Grammars and introduction to machine learning. Computers Playing Jeopardy! Course Stony Brook University
|
|
|
- Jasmine Penelope Curtis
- 6 years ago
- Views:
Transcription
1 Grammars and introduction to machine learning Computers Playing Jeopardy! Course Stony Brook University
2 Last class: grammars and parsing in Prolog Noun -> roller Verb thrills VP Verb NP S NP VP NP S VP Verb NP A roller coaster thrills every teenager 2
3 Today: NLP ambiguity Example: books: NOUN OR VERB You do not need books for this class. She books her trips early. Another example: Thank you for not smoking or playing ipods without earphones. Thank you for not smoking () without earphones These cases can be detected as special uses of the same word Caveout: If we write too many rules, we may write unnatural grammars special rules became general rules it puts a burden too large on the person writing the grammar 3
4 Ambiguity in Parsing S NP VP S NP Det N NP NP PP VP V NP NP VP VP VP PP PP P NP NP Papa Papa VP PP N caviar N spoon V NP P NP V spoon V ate P with ate Det N with Det N Det the Det a the caviar a spoon 4
5 Ambiguity in Parsing S NP VP S NP Det N NP NP PP VP V NP NP VP VP VP PP PP P NP NP Papa Papa V NP N caviar N spoon ate NP PP V spoon V ate Det N P NP P with Det the Det a the caviar with Det N 5 a spoon
6 Scores P A R S E R correct test trees s c o r e r accuracy test sentences Grammar Recent parsers quite accurate good enough to help NLP tasks! 6
7 Speech processing ambiguity Speech processing is a very hard problem (gender, accent, background noise) Solution: n-grams Letter or word frequencies: 1-grams: THE, COURSE useful in solving cryptograms If you know the previous letter/word: 2-grams h is rare in English (4%; 4 points in Scrabble) but h is common after t (20%)!!! If you know the previous 2 letters/words: 3-grams h is really common after (space) t 7
8 N-grams An n-gram is a contiguous sequence of n items from a given sequence the items can be: letters, words, phonemes, syllables, etc. Examples: Consider the paragraph: Suppose you should be walking down Broadway after dinner, with ten minutes allotted to the consummation of your cigar while you are choosing between a diverting tragedy and something serious in the way of vaudeville. Suddenly a hand is laid upon your arm. (from the The green door, The Four Million novel, by O. Henry) unigrams (n-grams of size 1): Suppose, you, should, be, walking,... bigrams (n-grams of size 2): Suppose you, you should, should be, be walking,... trigrams (n-grams of size 3): Suppose you should, you should be, should be walking,... four-grams: Suppose you should be, you should be walking,... 8
9 N-grams 9 An n-gram model is a type of probabilistic language model for predicting the next item in such a sequence Example: from a novel, we can extract all bigrams (sequences of 2- words) with their probabilities of showing up: probability( you can )= number of you can s in text/total number of bigrams = probability( you should )= number of you should s in text/total number of bigrams = etc. Consider that the current word is you and we want to predict what is the next word: with probability 0.002%, the next word is can with probability 0.001%, the next word is should Advantages: easy training, simple/intuitive probabilistic model.
10 N-grams in NLP N-gram models are widely used in statistical natural language processing (NLP): in speech recognition, phonemes and sequences of phonemes are modeled using a n-gram distribution: due to multitude of accents, various voice pitches, gender, etc., speech recognition is very error prone, so information about the predicted next phonemes is very useful to detect the exact transcription in parsing text, words are modeled such that each n-gram is composed of n words there is an infinite number of ways to express ideas in natural language. However, there are common and standardized ways used by humans to convert information. A probabilistic model is useful to the parser to construct a data structure that best fits the grammatical rules. in language identification, sequences of characters are modeled for different languages (e.g., in English, t and w are followed by an h 90% of the time). 10
11 N-grams in NLP Other applications: plagiarism detection, find candidates for the correct spelling of a misspelled word, optical character recognition (OCR), machine translation, correction codes (correct words that were garbled during transmission) Modern statistical models are typically made up of two parts: a prior distribution describing the inherent likelihood of a possible result and a likelihood function used to assess the compatibility of a possible result with observed data. 11
12 Probabilities and statistics descriptive: mean scores confirmatory: statistically significant? predictive: what will follow? Probability notation p(x Y): p(paul Revere wins weather s clear) = 0.9 Revere s won 90% of races with clear weather p(win clear) = p(win, clear) / p(clear) syntactic sugar logical conjunction of predicates predicate selecting races where weather s clear 12
13 Properties of p (axioms) p( ) = 0 p(all outcomes) = 1 p(x) p(y) for any X Y p(x Y) = p(x) + p(y) provided X Y= example: p(win & clear) + p(win & clear) = p(win) 13
14 Properties and Conjunction what happens as we add conjuncts to left of bar? p(paul Revere wins, Valentine places, Epitaph shows weather s clear) probability can only decrease what happens as we add conjuncts to right of bar? p(paul Revere wins weather s clear, ground is dry, jockey getting over sprain) probability can increase or decrease 14 Simplifying Right Side (Backing Off) - reasonable estimate p(paul Revere wins weather s clear, ground is dry, jockey getting over sprain)
15 Factoring Left Side: The Chain Rule p(revere, Valentine, Epitaph weather s clear) = p(revere Valentine, Epitaph, weather s clear) * p(valentine Epitaph, weather s clear) * p(epitaph weather s clear) 15 True because numerators cancel against denominators Makes perfect sense when read from bottom to top Revere? Valentine? Revere? Epitaph? Revere? Valentine? Revere? Epitaph, Valentine, Revere? 1/3 * 1/5 * 1/4
16 Factoring Left Side: The Chain Rule p(revere Valentine, Epitaph, weather s clear) conditional independence lets us use backed-off data from all four of these cases to estimate their shared probabilities If this prob is unchanged by backoff, we say Revere was CONDITIONALLY INDEPENDENT of Valentine and Epitaph (conditioned on the weather s being clear). no 3/4 Revere? yes 1/4 Valentine? no 3/4 Revere? yes 1/4 Epitaph? no 3/4 yes yes 1/4 Valentine? Revere? clear? irrelevant no 3/4 Revere? yes 1/
17 Bayes Theorem p(a B) = p(b A) * p(a) / p(b) Easy to check by removing syntactic sugar Use 1: Converts p(b A) to p(a B) Use 2: Updates p(a) to p(a B) 17 17
18 Probabilistic Algorithms Example: The Viterbi algorithm computes the probability of a sequence of observed events and the most likely sequence of hidden states (the Viterbi path) that result in the sequence of observed events. forward_viterbi(+observations, +States, +Start_probabilities, +Transition_probabilities, +Emission_probabilities, -Prob, -Viterbi_path, - Viterbi_prob) forward_viterbi(['walk', 'shop', 'clean'], ['Ranny', 'Sunny'], [0.6, 0.4], [[0.7, 0.3],[0.4,0.6]], [[0.1, 0.4, 0.5], [0.6, 0.3, 0.1]], Prob, Viterbi_path, Viterbi_prob) will return: Prob = , Viterbi_path = [Sunny, Rainy, Rainy, Rainy], Viterbi_prob=
19 Viterbi Algorithm Alice and Bob live far apart from each other. Bob does three activities: walks in the park, shops, and cleans his apartment. Alice has no definite information about the weather where Bob lives. Alice tries to guess what the weather is based on what Bob does: The weather operates as a discrete Markov chain There are two (hidden to Alice) states "Rainy" and "Sunny start_probability = {'Rainy': 0.6, 'Sunny': 0.4} 19 Wikipedia
20 Viterbi Algorithm A dynamic programming algorithm Input: a first-order hidden Markov model (HMM) states Y initial probabilities π i of being in state i transition probabilities a i,j of transitioning from state i to statej observations x 0,..., x T Output: The state sequence y 0,..., y T most likely to have produced the observations V t,k is the probability of the most probable state sequence responsible for the first t + 1 observations V 0,k = P(x 0 k) π i V T,k = P(x t k) max y Y (a y,k V t-1,y ) 20 Wikipedia


21 Viterbi Algorithm The transition_probability represents the change of the weather transition_probability = { 'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3}, 'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6}} The emission_probability represents how likely Bob is to perform a certain activity on each day: emission_probability = { 'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5}, 'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1}, } 21 Wikipedia
22 Viterbi Algorithm Alice talks to Bob and discovers the history of his activities: on the first day he went for a walk on the second day he went shopping on the third day he cleaned his apartment ['walk', 'shop', 'clean'] What is the most likely sequence of rainy/sunny days that would explain these observations? 22 Wikipedia

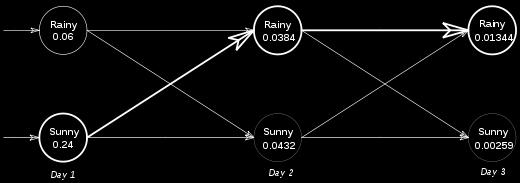
23 23 Wikipedia
Computers playing Jeopardy!
