1 1 2 2 2 2 K K K K x 1 x 2 x 3 x K Viterbi, Forward, Backward VITERBI FORWARD BACKWARD Initialization: V 0 (0) = 1 V k (0) = 0, for all k > 0 Initialization: f 0 (0) = 1 f k (0)
Expectation-Maximization (EM) algorithm
 algorithm") I529: Machine Learning in Bioinformatics (Spring 2017) Expectation-Maximization (EM) algorithm Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2017 Contents Introduce
I529: Machine Learning in Bioinformatics (Spring 2017) Expectation-Maximization (EM) algorithm Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2017 Contents Introduce
Recall: Modeling Time Series. CSE 586, Spring 2015 Computer Vision II. Hidden Markov Model and Kalman Filter. Modeling Time Series
 Recall: Modeling Time Series CSE 586, Spring 2015 Computer Vision II Hidden Markov Model and Kalman Filter State-Space Model: You have a Markov chain of latent (unobserved) states Each state generates
Recall: Modeling Time Series CSE 586, Spring 2015 Computer Vision II Hidden Markov Model and Kalman Filter State-Space Model: You have a Markov chain of latent (unobserved) states Each state generates
An Introduction to Bioinformatics Algorithms Hidden Markov Models
 Hidden Markov Models Hidden Markov Models Outline CG-islands The Fair Bet Casino Hidden Markov Model Decoding Algorithm Forward-Backward Algorithm Profile HMMs HMM Parameter Estimation Viterbi training
Hidden Markov Models Hidden Markov Models Outline CG-islands The Fair Bet Casino Hidden Markov Model Decoding Algorithm Forward-Backward Algorithm Profile HMMs HMM Parameter Estimation Viterbi training
1. Markov models. 1.1 Markov-chain
 1. Markov models 1.1 Markov-chain Let X be a random variable X = (X 1,..., X t ) taking values in some set S = {s 1,..., s N }. The sequence is Markov chain if it has the following properties: 1. Limited
1. Markov models 1.1 Markov-chain Let X be a random variable X = (X 1,..., X t ) taking values in some set S = {s 1,..., s N }. The sequence is Markov chain if it has the following properties: 1. Limited
Lecture 4: Hidden Markov Models: An Introduction to Dynamic Decision Making. November 11, 2010
 Hidden Lecture 4: Hidden : An Introduction to Dynamic Decision Making November 11, 2010 Special Meeting 1/26 Markov Model Hidden When a dynamical system is probabilistic it may be determined by the transition
Hidden Lecture 4: Hidden : An Introduction to Dynamic Decision Making November 11, 2010 Special Meeting 1/26 Markov Model Hidden When a dynamical system is probabilistic it may be determined by the transition
Speech Recognition HMM
 Speech Recognition HMM Jan Černocký, Valentina Hubeika {cernocky ihubeika}@fit.vutbr.cz FIT BUT Brno Speech Recognition HMM Jan Černocký, Valentina Hubeika, DCGM FIT BUT Brno 1/38 Agenda Recap variability
Speech Recognition HMM Jan Černocký, Valentina Hubeika {cernocky ihubeika}@fit.vutbr.cz FIT BUT Brno Speech Recognition HMM Jan Černocký, Valentina Hubeika, DCGM FIT BUT Brno 1/38 Agenda Recap variability
HMM: Parameter Estimation
 I529: Machine Learning in Bioinformatics (Spring 2017) HMM: Parameter Estimation Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2017 Content Review HMM: three problems
I529: Machine Learning in Bioinformatics (Spring 2017) HMM: Parameter Estimation Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2017 Content Review HMM: three problems
CISC 889 Bioinformatics (Spring 2004) Hidden Markov Models (II)
 Hidden Markov Models (II)") CISC 889 Bioinformatics (Spring 24) Hidden Markov Models (II) a. Likelihood: forward algorithm b. Decoding: Viterbi algorithm c. Model building: Baum-Welch algorithm Viterbi training Hidden Markov models
