Principal Component Analysis and Singular Value Decomposition. Volker Tresp, Clemens Otte Summer 2014
|
|
|
- Curtis Short
- 6 years ago
- Views:
Transcription
1 Principal Component Analysis and Singular Value Decomposition Volker Tresp, Clemens Otte Summer
2 Motivation So far we always argued for a high-dimensional feature space Still, in some cases it makes sense to first reduce the dimensionality before applying a learning algorithm Example: The data are pixels in an image 2
3 Dimensionality Reduction We want to compress the M-dimensional x to an r dimensional z using a linear transformation We want x to be reconstructed from z as well as possible in the mean squared error sense for all data points x i (x i V z i ) T (x i V z i ) where V is an M r matrix. i 3
4 zl = v1,l x1 + v2,l x vm,l xm
5 First Component Let s first look at r = 1 and we want to find the vector v Without loss of generality, we assume that v = 1 The reconstruction error for a particular x i is given by (x i ˆx i ) T (x i ˆx i ) = (x i vz i ) T (x i vz i ). The optimal z i is then (see figure) z i = v T x i (note: z i is scalar) Thus we get ˆx i = vv T x i 4
6
7 Example: 50 data points in 2d 6 First principal component 4 2 x Second principal component x 1 First principal vector is the direction that maximizes the variance of the projected data It is also the direction that minimizes the reconstruction error Here we centered the data (i.e. subtracted the sample mean) before applying PCA. More on that later 5
8 Computing the First Principal Vector So what is v? We are looking for a v that minimizes the reconstruction error over all data points. We use the Lagrange parameter λ to guarantee length 1 L = N (vv T x i x i ) T (vv T x i x i ) + λ(v T v 1) i=1 = N i=1 x T i vvt vv T x i + x T i x i x T i vvt x i x T i vvt x i + λ(v T v 1) = N i=1 x T i x i x T i vvt x i + λ(v T v 1) 6
9 Computing the First Principal Vector (cont d) We take the derivative with respect to v and obtain v xt i vvt x i = ( ) v (vt x i ) T (v T x i ) = 2 v vt x i (v T x i ) and = 2x i (v T x i ) = 2x i (x T i v) = 2(x ix T i )v v λvt v = 2λv We set the derivative to zero and get N x i x T i v = λv i=1 7
10 or in matrix form Σv = λv where Σ = X T X Recall that the Lagrangian is maximized with respect to λ Thus the first principal vector v is the first eigenvector of Σ (with the largest eigenvalue) z i = v T x i is called the first principal component of x i
11 Computing all Principal Vectors / Rank-r approx. The second principal vector is given by the second eigenvector of Σ and so on Note: the principal vectors are mutually orthogonal For a rank-r approximation we get z i = V T r x i and the optimal reconstruction is ˆx i = V r z i 8
12 PCA Applications 9
13 Classification and Regression First perform a PCA of X and then use as input to the model z i instead of x i, where z i = V T r x i Example: Linear regression on z i is called PCR (Principal Component Regression) 10
14 Similarity and Novelty A distance measure (Euclidian distance) based on the principal components is often more meaningful than a distance measure calculated in the original space Novelty detection / outlier detection: We calculate the reconstruction of a new vector x and calculate x V r V T r x = V T rx If this distance is large, then the new input is unusual, i.e. might be an outlier Here V r contains the M r eigenvectors v r+1,..., v M of Σ. 11
15 Practical Hint 1 Scaling of inputs affects the resulting principal components If the given scaling is arbitrary (e.g. different physical units: mbar, PSI, K), consider standardizing data before performing PCA (e.g. x = x/std(x)) Example shows first principal vector. Right side: x 2 scaled by factor 3 x 2 scaled by factor x 2 0 x x 1 x 1 12
16 Practical Hint 2 PCA does not consider class information (i.e. it is an unsupervised method) Example: Projecting the shown data onto the first principal vector removes the class separability completely! There are methods that include class information, e.g. Partial Least Squares, or combinations of PCA with supervised methods, e.g. Supervised Principal Components [Hastie et al., ESLII, p.674] 10 First principal vector Class B 2 x Class A x 1 13
17 PCA Example: Handwritten Digits 14
18 Data Set 130 handwritten digits 3 (in total: 658): significant difference in style The images have grey valued pixels. Each input vector x consists of the 256 grey values of the pixels. Applying a linear classifier to the original pixels gives bad results 15

19
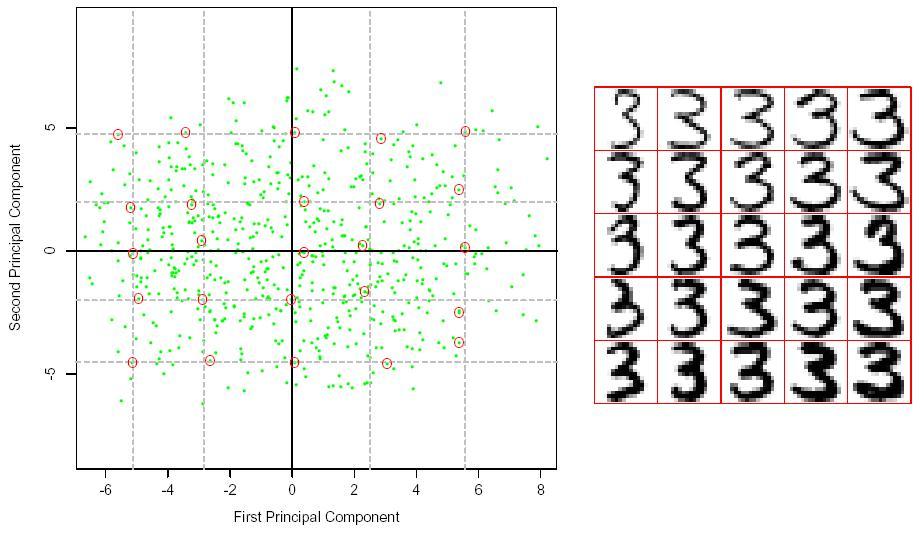