 Computers playing Jeopardy! CSE 392, Computers Playing Jeopardy!, Fall 2011 Stony Brook University http://www.cs.stonybrook.edu/~cse392 1 Last class: grammars and parsing in Prolog Verb thrills VP Verb
Computers playing Jeopardy! CSE 392, Computers Playing Jeopardy!, Fall 2011 Stony Brook University http://www.cs.stonybrook.edu/~cse392 1 Last class: grammars and parsing in Prolog Verb thrills VP Verb
How to Use Probabilities. The Crash Course
 How to Use Probabilities The Crash Course 1 Goals of this lecture Probability notation like p(y X): What does this expression mean? How can I manipulate it? How can I estimate its value in practice? Probability
How to Use Probabilities The Crash Course 1 Goals of this lecture Probability notation like p(y X): What does this expression mean? How can I manipulate it? How can I estimate its value in practice? Probability
10/17/04. Today s Main Points
 Part-of-speech Tagging & Hidden Markov Model Intro Lecture #10 Introduction to Natural Language Processing CMPSCI 585, Fall 2004 University of Massachusetts Amherst Andrew McCallum Today s Main Points
Part-of-speech Tagging & Hidden Markov Model Intro Lecture #10 Introduction to Natural Language Processing CMPSCI 585, Fall 2004 University of Massachusetts Amherst Andrew McCallum Today s Main Points
The Noisy Channel Model and Markov Models
 1/24 The Noisy Channel Model and Markov Models Mark Johnson September 3, 2014 2/24 The big ideas The story so far: machine learning classifiers learn a function that maps a data item X to a label Y handle
1/24 The Noisy Channel Model and Markov Models Mark Johnson September 3, 2014 2/24 The big ideas The story so far: machine learning classifiers learn a function that maps a data item X to a label Y handle
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging
 Tagging") ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
DT2118 Speech and Speaker Recognition
 DT2118 Speech and Speaker Recognition Language Modelling Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 56 Outline Introduction Formal Language Theory Stochastic Language Models (SLM) N-gram Language
DT2118 Speech and Speaker Recognition Language Modelling Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 56 Outline Introduction Formal Language Theory Stochastic Language Models (SLM) N-gram Language
8: Hidden Markov Models
 8: Hidden Markov Models Machine Learning and Real-world Data Helen Yannakoudakis 1 Computer Laboratory University of Cambridge Lent 2018 1 Based on slides created by Simone Teufel So far we ve looked at
8: Hidden Markov Models Machine Learning and Real-world Data Helen Yannakoudakis 1 Computer Laboratory University of Cambridge Lent 2018 1 Based on slides created by Simone Teufel So far we ve looked at
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs
 Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Midterm sample questions
 Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Hidden Markov Models, I. Examples. Steven R. Dunbar. Toy Models. Standard Mathematical Models. Realistic Hidden Markov Models.
 , I. Toy Markov, I. February 17, 2017 1 / 39 Outline, I. Toy Markov 1 Toy 2 3 Markov 2 / 39 , I. Toy Markov A good stack of examples, as large as possible, is indispensable for a thorough understanding
, I. Toy Markov, I. February 17, 2017 1 / 39 Outline, I. Toy Markov 1 Toy 2 3 Markov 2 / 39 , I. Toy Markov A good stack of examples, as large as possible, is indispensable for a thorough understanding
Hidden Markov Models
 Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
We Live in Exciting Times. CSCI-567: Machine Learning (Spring 2019) Outline. Outline. ACM (an international computing research society) has named
 Outline. Outline. ACM (an international computing research society) has named") We Live in Exciting Times ACM (an international computing research society) has named CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Apr. 2, 2019 Yoshua Bengio,
We Live in Exciting Times ACM (an international computing research society) has named CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Apr. 2, 2019 Yoshua Bengio,
Parsing. Based on presentations from Chris Manning s course on Statistical Parsing (Stanford)
") Parsing Based on presentations from Chris Manning s course on Statistical Parsing (Stanford) S N VP V NP D N John hit the ball Levels of analysis Level Morphology/Lexical POS (morpho-synactic), WSD Elements
Parsing Based on presentations from Chris Manning s course on Statistical Parsing (Stanford) S N VP V NP D N John hit the ball Levels of analysis Level Morphology/Lexical POS (morpho-synactic), WSD Elements
LECTURER: BURCU CAN Spring
 LECTURER: BURCU CAN 2017-2018 Spring Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can
LECTURER: BURCU CAN 2017-2018 Spring Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can
1. Markov models. 1.1 Markov-chain
 1. Markov models 1.1 Markov-chain Let X be a random variable X = (X 1,..., X t ) taking values in some set S = {s 1,..., s N }. The sequence is Markov chain if it has the following properties: 1. Limited
1. Markov models 1.1 Markov-chain Let X be a random variable X = (X 1,..., X t ) taking values in some set S = {s 1,..., s N }. The sequence is Markov chain if it has the following properties: 1. Limited
HMM part 1. Dr Philip Jackson
 Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. HMM part 1 Dr Philip Jackson Probability fundamentals Markov models State topology diagrams Hidden Markov models -
Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. HMM part 1 Dr Philip Jackson Probability fundamentals Markov models State topology diagrams Hidden Markov models -
Natural Language Processing. Statistical Inference: n-grams
 Natural Language Processing Statistical Inference: n-grams Updated 3/2009 Statistical Inference Statistical Inference consists of taking some data (generated in accordance with some unknown probability
Natural Language Processing Statistical Inference: n-grams Updated 3/2009 Statistical Inference Statistical Inference consists of taking some data (generated in accordance with some unknown probability
Text Mining. March 3, March 3, / 49
 Text Mining March 3, 2017 March 3, 2017 1 / 49 Outline Language Identification Tokenisation Part-Of-Speech (POS) tagging Hidden Markov Models - Sequential Taggers Viterbi Algorithm March 3, 2017 2 / 49
