Predicting Graph Labels using Perceptron. Shuang Song
|
|
|
- Laura Harris
- 5 years ago
- Views:
Transcription
1 Predicting Graph Labels using Perceptron Shuang Song
2 Online learning over graphs M. Herbster, M. Pontil, and L. Wainer, Proc. 22nd Int. Conf. Machine Learning (ICML'05), 2005 Prediction on a graph with a perceptron M. Herbster, and M. Pontil, NIPS 20, 2006
3 Outline 1. Problem Setting 2. Perceptron 3. Properties of Graphs 4. Bound # of mistakes
4 Problem Setting Known graph, unknown labels on vertices eg. Advertisement service on web page eg. Digit recognition task on USPS (graph is built using NN)
5
6 Problem Setting Given a graph G = (V, E) where V = {1,, n} for t = 1,, l nature selects v t V learner predicts y t {1, 1} nature reveals y t {1, 1} if y t y t, mistakes = mistakes + 1 minimize mistakes
7 Node Predict Nature Mistakes
8 easy hard
9 Problem Setting Implicit assumption: adjacent nodes have similar labels The nature can be adversarial, and the learner can always make mistake; yet if the nature is regular and simple, then it is possible for the learner to make only a few mistake. Bound mistakes using complexity of nature s labelling Assume graph is connected, unweighted
10 What algorithm are we going to use?
11 Perceptron simply linear classification assume linearly separable with margin 1
12 Perceptron: algorithm data: x 1, y 1,, (x l, y l ) H 1, 1 l Initial w 1 = 0 H For t = 1,, l receive x t H predict y t = sign( w t, x t ) receive y t {1, 1} if y t y t mistake = mistake + 1 w t+1 = w t + y t x t else w t+1 = w t
13 Perceptron: mistake bound l Theorem: given a sequence x t, y t t=1 H { 1,1}, and M as the set of trails in which the perceptron predicted incorrectly, then for all w M w 2 max x t 2 t M 1,1 n st. w t = y t, t = 1,, l norm is taken w.r.t. the inner product of H
14 Perceptron: how to use For us, what is the inner product? what is x t? We would want a x t that captures the structure of the whole graph.
15 Perceptron: algorithm data: x 1, y 1,, (x l, y l ) H 1, 1 l Initial w 1 = 0 H For t = 1,, l receive x t H predict y t = sign( w t, x t ) receive y t {1, 1} if y t y t mistake = mistake + 1 w t+1 = w t + y t x t else w t+1 = w t For us, what is x t? What is the inner product? We would want a x t that captures the structure of the whole graph.
16 Properties of Graphs Graph Laplacian L = D A, where A is adjacency matrix and D = diag(d 1,, d n ) Inner product: f, g = f T Lg, f, g R n Semi-norm: f 2 = f, f = f i f j 2 i,j E
17 Properties of Graphs Norm measures smoothness or complexity of a labelling g: g 2 = 3 4 g 2 = 12 4

18 Properties of Graphs g 2 = 1 4 g 2 = 9 4
19 Properties of Graphs Eigenvalue λ i and eigenvector u i of L: Connected 0 = λ 1 < λ 2 λ 3 λ n with u 1 as constant vector H = span u 2,, u n = {g: g T u 1 = 0} = {g: n i=1 g i = 0} Semi-norm becomes norm
20 Properties of Graphs Pseudoinverse K = L + = n i=2 λ i 1 u i u i T It is the reproducing kernel of H: g H, K i = K(:, i) K i, g = g i K t 2 = K tt measures the remoteness of vertex t and it decreases with connectivity
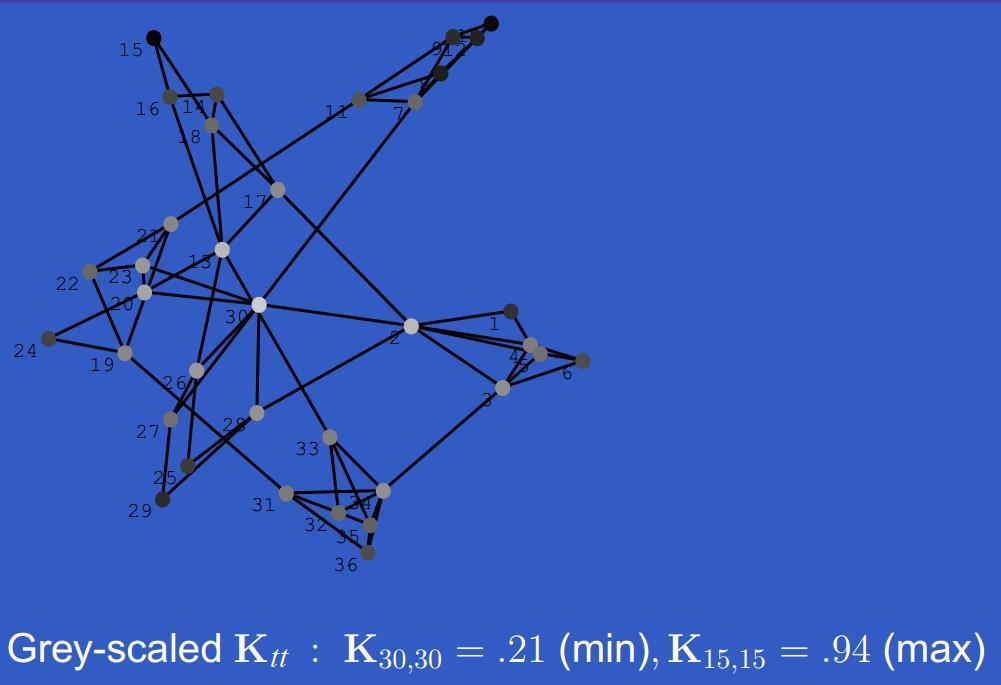
