Composite Quantization for Approximate Nearest Neighbor Search
|
|
|
- Giles Cross
- 5 years ago
- Views:
Transcription

1 Composite Quantization for Approximate Nearest Neighbor Search Jingdong Wang Lead Researcher Microsoft Research ICML 104, joint work with my interns Ting Zhang from USTC and Chao Du from Tsinghua University
2 Outline Introduction Problem Product quantization Cartesian k-means Composite quantization Experiments
3 Nearest neighbor search Application to similar image search query

4 Nearest neighbor search Application to particular object retrieval query

5 Nearest neighbor search Application to duplicate image search

6 Nearest neighbor search Similar image search Application to K-NN annotation: Annotate the query image using the similar images
7 Nearest neighbor search Definition Database: Query: Nearest neighbor: R d x q
8 Nearest neighbor search Exact nearest neighbor search linear scan:
9 Nearest neighbor search - speedup K-dimensional tree (Kd tree) Generalized binary search tree Metric tree Ball tree VP tree BD tree Cover tree
10 Nearest neighbor search Exact nearest neighbor search linear scan: Costly and impractical for large scale high-dimensional cases Approximate nearest neighbor (ANN) search Efficient Acceptable accuracy Practically used
11 Two principles for ANN search Recall the complexity of linear scan: 1. Reduce the number of distance computations Time complexity: Tree structure, neighborhood graph search and inverted index
12 Our work: TP Tree + NG Search TP Tree Jingdong Wang, Naiyan Wang, You Jia, Jian Li, Gang Zeng, Hongbin Zha, Xian-Sheng Hua:Trinary- Projection Trees for Approximate Nearest Neighbor Search. IEEE Trans. Pattern Anal. Mach. Intell. 36(): (014) You Jia, Jingdong Wang, Gang Zeng, Hongbin Zha, Xian-Sheng Hua: Optimizing kd-trees for scalable visual descriptor indexing. CVPR 010: Neighborhood graph search Jingdong Wang, Shipeng Li:Query-driven iterated neighborhood graph search for large scale indexing. ACM Multimedia 01: Jing Wang, Jingdong Wang, Gang Zeng, Rui Gan, Shipeng Li, Baining Guo: Fast Neighborhood Graph Search Using Cartesian Concatenation. ICCV 013: Neighborhood graph construction Jing Wang, Jingdong Wang, Gang Zeng, Zhuowen Tu, Rui Gan, Shipeng Li: Scalable k-nn graph construction for visual descriptors. CVPR 01:
13 Comparison over SIFT 1M ICCV13 ACMMM1 CVPR10 1 NN 13
14 Comparison over GIST 1M ICCV13 ACMMM1 CVPR10 1 NN 14
15 Comparison over HOG 10M ICCV13 ACMMM1 CVPR10 1 NN 15
16 Neighborhood Graph Search Shipped to Bing ClusterBed Number Index building time on 40M documents is only hours and 10 minutes. Search DPS on each NNS machine stable at 950 without retry and errors Five times faster improved FLANN
17 Two principles for ANN search Recall the complexity of linear scan: 1. Reduce the number of distance computations Time complexity: 1. High efficiency. Large memory cost Tree structure, neighborhood graph search and inverted index. Reduce the cost of each distance computation Time complexity: Hashing (compact codes) 1. Small memory cost. Low efficiency
18 Approximate nearest neighbor search Binary embedding methods (hashing) Produce a few distinct distances Limited ability and flexibility of distance approximation Vector quantization (compact codes) K-means Impossible to use for medium and large code length Impossible to learn the codebook Impossible to compute a code for a vector Product quantization Cartesian k-means
19 Combined solution for very large scale search Retrieve candidates with an index structure using compact codes Load raw features for retrieved candidates from disk Reranking using the true distances Efficient and small memory consumption IO cost is small
20 Outline Introduction Problem Product quantization Cartesian k-means Composite quantization Experiments
21 Product quantization Approximate x by the concatenation of M subvectors
22 Product quantization Approximate x by the concatenation of M subvectors x 1i1 p 1i1 {p 11, p 1,, p 1K } Codebook in the 1 st subspace x = x i x = p i {p 1, p,, p K } Codebook in the nd subspace x MiM p MiM {p M1, p M,, p MK } Codebook in the M th subspace
23 Product quantization Approximate x by the concatenation of M subvectors x 1 p 1i1 {p 11, p 1,, p 1K } Codebook in the 1 st subspace x = x x = p i {p 1, p,, p K } Codebook in the nd subspace x M p MiM {p M1, p M,, p MK } Codebook in the M th subspace
24 Product quantization Approximate x by the concatenation of M subvectors x 1 p 1i1 {p 11, p 1,, p 1K } Codebook in the 1 st subspace x = x x = p i {p 1, p,, p K } Codebook in the nd subspace x M p MiM {p M1, p M,, p MK } Codebook in the M th subspace
25 Product quantization Approximate x by the concatenation of M subvectors x 1 p 1i1 {p 11, p 1,, p 1K } Codebook in the 1 st subspace x = x x = p i {p 1, p,, p K } Codebook in the nd subspace x M p MiM {p M1, p M,, p MK } Codebook in the M th subspace
26 Product quantization Approximate x by the concatenation of M subvectors Code presentation: (i 1, i,, i M ) Distance computation: d q, x = d q 1, p 1i1 + d q, p i + + d qm, p MiM M additions using a pre-computed distance table x 1 p 1i1 d( {p 11, p 1,, p 1K }, qcodebook in the 1 st 1 ) subspace {d q 1, p 11, d q 1, p 1,, d(q 1, p 1K )} x = x x = p i d( {p 1, p,, p K }, qcodebook ) in the nd subspace q 1 x M p MiM d( {p M1, p M,, p MK }, qcodebook in the M th M ) subspace
27 Product quantization M = Approximate x by the concatenation of M subvectors Codebook generation Do k-means for each subspace
28 Product quantization M =, K = 3 Approximate x by the concatenation of M subvectors Codebook generation Do k-means for each subspace p 3 p p 1 p 11 p 1 p 13
29 Product quantization M =, K = 3 Approximate x by the concatenation of M subvectors Codebook generation Do k-means for each subspace Result in K M groups p 3 p The center of each is the concatenation of M subvectorsp 1 p 11 p 1 p 13 = p 11 p 1
30 Product quantization M =, K = 3 Approximate x by the concatenation of M subvectors Codebook generation Do k-means for each subspace Result in K M groups The center of each is the concatenation of M subvectors
31 Product quantization M =, K = 3 Approximate x by the concatenation of M subvectors Codebook generation Do k-means for each subspace Result in K M groups The center of each is the concatenation of M subvectors
32 Product quantization M =, K = 3 Approximate x by the concatenation of M subvectors Codebook generation Do k-means for each subspace Result in K M groups The center of each is the concatenation of M subvectors p x p 13 x x = p 13 p
33 Outline Introduction Problem Product quantization Cartesian k-means Composite quantization Experiments
34 Cartesian K-means Extended product quantization Optimal space rotation Perform PQ over the rotated space p 1i1 x x = R p i p MiM
35 Cartesian K-means Extended product quantization Optimal space rotation Perform PQ over the rotated space p 3 p p 13 x x = R p 1i1 p i p 1 p 1 p 11 p MiM
36 Cartesian K-means Extended product quantization Optimal space rotation Perform PQ over the rotated space p 3 p x p 13 x x = R p 1i1 p i p MiM p 1 p 1 p 11 x x = R p 13 p
37 Outline Introduction Composite quantization Experiments
38 Composite quantization Approximate x by the addition of M vectors x x = c 1i1 + c i + + c MiM {c 11, c 1,, c 1K } {c 1, c,, c K } {c M1, c M,, c MK } Source codebook 1 Source codebook Source codebook M Each source codebook is composed of K d-dimensional vectors
39 Composite quantization source codebooks: {c 11, c 1, c 13 } {c 1, c, c 3 } c 11 c 3 c 1 c 1 c c 13
40 Composite quantization c 11 source codebooks: {c 11, c 1, c 13 } {c 1, c, c 3 } Composite center: = c 11 + c 1 c 1
41 Composite quantization c 11 source codebooks: {c 11, c 1, c 13 } {c 1, c, c 3 } Composite center: = c 11 + c c
42 Composite quantization c 11 c 3 source codebooks: {c 11, c 1, c 13 } {c 1, c, c 3 } Composite center: = c 11 + c 3
43 Composite quantization source codebooks: {c 11, c 1, c 13 } {c 1, c, c 3 } More composite centers
44 Composite quantization Source codebook: {c 11, c 1, c 13 } {c 1, c, c 3 } Composite codebook: 9 composite centers
45 Composite quantization x Source codebook: {c 11, c 1, c 13 } {c 1, c, c 3 } c 11 Space partition: 9 groups c x x = c 11 + c
46 Composite quantization Approximate x by the addition of M vectors x x = c 1i1 + c i + + c MiM {c 11, c 1,, c 1K } {c 1, c,, c K } {c M1, c M,, c MK } Source codebook 1 Source codebook Source codebook M
47 Composite quantization Approximate x by the addition of M vectors Code representation: i 1 i i M length: MlogK x x = c 1i1 + c i + + c MiM {c 11, c 1,, c 1K } {c 1, c,, c K } {c M1, c M,, c MK } Source codebook 1 Source codebook Source codebook M
48 Connection to product quantization Concatenation in product quantization p 1i1 p 1i1 0 0 x x = p i = 0 + p i p MiM 0 0 p MiM
49 Connection to product quantization Concatenation in product quantization = addition p 1i1 p 1i1 0 0 x x = p i = 0 + p i p MiM 0 0 p MiM
50 Connection to product quantization Concatenation in product quantization = addition p 1i1 p 1i1 0 0 x x = p i = 0 + p i p MiM 0 0 p MiM
51 Connection to product quantization Concatenation in product quantization = addition p 1i1 p 1i1 0 0 x x = p i = 0 + p i p MiM 0 0 p MiM
52 Connection to product quantization Concatenation in product quantization = addition p 1i1 p 1i1 0 0 x x = p i = 0 + p i p MiM 0 0 p MiM Product quantization is constrained Composite quantization composite quantization x x = c 1i1 + c i + + c MiM
53 Connection to Cartesian k-means Concatenation in Cartesian k-means = addition p 1i1 p 1i1 0 0 x x = R p i = R 0 + R p i + + R 0 p MiM 0 0 p MiM
54 Connection to Cartesian k-means Concatenation in Cartesian k-means = addition p 1i1 p 1i1 0 0 x x = R p i = R 0 + R p i + + R 0 p MiM 0 0 p MiM
55 Connection to Cartesian k-means Concatenation in Cartesian k-means = addition p 1i1 p 1i1 0 0 x x = R p i = R 0 + R p i + + R 0 p MiM 0 0 p MiM Cartesian k-means is constrained Composite quantization composite quantization x x = c 1i1 + c i + + c MiM
56 Composite quantization Composite quantization Generalizing product quantization and Cartesian k-means Advantages More flexible codebooks More accurate data approximation Higher search accuracy Search efficiency? Depend on the efficiency of the distance computation Product quantization: Coordinate aligned space partition Cartesian k-means: Rotated coordinate aligned space partition Composite quantization: Flexible space partition
57 Approximate distance computation Recall the data approximation M x x = m=1 c mim x Approximate distance to the query q q x q M m=1 c mim x Time-consuming
58 Approximate distance computation Expanded into three terms q M m=1 = m=1 c mim x M q c mim (x) M 1 q + m l c mim (x) T c lil (x)
59 Approximate distance computation q M m=1 = m=1 c mim x M q c mim (x) M 1 q + m l c mim (x) O(M) additions Implemented with a pre-computed distance lookup table Distance lookup table: Store the distances from source codebook elements to q T c lil (x)
60 Approximate distance computation q M m=1 = m=1 c mim x M q c mim (x) M 1 q + m l c mim (x) T c lil (x) O(M) additions Constant
61 Approximate distance computation q M m=1 = m=1 c mim x M q c mim (x) M 1 q + m l c mim (x) T c lil (x) O(M) additions Constant O(M ) additions Using a pre-computed dot product lookup table Dot product lookup table: Store the dot products between codebook elements
62 Approximate distance computation q M m=1 = m=1 c mim x M q c mim (x) M 1 q + m l c mim (x) T c lil (x) O(M) additions Constant O(M ) additions O(M ): still expensive
63 Approximate distance computation q M m=1 = m=1 c mim x M q c mim (x) M 1 q + m l c mim (x) T c lil (x) O(M) additions Constant If constant
64 Approximate distance computation q M m=1 = m=1 c mim x M q c mim (x) M 1 q + m l c mim (x) T c lil (x) O(M) additions Constant If constant Computing this is enough for search
65 Formulation q M m=1 = m=1 c mim x M q c mim (x) M 1 q + m l c mim (x) T c lil (x) Minimize quantization error: x M m=1 c mim x Constant Subject to the third term is a constant
66 Formulation Constrained formulation min C m, i m x,ε x x M m=1 T c mim x s. t. m l c mim (x) c lil (x) = ε Minimize quantization error for search accuracy Constant constraint for search efficiency
67 Connection to PQ and CKM Constrained formulation min C m, i m x,ε x x M m=1 T c mim x s. t. m l c mim (x) c lil (x) = ε Minimize quantization error for search accuracy Constant constraint for search efficiency
68 Connection to PQ and CKM Constrained formulation min C m, i m x,ε x x M m=1 T c mim x s. t. m l c mim (x) c lil (x) = ε Minimize quantization error for search accuracy Constant constraint for search efficiency Product quantization and Cartesian k-means: suboptimal solutions of our approach Non-overlapped space partitioning Codebooks are mutually orthogonal m l T c mim (x) c lil (x) = ε Product quantization and Cartesian k-means
69 Formulation Constrained formulation min C m, i m x,ε x x M m=1 T c mim x s. t. m l c mim (x) c lil (x) = ε Minimize quantization error for search accuracy Constant constraint for search efficiency Transformed to unconstrained formulation Add the constraints into the objective function φ {C m, i m (x), ε) = x x M m=1 c mim x + μ T x m l c mim (x) c lil (x) ε
70 Optimization Unconstrained formulation φ {C m, i m (x), ε) = x x M m=1 c mim x Distortion error + μ T x m l c mim (x) c lil (x) ε Alternative optimization between C m, i m (x), ε Constraints violation Selected by validation
71 Alternative optimization Update {i m (x)} Iteratively alternative optimization, fixing i l (x) l m, update i m (x) Update ε Closed form solution,ε = 1 #{x} Update {C m } L-BFGS algorithm T x m l c mim x c lil (x)
72 Complexity Update {i m (x)} Iteratively alternative optimization, fixing i l (x) l m, update i m (x) O(MKdT d ) Update ε Closed form solution,ε = 1 #{x} O(NM ) Update {C m } L-BFGS algorithm O(NMdT l T c ) T x m l c mim x Convergency? c lil (x)
73 Convergence 1MSIFT, 64 bits Converge about 10~15 iterations
74 Outline Introduction Composite quantization Experiments
75 Experiments on ANN search Datasets 1 million of 18D SIFT vectors, queries 1 million of 960D GIST vectors, 1000 queries 1 billion of 18D SIFT vectors, 1000 queries Evaluation Recall@R the fraction of queries for which the ground-truth Euclidean nearest neighbor is in the R retrieved items
76 Search pipeline Source codebooks Code of database vector x Query q Distance tables (between query and codebook elements) Distance between q and x Output the nearest vectors Repeated for n database vectors
77 Comparison on 1M SIFT and 1M GIST
78 Comparison on 1M SIFT and 1M GIST 64 btis Our:71.59% CKM:63.83%
79 Comparison on 1M SIFT and 1M GIST Our:71.59% CKM:63.83% Relatively small improvement on 1M GIST might be that CKM has already achieved large improvement
80 Comparison on 1M SIFT and 1M GIST Our:71.59% 64 bits ITQ: 53.95% 18 bits ITQ without asymmetric distance underperformed ITQ with asymmetric distance Our approach with 64 bits outperforms (A) ITQ with 18 bits, with slightly smaller search cost
81 Comparison on 1B SIFT
82 Comparison on 1B SIFT Our:70.1% CKM:64.57%
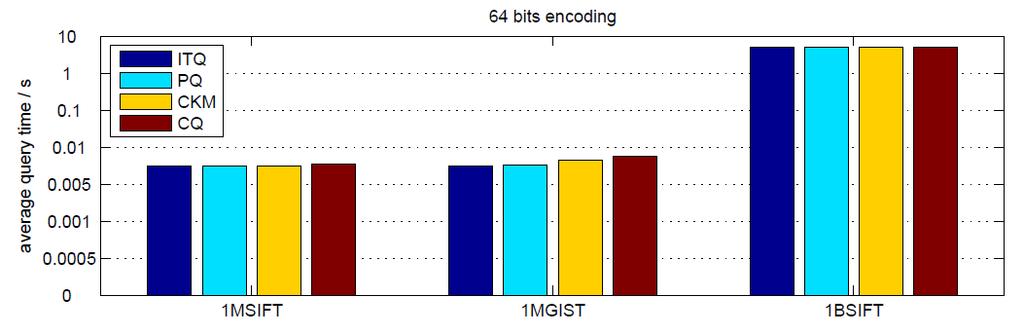
83 Average query time Average query time
84 Application to object retrieval Two datasets INRIA Holidays contains 500 queries and 991 corresponding relevant images UKBench contains 550 groups of 4 images each Results MAP on the holiday dataset Scores on the UKBench dataset
 Search performance with learnt ε is better, since learning ε is more")
85 Discussion The effect of ε min x x x T T subject to m l c mim (x) c lil (x) = ε m l c mim (x) c lil (x) = 0 Indicate the dictionaries are mutual orthogonal like splitting the space (R,T) Search performance with learnt ε is better, since learning ε is more flexible
 Contribution of the offset is relatively small compared with the composite")
86 Discussion The effect of translation min x x x T subject to m l c mim (x) c lil (x) = ε search performance doesn t change too much x x t x (R,T) Contribution of the offset is relatively small compared with the composite quantization
87 Extension (CVPR15) Constrained formulation min C m, i m x,ε x x M m=1 T c mim x s. t. m l c mim (x) c lil (x) = ε Minimize quantization error for search accuracy Constant constraint for search efficiency m C m 1 T Sparsity constraint for precomputation efficiency
88 Extension (CVPR15) Constrained formulation min C m, i m x,ε x x P M m=1 T c mim x s. t. m l c mim (x) c lil (x) = ε Minimize quantization error for search accuracy Constant constraint for search efficiency m C m 1 T Sparsity constraint for precomputation efficiency Dimension reduction
89 Multi-stage vector quantization Database X Vector quantization (1) Residuals Vector quantization () Residuals Residuals Vector quantization (M)
90 Conclusion Composite quantization A compact coding approach for approximate nearest neighbor search Joint optimization of search accuracy and search efficiency State-of-the-art performance

91 A Survey on Learning to Hash

92 Call for papers

93 Call for papers
94 Thanks Q&A
95 A distance preserving view of quantization Quantization Data approximation: x x x x q Better search If better distance preserving: q x q x Distance preserving view Triangle inequality: q x q x x x Minimize the upper bound: x x x
96 A joint minimization view Generalized triangle inequality d q, x d(q, x) x x + δ 1/ Triangle inequality q x q x x x Distortion Efficiency M d q, x = (Σ m=1 q c mim x ) 1/ d q, x = ( q x + M 1 q ) 1/ T δ = Σ m l c mim (x) c lil (x) x = Σ M m=1 c mim (x)
97 A joint minimization view Generalized triangle inequality d q, x d(q, x) x x + δ 1/ Distortion Efficiency Our formulation min Σ x x x C m, i m x,ε s. t. δ = ε Minimize distortion for search accuracy Constant constraint for search efficiency
NEAREST neighbor (NN) search has been a fundamental
 search has been a fundamental") JOUNAL OF L A T E X CLASS FILES, VOL. 3, NO. 9, JUNE 26 Composite Quantization Jingdong Wang and Ting Zhang arxiv:72.955v [cs.cv] 4 Dec 27 Abstract This paper studies the compact coding approach to approximate
JOUNAL OF L A T E X CLASS FILES, VOL. 3, NO. 9, JUNE 26 Composite Quantization Jingdong Wang and Ting Zhang arxiv:72.955v [cs.cv] 4 Dec 27 Abstract This paper studies the compact coding approach to approximate
Tailored Bregman Ball Trees for Effective Nearest Neighbors
 Tailored Bregman Ball Trees for Effective Nearest Neighbors Frank Nielsen 1 Paolo Piro 2 Michel Barlaud 2 1 Ecole Polytechnique, LIX, Palaiseau, France 2 CNRS / University of Nice-Sophia Antipolis, Sophia
Tailored Bregman Ball Trees for Effective Nearest Neighbors Frank Nielsen 1 Paolo Piro 2 Michel Barlaud 2 1 Ecole Polytechnique, LIX, Palaiseau, France 2 CNRS / University of Nice-Sophia Antipolis, Sophia
Stochastic Generative Hashing
 Stochastic Generative Hashing B. Dai 1, R. Guo 2, S. Kumar 2, N. He 3 and L. Song 1 1 Georgia Institute of Technology, 2 Google Research, NYC, 3 University of Illinois at Urbana-Champaign Discussion by
Stochastic Generative Hashing B. Dai 1, R. Guo 2, S. Kumar 2, N. He 3 and L. Song 1 1 Georgia Institute of Technology, 2 Google Research, NYC, 3 University of Illinois at Urbana-Champaign Discussion by
Supervised Quantization for Similarity Search
 Supervised Quantization for Similarity Search Xiaojuan Wang 1 Ting Zhang 2 Guo-Jun Qi 3 Jinhui Tang 4 Jingdong Wang 5 1 Sun Yat-sen University, China 2 University of Science and Technology of China, China
Supervised Quantization for Similarity Search Xiaojuan Wang 1 Ting Zhang 2 Guo-Jun Qi 3 Jinhui Tang 4 Jingdong Wang 5 1 Sun Yat-sen University, China 2 University of Science and Technology of China, China
arxiv: v1 [cs.cv] 22 Dec 2015
![arxiv: v1 [cs.cv] 22 Dec 2015](/thumbs/80/81849508.jpg "arxiv: v1 [cs.cv] 22 Dec 2015") Transformed Residual Quantization for Approximate Nearest Neighbor Search Jiangbo Yuan Florida State University jyuan@cs.fsu.edu Xiuwen Liu Florida State University liux@cs.fsu.edu arxiv:1512.06925v1 [cs.cv]
Transformed Residual Quantization for Approximate Nearest Neighbor Search Jiangbo Yuan Florida State University jyuan@cs.fsu.edu Xiuwen Liu Florida State University liux@cs.fsu.edu arxiv:1512.06925v1 [cs.cv]
Optimized Product Quantization for Approximate Nearest Neighbor Search
 Optimized Product Quantization for Approximate Nearest Neighbor Search Tiezheng Ge Kaiming He 2 Qifa Ke 3 Jian Sun 2 University of Science and Technology of China 2 Microsoft Research Asia 3 Microsoft
Optimized Product Quantization for Approximate Nearest Neighbor Search Tiezheng Ge Kaiming He 2 Qifa Ke 3 Jian Sun 2 University of Science and Technology of China 2 Microsoft Research Asia 3 Microsoft
Image retrieval, vector quantization and nearest neighbor search
 Image retrieval, vector quantization and nearest neighbor search Yannis Avrithis National Technical University of Athens Rennes, October 2014 Part I: Image retrieval Particular object retrieval Match images
Image retrieval, vector quantization and nearest neighbor search Yannis Avrithis National Technical University of Athens Rennes, October 2014 Part I: Image retrieval Particular object retrieval Match images
Correlation Autoencoder Hashing for Supervised Cross-Modal Search
 Correlation Autoencoder Hashing for Supervised Cross-Modal Search Yue Cao, Mingsheng Long, Jianmin Wang, and Han Zhu School of Software Tsinghua University The Annual ACM International Conference on Multimedia
Correlation Autoencoder Hashing for Supervised Cross-Modal Search Yue Cao, Mingsheng Long, Jianmin Wang, and Han Zhu School of Software Tsinghua University The Annual ACM International Conference on Multimedia
Collaborative Quantization for Cross-Modal Similarity Search
 Collaborative Quantization for Cross-Modal Similarity Search ing Zhang 1 Jingdong Wang 2 1 University of Science and echnology, China 2 Microsoft Research, Beijing, China 1 zting@mail.ustc.edu.cn 2 jingdw@microsoft.com
Collaborative Quantization for Cross-Modal Similarity Search ing Zhang 1 Jingdong Wang 2 1 University of Science and echnology, China 2 Microsoft Research, Beijing, China 1 zting@mail.ustc.edu.cn 2 jingdw@microsoft.com
Compressed Fisher vectors for LSVR
 XRCE@ILSVRC2011 Compressed Fisher vectors for LSVR Florent Perronnin and Jorge Sánchez* Xerox Research Centre Europe (XRCE) *Now with CIII, Cordoba University, Argentina Our system in a nutshell High-dimensional
XRCE@ILSVRC2011 Compressed Fisher vectors for LSVR Florent Perronnin and Jorge Sánchez* Xerox Research Centre Europe (XRCE) *Now with CIII, Cordoba University, Argentina Our system in a nutshell High-dimensional
Collaborative Quantization for Cross-Modal Similarity Search
 Collaborative Quantization for Cross-Modal Similarity Search ing Zhang 1 Jingdong Wang 2 1 University of Science and echnology of China, China 2 Microsoft Research, China 1 zting@mail.ustc.edu.cn 2 jingdw@microsoft.com
Collaborative Quantization for Cross-Modal Similarity Search ing Zhang 1 Jingdong Wang 2 1 University of Science and echnology of China, China 2 Microsoft Research, China 1 zting@mail.ustc.edu.cn 2 jingdw@microsoft.com
Iterative Laplacian Score for Feature Selection
 Iterative Laplacian Score for Feature Selection Linling Zhu, Linsong Miao, and Daoqiang Zhang College of Computer Science and echnology, Nanjing University of Aeronautics and Astronautics, Nanjing 2006,
Iterative Laplacian Score for Feature Selection Linling Zhu, Linsong Miao, and Daoqiang Zhang College of Computer Science and echnology, Nanjing University of Aeronautics and Astronautics, Nanjing 2006,
Similarity-Preserving Binary Signature for Linear Subspaces
 Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence Similarity-Preserving Binary Signature for Linear Subspaces Jianqiu Ji, Jianmin Li, Shuicheng Yan, Qi Tian, Bo Zhang State Key
Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence Similarity-Preserving Binary Signature for Linear Subspaces Jianqiu Ji, Jianmin Li, Shuicheng Yan, Qi Tian, Bo Zhang State Key
WITH the explosive growth of multimedia data, compressing
 JOURAL OF L A TEX CLASS FILES, VOL. 14, O. 8, AUGUST 2015 1 PQTable: on-exhaustive Fast Search for Product-quantized Codes using Hash Tables Yusuke Matsui, Member, IEEE, Toshihiko Yamasaki, Member, IEEE,
JOURAL OF L A TEX CLASS FILES, VOL. 14, O. 8, AUGUST 2015 1 PQTable: on-exhaustive Fast Search for Product-quantized Codes using Hash Tables Yusuke Matsui, Member, IEEE, Toshihiko Yamasaki, Member, IEEE,
Algorithms for Picture Analysis. Lecture 07: Metrics. Axioms of a Metric
 Axioms of a Metric Picture analysis always assumes that pictures are defined in coordinates, and we apply the Euclidean metric as the golden standard for distance (or derived, such as area) measurements.
Axioms of a Metric Picture analysis always assumes that pictures are defined in coordinates, and we apply the Euclidean metric as the golden standard for distance (or derived, such as area) measurements.
Nearest Neighbor Search for Relevance Feedback
 Nearest Neighbor earch for Relevance Feedbac Jelena Tešić and B.. Manjunath Electrical and Computer Engineering Department University of California, anta Barbara, CA 93-9 {jelena, manj}@ece.ucsb.edu Abstract
Nearest Neighbor earch for Relevance Feedbac Jelena Tešić and B.. Manjunath Electrical and Computer Engineering Department University of California, anta Barbara, CA 93-9 {jelena, manj}@ece.ucsb.edu Abstract
Optimized Product Quantization
 OPTIMIZED PRODUCT QUATIZATIO Optimized Product Quantization Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun Abstract Product quantization (PQ) is an effective vector quantization method. A product quantizer
OPTIMIZED PRODUCT QUATIZATIO Optimized Product Quantization Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun Abstract Product quantization (PQ) is an effective vector quantization method. A product quantizer
Isotropic Hashing. Abstract
 Isotropic Hashing Weihao Kong, Wu-Jun Li Shanghai Key Laboratory of Scalable Computing and Systems Department of Computer Science and Engineering, Shanghai Jiao Tong University, China {kongweihao,liwujun}@cs.sjtu.edu.cn
Isotropic Hashing Weihao Kong, Wu-Jun Li Shanghai Key Laboratory of Scalable Computing and Systems Department of Computer Science and Engineering, Shanghai Jiao Tong University, China {kongweihao,liwujun}@cs.sjtu.edu.cn
Academic Editors: Andreas Holzinger, Adom Giffin and Kevin H. Knuth Received: 26 February 2016; Accepted: 16 August 2016; Published: 24 August 2016
 entropy Article Distribution Entropy Boosted VLAD for Image Retrieval Qiuzhan Zhou 1,2,3, *, Cheng Wang 2, Pingping Liu 4,5,6, Qingliang Li 4, Yeran Wang 4 and Shuozhang Chen 2 1 State Key Laboratory of
entropy Article Distribution Entropy Boosted VLAD for Image Retrieval Qiuzhan Zhou 1,2,3, *, Cheng Wang 2, Pingping Liu 4,5,6, Qingliang Li 4, Yeran Wang 4 and Shuozhang Chen 2 1 State Key Laboratory of
Learning to Hash with Partial Tags: Exploring Correlation Between Tags and Hashing Bits for Large Scale Image Retrieval
 Learning to Hash with Partial Tags: Exploring Correlation Between Tags and Hashing Bits for Large Scale Image Retrieval Qifan Wang 1, Luo Si 1, and Dan Zhang 2 1 Department of Computer Science, Purdue
Learning to Hash with Partial Tags: Exploring Correlation Between Tags and Hashing Bits for Large Scale Image Retrieval Qifan Wang 1, Luo Si 1, and Dan Zhang 2 1 Department of Computer Science, Purdue
Algorithms for Nearest Neighbors
 Algorithms for Nearest Neighbors Background and Two Challenges Yury Lifshits Steklov Institute of Mathematics at St.Petersburg http://logic.pdmi.ras.ru/~yura McGill University, July 2007 1 / 29 Outline
Algorithms for Nearest Neighbors Background and Two Challenges Yury Lifshits Steklov Institute of Mathematics at St.Petersburg http://logic.pdmi.ras.ru/~yura McGill University, July 2007 1 / 29 Outline
Random Angular Projection for Fast Nearest Subspace Search
 Random Angular Projection for Fast Nearest Subspace Search Binshuai Wang 1, Xianglong Liu 1, Ke Xia 1, Kotagiri Ramamohanarao, and Dacheng Tao 3 1 State Key Lab of Software Development Environment, Beihang
Random Angular Projection for Fast Nearest Subspace Search Binshuai Wang 1, Xianglong Liu 1, Ke Xia 1, Kotagiri Ramamohanarao, and Dacheng Tao 3 1 State Key Lab of Software Development Environment, Beihang
Spectral Hashing. Antonio Torralba 1 1 CSAIL, MIT, 32 Vassar St., Cambridge, MA Abstract
 Spectral Hashing Yair Weiss,3 3 School of Computer Science, Hebrew University, 9904, Jerusalem, Israel yweiss@cs.huji.ac.il Antonio Torralba CSAIL, MIT, 32 Vassar St., Cambridge, MA 0239 torralba@csail.mit.edu
Spectral Hashing Yair Weiss,3 3 School of Computer Science, Hebrew University, 9904, Jerusalem, Israel yweiss@cs.huji.ac.il Antonio Torralba CSAIL, MIT, 32 Vassar St., Cambridge, MA 0239 torralba@csail.mit.edu
The Power of Asymmetry in Binary Hashing
 The Power of Asymmetry in Binary Hashing Behnam Neyshabur Yury Makarychev Toyota Technological Institute at Chicago Russ Salakhutdinov University of Toronto Nati Srebro Technion/TTIC Search by Image Image
The Power of Asymmetry in Binary Hashing Behnam Neyshabur Yury Makarychev Toyota Technological Institute at Chicago Russ Salakhutdinov University of Toronto Nati Srebro Technion/TTIC Search by Image Image
Issues Concerning Dimensionality and Similarity Search
 Issues Concerning Dimensionality and Similarity Search Jelena Tešić, Sitaram Bhagavathy, and B. S. Manjunath Electrical and Computer Engineering Department University of California, Santa Barbara, CA 936-956
Issues Concerning Dimensionality and Similarity Search Jelena Tešić, Sitaram Bhagavathy, and B. S. Manjunath Electrical and Computer Engineering Department University of California, Santa Barbara, CA 936-956
Minimal Loss Hashing for Compact Binary Codes
 Mohammad Norouzi David J. Fleet Department of Computer Science, University of oronto, Canada norouzi@cs.toronto.edu fleet@cs.toronto.edu Abstract We propose a method for learning similaritypreserving hash
Mohammad Norouzi David J. Fleet Department of Computer Science, University of oronto, Canada norouzi@cs.toronto.edu fleet@cs.toronto.edu Abstract We propose a method for learning similaritypreserving hash
Beyond Spatial Pyramids
 Beyond Spatial Pyramids Receptive Field Learning for Pooled Image Features Yangqing Jia 1 Chang Huang 2 Trevor Darrell 1 1 UC Berkeley EECS 2 NEC Labs America Goal coding pooling Bear Analysis of the pooling
Beyond Spatial Pyramids Receptive Field Learning for Pooled Image Features Yangqing Jia 1 Chang Huang 2 Trevor Darrell 1 1 UC Berkeley EECS 2 NEC Labs America Goal coding pooling Bear Analysis of the pooling
SPATIAL INDEXING. Vaibhav Bajpai
 SPATIAL INDEXING Vaibhav Bajpai Contents Overview Problem with B+ Trees in Spatial Domain Requirements from a Spatial Indexing Structure Approaches SQL/MM Standard Current Issues Overview What is a Spatial
SPATIAL INDEXING Vaibhav Bajpai Contents Overview Problem with B+ Trees in Spatial Domain Requirements from a Spatial Indexing Structure Approaches SQL/MM Standard Current Issues Overview What is a Spatial
Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig
 Multimedia Databases Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 13 Indexes for Multimedia Data 13 Indexes for Multimedia
Multimedia Databases Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 13 Indexes for Multimedia Data 13 Indexes for Multimedia
Supervised Hashing via Uncorrelated Component Analysis
 Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16) Supervised Hashing via Uncorrelated Component Analysis SungRyull Sohn CG Research Team Electronics and Telecommunications
Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16) Supervised Hashing via Uncorrelated Component Analysis SungRyull Sohn CG Research Team Electronics and Telecommunications
Improved Hamming Distance Search using Variable Length Hashing
 Improved Hamming istance Search using Variable Length Hashing Eng-Jon Ong and Miroslaw Bober Centre for Vision, Speech and Signal Processing University of Surrey, Guildford, UK e.ong,m.bober@surrey.ac.uk
Improved Hamming istance Search using Variable Length Hashing Eng-Jon Ong and Miroslaw Bober Centre for Vision, Speech and Signal Processing University of Surrey, Guildford, UK e.ong,m.bober@surrey.ac.uk
Vector Quantization Encoder Decoder Original Form image Minimize distortion Table Channel Image Vectors Look-up (X, X i ) X may be a block of l
 X may be a block of l") Vector Quantization Encoder Decoder Original Image Form image Vectors X Minimize distortion k k Table X^ k Channel d(x, X^ Look-up i ) X may be a block of l m image or X=( r, g, b ), or a block of DCT
Vector Quantization Encoder Decoder Original Image Form image Vectors X Minimize distortion k k Table X^ k Channel d(x, X^ Look-up i ) X may be a block of l m image or X=( r, g, b ), or a block of DCT
Multimedia Databases 1/29/ Indexes for Multimedia Data Indexes for Multimedia Data Indexes for Multimedia Data
 1/29/2010 13 Indexes for Multimedia Data 13 Indexes for Multimedia Data 13.1 R-Trees Multimedia Databases Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig
1/29/2010 13 Indexes for Multimedia Data 13 Indexes for Multimedia Data 13.1 R-Trees Multimedia Databases Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig
Geometric View of Machine Learning Nearest Neighbor Classification. Slides adapted from Prof. Carpuat
 Geometric View of Machine Learning Nearest Neighbor Classification Slides adapted from Prof. Carpuat What we know so far Decision Trees What is a decision tree, and how to induce it from data Fundamental
Geometric View of Machine Learning Nearest Neighbor Classification Slides adapted from Prof. Carpuat What we know so far Decision Trees What is a decision tree, and how to induce it from data Fundamental
Impression Store: Compressive Sensing-based Storage for. Big Data Analytics
 Impression Store: Compressive Sensing-based Storage for Big Data Analytics Jiaxing Zhang, Ying Yan, Liang Jeff Chen, Minjie Wang, Thomas Moscibroda & Zheng Zhang Microsoft Research The Curse of O(N) in
Impression Store: Compressive Sensing-based Storage for Big Data Analytics Jiaxing Zhang, Ying Yan, Liang Jeff Chen, Minjie Wang, Thomas Moscibroda & Zheng Zhang Microsoft Research The Curse of O(N) in
Randomized Algorithms
 Randomized Algorithms Saniv Kumar, Google Research, NY EECS-6898, Columbia University - Fall, 010 Saniv Kumar 9/13/010 EECS6898 Large Scale Machine Learning 1 Curse of Dimensionality Gaussian Mixture Models
Randomized Algorithms Saniv Kumar, Google Research, NY EECS-6898, Columbia University - Fall, 010 Saniv Kumar 9/13/010 EECS6898 Large Scale Machine Learning 1 Curse of Dimensionality Gaussian Mixture Models
Fantope Regularization in Metric Learning
 Fantope Regularization in Metric Learning CVPR 2014 Marc T. Law (LIP6, UPMC), Nicolas Thome (LIP6 - UPMC Sorbonne Universités), Matthieu Cord (LIP6 - UPMC Sorbonne Universités), Paris, France Introduction
Fantope Regularization in Metric Learning CVPR 2014 Marc T. Law (LIP6, UPMC), Nicolas Thome (LIP6 - UPMC Sorbonne Universités), Matthieu Cord (LIP6 - UPMC Sorbonne Universités), Paris, France Introduction
Making Nearest Neighbors Easier. Restrictions on Input Algorithms for Nearest Neighbor Search: Lecture 4. Outline. Chapter XI
 Restrictions on Input Algorithms for Nearest Neighbor Search: Lecture 4 Yury Lifshits http://yury.name Steklov Institute of Mathematics at St.Petersburg California Institute of Technology Making Nearest
Restrictions on Input Algorithms for Nearest Neighbor Search: Lecture 4 Yury Lifshits http://yury.name Steklov Institute of Mathematics at St.Petersburg California Institute of Technology Making Nearest
Vector Quantization. Institut Mines-Telecom. Marco Cagnazzo, MN910 Advanced Compression
 Institut Mines-Telecom Vector Quantization Marco Cagnazzo, cagnazzo@telecom-paristech.fr MN910 Advanced Compression 2/66 19.01.18 Institut Mines-Telecom Vector Quantization Outline Gain-shape VQ 3/66 19.01.18
Institut Mines-Telecom Vector Quantization Marco Cagnazzo, cagnazzo@telecom-paristech.fr MN910 Advanced Compression 2/66 19.01.18 Institut Mines-Telecom Vector Quantization Outline Gain-shape VQ 3/66 19.01.18
Global Scene Representations. Tilke Judd
 Global Scene Representations Tilke Judd Papers Oliva and Torralba [2001] Fei Fei and Perona [2005] Labzebnik, Schmid and Ponce [2006] Commonalities Goal: Recognize natural scene categories Extract features
Global Scene Representations Tilke Judd Papers Oliva and Torralba [2001] Fei Fei and Perona [2005] Labzebnik, Schmid and Ponce [2006] Commonalities Goal: Recognize natural scene categories Extract features
Hamming Compatible Quantization for Hashing
 Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015) Hamming Compatible Quantization for Hashing Zhe Wang, Ling-Yu Duan, Jie Lin, Xiaofang Wang, Tiejun
Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015) Hamming Compatible Quantization for Hashing Zhe Wang, Ling-Yu Duan, Jie Lin, Xiaofang Wang, Tiejun
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Clustering Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu May 2, 2017 Announcements Homework 2 due later today Due May 3 rd (11:59pm) Course project
CS249: ADVANCED DATA MINING Clustering Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu May 2, 2017 Announcements Homework 2 due later today Due May 3 rd (11:59pm) Course project
University of Florida CISE department Gator Engineering. Clustering Part 1
 Clustering Part 1 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville What is Cluster Analysis? Finding groups of objects such that the objects
Clustering Part 1 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville What is Cluster Analysis? Finding groups of objects such that the objects
Efficient Storage and Decoding of SURF Feature Points
 Efficient Storage and Decoding of SURF Feature Points Kevin McGuinness, Kealan McCusker, Neil O Hare, and Noel E. O Connor CLARITY: Center for Sensor Web Technologies, Dublin City University Abstract.
Efficient Storage and Decoding of SURF Feature Points Kevin McGuinness, Kealan McCusker, Neil O Hare, and Noel E. O Connor CLARITY: Center for Sensor Web Technologies, Dublin City University Abstract.
The University of Texas at Austin Department of Electrical and Computer Engineering. EE381V: Large Scale Learning Spring 2013.
