LECTURER: BURCU CAN Spring
|
|
|
- Justina Mitchell
- 5 years ago
- Views:
Transcription

1 LECTURER: BURCU CAN Spring
2 Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can model a more powerful class of languages than HMMs. Can we take advantage of this property?
3 Production Rule: <Left-Hand Side> <Right-Hand Side> (Probability) Example Grammar: S N V (1.0) N Bob (0.3) Jane (0.7) Example Parse: S V V V N (0.4) loves (0.6) N Jane V N loves Bob

4 Natural Language Processing: parsing written sentences BioInformatics: RNA sequences Stock Markets: model rise/fall of the Dow Jones Computer Vision: parsing architectural scenes
5 Statistical parsing uses a probabilistic model of syntax in order to assign probabilities to each parse tree. Provides principled approach to resolving syntactic ambiguity. Allows supervised learning of parsers from tree-banks of parse trees provided by human linguists. Also allows unsupervised learning of parsers from unannotated text, but the accuracy of such parsers has been limited. 5
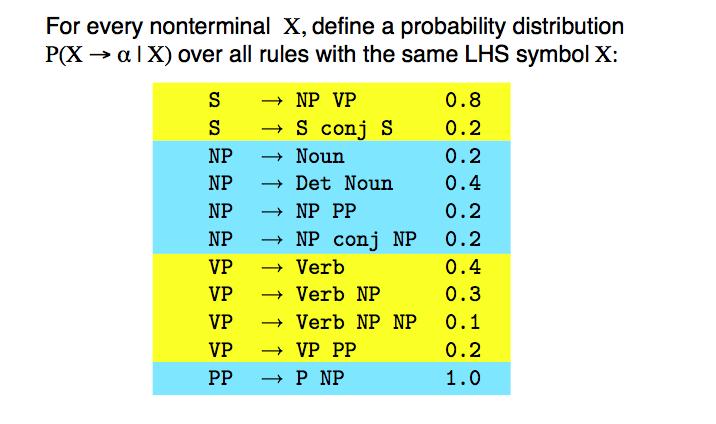
6 A PCFG is a probabilistic version of a CFG where each production has a probability. Probabilities of all productions rewriting a given non-terminal must add to 1, defining a distribution for each non-terminal.
7
8
9 S NP VP VP V NP VP V PP VP V NP PP NP NP NP NP NP PP NP N PP P NP people fish tanks people fish with rods N people N fish N tanks N rods V people V fish V tanks P with

10 S NP VP 1.0 VP V NP 0.6 VP V NP PP 0.4 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP 1.0 N people 0.5 N fish 0.2 N tanks 0.2 N rods 0.1 V people 0.1 V fish 0.6 V tanks 0.3 P with 1.0
11 P(t) The probability of a tree t is the product of the probabilities of the rules used to generate it. P(s) The probability of the string s is the sum of the probabilities of the trees which have that string as their yield P(s) = Σ j P(s, t) where t is a parse of s = Σ j P(t)
12 EXAMPLE - 1
13
14 s = people fish tanks with rods P(t 1 ) = = P(t 2 ) = = P(s) = P(t 1 ) + P(t 2 ) = =
15 EXAMPLE - 2
16
17
18
19 All rules are of the form X Y Z or X w X, Y, Z N (non-terminals) and w T (terminals) A transformation to this form doesn t change the generative capacity of a CFG That is, it recognizes the same language But maybe with different trees Empties and unaries are removed recursively n-ary rules are divided by introducing new nonterminals (n > 2)
20

21
22

23
24 Observation likelihood: To classify and order sentences. Most likely derivation: To determine the most likely parse tree for a sentence. Maximum likelihood training: To train a PCFG to fit empirical training data. 24
25 There is an analog to the Viterbi algorithm to efficiently determine the most probable derivation (parse tree) for a sentence. S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP English John liked the dog in the pen. S XNP VP PCFG John V NP PP Parser liked the dog in the pen
26 There is an analog to the Viterbi algorithm to efficiently determine the most probable derivation (parse tree) for a sentence. S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP English John liked the dog in the pen. PCFG Parser S NP VP John V NP liked the dog in the pen 26
27 CKY can be modified for PCFG parsing by including in each cell a probability for each non-terminal. Cell[i,j] must retain the most probable derivation of each constituent (non-terminal) covering words i +1 through j together with its associated probability. When transforming the grammar to CNF, must set production probabilities to preserve the probability of derivations.
28 Original Grammar S NP VP S Aux NP VP S VP NP Pronoun NP Proper-Noun NP Det Nominal Nominal Noun Nominal Nominal Noun Nominal Nominal PP VP Verb VP Verb NP VP VP PP PP Prep NP Chomsky Normal Form S NP VP S X1 VP X1 Aux NP S book include prefer S Verb NP S VP PP NP I he she me NP Houston NWA NP Det Nominal Nominal book flight meal money Nominal Nominal Noun Nominal Nominal PP VP book include prefer VP Verb NP VP VP PP PP Prep NP
29 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 Det:.6 NP:.6*.6*.15 =.054 Nominal:.15 Noun:.5 29
30 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 VP:.5*.5*.054 =.0135 Det:.6 NP:.6*.6*.15 =.054 Nominal:.15 Noun:.5 30
31 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 S:.05*.5*.054 = VP:.5*.5*.054 =.0135 Det:.6 NP:.6*.6*.15 =.054 Nominal:.15 Noun:.5 31
32 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 S:.05*.5*.054 = VP:.5*.5*.054 =.0135 Det:.6 NP:.6*.6*.15 =.054 Nominal:.15 Noun:.5 Prep:.2 32
33 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 S:.05*.5*.054 = VP:.5*.5*.054 =.0135 Det:.6 NP:.6*.6*.15 =.054 Nominal:.15 Noun:.5 Prep:.2 PP:1.0*.2*.16 =.032 NP:.16 PropNoun:.8 33
34 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 S:.05*.5*.054 = VP:.5*.5*.054 =.0135 Det:.6 NP:.6*.6*.15 =.054 Nominal:.15 Noun:.5 Nominal:.5*.15*.032 =.0024 Prep:.2 PP:1.0*.2*.16 =.032 NP:.16 PropNoun:.8 34
35 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 S:.05*.5*.054 = VP:.5*.5*.054 =.0135 Det:.6 NP:.6*.6*.15 =.054 NP:.6*.6*.0024 = Nominal:.15 Noun:.5 Nominal:.5*.15*.032 =.0024 Prep:.2 PP:1.0*.2*.16 =.032 NP:.16 PropNoun:.8 35
36 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 S:.05*.5*.054 = VP:.5*.5*.054 =.0135 S:.05*.5* = Det:.6 NP:.6*.6*.15 =.054 NP:.6*.6*.0024 = Nominal:.15 Noun:.5 Nominal:.5*.15*.032 =.0024 Prep:.2 PP:1.0*.2*.16 =.032 NP:.16 PropNoun:.8 36
37 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 S:.05*.5*.054 = VP:.5*.5*.054 =.0135 S:.03*.0135*.032 = S: Det:.6 NP:.6*.6*.15 =.054 NP:.6*.6*.0024 = Nominal:.15 Noun:.5 Nominal:.5*.15*.032 =.0024 Prep:.2 PP:1.0*.2*.16 =.032 NP:.16 PropNoun:.8 37
38 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 Det:.6 S:.05*.5*.054 = VP:.5*.5*.054 =.0135 NP:.6*.6*.15 =.054 Nominal:.15 Noun:.5 S: NP:.6*.6*.0024 = Nominal:.5*.15*.032 =.0024 Pick most probable parse, i.e. take max to combine probabilities of multiple derivations of each constituent in each cell. Prep:.2 PP:1.0*.2*.16 =.032 NP:.16 PropNoun:.8 38
39 S NP VP VP V NP VP V NP PP NP NP NP NP NP PP NP N NP e PP P NP N people N fish N tanks N rods V people V fish V tanks P with Epsilon removal.