21
22 This will be our feature of a vertex, i.e., x t = K t
23 Properties of Graphs For p V, define Distance (of two vertices): d p, q = min P(p, q) where P is a path from p to q Eccentricity (of a vertex): ρ p = max q V d(p, q) Diameter (of a graph): D G = max p ρ p
24 Bound M w 2 max t M x t 2 We want to know what w 2 and max t M x t 2 is with the properties of graph
25 Bound # of mistakes: w 2 Firstly we look at w: w 1, +1 n w 2 = w i w j 2 i,j E smoothness or complexity w 2 = 4 (# edges spanning different labels)

26 Bound # of mistakes: x t 2 Then we look at x t = K t : K t 2 = K tt. So we want to bound K tt Theorem: For a connected graph G with Laplacian kernel K, K tt min 1 λ 2, ρ t, t V 2nd smallest eigenvalue eccentricity: ρ t = max min q V P(p, q)
27 Bound # of mistakes : x t 2 Proof: K tt 1 λ 2 g T Lg λ 2 g T g, g H Taking g = K t, K tt λ 2 g p 2 λ 2 K tt 2 K tt ρ t If g t > 0, then s, s.t. g s < 0 path P from t to s, s.t. E P ρ t
28 Bound # of mistakes : x t 2 g i g j g t g s > g t i,j E(P) n n By n i=1 a 2 i i=1 a i for non negative {a i }, we have i,j E(P) 2 i,j E P g i g j g i g j E(P) i,j E P ρ t 2 g i g j 2 g t 2 ρ t 2
29 Bound # of mistakes : x t 2 Taking g = K t, we have K 2 2 t = i,j E(G) K ti K tj and K 2 t = K t, K t = K tt 2 K 2 K tt = K ti K tj tt i,j E(G) ρ t K tt 1 λ 2 and K tt ρ t
30 Bound # of mistakes M w 2 max t M x t 2 4 # edges spanning different labels min 1 λ 2, ρ t
31 Further improvement Noisy samples: M 2 M M w + w 2 X M M w w 2 X 2 + w 4 X 4 Bound K pp using resistance K pp r(p, q) max p,q V 2 4
CS 590D Lecture Notes
 CS 590D Lecture Notes David Wemhoener December 017 1 Introduction Figure 1: Various Separators We previously looked at the perceptron learning algorithm, which gives us a separator for linearly separable
CS 590D Lecture Notes David Wemhoener December 017 1 Introduction Figure 1: Various Separators We previously looked at the perceptron learning algorithm, which gives us a separator for linearly separable
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Beyond the Point Cloud: From Transductive to Semi-Supervised Learning
 Beyond the Point Cloud: From Transductive to Semi-Supervised Learning Vikas Sindhwani, Partha Niyogi, Mikhail Belkin Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of
Beyond the Point Cloud: From Transductive to Semi-Supervised Learning Vikas Sindhwani, Partha Niyogi, Mikhail Belkin Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of
A graph based approach to semi-supervised learning
 A graph based approach to semi-supervised learning 1 Feb 2011 Two papers M. Belkin, P. Niyogi, and V Sindhwani. Manifold regularization: a geometric framework for learning from labeled and unlabeled examples.
A graph based approach to semi-supervised learning 1 Feb 2011 Two papers M. Belkin, P. Niyogi, and V Sindhwani. Manifold regularization: a geometric framework for learning from labeled and unlabeled examples.
Non-linear Dimensionality Reduction
 Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Nonlinear Methods. Data often lies on or near a nonlinear low-dimensional curve aka manifold.
 Nonlinear Methods Data often lies on or near a nonlinear low-dimensional curve aka manifold. 27 Laplacian Eigenmaps Linear methods Lower-dimensional linear projection that preserves distances between all
Nonlinear Methods Data often lies on or near a nonlinear low-dimensional curve aka manifold. 27 Laplacian Eigenmaps Linear methods Lower-dimensional linear projection that preserves distances between all
Online Learning. Jordan Boyd-Graber. University of Colorado Boulder LECTURE 21. Slides adapted from Mohri
 Online Learning Jordan Boyd-Graber University of Colorado Boulder LECTURE 21 Slides adapted from Mohri Jordan Boyd-Graber Boulder Online Learning 1 of 31 Motivation PAC learning: distribution fixed over
Online Learning Jordan Boyd-Graber University of Colorado Boulder LECTURE 21 Slides adapted from Mohri Jordan Boyd-Graber Boulder Online Learning 1 of 31 Motivation PAC learning: distribution fixed over
A Brief Survey on Semi-supervised Learning with Graph Regularization
 000 00 002 003 004 005 006 007 008 009 00 0 02 03 04 05 06 07 08 09 020 02 022 023 024 025 026 027 028 029 030 03 032 033 034 035 036 037 038 039 040 04 042 043 044 045 046 047 048 049 050 05 052 053 A
000 00 002 003 004 005 006 007 008 009 00 0 02 03 04 05 06 07 08 09 020 02 022 023 024 025 026 027 028 029 030 03 032 033 034 035 036 037 038 039 040 04 042 043 044 045 046 047 048 049 050 05 052 053 A
18.312: Algebraic Combinatorics Lionel Levine. Lecture 19
 832: Algebraic Combinatorics Lionel Levine Lecture date: April 2, 20 Lecture 9 Notes by: David Witmer Matrix-Tree Theorem Undirected Graphs Let G = (V, E) be a connected, undirected graph with n vertices,
832: Algebraic Combinatorics Lionel Levine Lecture date: April 2, 20 Lecture 9 Notes by: David Witmer Matrix-Tree Theorem Undirected Graphs Let G = (V, E) be a connected, undirected graph with n vertices,
Active and Semi-supervised Kernel Classification
 Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
CMPSCI 791BB: Advanced ML: Laplacian Learning
 CMPSCI 791BB: Advanced ML: Laplacian Learning Sridhar Mahadevan Outline! Spectral graph operators! Combinatorial graph Laplacian! Normalized graph Laplacian! Random walks! Machine learning on graphs! Clustering!
CMPSCI 791BB: Advanced ML: Laplacian Learning Sridhar Mahadevan Outline! Spectral graph operators! Combinatorial graph Laplacian! Normalized graph Laplacian! Random walks! Machine learning on graphs! Clustering!
An Introduction to Spectral Graph Theory
 An Introduction to Spectral Graph Theory Mackenzie Wheeler Supervisor: Dr. Gary MacGillivray University of Victoria WheelerM@uvic.ca Outline Outline 1. How many walks are there from vertices v i to v j
An Introduction to Spectral Graph Theory Mackenzie Wheeler Supervisor: Dr. Gary MacGillivray University of Victoria WheelerM@uvic.ca Outline Outline 1. How many walks are there from vertices v i to v j
Mistake Bound Model, Halving Algorithm, Linear Classifiers, & Perceptron
 Stat 928: Statistical Learning Theory Lecture: 18 Mistake Bound Model, Halving Algorithm, Linear Classifiers, & Perceptron Instructor: Sham Kakade 1 Introduction This course will be divided into 2 parts.
Stat 928: Statistical Learning Theory Lecture: 18 Mistake Bound Model, Halving Algorithm, Linear Classifiers, & Perceptron Instructor: Sham Kakade 1 Introduction This course will be divided into 2 parts.
Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking p. 1/31
 Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking Dengyong Zhou zhou@tuebingen.mpg.de Dept. Schölkopf, Max Planck Institute for Biological Cybernetics, Germany Learning from
Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking Dengyong Zhou zhou@tuebingen.mpg.de Dept. Schölkopf, Max Planck Institute for Biological Cybernetics, Germany Learning from
Fast and Optimal Algorithms for Weighted Graph Prediction
 Fast and Optimal Algorithms for Weighted raph Prediction Nicolò Cesa-Bianchi Università di Milano, Italy cesa-bianchi@dsi.unimi.it Fabio Vitale Università di Milano, Italy fabio.vitale@unimi.it Claudio
Fast and Optimal Algorithms for Weighted raph Prediction Nicolò Cesa-Bianchi Università di Milano, Italy cesa-bianchi@dsi.unimi.it Fabio Vitale Università di Milano, Italy fabio.vitale@unimi.it Claudio
Machine Learning for Data Science (CS4786) Lecture 11
 Lecture 11") Machine Learning for Data Science (CS4786) Lecture 11 Spectral clustering Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016sp/ ANNOUNCEMENT 1 Assignment P1 the Diagnostic assignment 1 will
Machine Learning for Data Science (CS4786) Lecture 11 Spectral clustering Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016sp/ ANNOUNCEMENT 1 Assignment P1 the Diagnostic assignment 1 will
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Analysis of Spectral Kernel Design based Semi-supervised Learning
 Analysis of Spectral Kernel Design based Semi-supervised Learning Tong Zhang IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Rie Kubota Ando IBM T. J. Watson Research Center Yorktown Heights,
Analysis of Spectral Kernel Design based Semi-supervised Learning Tong Zhang IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Rie Kubota Ando IBM T. J. Watson Research Center Yorktown Heights,
Learning on Graphs and Manifolds. CMPSCI 689 Sridhar Mahadevan U.Mass Amherst
 Learning on Graphs and Manifolds CMPSCI 689 Sridhar Mahadevan U.Mass Amherst Outline Manifold learning is a relatively new area of machine learning (2000-now). Main idea Model the underlying geometry of
Learning on Graphs and Manifolds CMPSCI 689 Sridhar Mahadevan U.Mass Amherst Outline Manifold learning is a relatively new area of machine learning (2000-now). Main idea Model the underlying geometry of
Semi-Supervised Learning in Gigantic Image Collections. Rob Fergus (New York University) Yair Weiss (Hebrew University) Antonio Torralba (MIT)
 Yair Weiss (Hebrew University) Antonio Torralba (MIT)") Semi-Supervised Learning in Gigantic Image Collections Rob Fergus (New York University) Yair Weiss (Hebrew University) Antonio Torralba (MIT) Gigantic Image Collections What does the world look like? High
Semi-Supervised Learning in Gigantic Image Collections Rob Fergus (New York University) Yair Weiss (Hebrew University) Antonio Torralba (MIT) Gigantic Image Collections What does the world look like? High
How to learn from very few examples?
 How to learn from very few examples? Dengyong Zhou Department of Empirical Inference Max Planck Institute for Biological Cybernetics Spemannstr. 38, 72076 Tuebingen, Germany Outline Introduction Part A
How to learn from very few examples? Dengyong Zhou Department of Empirical Inference Max Planck Institute for Biological Cybernetics Spemannstr. 38, 72076 Tuebingen, Germany Outline Introduction Part A
Manifold Regularization
 Manifold Regularization Vikas Sindhwani Department of Computer Science University of Chicago Joint Work with Mikhail Belkin and Partha Niyogi TTI-C Talk September 14, 24 p.1 The Problem of Learning is
Manifold Regularization Vikas Sindhwani Department of Computer Science University of Chicago Joint Work with Mikhail Belkin and Partha Niyogi TTI-C Talk September 14, 24 p.1 The Problem of Learning is
Support Vector Machines: Maximum Margin Classifiers
 Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Logistic Regression Logistic
 Case Study 1: Estimating Click Probabilities L2 Regularization for Logistic Regression Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 10 th,
Case Study 1: Estimating Click Probabilities L2 Regularization for Logistic Regression Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 10 th,
Locally-biased analytics
 Locally-biased analytics You have BIG data and want to analyze a small part of it: Solution 1: Cut out small part and use traditional methods Challenge: cutting out may be difficult a priori Solution 2:
Locally-biased analytics You have BIG data and want to analyze a small part of it: Solution 1: Cut out small part and use traditional methods Challenge: cutting out may be difficult a priori Solution 2:
Kernels for Multi task Learning
 Kernels for Multi task Learning Charles A Micchelli Department of Mathematics and Statistics State University of New York, The University at Albany 1400 Washington Avenue, Albany, NY, 12222, USA Massimiliano
Kernels for Multi task Learning Charles A Micchelli Department of Mathematics and Statistics State University of New York, The University at Albany 1400 Washington Avenue, Albany, NY, 12222, USA Massimiliano
Multisurface Proximal Support Vector Machine Classification via Generalized Eigenvalues
 Multisurface Proximal Support Vector Machine Classification via Generalized Eigenvalues O. L. Mangasarian and E. W. Wild Presented by: Jun Fang Multisurface Proximal Support Vector Machine Classification
Multisurface Proximal Support Vector Machine Classification via Generalized Eigenvalues O. L. Mangasarian and E. W. Wild Presented by: Jun Fang Multisurface Proximal Support Vector Machine Classification
What is semi-supervised learning?
 What is semi-supervised learning? In many practical learning domains, there is a large supply of unlabeled data but limited labeled data, which can be expensive to generate text processing, video-indexing,
What is semi-supervised learning? In many practical learning domains, there is a large supply of unlabeled data but limited labeled data, which can be expensive to generate text processing, video-indexing,
HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH
 HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH Hoang Trang 1, Tran Hoang Loc 1 1 Ho Chi Minh City University of Technology-VNU HCM, Ho Chi
HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH Hoang Trang 1, Tran Hoang Loc 1 1 Ho Chi Minh City University of Technology-VNU HCM, Ho Chi
6.867 Machine learning
 6.867 Machine learning Mid-term eam October 8, 6 ( points) Your name and MIT ID: .5.5 y.5 y.5 a).5.5 b).5.5.5.5 y.5 y.5 c).5.5 d).5.5 Figure : Plots of linear regression results with different types of
6.867 Machine learning Mid-term eam October 8, 6 ( points) Your name and MIT ID: .5.5 y.5 y.5 a).5.5 b).5.5.5.5 y.5 y.5 c).5.5 d).5.5 Figure : Plots of linear regression results with different types of
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x))
 e.g. s ij = diag(l i (x))") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
6.036 midterm review. Wednesday, March 18, 15
 6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
Manifold Coarse Graining for Online Semi-supervised Learning
 for Online Semi-supervised Learning Mehrdad Farajtabar, Amirreza Shaban, Hamid R. Rabiee, Mohammad H. Rohban Digital Media Lab, Department of Computer Engineering, Sharif University of Technology, Tehran,
for Online Semi-supervised Learning Mehrdad Farajtabar, Amirreza Shaban, Hamid R. Rabiee, Mohammad H. Rohban Digital Media Lab, Department of Computer Engineering, Sharif University of Technology, Tehran,
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
L 2,1 Norm and its Applications
 L 2, Norm and its Applications Yale Chang Introduction According to the structure of the constraints, the sparsity can be obtained from three types of regularizers for different purposes.. Flat Sparsity.
L 2, Norm and its Applications Yale Chang Introduction According to the structure of the constraints, the sparsity can be obtained from three types of regularizers for different purposes.. Flat Sparsity.
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Multiclass Classification-1
 CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Applied Machine Learning Annalisa Marsico
 Applied Machine Learning Annalisa Marsico OWL RNA Bionformatics group Max Planck Institute for Molecular Genetics Free University of Berlin 29 April, SoSe 2015 Support Vector Machines (SVMs) 1. One of
Applied Machine Learning Annalisa Marsico OWL RNA Bionformatics group Max Planck Institute for Molecular Genetics Free University of Berlin 29 April, SoSe 2015 Support Vector Machines (SVMs) 1. One of
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Support Vector Machine
 Support Vector Machine Kernel: Kernel is defined as a function returning the inner product between the images of the two arguments k(x 1, x 2 ) = ϕ(x 1 ), ϕ(x 2 ) k(x 1, x 2 ) = k(x 2, x 1 ) modularity-
Support Vector Machine Kernel: Kernel is defined as a function returning the inner product between the images of the two arguments k(x 1, x 2 ) = ϕ(x 1 ), ϕ(x 2 ) k(x 1, x 2 ) = k(x 2, x 1 ) modularity-
A Statistical Look at Spectral Graph Analysis. Deep Mukhopadhyay
 A Statistical Look at Spectral Graph Analysis Deep Mukhopadhyay Department of Statistics, Temple University Office: Speakman 335 deep@temple.edu http://sites.temple.edu/deepstat/ Graph Signal Processing
A Statistical Look at Spectral Graph Analysis Deep Mukhopadhyay Department of Statistics, Temple University Office: Speakman 335 deep@temple.edu http://sites.temple.edu/deepstat/ Graph Signal Processing
Efficient and Principled Online Classification Algorithms for Lifelon
 Efficient and Principled Online Classification Algorithms for Lifelong Learning Toyota Technological Institute at Chicago Chicago, IL USA Talk @ Lifelong Learning for Mobile Robotics Applications Workshop,
Efficient and Principled Online Classification Algorithms for Lifelong Learning Toyota Technological Institute at Chicago Chicago, IL USA Talk @ Lifelong Learning for Mobile Robotics Applications Workshop,
Kernel Methods. Foundations of Data Analysis. Torsten Möller. Möller/Mori 1
 Kernel Methods Foundations of Data Analysis Torsten Möller Möller/Mori 1 Reading Chapter 6 of Pattern Recognition and Machine Learning by Bishop Chapter 12 of The Elements of Statistical Learning by Hastie,
Kernel Methods Foundations of Data Analysis Torsten Möller Möller/Mori 1 Reading Chapter 6 of Pattern Recognition and Machine Learning by Bishop Chapter 12 of The Elements of Statistical Learning by Hastie,
Machine learning for pervasive systems Classification in high-dimensional spaces
 Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Semi-Supervised Learning
 Semi-Supervised Learning getting more for less in natural language processing and beyond Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1 Semi-supervised Learning many human
Semi-Supervised Learning getting more for less in natural language processing and beyond Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1 Semi-supervised Learning many human
Pattern Recognition and Machine Learning. Perceptrons and Support Vector machines
 Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Semi Supervised Distance Metric Learning
 Semi Supervised Distance Metric Learning wliu@ee.columbia.edu Outline Background Related Work Learning Framework Collaborative Image Retrieval Future Research Background Euclidean distance d( x, x ) =
Semi Supervised Distance Metric Learning wliu@ee.columbia.edu Outline Background Related Work Learning Framework Collaborative Image Retrieval Future Research Background Euclidean distance d( x, x ) =
Kernel Methods & Support Vector Machines
 Kernel Methods & Support Vector Machines Mahdi pakdaman Naeini PhD Candidate, University of Tehran Senior Researcher, TOSAN Intelligent Data Miners Outline Motivation Introduction to pattern recognition
Kernel Methods & Support Vector Machines Mahdi pakdaman Naeini PhD Candidate, University of Tehran Senior Researcher, TOSAN Intelligent Data Miners Outline Motivation Introduction to pattern recognition
Machine Learning for Structured Prediction
 Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Graph Partitioning Using Random Walks
 Graph Partitioning Using Random Walks A Convex Optimization Perspective Lorenzo Orecchia Computer Science Why Spectral Algorithms for Graph Problems in practice? Simple to implement Can exploit very efficient
Graph Partitioning Using Random Walks A Convex Optimization Perspective Lorenzo Orecchia Computer Science Why Spectral Algorithms for Graph Problems in practice? Simple to implement Can exploit very efficient
Efficient Bandit Algorithms for Online Multiclass Prediction
 Efficient Bandit Algorithms for Online Multiclass Prediction Sham Kakade, Shai Shalev-Shwartz and Ambuj Tewari Presented By: Nakul Verma Motivation In many learning applications, true class labels are
Efficient Bandit Algorithms for Online Multiclass Prediction Sham Kakade, Shai Shalev-Shwartz and Ambuj Tewari Presented By: Nakul Verma Motivation In many learning applications, true class labels are
Predicting a Switching Sequence of Graph Labelings
 Journal of Machine Learning Research 16 (2015 2003-2022 Submitted 7/15; Published 9/15 Predicting a Switching Sequence of Graph Labelings Mark Herbster Stephen Pasteris Massimiliano Pontil Department of
Journal of Machine Learning Research 16 (2015 2003-2022 Submitted 7/15; Published 9/15 Predicting a Switching Sequence of Graph Labelings Mark Herbster Stephen Pasteris Massimiliano Pontil Department of
Perceptron Mistake Bounds
 Perceptron Mistake Bounds Mehryar Mohri, and Afshin Rostamizadeh Google Research Courant Institute of Mathematical Sciences Abstract. We present a brief survey of existing mistake bounds and introduce
Perceptron Mistake Bounds Mehryar Mohri, and Afshin Rostamizadeh Google Research Courant Institute of Mathematical Sciences Abstract. We present a brief survey of existing mistake bounds and introduce
THE ADVICEPTRON: GIVING ADVICE TO THE PERCEPTRON
 THE ADVICEPTRON: GIVING ADVICE TO THE PERCEPTRON Gautam Kunapuli Kristin P. Bennett University of Wisconsin Madison Rensselaer Polytechnic Institute Madison, WI 5375 Troy, NY 1218 kunapg@wisc.edu bennek@rpi.edu
THE ADVICEPTRON: GIVING ADVICE TO THE PERCEPTRON Gautam Kunapuli Kristin P. Bennett University of Wisconsin Madison Rensselaer Polytechnic Institute Madison, WI 5375 Troy, NY 1218 kunapg@wisc.edu bennek@rpi.edu
Support Vector and Kernel Methods
 SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
SVMs: nonlinearity through kernels
 Non-separable data e-8. Support Vector Machines 8.. The Optimal Hyperplane Consider the following two datasets: SVMs: nonlinearity through kernels ER Chapter 3.4, e-8 (a) Few noisy data. (b) Nonlinearly
Non-separable data e-8. Support Vector Machines 8.. The Optimal Hyperplane Consider the following two datasets: SVMs: nonlinearity through kernels ER Chapter 3.4, e-8 (a) Few noisy data. (b) Nonlinearly
Semi-Supervised Learning with Graphs. Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University
 Zhu School of Computer Science Carnegie Mellon University") Semi-Supervised Learning with Graphs Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1 Semi-supervised Learning classification classifiers need labeled data to train labeled data
Semi-Supervised Learning with Graphs Xiaojin (Jerry) Zhu School of Computer Science Carnegie Mellon University 1 Semi-supervised Learning classification classifiers need labeled data to train labeled data
Perceptron Revisited: Linear Separators. Support Vector Machines
 Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
MATH 829: Introduction to Data Mining and Analysis Clustering II
 his lecture is based on U. von Luxburg, A Tutorial on Spectral Clustering, Statistics and Computing, 17 (4), 2007. MATH 829: Introduction to Data Mining and Analysis Clustering II Dominique Guillot Departments
his lecture is based on U. von Luxburg, A Tutorial on Spectral Clustering, Statistics and Computing, 17 (4), 2007. MATH 829: Introduction to Data Mining and Analysis Clustering II Dominique Guillot Departments
Kernels A Machine Learning Overview
 Kernels A Machine Learning Overview S.V.N. Vishy Vishwanathan vishy@axiom.anu.edu.au National ICT of Australia and Australian National University Thanks to Alex Smola, Stéphane Canu, Mike Jordan and Peter
Kernels A Machine Learning Overview S.V.N. Vishy Vishwanathan vishy@axiom.anu.edu.au National ICT of Australia and Australian National University Thanks to Alex Smola, Stéphane Canu, Mike Jordan and Peter
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec Stanford University Jure Leskovec, Stanford University http://cs224w.stanford.edu Task: Find coalitions in signed networks Incentives: European
CS224W: Social and Information Network Analysis Jure Leskovec Stanford University Jure Leskovec, Stanford University http://cs224w.stanford.edu Task: Find coalitions in signed networks Incentives: European
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA
 Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Nonlinear Dimensionality Reduction. Jose A. Costa
 Nonlinear Dimensionality Reduction Jose A. Costa Mathematics of Information Seminar, Dec. Motivation Many useful of signals such as: Image databases; Gene expression microarrays; Internet traffic time
Nonlinear Dimensionality Reduction Jose A. Costa Mathematics of Information Seminar, Dec. Motivation Many useful of signals such as: Image databases; Gene expression microarrays; Internet traffic time
Nonlinear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Graph-Laplacian PCA: Closed-form Solution and Robustness
 2013 IEEE Conference on Computer Vision and Pattern Recognition Graph-Laplacian PCA: Closed-form Solution and Robustness Bo Jiang a, Chris Ding b,a, Bin Luo a, Jin Tang a a School of Computer Science and
2013 IEEE Conference on Computer Vision and Pattern Recognition Graph-Laplacian PCA: Closed-form Solution and Robustness Bo Jiang a, Chris Ding b,a, Bin Luo a, Jin Tang a a School of Computer Science and
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Kernel Methods. Barnabás Póczos
 Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Statistical Learning Notes III-Section 2.4.3
 Statistical Learning Notes III-Section 2.4.3 "Graphical" Spectral Features Stephen Vardeman Analytics Iowa LLC January 2019 Stephen Vardeman (Analytics Iowa LLC) Statistical Learning Notes III-Section
Statistical Learning Notes III-Section 2.4.3 "Graphical" Spectral Features Stephen Vardeman Analytics Iowa LLC January 2019 Stephen Vardeman (Analytics Iowa LLC) Statistical Learning Notes III-Section
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center
 Fei Wang and Jimeng Sun IBM TJ Watson Research Center") Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Spectra of Adjacency and Laplacian Matrices
 Spectra of Adjacency and Laplacian Matrices Definition: University of Alicante (Spain) Matrix Computing (subject 3168 Degree in Maths) 30 hours (theory)) + 15 hours (practical assignment) Contents 1. Spectra
Spectra of Adjacency and Laplacian Matrices Definition: University of Alicante (Spain) Matrix Computing (subject 3168 Degree in Maths) 30 hours (theory)) + 15 hours (practical assignment) Contents 1. Spectra
Lecture 12 : Graph Laplacians and Cheeger s Inequality
 CPS290: Algorithmic Foundations of Data Science March 7, 2017 Lecture 12 : Graph Laplacians and Cheeger s Inequality Lecturer: Kamesh Munagala Scribe: Kamesh Munagala Graph Laplacian Maybe the most beautiful
CPS290: Algorithmic Foundations of Data Science March 7, 2017 Lecture 12 : Graph Laplacians and Cheeger s Inequality Lecturer: Kamesh Munagala Scribe: Kamesh Munagala Graph Laplacian Maybe the most beautiful
CS-E4830 Kernel Methods in Machine Learning
 CS-E4830 Kernel Methods in Machine Learning Lecture 5: Multi-class and preference learning Juho Rousu 11. October, 2017 Juho Rousu 11. October, 2017 1 / 37 Agenda from now on: This week s theme: going
CS-E4830 Kernel Methods in Machine Learning Lecture 5: Multi-class and preference learning Juho Rousu 11. October, 2017 Juho Rousu 11. October, 2017 1 / 37 Agenda from now on: This week s theme: going
MULTIPLEKERNELLEARNING CSE902
 MULTIPLEKERNELLEARNING CSE902 Multiple Kernel Learning -keywords Heterogeneous information fusion Feature selection Max-margin classification Multiple kernel learning MKL Convex optimization Kernel classification
MULTIPLEKERNELLEARNING CSE902 Multiple Kernel Learning -keywords Heterogeneous information fusion Feature selection Max-margin classification Multiple kernel learning MKL Convex optimization Kernel classification
Overview of Statistical Tools. Statistical Inference. Bayesian Framework. Modeling. Very simple case. Things are usually more complicated
 Fall 3 Computer Vision Overview of Statistical Tools Statistical Inference Haibin Ling Observation inference Decision Prior knowledge http://www.dabi.temple.edu/~hbling/teaching/3f_5543/index.html Bayesian
Fall 3 Computer Vision Overview of Statistical Tools Statistical Inference Haibin Ling Observation inference Decision Prior knowledge http://www.dabi.temple.edu/~hbling/teaching/3f_5543/index.html Bayesian
A summary of Deep Learning without Poor Local Minima
 A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Linear, threshold units. Linear Discriminant Functions and Support Vector Machines. Biometrics CSE 190 Lecture 11. X i : inputs W i : weights
 Linear Discriminant Functions and Support Vector Machines Linear, threshold units CSE19, Winter 11 Biometrics CSE 19 Lecture 11 1 X i : inputs W i : weights θ : threshold 3 4 5 1 6 7 Courtesy of University
Linear Discriminant Functions and Support Vector Machines Linear, threshold units CSE19, Winter 11 Biometrics CSE 19 Lecture 11 1 X i : inputs W i : weights θ : threshold 3 4 5 1 6 7 Courtesy of University
CS 231A Section 1: Linear Algebra & Probability Review
 CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
The Perceptron Algorithm, Margins
 The Perceptron Algorithm, Margins MariaFlorina Balcan 08/29/2018 The Perceptron Algorithm Simple learning algorithm for supervised classification analyzed via geometric margins in the 50 s [Rosenblatt
The Perceptron Algorithm, Margins MariaFlorina Balcan 08/29/2018 The Perceptron Algorithm Simple learning algorithm for supervised classification analyzed via geometric margins in the 50 s [Rosenblatt
CS 231A Section 1: Linear Algebra & Probability Review. Kevin Tang
 CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
On the inverse matrix of the Laplacian and all ones matrix
 On the inverse matrix of the Laplacian and all ones matrix Sho Suda (Joint work with Michio Seto and Tetsuji Taniguchi) International Christian University JSPS Research Fellow PD November 21, 2012 Sho
On the inverse matrix of the Laplacian and all ones matrix Sho Suda (Joint work with Michio Seto and Tetsuji Taniguchi) International Christian University JSPS Research Fellow PD November 21, 2012 Sho
Data dependent operators for the spatial-spectral fusion problem
 Data dependent operators for the spatial-spectral fusion problem Wien, December 3, 2012 Joint work with: University of Maryland: J. J. Benedetto, J. A. Dobrosotskaya, T. Doster, K. W. Duke, M. Ehler, A.
Data dependent operators for the spatial-spectral fusion problem Wien, December 3, 2012 Joint work with: University of Maryland: J. J. Benedetto, J. A. Dobrosotskaya, T. Doster, K. W. Duke, M. Ehler, A.
Perceptron (Theory) + Linear Regression
 + Linear Regression") 10601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron (Theory) Linear Regression Matt Gormley Lecture 6 Feb. 5, 2018 1 Q&A
10601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron (Theory) Linear Regression Matt Gormley Lecture 6 Feb. 5, 2018 1 Q&A
CS 446: Machine Learning Lecture 4, Part 2: On-Line Learning
 CS 446: Machine Learning Lecture 4, Part 2: On-Line Learning 0.1 Linear Functions So far, we have been looking at Linear Functions { as a class of functions which can 1 if W1 X separate some data and not
CS 446: Machine Learning Lecture 4, Part 2: On-Line Learning 0.1 Linear Functions So far, we have been looking at Linear Functions { as a class of functions which can 1 if W1 X separate some data and not
Outline. Motivation. Mapping the input space to the feature space Calculating the dot product in the feature space
 to The The A s s in to Fabio A. González Ph.D. Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá April 2, 2009 to The The A s s in 1 Motivation Outline 2 The Mapping the
to The The A s s in to Fabio A. González Ph.D. Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá April 2, 2009 to The The A s s in 1 Motivation Outline 2 The Mapping the
Support Vector Machines for Classification: A Statistical Portrait
 Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Graphs, Geometry and Semi-supervised Learning
 Graphs, Geometry and Semi-supervised Learning Mikhail Belkin The Ohio State University, Dept of Computer Science and Engineering and Dept of Statistics Collaborators: Partha Niyogi, Vikas Sindhwani In
Graphs, Geometry and Semi-supervised Learning Mikhail Belkin The Ohio State University, Dept of Computer Science and Engineering and Dept of Statistics Collaborators: Partha Niyogi, Vikas Sindhwani In
Finding normalized and modularity cuts by spectral clustering. Ljubjana 2010, October
 Finding normalized and modularity cuts by spectral clustering Marianna Bolla Institute of Mathematics Budapest University of Technology and Economics marib@math.bme.hu Ljubjana 2010, October Outline Find
Finding normalized and modularity cuts by spectral clustering Marianna Bolla Institute of Mathematics Budapest University of Technology and Economics marib@math.bme.hu Ljubjana 2010, October Outline Find
Diffusion and random walks on graphs
 Diffusion and random walks on graphs Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural
Diffusion and random walks on graphs Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural
1 Inner Product and Orthogonality
 CSCI 4/Fall 6/Vora/GWU/Orthogonality and Norms Inner Product and Orthogonality Definition : The inner product of two vectors x and y, x x x =.., y =. x n y y... y n is denoted x, y : Note that n x, y =
CSCI 4/Fall 6/Vora/GWU/Orthogonality and Norms Inner Product and Orthogonality Definition : The inner product of two vectors x and y, x x x =.., y =. x n y y... y n is denoted x, y : Note that n x, y =
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
A PROBABILISTIC INTERPRETATION OF SAMPLING THEORY OF GRAPH SIGNALS. Akshay Gadde and Antonio Ortega
 A PROBABILISTIC INTERPRETATION OF SAMPLING THEORY OF GRAPH SIGNALS Akshay Gadde and Antonio Ortega Department of Electrical Engineering University of Southern California, Los Angeles Email: agadde@usc.edu,
A PROBABILISTIC INTERPRETATION OF SAMPLING THEORY OF GRAPH SIGNALS Akshay Gadde and Antonio Ortega Department of Electrical Engineering University of Southern California, Los Angeles Email: agadde@usc.edu,
Oslo Class 2 Tikhonov regularization and kernels
 RegML2017@SIMULA Oslo Class 2 Tikhonov regularization and kernels Lorenzo Rosasco UNIGE-MIT-IIT May 3, 2017 Learning problem Problem For H {f f : X Y }, solve min E(f), f H dρ(x, y)l(f(x), y) given S n
RegML2017@SIMULA Oslo Class 2 Tikhonov regularization and kernels Lorenzo Rosasco UNIGE-MIT-IIT May 3, 2017 Learning problem Problem For H {f f : X Y }, solve min E(f), f H dρ(x, y)l(f(x), y) given S n