A Tour of Reinforcement Learning The View from Continuous Control. Benjamin Recht University of California, Berkeley
|
|
|
- Marlene Lindsey
- 5 years ago
- Views:
Transcription
1 A Tour of Reinforcement Learning The View from Continuous Control Benjamin Recht University of California, Berkeley


2 trustable, scalable, predictable
3 Control Theory! Reinforcement Learning is the study of how to use past data to enhance the future manipulation of a dynamical system
4 Disciplinary Biases AE/CE/EE/ME CS Control Theory Reinforcement Learning RL Control continuous discrete model action data action IEEE Transactions Science Magazine
5 Disciplinary Biases AE/CE/EE/ME CS Control Theory Reinforcement Learning Today s talk will try to unify these camps and point out how to merge their perspectives. RL Control continuous discrete model action data action IEEE Transactions Science Magazine
6 Main research challenge: What are the fundamental limits of learning systems that interact with the physical environment? How well must we understand a system in order to control it? statistical learning theory theoretical foundations robust control theory core optimization
7 <latexit sha1_base64="3llepiax9qvytt6zax6fkoslpuu=">aaacjhicbvfdsxtbfj2stbxr2qgppvgygfoilbbbhbakicq2dz4oghxistyd3e0gz2exmbussotx+nr+op4bz2mkjumfgcm592pupxgupcxf/1vzlt4sv3238r6+uvzh/wnjy/pgzour2bgzysxddbav1nghsqrvcooqxgpv44etsr99rgnlpq9plgoyql/lraogr0wn7wfu0pdgzd8f8qq1jgi/igivxo8atb/tt4ivgmakmmwaf9fglbzvzajiuznqyg038hmkszakhcjx/b6wmin4gd52hdsqog3ly Control theory is the study of dynamical systems with inputs y u x t+1 = f(x t, u t ) xt xt is called the state, and the dimension of the state is called the degree, d. ut is called the input, and the dimension is p.
8 <latexit sha1_base64="czc6ncmduginlqxul3yvjwrap1a=">aaacqhicbvfbaxnbfj6sl9z6s+2jl4nbsbsexsvos6gooa99igiasriss5otzojcmdkrg9b0f/hrfnwf4l9xno3qjb4y+pi+c5lzvtxk4tgo/zsigzdv3d7zvbn39979bw+b+4/ovckchz430rjznhmqqkmfbuo4tw6yyium8ot3tt74bs4lo7/g3ekq2fslieama5u1j2y7zcp8kswuv1+ovg7kyjkpiw59dkzpdbhmkb4wgxzo1mzf3xgzdbskk9aiq+hl+410nda8ukcrs+b9miktphvzkliexd6o8gazv2btgaaomqkfvsvtfvrpymz0ylx4gumsvv5rmex9xouhuzgc+u2tjv+ndqucvekrow2bopnvoekhkrpan4qohqooch4a406ev1i+y45xdaddm7lsbygvbvkvhrbcjggdlviiy4h0giojxw9vfrbs0s9me3oqpjp8p4a2tdx+l6yc/efpce13tpkdicnm+bfb2ctuenett69aj29x1uysx+qjazoevcyn5cppkt7h5af5sx6r39hzqbcnoq9xqvfjvxna1ilk/wj4d9ry</latexit> Reinforcement Learning Control theory is the study of dynamical systems with inputs ^ discrete y xt u p(x t+1 past) =p(x t+1 x t, u t ) Markov Decision Process (MDP) xt is the state, and it takes values in [d] ut is called the input, and takes values in [p].
9 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late <latexit sha1_base64="otgopnlc3lpbujxkzhalqk3gehs=">aaacoxicbvhbahsxejw3tzs9oe1jx0rnwqhx7izc8xiibaet5mg9oanyyzkrhdsiwmmrrsvm8u/0a/ra/kx/plrhgdrugobwzlw0z/jksudx/kcv3bp95+69vfv7dx4+evykffd03blvbq6fucze5ubqsy1dkqtwsriiza7wir961+gx39e6afq3wlsyljdvciifukcydm9m4dpij7zrs6q3vouh1/nzta+szw+extfupkpdrn2j+/eq+c5i1qdd1jhidlrpuddcl6hjkhbulmqvptvykklhcn/shvygrmckowa1lojserxwkr8mtmenxoania/yfytqkj1blhnilifmbltryp9pi0+t47swuvkewlwpmnjfyfdgi15ii4luigaqvoa/cjedc4kckxttvr0rfbub1hovptafbrgk5mqhka6pbkmbreopuin+fbtjz3i6oxs1tg3k7ns5lch9s3aufbitha6sbnu/c86p+knctz6/7py+xz9mjz1nl1ixjewno2uf2yanmwa/2e/2i/2ootgnabb9uu6nwuuaz2wjotffdanq+g==</latexit> <latexit sha1_base64="dox/ktybitgjchwuzwtodyh8jia=">aaacghicbvfdsxtbfj1s1apt/aipvgwgiykkuyk09elaqr98udqqjeu4o7ljls7obmfufspi7+hr/vn+ Optimal control h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) x xt u e Ct is the cost. If you maximize, it s called a reward. et is a noise process ft is the state-transition function t =(u 1,...,u t 1, x 0,...,x t ) is an observed trajectory t ( t ) is the policy. This is the optimization decision variable.
10 <latexit sha1_base64="mr94ezqth17vzwjopx3thjsdtck=">aaacg3icbvfbaxnred5ztdz6aaqpvhwmqousdktbfsguffshdxwnlsrlmd2zjeppztlntiqu+sw+6o/y33g2jwasbwy+vm/uu5saaqfp71zy5+69nfu7d/yepnr8zl998prbcjvx2fnoo39vqebnfntm <latexit sha1_base64="ljvoamm0zxufsbpjh2gmnfj3dfs=">aaacl3icbvfdaxnbfj2svwv9avwtvgwgiquju0wwfvccfu1dh1psbcfzl7utm2tofcwzdyvhmx/gr/fvf4r/xtk0bzn4yebwzrn3zr03l5t0fmd/gtgdjbv37m8+2hr46pgtp9s7z756wzqbxwgvdzc5eftsyjckkbwshilofv7kvx9r/ei7oi+toadpgamgkzfdkyaclw03+77uwuxv4tm3c55k1xvrktfelly/72phpbjmfl <latexit sha1_base64="oi5ov9kcoehyn9bwcwwjat8txu4=">aaac4hicbvhlihnbfk1ux2p7yujstwfqrkyyxslmufagfhqxixgnm5buqnx1taeyquqm6ryknp0brsstn+xop3fpdrjlknih4hdouy+6n6uudbjhv4lwytvr12/s3ixu3b5z915v9/5nv9zwwfcuqrtngxegpiehslrwxlngolnwll286fszl2cdlm0nnfeqal4yozgco6fgptubn7jpwvqkjhku0jsz5mjlri0yfuiztzioxgiw+t+xy2rppo02k+ikyqfa85fdto7suttu9enbvai6ddgk9mkqtse7qzrkpag1gbskozdicyvpwy1koacnktpbxcufl2dkoeeaxnos1tlsx57j6as0/hmkc/zyrso1c3odeacfdoo2ty78nzaqcxkuntjunyiry0atwlesabdjmkslatxcay6s9lnsmewwc/sxwouyqf2bwptjm6unfguog6zcgvrusqeouttdr5p3uin6krtht2qxxb+ql9vje29lide9o/hnnk+3zp4gbhp922d4fpbywd686b+/xl <latexit sha1_base64="+ojsm2yurvuosb1y5f0dyh5w9ea=">aaaco3icbvhbbtnaen2ywym3fb55wrgbioscjzbahkcvqikhpbroakxyisbritpqem3tjqsek5/b1/akh8hfse4digkjrfbonllpwmlyhia/osgvq9eu39i5uxvr9p2 Newton s Laws z t+1 = z t + v t v t+1 = v t + a t ma t = u t minimize TX 1 t=0 subject to x t+1 = 1 (xt ) 1 > apple x t + apple 0 1/m u t x t = apple zt v t
11 <latexit sha1_base64="mr94ezqth17vzwjopx3thjsdtck=">aaacg3icbvfbaxnred5ztdz6aaqpvhwmqousdktbfsguffshdxwnlsrlmd2zjeppztlntiqu+sw+6o/y33g2jwasbwy+vm/uu5saaqfp71zy5+69nfu7d/yepnr8zl998prbcjvx2fnoo39vqebnfntm <latexit sha1_base64="c3vasflhsyp2zenoal07qvhm1sk=">aaaci3icbvfdsxtbfj1sbwttq7e++ncxoaeqoyrdeaqlgvhbffdbulofzf3utm6swznzzeaujcz5nx1tf5d/xtmyqpp0wsdhnpsx9540v9jrgd7ugmcrz1+8xh219vrn2/wn+ua7ny4r <latexit sha1_base64="oi5ov9kcoehyn9bwcwwjat8txu4=">aaac4hicbvhlihnbfk1ux2p7yujstwfqrkyyxslmufagfhqxixgnm5buqnx1taeyquqm6ryknp0brsstn+xop3fpdrjlknih4hdouy+6n6uudbjhv4lwytvr12/s3ixu3b5z915v9/5nv9zwwfcuqrtngxegpiehslrwxlngolnwll286fszl2cdlm0nnfeqal4yozgco6fgptubn7jpwvqkjhku0jsz5mjlri0yfuiztzioxgiw+t+xy2rppo02k+ikyqfa85fdto7suttu9enbvai6ddgk9mkqtse7qzrkpag1gbskozdicyvpwy1koacnktpbxcufl2dkoeeaxnos1tlsx57j6as0/hmkc/zyrso1c3odeacfdoo2ty78nzaqcxkuntjunyiry0atwlesabdjmkslatxcay6s9lnsmewwc/sxwouyqf2bwptjm6unfguog6zcgvrusqeouttdr5p3uin6krtht2qxxb+ql9vje29lide9o/hnnk+3zp4gbhp922d4fpbywd686b+/xl <latexit sha1_base64="+ojsm2yurvuosb1y5f0dyh5w9ea=">aaaco3icbvhbbtnaen2ywym3fb55wrgbioscjzbahkcvqikhpbroakxyisbritpqem3tjqsek5/b1/akh8hfse4digkjrfbonllpwmlyhia/osgvq9eu39i5uxvr9p2 Newton s Laws z t+1 = z t + v t v t+1 = v t + a t ma t = u t minimize TX (x t ) 2 1 t=0 subject to x t+1 = +ru 2 t apple x t + apple 0 1/m u t x t = apple zt v t
12 <latexit sha1_base64="mr94ezqth17vzwjopx3thjsdtck=">aaacg3icbvfbaxnred5ztdz6aaqpvhwmqousdktbfsguffshdxwnlsrlmd2zjeppztlntiqu+sw+6o/y33g2jwasbwy+vm/uu5saaqfp71zy5+69nfu7d/yepnr8zl998prbcjvx2fnoo39vqebnfntm <latexit sha1_base64="c3vasflhsyp2zenoal07qvhm1sk=">aaaci3icbvfdsxtbfj1sbwttq7e++ncxoaeqoyrdeaqlgvhbffdbulofzf3utm6swznzzeaujcz5nx1tf5d/xtmyqpp0wsdhnpsx9540v9jrgd7ugmcrz1+8xh219vrn2/wn+ua7ny4r <latexit sha1_base64="oi5ov9kcoehyn9bwcwwjat8txu4=">aaac4hicbvhlihnbfk1ux2p7yujstwfqrkyyxslmufagfhqxixgnm5buqnx1taeyquqm6ryknp0brsstn+xop3fpdrjlknih4hdouy+6n6uudbjhv4lwytvr12/s3ixu3b5z915v9/5nv9zwwfcuqrtngxegpiehslrwxlngolnwll286fszl2cdlm0nnfeqal4yozgco6fgptubn7jpwvqkjhku0jsz5mjlri0yfuiztzioxgiw+t+xy2rppo02k+ikyqfa85fdto7suttu9enbvai6ddgk9mkqtse7qzrkpag1gbskozdicyvpwy1koacnktpbxcufl2dkoeeaxnos1tlsx57j6as0/hmkc/zyrso1c3odeacfdoo2ty78nzaqcxkuntjunyiry0atwlesabdjmkslatxcay6s9lnsmewwc/sxwouyqf2bwptjm6unfguog6zcgvrusqeouttdr5p3uin6krtht2qxxb+ql9vje29lide9o/hnnk+3zp4gbhp922d4fpbywd686b+/xl <latexit sha1_base64="+ojsm2yurvuosb1y5f0dyh5w9ea=">aaaco3icbvhbbtnaen2ywym3fb55wrgbioscjzbahkcvqikhpbroakxyisbritpqem3tjqsek5/b1/akh8hfse4digkjrfbonllpwmlyhia/osgvq9eu39i5uxvr9p2 minimize subject to x t+1 = TX (x +ru 2 t ) 2 1 t t=0 x t = apple x t + apple zt v t apple 0 1/m u t
13 <latexit sha1_base64="j4lebcdojzuwdwucyrzfilabtyq=">aaadhhicbvlfb9mwehbcr1eydpdii0ufggxvcsdba5xgamhdhjzot0lnfjmu01qznci+obyr/wqv/co8iv6r+g+wuydrjpoiu3zf3dl3n/nkcanr9dsil12+cvxaxvxojzubt253t+4cmblwli1okup9khpdbfdsbbweo6k0izix7dg/e+p5489mg16qiswqlkoyvbzglicdsu63jgdtrizrmiwak0ttswrezq3kikv+htx4iu4kgvme23dnilgb46tqhnq4scmgj6awmyvb3jwo8tyd08f40hu8g+vl30fve82nm0itpo1u+td3neeudcdu8ac/bov2flrzlinowtskvvnw7ux9agn4yhc3qq+1dpbtbwkykwktmqiqidhjokogde2au8hcmlvhfafnzmrgllremppa5uyb/mahe1yu2n0k8bl9t8isacxc5i7t78ascx78hzeuoxizwq6qgpii5wcvtcbqyi8pnndnkiifcwjv3n0v0xlx6wyn4sopy94voyut2hmtoc0nba0vmadnhggysmkvn8q+50lgt0qzvo/v+cu6tp7efsunhmytffds1kmlyu6qeh39f4ojp/046sehz3u7e600g+geuo+2uyxeof30ar2gealbzvasebumwq/h9/bh+pm8nqzamrtoxcjffwdk/f3k</latexit> <latexit sha1_base64="mr94ezqth17vzwjopx3thjsdtck=">aaacg3icbvfbaxnred5ztdz6aaqpvhwmqousdktbfsguffshdxwnlsrlmd2zjeppztlntiqu+sw+6o/y33g2jwasbwy+vm/uu5saaqfp71zy5+69nfu7d/yepnr8zl998prbcjvx2fnoo39vqebnfntm <latexit sha1_base64="c3vasflhsyp2zenoal07qvhm1sk=">aaaci3icbvfdsxtbfj1sbwttq7e++ncxoaeqoyrdeaqlgvhbffdbulofzf3utm6swznzzeaujcz5nx1tf5d/xtmyqpp0wsdhnpsx9540v9jrgd7ugmcrz1+8xh219vrn2/wn+ua7ny4r <latexit sha1_base64="oi5ov9kcoehyn9bwcwwjat8txu4=">aaac4hicbvhlihnbfk1ux2p7yujstwfqrkyyxslmufagfhqxixgnm5buqnx1taeyquqm6ryknp0brsstn+xop3fpdrjlknih4hdouy+6n6uudbjhv4lwytvr12/s3ixu3b5z915v9/5nv9zwwfcuqrtngxegpiehslrwxlngolnwll286fszl2cdlm0nnfeqal4yozgco6fgptubn7jpwvqkjhku0jsz5mjlri0yfuiztzioxgiw+t+xy2rppo02k+ikyqfa85fdto7suttu9enbvai6ddgk9mkqtse7qzrkpag1gbskozdicyvpwy1koacnktpbxcufl2dkoeeaxnos1tlsx57j6as0/hmkc/zyrso1c3odeacfdoo2ty78nzaqcxkuntjunyiry0atwlesabdjmkslatxcay6s9lnsmewwc/sxwouyqf2bwptjm6unfguog6zcgvrusqeouttdr5p3uin6krtht2qxxb+ql9vje29lide9o/hnnk+3zp4gbhp922d4fpbywd686b+/xl <latexit sha1_base64="+ojsm2yurvuosb1y5f0dyh5w9ea=">aaaco3icbvhbbtnaen2ywym3fb55wrgbioscjzbahkcvqikhpbroakxyisbritpqem3tjqsek5/b1/akh8hfse4digkjrfbonllpwmlyhia/osgvq9eu39i5uxvr9p2 Simplest Example: Linear Quadratic Regulator minimize s.t. E h 1 T P T t=1 x t Qx t + u t Ru t i x t+1 = Ax t + Bu t + e t quadratic cost linear dynamics minimize TX (x t ) 2 1 t=0 subject to x t+1 = x t = +ru 2 t apple x t + apple zt v t apple 0 1/m u t
14 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late Optimal control h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) x G x t u e u t = t ( t ) generic solutions with known dynamics: Batch Optimization Dynamic Programming
15 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late <latexit sha1_base64="otgopnlc3lpbujxkzhalqk3gehs=">aaacoxicbvhbahsxejw3tzs9oe1jx0rnwqhx7izc8xiibaet5mg9oanyyzkrhdsiwmmrrsvm8u/0a/ra/kx/plrhgdrugobwzlw0z/jksudx/kcv3bp95+69vfv7dx4+evykffd03blvbq6fucze5ubqsy1dkqtwsriiza7wir961+gx39e6afq3wlsyljdvciifukcydm9m4dpij7zrs6q3vouh1/nzta+szw+extfupkpdrn2j+/eq+c5i1qdd1jhidlrpuddcl6hjkhbulmqvptvykklhcn/shvygrmckowa1lojserxwkr8mtmenxoania/yfytqkj1blhnilifmbltryp9pi0+t47swuvkewlwpmnjfyfdgi15ii4luigaqvoa/cjedc4kckxttvr0rfbub1hovptafbrgk5mqhka6pbkmbreopuin+fbtjz3i6oxs1tg3k7ns5lch9s3aufbitha6sbnu/c86p+knctz6/7py+xz9mjz1nl1ixjewno2uf2yanmwa/2e/2i/2ootgnabb9uu6nwuuaz2wjotffdanq+g==</latexit> <latexit sha1_base64="dox/ktybitgjchwuzwtodyh8jia=">aaacghicbvfdsxtbfj1s1apt/aipvgwgiykkuyk09elaqr98udqqjeu4o7ljls7obmfufspi7+hr/vn+ Learning to control h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) x xt u e Ct is the cost. If you maximize, it s called a reward. et is a noise process ft is the state-transition function unknown! t =(u 1,...,u t 1, x 0,...,x t ) is an observed trajectory t ( t ) is the policy. This is the optimization decision variable. Major challenge: how to perform optimal control when the system is unknown? Today: Reinvent RL attempting to answer this question
 sensor state")
16 HVAC ROOM t ( u)+ ( u u + pi) = + g M T = Q +ṁ s c p (T s T ) sensor state action
17 Identify everything Identify a coarse model We don t need no stinking models! HVAC ROOM t ( u)+ ( u u + pi) = + g M T = Q +ṁ s c p (T s T ) sensor state action PDE control High performance aerodynamics model predictive control reinforcement learning PID control? We need robust fundamentals to distinguish these approaches
 2 parameters suffice for 95% of all control applications. How much needs to be modeled for more advanced control?")
18 But PID control works 50 Bode Diagram One decade Magnitude (db) dB Gain crossover point 0.5-6dB -20 Loglog slope = Frequency (rad/sec) 2 parameters suffice for 95% of all control applications. How much needs to be modeled for more advanced control? Can we learn to compensate for poor models, changing conditions?
19 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late <latexit sha1_base64="otgopnlc3lpbujxkzhalqk3gehs=">aaacoxicbvhbahsxejw3tzs9oe1jx0rnwqhx7izc8xiibaet5mg9oanyyzkrhdsiwmmrrsvm8u/0a/ra/kx/plrhgdrugobwzlw0z/jksudx/kcv3bp95+69vfv7dx4+evykffd03blvbq6fucze5ubqsy1dkqtwsriiza7wir961+gx39e6afq3wlsyljdvciifukcydm9m4dpij7zrs6q3vouh1/nzta+szw+extfupkpdrn2j+/eq+c5i1qdd1jhidlrpuddcl6hjkhbulmqvptvykklhcn/shvygrmckowa1lojserxwkr8mtmenxoania/yfytqkj1blhnilifmbltryp9pi0+t47swuvkewlwpmnjfyfdgi15ii4luigaqvoa/cjedc4kckxttvr0rfbub1hovptafbrgk5mqhka6pbkmbreopuin+fbtjz3i6oxs1tg3k7ns5lch9s3aufbitha6sbnu/c86p+knctz6/7py+xz9mjz1nl1ixjewno2uf2yanmwa/2e/2i/2ootgnabb9uu6nwuuaz2wjotffdanq+g==</latexit> <latexit sha1_base64="dox/ktybitgjchwuzwtodyh8jia=">aaacghicbvfdsxtbfj1s1apt/aipvgwgiykkuyk09elaqr98udqqjeu4o7ljls7obmfufspi7+hr/vn+ Learning to control h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) x xt u e Ct is the cost. If you maximize, it s called a reward. et is a noise process ft is the state-transition function unknown! t =(u 1,...,u t 1, x 0,...,x t ) is an observed trajectory t ( t ) is the policy. This is the optimization decision variable. Major challenge: how to perform optimal control when the system is unknown? Today: Reinvent RL attempting to answer this question
20 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late Learning to control h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) x xt u e Oracle: You can generate N trajectories of length T. Challenge: Build a controller with smallest error with fixed sampling budget (N x T). What is the optimal estimation/design scheme? How many samples are needed for near optimal control?
21 The Linearization Principle If a machine learning algorithm does crazy things when restricted to linear models, it s going to do crazy things on complex nonlinear models too. Would you believe someone had a good SAT solver if it couldn t solve 2-SAT? This has been a fruitful research direction: Recurrent neural networks (Hardt, Ma, R. 2016) Generalization and Margin in Neural Nets (Zhang et al 2017) Residual Networks (Hardt and Ma 2017) Bayesian Optimization (Jamieson et al 2017) Adaptive gradient methods (Wilson et al 2017)
22 <latexit sha1_base64="j4lebcdojzuwdwucyrzfilabtyq=">aaadhhicbvlfb9mwehbcr1eydpdii0ufggxvcsdba5xgamhdhjzot0lnfjmu01qznci+obyr/wqv/co8iv6r+g+wuydrjpoiu3zf3dl3n/nkcanr9dsil12+cvxaxvxojzubt253t+4cmblwli1okup9khpdbfdsbbweo6k0izix7dg/e+p5489mg16qiswqlkoyvbzglicdsu63jgdtrizrmiwak0ttswrezq3kikv+htx4iu4kgvme23dnilgb46tqhnq4scmgj6awmyvb3jwo8tyd08f40hu8g+vl30fve82nm0itpo1u+td3neeudcdu8ac/bov2flrzlinowtskvvnw7ux9agn4yhc3qq+1dpbtbwkykwktmqiqidhjokogde2au8hcmlvhfafnzmrgllremppa5uyb/mahe1yu2n0k8bl9t8isacxc5i7t78ascx78hzeuoxizwq6qgpii5wcvtcbqyi8pnndnkiifcwjv3n0v0xlx6wyn4sopy94voyut2hmtoc0nba0vmadnhggysmkvn8q+50lgt0qzvo/v+cu6tp7efsunhmytffds1kmlyu6qeh39f4ojp/046sehz3u7e600g+geuo+2uyxeof30ar2gealbzvasebumwq/h9/bh+pm8nqzamrtoxcjffwdk/f3k</latexit> <latexit sha1_base64="mr94ezqth17vzwjopx3thjsdtck=">aaacg3icbvfbaxnred5ztdz6aaqpvhwmqousdktbfsguffshdxwnlsrlmd2zjeppztlntiqu+sw+6o/y33g2jwasbwy+vm/uu5saaqfp71zy5+69nfu7d/yepnr8zl998prbcjvx2fnoo39vqebnfntm <latexit sha1_base64="c3vasflhsyp2zenoal07qvhm1sk=">aaaci3icbvfdsxtbfj1sbwttq7e++ncxoaeqoyrdeaqlgvhbffdbulofzf3utm6swznzzeaujcz5nx1tf5d/xtmyqpp0wsdhnpsx9540v9jrgd7ugmcrz1+8xh219vrn2/wn+ua7ny4r <latexit sha1_base64="oi5ov9kcoehyn9bwcwwjat8txu4=">aaac4hicbvhlihnbfk1ux2p7yujstwfqrkyyxslmufagfhqxixgnm5buqnx1taeyquqm6ryknp0brsstn+xop3fpdrjlknih4hdouy+6n6uudbjhv4lwytvr12/s3ixu3b5z915v9/5nv9zwwfcuqrtngxegpiehslrwxlngolnwll286fszl2cdlm0nnfeqal4yozgco6fgptubn7jpwvqkjhku0jsz5mjlri0yfuiztzioxgiw+t+xy2rppo02k+ikyqfa85fdto7suttu9enbvai6ddgk9mkqtse7qzrkpag1gbskozdicyvpwy1koacnktpbxcufl2dkoeeaxnos1tlsx57j6as0/hmkc/zyrso1c3odeacfdoo2ty78nzaqcxkuntjunyiry0atwlesabdjmkslatxcay6s9lnsmewwc/sxwouyqf2bwptjm6unfguog6zcgvrusqeouttdr5p3uin6krtht2qxxb+ql9vje29lide9o/hnnk+3zp4gbhp922d4fpbywd686b+/xl <latexit sha1_base64="+ojsm2yurvuosb1y5f0dyh5w9ea=">aaaco3icbvhbbtnaen2ywym3fb55wrgbioscjzbahkcvqikhpbroakxyisbritpqem3tjqsek5/b1/akh8hfse4digkjrfbonllpwmlyhia/osgvq9eu39i5uxvr9p2 Simplest Example: LQR minimize s.t. E h 1 T P T t=1 x t Qx t + u t Ru t i x t+1 = Ax t + Bu t + e t minimize TX (x t ) 2 1 t=0 subject to x t+1 = x t = +ru 2 t apple x t + apple zt v t apple 0 1/m u t
23 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late RL Methods x G x t u e h i PT minimize E e t=1 C t(x t, u t ) approximate dynamic programming s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) model-based direct policy search How to solve optimal control when the model f is unknown? Model-based: fit model from data Model-free - Approximate dynamic programming: estimate cost from data - Direct policy search: search for actions from data
24 <latexit sha1_base64="wtso4cvxqkkm5sp9ikogdmu8yxs=">aaadghicbvjnb9qwehxcv7t8behixwjftrxvnkfileoliolg0emr3bbsoksod7jr1xeie4j2ifjhupjhucgu3pg3ontuynczydl4vednz4ytqkmlqfdh82/cvhx7zszm5+69+w8edrcendm8nakgile5uui4bsu1dfgigovcam8sbefj5vhdn38by2wut3feqjtxizapfbwdfhe/swqmulfcgd6vk6xqdsusffzlustmfowablowczwmsfwujoepshhebjnffr6e9edtehrjfxbjbhnjdjnymswisdbgdndqwmyc+nly0woaxmt3odgzzjz1g0ewqjojhrzx6tdq4/zvcbcxdijf0pukbjmeaemk3viins5fmyfgobi1ozaomhj2kiucv2jpoedikk9g5flnm7brtehmtz85zezt3lilks7qf09upln2nivo2ftfrnin+d9uvgk6h1vsfywcflcxpawimnnmnhqsdqhuc5dwyar7kxvtbrhan8clwxbebyilsqpzqaxix7cckpyh4q60gbmxuqmqei+vop+4tvs4gdg162wbuv9wtita3wp3s/tomtgnjfxt/3py9miqbopw48ve4zt2nbvkcxlk+iqkr8gh+uboyjaib9pb8/a91/43/4f/0/91jfw99sxjsht+77+2e/1q</late <latexit sha1_base64="qv2lanekunbubcf2z1ek6m/o+og=">aaacnxicbvhbahsxejw3tzs9oe1jhypqcg4jzrcuksfqc+2dksmt44b3wwblss2ilyq0g2ww/0k/pq/tf/rvqnvcqo0oca7nzeuzp7bkeorj363o1u07d+/t3d9/8pdr4yftg6cx3lro4eayzdxlar6v1dggsqovrumoc4xd4updow+v0xlp9ddawmxkmgo5kqiouhm7o89rokqwpavrnznz9bqcncna03gv0ye/4qkoig934l68cr4lkjxoshwc5wetlb0buzwossjwfptelriahemhclmfvh4ticuy4ihadsx6rf6ttosvajpme+pc08rx7l8vnztel8oizjzam7+tnet/tfffk9osltpwhfrcdjpuipphzx34wdoupbybghay/jwlgtgqfk64mwxv26ly2ksev1okm8ytvtgchatsi5ugdbnv/veqxb <latexit sha1_base64="z65z1fewznivdrnx0njfmyzk9iw=">aaaczhicbvfnb9naen2yrxk+0nlksiicpakn7aqjxooqgqshqiqcnjvi15psnvaq67w1o64sbxzlx/fdohof/8a6nyikjlts2/fezozojaspdpr+95z36/adu/e27rcfphz0+elne+fc5kvmfmbymeulmrguheidfcj5rae5zgpjh+ord7u+vobaifx9wxnbowwsjaacatoq7gzdfncg16clvft0iiagkzatkv5lvqshkbpy4pffxdrt/acii8xm3v85te8bx28w414z4+5icxnqjjtdv+8vg26coafd0srzvn2kwknoyowrzbkmgqv+gzefjyjjxrxd0vac2bukfosggoybyc4nunexjpnqaa7duuix7l8zfjjj5tnyotpa1kxrnfk/bvti9dcyqhulcsvugk1lstgn9tjprgjoum4dakafeytlkwhg6ia+0mvzu+bs5sd2virb8glfyyxouimjdccmhkp/zt8ikelnuiaeictfp6orw8u99yirapzo3gbv7obzlsryh/8mod/ob34/+ps6e/y2wc0weuaekx4jybtytd6smzigjhwjp8hp8ss79dczxnvj9vpnzloyet7x35/24uw=</latexit> <latexit sha1_base64="7wws5p4/hlk3102z185pb4izzt8=">aaadjnicbvjnbxmxepuuxyv8pxdgwmuiokrvarwlkoasqajaofrqrnnwipev13e2vm3vyp6telb7f7jyr7ghxi2fgjdzeekyydlovzlnzzynhrqwwvcn51+7fupmra3bntt3791/0n1+egbz0ja+zlnmzuvklzdc8yeikpyimjyqvplz9pkw4c+vulei16cwl3isakbfrdakdkq6x0nkm6eragyd15wudyeonj9vsmihxgde4x1mfivpmlzv64tkimeusd6bebglsioyrpwnu3yyqh+wwh6zwc4xiptcteirzqmigp2zq96lajza5iqayir+dua9vfrowhxtyicnsch6bghddwjx4/ansbcxbuei8gystukptxgsbhsxgeesvfwdk9taurqweds5eexyn3bpeuhzjc34ykwakm7jarhbgj9zybhpcuoobrxa/+2oqlj2rljx2wzjrnmn+d9uvmlkvvwjxztanvtencklhhw3rugxmjybnluemipcwzgbukmzodtxbllof5yttflnsi1ypuzrqiqzgopay0frozupqimhjf5itcxhjxn/wcfb0p03ihng94/dn9g7g8xokgh9/zvj2fmgcopow4vewevwmi30bd1ffrshl+gavucnaiiy99gbeo+8i/+l/83/7v9ylvpe2/miryt/6zcbuwox</latexit> h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f(x t, u t, e t ) u t = t ( t ) Model-based RL Collect some simulation data. Should have x t+1 '(x t, u t )+ t Fit dynamics with supervised learning: ˆ' = arg min ' NX 1 t=0 x t+1 '(x t, u t ) 2 Solve approximate problem: h i PT minimize E! t=1 C t(x t, u t ) s.t. x t+1 = '(x t, u t )+! t u t = ( t )
25 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) Approximate Dynamic Programming Both the methods and analyses are complicated, but this is the core of classical RL. Sadly, if you don t already know it, this probably won t make a ton of sense until the sixth time you see it
26 <latexit sha1_base64="grssga6zww1mji/7bvhjebazq1i=">aaadp3icbvjnj9mwee3c11k+undkylgxarvvlsakufrassa47gerbxeljgthdvprbsekjyglcv+nk/+ax8ancexgjbsebrkpyvi9n8/2jknucgou+812rly9dv3g3s3ordt37t7r7t+fmstpgj+yrcbzeuqnl0lzkqiq/dznofwr5gfrxxhnn33kmrgjnsa65ygisy1iwsggfha/+hffcl3slkprqpsy6vgqsopscs2u+mqrckb8rwevrewrkus+5dhmfzorsisxv72fkomq+kuiwzyeatnezyzlcnlovqg1/4gfieukat9v3c0irruz6gb5mibxx5mhr6ph5yl0xgvwhbdeuognaju+0lyhc6tzjs/1oj182o25i7cjspt4bdkz2jgn9+3axyqsv1wdk9syueemekadccy5dii3pkxsgi75hfnnftdb2ts9io8rwza4yfdtqbr034qskmpwkkjl3t6zzdxg/7h5dvhzobq6zyfrdrlrnesccaknsbyi4wzkghpkmofnjwxfm8oa57yxs+odcrzxk7litwdjgm+hegrikikgg6jc17cqxwspytuqdtmpb/ihrdua7r8uswfmeikpsq92xdgqb7v9u8nsychzr97bp72jf+1o9qyh1iorb3nwm+viemodwlol2a49s0p7g/pf+e78ch5esh27rxlgbytz6zcj2atr</latexit> <latexit sha1_base64="ldfathodcbsxbnkyp0bbdyoxdua=">aaacl3icbvfna9taef2rtzs6aeu0p9llehnwadbskssx0tcunoccyhonavui0xpkl1mtxo6o2ajf+2tytf9k/k1wigu13ygbx3vzpxgupcxfv294t55uphu++ak5tf3y1evwzptlmxvgyf9kkjpxmvhuumofjcm8zg1cgiu8im9okv3qfxorm31bsxzdfmzajliaospq7q5toikavfbmuxnxizh3pgffpv/mt6kkhs2o1fa7fm18hqql0gylo492gufwlikiru1cgbwdwm8plmgqfarnzwfhmqdxa2mcokghrruw9tjzvueyeu8y41wtr9l/m0pirz2lsyusrrerwkx+txsulbyfpdr5qajfy6okujwyxl2gj6rbqwrmaagj3axctmcaihe/ps517rzf0ibltnbszcncyrvnyyajlvikuldblt+kuvwnamvp5hhc <latexit sha1_base64="jr0fil7h3ixdb569omcbnwfjmhe=">aaac3hicbvfdaxnbfj2sx239akqpvgwgaujd2bvbx4rifx3oq4umlwtxzxzydznkdnazusmjy775jr76r/od/b2+kjibrdcjfwyo55z7mfcmprqgff9hy7tx89btozu7e3fv3x+w3z54egekqzkmeselfzuwa1iogkjacvelbpynei6t6umjx34gbushpuk8hchnmrkp4awdfbezmgc44uxw53vctevurg979bu9iadleetdxki4sof1wpok1vvnhdqukokirucfbxu3xab2ode3h71qi2ycudzu+an/exqbbcvqias4iw9autguum1bizfmmfhglxhvtkpgeuq90boogz+ydeyokpadiarfrmr61dfjmhbapyv0wf6bubhcmhmeogczv9nugvj/2shi+jkqhcotgullrqmvfavarjeohqaocu4a41q4wsmfmm04uiosdvnulogv/asawsv4myynvuimnxokacyzum2vqndcsvqbkunpmx3/vv3zru6+ezla0z91l1a9lbm7slc5/m1w8wwq+ipg/hnn+pxqndvkmxlcuiqgl8gxeu/oyjbwck1+kl/kt/fj++j99b4trv5rlfoirix3/q+op+jg</latexit> <latexit sha1_base64="lshcpireyf9ravckbgzrynvjh1o=">aaacp3icbvfdi9nafj3gr3x96uqjl4nfagepysloi7cooa8l7qltfpoqbqbt9jljjmzckzbq/+gv8vx/gv/gsbecbb0wcdjnzp3maowwwvb3j7h1+87de0f3jx88fpt4sffk6dhwzgg5epwqzcqdkxvqosikjse1kvbmsl5nxftwv/4mjcvkf6vvlzmsco1zfecesrtncy1p0y8jxfom+fseg8njenxaudwps6cfanvcrb1pmranbsdtbi8chpvghydagh7bxmv60kniwsvcktujbdzoo7cmpafdkjrch8foyhpeabmceqihldzpnsot+uvpzpi8mv5p4hv23x8nlnauysw7227tvtas/9omjuzvkgz17uhqcvno7hsnireb4jm0upbaeqdcoo+viwuyeot3uvnlk7uwymeszuk0imom91hfszlgssupbnttvm1hvip/aw35beyl+qv6tk3c/4a5kj298eftgwozp0i0v/5dmd4bruewunrvo3+3pc0re85esd6l2gt2zj6xszzign1np9hp9isybj+dctc5sqad7z9nbccc+apcetqw</latexit> <latexit sha1_base64="68qcoiaaa5s0wbugkdbygrmb3dm=">aaacjnicbvfdsxtbfj1s1wq0nbzp4svqiesqscvslojuvnahh5q2kirludu5sybmzi4zd0vcevw1vurv8d84gym0ircuhm653zdklbtk+88l78ps8srh1bxy+sanz5uvrs83nsmmwizivgluircopmygsvj4lxqeofj4gw1oc/32hxore/2xrimgmfs07eob5kh2zxvt6fcrbuolupn1uj0h49pwp9 Dynamic Programming h i PT minimize E e t=1 C t(x t, u t )+C f (x T+1, u T+1 ) s.t. x t+1 = f t (x t, u t, e t ), x 1 = x u t = t ( t ), u 1 = u Terminal Q-function: Q T+1 (x, u) =C f (x, u) =: Q 1 (x, u) Q-function Recursive formula (recurse backwards): Q k (x, u) =C k (x, u)+mine e [Q k+1 (f k (x, u, e), u 0 )] u 0 Optimal Policy: k ( k ) = arg min Q k (x k, u) u