20 Visualisation We see the first two principal vectors v 1, v 2 v 1 prolongs the lower portion of the 3 v 2 modulates thickness 16
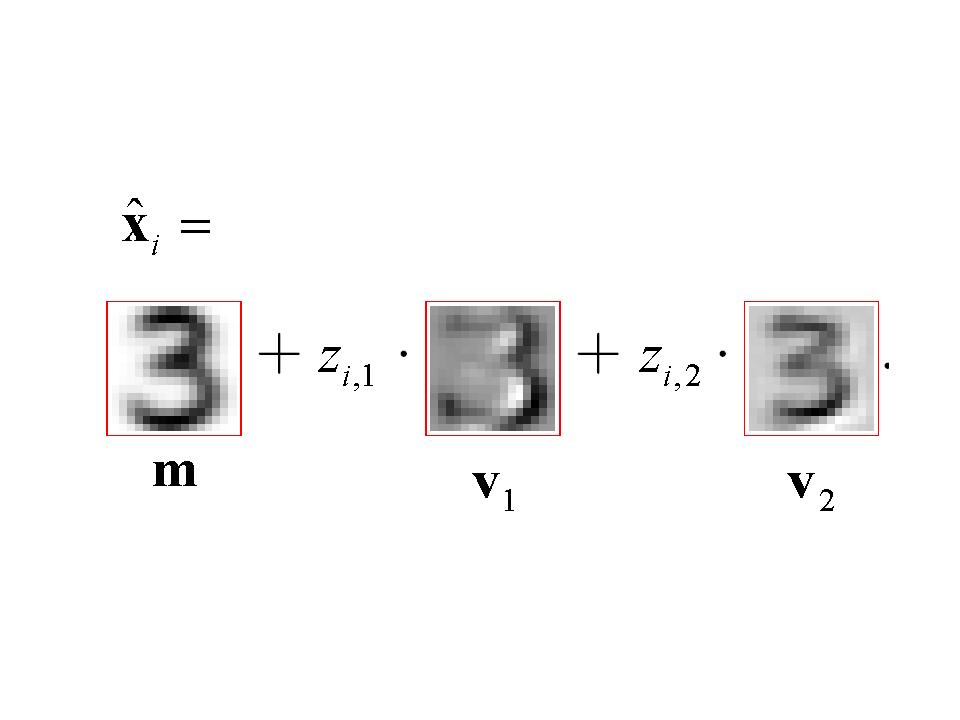
21
22 Visualisation: Reconstruction For different values of the principal components z 1 and z 2 the reconstructed image is shown ˆx = m + z 1 v 1 + z 2 v 2 m is a mean vector that was subtracted before the PCA was performed and is now added again. m represents 256 mean pixel values averaged over all samples 17
23
24 Eigenfaces 18
25 Data Set PCA for face recognition images from 3000 persons x i contains the pixel values of the i-th image. Obviously it does not make sense to build a classifier directly on the = pixel values Eigenfaces were calculated based on 128 images (eigenfaces might sound cooler than principal vectors!) (training set) For recognition on test images, the first r = 20 principal components are used Almost each person had at least 2 images; many persons had images with varying facial expression, different hair style, different beards,... 19

26
27 Similarity Search based on Principal Components The upper left image is the test image. Based on the Euclidian distance in PCA-space the other 15 images were classified as nearest neighbors. All 15 images came from the correct person, although the data base contained more than 7562 images! Thus, distance is evaluated following z z i 20
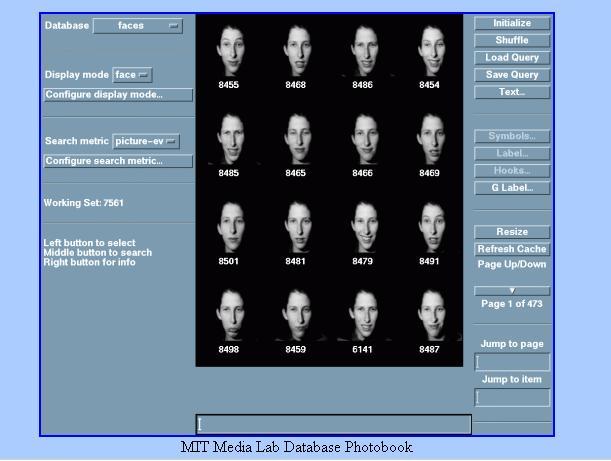
28
29 Recognition Rate 200 pictures were selected randomly from the test set. In 96% of all cases the nearest neighbor was the correct person 21
30 Modular Eigenspaces The method can also be applied to facial features as eigeneyes, eigennoses, eigenmouths. Analysis of human eye movements also showed that humans concentrate on these local features as well 22
31
32 Automatically Finding the Facial Features The modular methods require an automatic way of finding the facial features (eyes, nose, mouth) One defines rectangular windows that are indexed by the central pixel in the window One computes the anomaly of the image window for all locations, where the detector was trained on a feature class (e.g., left eye) by using a rank 10 PCA. When the anomaly is minimum the feature (eye) is detected. AN left eye (x posk ) = x posk V r V T r x posk 2 In the following images, brightness is anomaly 23

33 Input Image 24

34 Distances 25
35 Detection 26
36 Training Templates 27

37
38 Typical Detections 28

39
40 Detection Rate The next plot shows the performance of the left-eye-detector based on AN left eye (z posk ) (labeled as DFFS) with rank one and with rank 10. Also shown are the results for simple template matching (distance to the mean left eye image (SSD)). Definition of Detection: The global optimum is below a threshold value α and is within 5 pixels of the correct location Definition of False Alarm: The global optimum is below a threshold value α and is outside of 5 pixels of the correct location In the curves, α is varied. DFFS(10) reaches a correct detection of 94% at a false alarm rate of 6%. this means that in 94% of all cases, where a left eye has been detected in the image, it was detected at the right location and in 6% of all cases, where a left eye has been detected in the image, it was detected at the wrong location 29
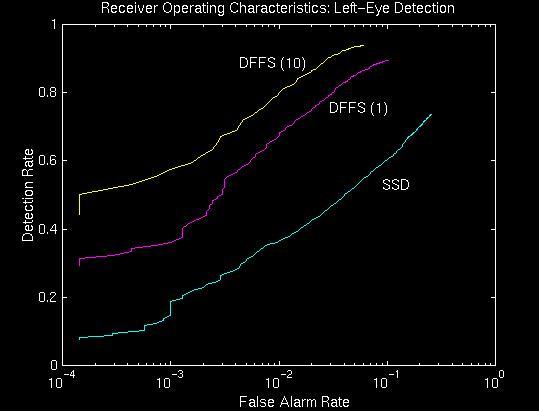
41
42 Robustness A potential advantage of the eigenfeature layer is the ability to overcome the shortcomings of the standard eigenface method. A pure eigenface recognition system can be fooled by gross variations in the input image (hats, beards, etc.). The first row of the figure above shows additional testing views of 3 individuals in the above dataset of 45. These test images are indicative of the type of variations which can lead to false matches: a hand near the face, a painted face, and a beard. The second row in the figure above shows the nearest matches found based on a standard eigenface classification. Neither of the 3 matches correspond to the correct individual. On the other hand, the third row shows the nearest matches based on the eyes and nose features, and results in correct identification in each case. This simple example illustrates the advantage of a modular representation in disambiguating false eigenface matches. 30

43
44 PCA with Centered Data Often the mean is subtracted first x i,j = x i,j m j where m j = 1 N N i=1 x i,j X now contains the centered data as (N, M) matrix Note: X T X/N is the empirical covariance matrix Centering is particularly recommended when data are approximately Gaussian distributed 31
