Today. Finish word sense disambigua1on. Midterm Review
|
|
|
- Sabina Matilda Randall
- 6 years ago
- Views:
Transcription
1 Today Finish word sense disambigua1on Midterm Review The midterm is Thursday during class 1me. H students and 20 regular students are assigned to 517 Hamilton. Make-up for those with same 1me midterm is Thurs 6pm. For those with serious problems, second make-up Mon 6pm, but will be harder. RECOMMENDATION: Thurs 6pm if you can. Review ques1ons and answer on NLP website. On Thursday, I will not be here. I am at a mee1ng in Maryland. Tas will proctor
2 Naïve Bayes Test On a corpus of examples of uses of the word line, naïve Bayes achieved about 73% correct Good?
3 Decision Lists: another popular method A case statement.
4 Learning Decision Lists Restrict the lists to rules that test a single feature (1-decisionlist rules) Evaluate each possible test and rank them based on how well they work. Glue the top-n tests together and call that your decision list.
5 Yarowsky On a binary (homonymy) dis1nc1on used the following metric to rank the tests P(Sense 1 Feature) P(Sense 2 Feature) This gives about 95% on this test
6 WSD Evaluations and baselines In vivo versus in vitro evalua1on In vitro evalua1on is most common now Exact match accuracy % of words tagged iden1cally with manual sense tags Usually evaluate using held-out data from same labeled corpus Problems? Why do we do it anyhow? Baselines Most frequent sense The Lesk algorithm
7 Most Frequent Sense Wordnet senses are ordered in frequency order So most frequent sense in wordnet = take the first sense Sense frequencies come from SemCor
8 Ceiling Human inter-annotator agreement Compare annota1ons of two humans On same data Given same tagging guidelines Human agreements on all-words corpora with Wordnet style senses 75%-80%
9 Problems Given these general ML approaches, how many classifiers do I need to perform WSD robustly One for each ambiguous word in the language How do you decide what set of tags/ labels/senses to use for a given word? Depends on the applica1on
10 WordNet Bass Tagging with this set of senses is an impossibly hard task that s probably overkill for any realis1c applica1on 1. bass - (the lowest part of the musical range) 2. bass, bass part - (the lowest part in polyphonic music) 3. bass, basso - (an adult male singer with the lowest voice) 4. sea bass, bass - (flesh of lean-fleshed saltwater fish of the family Serranidae) 5. freshwater bass, bass - (any of various North American lean-fleshed freshwater fishes especially of the genus Micropterus) 6. bass, bass voice, basso - (the lowest adult male singing voice) 7. bass - (the member with the lowest range of a family of musical instruments) 8. bass -(nontechnical name for any of numerous edible marine and freshwater spiny-finned fishes)
11 Senseval History ACL-SIGLEX workshop (1997) Yarowsky and Resnik paper SENSEVAL-I (1998) Lexical Sample for English, French, and Italian SENSEVAL-II (Toulouse, 2001) Lexical Sample and All Words Organiza1on: Kilkgarriff (Brighton) SENSEVAL-III (2004) SENSEVAL-IV -> SEMEVAL (2007) SEMEVAL (2010) SEMEVAL 2017: hpp://alt.qcri.org/semeval2017/index.php?id=tasks SLIDE ADAPTED FROM CHRIS MANNING
12 WSD Performance Varies widely depending on how difficult the disambigua1on task is Accuracies of over 90% are commonly reported on some of the classic, oren fairly easy, WSD tasks (pike, star, interest) Senseval brought careful evalua1on of difficult WSD (many senses, different POS) Senseval 1: more fine grained senses, wider range of types: Overall: about 75% accuracy Nouns: about 80% accuracy Verbs: about 70% accuracy
13 Summary Lexical Seman1cs Homonymy, Polysemy, Synonymy Thema1c roles Computa1onal resource for lexical seman1cs WordNet Task Word sense disambigua1on Arer midterm: seman1c parsing, distribu1onal seman1cs, neural nets
14 Requested topics POS tagging HMM Early parsing algorithm
15 POS tagging
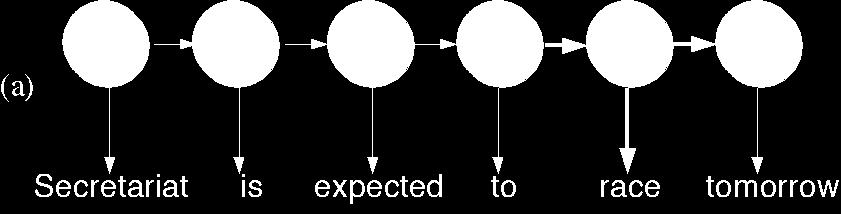
16 POS tagging as a sequence classikication task We are given a sentence (an observa1on or sequence of observa1ons ) Secretariat is expected to race tomorrow 10/16/17 What is the best sequence of tags which corresponds to this sequence of observa1ons? Probabilis1c view: Consider all possible sequences of tags Choose the tag sequence which is most probable given the observa1on sequence of n words w1 wn. 16
17 Getting to HMM Out of all sequences of n tags t 1 t n want the single tag sequence such that P(t 1 t n w 1 w n ) is highest. 10/16/17 Hat ^ means our es1mate of the best one Argmax x f(x) means the x such that f(x) is maximized 17
18 Using Bayes Rule 10/16/17 18
19 x y 10/16/17 19

20 Likelihood and prior n
21 Two kinds of probabilities (1) Tag transi1on probabili1es p(t i t i-1 ) Determiners likely to precede adjs and nouns That/DT flight/nn The/DT yellow/jj hat/nn So we expect P(NN DT) and P(JJ DT) to be high But P(DT JJ) to be low Compute P(NN DT) by coun1ng in a labeled corpus:
22 Two kinds of probabilities (2) Word likelihood probabili1es p(w i t i ) VBZ (3sg Pres verb) likely to be is Compute P(is VBZ) by coun1ng in a labeled corpus: 10/16/17 22
23 An Example: the verb race Secretariat/NNP is/vbz expected/vbn to/to race/vb tomorrow/nr People/NNS con1nue/vb to/to inquire/vb the/dt reason/nn for/in the/dt race/nn for/in outer/jj space/nn How do we pick the right tag? 10/16/17 23
24 Disambiguating race 10/16/17 24
25 Disambiguating race 10/16/17 25

26 Disambiguating race 10/16/17 26

27 Disambiguating race 10/16/17 27
28 P(NN TO) = P(VB TO) =.83 P(race NN) = P(race VB) = P(NR VB) =.0027 P(NR NN) =.0012 P(VB TO)P(NR VB)P(race VB) = P(NN TO)P(NR NN)P(race NN)= So we (correctly) choose the verb reading, 10/16/17 28
29 Problem Observa1on likelihood: Promise Count (#promise, VB)/#all verbs I promise to back the bill (N). I promise to back the bill (V)
30 HMMS
31 Hidden Markov Models We don t observe POS tags We infer them from the words we see 10/16/17 Observed events Hidden events 31
32 Hidden Markov Model For Markov chains, the output symbols are the same as the states. See hot weather: we re in state hot But in part-of-speech tagging (and other things) The output symbols are words The hidden states are part-of-speech tags So we need an extension! A Hidden Markov Model is an extension of a Markov chain in which the input symbols are not the same as the states. This means we don t know which state we are in. 10/16/17 32
33 Hidden Markov Models States Q = q 1, q 2 q N; Observa1ons O= o 1, o 2 o N; Each observa1on is a symbol from a vocabulary V = {v 1,v 2, v V } Transi1on probabili1es Transition probability matrix A = {a ij } a ij = P(q t = j q t 1 = i) 1 i, j N Observa1on likelihoods Output probability matrix B={b i (k)} b i (k) = P(X t = o k q t = i) Special ini1al probability vector π π i = P(q 1 = i) 1 i N
34 Hidden Markov Models Some constraints N j=1 a ij =1; 1 i N π i = P(q 1 = i) 1 i N 10/16/17 M b i (k) =1 π j =1 k=1 N j=1 34
35 Assumptions Markov assump=on: Output-independence assump=on P(q i q 1...q i 1 ) = P(q i q i 1 ) 10/16/17 P(o t O 1 t 1,q 1 t ) = P(o t q t ) 35
36 Three fundamental Problems for HMMs Likelihood: Given an HMM λ = (A,B) and an observa1on sequence O, determine the likelihood P(O, λ). Decoding: Given an observa1on sequence O and an HMM λ = (A,B), discover the best hidden state sequence Q. Learning: Given an observa1on sequence O and the set of states in the HMM, learn the HMM parameters A and B. What kind of data would we need to learn the HMM parameters? 10/16/17 36
37 Decoding The best hidden sequence Weather sequence in the ice cream task POS sequence given an input sentence We could use argmax over the probability of each possible hidden state sequence Why not? Viterbi algorithm Dynamic programming algorithm Uses a dynamic programming trellis Each trellis cell represents, v t (j), represents the probability that the HMM is in state j arer seeing the first t observa1ons and passing through the most likely state sequence 10/16/17 37
38 Viterbi intuition: we are looking for the best path S 1 S 2 S 3 S 4 S 5 RB 10/16/17 NN VBN VBD TO JJ VB DT NNP VB NN promised to back the bill 38 Slide from Dekang Lin

39 Intuition The value in each cell is computed by taking the MAX over all paths that lead to this cell. 10/16/17 An extension of a path from state i at 1me t-1 is computed by mul1plying: 39
40 The Viterbi Algorithm 10/16/17 40
41 The A matrix for the POS HMM 10/16/17 What is P(VB TO)? What is P(NN TO)? Why does this make sense? What is P(TO VB)? What is P(TO NN)? Why does this make sense? 41
42 The B matrix for the POS HMM 10/16/17 Look at P(want VB) and P(want NN). Give an explanation for the difference in the probabilities. 42
43
44 Problem I want to race (possible states: PPS VB TO NN)
45 Viterbi example 10/16/17 t=1 45
46 X Viterbi example 10/16/17 t=1 46
47 X Viterbi example J=NN 10/16/17 I=S t=1 47
48 The A matrix for the POS HMM 10/16/17 48
49 Viterbi example J=NN X.041X 10/16/17 I=S t=1 49
50 The B matrix for the POS HMM 10/16/17 Look at P(want VB) and P(want NN). Give an explanation for the difference in the probabilities. 50
51 Viterbi 0 example J=NN X.041X 0 10/16/17 I=S t=1 51
52 Viterbi 0 example J=NN 0 X.041X /16/ I=S t=1 52
53 Viterbi 0 example J=NN 0 Show the 4 formulas you would use to compute the value at this node and the max. 0 10/16/ I=S t=1 53
54 Early Algorithm
55 Earley Algorithm March through chart ler-to-right. At each step, apply 1 of 3 operators Predictor Create new states represen1ng top-down expecta1ons Scanner Match word predic1ons (rule with word arer dot) to words Completer When a state is complete, see what rules were looking for that completed cons1tuent 55
56 Predictor Given a state With a non-terminal to right of dot (not a part-of-speech category) Create a new state for each expansion of the non-terminal Place these new states into same chart entry as generated state, beginning and ending where genera1ng state ends. So predictor looking at S ->. VP [0,0] results in VP ->. Verb [0,0] VP ->. Verb NP [0,0] 56
57 Scanner Given a state With a non-terminal to right of dot that is a part-of-speech category If the next word in the input matches this POS Create a new state with dot moved over the non-terminal So scanner looking at VP ->. Verb NP [0,0] If the next word, book, can be a verb, add new state: VP -> Verb. NP [0,1] Add this state to chart entry following current one Note: Earley algorithm uses top-down input to disambiguate POS! Only POS predicted by some state can get added to chart! 57
58 Completer Applied to a state when its dot has reached right end of role. Parser has discovered a category over some span of input. Find and advance all previous states that were looking for this category copy state, move dot, insert in current chart entry Given: NP -> Det Nominal. [1,3] VP -> Verb. NP [0,1] Add VP -> Verb NP. [0,3] 58
59 How do we know we are done? Find an S state in the final column that spans from 0 to n+1 and is complete. If that s the case you re done. S > α [0,n+1] 59
60 Earley More specifically 1. Predict all the states you can upfront 2. Read a word 1. Extend states based on matches 2. Add new predic1ons 3. Go to 2 3. Look at N+1 to see if you have a winner 60
61 Example Book that flight We should find an S from 0 to 3 that is a completed state 61
62 CFG for Fragment of English S à NP VP S à Aux NP VP VP à V PP -> Prep NP NP à Det Nom N à old dog footsteps young flight NP àpropn V à dog include prefer book Nom -> Adj Nom Nom à N Aux à does Prep àfrom to on of Nom à N Nom PropN à Bush McCain Obama Nom à Nom PP VP à V NP Det à that this a the Adj -> old green red
63 S à NP VP, S -> VP S à Aux NP VP VP à V PP -> Prep NP NP à Det Nom N à old dog footsteps young flight NP àpropn, NP -> Pro Nom à N V à dog include prefer book Aux à does Prep àfrom to on of Nom à N Nom PropN à Bush McCain Obama Nom à Nom PP VP à V NP, VP -> V NP PP, VP -> V PP, VP -> VP PP Det à that this a the Adj -> old green red
64 S à NP VP, S -> VP S à Aux NP VP VP à V PP -> Prep NP NP à Det Nom N à old dog footsteps young flight NP àpropn, NP -> Pro Nom à N V à dog include prefer book Aux à does Prep àfrom to on of Nom à N Nom PropN à Bush McCain Obama Nom à Nom PP VP à V NP, VP -> V NP PP, VP -> V PP, VP -> VP PP Det à that this a the Adj -> old green red
