Time Series Anomaly Detection
|
|
|
- Whitney Greene
- 5 years ago
- Views:
Transcription

1 Time Series Anomaly Detection Detection of Anomalous Drops with Limited Features and Sparse Examples in Noisy Highly Periodic Data Dominique T. Shipmon, Jason M. Gurevitch, Paolo M. Piselli, Steve Edwards Google, Inc. Cambridge, MA, USA {dshipmon205, 1 Abstract Google uses continuous streams of data from industry partners in order to deliver accurate results to users. Unexpected drops in traffic can be an indication of an underlying issue and may be an early warning that remedial action may be necessary. Detecting such drops is non-trivial because streams are variable and noisy, with roughly regular spikes (in many different shapes) in traffic data. We investigated the question of whether or not we can predict anomalies in these data streams. Our goal is to utilize Machine Learning and statistical approaches to classify anomalous drops in periodic, but noisy, traffic patterns. Since we do not have a large body of labeled examples to directly apply supervised learning for anomaly classification, we approached the problem in two parts. First we used TensorFlow to train our various models including DNNs, RNNs, and LSTMs to perform regression and predict the expected value in the time series. Secondly we created anomaly detection rules that compared the actual values to predicted values. Since the problem requires finding sustained anomalies, rather than just short delays or momentary inactivity in the data, our two detection methods focused on continuous sections of activity rather than just single points. We tried multiple combinations of our models and rules and found that using the intersection of our two anomaly detection methods proved to be an effective method of detecting anomalies on almost all of our models. In the process we also found that not all data fell within our experimental assumptions, as one data stream had no periodicity, and therefore no time based model could predict it. Keywords Anomaly; Outlier; Anomaly Detection; Outlier Detection; Deep Neural Networks; Recurrent Neural Networks; Long short-term Memory; I. INTRODUCTION A. About the Data We looked at 14 different sets of data that were saved at 5 minute intervals. This means that that each hour had 12 data points, and each day had 288. Our goal is to detect anomalies such as absences of daily traffic bursts on unexpected decreases in the throughput volume, while not detecting anomalies on regular low -- or even 0-- values. The only two attributes of this dataset were a unix timestamp and the bytes per second value, both sampled every 5 minutes. Although there are no accurate markings of anomalies within this data, there does not mean that they do not exist, only that we had no information of the at the beginning of this project. B. About the Problem When there are clear labels for anomalous data a binary classifier can be built predict anomalies and non-anomalous points. For these problems there exist a plethora of techniques to choose from, including clustering analysis, isolations forests, and classifiers built using artificial neural networks. These have all shown promise in the field of anomaly detection [1]. The first two of these techniques not only require labels for training, but also are most effective when there are many features. For these reasons they are not as useful on time series data, especially when there are not other features that we have access to. Neural networks can effectively predict periodic time series data, as can simpler techniques such as Fourier series. However, because what counts as an anomaly can vary based on the data, each problem potentially requires its own model. Some problems have many features to work with or need to never give a false positive, while others, like ours, have few features and look for continuous, rather than point anomalies. We trained a separate model for each data stream since we found no significant correlation between each of the data streams. Our models returned predictions that we compared to the actual data stream values using our anomaly detection rules to determine if the current point is anomalous. Although all of our models and metrics are done in an offline environment, they are all approaches that are adaptable to online training, predicting, and anomaly detection. The adaptability of our models is a result of our machine learning models and anomaly detection rules only requiring either the past or current points. Additionally, to make sure our models 1 Dominique Shipmon and Jason Gurevitch were summer interns at Google when they did this work. 1
2 were effective we compared them to a threshold model, which would constantly predict a very low value. Since our models are only predicting a point through regression, we need a defined rule to determine whether a point is anomalous or not by comparing the prediction and actual value. The intuitive approach for comparing the predictions actual value to determine whether a point is anomalous or not is by simply calculating the euclidean distance and setting a threshold. However, this could lead to numerous false positives especially with noisy data. Therefore, we implemented two different detection rules for anomaly detection: one using an accumulator to detect continuous outages and another using a probabilistic approach as outlined by Ahmad and Purdy [2]. Both methods attempt to mitigate high false positive rates by avoiding a simple threshold technique applied to one datapoint. The accumulator method works by having a metric defined to determine a local outage, and then increment the counter for every outage and decrement it for every