 The University of Texas at Austin Department of Electrical and Computer Engineering EE381V: Large Scale Learning Spring 2013 Assignment 1 Caramanis/Sanghavi Due: Thursday, Feb. 7, 2013. (Problems 1 and
The University of Texas at Austin Department of Electrical and Computer Engineering EE381V: Large Scale Learning Spring 2013 Assignment 1 Caramanis/Sanghavi Due: Thursday, Feb. 7, 2013. (Problems 1 and
Anti-sparse coding for approximate nearest neighbor search
 Anti-sparse coding for approximate nearest neighbor search Hervé Jégou, Teddy Furon, Jean-Jacques Fuchs To cite this version: Hervé Jégou, Teddy Furon, Jean-Jacques Fuchs. Anti-sparse coding for approximate
Anti-sparse coding for approximate nearest neighbor search Hervé Jégou, Teddy Furon, Jean-Jacques Fuchs To cite this version: Hervé Jégou, Teddy Furon, Jean-Jacques Fuchs. Anti-sparse coding for approximate
Riemannian Metric Learning for Symmetric Positive Definite Matrices
 CMSC 88J: Linear Subspaces and Manifolds for Computer Vision and Machine Learning Riemannian Metric Learning for Symmetric Positive Definite Matrices Raviteja Vemulapalli Guide: Professor David W. Jacobs
CMSC 88J: Linear Subspaces and Manifolds for Computer Vision and Machine Learning Riemannian Metric Learning for Symmetric Positive Definite Matrices Raviteja Vemulapalli Guide: Professor David W. Jacobs
Metric Embedding of Task-Specific Similarity. joint work with Trevor Darrell (MIT)
") Metric Embedding of Task-Specific Similarity Greg Shakhnarovich Brown University joint work with Trevor Darrell (MIT) August 9, 2006 Task-specific similarity A toy example: Task-specific similarity A toy
Metric Embedding of Task-Specific Similarity Greg Shakhnarovich Brown University joint work with Trevor Darrell (MIT) August 9, 2006 Task-specific similarity A toy example: Task-specific similarity A toy
Nearest Neighbor Search with Keywords in Spatial Databases
 776 Nearest Neighbor Search with Keywords in Spatial Databases 1 Sphurti S. Sao, 2 Dr. Rahila Sheikh 1 M. Tech Student IV Sem, Dept of CSE, RCERT Chandrapur, MH, India 2 Head of Department, Dept of CSE,
776 Nearest Neighbor Search with Keywords in Spatial Databases 1 Sphurti S. Sao, 2 Dr. Rahila Sheikh 1 M. Tech Student IV Sem, Dept of CSE, RCERT Chandrapur, MH, India 2 Head of Department, Dept of CSE,
A Randomized Approach for Crowdsourcing in the Presence of Multiple Views
 A Randomized Approach for Crowdsourcing in the Presence of Multiple Views Presenter: Yao Zhou joint work with: Jingrui He - 1 - Roadmap Motivation Proposed framework: M2VW Experimental results Conclusion
A Randomized Approach for Crowdsourcing in the Presence of Multiple Views Presenter: Yao Zhou joint work with: Jingrui He - 1 - Roadmap Motivation Proposed framework: M2VW Experimental results Conclusion
Pictorial Structures Revisited: People Detection and Articulated Pose Estimation. Department of Computer Science TU Darmstadt
 Pictorial Structures Revisited: People Detection and Articulated Pose Estimation Mykhaylo Andriluka Stefan Roth Bernt Schiele Department of Computer Science TU Darmstadt Generic model for human detection
Pictorial Structures Revisited: People Detection and Articulated Pose Estimation Mykhaylo Andriluka Stefan Roth Bernt Schiele Department of Computer Science TU Darmstadt Generic model for human detection
Locality-Sensitive Hashing for Chi2 Distance
 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. XXXX, NO. XXX, JUNE 010 1 Locality-Sensitive Hashing for Chi Distance David Gorisse, Matthieu Cord, and Frederic Precioso Abstract In
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. XXXX, NO. XXX, JUNE 010 1 Locality-Sensitive Hashing for Chi Distance David Gorisse, Matthieu Cord, and Frederic Precioso Abstract In
Accelerated Manhattan hashing via bit-remapping with location information
 DOI 1.17/s1142-15-3217-x Accelerated Manhattan hashing via bit-remapping with location information Wenshuo Chen 1 Guiguang Ding 1 Zijia Lin 2 Jisheng Pei 2 Received: 2 May 215 / Revised: 2 December 215
DOI 1.17/s1142-15-3217-x Accelerated Manhattan hashing via bit-remapping with location information Wenshuo Chen 1 Guiguang Ding 1 Zijia Lin 2 Jisheng Pei 2 Received: 2 May 215 / Revised: 2 December 215
Dominant Feature Vectors Based Audio Similarity Measure
 Dominant Feature Vectors Based Audio Similarity Measure Jing Gu 1, Lie Lu 2, Rui Cai 3, Hong-Jiang Zhang 2, and Jian Yang 1 1 Dept. of Electronic Engineering, Tsinghua Univ., Beijing, 100084, China 2 Microsoft
Dominant Feature Vectors Based Audio Similarity Measure Jing Gu 1, Lie Lu 2, Rui Cai 3, Hong-Jiang Zhang 2, and Jian Yang 1 1 Dept. of Electronic Engineering, Tsinghua Univ., Beijing, 100084, China 2 Microsoft
Linear Spectral Hashing
 Linear Spectral Hashing Zalán Bodó and Lehel Csató Babeş Bolyai University - Faculty of Mathematics and Computer Science Kogălniceanu 1., 484 Cluj-Napoca - Romania Abstract. assigns binary hash keys to
Linear Spectral Hashing Zalán Bodó and Lehel Csató Babeş Bolyai University - Faculty of Mathematics and Computer Science Kogălniceanu 1., 484 Cluj-Napoca - Romania Abstract. assigns binary hash keys to
Optimal Data-Dependent Hashing for Approximate Near Neighbors
 Optimal Data-Dependent Hashing for Approximate Near Neighbors Alexandr Andoni 1 Ilya Razenshteyn 2 1 Simons Institute 2 MIT, CSAIL April 20, 2015 1 / 30 Nearest Neighbor Search (NNS) Let P be an n-point
Optimal Data-Dependent Hashing for Approximate Near Neighbors Alexandr Andoni 1 Ilya Razenshteyn 2 1 Simons Institute 2 MIT, CSAIL April 20, 2015 1 / 30 Nearest Neighbor Search (NNS) Let P be an n-point
Nonnegative Matrix Factorization Clustering on Multiple Manifolds
 Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) Nonnegative Matrix Factorization Clustering on Multiple Manifolds Bin Shen, Luo Si Department of Computer Science,
Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) Nonnegative Matrix Factorization Clustering on Multiple Manifolds Bin Shen, Luo Si Department of Computer Science,
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center
 Fei Wang and Jimeng Sun IBM TJ Watson Research Center") Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
LOCALITY SENSITIVE HASHING FOR BIG DATA
 1 LOCALITY SENSITIVE HASHING FOR BIG DATA Wei Wang, University of New South Wales Outline 2 NN and c-ann Existing LSH methods for Large Data Our approach: SRS [VLDB 2015] Conclusions NN and c-ann Queries
1 LOCALITY SENSITIVE HASHING FOR BIG DATA Wei Wang, University of New South Wales Outline 2 NN and c-ann Existing LSH methods for Large Data Our approach: SRS [VLDB 2015] Conclusions NN and c-ann Queries
Pivot Selection Techniques
 Pivot Selection Techniques Proximity Searching in Metric Spaces by Benjamin Bustos, Gonzalo Navarro and Edgar Chávez Catarina Moreira Outline Introduction Pivots and Metric Spaces Pivots in Nearest Neighbor
Pivot Selection Techniques Proximity Searching in Metric Spaces by Benjamin Bustos, Gonzalo Navarro and Edgar Chávez Catarina Moreira Outline Introduction Pivots and Metric Spaces Pivots in Nearest Neighbor
Data preprocessing. DataBase and Data Mining Group 1. Data set types. Tabular Data. Document Data. Transaction Data. Ordered Data
 Elena Baralis and Tania Cerquitelli Politecnico di Torino Data set types Record Tables Document Data Transaction Data Graph World Wide Web Molecular Structures Ordered Spatial Data Temporal Data Sequential
Elena Baralis and Tania Cerquitelli Politecnico di Torino Data set types Record Tables Document Data Transaction Data Graph World Wide Web Molecular Structures Ordered Spatial Data Temporal Data Sequential
arxiv:cs/ v1 [cs.cg] 7 Feb 2006
![arxiv:cs/ v1 [cs.cg] 7 Feb 2006](/thumbs/90/102634153.jpg "arxiv:cs/ v1 [cs.cg] 7 Feb 2006") Approximate Weighted Farthest Neighbors and Minimum Dilation Stars John Augustine, David Eppstein, and Kevin A. Wortman Computer Science Department University of California, Irvine Irvine, CA 92697, USA
Approximate Weighted Farthest Neighbors and Minimum Dilation Stars John Augustine, David Eppstein, and Kevin A. Wortman Computer Science Department University of California, Irvine Irvine, CA 92697, USA
Photo Tourism and im2gps: 3D Reconstruction and Geolocation of Internet Photo Collections Part II
 Photo Tourism and im2gps: 3D Reconstruction and Geolocation of Internet Photo Collections Part II Noah Snavely Cornell James Hays CMU MIT (Fall 2009) Brown (Spring 2010 ) Complexity of the Visual World
Photo Tourism and im2gps: 3D Reconstruction and Geolocation of Internet Photo Collections Part II Noah Snavely Cornell James Hays CMU MIT (Fall 2009) Brown (Spring 2010 ) Complexity of the Visual World
Spectral Hashing: Learning to Leverage 80 Million Images
 Spectral Hashing: Learning to Leverage 80 Million Images Yair Weiss, Antonio Torralba, Rob Fergus Hebrew University, MIT, NYU Outline Motivation: Brute Force Computer Vision. Semantic Hashing. Spectral
Spectral Hashing: Learning to Leverage 80 Million Images Yair Weiss, Antonio Torralba, Rob Fergus Hebrew University, MIT, NYU Outline Motivation: Brute Force Computer Vision. Semantic Hashing. Spectral
Vector Quantization Techniques for Approximate Nearest Neighbor Search on Large- Scale Datasets
 Tampere University of Technology Vector Quantization Techniques for Approximate Nearest Neighbor Search on Large- Scale Datasets Citation Ozan, E. C. (017). Vector Quantization Techniques for Approximate
Tampere University of Technology Vector Quantization Techniques for Approximate Nearest Neighbor Search on Large- Scale Datasets Citation Ozan, E. C. (017). Vector Quantization Techniques for Approximate
Supplemental Material for Discrete Graph Hashing
 Supplemental Material for Discrete Graph Hashing Wei Liu Cun Mu Sanjiv Kumar Shih-Fu Chang IM T. J. Watson Research Center Columbia University Google Research weiliu@us.ibm.com cm52@columbia.edu sfchang@ee.columbia.edu
Supplemental Material for Discrete Graph Hashing Wei Liu Cun Mu Sanjiv Kumar Shih-Fu Chang IM T. J. Watson Research Center Columbia University Google Research weiliu@us.ibm.com cm52@columbia.edu sfchang@ee.columbia.edu
Large-scale Collaborative Ranking in Near-Linear Time
 Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts of Statistics and Computer Science UC Davis KDD 17, Halifax, Canada August 13-17, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts of Statistics and Computer Science UC Davis KDD 17, Halifax, Canada August 13-17, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
CHAPTER 3. Transformed Vector Quantization with Orthogonal Polynomials Introduction Vector quantization
 3.1. Introduction CHAPTER 3 Transformed Vector Quantization with Orthogonal Polynomials In the previous chapter, a new integer image coding technique based on orthogonal polynomials for monochrome images
3.1. Introduction CHAPTER 3 Transformed Vector Quantization with Orthogonal Polynomials In the previous chapter, a new integer image coding technique based on orthogonal polynomials for monochrome images
Face recognition Computer Vision Spring 2018, Lecture 21
 Face recognition http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 2018, Lecture 21 Course announcements Homework 6 has been posted and is due on April 27 th. - Any questions about the homework?
Face recognition http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 2018, Lecture 21 Course announcements Homework 6 has been posted and is due on April 27 th. - Any questions about the homework?
CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors. Furong Huang /
 CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors Furong Huang / furongh@cs.umd.edu What we know so far Decision Trees What is a decision tree, and how to induce it from
CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors Furong Huang / furongh@cs.umd.edu What we know so far Decision Trees What is a decision tree, and how to induce it from
Multiple Similarities Based Kernel Subspace Learning for Image Classification
 Multiple Similarities Based Kernel Subspace Learning for Image Classification Wang Yan, Qingshan Liu, Hanqing Lu, and Songde Ma National Laboratory of Pattern Recognition, Institute of Automation, Chinese
Multiple Similarities Based Kernel Subspace Learning for Image Classification Wang Yan, Qingshan Liu, Hanqing Lu, and Songde Ma National Laboratory of Pattern Recognition, Institute of Automation, Chinese
IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS 1. Erkun Yang, Cheng Deng, Member, IEEE, Chao Li, Wei Liu, Jie Li, and Dacheng Tao
 IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS 1 Shared Predictive Cross-Modal Deep Quantization Erkun Yang, Cheng Deng, Member, IEEE, Chao Li, Wei Liu, Jie Li, and Dacheng Tao, Fellow, IEEE
IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS 1 Shared Predictive Cross-Modal Deep Quantization Erkun Yang, Cheng Deng, Member, IEEE, Chao Li, Wei Liu, Jie Li, and Dacheng Tao, Fellow, IEEE
Large-Scale Behavioral Targeting
 Large-Scale Behavioral Targeting Ye Chen, Dmitry Pavlov, John Canny ebay, Yandex, UC Berkeley (This work was conducted at Yahoo! Labs.) June 30, 2009 Chen et al. (KDD 09) Large-Scale Behavioral Targeting
Large-Scale Behavioral Targeting Ye Chen, Dmitry Pavlov, John Canny ebay, Yandex, UC Berkeley (This work was conducted at Yahoo! Labs.) June 30, 2009 Chen et al. (KDD 09) Large-Scale Behavioral Targeting
Multiple-Site Distributed Spatial Query Optimization using Spatial Semijoins
 11 Multiple-Site Distributed Spatial Query Optimization using Spatial Semijoins Wendy OSBORN a, 1 and Saad ZAAMOUT a a Department of Mathematics and Computer Science, University of Lethbridge, Lethbridge,
11 Multiple-Site Distributed Spatial Query Optimization using Spatial Semijoins Wendy OSBORN a, 1 and Saad ZAAMOUT a a Department of Mathematics and Computer Science, University of Lethbridge, Lethbridge,
Configuring Spatial Grids for Efficient Main Memory Joins
 Configuring Spatial Grids for Efficient Main Memory Joins Farhan Tauheed, Thomas Heinis, and Anastasia Ailamaki École Polytechnique Fédérale de Lausanne (EPFL), Imperial College London Abstract. The performance
Configuring Spatial Grids for Efficient Main Memory Joins Farhan Tauheed, Thomas Heinis, and Anastasia Ailamaki École Polytechnique Fédérale de Lausanne (EPFL), Imperial College London Abstract. The performance
Term Filtering with Bounded Error
 Term Filtering with Bounded Error Zi Yang, Wei Li, Jie Tang, and Juanzi Li Knowledge Engineering Group Department of Computer Science and Technology Tsinghua University, China {yangzi, tangjie, ljz}@keg.cs.tsinghua.edu.cn
Term Filtering with Bounded Error Zi Yang, Wei Li, Jie Tang, and Juanzi Li Knowledge Engineering Group Department of Computer Science and Technology Tsinghua University, China {yangzi, tangjie, ljz}@keg.cs.tsinghua.edu.cn
A Domain Decomposition Based Jacobi-Davidson Algorithm for Quantum Dot Simulation
 A Domain Decomposition Based Jacobi-Davidson Algorithm for Quantum Dot Simulation Tao Zhao 1, Feng-Nan Hwang 2 and Xiao-Chuan Cai 3 Abstract In this paper, we develop an overlapping domain decomposition
A Domain Decomposition Based Jacobi-Davidson Algorithm for Quantum Dot Simulation Tao Zhao 1, Feng-Nan Hwang 2 and Xiao-Chuan Cai 3 Abstract In this paper, we develop an overlapping domain decomposition
LOCALITY PRESERVING HASHING. Electrical Engineering and Computer Science University of California, Merced Merced, CA 95344, USA
 LOCALITY PRESERVING HASHING Yi-Hsuan Tsai Ming-Hsuan Yang Electrical Engineering and Computer Science University of California, Merced Merced, CA 95344, USA ABSTRACT The spectral hashing algorithm relaxes
LOCALITY PRESERVING HASHING Yi-Hsuan Tsai Ming-Hsuan Yang Electrical Engineering and Computer Science University of California, Merced Merced, CA 95344, USA ABSTRACT The spectral hashing algorithm relaxes
Ranking from Crowdsourced Pairwise Comparisons via Matrix Manifold Optimization
 Ranking from Crowdsourced Pairwise Comparisons via Matrix Manifold Optimization Jialin Dong ShanghaiTech University 1 Outline Introduction FourVignettes: System Model and Problem Formulation Problem Analysis
Ranking from Crowdsourced Pairwise Comparisons via Matrix Manifold Optimization Jialin Dong ShanghaiTech University 1 Outline Introduction FourVignettes: System Model and Problem Formulation Problem Analysis
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar 1 Types of data sets Record Tables Document Data Transaction Data Graph World Wide Web Molecular Structures
Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar 1 Types of data sets Record Tables Document Data Transaction Data Graph World Wide Web Molecular Structures
Toward Correlating and Solving Abstract Tasks Using Convolutional Neural Networks Supplementary Material
 Toward Correlating and Solving Abstract Tasks Using Convolutional Neural Networks Supplementary Material Kuan-Chuan Peng Cornell University kp388@cornell.edu Tsuhan Chen Cornell University tsuhan@cornell.edu
Toward Correlating and Solving Abstract Tasks Using Convolutional Neural Networks Supplementary Material Kuan-Chuan Peng Cornell University kp388@cornell.edu Tsuhan Chen Cornell University tsuhan@cornell.edu
Face Recognition. Face Recognition. Subspace-Based Face Recognition Algorithms. Application of Face Recognition
 ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
Asymmetric Minwise Hashing for Indexing Binary Inner Products and Set Containment
 Asymmetric Minwise Hashing for Indexing Binary Inner Products and Set Containment Anshumali Shrivastava and Ping Li Cornell University and Rutgers University WWW 25 Florence, Italy May 2st 25 Will Join
Asymmetric Minwise Hashing for Indexing Binary Inner Products and Set Containment Anshumali Shrivastava and Ping Li Cornell University and Rutgers University WWW 25 Florence, Italy May 2st 25 Will Join
Ch. 10 Vector Quantization. Advantages & Design
 Ch. 10 Vector Quantization Advantages & Design 1 Advantages of VQ There are (at least) 3 main characteristics of VQ that help it outperform SQ: 1. Exploit Correlation within vectors 2. Exploit Shape Flexibility
Ch. 10 Vector Quantization Advantages & Design 1 Advantages of VQ There are (at least) 3 main characteristics of VQ that help it outperform SQ: 1. Exploit Correlation within vectors 2. Exploit Shape Flexibility
Mid Term-1 : Practice problems
 Mid Term-1 : Practice problems These problems are meant only to provide practice; they do not necessarily reflect the difficulty level of the problems in the exam. The actual exam problems are likely to
Mid Term-1 : Practice problems These problems are meant only to provide practice; they do not necessarily reflect the difficulty level of the problems in the exam. The actual exam problems are likely to
Semi Supervised Distance Metric Learning
 Semi Supervised Distance Metric Learning wliu@ee.columbia.edu Outline Background Related Work Learning Framework Collaborative Image Retrieval Future Research Background Euclidean distance d( x, x ) =
Semi Supervised Distance Metric Learning wliu@ee.columbia.edu Outline Background Related Work Learning Framework Collaborative Image Retrieval Future Research Background Euclidean distance d( x, x ) =
High Dimensional Geometry, Curse of Dimensionality, Dimension Reduction
 Chapter 11 High Dimensional Geometry, Curse of Dimensionality, Dimension Reduction High-dimensional vectors are ubiquitous in applications (gene expression data, set of movies watched by Netflix customer,
Chapter 11 High Dimensional Geometry, Curse of Dimensionality, Dimension Reduction High-dimensional vectors are ubiquitous in applications (gene expression data, set of movies watched by Netflix customer,
Efficient identification of Tanimoto nearest neighbors
 Int J Data Sci Anal (2017) 4:153 172 DOI 10.1007/s41060-017-0064-z REGULAR PAPER Efficient identification of Tanimoto nearest neighbors All-pairs similarity search using the extended Jaccard coefficient
Int J Data Sci Anal (2017) 4:153 172 DOI 10.1007/s41060-017-0064-z REGULAR PAPER Efficient identification of Tanimoto nearest neighbors All-pairs similarity search using the extended Jaccard coefficient
Efficient Data Reduction and Summarization
 Ping Li Efficient Data Reduction and Summarization December 8, 2011 FODAVA Review 1 Efficient Data Reduction and Summarization Ping Li Department of Statistical Science Faculty of omputing and Information
Ping Li Efficient Data Reduction and Summarization December 8, 2011 FODAVA Review 1 Efficient Data Reduction and Summarization Ping Li Department of Statistical Science Faculty of omputing and Information
For Review Only. Codebook-free Compact Descriptor for Scalable Visual Search
 Page of 0 0 0 0 0 0 Codebook-free Compact Descriptor for Scalable Visual Search Yuwei u, Feng Gao, Yicheng Huang, Jie Lin Member, IEEE, Vijay Chandrasekhar Member, IEEE, Junsong Yuan Senior Member, IEEE,
Page of 0 0 0 0 0 0 Codebook-free Compact Descriptor for Scalable Visual Search Yuwei u, Feng Gao, Yicheng Huang, Jie Lin Member, IEEE, Vijay Chandrasekhar Member, IEEE, Junsong Yuan Senior Member, IEEE,
A Multi-task Learning Strategy for Unsupervised Clustering via Explicitly Separating the Commonality
 A Multi-task Learning Strategy for Unsupervised Clustering via Explicitly Separating the Commonality Shu Kong, Donghui Wang Dept. of Computer Science and Technology, Zhejiang University, Hangzhou 317,
A Multi-task Learning Strategy for Unsupervised Clustering via Explicitly Separating the Commonality Shu Kong, Donghui Wang Dept. of Computer Science and Technology, Zhejiang University, Hangzhou 317,
HARMONIC VECTOR QUANTIZATION
 HARMONIC VECTOR QUANTIZATION Volodya Grancharov, Sigurdur Sverrisson, Erik Norvell, Tomas Toftgård, Jonas Svedberg, and Harald Pobloth SMN, Ericsson Research, Ericsson AB 64 8, Stockholm, Sweden ABSTRACT
HARMONIC VECTOR QUANTIZATION Volodya Grancharov, Sigurdur Sverrisson, Erik Norvell, Tomas Toftgård, Jonas Svedberg, and Harald Pobloth SMN, Ericsson Research, Ericsson AB 64 8, Stockholm, Sweden ABSTRACT
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Dan Oneaţă 1 Introduction Probabilistic Latent Semantic Analysis (plsa) is a technique from the category of topic models. Its main goal is to model cooccurrence information
Probabilistic Latent Semantic Analysis Dan Oneaţă 1 Introduction Probabilistic Latent Semantic Analysis (plsa) is a technique from the category of topic models. Its main goal is to model cooccurrence information
Self-Tuning Semantic Image Segmentation
 Self-Tuning Semantic Image Segmentation Sergey Milyaev 1,2, Olga Barinova 2 1 Voronezh State University sergey.milyaev@gmail.com 2 Lomonosov Moscow State University obarinova@graphics.cs.msu.su Abstract.
Self-Tuning Semantic Image Segmentation Sergey Milyaev 1,2, Olga Barinova 2 1 Voronezh State University sergey.milyaev@gmail.com 2 Lomonosov Moscow State University obarinova@graphics.cs.msu.su Abstract.
Ad Placement Strategies
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Dimension reduction methods: Algorithms and Applications Yousef Saad Department of Computer Science and Engineering University of Minnesota
 Dimension reduction methods: Algorithms and Applications Yousef Saad Department of Computer Science and Engineering University of Minnesota Université du Littoral- Calais July 11, 16 First..... to the
Dimension reduction methods: Algorithms and Applications Yousef Saad Department of Computer Science and Engineering University of Minnesota Université du Littoral- Calais July 11, 16 First..... to the
Face detection and recognition. Detection Recognition Sally
 Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Transforming Hierarchical Trees on Metric Spaces
 CCCG 016, Vancouver, British Columbia, August 3 5, 016 Transforming Hierarchical Trees on Metric Spaces Mahmoodreza Jahanseir Donald R. Sheehy Abstract We show how a simple hierarchical tree called a cover
CCCG 016, Vancouver, British Columbia, August 3 5, 016 Transforming Hierarchical Trees on Metric Spaces Mahmoodreza Jahanseir Donald R. Sheehy Abstract We show how a simple hierarchical tree called a cover
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional