Introduction to Machine Learning CMU-10701
|
|
|
- Chad Rice
- 5 years ago
- Views:
Transcription
1 Introduction to Machine Learning CMU Stochastic Convergence Barnabás Póczos
2 Motivation 2
3 What have we seen so far? Several algorithms that seem to work fine on training datasets: Linear regression Naïve Bayes classifier Perceptron classifier Support Vector Machines for regression and classification How good are these algorithms on unknown test sets? How many training samples do we need to achieve small error? What is the smallest possible error we can achieve? ) Learning Theory To answer these questions, we will need a few powerful tools 3
4 Basic Estimation Theory 4


5 Tossing a Dice, Estimation of parameters 1, 2,, Does the MLE estimation converge to the right value? How fast does it converge?

6 Tossing a Dice Calculating the Empirical Average Does the empirical average converge to the true mean? How fast does it converge? 6
7 Tossing a Dice, Calculating the Empirical Average 5 sample traces How fast do they converge? 7
8 Key Questions Do empirical averages converge? Does the MLE converge in the dice tossing problem? What do we mean on convergence? What is the rate of convergence? I want to know the coin parameter 2[0,1] within = 0.1 error, with probability at least 1- = How many flips do I need? Applications: drug testing (Does this drug modifies the average blood pressure?) user interface design (We will see later) 8
9 Outline Theory: Stochastic Convergences: Weak convergence Convergence in probability Strong (almost surely) Limit theorems: Law of large numbers Central limit theorem Tail bounds: Markov, Chebyshev,Chernoff, Hoeffding, Bernstein, McDiarmid inequalities Application: A/B testing for page layout 9
10 Stochastic convergence definitions and properties 10
11 Convergence of vectors 11
12 Convergence in Distribution = Convergence Weakly = Convergence in Law Let {Z, Z 1, Z 2, } be a sequence of random variables. Notation: Definition: This is the weakest convergence. 12
13 Convergence in Distribution = Convergence Weakly = Convergence in Law Only the distribution functions converge! (NOT the values of the random variables) 1 0 a 13
14 Convergence in Distribution = Convergence Weakly = Convergence in Law Continuity is important! Example: Proof: /n The limit random variable is constant 0: In this example the limit Z is discrete, not random (constant 0), although Z n is a continuous random variable. 14

")
15 Properties Convergence in Distribution = Convergence Weakly = Convergence in Law Z n and Z can still be independent even if their distributions are the same! Scheffe's theorem: convergence of the probability density functions ) convergence in distribution Example: (Central Limit Theorem) 15
 and Z( ) are from each")
16 Convergence in Probability Notation: Definition: This indeed measures how far the values of Z n ( ) and Z( ) are from each other. 16
17 Almost Surely Convergence Notation: Definition: 17
18 Convergence in p-th mean, L p norm Notation: Definition: Properties: 18
19 Counter Examples 19
20 Further Readings on Stochastic convergence Patrick Billingsley: Probability and Measure Patrick Billingsley: Convergence of Probability Measures 20
21 Finite sample tail bounds Useful tools! 21




22 Gauss Markov inequality If X is any nonnegative random variable and a > 0, then Proof: Decompose the expectation Corollary: Chebyshev's inequality 22
 is the variance of X, defined as: Proof:")
23 Chebyshev inequality If X is any nonnegative random variable and a > 0, then Here Var(X) is the variance of X, defined as: Proof: 23

 There are lots of other generalizations, for")
24 Chebyshev: Generalizations of Chebyshev's inequality This is equivalent to this: Symmetric two-sided case (X is symmetric distribution) Asymmetric two-sided case (X is asymmetric distribution) There are lots of other generalizations, for example multivariate X. 24
25 Higher moments? Markov: Chebyshev: Higher moments: where n 1 Other functions instead of polynomials? Exp function: Proof: (Markov ineq.) 25
26 Law of Large Numbers 26
27 Do empirical averages converge? Chebyshev s inequality is good enough to study the question: Do the empirical averages converge to the true mean? Answer: Yes, they do. (Law of large numbers) 27


28 Law of Large Numbers Weak Law of Large Numbers: Strong Law of Large Numbers: 28
29 Weak Law of Large Numbers Proof I: Assume finite variance. (Not very important) Therefore, As n approaches infinity, this expression approaches 1. 29
30 Fourier Transform and Characteristic Function 30
31 Fourier Transform Fourier transform unitary transf. Inverse Fourier transform Other conventions: Where to put 2? Not preferred: not unitary transf. Doesn t preserve inner product unitary transf. 31


32 Fourier Transform Fourier transform Inverse Fourier transform Properties: Inverse is really inverse: and lots of other important ones Fourier transformation will be used to define the characteristic function, and represent the distributions in an alternative way. 32
33 Characteristic function How can we describe a random variable? cumulative distribution function (cdf) probability density function (pdf) The Characteristic function provides an alternative way for describing a random variable Definition: The Fourier transform of the density/ 33

34 Characteristic function Properties For example, Cauchy doesn t have mean but still has characteristic function. Continuous on the entire space, even if X is not continuous. Bounded, even if X is not bounded Characteristic function of constant a: Levi s: continuity theorem 34

 Limit is a constant distribution")
35 Weak Law of Large Numbers Proof II: Taylor's theorem for complex functions The Characteristic function Properties of characteristic functions : Levi s continuity theorem ) Limit is a constant distribution with mean mean 35



36 Convergence rate for LLN Gauss-Markov: Doesn t give rate Chebyshev: with probability 1- Can we get smaller, logarithmic error in δ??? 36
37 Further Readings on LLN, Characteristic Functions, etc

38 More tail bounds More useful tools! 38
 It only contains")

39 Hoeffding s inequality (1963) It only contains the range of the variables, but not the variances. 39
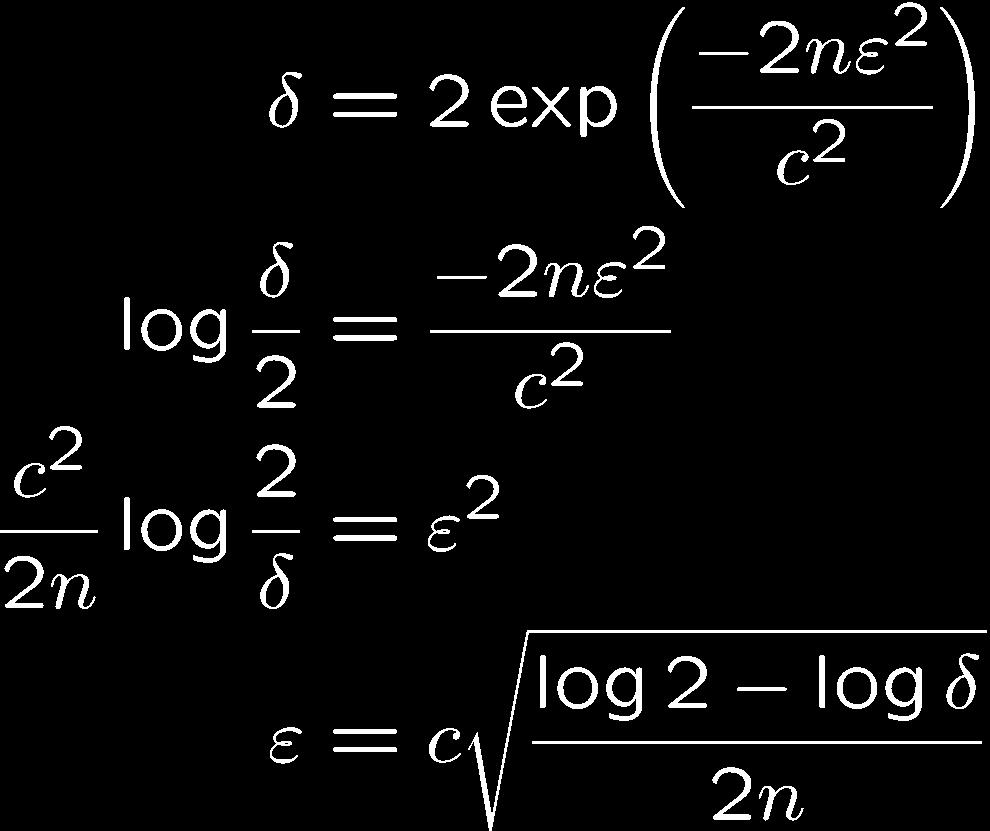

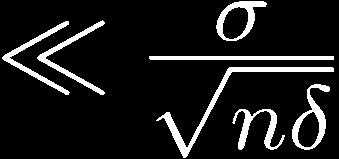
40 Convergence rate for LLN Hoeffding from Hoeffding 40
41 Proof of Hoeffding s Inequality A few minutes of calculations. 41

42 Bernstein s inequality (1946) It contains the variances, too, and can give tighter bounds than Hoeffding. 42
 Proof: )")

43 Benett s inequality (1962) Proof: Benett s inequality ) Bernstein s inequality. 43
44 McDiarmid s Bounded Difference Inequality It follows that 44
45 Further Readings on Tail bounds (McDiarmid)
46 Limit Distribution? 46

47 Central Limit Theorem Lindeberg-Lévi CLT: Lyapunov CLT: + some other conditions Generalizations: multi dim, time processes 47


48 Central Limit Theorem in Practice unscaled scaled 48
 CLT characteristic function of Gauss distribution")
49 Proof of CLT From Taylor series around 0: Properties of characteristic functions : Levi s continuity theorem + uniqueness ) CLT characteristic function of Gauss distribution 49

50 How fast do we converge to Gauss distribution? CLT: It doesn t tell us anything about the convergence rate. Berry-Esseen Theorem Independently discovered by A. C. Berry (in 1941) and C.-G. Esseen (1942) 50
51 Did we answer the questions we asked? Do empirical averages converge? What do we mean on convergence? What is the rate of convergence? What is the limit distrib. of standardized averages? Next time we will continue with these questions: How good are the ML algorithms on unknown test sets? How many training samples do we need to achieve small error? What is the smallest possible error we can achieve? 51
52 Further Readings on CLT


53 Tail bounds in practice 53

54 A/B testing Two possible webpage layouts Which layout is better? Experiment Some users see A The others see design B How many trials do we need to decide which page attracts more clicks? 54
55 A/B testing Let us simplify this question a bit: Assume that in group A p(click A) = 0.10 click and p(noclick A) = 0.90 Assume that in group B p(click B) = 0.11 click and p(noclick A) = 0.89 Assume also that we know these probabilities in group A, but we don t know yet them in group B. We want to estimate p(click B) with less than 0.01 error 55