40 S NP VP S VP VP V NP VP V VP V NP PP VP V PP NP NP NP NP NP NP NP PP NP PP NP N PP P NP PP P N people N fish N tanks N rods V people V fish V tanks P with Remove unary rules. (remove S VP)
41 S NP VP VP V NP S V NP VP V S V VP V NP PP S V NP PP VP V PP S V PP NP NP NP NP NP NP NP PP NP PP NP N N people N fish N tanks N rods V people V fish V tanks P with PP P NP PP P Remove unary rules. (remove S V)
42 S NP VP VP V NP S V NP VP V VP V NP PP S V NP PP VP V PP S V PP NP NP NP NP NP NP NP PP NP PP NP N PP P NP PP P N people N fish N tanks N rods V people S people V fish S fish V tanks S tanks P with Remove unary rules. (remove VP V)
43 S NP VP VP V NP S V NP VP V NP PP S V NP PP VP V PP S V PP NP NP NP NP NP NP NP PP NP PP NP N PP P NP PP P N people N fish N tanks N rods V people S people VP people V fish S fish VP fish V tanks S tanks VP tanks P with Remove unary rules. (remove NP NP, NP N, PP P)
44 S NP VP VP V NP S V NP VP V NP PP S V NP PP VP V PP S V PP NP NP NP NP NP PP NP P NP PP P NP NP people NP fish NP tanks NP rods V people S people VP people V fish S fish VP fish V tanks S tanks VP tanks P with PP with Binarize now.
45 S NP VP VP V NP S V NP NP PP NP PP VP V PP S V PP NP NP NP NP NP PP NP P NP PP P NP NP people NP fish NP tanks NP rods V people S people VP people V fish S fish VP fish V tanks S tanks VP tanks P with PP with Chomsky Normal Form!
46 S NP VP VP V NP VP V NP PP NP NP NP NP NP PP NP N NP e PP P NP N people N fish N tanks N rods V people V fish V tanks P with Initial grammar.
47 S NP VP VP V NP S V NP NP PP NP PP VP V PP S V PP NP NP NP NP NP PP NP P NP PP P NP NP people NP fish NP tanks NP rods V people S people VP people V fish S fish VP fish V tanks S tanks VP tanks P with PP with Final CNF grammar.
48 You should think of this as a transformation for efficient parsing Binarization is crucial for cubic time CFG parsing The rest isn t necessary; it just makes the algorithms cleaner and a bit quicker
49 S NP VP 0.9 S VP 0.1 VP V NP 0.5 VP V 0.1 VP 0.3 VP V PP NP PP 1.0 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP 1.0 N people 0.5 N fish 0.2 N tanks 0.2 N rods 0.1 V people 0.1 V fish 0.6 V tanks 0.3 P with 1.0
50 fish people fish tanks score[0][1] score[0][2] score[0][3] score[0][4] 1 score[1][2] score[1][3] score[1][4] 2 score[2][3] score[2][4] 3 score[3][4] 4
51 S NP VP 0.9 S VP 0.1 VP V NP 0.5 VP V 0.1 VP 0.3 VP V PP NP PP 1.0 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP fish people fish tanks N people 0.5 N fish 0.2 N tanks 0.2 N rods 0.1 V people 0.1 V fish 0.6 V tanks 0.3 P with for i=0;; i<#(words);; i++ for A in nonterms if A -> words[i] in grammar score[i][i+1][a] = P(A -> words[i]);;
52 S NP VP 0.9 S VP 0.1 VP V NP 0.5 VP V 0.1 VP 0.3 VP V PP NP PP 1.0 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP fish people fish tanks N fish 0.2 V fish 0.6 N people 0.5 V people 0.1 N fish 0.2 V fish 0.6 N people 0.5 N fish 0.2 N tanks 0.2 N rods 0.1 V people 0.1 V fish 0.6 V tanks 0.3 P with 1.0 // handle unaries boolean 3 added = true while added added = false for A, B in nonterms if score[i][i+1][b] > 0 && A->B in grammar prob = P(A->B)*score[i][i+1][B] if(prob > score[i][i+1][a]) 4 score[i][i+1][a] = prob back[i][i+1][a] = B added = true N tanks 0.2 V tanks 0.1
53 S NP VP 0.9 S VP 0.1 VP V NP 0.5 VP V 0.1 VP 0.3 VP V PP NP PP 1.0 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP 1.0 N people 0.5 N fish 0.2 N tanks 0.2 N rods 0.1 V people 0.1 V fish 0.6 V tanks 0.3 P with fish people fish tanks N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP N people 0.5 V people 0.1 NP N 0.35 VP V 0.01 S VP //handle binaries prob=score[begin][split][b]*score[split][end][c]*p(a->bc) if (prob > score[begin][end][a]) score[begin]end][a] = prob back[begin][end][a] = new Triple(split,B,C) N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP N tanks 0.2 V tanks 0.1 NP N 0.14 VP V 0.03 S VP 0.003
54 S NP VP 0.9 S VP 0.1 VP V NP 0.5 VP V 0.1 VP 0.3 VP V PP NP PP 1.0 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP 1.0 N people 0.5 N fish 0.2 N tanks 0.2 N rods 0.1 V people 0.1 V fish 0.6 V tanks 0.3 P with fish people fish tanks N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP NP NP NP VP V NP S NP VP N people 0.5 V people 0.1 NP N 0.35 VP V 0.01 S VP //handle unaries boolean added = true while added added = false for A, B in nonterms prob = P(A->B)*score[begin][end][B];; if prob > score[begin][end][a] score[begin][end][a] = prob back[begin][end][a] = B added = true NP NP NP VP V NP S NP VP N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP NP NP NP VP V NP S NP VP N tanks 0.2 V tanks 0.1 NP N 0.14 VP V 0.03 S VP 0.003
55 S NP VP 0.9 S VP 0.1 VP V NP 0.5 VP V 0.1 VP 0.3 VP V PP NP PP 1.0 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP 1.0 N people 0.5 N fish 0.2 N tanks 0.2 N rods 0.1 V people 0.1 V fish 0.6 V tanks 0.3 P with fish people fish tanks N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP NP NP NP VP V NP S VP N people 0.5 V people 0.1 NP N 0.35 VP V 0.01 S VP NP NP NP VP V NP S NP VP N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP for split = begin+1 to end-1 for A,B,C in nonterms prob=score[begin][split][b]*score[split][end][c]*p(a->bc) if prob > score[begin][end][a] score[begin]end][a] = prob back[begin][end][a] = new Triple(split,B,C) NP NP NP VP V NP S VP N tanks 0.2 V tanks 0.1 NP N 0.14 VP V 0.03 S VP 0.003
56 S NP VP 0.9 S VP 0.1 VP V NP 0.5 VP V 0.1 VP 0.3 VP V PP NP PP 1.0 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP 1.0 N people 0.5 N fish 0.2 N tanks 0.2 N rods 0.1 V people 0.1 V fish 0.6 V tanks 0.3 P with fish people fish tanks N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP NP NP NP VP V NP S VP N people 0.5 V people 0.1 NP N 0.35 VP V 0.01 S VP NP NP NP VP V NP S NP VP NP NP NP VP V NP S NP VP N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP for split = begin+1 to end-1 for A,B,C in nonterms prob=score[begin][split][b]*score[split][end][c]*p(a->bc) if prob > score[begin][end][a] score[begin]end][a] = prob back[begin][end][a] = new Triple(split,B,C) NP NP NP VP V NP S VP N tanks 0.2 V tanks 0.1 NP N 0.14 VP V 0.03 S VP 0.003