45 PCA with Centered Data (cont d) Let ṽ l, l = 1,..., r, be the first r principal vectors. Then ˆx i = m + r l=1 ṽ l z i,l with m = (m 1,..., m M ) T zi,l = ṽ T l x i 32
46 ( d l / N is the standard deviation of the projected samples along the l-th principal direction. More on that later)
47 PCA and Singular Value Decomposition 33
48 Singular Value Decomposition (SVD) Any N M matrix X can be factored as X = UDV T where U and V are both orthogonal matrices (i.e. their rows and columns are pairwise orthonormal). U is an N N matrix and V is an M M matrix. D is an N M diagonal matrix with diagonal entries (singular values) d i 0, i = 1,..., r, with r = min(m, N) The u j (columns of U) are the left singular vectors The v j (columns of V ) are the right singular vectors The d j are the singular values 34
49
50 Interpretation of SVD X = UDV T Linear mapping Xa for all vectors a R M can be decomposed rotate (by V T ) scale axes by d i (d i = 0 for i > r) rotate (by U) 35
51 Covariance Matrix and Kernel Matrix With centered X we get for the (M M) empirical covariance matrix Σ = 1 N XT X = 1 N V DT U T UDV T = 1 N V DT DV T = 1 N V D V V T And for the (N N) empirical kernel matrix K = 1 M XXT = 1 M UDV T V D T U T = 1 M UDDT U T = 1 M UD UU T With ΣV = 1 N V D V KU = 1 M UD U one sees that the columns of V are the eigenvectors of Σ and the columns of U are the eigenvectors of K. The eigenvalues are the diagonal entries of D V (same as in D U ). 36
52 Apparent by now: The columns of V are the principal vectors! Thus, the j-th principal component is given by z j = Xv j j-th column of V. Its variance is where v j denotes the Var(z j ) = Var(Xv j ) = d 2 j /N We have seen that PCA can be performed by SVD on the centered X. As there are good, numerically stable algorithms for calculating SVD, many implementations of PCA (e.g. pca() in Matlab) internally use SVD.
53 More Expressions (used on next slide) The SVD is X = UDV T from which we get X = UU T X X = XV V T 37
54 Reduced Rank In the SVD, the d i are ordered: d 1 d 2 d 3... d r. In many cases one can neglect d i, i > r and one obtains a rank-r approximation. Let D r be a diagonal matrix with the corresponding entries. Then we get the approximation ˆX = U r D r V T r ˆX = U r U T r X ˆX = XV r V T r where U r contains the first r columns of U. Correspondingly, V r. 38
55 Best Approximation The approximation above is the best rank-r approximation with respect to the squared error (Frobenius Norm). The approximation error is N M (x i,j ˆx i,j ) 2 = i=1 j=1 r j=r+1 d 2 j 39
56 LSA: Similarities Between Documents 40
57 Feature Vectors for Documents Given a collection of N documents and M keywords X is the term-frequency (tf) matrix; x i,j indicates how often word j occurred in document i. Some classifiers use this representation as inputs On the other hand, two documents might discuss similar topics (are semantically similar ) without using the same key words By doing a PCA we can find document representations z i = V T x T i, with a good similarity measure between documents that provide us New: We can also find an improved representation of words via t j = U T x,j! This is known as Latent Semantic Analysis (LSA) 41
58 Simple Example In total 9 sentences (documents): 5 documents on human-computer interaction (c1 - c5) 4 documents on mathematical graph theory (m1 - m4) The 12 key words are in italic letters From: Landauer, T. K., Foltz, P. W., Laham, D. (1998). Introduction to Latent Semantic Analysis. Discourse Processes, 25,
59
60 tf-matrix and Word Correlations The tf-matrix X Based on the original data, the Pearson correlation between human and user is negative, although one would assume a large semantic correlation 43
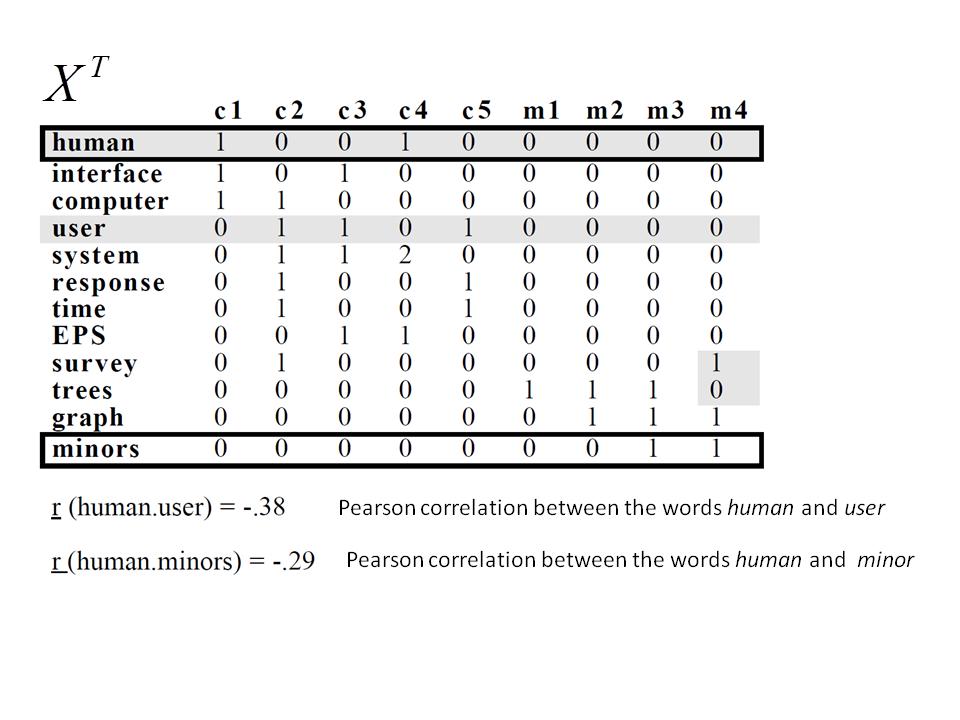
61
62 Site note: Pearson Correlation Measures linear correlation (dependence) between two random variables X, Y R r XY = cov(x, Y ) std(x)std(y ) [ 1, 1] 44
63 Singular Value Decomposition Decomposition X = UDV T 45
64
65 Approximation with r = 2 and Word Correlations Reconstruction ˆX with r = 2 Shown is ˆX T Based on ˆX the correlation between human and user is almost one! The similarity between human and minors is strongly negative (as it should be) In document m4: Graph minors: a survey the word survey which is in the original document gets a smaller value than the term trees, which was not in the document originally 46
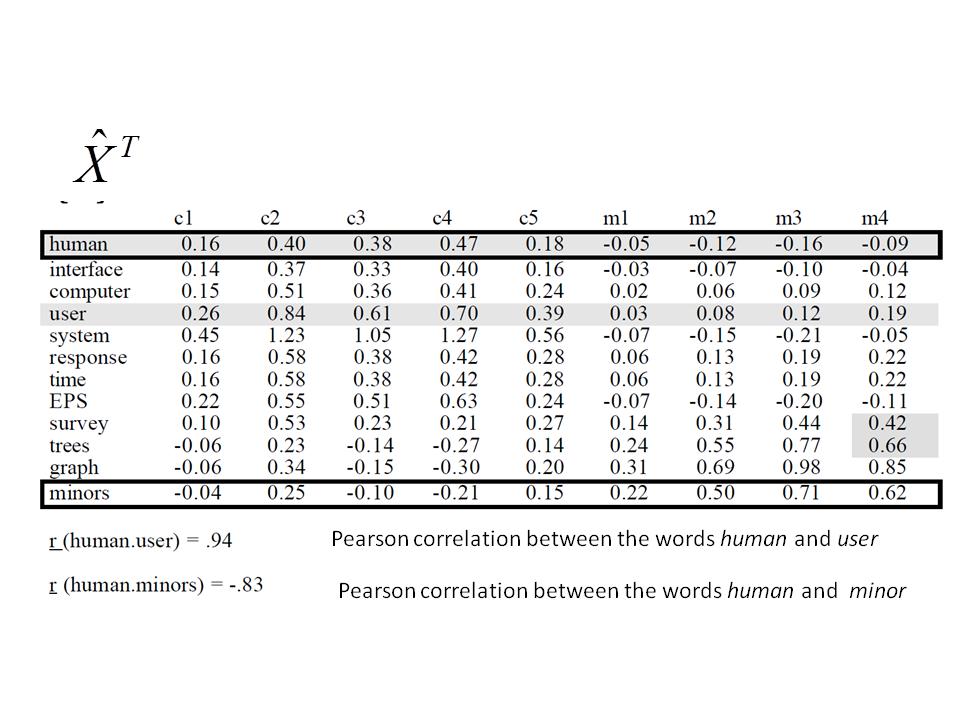
66
67 Document Correlations in the Original and the Reconstructed Data Top: document correlation in the original data X: The average correlation between documents in the c-class is almost zero Bottom: in ˆX there is a strong correlation between documents in the same class and strong negative correlation across document classes 47