27 <latexit sha1_base64="djbuqd6sqjxgss29bfvvuzlzhwe=">aaadjhicbvjnb9naef2brxk+uhanlisiukeq2qgjjfsplfzw6cgfpk0up9z6m0lw3v1bu2pkypnvcowpcemcupbbwkdgigkjwfvmzcybnr0nmrqwg+cx51+6foxqty3rrrs3b e2zt3hay8fsm5jrhfqtqmecbek4za0wlek6s83d1/oqzgcts3cd5bipfplpmbgfoqlj9lupgkntjjghzqpsyakuqsytscs2u+aivfuwjxxcwjovbfumy4dcyuypl3amrs7l/pkxoeepzu3pun3sb5gvvy306r4j7zuvf/rpfrkxnoiqipovtyrfuudi5bse0q982intnoctyikcpmxvg7u7qdrzg10hyga5prbdveqnonpjcguyumbxdmmhw5orqcalu3nxcxvg5m8lqqc0u2fg5enmkpnlmme5s4z6ndmh+w1eyze1cjs6zfio7gqvj/8wgou5ej0qhsxxb84tgk1xstgm9jjowbjjkuqomg+husvmmgcbrlxopy0i7a740svnkwvb0dcusxainc6qfvezoeqryvzcsfmla0sn6o3+jtryob+2lqud77nd9mfrjwrjbslj6/ovg+eu3dlrh0cvo7l6zmg3ygdwkwyqkr8gu+ub6zec4d b/5x/7v/w/95kep7tc09smt+7z8pdp9v</latexit> <latexit sha1_base64="m6dq+f0daawnmjqnstxxnbujh2k=">aaac3hicbvfdi9nafj3gr3x92k4++jjyzfu2leqefrewv9ghfdhfu7vqxdcz3qtdtizh5o60hlz5jr76r/wb/g5ffzykfwzrhyhdoed+zl1jkyvb3//r8a5dv3hz1s7t3tt3793f6+4/odef1rzgvjcfvkyyaskujfgghmtsa8stcrfj1xgjx3wcbushpucihchnmrkp4awdfxezmgc440xwz3vcyd2fd+2avqthms7hiq1zoelkhtstnumqn84jdsghxqldzz8m6n66tb3cyggpbqew2qyjunvzr34bdbsek9ajqzin9ztroc24zuehl8yysecxgfvmo+as6t3qgigzv2iztbxulactve1gavremvoafto9hbrl/82owg7mik+cs5nfbgon+t9tyjf9evvclrzb8wwj1eqkbw3ws6dca0e5cibxldyslm+yzhzdeda6tlvl4gs/qezwcv5myyovoefnhgkacyzu86vqrzcsvmfk0jnmx39vv7ar+69fjtamt9yl1wdl7a4sbk5/g5w/hqx+kdh71jt6ttrndnlehpm+cchzcktekvmyjpx8jz/jl/lb++h99r54x5dwr7pkeujwwvv2b/ny6oo=</latexit> <latexit sha1_base64="gfwatzji+wvy/qcqupt/r+au3ja=">aaacyhicbvflb9naen6yvymvtd1ygrehpq2nbiqel0pnqakhhljk2kqje60342tv9drahdngvi78k34kj67wl1inqwgsrlrpm++bx85mlclpyfd/vrw7d+/df7dxcppr4ydpn1w3tk9tmhubxzgq1jxh3kksgrsksef5zpankckz6oj9qz99q2nlqr/snmmw4wmtyyk4owpypekmc5rbarw3woo90mkesxbswz8p2tbxgfp9s6n9i+wboz7q7qdyl73bhtworwg15jf9uce6cbagxhbwgw5vwv4ofxmcmoti1vycp6ow4iakudjb7ocwmy4u+bh7dmqeoa2l+fqzeomyecspcu8tznnbgqvprj0mkytmoe3sqlas/9n6ocxvwklqlcfu4rprncugfmpvwkgafksmdnbhppsriak3xjbb+fkxee0mxdikxvwupuhhumiquildhwmrei51ovxxusofj1xbocrxfqo6sqvc/ydhkuyri3dvvbsw7a4srk5/hzy+bgz+mzh+uztsl06zwz6zf6zoavawhbjprmo6tlaf7bf7zf54n73mu/sm16fezzgzw5bm+/4xd+lcsa==</latexit> <latexit sha1_base64="ulyffeiajau+btazsckibelnurq=">aaactxicbvfbsxtbfj6svai9goujl0ndidyadkvbuhbiwlcod+klksq1zm6etqznz5azs5kw5o/4a3xtwx/j7jrsjumbge9837nmosfkpldo+3c1b+xr4ydpv9fwnz1/8xkjvvnq1orccohxlbu5j5gfkrt0ukce88wasymjz9hv51i/uwzjhvy/czjbmlkheongdb01qlfzqyftekd3mp3lt13n7azt2qg79pvozbfx4r/0ir2x0qefvlzjltoon/ywxxldbsemnmjmuopnwngra56nojblzm0/8dmmc2zqcant9yvcqsb4frtc30hfurbhuy06pw8ce9neg/cu0or9n6ngqbwtnhkrkcorxdrk8n9ap8fky1gileuiij80snjjudnybzqwbjjkiqomg+h+svmigcbrbxeus1u7az43stholea6hgvw4hgnc6qftjlq5vtfkzcs/mdk0hmxhoef1zut5eyxmrro3524e6qdpwb3kgbx/cvg9h0r8fvbtw+ndmd2mlwytv6tjgnipmmty9ilpcljdbklv8hvb98lvdhlhkk92ixni8yzp+8bbmvxcg==</latexit> <latexit sha1_base64="5x54r8f6hf48nlpem/eosrxkbt4=">aaaclnicbvfna9taef2razu4x057cesyrsk4jripfnpls0gbkkmodrwtgk2k0xpsl1mtxo6oyaif82t6tx5l/01wjgo13ygbx3vzpxgmpcxf/1vzhm08fvj0c6v+7pmll68a26/pbzobgt2rqtrcxmbrsy09kqtwmjmisazwir76xukxv9fymeouttmmexhrozicyffr4+0gazoiuoxzlcq7s1axn+/xr7z49yf3oi4v6lgj6bf9uff1ecxaky2se23xwsewfxmcmoqca/ubn1fygiepfm7qg9xibuikxth3ueocniznu8z4e8cm+sg1zjxxoftvrgmjtdmkdphv5hzvq8j/af2cr <latexit sha1_base64="kzenm3t/sfpvg7w5nchcv8vicq4=">aaacq3icbvhbbhmxehwwwwmxpvdii0welbkidhecxpbkqykhpqsutbxjspp1jolvr3dlj9fgq/wjx8mr/ab/gzdnjziwkquz58zfm5mwslokwz+n4nr1gzdv7dxu3rl77/5ua+/bqc2detgqucrneqowldq4iekkzwudkkukz9kl97v+9h2nlbn+qvmc4wymwk6kapju0nr1lpffnvjjxviudx595s6jzruye+j2vd9pkupgiyvgaykhztjqh71waxwbrcvqzivrj3unedtohctqk1bg7takc4ormcsfwkvz5cwwic5gikmpnwro42o54ii/8cyyt3ljnya+zp/nqcczdp6lpjidmtlnrsb/pw0dtd7eldsfi9tistheku45r7ffx9kgidx3aisr/q9czmcail/tts7l2gwktumq0mkp8jfusipkmubji5sb1pvu1uepfd8bbfmrnm7osvvla7nzqu4l2wdh/nb6fyvyhytaxp82oh3ri8jedpyyfxc4os0oe8qesw6l2gt2wd6xphswwx6wn+wx+x08d06cr8homjrorhiesjul8c/whnbe</latexit> Simplest Example: LQR minimize s.t. E h PT 1 t=1 x t Qx t + u t Ru t + x T P Tx T i x t+1 = Ax t + Bu t + e t Dynamic Programming: Q T (x, u) =x P T x Q t (x, u) =C t (x, u)+mine e [Q t+1 (f t (x, u, e), u 0 )] u 0 = x Qx + u Ru +(Ax + Bu) P t+1 (Ax + Bu)+c t P t = Q + A P t+1 A A P t+1 B (R + B P t+1 B) 1 B P t+1 A u t = (B P t+1 B + R) 1 B P t+1 Ax t =: K t x t
28 <latexit sha1_base64="euyqlm8oqoqnwpvqldlbjjbjanm=">aaadnxicbvjlbxmxepyurxietehixskikhrfuwgjlpvkacehhxastfk8jbyon7fqe1f2lcry+7u48jc4cenc+qt400uicsnzm/7m5znpasgfhsj6horxrl67fmprzuvw7tt3t9s794y2lw3ja5bl3jyl1hipnb+aamnpcsopsiu/ts9e1/7tt9xykes+laqekdrvihomgofg7w8k5vohhtwglionzduiks3ntgktlpjck7ylirrq7preiokmfgt+mqidwaiiisistd3bikiewyhkhjixv65fywjlnwqhcxxex/mxnd/bj7xg+7hc3j7u+rjmqkjt1nahw7ec+9t9umih+fwtdfshe83h0cjct5onj9udqbstbw8acwn0ucph450gizoclypryjjao4qjahjfdgst3m9fwl5qdkgnforntrw3ivuuuskppdlbww780ycx6l8zjiprfyr1kfvu7lqvbv/ng5wqvuyc0eujxlplrlkpmes45g1phoem5miblbnh34rzjpp1g2d3pcuydshzyiruxmrb8glfqyxmwvapwg6kelb9vo6dkbj/pnrixs3ox68vw7v33oipapu057+qfrwr7amj19e/aqyfdeoog5887xwendrsoqfoidpdmxqbdtf7diwgiaw7qs8ybmpwa/gj/bn+ugwngybnplqr8pcfxx4jrw==</latexit> Simplest Example: LQR minimize s.t. lim T!1 E h 1 T x t+1 = Ax t + Bu t + e t P T t=1 x t Qx t + u t Ru t i When (A,B) known, optimal to build control ut = Kxt u t = (B PB + R) 1 B PAx t =: Kx t P = Q + A PA A PB (R + B PB) 1 B PA Discrete Algebraic Riccati Equation Dynamic programming has simple form because quadratics are miraculous. Solution is independent of noise variance. For finite time horizons, we could solve this with a variety of batch solvers. Note that the solution is only time invariant on the infinite time horizon.
29 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late <latexit sha1_base64="dotahzs9wvppy6qt/mbyvkeldke=">aaac2xicbvfni9nagj7gr3x96urry2crbdlsehh0oiysooc97kldxuhcmezftemnkzdzjrsehlyjv/+v/8b/4vvpttiktvwfgyfneb/mednscoo+/6pjxbt+4+atvdv7d+7eu/+ge/dwwhrwcxjzqhb6kmugpfawroesrkonle8lxkbzk0a//ataiej9xgujcc6msmscm3ru0p1eocmzz7i6r5nqxvcxqzugr+hjml/bi9pmpgn1tk4gkpbhgovcjzu9rdelj4k6n63qhjay2snbpmv0hnhs7fkjvw26c4i16jf1ncuhntiafnzmojblzkwy+cxgfdmouir6p7igssbnbaqhg4rlyokqtaomtx0zovmh3vniw/bfiorlxizz1gu2+5ttrsh/p4uws5dxjvrperrfdcqspfjqxls6ero4yqudjgvhdqv8xjtj6c6wmaxtxqlf+em1serwygjbrmqfauzia5gzozpfve+elpqdu4aenh7/vv3bru6/evobznjqzqwgo8nuimg2/bvg4tko8efb+fpe8ev1afbiy/ke9elaxpbj8p6ckthh5dv5sx6r317offa+ef9xqv5nxfoibit37q+d/eem</latexit> <latexit sha1_base64="7iiezmwg4lfdwbaccsk9moqqpus=">aaacpnicbvfdi9nafj3gr3x96uqjl4nfagepiqj6srcooa+l7kldljqh3kyn6swtszi5s7se/g5/ja/6g/w3trovboufgcm5z+5nviu0fia/o8gt23fu3ju4f/jg4apht7phty9t5yyqi1gpylxlykvclueeporvbssumzljrhjf6unrasxw+ista5mukgucoqdyvnqn4hrtoh8tulqy8bmeg8njenxaubwps6c5anvcrlxpkrbhbpb2e+ewxaffb9eg9ngmztojthjpk+fkqukoshyshtuldrhcoetqmhzw1iakyoxeqw2ltemznm3fx3pmymev8u8tx7p//migthzzzt7znmt3tzb8nzzxnhubnkhrr1klm0izpzhvvf0un6krgttsaxagfa9czmgail/orsrr3luuw5m0c6drvfo5wypakafpwkklog6naj6iuvwlamvpmj/tx9wnbex+b8yr7pgzv5ke7jn9qald9e+dy1fdkbxgf697p+82pzlgz9kl1mcre8no2sd2zkzmso/sb/vjfgx94hmwcsy31qcz+fombuxw7q9ir9ps</latexit> h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) Approximate Dynamic Programming Recursive formula: Q k (x, u) =C k (x, u)+e e applemin u 0 Q k+1 (f k (x, u, e), u 0 ) Optimal Policy: k ( k ) = arg min Q k (x k, u) u
30 <latexit sha1_base64="c96nrog7aifhrw62vbldao2qo+c=">aaadihicbvjdb9mwfhxc1ygfa+grf4ukqrntlsck8vkpmba87geiuk2qs8hxndsa7ut2dwqj8md45y/whniex4ptzrjtuvkk63pppfa9j0khhyug+o35n27eun1n527n3v0hd3e7vuenni8n4xowy9ycj9ryktsfgadjzwvdquokp0suj5r62rdurmj1z1gwpfi00yivjikd4u53kvbm6ioaq5d1jwxdisrjf5uswijxldd4dxnfyz4k1bs65ktyfkbeliquybtwf0tofjayzfqpegh4alci4acmyz8ykc0hiqsvtemynnil1/k8rpeip9fca97wswcpu8oifgjagdyahcl1rh1d3o0hw2avedsj26sp2jije15ezjkrfdfajlv2ggyfre4objpcjvpaxlb2stm+dammituowm21xs8cmsnpbtynaa/qfzsqqqxdqsqxm/3yzvod/q82lsf9fvvcfyvwza4uskujicenrxgmdgcgly6hzaj3vszm1fagzsi1w1babwdrk1sluguwz/ggkmebhjrqclduueamqt4lkfenqi0+bsy6rjrzpjx4kzib9udy/s16f4vsdak317+dnl4yhsew/piyp37twrodnqcnaibcdijg6am6qrpevj536i291/43/4f/0/91rfw9tucxwgv/z1+kywfm</latexit> <latexit sha1_base64="881ddg/md6xwd8c/m07dn8n1mzg=">aaacu3icbvfnb9naen2yj5bylckry4oinvwjyezi5yjuuqqcemgfasvfljxebjzfu2trdxylsvkp+dxcepwy1m4qjggklz7eezozm5nvulgmwx+d4nbto3d3du/t3x/w8nhj7v6ts1s6w/iilbi01xlyloxmixqo+xvlokhm8qusog30q6/cwfhqz7ioekig12iqgkcn0u77i/48lqyulq5pdfvlyjk9/usd0tghpydgsui0dgdl2ituxvg0hlid1qc9m+32wmhybt0g0qr0ycro0/1oek9k5htxycryo47ccpmadaom+xivdpzxwari+dhddyrbpg4hxtixnpnqawn800hb9t+mgps1c5v5pwkc2u2tif+njr1oxye10jvdrtlno6mtfevabi9ohoem5cidyeb4v1i2awmm/y7xurs1k87wjqnntgtwtvggk3gobjxposoqupmq/ickpj9aw3om8hn+ux3zru6/e7laozjzh9shw2z/kghz/dvg8uuwcofrxaveydvvaxbjm/kc9elejskj+ujoyygw8o18jz/jr+bnwiivgbyxbp1vzloyfoh7dske2bk=</latexit> <latexit sha1_base64="a3vylzvfult7aea2lan03t/af8q=">aaadaxicbvjnbxmxepuux234sssfiytphjqoabslkmofvklicoiheastli1wjneswlg9k3sweq32xju/wg1x5zfwn/gfennunakjwxp6783ym+nhjoxfipjt+bdu37l7b2u7dv/bw0ep6zu75zbndycet2vqlofmghqaeihqwmvmgkmhhivh9ktslz6dsslvn3cewucxsryjwrk6kq5/2+7graqytowqnhwpy+ysnrbzenqib2gzpiwawyt242tpkpmblkna6tssmmlmyt/+gezjpprtlnbxke+xdlngmt0iy3a+34qmge+wvyvrjaatlijugnajgmqzz/gon4islocknhljro2hqyadghkuxejzi3ilgentnoa+g5opsinimbasvnbmqkepcucjxba3mwqmrj2roxnwd7frwkx+t+vnoho9kitocgtnry4a5zjisqsd0eqy4cjndjbuhhsr5rnmgee3qzvbfruz4cudflncc54msmzknkfhjrsaiglddvw8f1lsj0xbelon+vp1zsu5+u6mbdr2qfsourvhdgsj18e/cc5fdskge3zfny7fllezrz6rpdikitkix+qdosm9wskf76n33nvzv/rf/r/+zyur7y1znpcv8h/9bfbf8pc=</latexit> <latexit sha1_base64="chts3dwlbfpwzdeaehmw1r7+l4k=">aaac1xicbvhljtmwfhxdaxhehviysajqtkkqeoqeg9bia4lflgyeny7urmfxb1jrbceyb1crkdvelr/ih/ghtrdgsys0bbms5anz7sm+nymksoj7pzvetes3bt7au71/5+69+w+6bw/pbv4admoey9xcjmycfbrgkfdcrwgaqutcjlk8bvtjfzbw5potlguifmu0savn6ki4+zludoecyeqs7i+g5yc+pl7dzygnm6yuo21kkltv6ricopsq4jruqsdvevjtqw3spnqig2f5oainyoyyxd2ep/lbolsgwimewcdpfncjwlnoswuauwtwtgo/wkhibgwxuo+hpywc8uuwwdrbzrtyqgqtqoltx8xomht3nnkwvvprmwxtuiuus3m33dya8n/atmt0vvqjxzqimq8gpawkmnpgvzotbjjkpqomg+hesvmcgcbrub8xpe1dan/4sbuoted5dlzyiqs0zjewudghm19v74wu9cptlp40hv9txdtg7r8vmua7pher1oodzleqynv+xxd+fbt4o+dsre/ozxo1e+qxeul6jcavyrh5qe7jmhdyg/wiv8kfb+lv3lfv2yrv66xrhpgn8l7/bvuw5yc=</latexit> <latexit sha1_base64="dishvlgdk4qnfitkbqm4rs1iya4=">aaacm3icbvhdahnbfj6sf7x+pxopwmbqeihhv4t2rihwucqxlzq2kf3c2clkc+jm7djzrhkwvifp462+ig/jbbrbjb448pf95//klujhcfy7fd26fefuvb37+w8epnr8ph3w9mkv3go5fkuq7vuotio0ckhisl5vvololbzmr08b/fkbta5l85uwlcw0faankiacnw6/tivsznv8hu/bfqlgm679kqcaacza1efl7vzq98btttypv8z3qbighba2s/fbk0snpfbaghiknbslcuvzdzzqklnct72tfyhrkoqoqanauqxelbtkrwiz4dpsbjfev+y/gtvo5xy6d5hnog5ba8j/asnp0+osrln5kkbcnjp6xankzxx4bk0upbybglayzuvibhyehrtudfnvrqty2ksee4oinmgtvtgclatssdkaptmq/ohk8s9ghb9gmao/aijbyn0pwcc5w0f4lontbiehjnvn3wuxb/pj3e/o33zo3q9fs8ees5esyxj2 P 1 minimize E e t=1 t C(x t, u t ) s.t. x t+1 = f(x t, u t, e t ) u t = ( t ) discount factor Approximate Dynamic Programming Bellman Equation: Optimal Policy: Q(x, u) =C(x, u)+ E e applemin u 0 Q(f(x, u, e), u 0 ) (x) = arg min Q(x, u) u Generate algorithms using the insight: Q(x k, u k ) C(x k, u k )+ min u 0 Q(x k+1, u 0 )+ k Q-learning: Q new (x k, u k )=(1 )Q old (x k, u k ) C(x k, u k )+ stochastic approximation min Q old (x k+1, u 0 ) u 0
31 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) Direct Policy Search
32 <latexit sha1_base64="bnc2p7snadzkkyaqpftniewfeuq=">aaact3icbvhbbtnaen2ys9tws+grlxurkjvqzcmkyltvkochd+gstlicovv6bi+6xpvdmwpq+x/4gl6bv2gdgokkjdts0tlzn6huamn3f/e8gzdv3d7z3evfuxvv/opb/sntw1rgwlqwqjdnkbcgumoukbsclwzehik4iy7etprznzawc/2zlixmc5fqtfakctricbxgkkkuhtfi2drknf29mee9qk9c1geukiui+mpzjw74m87dsyajqwped0hhxdjimpth/sr4ngg6mgsdtrb7vxkyf7lkqznuwtpz4jc0d+uipykmh1ywsievr min <latexit sha1_base64="zcjli+x7yefdo <latexit sha1_base64="xncvduignbply0pxcjg0898xebs=">aaac4nicbvhlitrafk1kfizjq0exbgobiq3sjiogimlga0vm0ai9m9ajovk5syqpvelvzta9it/gttz6v678fhdwutthd3uh4hdofds9j6mlmoj7pxx358rva9d3b+zdvhx7zt3b/r1juzwaw5rxstknctmghyipcprwwmtgzslhjdl71esn56cnqnqnnncqlsxxihocoaxiqrkqlkhg33vhodnyalirfuhdkmgrjo2blm5r7/l5x7eljwq4cyef8c5hdfket38sohrkkqfrraeweyerjqddf+wvgm6dyawgzbwten+jwrtitqkkuwtgzak/xqi1jqwx0o2fjyga8toww8xcxuowubu4s0cfwsalwaxtu0gx7l8vlsunmzejzez3nztat/5pmzwypytaoeogqfhlokyrfcvah5mmqgnhobeacs3sxykvmgycrrvruxa9a+brm7qxjrk8smgdlxibmlnsajzmqh6r9q2qkn5kytcj/si/vdu2l73xihdohh9zv9vok9kaemyefxsch4wdfxx8edi8flmyzpc8ia+jrwlylbysd2rcpost7+sn4zo7bup+dr+4x5eprroquu/wwv32c33a6oi=</latexit> min <latexit sha1_base64="54fqrxzqyz <latexit sha1_base64="cihlzcnuhll5+u92cyhc02yuj8o=">aaacuxicbvfbi9nafj7g2269dfxrl8gidefkiokcl4uu6mm+vls7c00ik8lpctzjjmycynaqp+sv8xx9nu66ewzrgqmf33fuj6kuwvl9q4f34+at23f29od3791/8hb08ojulrwrmjelks15iiwo1danjaxnlqfrjarokov3nx72hyzfun+lvqvritkns5schbwpjsmemtsnmeas2kapdrgffqjjppr8ogz5cx4wgvikat60cbxg4sxhj/bogijo+7r4npan/tr4lgh6mga9zekdqrsmpawl0csvshyr+bvfrhyhvnaow9pcjesfygdhobyf2khzr9vyz45j+bi0zjxxnftvrimka1df4ik72e221ph/0xy1ld9edeqqjtdyutgyvpxk <latexit sha1_base64="nigzqa0cicsnamj1ol8sebl/xgu=">aaaczxicbvfnb9naen2yrzz8pxdksiicjrkk7aqjsr1ufagolqictjfiy1pvjvaq67w1o66alubkv+j/cockv4f1ahbjggmlp/dm3uzmjkuubn3/e8e7dv3gzvs7u93bd+7eu9/be3biikpzmpbcfnqamanskjigqantugplewmnydmrrj89b21eot7hsoqoz6ksc8ezoirutcmeuqes05otaytl3d0nc6fig54zjrkgq+ltguymsysxb+ryloplw7/isj7rcjyjwewqrt0q1ly1int9f+svgm6doav90sy43ute4bzgvq4kuwtgzak/xmjzoeas6m5ygsgzp2mpzbxulact2dukavremxo6klr7cumk/bfcstyyzz64zgyus6k15p+0wywlg8gkvvyiil81wlssykgbfdk50mbrlh1gxav3v8ozphlht/ <latexit sha1_base64="i0aeayt9hihuk/vjtsdd2czegl8=">aaachhicbvfdaxpbfb03bwrtrzr57mtqksii7lyjlyueaqstxyeu1ijoinfhqw6znv1m7gzl8zfktf1r/tedvqtve+hc4zz7fanusuu+/7vkht14epy Sampling to Search min z2r d (z) =<latexit sha1_base64="zcjli+x7yefdo p(z) E p [ (z)] apple<latexit sha1_base64="54fqrxzqyz # E p(z;#) [ (z)] =: J(#) Search over probability distributions Use function approximations that might not capture optimal distribution Can build (incredibly high variance) stochastic gradient estimates by sampling: rj(#) =E p(z;#) [ (z)r # log p(z; #)]
33 <latexit sha1_base64="dqebqq2yo/bjn7jctcmtxxkfwfa=">aaacq3icbvhdahnbfj6svwvqt6qx3gygwgy07iqokelxb6x0iqwmlwaxchzykh06o7vmnc1nl7yjt+nt+wk+jbnpxcbxwigp7zv/jymutbqevxvery3bd+5u3mtu3x/w8ffr+/grzusjsc9ylzutbcwqqbfpkhsefayhsxqej6efav34di2vuf5o0wljdczajquactsw9xrpj87auioenxcfejqbpulsfzknq8k/ep9pna141eulf9hhcxpyagfdyg58hyql0gyl6w23g3e0ykwzosahwnpbgbquv666fapnzai0wia4hqkohnsqoy2r+yizvuoyer/nxrkmpmdvzlsqwtvnehdzz29xtzr8nzyoafw2rqquskitrhuns8up5/w1+egafksmdoaw0s3krqogblmblnwz1y5qlg1snzdainyek6yiczlgsiuugdt1vtvx <latexit sha1_base64="oo9jp+19oa2n8nsqhpl71jm7sec=">aaacynicbvfbaxnbfj6st7beun30ztaog5cwwwqlrsgqkjkhikytzjdwdvyko3r2dpk5w5osefnf+ut89fx/hlnplcbpgyfvvu/ct1iqaskifra8w7fv3l23s7t3/8hdr4/b+09obfezgunrqmkcjwbrsy1dkqtwrdqiealwndl/3+inf2islpq3mpuy5zdvciifkkpg7efupcfrmk6jczcuicgcf/b/f7r85vsesu08gmtsn3f5df6lpz+6fphox+1o0auwxrdbuaidtrlbel8vr2khqhw1cqxwjskgplh2oavqunilkoslihoy4shbdtnauf7ov+avhjpyswhcc50u2esrnetwzvleeezamd3ugvimbvtr5dcups4rqi2uck0qxangztj5kg0kujmhqbjpeuuiawoc3mrxqixzlyjwjqkvky1fkeigq+isddjsiuugdtnv/veqxb+ctrwvpxn9u13arvy/ykkk+6rv7qq7w87uiohm+rfbyuevdhrhl9ed43er0+ywz+w581ni3rbj9okn2jaj9op9yr/zh6/vgw/m1veuxmsv85stmff9l/yh4fa=</latexit> <latexit sha1_base64="nbbn4o5cmynrkblxni3vhtvu0jm=">aaac23icbvfnixnbeo2mh7uux1k9emkmwgqkzcycwiiskuhhdxhn7kjmcdwdmkyzpt1dd82yyzctn/hqv/ip+de86sgebbqzsadh9xtv1v2vkljjs0hwvendu37j5s7urb3bd+7eu9/df3bii8oihilcfeysaytkahyrjivnpuhie4wnyfnrrj+9qgnlot/svmq4h5mwqrrajpp005c8kpp4nmykv+jzsgfkfpqaehwkivewqamlmjqhwzkx/ulw77w/rfv3ymhzrv1wgp8ujt1emahwwbdbuay9to7hzl8tr9ncvdlqegqshydbsxhtekqhclkxvrzleocww7gdgnk0cb0yzmmfogbk08k444zbsf9w1jbbo88tl5kdzbatnet/thff6yu4lrqsclw4eiitfkecn+7yqtqosm0daggk+ysxgtgzye1g45vv7xlfxit1zawlkkbyyhvdkgfhwqqcpg6mqt9kpfgh0jyfn67/uv3brvbfyjkk+/tylvr3t5ldqsk2/dvg5gaqbopw/bpe0av1anbzi/ay+sxkz9kre8egbmqe+8z+sj/slxd7n7zp3pervk+zrnninsl7+htfc+ml</latexit> <latexit sha1_base64="7ypzmnmmi6uohph3ssog/g0xytm=">aaacy3icbvfdi9nafj3gr931q6upvgwwiqupysioilcooa8rvltdhsaum8ltmuxkemzulm1jh/1x/hfffduf4arbxbzegdicc+bo3hotskllqfc94127fupmrb39g9t37t673z18mlzlbqsorklkc5aarsu1jkiswrpkibsjwtpk/e2rn16gsblun2leyvxapuvmcibhtbvjvzysmnikcey+j4a59bd9hmlifeyb6aim5uiwdi4y45w/epmxczyjs5z6w3s62j92e8egwbxfbeea9ni6htpdthylpagl1cquwdsjg4rixvwuquhyikotvidoicojgxokthgzcmdjnzgm5bpsuoogwbh/3migshzejm5zaov2w2vj/2mtmmyv4kbqqibu4uqhwa04lbxnk6fsoca1dwceke6vxorgqjdlfoovve8kxcykzwwtpsht3givxzibr1qkaqrup2resax4j9cwn7sp/1fd21b238pmkn164har+ztmt5bwo/5dmd4ahmeg/pisd/x6vzo99og9zj4l2xn2zn6zirsxwb6xh+wn++v98ky38l5cwb3o+s5dtlhe19/on+ht</latexit> <latexit sha1_base64="fa1z8kn/imf/v9cyloes1fopwme=">aaacz3icbvfbi9nafj7g27reuvroy2arwpcsikcwlcxe0id96kldxwxcojmejsnojmhmzn1uipjqv/jv+ad81z/gpfvfth4y+pi+c5nznaru0plvf+94v65eu35j6+b2rdt37t7r7tw/skvlbi5foqpzkobfjtwoszlck9ig5inc4+t0vasfn6gxstafaf5ileoq5uwkieff3y97pmybsisp3zrxxfyvdsmzmjqhwaajfc5owsnrjvsxax5qsbte9d+mhoeqsplqfq+ntdok4m7ph/ql4jsgwiiew8yo3ule4bqqvy6ahajrj4ffuls7xlioblbdymij4hrsndioiucb1qstgv7ymvm+k4x7mvic/beihtzaez64zhzhu6615p+0suwzf1etdvkrane5afyptgvvhevtavcqmjsawkj3vy4ymcdi+b4yzdg7rlgysx1easmkka6xis7jgcmtug5st1vvb6vs/d1oyw9aj/+orm0r91/lvjj9cucoqwcbye4gwbr9m+do6tdwh8hhs97+y+vptthd9oj1wcces332jo3yman2jf1gp9kv79d75h32vlymep1lzqo2et7x30+55pi=</latexit> Reinforce Algorithm J(#) :=E p(z;#) [ (z)] Z r # J(#) = (z)r # p(z; #)dz Z = (z) Z r# p(z; #) p(z; #)dz p(z; #) = ( (z)r # log p(z; #)) p(z; #)dz = E p(z;#) [ (z)r # log p(z; #)]
34 <latexit sha1_base64="dqebqq2yo/bjn7jctcmtxxkfwfa=">aaacq3icbvhdahnbfj6svwvqt6qx3gygwgy07iqokelxb6x0iqwmlwaxchzykh06o7vmnc1nl7yjt+nt+wk+jbnpxcbxwigp7zv/jymutbqevxvery3bd+5u3mtu3x/w8ffr+/grzusjsc9ylzutbcwqqbfpkhsefayhsxqej6efav34di2vuf5o0wljdczajquactsw9xrpj87auioenxcfejqbpulsfzknq8k/ep9pna141eulf9hhcxpyagfdyg58hyql0gyl6w23g3e0ykwzosahwnpbgbquv666fapnzai0wia4hqkohnsqoy2r+yizvuoyer/nxrkmpmdvzlsqwtvnehdzz29xtzr8nzyoafw2rqquskitrhuns8up5/w1+egafksmdoaw0s3krqogblmblnwz1y5qlg1snzdainyek6yiczlgsiuugdt1vtvx <latexit sha1_base64="xncvduignbply0pxcjg0898xebs=">aaac4nicbvhlitrafk1kfizjq0exbgobiq3sjiogimlga0vm0ai9m9ajovk5syqpvelvzta9it/gttz6v678fhdwutthd3uh4hdofds9j6mlmoj7pxx358rva9d3b+zdvhx7zt3b/r1juzwaw5rxstknctmghyipcprwwmtgzslhjdl71esn56cnqnqnnncqlsxxihocoaxiqrkqlkhg33vhodnyalirfuhdkmgrjo2blm5r7/l5x7eljwq4cyef8c5hdfket38sohrkkqfrraeweyerjqddf+wvgm6dyawgzbwten+jwrtitqkkuwtgzak/xqi1jqwx0o2fjyga8toww8xcxuowubu4s0cfwsalwaxtu0gx7l8vlsunmzejzez3nztat/5pmzwypytaoeogqfhlokyrfcvah5mmqgnhobeacs3sxykvmgycrrvruxa9a+brm7qxjrk8smgdlxibmlnsajzmqh6r9q2qkn5kytcj/si/vdu2l73xihdohh9zv9vok9kaemyefxsch4wdfxx8edi8flmyzpc8ia+jrwlylbysd2rcpost7+sn4zo7bup+dr+4x5eprroquu/wwv32c33a6oi=</latexit> <latexit sha1_base64="jj1kekwesntnojcyyygyte4uvyc=">aaacjnicbvftaxnben6cl631ldvp4pffikqg4u7eciiwfeyhfqho2kjyhhobstjkd+/ynstnj+kv8av+hv+ne2kekziw8pa8m8/szosljs9x/lsv3bh56/bw9p2du/fup3jy3n104ovkkeyrqhfulaepmiz2mvjjwekqtk7xnj99bpttc3secvun5ywmbiawxqsaa5w1n1xmmzn0zgtzvxw7pafhu2tizntzuxp34kxitzasqucs4zjbbaxduaeqg <latexit sha1_base64="pp9kp46qo/izm8uhki7xz6n6m8w=">aaacwnicbvfti9naen7gt7v61topflksqgthsurqeohqg/pdcrxt3uetwmq7tdzunnf3clyn/vx+mvuqf8rnr0jfhfh4ej5nznzmkljjs75/3fju3b5z997efvv+g4ephnconpzzojicr6jqhbliwkksgkckseffardyrof5mvvq6oexakws9fealxjlkgo5lqliuxhn0/5j70c8owwvwvcgbpgsz9/xcjjjhu/zueoiik7xdaseqillzwn4u57yjjtdf+avg++cyaw6bbxd+kavhzncvdlqegqshqd+svhtakqhcneok4slibmkohzqq442qpdzl/glx0z4tdduaejldj2jhtzaez44zw6u2w2tif+njsuavolqqcukuiubrtnkcsp4s0q+kqyfqbkdiix0f+uiawoc3ko3uixrlyg2jqmvki1fmcetvtevgxckrcpb6maq+kqqxb+atvxuphn9u13zru4dy1ssptx199t9hbm7slc9/l1w9niq+ipg86vu0fvvafbym/ac9vjaxrmj9pen2ygj9otds9/sj3fsffo+e/bg6rvwou/zrng//wln8t5q</latexit> <latexit sha1_base64="/6wnxjvti3ogtr3oxgqus2ijbjg=">aaacshicbvfna9taef2rx2n6eac95rlebbyagikeggif0aasqw4prrodlcropby2wq3e7ijeff4x/tw9tsf+m64cl8z2bhye78282zmjcyut+f6fhvfo8zonz9aer794+er1rnpzzaxnsyowk3kvm14mfpxu2cvjcnufqchihvdx+rnwr27qwjnrbzqpmmxgrovicibhrc2jwq0yspagqtj3wzr/5p+zll/na1bfuspt9vco3bsn7kbnlt/xz8fxqtahltapi2izeq6gusgz1cquwnsp/ilcyllkoxc6pigtfibsggpfqq0z2rcattnlo44z8lfu3npez+z9igoyaydz7dizomquazx5knyvaxqyvlixjaewd41gpeku83plfcgnclitb0ay6f7krqigblnflnszercofiapbkstrt7ejvbrlrlwpexkqop6qupuksw/grb8xi4t+qc621pun8ixjlt37q6nd1es3ugc5fwvgsv9tub3gi8hrenp89osss22zdosyb/ymttjf6zlbpvbf Reinforce Algorithm J(#) :=E p(z;#) [ (z)] rj(#) =E p(z;#) [ (z)r # log p(z; #)] Sample z k p(z; # k ) Compute G(z k, # k )= (z k )r #k log p(z k ; # k ) Update # k+1 = # k k G(z k, # k )
35 <latexit sha1_base64="qqxcfhphmdwqztemz4v5odvaqpm=">aaachxicbvhfaxnben6cra1t1vqffvkahbbacfek+qqfbfvqh4qmletomlc3sybu7r27c6xxyh/iq/5p/jfupsmyxigbj++b35owmhyh4z9w8ght/fhg5pot7z2nz563d19cuqkycnuq0iw9tsghjom9jtz4xvqepnv4ld58bpsrw7socvonjyumoywmdukbe2rqbv+qmrkz10fryr <latexit sha1_base64="dqebqq2yo/bjn7jctcmtxxkfwfa=">aaacq3icbvhdahnbfj6svwvqt6qx3gygwgy07iqokelxb6x0iqwmlwaxchzykh06o7vmnc1nl7yjt+nt+wk+jbnpxcbxwigp7zv/jymutbqevxvery3bd+5u3mtu3x/w8ffr+/grzusjsc9ylzutbcwqqbfpkhsefayhsxqej6efav34di2vuf5o0wljdczajquactsw9xrpj87auioenxcfejqbpulsfzknq8k/ep9pna141eulf9hhcxpyagfdyg58hyql0gyl6w23g3e0ykwzosahwnpbgbquv666fapnzai0wia4hqkohnsqoy2r+yizvuoyer/nxrkmpmdvzlsqwtvnehdzz29xtzr8nzyoafw2rqquskitrhuns8up5/w1+egafksmdoaw0s3krqogblmblnwz1y5qlg1snzdainyek6yiczlgsiuugdt1vtvx <latexit sha1_base64="jj1kekwesntnojcyyygyte4uvyc=">aaacjnicbvftaxnben6cl631ldvp4pffikqg4u7eciiwfeyhfqho2kjyhhobstjkd+/ynstnj+kv8av+hv+ne2kekziw8pa8m8/szosljs9x/lsv3bh56/bw9p2du/fup3jy3n104ovkkeyrqhfulaepmiz2mvjjwekqtk7xnj99bpttc3secvun5ywmbiawxqsaa5w1n1xmmzn0zgtzvxw7pafhu2tizntzuxp34kxitzasqucs4zjbbaxduaeqg <latexit sha1_base64="pp9kp46qo/izm8uhki7xz6n6m8w=">aaacwnicbvfti9naen7gt7v61topflksqgthsurqeohqg/pdcrxt3uetwmq7tdzunnf3clyn/vx+mvuqf8rnr0jfhfh4ej5nznzmkljjs75/3fju3b5z997efvv+g4ephnconpzzojicr6jqhbliwkksgkckseffardyrof5mvvq6oexakws9fealxjlkgo5lqliuxhn0/5j70c8owwvwvcgbpgsz9/xcjjjhu/zueoiik7xdaseqillzwn4u57yjjtdf+avg++cyaw6bbxd+kavhzncvdlqegqshqd+svhtakqhcneok4slibmkohzqq442qpdzl/glx0z4tdduaejldj2jhtzaez44zw6u2w2tif+njsuavolqqcukuiubrtnkcsp4s0q+kqyfqbkdiix0f+uiawoc3ko3uixrlyg2jqmvki1fmcetvtevgxckrcpb6maq+kqqxb+atvxuphn9u13zru4dy1ssptx199t9hbm7slc9/l1w9niq+ipg86vu0fvvafbym/ac9vjaxrmj9pen2ygj9otds9/sj3fsffo+e/bg6rvwou/zrng//wln8t5q</latexit> <latexit sha1_base64="/6wnxjvti3ogtr3oxgqus2ijbjg=">aaacshicbvfna9taef2rx2n6eac95rlebbyagikeggif0aasqw4prrodlcropby2wq3e7ijeff4x/tw9tsf+m64cl8z2bhye78282zmjcyut+f6fhvfo8zonz9aer794+er1rnpzzaxnsyowk3kvm14mfpxu2cvjcnufqchihvdx+rnwr27qwjnrbzqpmmxgrovicibhrc2jwq0yspagqtj3wzr/5p+zll/na1bfuspt9vco3bsn7kbnlt/xz8fxqtahltapi2izeq6gusgz1cquwnsp/ilcyllkoxc6pigtfibsggpfqq0z2rcattnlo44z8lfu3npez+z9igoyaydz7dizomquazx5knyvaxqyvlixjaewd41gpeku83plfcgnclitb0ay6f7krqigblnflnszercofiapbkstrt7ejvbrlrlwpexkqop6qupuksw/grb8xi4t+qc621pun8ixjlt37q6nd1es3ugc5fwvgsv9tub3gi8hrenp89osss22zdosyb/ymttjf6zlbpvbf <latexit sha1_base64="ys3klrjikvg9dud1jmmn7l7zgpg=">aaacz3icbvhlbtnafj2yvympprbkmyjcslsibiren5uqqijff6kgbuvswdetm3jk8diaus4nvhbb/orf4afywicwtonoeq40o6nz7mpm3kru0plv/2h5167fuhlr6/b2nbv37u+0dx+c2kiyaoeiuiu5s8cikhqhjenhwwkq8kthazk9bvttczrwfvodzuqmcphqozecyffx+2n4dozsjijrbc+y8wp+j8n4mx6cktmghonudj/hwa+5+b4pixinuge05fgt6htevvla68xtjt/3f8e3qbaehbamqbzbisjxiaocnqkf1o4cv6sodj2ludjfdiuljygmpjhysblso3phwpw/ccyytwrjjia+yk9w1jbbo8stl5kdpxzda8j/aaokjvtrlxvzewpxowhsku4fbxzly2lqkjo5amji91yuujagypm+mmxru0sx8pp6otjsfgncyxvdkafhwqqcpg5+vb+vsvh3oc0/ktou/qqubsn338ipjpv0yc1x9zas3ukcdfs3wcnzfud3g+mxncnxy9vssufsmeuygl1kh+wdg7ahe+w7+8l+sd/esffj++j9vuz1wsuah2wlvg9/ajo45di=</latexit> <latexit sha1_base64="jwaab2pnwnllfm05bp8bogpjn2w=">aaac1nicbvfnixnbeo2mx+v6svk9emkmqoiazkrqkjufbt3syuwzg8imq6wnjmm2p2forlksh3gtr/4rf4m/wqte7zle2sqwndzee13v/wpckgnj93+0veuxr1y9tnn998bnw7f32vt3tmxegoedkavcdmdguumna5kkcfgyhgys8hr89qrwt8/rwjnrdzqvmmpgomuqbzcj4jyu3u8vwnmwnewchj/gywhyjk7kqbd4mpawnscqegfof0v+zxnl3mjjp77ipwyonvfc7vh9vym+dyiv6lbvhcf7rshmclfmqekoshyu+avflesphclfblhaleccwqrhdmri0ezvk8wcp3bmwtpcukojn+zfgxvk1s6zsxnmqfo7qdxk/7rrsenzqjk6kam1wa5ks8up53wwpjegbam5aycmdg/lygoupxlxr01pehco1n5szuotrz7gbqtorgycazeyklr+vfvgksxfg7b8se6m9fd1bwu5+1pojnlhr27hurdldgsjnupfbidp+ohfd9497ry+xk1mh91j91mxbewzo2rv2tebmmg+s5/sf/vtdb3p3hfv69lqtvz37rk18r79aak+59q=</latexit> Reinforce Algorithm J(#) :=E p(z;#) [ (z)] Sample z k p(z; # k ) Compute G(z k, # k )= (z k )r #k log p(z k ; # k ) Update # k+1 = # k k G(z k, # k ) Generic algorithm for solving discrete optimization: z 2 { 1, 1} d p(z; #) = dy i=1 exp(z i # i ) exp( # i )+exp(# i ) # k+1 = # k k (z k )(z k + tanh(# k )) Does this solve any discrete problem?