57 S NP VP 0.9 S VP 0.1 VP V NP 0.5 VP V 0.1 VP 0.3 VP V PP NP PP 1.0 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP 1.0 N people 0.5 N fish 0.2 N tanks 0.2 N rods 0.1 V people 0.1 V fish 0.6 V tanks 0.3 P with fish people fish tanks N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP NP NP NP VP V NP S VP N people 0.5 V people 0.1 NP N 0.35 VP V 0.01 S VP NP NP NP VP V NP S NP VP NP NP NP VP V NP S NP VP N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP for split = begin+1 to end-1 for A,B,C in nonterms prob=score[begin][split][b]*score[split][end][c]*p(a->bc) if prob > score[begin][end][a] score[begin]end][a] = prob back[begin][end][a] = new Triple(split,B,C) NP NP NP VP V NP S NP VP NP NP NP VP V NP S VP N tanks 0.2 V tanks 0.1 NP N 0.14 VP V 0.03 S VP 0.003
58 S NP VP 0.9 S VP 0.1 VP V NP 0.5 VP V 0.1 VP 0.3 VP V PP NP PP 1.0 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP 1.0 N people 0.5 N fish 0.2 N tanks 0.2 N rods 0.1 V people 0.1 V fish 0.6 V tanks fish people fish tanks N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP NP NP NP VP V NP S VP N people 0.5 V people 0.1 NP N 0.35 VP V 0.01 S VP NP NP NP VP V NP S NP VP NP NP NP VP V NP S NP VP N fish 0.2 V fish 0.6 NP N 0.14 VP V 0.06 S VP P with 1.0 Call buildtree(score, back) to get the best parse NP NP NP VP V NP S NP VP NP NP NP VP V NP S NP VP NP NP NP VP V NP S VP N tanks 0.2 V tanks 0.1 NP N 0.14 VP V 0.03 S VP 0.003
59 There is an analog to Forward algorithm for HMMs called the Inside algorithm for efficiently determining how likely a string is to be produced by a PCFG. Can use a PCFG as a language model to choose between alternative sentences for speech recognition or machine translation. 59 S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP English ?? O 1 The dog big barked. The big dog barked O 2 P(O 2 English) > P(O 1 English)?
60 Use CKY probabilistic parsing algorithm but combine probabilities of multiple derivations of any constituent using addition instead of max. 60
61 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 S:.05*.5*.054 = VP:.5*.5*.054 =.0135 S: S: Det:.6 NP:.6*.6*.15 =.054 NP:.6*.6*.0024 = Nominal:.15 Noun:.5 Nominal:.5*.15*.032 =.0024 Prep:.2 PP:1.0*.2*.16 =.032 NP:.16 PropNoun:.8 61
62 Book the flight through Houston S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 Det:.6 S:.05*.5*.054 = VP:.5*.5*.054 =.0135 NP:.6*.6*.15 =.054 S: Sum probabilities = of multiple derivations NP:.6*.6*.0024 = of each constituent in each cell. Nominal:.15 Noun:.5 Nominal:.5*.15*.032 =.0024 Prep:.2 PP:1.0*.2*.16 =.032 NP:.16 PropNoun:.8 62
63 If parse trees are provided for training sentences, a grammar and its parameters can be can all be estimated directly from counts accumulated from the treebank (with appropriate smoothing). S Tree Bank NP 63 VP John V NP PP NP S put the dog in the pen VP John V NP PP put the dog in the pen. Supervised PCFG Training S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP English
64 Set of production rules can be taken directly from the set of rewrites in the treebank. Parameters can be directly estimated from frequency counts in the treebank. P( a b a ) = count( a b ) count( a g ) å g = count( a b ) count( a ) 64
65 Given a set of sentences, induce a grammar that maximizes the probability that this data was generated from this grammar. Assume the number of non-terminals in the grammar is specified. Only need to have an unannotated set of sequences generated from the model. Does not need correct parse trees for these sentences. In this sense, it is unsupervised. 65
66 Training Sentences John ate the apple A dog bit Mary Mary hit the dog John gave Mary the cat.. PCFG Training S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP English
67 The Inside-Outside algorithm is a version of EM for unsupervised learning of a PCFG. Analogous to Baum-Welch (forward-backward) for HMMs Given the number of non-terminals, construct all possible CNF productions with these non-terminals and observed terminal symbols. Use EM to iteratively train the probabilities of these productions to locally maximize the likelihood of the data. See Manning and Schütze text for details Experimental results are not impressive, but recent work imposes additional constraints to improve unsupervised grammar learning.
68 Specialized productions can be generated by including the head word and its POS of each non-terminal as part of that non-terminal s symbol. NP NNP John S John-NNP liked-vbd VBD liked VP liked-vbd the DT NP Nominal Nominal PP NN dog dog-nn dog-nn IN in Nominaldog-NN Nominaldog-NN PPin-IN dog-nn in-in NP DT pen-nn Nominal pen-nn the NN pen
69 NP NNP John S John-NNP VBD put-vbd VP put DT the VP put-vbd NP put-vbd dog-nn Nominal NN dog dog-nn IN PP in-in NP in DT the VPput-VBD VPput-VBD PPin-IN pen-nn Nominal NN pen pen-nn
70 Accurately estimating parameters on such a large number of very specialized productions could require enormous amounts of treebank data. Need some way of estimating parameters for lexicalized productions that makes reasonable independence assumptions so that accurate probabilities for very specific rules can be learned.
71 English Penn Treebank: Standard corpus for testing syntactic parsing consists of 1.2 M words of text from the Wall Street Journal (WSJ). Typical to train on about 40,000 parsed sentences and test on an additional standard disjoint test set of 2,416 sentences. Chinese Penn Treebank: 100K words from the Xinhua news service. 71
72 72 ( (S (NP-SBJ (NP (NNP Pierre) (NNP Vinken) ) (,,) (ADJP (NP (CD 61) (NNS years) ) (JJ old) ) (,,) ) (VP (MD will) (VP (VB join) (NP (DT the) (NN board) ) (PP-CLR (IN as) (NP (DT a) (JJ nonexecutive) (NN director) )) (NP-TMP (NNP Nov.) (CD 29) ))) (..) ))

73 Eryiğit et al. Multiword Expressions in Statistical Dependency Parsing, SPMRL, sentences Uses CoNLL format
74 PARSEVAL metrics measure the fraction of the constituents that match between the computed and human parse trees. If P is the system s parse tree and T is the human parse tree (the gold standard ): Recall = (# correct constituents in P) / (# constituents in T) Precision = (# correct constituents in P) / (# constituents in P) F 1 is the harmonic mean of precision and recall.
