Mid-year Report Linear and Non-linear Dimentionality. Reduction. applied to gene expression data of cancer tissue samples
|
|
|
- Dominic Ford
- 5 years ago
- Views:
Transcription
1 Mid-year Report Linear and Non-linear Dimentionality applied to gene expression data of cancer tissue samples Franck Olivier Ndjakou Njeunje Applied Mathematics, Statistics, and Scientific Computation Advisers Wojtek Czaja John J. Benedetto Norbert Wiener Center for Harmonic Department of Mathematics University of Maryland - College Park December 2, / 26
2 Outline 2 / 26

3 DNA Microarray [2] 3 / 26
4 DNA Microarray [2] Gene expression matrix 3 / 26
5 Project goal In this project I would like to demonstrate the effectiveness of Non-linear versus Linear algorithm in capturing biologically relevant structures in cancer expression dataset. 4 / 26
6 Project goal In this project I would like to demonstrate the effectiveness of Non-linear versus Linear algorithm in capturing biologically relevant structures in cancer expression dataset. I will be using clustering analysis and rand index as tools to measure the preservation of the structure between the original and the reduced dataset. 4 / 26
7 I am considering the following methods: 1. Dimension reduction algorithms 12 LDR: (PCA) [1] NDR: Laplacian Eigenmap (LE) [3] 1 Jinlong Shi, Zhigang Luo, Nonlinear dimensionality reduction. 2 Mikhail Belkin, Partha Niyogi, Laplacian Eigenmaps. 5 / 26
8 I am considering the following methods: 1. Dimension reduction algorithms 12 LDR: (PCA) [1] NDR: Laplacian Eigenmap (LE) [3] 2. Clustering algorithm K-means (KM) Hierachical clustering (HC) 1 Jinlong Shi, Zhigang Luo, Nonlinear dimensionality reduction. 2 Mikhail Belkin, Partha Niyogi, Laplacian Eigenmaps. 5 / 26
9 Step 1: Compute the standardized matrix X of the original matrix X, X = ( x 1, x 2,..., x M ) (1) = ( x 1 x 1, x 2 x 2,..., x M x M ). (2) σ11 σmm σ22 Here, x 1, x 2,..., x M and σ 11, σ 22,..., σ MM are respectively the mean values and the variances for corresponding variable vectors. 6 / 26
10 Step 2: Compute the covariance matrix of X, then make spectral decomposition to get the eigenvalues and its corresponding eigenvectors. C = X X = UΛU. (3) Here Λ = diag(λ 1, λ 2,..., λ M ), λ 1 λ 2... λ M, U = (u 1, u 2,..., u M ). λ i and u i are separately the ith eigenvalue corresponding eigenvector for covariance matrix C. Step 3: Determine the number of principal components based on the preconcerted value. Supposing the number to be m, the i th principal component can be computed as Xu i, and the reduced dimentional (N m) subspace is XU m. 7 / 26
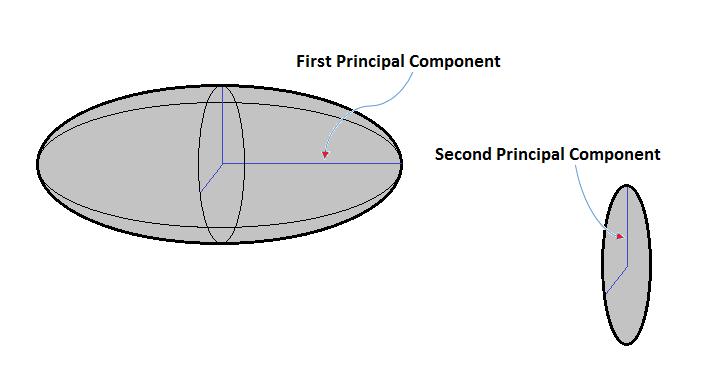
11 Illustration 8 / 26
12 Loading vectors components are in short a linear combination of the original component making up the matrix X. 9 / 26
13 Loading vectors components are in short a linear combination of the original component making up the matrix X. The vector carrying the coefficients associated with the combination are known as the loading vectors. 9 / 26
14 Loading vectors components are in short a linear combination of the original component making up the matrix X. The vector carrying the coefficients associated with the combination are known as the loading vectors. Finding the first loading vector u 1 must be done so that the magnitude of the first principal component is maximized. 9 / 26
15 First loading vectors: Rayleigh quotient u 1 = arg max u=1 y 1 2 (4) = arg max u=1 Xu 2 (5) = arg max u=1 u X Xu u u (6) = arg max u=1 u Cu u u (7) 10 / 26
16 First loading vectors: Rayleigh quotient u 1 = arg max u=1 y 1 2 (4) = arg max u=1 Xu 2 (5) = arg max u=1 u X Xu u u (6) = arg max u=1 u Cu u u (7) The quantity to be maximized is well-known as the Rayleigh quotient for symmetric matrices. The solution to this optimization problem is known to be the eigenvector of C corresponding to the eigenvalue of largest magnitude. 10 / 26
17 Remaining loading vectors To find the remaining loading vectors u k for k = 2... m, we will apply the same idea to the modified matrix X k. k 1 X k = X Xu i u i (8) i=1 where all correlation with the previously found loading vectors has been removed. 11 / 26
18 Covariance matrix With C R M M as our symmetric covariance matrix, The set {u j } of unit eigenvectors of C with j = 1... M, where M M, forms a basis of R M. The corresponding eigenvalues {λ j }, are such that λ 1 > λ 2 >... > λ M. 12 / 26
19 Covariance matrix With C R M M as our symmetric covariance matrix, The set {u j } of unit eigenvectors of C with j = 1... M, where M M, forms a basis of R M. The corresponding eigenvalues {λ j }, are such that λ 1 > λ 2 >... > λ M. So any vector u (0) R M can be written as: u (0) = c 1 u 1 + c 2 u c M u M (9) for some c 1, c 2,..., c M R. 12 / 26
20 [4] Assuming that c 1 0. Au (0) = c 1 λ 1 u 1 + c 2 λ 2 u c M λ M u M A k u (0) = c 1 λ k 1u 1 + c 2 λ k 2u c M λ k M u M A k u (0) = λ k 1(c 1 u 1 + c 2 ( λ 2 λ 1 ) k u c M ( λ M λ 1 ) k u M ). 13 / 26
21 [4] Assuming that c 1 0. Au (0) = c 1 λ 1 u 1 + c 2 λ 2 u c M λ M u M A k u (0) = c 1 λ k 1u 1 + c 2 λ k 2u c M λ k M u M A k u (0) = λ k 1(c 1 u 1 + c 2 ( λ 2 λ 1 ) k u c M ( λ M λ 1 ) k u M ). So, as k increases we get, u 1 Ak u (0) A k u (0). (10) 13 / 26
22 Algorithm 3 Pick a starting vector u (0) with u (0) = 1 While u (k) u (k 1) > 10 6 Let w = Au (k 1) Let u (k) = w w Note: The convergence rate depends on the magnitude of the second largest eigenvalue. 3 Gene H. Golub, Henk A. van der Vorstb, Eigenvalue computation in the 20th century. 14 / 26
23 Data set [5] The matrix X has dimension: / 26
24 Variability: This number reflects the amount of variance captured in the reduction. It is the percentage of total magnitude of eigenvalues corresponding to the eigenvectors (loading vectors) used. DR Toolbox PCA My PCA: 90% variability 16 / 26
![Data set [5] The matrix X](/docs-images/84/89704737/images/25-0.jpg "has dimension: 20000 3 17 /")
25 Data set [5] The matrix X has dimension: / 26
26 DR Toolbox PCA My PCA: 99% variability 18 / 26
27 [6] Rank index is a measure of agreement between two data clustering. Given a set of n elements S and two partition X and Y of the set S, the rand index r is given by: r = a + b C(n, 2) (11) 19 / 26
28 [6] Rank index is a measure of agreement between two data clustering. Given a set of n elements S and two partition X and Y of the set S, the rand index r is given by: where: r = a + b C(n, 2) a, the number of pairs of elements in S that are in the same set in X and in the same set in Y. b, the number of pairs of elements in S that are in different sets in X and in different sets in Y. (11) 19 / 26

29 K-means Clustering The matrix X has dimension: Raw clustering labels 2D labels: 83% agreement 20 / 26
30 Hierarchycal Clustering The matrix X has dimension: Raw clustering labels 2D labels: 73% agreement 21 / 26
31 22 / 26
32 Variability preserved within data 23 / 26
33 Conclusion : Kmeans vs Hierarchycal 83% vs 73% agreement 24 / 26
34 Conclusion : Kmeans vs Hierarchycal 83% vs 73% agreement Laplacian Eigenmap: Kmeans vs Hierarchycal??% vs??% agreement 24 / 26
35 Conclusion : Kmeans vs Hierarchycal 83% vs 73% agreement Laplacian Eigenmap: Kmeans vs Hierarchycal??% vs??% agreement vs Laplacian Eigenmap??% vs??% agreement 24 / 26
36 References: Jinlong Shi, Zhigang Luo, Nonlinear dimensionality reduction of gene expression data for visualization and clustering analysis of cancer tissue samples. Computers in Biology and Medicine 40 (2010) Larssono, September 2007, Microarray-schema. Via Wikipedia - DNA microarray page. Mikhail Belkin, Partha Niyogi, Laplacian Eigenmaps for Dimentionality and Data Representation. Neural Computation 15, (2003) Gene H. Golub, Henk A. van der Vorstb, Eigenvalue computation in the 20th century. Journal of Computational and Applied Mathematics 123 (2000) / 26
37 References: Laurens van der Maaten, Affiliation: Delft University of Technology. Matlab Toolbox for (v0.8.1b) March 21, W. M. Rand (1971), Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association, 66 (336): / 26
Linear and Non-linear Dimension Reduction Applied to Gene Expression Data of Cancer Tissue Samples
 Linear and Non-linear Dimension Reduction Applied to Gene Expression Data of Cancer Tissue Samples Franck Olivier Ndjakou Njeunje Applied Mathematics, Statistics, and Scientific Computation University
Linear and Non-linear Dimension Reduction Applied to Gene Expression Data of Cancer Tissue Samples Franck Olivier Ndjakou Njeunje Applied Mathematics, Statistics, and Scientific Computation University
Data-dependent representations: Laplacian Eigenmaps
 Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Nonlinear Dimensionality Reduction. Jose A. Costa
 Nonlinear Dimensionality Reduction Jose A. Costa Mathematics of Information Seminar, Dec. Motivation Many useful of signals such as: Image databases; Gene expression microarrays; Internet traffic time
Nonlinear Dimensionality Reduction Jose A. Costa Mathematics of Information Seminar, Dec. Motivation Many useful of signals such as: Image databases; Gene expression microarrays; Internet traffic time
CSE 291. Assignment Spectral clustering versus k-means. Out: Wed May 23 Due: Wed Jun 13
 CSE 291. Assignment 3 Out: Wed May 23 Due: Wed Jun 13 3.1 Spectral clustering versus k-means Download the rings data set for this problem from the course web site. The data is stored in MATLAB format as
CSE 291. Assignment 3 Out: Wed May 23 Due: Wed Jun 13 3.1 Spectral clustering versus k-means Download the rings data set for this problem from the course web site. The data is stored in MATLAB format as
December 20, MAA704, Multivariate analysis. Christopher Engström. Multivariate. analysis. Principal component analysis
 .. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
.. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
Course 495: Advanced Statistical Machine Learning/Pattern Recognition
 Course 495: Advanced Statistical Machine Learning/Pattern Recognition Deterministic Component Analysis Goal (Lecture): To present standard and modern Component Analysis (CA) techniques such as Principal
Course 495: Advanced Statistical Machine Learning/Pattern Recognition Deterministic Component Analysis Goal (Lecture): To present standard and modern Component Analysis (CA) techniques such as Principal
Unsupervised dimensionality reduction
 Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Statistical and Computational Analysis of Locality Preserving Projection
 Statistical and Computational Analysis of Locality Preserving Projection Xiaofei He xiaofei@cs.uchicago.edu Department of Computer Science, University of Chicago, 00 East 58th Street, Chicago, IL 60637
Statistical and Computational Analysis of Locality Preserving Projection Xiaofei He xiaofei@cs.uchicago.edu Department of Computer Science, University of Chicago, 00 East 58th Street, Chicago, IL 60637
MATH 829: Introduction to Data Mining and Analysis Principal component analysis
 1/11 MATH 829: Introduction to Data Mining and Analysis Principal component analysis Dominique Guillot Departments of Mathematical Sciences University of Delaware April 4, 2016 Motivation 2/11 High-dimensional
1/11 MATH 829: Introduction to Data Mining and Analysis Principal component analysis Dominique Guillot Departments of Mathematical Sciences University of Delaware April 4, 2016 Motivation 2/11 High-dimensional
Lecture 13. Principal Component Analysis. Brett Bernstein. April 25, CDS at NYU. Brett Bernstein (CDS at NYU) Lecture 13 April 25, / 26
 Lecture 13 April 25, / 26") Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation
 Introduction and Data Representation Mikhail Belkin & Partha Niyogi Department of Electrical Engieering University of Minnesota Mar 21, 2017 1/22 Outline Introduction 1 Introduction 2 3 4 Connections to
Introduction and Data Representation Mikhail Belkin & Partha Niyogi Department of Electrical Engieering University of Minnesota Mar 21, 2017 1/22 Outline Introduction 1 Introduction 2 3 4 Connections to
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
PCA and admixture models
 PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
Principal component analysis (PCA) for clustering gene expression data
 for clustering gene expression data") Principal component analysis (PCA) for clustering gene expression data Ka Yee Yeung Walter L. Ruzzo Bioinformatics, v17 #9 (2001) pp 763-774 1 Outline of talk Background and motivation Design of our empirical
Principal component analysis (PCA) for clustering gene expression data Ka Yee Yeung Walter L. Ruzzo Bioinformatics, v17 #9 (2001) pp 763-774 1 Outline of talk Background and motivation Design of our empirical
Data dependent operators for the spatial-spectral fusion problem
 Data dependent operators for the spatial-spectral fusion problem Wien, December 3, 2012 Joint work with: University of Maryland: J. J. Benedetto, J. A. Dobrosotskaya, T. Doster, K. W. Duke, M. Ehler, A.
Data dependent operators for the spatial-spectral fusion problem Wien, December 3, 2012 Joint work with: University of Maryland: J. J. Benedetto, J. A. Dobrosotskaya, T. Doster, K. W. Duke, M. Ehler, A.
Invariant Subspace Perturbations or: How I Learned to Stop Worrying and Love Eigenvectors
 Invariant Subspace Perturbations or: How I Learned to Stop Worrying and Love Eigenvectors Alexander Cloninger Norbert Wiener Center Department of Mathematics University of Maryland, College Park http://www.norbertwiener.umd.edu
Invariant Subspace Perturbations or: How I Learned to Stop Worrying and Love Eigenvectors Alexander Cloninger Norbert Wiener Center Department of Mathematics University of Maryland, College Park http://www.norbertwiener.umd.edu
Fisher s Linear Discriminant Analysis
 Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Non-linear Dimensionality Reduction
 Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Principal Components Analysis (PCA)
") Principal Components Analysis (PCA) Principal Components Analysis (PCA) a technique for finding patterns in data of high dimension Outline:. Eigenvectors and eigenvalues. PCA: a) Getting the data b) Centering
Principal Components Analysis (PCA) Principal Components Analysis (PCA) a technique for finding patterns in data of high dimension Outline:. Eigenvectors and eigenvalues. PCA: a) Getting the data b) Centering
Nonlinear Methods. Data often lies on or near a nonlinear low-dimensional curve aka manifold.
 Nonlinear Methods Data often lies on or near a nonlinear low-dimensional curve aka manifold. 27 Laplacian Eigenmaps Linear methods Lower-dimensional linear projection that preserves distances between all
Nonlinear Methods Data often lies on or near a nonlinear low-dimensional curve aka manifold. 27 Laplacian Eigenmaps Linear methods Lower-dimensional linear projection that preserves distances between all
Numerical Methods I Singular Value Decomposition
 Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Data Mining and Analysis: Fundamental Concepts and Algorithms
 Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
Inverse Power Method for Non-linear Eigenproblems
 Inverse Power Method for Non-linear Eigenproblems Matthias Hein and Thomas Bühler Anubhav Dwivedi Department of Aerospace Engineering & Mechanics 7th March, 2017 1 / 30 OUTLINE Motivation Non-Linear Eigenproblems
Inverse Power Method for Non-linear Eigenproblems Matthias Hein and Thomas Bühler Anubhav Dwivedi Department of Aerospace Engineering & Mechanics 7th March, 2017 1 / 30 OUTLINE Motivation Non-Linear Eigenproblems
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation)
") Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Linear Algebra Methods for Data Mining
 Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Linear Discriminant Analysis Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki Principal
Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Linear Discriminant Analysis Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki Principal
Graph Functional Methods for Climate Partitioning
 Graph Functional Methods for Climate Partitioning Mathilde Mougeot - with D. Picard, V. Lefieux*, M. Marchand* Université Paris Diderot, France *Réseau Transport Electrique (RTE) Buenos Aires, 2015 Mathilde
Graph Functional Methods for Climate Partitioning Mathilde Mougeot - with D. Picard, V. Lefieux*, M. Marchand* Université Paris Diderot, France *Réseau Transport Electrique (RTE) Buenos Aires, 2015 Mathilde
Nonlinear Dimensionality Reduction
 Nonlinear Dimensionality Reduction Piyush Rai CS5350/6350: Machine Learning October 25, 2011 Recap: Linear Dimensionality Reduction Linear Dimensionality Reduction: Based on a linear projection of the
Nonlinear Dimensionality Reduction Piyush Rai CS5350/6350: Machine Learning October 25, 2011 Recap: Linear Dimensionality Reduction Linear Dimensionality Reduction: Based on a linear projection of the
Linear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Apprentissage non supervisée
 Apprentissage non supervisée Cours 3 Higher dimensions Jairo Cugliari Master ECD 2015-2016 From low to high dimension Density estimation Histograms and KDE Calibration can be done automacally But! Let
Apprentissage non supervisée Cours 3 Higher dimensions Jairo Cugliari Master ECD 2015-2016 From low to high dimension Density estimation Histograms and KDE Calibration can be done automacally But! Let
20 Unsupervised Learning and Principal Components Analysis (PCA)
") 116 Jonathan Richard Shewchuk 20 Unsupervised Learning and Principal Components Analysis (PCA) UNSUPERVISED LEARNING We have sample points, but no labels! No classes, no y-values, nothing to predict. Goal:
116 Jonathan Richard Shewchuk 20 Unsupervised Learning and Principal Components Analysis (PCA) UNSUPERVISED LEARNING We have sample points, but no labels! No classes, no y-values, nothing to predict. Goal:
Intrinsic Structure Study on Whale Vocalizations
 1 2015 DCLDE Conference Intrinsic Structure Study on Whale Vocalizations Yin Xian 1, Xiaobai Sun 2, Yuan Zhang 3, Wenjing Liao 3 Doug Nowacek 1,4, Loren Nolte 1, Robert Calderbank 1,2,3 1 Department of
1 2015 DCLDE Conference Intrinsic Structure Study on Whale Vocalizations Yin Xian 1, Xiaobai Sun 2, Yuan Zhang 3, Wenjing Liao 3 Doug Nowacek 1,4, Loren Nolte 1, Robert Calderbank 1,2,3 1 Department of
CS168: The Modern Algorithmic Toolbox Lecture #8: How PCA Works
 CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
Principal Component Analysis (PCA) CSC411/2515 Tutorial
 CSC411/2515 Tutorial") Principal Component Analysis (PCA) CSC411/2515 Tutorial Harris Chan Based on previous tutorial slides by Wenjie Luo, Ladislav Rampasek University of Toronto hchan@cs.toronto.edu October 19th, 2017 (UofT)
Principal Component Analysis (PCA) CSC411/2515 Tutorial Harris Chan Based on previous tutorial slides by Wenjie Luo, Ladislav Rampasek University of Toronto hchan@cs.toronto.edu October 19th, 2017 (UofT)
Principal Component Analysis
 CSci 5525: Machine Learning Dec 3, 2008 The Main Idea Given a dataset X = {x 1,..., x N } The Main Idea Given a dataset X = {x 1,..., x N } Find a low-dimensional linear projection The Main Idea Given
CSci 5525: Machine Learning Dec 3, 2008 The Main Idea Given a dataset X = {x 1,..., x N } The Main Idea Given a dataset X = {x 1,..., x N } Find a low-dimensional linear projection The Main Idea Given
Dimensionality Reduction
 Dimensionality Reduction Le Song Machine Learning I CSE 674, Fall 23 Unsupervised learning Learning from raw (unlabeled, unannotated, etc) data, as opposed to supervised data where a classification of
Dimensionality Reduction Le Song Machine Learning I CSE 674, Fall 23 Unsupervised learning Learning from raw (unlabeled, unannotated, etc) data, as opposed to supervised data where a classification of
Analysis of Spectral Kernel Design based Semi-supervised Learning
 Analysis of Spectral Kernel Design based Semi-supervised Learning Tong Zhang IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Rie Kubota Ando IBM T. J. Watson Research Center Yorktown Heights,
Analysis of Spectral Kernel Design based Semi-supervised Learning Tong Zhang IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Rie Kubota Ando IBM T. J. Watson Research Center Yorktown Heights,
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Salvador Dalí, Galatea of the Spheres CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang Some slides from Derek Hoiem and Alysha
Principal Component Analysis (PCA) Salvador Dalí, Galatea of the Spheres CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang Some slides from Derek Hoiem and Alysha
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA
 Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
1 Singular Value Decomposition and Principal Component
 Singular Value Decomposition and Principal Component Analysis In these lectures we discuss the SVD and the PCA, two of the most widely used tools in machine learning. Principal Component Analysis (PCA)
Singular Value Decomposition and Principal Component Analysis In these lectures we discuss the SVD and the PCA, two of the most widely used tools in machine learning. Principal Component Analysis (PCA)
What is Principal Component Analysis?
 What is Principal Component Analysis? Principal component analysis (PCA) Reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables Retains most
What is Principal Component Analysis? Principal component analysis (PCA) Reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables Retains most
DIMENSION REDUCTION AND CLUSTER ANALYSIS
 DIMENSION REDUCTION AND CLUSTER ANALYSIS EECS 833, 6 March 2006 Geoff Bohling Assistant Scientist Kansas Geological Survey geoff@kgs.ku.edu 864-2093 Overheads and resources available at http://people.ku.edu/~gbohling/eecs833
DIMENSION REDUCTION AND CLUSTER ANALYSIS EECS 833, 6 March 2006 Geoff Bohling Assistant Scientist Kansas Geological Survey geoff@kgs.ku.edu 864-2093 Overheads and resources available at http://people.ku.edu/~gbohling/eecs833
Principal Component Analysis
 Principal Component Analysis Yuanzhen Shao MA 26500 Yuanzhen Shao PCA 1 / 13 Data as points in R n Assume that we have a collection of data in R n. x 11 x 21 x 12 S = {X 1 =., X x 22 2 =.,, X x m2 m =.
Principal Component Analysis Yuanzhen Shao MA 26500 Yuanzhen Shao PCA 1 / 13 Data as points in R n Assume that we have a collection of data in R n. x 11 x 21 x 12 S = {X 1 =., X x 22 2 =.,, X x m2 m =.
Learning gradients: prescriptive models
 Department of Statistical Science Institute for Genome Sciences & Policy Department of Computer Science Duke University May 11, 2007 Relevant papers Learning Coordinate Covariances via Gradients. Sayan
Department of Statistical Science Institute for Genome Sciences & Policy Department of Computer Science Duke University May 11, 2007 Relevant papers Learning Coordinate Covariances via Gradients. Sayan
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Iterative Laplacian Score for Feature Selection
 Iterative Laplacian Score for Feature Selection Linling Zhu, Linsong Miao, and Daoqiang Zhang College of Computer Science and echnology, Nanjing University of Aeronautics and Astronautics, Nanjing 2006,
Iterative Laplacian Score for Feature Selection Linling Zhu, Linsong Miao, and Daoqiang Zhang College of Computer Science and echnology, Nanjing University of Aeronautics and Astronautics, Nanjing 2006,
Spectra of Adjacency and Laplacian Matrices
 Spectra of Adjacency and Laplacian Matrices Definition: University of Alicante (Spain) Matrix Computing (subject 3168 Degree in Maths) 30 hours (theory)) + 15 hours (practical assignment) Contents 1. Spectra
Spectra of Adjacency and Laplacian Matrices Definition: University of Alicante (Spain) Matrix Computing (subject 3168 Degree in Maths) 30 hours (theory)) + 15 hours (practical assignment) Contents 1. Spectra
Lecture 7 Spectral methods
 CSE 291: Unsupervised learning Spring 2008 Lecture 7 Spectral methods 7.1 Linear algebra review 7.1.1 Eigenvalues and eigenvectors Definition 1. A d d matrix M has eigenvalue λ if there is a d-dimensional
CSE 291: Unsupervised learning Spring 2008 Lecture 7 Spectral methods 7.1 Linear algebra review 7.1.1 Eigenvalues and eigenvectors Definition 1. A d d matrix M has eigenvalue λ if there is a d-dimensional
Nonlinear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Structure in Data. A major objective in data analysis is to identify interesting features or structure in the data.
 Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Preprocessing & dimensionality reduction
 Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Dimensionality Reduc1on
 Dimensionality Reduc1on contd Aarti Singh Machine Learning 10-601 Nov 10, 2011 Slides Courtesy: Tom Mitchell, Eric Xing, Lawrence Saul 1 Principal Component Analysis (PCA) Principal Components are the
Dimensionality Reduc1on contd Aarti Singh Machine Learning 10-601 Nov 10, 2011 Slides Courtesy: Tom Mitchell, Eric Xing, Lawrence Saul 1 Principal Component Analysis (PCA) Principal Components are the
Data Analysis and Manifold Learning Lecture 7: Spectral Clustering
 Data Analysis and Manifold Learning Lecture 7: Spectral Clustering Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture 7 What is spectral
Data Analysis and Manifold Learning Lecture 7: Spectral Clustering Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture 7 What is spectral
Statistics for Applications. Chapter 9: Principal Component Analysis (PCA) 1/16
 1/16") Statistics for Applications Chapter 9: Principal Component Analysis (PCA) 1/16 Multivariate statistics and review of linear algebra (1) Let X be a d-dimensional random vector and X 1,..., X n be n independent
Statistics for Applications Chapter 9: Principal Component Analysis (PCA) 1/16 Multivariate statistics and review of linear algebra (1) Let X be a d-dimensional random vector and X 1,..., X n be n independent
LECTURE NOTE #11 PROF. ALAN YUILLE
 LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
CSE 554 Lecture 7: Alignment
 CSE 554 Lecture 7: Alignment Fall 2012 CSE554 Alignment Slide 1 Review Fairing (smoothing) Relocating vertices to achieve a smoother appearance Method: centroid averaging Simplification Reducing vertex
CSE 554 Lecture 7: Alignment Fall 2012 CSE554 Alignment Slide 1 Review Fairing (smoothing) Relocating vertices to achieve a smoother appearance Method: centroid averaging Simplification Reducing vertex
Spectral Clustering on Handwritten Digits Database
 University of Maryland-College Park Advance Scientific Computing I,II Spectral Clustering on Handwritten Digits Database Author: Danielle Middlebrooks Dmiddle1@math.umd.edu Second year AMSC Student Advisor:
University of Maryland-College Park Advance Scientific Computing I,II Spectral Clustering on Handwritten Digits Database Author: Danielle Middlebrooks Dmiddle1@math.umd.edu Second year AMSC Student Advisor:
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis. Massimiliano Pontil
 2. Least Squares and Principal Components Analysis. Massimiliano Pontil") GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings
 Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline
Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Unsupervised Learning Techniques Class 07, 1 March 2006 Andrea Caponnetto
 Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
Table of Contents. Multivariate methods. Introduction II. Introduction I
 Table of Contents Introduction Antti Penttilä Department of Physics University of Helsinki Exactum summer school, 04 Construction of multinormal distribution Test of multinormality with 3 Interpretation
Table of Contents Introduction Antti Penttilä Department of Physics University of Helsinki Exactum summer school, 04 Construction of multinormal distribution Test of multinormality with 3 Interpretation
PCA: Principal Component Analysis
 PCA: Principal Component Analysis Lyron Winderbaum University of Adelaide January 29, 2015 PCA is the vanilla flavour of Component Analysis What is a component? What makes a component principal? A Contrived
PCA: Principal Component Analysis Lyron Winderbaum University of Adelaide January 29, 2015 PCA is the vanilla flavour of Component Analysis What is a component? What makes a component principal? A Contrived
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen PCA. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen PCA Tobias Scheffer Overview Principal Component Analysis (PCA) Kernel-PCA Fisher Linear Discriminant Analysis t-sne 2 PCA: Motivation
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen PCA Tobias Scheffer Overview Principal Component Analysis (PCA) Kernel-PCA Fisher Linear Discriminant Analysis t-sne 2 PCA: Motivation
Relations Between Adjacency And Modularity Graph Partitioning: Principal Component Analysis vs. Modularity Component Analysis
 Relations Between Adjacency And Modularity Graph Partitioning: Principal Component Analysis vs. Modularity Component Analysis Hansi Jiang Carl Meyer North Carolina State University October 27, 2015 1 /
Relations Between Adjacency And Modularity Graph Partitioning: Principal Component Analysis vs. Modularity Component Analysis Hansi Jiang Carl Meyer North Carolina State University October 27, 2015 1 /
Principal Component Analysis
 Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
1 Principal Components Analysis
 Lecture 3 and 4 Sept. 18 and Sept.20-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Principal Components Analysis Principal components analysis (PCA) is a very popular technique for
Lecture 3 and 4 Sept. 18 and Sept.20-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Principal Components Analysis Principal components analysis (PCA) is a very popular technique for
Dimensionality Reduction
 Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach
 A First Dimensionality Reduction Approach") LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
Math 102, Winter Final Exam Review. Chapter 1. Matrices and Gaussian Elimination
 Math 0, Winter 07 Final Exam Review Chapter. Matrices and Gaussian Elimination { x + x =,. Different forms of a system of linear equations. Example: The x + 4x = 4. [ ] [ ] [ ] vector form (or the column
Math 0, Winter 07 Final Exam Review Chapter. Matrices and Gaussian Elimination { x + x =,. Different forms of a system of linear equations. Example: The x + 4x = 4. [ ] [ ] [ ] vector form (or the column
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
Neuroscience Introduction
 Neuroscience Introduction The brain As humans, we can identify galaxies light years away, we can study particles smaller than an atom. But we still haven t unlocked the mystery of the three pounds of matter
Neuroscience Introduction The brain As humans, we can identify galaxies light years away, we can study particles smaller than an atom. But we still haven t unlocked the mystery of the three pounds of matter
Dimension Reduction and Low-dimensional Embedding
 Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Machine Learning 11. week
 Machine Learning 11. week Feature Extraction-Selection Dimension reduction PCA LDA 1 Feature Extraction Any problem can be solved by machine learning methods in case of that the system must be appropriately
Machine Learning 11. week Feature Extraction-Selection Dimension reduction PCA LDA 1 Feature Extraction Any problem can be solved by machine learning methods in case of that the system must be appropriately
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
The Nyström Extension and Spectral Methods in Learning
 Introduction Main Results Simulation Studies Summary The Nyström Extension and Spectral Methods in Learning New bounds and algorithms for high-dimensional data sets Patrick J. Wolfe (joint work with Mohamed-Ali
Introduction Main Results Simulation Studies Summary The Nyström Extension and Spectral Methods in Learning New bounds and algorithms for high-dimensional data sets Patrick J. Wolfe (joint work with Mohamed-Ali
15 Singular Value Decomposition
 15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Notes on Implementation of Component Analysis Techniques
 Notes on Implementation of Component Analysis Techniques Dr. Stefanos Zafeiriou January 205 Computing Principal Component Analysis Assume that we have a matrix of centered data observations X = [x µ,...,
Notes on Implementation of Component Analysis Techniques Dr. Stefanos Zafeiriou January 205 Computing Principal Component Analysis Assume that we have a matrix of centered data observations X = [x µ,...,
Dimension Reduction Techniques. Presented by Jie (Jerry) Yu
 Yu") Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi
 presented by Hassan A. Kingravi") Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Machine Learning (CSE 446): Unsupervised Learning: K-means and Principal Component Analysis
: Unsupervised Learning: K-means and Principal Component Analysis") Machine Learning (CSE 446): Unsupervised Learning: K-means and Principal Component Analysis Sham M Kakade c 2019 University of Washington cse446-staff@cs.washington.edu 0 / 10 Announcements Please do Q1
Machine Learning (CSE 446): Unsupervised Learning: K-means and Principal Component Analysis Sham M Kakade c 2019 University of Washington cse446-staff@cs.washington.edu 0 / 10 Announcements Please do Q1
Linear & Non-Linear Discriminant Analysis! Hugh R. Wilson
 Linear & Non-Linear Discriminant Analysis! Hugh R. Wilson PCA Review! Supervised learning! Fisher linear discriminant analysis! Nonlinear discriminant analysis! Research example! Multiple Classes! Unsupervised
Linear & Non-Linear Discriminant Analysis! Hugh R. Wilson PCA Review! Supervised learning! Fisher linear discriminant analysis! Nonlinear discriminant analysis! Research example! Multiple Classes! Unsupervised
EUSIPCO
 EUSIPCO 2013 1569741067 CLUSERING BY NON-NEGAIVE MARIX FACORIZAION WIH INDEPENDEN PRINCIPAL COMPONEN INIIALIZAION Liyun Gong 1, Asoke K. Nandi 2,3 1 Department of Electrical Engineering and Electronics,
EUSIPCO 2013 1569741067 CLUSERING BY NON-NEGAIVE MARIX FACORIZAION WIH INDEPENDEN PRINCIPAL COMPONEN INIIALIZAION Liyun Gong 1, Asoke K. Nandi 2,3 1 Department of Electrical Engineering and Electronics,