36 <latexit sha1_base64="o4j6otjoeqzpjitxt8gszcrluky=">aaadnxicbvjnixnbej0zv9b4ldwjl8zgsnglzerqkjwfvfsqw4qb7ei6dj2dmqtz7p6hu2zjhoz3efvvepamxv0l9iqjmsschur3xlv1vxwcswgx3//mb9eu37h5a+92487de/cfnpcfjmyagw5dnsruxmtmghqahihqwkvmgklywnl8evlx51dgrej1gs4zmcg20yirnkgdouzxgsnm6iizw5zliwxzocpof4uswijxgursjlqxnmdx8bamcojwkkykzqykehicu5urqmcjspx0rk4i7cycio+ws42yzxfcaz3r9rbxzvs49ufykios/fufqhvbg23ilo4inbmdiszdxterznaoya7whbsncnpapzlqtvq9/srirhpwtsur7tta9yd0mvjcguyumbxjsj/hxkvdwsw4/nmlgeoxbazj52qmwe6k1ahl8tqhu5kkxh2nzix+g1ewze1sxu5zdc1ucxx4p26cy/jyugid5qiarwslussykmpvzcomcjrl5zbuhhsr4xnmgee33y0qq9wz8i1oikwubu+nsivkxkbhdrsaiglddvw8e1ksj0xbmqhw+id1asu680bmbnrdgftcursjd <latexit sha1_base64="6+d+t3hyrysuqvej1zizpuxu/ba=">aaada3icbvjna9wwejxdryt92qs39ik6lxhpstih0fxsaimkhxxs2k0ca8dotbjxrjknna5zhi+99o/0vnrtd+n/6a+ovn6g7g4hbi/3nmy0mxqvghsiw9+ef+fuvfsp1ty3hj56/orpz3pr1bsvpmxac1ho8xexthdfbsbbspnsmyjhgp2nlg8b/eykacml9qwmjuskyrxpocxgqltzbf3owgayvwdxivlotumromhcgptwpo4ztainaitrhjtkppbvr/wfbpnd4mam3zid55lgnk3ke3gh3zbsrbpqu9ty9q2zdrphp5wfxgxrhhtrpe7sts+jxwwtjfnabtfmgiuljnav5vsweioudcsjvsq5gzqoigqmsbpb1fi1y8y4k7q7cvcmvx3demnmvi6cuxkymgwtif+ndsvi9hllvvkbu7qtlfucq4gbleax14ycmdpaqoburzhoibsquf0tvjnllhld6mrev4rtysywwahxoikjdqnjugq6skdccpyzkiopet6bf6pl28jbb55zmnvh7koo3orzlsrahv8qon3tr2e/+vs2e/b+vpo19ak9ragk0dt0gd6iezrafp3xnntd75x/1f/u//b/tlbfm995hhbc//uxpln0yg==</latexit> <latexit sha1_base64="eh+lm1eg20caiqwbiclxhabyf/4=">aaacxnicbvhlattafb2rrzr9oe2ym6gmiimxuii0m5racskii4tgscbsxdx4wh4ygomzq9rggppx/zyuum1/oynhhdruhweo59z3tusllqxbj4537/6dh492hu8+efrs+yvu3stlw1rg4eguqjdxkvhuuuoijcm8lg1cniq8sm+ogv3qfo2vhb6grylxdpmwuymahjv0z4/9qmgxg0f0c4zmsndnbzxsocu/slwe1hqqlr9c8cn/ntcgsqjpiyozwfnrsbu45yljzzunn3r7wtbygd8gyqt6rlwzzk8tr5ncvdlqegqshydbsxht2pfc4xi3qiywig4gw7gdgnk0cb2afcnfombcp4vxtxnfsf9g1jbbu8ht55kdzeym1pd/08yvtt/etdrlrajfxafpptgvvfkkn0idgttcarbgul65miebqw7da1vwuusua5pu80pluuxwg1u0jwooteg5sn1mvr9lpfhn0jafnpv/q7q0jex/kpkkozh1n9x9lwd3khbz/dvgcn8ybspw/f3v8gn7mh32mr1hpgvze3bittgzgzhbvrof7bf77z142qu8r3euxqenecxwzpv2b2p33yw=</latexit> (μ,λ)-evolution Bandit <latexit sha1_base64="kdgzh6hio9nc9jpwvim6pvpovhi=">aaacnhicbvftaxnben5cfwnrs9p6uzdficzqwp0i9ktliqufk1rs0kjyhnobsbj0b+/yns0jr36cv8av9of4b9xli5jegywh55mzz2cmlzs0fia/a8hwg4ephm/v7d55+uz5xn3/ogdzzwr2ra5yc52crsu1dkmswuvcigspwqv0plppv7dormz1jc0kjdmyazmsashtsf1tpzm4bumtjgjxyz6wlktkoo7m3y95pzln6nal1ojjvrg2w0xwtratqymt4ylzr8wdys5chpqeamv7uvhqxhovkrtodwfoyghibsby91bdhjyufxpn+rvpdpkon/5p4gv234osmmtnweozm <latexit sha1_base64="hbpv3rsxivbvxbvtlqyeh9u0gig=">aaack3icbvftaxnben5c1db6llb8jmhiefio4u4klqhstkbclyqmlesomlezxjbuy7e7jw1hvvlr/kp/xn/jxhrbja4mpdzpve9ekukpjn+3oo1bt+9sbt3dvnf/wcnh7z3dc28rj7avrllumgepshrskysfl6vd0lnci/zqbanffepnptvfavpipqewciwfu Random Search h PT i minimize E et,! t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = ( t ; # +!) Direct Policy Search! TX G(!, #) = C(x t, u t ) r log p(!) t=1 parameter perturbation G (m) (!, #) = 1 m mx i=1 C(# +! i ) C(#! i ) 2! i TX C(#) = C(x t, u t ) t=1! i N (0, I) random finite difference approximation to the gradient aka Strategies SPSA Convex Opt
37 <latexit sha1_base64="j4lebcdojzuwdwucyrzfilabtyq=">aaadhhicbvlfb9mwehbcr1eydpdii0ufggxvcsdba5xgamhdhjzot0lnfjmu01qznci+obyr/wqv/co8iv6r+g+wuydrjpoiu3zf3dl3n/nkcanr9dsil12+cvxaxvxojzubt253t+4cmblwli1okup9khpdbfdsbbweo6k0izix7dg/e+p5489mg16qiswqlkoyvbzglicdsu63jgdtrizrmiwak0ttswrezq3kikv+htx4iu4kgvme23dnilgb46tqhnq4scmgj6awmyvb3jwo8tyd08f40hu8g+vl30fve82nm0itpo1u+td3neeudcdu8ac/bov2flrzlinowtskvvnw7ux9agn4yhc3qq+1dpbtbwkykwktmqiqidhjokogde2au8hcmlvhfafnzmrgllremppa5uyb/mahe1yu2n0k8bl9t8isacxc5i7t78ascx78hzeuoxizwq6qgpii5wcvtcbqyi8pnndnkiifcwjv3n0v0xlx6wyn4sopy94voyut2hmtoc0nba0vmadnhggysmkvn8q+50lgt0qzvo/v+cu6tp7efsunhmytffds1kmlyu6qeh39f4ojp/046sehz3u7e600g+geuo+2uyxeof30ar2gealbzvasebumwq/h9/bh+pm8nqzamrtoxcjffwdk/f3k</latexit> <latexit sha1_base64="gbej/5jhfqpxmesx5rjmy6uj8yg=">aaacnhicbvhtahnbfj2sx7v+pfptkmegpqbhv4t2z9gcyipungkhu4s7k7vj0nmzzeaoniztg/g0/tuh8w2ctsoyxasdh3pux9x78kpjr3h8uxvdu37j5q2t29t37t67/6c983dojlccb8ioy09zckikxgfjunhawyqyv3isn71t9jovaj00+gvnk8xkmgpzsaeuqhh7ez+ncgsca8033ucveqqqmsgylj90uwk/e8lt7fm43yl78sl4jkiwomowctzeawxpxahfoiahwllreleu1wbjcoux26l3wie4gymoatrqosvqxuyx/flgjrwwnjxnfmh+w1fd6dy8zenmctrz61pd/k8besr2s1rqyhnqctwo8iqt4c15+erafktmaycw <latexit sha1_base64="b7badqzs7+mpsxwxgaronsg5mmk=">aaacmhicbvhtahnbfj2sx7v+tfpp/wwgiyusdougp4mktvckfqqtzndyd3kzuxrmdpm5kw1lhscn8a8+im/jbbrbjf4yojxz5n7mlsbpcfy7e924eev2na272/fup3j4agf38akva6dwqepduvmcpgqyogrijeevqzc5xrp88m2rn31d56m0x3hwywagsdqhbryoi51uamuzejiyncbtbbr5mo/f+y1xgph6ii/2givux4uqmybzgq5yxsnfbidlx6wqdvpwgrwfjxhfwqooswmcb6e1xwr <latexit sha1_base64="kwygz+w7cnkjjvpxrgavefkydqs=">aaachnicbvfdaxnbfj1sty1ra2iffrkmqoisdkvpxwqhfrtsq0stfpil3j3cjenmz5ezozvh6u/xvx+t/8bznijjvdbw5pz7fzncsuth+lsshdx4ehhufvr7/otp8bn64/nazs4i7itmzeymaytkauytjiu3uufie4xxyeky1k9v0viz6w+0yjfoyablvaogt43rdtcmfs5bn1+ptgsv/wdcb4adcg18h0qb0gqb640blxg0yyrluznqyo0wcnokczakhck72shzzeesyizddzwkaoni3fsdf+wzc Random Search for LQR minimize s.t. E h 1 T P T t=1 x t Qx t + u t Ru t i x t+1 = Ax t + Bu t + e t Greedy strategy : Build control ut = Kxt Sample a random perturbation: N (0, 2 I) Collect samples from control u t =(K + )x t : = {x 1,...,x T } Compute cost: J( )= T t=1 x t Qx t + u t Ru t Update: K K t J( )
38 <latexit sha1_base64="ry/q9u1/eodhnqdeowrn6r+2wk4=">aaadkxicbvlbbtnaelxnryrlu3idlxurvskiyeziikgisavxur+kanpkwwotn5nk1d21ttuueoy/ifd+hdfglr9hnqrbukaynhvombm7m05zksyg4q8/uht5ytvrw9cbn27eur3d3llzblpccbjwtgbmnguwpnawqiestnmdtkusttkz/zo/oqdjraapcj5drnhei7hgdb2unl/sfczcl8wynq9kkasgvwk2k5xqqolpujfdqhxdazqwr6qkhas7ryivltdgibwfskrci6qpr2q/wfzssxeoezmpxpsu7gwpe7xvzkkfrrxzi+o/6i7ufbsxs9ybwqfi3i4+o/i5pwcgp4cs06cgr6tnjs1w2asxqs4m0sppeas4thb8mi4yxijqycwzdhifocbodgwx4houlosmn7ejdf2qmqibl4vxvushq0zknbn3asql9n+kkilr5yp1ynpqdporwf9xwwlhz+js6lxa0hx50biqbdns74qmhagocu4sxo1wbyv8ygzj6da6dsvcowe+1kk5k7tg2qg2uikznmybflaxoeuuytdcsvkbauso6s39yz1ttbdfiola2z1wv43uxbc7husb47+yh <latexit sha1_base64="upao0ytgznfi8wjp4jzh6wbyake=">aaadbnicbvjda9rafj3er1q/tvoowucizmfdeilukeqhqn3oq8xdtrbjw81kdnfozbjmbsoucd999y/4jr76n/wlvjrzruvueifwoofmutp3jimkmoj7px332vubn29t3n68c/fe/qetryfhji814wowy1yfjmc4fiopukdkp4xmkcwsnytn+7v+csg1ebnq46zguqzjjuacavoqbn058ekeshtegmyjr+jqxrpkpkivnguwv7gbzm/6dn+bxtgty+zquivxbdshs3ncsfrzs6r/mpjtueeiif6ban35mbzxhgejptnin1enm9y41fz7/qloogga0cznhcvbthsmosszrpbjmgyy+avglc0vtpl5zlgaxga7hzefwqgg4yaqfrob02ewseko1/ztsbfsvycqyiyzzyl1zoats6rv5p+0yymj11elvfeiv+yy0aiufhnal4kmqnogcmybmc3sxsmbgaagdl1lxrbzbwdll6mmprist/kkk3gkgixpogygvp2q6kbist+cmvswnvef1cbwsvdojawa7qh9j1rnzwwxeqyofx0cv+offi/4sn3ee9uszom8jk+jrwkyq/bie3jebosrx84t57nzwv3sfnw/ud8vra7tnhlelsr98rszcvet</latexit> Policy Gradient h PT i minimize E et,u t t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t p(u x t ; #) Direct Policy Search probabilistic policy G(, #) = TX C(x t, u t )! XT 1 r # log p # (u t x t ; #)! t=1 t=0