 If we know that the click probability is < 0.")
56 Chebyshev Inequality Chebyshev: In group B the click probability is = 0.11 (we don t know this yet) Want failure probability of =5% If we have no prior knowledge, we can only bound the variance by σ 2 = 0.25 (Uniform distribution hast the largest variance 0.25) If we know that the click probability is < 0.15, then we can bound 2 at 0.15 * 0.85 = This requires at most 25,500 users. 56
57 Hoeffding s bound Hoeffding Random variable has bounded range [0, 1] (click or no click), hence c=1 Solve Hoeffding s inequality for n: This is better than Chebyshev. 57
58 Thanks for your attention 58
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Risk Minimization Barnabás Póczos What have we seen so far? Several classification & regression algorithms seem to work fine on training datasets: Linear
Advanced Introduction to Machine Learning CMU-10715 Risk Minimization Barnabás Póczos What have we seen so far? Several classification & regression algorithms seem to work fine on training datasets: Linear
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU10701 11. Learning Theory Barnabás Póczos Learning Theory We have explored many ways of learning from data But How good is our classifier, really? How much data do we
Introduction to Machine Learning CMU10701 11. Learning Theory Barnabás Póczos Learning Theory We have explored many ways of learning from data But How good is our classifier, really? How much data do we
Introduction to Machine Learning
 Introduction to Machine Learning Vapnik Chervonenkis Theory Barnabás Póczos Empirical Risk and True Risk 2 Empirical Risk Shorthand: True risk of f (deterministic): Bayes risk: Let us use the empirical
Introduction to Machine Learning Vapnik Chervonenkis Theory Barnabás Póczos Empirical Risk and True Risk 2 Empirical Risk Shorthand: True risk of f (deterministic): Bayes risk: Let us use the empirical
Theorem 2.1 (Caratheodory). A (countably additive) probability measure on a field has an extension. n=1
. A (countably additive) probability measure on a field has an extension. n=1") Chapter 2 Probability measures 1. Existence Theorem 2.1 (Caratheodory). A (countably additive) probability measure on a field has an extension to the generated σ-field Proof of Theorem 2.1. Let F 0 be
Chapter 2 Probability measures 1. Existence Theorem 2.1 (Caratheodory). A (countably additive) probability measure on a field has an extension to the generated σ-field Proof of Theorem 2.1. Let F 0 be
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
STAT 7032 Probability. Wlodek Bryc
 STAT 7032 Probability Wlodek Bryc Revised for Spring 2019 Printed: January 14, 2019 File: Grad-Prob-2019.TEX Department of Mathematical Sciences, University of Cincinnati, Cincinnati, OH 45221 E-mail address:
STAT 7032 Probability Wlodek Bryc Revised for Spring 2019 Printed: January 14, 2019 File: Grad-Prob-2019.TEX Department of Mathematical Sciences, University of Cincinnati, Cincinnati, OH 45221 E-mail address:
March 1, Florida State University. Concentration Inequalities: Martingale. Approach and Entropy Method. Lizhe Sun and Boning Yang.
 Florida State University March 1, 2018 Framework 1. (Lizhe) Basic inequalities Chernoff bounding Review for STA 6448 2. (Lizhe) Discrete-time martingales inequalities via martingale approach 3. (Boning)
Florida State University March 1, 2018 Framework 1. (Lizhe) Basic inequalities Chernoff bounding Review for STA 6448 2. (Lizhe) Discrete-time martingales inequalities via martingale approach 3. (Boning)
The main results about probability measures are the following two facts:
 Chapter 2 Probability measures The main results about probability measures are the following two facts: Theorem 2.1 (extension). If P is a (continuous) probability measure on a field F 0 then it has a
Chapter 2 Probability measures The main results about probability measures are the following two facts: Theorem 2.1 (extension). If P is a (continuous) probability measure on a field F 0 then it has a
Kernel Methods. Barnabás Póczos
 Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
STAT 7032 Probability Spring Wlodek Bryc
 STAT 7032 Probability Spring 2018 Wlodek Bryc Created: Friday, Jan 2, 2014 Revised for Spring 2018 Printed: January 9, 2018 File: Grad-Prob-2018.TEX Department of Mathematical Sciences, University of Cincinnati,
STAT 7032 Probability Spring 2018 Wlodek Bryc Created: Friday, Jan 2, 2014 Revised for Spring 2018 Printed: January 9, 2018 File: Grad-Prob-2018.TEX Department of Mathematical Sciences, University of Cincinnati,
CS 160: Lecture 16. Quantitative Studies. Outline. Random variables and trials. Random variables. Qualitative vs. Quantitative Studies
 Qualitative vs. Quantitative Studies CS 160: Lecture 16 Professor John Canny Qualitative: What we ve been doing so far: * Contextual Inquiry: trying to understand user s tasks and their conceptual model.
Qualitative vs. Quantitative Studies CS 160: Lecture 16 Professor John Canny Qualitative: What we ve been doing so far: * Contextual Inquiry: trying to understand user s tasks and their conceptual model.
Economics 583: Econometric Theory I A Primer on Asymptotics
 Economics 583: Econometric Theory I A Primer on Asymptotics Eric Zivot January 14, 2013 The two main concepts in asymptotic theory that we will use are Consistency Asymptotic Normality Intuition consistency:
Economics 583: Econometric Theory I A Primer on Asymptotics Eric Zivot January 14, 2013 The two main concepts in asymptotic theory that we will use are Consistency Asymptotic Normality Intuition consistency:
1 Appendix A: Matrix Algebra
 Appendix A: Matrix Algebra. Definitions Matrix A =[ ]=[A] Symmetric matrix: = for all and Diagonal matrix: 6=0if = but =0if 6= Scalar matrix: the diagonal matrix of = Identity matrix: the scalar matrix
Appendix A: Matrix Algebra. Definitions Matrix A =[ ]=[A] Symmetric matrix: = for all and Diagonal matrix: 6=0if = but =0if 6= Scalar matrix: the diagonal matrix of = Identity matrix: the scalar matrix