CISC 889 Bioinformatics (Spring 24) Hidden Markov Models (II) a. Likelihood: forward algorithm b. Decoding: Viterbi algorithm c. Model building: Baum-Welch algorithm Viterbi training Hidden Markov models
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
Hidden Markov Models
 Hidden Markov Models Slides revised and adapted to Bioinformática 55 Engª Biomédica/IST 2005 Ana Teresa Freitas Forward Algorithm For Markov chains we calculate the probability of a sequence, P(x) How
Hidden Markov Models Slides revised and adapted to Bioinformática 55 Engª Biomédica/IST 2005 Ana Teresa Freitas Forward Algorithm For Markov chains we calculate the probability of a sequence, P(x) How
O 3 O 4 O 5. q 3. q 4. Transition
 Hidden Markov Models Hidden Markov models (HMM) were developed in the early part of the 1970 s and at that time mostly applied in the area of computerized speech recognition. They are first described in
Hidden Markov Models Hidden Markov models (HMM) were developed in the early part of the 1970 s and at that time mostly applied in the area of computerized speech recognition. They are first described in
MAP adaptation with SphinxTrain
 MAP adaptation with SphinxTrain David Huggins-Daines dhuggins@cs.cmu.edu Language Technologies Institute Carnegie Mellon University MAP adaptation with SphinxTrain p.1/12 Theory of MAP adaptation Standard
MAP adaptation with SphinxTrain David Huggins-Daines dhuggins@cs.cmu.edu Language Technologies Institute Carnegie Mellon University MAP adaptation with SphinxTrain p.1/12 Theory of MAP adaptation Standard
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Outline of Today s Lecture
 University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Jeff A. Bilmes Lecture 12 Slides Feb 23 rd, 2005 Outline of Today s
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Jeff A. Bilmes Lecture 12 Slides Feb 23 rd, 2005 Outline of Today s
Data Mining in Bioinformatics HMM
 Data Mining in Bioinformatics HMM Microarray Problem: Major Objective n Major Objective: Discover a comprehensive theory of life s organization at the molecular level 2 1 Data Mining in Bioinformatics
Data Mining in Bioinformatics HMM Microarray Problem: Major Objective n Major Objective: Discover a comprehensive theory of life s organization at the molecular level 2 1 Data Mining in Bioinformatics
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Experiments with a Gaussian Merging-Splitting Algorithm for HMM Training for Speech Recognition
 Experiments with a Gaussian Merging-Splitting Algorithm for HMM Training for Speech Recognition ABSTRACT It is well known that the expectation-maximization (EM) algorithm, commonly used to estimate hidden
Experiments with a Gaussian Merging-Splitting Algorithm for HMM Training for Speech Recognition ABSTRACT It is well known that the expectation-maximization (EM) algorithm, commonly used to estimate hidden
Engineering Part IIB: Module 4F11 Speech and Language Processing Lectures 4/5 : Speech Recognition Basics
 Engineering Part IIB: Module 4F11 Speech and Language Processing Lectures 4/5 : Speech Recognition Basics Phil Woodland: pcw@eng.cam.ac.uk Lent 2013 Engineering Part IIB: Module 4F11 What is Speech Recognition?
Engineering Part IIB: Module 4F11 Speech and Language Processing Lectures 4/5 : Speech Recognition Basics Phil Woodland: pcw@eng.cam.ac.uk Lent 2013 Engineering Part IIB: Module 4F11 What is Speech Recognition?