39 <latexit sha1_base64="j4lebcdojzuwdwucyrzfilabtyq=">aaadhhicbvlfb9mwehbcr1eydpdii0ufggxvcsdba5xgamhdhjzot0lnfjmu01qznci+obyr/wqv/co8iv6r+g+wuydrjpoiu3zf3dl3n/nkcanr9dsil12+cvxaxvxojzubt253t+4cmblwli1okup9khpdbfdsbbweo6k0izix7dg/e+p5489mg16qiswqlkoyvbzglicdsu63jgdtrizrmiwak0ttswrezq3kikv+htx4iu4kgvme23dnilgb46tqhnq4scmgj6awmyvb3jwo8tyd08f40hu8g+vl30fve82nm0itpo1u+td3neeudcdu8ac/bov2flrzlinowtskvvnw7ux9agn4yhc3qq+1dpbtbwkykwktmqiqidhjokogde2au8hcmlvhfafnzmrgllremppa5uyb/mahe1yu2n0k8bl9t8isacxc5i7t78ascx78hzeuoxizwq6qgpii5wcvtcbqyi8pnndnkiifcwjv3n0v0xlx6wyn4sopy94voyut2hmtoc0nba0vmadnhggysmkvn8q+50lgt0qzvo/v+cu6tp7efsunhmytffds1kmlyu6qeh39f4ojp/046sehz3u7e600g+geuo+2uyxeof30ar2gealbzvasebumwq/h9/bh+pm8nqzamrtoxcjffwdk/f3k</latexit> <latexit sha1_base64="aqbp24lviyjw82kpzzckyu6idtc=">aaacpxicbvhbbhmxehwwwwmxpuwrf4sikqkkdhesfaluusr4kfilsvop2a5mnuli1etd2wouajxf4gt4hx/gb/bug0qsrrj8fm5cpdnpoaslmpzdcg7dvnp33s795oohjx7vtvb2bzz3rmbf5co3lylyvfjjnyqpvcwmqpyqveivtyr94hsak3pdo0wbcqztlsdsahkqayunnrgbozjii+uypksjahnv4/oerl7y8+rmr7irx1+qu5m02me3ri1vg2gf2mxlz8leix6nc+ey1cquwdumwoliegxjoxdzhdmlbyhrmolqqw0z2risw1vy554z80lu/nhea/bfibiyaxdz6j0zojnd1cryf9rq0eqwlquuhkewn4umtnhketunppygbamfbycm9h/lygygbplprlwpcxco1jop505lky9xg1u0jwoetegzsf11vx6usvgvoc0/ldmz/vv92krufjbtsfb1qv+zpthy9gujnse/dqzvulhyjc7fto/fr1azw56yz6zdivaohbnp7iz1mwdf2q/2k/0kxgsfg14wuhengquyj2znguqpro <latexit sha1_base64="np4otb/lzbrm8sy8kda7c6pm1ec=">aaaczxicbvfdaxnbfj2sx7v+pfroy2aqurfhvwr9eyovfcxyswkd2xs5ozubdj2zxwbu2ir18+q/8n/47qv+bmfticbxwsdhnpsx99y0lmjigh5vbveuxrt+y+vm9q3bd+7ea+/cp7gfm4z3wselm0jbcik076nayqel4absyu/t84ngp/3mjrwfpszzyuckxlrkggf6kmkp3iexapwyvwl+udny8hzbmokc/lukmdv0j8ygywkkod/oxghudx5bp5ikx4x1wxw8f/lq7rkk0wtpnittttglf0e3qbqehbkmo2snnyqzgjnfntij1g6jsmrrbqyfk7zejp3ljbbzgpohhxout6nqyufnh3smo3lh/nnif+y/fruoa2cq9znnunzda8j/auoh+ctrjxtpkgt2osh3kmjbgz9pjgxnkgceadpc/5wycrhg6f1fmbloxxk2skk1dvqwiunrrmqpgvck5aha6gar6q2qkn4cbemhge/wj+rbnnl3jrglte8p/wn17kayp0i0bv8mohnwi8je9pf5z//18jrb5cf5rlokii/ipnlhjkifmpkn/ca/ya/gq+ccl8h8mjvolwsekjuivv4gvjrkjq==</latexit> Policy Gradient for LQR minimize s.t. E h 1 T P T t=1 x t Qx t + u t Ru t i x t+1 = Ax t + Bu t + e t Greedy strategy : Build control ut = Kxt Sample a bunch of random vectors: t N (0, 2 I) Collect samples from control u t = Kx t + t : = {x 1,...,x T } Compute cost: C( ) = TX t=1 Update: K new K old t C( ) x t Qx t + u t Ru t T 1 X t=0 t x t policy gradient only has access to 0-th order information!!!
40 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late <latexit sha1_base64="ry/q9u1/eodhnqdeowrn6r+2wk4=">aaadkxicbvlbbtnaelxnryrlu3idlxurvskiyeziikgisavxur+kanpkwwotn5nk1d21ttuueoy/ifd+hdfglr9hnqrbukaynhvombm7m05zksyg4q8/uht5ytvrw9cbn27eur3d3llzblpccbjwtgbmnguwpnawqiestnmdtkusttkz/zo/oqdjraapcj5drnhei7hgdb2unl/sfczcl8wynq9kkasgvwk2k5xqqolpujfdqhxdazqwr6qkhas7ryivltdgibwfskrci6qpr2q/wfzssxeoezmpxpsu7gwpe7xvzkkfrrxzi+o/6i7ufbsxs9ybwqfi3i4+o/i5pwcgp4cs06cgr6tnjs1w2asxqs4m0sppeas4thb8mi4yxijqycwzdhifocbodgwx4houlosmn7ejdf2qmqibl4vxvushq0zknbn3asql9n+kkilr5yp1ynpqdporwf9xwwlhz+js6lxa0hx50biqbdns74qmhagocu4sxo1wbyv8ygzj6da6dsvcowe+1kk5k7tg2qg2uikznmybflaxoeuuytdcsvkbauso6s39yz1ttbdfiola2z1wv43uxbc7husb47+yh <latexit sha1_base64="o4j6otjoeqzpjitxt8gszcrluky=">aaadnxicbvjnixnbej0zv9b4ldwjl8zgsnglzerqkjwfvfsqw4qb7ei6dj2dmqtz7p6hu2zjhoz3efvvepamxv0l9iqjmsschur3xlv1vxwcswgx3//mb9eu37h5a+92487de/cfnpcfjmyagw5dnsruxmtmghqahihqwkvmgklywnl8evlx51dgrej1gs4zmcg20yirnkgdouzxgsnm6iizw5zliwxzocpof4uswijxgursjlqxnmdx8bamcojwkkykzqykehicu5urqmcjspx0rk4i7cycio+ws42yzxfcaz3r9rbxzvs49ufykios/fufqhvbg23ilo4inbmdiszdxterznaoya7whbsncnpapzlqtvq9/srirhpwtsur7tta9yd0mvjcguyumbxjsj/hxkvdwsw4/nmlgeoxbazj52qmwe6k1ahl8tqhu5kkxh2nzix+g1ewze1sxu5zdc1ucxx4p26cy/jyugid5qiarwslussykmpvzcomcjrl5zbuhhsr4xnmgee33y0qq9wz8i1oikwubu+nsivkxkbhdrsaiglddvw8e1ksj0xbmqhw+id1asu680bmbnrdgftcursjd h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) Direct Policy Search Policy Gradient h PT i minimize E et,u t t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t p(u x t ; #) probabilistic policy Random Search h PT i minimize E et,! t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = ( t ; # +!) parameter perturbation Reinforce applied to either problems does not depend on the dynamics. Both are Derivative-free algorithms!
41 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) Direct Policy Search Reinforce is NOT Magic What is the variance? What is the approximation error? Necessarily becomes derivative free as you are accessing the decision variable by sampling But it s certainly super easy!
42 <latexit sha1_base64="xgt0wleocfvmzdjzatvxno5/1pw=">aaadgxicbvjnbxmxepuuxyv8pxdkyhfrpakkdhesh1kliolg0emrtvspdiuvm0ms2t6vpys2lptlupjhucgunpg3enmfkzsrld29mxn2zhoak+kwin4f4axlv65e27jeuxhz1u073c27xy4rrichyfrmt1puqekdq5so4ds3whwq4cq922/yjx/bopmzi1zkmnz8zuruco6esrpfwqozaspulv/ulvj1h+k0kystjdtye9r0izlncz6m1es6aazgiipmcp1uubvxh47ofol9msgdisftzuvsjmpgwhk3weejufrqr3fnmzoa5v3y898g1tmihtbdynlplrjyhu8wmjp2wum3fw2izdclig5bj7rxmgwgyzbjrkhbofdcuvec5tj2ciifaj9j4sdn4ozpyosh4rrcufqus6ypptoh08z6y5au2x87kq6dw+juvzalceu5hvxfbltg9nm4kiyveiw4v2hakiozbbyhe2lbofp4wiwv/q1uzlnlar2dk7cstxmqk5nuzwgkycawxios0xjpokdnpwmmqt5ipeh7bhw9abz7k/wytbr/ss4kup0d/03m9ovib0i8vv6l4pjxii4g8bsnvb2xrtub5d55qpokjk/jhnlldsmqikatrmhz4ex4jfwwfg9/njegqdtzj6xe+pm3tg/+xa==</ <latexit sha1_base64="oz1hbsp9au1b8qrukgdgw/xawfs=">aaacinicbvfdaxnbfj2s1dzanbx45mtgecpi2a1cfueklehdh1rativkdxdn7yzdz2fxmbvsm <latexit sha1_base64="xgw0l/wqqx1xejhnsnmmrksowam=">aaacihicbvfdsxtbfj1sbwvtd2n97mtgecyuscuc9aviw7applhqv <latexit sha1_base64="xgw0l/wqqx1xejhnsnmmrksowam=">aaacihicbvfdsxtbfj1sbwvtd2n97mtgecyuscuc9aviw7applhqv <latexit sha1_base64="wqytepk1/a+rkav2lywtchwfcjc=">aaacfhicbvfdaxnbfj1sq631o6199gvofcpq2c2ippwcgn3oq0tnw0mwcnf2jrl0znazussjs39fx/wh <latexit sha1_base64="k+y4g+nrrzbrspgm+r2af5elkk0=">aaacfhicbvfbaxnbfj6swtn66cvhxwajufhdrps2t1jq0ic+vdrtjvnk2cljcsjm7djztiqs/rw+2h Sample Complexity? Discrete MDPs: h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 p(x x t, u t ) u t = t ( t ) ADP policy search model-based x 2 [d] u 2 [p] Algorithm Class Samples per iteration Parameters Model-based 1 d 2 p ADP 1 dp Policy search 1 dp optimal error after T rsteps d2 p T r dp T r dp T
43 <latexit sha1_base64="vs+14vgxeycwqa4/abiirwhhyzg=">aaadgnicbvjnb9naelxnv0n5sohizuvelyooshescfspoia49fbe01bkgmu9gser7q6t3tfkspxpupjhucguxpg3rfmjsmjilmbfe/n2z8zpiyxfmpzlb1euxrt+y+tmz/vw7tt3uzv3tm1egg4jnsvcnkfmghqarihqwnlhgkluwll6cdjwz5/awjhre1wuecs21sitnkgdku5xmsju6iozwxz1jwxdosrn55uswijxgwqys6hioevt6k2dajwq4zjauiuv7kf1xxnymgb/nucgthcpgjgdyuxpa2ohogws5k79okrjpsn+qgfqvndolnehr9fcojiia5w6fpskfvfs7yxdcblkm4napoe1czzs+dgd5lxuojflzu04cgumnr0klse1wvoogl9guxi7vdmfnq6w86zji4dmsjyb92kks/tfioopaxcqdcpmmnada8d/cemss+dxjxrrimh+evfwsoi5azzdjsiar7lwcengulcspmogcxqrxlll6v0ax+mkmpda8hwca6jeorrmqauomnbnv9vbisx5wlqlr83k/rdotqh7r8vuob0cuf9e722i3uki9ffvjqdphle4jn4/7r28alez5t3whnp9l/keeqfeo+/yg3nc3/yj/4x/mvgsfau+bz8upyhf1tz3vil4+rs0rp43</late <latexit sha1_base64="dd33rdohkxoghfa+mo9lmerjhho=">aaacgxicbvfbsxtbfj5stf6q9djhxwzdqame3vcoiihgox3wqdgokgzl7oxjmjg7s8yclyql/8px9l/133q2rjcjbw58fn+5nyrx0ley/qsf9axl <latexit sha1_base64="rp6zjsqfsh/b4zgbuz7ghax5ltw=">aaacixicbvfdsxtbfj1sp7taj1j71pehowbpcbtfuhwogox2wqelrovkcxdn7yads7przf0xhfa/+fr/kf+mszgcsbwwcdjnzv04nymvtbsgd63g2fmxl <latexit sha1_base64="b/6/jmsjrm4zmn67mhrkvmnr4yu=">aaacixicbvfdsxtbfj1sp7taj1j71pehowbpcbtfuhwogox2wqelrovkcx <latexit sha1_base64="xgw0l/wqqx1xejhnsnmmrksowam=">aaacihicbvfdsxtbfj1sbwvtd2n97mtgecyuscuc9aviw7applhqv <latexit sha1_base64="o7jy9jxqyyiasiikr1l5poerhw4=">aaach3icbvfdsxtbfj1sbav2w2gffrkachzkuivs+lqsfeydd9y2kitbchf2jrk4o7vm3c0js/5kx/uv+w86gyo <latexit sha1_base64="k+4wrtuzpjphifhocrwizawdit0=">aaach3icbvfdsxtbfj2s2vrvgvwxl0odofdsxzhqk1haab98snaokgzd3clncnf2dpm5kwll/oqv7v/qv+l Sample Complexity? Continuous Control: h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f t (x t, u t, e t ) u t = t ( t ) ADP policy search model-based x 2 R d u 2 R p Algorithm Samples per iteration LQR parameters Model-based d d 2 +dp ADP 1 d + p 2 optimal error after T rsteps d + p C T C d + p p T Policy search 1 dp C r dp T

44 Deep Reinforcement Learning Simply parameterize Q-function or policy as a deep net Note, ADP is tricky to analyze with function approximation Policy search is considerably more straightforward: make the log-prob a deep net.

45 <latexit sha1_base64="mr94ezqth17vzwjopx3thjsdtck=">aaacg3icbvfbaxnred5ztdz6aaqpvhwmqousdktbfsguffshdxwnlsrlmd2zjeppztlntiqu+sw+6o/y33g2jwasbwy+vm/uu5saaqfp71zy5+69nfu7d/yepnr8zl998prbcjvx2fnoo39vqebnfntm <latexit sha1_base64="c3vasflhsyp2zenoal07qvhm1sk=">aaaci3icbvfdsxtbfj1sbwttq7e++ncxoaeqoyrdeaqlgvhbffdbulofzf3utm6swznzzeaujcz5nx1tf5d/xtmyqpp0wsdhnpsx9540v9jrgd7ugmcrz1+8xh219vrn2/wn+ua7ny4r <latexit sha1_base64="oi5ov9kcoehyn9bwcwwjat8txu4=">aaac4hicbvhlihnbfk1ux2p7yujstwfqrkyyxslmufagfhqxixgnm5buqnx1taeyquqm6ryknp0brsstn+xop3fpdrjlknih4hdouy+6n6uudbjhv4lwytvr12/s3ixu3b5z915v9/5nv9zwwfcuqrtngxegpiehslrwxlngolnwll286fszl2cdlm0nnfeqal4yozgco6fgptubn7jpwvqkjhku0jsz5mjlri0yfuiztzioxgiw+t+xy2rppo02k+ikyqfa85fdto7suttu9enbvai6ddgk9mkqtse7qzrkpag1gbskozdicyvpwy1koacnktpbxcufl2dkoeeaxnos1tlsx57j6as0/hmkc/zyrso1c3odeacfdoo2ty78nzaqcxkuntjunyiry0atwlesabdjmkslatxcay6s9lnsmewwc/sxwouyqf2bwptjm6unfguog6zcgvrusqeouttdr5p3uin6krtht2qxxb+ql9vje29lide9o/hnnk+3zp4gbhp922d4fpbywd686b+/xl <latexit sha1_base64="+ojsm2yurvuosb1y5f0dyh5w9ea=">aaaco3icbvhbbtnaen2ywym3fb55wrgbioscjzbahkcvqikhpbroakxyisbritpqem3tjqsek5/b1/akh8hfse4digkjrfbonllpwmlyhia/osgvq9eu39i5uxvr9p2 Simplest Example: LQR minimize TX (x t ) 2 1 t=0 subject to x t+1 = x t = +ru 2 t apple x t + apple zt v t apple 0 1/m u t samples Model-based and ADP with 10 samples
46 Extraordinary Claims Require Extraordinary Evidence* * only if your prior is correct blog.openai.com/openai-baselines-dqn/ Reinforcement learning results are tricky to reproduce: performance is very noisy, algorithms have many moving parts which allow for subtle bugs, and many papers don t report all the required tricks. RL algorithms are challenging to implement correctly; good results typically only come after fixing many seemingly-trivial bugs. Average Return Average Return arxiv: HalfCheetah-v1 (TRPO, Different Random Seeds) Random Average (5 runs) Random Average (5 runs) Timesteps 10 6 HalfCheetah-v1 (TRPO, Codebase Comparison) 500 There has to be a better way! Schulman 2015 Schulman 2017 Duan Timesteps 10 6

47 <latexit sha1_base64="mr94ezqth17vzwjopx3thjsdtck=">aaacg3icbvfbaxnred5ztdz6aaqpvhwmqousdktbfsguffshdxwnlsrlmd2zjeppztlntiqu+sw+6o/y33g2jwasbwy+vm/uu5saaqfp71zy5+69nfu7d/yepnr8zl998prbcjvx2fnoo39vqebnfntm <latexit sha1_base64="c3vasflhsyp2zenoal07qvhm1sk=">aaaci3icbvfdsxtbfj1sbwttq7e++ncxoaeqoyrdeaqlgvhbffdbulofzf3utm6swznzzeaujcz5nx1tf5d/xtmyqpp0wsdhnpsx9540v9jrgd7ugmcrz1+8xh219vrn2/wn+ua7ny4r <latexit sha1_base64="oi5ov9kcoehyn9bwcwwjat8txu4=">aaac4hicbvhlihnbfk1ux2p7yujstwfqrkyyxslmufagfhqxixgnm5buqnx1taeyquqm6ryknp0brsstn+xop3fpdrjlknih4hdouy+6n6uudbjhv4lwytvr12/s3ixu3b5z915v9/5nv9zwwfcuqrtngxegpiehslrwxlngolnwll286fszl2cdlm0nnfeqal4yozgco6fgptubn7jpwvqkjhku0jsz5mjlri0yfuiztzioxgiw+t+xy2rppo02k+ikyqfa85fdto7suttu9enbvai6ddgk9mkqtse7qzrkpag1gbskozdicyvpwy1koacnktpbxcufl2dkoeeaxnos1tlsx57j6as0/hmkc/zyrso1c3odeacfdoo2ty78nzaqcxkuntjunyiry0atwlesabdjmkslatxcay6s9lnsmewwc/sxwouyqf2bwptjm6unfguog6zcgvrusqeouttdr5p3uin6krtht2qxxb+ql9vje29lide9o/hnnk+3zp4gbhp922d4fpbywd686b+/xl <latexit sha1_base64="+ojsm2yurvuosb1y5f0dyh5w9ea=">aaaco3icbvhbbtnaen2ywym3fb55wrgbioscjzbahkcvqikhpbroakxyisbritpqem3tjqsek5/b1/akh8hfse4digkjrfbonllpwmlyhia/osgvq9eu39i5uxvr9p2 Simplest Example: LQR minimize TX (x t ) 2 1 t=0 subject to x t+1 = x t = +ru 2 t apple x t + apple zt v t apple 0 1/m u t samples Model-based and ADP with 10 samples