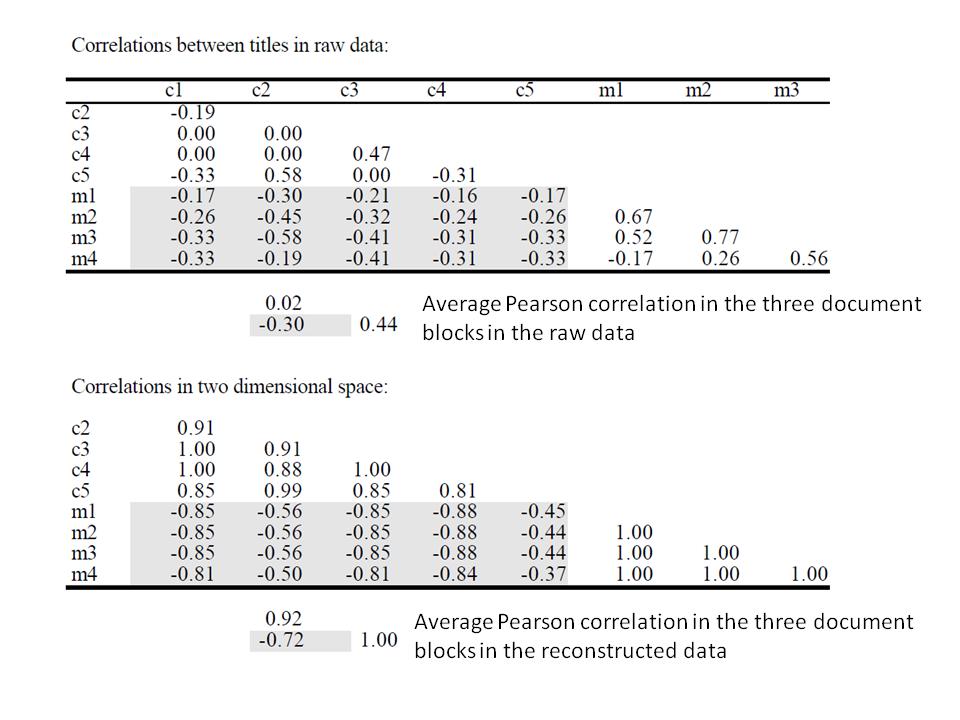
68
69 Applications of LSA LSA-similarity often corresponds to the human perception of document or word similarity There are commercial applications in the evaluation of term papers There are indications that search engine providers like Google and Yahoo, use LSA for the ranking of pages and to filter out spam (spam is unusual, novel) 48
70 Recommendation Engines The requirement that the approximation is optimal for any r lead to the PCA/SVD as unique solution If we only require a decomposition of the form X = AB T where A and B have r columns, then the solution is not unique and the columns of A and B are not necessarily orthonormal Such a decomposition is the basis for recommender systems where matrix entries correspond to rating of a user (row) for a movie (column) The components of A and B are regularized and the Frobenius norm is only calculated with respect to known ratings (which means that missing ratings are ignored in the optimization) 49
71 Further Example: PCA on Turbine Data 9000 data points, each with 279 inputs (sensor measurements), 1 output (emission) Visualizing first 3 principal components gives a good impression of the data distribution (here: trajectories in state space). The first 3 PCs explain nearly 90 percent of the variance of the data However, the principal components are not easy to interpret (linear combination of the original inputs) As Matlab code: [coef,scores,variances] = pca(x); percent_explained = 100*variances/sum(variances); figure; pareto(percent_explained) xlabel( Principal Component ) ylabel( Variance Explained (%) ) figure; scatter3(scores(:,1),scores(:,2),scores(:,3),10,y); xlabel( 1.PC ); ylabel( 2.PC ); zlabel( 3.PC ); set(get(colorbar, ylabel ), String, Emission ); 50
72 % 15 2 Variance Explained (%) Principal Component 80% 70% 60% 50% 40% 30% 20% 10% 0% 3.PC PC PC Emission
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Lecture 24: Principal Component Analysis. Aykut Erdem May 2016 Hacettepe University
 Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Principal Component Analysis
 B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
Dimensionality Reduction: PCA. Nicholas Ruozzi University of Texas at Dallas
 Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Robot Image Credit: Viktoriya Sukhanova 123RF.com. Dimensionality Reduction
 Robot Image Credit: Viktoriya Sukhanova 13RF.com Dimensionality Reduction Feature Selection vs. Dimensionality Reduction Feature Selection (last time) Select a subset of features. When classifying novel
Robot Image Credit: Viktoriya Sukhanova 13RF.com Dimensionality Reduction Feature Selection vs. Dimensionality Reduction Feature Selection (last time) Select a subset of features. When classifying novel
Lecture 8. Principal Component Analysis. Luigi Freda. ALCOR Lab DIAG University of Rome La Sapienza. December 13, 2016
 Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Face Detection and Recognition
 Face Detection and Recognition Face Recognition Problem Reading: Chapter 18.10 and, optionally, Face Recognition using Eigenfaces by M. Turk and A. Pentland Queryimage face query database Face Verification
Face Detection and Recognition Face Recognition Problem Reading: Chapter 18.10 and, optionally, Face Recognition using Eigenfaces by M. Turk and A. Pentland Queryimage face query database Face Verification
Unsupervised Machine Learning and Data Mining. DS 5230 / DS Fall Lecture 7. Jan-Willem van de Meent
 Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Machine Learning - MT & 14. PCA and MDS
 Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Linear Subspace Models
 Linear Subspace Models Goal: Explore linear models of a data set. Motivation: A central question in vision concerns how we represent a collection of data vectors. The data vectors may be rasterized images,
Linear Subspace Models Goal: Explore linear models of a data set. Motivation: A central question in vision concerns how we represent a collection of data vectors. The data vectors may be rasterized images,
Numerical Methods I Singular Value Decomposition
 Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Machine Learning 2nd Edition
 INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation)
") Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
Data Mining. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Structure in Data. A major objective in data analysis is to identify interesting features or structure in the data.
 Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Main matrix factorizations
 Main matrix factorizations A P L U P permutation matrix, L lower triangular, U upper triangular Key use: Solve square linear system Ax b. A Q R Q unitary, R upper triangular Key use: Solve square or overdetrmined
Main matrix factorizations A P L U P permutation matrix, L lower triangular, U upper triangular Key use: Solve square linear system Ax b. A Q R Q unitary, R upper triangular Key use: Solve square or overdetrmined
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 12 Jan-Willem van de Meent (credit: Yijun Zhao, Percy Liang) DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Linear Dimensionality
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 12 Jan-Willem van de Meent (credit: Yijun Zhao, Percy Liang) DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Linear Dimensionality
CS 340 Lec. 6: Linear Dimensionality Reduction
 CS 340 Lec. 6: Linear Dimensionality Reduction AD January 2011 AD () January 2011 1 / 46 Linear Dimensionality Reduction Introduction & Motivation Brief Review of Linear Algebra Principal Component Analysis
CS 340 Lec. 6: Linear Dimensionality Reduction AD January 2011 AD () January 2011 1 / 46 Linear Dimensionality Reduction Introduction & Motivation Brief Review of Linear Algebra Principal Component Analysis
Machine Learning. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
Eigenimaging for Facial Recognition
 Eigenimaging for Facial Recognition Aaron Kosmatin, Clayton Broman December 2, 21 Abstract The interest of this paper is Principal Component Analysis, specifically its area of application to facial recognition
Eigenimaging for Facial Recognition Aaron Kosmatin, Clayton Broman December 2, 21 Abstract The interest of this paper is Principal Component Analysis, specifically its area of application to facial recognition
Machine Learning. Principal Components Analysis. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Learning with Singular Vectors
 Learning with Singular Vectors CIS 520 Lecture 30 October 2015 Barry Slaff Based on: CIS 520 Wiki Materials Slides by Jia Li (PSU) Works cited throughout Overview Linear regression: Given X, Y find w:
Learning with Singular Vectors CIS 520 Lecture 30 October 2015 Barry Slaff Based on: CIS 520 Wiki Materials Slides by Jia Li (PSU) Works cited throughout Overview Linear regression: Given X, Y find w:
Machine Learning. B. Unsupervised Learning B.2 Dimensionality Reduction. Lars Schmidt-Thieme, Nicolas Schilling
 Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
Principal components analysis COMS 4771
 Principal components analysis COMS 4771 1. Representation learning Useful representations of data Representation learning: Given: raw feature vectors x 1, x 2,..., x n R d. Goal: learn a useful feature
Principal components analysis COMS 4771 1. Representation learning Useful representations of data Representation learning: Given: raw feature vectors x 1, x 2,..., x n R d. Goal: learn a useful feature
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Machine learning for pervasive systems Classification in high-dimensional spaces
 Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis. Massimiliano Pontil
 2. Least Squares and Principal Components Analysis. Massimiliano Pontil") GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
Principal Component Analysis
 Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
System 1 (last lecture) : limited to rigidly structured shapes. System 2 : recognition of a class of varying shapes. Need to:
 : limited to rigidly structured shapes. System 2 : recognition of a class of varying shapes. Need to:") System 2 : Modelling & Recognising Modelling and Recognising Classes of Classes of Shapes Shape : PDM & PCA All the same shape? System 1 (last lecture) : limited to rigidly structured shapes System 2 :
System 2 : Modelling & Recognising Modelling and Recognising Classes of Classes of Shapes Shape : PDM & PCA All the same shape? System 1 (last lecture) : limited to rigidly structured shapes System 2 :
Deriving Principal Component Analysis (PCA)
") -0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
-0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
CS4495/6495 Introduction to Computer Vision. 8B-L2 Principle Component Analysis (and its use in Computer Vision)
") CS4495/6495 Introduction to Computer Vision 8B-L2 Principle Component Analysis (and its use in Computer Vision) Wavelength 2 Wavelength 2 Principal Components Principal components are all about the directions
CS4495/6495 Introduction to Computer Vision 8B-L2 Principle Component Analysis (and its use in Computer Vision) Wavelength 2 Wavelength 2 Principal Components Principal components are all about the directions
20 Unsupervised Learning and Principal Components Analysis (PCA)
") 116 Jonathan Richard Shewchuk 20 Unsupervised Learning and Principal Components Analysis (PCA) UNSUPERVISED LEARNING We have sample points, but no labels! No classes, no y-values, nothing to predict. Goal:
116 Jonathan Richard Shewchuk 20 Unsupervised Learning and Principal Components Analysis (PCA) UNSUPERVISED LEARNING We have sample points, but no labels! No classes, no y-values, nothing to predict. Goal:
Example: Face Detection
 Announcements HW1 returned New attendance policy Face Recognition: Dimensionality Reduction On time: 1 point Five minutes or more late: 0.5 points Absent: 0 points Biometrics CSE 190 Lecture 14 CSE190,
Announcements HW1 returned New attendance policy Face Recognition: Dimensionality Reduction On time: 1 point Five minutes or more late: 0.5 points Absent: 0 points Biometrics CSE 190 Lecture 14 CSE190,
What is Principal Component Analysis?
 What is Principal Component Analysis? Principal component analysis (PCA) Reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables Retains most
What is Principal Component Analysis? Principal component analysis (PCA) Reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables Retains most
Unsupervised Learning: K- Means & PCA
 Unsupervised Learning: K- Means & PCA Unsupervised Learning Supervised learning used labeled data pairs (x, y) to learn a func>on f : X Y But, what if we don t have labels? No labels = unsupervised learning
Unsupervised Learning: K- Means & PCA Unsupervised Learning Supervised learning used labeled data pairs (x, y) to learn a func>on f : X Y But, what if we don t have labels? No labels = unsupervised learning
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach
 A First Dimensionality Reduction Approach") LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Unsupervised Learning: Dimensionality Reduction
 Unsupervised Learning: Dimensionality Reduction CMPSCI 689 Fall 2015 Sridhar Mahadevan Lecture 3 Outline In this lecture, we set about to solve the problem posed in the previous lecture Given a dataset,
Unsupervised Learning: Dimensionality Reduction CMPSCI 689 Fall 2015 Sridhar Mahadevan Lecture 3 Outline In this lecture, we set about to solve the problem posed in the previous lecture Given a dataset,
Data Preprocessing Tasks
 Data Tasks 1 2 3 Data Reduction 4 We re here. 1 Dimensionality Reduction Dimensionality reduction is a commonly used approach for generating fewer features. Typically used because too many features can
Data Tasks 1 2 3 Data Reduction 4 We re here. 1 Dimensionality Reduction Dimensionality reduction is a commonly used approach for generating fewer features. Typically used because too many features can
Expectation Maximization
 Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Novelty Detection. Cate Welch. May 14, 2015
 Novelty Detection Cate Welch May 14, 2015 1 Contents 1 Introduction 2 11 The Four Fundamental Subspaces 2 12 The Spectral Theorem 4 1 The Singular Value Decomposition 5 2 The Principal Components Analysis
Novelty Detection Cate Welch May 14, 2015 1 Contents 1 Introduction 2 11 The Four Fundamental Subspaces 2 12 The Spectral Theorem 4 1 The Singular Value Decomposition 5 2 The Principal Components Analysis
MATH 829: Introduction to Data Mining and Analysis Principal component analysis
 1/11 MATH 829: Introduction to Data Mining and Analysis Principal component analysis Dominique Guillot Departments of Mathematical Sciences University of Delaware April 4, 2016 Motivation 2/11 High-dimensional
1/11 MATH 829: Introduction to Data Mining and Analysis Principal component analysis Dominique Guillot Departments of Mathematical Sciences University of Delaware April 4, 2016 Motivation 2/11 High-dimensional
Dimensionality Reduction and Principle Components Analysis
 Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Face Recognition. Face Recognition. Subspace-Based Face Recognition Algorithms. Application of Face Recognition
 ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
Linear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
Principal Component Analysis
 Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
Classification. The goal: map from input X to a label Y. Y has a discrete set of possible values. We focused on binary Y (values 0 or 1).
.") Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Dimensionality Reduction
 Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Linear Methods in Data Mining
 Why Methods? linear methods are well understood, simple and elegant; algorithms based on linear methods are widespread: data mining, computer vision, graphics, pattern recognition; excellent general software
Why Methods? linear methods are well understood, simple and elegant; algorithms based on linear methods are widespread: data mining, computer vision, graphics, pattern recognition; excellent general software
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Dimensionality Reduction Using PCA/LDA. Hongyu Li School of Software Engineering TongJi University Fall, 2014
 Dimensionality Reduction Using PCA/LDA Hongyu Li School of Software Engineering TongJi University Fall, 2014 Dimensionality Reduction One approach to deal with high dimensional data is by reducing their
Dimensionality Reduction Using PCA/LDA Hongyu Li School of Software Engineering TongJi University Fall, 2014 Dimensionality Reduction One approach to deal with high dimensional data is by reducing their
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, data types 3 Data sources and preparation Project 1 out 4
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, data types 3 Data sources and preparation Project 1 out 4 Data reduction, similarity & distance, data augmentation
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, data types 3 Data sources and preparation Project 1 out 4 Data reduction, similarity & distance, data augmentation
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Dimensionality reduction
 Dimensionality Reduction PCA continued Machine Learning CSE446 Carlos Guestrin University of Washington May 22, 2013 Carlos Guestrin 2005-2013 1 Dimensionality reduction n Input data may have thousands
Dimensionality Reduction PCA continued Machine Learning CSE446 Carlos Guestrin University of Washington May 22, 2013 Carlos Guestrin 2005-2013 1 Dimensionality reduction n Input data may have thousands
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 23, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 47 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 23, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 47 High dimensional
CITS 4402 Computer Vision
 CITS 4402 Computer Vision A/Prof Ajmal Mian Adj/A/Prof Mehdi Ravanbakhsh Lecture 06 Object Recognition Objectives To understand the concept of image based object recognition To learn how to match images
CITS 4402 Computer Vision A/Prof Ajmal Mian Adj/A/Prof Mehdi Ravanbakhsh Lecture 06 Object Recognition Objectives To understand the concept of image based object recognition To learn how to match images
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
Image Analysis & Retrieval. Lec 14. Eigenface and Fisherface
 Image Analysis & Retrieval Lec 14 Eigenface and Fisherface Zhu Li Dept of CSEE, UMKC Office: FH560E, Email: lizhu@umkc.edu, Ph: x 2346. http://l.web.umkc.edu/lizhu Z. Li, Image Analysis & Retrv, Spring
Image Analysis & Retrieval Lec 14 Eigenface and Fisherface Zhu Li Dept of CSEE, UMKC Office: FH560E, Email: lizhu@umkc.edu, Ph: x 2346. http://l.web.umkc.edu/lizhu Z. Li, Image Analysis & Retrv, Spring
Modeling Classes of Shapes Suppose you have a class of shapes with a range of variations: System 2 Overview
 4 4 4 6 4 4 4 6 4 4 4 6 4 4 4 6 4 4 4 6 4 4 4 6 4 4 4 6 4 4 4 6 Modeling Classes of Shapes Suppose you have a class of shapes with a range of variations: System processes System Overview Previous Systems:
4 4 4 6 4 4 4 6 4 4 4 6 4 4 4 6 4 4 4 6 4 4 4 6 4 4 4 6 4 4 4 6 Modeling Classes of Shapes Suppose you have a class of shapes with a range of variations: System processes System Overview Previous Systems:
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
Structured matrix factorizations. Example: Eigenfaces
 Structured matrix factorizations Example: Eigenfaces An extremely large variety of interesting and important problems in machine learning can be formulated as: Given a matrix, find a matrix and a matrix
Structured matrix factorizations Example: Eigenfaces An extremely large variety of interesting and important problems in machine learning can be formulated as: Given a matrix, find a matrix and a matrix
STATISTICAL LEARNING SYSTEMS
 STATISTICAL LEARNING SYSTEMS LECTURE 8: UNSUPERVISED LEARNING: FINDING STRUCTURE IN DATA Institute of Computer Science, Polish Academy of Sciences Ph. D. Program 2013/2014 Principal Component Analysis
STATISTICAL LEARNING SYSTEMS LECTURE 8: UNSUPERVISED LEARNING: FINDING STRUCTURE IN DATA Institute of Computer Science, Polish Academy of Sciences Ph. D. Program 2013/2014 Principal Component Analysis
Introduction to Machine Learning. Introduction to ML - TAU 2016/7 1
 Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Dimensionality Reduction
 Dimensionality Reduction Le Song Machine Learning I CSE 674, Fall 23 Unsupervised learning Learning from raw (unlabeled, unannotated, etc) data, as opposed to supervised data where a classification of
Dimensionality Reduction Le Song Machine Learning I CSE 674, Fall 23 Unsupervised learning Learning from raw (unlabeled, unannotated, etc) data, as opposed to supervised data where a classification of
Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes. October 3, Statistics 202: Data Mining
 Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes October 3, 2012 1 / 1 Combinations of features Given a data matrix X n p with p fairly large, it can
Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes October 3, 2012 1 / 1 Combinations of features Given a data matrix X n p with p fairly large, it can
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Salvador Dalí, Galatea of the Spheres CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang Some slides from Derek Hoiem and Alysha
Principal Component Analysis (PCA) Salvador Dalí, Galatea of the Spheres CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang Some slides from Derek Hoiem and Alysha
IV. Matrix Approximation using Least-Squares
 IV. Matrix Approximation using Least-Squares The SVD and Matrix Approximation We begin with the following fundamental question. Let A be an M N matrix with rank R. What is the closest matrix to A that
IV. Matrix Approximation using Least-Squares The SVD and Matrix Approximation We begin with the following fundamental question. Let A be an M N matrix with rank R. What is the closest matrix to A that
Information Retrieval
 Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Introduction PCA classic Generative models Beyond and summary. PCA, ICA and beyond
 PCA, ICA and beyond Summer School on Manifold Learning in Image and Signal Analysis, August 17-21, 2009, Hven Technical University of Denmark (DTU) & University of Copenhagen (KU) August 18, 2009 Motivation
PCA, ICA and beyond Summer School on Manifold Learning in Image and Signal Analysis, August 17-21, 2009, Hven Technical University of Denmark (DTU) & University of Copenhagen (KU) August 18, 2009 Motivation
EECS490: Digital Image Processing. Lecture #26
 Lecture #26 Moments; invariant moments Eigenvector, principal component analysis Boundary coding Image primitives Image representation: trees, graphs Object recognition and classes Minimum distance classifiers
Lecture #26 Moments; invariant moments Eigenvector, principal component analysis Boundary coding Image primitives Image representation: trees, graphs Object recognition and classes Minimum distance classifiers
Linear Algebra (Review) Volker Tresp 2017
 Volker Tresp 2017") Linear Algebra (Review) Volker Tresp 2017 1 Vectors k is a scalar (a number) c is a column vector. Thus in two dimensions, c = ( c1 c 2 ) (Advanced: More precisely, a vector is defined in a vector space.
Linear Algebra (Review) Volker Tresp 2017 1 Vectors k is a scalar (a number) c is a column vector. Thus in two dimensions, c = ( c1 c 2 ) (Advanced: More precisely, a vector is defined in a vector space.
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Lecture 6: Methods for high-dimensional problems
 Lecture 6: Methods for high-dimensional problems Hector Corrada Bravo and Rafael A. Irizarry March, 2010 In this Section we will discuss methods where data lies on high-dimensional spaces. In particular,
Lecture 6: Methods for high-dimensional problems Hector Corrada Bravo and Rafael A. Irizarry March, 2010 In this Section we will discuss methods where data lies on high-dimensional spaces. In particular,
Machine Learning (Spring 2012) Principal Component Analysis
 Principal Component Analysis") 1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
CSC 411 Lecture 12: Principal Component Analysis
 CSC 411 Lecture 12: Principal Component Analysis Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 12-PCA 1 / 23 Overview Today we ll cover the first unsupervised
CSC 411 Lecture 12: Principal Component Analysis Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 12-PCA 1 / 23 Overview Today we ll cover the first unsupervised
Singular Value Decomposition
 Singular Value Decomposition Motivatation The diagonalization theorem play a part in many interesting applications. Unfortunately not all matrices can be factored as A = PDP However a factorization A =
Singular Value Decomposition Motivatation The diagonalization theorem play a part in many interesting applications. Unfortunately not all matrices can be factored as A = PDP However a factorization A =
PROBABILISTIC LATENT SEMANTIC ANALYSIS
 PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen PCA. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen PCA Tobias Scheffer Overview Principal Component Analysis (PCA) Kernel-PCA Fisher Linear Discriminant Analysis t-sne 2 PCA: Motivation
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen PCA Tobias Scheffer Overview Principal Component Analysis (PCA) Kernel-PCA Fisher Linear Discriminant Analysis t-sne 2 PCA: Motivation
Lecture 13. Principal Component Analysis. Brett Bernstein. April 25, CDS at NYU. Brett Bernstein (CDS at NYU) Lecture 13 April 25, / 26
 Lecture 13 April 25, / 26") Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Vector Space Models. wine_spectral.r
 Vector Space Models 137 wine_spectral.r Latent Semantic Analysis Problem with words Even a small vocabulary as in wine example is challenging LSA Reduce number of columns of DTM by principal components
Vector Space Models 137 wine_spectral.r Latent Semantic Analysis Problem with words Even a small vocabulary as in wine example is challenging LSA Reduce number of columns of DTM by principal components
Linear Algebra (Review) Volker Tresp 2018
 Volker Tresp 2018") Linear Algebra (Review) Volker Tresp 2018 1 Vectors k, M, N are scalars A one-dimensional array c is a column vector. Thus in two dimensions, ( ) c1 c = c 2 c i is the i-th component of c c T = (c 1, c
Linear Algebra (Review) Volker Tresp 2018 1 Vectors k, M, N are scalars A one-dimensional array c is a column vector. Thus in two dimensions, ( ) c1 c = c 2 c i is the i-th component of c c T = (c 1, c
15 Singular Value Decomposition
 15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Face detection and recognition. Detection Recognition Sally
 Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Lecture 6 Sept Data Visualization STAT 442 / 890, CM 462
 Lecture 6 Sept. 25-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Dual PCA It turns out that the singular value decomposition also allows us to formulate the principle components
Lecture 6 Sept. 25-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Dual PCA It turns out that the singular value decomposition also allows us to formulate the principle components
Lecture 15: Random Projections
 Lecture 15: Random Projections Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 15 1 / 11 Review of PCA Unsupervised learning technique Performs dimensionality reduction
Lecture 15: Random Projections Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 15 1 / 11 Review of PCA Unsupervised learning technique Performs dimensionality reduction
Principal Component Analysis
 Principal Component Analysis Anders Øland David Christiansen 1 Introduction Principal Component Analysis, or PCA, is a commonly used multi-purpose technique in data analysis. It can be used for feature
Principal Component Analysis Anders Øland David Christiansen 1 Introduction Principal Component Analysis, or PCA, is a commonly used multi-purpose technique in data analysis. It can be used for feature
PRINCIPAL COMPONENTS ANALYSIS
 121 CHAPTER 11 PRINCIPAL COMPONENTS ANALYSIS We now have the tools necessary to discuss one of the most important concepts in mathematical statistics: Principal Components Analysis (PCA). PCA involves
121 CHAPTER 11 PRINCIPAL COMPONENTS ANALYSIS We now have the tools necessary to discuss one of the most important concepts in mathematical statistics: Principal Components Analysis (PCA). PCA involves
November 28 th, Carlos Guestrin 1. Lower dimensional projections
 PCA Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University November 28 th, 2007 1 Lower dimensional projections Rather than picking a subset of the features, we can new features that are
PCA Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University November 28 th, 2007 1 Lower dimensional projections Rather than picking a subset of the features, we can new features that are
CS 231A Section 1: Linear Algebra & Probability Review
 CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
Assignment #10: Diagonalization of Symmetric Matrices, Quadratic Forms, Optimization, Singular Value Decomposition. Name:
 Assignment #10: Diagonalization of Symmetric Matrices, Quadratic Forms, Optimization, Singular Value Decomposition Due date: Friday, May 4, 2018 (1:35pm) Name: Section Number Assignment #10: Diagonalization
Assignment #10: Diagonalization of Symmetric Matrices, Quadratic Forms, Optimization, Singular Value Decomposition Due date: Friday, May 4, 2018 (1:35pm) Name: Section Number Assignment #10: Diagonalization
CS 231A Section 1: Linear Algebra & Probability Review. Kevin Tang
 CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
1 Principal Components Analysis
 Lecture 3 and 4 Sept. 18 and Sept.20-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Principal Components Analysis Principal components analysis (PCA) is a very popular technique for
Lecture 3 and 4 Sept. 18 and Sept.20-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Principal Components Analysis Principal components analysis (PCA) is a very popular technique for