Image Analysis & Retrieval Lec 13 - Feature Dimension Reduction
 CS/EE 5590 / ENG 401 Special Topics, Spring 2018 Image Analysis & Retrieval Lec 13 - Feature Dimension Reduction Zhu Li Dept of CSEE, UMKC http://l.web.umkc.edu/lizhu Office Hour: Tue/Thr 2:30-4pm@FH560E,
CS/EE 5590 / ENG 401 Special Topics, Spring 2018 Image Analysis & Retrieval Lec 13 - Feature Dimension Reduction Zhu Li Dept of CSEE, UMKC http://l.web.umkc.edu/lizhu Office Hour: Tue/Thr 2:30-4pm@FH560E,
Lecture 8. Principal Component Analysis. Luigi Freda. ALCOR Lab DIAG University of Rome La Sapienza. December 13, 2016
 Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Maximum variance formulation
 12.1. Principal Component Analysis 561 Figure 12.2 Principal component analysis seeks a space of lower dimensionality, known as the principal subspace and denoted by the magenta line, such that the orthogonal
12.1. Principal Component Analysis 561 Figure 12.2 Principal component analysis seeks a space of lower dimensionality, known as the principal subspace and denoted by the magenta line, such that the orthogonal
Locality Preserving Projections
 Locality Preserving Projections Xiaofei He Department of Computer Science The University of Chicago Chicago, IL 60637 xiaofei@cs.uchicago.edu Partha Niyogi Department of Computer Science The University
Locality Preserving Projections Xiaofei He Department of Computer Science The University of Chicago Chicago, IL 60637 xiaofei@cs.uchicago.edu Partha Niyogi Department of Computer Science The University
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Singular Value Decomposition and Principal Component Analysis (PCA) I
 I") Singular Value Decomposition and Principal Component Analysis (PCA) I Prof Ned Wingreen MOL 40/50 Microarray review Data per array: 0000 genes, I (green) i,i (red) i 000 000+ data points! The expression
Singular Value Decomposition and Principal Component Analysis (PCA) I Prof Ned Wingreen MOL 40/50 Microarray review Data per array: 0000 genes, I (green) i,i (red) i 000 000+ data points! The expression
Spectral Techniques for Clustering
 Nicola Rebagliati 1/54 Spectral Techniques for Clustering Nicola Rebagliati 29 April, 2010 Nicola Rebagliati 2/54 Thesis Outline 1 2 Data Representation for Clustering Setting Data Representation and Methods
Nicola Rebagliati 1/54 Spectral Techniques for Clustering Nicola Rebagliati 29 April, 2010 Nicola Rebagliati 2/54 Thesis Outline 1 2 Data Representation for Clustering Setting Data Representation and Methods
Lecture 10: Dimension Reduction Techniques
 Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
CHARACTERIZATION OF NONLINEAR NEURON RESPONSES
 CHARACTERIZATION OF NONLINEAR NEURON RESPONSES Matt Whiteway whit8022@umd.edu Dr. Daniel A. Butts dab@umd.edu Neuroscience and Cognitive Science (NACS) Applied Mathematics and Scientific Computation (AMSC)
CHARACTERIZATION OF NONLINEAR NEURON RESPONSES Matt Whiteway whit8022@umd.edu Dr. Daniel A. Butts dab@umd.edu Neuroscience and Cognitive Science (NACS) Applied Mathematics and Scientific Computation (AMSC)
System 1 (last lecture) : limited to rigidly structured shapes. System 2 : recognition of a class of varying shapes. Need to:
 : limited to rigidly structured shapes. System 2 : recognition of a class of varying shapes. Need to:") System 2 : Modelling & Recognising Modelling and Recognising Classes of Classes of Shapes Shape : PDM & PCA All the same shape? System 1 (last lecture) : limited to rigidly structured shapes System 2 :
System 2 : Modelling & Recognising Modelling and Recognising Classes of Classes of Shapes Shape : PDM & PCA All the same shape? System 1 (last lecture) : limited to rigidly structured shapes System 2 :
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center
 Fei Wang and Jimeng Sun IBM TJ Watson Research Center") Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Advanced data analysis
 Advanced data analysis Akisato Kimura ( 木村昭悟 ) NTT Communication Science Laboratories E-mail: akisato@ieee.org Advanced data analysis 1. Introduction (Aug 20) 2. Dimensionality reduction (Aug 20,21) PCA,
Advanced data analysis Akisato Kimura ( 木村昭悟 ) NTT Communication Science Laboratories E-mail: akisato@ieee.org Advanced data analysis 1. Introduction (Aug 20) 2. Dimensionality reduction (Aug 20,21) PCA,
Discriminative K-means for Clustering
 Discriminative K-means for Clustering Jieping Ye Arizona State University Tempe, AZ 85287 jieping.ye@asu.edu Zheng Zhao Arizona State University Tempe, AZ 85287 zhaozheng@asu.edu Mingrui Wu MPI for Biological
Discriminative K-means for Clustering Jieping Ye Arizona State University Tempe, AZ 85287 jieping.ye@asu.edu Zheng Zhao Arizona State University Tempe, AZ 85287 zhaozheng@asu.edu Mingrui Wu MPI for Biological