Truth Discovery and Crowdsourcing Aggregation: A Unified Perspective
|
|
|
- Marilynn Fowler
- 6 years ago
- Views:
Transcription

1 Truth Discovery and Crowdsourcing Aggregation: A Unified Perspective Jing Gao 1, Qi Li 1, Bo Zhao 2, Wei Fan 3, and Jiawei Han 4 1 SUNY Buffalo; 2 LinkedIn; 3 Baidu Research Big Data Lab; 4 University of Illinois 1
2 Overview Introduction Comparison of Existing Truth Discovery and Crowdsourced Data Aggregation Setting Models of Truth Discovery and Crowdsourced Data Aggregation Truth Discovery for Crowdsourced Data Aggregation Related Areas Open Questions and Resources References 2
3 Overview Introduction Comparison of Existing Truth Discovery and Crowdsourced Data Aggregation Setting Models of Truth Discovery and Crowdsourced Data Aggregation Truth Discovery for Crowdsourced Data Aggregation Related Areas Open Questions and Resources References 3
4 Truth Discovery Conflict resolution in data fusion 4

5 5









6 Object Integration Source 1 Source 2 Source 3 Source 4 Source 5 6
7 A Straightforward Fusion Solution Voting/Averaging Take the value that is claimed by majority of the sources Or compute the mean of all the claims Limitation Ignore source reliability Source reliability Is crucial for finding the true fact but unknown 7
8 Truth Discovery What is truth discovery? Goal: To discover truths by integrating source reliability estimation in the process of data fusion 8


9 Crowdsourcing requester worker 9








10 An Example on Mturk Are the two images of the same person? Definitely Same Maybe Same Not Sure Annotation Results Definitely Same Maybe Same Not Sure Maybe Different Definitely Different Final Answer: Same 10
11 Crowdsourced Data Aggregation What is crowdsourced data aggregation? Goal: To resolve disagreement between responses. 11
12 Overview Introduction Comparison of Existing Truth Discovery and Crowdsourced Data Aggregation Setting Models of Truth Discovery and Crowdsourced Data Aggregation Truth Discovery for Crowdsourced Data Aggregation Related Areas Open Questions and Resources References 12
13 Similarity A common goal to improve the quality of the aggregation/fusion results Via a common method To aggregate by estimating source reliabilities Similar principles Data from reliable sources are more likely to be accurate A source is reliable if it provides accurate information Mutual challenge Prior knowledge and labels are rarely available 13
14 Differences Data collection and generation Data format of claims 14
15 Data Collection and Generation Truth discovery We can t control generation step. We only collect. Crowdsourced data aggregation We can control data generation to a certain degree What to ask How to ask How many labels per question 15
16 Data Format of Claims Truth discovery Data is collected from open domain. Can t define data space type of data range of data Crowdsourced data aggregation Data generation is controlled For easier validation of answers, requesters usually choose Multi-choice question Scoring in a range 16
17 Overview Introduction Comparison of Existing Truth Discovery and Crowdsourced Data Aggregation Setting Models of Truth Discovery and Crowdsourced Data Aggregation Truth Discovery for Crowdsourced Data Aggregation Related Areas Open Questions and Resources References 17
18 Model Categories Statistical model (STA) Probabilistic graphical model (PGM) Optimization model (OPT) Extension (EXT) Source correlation 18
19 Statistical Model (STA) General goal: To find the (conditional) probability of a claim being true Source reliability: Probability(ies) of a source/worker making a true claim 19

20 Correct answer STA - Maximum Likelihood Estimation Multiple choice questions with fixed answer space For each worker, the reliability is a confusion matrix. Worker s answer A B C D A B C D : the probability that worker k answers l when j is the correct answer. p j : the probability that a randomly chosen question has correct answer j. π jl k [Dawid&Skene, 1979] 20
21 STA - Maximum Likelihood Estimation likelihood i k q is correct = J l=1 π ql k likelihood i q is correct = K J π ql k k l=1 likelihood i = J p j K J π jl k 1 j=q j=1 k l=1 21
 are known. What if we don t know the correct answers?")
22 STA - Maximum Likelihood Estimation I J K J 1 j i =q i likelihood = p j π jl k i j=1 k l=1 This is the likelihood if the correct answers (i.e., q i s) are known. What if we don t know the correct answers? Unknown parameters are p j, q, π jl k EM algorithm 22
23 STA - Extension and Theoretical Analysis Extensions Naïve Bayesian [Snow et al., 2008] Finding a good initial point [Zhang et al., 2014] Adding instances feature vectors [Raykar et al., 2010] [Lakkaraju et al. 2015] Using prior over worker confusion matrices [Raykar et al., 2010][Liu et al., 2012] [Lakkaraju et al. 2015] Clustering workers/instances [Lakkaraju et al. 2015] Theoretical analysis Error bound [Li et al., 2013] [Zhang et al., 2014] 23
24 STA - TruthFinder Different websites often provide conflicting information on a subject, e.g., Authors of Rapid Contextual Design Online Store Powell s books Barnes & Noble A1 Books Cornwall books Mellon s books Lakeside books Blackwell online Authors Holtzblatt, Karen Karen Holtzblatt, Jessamyn Wendell, Shelley Wood Karen Holtzblatt, Jessamyn Burns Wendell, Shelley Wood Holtzblatt-Karen, Wendell-Jessamyn Burns, Wood Wendell, Jessamyn WENDELL, JESSAMYNHOLTZBLATT, KARENWOOD, SHELLEY Wendell, Jessamyn, Holtzblatt, Karen, Wood, Shelley [Yin et al., 2008] 24
25 STA - TruthFinder Each object has a set of conflictive facts E.g., different author lists for a book And each web site provides some facts How to find the true fact for each object? Web sites Facts Objects w 1 f 1 w 2 f 2 o 1 f 3 w 3 w 4 f 4 f 5 o 2 25
26 STA - TruthFinder 1. There is usually only one true fact for a property of an object 2. This true fact appears to be the same or similar on different web sites E.g., Jennifer Widom vs. J. Widom 3. The false facts on different web sites are less likely to be the same or similar False facts are often introduced by random factors 4. A web site that provides mostly true facts for many objects will likely provide true facts for other objects 26
27 STA - TruthFinder Confidence of facts Trustworthiness of web sites A fact has high confidence if it is provided by (many) trustworthy web sites A web site is trustworthy if it provides many facts with high confidence Iterative steps Initially, each web site is equally trustworthy Based on the four heuristics, infer fact confidence from web site trustworthiness, and then backwards Repeat until achieving stable state 27
28 STA - TruthFinder Web sites Facts Objects w 1 f 1 o 1 w 2 f 2 w 3 f 3 o 2 w 4 f 4 28
29 STA - TruthFinder Web sites Facts Objects w 1 f 1 o 1 w 2 f 2 w 3 f 3 o 2 w 4 f 4 29
30 STA - TruthFinder Web sites Facts Objects w 1 f 1 o 1 w 2 f 2 w 3 f 3 o 2 w 4 f 4 30
31 STA - TruthFinder Web sites Facts Objects w 1 f 1 o 1 w 2 f 2 w 3 f 3 o 2 w 4 f 4 31
32 STA - TruthFinder The trustworthiness of a web site w: t(w) Average confidence of facts it provides t w f F F s f w w Sum of fact confidence Set of facts provided by w The confidence of a fact f: s(f) One minus the probability that all web sites providing f are wrong f s 1 1 t w W f w Probability that w is wrong Set of websites providing f t(w 1 ) w 1 t(w 2 ) w 2 s(f 1 ) f 1 32