Text Mining March 3, 2017 March 3, 2017 1 / 49 Outline Language Identification Tokenisation Part-Of-Speech (POS) tagging Hidden Markov Models - Sequential Taggers Viterbi Algorithm March 3, 2017 2 / 49
Course 495: Advanced Statistical Machine Learning/Pattern Recognition
 Course 495: Advanced Statistical Machine Learning/Pattern Recognition Lecturer: Stefanos Zafeiriou Goal (Lectures): To present discrete and continuous valued probabilistic linear dynamical systems (HMMs
Course 495: Advanced Statistical Machine Learning/Pattern Recognition Lecturer: Stefanos Zafeiriou Goal (Lectures): To present discrete and continuous valued probabilistic linear dynamical systems (HMMs
Doctoral Course in Speech Recognition. May 2007 Kjell Elenius
 Doctoral Course in Speech Recognition May 2007 Kjell Elenius CHAPTER 12 BASIC SEARCH ALGORITHMS State-based search paradigm Triplet S, O, G S, set of initial states O, set of operators applied on a state
Doctoral Course in Speech Recognition May 2007 Kjell Elenius CHAPTER 12 BASIC SEARCH ALGORITHMS State-based search paradigm Triplet S, O, G S, set of initial states O, set of operators applied on a state
N-grams. Motivation. Simple n-grams. Smoothing. Backoff. N-grams L545. Dept. of Linguistics, Indiana University Spring / 24
 L545 Dept. of Linguistics, Indiana University Spring 2013 1 / 24 Morphosyntax We just finished talking about morphology (cf. words) And pretty soon we re going to discuss syntax (cf. sentences) In between,
L545 Dept. of Linguistics, Indiana University Spring 2013 1 / 24 Morphosyntax We just finished talking about morphology (cf. words) And pretty soon we re going to discuss syntax (cf. sentences) In between,
CSCI 5832 Natural Language Processing. Today 2/19. Statistical Sequence Classification. Lecture 9
 CSCI 5832 Natural Language Processing Jim Martin Lecture 9 1 Today 2/19 Review HMMs for POS tagging Entropy intuition Statistical Sequence classifiers HMMs MaxEnt MEMMs 2 Statistical Sequence Classification
CSCI 5832 Natural Language Processing Jim Martin Lecture 9 1 Today 2/19 Review HMMs for POS tagging Entropy intuition Statistical Sequence classifiers HMMs MaxEnt MEMMs 2 Statistical Sequence Classification
Fun with weighted FSTs
 Fun with weighted FSTs Informatics 2A: Lecture 18 Shay Cohen School of Informatics University of Edinburgh 29 October 2018 1 / 35 Kedzie et al. (2018) - Content Selection in Deep Learning Models of Summarization
Fun with weighted FSTs Informatics 2A: Lecture 18 Shay Cohen School of Informatics University of Edinburgh 29 October 2018 1 / 35 Kedzie et al. (2018) - Content Selection in Deep Learning Models of Summarization
CS460/626 : Natural Language
 CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 27 SMT Assignment; HMM recap; Probabilistic Parsing cntd) Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th March, 2011 CMU Pronunciation
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 27 SMT Assignment; HMM recap; Probabilistic Parsing cntd) Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th March, 2011 CMU Pronunciation
Statistical Methods for NLP
 Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing
 Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing CS 4120/6120 Spring 2017 Northeastern University David Smith with some slides from Jason Eisner & Andrew
Context-Free Parsing: CKY & Earley Algorithms and Probabilistic Parsing Natural Language Processing CS 4120/6120 Spring 2017 Northeastern University David Smith with some slides from Jason Eisner & Andrew
NLP Programming Tutorial 11 - The Structured Perceptron
 NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Hidden Markov Models
 INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 18, 2017 Recap: Probabilistic Language
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 18, 2017 Recap: Probabilistic Language
Lecture 2: N-gram. Kai-Wei Chang University of Virginia Couse webpage:
 Lecture 2: N-gram Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS 6501: Natural Language Processing 1 This lecture Language Models What are
Lecture 2: N-gram Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS 6501: Natural Language Processing 1 This lecture Language Models What are
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Hidden Markov Models
 INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 27, 2016 Recap: Probabilistic Language
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 27, 2016 Recap: Probabilistic Language
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Lecture 3: ASR: HMMs, Forward, Viterbi
 Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Sequences and Information
 Sequences and Information Rahul Siddharthan The Institute of Mathematical Sciences, Chennai, India http://www.imsc.res.in/ rsidd/ Facets 16, 04/07/2016 This box says something By looking at the symbols
Sequences and Information Rahul Siddharthan The Institute of Mathematical Sciences, Chennai, India http://www.imsc.res.in/ rsidd/ Facets 16, 04/07/2016 This box says something By looking at the symbols
A.I. in health informatics lecture 8 structured learning. kevin small & byron wallace
 A.I. in health informatics lecture 8 structured learning kevin small & byron wallace today models for structured learning: HMMs and CRFs structured learning is particularly useful in biomedical applications:
A.I. in health informatics lecture 8 structured learning kevin small & byron wallace today models for structured learning: HMMs and CRFs structured learning is particularly useful in biomedical applications:
Parametric Models Part III: Hidden Markov Models
 Parametric Models Part III: Hidden Markov Models Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2014 CS 551, Spring 2014 c 2014, Selim Aksoy (Bilkent
Parametric Models Part III: Hidden Markov Models Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2014 CS 551, Spring 2014 c 2014, Selim Aksoy (Bilkent
CS325 Artificial Intelligence Ch. 15,20 Hidden Markov Models and Particle Filtering
 CS325 Artificial Intelligence Ch. 15,20 Hidden Markov Models and Particle Filtering Cengiz Günay, Emory Univ. Günay Ch. 15,20 Hidden Markov Models and Particle FilteringSpring 2013 1 / 21 Get Rich Fast!
CS325 Artificial Intelligence Ch. 15,20 Hidden Markov Models and Particle Filtering Cengiz Günay, Emory Univ. Günay Ch. 15,20 Hidden Markov Models and Particle FilteringSpring 2013 1 / 21 Get Rich Fast!
Log-Linear Models, MEMMs, and CRFs
 Log-Linear Models, MEMMs, and CRFs Michael Collins 1 Notation Throughout this note I ll use underline to denote vectors. For example, w R d will be a vector with components w 1, w 2,... w d. We use expx
Log-Linear Models, MEMMs, and CRFs Michael Collins 1 Notation Throughout this note I ll use underline to denote vectors. For example, w R d will be a vector with components w 1, w 2,... w d. We use expx
NLP: N-Grams. Dan Garrette December 27, Predictive text (text messaging clients, search engines, etc)
") NLP: N-Grams Dan Garrette dhg@cs.utexas.edu December 27, 2013 1 Language Modeling Tasks Language idenfication / Authorship identification Machine Translation Speech recognition Optical character recognition
NLP: N-Grams Dan Garrette dhg@cs.utexas.edu December 27, 2013 1 Language Modeling Tasks Language idenfication / Authorship identification Machine Translation Speech recognition Optical character recognition
Part A. P (w 1 )P (w 2 w 1 )P (w 3 w 1 w 2 ) P (w M w 1 w 2 w M 1 ) P (w 1 )P (w 2 w 1 )P (w 3 w 2 ) P (w M w M 1 )
P (w 2 w 1 )P (w 3 w 1 w 2 ) P (w M w 1 w 2 w M 1 ) P (w 1 )P (w 2 w 1 )P (w 3 w 2 ) P (w M w M 1 )") Part A 1. A Markov chain is a discrete-time stochastic process, defined by a set of states, a set of transition probabilities (between states), and a set of initial state probabilities; the process proceeds
Part A 1. A Markov chain is a discrete-time stochastic process, defined by a set of states, a set of transition probabilities (between states), and a set of initial state probabilities; the process proceeds
Language Modeling. Michael Collins, Columbia University
 Language Modeling Michael Collins, Columbia University Overview The language modeling problem Trigram models Evaluating language models: perplexity Estimation techniques: Linear interpolation Discounting
Language Modeling Michael Collins, Columbia University Overview The language modeling problem Trigram models Evaluating language models: perplexity Estimation techniques: Linear interpolation Discounting
Variational Decoding for Statistical Machine Translation
 Variational Decoding for Statistical Machine Translation Zhifei Li, Jason Eisner, and Sanjeev Khudanpur Center for Language and Speech Processing Computer Science Department Johns Hopkins University 1
Variational Decoding for Statistical Machine Translation Zhifei Li, Jason Eisner, and Sanjeev Khudanpur Center for Language and Speech Processing Computer Science Department Johns Hopkins University 1
8: Hidden Markov Models
 8: Hidden Markov Models Machine Learning and Real-world Data Simone Teufel and Ann Copestake Computer Laboratory University of Cambridge Lent 2017 Last session: catchup 1 Research ideas from sentiment
8: Hidden Markov Models Machine Learning and Real-world Data Simone Teufel and Ann Copestake Computer Laboratory University of Cambridge Lent 2017 Last session: catchup 1 Research ideas from sentiment
Natural Language Processing SoSe Words and Language Model
 Natural Language Processing SoSe 2016 Words and Language Model Dr. Mariana Neves May 2nd, 2016 Outline 2 Words Language Model Outline 3 Words Language Model Tokenization Separation of words in a sentence
Natural Language Processing SoSe 2016 Words and Language Model Dr. Mariana Neves May 2nd, 2016 Outline 2 Words Language Model Outline 3 Words Language Model Tokenization Separation of words in a sentence
Hidden Markov Models
 CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
Structured Output Prediction: Generative Models
 Structured Output Prediction: Generative Models CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 17.3, 17.4, 17.5.1 Structured Output Prediction Supervised
Structured Output Prediction: Generative Models CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 17.3, 17.4, 17.5.1 Structured Output Prediction Supervised
Basic Probability and Statistics
 Basic Probability and Statistics Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Jerry Zhu, Mark Craven] slide 1 Reasoning with Uncertainty
Basic Probability and Statistics Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Jerry Zhu, Mark Craven] slide 1 Reasoning with Uncertainty
Probabilistic Language Modeling
 Predicting String Probabilities Probabilistic Language Modeling Which string is more likely? (Which string is more grammatical?) Grill doctoral candidates. Regina Barzilay EECS Department MIT November
Predicting String Probabilities Probabilistic Language Modeling Which string is more likely? (Which string is more grammatical?) Grill doctoral candidates. Regina Barzilay EECS Department MIT November
CS 188: Artificial Intelligence Fall 2011
 CS 188: Artificial Intelligence Fall 2011 Lecture 20: HMMs / Speech / ML 11/8/2011 Dan Klein UC Berkeley Today HMMs Demo bonanza! Most likely explanation queries Speech recognition A massive HMM! Details
CS 188: Artificial Intelligence Fall 2011 Lecture 20: HMMs / Speech / ML 11/8/2011 Dan Klein UC Berkeley Today HMMs Demo bonanza! Most likely explanation queries Speech recognition A massive HMM! Details
Bayesian Learning. Examples. Conditional Probability. Two Roles for Bayesian Methods. Prior Probability and Random Variables. The Chain Rule P (B)
") Examples My mood can take 2 possible values: happy, sad. The weather can take 3 possible vales: sunny, rainy, cloudy My friends know me pretty well and say that: P(Mood=happy Weather=rainy) = 0.25 P(Mood=happy
Examples My mood can take 2 possible values: happy, sad. The weather can take 3 possible vales: sunny, rainy, cloudy My friends know me pretty well and say that: P(Mood=happy Weather=rainy) = 0.25 P(Mood=happy
Foundations of Natural Language Processing Lecture 5 More smoothing and the Noisy Channel Model
 Foundations of Natural Language Processing Lecture 5 More smoothing and the Noisy Channel Model Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipop Koehn) 30 January
Foundations of Natural Language Processing Lecture 5 More smoothing and the Noisy Channel Model Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipop Koehn) 30 January
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Ngram Review. CS 136 Lecture 10 Language Modeling. Thanks to Dan Jurafsky for these slides. October13, 2017 Professor Meteer
 + Ngram Review October13, 2017 Professor Meteer CS 136 Lecture 10 Language Modeling Thanks to Dan Jurafsky for these slides + ASR components n Feature Extraction, MFCCs, start of Acoustic n HMMs, the Forward
+ Ngram Review October13, 2017 Professor Meteer CS 136 Lecture 10 Language Modeling Thanks to Dan Jurafsky for these slides + ASR components n Feature Extraction, MFCCs, start of Acoustic n HMMs, the Forward
Parsing with Context-Free Grammars
 Parsing with Context-Free Grammars Berlin Chen 2005 References: 1. Natural Language Understanding, chapter 3 (3.1~3.4, 3.6) 2. Speech and Language Processing, chapters 9, 10 NLP-Berlin Chen 1 Grammars
Parsing with Context-Free Grammars Berlin Chen 2005 References: 1. Natural Language Understanding, chapter 3 (3.1~3.4, 3.6) 2. Speech and Language Processing, chapters 9, 10 NLP-Berlin Chen 1 Grammars
Empirical Methods in Natural Language Processing Lecture 10a More smoothing and the Noisy Channel Model
 Empirical Methods in Natural Language Processing Lecture 10a More smoothing and the Noisy Channel Model (most slides from Sharon Goldwater; some adapted from Philipp Koehn) 5 October 2016 Nathan Schneider
Empirical Methods in Natural Language Processing Lecture 10a More smoothing and the Noisy Channel Model (most slides from Sharon Goldwater; some adapted from Philipp Koehn) 5 October 2016 Nathan Schneider
Lecture 13: Structured Prediction
 Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Hidden Markov Models in Language Processing
 Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Chapter 3: Basics of Language Modelling
 Chapter 3: Basics of Language Modelling Motivation Language Models are used in Speech Recognition Machine Translation Natural Language Generation Query completion For research and development: need a simple
Chapter 3: Basics of Language Modelling Motivation Language Models are used in Speech Recognition Machine Translation Natural Language Generation Query completion For research and development: need a simple
Penn Treebank Parsing. Advanced Topics in Language Processing Stephen Clark
 Penn Treebank Parsing Advanced Topics in Language Processing Stephen Clark 1 The Penn Treebank 40,000 sentences of WSJ newspaper text annotated with phrasestructure trees The trees contain some predicate-argument
Penn Treebank Parsing Advanced Topics in Language Processing Stephen Clark 1 The Penn Treebank 40,000 sentences of WSJ newspaper text annotated with phrasestructure trees The trees contain some predicate-argument
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Language Models & Hidden Markov Models
 1 University of Oslo : Department of Informatics INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Language Models & Hidden Markov Models Stephan Oepen & Erik Velldal Language
1 University of Oslo : Department of Informatics INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Language Models & Hidden Markov Models Stephan Oepen & Erik Velldal Language
More on HMMs and other sequence models. Intro to NLP - ETHZ - 18/03/2013
 More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
Dynamic Programming: Hidden Markov Models
 University of Oslo : Department of Informatics Dynamic Programming: Hidden Markov Models Rebecca Dridan 16 October 2013 INF4820: Algorithms for AI and NLP Topics Recap n-grams Parts-of-speech Hidden Markov
University of Oslo : Department of Informatics Dynamic Programming: Hidden Markov Models Rebecca Dridan 16 October 2013 INF4820: Algorithms for AI and NLP Topics Recap n-grams Parts-of-speech Hidden Markov
Sequential Data Modeling - The Structured Perceptron
 Sequential Data Modeling - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, predict y 2 Prediction Problems Given x, A book review
Sequential Data Modeling - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, predict y 2 Prediction Problems Given x, A book review
Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT. Slides credit: Graham Neubig
 Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Slides credit: Graham Neubig Outline Perceptron: recap and limitations Neural networks Multi-layer perceptron Forward propagation
Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Slides credit: Graham Neubig Outline Perceptron: recap and limitations Neural networks Multi-layer perceptron Forward propagation
Language Modeling. Introduction to N-grams. Many Slides are adapted from slides by Dan Jurafsky
 Language Modeling Introduction to N-grams Many Slides are adapted from slides by Dan Jurafsky Probabilistic Language Models Today s goal: assign a probability to a sentence Why? Machine Translation: P(high
Language Modeling Introduction to N-grams Many Slides are adapted from slides by Dan Jurafsky Probabilistic Language Models Today s goal: assign a probability to a sentence Why? Machine Translation: P(high
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
CS626: NLP, Speech and the Web. Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture 14: Parsing Algorithms 30 th August, 2012
 CS626: NLP, Speech and the Web Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture 14: Parsing Algorithms 30 th August, 2012 Parsing Problem Semantics Part of Speech Tagging NLP Trinity Morph Analysis
CS626: NLP, Speech and the Web Pushpak Bhattacharyya CSE Dept., IIT Bombay Lecture 14: Parsing Algorithms 30 th August, 2012 Parsing Problem Semantics Part of Speech Tagging NLP Trinity Morph Analysis
CS 188 Introduction to AI Fall 2005 Stuart Russell Final
 NAME: SID#: Section: 1 CS 188 Introduction to AI all 2005 Stuart Russell inal You have 2 hours and 50 minutes. he exam is open-book, open-notes. 100 points total. Panic not. Mark your answers ON HE EXAM
NAME: SID#: Section: 1 CS 188 Introduction to AI all 2005 Stuart Russell inal You have 2 hours and 50 minutes. he exam is open-book, open-notes. 100 points total. Panic not. Mark your answers ON HE EXAM
Machine Learning for natural language processing
 Machine Learning for natural language processing N-grams and language models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 25 Introduction Goals: Estimate the probability that a
Machine Learning for natural language processing N-grams and language models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 25 Introduction Goals: Estimate the probability that a
Probabilistic Context-free Grammars
 Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
Natural Language Processing CS Lecture 06. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Natural Language Processing CS 6840 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Statistical Parsing Define a probabilistic model of syntax P(T S):
Natural Language Processing CS 6840 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Statistical Parsing Define a probabilistic model of syntax P(T S):
Lecture 9: Hidden Markov Model
 Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501 Natural Language Processing 1 This lecture v Hidden Markov
Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501 Natural Language Processing 1 This lecture v Hidden Markov
Natural Language Processing SoSe Language Modelling. (based on the slides of Dr. Saeedeh Momtazi)
") Natural Language Processing SoSe 2015 Language Modelling Dr. Mariana Neves April 20th, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline 2 Motivation Estimation Evaluation Smoothing Outline 3 Motivation
Natural Language Processing SoSe 2015 Language Modelling Dr. Mariana Neves April 20th, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline 2 Motivation Estimation Evaluation Smoothing Outline 3 Motivation
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models. The ischool University of Maryland. Wednesday, September 30, 2009
 CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
Advanced Natural Language Processing Syntactic Parsing
 Advanced Natural Language Processing Syntactic Parsing Alicia Ageno ageno@cs.upc.edu Universitat Politècnica de Catalunya NLP statistical parsing 1 Parsing Review Statistical Parsing SCFG Inside Algorithm
Advanced Natural Language Processing Syntactic Parsing Alicia Ageno ageno@cs.upc.edu Universitat Politècnica de Catalunya NLP statistical parsing 1 Parsing Review Statistical Parsing SCFG Inside Algorithm
HMM and Part of Speech Tagging. Adam Meyers New York University
 HMM and Part of Speech Tagging Adam Meyers New York University Outline Parts of Speech Tagsets Rule-based POS Tagging HMM POS Tagging Transformation-based POS Tagging Part of Speech Tags Standards There
HMM and Part of Speech Tagging Adam Meyers New York University Outline Parts of Speech Tagsets Rule-based POS Tagging HMM POS Tagging Transformation-based POS Tagging Part of Speech Tags Standards There
Lecture 2: Probability, Naive Bayes
 Lecture 2: Probability, Naive Bayes CS 585, Fall 205 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp205/ Brendan O Connor Today Probability Review Naive Bayes classification
Lecture 2: Probability, Naive Bayes CS 585, Fall 205 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp205/ Brendan O Connor Today Probability Review Naive Bayes classification
HIDDEN MARKOV MODELS IN SPEECH RECOGNITION
 HIDDEN MARKOV MODELS IN SPEECH RECOGNITION Wayne Ward Carnegie Mellon University Pittsburgh, PA 1 Acknowledgements Much of this talk is derived from the paper "An Introduction to Hidden Markov Models",
HIDDEN MARKOV MODELS IN SPEECH RECOGNITION Wayne Ward Carnegie Mellon University Pittsburgh, PA 1 Acknowledgements Much of this talk is derived from the paper "An Introduction to Hidden Markov Models",
Statistical methods in NLP, lecture 7 Tagging and parsing
 Statistical methods in NLP, lecture 7 Tagging and parsing Richard Johansson February 25, 2014 overview of today's lecture HMM tagging recap assignment 3 PCFG recap dependency parsing VG assignment 1 overview
Statistical methods in NLP, lecture 7 Tagging and parsing Richard Johansson February 25, 2014 overview of today's lecture HMM tagging recap assignment 3 PCFG recap dependency parsing VG assignment 1 overview
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields
 Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Graphical models for part of speech tagging
 Indian Institute of Technology, Bombay and Research Division, India Research Lab Graphical models for part of speech tagging Different Models for POS tagging HMM Maximum Entropy Markov Models Conditional
Indian Institute of Technology, Bombay and Research Division, India Research Lab Graphical models for part of speech tagging Different Models for POS tagging HMM Maximum Entropy Markov Models Conditional
LI 569 Intro to Computational Linguistics Assignment 1: Probability Exercises
 LI 569 Intro to Computational Linguistics Assignment 1: Probability Exercises Prof. J. Eisner Summer 2013 Due date: Sunday, June 30 General homework policies for this class: For all assignments, unless
LI 569 Intro to Computational Linguistics Assignment 1: Probability Exercises Prof. J. Eisner Summer 2013 Due date: Sunday, June 30 General homework policies for this class: For all assignments, unless
An introduction to PRISM and its applications
 An introduction to PRISM and its applications Yoshitaka Kameya Tokyo Institute of Technology 2007/9/17 FJ-2007 1 Contents What is PRISM? Two examples: from population genetics from statistical natural
An introduction to PRISM and its applications Yoshitaka Kameya Tokyo Institute of Technology 2007/9/17 FJ-2007 1 Contents What is PRISM? Two examples: from population genetics from statistical natural
Natural Language Processing
 Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Lecture 2: Probability and Language Models
 Lecture 2: Probability and Language Models Intro to NLP, CS585, Fall 2014 Brendan O Connor (http://brenocon.com) 1 Admin Waitlist Moodle access: Email me if you don t have it Did you get an announcement
Lecture 2: Probability and Language Models Intro to NLP, CS585, Fall 2014 Brendan O Connor (http://brenocon.com) 1 Admin Waitlist Moodle access: Email me if you don t have it Did you get an announcement
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
TnT Part of Speech Tagger
 TnT Part of Speech Tagger By Thorsten Brants Presented By Arghya Roy Chaudhuri Kevin Patel Satyam July 29, 2014 1 / 31 Outline 1 Why Then? Why Now? 2 Underlying Model Other technicalities 3 Evaluation
TnT Part of Speech Tagger By Thorsten Brants Presented By Arghya Roy Chaudhuri Kevin Patel Satyam July 29, 2014 1 / 31 Outline 1 Why Then? Why Now? 2 Underlying Model Other technicalities 3 Evaluation
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Probabilistic Graphical Models: MRFs and CRFs. CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov
 Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Hidden Markov Models. George Konidaris
 Hidden Markov Models George Konidaris gdk@cs.brown.edu Fall 2018 Recall: Bayesian Network Flu Allergy Sinus Nose Headache Recall: BN Flu Allergy Flu P True 0.6 False 0.4 Sinus Allergy P True 0.2 False
Hidden Markov Models George Konidaris gdk@cs.brown.edu Fall 2018 Recall: Bayesian Network Flu Allergy Sinus Nose Headache Recall: BN Flu Allergy Flu P True 0.6 False 0.4 Sinus Allergy P True 0.2 False
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical NLP: Hidden Markov Models. Updated 12/15
 Statistical NLP: Hidden Markov Models Updated 12/15 Markov Models Markov models are statistical tools that are useful for NLP because they can be used for part-of-speech-tagging applications Their first
Statistical NLP: Hidden Markov Models Updated 12/15 Markov Models Markov models are statistical tools that are useful for NLP because they can be used for part-of-speech-tagging applications Their first
Recap: Language models. Foundations of Natural Language Processing Lecture 4 Language Models: Evaluation and Smoothing. Two types of evaluation in NLP
 Recap: Language models Foundations of atural Language Processing Lecture 4 Language Models: Evaluation and Smoothing Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipp
Recap: Language models Foundations of atural Language Processing Lecture 4 Language Models: Evaluation and Smoothing Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipp
ACS Introduction to NLP Lecture 3: Language Modelling and Smoothing
 ACS Introduction to NLP Lecture 3: Language Modelling and Smoothing Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk Language Modelling 2 A language model is a probability
ACS Introduction to NLP Lecture 3: Language Modelling and Smoothing Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk Language Modelling 2 A language model is a probability
To make a grammar probabilistic, we need to assign a probability to each context-free rewrite
 Notes on the Inside-Outside Algorithm To make a grammar probabilistic, we need to assign a probability to each context-free rewrite rule. But how should these probabilities be chosen? It is natural to
Notes on the Inside-Outside Algorithm To make a grammar probabilistic, we need to assign a probability to each context-free rewrite rule. But how should these probabilities be chosen? It is natural to
Deep Learning for NLP
 Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Parsing. Probabilistic CFG (PCFG) Laura Kallmeyer. Winter 2017/18. Heinrich-Heine-Universität Düsseldorf 1 / 22
 Laura Kallmeyer. Winter 2017/18. Heinrich-Heine-Universität Düsseldorf 1 / 22") Parsing Probabilistic CFG (PCFG) Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Winter 2017/18 1 / 22 Table of contents 1 Introduction 2 PCFG 3 Inside and outside probability 4 Parsing Jurafsky
Parsing Probabilistic CFG (PCFG) Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Winter 2017/18 1 / 22 Table of contents 1 Introduction 2 PCFG 3 Inside and outside probability 4 Parsing Jurafsky