Techniques for Dimensionality Reduction. PCA and Other Matrix Factorization Methods
|
|
|
- Camilla Casey
- 5 years ago
- Views:
Transcription
1 Techniques for Dimensionality Reduction PCA and Other Matrix Factorization Methods
2 Outline Principle Compoments Analysis (PCA) Example (Bishop, ch 12) PCA as a mixture model variant With a continuous latent variable Breaking down PCA Optimization problem Solution Intuitions General matrix factorization Application to collaborative filtering Algorithms Wrap-up
3 A Motivating Example The MNist digits problem was simplified because the digits were Centered In a canonical position Scaled to the same size What if they weren t?

4 A Motivating Example Take a single 64*64 digit and create a dataset by repeatedly Move it to a 100*100 image Shift by x,y and rotate by θ Dataset has 10,000 features but really only needs 3
5 A Motivating Example prototype = a vector of the same dimension as the instances PCA: reduces each instance to a linear combination of a few prototypes (blue+, green-). These are the first 5: A specific choice of prototypes are the principle components
6 A Motivating Example prototype = a vector of the same dimension as the instances PCA: reduces each instance to a linear combination of a few prototypes (blue+, green-). These are the first 5: Σ
7 PC1 PCA as matrices 2 prototypes 10,000 pixels 1000 * 10,000,00 x1 x2.. y1 y2.. a1 a2.. am b1 b2 bm ~ v images vij xn yn PC2 vnm V[i,j] = pixel j in image i

8 PC1 1.4*PC *PC2 = 2 prototypes 10,000 pixels 1000 * 10,000, x2 y2.... a1 a2.. am b1 b2 bm v images vij xn yn PC2 vnm V[i,j] = pixel j in image i

9 PCA for movie recommendation m movies m movies x1 x2.. y1 y2.. a1 a2.. am b1 b2 bm ~ v11 n users vij V Bob xn yn vnm V[i,j] = user i s rating of movie j

10 Bob

11 A Cartoon of PCA Red: the dataset



12 A Cartoon of PCA Green: the reconstruction of the original data Magenta: the lowerdimensional model (linear combinations of one prototype ) In PCA we find a model that minimizes the reconstruction error (blue lines).
13 A 3D Cartoon of PCA

14 Some more cartoons

15 PCA vs Linear Regression r features (eg 4) m=1 regressors predictions n instances (e.g., 150) pl1 pw1 sl1 sw1 pl2 pw2 sl2 sw2.... W w1 w2 w3 w4 H ~ y1 yi Y pln pwn yn Y[i,1] = instance i s prediction


16 PCA vs Linear Regression In contrast: in regression we d minimize square error on one dimension (x 2 ) using a linear combination the other dimensions
 Gaussian")
 z 1 z 2 z N x 1 x 2 x N Plate")
17 PCA vs mixture of Gaussians Mixture of Gaussians For each point: Pick the index of the (latent) Gaussian Z=k Pick the the point x from that the k-th Gaussian, x ~ N(µ k,σ k ) z 1 z 2 z N x 1 x 2 x N Plate notation
18 PCA vs mixture of Gaussians Mixture of Gaussians Pick the index of the (latent) Gaussian Z=k Pick the the point x from that the k-th Gaussian, x ~ N(µ k,σ k )
19 PCA vs mixture of Gaussians PCA Pick a continuous value z, which will be used to combine the prototypes u in the model Pick the the point x from a spherical Gaussian centered on zu u u ẑ u
20 PCA vs mixture of Gaussians z is discrete z is continuous u Comment: we can preprocess the data so that the mean is 0 to simplify the model
21 Finding the Principle Components There are different algorithms that can be used EM (Roweis, NIPS 2007) Can also be turned into an eigenvector computation (next)
22 Outline PCA Example (Bishop, ch 12) PCA as a mixture model variant With a continuous latent variable Breaking down PCA Optimization problem Solution Intuition
23 The PCA Problem (vectors) Start with a zero-mean dataset, where x t is a the t-th instance: We want to find small number of orthogonal prototypes u 1,..u k and k weights z t 1,, zt k for each instance xt so that if we approximate x t by the approximation error will be small: we want to find u s and z s to minimize
24 The PCA Problem (matrices) Given a zero-mean dataset Find factors U and Z so that X is approximately their outer product: Specifically minimizing the square of the reconstruction error under the constraint that the rows of U are orthogonal.
25 A PCA Algorithm Start with a zero-mean dataset, where x t is a the t-th instance f i is a column of feature values for the i-th feature. Compute the sample covariance matrix i.e., Find the largest k eigenvectors of C X. These are the prototypes, U. Now find Z given X and U.