75 Correct Tree T S Computed Tree P S Verb book VP the NP Det Nominal Nominal Noun flight Prep PP through NP Proper-Noun Houston Verb book VP the NP Det Nominal Noun flight Prep through # Constituents: 12 # Constituents: 12 # Correct Constituents: 10 Recall = 10/12= 83.3% Precision = 10/12=83.3% F 1 = 83.3% VP PP NP Proper-Noun Houston
76 Statistical models such as PCFGs allow for probabilistic resolution of ambiguities. PCFGs can be easily learned from treebanks. Lexicalization is required to effectively resolve many ambiguities. Current statistical parsers are quite accurate but not yet at the level of human-expert agreement. 76
77 Raymond Mooney, Statistical Parsing. University of Texas Grant Schindler, PCFGs. Julia Hockenmaier, More on PCFG Parsing
Probabilistic Context Free Grammars. Many slides from Michael Collins and Chris Manning
 Probabilistic Context Free Grammars Many slides from Michael Collins and Chris Manning Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic
Probabilistic Context Free Grammars Many slides from Michael Collins and Chris Manning Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic
CS 6120/CS4120: Natural Language Processing
 CS 6120/CS4120: Natural Language Processing Instructor: Prof. Lu Wang College of Computer and Information Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Assignment/report submission
CS 6120/CS4120: Natural Language Processing Instructor: Prof. Lu Wang College of Computer and Information Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Assignment/report submission
Natural Language Processing CS Lecture 06. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Natural Language Processing CS 6840 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Statistical Parsing Define a probabilistic model of syntax P(T S):
Natural Language Processing CS 6840 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Statistical Parsing Define a probabilistic model of syntax P(T S):
S NP VP 0.9 S VP 0.1 VP V NP 0.5 VP V 0.1 VP V PP 0.1 NP NP NP 0.1 NP NP PP 0.2 NP N 0.7 PP P NP 1.0 VP NP PP 1.0. N people 0.
 /6/7 CS 6/CS: Natural Language Processing Instructor: Prof. Lu Wang College of Computer and Information Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang The grammar: Binary, no epsilons,.9..5
/6/7 CS 6/CS: Natural Language Processing Instructor: Prof. Lu Wang College of Computer and Information Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang The grammar: Binary, no epsilons,.9..5
Attendee information. Seven Lectures on Statistical Parsing. Phrase structure grammars = context-free grammars. Assessment.
 even Lectures on tatistical Parsing Christopher Manning LA Linguistic Institute 7 LA Lecture Attendee information Please put on a piece of paper: ame: Affiliation: tatus (undergrad, grad, industry, prof,
even Lectures on tatistical Parsing Christopher Manning LA Linguistic Institute 7 LA Lecture Attendee information Please put on a piece of paper: ame: Affiliation: tatus (undergrad, grad, industry, prof,
Probabilistic Context-free Grammars
 Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
Parsing with Context-Free Grammars
 Parsing with Context-Free Grammars CS 585, Fall 2017 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp2017 Brendan O Connor College of Information and Computer Sciences
Parsing with Context-Free Grammars CS 585, Fall 2017 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp2017 Brendan O Connor College of Information and Computer Sciences
Parsing. Based on presentations from Chris Manning s course on Statistical Parsing (Stanford)
") Parsing Based on presentations from Chris Manning s course on Statistical Parsing (Stanford) S N VP V NP D N John hit the ball Levels of analysis Level Morphology/Lexical POS (morpho-synactic), WSD Elements
Parsing Based on presentations from Chris Manning s course on Statistical Parsing (Stanford) S N VP V NP D N John hit the ball Levels of analysis Level Morphology/Lexical POS (morpho-synactic), WSD Elements
Probabilistic Context-Free Grammars. Michael Collins, Columbia University
 Probabilistic Context-Free Grammars Michael Collins, Columbia University Overview Probabilistic Context-Free Grammars (PCFGs) The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Probabilistic Context-Free Grammars Michael Collins, Columbia University Overview Probabilistic Context-Free Grammars (PCFGs) The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Statistical Methods for NLP
 Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch. COMP-599 Oct 1, 2015
 Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
10/17/04. Today s Main Points
 Part-of-speech Tagging & Hidden Markov Model Intro Lecture #10 Introduction to Natural Language Processing CMPSCI 585, Fall 2004 University of Massachusetts Amherst Andrew McCallum Today s Main Points
Part-of-speech Tagging & Hidden Markov Model Intro Lecture #10 Introduction to Natural Language Processing CMPSCI 585, Fall 2004 University of Massachusetts Amherst Andrew McCallum Today s Main Points
Advanced Natural Language Processing Syntactic Parsing
 Advanced Natural Language Processing Syntactic Parsing Alicia Ageno ageno@cs.upc.edu Universitat Politècnica de Catalunya NLP statistical parsing 1 Parsing Review Statistical Parsing SCFG Inside Algorithm
Advanced Natural Language Processing Syntactic Parsing Alicia Ageno ageno@cs.upc.edu Universitat Politècnica de Catalunya NLP statistical parsing 1 Parsing Review Statistical Parsing SCFG Inside Algorithm
Constituency Parsing
 CS5740: Natural Language Processing Spring 2017 Constituency Parsing Instructor: Yoav Artzi Slides adapted from Dan Klein, Dan Jurafsky, Chris Manning, Michael Collins, Luke Zettlemoyer, Yejin Choi, and
CS5740: Natural Language Processing Spring 2017 Constituency Parsing Instructor: Yoav Artzi Slides adapted from Dan Klein, Dan Jurafsky, Chris Manning, Michael Collins, Luke Zettlemoyer, Yejin Choi, and
Probabilistic Context Free Grammars. Many slides from Michael Collins
 Probabilistic Context Free Grammars Many slides from Michael Collins Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Probabilistic Context Free Grammars Many slides from Michael Collins Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
CKY & Earley Parsing. Ling 571 Deep Processing Techniques for NLP January 13, 2016
 CKY & Earley Parsing Ling 571 Deep Processing Techniques for NLP January 13, 2016 No Class Monday: Martin Luther King Jr. Day CKY Parsing: Finish the parse Recognizer à Parser Roadmap Earley parsing Motivation:
CKY & Earley Parsing Ling 571 Deep Processing Techniques for NLP January 13, 2016 No Class Monday: Martin Luther King Jr. Day CKY Parsing: Finish the parse Recognizer à Parser Roadmap Earley parsing Motivation:
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Hidden Markov Models
 CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Natural Language Processing : Probabilistic Context Free Grammars. Updated 5/09
 Natural Language Processing : Probabilistic Context Free Grammars Updated 5/09 Motivation N-gram models and HMM Tagging only allowed us to process sentences linearly. However, even simple sentences require
Natural Language Processing : Probabilistic Context Free Grammars Updated 5/09 Motivation N-gram models and HMM Tagging only allowed us to process sentences linearly. However, even simple sentences require
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing
 Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing CS 4120/6120 Spring 2017 Northeastern University David Smith with some slides from Jason Eisner & Andrew
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing CS 4120/6120 Spring 2017 Northeastern University David Smith with some slides from Jason Eisner & Andrew
CS 545 Lecture XVI: Parsing
 CS 545 Lecture XVI: Parsing brownies_choco81@yahoo.com brownies_choco81@yahoo.com Benjamin Snyder Parsing Given a grammar G and a sentence x = (x1, x2,..., xn), find the best parse tree. We re not going
CS 545 Lecture XVI: Parsing brownies_choco81@yahoo.com brownies_choco81@yahoo.com Benjamin Snyder Parsing Given a grammar G and a sentence x = (x1, x2,..., xn), find the best parse tree. We re not going
Hidden Markov Models (HMMs)
") Hidden Markov Models HMMs Raymond J. Mooney University of Texas at Austin 1 Part Of Speech Tagging Annotate each word in a sentence with a part-of-speech marker. Lowest level of syntactic analysis. John
Hidden Markov Models HMMs Raymond J. Mooney University of Texas at Austin 1 Part Of Speech Tagging Annotate each word in a sentence with a part-of-speech marker. Lowest level of syntactic analysis. John
Natural Language Processing 1. lecture 7: constituent parsing. Ivan Titov. Institute for Logic, Language and Computation
 atural Language Processing 1 lecture 7: constituent parsing Ivan Titov Institute for Logic, Language and Computation Outline Syntax: intro, CFGs, PCFGs PCFGs: Estimation CFGs: Parsing PCFGs: Parsing Parsing
atural Language Processing 1 lecture 7: constituent parsing Ivan Titov Institute for Logic, Language and Computation Outline Syntax: intro, CFGs, PCFGs PCFGs: Estimation CFGs: Parsing PCFGs: Parsing Parsing
Natural Language Processing
 SFU NatLangLab Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class Simon Fraser University September 27, 2018 0 Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class
SFU NatLangLab Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class Simon Fraser University September 27, 2018 0 Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class
Parsing with Context-Free Grammars
 Parsing with Context-Free Grammars Berlin Chen 2005 References: 1. Natural Language Understanding, chapter 3 (3.1~3.4, 3.6) 2. Speech and Language Processing, chapters 9, 10 NLP-Berlin Chen 1 Grammars
Parsing with Context-Free Grammars Berlin Chen 2005 References: 1. Natural Language Understanding, chapter 3 (3.1~3.4, 3.6) 2. Speech and Language Processing, chapters 9, 10 NLP-Berlin Chen 1 Grammars
Review. Earley Algorithm Chapter Left Recursion. Left-Recursion. Rule Ordering. Rule Ordering
 Review Earley Algorithm Chapter 13.4 Lecture #9 October 2009 Top-Down vs. Bottom-Up Parsers Both generate too many useless trees Combine the two to avoid over-generation: Top-Down Parsing with Bottom-Up
Review Earley Algorithm Chapter 13.4 Lecture #9 October 2009 Top-Down vs. Bottom-Up Parsers Both generate too many useless trees Combine the two to avoid over-generation: Top-Down Parsing with Bottom-Up
Processing/Speech, NLP and the Web
 CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 25 Probabilistic Parsing) Pushpak Bhattacharyya CSE Dept., IIT Bombay 14 th March, 2011 Bracketed Structure: Treebank Corpus [ S1[
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 25 Probabilistic Parsing) Pushpak Bhattacharyya CSE Dept., IIT Bombay 14 th March, 2011 Bracketed Structure: Treebank Corpus [ S1[
A Context-Free Grammar
 Statistical Parsing A Context-Free Grammar S VP VP Vi VP Vt VP VP PP DT NN PP PP P Vi sleeps Vt saw NN man NN dog NN telescope DT the IN with IN in Ambiguity A sentence of reasonable length can easily
Statistical Parsing A Context-Free Grammar S VP VP Vi VP Vt VP VP PP DT NN PP PP P Vi sleeps Vt saw NN man NN dog NN telescope DT the IN with IN in Ambiguity A sentence of reasonable length can easily
Unit 2: Tree Models. CS 562: Empirical Methods in Natural Language Processing. Lectures 19-23: Context-Free Grammars and Parsing
 CS 562: Empirical Methods in Natural Language Processing Unit 2: Tree Models Lectures 19-23: Context-Free Grammars and Parsing Oct-Nov 2009 Liang Huang (lhuang@isi.edu) Big Picture we have already covered...
CS 562: Empirical Methods in Natural Language Processing Unit 2: Tree Models Lectures 19-23: Context-Free Grammars and Parsing Oct-Nov 2009 Liang Huang (lhuang@isi.edu) Big Picture we have already covered...
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs
 Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Multiword Expression Identification with Tree Substitution Grammars
 Multiword Expression Identification with Tree Substitution Grammars Spence Green, Marie-Catherine de Marneffe, John Bauer, and Christopher D. Manning Stanford University EMNLP 2011 Main Idea Use syntactic
Multiword Expression Identification with Tree Substitution Grammars Spence Green, Marie-Catherine de Marneffe, John Bauer, and Christopher D. Manning Stanford University EMNLP 2011 Main Idea Use syntactic
Parsing with CFGs L445 / L545 / B659. Dept. of Linguistics, Indiana University Spring Parsing with CFGs. Direction of processing
 L445 / L545 / B659 Dept. of Linguistics, Indiana University Spring 2016 1 / 46 : Overview Input: a string Output: a (single) parse tree A useful step in the process of obtaining meaning We can view the
L445 / L545 / B659 Dept. of Linguistics, Indiana University Spring 2016 1 / 46 : Overview Input: a string Output: a (single) parse tree A useful step in the process of obtaining meaning We can view the
Parsing with CFGs. Direction of processing. Top-down. Bottom-up. Left-corner parsing. Chart parsing CYK. Earley 1 / 46.
 : Overview L545 Dept. of Linguistics, Indiana University Spring 2013 Input: a string Output: a (single) parse tree A useful step in the process of obtaining meaning We can view the problem as searching
: Overview L545 Dept. of Linguistics, Indiana University Spring 2013 Input: a string Output: a (single) parse tree A useful step in the process of obtaining meaning We can view the problem as searching
CS460/626 : Natural Language
 CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 23, 24 Parsing Algorithms; Parsing in case of Ambiguity; Probabilistic Parsing) Pushpak Bhattacharyya CSE Dept., IIT Bombay 8 th,
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 23, 24 Parsing Algorithms; Parsing in case of Ambiguity; Probabilistic Parsing) Pushpak Bhattacharyya CSE Dept., IIT Bombay 8 th,
CS838-1 Advanced NLP: Hidden Markov Models
 CS838-1 Advanced NLP: Hidden Markov Models Xiaojin Zhu 2007 Send comments to jerryzhu@cs.wisc.edu 1 Part of Speech Tagging Tag each word in a sentence with its part-of-speech, e.g., The/AT representative/nn
CS838-1 Advanced NLP: Hidden Markov Models Xiaojin Zhu 2007 Send comments to jerryzhu@cs.wisc.edu 1 Part of Speech Tagging Tag each word in a sentence with its part-of-speech, e.g., The/AT representative/nn
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Hidden Markov Models
 INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 27, 2016 Recap: Probabilistic Language
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 27, 2016 Recap: Probabilistic Language
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing
 Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing! CS 6120 Spring 2014! Northeastern University!! David Smith! with some slides from Jason Eisner & Andrew
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing! CS 6120 Spring 2014! Northeastern University!! David Smith! with some slides from Jason Eisner & Andrew
Lecture 13: Structured Prediction
 Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Spectral Unsupervised Parsing with Additive Tree Metrics
 Spectral Unsupervised Parsing with Additive Tree Metrics Ankur Parikh, Shay Cohen, Eric P. Xing Carnegie Mellon, University of Edinburgh Ankur Parikh 2014 1 Overview Model: We present a novel approach
Spectral Unsupervised Parsing with Additive Tree Metrics Ankur Parikh, Shay Cohen, Eric P. Xing Carnegie Mellon, University of Edinburgh Ankur Parikh 2014 1 Overview Model: We present a novel approach
Recap: HMM. ANLP Lecture 9: Algorithms for HMMs. More general notation. Recap: HMM. Elements of HMM: Sharon Goldwater 4 Oct 2018.
