Data Science Mastery Program
|
|
|
- Alannah Stevenson
- 6 years ago
- Views:
Transcription
1 Data Science Mastery Program
2 Copyright Policy All content included on the Site or third-party platforms as part of the class, such as text, graphics, logos, button icons, images, audio clips, video clips, live streams, digital downloads, data compilations, and software, is the property of BitTiger or its content suppliers and protected by copyright laws. Any attempt to redistribute or resell BitTiger content will result in the appropriate legal action being taken. We thank you in advance for respecting our copyrighted content. For more info see and
3 BitTiger
4 Outline Matrix Factorization in Clustering and Dimensionality Reduction Non-negative Matrix Factorization Singular Value Decomposition Recommender Examples Approaches in Recommenders Content-Based Collaborative Filtering Item-Item User-User Matrix Factorization UV Decomposition
5 Matrix Factorization
6 Non-negative Matrix Factorization

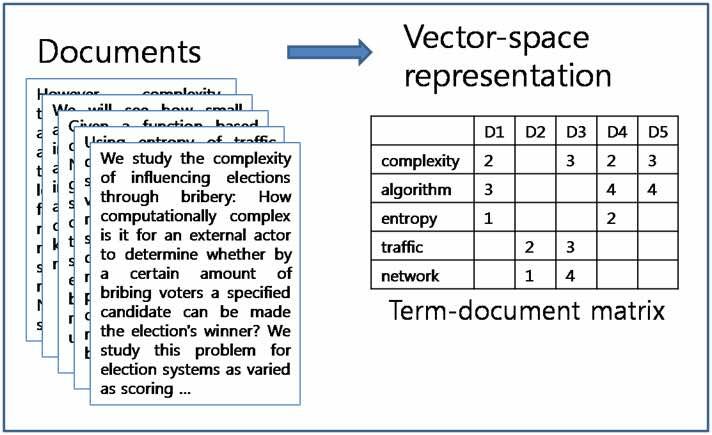
7 Non-negative Matrix Factorization(NMF) Matrix*Vm#x#n#*where*each*entry*vij* *0** m*x*r" r*x*n* m*x*n* also*wij* *0* *********hij* *0* Cannot*be*solved analy(cally,*so* approximated* numerically* r*set*by*user; $**r*<*min(m,n)**
8 No(ce*the*columns*of*V*are*sum*of*columns*of*W*weighted by*corresponding*column*in*hi NMF*is*a*rela(vely*new*way*of*reducing*dimensionality*of data*into*linear*combina(on*of*bases $**Columns*of*W*as*basis,*weighted*by*hi Non$nega(vity*constraint $**Unlike*the*decomposi(ons*we ve*looked*at*thus*far*

9 Document*Clustering*with*NMF* * 500*documents* 10,000*words* * V*****=*****W*****H* * * *
10 W:* Think*of*column*of*W*as*document*archetype* where*the*higher*the*word s*cell*value,*the* higher*the*word s*rank*for*that*latent*feature.* H:* Think*of*column*of*H*as*the*original* document,*where*cell*value*is*document s* rank*for*a*par(cular*latent*feature.* Recall* V:* Think*of*recons(tu(ng*a*par(cular*document*as* linear*combina(on*of* document*archetypes * weighed*by*how*important*they*are.*** NMF (least-squares objective) = a relaxed form of K-means Clustering: W contains cluster centroids H contains cluster membership indicators
 Repeat*following* $")

11 Mechanics* *Alterna(ng*LS* *Minimize* *with*respect*to*w*and*h# *subject*to*w,*h* *0* Steps* (1) Randomly*ini(alize*W*and*H*to*the*appropriate*shapes* (2) Repeat*following* $ Holding*W*fixed,*update*H*by*minimizing*sum*of*squared*errors.**Ensure*all*H>0.* $ Holding*H*fixed,*update*W*by*minimizing*sum*of*squared*errors.**Ensure*all*W>0.* (3) Stop*when*some*threshold*is*met* Decrease*in*RMSE,*#*of*itera(ons,*etc.
12 NMF Algorithm
13 NMF Algorithm

14 Computer*Visioning Popular*Applica(ons* Iden(fy*/*classifying*objects Generally*reducing*feature*space *of*images* Document*Clustering Recommender*systems
15 hnp://
16 Singular Value Decomposition
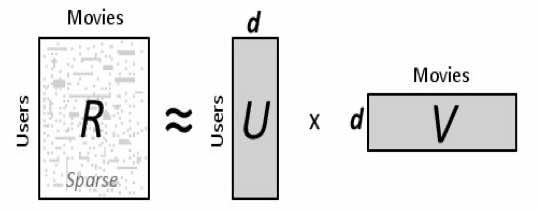
17 Singular Value Decomposition A [n x m] = U [n x r] L [ r x r] (V [m x r] ) T A: n x m matrix (e.g., n documents, m terms) U: n x r matrix (n documents, r concepts) L: r x r diagonal matrix (strength of each concept ) (r: rank of the matrix) V: m x r matrix (m terms, r concepts)
18 Singular Value Decomposition m: # of users n: # of items k: # of latent features (also rank of A)
19 SVD - Properties THEOREM: always possible to decompose matrix A into A = U L V T, where U, L, V: unique (*) U, V: column orthonormal (i.e., columns are unit vectors, orthogonal to each other) U T U = I; V T V = I (I: identity matrix) L: singular value are positive, and sorted in decreasing order
20 SVD - Properties spectral decomposition of the matrix: = x x u 1 u 2 l 1 l 2 v 1 v 2
21 SVD - Interpretation documents, terms and concepts : U: document-to-concept similarity matrix V: term-to-concept similarity matrix L: its diagonal elements: strength of each concept Projection: best axis to project on: ( best = min sum of squares of projection errors)
22 SVD - Example A = U L V T - example: Documents data information retrieval brain lung CS-TR CS-TR CS-TR CS-TR MED-TR MED-TR MED-TR
23 SVD - Example CS MD A = U L V T - example: data info. retrieval brain lung = x x
24 SVD - Example CS MD A = U L V T - example: doc-to-concept similarity matrix CS-concept MD-concept data info. retrieval brain lung = x x
25 SVD - Example CS MD A = U L V T - example: data info. retrieval = brain lung strength of CS-concept x x
26 SVD - Example CS MD A = U L V T - example: data info. retrieval = brain lung CS-concept x term-to-concept similarity matrix x
27 SVD Dimensionality reduction Q: how exactly is dimensionality reduction done? A: set the smallest singular values to zero: = x x
28 SVD - Dimensionality reduction Reduced matrices ~ x 9.64 x
29 SVD - Dimensionality reduction Reduced matrices ~
30 Intro to Recommenders
31 Recommenders Where are recommenders used? What does our dataset look like? What are the high-level approaches to building a recommender? Content-based Collaborative filtering Matrix factorization How do we evaluate our recommender system? What are the challenges in our recommender system? What are the computational performance concerns?


32

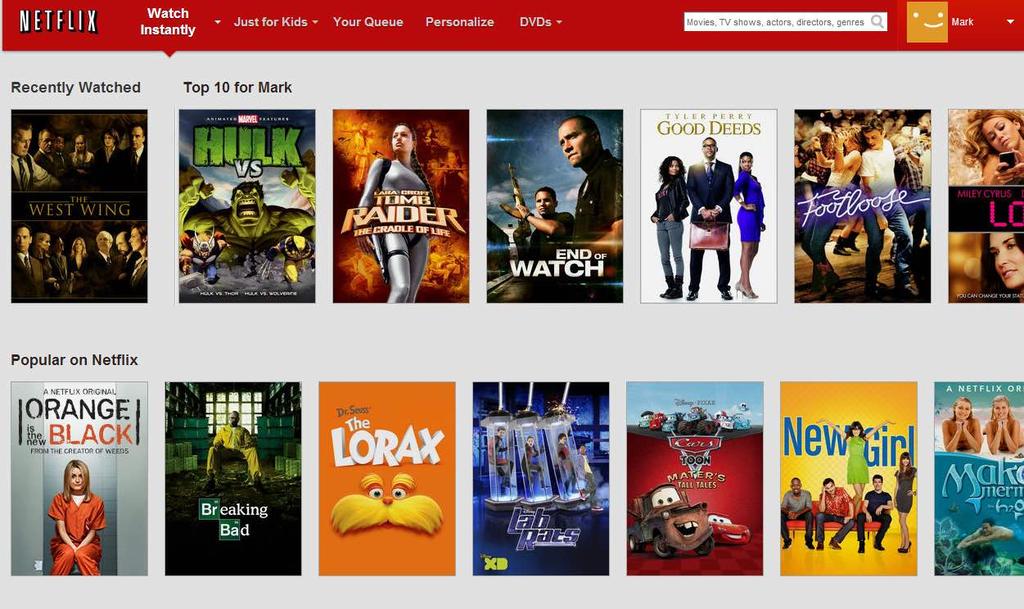
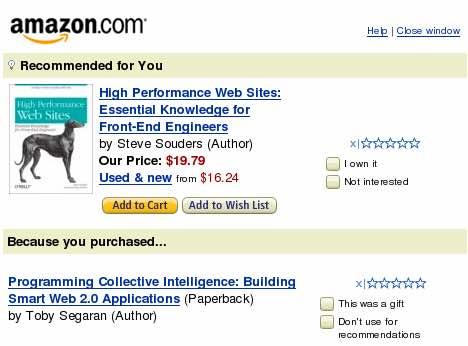
33
34 Recommenders in Industry Netflix: 2/3 of the movies watched are recommended Google News: recommendations generate 38% more click-through Amazon: 35% sales from recommendations Stitch Fix: 100% of their revenue is based on recommendations
35 Business Goals What will the user like? What will the user buy? What will the user click?

36 Data Science Canon: Netflix s $1,000,000 Prize (Oct July 2009) Goal: Beat Netflix s own recommender by 10%. Took almost 3 years. The winning team used gradient boosted decision trees over the predictions of 500 other models. Netflix never deployed the winning algorithm.
37 What are the high-level approaches to building a recommender? Popularity: Make the same recommendation to every user, based only on the popularity of an item. E.g. Twitter Moments Content-based (aka, Content filtering): Predictions are made based on the properties/characteristics of an item. Other users behavior is not considered. E.g. Pandora Radio Collaborative filtering: Only consider past user behavior. (not content properties...) User-User similarity: Item-Item similarity:... E.g. Netflix & Amazon Recommendations, Google Ads, Facebook Ads, Search, Friends Rec., News feed, Trending news, Rank Notifications, Rank Comments Matrix Factorization Methods: Find latent features (aka, factors)
38 Content-Based Recommendation
39 Content-based recommendation Recommendations based on information on the content of items rather than on other users opinions/interactions Use a machine learning algorithm or a heuristic approach to induce a model of the users preferences from examples based on a featural description of content. In content-based recommendations, the system tries to recommend items similar to those a given user has liked in the past A pure content-based recommender system makes recommendations for a user based solely on the profile built up by analyzing the content of items which that user has rated in the past.
40 What is content? What is the content of an item? It can be explicit attributes or characteristics of the item. For example for a film: Genre: Action / adventure Feature: Bruce Willis Year: 1995 It can also be textual content (title, description, table of content, etc.) Several techniques to compute the distance between two textual documents Can use NLP techniques to extract content features Can be extracted from the signal itself (audio, image)
41 Content-based Recommendation Common for recommending text-based products (web pages, use net news messages, ) Items to recommend are described by their associated features (e.g. keywords) User Model structured in a similar way as the content: features/keywords more likely to occur in the preferred documents (lazy approach) Text documents recommended based on a comparison between their content (words appearing) and user model (a set of preferred words) The user model can also be a classifier based on whatever technique (Neural Networks, Nai ve Bayes...)
42 Advantages of content-based Recommendation No need for data on other users. No cold-start or sparsity problems. Able to recommend to users with unique tastes. Able to recommend new and unpopular items No first-rater problem. Can provide explanations of recommended items by listing content-features that caused an item to be recommended
43 Disadvantages of content-based Recommendation Requires content that can be encoded as meaningful features. Some kind of items are not amenable to easy feature extraction methods (e.g. movies, music) Even for texts, IR techniques cannot consider multimedia information, aesthetic qualities, download me... If you rate positively a page it could be not related to the presence of certain keywords Users tastes must be represented as a learnable function of these content features. Hard to exploit quality judgments of other users. Easy to overfit (e.g. for a user with few data points we may pigeon hole her)
44 Clustering in Recommender
45 Clustering Another way to make recommendations based on past purchases is to cluster customers Each cluster will be assigned typical preferences, based on preferences of customers who belong to the cluster Customers within each cluster will receive recommendations computed at the cluster level
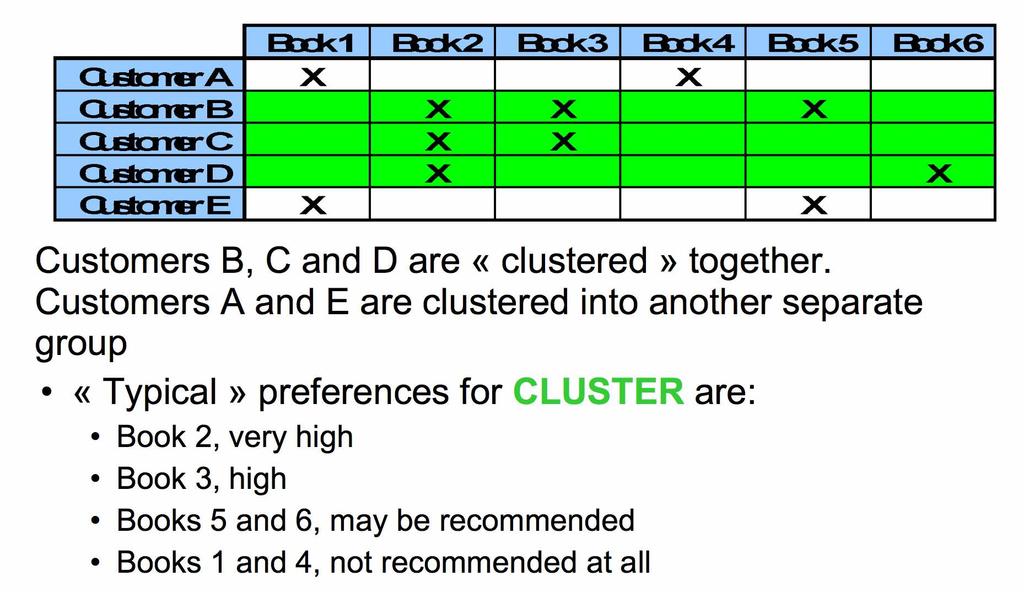
46 Clustering
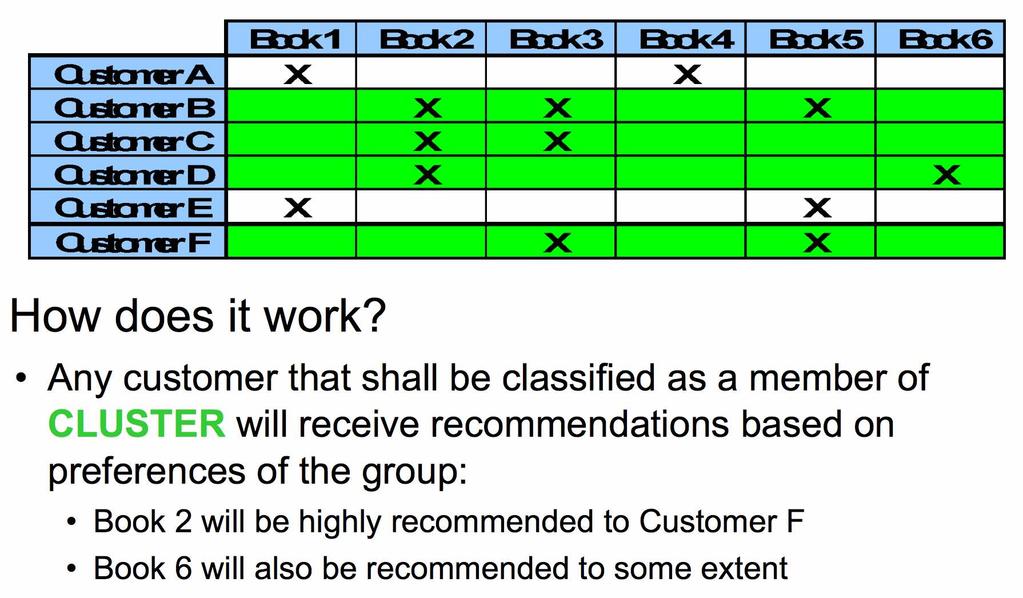
47 Clustering
48 Clustering Pros: Clustering techniques can be used to work on aggregated data Can also be applied as a first step for shrinking the selection of relevant neighbors in a collaborative filtering algorithm and improve performance Can be used to capture latent similarities between users or items Cons: Recommendations (per cluster) may be less relevant than collaborative filtering (per individual)
49 Collaborative Filtering Recommender