Hidden Markov Models for biological sequence analysis
 Hidden Markov Models for biological sequence analysis Master in Bioinformatics UPF 2017-2018 http://comprna.upf.edu/courses/master_agb/ Eduardo Eyras Computational Genomics Pompeu Fabra University - ICREA
Hidden Markov Models for biological sequence analysis Master in Bioinformatics UPF 2017-2018 http://comprna.upf.edu/courses/master_agb/ Eduardo Eyras Computational Genomics Pompeu Fabra University - ICREA
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Robert Collins CSE586 CSE 586, Spring 2015 Computer Vision II
 CSE 586, Spring 2015 Computer Vision II Hidden Markov Model and Kalman Filter Recall: Modeling Time Series State-Space Model: You have a Markov chain of latent (unobserved) states Each state generates
CSE 586, Spring 2015 Computer Vision II Hidden Markov Model and Kalman Filter Recall: Modeling Time Series State-Space Model: You have a Markov chain of latent (unobserved) states Each state generates
Hidden Markov Models
 Hidden Markov Models Outline CG-islands The Fair Bet Casino Hidden Markov Model Decoding Algorithm Forward-Backward Algorithm Profile HMMs HMM Parameter Estimation Viterbi training Baum-Welch algorithm
Hidden Markov Models Outline CG-islands The Fair Bet Casino Hidden Markov Model Decoding Algorithm Forward-Backward Algorithm Profile HMMs HMM Parameter Estimation Viterbi training Baum-Welch algorithm
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
6.864: Lecture 5 (September 22nd, 2005) The EM Algorithm
 The EM Algorithm") 6.864: Lecture 5 (September 22nd, 2005) The EM Algorithm Overview The EM algorithm in general form The EM algorithm for hidden markov models (brute force) The EM algorithm for hidden markov models (dynamic
6.864: Lecture 5 (September 22nd, 2005) The EM Algorithm Overview The EM algorithm in general form The EM algorithm for hidden markov models (brute force) The EM algorithm for hidden markov models (dynamic
Lecture 3. Gaussian Mixture Models and Introduction to HMM s. Michael Picheny, Bhuvana Ramabhadran, Stanley F. Chen, Markus Nussbaum-Thom
 Lecture 3 Gaussian Mixture Models and Introduction to HMM s Michael Picheny, Bhuvana Ramabhadran, Stanley F. Chen, Markus Nussbaum-Thom Watson Group IBM T.J. Watson Research Center Yorktown Heights, New
Lecture 3 Gaussian Mixture Models and Introduction to HMM s Michael Picheny, Bhuvana Ramabhadran, Stanley F. Chen, Markus Nussbaum-Thom Watson Group IBM T.J. Watson Research Center Yorktown Heights, New
1 What is a hidden Markov model?
 1 What is a hidden Markov model? Consider a Markov chain {X k }, where k is a non-negative integer. Suppose {X k } embedded in signals corrupted by some noise. Indeed, {X k } is hidden due to noise and
1 What is a hidden Markov model? Consider a Markov chain {X k }, where k is a non-negative integer. Suppose {X k } embedded in signals corrupted by some noise. Indeed, {X k } is hidden due to noise and
Hidden Markov Models. Dr. Naomi Harte
 Hidden Markov Models Dr. Naomi Harte The Talk Hidden Markov Models What are they? Why are they useful? The maths part Probability calculations Training optimising parameters Viterbi unseen sequences Real
Hidden Markov Models Dr. Naomi Harte The Talk Hidden Markov Models What are they? Why are they useful? The maths part Probability calculations Training optimising parameters Viterbi unseen sequences Real
Master 2 Informatique Probabilistic Learning and Data Analysis
 Master 2 Informatique Probabilistic Learning and Data Analysis Faicel Chamroukhi Maître de Conférences USTV, LSIS UMR CNRS 7296 email: chamroukhi@univ-tln.fr web: chamroukhi.univ-tln.fr 2013/2014 Faicel
Master 2 Informatique Probabilistic Learning and Data Analysis Faicel Chamroukhi Maître de Conférences USTV, LSIS UMR CNRS 7296 email: chamroukhi@univ-tln.fr web: chamroukhi.univ-tln.fr 2013/2014 Faicel
Basic math for biology
 Basic math for biology Lei Li Florida State University, Feb 6, 2002 The EM algorithm: setup Parametric models: {P θ }. Data: full data (Y, X); partial data Y. Missing data: X. Likelihood and maximum likelihood
Basic math for biology Lei Li Florida State University, Feb 6, 2002 The EM algorithm: setup Parametric models: {P θ }. Data: full data (Y, X); partial data Y. Missing data: X. Likelihood and maximum likelihood
Introduction to Markov systems
 1. Introduction Up to now, we have talked a lot about building statistical models from data. However, throughout our discussion thus far, we have made the sometimes implicit, simplifying assumption that
1. Introduction Up to now, we have talked a lot about building statistical models from data. However, throughout our discussion thus far, we have made the sometimes implicit, simplifying assumption that
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Hidden Markov Models. Hosein Mohimani GHC7717
 Hidden Markov Models Hosein Mohimani GHC7717 hoseinm@andrew.cmu.edu Fair et Casino Problem Dealer flips a coin and player bets on outcome Dealer use either a fair coin (head and tail equally likely) or
Hidden Markov Models Hosein Mohimani GHC7717 hoseinm@andrew.cmu.edu Fair et Casino Problem Dealer flips a coin and player bets on outcome Dealer use either a fair coin (head and tail equally likely) or