26 PCA Algorithm: Intuitions Start with a zero-mean dataset, where x t is a the t-th instance f i is a column of feature values for the i-th feature. Compute the sample covariance matrix Some intuitions: 1. Suppose you wanted to predict feature i from feature j. Your best guess would be 2. If you wanted to predict feature i from all other feature s j, a plausible guess is 3. Any eigenvector, e, of C X leads to an internally consistent* set of predictions * up to a multiplier

27 PCA: Eigenfaces Turk and Pentland, 1991


28 PCA: Eigenfaces Turk and Pentland, 1991 Average face Six eigenfaces (PC s)


29 PCA: Eigenfaces Turk and Pentland, 1991
30 PCA: Eigenfaces
31 PCA: Eigenfaces How is this done? Simplest approach: Add the image with missing values to the data matrix Minimize reconstruction error over the non-missing values?
32 for image denoising
33 Outline Principle Compoments Analysis (PCA) Other types of/applications of matrix factorization Collaborative filtering/recommendation Matrix factorization for CF using gradient descent

34 What is collaborative filtering?

35 What is collaborative filtering?
36 What is collaborative filtering?


37 What is collaborative filtering?
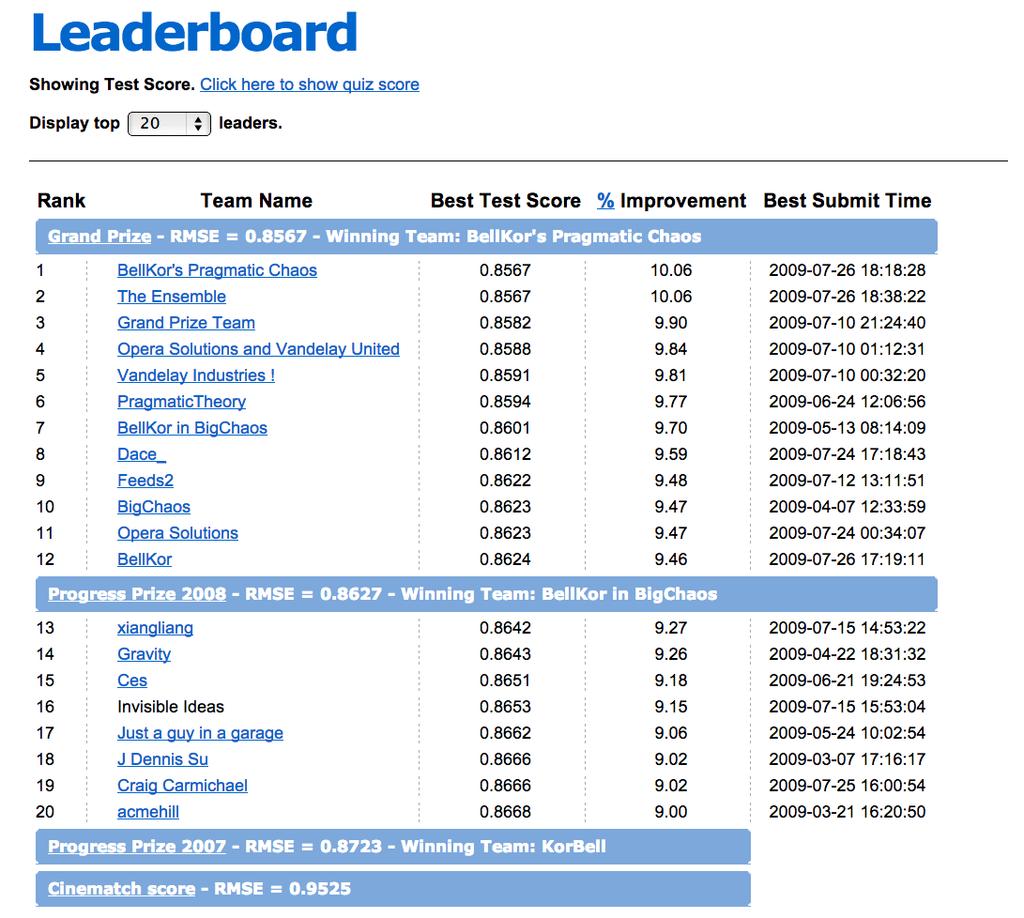
38
39 What is collaborative filtering?

40 Other examples of social filtering.

41 Other examples of social filtering.
42 Everyday Examples of Collaborative Filtering... Bestseller lists Top 40 music lists The recent returns shelf at the library Unmarked but well-used paths thru the woods The printer room at work Read any good books lately?... Common insight: personal tastes are correlated: If Alice and Bob both like X and Alice likes Y then Bob is more likely to like Y especially (perhaps) if Bob knows Alice
43 Outline Principle Compoments Analysis (PCA) Other types of/applications of matrix factorization Collaborative filtering/recommendation Algorithms: K-NN type methods Classification-base methods Matrix factorization
44 Recovering latent factors in a matrix m movies v11 n users vij vnm V[i,j] = user i s rating of movie j
45 Recovering latent factors in a matrix m movies m movies x1 x2.. y1 y2.. a1 a2.. am b1 b2 bm ~ v11 n users xn yn Minimize squared error reconstruction error and force the prototype users to be orthogonal è PCA vij vnm V[i,j] = user i s rating of movie j



46 talk pilfered from à.. KDD 2011
47
48 Recovering latent factors in a matrix r m movies m movies x1 x2.. y1 y2.. H a1 a2.. am b1 b2 bm ~ v11 n users W vij V xn yn vnm V[i,j] = user i s rating of movie j
49
50 user-specific bias term movie-specific bias term
51
52 Recovering latent factors in a matrix r m movies m movies x1 x2.. y1 y2.. H a1 a2.. am b1 b2 bm ~ v11 n users W vij V xn yn vnm V[i,j] = user i s rating of movie j
53 is like Linear Regression. r features (eg 4) m=1 regressors predictions n instances (e.g., 150) pl1 pw1 sl1 sw1 pl2 pw2 sl2 sw2.... W w1 w2 w3 w4 H ~ y1 yi Y pln pwn yn Y[i,1] = instance i s prediction
54 .. for many outputs at once. r features (eg 4) m regressors predictions n instances (e.g., 150) pl1 pw1 sl1 sw1 pl2 pw2 sl2 sw2.... W w11 w12 w21.. H w31.. w41.. ~ y11 y12 Y ym pln yn1 ynm where we also have to Oind the dataset! Y[I,j] = instance i s prediction for regression task j
55 Matrix factorization as SGD step size
56 Matrix factorization as SGD - why does this work? step size

57 Matrix factorization as SGD - why does this work? Here s the key claim:
58 Checking the claim Think for SGD for logistic regression LR loss = compare y and ŷ = dot(w,x) similar but now update w (user weights) and x (movie weight)

59 What loss functions are possible? N1, N2 - diagonal matrixes, sort of like IDF factors for the users/ movies generalized KL- divergence
60 What loss functions are possible?
61 What loss functions are possible?
62 ALS = alternating least squares
63 Wrapup: Matrix Multiplications in Machine Learning
64 Recovering latent factors in a matrix r m movies m movies x1 x2.. y1 y2.. H a1 a2.. am b1 b2 bm ~ v11 n users W vij V xn yn vnm V[i,j] = user i s rating of movie j
65 vs PCA r m movies m movies x1 x2.. y1 y2.. H a1 a2.. am b1 b2 bm ~ v11 n users W xn yn Minimize squared error reconstruction error and force the prototype users to be orthogonal è PCA vij V vnm V[i,j] = user i s rating of movie j
66 Flashback to NN lecture.. vs autoencoders & nonlinear PCA Assume we would like to learn the following (trivial?) output function: Using the following network: Input Output With linear hidden units, how do the weights match up to W and H?
67 indicators for r clusters.. vs k- means cluster means original data set M a1 a2.. am b1 b2 bm ~ v11 n examples Z vij X xn yn vnm
Dimensionality Reduction and Principle Components Analysis
 Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Matrix Factorization and Collaborative Filtering
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Matrix Factorization and Collaborative Filtering MF Readings: (Koren et al., 2009)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Matrix Factorization and Collaborative Filtering MF Readings: (Koren et al., 2009)
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Expectation Maximization
 Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
CS4495/6495 Introduction to Computer Vision. 8B-L2 Principle Component Analysis (and its use in Computer Vision)
") CS4495/6495 Introduction to Computer Vision 8B-L2 Principle Component Analysis (and its use in Computer Vision) Wavelength 2 Wavelength 2 Principal Components Principal components are all about the directions
CS4495/6495 Introduction to Computer Vision 8B-L2 Principle Component Analysis (and its use in Computer Vision) Wavelength 2 Wavelength 2 Principal Components Principal components are all about the directions
Matrix and Tensor Factorization from a Machine Learning Perspective
 Matrix and Tensor Factorization from a Machine Learning Perspective Christoph Freudenthaler Information Systems and Machine Learning Lab, University of Hildesheim Research Seminar, Vienna University of
Matrix and Tensor Factorization from a Machine Learning Perspective Christoph Freudenthaler Information Systems and Machine Learning Lab, University of Hildesheim Research Seminar, Vienna University of
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Lecture 11: Unsupervised Machine Learning
 CSE517A Machine Learning Spring 2018 Lecture 11: Unsupervised Machine Learning Instructor: Marion Neumann Scribe: Jingyu Xin Reading: fcml Ch6 (Intro), 6.2 (k-means), 6.3 (Mixture Models); [optional]:
CSE517A Machine Learning Spring 2018 Lecture 11: Unsupervised Machine Learning Instructor: Marion Neumann Scribe: Jingyu Xin Reading: fcml Ch6 (Intro), 6.2 (k-means), 6.3 (Mixture Models); [optional]:
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Lecture 24: Principal Component Analysis. Aykut Erdem May 2016 Hacettepe University
 Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent
 Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
Dimensionality Reduction
 Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
All you want to know about GPs: Linear Dimensionality Reduction
 All you want to know about GPs: Linear Dimensionality Reduction Raquel Urtasun and Neil Lawrence TTI Chicago, University of Sheffield June 16, 2012 Urtasun & Lawrence () GP tutorial June 16, 2012 1 / 40
All you want to know about GPs: Linear Dimensionality Reduction Raquel Urtasun and Neil Lawrence TTI Chicago, University of Sheffield June 16, 2012 Urtasun & Lawrence () GP tutorial June 16, 2012 1 / 40
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 21: Review Jan-Willem van de Meent Schedule Topics for Exam Pre-Midterm Probability Information Theory Linear Regression Classification Clustering
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 21: Review Jan-Willem van de Meent Schedule Topics for Exam Pre-Midterm Probability Information Theory Linear Regression Classification Clustering
ECE521 Lecture7. Logistic Regression
 ECE521 Lecture7 Logistic Regression Outline Review of decision theory Logistic regression A single neuron Multi-class classification 2 Outline Decision theory is conceptually easy and computationally hard
ECE521 Lecture7 Logistic Regression Outline Review of decision theory Logistic regression A single neuron Multi-class classification 2 Outline Decision theory is conceptually easy and computationally hard
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Collaborative Filtering. Radek Pelánek
 Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Principal Component Analysis
 B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
Machine learning for pervasive systems Classification in high-dimensional spaces
 Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
CPSC 340: Machine Learning and Data Mining. Sparse Matrix Factorization Fall 2018
 CPSC 340: Machine Learning and Data Mining Sparse Matrix Factorization Fall 2018 Last Time: PCA with Orthogonal/Sequential Basis When k = 1, PCA has a scaling problem. When k > 1, have scaling, rotation,
CPSC 340: Machine Learning and Data Mining Sparse Matrix Factorization Fall 2018 Last Time: PCA with Orthogonal/Sequential Basis When k = 1, PCA has a scaling problem. When k > 1, have scaling, rotation,
Unsupervised Machine Learning and Data Mining. DS 5230 / DS Fall Lecture 7. Jan-Willem van de Meent
 Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Social/Collaborative Filtering
 Social/Collaborative Filtering Outline Recap SVD vs PCA Collaborative
Social/Collaborative Filtering Outline Recap SVD vs PCA Collaborative
CPSC 340: Machine Learning and Data Mining. More PCA Fall 2017
 CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
Unsupervised Learning: Dimensionality Reduction
 Unsupervised Learning: Dimensionality Reduction CMPSCI 689 Fall 2015 Sridhar Mahadevan Lecture 3 Outline In this lecture, we set about to solve the problem posed in the previous lecture Given a dataset,
Unsupervised Learning: Dimensionality Reduction CMPSCI 689 Fall 2015 Sridhar Mahadevan Lecture 3 Outline In this lecture, we set about to solve the problem posed in the previous lecture Given a dataset,
Matrix Factorization & Latent Semantic Analysis Review. Yize Li, Lanbo Zhang
 Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 12 Jan-Willem van de Meent (credit: Yijun Zhao, Percy Liang) DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Linear Dimensionality
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 12 Jan-Willem van de Meent (credit: Yijun Zhao, Percy Liang) DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Linear Dimensionality
CSC321 Lecture 20: Autoencoders
 CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Principal Component Analysis (PCA) CSC411/2515 Tutorial
 CSC411/2515 Tutorial") Principal Component Analysis (PCA) CSC411/2515 Tutorial Harris Chan Based on previous tutorial slides by Wenjie Luo, Ladislav Rampasek University of Toronto hchan@cs.toronto.edu October 19th, 2017 (UofT)
Principal Component Analysis (PCA) CSC411/2515 Tutorial Harris Chan Based on previous tutorial slides by Wenjie Luo, Ladislav Rampasek University of Toronto hchan@cs.toronto.edu October 19th, 2017 (UofT)
Lecture 3: Latent Variables Models and Learning with the EM Algorithm. Sam Roweis. Tuesday July25, 2006 Machine Learning Summer School, Taiwan
 Lecture 3: Latent Variables Models and Learning with the EM Algorithm Sam Roweis Tuesday July25, 2006 Machine Learning Summer School, Taiwan Latent Variable Models What to do when a variable z is always
Lecture 3: Latent Variables Models and Learning with the EM Algorithm Sam Roweis Tuesday July25, 2006 Machine Learning Summer School, Taiwan Latent Variable Models What to do when a variable z is always
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Latent Variable Models and EM algorithm
 Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Scaling Neighbourhood Methods
 Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
Dimension Reduction. David M. Blei. April 23, 2012
 Dimension Reduction David M. Blei April 23, 2012 1 Basic idea Goal: Compute a reduced representation of data from p -dimensional to q-dimensional, where q < p. x 1,...,x p z 1,...,z q (1) We want to do
Dimension Reduction David M. Blei April 23, 2012 1 Basic idea Goal: Compute a reduced representation of data from p -dimensional to q-dimensional, where q < p. x 1,...,x p z 1,...,z q (1) We want to do
Collaborative Filtering: A Machine Learning Perspective
 Collaborative Filtering: A Machine Learning Perspective Chapter 6: Dimensionality Reduction Benjamin Marlin Presenter: Chaitanya Desai Collaborative Filtering: A Machine Learning Perspective p.1/18 Topics
Collaborative Filtering: A Machine Learning Perspective Chapter 6: Dimensionality Reduction Benjamin Marlin Presenter: Chaitanya Desai Collaborative Filtering: A Machine Learning Perspective p.1/18 Topics
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Andriy Mnih and Ruslan Salakhutdinov
 MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
Structured matrix factorizations. Example: Eigenfaces
 Structured matrix factorizations Example: Eigenfaces An extremely large variety of interesting and important problems in machine learning can be formulated as: Given a matrix, find a matrix and a matrix
Structured matrix factorizations Example: Eigenfaces An extremely large variety of interesting and important problems in machine learning can be formulated as: Given a matrix, find a matrix and a matrix
Lecture: Face Recognition
 Lecture: Face Recognition Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 12-1 What we will learn today Introduction to face recognition The Eigenfaces Algorithm Linear
Lecture: Face Recognition Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 12-1 What we will learn today Introduction to face recognition The Eigenfaces Algorithm Linear
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
Nonnegative Matrix Factorization
 Nonnegative Matrix Factorization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Nonnegative Matrix Factorization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
The Perceptron. Volker Tresp Summer 2016
 The Perceptron Volker Tresp Summer 2016 1 Elements in Learning Tasks Collection, cleaning and preprocessing of training data Definition of a class of learning models. Often defined by the free model parameters
The Perceptron Volker Tresp Summer 2016 1 Elements in Learning Tasks Collection, cleaning and preprocessing of training data Definition of a class of learning models. Often defined by the free model parameters
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
Machine Learning for Data Science (CS4786) Lecture 12
 Lecture 12") Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Mixtures of Gaussians. Sargur Srihari
 Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties
 ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties Prof. James She james.she@ust.hk 1 Last lecture 2 Selected works from Tutorial
ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties Prof. James She james.she@ust.hk 1 Last lecture 2 Selected works from Tutorial
Collaborative Topic Modeling for Recommending Scientific Articles
 Collaborative Topic Modeling for Recommending Scientific Articles Chong Wang and David M. Blei Best student paper award at KDD 2011 Computer Science Department, Princeton University Presented by Tian Cao
Collaborative Topic Modeling for Recommending Scientific Articles Chong Wang and David M. Blei Best student paper award at KDD 2011 Computer Science Department, Princeton University Presented by Tian Cao
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis
 Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture
Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Clustering K-means. Machine Learning CSE546. Sham Kakade University of Washington. November 15, Review: PCA Start: unsupervised learning
 Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Factor Analysis (10/2/13)
") STA561: Probabilistic machine learning Factor Analysis (10/2/13) Lecturer: Barbara Engelhardt Scribes: Li Zhu, Fan Li, Ni Guan Factor Analysis Factor analysis is related to the mixture models we have studied.
STA561: Probabilistic machine learning Factor Analysis (10/2/13) Lecturer: Barbara Engelhardt Scribes: Li Zhu, Fan Li, Ni Guan Factor Analysis Factor analysis is related to the mixture models we have studied.
CS168: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA)
") CS68: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA) Tim Roughgarden & Gregory Valiant April 0, 05 Introduction. Lecture Goal Principal components analysis
CS68: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA) Tim Roughgarden & Gregory Valiant April 0, 05 Introduction. Lecture Goal Principal components analysis
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Gaussian Mixture Models
 Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Chris Bishop s PRML Ch. 8: Graphical Models
 Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
The Perceptron. Volker Tresp Summer 2018
 The Perceptron Volker Tresp Summer 2018 1 Elements in Learning Tasks Collection, cleaning and preprocessing of training data Definition of a class of learning models. Often defined by the free model parameters
The Perceptron Volker Tresp Summer 2018 1 Elements in Learning Tasks Collection, cleaning and preprocessing of training data Definition of a class of learning models. Often defined by the free model parameters
MATH 829: Introduction to Data Mining and Analysis Principal component analysis
 1/11 MATH 829: Introduction to Data Mining and Analysis Principal component analysis Dominique Guillot Departments of Mathematical Sciences University of Delaware April 4, 2016 Motivation 2/11 High-dimensional
1/11 MATH 829: Introduction to Data Mining and Analysis Principal component analysis Dominique Guillot Departments of Mathematical Sciences University of Delaware April 4, 2016 Motivation 2/11 High-dimensional
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees
 Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees Rafdord M. Neal and Jianguo Zhang Presented by Jiwen Li Feb 2, 2006 Outline Bayesian view of feature
Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees Rafdord M. Neal and Jianguo Zhang Presented by Jiwen Li Feb 2, 2006 Outline Bayesian view of feature
CSC 411 Lecture 12: Principal Component Analysis
 CSC 411 Lecture 12: Principal Component Analysis Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 12-PCA 1 / 23 Overview Today we ll cover the first unsupervised
CSC 411 Lecture 12: Principal Component Analysis Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 12-PCA 1 / 23 Overview Today we ll cover the first unsupervised
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task
 Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Clustering based tensor decomposition
 Clustering based tensor decomposition Huan He huan.he@emory.edu Shihua Wang shihua.wang@emory.edu Emory University November 29, 2017 (Huan)(Shihua) (Emory University) Clustering based tensor decomposition
Clustering based tensor decomposition Huan He huan.he@emory.edu Shihua Wang shihua.wang@emory.edu Emory University November 29, 2017 (Huan)(Shihua) (Emory University) Clustering based tensor decomposition
CPSC 340: Machine Learning and Data Mining. More PCA Fall 2016
 CPSC 340: Machine Learning and Data Mining More PCA Fall 2016 A2/Midterm: Admin Grades/solutions posted. Midterms can be viewed during office hours. Assignment 4: Due Monday. Extra office hours: Thursdays
CPSC 340: Machine Learning and Data Mining More PCA Fall 2016 A2/Midterm: Admin Grades/solutions posted. Midterms can be viewed during office hours. Assignment 4: Due Monday. Extra office hours: Thursdays
Course 495: Advanced Statistical Machine Learning/Pattern Recognition
 Course 495: Advanced Statistical Machine Learning/Pattern Recognition Deterministic Component Analysis Goal (Lecture): To present standard and modern Component Analysis (CA) techniques such as Principal
Course 495: Advanced Statistical Machine Learning/Pattern Recognition Deterministic Component Analysis Goal (Lecture): To present standard and modern Component Analysis (CA) techniques such as Principal
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 2 - Spring 2017 Lecture 6 Jan-Willem van de Meent (credit: Yijun Zhao, Chris Bishop, Andrew Moore, Hastie et al.) Project Project Deadlines 3 Feb: Form teams of
Data Mining Techniques CS 6220 - Section 2 - Spring 2017 Lecture 6 Jan-Willem van de Meent (credit: Yijun Zhao, Chris Bishop, Andrew Moore, Hastie et al.) Project Project Deadlines 3 Feb: Form teams of
PCA and admixture models
 PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Reward-modulated inference
 Buck Shlegeris Matthew Alger COMP3740, 2014 Outline Supervised, unsupervised, and reinforcement learning Neural nets RMI Results with RMI Types of machine learning supervised unsupervised reinforcement
Buck Shlegeris Matthew Alger COMP3740, 2014 Outline Supervised, unsupervised, and reinforcement learning Neural nets RMI Results with RMI Types of machine learning supervised unsupervised reinforcement
CS 4495 Computer Vision Principle Component Analysis
 CS 4495 Computer Vision Principle Component Analysis (and it s use in Computer Vision) Aaron Bobick School of Interactive Computing Administrivia PS6 is out. Due *** Sunday, Nov 24th at 11:55pm *** PS7
CS 4495 Computer Vision Principle Component Analysis (and it s use in Computer Vision) Aaron Bobick School of Interactive Computing Administrivia PS6 is out. Due *** Sunday, Nov 24th at 11:55pm *** PS7
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
Probabilistic & Unsupervised Learning
 Probabilistic & Unsupervised Learning Week 2: Latent Variable Models Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College
Probabilistic & Unsupervised Learning Week 2: Latent Variable Models Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Variables which are always unobserved are called latent variables or sometimes hidden variables. e.g. given y,x fit the model p(y x) = z p(y x,z)p(z)
 = z p(y x,z)p(z)") CSC2515 Machine Learning Sam Roweis Lecture 8: Unsupervised Learning & EM Algorithm October 31, 2006 Partially Unobserved Variables 2 Certain variables q in our models may be unobserved, either at training
CSC2515 Machine Learning Sam Roweis Lecture 8: Unsupervised Learning & EM Algorithm October 31, 2006 Partially Unobserved Variables 2 Certain variables q in our models may be unobserved, either at training
Chapter 14 Combining Models
 Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Introduction to Machine Learning HW6
 CS 189 Spring 2018 Introduction to Machine Learning HW6 Your self-grade URL is http://eecs189.org/self_grade?question_ids=1_1,1_ 2,2_1,2_2,3_1,3_2,3_3,4_1,4_2,4_3,4_4,4_5,4_6,5_1,5_2,6. This homework is
CS 189 Spring 2018 Introduction to Machine Learning HW6 Your self-grade URL is http://eecs189.org/self_grade?question_ids=1_1,1_ 2,2_1,2_2,3_1,3_2,3_3,4_1,4_2,4_3,4_4,4_5,4_6,5_1,5_2,6. This homework is
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 9 Sep. 26, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 9 Sep. 26, 2018 1 Reminders Homework 3:
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 9 Sep. 26, 2018 1 Reminders Homework 3:
EE613 Machine Learning for Engineers. Kernel methods Support Vector Machines. jean-marc odobez 2015
 EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
COMP 551 Applied Machine Learning Lecture 13: Dimension reduction and feature selection
 COMP 551 Applied Machine Learning Lecture 13: Dimension reduction and feature selection Instructor: Herke van Hoof (herke.vanhoof@cs.mcgill.ca) Based on slides by:, Jackie Chi Kit Cheung Class web page:
COMP 551 Applied Machine Learning Lecture 13: Dimension reduction and feature selection Instructor: Herke van Hoof (herke.vanhoof@cs.mcgill.ca) Based on slides by:, Jackie Chi Kit Cheung Class web page:
Introduction PCA classic Generative models Beyond and summary. PCA, ICA and beyond
 PCA, ICA and beyond Summer School on Manifold Learning in Image and Signal Analysis, August 17-21, 2009, Hven Technical University of Denmark (DTU) & University of Copenhagen (KU) August 18, 2009 Motivation
PCA, ICA and beyond Summer School on Manifold Learning in Image and Signal Analysis, August 17-21, 2009, Hven Technical University of Denmark (DTU) & University of Copenhagen (KU) August 18, 2009 Motivation
Sample questions for Fundamentals of Machine Learning 2018
 Sample questions for Fundamentals of Machine Learning 2018 Teacher: Mohammad Emtiyaz Khan A few important informations: In the final exam, no electronic devices are allowed except a calculator. Make sure
Sample questions for Fundamentals of Machine Learning 2018 Teacher: Mohammad Emtiyaz Khan A few important informations: In the final exam, no electronic devices are allowed except a calculator. Make sure
Eigenface-based facial recognition
 Eigenface-based facial recognition Dimitri PISSARENKO December 1, 2002 1 General This document is based upon Turk and Pentland (1991b), Turk and Pentland (1991a) and Smith (2002). 2 How does it work? The
Eigenface-based facial recognition Dimitri PISSARENKO December 1, 2002 1 General This document is based upon Turk and Pentland (1991b), Turk and Pentland (1991a) and Smith (2002). 2 How does it work? The