33 Probabilistic Graphical Model (PGM) Source reliability Truth 33
34 PGM - Latent Truth Model (LTM) Multiple facts can be true for each entity (object) One book may have 2+ authors A source can make multiple claims per entity, where more than one of them can be true A source may claim a book w. 3 authors Sources and objects are independent respectively Assume book websites and books are independent The majority of data coming from many sources are not erroneous Trust the majority of the claims [Zhao et al., 2012] 34
35 PGM - Latent Truth Model (LTM) False positive rate sensitivity Truth of Facts 35
36 PGM - Latent Truth Model (LTM) For each source k Generate false positive rate (with strong regularization, believing most sources have low FPR): φ k 0 Beta α 0,1, α 0,0 Generate its sensitivity (1-FNR) with uniform prior, indicating low FNR is more likely: φ k 1 Beta α 1,1, α 1,0 For each fact f Generate its prior truth prob, uniform prior: θ f Beta β 1, β 0 Generate its truth label: t f Bernoulli θ f For each claim c of fact f, generate observation of c. If f is false, use false positive rate of source:o c Bernoulli φ sc If f is true, use sensitivity of source: o c Bernoulli φ sc

37 PGM - GLAD Model Each image belongs to one of two possible categories of interest, i.e., binary labeling. Known variables: observed labels. [Whitehill et al., 2009] 37

38 PGM - GLAD Model Observed label True label p L ij = Z j α i, β j = Log odds for the obtained labels being correct e α iβ j Worker s accuracy. Always correct α i = + Always wrong α i = Difficulty of image. Very ambiguous 1/β j = + Very easy 1/β j = 0 38
39 Optimization Model (OPT) General model arg min g(w w s, v s, v o ) o o O s S s. t. δ 1 w s = 1, δ 2 v o = 1 What does the model mean? The optimal solution can minimize the objective function Joint estimate true claims v o and source reliability w s under some constraints δ 1, δ 2,.... Objective function g, can be distance, entropy, etc. 39
40 Optimization Model (OPT) General model arg min g(w w s, v s, v o ) o o O s S s. t. δ 1 w s = 1, δ 2 v o = 1 How to solve the problem? Convert the primal problem to its (Lagrangian) dual form Block coordinate descent to update parameters If each sub-problem is convex and smooth, then convergence is guaranteed 40
41 OPT - CRH Framework min X, W f(x, W)= K k=1 w k N i=1 M m=1 d m s. t. δ W = 1, W 0. ( ) (k) v im, vim Basic idea Truths should be close to the observations from reliable sources Minimize the overall weighted distance to the truths in which reliable sources have high weights [Li et al., 2014] 41
42 OPT - CRH Framework Loss function d m : loss on the data type of the m-th property Output a high score when the observation deviates from the truth Output a low score when the observation is close to the truth Constraint function The objective function may go to without constraints Regularize the weight distribution 42
43 OPT - CRH Framework Run the following until convergence Truth computation Minimize the weighted distance between the truth and the sources observations v im arg min v K k=1 Source reliability estimation w k d m v, v im k Assign a weight to each source based on the difference between the truths and the observations made by the source W arg min W f(x, W) 43
44 OPT - Minimax Entropy Workers: i = 1, 2,, m Items: j = 1, 2,, n Categories: k = 1, 2,, c Input: response tensor Z m n c z ijk = 1, if worker i labels item j as category k z ijk = 0, if worker i labels item j as others (not k) z ijk = unknown, if worker i does not label item j Goal: Estimate the ground truth y jl [Zhou et al., 2012] 44
45 OPT - Minimax Entropy item 1 item 2 item n worker 1 z 11 z 12 z 1n worker 2 z 21 z 22 z 2n worker m z m1 z 12 z mn 45
46 OPT - Minimax Entropy item 1 item 2 item n worker 1 π 11 π 12 π 1n worker 2 π 21 π 22 π 2n worker m π m1 π 12 π mn π ij is a vector that presents the underline distribution of the observation. i.e., z ij is drawn from π ij. 46
47 OPT - Minimax Entropy item 1 item 2 item n worker 1 π 11 π 12 π 1n worker 2 π 21 π 22 π 2n worker m π m1 π 12 π mn Column constraint: the number of votes per class per item i z ijk should match i π ijk 47
48 OPT - Minimax Entropy item 1 item 2 item n worker 1 π 11 π 12 π 1n worker 2 π 21 π 22 π 2n worker m π m1 π 12 π mn Row constraint : the empirical confusion matrix per worker j y jl z ijk should match j y jl π ijk 48
49 OPT - Minimax Entropy If we know the true label y jl Maximum entropy of π ijk under constraints 49
50 OPT - Minimax Entropy To estimate the true label y jl Minimizing the maximum entropy of π ijk 50

51 OPT - Minimax Entropy To estimate the true label y jl Minimizing the maximum entropy of π ijk Minimize entropy is equivalent to minimizing the KL divergence 51
52 EXT - Source Correlation High-level intuitions for copying detection Common error implies copying relation e.g., many same errors in s 1 s 2 imply source 1 and 2 are related Source reliability inconsistency implies copy direction e.g., s 1 s 2 and s 1 s 2 has similar accuracy, but s 1 s 2 and s 2 s 1 has different accuracy, so source 2 may be a copier. Objects covered by source 1 but not by source 2 s 1 s 2 Common objects s 1 s 2 Objects covered by source 2 but not by source 1 s 2 s 1 [Dong et al., 2009a] [Dong et al., 2009b] 52
53 EXT - Source Correlation Incorporate copying detection in truth discovery Step 2 Truth Discovery Source-accuracy Computation Step 3 Copying Detection Step 1 53
54 EXT - Source Correlation More general source correlations Sources may provide data from complementary domains (negative correlation) Sources may focus on different types of information (negative correlation) Sources may apply common rules in extraction (positive correlation) How to detect Hypothesis test of independence using joint precision and joint recall [Pochampally et al., 2014] 54
55 Overview Introduction Comparison of Existing Truth Discovery and Crowdsourced Data Aggregation Setting Models of Truth Discovery and Crowdsourced Data Aggregation Truth Discovery for Crowdsourced Data Aggregation Related Areas Open Questions and Resources References 55
56 Truth Discovery for Crowdsourced Data Aggregation Crowdsourced data Not limited to data collected from Mechanical Turk Can be collected from social media platforms, discussion forums, smartphones, Truth discovery is useful Open-space passively crowdsourced data Methods based on confusion matrix do not work New challenges for truth discovery 56

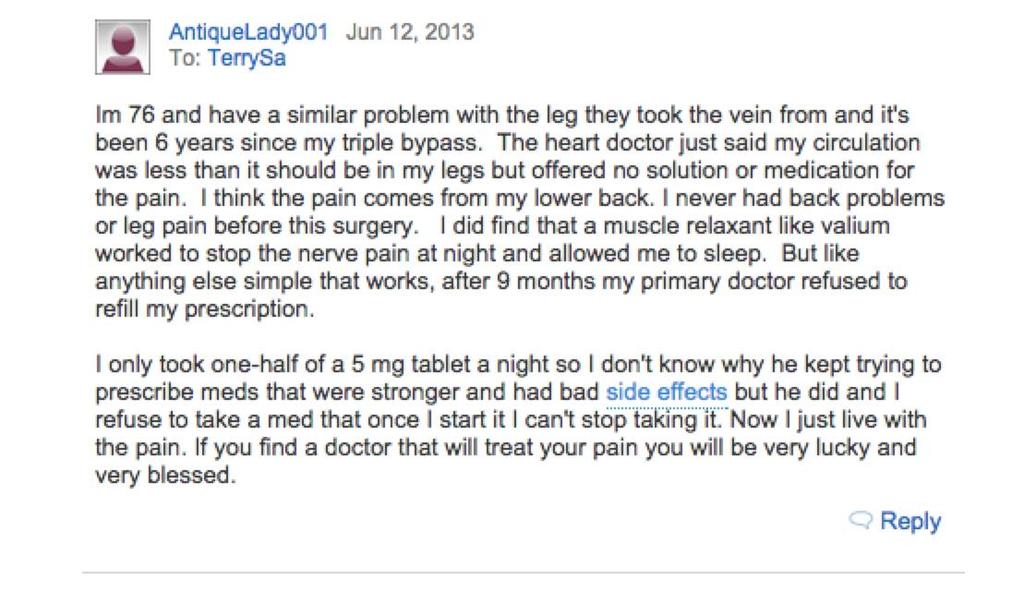
![cheeks, and shoulders when she is on [Depo].](/docs-images/80/81236567/images/57-1.jpg "... I have had no side effects from [Depo] (except.")

57 Passively Crowdsourced Data My girlfriend always gets a bad dry skin, rash on her upper arm, cheeks, and shoulders when she is on [Depo].... I have had no side effects from [Depo] (except... ), but otherwise no rashes DEPO USER1 Bad dry skin DEPO USER1 Rash DEPO USER2 No rashes DEPO Rash 57


 Good news.")


58 Passively Crowdsourced Data Made it through some pretty bad traffic! ( John F. Kennedy International Airport (JFK) in New York, NY) Good news...no traffic on George Washington bridge approach from Jersey JFK airport JFK airport Bad Traffic Good Traffic JFK Bad Traffic 58
59 CATD Model Long-tail phenomenon Most sources only provide very few claims and only a few sources makes plenty of claims. A confidence-aware approach not only estimates source reliability but also considers the confidence interval of the estimation [Li et al., 2015a] 59



60 50% 30% 19% 1% A B C D Which of these square numbers also happens to be the sum of two smaller numbers square?
61 Error Rate Comparison on Game Data Question level Majority Voting CATD

")



62 Goal FaitCrowd To learn fine-grained (topical-level) user expertise and the truths from conflicting crowd-contributed answers. Politics Physics Music [Ma et al., 2015] 62
63 FaitCrowd Input Question Set User Set Answer Set Question Content Output Questions Topic Topical-Level Users Expertise Question User u1 u2 u3 Word q a b q b c q a c q d e q5 2 1 e f q d f Topic Question K1 q1 q2 q3 K2 q4 q5 q6 User u1 u2 u3 Expertise K E K2 1.30E Truths Question q1 q2 q3 q4 q5 q6 Truth Question q1 q2 q3 q4 q5 q6 Ground Truth

64 FaitCrowd Overview Modeling Content y qm Modeling Answers u tq q w qm M q zq aqu N q bq Q ' K e K U 2 ' ' 2 Input Output Hyperparameter Intermediate Variable Jointly modeling question content and users answers by introducing latent topics. Modeling question content can help estimate reasonable user reliability, and in turn, modeling answers leads to the discovery of meaningful topics. Learning topics, topic-level user expertise and truths simultaneously. 64

65 FaitCrowd Answer Generation The correctness of a user s answer may be affected by the question s topic, user s expertise on the topic and the question s bias. y qm u tq q Draw user s expertise w qm M q zq aqu N q bq Q ' K e K U 2 ' ' 2 65
66 FaitCrowd Answer Generation The correctness of a user s answer may be affected by the question s topic, user s expertise on the topic and the question s bias. y qm u tq q Draw user s expertise w qm M q zq aqu N q bq Q Draw the truth ' K e K U 2 ' ' 2 66
67 FaitCrowd Answer Generation The correctness of a user s answer may be affected by the question s topic, user s expertise on the topic and the question s bias. y qm u tq q Draw user s expertise w qm M q zq aqu N q bq Q Draw the truth ' K e K U 2 ' Draw the bias ' 2 67
68 FaitCrowd Answer Generation The correctness of a user s answer may be affected by the question s topic, user s expertise on the topic and the question s bias. y qm u tq q Draw user s expertise w qm M q zq aqu N q bq Q Draw the truth ' K e K U 2 ' Draw the bias ' 2 Draw a user s answer 68
69 Overview Introduction Comparison of Existing Truth Discovery and Crowdsourced Data Aggregation Setting Models of Truth Discovery and Crowdsourced Data Aggregation Truth Discovery for Crowdsourced Data Aggregation Related Areas Open Questions and Resources References 69
70 Related Areas Information integration and data cleaning Data fusion and data integration schema mapping entity resolution They can be deemed as the pre-step of Truth Discovery Sensor data fusion Difference: the sources are treated indistinguishably Data cleaning Difference: single source VS multi-source 70
71 Related Areas Active Crowdsourcing Designing of crowdsourcing applications Designing of platforms Budget allocation Pricing mechanisms 71
72 Related Areas Ensemble learning Integrate different machine learning models Difference: supervised VS unsupervised Meta analysis Integrate different lab studies Difference: weights are calculated based on sample size Information trustworthiness analysis Rumor detection Trust propagation Difference: input may contain link information or features extracted from data 72
73 Overview Introduction Comparison of Existing Truth Discovery and Crowdsourced Data Aggregation Setting Models of Truth Discovery and Crowdsourced Data Aggregation Truth Discovery for Crowdsourced Data Aggregation Related Areas Open Questions and Resources References 73
74 Open Questions Data with complex relations Spatial and temporal Evaluation and theoretical analysis Information propagation Privacy preserving truth discovery Applications Health-oriented community question answering 74
75 Health-Oriented Community Question Answering Systems 75


76 Quality of Question-Answer Thread Truth Discovery 76


77 Impact of Medical Truth Discovery 77
78 Challenge (1): Noisy Input Raw textual data, unstructured Error introduced by extractor New data type: textual data 78
79 Number of Objects Number of Sources Challenge (2): Long-tail Phenomenon Long-tail on source side Each object still receives enough information. Long-tail on both object and source sides Most of objects receive few information. Number of Claims Number of Claims 79




80 Challenge (3): Multiple Linked Truths Truths can be multiple, and they are linked with each other. cough, fever Bronchitis Cold Tuberculosis 80
81 Challenge (4): Efficiency Issue Truth Discovery iterative procedure Initialize Weights of Sources Truth Computation Source Weight Estimation Truth and Source Weights Medical QA large-scale data One Chinese Medical Q&A forum: millions of registered patients hundreds of thousands of doctors thousands of new questions per day 81


82 Overview of Our System raw Data Filtering <Q, A> pairs Entity Extraction symptoms, diseases, drugs, etc application Extracted Knowledge 82