Probability Theory for Machine Learning. Chris Cremer September 2015
 Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
STAT 200C: High-dimensional Statistics
 STAT 200C: High-dimensional Statistics Arash A. Amini May 30, 2018 1 / 59 Classical case: n d. Asymptotic assumption: d is fixed and n. Basic tools: LLN and CLT. High-dimensional setting: n d, e.g. n/d
STAT 200C: High-dimensional Statistics Arash A. Amini May 30, 2018 1 / 59 Classical case: n d. Asymptotic assumption: d is fixed and n. Basic tools: LLN and CLT. High-dimensional setting: n d, e.g. n/d
Perhaps the simplest way of modeling two (discrete) random variables is by means of a joint PMF, defined as follows.
 random variables is by means of a joint PMF, defined as follows.") Chapter 5 Two Random Variables In a practical engineering problem, there is almost always causal relationship between different events. Some relationships are determined by physical laws, e.g., voltage
Chapter 5 Two Random Variables In a practical engineering problem, there is almost always causal relationship between different events. Some relationships are determined by physical laws, e.g., voltage
CPSC 340: Machine Learning and Data Mining. MLE and MAP Fall 2017
 CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
Product measure and Fubini s theorem
 Chapter 7 Product measure and Fubini s theorem This is based on [Billingsley, Section 18]. 1. Product spaces Suppose (Ω 1, F 1 ) and (Ω 2, F 2 ) are two probability spaces. In a product space Ω = Ω 1 Ω
Chapter 7 Product measure and Fubini s theorem This is based on [Billingsley, Section 18]. 1. Product spaces Suppose (Ω 1, F 1 ) and (Ω 2, F 2 ) are two probability spaces. In a product space Ω = Ω 1 Ω
A Primer on Asymptotics
 A Primer on Asymptotics Eric Zivot Department of Economics University of Washington September 30, 2003 Revised: October 7, 2009 Introduction The two main concepts in asymptotic theory covered in these
A Primer on Asymptotics Eric Zivot Department of Economics University of Washington September 30, 2003 Revised: October 7, 2009 Introduction The two main concepts in asymptotic theory covered in these
X = X X n, + X 2
 CS 70 Discrete Mathematics for CS Fall 2003 Wagner Lecture 22 Variance Question: At each time step, I flip a fair coin. If it comes up Heads, I walk one step to the right; if it comes up Tails, I walk
CS 70 Discrete Mathematics for CS Fall 2003 Wagner Lecture 22 Variance Question: At each time step, I flip a fair coin. If it comes up Heads, I walk one step to the right; if it comes up Tails, I walk
Review. DS GA 1002 Statistical and Mathematical Models. Carlos Fernandez-Granda
 Review DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall16 Carlos Fernandez-Granda Probability and statistics Probability: Framework for dealing with
Review DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall16 Carlos Fernandez-Granda Probability and statistics Probability: Framework for dealing with
Machine Learning: Assignment 1
 10-701 Machine Learning: Assignment 1 Due on Februrary 0, 014 at 1 noon Barnabas Poczos, Aarti Singh Instructions: Failure to follow these directions may result in loss of points. Your solutions for this
10-701 Machine Learning: Assignment 1 Due on Februrary 0, 014 at 1 noon Barnabas Poczos, Aarti Singh Instructions: Failure to follow these directions may result in loss of points. Your solutions for this
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining MLE and MAP Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due tonight. Assignment 5: Will be released
CPSC 340: Machine Learning and Data Mining MLE and MAP Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due tonight. Assignment 5: Will be released
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Machine Learning for Computational Advertising
 Machine Learning for Computational Advertising L1: Basics and Probability Theory Alexander J. Smola Yahoo! Labs Santa Clara, CA 95051 alex@smola.org UC Santa Cruz, April 2009 Alexander J. Smola: Machine
Machine Learning for Computational Advertising L1: Basics and Probability Theory Alexander J. Smola Yahoo! Labs Santa Clara, CA 95051 alex@smola.org UC Santa Cruz, April 2009 Alexander J. Smola: Machine
Lecture Notes 5 Convergence and Limit Theorems. Convergence with Probability 1. Convergence in Mean Square. Convergence in Probability, WLLN
 Lecture Notes 5 Convergence and Limit Theorems Motivation Convergence with Probability Convergence in Mean Square Convergence in Probability, WLLN Convergence in Distribution, CLT EE 278: Convergence and
Lecture Notes 5 Convergence and Limit Theorems Motivation Convergence with Probability Convergence in Mean Square Convergence in Probability, WLLN Convergence in Distribution, CLT EE 278: Convergence and
The Naïve Bayes Classifier. Machine Learning Fall 2017
 The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
Machine Learning Basics Lecture 4: SVM I. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, 2013
 Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Lecture Notes 3 Convergence (Chapter 5)
") Lecture Notes 3 Convergence (Chapter 5) 1 Convergence of Random Variables Let X 1, X 2,... be a sequence of random variables and let X be another random variable. Let F n denote the cdf of X n and let
Lecture Notes 3 Convergence (Chapter 5) 1 Convergence of Random Variables Let X 1, X 2,... be a sequence of random variables and let X be another random variable. Let F n denote the cdf of X n and let
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Exponential Tail Bounds
 Exponential Tail Bounds Mathias Winther Madsen January 2, 205 Here s a warm-up problem to get you started: Problem You enter the casino with 00 chips and start playing a game in which you double your capital