 Recap: HMM ANLP Lecture 9: Algorithms for HMMs Sharon Goldwater 4 Oct 2018 Elements of HMM: Set of states (tags) Output alphabet (word types) Start state (beginning of sentence) State transition probabilities
Recap: HMM ANLP Lecture 9: Algorithms for HMMs Sharon Goldwater 4 Oct 2018 Elements of HMM: Set of states (tags) Output alphabet (word types) Start state (beginning of sentence) State transition probabilities
Sequence Labeling: HMMs & Structured Perceptron
 Sequence Labeling: HMMs & Structured Perceptron CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu HMM: Formal Specification Q: a finite set of N states Q = {q 0, q 1, q 2, q 3, } N N Transition
Sequence Labeling: HMMs & Structured Perceptron CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu HMM: Formal Specification Q: a finite set of N states Q = {q 0, q 1, q 2, q 3, } N N Transition
Chapter 14 (Partially) Unsupervised Parsing
 Unsupervised Parsing") Chapter 14 (Partially) Unsupervised Parsing The linguistically-motivated tree transformations we discussed previously are very effective, but when we move to a new language, we may have to come up with
Chapter 14 (Partially) Unsupervised Parsing The linguistically-motivated tree transformations we discussed previously are very effective, but when we move to a new language, we may have to come up with
Probabilistic Context-Free Grammar
 Probabilistic Context-Free Grammar Petr Horáček, Eva Zámečníková and Ivana Burgetová Department of Information Systems Faculty of Information Technology Brno University of Technology Božetěchova 2, 612
Probabilistic Context-Free Grammar Petr Horáček, Eva Zámečníková and Ivana Burgetová Department of Information Systems Faculty of Information Technology Brno University of Technology Božetěchova 2, 612
Parsing. Probabilistic CFG (PCFG) Laura Kallmeyer. Winter 2017/18. Heinrich-Heine-Universität Düsseldorf 1 / 22
 Laura Kallmeyer. Winter 2017/18. Heinrich-Heine-Universität Düsseldorf 1 / 22") Parsing Probabilistic CFG (PCFG) Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Winter 2017/18 1 / 22 Table of contents 1 Introduction 2 PCFG 3 Inside and outside probability 4 Parsing Jurafsky
Parsing Probabilistic CFG (PCFG) Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Winter 2017/18 1 / 22 Table of contents 1 Introduction 2 PCFG 3 Inside and outside probability 4 Parsing Jurafsky
CS460/626 : Natural Language
 CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 27 SMT Assignment; HMM recap; Probabilistic Parsing cntd) Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th March, 2011 CMU Pronunciation
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 27 SMT Assignment; HMM recap; Probabilistic Parsing cntd) Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th March, 2011 CMU Pronunciation
DT2118 Speech and Speaker Recognition
 DT2118 Speech and Speaker Recognition Language Modelling Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 56 Outline Introduction Formal Language Theory Stochastic Language Models (SLM) N-gram Language
DT2118 Speech and Speaker Recognition Language Modelling Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 56 Outline Introduction Formal Language Theory Stochastic Language Models (SLM) N-gram Language
Lecture 9: Hidden Markov Model
 Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501 Natural Language Processing 1 This lecture v Hidden Markov
Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501 Natural Language Processing 1 This lecture v Hidden Markov
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing
 Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing CS 4120/6120 Spring 2016 Northeastern University David Smith with some slides from Jason Eisner & Andrew
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing CS 4120/6120 Spring 2016 Northeastern University David Smith with some slides from Jason Eisner & Andrew
Lecture 5: UDOP, Dependency Grammars
 Lecture 5: UDOP, Dependency Grammars Jelle Zuidema ILLC, Universiteit van Amsterdam Unsupervised Language Learning, 2014 Generative Model objective PCFG PTSG CCM DMV heuristic Wolff (1984) UDOP ML IO K&M
Lecture 5: UDOP, Dependency Grammars Jelle Zuidema ILLC, Universiteit van Amsterdam Unsupervised Language Learning, 2014 Generative Model objective PCFG PTSG CCM DMV heuristic Wolff (1984) UDOP ML IO K&M
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models. The ischool University of Maryland. Wednesday, September 30, 2009
 CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
Midterm sample questions
 Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Hidden Markov Models
 INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 18, 2017 Recap: Probabilistic Language
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 18, 2017 Recap: Probabilistic Language
More on HMMs and other sequence models. Intro to NLP - ETHZ - 18/03/2013
 More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
In this chapter, we explore the parsing problem, which encompasses several questions, including:
 Chapter 12 Parsing Algorithms 12.1 Introduction In this chapter, we explore the parsing problem, which encompasses several questions, including: Does L(G) contain w? What is the highest-weight derivation
Chapter 12 Parsing Algorithms 12.1 Introduction In this chapter, we explore the parsing problem, which encompasses several questions, including: Does L(G) contain w? What is the highest-weight derivation
Probabilistic Graphical Models
 CS 1675: Intro to Machine Learning Probabilistic Graphical Models Prof. Adriana Kovashka University of Pittsburgh November 27, 2018 Plan for This Lecture Motivation for probabilistic graphical models Directed
CS 1675: Intro to Machine Learning Probabilistic Graphical Models Prof. Adriana Kovashka University of Pittsburgh November 27, 2018 Plan for This Lecture Motivation for probabilistic graphical models Directed
Introduction to Computational Linguistics
 Introduction to Computational Linguistics Olga Zamaraeva (2018) Based on Bender (prev. years) University of Washington May 3, 2018 1 / 101 Midterm Project Milestone 2: due Friday Assgnments 4& 5 due dates
Introduction to Computational Linguistics Olga Zamaraeva (2018) Based on Bender (prev. years) University of Washington May 3, 2018 1 / 101 Midterm Project Milestone 2: due Friday Assgnments 4& 5 due dates
Multilevel Coarse-to-Fine PCFG Parsing
 Multilevel Coarse-to-Fine PCFG Parsing Eugene Charniak, Mark Johnson, Micha Elsner, Joseph Austerweil, David Ellis, Isaac Haxton, Catherine Hill, Shrivaths Iyengar, Jeremy Moore, Michael Pozar, and Theresa
Multilevel Coarse-to-Fine PCFG Parsing Eugene Charniak, Mark Johnson, Micha Elsner, Joseph Austerweil, David Ellis, Isaac Haxton, Catherine Hill, Shrivaths Iyengar, Jeremy Moore, Michael Pozar, and Theresa
Latent Variable Models in NLP
 Latent Variable Models in NLP Aria Haghighi with Slav Petrov, John DeNero, and Dan Klein UC Berkeley, CS Division Latent Variable Models Latent Variable Models Latent Variable Models Observed Latent Variable
Latent Variable Models in NLP Aria Haghighi with Slav Petrov, John DeNero, and Dan Klein UC Berkeley, CS Division Latent Variable Models Latent Variable Models Latent Variable Models Observed Latent Variable
Hidden Markov Models
 CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Language Models & Hidden Markov Models
 1 University of Oslo : Department of Informatics INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Language Models & Hidden Markov Models Stephan Oepen & Erik Velldal Language
1 University of Oslo : Department of Informatics INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Language Models & Hidden Markov Models Stephan Oepen & Erik Velldal Language
A* Search. 1 Dijkstra Shortest Path
 A* Search Consider the eight puzzle. There are eight tiles numbered 1 through 8 on a 3 by three grid with nine locations so that one location is left empty. We can move by sliding a tile adjacent to the
A* Search Consider the eight puzzle. There are eight tiles numbered 1 through 8 on a 3 by three grid with nine locations so that one location is left empty. We can move by sliding a tile adjacent to the
Penn Treebank Parsing. Advanced Topics in Language Processing Stephen Clark
 Penn Treebank Parsing Advanced Topics in Language Processing Stephen Clark 1 The Penn Treebank 40,000 sentences of WSJ newspaper text annotated with phrasestructure trees The trees contain some predicate-argument
Penn Treebank Parsing Advanced Topics in Language Processing Stephen Clark 1 The Penn Treebank 40,000 sentences of WSJ newspaper text annotated with phrasestructure trees The trees contain some predicate-argument
Aspects of Tree-Based Statistical Machine Translation
 Aspects of Tree-Based Statistical Machine Translation Marcello Federico Human Language Technology FBK 2014 Outline Tree-based translation models: Synchronous context free grammars Hierarchical phrase-based
Aspects of Tree-Based Statistical Machine Translation Marcello Federico Human Language Technology FBK 2014 Outline Tree-based translation models: Synchronous context free grammars Hierarchical phrase-based
Probabilistic Context-Free Grammars and beyond
 Probabilistic Context-Free Grammars and beyond Mark Johnson Microsoft Research / Brown University July 2007 1 / 87 Outline Introduction Formal languages and Grammars Probabilistic context-free grammars
Probabilistic Context-Free Grammars and beyond Mark Johnson Microsoft Research / Brown University July 2007 1 / 87 Outline Introduction Formal languages and Grammars Probabilistic context-free grammars
Lecture 15. Probabilistic Models on Graph
 Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Introduction to Probablistic Natural Language Processing
 Introduction to Probablistic Natural Language Processing Alexis Nasr Laboratoire d Informatique Fondamentale de Marseille Natural Language Processing Use computers to process human languages Machine Translation
Introduction to Probablistic Natural Language Processing Alexis Nasr Laboratoire d Informatique Fondamentale de Marseille Natural Language Processing Use computers to process human languages Machine Translation
NLP Programming Tutorial 11 - The Structured Perceptron
 NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
CS626: NLP, Speech and the Web. Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture 14: Parsing Algorithms 30 th August, 2012
 CS626: NLP, Speech and the Web Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture 14: Parsing Algorithms 30 th August, 2012 Parsing Problem Semantics Part of Speech Tagging NLP Trinity Morph Analysis
CS626: NLP, Speech and the Web Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture 14: Parsing Algorithms 30 th August, 2012 Parsing Problem Semantics Part of Speech Tagging NLP Trinity Morph Analysis
LING 473: Day 10. START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars
 LING 473: Day 10 START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars 1 Issues with Projects 1. *.sh files must have #!/bin/sh at the top (to run on Condor) 2. If run.sh is supposed
LING 473: Day 10 START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars 1 Issues with Projects 1. *.sh files must have #!/bin/sh at the top (to run on Condor) 2. If run.sh is supposed
Statistical Methods for NLP
 Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Text Mining. March 3, March 3, / 49
 Text Mining March 3, 2017 March 3, 2017 1 / 49 Outline Language Identification Tokenisation Part-Of-Speech (POS) tagging Hidden Markov Models - Sequential Taggers Viterbi Algorithm March 3, 2017 2 / 49
Text Mining March 3, 2017 March 3, 2017 1 / 49 Outline Language Identification Tokenisation Part-Of-Speech (POS) tagging Hidden Markov Models - Sequential Taggers Viterbi Algorithm March 3, 2017 2 / 49
Context- Free Parsing with CKY. October 16, 2014
 Context- Free Parsing with CKY October 16, 2014 Lecture Plan Parsing as Logical DeducBon Defining the CFG recognibon problem BoHom up vs. top down Quick review of Chomsky normal form The CKY algorithm
Context- Free Parsing with CKY October 16, 2014 Lecture Plan Parsing as Logical DeducBon Defining the CFG recognibon problem BoHom up vs. top down Quick review of Chomsky normal form The CKY algorithm
Dept. of Linguistics, Indiana University Fall 2009
 1 / 14 Markov L645 Dept. of Linguistics, Indiana University Fall 2009 2 / 14 Markov (1) (review) Markov A Markov Model consists of: a finite set of statesω={s 1,...,s n }; an signal alphabetσ={σ 1,...,σ
1 / 14 Markov L645 Dept. of Linguistics, Indiana University Fall 2009 2 / 14 Markov (1) (review) Markov A Markov Model consists of: a finite set of statesω={s 1,...,s n }; an signal alphabetσ={σ 1,...,σ
Features of Statistical Parsers
 Features of tatistical Parsers Preliminary results Mark Johnson Brown University TTI, October 2003 Joint work with Michael Collins (MIT) upported by NF grants LI 9720368 and II0095940 1 Talk outline tatistical
Features of tatistical Parsers Preliminary results Mark Johnson Brown University TTI, October 2003 Joint work with Michael Collins (MIT) upported by NF grants LI 9720368 and II0095940 1 Talk outline tatistical
Decoding and Inference with Syntactic Translation Models
 Decoding and Inference with Syntactic Translation Models March 5, 2013 CFGs S NP VP VP NP V V NP NP CFGs S NP VP S VP NP V V NP NP CFGs S NP VP S VP NP V NP VP V NP NP CFGs S NP VP S VP NP V NP VP V NP
Decoding and Inference with Syntactic Translation Models March 5, 2013 CFGs S NP VP VP NP V V NP NP CFGs S NP VP S VP NP V V NP NP CFGs S NP VP S VP NP V NP VP V NP NP CFGs S NP VP S VP NP V NP VP V NP
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging
 Tagging") ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
Soft Inference and Posterior Marginals. September 19, 2013
 Soft Inference and Posterior Marginals September 19, 2013 Soft vs. Hard Inference Hard inference Give me a single solution Viterbi algorithm Maximum spanning tree (Chu-Liu-Edmonds alg.) Soft inference
Soft Inference and Posterior Marginals September 19, 2013 Soft vs. Hard Inference Hard inference Give me a single solution Viterbi algorithm Maximum spanning tree (Chu-Liu-Edmonds alg.) Soft inference
Today s Agenda. Need to cover lots of background material. Now on to the Map Reduce stuff. Rough conceptual sketch of unsupervised training using EM
 Today s Agenda Need to cover lots of background material l Introduction to Statistical Models l Hidden Markov Models l Part of Speech Tagging l Applying HMMs to POS tagging l Expectation-Maximization (EM)
Today s Agenda Need to cover lots of background material l Introduction to Statistical Models l Hidden Markov Models l Part of Speech Tagging l Applying HMMs to POS tagging l Expectation-Maximization (EM)
A Supertag-Context Model for Weakly-Supervised CCG Parser Learning
 A Supertag-Context Model for Weakly-Supervised CCG Parser Learning Dan Garrette Chris Dyer Jason Baldridge Noah A. Smith U. Washington CMU UT-Austin CMU Contributions 1. A new generative model for learning
A Supertag-Context Model for Weakly-Supervised CCG Parser Learning Dan Garrette Chris Dyer Jason Baldridge Noah A. Smith U. Washington CMU UT-Austin CMU Contributions 1. A new generative model for learning
Expectation Maximization (EM)
") Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
{Probabilistic Stochastic} Context-Free Grammars (PCFGs)
") {Probabilistic Stochastic} Context-Free Grammars (PCFGs) 116 The velocity of the seismic waves rises to... S NP sg VP sg DT NN PP risesto... The velocity IN NP pl of the seismic waves 117 PCFGs APCFGGconsists
{Probabilistic Stochastic} Context-Free Grammars (PCFGs) 116 The velocity of the seismic waves rises to... S NP sg VP sg DT NN PP risesto... The velocity IN NP pl of the seismic waves 117 PCFGs APCFGGconsists
The Infinite PCFG using Hierarchical Dirichlet Processes
 S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise
S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise S NP VP NP PRP VP VBD NP NP DT NN PRP she VBD heard DT the NN noise
CMPT-825 Natural Language Processing. Why are parsing algorithms important?
 CMPT-825 Natural Language Processing Anoop Sarkar http://www.cs.sfu.ca/ anoop October 26, 2010 1/34 Why are parsing algorithms important? A linguistic theory is implemented in a formal system to generate
CMPT-825 Natural Language Processing Anoop Sarkar http://www.cs.sfu.ca/ anoop October 26, 2010 1/34 Why are parsing algorithms important? A linguistic theory is implemented in a formal system to generate
Statistical methods in NLP, lecture 7 Tagging and parsing
 Statistical methods in NLP, lecture 7 Tagging and parsing Richard Johansson February 25, 2014 overview of today's lecture HMM tagging recap assignment 3 PCFG recap dependency parsing VG assignment 1 overview
Statistical methods in NLP, lecture 7 Tagging and parsing Richard Johansson February 25, 2014 overview of today's lecture HMM tagging recap assignment 3 PCFG recap dependency parsing VG assignment 1 overview
Roger Levy Probabilistic Models in the Study of Language draft, October 2,
 Roger Levy Probabilistic Models in the Study of Language draft, October 2, 2012 224 Chapter 10 Probabilistic Grammars 10.1 Outline HMMs PCFGs ptsgs and ptags Highlight: Zuidema et al., 2008, CogSci; Cohn
Roger Levy Probabilistic Models in the Study of Language draft, October 2, 2012 224 Chapter 10 Probabilistic Grammars 10.1 Outline HMMs PCFGs ptsgs and ptags Highlight: Zuidema et al., 2008, CogSci; Cohn
Structured Output Prediction: Generative Models
 Structured Output Prediction: Generative Models CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 17.3, 17.4, 17.5.1 Structured Output Prediction Supervised
Structured Output Prediction: Generative Models CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 17.3, 17.4, 17.5.1 Structured Output Prediction Supervised
CSCI 5832 Natural Language Processing. Today 2/19. Statistical Sequence Classification. Lecture 9
 CSCI 5832 Natural Language Processing Jim Martin Lecture 9 1 Today 2/19 Review HMMs for POS tagging Entropy intuition Statistical Sequence classifiers HMMs MaxEnt MEMMs 2 Statistical Sequence Classification
CSCI 5832 Natural Language Processing Jim Martin Lecture 9 1 Today 2/19 Review HMMs for POS tagging Entropy intuition Statistical Sequence classifiers HMMs MaxEnt MEMMs 2 Statistical Sequence Classification
PCFGs 2 L645 / B659. Dept. of Linguistics, Indiana University Fall PCFGs 2. Questions. Calculating P(w 1m ) Inside Probabilities
 Inside Probabilities") 1 / 22 Inside L645 / B659 Dept. of Linguistics, Indiana University Fall 2015 Inside- 2 / 22 for PCFGs 3 questions for Probabilistic Context Free Grammars (PCFGs): What is the probability of a sentence
1 / 22 Inside L645 / B659 Dept. of Linguistics, Indiana University Fall 2015 Inside- 2 / 22 for PCFGs 3 questions for Probabilistic Context Free Grammars (PCFGs): What is the probability of a sentence
CS : Speech, NLP and the Web/Topics in AI
 CS626-449: Speech, NLP and the Web/Topics in AI Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture-17: Probabilistic parsing; insideoutside probabilities Probability of a parse tree (cont.) S 1,l NP 1,2
CS626-449: Speech, NLP and the Web/Topics in AI Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture-17: Probabilistic parsing; insideoutside probabilities Probability of a parse tree (cont.) S 1,l NP 1,2
This kind of reordering is beyond the power of finite transducers, but a synchronous CFG can do this.
 Chapter 12 Synchronous CFGs Synchronous context-free grammars are a generalization of CFGs that generate pairs of related strings instead of single strings. They are useful in many situations where one
Chapter 12 Synchronous CFGs Synchronous context-free grammars are a generalization of CFGs that generate pairs of related strings instead of single strings. They are useful in many situations where one
Dependency Parsing. Statistical NLP Fall (Non-)Projectivity. CoNLL Format. Lecture 9: Dependency Parsing
Projectivity. CoNLL Format. Lecture 9: Dependency Parsing") Dependency Parsing Statistical NLP Fall 2016 Lecture 9: Dependency Parsing Slav Petrov Google prep dobj ROOT nsubj pobj det PRON VERB DET NOUN ADP NOUN They solved the problem with statistics CoNLL Format
Dependency Parsing Statistical NLP Fall 2016 Lecture 9: Dependency Parsing Slav Petrov Google prep dobj ROOT nsubj pobj det PRON VERB DET NOUN ADP NOUN They solved the problem with statistics CoNLL Format
c(a) = X c(a! Ø) (13.1) c(a! Ø) ˆP(A! Ø A) = c(a)
 = X c(a! Ø) (13.1) c(a! Ø) ˆP(A! Ø A) = c(a)") Chapter 13 Statistical Parsg Given a corpus of trees, it is easy to extract a CFG and estimate its parameters. Every tree can be thought of as a CFG derivation, and we just perform relative frequency estimation
Chapter 13 Statistical Parsg Given a corpus of trees, it is easy to extract a CFG and estimate its parameters. Every tree can be thought of as a CFG derivation, and we just perform relative frequency estimation
The SUBTLE NL Parsing Pipeline: A Complete Parser for English Mitch Marcus University of Pennsylvania
 The SUBTLE NL Parsing Pipeline: A Complete Parser for English Mitch Marcus University of Pennsylvania 1 PICTURE OF ANALYSIS PIPELINE Tokenize Maximum Entropy POS tagger MXPOST Ratnaparkhi Core Parser Collins
The SUBTLE NL Parsing Pipeline: A Complete Parser for English Mitch Marcus University of Pennsylvania 1 PICTURE OF ANALYSIS PIPELINE Tokenize Maximum Entropy POS tagger MXPOST Ratnaparkhi Core Parser Collins
Aspects of Tree-Based Statistical Machine Translation
 Aspects of Tree-Based tatistical Machine Translation Marcello Federico (based on slides by Gabriele Musillo) Human Language Technology FBK-irst 2011 Outline Tree-based translation models: ynchronous context
Aspects of Tree-Based tatistical Machine Translation Marcello Federico (based on slides by Gabriele Musillo) Human Language Technology FBK-irst 2011 Outline Tree-based translation models: ynchronous context
To make a grammar probabilistic, we need to assign a probability to each context-free rewrite
 Notes on the Inside-Outside Algorithm To make a grammar probabilistic, we need to assign a probability to each context-free rewrite rule. But how should these probabilities be chosen? It is natural to
Notes on the Inside-Outside Algorithm To make a grammar probabilistic, we need to assign a probability to each context-free rewrite rule. But how should these probabilities be chosen? It is natural to
Sentence-level processing
 Sentence-level processing Oskar Kohonen 17 Jan, 2018 T-61.5020 Statistical Natural Language Processing - Lecture Outline Introduction Tagging Parsing References Sentence modeling This lecture could also
Sentence-level processing Oskar Kohonen 17 Jan, 2018 T-61.5020 Statistical Natural Language Processing - Lecture Outline Introduction Tagging Parsing References Sentence modeling This lecture could also