83 Preliminary Result: Example 25-year-old, cough, fever Extracted Knowledge by Our System Azithromycin Albuterol Bronchit is 25% Cold 45% Rifampin Tuberculosis 30% 83
84 Available Resources Survey for truth discovery [Gupta&Han, 2011] [Li et al., 2012] [Waguih et al., 2014] [Waguih et al., 2015] [Li et al., 2015b] Survey for crowdsourced data aggregation [Hung et al., 2013] [Sheshadri&Lease, 2013] 85
85 Available Resources Truth discovery data and code Crowdsourced data aggregation data and code
86 These slides are available at 87
87 References [Dawid&Skene, 1979] A. P. Dawid and A. M. Skene. Maximum likelihood estimation of observer error-rates using the EM algorithm. Journal of the Royal Statistical Society, Series C, pages 20 28, [Snow et al., 2008] R. Snow, B. O Connor, D. Jurafsky, and A.Y. Ng. Cheap and fast but is it good? Evaluating non-expert Annotations for natural language tasks. In Proceedings of the conference on empirical methods in natural language processing, pages , [Zhang et al., 2014] Y. Zhang, X. Chen, D. Zhou, and M. I. Jordan. Spectral methods meet EM: A provably Optimal Algorithm for Crowdsourcing. In Advances in Neural Information Processing Systems, pages , [Raykar et al., 2010] V. C. Raykar, S. Yu, L. H. Zhao, G.H. Valadez, C. Florin, L. Bogoni, and L. Moy. Learning from crowds. The Journal of Machine Learning Research, 11: ,
88 [Liu et al., 2012]Q. Liu, J. Peng, and A. Ihler. Variational Inference for crowdsourcing. In Advances in Neural Information Processing Systems, pages , [Li et al., 2013] H. Li, B. Yu, and D. Zhou. Error rate analysis of labeling by crowdsourcing. In ICML Workshop: Machine Learning Meets Crowdsourcing, [Lakkaraju et al., 2015] H. Lakkaraju, J. Leskovec, J. Kleinberg, and S. Mullainathan. A Bayesian framework for modeling human evaluations. In Proc. of the SIAM International Conference on Data Mining, [Yin et al., 2008] X. Yin, J. Han, and P. S. Yu. Truth discovery with multiple conflicting information providers on the web. IEEE Transactions on Knowledge and Data Engineering, 20(6): , [Zhao et al., 2012] B. Zhao, B. I. P. Rubinstein, J. Gemmell, and J. Han. A Bayesian approach to discovering truth from conflicting sources for data integration. Proc. VLDB Endow., 5(6): , Feb [Whitehill et al., 2009] J. Whitehill, P. Ruvolo, T. Wu, J. Bergsma, and J. Movellan. Whose vote should count more: Optimal integration of labelers of unknown expertise. In Advances in Neural Information Processing Systems, pages ,
89 [Zhou et al., 2012] D. Zhou, J. Platt, S. Basu, and Y. Mao. Learning from the wisdom of crowds by minimax entropy. In Advances in Neural Information Processing Systems, pages , [Li et al., 2014] Q. Li, Y. Li, J. Gao, B. Zhao, W. Fan, and J. Han. Resolving Conflicts in heterogeneous data by truth discovery and source reliability estimation. In Proc. of the ACM SIGMOD International Conference on Management of Data, pages , [Dong et al., 2009a] X. L. Dong, L. Berti-Equille,and D. Srivastava. Integrating conflicting data: The role of source dependence. PVLDB, pages , [Dong et al., 2009b] X. L. Dong, L. Berti-Equille,and D. Srivastava. Truth discovery and copying detection in a dynamic world. PVLDB, pages , [Pochampally et al., 2014] R. Pochampally, A. D. Sarma, X. L. Dong, A. Meliou, and D. Srivastava. Fusing data with correlations. In Proc. of the ACM SIGMOD International Conference on Management of Data, pages , [Li et al., 2015a] Q. Li, Y. Li, J. Gao, L. Su, B. Zhao, M. Demirbas, W. Fan, and J. Han. A confidence-aware approach for truth discovery on long-tail data. PVLDB, 8(4),
90 [Mukherjee et al., 2014] S. Mukherjee, G. Weikum, and C. Danescu- Niculescu-Mizil. People on drugs: credibility of user statements in health communities. In Proc. of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 65 74, [Ma et al., 2015] F. Ma, Y. Li, Q. Li, M. Qui, J. Gao, S. Zhi, L. Su, B. Zhao, H. Ji, and J. Han. Faitcrowd: Fine grained truth discovery for crowdsourced data aggregation. In Proc. of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, [Gupta&Han, 2011] M. Gupta and J. Han. Heterogeneous network-based trust analysis: A survey. ACM SIGKDD Explorations Newsletter, 13(1):54 71, [Li et al., 2012] X. Li, X. L. Dong, K. B. Lyons, W. Meng, and D. Srivastava. Truth finding on the deep web: Is the problem solved? PVLDB, 6(2):97 108, [Waguih et al., 2014] D. A. Waguih and L. Berti-Equille. Truth discovery algorithms: An experimental evaluation. arxiv preprint arxiv: , [Waguih et al., 2015] D. A. Waguih, N. Goel, H. M. Hammady, and L. Berti- Equille. Allegatortrack: Combining and reporting results of truth discovery from multi-source data. In Proc. of the IEEE International Conference on Data Engineering,
91 [Li et al., 2015b] Y. Li, J. Gao, C. Meng, Q. Li, L. Su, B. Zhao, W. Fan, and J. Han. A survey on truth discovery. arxiv preprint arxiv: , [Hung et al., 2013] N. Q. V. Hung, N. T. Tam, L. N. Tran, and K. Aberer. An evaluation of aggregation techniques in crowdsourcing. In Web Information Systems Engineering, pages [Sheshadri&Lease, 2013] A. Sheshadri and M. Lease. SQUARE: A benchmark for research on computing crowd consensus. In Proc. of the AAAI Conference on Human Computation, pages ,
Truth Discovery for Passive and Active Crowdsourcing. Jing Gao 1, Qi Li 1, and Wei Fan 2 1. SUNY Buffalo; 2 Baidu Research Big Data Lab
 Truth Discovery for Passive and Active Crowdsourcing Jing Gao 1, Qi Li 1, and Wei Fan 2 1 SUNY Buffalo; 2 Baidu Research Big Data Lab 1 Overview 1 2 3 4 5 6 7 Introduction of Crowdsourcing Crowdsourced
Truth Discovery for Passive and Active Crowdsourcing Jing Gao 1, Qi Li 1, and Wei Fan 2 1 SUNY Buffalo; 2 Baidu Research Big Data Lab 1 Overview 1 2 3 4 5 6 7 Introduction of Crowdsourcing Crowdsourced
Learning from the Wisdom of Crowds by Minimax Entropy. Denny Zhou, John Platt, Sumit Basu and Yi Mao Microsoft Research, Redmond, WA
 Learning from the Wisdom of Crowds by Minimax Entropy Denny Zhou, John Platt, Sumit Basu and Yi Mao Microsoft Research, Redmond, WA Outline 1. Introduction 2. Minimax entropy principle 3. Future work and
Learning from the Wisdom of Crowds by Minimax Entropy Denny Zhou, John Platt, Sumit Basu and Yi Mao Microsoft Research, Redmond, WA Outline 1. Introduction 2. Minimax entropy principle 3. Future work and
Uncovering the Latent Structures of Crowd Labeling
 Uncovering the Latent Structures of Crowd Labeling Tian Tian and Jun Zhu Presenter:XXX Tsinghua University 1 / 26 Motivation Outline 1 Motivation 2 Related Works 3 Crowdsourcing Latent Class 4 Experiments
Uncovering the Latent Structures of Crowd Labeling Tian Tian and Jun Zhu Presenter:XXX Tsinghua University 1 / 26 Motivation Outline 1 Motivation 2 Related Works 3 Crowdsourcing Latent Class 4 Experiments
Improving Quality of Crowdsourced Labels via Probabilistic Matrix Factorization
 Human Computation AAAI Technical Report WS-12-08 Improving Quality of Crowdsourced Labels via Probabilistic Matrix Factorization Hyun Joon Jung School of Information University of Texas at Austin hyunjoon@utexas.edu
Human Computation AAAI Technical Report WS-12-08 Improving Quality of Crowdsourced Labels via Probabilistic Matrix Factorization Hyun Joon Jung School of Information University of Texas at Austin hyunjoon@utexas.edu
Crowdsourcing via Tensor Augmentation and Completion (TAC)
") Crowdsourcing via Tensor Augmentation and Completion (TAC) Presenter: Yao Zhou joint work with: Dr. Jingrui He - 1 - Roadmap Background Related work Crowdsourcing based on TAC Experimental results Conclusion
Crowdsourcing via Tensor Augmentation and Completion (TAC) Presenter: Yao Zhou joint work with: Dr. Jingrui He - 1 - Roadmap Background Related work Crowdsourcing based on TAC Experimental results Conclusion
Influence-Aware Truth Discovery
 Influence-Aware Truth Discovery Hengtong Zhang, Qi Li, Fenglong Ma, Houping Xiao, Yaliang Li, Jing Gao, Lu Su SUNY Buffalo, Buffalo, NY USA {hengtong, qli22, fenglong, houpingx, yaliangl, jing, lusu}@buffaloedu
Influence-Aware Truth Discovery Hengtong Zhang, Qi Li, Fenglong Ma, Houping Xiao, Yaliang Li, Jing Gao, Lu Su SUNY Buffalo, Buffalo, NY USA {hengtong, qli22, fenglong, houpingx, yaliangl, jing, lusu}@buffaloedu
Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy. Denny Zhou Qiang Liu John Platt Chris Meek
 Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy Denny Zhou Qiang Liu John Platt Chris Meek 2 Crowds vs experts labeling: strength Time saving Money saving Big labeled data More data
Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy Denny Zhou Qiang Liu John Platt Chris Meek 2 Crowds vs experts labeling: strength Time saving Money saving Big labeled data More data
Discovering Truths from Distributed Data
 217 IEEE International Conference on Data Mining Discovering Truths from Distributed Data Yaqing Wang, Fenglong Ma, Lu Su, and Jing Gao SUNY Buffalo, Buffalo, USA {yaqingwa, fenglong, lusu, jing}@buffalo.edu
217 IEEE International Conference on Data Mining Discovering Truths from Distributed Data Yaqing Wang, Fenglong Ma, Lu Su, and Jing Gao SUNY Buffalo, Buffalo, USA {yaqingwa, fenglong, lusu, jing}@buffalo.edu
arxiv: v1 [cs.db] 14 May 2017
![arxiv: v1 [cs.db] 14 May 2017](/thumbs/78/77272323.jpg "arxiv: v1 [cs.db] 14 May 2017") Discovering Multiple Truths with a Model Furong Li Xin Luna Dong Anno Langen Yang Li National University of Singapore Google Inc., Mountain View, CA, USA furongli@comp.nus.edu.sg {lunadong, arl, ngli}@google.com
Discovering Multiple Truths with a Model Furong Li Xin Luna Dong Anno Langen Yang Li National University of Singapore Google Inc., Mountain View, CA, USA furongli@comp.nus.edu.sg {lunadong, arl, ngli}@google.com
arxiv: v2 [cs.lg] 17 Nov 2016
![arxiv: v2 [cs.lg] 17 Nov 2016](/thumbs/96/127231188.jpg "arxiv: v2 [cs.lg] 17 Nov 2016") Approximating Wisdom of Crowds using K-RBMs Abhay Gupta Microsoft India R&D Pvt. Ltd. abhgup@microsoft.com arxiv:1611.05340v2 [cs.lg] 17 Nov 2016 Abstract An important way to make large training sets is
Approximating Wisdom of Crowds using K-RBMs Abhay Gupta Microsoft India R&D Pvt. Ltd. abhgup@microsoft.com arxiv:1611.05340v2 [cs.lg] 17 Nov 2016 Abstract An important way to make large training sets is
Adaptive Crowdsourcing via EM with Prior
 Adaptive Crowdsourcing via EM with Prior Peter Maginnis and Tanmay Gupta May, 205 In this work, we make two primary contributions: derivation of the EM update for the shifted and rescaled beta prior and
Adaptive Crowdsourcing via EM with Prior Peter Maginnis and Tanmay Gupta May, 205 In this work, we make two primary contributions: derivation of the EM update for the shifted and rescaled beta prior and
Content-based Recommendation
 Content-based Recommendation Suthee Chaidaroon June 13, 2016 Contents 1 Introduction 1 1.1 Matrix Factorization......................... 2 2 slda 2 2.1 Model................................. 3 3 flda 3
Content-based Recommendation Suthee Chaidaroon June 13, 2016 Contents 1 Introduction 1 1.1 Matrix Factorization......................... 2 2 slda 2 2.1 Model................................. 3 3 flda 3
Towards Confidence in the Truth: A Bootstrapping based Truth Discovery Approach
 Towards Confidence in the Truth: A Bootstrapping based Truth Discovery Approach Houping Xiao 1, Jing Gao 1, Qi Li 1, Fenglong Ma 1, Lu Su 1 Yunlong Feng, and Aidong Zhang 1 1 SUNY Buffalo, Buffalo, NY
Towards Confidence in the Truth: A Bootstrapping based Truth Discovery Approach Houping Xiao 1, Jing Gao 1, Qi Li 1, Fenglong Ma 1, Lu Su 1 Yunlong Feng, and Aidong Zhang 1 1 SUNY Buffalo, Buffalo, NY
Corroborating Information from Disagreeing Views
 Corroboration A. Galland WSDM 2010 1/26 Corroborating Information from Disagreeing Views Alban Galland 1 Serge Abiteboul 1 Amélie Marian 2 Pierre Senellart 3 1 INRIA Saclay Île-de-France 2 Rutgers University
Corroboration A. Galland WSDM 2010 1/26 Corroborating Information from Disagreeing Views Alban Galland 1 Serge Abiteboul 1 Amélie Marian 2 Pierre Senellart 3 1 INRIA Saclay Île-de-France 2 Rutgers University
Believe it Today or Tomorrow? Detecting Untrustworthy Information from Dynamic Multi-Source Data
 SDM 15 Vancouver, CAN Believe it Today or Tomorrow? Detecting Untrustworthy Information from Dynamic Multi-Source Data Houping Xiao 1, Yaliang Li 1, Jing Gao 1, Fei Wang 2, Liang Ge 3, Wei Fan 4, Long
SDM 15 Vancouver, CAN Believe it Today or Tomorrow? Detecting Untrustworthy Information from Dynamic Multi-Source Data Houping Xiao 1, Yaliang Li 1, Jing Gao 1, Fei Wang 2, Liang Ge 3, Wei Fan 4, Long
Crowdsourcing & Optimal Budget Allocation in Crowd Labeling
 Crowdsourcing & Optimal Budget Allocation in Crowd Labeling Madhav Mohandas, Richard Zhu, Vincent Zhuang May 5, 2016 Table of Contents 1. Intro to Crowdsourcing 2. The Problem 3. Knowledge Gradient Algorithm
Crowdsourcing & Optimal Budget Allocation in Crowd Labeling Madhav Mohandas, Richard Zhu, Vincent Zhuang May 5, 2016 Table of Contents 1. Intro to Crowdsourcing 2. The Problem 3. Knowledge Gradient Algorithm
Online Truth Discovery on Time Series Data
 Online Truth Discovery on Time Series Data Liuyi Yao Lu Su Qi Li Yaliang Li Fenglong Ma Jing Gao Aidong Zhang Abstract Truth discovery, with the goal of inferring true information from massive data through
Online Truth Discovery on Time Series Data Liuyi Yao Lu Su Qi Li Yaliang Li Fenglong Ma Jing Gao Aidong Zhang Abstract Truth discovery, with the goal of inferring true information from massive data through
Budget-Optimal Task Allocation for Reliable Crowdsourcing Systems
 Budget-Optimal Task Allocation for Reliable Crowdsourcing Systems Sewoong Oh Massachusetts Institute of Technology joint work with David R. Karger and Devavrat Shah September 28, 2011 1 / 13 Crowdsourcing
Budget-Optimal Task Allocation for Reliable Crowdsourcing Systems Sewoong Oh Massachusetts Institute of Technology joint work with David R. Karger and Devavrat Shah September 28, 2011 1 / 13 Crowdsourcing
Approximating Global Optimum for Probabilistic Truth Discovery
 Approximating Global Optimum for Probabilistic Truth Discovery Shi Li, Jinhui Xu, and Minwei Ye State University of New York at Buffalo {shil,jinhui,minweiye}@buffalo.edu Abstract. The problem of truth
Approximating Global Optimum for Probabilistic Truth Discovery Shi Li, Jinhui Xu, and Minwei Ye State University of New York at Buffalo {shil,jinhui,minweiye}@buffalo.edu Abstract. The problem of truth
Time Series Data Cleaning
 Time Series Data Cleaning Shaoxu Song http://ise.thss.tsinghua.edu.cn/sxsong/ Dirty Time Series Data Unreliable Readings Sensor monitoring GPS trajectory J. Freire, A. Bessa, F. Chirigati, H. T. Vo, K.
Time Series Data Cleaning Shaoxu Song http://ise.thss.tsinghua.edu.cn/sxsong/ Dirty Time Series Data Unreliable Readings Sensor monitoring GPS trajectory J. Freire, A. Bessa, F. Chirigati, H. T. Vo, K.
Leveraging Data Relationships to Resolve Conflicts from Disparate Data Sources. Romila Pradhan, Walid G. Aref, Sunil Prabhakar
 Leveraging Data Relationships to Resolve Conflicts from Disparate Data Sources Romila Pradhan, Walid G. Aref, Sunil Prabhakar Fusing data from multiple sources Data Item S 1 S 2 S 3 S 4 S 5 Basera 745
Leveraging Data Relationships to Resolve Conflicts from Disparate Data Sources Romila Pradhan, Walid G. Aref, Sunil Prabhakar Fusing data from multiple sources Data Item S 1 S 2 S 3 S 4 S 5 Basera 745
The Web is Great. Divesh Srivastava AT&T Labs Research
 The Web is Great Divesh Srivastava AT&T Labs Research A Lot of Information on the Web Information Can Be Erroneous The story, marked Hold for release Do not use, was sent in error to the news service s
The Web is Great Divesh Srivastava AT&T Labs Research A Lot of Information on the Web Information Can Be Erroneous The story, marked Hold for release Do not use, was sent in error to the news service s
On the Impossibility of Convex Inference in Human Computation
 On the Impossibility of Convex Inference in Human Computation Nihar B. Shah U.C. Berkeley nihar@eecs.berkeley.edu Dengyong Zhou Microsoft Research dengyong.zhou@microsoft.com Abstract Human computation
On the Impossibility of Convex Inference in Human Computation Nihar B. Shah U.C. Berkeley nihar@eecs.berkeley.edu Dengyong Zhou Microsoft Research dengyong.zhou@microsoft.com Abstract Human computation
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding
 Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Learning From Crowds. Presented by: Bei Peng 03/24/15
 Learning From Crowds Presented by: Bei Peng 03/24/15 1 Supervised Learning Given labeled training data, learn to generalize well on unseen data Binary classification ( ) Multi-class classification ( y
Learning From Crowds Presented by: Bei Peng 03/24/15 1 Supervised Learning Given labeled training data, learn to generalize well on unseen data Binary classification ( ) Multi-class classification ( y
The Benefits of a Model of Annotation
 The Benefits of a Model of Annotation Rebecca J. Passonneau and Bob Carpenter Columbia University Center for Computational Learning Systems Department of Statistics LAW VII, August 2013 Conventional Approach
The Benefits of a Model of Annotation Rebecca J. Passonneau and Bob Carpenter Columbia University Center for Computational Learning Systems Department of Statistics LAW VII, August 2013 Conventional Approach
Classification Semi-supervised learning based on network. Speakers: Hanwen Wang, Xinxin Huang, and Zeyu Li CS Winter
 Classification Semi-supervised learning based on network Speakers: Hanwen Wang, Xinxin Huang, and Zeyu Li CS 249-2 2017 Winter Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions Xiaojin
Classification Semi-supervised learning based on network Speakers: Hanwen Wang, Xinxin Huang, and Zeyu Li CS 249-2 2017 Winter Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions Xiaojin
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2014
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
UnSAID: Uncertainty and Structure in the Access to Intensional Data
 UnSAID: Uncertainty and Structure in the Access to Intensional Data Pierre Senellart 3 July 214, Univ. Rennes 1 Uncertain data is everywhere Numerous sources of uncertain data: Measurement errors Data
UnSAID: Uncertainty and Structure in the Access to Intensional Data Pierre Senellart 3 July 214, Univ. Rennes 1 Uncertain data is everywhere Numerous sources of uncertain data: Measurement errors Data
Crowdsourcing with Multi-Dimensional Trust
 18th International Conference on Information Fusion Washington, DC - July 6-9, 2015 Crowdsourcing with Multi-Dimensional Trust Xiangyang Liu, He He, John S. Baras Institute for Systems Research and Dept.
18th International Conference on Information Fusion Washington, DC - July 6-9, 2015 Crowdsourcing with Multi-Dimensional Trust Xiangyang Liu, He He, John S. Baras Institute for Systems Research and Dept.
Permuation Models meet Dawid-Skene: A Generalised Model for Crowdsourcing
 Permuation Models meet Dawid-Skene: A Generalised Model for Crowdsourcing Ankur Mallick Electrical and Computer Engineering Carnegie Mellon University amallic@andrew.cmu.edu Abstract The advent of machine
Permuation Models meet Dawid-Skene: A Generalised Model for Crowdsourcing Ankur Mallick Electrical and Computer Engineering Carnegie Mellon University amallic@andrew.cmu.edu Abstract The advent of machine
Discrete Probability and State Estimation
 6.01, Fall Semester, 2007 Lecture 12 Notes 1 MASSACHVSETTS INSTITVTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.01 Introduction to EECS I Fall Semester, 2007 Lecture 12 Notes
6.01, Fall Semester, 2007 Lecture 12 Notes 1 MASSACHVSETTS INSTITVTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.01 Introduction to EECS I Fall Semester, 2007 Lecture 12 Notes
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Supporting Statistical Hypothesis Testing Over Graphs
 Supporting Statistical Hypothesis Testing Over Graphs Jennifer Neville Departments of Computer Science and Statistics Purdue University (joint work with Tina Eliassi-Rad, Brian Gallagher, Sergey Kirshner,
Supporting Statistical Hypothesis Testing Over Graphs Jennifer Neville Departments of Computer Science and Statistics Purdue University (joint work with Tina Eliassi-Rad, Brian Gallagher, Sergey Kirshner,
Learning Medical Diagnosis Models from Multiple Experts
 Learning Medical Diagnosis Models from Multiple Experts Hamed Valizadegan, Quang Nguyen, Milos Hauskrecht 1 Department of Computer Science, University of Pittsburgh, email: hamed, quang, milos@cs.pitt.edu
Learning Medical Diagnosis Models from Multiple Experts Hamed Valizadegan, Quang Nguyen, Milos Hauskrecht 1 Department of Computer Science, University of Pittsburgh, email: hamed, quang, milos@cs.pitt.edu
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
Mobility Analytics through Social and Personal Data. Pierre Senellart
 Mobility Analytics through Social and Personal Data Pierre Senellart Session: Big Data & Transport Business Convention on Big Data Université Paris-Saclay, 25 novembre 2015 Analyzing Transportation and
Mobility Analytics through Social and Personal Data Pierre Senellart Session: Big Data & Transport Business Convention on Big Data Université Paris-Saclay, 25 novembre 2015 Analyzing Transportation and
Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text
 Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text Yi Zhang Machine Learning Department Carnegie Mellon University yizhang1@cs.cmu.edu Jeff Schneider The Robotics Institute
Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text Yi Zhang Machine Learning Department Carnegie Mellon University yizhang1@cs.cmu.edu Jeff Schneider The Robotics Institute
arxiv: v3 [cs.lg] 25 Aug 2017
![arxiv: v3 [cs.lg] 25 Aug 2017](/thumbs/84/89382803.jpg "arxiv: v3 [cs.lg] 25 Aug 2017") Achieving Budget-optimality with Adaptive Schemes in Crowdsourcing Ashish Khetan and Sewoong Oh arxiv:602.0348v3 [cs.lg] 25 Aug 207 Abstract Crowdsourcing platforms provide marketplaces where task requesters
Achieving Budget-optimality with Adaptive Schemes in Crowdsourcing Ashish Khetan and Sewoong Oh arxiv:602.0348v3 [cs.lg] 25 Aug 207 Abstract Crowdsourcing platforms provide marketplaces where task requesters
Star-Structured High-Order Heterogeneous Data Co-clustering based on Consistent Information Theory
 Star-Structured High-Order Heterogeneous Data Co-clustering based on Consistent Information Theory Bin Gao Tie-an Liu Wei-ing Ma Microsoft Research Asia 4F Sigma Center No. 49 hichun Road Beijing 00080
Star-Structured High-Order Heterogeneous Data Co-clustering based on Consistent Information Theory Bin Gao Tie-an Liu Wei-ing Ma Microsoft Research Asia 4F Sigma Center No. 49 hichun Road Beijing 00080
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Crowdsourcing label quality: a theoretical analysis
 . RESEARCH PAPER. SCIENCE CHINA Information Sciences November 5, Vol. 58 xxxxxx: xxxxxx: doi: xxxxxxxxxxxxxx Crowdsourcing label quality: a theoretical analysis WANG Wei & ZHOU Zhi-Hua * National Key Laboratory
. RESEARCH PAPER. SCIENCE CHINA Information Sciences November 5, Vol. 58 xxxxxx: xxxxxx: doi: xxxxxxxxxxxxxx Crowdsourcing label quality: a theoretical analysis WANG Wei & ZHOU Zhi-Hua * National Key Laboratory
A Randomized Approach for Crowdsourcing in the Presence of Multiple Views
 A Randomized Approach for Crowdsourcing in the Presence of Multiple Views Presenter: Yao Zhou joint work with: Jingrui He - 1 - Roadmap Motivation Proposed framework: M2VW Experimental results Conclusion
A Randomized Approach for Crowdsourcing in the Presence of Multiple Views Presenter: Yao Zhou joint work with: Jingrui He - 1 - Roadmap Motivation Proposed framework: M2VW Experimental results Conclusion
1 Overview. 2 Learning from Experts. 2.1 Defining a meaningful benchmark. AM 221: Advanced Optimization Spring 2016
 AM 1: Advanced Optimization Spring 016 Prof. Yaron Singer Lecture 11 March 3rd 1 Overview In this lecture we will introduce the notion of online convex optimization. This is an extremely useful framework
AM 1: Advanced Optimization Spring 016 Prof. Yaron Singer Lecture 11 March 3rd 1 Overview In this lecture we will introduce the notion of online convex optimization. This is an extremely useful framework
Modeling of Growing Networks with Directional Attachment and Communities
 Modeling of Growing Networks with Directional Attachment and Communities Masahiro KIMURA, Kazumi SAITO, Naonori UEDA NTT Communication Science Laboratories 2-4 Hikaridai, Seika-cho, Kyoto 619-0237, Japan
Modeling of Growing Networks with Directional Attachment and Communities Masahiro KIMURA, Kazumi SAITO, Naonori UEDA NTT Communication Science Laboratories 2-4 Hikaridai, Seika-cho, Kyoto 619-0237, Japan
Topic Models and Applications to Short Documents
 Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Mixtures of Gaussians. Sargur Srihari
 Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Feature Engineering, Model Evaluations
 Feature Engineering, Model Evaluations Giri Iyengar Cornell University gi43@cornell.edu Feb 5, 2018 Giri Iyengar (Cornell Tech) Feature Engineering Feb 5, 2018 1 / 35 Overview 1 ETL 2 Feature Engineering
Feature Engineering, Model Evaluations Giri Iyengar Cornell University gi43@cornell.edu Feb 5, 2018 Giri Iyengar (Cornell Tech) Feature Engineering Feb 5, 2018 1 / 35 Overview 1 ETL 2 Feature Engineering
Machine Learning (CS 567) Lecture 2
 Lecture 2") Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Discrete Probability and State Estimation
 6.01, Spring Semester, 2008 Week 12 Course Notes 1 MASSACHVSETTS INSTITVTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.01 Introduction to EECS I Spring Semester, 2008 Week
6.01, Spring Semester, 2008 Week 12 Course Notes 1 MASSACHVSETTS INSTITVTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.01 Introduction to EECS I Spring Semester, 2008 Week
Latent Dirichlet Allocation Introduction/Overview
 Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Whom to Ask? Jury Selection for Decision Making Tasks on Micro-blog Services
 Whom to Ask? Jury Selection for Decision Making Tasks on Micro-blog Services Caleb Chen CAO, Jieying SHE, Yongxin TONG, Lei CHEN The Hong Kong University of Science and Technology Is Istanbul the capital
Whom to Ask? Jury Selection for Decision Making Tasks on Micro-blog Services Caleb Chen CAO, Jieying SHE, Yongxin TONG, Lei CHEN The Hong Kong University of Science and Technology Is Istanbul the capital
Active and Semi-supervised Kernel Classification
 Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Bayesian Contextual Multi-armed Bandits
 Bayesian Contextual Multi-armed Bandits Xiaoting Zhao Joint Work with Peter I. Frazier School of Operations Research and Information Engineering Cornell University October 22, 2012 1 / 33 Outline 1 Motivating
Bayesian Contextual Multi-armed Bandits Xiaoting Zhao Joint Work with Peter I. Frazier School of Operations Research and Information Engineering Cornell University October 22, 2012 1 / 33 Outline 1 Motivating
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
Be able to define the following terms and answer basic questions about them:
 CS440/ECE448 Section Q Fall 2017 Final Review Be able to define the following terms and answer basic questions about them: Probability o Random variables, axioms of probability o Joint, marginal, conditional
CS440/ECE448 Section Q Fall 2017 Final Review Be able to define the following terms and answer basic questions about them: Probability o Random variables, axioms of probability o Joint, marginal, conditional
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Click Prediction and Preference Ranking of RSS Feeds
 Click Prediction and Preference Ranking of RSS Feeds 1 Introduction December 11, 2009 Steven Wu RSS (Really Simple Syndication) is a family of data formats used to publish frequently updated works. RSS
Click Prediction and Preference Ranking of RSS Feeds 1 Introduction December 11, 2009 Steven Wu RSS (Really Simple Syndication) is a family of data formats used to publish frequently updated works. RSS
Introduction to Logistic Regression
 Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Essence of Machine Learning (and Deep Learning) Hoa M. Le Data Science Lab, HUST hoamle.github.io
 Hoa M. Le Data Science Lab, HUST hoamle.github.io") Essence of Machine Learning (and Deep Learning) Hoa M. Le Data Science Lab, HUST hoamle.github.io 1 Examples https://www.youtube.com/watch?v=bmka1zsg2 P4 http://www.r2d3.us/visual-intro-to-machinelearning-part-1/
Essence of Machine Learning (and Deep Learning) Hoa M. Le Data Science Lab, HUST hoamle.github.io 1 Examples https://www.youtube.com/watch?v=bmka1zsg2 P4 http://www.r2d3.us/visual-intro-to-machinelearning-part-1/
Learning to Learn and Collaborative Filtering
 Appearing in NIPS 2005 workshop Inductive Transfer: Canada, December, 2005. 10 Years Later, Whistler, Learning to Learn and Collaborative Filtering Kai Yu, Volker Tresp Siemens AG, 81739 Munich, Germany
Appearing in NIPS 2005 workshop Inductive Transfer: Canada, December, 2005. 10 Years Later, Whistler, Learning to Learn and Collaborative Filtering Kai Yu, Volker Tresp Siemens AG, 81739 Munich, Germany
Variational Inference for Crowdsourcing
 Variational Inference for Crowdsourcing Qiang Liu ICS, UC Irvine qliu1@ics.uci.edu Jian Peng TTI-C & CSAIL, MIT jpeng@csail.mit.edu Alexander Ihler ICS, UC Irvine ihler@ics.uci.edu Abstract Crowdsourcing
Variational Inference for Crowdsourcing Qiang Liu ICS, UC Irvine qliu1@ics.uci.edu Jian Peng TTI-C & CSAIL, MIT jpeng@csail.mit.edu Alexander Ihler ICS, UC Irvine ihler@ics.uci.edu Abstract Crowdsourcing
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Aspect Term Extraction with History Attention and Selective Transformation 1
 Aspect Term Extraction with History Attention and Selective Transformation 1 Xin Li 1, Lidong Bing 2, Piji Li 1, Wai Lam 1, Zhimou Yang 3 Presenter: Lin Ma 2 1 The Chinese University of Hong Kong 2 Tencent
Aspect Term Extraction with History Attention and Selective Transformation 1 Xin Li 1, Lidong Bing 2, Piji Li 1, Wai Lam 1, Zhimou Yang 3 Presenter: Lin Ma 2 1 The Chinese University of Hong Kong 2 Tencent
CS 188: Artificial Intelligence Spring Today
 CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
COMS 4771 Lecture Course overview 2. Maximum likelihood estimation (review of some statistics)
") COMS 4771 Lecture 1 1. Course overview 2. Maximum likelihood estimation (review of some statistics) 1 / 24 Administrivia This course Topics http://www.satyenkale.com/coms4771/ 1. Supervised learning Core
COMS 4771 Lecture 1 1. Course overview 2. Maximum likelihood estimation (review of some statistics) 1 / 24 Administrivia This course Topics http://www.satyenkale.com/coms4771/ 1. Supervised learning Core
Unsupervised Learning
 2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Study Notes on the Latent Dirichlet Allocation
 Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Lecture 10: Introduction to reasoning under uncertainty. Uncertainty
 Lecture 10: Introduction to reasoning under uncertainty Introduction to reasoning under uncertainty Review of probability Axioms and inference Conditional probability Probability distributions COMP-424,
Lecture 10: Introduction to reasoning under uncertainty Introduction to reasoning under uncertainty Review of probability Axioms and inference Conditional probability Probability distributions COMP-424,
Joint Emotion Analysis via Multi-task Gaussian Processes
 Joint Emotion Analysis via Multi-task Gaussian Processes Daniel Beck, Trevor Cohn, Lucia Specia October 28, 2014 1 Introduction 2 Multi-task Gaussian Process Regression 3 Experiments and Discussion 4 Conclusions
Joint Emotion Analysis via Multi-task Gaussian Processes Daniel Beck, Trevor Cohn, Lucia Specia October 28, 2014 1 Introduction 2 Multi-task Gaussian Process Regression 3 Experiments and Discussion 4 Conclusions
Sum-Product Networks. STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 17, 2017
 Sum-Product Networks STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 17, 2017 Introduction Outline What is a Sum-Product Network? Inference Applications In more depth
Sum-Product Networks STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 17, 2017 Introduction Outline What is a Sum-Product Network? Inference Applications In more depth
Introduction to AI Learning Bayesian networks. Vibhav Gogate
 Introduction to AI Learning Bayesian networks Vibhav Gogate Inductive Learning in a nutshell Given: Data Examples of a function (X, F(X)) Predict function F(X) for new examples X Discrete F(X): Classification
Introduction to AI Learning Bayesian networks Vibhav Gogate Inductive Learning in a nutshell Given: Data Examples of a function (X, F(X)) Predict function F(X) for new examples X Discrete F(X): Classification
Statistical Quality Control for Human Computation and Crowdsourcing
 Statistical Quality Control for Human Computation and Crowdsourcing Yukino aba (University of Tsukuba) Early career spotlight talk @ IJCI-ECI 2018 July 18, 2018 HUMN COMPUTTION Humans and computers collaboratively
Statistical Quality Control for Human Computation and Crowdsourcing Yukino aba (University of Tsukuba) Early career spotlight talk @ IJCI-ECI 2018 July 18, 2018 HUMN COMPUTTION Humans and computers collaboratively
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Deep Poisson Factorization Machines: a factor analysis model for mapping behaviors in journalist ecosystem
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Expectation-Maximization
 Expectation-Maximization Léon Bottou NEC Labs America COS 424 3/9/2010 Agenda Goals Representation Capacity Control Operational Considerations Computational Considerations Classification, clustering, regression,
Expectation-Maximization Léon Bottou NEC Labs America COS 424 3/9/2010 Agenda Goals Representation Capacity Control Operational Considerations Computational Considerations Classification, clustering, regression,
Bandit-Based Task Assignment for Heterogeneous Crowdsourcing
 Neural Computation, vol.27, no., pp.2447 2475, 205. Bandit-Based Task Assignment for Heterogeneous Crowdsourcing Hao Zhang Department of Computer Science, Tokyo Institute of Technology, Japan Yao Ma Department
Neural Computation, vol.27, no., pp.2447 2475, 205. Bandit-Based Task Assignment for Heterogeneous Crowdsourcing Hao Zhang Department of Computer Science, Tokyo Institute of Technology, Japan Yao Ma Department
The Veracity of Big Data
 The Veracity of Big Data Pierre Senellart École normale supérieure 13 October 2016, Big Data & Market Insights 23 April 2013, Dow Jones (cnn.com) 23 April 2013, Dow Jones (cnn.com) 23 April 2013, Dow Jones
The Veracity of Big Data Pierre Senellart École normale supérieure 13 October 2016, Big Data & Market Insights 23 April 2013, Dow Jones (cnn.com) 23 April 2013, Dow Jones (cnn.com) 23 April 2013, Dow Jones
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Performance evaluation of binary classifiers
 Performance evaluation of binary classifiers Kevin P. Murphy Last updated October 10, 2007 1 ROC curves We frequently design systems to detect events of interest, such as diseases in patients, faces in
Performance evaluation of binary classifiers Kevin P. Murphy Last updated October 10, 2007 1 ROC curves We frequently design systems to detect events of interest, such as diseases in patients, faces in
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
Probabilistic Matrix Factorization
 Probabilistic Matrix Factorization David M. Blei Columbia University November 25, 2015 1 Dyadic data One important type of modern data is dyadic data. Dyadic data are measurements on pairs. The idea is
Probabilistic Matrix Factorization David M. Blei Columbia University November 25, 2015 1 Dyadic data One important type of modern data is dyadic data. Dyadic data are measurements on pairs. The idea is
MODULE -4 BAYEIAN LEARNING
 MODULE -4 BAYEIAN LEARNING CONTENT Introduction Bayes theorem Bayes theorem and concept learning Maximum likelihood and Least Squared Error Hypothesis Maximum likelihood Hypotheses for predicting probabilities
MODULE -4 BAYEIAN LEARNING CONTENT Introduction Bayes theorem Bayes theorem and concept learning Maximum likelihood and Least Squared Error Hypothesis Maximum likelihood Hypotheses for predicting probabilities
Probability and Information Theory. Sargur N. Srihari
 Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Stat 315c: Introduction
 Stat 315c: Introduction Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Stat 315c: Introduction 1 / 14 Stat 315c Analysis of Transposable Data Usual Statistics Setup there s Y (we ll
Stat 315c: Introduction Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Stat 315c: Introduction 1 / 14 Stat 315c Analysis of Transposable Data Usual Statistics Setup there s Y (we ll
Does Better Inference mean Better Learning?
 Does Better Inference mean Better Learning? Andrew E. Gelfand, Rina Dechter & Alexander Ihler Department of Computer Science University of California, Irvine {agelfand,dechter,ihler}@ics.uci.edu Abstract
Does Better Inference mean Better Learning? Andrew E. Gelfand, Rina Dechter & Alexander Ihler Department of Computer Science University of California, Irvine {agelfand,dechter,ihler}@ics.uci.edu Abstract
Generative Models for Discrete Data
 Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
RETRIEVAL MODELS. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
An Approach to Classification Based on Fuzzy Association Rules
 An Approach to Classification Based on Fuzzy Association Rules Zuoliang Chen, Guoqing Chen School of Economics and Management, Tsinghua University, Beijing 100084, P. R. China Abstract Classification based
An Approach to Classification Based on Fuzzy Association Rules Zuoliang Chen, Guoqing Chen School of Economics and Management, Tsinghua University, Beijing 100084, P. R. China Abstract Classification based
Multi-theme Sentiment Analysis using Quantified Contextual
 Multi-theme Sentiment Analysis using Quantified Contextual Valence Shifters Hongkun Yu, Jingbo Shang, MeichunHsu, Malú Castellanos, Jiawei Han Presented by Jingbo Shang University of Illinois at Urbana-Champaign
Multi-theme Sentiment Analysis using Quantified Contextual Valence Shifters Hongkun Yu, Jingbo Shang, MeichunHsu, Malú Castellanos, Jiawei Han Presented by Jingbo Shang University of Illinois at Urbana-Champaign
Oriental Medical Data Mining and Diagnosis Based On Binary Independent Factor Model
 Oriental Medical Data Mining and Diagnosis Based On Binary Independent Factor Model Jeong-Yon Shim, Lei Xu Dept. of Computer Software, YongIn SongDam College MaPyeong Dong 571-1, YongIn Si, KyeongKi Do,
Oriental Medical Data Mining and Diagnosis Based On Binary Independent Factor Model Jeong-Yon Shim, Lei Xu Dept. of Computer Software, YongIn SongDam College MaPyeong Dong 571-1, YongIn Si, KyeongKi Do,
Deconstructing Data Science
 Deconstructing Data Science David Bamman, UC Berkeley Info 290 Lecture 3: Classification overview Jan 24, 2017 Auditors Send me an email to get access to bcourses (announcements, readings, etc.) Classification
Deconstructing Data Science David Bamman, UC Berkeley Info 290 Lecture 3: Classification overview Jan 24, 2017 Auditors Send me an email to get access to bcourses (announcements, readings, etc.) Classification