65 Example 65
66 Example Completer 66
67 Example Completer 67
68 Example 68
69 Details What kind of algorithms did we just describe Not parsers recognizers The presence of an S state with the right apributes in the right place indicates a successful recogni1on. But no parse tree no parser That s how we solve (not) an exponen1al problem in polynomial 1me 69
70 Converting Earley from Recognizer to Parser With the addi1on of a few pointers we have a parser Augment the Completer to point to where we came from. 70
71 Augmenting the chart with structural information S8 S9 S10 S11 S12 S13 S8 S9 S8
CSCI 5832 Natural Language Processing. Today 2/19. Statistical Sequence Classification. Lecture 9
 CSCI 5832 Natural Language Processing Jim Martin Lecture 9 1 Today 2/19 Review HMMs for POS tagging Entropy intuition Statistical Sequence classifiers HMMs MaxEnt MEMMs 2 Statistical Sequence Classification
CSCI 5832 Natural Language Processing Jim Martin Lecture 9 1 Today 2/19 Review HMMs for POS tagging Entropy intuition Statistical Sequence classifiers HMMs MaxEnt MEMMs 2 Statistical Sequence Classification
Lecture 9: Hidden Markov Model
 Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501 Natural Language Processing 1 This lecture v Hidden Markov
Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501 Natural Language Processing 1 This lecture v Hidden Markov
Review. Earley Algorithm Chapter Left Recursion. Left-Recursion. Rule Ordering. Rule Ordering
 Review Earley Algorithm Chapter 13.4 Lecture #9 October 2009 Top-Down vs. Bottom-Up Parsers Both generate too many useless trees Combine the two to avoid over-generation: Top-Down Parsing with Bottom-Up
Review Earley Algorithm Chapter 13.4 Lecture #9 October 2009 Top-Down vs. Bottom-Up Parsers Both generate too many useless trees Combine the two to avoid over-generation: Top-Down Parsing with Bottom-Up
CKY & Earley Parsing. Ling 571 Deep Processing Techniques for NLP January 13, 2016
 CKY & Earley Parsing Ling 571 Deep Processing Techniques for NLP January 13, 2016 No Class Monday: Martin Luther King Jr. Day CKY Parsing: Finish the parse Recognizer à Parser Roadmap Earley parsing Motivation:
CKY & Earley Parsing Ling 571 Deep Processing Techniques for NLP January 13, 2016 No Class Monday: Martin Luther King Jr. Day CKY Parsing: Finish the parse Recognizer à Parser Roadmap Earley parsing Motivation:
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch. COMP-599 Oct 1, 2015
 Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
LECTURER: BURCU CAN Spring
 LECTURER: BURCU CAN 2017-2018 Spring Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can
LECTURER: BURCU CAN 2017-2018 Spring Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can
Sequence Labeling: HMMs & Structured Perceptron
 Sequence Labeling: HMMs & Structured Perceptron CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu HMM: Formal Specification Q: a finite set of N states Q = {q 0, q 1, q 2, q 3, } N N Transition
Sequence Labeling: HMMs & Structured Perceptron CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu HMM: Formal Specification Q: a finite set of N states Q = {q 0, q 1, q 2, q 3, } N N Transition
Parsing with Context-Free Grammars
 Parsing with Context-Free Grammars Berlin Chen 2005 References: 1. Natural Language Understanding, chapter 3 (3.1~3.4, 3.6) 2. Speech and Language Processing, chapters 9, 10 NLP-Berlin Chen 1 Grammars
Parsing with Context-Free Grammars Berlin Chen 2005 References: 1. Natural Language Understanding, chapter 3 (3.1~3.4, 3.6) 2. Speech and Language Processing, chapters 9, 10 NLP-Berlin Chen 1 Grammars
Parsing. Based on presentations from Chris Manning s course on Statistical Parsing (Stanford)
") Parsing Based on presentations from Chris Manning s course on Statistical Parsing (Stanford) S N VP V NP D N John hit the ball Levels of analysis Level Morphology/Lexical POS (morpho-synactic), WSD Elements
Parsing Based on presentations from Chris Manning s course on Statistical Parsing (Stanford) S N VP V NP D N John hit the ball Levels of analysis Level Morphology/Lexical POS (morpho-synactic), WSD Elements
Probabilistic Context-free Grammars
 Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Hidden Markov Models
 INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 27, 2016 Recap: Probabilistic Language
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 27, 2016 Recap: Probabilistic Language
Structured Output Prediction: Generative Models
 Structured Output Prediction: Generative Models CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 17.3, 17.4, 17.5.1 Structured Output Prediction Supervised
Structured Output Prediction: Generative Models CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 17.3, 17.4, 17.5.1 Structured Output Prediction Supervised
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models. The ischool University of Maryland. Wednesday, September 30, 2009
 CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
CS460/626 : Natural Language
 CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 23, 24 Parsing Algorithms; Parsing in case of Ambiguity; Probabilistic Parsing) Pushpak Bhattacharyya CSE Dept., IIT Bombay 8 th,
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 23, 24 Parsing Algorithms; Parsing in case of Ambiguity; Probabilistic Parsing) Pushpak Bhattacharyya CSE Dept., IIT Bombay 8 th,
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging
 Tagging") ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
Hidden Markov Models
 Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Language Models & Hidden Markov Models
 1 University of Oslo : Department of Informatics INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Language Models & Hidden Markov Models Stephan Oepen & Erik Velldal Language
1 University of Oslo : Department of Informatics INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Language Models & Hidden Markov Models Stephan Oepen & Erik Velldal Language
Recap: HMM. ANLP Lecture 9: Algorithms for HMMs. More general notation. Recap: HMM. Elements of HMM: Sharon Goldwater 4 Oct 2018.
 Recap: HMM ANLP Lecture 9: Algorithms for HMMs Sharon Goldwater 4 Oct 2018 Elements of HMM: Set of states (tags) Output alphabet (word types) Start state (beginning of sentence) State transition probabilities
Recap: HMM ANLP Lecture 9: Algorithms for HMMs Sharon Goldwater 4 Oct 2018 Elements of HMM: Set of states (tags) Output alphabet (word types) Start state (beginning of sentence) State transition probabilities
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Hidden Markov Models
 INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 18, 2017 Recap: Probabilistic Language
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 18, 2017 Recap: Probabilistic Language
Machine Learning & Data Mining CS/CNS/EE 155. Lecture 8: Hidden Markov Models
 Machine Learning & Data Mining CS/CNS/EE 155 Lecture 8: Hidden Markov Models 1 x = Fish Sleep y = (N, V) Sequence Predic=on (POS Tagging) x = The Dog Ate My Homework y = (D, N, V, D, N) x = The Fox Jumped
Machine Learning & Data Mining CS/CNS/EE 155 Lecture 8: Hidden Markov Models 1 x = Fish Sleep y = (N, V) Sequence Predic=on (POS Tagging) x = The Dog Ate My Homework y = (D, N, V, D, N) x = The Fox Jumped
Machine Learning & Data Mining CS/CNS/EE 155. Lecture 11: Hidden Markov Models
 Machine Learning & Data Mining CS/CNS/EE 155 Lecture 11: Hidden Markov Models 1 Kaggle Compe==on Part 1 2 Kaggle Compe==on Part 2 3 Announcements Updated Kaggle Report Due Date: 9pm on Monday Feb 13 th
Machine Learning & Data Mining CS/CNS/EE 155 Lecture 11: Hidden Markov Models 1 Kaggle Compe==on Part 1 2 Kaggle Compe==on Part 2 3 Announcements Updated Kaggle Report Due Date: 9pm on Monday Feb 13 th
Natural Language Processing CS Lecture 06. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Natural Language Processing CS 6840 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Statistical Parsing Define a probabilistic model of syntax P(T S):
Natural Language Processing CS 6840 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Statistical Parsing Define a probabilistic model of syntax P(T S):
Text Mining. March 3, March 3, / 49
 Text Mining March 3, 2017 March 3, 2017 1 / 49 Outline Language Identification Tokenisation Part-Of-Speech (POS) tagging Hidden Markov Models - Sequential Taggers Viterbi Algorithm March 3, 2017 2 / 49
Text Mining March 3, 2017 March 3, 2017 1 / 49 Outline Language Identification Tokenisation Part-Of-Speech (POS) tagging Hidden Markov Models - Sequential Taggers Viterbi Algorithm March 3, 2017 2 / 49
Probabilistic Context-Free Grammars. Michael Collins, Columbia University
 Probabilistic Context-Free Grammars Michael Collins, Columbia University Overview Probabilistic Context-Free Grammars (PCFGs) The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Probabilistic Context-Free Grammars Michael Collins, Columbia University Overview Probabilistic Context-Free Grammars (PCFGs) The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Lecture 13: Structured Prediction
 Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Part-of-Speech Tagging
 Part-of-Speech Tagging Informatics 2A: Lecture 17 Adam Lopez School of Informatics University of Edinburgh 27 October 2016 1 / 46 Last class We discussed the POS tag lexicon When do words belong to the
Part-of-Speech Tagging Informatics 2A: Lecture 17 Adam Lopez School of Informatics University of Edinburgh 27 October 2016 1 / 46 Last class We discussed the POS tag lexicon When do words belong to the
Parsing with Context-Free Grammars
 Parsing with Context-Free Grammars CS 585, Fall 2017 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp2017 Brendan O Connor College of Information and Computer Sciences
Parsing with Context-Free Grammars CS 585, Fall 2017 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp2017 Brendan O Connor College of Information and Computer Sciences
Processing/Speech, NLP and the Web
 CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 25 Probabilistic Parsing) Pushpak Bhattacharyya CSE Dept., IIT Bombay 14 th March, 2011 Bracketed Structure: Treebank Corpus [ S1[
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 25 Probabilistic Parsing) Pushpak Bhattacharyya CSE Dept., IIT Bombay 14 th March, 2011 Bracketed Structure: Treebank Corpus [ S1[
Probabilistic Context Free Grammars. Many slides from Michael Collins
 Probabilistic Context Free Grammars Many slides from Michael Collins Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Probabilistic Context Free Grammars Many slides from Michael Collins Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Statistical Methods for NLP
 Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
10/17/04. Today s Main Points
 Part-of-speech Tagging & Hidden Markov Model Intro Lecture #10 Introduction to Natural Language Processing CMPSCI 585, Fall 2004 University of Massachusetts Amherst Andrew McCallum Today s Main Points
Part-of-speech Tagging & Hidden Markov Model Intro Lecture #10 Introduction to Natural Language Processing CMPSCI 585, Fall 2004 University of Massachusetts Amherst Andrew McCallum Today s Main Points
POS-Tagging. Fabian M. Suchanek
 POS-Tagging Fabian M. Suchanek 100 Def: POS A Part-of-Speech (also: POS, POS-tag, word class, lexical class, lexical category) is a set of words with the same grammatical role. Alizée wrote a really great
POS-Tagging Fabian M. Suchanek 100 Def: POS A Part-of-Speech (also: POS, POS-tag, word class, lexical class, lexical category) is a set of words with the same grammatical role. Alizée wrote a really great
HMM and Part of Speech Tagging. Adam Meyers New York University
 HMM and Part of Speech Tagging Adam Meyers New York University Outline Parts of Speech Tagsets Rule-based POS Tagging HMM POS Tagging Transformation-based POS Tagging Part of Speech Tags Standards There
HMM and Part of Speech Tagging Adam Meyers New York University Outline Parts of Speech Tagsets Rule-based POS Tagging HMM POS Tagging Transformation-based POS Tagging Part of Speech Tags Standards There
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP
 Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
NLP Programming Tutorial 11 - The Structured Perceptron
 NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
Statistical methods in NLP, lecture 7 Tagging and parsing
 Statistical methods in NLP, lecture 7 Tagging and parsing Richard Johansson February 25, 2014 overview of today's lecture HMM tagging recap assignment 3 PCFG recap dependency parsing VG assignment 1 overview
Statistical methods in NLP, lecture 7 Tagging and parsing Richard Johansson February 25, 2014 overview of today's lecture HMM tagging recap assignment 3 PCFG recap dependency parsing VG assignment 1 overview
Parsing with CFGs L445 / L545 / B659. Dept. of Linguistics, Indiana University Spring Parsing with CFGs. Direction of processing
 L445 / L545 / B659 Dept. of Linguistics, Indiana University Spring 2016 1 / 46 : Overview Input: a string Output: a (single) parse tree A useful step in the process of obtaining meaning We can view the
L445 / L545 / B659 Dept. of Linguistics, Indiana University Spring 2016 1 / 46 : Overview Input: a string Output: a (single) parse tree A useful step in the process of obtaining meaning We can view the
Parsing with CFGs. Direction of processing. Top-down. Bottom-up. Left-corner parsing. Chart parsing CYK. Earley 1 / 46.
 : Overview L545 Dept. of Linguistics, Indiana University Spring 2013 Input: a string Output: a (single) parse tree A useful step in the process of obtaining meaning We can view the problem as searching
: Overview L545 Dept. of Linguistics, Indiana University Spring 2013 Input: a string Output: a (single) parse tree A useful step in the process of obtaining meaning We can view the problem as searching
Machine Learning for natural language processing
 Machine Learning for natural language processing Hidden Markov Models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 33 Introduction So far, we have classified texts/observations
Machine Learning for natural language processing Hidden Markov Models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 33 Introduction So far, we have classified texts/observations
Hidden Markov Models
 CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
Midterm sample questions
 Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Lecture 3: ASR: HMMs, Forward, Viterbi
 Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Multiword Expression Identification with Tree Substitution Grammars
 Multiword Expression Identification with Tree Substitution Grammars Spence Green, Marie-Catherine de Marneffe, John Bauer, and Christopher D. Manning Stanford University EMNLP 2011 Main Idea Use syntactic
Multiword Expression Identification with Tree Substitution Grammars Spence Green, Marie-Catherine de Marneffe, John Bauer, and Christopher D. Manning Stanford University EMNLP 2011 Main Idea Use syntactic
More on HMMs and other sequence models. Intro to NLP - ETHZ - 18/03/2013
 More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
A brief introduction to Conditional Random Fields
 A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
Sta$s$cal sequence recogni$on
 Sta$s$cal sequence recogni$on Determinis$c sequence recogni$on Last $me, temporal integra$on of local distances via DP Integrates local matches over $me Normalizes $me varia$ons For cts speech, segments
Sta$s$cal sequence recogni$on Determinis$c sequence recogni$on Last $me, temporal integra$on of local distances via DP Integrates local matches over $me Normalizes $me varia$ons For cts speech, segments
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Part-of-Speech Tagging
 Part-of-Speech Tagging Informatics 2A: Lecture 17 Shay Cohen School of Informatics University of Edinburgh 26 October 2018 1 / 48 Last class We discussed the POS tag lexicon When do words belong to the
Part-of-Speech Tagging Informatics 2A: Lecture 17 Shay Cohen School of Informatics University of Edinburgh 26 October 2018 1 / 48 Last class We discussed the POS tag lexicon When do words belong to the
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Probabilistic Context Free Grammars. Many slides from Michael Collins and Chris Manning
 Probabilistic Context Free Grammars Many slides from Michael Collins and Chris Manning Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic
Probabilistic Context Free Grammars Many slides from Michael Collins and Chris Manning Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic
CSC401/2511 Spring CSC401/2511 Natural Language Computing Spring 2019 Lecture 5 Frank Rudzicz and Chloé Pou-Prom University of Toronto
 CSC401/2511 Natural Language Computing Spring 2019 Lecture 5 Frank Rudzicz and Chloé Pou-Prom University of Toronto Revisiting PoS tagging Will/MD the/dt chair/nn chair/?? the/dt meeting/nn from/in that/dt
CSC401/2511 Natural Language Computing Spring 2019 Lecture 5 Frank Rudzicz and Chloé Pou-Prom University of Toronto Revisiting PoS tagging Will/MD the/dt chair/nn chair/?? the/dt meeting/nn from/in that/dt
A gentle introduction to Hidden Markov Models
 A gentle introduction to Hidden Markov Models Mark Johnson Brown University November 2009 1 / 27 Outline What is sequence labeling? Markov models Hidden Markov models Finding the most likely state sequence
A gentle introduction to Hidden Markov Models Mark Johnson Brown University November 2009 1 / 27 Outline What is sequence labeling? Markov models Hidden Markov models Finding the most likely state sequence
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing
 Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing CS 4120/6120 Spring 2017 Northeastern University David Smith with some slides from Jason Eisner & Andrew
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing CS 4120/6120 Spring 2017 Northeastern University David Smith with some slides from Jason Eisner & Andrew
Bayesian networks Lecture 18. David Sontag New York University
 Bayesian networks Lecture 18 David Sontag New York University Outline for today Modeling sequen&al data (e.g., =me series, speech processing) using hidden Markov models (HMMs) Bayesian networks Independence
Bayesian networks Lecture 18 David Sontag New York University Outline for today Modeling sequen&al data (e.g., =me series, speech processing) using hidden Markov models (HMMs) Bayesian networks Independence
Sequence Modelling with Features: Linear-Chain Conditional Random Fields. COMP-599 Oct 6, 2015
 Sequence Modelling with Features: Linear-Chain Conditional Random Fields COMP-599 Oct 6, 2015 Announcement A2 is out. Due Oct 20 at 1pm. 2 Outline Hidden Markov models: shortcomings Generative vs. discriminative
Sequence Modelling with Features: Linear-Chain Conditional Random Fields COMP-599 Oct 6, 2015 Announcement A2 is out. Due Oct 20 at 1pm. 2 Outline Hidden Markov models: shortcomings Generative vs. discriminative
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
CMPT-825 Natural Language Processing. Why are parsing algorithms important?
 CMPT-825 Natural Language Processing Anoop Sarkar http://www.cs.sfu.ca/ anoop October 26, 2010 1/34 Why are parsing algorithms important? A linguistic theory is implemented in a formal system to generate
CMPT-825 Natural Language Processing Anoop Sarkar http://www.cs.sfu.ca/ anoop October 26, 2010 1/34 Why are parsing algorithms important? A linguistic theory is implemented in a formal system to generate
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs
 Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Language Processing with Perl and Prolog
 Language Processing with Perl and Prolog es Pierre Nugues Lund University Pierre.Nugues@cs.lth.se http://cs.lth.se/pierre_nugues/ Pierre Nugues Language Processing with Perl and Prolog 1 / 12 Training
Language Processing with Perl and Prolog es Pierre Nugues Lund University Pierre.Nugues@cs.lth.se http://cs.lth.se/pierre_nugues/ Pierre Nugues Language Processing with Perl and Prolog 1 / 12 Training
Statistical NLP Spring 2010
 Statistical NLP Spring 2010 Lecture 5: WSD / Maxent Dan Klein UC Berkeley Unsupervised Learning with EM Goal, learn parameters without observing labels y y y θ x x x x x x x x x 1 EM: More Formally Hard
Statistical NLP Spring 2010 Lecture 5: WSD / Maxent Dan Klein UC Berkeley Unsupervised Learning with EM Goal, learn parameters without observing labels y y y θ x x x x x x x x x 1 EM: More Formally Hard
Maxent Models and Discriminative Estimation
 Maxent Models and Discriminative Estimation Generative vs. Discriminative models (Reading: J+M Ch6) Introduction So far we ve looked at generative models Language models, Naive Bayes But there is now much
Maxent Models and Discriminative Estimation Generative vs. Discriminative models (Reading: J+M Ch6) Introduction So far we ve looked at generative models Language models, Naive Bayes But there is now much
Dynamic Programming: Hidden Markov Models
 University of Oslo : Department of Informatics Dynamic Programming: Hidden Markov Models Rebecca Dridan 16 October 2013 INF4820: Algorithms for AI and NLP Topics Recap n-grams Parts-of-speech Hidden Markov
University of Oslo : Department of Informatics Dynamic Programming: Hidden Markov Models Rebecca Dridan 16 October 2013 INF4820: Algorithms for AI and NLP Topics Recap n-grams Parts-of-speech Hidden Markov
CS838-1 Advanced NLP: Hidden Markov Models
 CS838-1 Advanced NLP: Hidden Markov Models Xiaojin Zhu 2007 Send comments to jerryzhu@cs.wisc.edu 1 Part of Speech Tagging Tag each word in a sentence with its part-of-speech, e.g., The/AT representative/nn
CS838-1 Advanced NLP: Hidden Markov Models Xiaojin Zhu 2007 Send comments to jerryzhu@cs.wisc.edu 1 Part of Speech Tagging Tag each word in a sentence with its part-of-speech, e.g., The/AT representative/nn
CSE 490 U Natural Language Processing Spring 2016
 CSE 490 U Natural Language Processing Spring 2016 Feature Rich Models Yejin Choi - University of Washington [Many slides from Dan Klein, Luke Zettlemoyer] Structure in the output variable(s)? What is the
CSE 490 U Natural Language Processing Spring 2016 Feature Rich Models Yejin Choi - University of Washington [Many slides from Dan Klein, Luke Zettlemoyer] Structure in the output variable(s)? What is the
Natural Language Processing : Probabilistic Context Free Grammars. Updated 5/09
 Natural Language Processing : Probabilistic Context Free Grammars Updated 5/09 Motivation N-gram models and HMM Tagging only allowed us to process sentences linearly. However, even simple sentences require
Natural Language Processing : Probabilistic Context Free Grammars Updated 5/09 Motivation N-gram models and HMM Tagging only allowed us to process sentences linearly. However, even simple sentences require
Advanced Natural Language Processing Syntactic Parsing
 Advanced Natural Language Processing Syntactic Parsing Alicia Ageno ageno@cs.upc.edu Universitat Politècnica de Catalunya NLP statistical parsing 1 Parsing Review Statistical Parsing SCFG Inside Algorithm
Advanced Natural Language Processing Syntactic Parsing Alicia Ageno ageno@cs.upc.edu Universitat Politècnica de Catalunya NLP statistical parsing 1 Parsing Review Statistical Parsing SCFG Inside Algorithm
CS626: NLP, Speech and the Web. Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture 14: Parsing Algorithms 30 th August, 2012
 CS626: NLP, Speech and the Web Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture 14: Parsing Algorithms 30 th August, 2012 Parsing Problem Semantics Part of Speech Tagging NLP Trinity Morph Analysis
CS626: NLP, Speech and the Web Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture 14: Parsing Algorithms 30 th August, 2012 Parsing Problem Semantics Part of Speech Tagging NLP Trinity Morph Analysis
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields
 Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
IN FALL NATURAL LANGUAGE PROCESSING. Jan Tore Lønning
 1 IN4080 2018 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning 2 Logistic regression Lecture 8, 26 Sept Today 3 Recap: HMM-tagging Generative and discriminative classifiers Linear classifiers Logistic
1 IN4080 2018 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning 2 Logistic regression Lecture 8, 26 Sept Today 3 Recap: HMM-tagging Generative and discriminative classifiers Linear classifiers Logistic
Probabilistic Graphical Models: MRFs and CRFs. CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov
 Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
A.I. in health informatics lecture 8 structured learning. kevin small & byron wallace
 A.I. in health informatics lecture 8 structured learning kevin small & byron wallace today models for structured learning: HMMs and CRFs structured learning is particularly useful in biomedical applications:
A.I. in health informatics lecture 8 structured learning kevin small & byron wallace today models for structured learning: HMMs and CRFs structured learning is particularly useful in biomedical applications:
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 8 POS tagset) Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th Jan, 2012
 Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th Jan, 2012") CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 8 POS tagset) Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th Jan, 2012 HMM: Three Problems Problem Problem 1: Likelihood of a
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 8 POS tagset) Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th Jan, 2012 HMM: Three Problems Problem Problem 1: Likelihood of a
A Supertag-Context Model for Weakly-Supervised CCG Parser Learning
 A Supertag-Context Model for Weakly-Supervised CCG Parser Learning Dan Garrette Chris Dyer Jason Baldridge Noah A. Smith U. Washington CMU UT-Austin CMU Contributions 1. A new generative model for learning
A Supertag-Context Model for Weakly-Supervised CCG Parser Learning Dan Garrette Chris Dyer Jason Baldridge Noah A. Smith U. Washington CMU UT-Austin CMU Contributions 1. A new generative model for learning
Linear Classifiers IV
 Universität Potsdam Institut für Informatik Lehrstuhl Linear Classifiers IV Blaine Nelson, Tobias Scheffer Contents Classification Problem Bayesian Classifier Decision Linear Classifiers, MAP Models Logistic
Universität Potsdam Institut für Informatik Lehrstuhl Linear Classifiers IV Blaine Nelson, Tobias Scheffer Contents Classification Problem Bayesian Classifier Decision Linear Classifiers, MAP Models Logistic
CS388: Natural Language Processing Lecture 4: Sequence Models I
 CS388: Natural Language Processing Lecture 4: Sequence Models I Greg Durrett Mini 1 due today Administrivia Project 1 out today, due September 27 Viterbi algorithm, CRF NER system, extension Extension
CS388: Natural Language Processing Lecture 4: Sequence Models I Greg Durrett Mini 1 due today Administrivia Project 1 out today, due September 27 Viterbi algorithm, CRF NER system, extension Extension
Natural Language Processing
 SFU NatLangLab Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class Simon Fraser University September 27, 2018 0 Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class
SFU NatLangLab Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class Simon Fraser University September 27, 2018 0 Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class
CSE 473: Ar+ficial Intelligence. Hidden Markov Models. Bayes Nets. Two random variable at each +me step Hidden state, X i Observa+on, E i
 CSE 473: Ar+ficial Intelligence Bayes Nets Daniel Weld [Most slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at hnp://ai.berkeley.edu.]
CSE 473: Ar+ficial Intelligence Bayes Nets Daniel Weld [Most slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at hnp://ai.berkeley.edu.]
Hidden Markov Models (HMMs)
") Hidden Markov Models HMMs Raymond J. Mooney University of Texas at Austin 1 Part Of Speech Tagging Annotate each word in a sentence with a part-of-speech marker. Lowest level of syntactic analysis. John
Hidden Markov Models HMMs Raymond J. Mooney University of Texas at Austin 1 Part Of Speech Tagging Annotate each word in a sentence with a part-of-speech marker. Lowest level of syntactic analysis. John
Chapter 14 (Partially) Unsupervised Parsing
 Unsupervised Parsing") Chapter 14 (Partially) Unsupervised Parsing The linguistically-motivated tree transformations we discussed previously are very effective, but when we move to a new language, we may have to come up with
Chapter 14 (Partially) Unsupervised Parsing The linguistically-motivated tree transformations we discussed previously are very effective, but when we move to a new language, we may have to come up with
Spectral Unsupervised Parsing with Additive Tree Metrics
 Spectral Unsupervised Parsing with Additive Tree Metrics Ankur Parikh, Shay Cohen, Eric P. Xing Carnegie Mellon, University of Edinburgh Ankur Parikh 2014 1 Overview Model: We present a novel approach
Spectral Unsupervised Parsing with Additive Tree Metrics Ankur Parikh, Shay Cohen, Eric P. Xing Carnegie Mellon, University of Edinburgh Ankur Parikh 2014 1 Overview Model: We present a novel approach
Sequential Data Modeling - The Structured Perceptron
 Sequential Data Modeling - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, predict y 2 Prediction Problems Given x, A book review
Sequential Data Modeling - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, predict y 2 Prediction Problems Given x, A book review
CSE 473: Ar+ficial Intelligence. Probability Recap. Markov Models - II. Condi+onal probability. Product rule. Chain rule.