Exponential Tail Bounds Mathias Winther Madsen January 2, 205 Here s a warm-up problem to get you started: Problem You enter the casino with 00 chips and start playing a game in which you double your capital
3. Review of Probability and Statistics
 3. Review of Probability and Statistics ECE 830, Spring 2014 Probabilistic models will be used throughout the course to represent noise, errors, and uncertainty in signal processing problems. This lecture
3. Review of Probability and Statistics ECE 830, Spring 2014 Probabilistic models will be used throughout the course to represent noise, errors, and uncertainty in signal processing problems. This lecture
Lecture 2 Sep 5, 2017
 CS 388R: Randomized Algorithms Fall 2017 Lecture 2 Sep 5, 2017 Prof. Eric Price Scribe: V. Orestis Papadigenopoulos and Patrick Rall NOTE: THESE NOTES HAVE NOT BEEN EDITED OR CHECKED FOR CORRECTNESS 1
CS 388R: Randomized Algorithms Fall 2017 Lecture 2 Sep 5, 2017 Prof. Eric Price Scribe: V. Orestis Papadigenopoulos and Patrick Rall NOTE: THESE NOTES HAVE NOT BEEN EDITED OR CHECKED FOR CORRECTNESS 1
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Machine Learning. Instructor: Pranjal Awasthi
 Machine Learning Instructor: Pranjal Awasthi Course Info Requested an SPN and emailed me Wait for Carol Difrancesco to give them out. Not registered and need SPN Email me after class No promises It s a
Machine Learning Instructor: Pranjal Awasthi Course Info Requested an SPN and emailed me Wait for Carol Difrancesco to give them out. Not registered and need SPN Email me after class No promises It s a
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Gaussian Processes Barnabás Póczos http://www.gaussianprocess.org/ 2 Some of these slides in the intro are taken from D. Lizotte, R. Parr, C. Guesterin
Advanced Introduction to Machine Learning CMU-10715 Gaussian Processes Barnabás Póczos http://www.gaussianprocess.org/ 2 Some of these slides in the intro are taken from D. Lizotte, R. Parr, C. Guesterin
15-388/688 - Practical Data Science: Basic probability. J. Zico Kolter Carnegie Mellon University Spring 2018
 15-388/688 - Practical Data Science: Basic probability J. Zico Kolter Carnegie Mellon University Spring 2018 1 Announcements Logistics of next few lectures Final project released, proposals/groups due
15-388/688 - Practical Data Science: Basic probability J. Zico Kolter Carnegie Mellon University Spring 2018 1 Announcements Logistics of next few lectures Final project released, proposals/groups due
High Dimensional Probability
 High Dimensional Probability for Mathematicians and Data Scientists Roman Vershynin 1 1 University of Michigan. Webpage: www.umich.edu/~romanv ii Preface Who is this book for? This is a textbook in probability
High Dimensional Probability for Mathematicians and Data Scientists Roman Vershynin 1 1 University of Michigan. Webpage: www.umich.edu/~romanv ii Preface Who is this book for? This is a textbook in probability
Probability and Statistics Concepts
 University of Central Florida Computer Science Division COT 5611 - Operating Systems. Spring 014 - dcm Probability and Statistics Concepts Random Variable: a rule that assigns a numerical value to each
University of Central Florida Computer Science Division COT 5611 - Operating Systems. Spring 014 - dcm Probability and Statistics Concepts Random Variable: a rule that assigns a numerical value to each
Discrete Mathematics for CS Spring 2007 Luca Trevisan Lecture 20
 CS 70 Discrete Mathematics for CS Spring 2007 Luca Trevisan Lecture 20 Today we shall discuss a measure of how close a random variable tends to be to its expectation. But first we need to see how to compute
CS 70 Discrete Mathematics for CS Spring 2007 Luca Trevisan Lecture 20 Today we shall discuss a measure of how close a random variable tends to be to its expectation. But first we need to see how to compute
6.1 Moment Generating and Characteristic Functions
 Chapter 6 Limit Theorems The power statistics can mostly be seen when there is a large collection of data points and we are interested in understanding the macro state of the system, e.g., the average,
Chapter 6 Limit Theorems The power statistics can mostly be seen when there is a large collection of data points and we are interested in understanding the macro state of the system, e.g., the average,
Midterm: CS 6375 Spring 2018
 Midterm: CS 6375 Spring 2018 The exam is closed book (1 cheat sheet allowed). Answer the questions in the spaces provided on the question sheets. If you run out of room for an answer, use an additional
Midterm: CS 6375 Spring 2018 The exam is closed book (1 cheat sheet allowed). Answer the questions in the spaces provided on the question sheets. If you run out of room for an answer, use an additional
Lecture 1 Measure concentration
 CSE 29: Learning Theory Fall 2006 Lecture Measure concentration Lecturer: Sanjoy Dasgupta Scribe: Nakul Verma, Aaron Arvey, and Paul Ruvolo. Concentration of measure: examples We start with some examples
CSE 29: Learning Theory Fall 2006 Lecture Measure concentration Lecturer: Sanjoy Dasgupta Scribe: Nakul Verma, Aaron Arvey, and Paul Ruvolo. Concentration of measure: examples We start with some examples
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Bayesian Learning (II)
") Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Machine Learning CSE546 Sham Kakade University of Washington. Oct 4, What about continuous variables?
 Linear Regression Machine Learning CSE546 Sham Kakade University of Washington Oct 4, 2016 1 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do
Linear Regression Machine Learning CSE546 Sham Kakade University of Washington Oct 4, 2016 1 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do
Why should you care?? Intellectual curiosity. Gambling. Mathematically the same as the ESP decision problem we discussed in Week 4.
 I. Probability basics (Sections 4.1 and 4.2) Flip a fair (probability of HEADS is 1/2) coin ten times. What is the probability of getting exactly 5 HEADS? What is the probability of getting exactly 10
I. Probability basics (Sections 4.1 and 4.2) Flip a fair (probability of HEADS is 1/2) coin ten times. What is the probability of getting exactly 5 HEADS? What is the probability of getting exactly 10
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, What about continuous variables?
 Linear Regression Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2014 1 What about continuous variables? n Billionaire says: If I am measuring a continuous variable, what
Linear Regression Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2014 1 What about continuous variables? n Billionaire says: If I am measuring a continuous variable, what
The PAC Learning Framework -II
 The PAC Learning Framework -II Prof. Dan A. Simovici UMB 1 / 1 Outline 1 Finite Hypothesis Space - The Inconsistent Case 2 Deterministic versus stochastic scenario 3 Bayes Error and Noise 2 / 1 Outline
The PAC Learning Framework -II Prof. Dan A. Simovici UMB 1 / 1 Outline 1 Finite Hypothesis Space - The Inconsistent Case 2 Deterministic versus stochastic scenario 3 Bayes Error and Noise 2 / 1 Outline
Lecture 2: Review of Basic Probability Theory
 ECE 830 Fall 2010 Statistical Signal Processing instructor: R. Nowak, scribe: R. Nowak Lecture 2: Review of Basic Probability Theory Probabilistic models will be used throughout the course to represent
ECE 830 Fall 2010 Statistical Signal Processing instructor: R. Nowak, scribe: R. Nowak Lecture 2: Review of Basic Probability Theory Probabilistic models will be used throughout the course to represent
Discrete Mathematics and Probability Theory Fall 2015 Lecture 21
 CS 70 Discrete Mathematics and Probability Theory Fall 205 Lecture 2 Inference In this note we revisit the problem of inference: Given some data or observations from the world, what can we infer about
CS 70 Discrete Mathematics and Probability Theory Fall 205 Lecture 2 Inference In this note we revisit the problem of inference: Given some data or observations from the world, what can we infer about
Why study probability? Set theory. ECE 6010 Lecture 1 Introduction; Review of Random Variables
 ECE 6010 Lecture 1 Introduction; Review of Random Variables Readings from G&S: Chapter 1. Section 2.1, Section 2.3, Section 2.4, Section 3.1, Section 3.2, Section 3.5, Section 4.1, Section 4.2, Section
ECE 6010 Lecture 1 Introduction; Review of Random Variables Readings from G&S: Chapter 1. Section 2.1, Section 2.3, Section 2.4, Section 3.1, Section 3.2, Section 3.5, Section 4.1, Section 4.2, Section
DS-GA 1003: Machine Learning and Computational Statistics Homework 7: Bayesian Modeling
 DS-GA 1003: Machine Learning and Computational Statistics Homework 7: Bayesian Modeling Due: Tuesday, May 10, 2016, at 6pm (Submit via NYU Classes) Instructions: Your answers to the questions below, including
DS-GA 1003: Machine Learning and Computational Statistics Homework 7: Bayesian Modeling Due: Tuesday, May 10, 2016, at 6pm (Submit via NYU Classes) Instructions: Your answers to the questions below, including
18.175: Lecture 13 Infinite divisibility and Lévy processes
 18.175 Lecture 13 18.175: Lecture 13 Infinite divisibility and Lévy processes Scott Sheffield MIT Outline Poisson random variable convergence Extend CLT idea to stable random variables Infinite divisibility
18.175 Lecture 13 18.175: Lecture 13 Infinite divisibility and Lévy processes Scott Sheffield MIT Outline Poisson random variable convergence Extend CLT idea to stable random variables Infinite divisibility
IFT Lecture 7 Elements of statistical learning theory
 IFT 6085 - Lecture 7 Elements of statistical learning theory This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s): Brady Neal and
IFT 6085 - Lecture 7 Elements of statistical learning theory This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s): Brady Neal and
18.175: Lecture 8 Weak laws and moment-generating/characteristic functions
 18.175: Lecture 8 Weak laws and moment-generating/characteristic functions Scott Sheffield MIT 18.175 Lecture 8 1 Outline Moment generating functions Weak law of large numbers: Markov/Chebyshev approach
18.175: Lecture 8 Weak laws and moment-generating/characteristic functions Scott Sheffield MIT 18.175 Lecture 8 1 Outline Moment generating functions Weak law of large numbers: Markov/Chebyshev approach
Lecture 3: Statistical sampling uncertainty
 Lecture 3: Statistical sampling uncertainty c Christopher S. Bretherton Winter 2015 3.1 Central limit theorem (CLT) Let X 1,..., X N be a sequence of N independent identically-distributed (IID) random
Lecture 3: Statistical sampling uncertainty c Christopher S. Bretherton Winter 2015 3.1 Central limit theorem (CLT) Let X 1,..., X N be a sequence of N independent identically-distributed (IID) random
Expectation is linear. So far we saw that E(X + Y ) = E(X) + E(Y ). Let α R. Then,
 = E(X) + E(Y ). Let α R. Then,") Expectation is linear So far we saw that E(X + Y ) = E(X) + E(Y ). Let α R. Then, E(αX) = ω = ω (αx)(ω) Pr(ω) αx(ω) Pr(ω) = α ω X(ω) Pr(ω) = αe(x). Corollary. For α, β R, E(αX + βy ) = αe(x) + βe(y ).
Expectation is linear So far we saw that E(X + Y ) = E(X) + E(Y ). Let α R. Then, E(αX) = ω = ω (αx)(ω) Pr(ω) αx(ω) Pr(ω) = α ω X(ω) Pr(ω) = αe(x). Corollary. For α, β R, E(αX + βy ) = αe(x) + βe(y ).
Statistical Machine Learning
 Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 2: Introduction to statistical learning theory. 1 / 22 Goals of statistical learning theory SLT aims at studying the performance of
Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 2: Introduction to statistical learning theory. 1 / 22 Goals of statistical learning theory SLT aims at studying the performance of
COMPSCI 240: Reasoning Under Uncertainty
 COMPSCI 240: Reasoning Under Uncertainty Andrew Lan and Nic Herndon University of Massachusetts at Amherst Spring 2019 Lecture 20: Central limit theorem & The strong law of large numbers Markov and Chebyshev
COMPSCI 240: Reasoning Under Uncertainty Andrew Lan and Nic Herndon University of Massachusetts at Amherst Spring 2019 Lecture 20: Central limit theorem & The strong law of large numbers Markov and Chebyshev
Quick Tour of Basic Probability Theory and Linear Algebra
 Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra CS224w: Social and Information Network Analysis Fall 2011 Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra Outline Definitions
Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra CS224w: Social and Information Network Analysis Fall 2011 Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra Outline Definitions
CSC 411: Lecture 09: Naive Bayes
 CSC 411: Lecture 09: Naive Bayes Class based on Raquel Urtasun & Rich Zemel s lectures Sanja Fidler University of Toronto Feb 8, 2015 Urtasun, Zemel, Fidler (UofT) CSC 411: 09-Naive Bayes Feb 8, 2015 1
CSC 411: Lecture 09: Naive Bayes Class based on Raquel Urtasun & Rich Zemel s lectures Sanja Fidler University of Toronto Feb 8, 2015 Urtasun, Zemel, Fidler (UofT) CSC 411: 09-Naive Bayes Feb 8, 2015 1
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Quantitative Introduction ro Risk and Uncertainty in Business Module 5: Hypothesis Testing
 Quantitative Introduction ro Risk and Uncertainty in Business Module 5: Hypothesis Testing M. Vidyasagar Cecil & Ida Green Chair The University of Texas at Dallas Email: M.Vidyasagar@utdallas.edu October
Quantitative Introduction ro Risk and Uncertainty in Business Module 5: Hypothesis Testing M. Vidyasagar Cecil & Ida Green Chair The University of Texas at Dallas Email: M.Vidyasagar@utdallas.edu October
EE514A Information Theory I Fall 2013
 EE514A Information Theory I Fall 2013 K. Mohan, Prof. J. Bilmes University of Washington, Seattle Department of Electrical Engineering Fall Quarter, 2013 http://j.ee.washington.edu/~bilmes/classes/ee514a_fall_2013/
EE514A Information Theory I Fall 2013 K. Mohan, Prof. J. Bilmes University of Washington, Seattle Department of Electrical Engineering Fall Quarter, 2013 http://j.ee.washington.edu/~bilmes/classes/ee514a_fall_2013/
Learning Theory. Aar$ Singh and Barnabas Poczos. Machine Learning / Apr 17, Slides courtesy: Carlos Guestrin
 Learning Theory Aar$ Singh and Barnabas Poczos Machine Learning 10-701/15-781 Apr 17, 2014 Slides courtesy: Carlos Guestrin Learning Theory We have explored many ways of learning from data But How good
Learning Theory Aar$ Singh and Barnabas Poczos Machine Learning 10-701/15-781 Apr 17, 2014 Slides courtesy: Carlos Guestrin Learning Theory We have explored many ways of learning from data But How good
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Convex Optimization CMU-10725
 Convex Optimization CMU-10725 Simulated Annealing Barnabás Póczos & Ryan Tibshirani Andrey Markov Markov Chains 2 Markov Chains Markov chain: Homogen Markov chain: 3 Markov Chains Assume that the state
Convex Optimization CMU-10725 Simulated Annealing Barnabás Póczos & Ryan Tibshirani Andrey Markov Markov Chains 2 Markov Chains Markov chain: Homogen Markov chain: 3 Markov Chains Assume that the state
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Overview. Confidence Intervals Sampling and Opinion Polls Error Correcting Codes Number of Pet Unicorns in Ireland
 Overview Confidence Intervals Sampling and Opinion Polls Error Correcting Codes Number of Pet Unicorns in Ireland Confidence Intervals When a random variable lies in an interval a X b with a specified
Overview Confidence Intervals Sampling and Opinion Polls Error Correcting Codes Number of Pet Unicorns in Ireland Confidence Intervals When a random variable lies in an interval a X b with a specified
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
Learning Theory. Sridhar Mahadevan. University of Massachusetts. p. 1/38
 Learning Theory Sridhar Mahadevan mahadeva@cs.umass.edu University of Massachusetts p. 1/38 Topics Probability theory meet machine learning Concentration inequalities: Chebyshev, Chernoff, Hoeffding, and
Learning Theory Sridhar Mahadevan mahadeva@cs.umass.edu University of Massachusetts p. 1/38 Topics Probability theory meet machine learning Concentration inequalities: Chebyshev, Chernoff, Hoeffding, and
CS 246 Review of Proof Techniques and Probability 01/14/19
 Note: This document has been adapted from a similar review session for CS224W (Autumn 2018). It was originally compiled by Jessica Su, with minor edits by Jayadev Bhaskaran. 1 Proof techniques Here we
Note: This document has been adapted from a similar review session for CS224W (Autumn 2018). It was originally compiled by Jessica Su, with minor edits by Jayadev Bhaskaran. 1 Proof techniques Here we
Example continued. Math 425 Intro to Probability Lecture 37. Example continued. Example
 continued : Coin tossing Math 425 Intro to Probability Lecture 37 Kenneth Harris kaharri@umich.edu Department of Mathematics University of Michigan April 8, 2009 Consider a Bernoulli trials process with
continued : Coin tossing Math 425 Intro to Probability Lecture 37 Kenneth Harris kaharri@umich.edu Department of Mathematics University of Michigan April 8, 2009 Consider a Bernoulli trials process with
Math 105 Course Outline
 Math 105 Course Outline Week 9 Overview This week we give a very brief introduction to random variables and probability theory. Most observable phenomena have at least some element of randomness associated
Math 105 Course Outline Week 9 Overview This week we give a very brief introduction to random variables and probability theory. Most observable phenomena have at least some element of randomness associated
The Central Limit Theorem
 The Central Limit Theorem Patrick Breheny September 27 Patrick Breheny University of Iowa Biostatistical Methods I (BIOS 5710) 1 / 31 Kerrich s experiment Introduction 10,000 coin flips Expectation and
The Central Limit Theorem Patrick Breheny September 27 Patrick Breheny University of Iowa Biostatistical Methods I (BIOS 5710) 1 / 31 Kerrich s experiment Introduction 10,000 coin flips Expectation and
Function Approximation
 1 Function Approximation This is page i Printer: Opaque this 1.1 Introduction In this chapter we discuss approximating functional forms. Both in econometric and in numerical problems, the need for an approximating
1 Function Approximation This is page i Printer: Opaque this 1.1 Introduction In this chapter we discuss approximating functional forms. Both in econometric and in numerical problems, the need for an approximating
Introduction to Machine Learning
 Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB
Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB
Review (Probability & Linear Algebra)
") Review (Probability & Linear Algebra) CE-725 : Statistical Pattern Recognition Sharif University of Technology Spring 2013 M. Soleymani Outline Axioms of probability theory Conditional probability, Joint
Review (Probability & Linear Algebra) CE-725 : Statistical Pattern Recognition Sharif University of Technology Spring 2013 M. Soleymani Outline Axioms of probability theory Conditional probability, Joint
Part IA Probability. Definitions. Based on lectures by R. Weber Notes taken by Dexter Chua. Lent 2015
 Part IA Probability Definitions Based on lectures by R. Weber Notes taken by Dexter Chua Lent 2015 These notes are not endorsed by the lecturers, and I have modified them (often significantly) after lectures.
Part IA Probability Definitions Based on lectures by R. Weber Notes taken by Dexter Chua Lent 2015 These notes are not endorsed by the lecturers, and I have modified them (often significantly) after lectures.
The Representor Theorem, Kernels, and Hilbert Spaces
 The Representor Theorem, Kernels, and Hilbert Spaces We will now work with infinite dimensional feature vectors and parameter vectors. The space l is defined to be the set of sequences f 1, f, f 3,...
The Representor Theorem, Kernels, and Hilbert Spaces We will now work with infinite dimensional feature vectors and parameter vectors. The space l is defined to be the set of sequences f 1, f, f 3,...
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
ELEG 3143 Probability & Stochastic Process Ch. 2 Discrete Random Variables
 Department of Electrical Engineering University of Arkansas ELEG 3143 Probability & Stochastic Process Ch. 2 Discrete Random Variables Dr. Jingxian Wu wuj@uark.edu OUTLINE 2 Random Variable Discrete Random
Department of Electrical Engineering University of Arkansas ELEG 3143 Probability & Stochastic Process Ch. 2 Discrete Random Variables Dr. Jingxian Wu wuj@uark.edu OUTLINE 2 Random Variable Discrete Random
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning
 SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Chapter 6. Convergence. Probability Theory. Four different convergence concepts. Four different convergence concepts. Convergence in probability
 Probability Theory Chapter 6 Convergence Four different convergence concepts Let X 1, X 2, be a sequence of (usually dependent) random variables Definition 1.1. X n converges almost surely (a.s.), or with
Probability Theory Chapter 6 Convergence Four different convergence concepts Let X 1, X 2, be a sequence of (usually dependent) random variables Definition 1.1. X n converges almost surely (a.s.), or with
8 Laws of large numbers
 8 Laws of large numbers 8.1 Introduction We first start with the idea of standardizing a random variable. Let X be a random variable with mean µ and variance σ 2. Then Z = (X µ)/σ will be a random variable
8 Laws of large numbers 8.1 Introduction We first start with the idea of standardizing a random variable. Let X be a random variable with mean µ and variance σ 2. Then Z = (X µ)/σ will be a random variable
Lecture 11. Probability Theory: an Overveiw
 Math 408 - Mathematical Statistics Lecture 11. Probability Theory: an Overveiw February 11, 2013 Konstantin Zuev (USC) Math 408, Lecture 11 February 11, 2013 1 / 24 The starting point in developing the
Math 408 - Mathematical Statistics Lecture 11. Probability Theory: an Overveiw February 11, 2013 Konstantin Zuev (USC) Math 408, Lecture 11 February 11, 2013 1 / 24 The starting point in developing the
Topics we covered. Machine Learning. Statistics. Optimization. Systems! Basics of probability Tail bounds Density Estimation Exponential Families
 Midterm Review Topics we covered Machine Learning Optimization Basics of optimization Convexity Unconstrained: GD, SGD Constrained: Lagrange, KKT Duality Linear Methods Perceptrons Support Vector Machines
Midterm Review Topics we covered Machine Learning Optimization Basics of optimization Convexity Unconstrained: GD, SGD Constrained: Lagrange, KKT Duality Linear Methods Perceptrons Support Vector Machines
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CS 361: Probability & Statistics
 February 19, 2018 CS 361: Probability & Statistics Random variables Markov s inequality This theorem says that for any random variable X and any value a, we have A random variable is unlikely to have an
February 19, 2018 CS 361: Probability & Statistics Random variables Markov s inequality This theorem says that for any random variable X and any value a, we have A random variable is unlikely to have an
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probability and Estimation. Alan Moses
 Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Review of Probabilities and Basic Statistics
 Alex Smola Barnabas Poczos TA: Ina Fiterau 4 th year PhD student MLD Review of Probabilities and Basic Statistics 10-701 Recitations 1/25/2013 Recitation 1: Statistics Intro 1 Overview Introduction to
Alex Smola Barnabas Poczos TA: Ina Fiterau 4 th year PhD student MLD Review of Probabilities and Basic Statistics 10-701 Recitations 1/25/2013 Recitation 1: Statistics Intro 1 Overview Introduction to
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff