Presented By: Omer Shmueli and Sivan Niv
|
|
|
- Giles O’Neal’
- 5 years ago
- Views:
Transcription

1 Deep Speaker: an End-to-End Neural Speaker Embedding System Chao Li, Xiaokong Ma, Bing Jiang, Xiangang Li, Xuewei Zhang, Xiao Liu, Ying Cao, Ajay Kannan, Zhenyao Zhu Presented By: Omer Shmueli and Sivan Niv
2 (Source: lilt.cslt.org/talks/ Deep%20Speaker%20Embedding%20for%20SRE.pptx) Where is he/she from? What language was spoken? What was spoken? Accent Recognition Language Recognition Speech Recognition Emotion Recognition Gender Recognition Speaker Recognition Positive? Negative? Happy? Sad? Male or Female? Who spoke?
3 Speaker Recognition motivation Speaker recognition may be used for authentication. Enable the use of app only by specific user. Computer games. Improve other speech signal tasks.

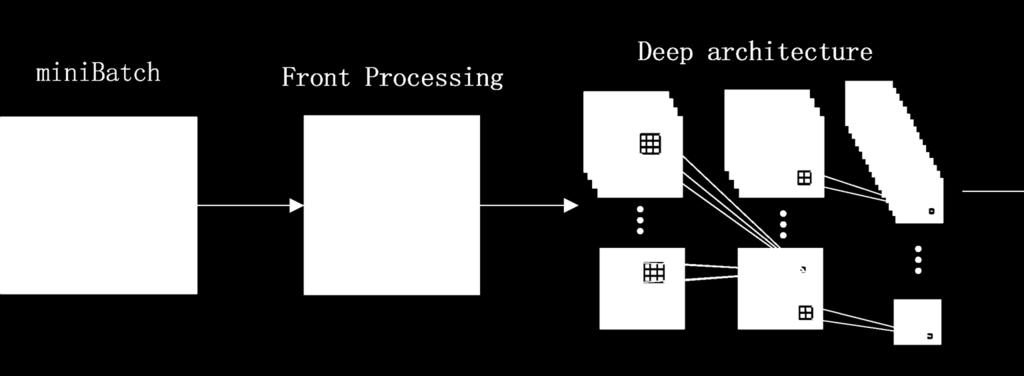
4 The System

5 MFCC-mel-frequency cepstral coefficient front processing


6 mel-frequency Transform Human ear perception. logarithmic linear
7 The System
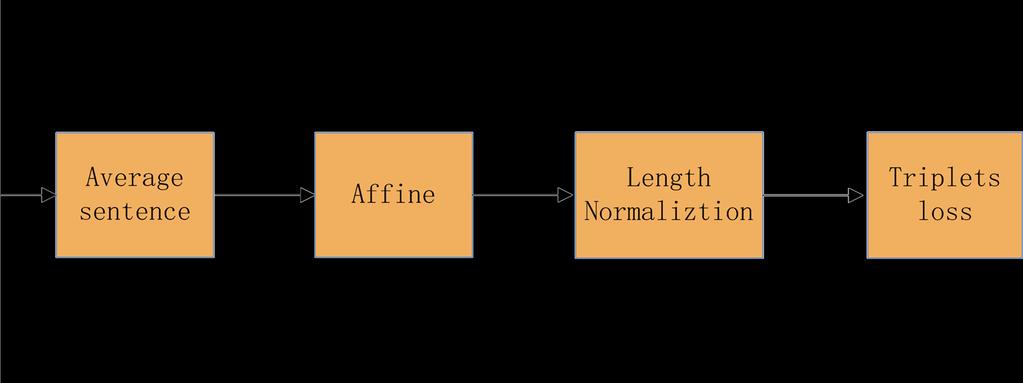
8 Average Layer The average layer in the network averages all feature dimensions over the time axis T 1 h = 1 x t T t=0 T is the number of frames in the utterance
9 Affine Layer The affine layer is a normal fully connected layer Reduces feature dimension Normalization Layer Normalize inputs for Triplet Loss
10 The System

11 Triplet Loss

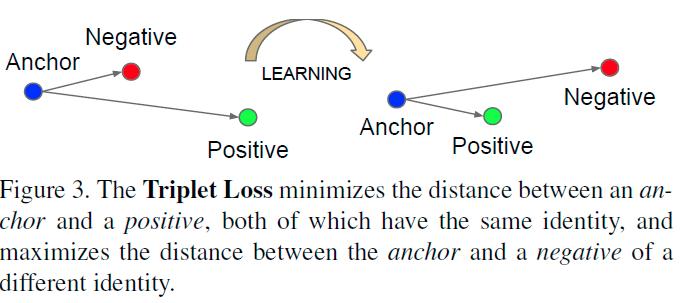
12 Triplet Loss FaceNet
13 Triplet Loss Anchor Negative Positive learning Positive Negative


14 Triplet Loss Hard Negative The constraint is easily meet. In order to find AP that aren't satisfying the constraint multiple GPU are used.
15 The System Softmax
16 Softmax vs Triplet Loss Triplet Loss has better performance than Softmax. Triplet Loss with preprocessed Softmax is even better. Epoch trained Epoch trained
17 The System ResCNN

18 ResCNN 24 million parameters in total.
19 The System GRU
20 LSTM (review) f t =σ g W f x t + U f h t 1 + b f i t =σ g W i x t + U i h t 1 + b i o t =σ g W o x t + U o h t 1 + b o c t =f t c t 1 + i t σ c W c x t + U c h t 1 + b c h t =o t σ h c t σ g sigmoid function σ h hyperbolic tangent function σ c hyperbolic tangent function or a variation (Source: LSTMs)


21 Peephole LSTM f t =σ g W f x t + U f c t 1 + b f i t =σ g W i x t + U i c t 1 + b i o t =σ g W o x t + U o c t 1 + b o c t =f t c t 1 + i t σ c W c x t + U c h t 1 + b c h t =o t σ h c t σ g sigmoid function σ h hyperbolic tangent function σ c hyperbolic tangent function or a variation (Source: Graves, A., Mohamed, A. R., & Hinton, G. "Speech recognition with deep recurrent neural networks." Acoustics, speech and signal processing (icassp), 2013 ieee international conference on. IEEE, 2013)
22 LSTM (review) f t =σ g W f x t + U f h t 1 + b f i t =σ g W i x t + U i h t 1 + b i o t =σ g W o x t + U o h t 1 + b o c t =f t c t 1 + i t σ c W c x t + U c h t 1 + b c h t =o t σ h c t σ g sigmoid function σ h hyperbolic tangent function σ c hyperbolic tangent function or a variation (Source: LSTMs)
 σ h W h x t + U h r t h t 1")

23 GRU (Gated recurrent unit) z t =σ g W z x t + U z h t 1 + b z r t =σ g W r x t + U r h t 1 + b r o t =σ g W o x t + U o h t 1 + b o h t =z t h t 1 + (1 z t ) σ h W h x t + U h r t h t 1 + b h h t =o t σ h c t σ g sigmoid function σ h hyperbolic tangent function σ c hyperbolic tangent function or a variation (Source: LSTMs)
24 GRU (Gated recurrent unit) z t =σ g W z x t + U z h t 1 + b z r t =σ g W r x t + U r h t 1 + b r h t =z t h t z t σ h W h x t + U h r t h t 1 + b h z t r t σ g sigmoid function σ h hyperbolic tangent function σ c hyperbolic tangent function or a variation

25 GRU (Gated recurrent unit) 23 million parameters in total.
26 The Datasets Chinese anonymized voice search queries from anonymous phone users Chinese The phrase Xiaodu, Xiaodu Like Okay, Google but Chinese English scripted English utterances from the Amazon Mechanical Turk

")
27 EER (equal error rate)
28 DNN i-vector The i-vector approach assumes that the sound is composed of: s Conversation side supervector = m Speaker independent component + T Total variability matrix w i vector The DNN i-vector learns m and T To calculate who is the speaker find the closest vector between w and the anchor i vector Prior to this paper the DNN i-vector system was the state-of-the-art


29 Results Mandarin text-independent speaker English text-independent speaker (MTurk dataset)
30 Conclusions The experiments show that the Deep Speaker algorithm significantly improves the text-independent speaker recognition system as compared to the traditional DNN-based i-vector approach. Mandarin dataset UIDs, the EER decreases roughly 50% relative and error decreases by 60% In the English dataset MTurk, the equal error rate decreases by 30% relatively, and error decreases by 50%.

31
32 Resources / References Papers: Deep Speaker: an End-to-End Neural Speaker Embedding System FaceNet: A Unified Embedding for Face Recognition and Clustering Learning Phrase Representations using RNN Encoder Decoder for Statistical Machine Translation, Cho et al Slides and graphs: lilt.cslt.org/talks/ deep%20speaker%20embedding%20for%20sre.pptx Tronci R, Giacinto G, Roli F. Dynamic Score Combination: A Supervised and Unsupervised Score Combination Method. InMLDM 2009 Jul 21 (pp ). The EER graph
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook
 Sumit Chopra Facebook") Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
WaveNet: A Generative Model for Raw Audio
 WaveNet: A Generative Model for Raw Audio Ido Guy & Daniel Brodeski Deep Learning Seminar 2017 TAU Outline Introduction WaveNet Experiments Introduction WaveNet is a deep generative model of raw audio
WaveNet: A Generative Model for Raw Audio Ido Guy & Daniel Brodeski Deep Learning Seminar 2017 TAU Outline Introduction WaveNet Experiments Introduction WaveNet is a deep generative model of raw audio
Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions
 2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
2018 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 18) Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions Authors: S. Scardapane, S. Van Vaerenbergh,
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Deep Neural Networks
 Deep Neural Networks DT2118 Speech and Speaker Recognition Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 45 Outline State-to-Output Probability Model Artificial Neural Networks Perceptron Multi
Deep Neural Networks DT2118 Speech and Speaker Recognition Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 45 Outline State-to-Output Probability Model Artificial Neural Networks Perceptron Multi
EE-559 Deep learning Recurrent Neural Networks
 EE-559 Deep learning 11.1. Recurrent Neural Networks François Fleuret https://fleuret.org/ee559/ Sun Feb 24 20:33:31 UTC 2019 Inference from sequences François Fleuret EE-559 Deep learning / 11.1. Recurrent
EE-559 Deep learning 11.1. Recurrent Neural Networks François Fleuret https://fleuret.org/ee559/ Sun Feb 24 20:33:31 UTC 2019 Inference from sequences François Fleuret EE-559 Deep learning / 11.1. Recurrent
Deep Learning for Speech Recognition. Hung-yi Lee
 Deep Learning for Speech Recognition Hung-yi Lee Outline Conventional Speech Recognition How to use Deep Learning in acoustic modeling? Why Deep Learning? Speaker Adaptation Multi-task Deep Learning New
Deep Learning for Speech Recognition Hung-yi Lee Outline Conventional Speech Recognition How to use Deep Learning in acoustic modeling? Why Deep Learning? Speaker Adaptation Multi-task Deep Learning New
An exploration of dropout with LSTMs
 An exploration of out with LSTMs Gaofeng Cheng 1,3, Vijayaditya Peddinti 4,5, Daniel Povey 4,5, Vimal Manohar 4,5, Sanjeev Khudanpur 4,5,Yonghong Yan 1,2,3 1 Key Laboratory of Speech Acoustics and Content
An exploration of out with LSTMs Gaofeng Cheng 1,3, Vijayaditya Peddinti 4,5, Daniel Povey 4,5, Vimal Manohar 4,5, Sanjeev Khudanpur 4,5,Yonghong Yan 1,2,3 1 Key Laboratory of Speech Acoustics and Content
Segmental Recurrent Neural Networks for End-to-end Speech Recognition
 Segmental Recurrent Neural Networks for End-to-end Speech Recognition Liang Lu, Lingpeng Kong, Chris Dyer, Noah Smith and Steve Renals TTI-Chicago, UoE, CMU and UW 9 September 2016 Background A new wave
Segmental Recurrent Neural Networks for End-to-end Speech Recognition Liang Lu, Lingpeng Kong, Chris Dyer, Noah Smith and Steve Renals TTI-Chicago, UoE, CMU and UW 9 September 2016 Background A new wave
Why DNN Works for Acoustic Modeling in Speech Recognition?
 Why DNN Works for Acoustic Modeling in Speech Recognition? Prof. Hui Jiang Department of Computer Science and Engineering York University, Toronto, Ont. M3J 1P3, CANADA Joint work with Y. Bao, J. Pan,
Why DNN Works for Acoustic Modeling in Speech Recognition? Prof. Hui Jiang Department of Computer Science and Engineering York University, Toronto, Ont. M3J 1P3, CANADA Joint work with Y. Bao, J. Pan,
Deep Recurrent Neural Networks
 Deep Recurrent Neural Networks Artem Chernodub e-mail: a.chernodub@gmail.com web: http://zzphoto.me ZZ Photo IMMSP NASU 2 / 28 Neuroscience Biological-inspired models Machine Learning p x y = p y x p(x)/p(y)
Deep Recurrent Neural Networks Artem Chernodub e-mail: a.chernodub@gmail.com web: http://zzphoto.me ZZ Photo IMMSP NASU 2 / 28 Neuroscience Biological-inspired models Machine Learning p x y = p y x p(x)/p(y)
BIDIRECTIONAL LSTM-HMM HYBRID SYSTEM FOR POLYPHONIC SOUND EVENT DETECTION
 BIDIRECTIONAL LSTM-HMM HYBRID SYSTEM FOR POLYPHONIC SOUND EVENT DETECTION Tomoki Hayashi 1, Shinji Watanabe 2, Tomoki Toda 1, Takaaki Hori 2, Jonathan Le Roux 2, Kazuya Takeda 1 1 Nagoya University, Furo-cho,
BIDIRECTIONAL LSTM-HMM HYBRID SYSTEM FOR POLYPHONIC SOUND EVENT DETECTION Tomoki Hayashi 1, Shinji Watanabe 2, Tomoki Toda 1, Takaaki Hori 2, Jonathan Le Roux 2, Kazuya Takeda 1 1 Nagoya University, Furo-cho,
Recurrent Neural Networks. deeplearning.ai. Why sequence models?
 Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Recurrent Neural Networks deeplearning.ai Why sequence models? Examples of sequence data The quick brown fox jumped over the lazy dog. Speech recognition Music generation Sentiment classification There
Machine Learning for Signal Processing Neural Networks Continue. Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016
 Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Machine Learning for Signal Processing Neural Networks Continue Instructor: Bhiksha Raj Slides by Najim Dehak 1 Dec 2016 1 So what are neural networks?? Voice signal N.Net Transcription Image N.Net Text
Memory-Augmented Attention Model for Scene Text Recognition
 Memory-Augmented Attention Model for Scene Text Recognition Cong Wang 1,2, Fei Yin 1,2, Cheng-Lin Liu 1,2,3 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences
Memory-Augmented Attention Model for Scene Text Recognition Cong Wang 1,2, Fei Yin 1,2, Cheng-Lin Liu 1,2,3 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences
Improved Learning through Augmenting the Loss
 Improved Learning through Augmenting the Loss Hakan Inan inanh@stanford.edu Khashayar Khosravi khosravi@stanford.edu Abstract We present two improvements to the well-known Recurrent Neural Network Language
Improved Learning through Augmenting the Loss Hakan Inan inanh@stanford.edu Khashayar Khosravi khosravi@stanford.edu Abstract We present two improvements to the well-known Recurrent Neural Network Language
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Gate Activation Signal Analysis for Gated Recurrent Neural Networks and Its Correlation with Phoneme Boundaries
 INTERSPEECH 2017 August 20 24, 2017, Stockholm, Sweden Gate Activation Signal Analysis for Gated Recurrent Neural Networks and Its Correlation with Phoneme Boundaries Yu-Hsuan Wang, Cheng-Tao Chung, Hung-yi
INTERSPEECH 2017 August 20 24, 2017, Stockholm, Sweden Gate Activation Signal Analysis for Gated Recurrent Neural Networks and Its Correlation with Phoneme Boundaries Yu-Hsuan Wang, Cheng-Tao Chung, Hung-yi
Boundary Contraction Training for Acoustic Models based on Discrete Deep Neural Networks
 INTERSPEECH 2014 Boundary Contraction Training for Acoustic Models based on Discrete Deep Neural Networks Ryu Takeda, Naoyuki Kanda, and Nobuo Nukaga Central Research Laboratory, Hitachi Ltd., 1-280, Kokubunji-shi,
INTERSPEECH 2014 Boundary Contraction Training for Acoustic Models based on Discrete Deep Neural Networks Ryu Takeda, Naoyuki Kanda, and Nobuo Nukaga Central Research Laboratory, Hitachi Ltd., 1-280, Kokubunji-shi,
Trajectory-based Radical Analysis Network for Online Handwritten Chinese Character Recognition
 Trajectory-based Radical Analysis Network for Online Handwritten Chinese Character Recognition Jianshu Zhang, Yixing Zhu, Jun Du and Lirong Dai National Engineering Laboratory for Speech and Language Information
Trajectory-based Radical Analysis Network for Online Handwritten Chinese Character Recognition Jianshu Zhang, Yixing Zhu, Jun Du and Lirong Dai National Engineering Laboratory for Speech and Language Information
TTIC 31230, Fundamentals of Deep Learning David McAllester, April Sequence to Sequence Models and Attention
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Sequence to Sequence Models and Attention Encode-Decode Architectures for Machine Translation [Figure from Luong et al.] In Sutskever
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 Sequence to Sequence Models and Attention Encode-Decode Architectures for Machine Translation [Figure from Luong et al.] In Sutskever
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
arxiv: v1 [cs.lg] 27 Oct 2017
![arxiv: v1 [cs.lg] 27 Oct 2017](/thumbs/96/127081376.jpg "arxiv: v1 [cs.lg] 27 Oct 2017") ADVANCED LSTM: A STUDY ABOUT BETTER TIME DEPENDENCY MODELING IN EMOTION RECOGNITION Fei Tao 1, Gang Liu 2 1. Multimodal Signal Processing (MSP) Lab, The University of Texas at Dallas, Richardson TX 2.
ADVANCED LSTM: A STUDY ABOUT BETTER TIME DEPENDENCY MODELING IN EMOTION RECOGNITION Fei Tao 1, Gang Liu 2 1. Multimodal Signal Processing (MSP) Lab, The University of Texas at Dallas, Richardson TX 2.
Speaker recognition by means of Deep Belief Networks
 Speaker recognition by means of Deep Belief Networks Vasileios Vasilakakis, Sandro Cumani, Pietro Laface, Politecnico di Torino, Italy {first.lastname}@polito.it 1. Abstract Most state of the art speaker
Speaker recognition by means of Deep Belief Networks Vasileios Vasilakakis, Sandro Cumani, Pietro Laface, Politecnico di Torino, Italy {first.lastname}@polito.it 1. Abstract Most state of the art speaker
Unfolded Recurrent Neural Networks for Speech Recognition
 INTERSPEECH 2014 Unfolded Recurrent Neural Networks for Speech Recognition George Saon, Hagen Soltau, Ahmad Emami and Michael Picheny IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
INTERSPEECH 2014 Unfolded Recurrent Neural Networks for Speech Recognition George Saon, Hagen Soltau, Ahmad Emami and Michael Picheny IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
Highway-LSTM and Recurrent Highway Networks for Speech Recognition
 Highway-LSTM and Recurrent Highway Networks for Speech Recognition Golan Pundak, Tara N. Sainath Google Inc., New York, NY, USA {golan, tsainath}@google.com Abstract Recently, very deep networks, with
Highway-LSTM and Recurrent Highway Networks for Speech Recognition Golan Pundak, Tara N. Sainath Google Inc., New York, NY, USA {golan, tsainath}@google.com Abstract Recently, very deep networks, with
Tensor-Train Long Short-Term Memory for Monaural Speech Enhancement
 1 Tensor-Train Long Short-Term Memory for Monaural Speech Enhancement Suman Samui, Indrajit Chakrabarti, and Soumya K. Ghosh, arxiv:1812.10095v1 [cs.sd] 25 Dec 2018 Abstract In recent years, Long Short-Term
1 Tensor-Train Long Short-Term Memory for Monaural Speech Enhancement Suman Samui, Indrajit Chakrabarti, and Soumya K. Ghosh, arxiv:1812.10095v1 [cs.sd] 25 Dec 2018 Abstract In recent years, Long Short-Term
BLSTM-HMM HYBRID SYSTEM COMBINED WITH SOUND ACTIVITY DETECTION NETWORK FOR POLYPHONIC SOUND EVENT DETECTION
 BLSTM-HMM HYBRID SYSTEM COMBINED WITH SOUND ACTIVITY DETECTION NETWORK FOR POLYPHONIC SOUND EVENT DETECTION Tomoki Hayashi 1, Shinji Watanabe 2, Tomoki Toda 1, Takaaki Hori 2, Jonathan Le Roux 2, Kazuya
BLSTM-HMM HYBRID SYSTEM COMBINED WITH SOUND ACTIVITY DETECTION NETWORK FOR POLYPHONIC SOUND EVENT DETECTION Tomoki Hayashi 1, Shinji Watanabe 2, Tomoki Toda 1, Takaaki Hori 2, Jonathan Le Roux 2, Kazuya
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Robust Speaker Identification
 Robust Speaker Identification by Smarajit Bose Interdisciplinary Statistical Research Unit Indian Statistical Institute, Kolkata Joint work with Amita Pal and Ayanendranath Basu Overview } } } } } } }
Robust Speaker Identification by Smarajit Bose Interdisciplinary Statistical Research Unit Indian Statistical Institute, Kolkata Joint work with Amita Pal and Ayanendranath Basu Overview } } } } } } }
EE-559 Deep learning LSTM and GRU
 EE-559 Deep learning 11.2. LSTM and GRU François Fleuret https://fleuret.org/ee559/ Mon Feb 18 13:33:24 UTC 2019 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The Long-Short Term Memory unit (LSTM) by Hochreiter
EE-559 Deep learning 11.2. LSTM and GRU François Fleuret https://fleuret.org/ee559/ Mon Feb 18 13:33:24 UTC 2019 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The Long-Short Term Memory unit (LSTM) by Hochreiter
Task-Oriented Dialogue System (Young, 2000)
") 2 Review Task-Oriented Dialogue System (Young, 2000) 3 http://rsta.royalsocietypublishing.org/content/358/1769/1389.short Speech Signal Speech Recognition Hypothesis are there any action movies to see
2 Review Task-Oriented Dialogue System (Young, 2000) 3 http://rsta.royalsocietypublishing.org/content/358/1769/1389.short Speech Signal Speech Recognition Hypothesis are there any action movies to see
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Recurrent Neural Networks. Jian Tang
 Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Usually the estimation of the partition function is intractable and it becomes exponentially hard when the complexity of the model increases. However,
 Odyssey 2012 The Speaker and Language Recognition Workshop 25-28 June 2012, Singapore First attempt of Boltzmann Machines for Speaker Verification Mohammed Senoussaoui 1,2, Najim Dehak 3, Patrick Kenny
Odyssey 2012 The Speaker and Language Recognition Workshop 25-28 June 2012, Singapore First attempt of Boltzmann Machines for Speaker Verification Mohammed Senoussaoui 1,2, Najim Dehak 3, Patrick Kenny
Deep Learning Architectures and Algorithms
 Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
Machine Learning. Boris
 Machine Learning Boris Nadion boris@astrails.com @borisnadion @borisnadion boris@astrails.com astrails http://astrails.com awesome web and mobile apps since 2005 terms AI (artificial intelligence)
Machine Learning Boris Nadion boris@astrails.com @borisnadion @borisnadion boris@astrails.com astrails http://astrails.com awesome web and mobile apps since 2005 terms AI (artificial intelligence)
RARE SOUND EVENT DETECTION USING 1D CONVOLUTIONAL RECURRENT NEURAL NETWORKS
 RARE SOUND EVENT DETECTION USING 1D CONVOLUTIONAL RECURRENT NEURAL NETWORKS Hyungui Lim 1, Jeongsoo Park 1,2, Kyogu Lee 2, Yoonchang Han 1 1 Cochlear.ai, Seoul, Korea 2 Music and Audio Research Group,
RARE SOUND EVENT DETECTION USING 1D CONVOLUTIONAL RECURRENT NEURAL NETWORKS Hyungui Lim 1, Jeongsoo Park 1,2, Kyogu Lee 2, Yoonchang Han 1 1 Cochlear.ai, Seoul, Korea 2 Music and Audio Research Group,
Autoregressive Neural Models for Statistical Parametric Speech Synthesis
 Autoregressive Neural Models for Statistical Parametric Speech Synthesis シンワン Xin WANG 2018-01-11 contact: wangxin@nii.ac.jp we welcome critical comments, suggestions, and discussion 1 https://www.slideshare.net/kotarotanahashi/deep-learning-library-coyotecnn
Autoregressive Neural Models for Statistical Parametric Speech Synthesis シンワン Xin WANG 2018-01-11 contact: wangxin@nii.ac.jp we welcome critical comments, suggestions, and discussion 1 https://www.slideshare.net/kotarotanahashi/deep-learning-library-coyotecnn
Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation
 Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation Dr. Yanjun Qi Department of Computer Science University of Virginia Tutorial @ ACM BCB-2018 8/29/18 Yanjun Qi / UVA
Making Deep Learning Understandable for Analyzing Sequential Data about Gene Regulation Dr. Yanjun Qi Department of Computer Science University of Virginia Tutorial @ ACM BCB-2018 8/29/18 Yanjun Qi / UVA
Recurrent Neural Network
 Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Recurrent Neural Network Xiaogang Wang xgwang@ee..edu.hk March 2, 2017 Xiaogang Wang (linux) Recurrent Neural Network March 2, 2017 1 / 48 Outline 1 Recurrent neural networks Recurrent neural networks
Recurrent Neural Networks Deep Learning Lecture 5. Efstratios Gavves
 Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Machine Translation. 10: Advanced Neural Machine Translation Architectures. Rico Sennrich. University of Edinburgh. R. Sennrich MT / 26
 Machine Translation 10: Advanced Neural Machine Translation Architectures Rico Sennrich University of Edinburgh R. Sennrich MT 2018 10 1 / 26 Today s Lecture so far today we discussed RNNs as encoder and
Machine Translation 10: Advanced Neural Machine Translation Architectures Rico Sennrich University of Edinburgh R. Sennrich MT 2018 10 1 / 26 Today s Lecture so far today we discussed RNNs as encoder and
Recurrent and Recursive Networks
 Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
Neural Networks with Applications to Vision and Language Recurrent and Recursive Networks Marco Kuhlmann Introduction Applications of sequence modelling Map unsegmented connected handwriting to strings.
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Deep Reinforcement Learning for Unsupervised Video Summarization with Diversity- Representativeness Reward
 Deep Reinforcement Learning for Unsupervised Video Summarization with Diversity- Representativeness Reward Kaiyang Zhou, Yu Qiao, Tao Xiang AAAI 2018 What is video summarization? Goal: to automatically
Deep Reinforcement Learning for Unsupervised Video Summarization with Diversity- Representativeness Reward Kaiyang Zhou, Yu Qiao, Tao Xiang AAAI 2018 What is video summarization? Goal: to automatically
Biologically Plausible Speech Recognition with LSTM Neural Nets
 Biologically Plausible Speech Recognition with LSTM Neural Nets Alex Graves, Douglas Eck, Nicole Beringer, Juergen Schmidhuber Istituto Dalle Molle di Studi sull Intelligenza Artificiale, Galleria 2, 6928
Biologically Plausible Speech Recognition with LSTM Neural Nets Alex Graves, Douglas Eck, Nicole Beringer, Juergen Schmidhuber Istituto Dalle Molle di Studi sull Intelligenza Artificiale, Galleria 2, 6928
Tracking the World State with Recurrent Entity Networks
 Tracking the World State with Recurrent Entity Networks Mikael Henaff, Jason Weston, Arthur Szlam, Antoine Bordes, Yann LeCun Task At each timestep, get information (in the form of a sentence) about the
Tracking the World State with Recurrent Entity Networks Mikael Henaff, Jason Weston, Arthur Szlam, Antoine Bordes, Yann LeCun Task At each timestep, get information (in the form of a sentence) about the
Modeling Time-Frequency Patterns with LSTM vs. Convolutional Architectures for LVCSR Tasks
 Modeling Time-Frequency Patterns with LSTM vs Convolutional Architectures for LVCSR Tasks Tara N Sainath, Bo Li Google, Inc New York, NY, USA {tsainath, boboli}@googlecom Abstract Various neural network
Modeling Time-Frequency Patterns with LSTM vs Convolutional Architectures for LVCSR Tasks Tara N Sainath, Bo Li Google, Inc New York, NY, USA {tsainath, boboli}@googlecom Abstract Various neural network
Estimation of Relative Operating Characteristics of Text Independent Speaker Verification
 International Journal of Engineering Science Invention Volume 1 Issue 1 December. 2012 PP.18-23 Estimation of Relative Operating Characteristics of Text Independent Speaker Verification Palivela Hema 1,
International Journal of Engineering Science Invention Volume 1 Issue 1 December. 2012 PP.18-23 Estimation of Relative Operating Characteristics of Text Independent Speaker Verification Palivela Hema 1,
Introduction to RNNs!
 Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
Introduction to RNNs Arun Mallya Best viewed with Computer Modern fonts installed Outline Why Recurrent Neural Networks (RNNs)? The Vanilla RNN unit The RNN forward pass Backpropagation refresher The RNN
Combining Static and Dynamic Information for Clinical Event Prediction
 Combining Static and Dynamic Information for Clinical Event Prediction Cristóbal Esteban 1, Antonio Artés 2, Yinchong Yang 1, Oliver Staeck 3, Enrique Baca-García 4 and Volker Tresp 1 1 Siemens AG and
Combining Static and Dynamic Information for Clinical Event Prediction Cristóbal Esteban 1, Antonio Artés 2, Yinchong Yang 1, Oliver Staeck 3, Enrique Baca-García 4 and Volker Tresp 1 1 Siemens AG and
Attention Based Joint Model with Negative Sampling for New Slot Values Recognition. By: Mulan Hou
 Attention Based Joint Model with Negative Sampling for New Slot Values Recognition By: Mulan Hou houmulan@bupt.edu.cn CONTE NTS 1 2 3 4 5 6 Introduction Related work Motivation Proposed model Experiments
Attention Based Joint Model with Negative Sampling for New Slot Values Recognition By: Mulan Hou houmulan@bupt.edu.cn CONTE NTS 1 2 3 4 5 6 Introduction Related work Motivation Proposed model Experiments
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
arxiv: v1 [cs.cl] 21 May 2017
![arxiv: v1 [cs.cl] 21 May 2017](/thumbs/92/109535705.jpg "arxiv: v1 [cs.cl] 21 May 2017") Spelling Correction as a Foreign Language Yingbo Zhou yingbzhou@ebay.com Utkarsh Porwal uporwal@ebay.com Roberto Konow rkonow@ebay.com arxiv:1705.07371v1 [cs.cl] 21 May 2017 Abstract In this paper, we
Spelling Correction as a Foreign Language Yingbo Zhou yingbzhou@ebay.com Utkarsh Porwal uporwal@ebay.com Roberto Konow rkonow@ebay.com arxiv:1705.07371v1 [cs.cl] 21 May 2017 Abstract In this paper, we
Large Vocabulary Continuous Speech Recognition with Long Short-Term Recurrent Networks
 Large Vocabulary Continuous Speech Recognition with Long Short-Term Recurrent Networks Haşim Sak, Andrew Senior, Oriol Vinyals, Georg Heigold, Erik McDermott, Rajat Monga, Mark Mao, Françoise Beaufays
Large Vocabulary Continuous Speech Recognition with Long Short-Term Recurrent Networks Haşim Sak, Andrew Senior, Oriol Vinyals, Georg Heigold, Erik McDermott, Rajat Monga, Mark Mao, Françoise Beaufays
Robust Sound Event Detection in Continuous Audio Environments
 Robust Sound Event Detection in Continuous Audio Environments Haomin Zhang 1, Ian McLoughlin 2,1, Yan Song 1 1 National Engineering Laboratory of Speech and Language Information Processing The University
Robust Sound Event Detection in Continuous Audio Environments Haomin Zhang 1, Ian McLoughlin 2,1, Yan Song 1 1 National Engineering Laboratory of Speech and Language Information Processing The University
Gated Recurrent Neural Tensor Network
 Gated Recurrent Neural Tensor Network Andros Tjandra, Sakriani Sakti, Ruli Manurung, Mirna Adriani and Satoshi Nakamura Faculty of Computer Science, Universitas Indonesia, Indonesia Email: andros.tjandra@gmail.com,
Gated Recurrent Neural Tensor Network Andros Tjandra, Sakriani Sakti, Ruli Manurung, Mirna Adriani and Satoshi Nakamura Faculty of Computer Science, Universitas Indonesia, Indonesia Email: andros.tjandra@gmail.com,
Deep Learning for Automatic Speech Recognition Part I
 Deep Learning for Automatic Speech Recognition Part I Xiaodong Cui IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Fall, 2018 Outline A brief history of automatic speech recognition Speech
Deep Learning for Automatic Speech Recognition Part I Xiaodong Cui IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Fall, 2018 Outline A brief history of automatic speech recognition Speech
arxiv: v2 [cs.sd] 7 Feb 2018
![arxiv: v2 [cs.sd] 7 Feb 2018](/thumbs/92/108747184.jpg "arxiv: v2 [cs.sd] 7 Feb 2018") AUDIO SET CLASSIFICATION WITH ATTENTION MODEL: A PROBABILISTIC PERSPECTIVE Qiuqiang ong*, Yong Xu*, Wenwu Wang, Mark D. Plumbley Center for Vision, Speech and Signal Processing, University of Surrey, U
AUDIO SET CLASSIFICATION WITH ATTENTION MODEL: A PROBABILISTIC PERSPECTIVE Qiuqiang ong*, Yong Xu*, Wenwu Wang, Mark D. Plumbley Center for Vision, Speech and Signal Processing, University of Surrey, U
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (CS753) Lecture 21: Speaker Adaptation Instructor: Preethi Jyothi Oct 23, 2017 Speaker variations Major cause of variability in speech is the differences between speakers Speaking
Automatic Speech Recognition (CS753) Lecture 21: Speaker Adaptation Instructor: Preethi Jyothi Oct 23, 2017 Speaker variations Major cause of variability in speech is the differences between speakers Speaking
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (CS753) Lecture 12: Acoustic Feature Extraction for ASR Instructor: Preethi Jyothi Feb 13, 2017 Speech Signal Analysis Generate discrete samples A frame Need to focus on short
Automatic Speech Recognition (CS753) Lecture 12: Acoustic Feature Extraction for ASR Instructor: Preethi Jyothi Feb 13, 2017 Speech Signal Analysis Generate discrete samples A frame Need to focus on short
A QUESTION ANSWERING SYSTEM USING ENCODER-DECODER, SEQUENCE-TO-SEQUENCE, RECURRENT NEURAL NETWORKS. A Project. Presented to
 A QUESTION ANSWERING SYSTEM USING ENCODER-DECODER, SEQUENCE-TO-SEQUENCE, RECURRENT NEURAL NETWORKS A Project Presented to The Faculty of the Department of Computer Science San José State University In
A QUESTION ANSWERING SYSTEM USING ENCODER-DECODER, SEQUENCE-TO-SEQUENCE, RECURRENT NEURAL NETWORKS A Project Presented to The Faculty of the Department of Computer Science San José State University In
MULTI-LABEL VS. COMBINED SINGLE-LABEL SOUND EVENT DETECTION WITH DEEP NEURAL NETWORKS. Emre Cakir, Toni Heittola, Heikki Huttunen and Tuomas Virtanen
 MULTI-LABEL VS. COMBINED SINGLE-LABEL SOUND EVENT DETECTION WITH DEEP NEURAL NETWORKS Emre Cakir, Toni Heittola, Heikki Huttunen and Tuomas Virtanen Department of Signal Processing, Tampere University
MULTI-LABEL VS. COMBINED SINGLE-LABEL SOUND EVENT DETECTION WITH DEEP NEURAL NETWORKS Emre Cakir, Toni Heittola, Heikki Huttunen and Tuomas Virtanen Department of Signal Processing, Tampere University
IMISOUND: An Unsupervised System for Sound Query by Vocal Imitation
 IMISOUND: An Unsupervised System for Sound Query by Vocal Imitation Yichi Zhang and Zhiyao Duan Audio Information Research (AIR) Lab Department of Electrical and Computer Engineering University of Rochester
IMISOUND: An Unsupervised System for Sound Query by Vocal Imitation Yichi Zhang and Zhiyao Duan Audio Information Research (AIR) Lab Department of Electrical and Computer Engineering University of Rochester
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
APPLIED DEEP LEARNING PROF ALEXIEI DINGLI
 APPLIED DEEP LEARNING PROF ALEXIEI DINGLI TECH NEWS TECH NEWS HOW TO DO IT? TECH NEWS APPLICATIONS TECH NEWS TECH NEWS NEURAL NETWORKS Interconnected set of nodes and edges Designed to perform complex
APPLIED DEEP LEARNING PROF ALEXIEI DINGLI TECH NEWS TECH NEWS HOW TO DO IT? TECH NEWS APPLICATIONS TECH NEWS TECH NEWS NEURAL NETWORKS Interconnected set of nodes and edges Designed to perform complex
RECURRENT NEURAL NETWORKS WITH FLEXIBLE GATES USING KERNEL ACTIVATION FUNCTIONS
 2018 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 17 20, 2018, AALBORG, DENMARK RECURRENT NEURAL NETWORKS WITH FLEXIBLE GATES USING KERNEL ACTIVATION FUNCTIONS Simone Scardapane,
2018 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 17 20, 2018, AALBORG, DENMARK RECURRENT NEURAL NETWORKS WITH FLEXIBLE GATES USING KERNEL ACTIVATION FUNCTIONS Simone Scardapane,
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1
 What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
What Do Neural Networks Do? MLP Lecture 3 Multi-layer networks 1 Multi-layer networks Steve Renals Machine Learning Practical MLP Lecture 3 7 October 2015 MLP Lecture 3 Multi-layer networks 2 What Do Single
Speech and Language Processing
 Speech and Language Processing Lecture 5 Neural network based acoustic and language models Information and Communications Engineering Course Takahiro Shinoaki 08//6 Lecture Plan (Shinoaki s part) I gives
Speech and Language Processing Lecture 5 Neural network based acoustic and language models Information and Communications Engineering Course Takahiro Shinoaki 08//6 Lecture Plan (Shinoaki s part) I gives
Speech recognition. Lecture 14: Neural Networks. Andrew Senior December 12, Google NYC
 Andrew Senior 1 Speech recognition Lecture 14: Neural Networks Andrew Senior Google NYC December 12, 2013 Andrew Senior 2 1
Andrew Senior 1 Speech recognition Lecture 14: Neural Networks Andrew Senior Google NYC December 12, 2013 Andrew Senior 2 1
Hidden Markov Model and Speech Recognition
 1 Dec,2006 Outline Introduction 1 Introduction 2 3 4 5 Introduction What is Speech Recognition? Understanding what is being said Mapping speech data to textual information Speech Recognition is indeed
1 Dec,2006 Outline Introduction 1 Introduction 2 3 4 5 Introduction What is Speech Recognition? Understanding what is being said Mapping speech data to textual information Speech Recognition is indeed
AUDIO SET CLASSIFICATION WITH ATTENTION MODEL: A PROBABILISTIC PERSPECTIVE. Qiuqiang Kong*, Yong Xu*, Wenwu Wang, Mark D. Plumbley
 AUDIO SET CLASSIFICATION WITH ATTENTION MODEL: A PROBABILISTIC PERSPECTIVE Qiuqiang ong*, Yong Xu*, Wenwu Wang, Mark D. Plumbley Center for Vision, Speech and Signal Processing, University of Surrey, U
AUDIO SET CLASSIFICATION WITH ATTENTION MODEL: A PROBABILISTIC PERSPECTIVE Qiuqiang ong*, Yong Xu*, Wenwu Wang, Mark D. Plumbley Center for Vision, Speech and Signal Processing, University of Surrey, U
Generating Sequences with Recurrent Neural Networks
 Generating Sequences with Recurrent Neural Networks Alex Graves University of Toronto & Google DeepMind Presented by Zhe Gan, Duke University May 15, 2015 1 / 23 Outline Deep recurrent neural network based
Generating Sequences with Recurrent Neural Networks Alex Graves University of Toronto & Google DeepMind Presented by Zhe Gan, Duke University May 15, 2015 1 / 23 Outline Deep recurrent neural network based
Design of Chinese Natural Language in Fuzzy Boundary Determination Algorithm Based on Big Data
 Journal of Information Hiding and Multimedia Signal Processing c 2017 ISSN 2073-4212 Ubiquitous International Volume 8, Number 2, March 2017 Design of Chinese Natural Language in Fuzzy Boundary Determination
Journal of Information Hiding and Multimedia Signal Processing c 2017 ISSN 2073-4212 Ubiquitous International Volume 8, Number 2, March 2017 Design of Chinese Natural Language in Fuzzy Boundary Determination
Synaptic Devices and Neuron Circuits for Neuron-Inspired NanoElectronics
 Synaptic Devices and Neuron Circuits for Neuron-Inspired NanoElectronics Byung-Gook Park Inter-university Semiconductor Research Center & Department of Electrical and Computer Engineering Seoul National
Synaptic Devices and Neuron Circuits for Neuron-Inspired NanoElectronics Byung-Gook Park Inter-university Semiconductor Research Center & Department of Electrical and Computer Engineering Seoul National
Deep Learning Sequence to Sequence models: Attention Models. 17 March 2018
 Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
arxiv: v1 [stat.ml] 18 Nov 2017
![arxiv: v1 [stat.ml] 18 Nov 2017](/thumbs/72/67293632.jpg "arxiv: v1 [stat.ml] 18 Nov 2017") MinimalRNN: Toward More Interpretable and Trainable Recurrent Neural Networks arxiv:1711.06788v1 [stat.ml] 18 Nov 2017 Minmin Chen Google Mountain view, CA 94043 minminc@google.com Abstract We introduce
MinimalRNN: Toward More Interpretable and Trainable Recurrent Neural Networks arxiv:1711.06788v1 [stat.ml] 18 Nov 2017 Minmin Chen Google Mountain view, CA 94043 minminc@google.com Abstract We introduce
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Today s Lecture. Dropout
 Today s Lecture so far we discussed RNNs as encoder and decoder we discussed some architecture variants: RNN vs. GRU vs. LSTM attention mechanisms Machine Translation 1: Advanced Neural Machine Translation
Today s Lecture so far we discussed RNNs as encoder and decoder we discussed some architecture variants: RNN vs. GRU vs. LSTM attention mechanisms Machine Translation 1: Advanced Neural Machine Translation
Speaker Representation and Verification Part II. by Vasileios Vasilakakis
 Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials
 Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials Contents 1 Pseudo-code for the damped Gauss-Newton vector product 2 2 Details of the pathological synthetic problems
Learning Recurrent Neural Networks with Hessian-Free Optimization: Supplementary Materials Contents 1 Pseudo-code for the damped Gauss-Newton vector product 2 2 Details of the pathological synthetic problems
CSCI 315: Artificial Intelligence through Deep Learning
 CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7) Recall our first-week discussion... How do we know stuff? (MIT Press 1996)
CSCI 315: Artificial Intelligence through Deep Learning W&L Winter Term 2017 Prof. Levy Recurrent Neural Networks (Chapter 7) Recall our first-week discussion... How do we know stuff? (MIT Press 1996)
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Google s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
 Google s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation Y. Wu, M. Schuster, Z. Chen, Q.V. Le, M. Norouzi, et al. Google arxiv:1609.08144v2 Reviewed by : Bill
Google s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation Y. Wu, M. Schuster, Z. Chen, Q.V. Le, M. Norouzi, et al. Google arxiv:1609.08144v2 Reviewed by : Bill
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Based on the original slides of Hung-yi Lee
 Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Based on the original slides of Hung-yi Lee New Activation Function Rectified Linear Unit (ReLU) σ z a a = z Reason: 1. Fast to compute 2. Biological reason a = 0 [Xavier Glorot, AISTATS 11] [Andrew L.
Front-End Factor Analysis For Speaker Verification
 IEEE TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING Front-End Factor Analysis For Speaker Verification Najim Dehak, Patrick Kenny, Réda Dehak, Pierre Dumouchel, and Pierre Ouellet, Abstract This
IEEE TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING Front-End Factor Analysis For Speaker Verification Najim Dehak, Patrick Kenny, Réda Dehak, Pierre Dumouchel, and Pierre Ouellet, Abstract This
Sequence Transduction with Recurrent Neural Networks
 Alex Graves graves@cs.toronto.edu Department of Computer Science, University of Toronto, Toronto, ON M5S 3G4 Abstract Many machine learning tasks can be expressed as the transformation or transduction
Alex Graves graves@cs.toronto.edu Department of Computer Science, University of Toronto, Toronto, ON M5S 3G4 Abstract Many machine learning tasks can be expressed as the transformation or transduction
Faster Training of Very Deep Networks Via p-norm Gates
 Faster Training of Very Deep Networks Via p-norm Gates Trang Pham, Truyen Tran, Dinh Phung, Svetha Venkatesh Center for Pattern Recognition and Data Analytics Deakin University, Geelong Australia Email:
Faster Training of Very Deep Networks Via p-norm Gates Trang Pham, Truyen Tran, Dinh Phung, Svetha Venkatesh Center for Pattern Recognition and Data Analytics Deakin University, Geelong Australia Email:
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Lecture 5: GMM Acoustic Modeling and Feature Extraction
 CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 5: GMM Acoustic Modeling and Feature Extraction Original slides by Dan Jurafsky Outline for Today Acoustic
CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 5: GMM Acoustic Modeling and Feature Extraction Original slides by Dan Jurafsky Outline for Today Acoustic
Neural Architectures for Image, Language, and Speech Processing
 Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
Neural Architectures for Image, Language, and Speech Processing Karl Stratos June 26, 2018 1 / 31 Overview Feedforward Networks Need for Specialized Architectures Convolutional Neural Networks (CNNs) Recurrent
arxiv: v1 [cs.ne] 14 Nov 2012
![arxiv: v1 [cs.ne] 14 Nov 2012](/thumbs/83/87994863.jpg "arxiv: v1 [cs.ne] 14 Nov 2012") Alex Graves Department of Computer Science, University of Toronto, Canada graves@cs.toronto.edu arxiv:1211.3711v1 [cs.ne] 14 Nov 2012 Abstract Many machine learning tasks can be expressed as the transformation
Alex Graves Department of Computer Science, University of Toronto, Canada graves@cs.toronto.edu arxiv:1211.3711v1 [cs.ne] 14 Nov 2012 Abstract Many machine learning tasks can be expressed as the transformation
Maximum Likelihood and Maximum A Posteriori Adaptation for Distributed Speaker Recognition Systems
 Maximum Likelihood and Maximum A Posteriori Adaptation for Distributed Speaker Recognition Systems Chin-Hung Sit 1, Man-Wai Mak 1, and Sun-Yuan Kung 2 1 Center for Multimedia Signal Processing Dept. of
Maximum Likelihood and Maximum A Posteriori Adaptation for Distributed Speaker Recognition Systems Chin-Hung Sit 1, Man-Wai Mak 1, and Sun-Yuan Kung 2 1 Center for Multimedia Signal Processing Dept. of
Multimodal Machine Learning
 Multimodal Machine Learning Louis-Philippe (LP) Morency CMU Multimodal Communication and Machine Learning Laboratory [MultiComp Lab] 1 CMU Course 11-777: Multimodal Machine Learning 2 Lecture Objectives
Multimodal Machine Learning Louis-Philippe (LP) Morency CMU Multimodal Communication and Machine Learning Laboratory [MultiComp Lab] 1 CMU Course 11-777: Multimodal Machine Learning 2 Lecture Objectives