 CSE 473: Ar+ficial Intelligence Markov Models - II Daniel S. Weld - - - University of Washington [Most slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188
CSE 473: Ar+ficial Intelligence Markov Models - II Daniel S. Weld - - - University of Washington [Most slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188
Natural Language Processing. Lecture 13: More on CFG Parsing
 Natural Language Processing Lecture 13: More on CFG Parsing Probabilistc/Weighted Parsing Example: ambiguous parse Probabilistc CFG Ambiguous parse w/probabilites 0.05 0.05 0.20 0.10 0.30 0.20 0.60 0.75
Natural Language Processing Lecture 13: More on CFG Parsing Probabilistc/Weighted Parsing Example: ambiguous parse Probabilistc CFG Ambiguous parse w/probabilites 0.05 0.05 0.20 0.10 0.30 0.20 0.60 0.75
Part A. P (w 1 )P (w 2 w 1 )P (w 3 w 1 w 2 ) P (w M w 1 w 2 w M 1 ) P (w 1 )P (w 2 w 1 )P (w 3 w 2 ) P (w M w M 1 )
P (w 2 w 1 )P (w 3 w 1 w 2 ) P (w M w 1 w 2 w M 1 ) P (w 1 )P (w 2 w 1 )P (w 3 w 2 ) P (w M w M 1 )") Part A 1. A Markov chain is a discrete-time stochastic process, defined by a set of states, a set of transition probabilities (between states), and a set of initial state probabilities; the process proceeds
Part A 1. A Markov chain is a discrete-time stochastic process, defined by a set of states, a set of transition probabilities (between states), and a set of initial state probabilities; the process proceeds
A* Search. 1 Dijkstra Shortest Path
 A* Search Consider the eight puzzle. There are eight tiles numbered 1 through 8 on a 3 by three grid with nine locations so that one location is left empty. We can move by sliding a tile adjacent to the
A* Search Consider the eight puzzle. There are eight tiles numbered 1 through 8 on a 3 by three grid with nine locations so that one location is left empty. We can move by sliding a tile adjacent to the
LING 473: Day 10. START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars
 LING 473: Day 10 START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars 1 Issues with Projects 1. *.sh files must have #!/bin/sh at the top (to run on Condor) 2. If run.sh is supposed
LING 473: Day 10 START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars 1 Issues with Projects 1. *.sh files must have #!/bin/sh at the top (to run on Condor) 2. If run.sh is supposed
NLP Homework: Dependency Parsing with Feed-Forward Neural Network
 NLP Homework: Dependency Parsing with Feed-Forward Neural Network Submission Deadline: Monday Dec. 11th, 5 pm 1 Background on Dependency Parsing Dependency trees are one of the main representations used
NLP Homework: Dependency Parsing with Feed-Forward Neural Network Submission Deadline: Monday Dec. 11th, 5 pm 1 Background on Dependency Parsing Dependency trees are one of the main representations used
Natural Language Processing Prof. Pawan Goyal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur
 Natural Language Processing Prof. Pawan Goyal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 18 Maximum Entropy Models I Welcome back for the 3rd module
Natural Language Processing Prof. Pawan Goyal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 18 Maximum Entropy Models I Welcome back for the 3rd module
Statistical NLP: Hidden Markov Models. Updated 12/15
 Statistical NLP: Hidden Markov Models Updated 12/15 Markov Models Markov models are statistical tools that are useful for NLP because they can be used for part-of-speech-tagging applications Their first
Statistical NLP: Hidden Markov Models Updated 12/15 Markov Models Markov models are statistical tools that are useful for NLP because they can be used for part-of-speech-tagging applications Their first
8: Hidden Markov Models
 8: Hidden Markov Models Machine Learning and Real-world Data Helen Yannakoudakis 1 Computer Laboratory University of Cambridge Lent 2018 1 Based on slides created by Simone Teufel So far we ve looked at
8: Hidden Markov Models Machine Learning and Real-world Data Helen Yannakoudakis 1 Computer Laboratory University of Cambridge Lent 2018 1 Based on slides created by Simone Teufel So far we ve looked at
Context- Free Parsing with CKY. October 16, 2014
 Context- Free Parsing with CKY October 16, 2014 Lecture Plan Parsing as Logical DeducBon Defining the CFG recognibon problem BoHom up vs. top down Quick review of Chomsky normal form The CKY algorithm
Context- Free Parsing with CKY October 16, 2014 Lecture Plan Parsing as Logical DeducBon Defining the CFG recognibon problem BoHom up vs. top down Quick review of Chomsky normal form The CKY algorithm
CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on
 CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on Professor Wei-Min Shen Week 13.1 and 13.2 1 Status Check Extra credits? Announcement Evalua/on process will start soon
CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on Professor Wei-Min Shen Week 13.1 and 13.2 1 Status Check Extra credits? Announcement Evalua/on process will start soon
Natural Language Processing
 Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
Parsing. Probabilistic CFG (PCFG) Laura Kallmeyer. Winter 2017/18. Heinrich-Heine-Universität Düsseldorf 1 / 22
 Laura Kallmeyer. Winter 2017/18. Heinrich-Heine-Universität Düsseldorf 1 / 22") Parsing Probabilistic CFG (PCFG) Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Winter 2017/18 1 / 22 Table of contents 1 Introduction 2 PCFG 3 Inside and outside probability 4 Parsing Jurafsky
Parsing Probabilistic CFG (PCFG) Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Winter 2017/18 1 / 22 Table of contents 1 Introduction 2 PCFG 3 Inside and outside probability 4 Parsing Jurafsky
DT2118 Speech and Speaker Recognition
 DT2118 Speech and Speaker Recognition Language Modelling Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 56 Outline Introduction Formal Language Theory Stochastic Language Models (SLM) N-gram Language
DT2118 Speech and Speaker Recognition Language Modelling Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 56 Outline Introduction Formal Language Theory Stochastic Language Models (SLM) N-gram Language
Introduction to Artificial Intelligence (AI)
") Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 9 Oct, 11, 2011 Slide credit Approx. Inference : S. Thrun, P, Norvig, D. Klein CPSC 502, Lecture 9 Slide 1 Today Oct 11 Bayesian
Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 9 Oct, 11, 2011 Slide credit Approx. Inference : S. Thrun, P, Norvig, D. Klein CPSC 502, Lecture 9 Slide 1 Today Oct 11 Bayesian