non-anomalous value. The statistical method based on the Numenta s formulation [2] worked by comparing short term variance to long term variance, meaning that it would also adjust to the data in addition to our model [2]. We found both of these methods to work similarly well; they both fired at almost exactly the same points. Despite this, each offers theoretical and practical approaches, particularly in potential future experiments, since the accumulator method is easily modifiable and controllable, and the statistical method gives a percentage chance of being an outlier, which could be multiplied between models to give a more robust score [2]. We found that for this problem it was the anomaly detection method that mattered more than the model itself, since our anomaly rules were able to be quite effective on most of our models. II. RELATED WORK Anomaly detection is actively and heavily researched [3][4]. While classification techniques are a popular approach to solve anomaly detection, it is unrealistic to expect to always have a dataset with a sufficient and diverse set of labeled anomalies [1]. Statistical and regression techniques seem more promising in these cases. Netflix recently released their solution for anomaly detection in big data using Robust Principle Component Analysis [5]. Netflix s solution proved to be successful however, their statistical approach relies on high cardinality data sets to compute a low rank approximation which limits its applications [5]. Twitter also released an approach to anomaly detection which considers seasonality using the Seasonal Hybrid Extreme Studentized Deviate test (S-H-ESD) [6]. The technique employed by Twitter is promising as it is suited for breakout anomalies, not just point anomalies [6]. There are many other machine learning techniques that could be used to detect anomalies, such as regression using LSTMs, RNNs, DNNs or other model types [1]. In this paper we focus on the performance of regression-based machine learning techniques on periodic time series data with limited features and few labeled examples of anomalies. III. DATA PREPROCESSING AND INITIAL ANALYTICS The only feature available for us to use is the unix time stamp and the only label is the number of bytes (amount of data) received. Therefore, we wanted to figure out what methods, if any, we could use to create other features that are not linearly correlated with the original timestamp feature. While a Fourier Series can only work on a single value, other machine learning approaches work better with more features. Furthermore, since we are training on labels, it cannot be an input feature, which means without any feature engineering there is only one feature for our model to use. We decided to see if any form of composite data streams would make sense as a feature, such as the average value of all streams or using the principal components to decrease it to a few significant streams. However, we found that almost none of the streams had any linear correlation to each other through calculating the covariance matrix, meaning that a composite based on principal component analysis would not add information As a result, all of our features had to come from just the single data stream we were working with. For each of our network models we converted the unix timestamp into a weekday, hour, and minutes feature. Then we decomposed the time features into multiple, non-linearly correlated features by converting hours and weekday into one hot encodings, while adding a linear minutes feature in the hopes that it could help the model learn better by creating more features with more complicated relations. We also decided to experiment with using the derivative of past labels as a feature. The only variance possible without using the derivative is within the largest timeframe fed into the models, which in our case was a week. This means that the same values would be predicted every week by our models. Furthermore the choice of using the derivative of past data points was driven by its ability to be used in online monitoring. Although using features computed from the values we are trying to predict is often poor practice due to overfitting, we hoped that the derivative would be weakly related enough --especially as a non-linear transform of the labels-- that the models learned time as a more important feature. When we simulated the anomaly to be a continuous value, such as 0, we found that it continue to predict spikes, although they were slightly smaller, showing that our models were not overfitting on the derivative. We normalized the bytes per second metric to be from 0 to 1 because while the Fourier Model could work with values as high and variable as our inputs, approaches with Neural 2
3 Networks are much less effective when the values are that high. Furthermore, setting these bounds allowed us to use activation functions that transformed data to be from -1 to 1 or 0 to 1 like the hyperbolic tangent function (tanh) and the sigmoid function, to try more methods to optimize our models. Additionally normalizing the data made training faster even for the Fourier Model, so we used normalized data for all of our models. IV. DETECTION RULES We experimented with two types of detection rules, an accumulator method and a gaussian tail probability method. Through our experimentation we found that with each data stream either anomaly detection rule was more effective. Therefore we found that a hybrid model which is simply the intersection of the two models was even more effective at identifying anomalous points. We found instances where each detection rule worked better than the other, therefore we used the intersection of the