48 Extraordinary Claims Require Extraordinary Evidence* * only if your prior is correct blog.openai.com/openai-baselines-dqn/ Reinforcement learning results are tricky to reproduce: performance is very noisy, algorithms have many moving parts which allow for subtle bugs, and many papers don t report all the required tricks. RL algorithms are challenging to implement correctly; good results typically only come after fixing many seemingly-trivial bugs. Average Return Average Return arxiv: HalfCheetah-v1 (TRPO, Different Random Seeds) Random Average (5 runs) Random Average (5 runs) Timesteps 10 6 HalfCheetah-v1 (TRPO, Codebase Comparison) 500 There has to be a better way! Schulman 2015 Schulman 2017 Duan Timesteps 10 6
49 <latexit sha1_base64="wtso4cvxqkkm5sp9ikogdmu8yxs=">aaadghicbvjnb9qwehxcv7t8behixwjftrxvnkfileoliolg0emr3bbsoksod7jr1xeie4j2ifjhupjhucgu3pg3ontuynczydl4vednz4ytqkmlqfdh82/cvhx7zszm5+69+w8edrcendm8nakgile5uui4bsu1dfgigovcam8sbefj5vhdn38by2wut3feqjtxizapfbwdfhe/swqmulfcgd6vk6xqdsusffzlustmfowablowczwmsfwujoepshhebjnffr6e9edtehrjfxbjbhnjdjnymswisdbgdndqwmyc+nly0woaxmt3odgzzjz1g0ewqjojhrzx6tdq4/zvcbcxdijf0pukbjmeaemk3viins5fmyfgobi1ozaomhj2kiucv2jpoedikk9g5flnm7brtehmtz85zezt3lilks7qf09upln2nivo2ftfrnin+d9uvgk6h1vsfywcflcxpawimnnmnhqsdqhuc5dwyar7kxvtbrhan8clwxbebyilsqpzqaxix7cckpyh4q60gbmxuqmqei+vop+4tvs4gdg162wbuv9wtita3wp3s/tomtgnjfxt/3py9miqbopw48ve4zt2nbvkcxlk+iqkr8gh+uboyjaib9pb8/a91/43/4f/0/91jfw99sxjsht+77+2e/1q</late <latexit sha1_base64="qv2lanekunbubcf2z1ek6m/o+og=">aaacnxicbvhbahsxejw3tzs9oe1jhypqcg4jzrcuksfqc+2dksmt44b3wwblss2ilyq0g2ww/0k/pq/tf/rvqnvcqo0oca7nzeuzp7bkeorj363o1u07d+/t3d9/8pdr4yftg6cx3lro4eayzdxlar6v1dggsqovrumoc4xd4updow+v0xlp9ddawmxkmgo5kqiouhm7o89rokqwpavrnznz9bqcncna03gv0ye/4qkoig934l68cr4lkjxoshwc5wetlb0buzwossjwfptelriahemhclmfvh4ticuy4ihadsx6rf6ttosvajpme+pc08rx7l8vnztel8oizjzam7+tnet/tfffk9osltpwhfrcdjpuipphzx34wdoupbybghay/jwlgtgqfk64mwxv26ly2ksev1okm8ytvtgchatsi5ugdbnv/veqxb <latexit sha1_base64="z65z1fewznivdrnx0njfmyzk9iw=">aaaczhicbvfnb9naen2yrxk+0nlksiicpakn7aqjxooqgqshqiqcnjvi15psnvaq67w1o64sbxzlx/fdohof/8a6nyikjlts2/fezozojaspdpr+95z36/adu/e27rcfphz0+elne+fc5kvmfmbymeulmrguheidfcj5rae5zgpjh+ord7u+vobaifx9wxnbowwsjaacatoq7gzdfncg16clvft0iiagkzatkv5lvqshkbpy4pffxdrt/acii8xm3v85te8bx28w414z4+5icxnqjjtdv+8vg26coafd0srzvn2kwknoyowrzbkmgqv+gzefjyjjxrxd0vac2bukfosggoybyc4nunexjpnqaa7duuix7l8zfjjj5tnyotpa1kxrnfk/bvti9dcyqhulcsvugk1lstgn9tjprgjoum4dakafeytlkwhg6ia+0mvzu+bs5sd2virb8glfyyxouimjdccmhkp/zt8ikelnuiaeictfp6orw8u99yirapzo3gbv7obzlsryh/8mod/ob34/+ps6e/y2wc0weuaekx4jybtytd6smzigjhwjp8hp8ss79dczxnvj9vpnzloyet7x35/24uw=</latexit> <latexit sha1_base64="7wws5p4/hlk3102z185pb4izzt8=">aaadjnicbvjnbxmxepuuxyv8pxdgwmuiokrvarwlkoasqajaofrqrnnwipev13e2vm3vyp6telb7f7jyr7ghxi2fgjdzeekyydlovzlnzzynhrqwwvcn51+7fupmra3bntt3791/0n1+egbz0ja+zlnmzuvklzdc8yeikpyimjyqvplz9pkw4c+vulei16cwl3isakbfrdakdkq6x0nkm6eragyd15wudyeonj9vsmihxgde4x1mfivpmlzv64tkimeusd6bebglsioyrpwnu3yyqh+wwh6zwc4xiptcteirzqmigp2zq96lajza5iqayir+dua9vfrowhxtyicnsch6bghddwjx4/ansbcxbuei8gystukptxgsbhsxgeesvfwdk9taurqweds5eexyn3bpeuhzjc34ykwakm7jarhbgj9zybhpcuoobrxa/+2oqlj2rljx2wzjrnmn+d9uvmlkvvwjxztanvtencklhhw3rugxmjybnluemipcwzgbukmzodtxbllof5yttflnsi1ypuzrqiqzgopay0frozupqimhjf5itcxhjxn/wcfb0p03ihng94/dn9g7g8xokgh9/zvj2fmgcopow4vewevwmi30bd1ffrshl+gavucnaiiy99gbeo+8i/+l/83/7v9ylvpe2/miryt/6zcbuwox</latexit> h i PT minimize E e t=1 C t(x t, u t ) s.t. x t+1 = f(x t, u t, e t ) u t = t ( t ) Model-based RL Collect some simulation data. Should have x t+1 '(x t, u t )+ t Fit dynamics with supervised learning: ˆ' = arg min ' NX 1 t=0 x t+1 '(x t, u t ) 2 Solve approximate problem: h i PT minimize E! t=1 C t(x t, u t ) s.t. x t+1 = '(x t, u t )+! t u t = ( t )
50 Coarse-ID control F u y K

51 Coarse-ID control v Δ ^ F w u High dimensional stats bounds the error Coarse-grained model is trivial to fit y K Design robust control for feedback loop
52 <latexit sha1_base64="6bzqpf3vhyc8ozgggdlvwhkvsy4=">aaac2nicbvfnbxmxehwwrxk+ujhysyha5aprbouehjcqgashchvbakxsduv1jsmotndlz6ke7z44ia78lp4af4mrhpcmqsini1l+em9mpj6xfqodhegpvndu/iwllzyut69cvxb9rmfz5gexl1bcqoyqt4ezckdqwicqfbwwfotofbxkxy8a/eajwie5eu/zahitjgbhkav5ku2m4wwmacphrzjxlvj1o84lsijya4sgb5vggxo/qr0rf5nlq37n7/hyltqt8hluh73h8um/tje/nkuh3+azfooto512dga0bjx2umevxarfb9esdnky9tpnvhkpcllqmcsvcg4yhqulvh2hvocnlb0uqh6lcqw9bgz1sbvysm3vembex7n1xxbfsp9wvei7n9ezz9scpu6s1pd/04yljz8mfzqijddy9kfxqtjlvnkuh6efswrugzaw/axctouvkrwhk68sehcgv35szuqdmh/bgvbrjkzwpapsak3zq+ovksxfcep4hk6m9ff1brt56yvovfup9rzr5v5asjckorv+dtdy6t3rrw8fd3f7s2c22g12h22xid1hu+w122cdjtl39pp9yr+djpgcfam+nqygrwxnlbyswbc/ks3qpw==</latexit> Coarse-ID control (static case) minimize u x Qx subject to x = Bu + x 0 B unknown! Collect data: {(x i, u i )} x i = Bu i + x 0 + e i Estimate B: minimize B P N i=1 kbu i + x 0 x i k 2 Guarantee: kb ˆBk apple with high probability ˆB Note: x = ˆBu + x 0 + B u Robust optimization problem: minimize sup k u B kapple kq 1/2 (x Bu)k subject to x = ˆBu + x 0
53 <latexit sha1_base64="6bzqpf3vhyc8ozgggdlvwhkvsy4=">aaac2nicbvfnbxmxehwwrxk+ujhysyha5aprbouehjcqgashchvbakxsduv1jsmotndlz6ke7z44ia78lp4af4mrhpcmqsini1l+em9mpj6xfqodhegpvndu/iwllzyut69cvxb9rmfz5gexl1bcqoyqt4ezckdqwicqfbwwfotofbxkxy8a/eajwie5eu/zahitjgbhkav5ku2m4wwmacphrzjxlvj1o84lsijya4sgb5vggxo/qr0rf5nlq37n7/hyltqt8hluh73h8um/tje/nkuh3+azfooto512dga0bjx2umevxarfb9esdnky9tpnvhkpcllqmcsvcg4yhqulvh2hvocnlb0uqh6lcqw9bgz1sbvysm3vembex7n1xxbfsp9wvei7n9ezz9scpu6s1pd/04yljz8mfzqijddy9kfxqtjlvnkuh6efswrugzaw/axctouvkrwhk68sehcgv35szuqdmh/bgvbrjkzwpapsak3zq+ovksxfcep4hk6m9ff1brt56yvovfup9rzr5v5asjckorv+dtdy6t3rrw8fd3f7s2c22g12h22xid1hu+w122cdjtl39pp9yr+djpgcfam+nqygrwxnlbyswbc/ks3qpw==</latexit> Coarse-ID control (static case) minimize u x Qx subject to x = Bu + x 0 B unknown! Collect data: {(x i, u i )} x i = Bu i + x 0 + e i Estimate B: minimize B P N i=1 kbu i + x 0 x i k 2 Guarantee: kb ˆBk apple with high probability ˆB Solve robust optimization problem: minimize sup k u B kapple kq 1/2 (x Bu)k subject to x = ˆBu + x 0 Relaxation: (Triangle inequality!) minimize kq 1/2 xk + kuk u subject to x = ˆBu + x 0
54 Coarse-ID control (static case) minimize u x Qx subject to x = Bu + x 0 B unknown! Collect data: {(x i, u i )} x i = Bu i + x 0 + e i Estimate B: Guarantee: P N minimize B i=1 kbu i x i k 2 kb ˆBk apple with high probability ˆB Relaxation: (Triangle inequality!) minimize kq 1/2 xk + kuk u subject to x = ˆBu + x 0 Generalization bound cost(û) apple cost(u? )+4 ku? kkq 1/2 x? k ku? k 2
55 <latexit sha1_base64="6bzqpf3vhyc8ozgggdlvwhkvsy4=">aaac2nicbvfnbxmxehwwrxk+ujhysyha5aprbouehjcqgashchvbakxsduv1jsmotndlz6ke7z44ia78lp4af4mrhpcmqsini1l+em9mpj6xfqodhegpvndu/iwllzyut69cvxb9rmfz5gexl1bcqoyqt4ezckdqwicqfbwwfotofbxkxy8a/eajwie5eu/zahitjgbhkav5ku2m4wwmacphrzjxlvj1o84lsijya4sgb5vggxo/qr0rf5nlq37n7/hyltqt8hluh73h8um/tje/nkuh3+azfooto512dga0bjx2umevxarfb9esdnky9tpnvhkpcllqmcsvcg4yhqulvh2hvocnlb0uqh6lcqw9bgz1sbvysm3vembex7n1xxbfsp9wvei7n9ezz9scpu6s1pd/04yljz8mfzqijddy9kfxqtjlvnkuh6efswrugzaw/axctouvkrwhk68sehcgv35szuqdmh/bgvbrjkzwpapsak3zq+ovksxfcep4hk6m9ff1brt56yvovfup9rzr5v5asjckorv+dtdy6t3rrw8fd3f7s2c22g12h22xid1hu+w122cdjtl39pp9yr+djpgcfam+nqygrwxnlbyswbc/ks3qpw==</latexit> Coarse-ID control (static case) minimize u x Qx subject to x = Bu + x 0 B unknown! Collect data: {(x i, u i )} x i = Bu i + x 0 + e i Estimate B: minimize B P N i=1 kbu i + x 0 x i k 2 Guarantee: kb ˆBk apple with high probability ˆB Relaxation: (Triangle inequality!) minimize kq 1/2 xk + kuk u subject to x = ˆBu + x 0 Generalization bound cost(û) =cost(u? )+O( )
56 <latexit sha1_base64="euyqlm8oqoqnwpvqldlbjjbjanm=">aaadnxicbvjlbxmxepyurxietehixskikhrfuwgjlpvkacehhxastfk8jbyon7fqe1f2lcry+7u48jc4cenc+qt400uicsnzm/7m5znpasgfhsj6horxrl67fmprzuvw7tt3t9s794y2lw3ja5bl3jyl1hipnb+aamnpcsopsiu/ts9e1/7tt9xykes+laqekdrvihomgofg7w8k5vohhtwglionzduiks3ntgktlpjck7ylirrq7preiokmfgt+mqidwaiiisistd3bikiewyhkhjixv65fywjlnwqhcxxex/mxnd/bj7xg+7hc3j7u+rjmqkjt1nahw7ec+9t9umih+fwtdfshe83h0cjct5onj9udqbstbw8acwn0ucph450gizoclypryjjao4qjahjfdgst3m9fwl5qdkgnforntrw3ivuuuskppdlbww780ycx6l8zjiprfyr1kfvu7lqvbv/ng5wqvuyc0eujxlplrlkpmes45g1phoem5miblbnh34rzjpp1g2d3pcuydshzyiruxmrb8glfqyxmwvapwg6kelb9vo6dkbj/pnrixs3ox68vw7v33oipapu057+qfrwr7amj19e/aqyfdeoog5887xwendrsoqfoidpdmxqbdtf7diwgiaw7qs8ybmpwa/gj/bn+ugwngybnplqr8pcfxx4jrw==</latexit> <latexit sha1_base64="uo+1skyh9ob/xn5keqmafdwhdva=">aaac03icbvfdixmxfe3hr3x92k4++hisqotsokxqfvtu0ieck253f5pustn3pmgtzgxyr7beerff/vn+ch+dr/pupq1gwy8edufcj9xzp4wsdnu9h43o2vubn2/t3n69c/fe/b3m/omtl5dwwfdkkrdnu+5asqndlkjgrlda9vtb6ftida2ffglrzg6ocv7awppmyfqkjogancfhlinlylcqbpz7iilisc1sy4vntmaan/dpo3ladcrpvoib8ilnmupmaq+lqao2gyxp0wfqoklyc96vklmym2fn0mz1ur1f0g0qr0clrojost8ysyqxpqadqnhnrngvwlhnfqvquo2y0khbxqxpybsg4rrc2c+cqoitwcq0zw14bumc/bfcc+3cxe9dzr2d29rq8n/aqmt05dhlu5qiriwhpawimnpavppicwlvpaaurax/pwlgg4syzf+bsuhdgfjbx Coarse-ID Control for LQR minimize s.t. lim T!1 E h Gaussian noise Assume stable A Run an experiment for T steps with random input. Then minimize (A,B) P T i=1 kx i+1 Ax i Bu i k 2 1 T x t+1 = Ax t + Bu t + e t P T t=1 x t Qx t + u t Ru t i If T Õ 2 (d + p) min( c ) 2 where c = A c A + BB controllability Gramian then A Â B ˆB and w.h.p. [Dean, Mania, Matni, R.,Tu, 2017] [Mania, R., Simchowitz, Tu, 2018]

57 <latexit sha1_base64="qybpfo5ltn9luocv7dk5zoe+lxe=">aaadhhicbvjnbxmxepuuxyvqsohixsjc2qhpuxuq4acoupgk2hykanpkcro5xm9i1fzubs9q5pqvcowpcenckfg3ejnuahjgsvt03njgm8/dgjnt4vhven65e+/+g7whtuep1588rw88o9f5qqjtkpzn6myinevm0q5hhtozqleshpyedi/2kv30g1wa5flytaraf3gkwcyinp4a1h+gtgfidyi0xsyeuubwwqbpg5wznwaiti/hhmqhvg3tyyhwwckbzvgjs7hzxs5mhlhvmt6sbjporagzo0nz3g4lo20hnyg6ppyvrtednljsndbngtkxylg4ew7sbctwettkn4ums8fodeqnedueblwfyrw0wdyobhtbh6u5kqwvhncsds+jc9o3wblgohu1vgpayhkbr7tnocsc6r6dbttbv55jyzyrf6sbu/b2dyuf1hmx9jnvuhpzq8j/ab3szo/6lsminfsswaos5ndkslihpkxryvjea0wu82+fziz9tow3cahlthzbycik9qqujoqpxwk5utike1jtizct1vr2n3eov2kpyafy4eb1zss5+srgzohwx/8u2vxj9oyky+tfbsft7stetr68aex+nfuzbl6alyaccxgldsfncas6gatrwevgffah/b7+dh+fv2epytc/8xwsrpjnh9uaaes=</latexit> Coarse-ID Control for LQR minimize u P sup lim 1 T k A k 2 apple A, k B k 2 apple B T!1 T t=1 x t Qx t + u t Ru t s.t. x t+1 =(Â + A)x t +(ˆB + B )u t Solving an SDP relaxation of this robust control problem yields J(ˆK) J? apple C cl J? r 2 min( c ) 1/2 (d + p) + kk? k 2 T w.h.p. c = A c A + BB controllability Gramian cl := k(zi A BK? ) 1 k H1 closed loop gain This also tells you when your cost is finite! Extends to unstable A case as well. [Dean, Mania, Matni, R., Tu 2017]
58 Why robust? x t+1 = x t u t + e t Slightly unstable system, system ID tends to think some nodes are stable


59 Least-squares estimate may yield unstable controller Robust synthesis yields stable controller

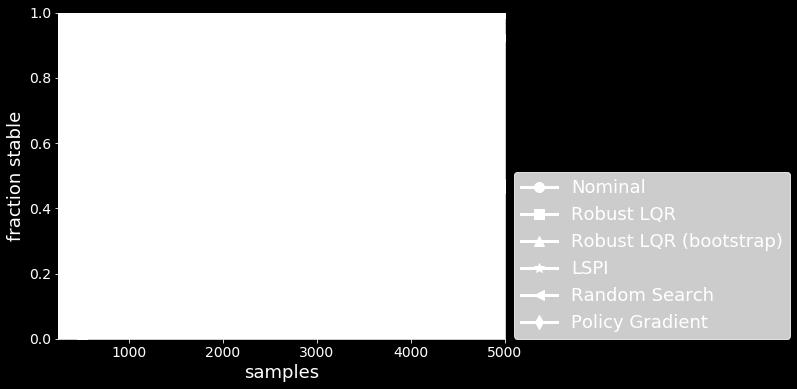
60 Model-free performs worse than model-based
61 Why has no one done this before? Coarse-ID control is the first non-asymptotic bound for this oracle model. Our guarantees for least-squares estimation required some heavy machinery. Indeed, best bounds building on very recent papers. Our SDP relaxation uses brand new techniques in controller parameterization (Systems Level Synthesis by Matni et al.) Key insight: Robustness makes analysis tractable The Singularity has arrived! Lots of work in the last years, to be highlighted in extended bib.


62 <latexit sha1_base64="eumgloqutsxkdwjk4wwvpysqp+q=">aaadknicbvjnaxsxen3dfqxur5z2miuokayj4+yaqnsqksmk2d6kte4clmnkrwylsnqnnftilp1hvfap9bz67q+p1nygtjsgelw3mthm0ygt3eau3frbg4ephj/zelp59vzfy+3qzqttk+aash5nrarpr8qwwrxraqfbzjpnibwjdja6pcr1sx9mg56q7zdl2ecsiejjtgk4alj9hceaunso8zsa7rt1/fyqgyc6shcaycgu0bfu4eyfhxmpydbiswcqpawikjw8hhal1zs5j0muiile3qvn6xd2pz5ofwgp4zvoojs+gbaw5pmp1cvyxgmwapecbphekotwmoxldszssrgf4iqjipxcurldai1qrvnamybegpq3jjphjj/asupzyrrqqyzpx1ega0s0ccpyucg5yrmhl2tc+g4qipkz2pl+c/twmqkap9odbwjo3r9hitrmjkcusxzergsl+t+tn8p4w8bylexaff00guccqypks1dcnamgzg4qqrl7k6jt4jyeztkvlvpagamrk9jrxhgajmynfxanmjjsmjceq3iqe8yfqn+imqhbonknurklhh7mew6m0xx/rtu3kp0h8fr6n8fpqxlhzfjru9rhx6u1w96u98ylvdh77x16x7wtr+drf9f/5lf9tvaz+b3cbn8wqyg/vppaw4ng7z9wcawm</latexit> where Even LQR is not simple!!! minimize J := t=1 x T t Qx t + u T t Ru t s.t. J(ˆK) J? apple C cl J? c = A c A + BB controllability Gramian x t+1 = Ax t + Bu t + e t Gaussian noise r 2 min( c ) 1/2 (d + p) log(1/ ) + kk? k 2 n cl := k(zi A BK? ) 1 k H1 closed loop gain Hard to estimate Control insensitive to mismatch Easy to estimate Control very sensitive to mismatch 50 papers on Cosma Shalizi s blog say otherwise! Need to fix learning theory for time series.
63 The Linearization Principle If a machine learning algorithm does crazy things when restricted to linear models, it s going to do crazy things on complex nonlinear models too. What happens when we return to nonlinear models?
64 <latexit sha1_base64="geqtxxms1vozi4hkkogwziugzue=">aaadzxicbvndb9mwfm1apkb42ucrf4ufizdndppm6dtgd0xcqnlwnmmpjsd1vquxexyn28jck/+pn975ithxgnjxpsjh555z73xsrfnccgxhj5vo99bto3dx79n3hzx89hht/cmnpc0kososjqk8ixboeybosdgv0jnmusyjhb5hs706fzynmmepofjxgr1zfc5yzahwmjpbx/kzrvscivlhqeiwrepcrgkhlb25cujejirpjguxzu+nqrimoxi8w5emfxxgxrmfuydpbzatqgjhaiftehq7vprsrxf5hpnzbxspdn1wulh6/2zlq5cygcwlznhb8moweavfgx14wtincmuotndp+x3hvh3n79pbpetupv00y4y2sq7g4lckgragwou1pxbqpu7ivsmlck/bbv6o6zzsd3ng7ptu4/eccgvpmu5mvdyneoofrtr3e54bgb9jqh/g1fjxqoe6agp5zmrph0bkbahmnd7urd1pwbfi2cqu9ye0e3hec4jmjk0errnwafrm/hzq2dog3izngjsatwddamn4tvy9nksk4fqokua8p0uwu+mss30delrzyzhtdjozpv1tdqxmnb+xzxwswavnteccsv3ojtbsoqpepm+veksvhktpvpyryf/ltgsvb+osiaxqvbdtkc4sofjq320wyzislvxpgilkelzaplhiovqfyoupgja3fbom3o3bnvrobuy+br/gqvxmem69tjc1y+1a+9bqglmk87bzufolu3ah3xn3uvvvsdsrreep9u90v/0cyxirpg==</latexit> Random search of linear policies outperforms Deep Reinforcement Learning Larger is better


65 <latexit sha1_base64="geqtxxms1vozi4hkkogwziugzue=">aaadzxicbvndb9mwfm1apkb42ucrf4ufizdndppm6dtgd0xcqnlwnmmpjsd1vquxexyn28jck/+pn975ithxgnjxpsjh555z73xsrfnccgxhj5vo99bto3dx79n3hzx89hht/cmnpc0kososjqk8ixboeybosdgv0jnmusyjhb5hs706fzynmmepofjxgr1zfc5yzahwmjpbx/kzrvscivlhqeiwrepcrgkhlb25cujejirpjguxzu+nqrimoxi8w5emfxxgxrmfuydpbzatqgjhaiftehq7vprsrxf5hpnzbxspdn1wulh6/2zlq5cygcwlznhb8moweavfgx14wtincmuotndp+x3hvh3n79pbpetupv00y4y2sq7g4lckgragwou1pxbqpu7ivsmlck/bbv6o6zzsd3ng7ptu4/eccgvpmu5mvdyneoofrtr3e54bgb9jqh/g1fjxqoe6agp5zmrph0bkbahmnd7urd1pwbfi2cqu9ye0e3hec4jmjk0errnwafrm/hzq2dog3izngjsatwddamn4tvy9nksk4fqokua8p0uwu+mss30delrzyzhtdjozpv1tdqxmnb+xzxwswavnteccsv3ojtbsoqpepm+veksvhktpvpyryf/ltgsvb+osiaxqvbdtkc4sofjq320wyzislvxpgilkelzaplhiovqfyoupgja3fbom3o3bnvrobuy+br/gqvxmem69tjc1y+1a+9bqglmk87bzufolu3ah3xn3uvvvsdsrreep9u90v/0cyxirpg==</latexit> Larger is better
66 AverageReward300 0 Swimmer-v Hopper-v HalfCheetah-v Ant-v Episodes AverageReward Walker2d-v Episodes Humanoid-v Episodes Larger is better
67 <latexit sha1_base64="rli7jlp75guz6h4r9bivhozu6ym=">aaadmhicbvjnj9mwehxc11k+undkyqhytdqqshasxcqtwnby2enxtlsr1svyxke11nyie4jsovcjupjh4is48itwukgwlsnfgr838+yzlzitwkiqfpf8a9dv3ly1c7t15+69+w/auw9pbzobxicslak5j6nlumg+aqgsn2eguxvlfhzfhnb82udurej1gfyznym60cirjikdovzxevof0cu1hq6qusqqrvscfquswijxivd4dxnfyrnh5dsq4ktybkbe5ioqyrhwh8b4mijueue/j6ch990xccdyvb9wpwleygkzqhpvo4bbreh4cdwe4urvc587gf7nigqhhevyww5zfsqtroyarfvbhot589qo3qkgwtrwdhi2sqc1myp2vrmzpyxxxaot1nppggqwc3igmoru9nzyjliluubtl2qquj2v6y1x+jld5jhjjfs04dx6b0djlburfbvkel92k6vb/3hthjjxs1lolaeu2evfss4xpli2dm+f4qzkyiwugeheitmsgsragxvllrv2xtmvscoi14klc76bsijauadadookxu9vhgkp8xuqlt6unfvdotma7r4rcwg2f+z+ht3bknaghjvr305onw/cybcevogcvg6s2ugp0vpursf6iq7qozrce8s8j96rn/jo/c/+n/+h//oy1peankfosvi/fgnhzqxm</latexit> <latexit sha1_base64="wjzwyrttwq4tjmeyxm+ahiuetcu=">aaacnxicbvhbihnbeo2mt3w9zfxrbxudmielzcycvgilf/qhyc6azujmggo6lumz3t1dd40kdpkfv8zx/q//xp5sbjnyuha4p+6vv0o6iqlfnedgzvu37xzcpbx3/8hdr92jxxeurk3akshvas9zckikwrfjunhzwqsdkxznv+9affwnrzol+urlclmnhzezkya8lxxdpjlhos/f8arskwhpsqze8uqdzqwo5nyvxehiuo5n3v40inbg90g8at22sbpsqjmm01lugg0jbc5n4qiitafluihchsa1wwrefrq48dcarpc265vw/ivnpnxwwu+g+jr9n6mb7dxs5z6yhdxtai35p21s0+x12kht1yrgxdea1yptydv78km0kegtpqbhpz+vizlyeosvunvlxbtcsbvjs6infouud1hfc7lgsyekqzp2q+ajvip/aep4ubzz+qv6sq0cvpefjhc89k8y/b1g/5b49/z74ojkeeed+pxl7/tt5juh7cl7zkiws1fslh1iz2zebpvofrcf7ffwl <latexit sha1_base64="3ongeklt0fc5aggqsz+4zr38bsc=">aaac13icbvhlihnbfk20r3f8teaxbgqdtiihda+cbpsbuxqxixk0mypppqmu3e6kqa5uqm5jqtg4e7f+lb/gt7jvpdvjbjn4oebwzn3vuvklhcew/nekrl2/cfpwzu3do3fv3d9r7z84n6xvhia8lkw+zjgbkrqmuacey0odkzijf9nvcanffajtrkk+4lycpgatjxlbgxoqbwdxwxdkmxrndeqiujvr2x59sy/taamf0kvglrk3dqqxhbxhcsfu6uxbvvz8whfzzvufen170iu1mewxsdudcbaugm6daau6zbwn6x4riccltwuo5jizm4rcchphnaouod6nrygk8ss2gzghihvgercwo6zppdomean9u0gx7l8vjhxgzivmzzbbm02tif+njszmlxinvgurff8oyq2kwnlgwtowgjjkuqema+f3pxzknopo/v+bsuhdav/7iztzjxg5hg1w4gw186qbljhqza/cwyelfc+uosenx39v37aru6/frkdpn/gjq95wsj9itgn/njg/hethidp71jl6ttrndnlehpmuichzcktekvmyjjx8jz/jl/i7+bh8dr4ex5epqwtv85csrfdtdzdm5ju=</latexit> <latexit sha1_base64="f/5zcsmbblu5nwsus+xucmwplxq=">aaac53icbvfdixmxfm2mh1vxr64++hissi1byowi+rkysip92iddtlslnxhipjk2bjizkhtpcfmbfbnf/vf6z8rmw8g2xggczrn33jt780pwa1h0kwhv3b5zd691b//+g4ephrcpnlya0mrkrrqupb7oiwgckzycdojdv5ormqt2ld+cnvrvf6ynl9unwfqslwsqemepau9lbz1iajnkhluomxfx3xnf9vaxxomxmnnwhnefh/g0g5vwhjf5ee7e1xllbctgneiummcp6w2r4ze3k7jhu9dnvb497cwat2eqzu1oniiwgxdbvaydti7z7cbik0ljrwqkqcdgjooogtqrdzwkvu8n1rck0bsyzwmpfzhmpg65nbq/8mwef6x2twfesv9wocknwcjczzbzm22tif+njs0ub1lhvwwbkbpqvfiboctnpvgea0zbldwgvhm/k6yzogkff4+nlkvvitgnn7i5vzywe7bfcpidjp40dcthqvmv+8cfwb+jmvis2fff1ds2cvcdn3iw/tn/dnxbsfyhibfxvwsuxw7iabbfvoqcvf2fpoweoeeoi2l0gp2gitphi0trt/q72ataiq+/ht/c76vumfjxpeubef74ay2y6nm=</latexit> Model Predictive Control h i PT minimize E e t=1 C t(x t, u t )+C f (x T+1 ) s.t. x t+1 = f t (x t, u t, e t ), x 1 = x u t = t ( t ) Optimal Policy: (x) = arg min Q 1 (x, u) u Q 1 (x, u) =C 1 (x, u)+e e applemin u 0 Q 2 (f 1 (x, u, e), u 0 ) MPC: use the Q-function for all time steps Q 1 (x, u) = HX t=1 C t (x, u)+e e applemin u 0 Q H+1 (f H (x, u, e), u 0 ) MPC ethos: plan on short time horizons, use feedback to correct modeling error and disturbance.


68 Model Predictive Control Videos from Todorov Lab

69 <latexit sha1_base64="6dxz3efk/7p3jrzushqr8eugzh8=">aaadmhicbvjnj9mwehxc11k+undkyqhytdqqshasxipwwtby2enxtlsr1svyxke11nyie4jsovcjupjh4is48itwukgwlsnfgr838+yzlzitwkiqfpf8a9dv3ly1c7t15+69+w/auw9pbzobxicslak5j6nlumg+aqgsn2eguxvlfhzfhnb82udurej1gfyznym60cirjikdovzxevof0cu1hq6qusqqrvscfquswijxivd4dxnfyrnh5dsq4ktybkbe5ioqyrhwh8b4mijueue/j6ch990xccdyvb9wpwleygkzqhpvo4bbreh4cdwe4urvc587gf7nigqhhevyww5zfsqtroyarfvbhot589qo3qkgwtrwdhi2sqc1myp2vrmzpyxxxaot1nppggqwc3igmoru9nzyjliluubtl2qquj2v6y1x+jld5jhjjfs04dx6b0djlburfbvkel92k6vb/3hthjjxs1lolaeu2evfss4xpli2dm+f4qzkyiwugeheitmsgsragxvllrv2xtmvscoi14klc76bsijauadadookxu9vhgkp8xuqlt6unfvdotma7r4rcwg2f+z+ht3bknaghjvr305onw/cybcevogcvg6s2ugp0vpursf6iq7qozrce8s8j96rn/jo/c/+n/+h//oy1peankfosvi/fgngmqxi</latexit> <latexit sha1_base64="f/5zcsmbblu5nwsus+xucmwplxq=">aaac53icbvfdixmxfm2mh1vxr64++hissi1byowi+rkysip92iddtlslnxhipjk2bjizkhtpcfmbfbnf/vf6z8rmw8g2xggczrn33jt780pwa1h0kwhv3b5zd691b//+g4ephrcpnlya0mrkrrqupb7oiwgckzycdojdv5ormqt2ld+cnvrvf6ynl9unwfqslwsqemepau9lbz1iajnkhluomxfx3xnf9vaxxomxmnnwhnefh/g0g5vwhjf5ee7e1xllbctgneiummcp6w2r4ze3k7jhu9dnvb497cwat2eqzu1oniiwgxdbvaydti7z7cbik0ljrwqkqcdgjooogtqrdzwkvu8n1rck0bsyzwmpfzhmpg65nbq/8mwef6x2twfesv9wocknwcjczzbzm22tif+njs0ub1lhvwwbkbpqvfiboctnpvgea0zbldwgvhm/k6yzogkff4+nlkvvitgnn7i5vzywe7bfcpidjp40dcthqvmv+8cfwb+jmvis2fff1ds2cvcdn3iw/tn/dnxbsfyhibfxvwsuxw7iabbfvoqcvf2fpoweoeeoi2l0gp2gitphi0trt/q72ataiq+/ht/c76vumfjxpeubef74ay2y6nm=</latexit> <latexit sha1_base64="wjzwyrttwq4tjmeyxm+ahiuetcu=">aaacnxicbvhbihnbeo2mt3w9zfxrbxudmielzcycvgilf/qhyc6azujmggo6lumz3t1dd40kdpkfv8zx/q//xp5sbjnyuha4p+6vv0o6iqlfnedgzvu37xzcpbx3/8hdr92jxxeurk3akshvas9zckikwrfjunhzwqsdkxznv+9affwnrzol+urlclmnhzezkya8lxxdpjlhos/f8arskwhpsqze8uqdzqwo5nyvxehiuo5n3v40inbg90g8at22sbpsqjmm01lugg0jbc5n4qiitafluihchsa1wwrefrq48dcarpc265vw/ivnpnxwwu+g+jr9n6mb7dxs5z6yhdxtai35p21s0+x12kht1yrgxdea1yptydv78km0kegtpqbhpz+vizlyeosvunvlxbtcsbvjs6infouud1hfc7lgsyekqzp2q+ajvip/aep4ubzz+qv6sq0cvpefjhc89k8y/b1g/5b49/z74ojkeeed+pxl7/tt5juh7cl7zkiws1fslh1iz2zebpvofrcf7ffwl Learning in MPC h PT i minimize E e t=1 C t(x t, u t )+C f (x T+1 ) s.t. x t+1 = f t (x t, u t, e t ), x 1 = x u t = t ( t ) MPC: use the Q-function for all time steps Q 1 (x, u) = HX t=1 Use past data to learn the terminal Q-function: The value of a state is the minimum value seen for the remainder of the episode from that state. Optimal Policy: (x) = arg min Q 1 (x, u) u C t (x, u)+e e applemin u 0 Q H+1 (f H (x, u, e), u 0 ) [Rosolia et al., 2016]
70 So many things left to do Are the coarse-id results optimal, even with respect to the parameters? Tight upper and lower sample complexities for LQR. (Is the optimal error scaling T -1/2 or T -1?) Finite analysis of learning in MPC. Adaptive control. Iterative learning control. Nonlinear models, constraints, and improper learning. Safe exploration, earning about uncertain environments. Implementing in test-beds.
71 Actionable Intelligence Control Theory Reinforcement Learning is the study of how to use past data to enhance the future manipulation of a dynamical system


72 Actionable Intelligence is the study of how to use past data to enhance the future manipulation of a dynamical system As soon as a machine learning system is unleashed in feedback with humans, that system is an actionable intelligence system, not a machine learning system.
73 Actionable Intelligence trustable, scalable, predictable






74 Collaborators Joint work with Sarah Dean, Aurelia Guy, Horia Mania, Nikolai Matni, Max Simchowitz, and Stephen Tu.
75 Recommended Texts D. Bertsekas. Dynamic Programming and Optimal Control. 4th edition, volumes 1 (2017) and 2 (2012). Athena Scientific. D. Bertsekas. and J. Tsitsiklis. Neuro-dynamic Programming. Athena Scientific, F. Borrelli, A. Bemporad, and M. Morari. Predictive Control for Linear and Hybrid Systems. Cambridge, B. Recht A Tour of Reinforcement Learning: The View from Continuous Control. arxiv:
76 References from the Actionable Intelligence Lab argmin.net On the Sample Complexity of the Linear Quadratic Regulator. S. Dean, H. Mania, N. Matni, B. Recht, and S. Tu. arxiv: Non-asymptotic Analysis of Robust Control from Coarse-grained Identification. S. Tu, R. Boczar, A. Packard, and B. Recht. arxiv: Least-squares Temporal Differencing for the Linear Quadratic Regulator S. Tu and B. Recht. In submission to ICML arxiv: Learning without Mixing. H. Mania, B. Recht, M. Simchowitz, and S. Tu. In submission to COLT arxiv: Simple random search provides a competitive approach to reinforcement learning. H. Mania, A. Guy, and B. Recht. arxiv: Regret Bounds for Robust Adaptive Control of the Linear Quadratic Regulator. S. Dean, H. Mania, N. Matni, B. Recht, and S. Tu. arxiv:
77 minimize u s.t. h lim E P i 1 T T!1 T t=1 x t Qx t + u t Ru t x t+1 = Ax t + Bu t + e t Key to formulation: Write (x,u) as linear function of disturbance minimize s.t. E [x t Qx t ]= 2 tx k=1 E [u t Ru t ]= 2 tx k=1 " Q apple xt u t = 0 R 1 2 tx k=1 apple Tr( x [k] Q x [k]) Tr( u [k] R u [k]) # apple x u 2 F x[k] u[k] x[t + 1] =A x [t]+b u [t] x[0] =I e t k
![Key to formulation: Write (x,u) as linear function of disturbance " # apple Q 1 2 2 0 x minimize sup k A k 2 apple A, k B k 2 apple 0 R 1 2 B u F s.t. x[t + 1] =(Â + A) x [t]+(ˆb + B ) u [t] x[0] =I apple xt u t = tx k=1 apple x[k] u[k] e t As in the static case, push robustness into cost.](/docs-images/84/90660863/images/78-1.jpg "k minimize s.t. sup k A k 2 apple A, k B k 2 apple B \" Q 1 2 0 0 R 1 2 x[t + 1] =Â x[t]+ˆb u [t] x[0] =I # apple x u (I + ) 1 2 F")
78 Key to formulation: Write (x,u) as linear function of disturbance " # apple Q x minimize sup k A k 2 apple A, k B k 2 apple 0 R 1 2 B u F s.t. x[t + 1] =(Â + A) x [t]+(ˆb + B ) u [t] x[0] =I apple xt u t = tx k=1 apple x[k] u[k] e t As in the static case, push robustness into cost. k minimize s.t. sup k A k 2 apple A, k B k 2 apple B " Q R 1 2 x[t + 1] =Â x[t]+ˆb u [t] x[0] =I # apple x u (I + ) 1 2 F
ECE7850 Lecture 7. Discrete Time Optimal Control and Dynamic Programming
 ECE7850 Lecture 7 Discrete Time Optimal Control and Dynamic Programming Discrete Time Optimal control Problems Short Introduction to Dynamic Programming Connection to Stabilization Problems 1 DT nonlinear
ECE7850 Lecture 7 Discrete Time Optimal Control and Dynamic Programming Discrete Time Optimal control Problems Short Introduction to Dynamic Programming Connection to Stabilization Problems 1 DT nonlinear
Optimal Control. McGill COMP 765 Oct 3 rd, 2017
 Optimal Control McGill COMP 765 Oct 3 rd, 2017 Classical Control Quiz Question 1: Can a PID controller be used to balance an inverted pendulum: A) That starts upright? B) That must be swung-up (perhaps
Optimal Control McGill COMP 765 Oct 3 rd, 2017 Classical Control Quiz Question 1: Can a PID controller be used to balance an inverted pendulum: A) That starts upright? B) That must be swung-up (perhaps
Lecture 5 Linear Quadratic Stochastic Control
 EE363 Winter 2008-09 Lecture 5 Linear Quadratic Stochastic Control linear-quadratic stochastic control problem solution via dynamic programming 5 1 Linear stochastic system linear dynamical system, over
EE363 Winter 2008-09 Lecture 5 Linear Quadratic Stochastic Control linear-quadratic stochastic control problem solution via dynamic programming 5 1 Linear stochastic system linear dynamical system, over
EE C128 / ME C134 Feedback Control Systems
 EE C128 / ME C134 Feedback Control Systems Lecture Additional Material Introduction to Model Predictive Control Maximilian Balandat Department of Electrical Engineering & Computer Science University of
EE C128 / ME C134 Feedback Control Systems Lecture Additional Material Introduction to Model Predictive Control Maximilian Balandat Department of Electrical Engineering & Computer Science University of
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation
 Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
EN Applied Optimal Control Lecture 8: Dynamic Programming October 10, 2018
 EN530.603 Applied Optimal Control Lecture 8: Dynamic Programming October 0, 08 Lecturer: Marin Kobilarov Dynamic Programming (DP) is conerned with the computation of an optimal policy, i.e. an optimal
EN530.603 Applied Optimal Control Lecture 8: Dynamic Programming October 0, 08 Lecturer: Marin Kobilarov Dynamic Programming (DP) is conerned with the computation of an optimal policy, i.e. an optimal
Problem 1 Cost of an Infinite Horizon LQR
 THE UNIVERSITY OF TEXAS AT SAN ANTONIO EE 5243 INTRODUCTION TO CYBER-PHYSICAL SYSTEMS H O M E W O R K # 5 Ahmad F. Taha October 12, 215 Homework Instructions: 1. Type your solutions in the LATEX homework
THE UNIVERSITY OF TEXAS AT SAN ANTONIO EE 5243 INTRODUCTION TO CYBER-PHYSICAL SYSTEMS H O M E W O R K # 5 Ahmad F. Taha October 12, 215 Homework Instructions: 1. Type your solutions in the LATEX homework
UCLA Chemical Engineering. Process & Control Systems Engineering Laboratory
 Constrained Innite-time Optimal Control Donald J. Chmielewski Chemical Engineering Department University of California Los Angeles February 23, 2000 Stochastic Formulation - Min Max Formulation - UCLA
Constrained Innite-time Optimal Control Donald J. Chmielewski Chemical Engineering Department University of California Los Angeles February 23, 2000 Stochastic Formulation - Min Max Formulation - UCLA
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Robotics. Control Theory. Marc Toussaint U Stuttgart
 Robotics Control Theory Topics in control theory, optimal control, HJB equation, infinite horizon case, Linear-Quadratic optimal control, Riccati equations (differential, algebraic, discrete-time), controllability,
Robotics Control Theory Topics in control theory, optimal control, HJB equation, infinite horizon case, Linear-Quadratic optimal control, Riccati equations (differential, algebraic, discrete-time), controllability,
Reinforcement Learning
 Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Optimal Control with Learned Forward Models
 Optimal Control with Learned Forward Models Pieter Abbeel UC Berkeley Jan Peters TU Darmstadt 1 Where we are? Reinforcement Learning Data = {(x i, u i, x i+1, r i )}} x u xx r u xx V (x) π (u x) Now V
Optimal Control with Learned Forward Models Pieter Abbeel UC Berkeley Jan Peters TU Darmstadt 1 Where we are? Reinforcement Learning Data = {(x i, u i, x i+1, r i )}} x u xx r u xx V (x) π (u x) Now V
MS&E338 Reinforcement Learning Lecture 1 - April 2, Introduction
 MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
Lecture 20: Linear Dynamics and LQG
 CSE599i: Online and Adaptive Machine Learning Winter 2018 Lecturer: Kevin Jamieson Lecture 20: Linear Dynamics and LQG Scribes: Atinuke Ademola-Idowu, Yuanyuan Shi Disclaimer: These notes have not been
CSE599i: Online and Adaptive Machine Learning Winter 2018 Lecturer: Kevin Jamieson Lecture 20: Linear Dynamics and LQG Scribes: Atinuke Ademola-Idowu, Yuanyuan Shi Disclaimer: These notes have not been
Lecture 10 Linear Quadratic Stochastic Control with Partial State Observation
 EE363 Winter 2008-09 Lecture 10 Linear Quadratic Stochastic Control with Partial State Observation partially observed linear-quadratic stochastic control problem estimation-control separation principle
EE363 Winter 2008-09 Lecture 10 Linear Quadratic Stochastic Control with Partial State Observation partially observed linear-quadratic stochastic control problem estimation-control separation principle
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Reinforcement Learning
 Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Partially Observable Markov Decision Processes (POMDPs) Pieter Abbeel UC Berkeley EECS
 Pieter Abbeel UC Berkeley EECS") Partially Observable Markov Decision Processes (POMDPs) Pieter Abbeel UC Berkeley EECS Many slides adapted from Jur van den Berg Outline POMDPs Separation Principle / Certainty Equivalence Locally Optimal
Partially Observable Markov Decision Processes (POMDPs) Pieter Abbeel UC Berkeley EECS Many slides adapted from Jur van den Berg Outline POMDPs Separation Principle / Certainty Equivalence Locally Optimal
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Approximate Dynamic Programming
 Approximate Dynamic Programming A. LAZARIC (SequeL Team @INRIA-Lille) Ecole Centrale - Option DAD SequeL INRIA Lille EC-RL Course Value Iteration: the Idea 1. Let V 0 be any vector in R N A. LAZARIC Reinforcement
Approximate Dynamic Programming A. LAZARIC (SequeL Team @INRIA-Lille) Ecole Centrale - Option DAD SequeL INRIA Lille EC-RL Course Value Iteration: the Idea 1. Let V 0 be any vector in R N A. LAZARIC Reinforcement
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer.
 This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
Lecture 4 Continuous time linear quadratic regulator
 EE363 Winter 2008-09 Lecture 4 Continuous time linear quadratic regulator continuous-time LQR problem dynamic programming solution Hamiltonian system and two point boundary value problem infinite horizon
EE363 Winter 2008-09 Lecture 4 Continuous time linear quadratic regulator continuous-time LQR problem dynamic programming solution Hamiltonian system and two point boundary value problem infinite horizon
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
EE363 homework 2 solutions
 EE363 Prof. S. Boyd EE363 homework 2 solutions. Derivative of matrix inverse. Suppose that X : R R n n, and that X(t is invertible. Show that ( d d dt X(t = X(t dt X(t X(t. Hint: differentiate X(tX(t =
EE363 Prof. S. Boyd EE363 homework 2 solutions. Derivative of matrix inverse. Suppose that X : R R n n, and that X(t is invertible. Show that ( d d dt X(t = X(t dt X(t X(t. Hint: differentiate X(tX(t =
The Kernel Trick, Gram Matrices, and Feature Extraction. CS6787 Lecture 4 Fall 2017
 The Kernel Trick, Gram Matrices, and Feature Extraction CS6787 Lecture 4 Fall 2017 Momentum for Principle Component Analysis CS6787 Lecture 3.1 Fall 2017 Principle Component Analysis Setting: find the
The Kernel Trick, Gram Matrices, and Feature Extraction CS6787 Lecture 4 Fall 2017 Momentum for Principle Component Analysis CS6787 Lecture 3.1 Fall 2017 Principle Component Analysis Setting: find the
Stochastic and Adaptive Optimal Control
 Stochastic and Adaptive Optimal Control Robert Stengel Optimal Control and Estimation, MAE 546 Princeton University, 2018! Nonlinear systems with random inputs and perfect measurements! Stochastic neighboring-optimal
Stochastic and Adaptive Optimal Control Robert Stengel Optimal Control and Estimation, MAE 546 Princeton University, 2018! Nonlinear systems with random inputs and perfect measurements! Stochastic neighboring-optimal
Path Integral Stochastic Optimal Control for Reinforcement Learning
 Preprint August 3, 204 The st Multidisciplinary Conference on Reinforcement Learning and Decision Making RLDM203 Path Integral Stochastic Optimal Control for Reinforcement Learning Farbod Farshidian Institute
Preprint August 3, 204 The st Multidisciplinary Conference on Reinforcement Learning and Decision Making RLDM203 Path Integral Stochastic Optimal Control for Reinforcement Learning Farbod Farshidian Institute
CDS 110b: Lecture 2-1 Linear Quadratic Regulators
 CDS 110b: Lecture 2-1 Linear Quadratic Regulators Richard M. Murray 11 January 2006 Goals: Derive the linear quadratic regulator and demonstrate its use Reading: Friedland, Chapter 9 (different derivation,
CDS 110b: Lecture 2-1 Linear Quadratic Regulators Richard M. Murray 11 January 2006 Goals: Derive the linear quadratic regulator and demonstrate its use Reading: Friedland, Chapter 9 (different derivation,
Controlled Diffusions and Hamilton-Jacobi Bellman Equations
 Controlled Diffusions and Hamilton-Jacobi Bellman Equations Emo Todorov Applied Mathematics and Computer Science & Engineering University of Washington Winter 2014 Emo Todorov (UW) AMATH/CSE 579, Winter
Controlled Diffusions and Hamilton-Jacobi Bellman Equations Emo Todorov Applied Mathematics and Computer Science & Engineering University of Washington Winter 2014 Emo Todorov (UW) AMATH/CSE 579, Winter
Reinforcement Learning as Variational Inference: Two Recent Approaches
 Reinforcement Learning as Variational Inference: Two Recent Approaches Rohith Kuditipudi Duke University 11 August 2017 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing
Reinforcement Learning as Variational Inference: Two Recent Approaches Rohith Kuditipudi Duke University 11 August 2017 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Hamilton-Jacobi-Bellman Equation Feb 25, 2008
 Hamilton-Jacobi-Bellman Equation Feb 25, 2008 What is it? The Hamilton-Jacobi-Bellman (HJB) equation is the continuous-time analog to the discrete deterministic dynamic programming algorithm Discrete VS
Hamilton-Jacobi-Bellman Equation Feb 25, 2008 What is it? The Hamilton-Jacobi-Bellman (HJB) equation is the continuous-time analog to the discrete deterministic dynamic programming algorithm Discrete VS
Non-Convex Optimization. CS6787 Lecture 7 Fall 2017
 Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
ESC794: Special Topics: Model Predictive Control
 ESC794: Special Topics: Model Predictive Control Nonlinear MPC Analysis : Part 1 Reference: Nonlinear Model Predictive Control (Ch.3), Grüne and Pannek Hanz Richter, Professor Mechanical Engineering Department
ESC794: Special Topics: Model Predictive Control Nonlinear MPC Analysis : Part 1 Reference: Nonlinear Model Predictive Control (Ch.3), Grüne and Pannek Hanz Richter, Professor Mechanical Engineering Department
EE363 Review Session 1: LQR, Controllability and Observability
 EE363 Review Session : LQR, Controllability and Observability In this review session we ll work through a variation on LQR in which we add an input smoothness cost, in addition to the usual penalties on
EE363 Review Session : LQR, Controllability and Observability In this review session we ll work through a variation on LQR in which we add an input smoothness cost, in addition to the usual penalties on
Reinforcement Learning for Continuous. Action using Stochastic Gradient Ascent. Hajime KIMURA, Shigenobu KOBAYASHI JAPAN
 Reinforcement Learning for Continuous Action using Stochastic Gradient Ascent Hajime KIMURA, Shigenobu KOBAYASHI Tokyo Institute of Technology, 4259 Nagatsuda, Midori-ku Yokohama 226-852 JAPAN Abstract:
Reinforcement Learning for Continuous Action using Stochastic Gradient Ascent Hajime KIMURA, Shigenobu KOBAYASHI Tokyo Institute of Technology, 4259 Nagatsuda, Midori-ku Yokohama 226-852 JAPAN Abstract:
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
The Art of Sequential Optimization via Simulations
 The Art of Sequential Optimization via Simulations Stochastic Systems and Learning Laboratory EE, CS* & ISE* Departments Viterbi School of Engineering University of Southern California (Based on joint
The Art of Sequential Optimization via Simulations Stochastic Systems and Learning Laboratory EE, CS* & ISE* Departments Viterbi School of Engineering University of Southern California (Based on joint
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Markov decision processes
 CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
Optimal Control. Quadratic Functions. Single variable quadratic function: Multi-variable quadratic function:
 Optimal Control Control design based on pole-placement has non unique solutions Best locations for eigenvalues are sometimes difficult to determine Linear Quadratic LQ) Optimal control minimizes a quadratic
Optimal Control Control design based on pole-placement has non unique solutions Best locations for eigenvalues are sometimes difficult to determine Linear Quadratic LQ) Optimal control minimizes a quadratic
Approximate Dynamic Programming
 Approximate Dynamic Programming A. LAZARIC (SequeL Team @INRIA-Lille) ENS Cachan - Master 2 MVA SequeL INRIA Lille MVA-RL Course Approximate Dynamic Programming (a.k.a. Batch Reinforcement Learning) A.
Approximate Dynamic Programming A. LAZARIC (SequeL Team @INRIA-Lille) ENS Cachan - Master 2 MVA SequeL INRIA Lille MVA-RL Course Approximate Dynamic Programming (a.k.a. Batch Reinforcement Learning) A.
Stochastic Primal-Dual Methods for Reinforcement Learning
 Stochastic Primal-Dual Methods for Reinforcement Learning Alireza Askarian 1 Amber Srivastava 1 1 Department of Mechanical Engineering University of Illinois at Urbana Champaign Big Data Optimization,
Stochastic Primal-Dual Methods for Reinforcement Learning Alireza Askarian 1 Amber Srivastava 1 1 Department of Mechanical Engineering University of Illinois at Urbana Champaign Big Data Optimization,
EE C128 / ME C134 Final Exam Fall 2014
 EE C128 / ME C134 Final Exam Fall 2014 December 19, 2014 Your PRINTED FULL NAME Your STUDENT ID NUMBER Number of additional sheets 1. No computers, no tablets, no connected device (phone etc.) 2. Pocket
EE C128 / ME C134 Final Exam Fall 2014 December 19, 2014 Your PRINTED FULL NAME Your STUDENT ID NUMBER Number of additional sheets 1. No computers, no tablets, no connected device (phone etc.) 2. Pocket
Robotics: Science & Systems [Topic 6: Control] Prof. Sethu Vijayakumar Course webpage:
![Robotics: Science & Systems [Topic 6: Control] Prof. Sethu Vijayakumar Course webpage:](/thumbs/75/71820311.jpg "Robotics: Science & Systems [Topic 6: Control] Prof. Sethu Vijayakumar Course webpage:") Robotics: Science & Systems [Topic 6: Control] Prof. Sethu Vijayakumar Course webpage: http://wcms.inf.ed.ac.uk/ipab/rss Control Theory Concerns controlled systems of the form: and a controller of the
Robotics: Science & Systems [Topic 6: Control] Prof. Sethu Vijayakumar Course webpage: http://wcms.inf.ed.ac.uk/ipab/rss Control Theory Concerns controlled systems of the form: and a controller of the
Optimal control and estimation
 Automatic Control 2 Optimal control and estimation Prof. Alberto Bemporad University of Trento Academic year 2010-2011 Prof. Alberto Bemporad (University of Trento) Automatic Control 2 Academic year 2010-2011
Automatic Control 2 Optimal control and estimation Prof. Alberto Bemporad University of Trento Academic year 2010-2011 Prof. Alberto Bemporad (University of Trento) Automatic Control 2 Academic year 2010-2011
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Formal models of interaction Daniel Hennes 27.11.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Taxonomy of domains Models of
Grundlagen der Künstlichen Intelligenz Formal models of interaction Daniel Hennes 27.11.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Taxonomy of domains Models of
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning
 REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
Markov Decision Processes and Solving Finite Problems. February 8, 2017
 Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Reinforcement Learning. Introduction
 Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Topic # Feedback Control Systems
 Topic #17 16.31 Feedback Control Systems Deterministic LQR Optimal control and the Riccati equation Weight Selection Fall 2007 16.31 17 1 Linear Quadratic Regulator (LQR) Have seen the solutions to the
Topic #17 16.31 Feedback Control Systems Deterministic LQR Optimal control and the Riccati equation Weight Selection Fall 2007 16.31 17 1 Linear Quadratic Regulator (LQR) Have seen the solutions to the
4F3 - Predictive Control
 4F3 Predictive Control - Lecture 2 p 1/23 4F3 - Predictive Control Lecture 2 - Unconstrained Predictive Control Jan Maciejowski jmm@engcamacuk 4F3 Predictive Control - Lecture 2 p 2/23 References Predictive
4F3 Predictive Control - Lecture 2 p 1/23 4F3 - Predictive Control Lecture 2 - Unconstrained Predictive Control Jan Maciejowski jmm@engcamacuk 4F3 Predictive Control - Lecture 2 p 2/23 References Predictive
MATH4406 (Control Theory) Unit 6: The Linear Quadratic Regulator (LQR) and Model Predictive Control (MPC) Prepared by Yoni Nazarathy, Artem
 Unit 6: The Linear Quadratic Regulator (LQR) and Model Predictive Control (MPC) Prepared by Yoni Nazarathy, Artem") MATH4406 (Control Theory) Unit 6: The Linear Quadratic Regulator (LQR) and Model Predictive Control (MPC) Prepared by Yoni Nazarathy, Artem Pulemotov, September 12, 2012 Unit Outline Goal 1: Outline linear
MATH4406 (Control Theory) Unit 6: The Linear Quadratic Regulator (LQR) and Model Predictive Control (MPC) Prepared by Yoni Nazarathy, Artem Pulemotov, September 12, 2012 Unit Outline Goal 1: Outline linear
Laplacian Agent Learning: Representation Policy Iteration
 Laplacian Agent Learning: Representation Policy Iteration Sridhar Mahadevan Example of a Markov Decision Process a1: $0 Heaven $1 Earth What should the agent do? a2: $100 Hell $-1 V a1 ( Earth ) = f(0,1,1,1,1,...)
Laplacian Agent Learning: Representation Policy Iteration Sridhar Mahadevan Example of a Markov Decision Process a1: $0 Heaven $1 Earth What should the agent do? a2: $100 Hell $-1 V a1 ( Earth ) = f(0,1,1,1,1,...)
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning and Control
 CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
CSC321 Lecture 5 Learning in a Single Neuron
 CSC321 Lecture 5 Learning in a Single Neuron Roger Grosse and Nitish Srivastava January 21, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 5 Learning in a Single Neuron January 21, 2015 1 / 14
CSC321 Lecture 5 Learning in a Single Neuron Roger Grosse and Nitish Srivastava January 21, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 5 Learning in a Single Neuron January 21, 2015 1 / 14
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Quadratic Stability of Dynamical Systems. Raktim Bhattacharya Aerospace Engineering, Texas A&M University
 .. Quadratic Stability of Dynamical Systems Raktim Bhattacharya Aerospace Engineering, Texas A&M University Quadratic Lyapunov Functions Quadratic Stability Dynamical system is quadratically stable if
.. Quadratic Stability of Dynamical Systems Raktim Bhattacharya Aerospace Engineering, Texas A&M University Quadratic Lyapunov Functions Quadratic Stability Dynamical system is quadratically stable if
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Policy Gradient Reinforcement Learning for Robotics
 Policy Gradient Reinforcement Learning for Robotics Michael C. Koval mkoval@cs.rutgers.edu Michael L. Littman mlittman@cs.rutgers.edu May 9, 211 1 Introduction Learning in an environment with a continuous
Policy Gradient Reinforcement Learning for Robotics Michael C. Koval mkoval@cs.rutgers.edu Michael L. Littman mlittman@cs.rutgers.edu May 9, 211 1 Introduction Learning in an environment with a continuous
OPTIMAL CONTROL. Sadegh Bolouki. Lecture slides for ECE 515. University of Illinois, Urbana-Champaign. Fall S. Bolouki (UIUC) 1 / 28
 1 / 28") OPTIMAL CONTROL Sadegh Bolouki Lecture slides for ECE 515 University of Illinois, Urbana-Champaign Fall 2016 S. Bolouki (UIUC) 1 / 28 (Example from Optimal Control Theory, Kirk) Objective: To get from
OPTIMAL CONTROL Sadegh Bolouki Lecture slides for ECE 515 University of Illinois, Urbana-Champaign Fall 2016 S. Bolouki (UIUC) 1 / 28 (Example from Optimal Control Theory, Kirk) Objective: To get from
Reinforcement learning
 Reinforcement learning Based on [Kaelbling et al., 1996, Bertsekas, 2000] Bert Kappen Reinforcement learning Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error
Reinforcement learning Based on [Kaelbling et al., 1996, Bertsekas, 2000] Bert Kappen Reinforcement learning Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error
Introduction to Reinforcement Learning
 CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
6 Reinforcement Learning
 6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
Mathematical Optimization Models and Applications
 Mathematical Optimization Models and Applications Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye Chapters 1, 2.1-2,
Mathematical Optimization Models and Applications Yinyu Ye Department of Management Science and Engineering Stanford University Stanford, CA 94305, U.S.A. http://www.stanford.edu/ yyye Chapters 1, 2.1-2,
Artificial Intelligence
 Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Reinforcement Learning
 1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
IEOR 265 Lecture 14 (Robust) Linear Tube MPC
 Linear Tube MPC") IEOR 265 Lecture 14 (Robust) Linear Tube MPC 1 LTI System with Uncertainty Suppose we have an LTI system in discrete time with disturbance: x n+1 = Ax n + Bu n + d n, where d n W for a bounded polytope
IEOR 265 Lecture 14 (Robust) Linear Tube MPC 1 LTI System with Uncertainty Suppose we have an LTI system in discrete time with disturbance: x n+1 = Ax n + Bu n + d n, where d n W for a bounded polytope
Linear-Quadratic Optimal Control: Full-State Feedback
 Chapter 4 Linear-Quadratic Optimal Control: Full-State Feedback 1 Linear quadratic optimization is a basic method for designing controllers for linear (and often nonlinear) dynamical systems and is actually
Chapter 4 Linear-Quadratic Optimal Control: Full-State Feedback 1 Linear quadratic optimization is a basic method for designing controllers for linear (and often nonlinear) dynamical systems and is actually
Overview of the Seminar Topic
 Overview of the Seminar Topic Simo Särkkä Laboratory of Computational Engineering Helsinki University of Technology September 17, 2007 Contents 1 What is Control Theory? 2 History
Overview of the Seminar Topic Simo Särkkä Laboratory of Computational Engineering Helsinki University of Technology September 17, 2007 Contents 1 What is Control Theory? 2 History
Control Theory : Course Summary
 Control Theory : Course Summary Author: Joshua Volkmann Abstract There are a wide range of problems which involve making decisions over time in the face of uncertainty. Control theory draws from the fields
Control Theory : Course Summary Author: Joshua Volkmann Abstract There are a wide range of problems which involve making decisions over time in the face of uncertainty. Control theory draws from the fields
Mathematical Formulation of Our Example
 Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Hidden Markov Models (HMM) and Support Vector Machine (SVM)
 and Support Vector Machine (SVM)") Hidden Markov Models (HMM) and Support Vector Machine (SVM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1 Hidden Markov Models (HMM)
Hidden Markov Models (HMM) and Support Vector Machine (SVM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1 Hidden Markov Models (HMM)
Kalman Filter Computer Vision (Kris Kitani) Carnegie Mellon University
 Carnegie Mellon University") Kalman Filter 16-385 Computer Vision (Kris Kitani) Carnegie Mellon University Examples up to now have been discrete (binary) random variables Kalman filtering can be seen as a special case of a temporal
Kalman Filter 16-385 Computer Vision (Kris Kitani) Carnegie Mellon University Examples up to now have been discrete (binary) random variables Kalman filtering can be seen as a special case of a temporal
Procedia Computer Science 00 (2011) 000 6
 000 6") Procedia Computer Science (211) 6 Procedia Computer Science Complex Adaptive Systems, Volume 1 Cihan H. Dagli, Editor in Chief Conference Organized by Missouri University of Science and Technology 211-
Procedia Computer Science (211) 6 Procedia Computer Science Complex Adaptive Systems, Volume 1 Cihan H. Dagli, Editor in Chief Conference Organized by Missouri University of Science and Technology 211-
Artificial Intelligence & Sequential Decision Problems
 Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Reinforcement Learning
 Reinforcement Learning March May, 2013 Schedule Update Introduction 03/13/2015 (10:15-12:15) Sala conferenze MDPs 03/18/2015 (10:15-12:15) Sala conferenze Solving MDPs 03/20/2015 (10:15-12:15) Aula Alpha
Reinforcement Learning March May, 2013 Schedule Update Introduction 03/13/2015 (10:15-12:15) Sala conferenze MDPs 03/18/2015 (10:15-12:15) Sala conferenze Solving MDPs 03/20/2015 (10:15-12:15) Aula Alpha
Optimal sequential decision making for complex problems agents. Damien Ernst University of Liège
 Optimal sequential decision making for complex problems agents Damien Ernst University of Liège Email: dernst@uliege.be 1 About the class Regular lectures notes about various topics on the subject with
Optimal sequential decision making for complex problems agents Damien Ernst University of Liège Email: dernst@uliege.be 1 About the class Regular lectures notes about various topics on the subject with
Optimal Control, Trajectory Optimization, Learning Dynamics
 Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Optimal Control, Trajectory Optimization, Learning Dynamics Katerina Fragkiadaki So far.. Most Reinforcement Learning
Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Optimal Control, Trajectory Optimization, Learning Dynamics Katerina Fragkiadaki So far.. Most Reinforcement Learning
Lecture 9: Discrete-Time Linear Quadratic Regulator Finite-Horizon Case
 Lecture 9: Discrete-Time Linear Quadratic Regulator Finite-Horizon Case Dr. Burak Demirel Faculty of Electrical Engineering and Information Technology, University of Paderborn December 15, 2015 2 Previous
Lecture 9: Discrete-Time Linear Quadratic Regulator Finite-Horizon Case Dr. Burak Demirel Faculty of Electrical Engineering and Information Technology, University of Paderborn December 15, 2015 2 Previous
Trust Region Policy Optimization
 Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
1 MDP Value Iteration Algorithm
 CS 0. - Active Learning Problem Set Handed out: 4 Jan 009 Due: 9 Jan 009 MDP Value Iteration Algorithm. Implement the value iteration algorithm given in the lecture. That is, solve Bellman s equation using
CS 0. - Active Learning Problem Set Handed out: 4 Jan 009 Due: 9 Jan 009 MDP Value Iteration Algorithm. Implement the value iteration algorithm given in the lecture. That is, solve Bellman s equation using
Introduction to Machine Learning Prof. Sudeshna Sarkar Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur
 Introduction to Machine Learning Prof. Sudeshna Sarkar Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Module 2 Lecture 05 Linear Regression Good morning, welcome
Introduction to Machine Learning Prof. Sudeshna Sarkar Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Module 2 Lecture 05 Linear Regression Good morning, welcome
Learning Tetris. 1 Tetris. February 3, 2009
 Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Generalization. A cat that once sat on a hot stove will never again sit on a hot stove or on a cold one either. Mark Twain
 Generalization Generalization A cat that once sat on a hot stove will never again sit on a hot stove or on a cold one either. Mark Twain 2 Generalization The network input-output mapping is accurate for
Generalization Generalization A cat that once sat on a hot stove will never again sit on a hot stove or on a cold one either. Mark Twain 2 Generalization The network input-output mapping is accurate for
Formula Sheet for Optimal Control
 Formula Sheet for Optimal Control Division of Optimization and Systems Theory Royal Institute of Technology 144 Stockholm, Sweden 23 December 1, 29 1 Dynamic Programming 11 Discrete Dynamic Programming
Formula Sheet for Optimal Control Division of Optimization and Systems Theory Royal Institute of Technology 144 Stockholm, Sweden 23 December 1, 29 1 Dynamic Programming 11 Discrete Dynamic Programming
Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan
 COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Approximate Dynamic Programming
 Master MVA: Reinforcement Learning Lecture: 5 Approximate Dynamic Programming Lecturer: Alessandro Lazaric http://researchers.lille.inria.fr/ lazaric/webpage/teaching.html Objectives of the lecture 1.
Master MVA: Reinforcement Learning Lecture: 5 Approximate Dynamic Programming Lecturer: Alessandro Lazaric http://researchers.lille.inria.fr/ lazaric/webpage/teaching.html Objectives of the lecture 1.
MDP Preliminaries. Nan Jiang. February 10, 2019
 MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming