Social/Collaborative Filtering
|
|
|
- Corey Harrington
- 5 years ago
- Views:
Transcription
1 Social/Collaborative Filtering
2 Outline Recap SVD vs PCA Collaborative <iltering aka Social recommendation k-nn CF methods classi<ication CF via MF MF vs SGD vs.
3 Dimensionality Reduction and Principle Components Analysis: Recap 3
4 More cartoons 4
5 PCA as matrices: the optimization problem



6 PCA as matrices PC1 2 mixing wts 10,000 pixels 1000 * 10,000,00 x1 x2.. y1 y2.. a1 a2.. am b1 b2 bm ~ v images vij xn yn PC2 vnm V[i,j] = pixel j in image i

7 Poll True or false: the weights for an example should add up to 1. True or false: the weights for a prototype should add up to 1
8 Implementing PCA Also: they are orthogonal to each other! 8
9 PCA FOR MODELING TEXT (SVD = SINGULAR VALUE DECOMPOSITION) 9
 the i-th eigenvec Columns of V ~= principle")
10 A Scalability Problem with PCA Covariance matrix is large in high dimensions With d features covariance matrix is d*d SVD is a closely-related method that can be implemented more ef<iciently in high dimensions Don t explicitly compute covariance matrix Instead write docterm matrix X as X=USV T S is k*k where k<<d S is diagonal and S[i,i]=sqrt(λ i ) the i-th eigenvec Columns of V ~= principle components Rows of US ~= embedding for examples 10
11 Recovering latent factors in a matrix U S m terms V T doc term matrix n documents x1 x2.. y1 y2.. s1 0 0 s2 a1 a2.. am b1 b2 bm ~ v11 vij xn yn vnm Docterm[i,j] = TFIDF score of term j in doc i 11
12 SVD example 12
13 The Neatest Little Guide to Stock Market Investing Investing For Dummies, 4th Edition The Little Book of Common Sense Investing: The Only Way to Guarantee Your Fair Share of Stock Market Returns The Little Book of Value Investing Value Investing: From Graham to Buffett and Beyond Rich Dad s Guide to Investing: What the Rich Invest in, That the Poor and the Middle Class Do Not! Investing in Real Estate, 5th Edition Stock Investing For Dummies Rich Dad s Advisors: The ABC s of Real Estate Investing: The Secrets of Finding Hidden Profits Most Investors Miss

14
15 =




16 InvesKng for real estate Rich Dad s Advisor s: The ABCs of Real Estate Investment




17 The liqle book of common sense inveskng: Neatest LiQle Guide to Stock Market InvesKng
18 My recap: SVD vs PCA Very closely related methods As described here SVD decomp doesn t require a square matrix PCA decomp is always applied to C X which is square and mean-centered You can implement PCA using SVD as a substep People sometimes use the terms interchangeably
19 Outline What is CF? Nearest-neighbor methods for CF One old-school paper: BellCore s movie recommender Some general discussion CF reduced to classi<ication CF reduced to matrix factoring Other uses of matrix factoring in ML
20 WHAT IS COLLABORATIVE FILTERING? AKA social filtering, recommendakon systems,

21 What is collaborative <iltering?

22 What is collaborative <iltering?
23 What is collaborative <iltering?


24 What is collaborative <iltering?
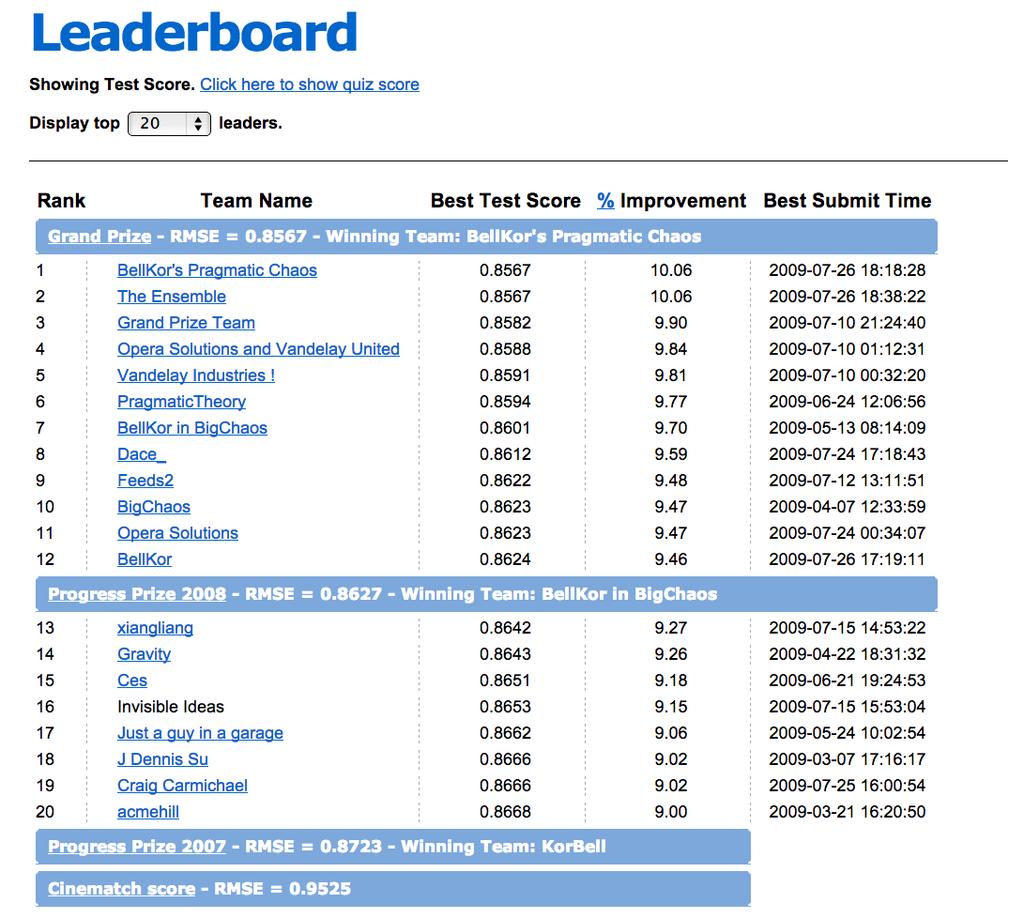
25
26 What is collaborative <iltering?

27 Other examples of social <iltering.

28 Other examples of social <iltering.
29 Other examples of social <iltering.

30 Other examples of social <iltering.
31 Everyday Examples of Collaborative Filtering... Bestseller lists Top 40 music lists The recent returns shelf at the library Unmarked but well-used paths thru the woods The printer room at work Read any good books lately?... Common insight: personal tastes are correlated: If Alice and Bob both like X and Alice likes Y then Bob is more likely to like Y especially (perhaps) if Bob knows Alice
32 SOCIAL/COLLABORATIVE FILTERING: NEAREST-NEIGHBOR METHODS
33 BellCore s MovieRecommender Recommending And Evaluating Choices In A Virtual Community Of Use. Will Hill, Larry Stead, Mark Rosenstein and George Furnas, Bellcore; CHI 1995 By virtual community we mean "a group of people who share characteriskcs and interact in essence or effect only". In other words, people in a Virtual Community influence each other as though they interacted but they do not interact. Thus we ask: "Is it possible to arrange for people to share some of the personalized informakonal benefits of community involvement without the associated communicakons costs?"
34 MovieRecommender Goals Recommendations should: simultaneously ease and encourage rather than replace social processes...should make it easy to participate while leaving in hooks for people to pursue more personal relationships if they wish. be for sets of people not just individuals...multi-person recommending is often important, for example, when two or more people want to choose a video to watch together. be from people not a black box machine or so-called "agent". tell how much con<idence to place in them, in other words they should include indications of how accurate they are.
35 BellCore s MovieRecommender Participants sent to videos@bellcore.com System replied with a list of 500 movies to rate on a 1-10 scale (250 random, 250 popular) Only subset need to be rated New participant P sends in rated movies via System compares ratings for P to ratings of (a random sample of) previous users Most similar users are used to predict scores for unrated movies (more later) System returns recommendations in an message.
36 Suggested Videos for: John A. Jamus. Your must-see list with predicted rakngs: 7.0 "Alien (1979)" 6.5 "Blade Runner" 6.2 "Close Encounters Of The Third Kind (1977)" Your video categories with average rakngs: 6.7 "AcKon/Adventure" 6.5 "Science FicKon/Fantasy" 6.3 "Children/Family" 6.0 "Mystery/Suspense" 5.9 "Comedy" 5.8 "Drama"
37 The viewing paqerns of 243 viewers were consulted. PaQerns of 7 viewers were found to be most similar. CorrelaKon with target viewer: 0.59 viewer-130 (unlisted@merl.com) 0.55 bullert,jane r (bullert@cc.bellcore.com) 0.51 jan_arst (jan_arst@khdld.decnet.philips.nl) 0.46 Ken Cross (moose@denali.ee.cornell.edu) 0.42 rskt (rskt@cc.bellcore.com) 0.41 kkgg (kkgg@athena.mit.edu) 0.41 bnn (bnn@cc.bellcore.com) By category, their joint rakngs recommend: AcKon/Adventure: "Excalibur" 8.0, 4 viewers "Apocalypse Now" 7.2, 4 viewers "Platoon" 8.3, 3 viewers Science FicKon/Fantasy: "Total Recall" 7.2, 5 viewers Children/Family: "Wizard Of Oz, The" 8.5, 4 viewers "Mary Poppins" 7.7, 3 viewers Mystery/Suspense: "Silence Of The Lambs, The" 9.3, 3 viewers Comedy: "NaKonal Lampoon's Animal House" 7.5, 4 viewers "Driving Miss Daisy" 7.5, 4 viewers "Hannah and Her Sisters" 8.0, 3 viewers Drama: "It's A Wonderful Life" 8.0, 5 viewers "Dead Poets Society" 7.0, 5 viewers "Rain Man" 7.5, 4 viewers CorrelaKon of predicted rakngs with your actual rakngs is: 0.64 This number measures ability to evaluate movies accurately for you means low ability means very good ability means fair ability.
38 BellCore s MovieRecommender Evaluation: Withhold 10% of the ratings of each user to use as a test set Measure correlation between predicted ratings and actual ratings for test-set movie/user pairs

39
40 BellCore s MovieRecommender Participants sent to videos@bellcore.com System replied with a list of 500 movies to rate New participant P sends in rated movies via System compares ratings for P to ratings of (a random sample of) previous users Most similar users are used to predict scores for unrated movies Empirical Analysis of Predictive Algorithms for Collaborative Filtering Breese, Heckerman, Kadie, UAI98 System returns recommendations in an message.
41 recap: k-nearest neighbor learning Given a test example x: 1. Find the k training-set examples (x1,y1),.,(xk,yk) that are closest to x. 2. Predict the most frequent label in that set.??
,.")

42 Breaking it down: To train: save the data To test: Very fast! For each test example x: 1. Find the k training-set examples (x 1,y 1 ),., (x k,y k ) that are closest to x. 2. Predict the most frequent label in that set. PredicKon is relakvely slow... but it doesn t depend on the number of classes, only the number of neighbors
43 recap: k-nearest neighbor learning Given a test example x: 1. Find the k training-set examples (x1,y1),.,(xk,yk) that are closest to x. 2. Predict the most frequent label in that set.??
 v i,j = vote of user i on item j I i = items for which user i has voted")

44 Algorithms for Collaborative Filtering 1: Memory-Based Algorithms (Breese et al, UAI98) v i,j = vote of user i on item j I i = items for which user i has voted Mean vote for i is Predicted vote for active user a for j is a weighted sum normalizer weights of n similar users weight is based on similarity between user a and i
 = 0 if i neighbors( a) else Pearson correlation coef<icient (Resnick 94, Grouplens): Cosine distance,")
45 Algorithms for Collaborative Filtering 1: Memory-Based Algorithms (Breese et al, UAI98) K-nearest neighbor 1 w( a, i) = 0 if i neighbors( a) else Pearson correlation coef<icient (Resnick 94, Grouplens): Cosine distance, etc,
46 SOCIAL/COLLABORATIVE FILTERING: TRADITIONAL CLASSIFICATION
47 What are other ways to formulate the collaborative <iltering problem? Treat it like ordinary classi<ication or regression
48 Collaborative + Content Filtering (Basu et al, AAAI98; Condliff et al, AI-STATS99) Joe Carol... 27,M, $70k 53,F, $20k Airplane Matrix comedy, $2M action, $70M Room with a View romance, $25M... Hidalgo... action, $30M Kumar U a 25,M, $22k 48,M, $81k ???
49 Collaborative + Content Filtering As Classification (Basu, Hirsh, Cohen, AAAI98) Classification task: map (user,movie) pair into {likes,dislikes} Training data: known likes/dislikes Test data: active users Features: any properties of user/movie pair Airplane Matrix Room with a View... Hidalgo comedy action romance... action Joe Carol 27,M,70k ,F,20k Kumar 25,M,22k U a 48,M,81k 0 1???
50 Collaborative + Content Filtering As Classification (Basu et al, AAAI98) Examples: genre(u,m), age(u,m), income(u,m),... genre(carol,matrix) = action income(kumar,hidalgo) = 22k/year Features: any properties of user/movie pair (U,M) Airplane Matrix Room with a View... Hidalgo comedy action romance... action Joe Carol 27,M,70k ,F,20k Kumar 25,M,22k U a 48,M,81k 0 1???
51 Collaborative + Content Filtering As Classification (Basu et al, AAAI98) Examples: userswholikedmovie(u,m): userswholikedmovie(carol,hidalgo) = {Joe,...,Kumar} userswholikedmovie(u a, Matrix) = {Joe,...} Features: any properties of user/movie pair (U,M) Airplane Matrix Room with a View... Hidalgo comedy action romance... action Joe Carol 27,M,70k ,F,20k Kumar 25,M,22k U a 48,M,81k 0 1???
52 Collaborative + Content Filtering As Classification (Basu et al, AAAI98) Examples: movieslikedbyuser(m,u): movieslikedbyuser(*,joe) = {Airplane,Matrix,...,Hidalgo} actionmovieslikedbyuser(*,joe)={matrix,hidalgo} Features: any properties of user/movie pair (U,M) Airplane Matrix Room with a View... Hidalgo comedy action romance... action Joe Carol 27,M,70k ,F,20k Kumar 25,M,22k U a 48,M,81k 0 1???
53 Collaborative + Content Filtering As Classification (Basu et al, AAAI98) genre={romance}, age=48, sex=male, income=81k, userswholikedmovie={carol}, movieslikedbyuser={matrix,airplane},... Features: any properties of user/movie pair (U,M) Airplane Matrix Room with a View... Hidalgo comedy action romance... action Joe Carol 27,M,70k ,F,20k Kumar 25,M,22k U a 48,M,81k 1 1???
54 Collaborative + Content Filtering As Classification (Basu et al, AAAI98) genre={romance}, age=48, sex=male, income=81k, userswholikedmovie={carol}, movieslikedbyuser={matrix,airplane},... genre={action}, age=48, sex=male, income=81k, userswholikedmovie = {Joe,Kumar}, movieslikedbyuser={matrix,airplane},... Airplane Matrix Room with a View... Hidalgo comedy action romance... action Joe Carol 27,M,70k ,F,20k Kumar 25,M,22k U a 48,M,81k 1 1???
55 Collaborative + Content Filtering As Classification (Basu et al, AAAI98) Classification learning algorithm: rule learning (RIPPER) If NakedGun33/13 movieslikedbyuser and Joe userswholikedmovie and genre=comedy then predict likes(u,m) If age>12 and age<17 and HolyGrail movieslikedbyuser and director=melbrooks then predict likes(u,m) If Ishtar movieslikedbyuser then predict likes(u,m)
56 Basu et al 98 - results Evaluation: Predict liked(u,m)= M in top quartile of U s ranking from features, evaluate recall and precision Features: Collaborative: UsersWhoLikedMovie, UsersWhoDislikedMovie, MoviesLikedByUser Content: Actors, Directors, Genre, MPAA rating,... Hybrid: ComediesLikedByUser, DramasLikedByUser, UsersWhoLikedFewDramas,... Results: at same level of recall (about 33%) Ripper with collaborative features only is worse than the original MovieRecommender (by about 5 pts precision 73 vs 78) Ripper with hybrid features is better than MovieRecommender (by about 5 pts precision)
57 Matrix Factorization for Collaborative Filtering

58 Recovering latent factors in a matrix m movies v11 n users vij vnm V[i,j] = user i s rating of movie j
59 Recovering latent factors in a matrix m movies m movies x1 x2.. y1 y2.. a1 a2.. am b1 b2 bm ~ v11 n users vij xn yn vnm V[i,j] = user i s rating of movie j


60 talk pilfered from à.. KDD 2011
61
62 Recovering latent factors in a matrix r m movies m movies x1 x2.. y1 y2.. H a1 a2.. am b1 b2 bm ~ v11 n users W vij V xn yn vnm V[i,j] = user i s rating of movie j

63
64
65 Recovering latent factors in a matrix r m movies m movies x1 x2.. y1 y2.. H a1 a2.. am b1 b2 bm ~ v11 n users W vij V xn yn vnm V[i,j] = user i s rating of movie j
66 is like Linear Regression. r features (eg 4) m=1 regressors predictions n instances (e.g., 150) pl1 pw1 sl1 sw1 pl2 pw2 sl2 sw2.... W w1 w2 w3 w4 H ~ y1 yi Y pln pwn yn Y[i,1] = instance i s prediction
67 .. for many outputs at once. r features (eg 4) m regressors predictions n instances (e.g., 150) pl1 pw1 sl1 sw1 pl2 pw2 sl2 sw2.... W w11 w12 w21.. H w31.. w41.. ~ y11 y12 Y ym pln yn1 ynm where we also have to <ind the dataset! Y[I,j] = instance i s prediction for regression task j
68 Matrix factorization as SGD step size
69 Matrix factorization as SGD - why does this work? step size


70 Matrix factorization as SGD - why does this work? Here s the key claim:
71 Checking the claim Think for SGD for logistic regression LR loss = compare y and ŷ = dot(w,x) similar but now update w (user weights) and x (movie weight)

72 What loss functions are possible? generalized KL-divergence
73 What loss functions are possible?
74 What loss functions are possible?
75 ALS = alternating least squares
76 Matrix Multiplications in Machine Learning: MF vs PCA vs SGD vs.
77 Recovering latent factors in a matrix r m movies m movies x1 x2.. y1 y2.. H a1 a2.. am b1 b2 bm ~ v11 n users W vij V xn yn vnm V[i,j] = user i s rating of movie j
78 .. vs k-means (1) indicators for r clusters cluster means original data set M a1 a2.. am b1 b2 bm ~ v11 n examples Z vij X xn yn vnm
79 Matrix multiplication - 1 (Gram matrix) r features (eg 2) transpose of X n instances (e.g., 150) x1 y1 x2 y2.... X x1 x2.. xn y1 y2 yn X T ~ <x1,x1> <xi,xj> V xn yn <xn,xn> V[i,j] = inner product of instances i and j (Gram matrix)
80 Matrix multiplication - 2 (Covariance matrix) r features (eg 2) transpose of X X T x1 y1 a1 a2 am b1 b2 bm x2 y2.... X xn yn ~ v11 v12 v21 v22 C X n C X (i, j) = x t t i x j = n cov(i, j) t=1 assuming mean(x)=0
 of a process where we predict each feature value X")

81 Matrix multiplication - 2 (PCA) V = C X = X T X variance/covariances I think of these as fixed point E = eigenvectors(v) of a process where we predict each feature value X E T = PCA(X) = Z from the others and C X Z(i,j) is similarity of example i to x1 y1 eigenvector j x2 y2.. X.. e11 e12 e21 e22 E T Eigenvecs of C X z1 z2.. Z z1 z2.. xn yn zn zn
82 Matrix multiplication - 2 (PCA) V = C X = X T X variance/covariances E = eigenvectors(v) X E T = PCA(X) = Z K or use E(1:K, :) instead of E x1 y1 x2.. X y2.. e11 e21 E K T top K eigenvecs of C X z1 z2.. Z K xn yn zn
83 Matrix multiplication - 3 (SVD) V = C X = X T X variance/covariances E = eigenvectors(v) X E T = PCA(X) = Z Eigenvecs of C X X = Z E = Z Σ -1 Σ E = U Σ E where U = Z Σ -1 i.e., factored version of X Usually written as X = U Σ V z1 z2.. Z z1 z2.. e11 e21 E e12 e22 x1 x2.. X y1 y2.. zn zn xn yn
84 Matrix multiplication - 3 (SVD) V = C X = X T X variance/covariances E = eigenvectors(v) X E K T = PCA(X) = Z K E K = E(1:K, :) instead of E Σ Eigenvecs of C X X Z K E K Z K Σ -1 Σ E U K Σ E where U K = Z K Σ -1 i.e., factored version of X z1 z2.. U K Σ1 e11 e21 E e12 e22 x1 x2.. X y1 y2.. zn xn yn


85 Matrix multiplication - 2 (SVD) K features with zero covar and unit variances Σ eigenvectors of C X x1 x2.. y1 y2.. Σ1 0 0 Σ2 x1 x2.. xn E y1 y2 yn ~ <x1,x1> n instances U K <xi,xj> X xn yn <xn,xn> original matrix
86 Recovering latent factors in a matrix r m movies m movies x1 x2.. y1 y2.. H a1 a2.. am b1 b2 bm ~ v11 n users W vij V xn yn vnm V[i,j] = user i s rating of movie j
Techniques for Dimensionality Reduction. PCA and Other Matrix Factorization Methods
 Techniques for Dimensionality Reduction PCA and Other Matrix Factorization Methods Outline Principle Compoments Analysis (PCA) Example (Bishop, ch 12) PCA as a mixture model variant With a continuous latent
Techniques for Dimensionality Reduction PCA and Other Matrix Factorization Methods Outline Principle Compoments Analysis (PCA) Example (Bishop, ch 12) PCA as a mixture model variant With a continuous latent
Dimensionality Reduction and Principle Components Analysis
 Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Matrix Factorization and Collaborative Filtering
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Matrix Factorization and Collaborative Filtering MF Readings: (Koren et al., 2009)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Matrix Factorization and Collaborative Filtering MF Readings: (Koren et al., 2009)
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task
 Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Learning representations
 Learning representations Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 4/11/2016 General problem For a dataset of n signals X := [ x 1 x
Learning representations Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 4/11/2016 General problem For a dataset of n signals X := [ x 1 x
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
Collaborative Filtering
 Collaborative Filtering Nicholas Ruozzi University of Texas at Dallas based on the slides of Alex Smola & Narges Razavian Collaborative Filtering Combining information among collaborating entities to make
Collaborative Filtering Nicholas Ruozzi University of Texas at Dallas based on the slides of Alex Smola & Narges Razavian Collaborative Filtering Combining information among collaborating entities to make
a Short Introduction
 Collaborative Filtering in Recommender Systems: a Short Introduction Norm Matloff Dept. of Computer Science University of California, Davis matloff@cs.ucdavis.edu December 3, 2016 Abstract There is a strong
Collaborative Filtering in Recommender Systems: a Short Introduction Norm Matloff Dept. of Computer Science University of California, Davis matloff@cs.ucdavis.edu December 3, 2016 Abstract There is a strong
Preliminaries. Data Mining. The art of extracting knowledge from large bodies of structured data. Let s put it to use!
 Data Mining The art of extracting knowledge from large bodies of structured data. Let s put it to use! 1 Recommendations 2 Basic Recommendations with Collaborative Filtering Making Recommendations 4 The
Data Mining The art of extracting knowledge from large bodies of structured data. Let s put it to use! 1 Recommendations 2 Basic Recommendations with Collaborative Filtering Making Recommendations 4 The
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Recommendation. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Recommendation Tobias Scheffer Recommendation Engines Recommendation of products, music, contacts,.. Based on user features, item
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Recommendation Tobias Scheffer Recommendation Engines Recommendation of products, music, contacts,.. Based on user features, item
Machine Learning. Principal Components Analysis. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 8: Evaluation & SVD Paul Ginsparg Cornell University, Ithaca, NY 20 Sep 2011
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 8: Evaluation & SVD Paul Ginsparg Cornell University, Ithaca, NY 20 Sep 2011
Scaling Neighbourhood Methods
 Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
Collaborative Filtering. Radek Pelánek
 Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
Structured matrix factorizations. Example: Eigenfaces
 Structured matrix factorizations Example: Eigenfaces An extremely large variety of interesting and important problems in machine learning can be formulated as: Given a matrix, find a matrix and a matrix
Structured matrix factorizations Example: Eigenfaces An extremely large variety of interesting and important problems in machine learning can be formulated as: Given a matrix, find a matrix and a matrix
Clustering based tensor decomposition
 Clustering based tensor decomposition Huan He huan.he@emory.edu Shihua Wang shihua.wang@emory.edu Emory University November 29, 2017 (Huan)(Shihua) (Emory University) Clustering based tensor decomposition
Clustering based tensor decomposition Huan He huan.he@emory.edu Shihua Wang shihua.wang@emory.edu Emory University November 29, 2017 (Huan)(Shihua) (Emory University) Clustering based tensor decomposition
Lecture Notes 10: Matrix Factorization
 Optimization-based data analysis Fall 207 Lecture Notes 0: Matrix Factorization Low-rank models. Rank- model Consider the problem of modeling a quantity y[i, j] that depends on two indices i and j. To
Optimization-based data analysis Fall 207 Lecture Notes 0: Matrix Factorization Low-rank models. Rank- model Consider the problem of modeling a quantity y[i, j] that depends on two indices i and j. To
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Information Retrieval
 Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Recommendation Systems
 Recommendation Systems Popularity Recommendation Systems Predicting user responses to options Offering news articles based on users interests Offering suggestions on what the user might like to buy/consume
Recommendation Systems Popularity Recommendation Systems Predicting user responses to options Offering news articles based on users interests Offering suggestions on what the user might like to buy/consume
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Dimensionality Reduction: PCA. Nicholas Ruozzi University of Texas at Dallas
 Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Structure in Data. A major objective in data analysis is to identify interesting features or structure in the data.
 Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Andriy Mnih and Ruslan Salakhutdinov
 MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
CS246 Final Exam, Winter 2011
 CS246 Final Exam, Winter 2011 1. Your name and student ID. Name:... Student ID:... 2. I agree to comply with Stanford Honor Code. Signature:... 3. There should be 17 numbered pages in this exam (including
CS246 Final Exam, Winter 2011 1. Your name and student ID. Name:... Student ID:... 2. I agree to comply with Stanford Honor Code. Signature:... 3. There should be 17 numbered pages in this exam (including
CS425: Algorithms for Web Scale Data
 CS: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS. The original slides can be accessed at: www.mmds.org Customer
CS: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS. The original slides can be accessed at: www.mmds.org Customer
Unsupervised Machine Learning and Data Mining. DS 5230 / DS Fall Lecture 7. Jan-Willem van de Meent
 Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Recommender Systems: Overview and. Package rectools. Norm Matloff. Dept. of Computer Science. University of California at Davis.
 Recommender December 13, 2016 What Are Recommender Systems? What Are Recommender Systems? Various forms, but here is a common one, say for data on movie ratings: What Are Recommender Systems? Various forms,
Recommender December 13, 2016 What Are Recommender Systems? What Are Recommender Systems? Various forms, but here is a common one, say for data on movie ratings: What Are Recommender Systems? Various forms,
Stat 406: Algorithms for classification and prediction. Lecture 1: Introduction. Kevin Murphy. Mon 7 January,
 1 Stat 406: Algorithms for classification and prediction Lecture 1: Introduction Kevin Murphy Mon 7 January, 2008 1 1 Slides last updated on January 7, 2008 Outline 2 Administrivia Some basic definitions.
1 Stat 406: Algorithms for classification and prediction Lecture 1: Introduction Kevin Murphy Mon 7 January, 2008 1 1 Slides last updated on January 7, 2008 Outline 2 Administrivia Some basic definitions.
Recommender Systems EE448, Big Data Mining, Lecture 10. Weinan Zhang Shanghai Jiao Tong University
 2018 EE448, Big Data Mining, Lecture 10 Recommender Systems Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of This Course Overview of
2018 EE448, Big Data Mining, Lecture 10 Recommender Systems Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of This Course Overview of
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Collaborative Filtering: A Machine Learning Perspective
 Collaborative Filtering: A Machine Learning Perspective Chapter 6: Dimensionality Reduction Benjamin Marlin Presenter: Chaitanya Desai Collaborative Filtering: A Machine Learning Perspective p.1/18 Topics
Collaborative Filtering: A Machine Learning Perspective Chapter 6: Dimensionality Reduction Benjamin Marlin Presenter: Chaitanya Desai Collaborative Filtering: A Machine Learning Perspective p.1/18 Topics
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Collaborative topic models: motivations cont
 Collaborative topic models: motivations cont Two topics: machine learning social network analysis Two people: " boy Two articles: article A! girl article B Preferences: The boy likes A and B --- no problem.
Collaborative topic models: motivations cont Two topics: machine learning social network analysis Two people: " boy Two articles: article A! girl article B Preferences: The boy likes A and B --- no problem.
Matrix Factorization & Latent Semantic Analysis Review. Yize Li, Lanbo Zhang
 Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Notes on Latent Semantic Analysis
 Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties
 ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties Prof. James She james.she@ust.hk 1 Last lecture 2 Selected works from Tutorial
ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties Prof. James She james.she@ust.hk 1 Last lecture 2 Selected works from Tutorial
Modeling User Rating Profiles For Collaborative Filtering
 Modeling User Rating Profiles For Collaborative Filtering Benjamin Marlin Department of Computer Science University of Toronto Toronto, ON, M5S 3H5, CANADA marlin@cs.toronto.edu Abstract In this paper
Modeling User Rating Profiles For Collaborative Filtering Benjamin Marlin Department of Computer Science University of Toronto Toronto, ON, M5S 3H5, CANADA marlin@cs.toronto.edu Abstract In this paper
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 12 Jan-Willem van de Meent (credit: Yijun Zhao, Percy Liang) DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Linear Dimensionality
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 12 Jan-Willem van de Meent (credit: Yijun Zhao, Percy Liang) DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Linear Dimensionality
CPSC 340: Machine Learning and Data Mining. More PCA Fall 2017
 CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
Recommendation Systems
 Recommendation Systems Pawan Goyal CSE, IITKGP October 29-30, 2015 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 29-30, 2015 1 / 61 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems Pawan Goyal CSE, IITKGP October 29-30, 2015 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 29-30, 2015 1 / 61 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Ad Placement Strategies
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 2 Often, our data can be represented by an m-by-n matrix. And this matrix can be closely approximated by the product of two matrices that share a small common dimension
Jeffrey D. Ullman Stanford University 2 Often, our data can be represented by an m-by-n matrix. And this matrix can be closely approximated by the product of two matrices that share a small common dimension
Probabilistic Partial User Model Similarity for Collaborative Filtering
 Probabilistic Partial User Model Similarity for Collaborative Filtering Amancio Bouza, Gerald Reif, Abraham Bernstein Department of Informatics, University of Zurich {bouza,reif,bernstein}@ifi.uzh.ch Abstract.
Probabilistic Partial User Model Similarity for Collaborative Filtering Amancio Bouza, Gerald Reif, Abraham Bernstein Department of Informatics, University of Zurich {bouza,reif,bernstein}@ifi.uzh.ch Abstract.
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent
 Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
Recommender Systems. Dipanjan Das Language Technologies Institute Carnegie Mellon University. 20 November, 2007
 Recommender Systems Dipanjan Das Language Technologies Institute Carnegie Mellon University 20 November, 2007 Today s Outline What are Recommender Systems? Two approaches Content Based Methods Collaborative
Recommender Systems Dipanjan Das Language Technologies Institute Carnegie Mellon University 20 November, 2007 Today s Outline What are Recommender Systems? Two approaches Content Based Methods Collaborative
Introduction PCA classic Generative models Beyond and summary. PCA, ICA and beyond
 PCA, ICA and beyond Summer School on Manifold Learning in Image and Signal Analysis, August 17-21, 2009, Hven Technical University of Denmark (DTU) & University of Copenhagen (KU) August 18, 2009 Motivation
PCA, ICA and beyond Summer School on Manifold Learning in Image and Signal Analysis, August 17-21, 2009, Hven Technical University of Denmark (DTU) & University of Copenhagen (KU) August 18, 2009 Motivation
CSE 258, Winter 2017: Midterm
 CSE 258, Winter 2017: Midterm Name: Student ID: Instructions The test will start at 6:40pm. Hand in your solution at or before 7:40pm. Answers should be written directly in the spaces provided. Do not
CSE 258, Winter 2017: Midterm Name: Student ID: Instructions The test will start at 6:40pm. Hand in your solution at or before 7:40pm. Answers should be written directly in the spaces provided. Do not
Statistics 202: Data Mining. c Jonathan Taylor. Week 2 Based in part on slides from textbook, slides of Susan Holmes. October 3, / 1
 Week 2 Based in part on slides from textbook, slides of Susan Holmes October 3, 2012 1 / 1 Part I Other datatypes, preprocessing 2 / 1 Other datatypes Document data You might start with a collection of
Week 2 Based in part on slides from textbook, slides of Susan Holmes October 3, 2012 1 / 1 Part I Other datatypes, preprocessing 2 / 1 Other datatypes Document data You might start with a collection of
Quick Introduction to Nonnegative Matrix Factorization
 Quick Introduction to Nonnegative Matrix Factorization Norm Matloff University of California at Davis 1 The Goal Given an u v matrix A with nonnegative elements, we wish to find nonnegative, rank-k matrices
Quick Introduction to Nonnegative Matrix Factorization Norm Matloff University of California at Davis 1 The Goal Given an u v matrix A with nonnegative elements, we wish to find nonnegative, rank-k matrices
Part I. Other datatypes, preprocessing. Other datatypes. Other datatypes. Week 2 Based in part on slides from textbook, slides of Susan Holmes
 Week 2 Based in part on slides from textbook, slides of Susan Holmes Part I Other datatypes, preprocessing October 3, 2012 1 / 1 2 / 1 Other datatypes Other datatypes Document data You might start with
Week 2 Based in part on slides from textbook, slides of Susan Holmes Part I Other datatypes, preprocessing October 3, 2012 1 / 1 2 / 1 Other datatypes Other datatypes Document data You might start with
Collaborative Topic Modeling for Recommending Scientific Articles
 Collaborative Topic Modeling for Recommending Scientific Articles Chong Wang and David M. Blei Best student paper award at KDD 2011 Computer Science Department, Princeton University Presented by Tian Cao
Collaborative Topic Modeling for Recommending Scientific Articles Chong Wang and David M. Blei Best student paper award at KDD 2011 Computer Science Department, Princeton University Presented by Tian Cao
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
Principal Component Analysis and Singular Value Decomposition. Volker Tresp, Clemens Otte Summer 2014
 Principal Component Analysis and Singular Value Decomposition Volker Tresp, Clemens Otte Summer 2014 1 Motivation So far we always argued for a high-dimensional feature space Still, in some cases it makes
Principal Component Analysis and Singular Value Decomposition Volker Tresp, Clemens Otte Summer 2014 1 Motivation So far we always argued for a high-dimensional feature space Still, in some cases it makes
Recommendation Systems
 Recommendation Systems Pawan Goyal CSE, IITKGP October 21, 2014 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 21, 2014 1 / 52 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems Pawan Goyal CSE, IITKGP October 21, 2014 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 21, 2014 1 / 52 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Leverage Sparse Information in Predictive Modeling
 Leverage Sparse Information in Predictive Modeling Liang Xie Countrywide Home Loans, Countrywide Bank, FSB August 29, 2008 Abstract This paper examines an innovative method to leverage information from
Leverage Sparse Information in Predictive Modeling Liang Xie Countrywide Home Loans, Countrywide Bank, FSB August 29, 2008 Abstract This paper examines an innovative method to leverage information from
Machine Learning for Software Engineering
 Machine Learning for Software Engineering Dimensionality Reduction Prof. Dr.-Ing. Norbert Siegmund Intelligent Software Systems 1 2 Exam Info Scheduled for Tuesday 25 th of July 11-13h (same time as the
Machine Learning for Software Engineering Dimensionality Reduction Prof. Dr.-Ing. Norbert Siegmund Intelligent Software Systems 1 2 Exam Info Scheduled for Tuesday 25 th of July 11-13h (same time as the
CS 3750 Advanced Machine Learning. Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya
 Cem Akkaya") CS 375 Advanced Machine Learning Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya Outline SVD and LSI Kleinberg s Algorithm PageRank Algorithm Vector Space Model Vector space model represents
CS 375 Advanced Machine Learning Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya Outline SVD and LSI Kleinberg s Algorithm PageRank Algorithm Vector Space Model Vector space model represents
Dimensionality Reduction
 Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Relational Stacked Denoising Autoencoder for Tag Recommendation. Hao Wang
 Relational Stacked Denoising Autoencoder for Tag Recommendation Hao Wang Dept. of Computer Science and Engineering Hong Kong University of Science and Technology Joint work with Xingjian Shi and Dit-Yan
Relational Stacked Denoising Autoencoder for Tag Recommendation Hao Wang Dept. of Computer Science and Engineering Hong Kong University of Science and Technology Joint work with Xingjian Shi and Dit-Yan
CS276A Text Information Retrieval, Mining, and Exploitation. Lecture 4 15 Oct 2002
 CS276A Text Information Retrieval, Mining, and Exploitation Lecture 4 15 Oct 2002 Recap of last time Index size Index construction techniques Dynamic indices Real world considerations 2 Back of the envelope
CS276A Text Information Retrieval, Mining, and Exploitation Lecture 4 15 Oct 2002 Recap of last time Index size Index construction techniques Dynamic indices Real world considerations 2 Back of the envelope
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Collaborative Filtering Matrix Completion Alternating Least Squares
 Case Study 4: Collaborative Filtering Collaborative Filtering Matrix Completion Alternating Least Squares Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade May 19, 2016
Case Study 4: Collaborative Filtering Collaborative Filtering Matrix Completion Alternating Least Squares Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade May 19, 2016
Sample questions for Fundamentals of Machine Learning 2018
 Sample questions for Fundamentals of Machine Learning 2018 Teacher: Mohammad Emtiyaz Khan A few important informations: In the final exam, no electronic devices are allowed except a calculator. Make sure
Sample questions for Fundamentals of Machine Learning 2018 Teacher: Mohammad Emtiyaz Khan A few important informations: In the final exam, no electronic devices are allowed except a calculator. Make sure
Data Preprocessing Tasks
 Data Tasks 1 2 3 Data Reduction 4 We re here. 1 Dimensionality Reduction Dimensionality reduction is a commonly used approach for generating fewer features. Typically used because too many features can
Data Tasks 1 2 3 Data Reduction 4 We re here. 1 Dimensionality Reduction Dimensionality reduction is a commonly used approach for generating fewer features. Typically used because too many features can
Data Science Mastery Program
 Data Science Mastery Program Copyright Policy All content included on the Site or third-party platforms as part of the class, such as text, graphics, logos, button icons, images, audio clips, video clips,
Data Science Mastery Program Copyright Policy All content included on the Site or third-party platforms as part of the class, such as text, graphics, logos, button icons, images, audio clips, video clips,
EE 381V: Large Scale Learning Spring Lecture 16 March 7
 EE 381V: Large Scale Learning Spring 2013 Lecture 16 March 7 Lecturer: Caramanis & Sanghavi Scribe: Tianyang Bai 16.1 Topics Covered In this lecture, we introduced one method of matrix completion via SVD-based
EE 381V: Large Scale Learning Spring 2013 Lecture 16 March 7 Lecturer: Caramanis & Sanghavi Scribe: Tianyang Bai 16.1 Topics Covered In this lecture, we introduced one method of matrix completion via SVD-based
Matrix Factorization Techniques For Recommender Systems. Collaborative Filtering
 Matrix Factorization Techniques For Recommender Systems Collaborative Filtering Markus Freitag, Jan-Felix Schwarz 28 April 2011 Agenda 2 1. Paper Backgrounds 2. Latent Factor Models 3. Overfitting & Regularization
Matrix Factorization Techniques For Recommender Systems Collaborative Filtering Markus Freitag, Jan-Felix Schwarz 28 April 2011 Agenda 2 1. Paper Backgrounds 2. Latent Factor Models 3. Overfitting & Regularization
Intelligent Data Analysis Lecture Notes on Document Mining
 Intelligent Data Analysis Lecture Notes on Document Mining Peter Tiňo Representing Textual Documents as Vectors Our next topic will take us to seemingly very different data spaces - those of textual documents.
Intelligent Data Analysis Lecture Notes on Document Mining Peter Tiňo Representing Textual Documents as Vectors Our next topic will take us to seemingly very different data spaces - those of textual documents.
Machine Learning, Fall 2009: Midterm
 10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 21: Review Jan-Willem van de Meent Schedule Topics for Exam Pre-Midterm Probability Information Theory Linear Regression Classification Clustering
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 21: Review Jan-Willem van de Meent Schedule Topics for Exam Pre-Midterm Probability Information Theory Linear Regression Classification Clustering
Principal Component Analysis
 Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
Similarity and recommender systems
 Similarity and recommender systems Hiroshi Shimodaira January-March 208 In this chapter we shall look at how to measure the similarity between items To be precise we ll look at a measure of the dissimilarity
Similarity and recommender systems Hiroshi Shimodaira January-March 208 In this chapter we shall look at how to measure the similarity between items To be precise we ll look at a measure of the dissimilarity
Vector Space Models. wine_spectral.r
 Vector Space Models 137 wine_spectral.r Latent Semantic Analysis Problem with words Even a small vocabulary as in wine example is challenging LSA Reduce number of columns of DTM by principal components
Vector Space Models 137 wine_spectral.r Latent Semantic Analysis Problem with words Even a small vocabulary as in wine example is challenging LSA Reduce number of columns of DTM by principal components
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Collaborative Filtering with Temporal Dynamics with Using Singular Value Decomposition
 ISSN 1330-3651 (Print), ISSN 1848-6339 (Online) https://doi.org/10.17559/tv-20160708140839 Original scientific paper Collaborative Filtering with Temporal Dynamics with Using Singular Value Decomposition
ISSN 1330-3651 (Print), ISSN 1848-6339 (Online) https://doi.org/10.17559/tv-20160708140839 Original scientific paper Collaborative Filtering with Temporal Dynamics with Using Singular Value Decomposition
Natural Language Processing. Topics in Information Retrieval. Updated 5/10
 Natural Language Processing Topics in Information Retrieval Updated 5/10 Outline Introduction to IR Design features of IR systems Evaluation measures The vector space model Latent semantic indexing Background
Natural Language Processing Topics in Information Retrieval Updated 5/10 Outline Introduction to IR Design features of IR systems Evaluation measures The vector space model Latent semantic indexing Background
Dimensionality Reduction
 394 Chapter 11 Dimensionality Reduction There are many sources of data that can be viewed as a large matrix. We saw in Chapter 5 how the Web can be represented as a transition matrix. In Chapter 9, the
394 Chapter 11 Dimensionality Reduction There are many sources of data that can be viewed as a large matrix. We saw in Chapter 5 how the Web can be represented as a transition matrix. In Chapter 9, the
Gaussian and Linear Discriminant Analysis; Multiclass Classification
 Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Latent Semantic Models. Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze
 Latent Semantic Models Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 Vector Space Model: Pros Automatic selection of index terms Partial matching of queries
Latent Semantic Models Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 Vector Space Model: Pros Automatic selection of index terms Partial matching of queries
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Machine Learning - MT & 14. PCA and MDS
 Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 18, 2016 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 18, 2016 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
Metric-based classifiers. Nuno Vasconcelos UCSD
 Metric-based classifiers Nuno Vasconcelos UCSD Statistical learning goal: given a function f. y f and a collection of eample data-points, learn what the function f. is. this is called training. two major
Metric-based classifiers Nuno Vasconcelos UCSD Statistical learning goal: given a function f. y f and a collection of eample data-points, learn what the function f. is. this is called training. two major
Machine learning for pervasive systems Classification in high-dimensional spaces
 Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Bayes Decision Theory - I
 Bayes Decision Theory - I Nuno Vasconcelos (Ken Kreutz-Delgado) UCSD Statistical Learning from Data Goal: Given a relationship between a feature vector and a vector y, and iid data samples ( i,y i ), find
Bayes Decision Theory - I Nuno Vasconcelos (Ken Kreutz-Delgado) UCSD Statistical Learning from Data Goal: Given a relationship between a feature vector and a vector y, and iid data samples ( i,y i ), find
Machine Learning (Spring 2012) Principal Component Analysis
 Principal Component Analysis") 1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
Machine Learning for Large-Scale Data Analysis and Decision Making A. Week #1
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Week #1 Today Introduction to machine learning The course (syllabus) Math review (probability + linear algebra) The future
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Week #1 Today Introduction to machine learning The course (syllabus) Math review (probability + linear algebra) The future
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
December 20, MAA704, Multivariate analysis. Christopher Engström. Multivariate. analysis. Principal component analysis
 .. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
.. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
APPLICATIONS OF MINING HETEROGENEOUS INFORMATION NETWORKS
 APPLICATIONS OF MINING HETEROGENEOUS INFORMATION NETWORKS Yizhou Sun College of Computer and Information Science Northeastern University yzsun@ccs.neu.edu July 25, 2015 Heterogeneous Information Networks
APPLICATIONS OF MINING HETEROGENEOUS INFORMATION NETWORKS Yizhou Sun College of Computer and Information Science Northeastern University yzsun@ccs.neu.edu July 25, 2015 Heterogeneous Information Networks
Recommender Systems. From Content to Latent Factor Analysis. Michael Hahsler
 Recommender Systems From Content to Latent Factor Analysis Michael Hahsler Intelligent Data Analysis Lab (IDA@SMU) CSE Department, Lyle School of Engineering Southern Methodist University CSE Seminar September
Recommender Systems From Content to Latent Factor Analysis Michael Hahsler Intelligent Data Analysis Lab (IDA@SMU) CSE Department, Lyle School of Engineering Southern Methodist University CSE Seminar September
Robot Image Credit: Viktoriya Sukhanova 123RF.com. Dimensionality Reduction
 Robot Image Credit: Viktoriya Sukhanova 13RF.com Dimensionality Reduction Feature Selection vs. Dimensionality Reduction Feature Selection (last time) Select a subset of features. When classifying novel
Robot Image Credit: Viktoriya Sukhanova 13RF.com Dimensionality Reduction Feature Selection vs. Dimensionality Reduction Feature Selection (last time) Select a subset of features. When classifying novel