50 Collaborative Filtering User Based Item Based.... Similar Users Both users read same books Similar Items Both Items read by same users Read by her Recommended to him Read red Recommend green
51 Ingredients of Collaborative Filtering List of m Users and a list of n Items Each user has a list of items with associated opinion Explicit opinion - a rating score Sometime the rating is implicitly purchase records or listen to tracks Active user for whom the CF prediction task is performed Metricfor measuring similarity between users/items Method for selecting a subset of neighbors Method for predicting a rating for items not currently rated by the active users
52 General Steps of Collaborative Filtering 1. Identify set of ratings for the target/active user 2. Identify set of users most similar to the target/active user according to a similarity function (neighborhood formation) 3. Identify the products these similar users liked 4. Generate a prediction - rating that would be given by the target user to the product - for each one of these products 5. Based on this predicted rating recommend a set of top N products
53 What does our dataset look like? Typically, data is a utility (rating) matrix, which captures user preferences/well-being: User rating of items User purchase decisions for items Unrated are coded as 0 or missing Most items are unrated matrix is sparse Use recommender: Determine which attributes users think are important Predict ratings for unrated items Better than trusting expert opinion
54 What does our dataset look like? Data can be: Explicit: User provided ratings (1 to 5 stars) User like/non-like Implicit: Infer user-item relationships from behavior More common Example: buy/not-buy; view/not-view To convert implicit to explicit, create a matrix of 1s (yes) and 0s (no)

55 Example 1: Explicit utility matrix We have explicit ratings, plus a bunch of missing values. What company might have data like this? Btw, we call this the utility matrix.
56 Example 2: Implicit utility matrix We have implicit feedback, and no missing values. What company might have data like this? Btw, we call this the utility matrix.

57 Explicit Rating vs. Implicit Feedback the company completely relied on its users rating titles with stars when it began personalization some years ago. At one point, it had over 10 billion 5-star ratings, and more than 50% of all members had rated more than 50 titles. However, over time, Netflix realized that explicit star ratings were less relevant than other signals. Users would rate documentaries with 5 stars, and silly movies with just 3 stars, but still watch silly movies more often than those high-rated documentaries.
58 Two types of similarity-based Collaborative Filtering User-based: predict based on similarities between users Performs well, but slow if many users Use item-based CF if Users Items Item-based: predict based on similarities between items Faster if you precompute item-item similarity Usually Users Items item-based CF is most popular Items-based tend to be more stable: Items often only in one category (e.g., action films) Stable over time Users may like variety or change preferences over time Items usually have more ratings than users items have more stable average ratings than users
59 User-User similarities We look at all pairs of users and calculate their similarity. How can we calculate the similarity of these row vectors?

60 Item-Item similarities We look at all pairs of items and calculate their similarity. How can we calculate the similarity of these column vectors?

61 User-User or Item-Item? User-User: Item-Item: Let: m = #users, n = #items We want to compute the similarity of all pairs. What is the algorithmic efficiency of each approach? User-User: O(m 2 n) Item-Item: O(mn 2 ) Which one is better?


62 Similarity Metric using Euclidean Distance What s the range? But we re interested in a similarity, so let s do this instead: What s the range? When use this?
63 Similarity Metric using Pearson Correlation What s the range? But we re interested in a similarity, so let s do this instead: What s the range? When use this?

64 Similarity Metric using Cosine Similarity What s the range? But we re interested in a standardized similarity, so let s do this instead: What s the range? When use this?

65 Similarity Metric using Jaccard Index What s the range? When use this?
66 The Similarity Matrix Pick a similarity metric, create the similarity matrix:
67 Item-Item based CF: How to make predictions Say user u hasn t rated item i. We want to predict the rating that this user would give this item. We order by descending predicted rating for a single user, and recommend the top k items to the user.
68 How to make predictions (using neighborhoods) This calculation of predicted ratings can be very costly. To mitigate this issue, we will only consider the n most similar items to an item when calculating the prediction.
69 How to make predictions How would you modify the prediction formula below for a user-based recommender? Hint: should you compute similarity between users or items?
70 How do we evaluate our recommender system? Is it possible to do cross-validation like normal? Before we continue, let s review: Why do we perform cross-validation? Quick warning: Recommenders are inherently hard to validate. There is a lot of discussion in academia (research papers) and industry (Kaggle, Netflix, etc) about this. There is no ONE answer for all dataset.

71 Cross-validation of ML models we have seen so far
72 Cross-validation for recommenders? For this slide, the question marks denote the holdout set (not missing values). We can calculate MSE between the targets and our predictions over the holdout set. (K-fold cross-validation is optional.) Recall: Why do we perform cross-validation? Why isn t the method above a true estimate of a recommender's performance in the field? Why would A/B testing be better?

73 Alternate way to validate What s the deal with this? I.e. Why might we prefer doing this instead of the more normal crossvalidation from the previous slide?

74 DON T DO THIS! Why?
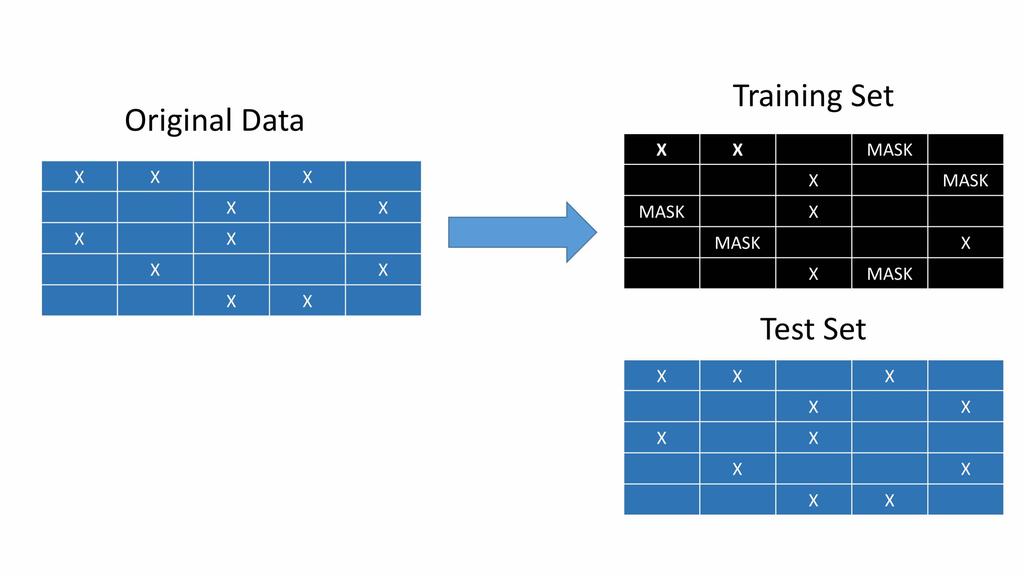
75 Cross-validation of Recommenders
76 How to deal with cold start? Scenario: A new user signs up. What will our recommender do (assume we re using item-item similarities)? One strategy: Force users to rate 5 items as part of the signup process. AND/OR Recommend popular items at first. Scenario: A new item is introduced. What will our recommender do (assume we re using item-item similarities)? One strategy: Put it in the new releases section until enough users rate it AND/OR use item metadata if any exists.
77 How to deal with cold start? Scenario: A new user signs up. What will our recommender do (assume we re Youtube and we re using item popularity to make recommendations)? This really isn t a problem... Scenario: A new item is introduced. What will our recommender do (assume we re Youtube and we re using item popularity to make recommendations)? One strategy: Don t use total number of views as the popularity metric (we d have a rich-get-richer situation). Use something else...
78 Deploying the recommender In the middle of the night: Compute similarities between all pairs of items. Compute the neighborhood of each item. At request time: Predict scores for candidate items, and make a recommendation.
79 Matrix Factorization for Recommendation
80 Matrix Factorization for Recommendation Recall: An explicit-rating utility matrix is usually VERY sparse We ve previously used SVD to find latent features (aka, factors)... Would SVD be good for this sparse utility matrix? (Hint: No!) What s the problem with using SVD on this sparse utility matrix?
81 Matrix Factorization for Recommendation UV Decomposition (UVD) UVD via Stochastic Gradient Descent (SGD) Matrix Factorization for Recommendation: Basic system: UVD + SGD... FTW Intermediate topics: regularization accounting for biases

82 UV Decomposition (UVD) You choose k. UV approximates R by necessity if k is less than the rank of R. Usually choose: k << min(n, m) Compute U and V such that: Least Squares!
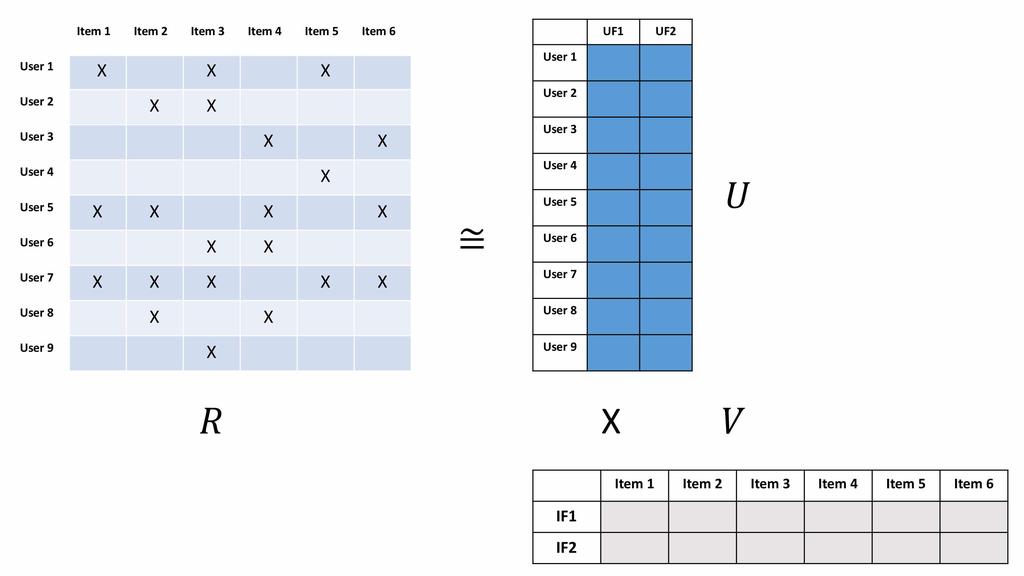
83 UV Decomposition (UVD)

84 Evaluating factorization To evaluate how well the factorization represents the original data, we use RMSE Root Mean Squared Error
85 UV Decomposition Algorithm

86 Evaluating Factorization To get the formulas for the updates, we take the partial derivative of the error formula
87 Evaluating Factorization To make prediction of ratings, we multiply the U and V matrices together. So to get a single rating, it's the dot product of one row in U with one column in V. Now the squared error can be calculated by:

88 Calculate the gradient Gradient Descent

89 Updating Formula Gradient Descent (cont d)
90 Regularization Since now we re fitting a large parameter set to sparse data, you ll most certainly need to regularize! Tune lambda: the amount of regularization
91 Accounting for Biases (let s capture our domain knowledge!) In practice, much of the observed variation in rating values is due to item bias and user bias: Some items (e.g. movies) have a tendency to be rated high, some low. Some users have a tendency to rate high, some low. We can capture this prior domain knowledge using a few bias terms: The overall bias of the rating by user i for item j The overall average rating (i.e. the overall bias) User i s average deviation from the overall average Item j s average deviation from the overall average
92 New Prediction The 4 parts of a prediction The prediction of user i rating item j The average rating User i s tendency to deviate from the average Item j s tendency to deviate from the average The prediction of how user i will interact with item j
93 Accounting for Biases (the new cost function) Ratings are now estimated as: The new cost function, with the biases included: New part! New part!
94 UVD vs NMF UVD: By convention: R ~= UV NMF is a specialization of UVD! Both are approximate factorizations, and both optimize to reduce the RSS. NMF: By convention: V ~= WH Same as UVD, but with one extra constraint: all values of V, W, and H must be non-negative!
95 UVD vs NMF (continued) UVD and NMF are both solved using either: Alternating Least Squares (ALS) Stochastic Gradient Descent (SGD)
96 ALS vs SGD ALS: Parallelizes very well Available in Spark/MLlib Only appropriate for matrices that don t have missing values SGD: Faster (if on single machine) Requires tuning learning rate Anecdotal evidence of better results Works with missing values
97 UVD (or NMF) + SGD FTW! UVD + SGD makes a lot of sense for recommender systems. In fact, UVD + SGD is best in class option for many recommender domains: No need to impute missing values. Use regularization to avoid overfitting. Optionally include biases terms to communicate prior knowledge. Can handle time-dynamics (e.g. change in user preference over time). Used by the winning entry in the Netflix challenge.
. The more refined models perform better (have lower error). Netflix s in-house model performs at RMSE=0.")
98 From the paper: Matrix Factorization Techniques for Recommender Systems Root mean square error over the Netflix dataset using various matrix factorization models. Numbers on the chart denote each model s dimensionality (k). The more refined models perform better (have lower error). Netflix s in-house model performs at RMSE= on this dataset, so even the simple matrix factorization models are beating it! Read the paper for details; it s a good read!
99 Summary
100 Summary Non-negative Matrix Factorization Singular Value Decomposition Content-Based Recommenders Collaborative Filtering Recommenders Item-Item User-User Matrix Factorization Recommenders UV Decomposition
Collaborative Filtering. Radek Pelánek
 Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
Recommendation Systems
 Recommendation Systems Pawan Goyal CSE, IITKGP October 21, 2014 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 21, 2014 1 / 52 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems Pawan Goyal CSE, IITKGP October 21, 2014 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 21, 2014 1 / 52 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems
 Recommendation Systems Pawan Goyal CSE, IITKGP October 29-30, 2015 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 29-30, 2015 1 / 61 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems Pawan Goyal CSE, IITKGP October 29-30, 2015 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 29-30, 2015 1 / 61 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems
 Recommendation Systems Popularity Recommendation Systems Predicting user responses to options Offering news articles based on users interests Offering suggestions on what the user might like to buy/consume
Recommendation Systems Popularity Recommendation Systems Predicting user responses to options Offering news articles based on users interests Offering suggestions on what the user might like to buy/consume
Matrix Factorization and Collaborative Filtering
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Matrix Factorization and Collaborative Filtering MF Readings: (Koren et al., 2009)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Matrix Factorization and Collaborative Filtering MF Readings: (Koren et al., 2009)
Scaling Neighbourhood Methods
 Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
CS425: Algorithms for Web Scale Data
 CS: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS. The original slides can be accessed at: www.mmds.org Customer
CS: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS. The original slides can be accessed at: www.mmds.org Customer
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 8: Evaluation & SVD Paul Ginsparg Cornell University, Ithaca, NY 20 Sep 2011
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 8: Evaluation & SVD Paul Ginsparg Cornell University, Ithaca, NY 20 Sep 2011
Generative Models for Discrete Data
 Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Recommender Systems. Dipanjan Das Language Technologies Institute Carnegie Mellon University. 20 November, 2007
 Recommender Systems Dipanjan Das Language Technologies Institute Carnegie Mellon University 20 November, 2007 Today s Outline What are Recommender Systems? Two approaches Content Based Methods Collaborative
Recommender Systems Dipanjan Das Language Technologies Institute Carnegie Mellon University 20 November, 2007 Today s Outline What are Recommender Systems? Two approaches Content Based Methods Collaborative
Matrix Factorization Techniques for Recommender Systems
 Matrix Factorization Techniques for Recommender Systems By Yehuda Koren Robert Bell Chris Volinsky Presented by Peng Xu Supervised by Prof. Michel Desmarais 1 Contents 1. Introduction 4. A Basic Matrix
Matrix Factorization Techniques for Recommender Systems By Yehuda Koren Robert Bell Chris Volinsky Presented by Peng Xu Supervised by Prof. Michel Desmarais 1 Contents 1. Introduction 4. A Basic Matrix
Collaborative Filtering Matrix Completion Alternating Least Squares
 Case Study 4: Collaborative Filtering Collaborative Filtering Matrix Completion Alternating Least Squares Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade May 19, 2016
Case Study 4: Collaborative Filtering Collaborative Filtering Matrix Completion Alternating Least Squares Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade May 19, 2016
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent
 Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
a Short Introduction
 Collaborative Filtering in Recommender Systems: a Short Introduction Norm Matloff Dept. of Computer Science University of California, Davis matloff@cs.ucdavis.edu December 3, 2016 Abstract There is a strong
Collaborative Filtering in Recommender Systems: a Short Introduction Norm Matloff Dept. of Computer Science University of California, Davis matloff@cs.ucdavis.edu December 3, 2016 Abstract There is a strong
Collaborative topic models: motivations cont
 Collaborative topic models: motivations cont Two topics: machine learning social network analysis Two people: " boy Two articles: article A! girl article B Preferences: The boy likes A and B --- no problem.
Collaborative topic models: motivations cont Two topics: machine learning social network analysis Two people: " boy Two articles: article A! girl article B Preferences: The boy likes A and B --- no problem.
Collaborative Filtering
 Collaborative Filtering Nicholas Ruozzi University of Texas at Dallas based on the slides of Alex Smola & Narges Razavian Collaborative Filtering Combining information among collaborating entities to make
Collaborative Filtering Nicholas Ruozzi University of Texas at Dallas based on the slides of Alex Smola & Narges Razavian Collaborative Filtering Combining information among collaborating entities to make
Matrix Factorization In Recommender Systems. Yong Zheng, PhDc Center for Web Intelligence, DePaul University, USA March 4, 2015
 Matrix Factorization In Recommender Systems Yong Zheng, PhDc Center for Web Intelligence, DePaul University, USA March 4, 2015 Table of Contents Background: Recommender Systems (RS) Evolution of Matrix
Matrix Factorization In Recommender Systems Yong Zheng, PhDc Center for Web Intelligence, DePaul University, USA March 4, 2015 Table of Contents Background: Recommender Systems (RS) Evolution of Matrix
Algorithms for Collaborative Filtering
 Algorithms for Collaborative Filtering or How to Get Half Way to Winning $1million from Netflix Todd Lipcon Advisor: Prof. Philip Klein The Real-World Problem E-commerce sites would like to make personalized
Algorithms for Collaborative Filtering or How to Get Half Way to Winning $1million from Netflix Todd Lipcon Advisor: Prof. Philip Klein The Real-World Problem E-commerce sites would like to make personalized
Matrix Factorization Techniques For Recommender Systems. Collaborative Filtering
 Matrix Factorization Techniques For Recommender Systems Collaborative Filtering Markus Freitag, Jan-Felix Schwarz 28 April 2011 Agenda 2 1. Paper Backgrounds 2. Latent Factor Models 3. Overfitting & Regularization
Matrix Factorization Techniques For Recommender Systems Collaborative Filtering Markus Freitag, Jan-Felix Schwarz 28 April 2011 Agenda 2 1. Paper Backgrounds 2. Latent Factor Models 3. Overfitting & Regularization
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
* Matrix Factorization and Recommendation Systems
 Matrix Factorization and Recommendation Systems Originally presented at HLF Workshop on Matrix Factorization with Loren Anderson (University of Minnesota Twin Cities) on 25 th September, 2017 15 th March,
Matrix Factorization and Recommendation Systems Originally presented at HLF Workshop on Matrix Factorization with Loren Anderson (University of Minnesota Twin Cities) on 25 th September, 2017 15 th March,
Collaborative Topic Modeling for Recommending Scientific Articles
 Collaborative Topic Modeling for Recommending Scientific Articles Chong Wang and David M. Blei Best student paper award at KDD 2011 Computer Science Department, Princeton University Presented by Tian Cao
Collaborative Topic Modeling for Recommending Scientific Articles Chong Wang and David M. Blei Best student paper award at KDD 2011 Computer Science Department, Princeton University Presented by Tian Cao
CSE 494/598 Lecture-6: Latent Semantic Indexing. **Content adapted from last year s slides
 CSE 494/598 Lecture-6: Latent Semantic Indexing LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **Content adapted from last year s slides Announcements Homework-1 and Quiz-1 Project part-2 released
CSE 494/598 Lecture-6: Latent Semantic Indexing LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **Content adapted from last year s slides Announcements Homework-1 and Quiz-1 Project part-2 released
CS246 Final Exam, Winter 2011
 CS246 Final Exam, Winter 2011 1. Your name and student ID. Name:... Student ID:... 2. I agree to comply with Stanford Honor Code. Signature:... 3. There should be 17 numbered pages in this exam (including
CS246 Final Exam, Winter 2011 1. Your name and student ID. Name:... Student ID:... 2. I agree to comply with Stanford Honor Code. Signature:... 3. There should be 17 numbered pages in this exam (including
Preliminaries. Data Mining. The art of extracting knowledge from large bodies of structured data. Let s put it to use!
 Data Mining The art of extracting knowledge from large bodies of structured data. Let s put it to use! 1 Recommendations 2 Basic Recommendations with Collaborative Filtering Making Recommendations 4 The
Data Mining The art of extracting knowledge from large bodies of structured data. Let s put it to use! 1 Recommendations 2 Basic Recommendations with Collaborative Filtering Making Recommendations 4 The
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Department of Computer Science, Guiyang University, Guiyang , GuiZhou, China
 doi:10.21311/002.31.12.01 A Hybrid Recommendation Algorithm with LDA and SVD++ Considering the News Timeliness Junsong Luo 1*, Can Jiang 2, Peng Tian 2 and Wei Huang 2, 3 1 College of Information Science
doi:10.21311/002.31.12.01 A Hybrid Recommendation Algorithm with LDA and SVD++ Considering the News Timeliness Junsong Luo 1*, Can Jiang 2, Peng Tian 2 and Wei Huang 2, 3 1 College of Information Science
Andriy Mnih and Ruslan Salakhutdinov
 MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task
 Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Recommender Systems EE448, Big Data Mining, Lecture 10. Weinan Zhang Shanghai Jiao Tong University
 2018 EE448, Big Data Mining, Lecture 10 Recommender Systems Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of This Course Overview of
2018 EE448, Big Data Mining, Lecture 10 Recommender Systems Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of This Course Overview of
Quick Introduction to Nonnegative Matrix Factorization
 Quick Introduction to Nonnegative Matrix Factorization Norm Matloff University of California at Davis 1 The Goal Given an u v matrix A with nonnegative elements, we wish to find nonnegative, rank-k matrices
Quick Introduction to Nonnegative Matrix Factorization Norm Matloff University of California at Davis 1 The Goal Given an u v matrix A with nonnegative elements, we wish to find nonnegative, rank-k matrices
From Non-Negative Matrix Factorization to Deep Learning
 The Math!! From Non-Negative Matrix Factorization to Deep Learning Intuitions and some Math too! luissarmento@gmailcom https://wwwlinkedincom/in/luissarmento/ October 18, 2017 The Math!! Introduction Disclaimer
The Math!! From Non-Negative Matrix Factorization to Deep Learning Intuitions and some Math too! luissarmento@gmailcom https://wwwlinkedincom/in/luissarmento/ October 18, 2017 The Math!! Introduction Disclaimer
Matrix Factorization Techniques for Recommender Systems
 Matrix Factorization Techniques for Recommender Systems Patrick Seemann, December 16 th, 2014 16.12.2014 Fachbereich Informatik Recommender Systems Seminar Patrick Seemann Topics Intro New-User / New-Item
Matrix Factorization Techniques for Recommender Systems Patrick Seemann, December 16 th, 2014 16.12.2014 Fachbereich Informatik Recommender Systems Seminar Patrick Seemann Topics Intro New-User / New-Item
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization
 CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization Tim Roughgarden February 28, 2017 1 Preamble This lecture fulfills a promise made back in Lecture #1,
CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization Tim Roughgarden February 28, 2017 1 Preamble This lecture fulfills a promise made back in Lecture #1,
Using SVD to Recommend Movies
 Michael Percy University of California, Santa Cruz Last update: December 12, 2009 Last update: December 12, 2009 1 / Outline 1 Introduction 2 Singular Value Decomposition 3 Experiments 4 Conclusion Last
Michael Percy University of California, Santa Cruz Last update: December 12, 2009 Last update: December 12, 2009 1 / Outline 1 Introduction 2 Singular Value Decomposition 3 Experiments 4 Conclusion Last
Collaborative Filtering
 Case Study 4: Collaborative Filtering Collaborative Filtering Matrix Completion Alternating Least Squares Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin
Case Study 4: Collaborative Filtering Collaborative Filtering Matrix Completion Alternating Least Squares Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin
CS425: Algorithms for Web Scale Data
 CS: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS. The original slides can be accessed at: www.mmds.org J. Leskovec,
CS: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS. The original slides can be accessed at: www.mmds.org J. Leskovec,
Circle-based Recommendation in Online Social Networks
 Circle-based Recommendation in Online Social Networks Xiwang Yang, Harald Steck*, and Yong Liu Polytechnic Institute of NYU * Bell Labs/Netflix 1 Outline q Background & Motivation q Circle-based RS Trust
Circle-based Recommendation in Online Social Networks Xiwang Yang, Harald Steck*, and Yong Liu Polytechnic Institute of NYU * Bell Labs/Netflix 1 Outline q Background & Motivation q Circle-based RS Trust
ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties
 ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties Prof. James She james.she@ust.hk 1 Last lecture 2 Selected works from Tutorial
ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties Prof. James She james.she@ust.hk 1 Last lecture 2 Selected works from Tutorial
Prediction of Citations for Academic Papers
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Ad Placement Strategies
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Matrix Factorization and Factorization Machines for Recommender Systems
 Talk at SDM workshop on Machine Learning Methods on Recommender Systems, May 2, 215 Chih-Jen Lin (National Taiwan Univ.) 1 / 54 Matrix Factorization and Factorization Machines for Recommender Systems Chih-Jen
Talk at SDM workshop on Machine Learning Methods on Recommender Systems, May 2, 215 Chih-Jen Lin (National Taiwan Univ.) 1 / 54 Matrix Factorization and Factorization Machines for Recommender Systems Chih-Jen
Decoupled Collaborative Ranking
 Decoupled Collaborative Ranking Jun Hu, Ping Li April 24, 2017 Jun Hu, Ping Li WWW2017 April 24, 2017 1 / 36 Recommender Systems Recommendation system is an information filtering technique, which provides
Decoupled Collaborative Ranking Jun Hu, Ping Li April 24, 2017 Jun Hu, Ping Li WWW2017 April 24, 2017 1 / 36 Recommender Systems Recommendation system is an information filtering technique, which provides
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Multiclass Classification-1
 CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
Click Prediction and Preference Ranking of RSS Feeds
 Click Prediction and Preference Ranking of RSS Feeds 1 Introduction December 11, 2009 Steven Wu RSS (Really Simple Syndication) is a family of data formats used to publish frequently updated works. RSS
Click Prediction and Preference Ranking of RSS Feeds 1 Introduction December 11, 2009 Steven Wu RSS (Really Simple Syndication) is a family of data formats used to publish frequently updated works. RSS
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017
 COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 2 Often, our data can be represented by an m-by-n matrix. And this matrix can be closely approximated by the product of two matrices that share a small common dimension
Jeffrey D. Ullman Stanford University 2 Often, our data can be represented by an m-by-n matrix. And this matrix can be closely approximated by the product of two matrices that share a small common dimension
Clustering based tensor decomposition
 Clustering based tensor decomposition Huan He huan.he@emory.edu Shihua Wang shihua.wang@emory.edu Emory University November 29, 2017 (Huan)(Shihua) (Emory University) Clustering based tensor decomposition
Clustering based tensor decomposition Huan He huan.he@emory.edu Shihua Wang shihua.wang@emory.edu Emory University November 29, 2017 (Huan)(Shihua) (Emory University) Clustering based tensor decomposition
Structured matrix factorizations. Example: Eigenfaces
 Structured matrix factorizations Example: Eigenfaces An extremely large variety of interesting and important problems in machine learning can be formulated as: Given a matrix, find a matrix and a matrix
Structured matrix factorizations Example: Eigenfaces An extremely large variety of interesting and important problems in machine learning can be formulated as: Given a matrix, find a matrix and a matrix
Natural Language Processing. Topics in Information Retrieval. Updated 5/10
 Natural Language Processing Topics in Information Retrieval Updated 5/10 Outline Introduction to IR Design features of IR systems Evaluation measures The vector space model Latent semantic indexing Background
Natural Language Processing Topics in Information Retrieval Updated 5/10 Outline Introduction to IR Design features of IR systems Evaluation measures The vector space model Latent semantic indexing Background
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
6.034 Introduction to Artificial Intelligence
 6.34 Introduction to Artificial Intelligence Tommi Jaakkola MIT CSAIL The world is drowning in data... The world is drowning in data...... access to information is based on recommendations Recommending
6.34 Introduction to Artificial Intelligence Tommi Jaakkola MIT CSAIL The world is drowning in data... The world is drowning in data...... access to information is based on recommendations Recommending
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Data Mining Recitation Notes Week 3
 Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Cost and Preference in Recommender Systems Junhua Chen LESS IS MORE
 Cost and Preference in Recommender Systems Junhua Chen, Big Data Research Center, UESTC Email:junmshao@uestc.edu.cn http://staff.uestc.edu.cn/shaojunming Abstract In many recommender systems (RS), user
Cost and Preference in Recommender Systems Junhua Chen, Big Data Research Center, UESTC Email:junmshao@uestc.edu.cn http://staff.uestc.edu.cn/shaojunming Abstract In many recommender systems (RS), user
Semantics with Dense Vectors. Reference: D. Jurafsky and J. Martin, Speech and Language Processing
 Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Collaborative Recommendation with Multiclass Preference Context
 Collaborative Recommendation with Multiclass Preference Context Weike Pan and Zhong Ming {panweike,mingz}@szu.edu.cn College of Computer Science and Software Engineering Shenzhen University Pan and Ming
Collaborative Recommendation with Multiclass Preference Context Weike Pan and Zhong Ming {panweike,mingz}@szu.edu.cn College of Computer Science and Software Engineering Shenzhen University Pan and Ming
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning
 SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
Lecture 9: September 28
 0-725/36-725: Convex Optimization Fall 206 Lecturer: Ryan Tibshirani Lecture 9: September 28 Scribes: Yiming Wu, Ye Yuan, Zhihao Li Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These
0-725/36-725: Convex Optimization Fall 206 Lecturer: Ryan Tibshirani Lecture 9: September 28 Scribes: Yiming Wu, Ye Yuan, Zhihao Li Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These
Joint user knowledge and matrix factorization for recommender systems
 World Wide Web (2018) 21:1141 1163 DOI 10.1007/s11280-017-0476-7 Joint user knowledge and matrix factorization for recommender systems Yonghong Yu 1,2 Yang Gao 2 Hao Wang 2 Ruili Wang 3 Received: 13 February
World Wide Web (2018) 21:1141 1163 DOI 10.1007/s11280-017-0476-7 Joint user knowledge and matrix factorization for recommender systems Yonghong Yu 1,2 Yang Gao 2 Hao Wang 2 Ruili Wang 3 Received: 13 February
Techniques for Dimensionality Reduction. PCA and Other Matrix Factorization Methods
 Techniques for Dimensionality Reduction PCA and Other Matrix Factorization Methods Outline Principle Compoments Analysis (PCA) Example (Bishop, ch 12) PCA as a mixture model variant With a continuous latent
Techniques for Dimensionality Reduction PCA and Other Matrix Factorization Methods Outline Principle Compoments Analysis (PCA) Example (Bishop, ch 12) PCA as a mixture model variant With a continuous latent
Collaborative Filtering Applied to Educational Data Mining
 Journal of Machine Learning Research (200) Submitted ; Published Collaborative Filtering Applied to Educational Data Mining Andreas Töscher commendo research 8580 Köflach, Austria andreas.toescher@commendo.at
Journal of Machine Learning Research (200) Submitted ; Published Collaborative Filtering Applied to Educational Data Mining Andreas Töscher commendo research 8580 Köflach, Austria andreas.toescher@commendo.at
Recommender Systems: Overview and. Package rectools. Norm Matloff. Dept. of Computer Science. University of California at Davis.
 Recommender December 13, 2016 What Are Recommender Systems? What Are Recommender Systems? Various forms, but here is a common one, say for data on movie ratings: What Are Recommender Systems? Various forms,
Recommender December 13, 2016 What Are Recommender Systems? What Are Recommender Systems? Various forms, but here is a common one, say for data on movie ratings: What Are Recommender Systems? Various forms,
Stat 406: Algorithms for classification and prediction. Lecture 1: Introduction. Kevin Murphy. Mon 7 January,
 1 Stat 406: Algorithms for classification and prediction Lecture 1: Introduction Kevin Murphy Mon 7 January, 2008 1 1 Slides last updated on January 7, 2008 Outline 2 Administrivia Some basic definitions.
1 Stat 406: Algorithms for classification and prediction Lecture 1: Introduction Kevin Murphy Mon 7 January, 2008 1 1 Slides last updated on January 7, 2008 Outline 2 Administrivia Some basic definitions.
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Prof. Chris Clifton 6 September 2017 Material adapted from course created by Dr. Luo Si, now leading Alibaba research group 1 Vector Space Model Disadvantages:
CS47300: Web Information Search and Management Prof. Chris Clifton 6 September 2017 Material adapted from course created by Dr. Luo Si, now leading Alibaba research group 1 Vector Space Model Disadvantages:
CPSC 340: Machine Learning and Data Mining. Stochastic Gradient Fall 2017
 CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
Information Retrieval
 Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Behavioral Data Mining. Lecture 7 Linear and Logistic Regression
 Behavioral Data Mining Lecture 7 Linear and Logistic Regression Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips Linear Regression
Behavioral Data Mining Lecture 7 Linear and Logistic Regression Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips Linear Regression
Machine Learning. Principal Components Analysis. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Lecture 5: Web Searching using the SVD
 Lecture 5: Web Searching using the SVD Information Retrieval Over the last 2 years the number of internet users has grown exponentially with time; see Figure. Trying to extract information from this exponentially
Lecture 5: Web Searching using the SVD Information Retrieval Over the last 2 years the number of internet users has grown exponentially with time; see Figure. Trying to extract information from this exponentially
Impact of Data Characteristics on Recommender Systems Performance
 Impact of Data Characteristics on Recommender Systems Performance Gediminas Adomavicius YoungOk Kwon Jingjing Zhang Department of Information and Decision Sciences Carlson School of Management, University
Impact of Data Characteristics on Recommender Systems Performance Gediminas Adomavicius YoungOk Kwon Jingjing Zhang Department of Information and Decision Sciences Carlson School of Management, University
CS 175: Project in Artificial Intelligence. Slides 4: Collaborative Filtering
 CS 175: Project in Artificial Intelligence Slides 4: Collaborative Filtering 1 Topic 6: Collaborative Filtering Some slides taken from Prof. Smyth (with slight modifications) 2 Outline General aspects
CS 175: Project in Artificial Intelligence Slides 4: Collaborative Filtering 1 Topic 6: Collaborative Filtering Some slides taken from Prof. Smyth (with slight modifications) 2 Outline General aspects
Dimensionality Reduction
 394 Chapter 11 Dimensionality Reduction There are many sources of data that can be viewed as a large matrix. We saw in Chapter 5 how the Web can be represented as a transition matrix. In Chapter 9, the
394 Chapter 11 Dimensionality Reduction There are many sources of data that can be viewed as a large matrix. We saw in Chapter 5 how the Web can be represented as a transition matrix. In Chapter 9, the
Introduction to Data Mining
 Introduction to Data Mining Lecture #21: Dimensionality Reduction Seoul National University 1 In This Lecture Understand the motivation and applications of dimensionality reduction Learn the definition
Introduction to Data Mining Lecture #21: Dimensionality Reduction Seoul National University 1 In This Lecture Understand the motivation and applications of dimensionality reduction Learn the definition
Point-of-Interest Recommendations: Learning Potential Check-ins from Friends
 Point-of-Interest Recommendations: Learning Potential Check-ins from Friends Huayu Li, Yong Ge +, Richang Hong, Hengshu Zhu University of North Carolina at Charlotte + University of Arizona Hefei University
Point-of-Interest Recommendations: Learning Potential Check-ins from Friends Huayu Li, Yong Ge +, Richang Hong, Hengshu Zhu University of North Carolina at Charlotte + University of Arizona Hefei University
Structure in Data. A major objective in data analysis is to identify interesting features or structure in the data.
 Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
13 Searching the Web with the SVD
 13 Searching the Web with the SVD 13.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
13 Searching the Web with the SVD 13.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
Nonnegative Matrix Factorization
 Nonnegative Matrix Factorization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Nonnegative Matrix Factorization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Recommender Systems Instructor: Yizhou Sun yzsun@cs.ucla.edu May 17, 2017 Methods Learnt: Last Lecture Classification Clustering Vector Data Text Data Recommender System Decision
CS249: ADVANCED DATA MINING Recommender Systems Instructor: Yizhou Sun yzsun@cs.ucla.edu May 17, 2017 Methods Learnt: Last Lecture Classification Clustering Vector Data Text Data Recommender System Decision
CS 277: Data Mining. Mining Web Link Structure. CS 277: Data Mining Lectures Analyzing Web Link Structure Padhraic Smyth, UC Irvine
 CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
CPSC 340: Machine Learning and Data Mining. Sparse Matrix Factorization Fall 2018
 CPSC 340: Machine Learning and Data Mining Sparse Matrix Factorization Fall 2018 Last Time: PCA with Orthogonal/Sequential Basis When k = 1, PCA has a scaling problem. When k > 1, have scaling, rotation,
CPSC 340: Machine Learning and Data Mining Sparse Matrix Factorization Fall 2018 Last Time: PCA with Orthogonal/Sequential Basis When k = 1, PCA has a scaling problem. When k > 1, have scaling, rotation,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Recommendation. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Recommendation Tobias Scheffer Recommendation Engines Recommendation of products, music, contacts,.. Based on user features, item
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Recommendation Tobias Scheffer Recommendation Engines Recommendation of products, music, contacts,.. Based on user features, item
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
Lecture Notes 10: Matrix Factorization
 Optimization-based data analysis Fall 207 Lecture Notes 0: Matrix Factorization Low-rank models. Rank- model Consider the problem of modeling a quantity y[i, j] that depends on two indices i and j. To
Optimization-based data analysis Fall 207 Lecture Notes 0: Matrix Factorization Low-rank models. Rank- model Consider the problem of modeling a quantity y[i, j] that depends on two indices i and j. To
Text Analytics (Text Mining)
") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Text Analytics (Text Mining) Concepts, Algorithms, LSI/SVD Duen Horng (Polo) Chau Assistant Professor Associate Director, MS
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Text Analytics (Text Mining) Concepts, Algorithms, LSI/SVD Duen Horng (Polo) Chau Assistant Professor Associate Director, MS
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Low Rank Matrix Completion Formulation and Algorithm
 1 2 Low Rank Matrix Completion and Algorithm Jian Zhang Department of Computer Science, ETH Zurich zhangjianthu@gmail.com March 25, 2014 Movie Rating 1 2 Critic A 5 5 Critic B 6 5 Jian 9 8 Kind Guy B 9
1 2 Low Rank Matrix Completion and Algorithm Jian Zhang Department of Computer Science, ETH Zurich zhangjianthu@gmail.com March 25, 2014 Movie Rating 1 2 Critic A 5 5 Critic B 6 5 Jian 9 8 Kind Guy B 9
Collaborative Filtering on Ordinal User Feedback
 Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence Collaborative Filtering on Ordinal User Feedback Yehuda Koren Google yehudako@gmail.com Joseph Sill Analytics Consultant
Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence Collaborative Filtering on Ordinal User Feedback Yehuda Koren Google yehudako@gmail.com Joseph Sill Analytics Consultant
A Gradient-based Adaptive Learning Framework for Efficient Personal Recommendation
 A Gradient-based Adaptive Learning Framework for Efficient Personal Recommendation Yue Ning 1 Yue Shi 2 Liangjie Hong 2 Huzefa Rangwala 3 Naren Ramakrishnan 1 1 Virginia Tech 2 Yahoo Research. Yue Shi
A Gradient-based Adaptive Learning Framework for Efficient Personal Recommendation Yue Ning 1 Yue Shi 2 Liangjie Hong 2 Huzefa Rangwala 3 Naren Ramakrishnan 1 1 Virginia Tech 2 Yahoo Research. Yue Shi
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 21: Review Jan-Willem van de Meent Schedule Topics for Exam Pre-Midterm Probability Information Theory Linear Regression Classification Clustering
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 21: Review Jan-Willem van de Meent Schedule Topics for Exam Pre-Midterm Probability Information Theory Linear Regression Classification Clustering
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Ensemble Methods for Machine Learning
 Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Lecture 21: Spectral Learning for Graphical Models
 10-708: Probabilistic Graphical Models 10-708, Spring 2016 Lecture 21: Spectral Learning for Graphical Models Lecturer: Eric P. Xing Scribes: Maruan Al-Shedivat, Wei-Cheng Chang, Frederick Liu 1 Motivation
10-708: Probabilistic Graphical Models 10-708, Spring 2016 Lecture 21: Spectral Learning for Graphical Models Lecturer: Eric P. Xing Scribes: Maruan Al-Shedivat, Wei-Cheng Chang, Frederick Liu 1 Motivation
Domokos Miklós Kelen. Online Recommendation Systems. Eötvös Loránd University. Faculty of Natural Sciences. Advisor:
 Eötvös Loránd University Faculty of Natural Sciences Online Recommendation Systems MSc Thesis Domokos Miklós Kelen Applied Mathematics MSc Advisor: András Benczúr Ph.D. Department of Operations Research
Eötvös Loránd University Faculty of Natural Sciences Online Recommendation Systems MSc Thesis Domokos Miklós Kelen Applied Mathematics MSc Advisor: András Benczúr Ph.D. Department of Operations Research