accumulator and the gaussian tail probability rules. A. Accumulator The goal of the accumulator rule was to require multiple point anomalies to occur in a short period of time before signalling a sustained anomaly. We tried two different rules for how a point anomaly is detected, and then tested both of them as part of the accumulator rule. This rule involved a counter that would grow as point anomalies are detected, and shrink in cases where the predicted value is correct. The goal of this is to prevent noise that a local anomaly detection algorithm would incur, by requiring multiple anomalies in a short timeframe to cause it to reach a threshold for signaling. For every local anomaly the accumulator grows by one, and for every non-anomalous value it shrinks by two so that pure noise causes the accumulator to shrink. The accumulator is capped between 0 and 1.5x the value of the threshold for signalling, although these numbers were chosen based on testing and other optimal values could be possible. 1) Threshold This algorithm defined a local anomaly as any value where the actual value is more than a given delta below the expected value, when the actual value is greater than a hardcoded threshold which says any value above it is not anomalous. This was just a simple algorithm, again parametric in nature where the values we chose worked for our dataset, but again may not be optimal for every possible one. 2) Variance Based We tried using local variance to determine outages by defining an outage as any value that is outside of 20 times the rolling variance from the current prediction, so that noisy areas would allow for more noise in anomalies. However, this method proved to be slightly less effective than the simple threshold. Because we found the threshold method to be more effective on our data, we used that in all of our anomaly detection for this paper. We observed that the accumulator rules frequently identified false positives after peaks due to an offset in the models inference compared to the ground-truth. This offset is likely due to training on a previous months where changes in periodicity could occur gradually into the next evaluation month. In an attempt to abate these false positives, we added a parameter for peak values that would decrement the accumulator by three following a peak, and allowing the accumulator to go below 0 (down to a negative the threshold). However, we only wanted this to affect prediction immediately after peaks, so the accumulator would decay back to 0 if more non-anomalous data points are found, effectively preventing it from predicting an anomaly immediately after a peak. For all of our models we defined the threshold for a non-anomalous value at 0.3, a peak value at 0.35, had a an accumulator threshold at 15 and had the delta for a local outage at 0.1 B. Gaussian Tail The second anomaly detection rule that we decided to test for our data is the Gaussian tail probability rule defined by Numenta. Numenta s rule first requires the computation of a raw anomaly score between the inference value and the ground truth [2]. The raw anomaly score calculation is simply the difference between the inference and ground-truth, however, points above inference are not considered as we are only concerned with a lack of activity. Therefore, our raw anomaly score is as follows, where f(x t ) is the prediction at time t and a t is the ground-truth: s t = max(f(xt) a t, 0) The series of resulting raw anomaly scores are used to calculate the rolling mean and variance. The rolling mean has two windows where the length of W2 < W1. The two rolling means and variance are used to calculate the tail probability which is the final anomaly likelihood score. V. PREDICTION MODELS We started with testing each of our models on two artificial sets that we created, before using them on real data. One of the artificial datasets was the sine function with a period of 288 data points to see if the models can predict periodic data of the same period as our data, and the other was a stepwise function based on the sine function with the same period, to see if the models could predict periodic data that changed rules at certain regular intervals. 3
4 Since our data was a continuous stream we broke each stream into months, and trained on April data and tested on May data. 13 of the 14 datasets we looked at were periodic in nature, although there was variance in exactly when spikes would start, in addition to the exact values of these spikes and the amount of noise present. For each of our models we evaluated them using both of our anomaly detection rules, the accumulator method, Numenta s tail probability method [2], as well as investigating the effectiveness of the intersection of both methods. Additionally, each model, except for the fourier model was trained using the Adam Optimizer, where the fourier model is trained using the Adagrad optimizer. A. Hyperparameters All hyperparameters were experimentally chosen based on effective models. We attempted to use hyperparameter optimization based on mean squared error loss, however, this did not provide useful models, consequently, we continued using our experimentally chosen hyperparameters. B. Baseline (Threshold model) Our most simple model was based on what is already in place in the system, which is just a simple threshold. We used this both as a base metric for our experiments, but also to see how effective the anomaly detection algorithms could be if only applied to what was currently in place. The value for this threshold was hardcoded to 0.065, since the goal was not to minimize distance from all data points, but rather to have a value the data should not go below. Although the accumulator model could be tweaked to be somewhat effective on this model, at least for detecting when data is abnormally low, the sliding windows method was not as effective at detecting anomalies for this model. This could in part be because variance of the error is only based on the labels, and not the labels and predictions in this model, so it cannot be as robust as it is supposed to be. The results for the baseline are in the following tables. Since our threshold was so low we needed to change the value of the delta for our accumulator model to 0.05 from 0.1 to detect a local outage. False Negatives True Positives False Positives C. Fourier Series As another fairly simplistic baseline model, we created a Fourier model under the assumption that most of our data has some level of periodicity to it. Rather than using a sum sines and cosines our formulation rather makes the phase parametric and summed with the harmonic as a argument of the sine.the formulation for the Fourier series used is as follows, where, a n is the amplitude, φ is the phase and ϕ is the number of harmonics: ϕ f (x) = a n sin(n + φ n ) n=0 The loss function is defined as Mean Squared Error (MSE) and the function is optimized using Adagrad Optimizer. For the Fourier model we experimented with having the period as either a week or a day. We found that both periods were similarly effective, therefore we decided to use the one with the longer period to capture more complexities in the data. We used 448 harmonics, or 64 for each of the 7 days, and trained with a learning rate of 0.5 for 3000 steps. For it s relative simplicity the fourier attained a fairly low loss value on our data set: Fourier Model and Loss MSE Loss The following table lists the confusion matrices for each anomaly detection rule using the Fourier model: Baseline and Loss MSE Loss N/A Confusion Matrices for Anomaly Rules Using Fourier Model True Negatives Confusion Matrices for Anomaly Rules Using Baseline True Negatives False Negatives True Positives False Positives
5 D. Deep Neural Network (DNN) For our Deep Neural Network we used the DNNRegressor within the TFLearn API. The TFLearn DNN Regressor is a fully connected feed-forward model that is connected with Relu6 activation function (Relu6 is just a standard relu that caps at 6) [7]. Our network has 10 layers of 200 neurons each, and was trained for 1200 steps with a batch size of 200 and a learning rate of with the Adam optimizer. that of the DNN. The following is a table of the RNN s loss for both testing and evaluation: RNN and Loss MSE Loss This model proved quite effective and stable, which could in part be due to other optimizations performed by the TFLearn implementation of the model. Confusion Matrices for Anomaly Rules Using RNN True Negatives DNN and Loss False Negatives MSE Loss True Positives False Positives The following table are the confusion matrices for each anomaly detection rule using the DNN: Confusion Matrices for Anomaly Rules Using DNN True Negatives False Negatives True Positives False Positives F. Long Short-Term Memory (LSTM) An LSTM is simply another form of RNN where rather than a simple recurrent loop at reach recurrent cell, the LSTM introduces a more complex cell architecture for more accurately maintaining memory of important correlations [9]. We use a 70 hidden layer size and 10 layer deep LSTM, and as with the RNN a single linear output layer. Our LSTM used ELU activations and is trained with a learning rate of and a batch size of 200 at 2500 steps. Furthermore, we use the standard non-peephole LSTM cell implementation. Similar to the RNN, the LSTM, despite the added complexity of temporal memory, did not perform significantly better than the DNN. The following is a table of the LSTM s loss for both testing and evaluation: E. Recurrent Neural Network (RNN) Unlike a feed-forward DNN, an RNN contains recurrent loops where the cells output state is feed back into the input state. Such recurrent connections give RNNs the ability to have information persistence or a temporal state, therefore forming what is short term memory [8]. We decided to experiment with RNNs as our intuition is that the short term memory nature of the RNN lends itself perfectly to using past information in the time series to make improved inference. We choose to use a 75 unit hidden size, 10 layer deep RNN, with a single linear output layer. The RNN used Exponential Linear Units (ELU) activations and trained with a learning rate of and batch size of 200 at 2500 steps. Despite the RNN being able to make inference temporally due to its recurrent nature, we did not find a significant increase in performance to 5 LSTM and Loss MSE Loss Confusion Matrices for Anomaly Rules Using LSTM True Negatives False Negatives
6 True Positives False Positives A. Anomaly Simulation VI. EXPERIMENT We first tested our models by simulating a fake anomaly to make sure they could detect something. However, since current anomaly detection methods for the data are poor we do not know what anomalies should look like, so we created a function that would create random noise around a specific value during the duration of the simulated anomaly. However, as we were testing on our data it became evident that there was an observed anomaly in late May in one of our streams. Because of this we utilized the May stream for our metrics, since we believed that anomaly to be more important to detect than our simulated ones, although we wanted to make sure our models could detect both different types. Since this anomaly was in the form of it purely missing a peak, while still sending normal data, it is hard to numerically discern exactly where the anomaly starts and ends for evaluation purposes. Therefore, we estimated those values based on our own analysis. Furthermore, these are just two examples of anomalies, but the fact that our models could pick up both types showed that they can be robust in detecting multiple types of anomalous data. B. Test/Train Split For our testing and training validation process we choose to use a new time frame (a different month) rather than randomly selecting points of test data. The rationale behind this was that it would provide a realistic environment for testing the anomaly detection rules with the test predictions as they rely on previous contiguous data points. Furthermore, testing in new temporal sequences is desired for models like the LSTM and RNN which, have temporal awareness. VII. FINDINGS The numerical results form the confusion matrix show two key findings. The first is that in every instance, the intersection between the accumulator method and the tail probability method reduced the amount of false positives flagged by the model. However, since the intersection makes a tighter bound around anomalous regions, the true positive rate is also decreased. The second important finding is that there is a very small difference between all of our neural network models with regards to their detection confusion matrices. This suggests that the most important factors are that the model can fit to nonlinear data and has online learning capabilities (to adjust to long term changes in the streaming time series). Furthermore, an important factor is the anomaly detection rule itself, as each neural network had a low loss and fit the test and validation data very well, the biggest difference 6 being between the anomaly detection rules and not the models. Finally, it should be noted that while some models did not numerically perform as desired within the bounds of the labeled anomalies, some models like the Fourier model, marked anomalies very close to the labeled anomalies. These results indicatet that observed model performance is also reliant on ground-truth labeling guidelines. The numerical results for each model also show important results both in anomaly detection performance and training validity. For training validity, the evaluation and training MSE scores demonstrate that overfitting is not occurring and the model is making a reasonable generalisation about the data as the validation scores are not significantly higher. While the numeric data didn t quite show how effective our models were compared to each other, the graphical data (shown in the Figures section) proved to be a very effective way to gauge which models were effective and the differences between them. This was in part because the outage we simulated was during a period where there wasn t supposed to be significant traffic, so our models barely detected that fake outage, but all of them but the baseline were able to detect the real anomalies within this timeframe. Outside of detecting those two anomalies, we found the graphical approach to be effective because it shows sustained false positives vs frequent, but smaller false positives. From analyzing the graphs we can see that the Fourier Series model fired the fewest false positives on our evaluation data set, firing only four times outside of our two anomalous points. Aside from this however the graphical data shows that all of the models had similar effectiveness, and the small differences can both be down to the models themselves and the specific parameters used for the anomaly detection methods. Despite this the Fourier, and RNN models were all slightly more effective, while the DNN and LSTM had more false positives, specifically right after peaks. However, because this is such a specific and recurring type of false positive the accumulator detection rule can be easily modified to have more resistance to predictions after peaks, which would make these models just as effective as the other ones. Although this paper only actively discusses our methods working on one of the streams and failing on one, it was able to successfully detect anomalies in 13 out of the 14 streams, and oftentimes exhibited improved performance on other streams, which are less erratic than the stream discussed in this paper. The one that our models could not work on was not due to a failure in our models, but instead because that stream was not periodic. VIII. CONCLUSION For the streams that we analyzed all of our models were very effective with the anomaly detection rules that we used. While the Fourier was slightly more effective than the others, this can also be due to the data itself, where each datastream
7 can have peculiarities that make one model work better than others. With access to more features, deep learning could provide even more accurate results. However, our results suggest that due to the limited set of features available it didn t provide significant advantages to simpler periodic models. Using two completely different anomaly detection rules, particularly one with statistical backing and another that can be easily tweaked by the user to manually remove recurring false positives allowed us to have a very robust method to detect anomalies. While these methods can be used for general purpose anomaly detection, the methods were somewhat specific to our problem because rather than looking at total distance from predictions we only looked at distance below prediction, although these methods should still work well on other data if we account for those differences. Room for further experimentation can be done by trying even more anomaly detection methods and seeing if another combination can work even better than the two we propose here. lso an optimization of our models using other metrics for hyperparameter optimization, that could either give us models with better results or less computationally expensive models with the same results. REFERENCES [1] V. Chandola, A. Banerjee, and V. Kumar, Anomaly Detection: a Survey, University of Minnesota, Minneapolis, MN, [2] S. Ahmad and S. Purdy, Real-time Anomaly Detection for Streaming Analytics, Numenta, Redwood City, CA, [3] The Science of Anomaly Detection, Numenta, Redwood City, CA, [4] K. Das, Detecting Patterns of Anomalies, Carnegie Mellon University, Pittsburg, PA, [5] (2015, February 10) RAD - Outlier Detection on Big Data, [Online]. Available: 6b [6] A. Kejariwal. (2015, January 6) Introducing practical and robust anomaly detection in a time series, [Online]. Available: -practical-and-robust-anomaly-detection-in-a-time-series.html [7] A. Krizhevsky, Convolutional Deep Belief Networks on CIFAR-10, University of Toronto, Toronto, ON, [8] T. Nikolov, Recurrent neural network based language model, Brno University of Technology, Brno, Czech Republic, [9] H. Sak, A. Senior, and F, Beaufays, Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling, Google Inc., Mountain View, CA, [10] X. Liu and P. S. Nielsen, Regression-based Online Anomaly Detection for Smart Grid Data, Technical University of Denmark, Kgs. Lyngby, Denmark [11] E. Busseti, I. Osband, and S. Wong Deep Learning for Time Series Modeling, Stanford University, Stanford, California,


8 Figures n.b. Tail method cannot predict anything during the first long window, which is a week, or 2016 points. Blue line is the actual values, green line is the predictions, and shaded red areas are the detected anomalies 8

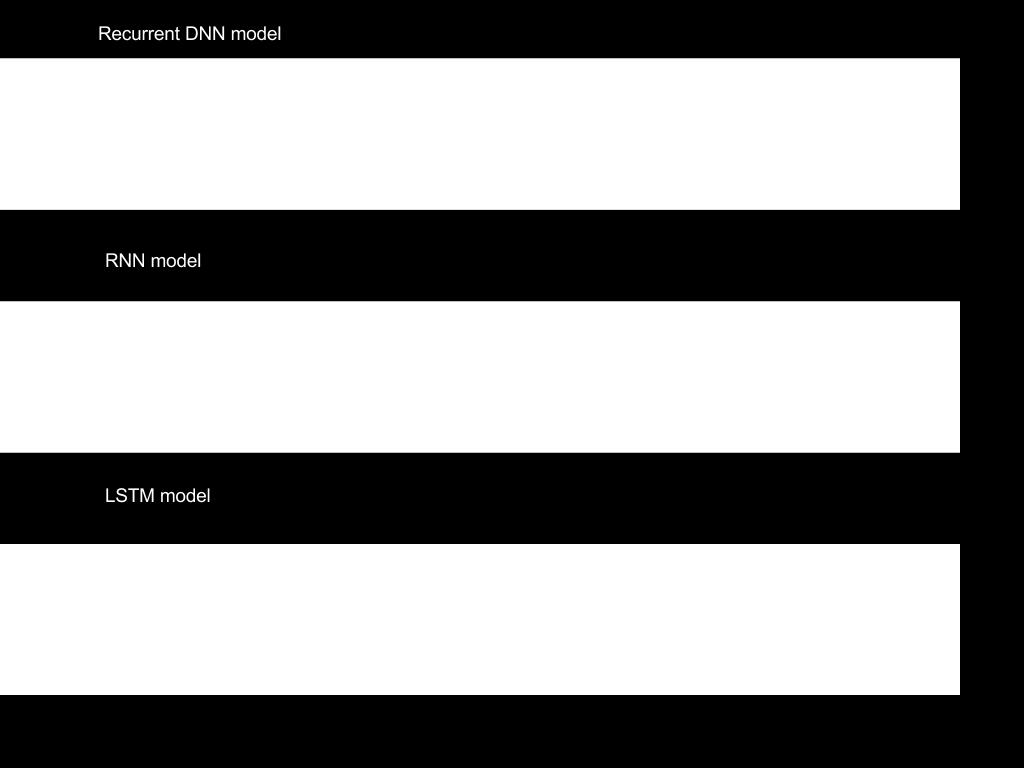

9 9
Caesar s Taxi Prediction Services
 1 Caesar s Taxi Prediction Services Predicting NYC Taxi Fares, Trip Distance, and Activity Paul Jolly, Boxiao Pan, Varun Nambiar Abstract In this paper, we propose three models each predicting either taxi
1 Caesar s Taxi Prediction Services Predicting NYC Taxi Fares, Trip Distance, and Activity Paul Jolly, Boxiao Pan, Varun Nambiar Abstract In this paper, we propose three models each predicting either taxi
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Deep Learning & Artificial Intelligence WS 2018/2019
 Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Anomaly Detection for the CERN Large Hadron Collider injection magnets
 Anomaly Detection for the CERN Large Hadron Collider injection magnets Armin Halilovic KU Leuven - Department of Computer Science In cooperation with CERN 2018-07-27 0 Outline 1 Context 2 Data 3 Preprocessing
Anomaly Detection for the CERN Large Hadron Collider injection magnets Armin Halilovic KU Leuven - Department of Computer Science In cooperation with CERN 2018-07-27 0 Outline 1 Context 2 Data 3 Preprocessing
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Machine Learning Linear Classification. Prof. Matteo Matteucci
 Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Recurrent Autoregressive Networks for Online Multi-Object Tracking. Presented By: Ishan Gupta
 Recurrent Autoregressive Networks for Online Multi-Object Tracking Presented By: Ishan Gupta Outline Multi Object Tracking Recurrent Autoregressive Networks (RANs) RANs for Online Tracking Other State
Recurrent Autoregressive Networks for Online Multi-Object Tracking Presented By: Ishan Gupta Outline Multi Object Tracking Recurrent Autoregressive Networks (RANs) RANs for Online Tracking Other State
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Classification of Higgs Boson Tau-Tau decays using GPU accelerated Neural Networks
 Classification of Higgs Boson Tau-Tau decays using GPU accelerated Neural Networks Mohit Shridhar Stanford University mohits@stanford.edu, mohit@u.nus.edu Abstract In particle physics, Higgs Boson to tau-tau
Classification of Higgs Boson Tau-Tau decays using GPU accelerated Neural Networks Mohit Shridhar Stanford University mohits@stanford.edu, mohit@u.nus.edu Abstract In particle physics, Higgs Boson to tau-tau
Lecture 4: Feed Forward Neural Networks
 Lecture 4: Feed Forward Neural Networks Dr. Roman V Belavkin Middlesex University BIS4435 Biological neurons and the brain A Model of A Single Neuron Neurons as data-driven models Neural Networks Training
Lecture 4: Feed Forward Neural Networks Dr. Roman V Belavkin Middlesex University BIS4435 Biological neurons and the brain A Model of A Single Neuron Neurons as data-driven models Neural Networks Training
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Neural Networks and Ensemble Methods for Classification
 Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Justin Appleby CS 229 Machine Learning Project Report 12/15/17 Kevin Chalhoub Building Electricity Load Forecasting
 Justin Appleby CS 229 Machine Learning Project Report 12/15/17 Kevin Chalhoub Building Electricity Load Forecasting with ARIMA and Sequential Linear Regression Abstract Load forecasting is an essential
Justin Appleby CS 229 Machine Learning Project Report 12/15/17 Kevin Chalhoub Building Electricity Load Forecasting with ARIMA and Sequential Linear Regression Abstract Load forecasting is an essential
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
18.6 Regression and Classification with Linear Models
 18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Prediction of Citations for Academic Papers
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
ECE521 Lecture7. Logistic Regression
 ECE521 Lecture7 Logistic Regression Outline Review of decision theory Logistic regression A single neuron Multi-class classification 2 Outline Decision theory is conceptually easy and computationally hard
ECE521 Lecture7 Logistic Regression Outline Review of decision theory Logistic regression A single neuron Multi-class classification 2 Outline Decision theory is conceptually easy and computationally hard
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Introduction to Machine Learning Midterm Exam Solutions
 10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
Dreem Challenge report (team Bussanati)
") Wavelet course, MVA 04-05 Simon Bussy, simon.bussy@gmail.com Antoine Recanati, arecanat@ens-cachan.fr Dreem Challenge report (team Bussanati) Description and specifics of the challenge We worked on the
Wavelet course, MVA 04-05 Simon Bussy, simon.bussy@gmail.com Antoine Recanati, arecanat@ens-cachan.fr Dreem Challenge report (team Bussanati) Description and specifics of the challenge We worked on the
CS168: The Modern Algorithmic Toolbox Lecture #6: Regularization
 CS168: The Modern Algorithmic Toolbox Lecture #6: Regularization Tim Roughgarden & Gregory Valiant April 18, 2018 1 The Context and Intuition behind Regularization Given a dataset, and some class of models
CS168: The Modern Algorithmic Toolbox Lecture #6: Regularization Tim Roughgarden & Gregory Valiant April 18, 2018 1 The Context and Intuition behind Regularization Given a dataset, and some class of models
Pulses Characterization from Raw Data for CDMS
 Pulses Characterization from Raw Data for CDMS Physical Sciences Francesco Insulla (06210287), Chris Stanford (05884854) December 14, 2018 Abstract In this project we seek to take a time series of current
Pulses Characterization from Raw Data for CDMS Physical Sciences Francesco Insulla (06210287), Chris Stanford (05884854) December 14, 2018 Abstract In this project we seek to take a time series of current
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
Source localization in an ocean waveguide using supervised machine learning
 Source localization in an ocean waveguide using supervised machine learning Haiqiang Niu, Emma Reeves, and Peter Gerstoft Scripps Institution of Oceanography, UC San Diego Part I Localization on Noise09
Source localization in an ocean waveguide using supervised machine learning Haiqiang Niu, Emma Reeves, and Peter Gerstoft Scripps Institution of Oceanography, UC San Diego Part I Localization on Noise09
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function
 Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Analysis of the Learning Process of a Recurrent Neural Network on the Last k-bit Parity Function Austin Wang Adviser: Xiuyuan Cheng May 4, 2017 1 Abstract This study analyzes how simple recurrent neural
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Real Estate Price Prediction with Regression and Classification CS 229 Autumn 2016 Project Final Report
 Real Estate Price Prediction with Regression and Classification CS 229 Autumn 2016 Project Final Report Hujia Yu, Jiafu Wu [hujiay, jiafuwu]@stanford.edu 1. Introduction Housing prices are an important
Real Estate Price Prediction with Regression and Classification CS 229 Autumn 2016 Project Final Report Hujia Yu, Jiafu Wu [hujiay, jiafuwu]@stanford.edu 1. Introduction Housing prices are an important
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
The connection of dropout and Bayesian statistics
 The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Article from. Predictive Analytics and Futurism. July 2016 Issue 13
 Article from Predictive Analytics and Futurism July 2016 Issue 13 Regression and Classification: A Deeper Look By Jeff Heaton Classification and regression are the two most common forms of models fitted
Article from Predictive Analytics and Futurism July 2016 Issue 13 Regression and Classification: A Deeper Look By Jeff Heaton Classification and regression are the two most common forms of models fitted
CS Homework 3. October 15, 2009
 CS 294 - Homework 3 October 15, 2009 If you have questions, contact Alexandre Bouchard (bouchard@cs.berkeley.edu) for part 1 and Alex Simma (asimma@eecs.berkeley.edu) for part 2. Also check the class website
CS 294 - Homework 3 October 15, 2009 If you have questions, contact Alexandre Bouchard (bouchard@cs.berkeley.edu) for part 1 and Alex Simma (asimma@eecs.berkeley.edu) for part 2. Also check the class website
Introduction to Convolutional Neural Networks 2018 / 02 / 23
 Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Probabilistic Graphical Models
 10-708 Probabilistic Graphical Models Homework 3 (v1.1.0) Due Apr 14, 7:00 PM Rules: 1. Homework is due on the due date at 7:00 PM. The homework should be submitted via Gradescope. Solution to each problem
10-708 Probabilistic Graphical Models Homework 3 (v1.1.0) Due Apr 14, 7:00 PM Rules: 1. Homework is due on the due date at 7:00 PM. The homework should be submitted via Gradescope. Solution to each problem
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
HOMEWORK #4: LOGISTIC REGRESSION
 HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2018 Due: Friday, February 23rd, 2018, 11:55 PM Submit code and report via EEE Dropbox You should submit a
HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2018 Due: Friday, February 23rd, 2018, 11:55 PM Submit code and report via EEE Dropbox You should submit a
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Predicting flight on-time performance
 1 Predicting flight on-time performance Arjun Mathur, Aaron Nagao, Kenny Ng I. INTRODUCTION Time is money, and delayed flights are a frequent cause of frustration for both travellers and airline companies.
1 Predicting flight on-time performance Arjun Mathur, Aaron Nagao, Kenny Ng I. INTRODUCTION Time is money, and delayed flights are a frequent cause of frustration for both travellers and airline companies.
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Training Neural Networks Practical Issues
 Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Discovery Through Situational Awareness
 Discovery Through Situational Awareness BRETT AMIDAN JIM FOLLUM NICK BETZSOLD TIM YIN (UNIVERSITY OF WYOMING) SHIKHAR PANDEY (WASHINGTON STATE UNIVERSITY) Pacific Northwest National Laboratory February
Discovery Through Situational Awareness BRETT AMIDAN JIM FOLLUM NICK BETZSOLD TIM YIN (UNIVERSITY OF WYOMING) SHIKHAR PANDEY (WASHINGTON STATE UNIVERSITY) Pacific Northwest National Laboratory February
Dynamic Data Modeling, Recognition, and Synthesis. Rui Zhao Thesis Defense Advisor: Professor Qiang Ji
 Dynamic Data Modeling, Recognition, and Synthesis Rui Zhao Thesis Defense Advisor: Professor Qiang Ji Contents Introduction Related Work Dynamic Data Modeling & Analysis Temporal localization Insufficient
Dynamic Data Modeling, Recognition, and Synthesis Rui Zhao Thesis Defense Advisor: Professor Qiang Ji Contents Introduction Related Work Dynamic Data Modeling & Analysis Temporal localization Insufficient
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project
 Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
HOMEWORK #4: LOGISTIC REGRESSION
 HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2019 Due: 11am Monday, February 25th, 2019 Submit scan of plots/written responses to Gradebook; submit your
HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2019 Due: 11am Monday, February 25th, 2019 Submit scan of plots/written responses to Gradebook; submit your
Machine Learning. Boris
 Machine Learning Boris Nadion boris@astrails.com @borisnadion @borisnadion boris@astrails.com astrails http://astrails.com awesome web and mobile apps since 2005 terms AI (artificial intelligence)
Machine Learning Boris Nadion boris@astrails.com @borisnadion @borisnadion boris@astrails.com astrails http://astrails.com awesome web and mobile apps since 2005 terms AI (artificial intelligence)
Multimodal context analysis and prediction
 Multimodal context analysis and prediction Valeria Tomaselli (valeria.tomaselli@st.com) Sebastiano Battiato Giovanni Maria Farinella Tiziana Rotondo (PhD student) Outline 2 Context analysis vs prediction
Multimodal context analysis and prediction Valeria Tomaselli (valeria.tomaselli@st.com) Sebastiano Battiato Giovanni Maria Farinella Tiziana Rotondo (PhD student) Outline 2 Context analysis vs prediction
Predicting New Search-Query Cluster Volume
 Predicting New Search-Query Cluster Volume Jacob Sisk, Cory Barr December 14, 2007 1 Problem Statement Search engines allow people to find information important to them, and search engine companies derive
Predicting New Search-Query Cluster Volume Jacob Sisk, Cory Barr December 14, 2007 1 Problem Statement Search engines allow people to find information important to them, and search engine companies derive
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Deep Learning Architecture for Univariate Time Series Forecasting
 CS229,Technical Report, 2014 Deep Learning Architecture for Univariate Time Series Forecasting Dmitry Vengertsev 1 Abstract This paper studies the problem of applying machine learning with deep architecture
CS229,Technical Report, 2014 Deep Learning Architecture for Univariate Time Series Forecasting Dmitry Vengertsev 1 Abstract This paper studies the problem of applying machine learning with deep architecture
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Introduction to Logistic Regression
 Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets)
") COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Different Criteria for Active Learning in Neural Networks: A Comparative Study
 Different Criteria for Active Learning in Neural Networks: A Comparative Study Jan Poland and Andreas Zell University of Tübingen, WSI - RA Sand 1, 72076 Tübingen, Germany Abstract. The field of active
Different Criteria for Active Learning in Neural Networks: A Comparative Study Jan Poland and Andreas Zell University of Tübingen, WSI - RA Sand 1, 72076 Tübingen, Germany Abstract. The field of active
Normalization Techniques in Training of Deep Neural Networks
 Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Introduction. Chapter 1
 Chapter 1 Introduction In this book we will be concerned with supervised learning, which is the problem of learning input-output mappings from empirical data (the training dataset). Depending on the characteristics
Chapter 1 Introduction In this book we will be concerned with supervised learning, which is the problem of learning input-output mappings from empirical data (the training dataset). Depending on the characteristics
Artificial Neural Networks Examination, June 2004
 Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION
 SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Reduced Order Greenhouse Gas Flaring Estimation
 Reduced Order Greenhouse Gas Flaring Estimation Sharad Bharadwaj, Sumit Mitra Energy Resources Engineering Stanford University Abstract Global gas flaring is difficult to sense, a tremendous source of
Reduced Order Greenhouse Gas Flaring Estimation Sharad Bharadwaj, Sumit Mitra Energy Resources Engineering Stanford University Abstract Global gas flaring is difficult to sense, a tremendous source of
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Random Coattention Forest for Question Answering
 Random Coattention Forest for Question Answering Jheng-Hao Chen Stanford University jhenghao@stanford.edu Ting-Po Lee Stanford University tingpo@stanford.edu Yi-Chun Chen Stanford University yichunc@stanford.edu
Random Coattention Forest for Question Answering Jheng-Hao Chen Stanford University jhenghao@stanford.edu Ting-Po Lee Stanford University tingpo@stanford.edu Yi-Chun Chen Stanford University yichunc@stanford.edu
Speaker Representation and Verification Part II. by Vasileios Vasilakakis
 Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Predicting Time of Peak Foreign Exchange Rates. Charles Mulemi, Lucio Dery 0. ABSTRACT
 Predicting Time of Peak Foreign Exchange Rates Charles Mulemi, Lucio Dery 0. ABSTRACT This paper explores various machine learning models of predicting the day foreign exchange rates peak in a given window.
Predicting Time of Peak Foreign Exchange Rates Charles Mulemi, Lucio Dery 0. ABSTRACT This paper explores various machine learning models of predicting the day foreign exchange rates peak in a given window.
Lecture 15: Exploding and Vanishing Gradients
 Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
Feed-forward Network Functions
 Feed-forward Network Functions Sargur Srihari Topics 1. Extension of linear models 2. Feed-forward Network Functions 3. Weight-space symmetries 2 Recap of Linear Models Linear Models for Regression, Classification
Feed-forward Network Functions Sargur Srihari Topics 1. Extension of linear models 2. Feed-forward Network Functions 3. Weight-space symmetries 2 Recap of Linear Models Linear Models for Regression, Classification