Data Analysis and Manifold Learning Lecture 9: Diffusion on Manifolds and on Graphs
|
|
|
- Kerrie Anthony
- 5 years ago
- Views:
Transcription
1 Data Analysis and Manifold Learning Lecture 9: Diffusion on Manifolds and on Graphs Radu Horaud INRIA Grenoble Rhone-Alpes, France
2 Outline of Lecture 9 Kernels on graphs The exponential diffusion kernel The heat kernel of discrete manifolds Properties of the heat kernel The auto-diffusion function Shape matching
3 Material for this lecture P. Bérard, G. Besson, & G. Gallot. Embedding Riemannian manifolds by their heat kernel. Geometric and Functional Analysis (1994): A rather theoretical paper. J. Shawe-Taylor & N. Cristianini. Kernel Methods in Pattern Analysis (chapter 10): A mild introduction to graph kernels. R. Kondor and J.-P. Vert: Diffusion Kernels in Kernel Methods in Computational Biology ed. B. Scholkopf, K. Tsuda and J.-P. Vert, (The MIT Press, 2004): An interesting paper to read. J. Sun, M. Ovsjanikov, & L. Guibas. A concise and provably informative multi-scale signature based on heat diffusion. Symposium on Geometric Processing (2009). A. Sharma & R. Horaud. Shape matching based on diffusion embedding and on mutual isometric consistency. NORDIA workshop (2010).
4 The Adjacency Matrix of a Graph (from Lecture #3) For a graph with n vertices and with binary edges, the entries of the n n adjacency matrix are defined by: A ij = 1 if there is an edge e ij A := A ij = 0 if there is no edge A ii = 0 A =
5 The Walks of Length 2 The number of walks of length 2 between two graph vertices: Examples: A 2 = N 2 (v i, v j ) = A 2 (i, j) N 2 (v 2, v 3 ) = 1; N 2 (v 2, v 2 ) =
6 The Number of Walks of Length k Theorem The number of walks of length k joining any two nodes v i and v j of a binary graph is given by the (i, j) entry of the matrix A k : N k (v i, v j ) = A k (i, j) A proof of this theorem is provided in: Godsil and Royle. (2001). Algebraic Graph Theory. Springer.
7 The Similarity Matrix of an Undirected Weighted Graph We consider undirected weighted graphs; Each edge e ij is weighted by ω ij > 0. We obtain: Ω(i, j) = ω(v i, v j ) = ω ij Ω := Ω(i, j) = 0 Ω(i, i) = 0 if there is an edge e ij if there is no edge We will refer to this matrix as the base similarity matrix
8 Walks of Length 2 The weight of the walk from v i to v j through v l is defined as the product of the corresponding edge weights: ω(v i, v l )ω(v l, v j ) The sum of weigths of all walks of length 2: ω 2 (v i, v j ) = n ω(v i, v l )ω(v l, v j ) = Ω 2 (i, j) l=1
9 Associated Feature Space Let Ω = UΛU, i.e., the spectral decomposition of a real symmetric matrix. We have Ω 2 = UΛ 2 U is symmetric semi-definite positive, hence it can be interpreted as a kernel matrix, with: ω 2 (v i, v j ) = n ω(v i, v l )ω(v l, v j ) l=1 Associated feature space: = (ω(v i, v l )) n l=1, (ω(v j, v l )) n l=1 = κ(v i, v j ) φ : v i φ(v i ) = (ω(v i, v 1 )... ω(v i, v l )... ω(v i, v n )) It is possible to enhance the base similarity matrix by linking vertices along walks of length 2.
10 Combining Powers of the Base Similarity Matrix More generally one can take powers of the base similarity matrix as well as linear combinations of these matrices: α 1 Ω α k Ω k α K Ω K The eigenvalues of such a matrix must be nonnegative to satisfy the kernel condition: α 1 Λ α k Λ k α K Λ K 0
11 The Exponential Diffusion Kernel Consider the following combination of powers of the base similarity matrix: µ k K = k! Ωk This corresponds to: k=0 K = e µω where µ is a decay factor chosen such that the influence of longer walks decreases, since they are less reliable. Spectral decomposition: K = Ue µλ U Hence K is a kernel matrix since its eigenvalues e µλ i 0.
12 Heat Diffusion on a Graph The ( heat-diffusion equation on a Riemannian manifold: t + ) M f(x; t) = 0 M denotes the geometric Laplace-Beltrami operator. f(x; t) is the distribution of heat over the manifold at time t. By extension, t + M can be referred to as the heat operator [Bérard et al. 1994]. This equation can also be written on a graph: ( ) t + L F (t) = 0 where the vector F (t) = (F 1 (t)... F n (t)) is indexed by the nodes of the graph.
13 The Fundamental Solution The fundamental solution of the (heat)-diffusion equation on Riemannian manifolds holds in the discrete case, i.e., for undirected weighted graphs. The solution in the discrete case is: F (t) = H(t)f where H denotes the discrete heat operator: H(t) = e tl f corresponds to the initial heat distribution: F (0) = f Starting with a point-heat distribution at vertex v i, e.g., (0... f i = ), the distribution at t, i.e., F (t) = (F 1 (t)... F n (t)) is given by the i-th column of the heat operator.
14 How to Compute the Heat Matrix? The exponential of a matrix: Hence: e A = e tl = k=0 A k k! ( t) k k=0 It belongs to the exponential diffusion family of kernels just introduced with µ = t, t > 0. k! L k
15 Spectral Properties of L We start by recalling some basic facts about the combinatorial graph Laplacian: Symmetric semi-definite positive matrix: L = UΛU Eigenvalues: 0 = λ 1 < λ 2... λ n Eigenvectors: u 1 = 1, u 2,..., u n λ 2 and u 2 are the Fiedler value and the Fiedler vector u i u j = δ ij u i>11 = 0 n i=1 u ik = 0, k {2,..., n} 1 < u ik < 1, i {1,..., n}, k {2,..., n} L = n λ k u k u k k=2
16 The Heat-kernel Matrix with: H(t) = e tuλu = Ue tλ U 0 e tλ = Diag[e tλ 1... e tλn ] Eigenvalues: 1 = e t0 > e tλ 2... e tλn Eigenvectors: same as the Laplacian matrix with their properties (previous slide). The heat trace (also referred to as the partition function): n Z(t) = tr(h) = e tλ k The determinant: det(h) = k=1 n e tλ k = e ttr(l) = e tvol(g) k=1
17 The Heat-kernel Computing the heat matrix: H(t) = n e tλ k u k u k k=2 where we applied a deflation to get rid of the constant eigenvector: H H u 1 u 1 The heat kernel (en entry of the matrix above): h(i, j; t) = n e tλ k u ik u jk k=2
18 Feature-space Embedding Using the Heat Kernel H(t) = (Ue 1 tλ) ( 2 Ue 1 tλ) 2 Each row of the n n matrix Ue tλ/2 can be viewed as the coordinates of a graph vertex in a feature space, i.e., the mapping φ : V R n 1, x i = φ(v i ): x i = ( e 1 2 tλ 2 u i2... e 1 2 tλ k u ik... e 1 2 tλn u in ) = (x i2... x ik... x in ) The heat-kernel computes the inner product in feature space: h(i, j; t) = φ(v i ), φ(v j )
19 The Auto-diffusion Function Each diagonal term of the heat matrix corresponds to the norm of a feature-space point: h(i, i; t) = n e tλ k u 2 ik = x i 2 k=2 This is also known as the auto-diffusion function (ADF), or the amount of heat that remains at a vertex at time t. The local maxima/minima of this function have been used for a feature-based scale-space representation of shapes. Associated shape descriptor: v i h(i, i; t) hence it is a scalar function defined over the graph.

20 The ADF as a Shape Descriptor t = 0 t = 50 t =
21 Spectral Distances The heat distance: d 2 t (i, j) = h(i, i; t) + h(j, j; t) 2h(i, j; t) = n (e 1 2 tλ k (u ik u jk )) 2 k=2 The commute-time distance: d 2 CTD (i, j) = = t=0 k=2 n k=2 n (e 1 2 tλ k (u ik u jk )) 2 dt ( λ 1/2 k (u ik u jk ) ) 2
22 Principal Component Analysis The covariance matrix in feature space: C X = 1 n n (x i x)(x i x) i=1 With: X = ( Ue 1 2 tλ) = [x1... x i... x n ] Remember that each column of U sums to zero. 1 < e 1 2 tλ k < x ik < e 1 2 tλ k < 1, 2 k n
23 Principal Component Analysis: The Mean x = 1 n n i=1 x i = 1 n e 1 2 tλ = 0. 0 n i=1 u i2. n i=1 u in
24 Principal Component Analysis: The Covariance C X = 1 n n x i x i i=1 = 1 n XX = 1 (Ue 1 tλ) 2 (Ue 1 tλ) 2 n = 1 n e tλ
25 Result I: The PCA of a Graph The eigenvectors (of the combinatorial Laplacian) are the principal components of the heat-kernel embedding: hence we obtain a maximum-variance embedding The associated variances are e tλ 2 /n,..., e tλn /n. The embedded points are strictly contained in a hyper-parallelepipedon with volume n i=2 e tλ i.
26 Dimensionality Reduction (1) Dimensionality reduction consists in selecting the K largest eigenvalues, K < n, conditioned by t, hence the criterion: choose K and t, such that (scree diagram): α(k) = K+1 i=2 e tλ i /n n i=2 e tλ i /n 0.95 This is not practical because one needs to compute all the eigenvalues.
27 Dimensionality Reduction (2) An alternative possibility is to use the determinant of the covariance matrix, and to choose the first K eigenvectors such that (with α > 1): which yields: α(k) = t α(k) = ln ( tr(l) K+1 i=2 e tλ i /n n i=2 e tλ i /n K+1 i=2 This allows to choose K for a scale t. λ i ) + (n K) ln n
28 Normalizing the Feature-space Observe that the heat-kernels collapse to 0 at infinity: lim t h(i, j; t) = 0. To prevent this problem, several normalizations are possible: Trace normalization Unit hyper-sphere normalization Time-invariant embedding
29 Trace Normalization Observe that lim t h(i, j; t) = 0 Use the trace of the operator to normalize the embedding: x i = x i Z(t) with: Z(t) K+1 k=2 e tλ k the k-component of the i-coordinate writes: ˆx ik (t) = ( e tλ k u 2 ik) 1/2 ( K+1 ) 1/2 l=2 e tλ l At the limit: x i (t ) = ( ui2 m... u i m+1 m ) where m is the multiplicity of the first non-null eigenvalue.
30 Unit Hyper-sphere Normalization The embedding lies on a unit hyper-sphere of dimension K: x i = x i x i The heat distance becomes a geodesic distance on a spherical manifold: d S (i, j; t) = arccos x i x j = arccos h(i, j; t) (h(i, i; t)h(j, j; t)) 1/2 At the limit (m is the multiplicity of the largest non-null eigenvalue): x i (t ) = ( u i2 ( P m+1 l=2 u2 il) 1/2... u i m+1 ( P m+1 l=2 u2 il) 1/ )
31 Time-invariant Embedding Integration over time: L = = 0 n k=2 H(t) = 0 n e tλ k u k u k dt k=2 1 λ k u k u k = UΛ U with: Λ = Diag[λ 1 2,..., λ 1 n ]. Matrix L is called the discrete Green s function [ChungYau2000], the Moore-Penrose pseudo-inverse of the Laplacian. ( ) Embedding: x i = λ 1/2 2 u i2... λ 1/2 K+1 u i K+1 Covariance: C X = 1 n Diag[λ 1 2,..., λ 1 K+1 ]


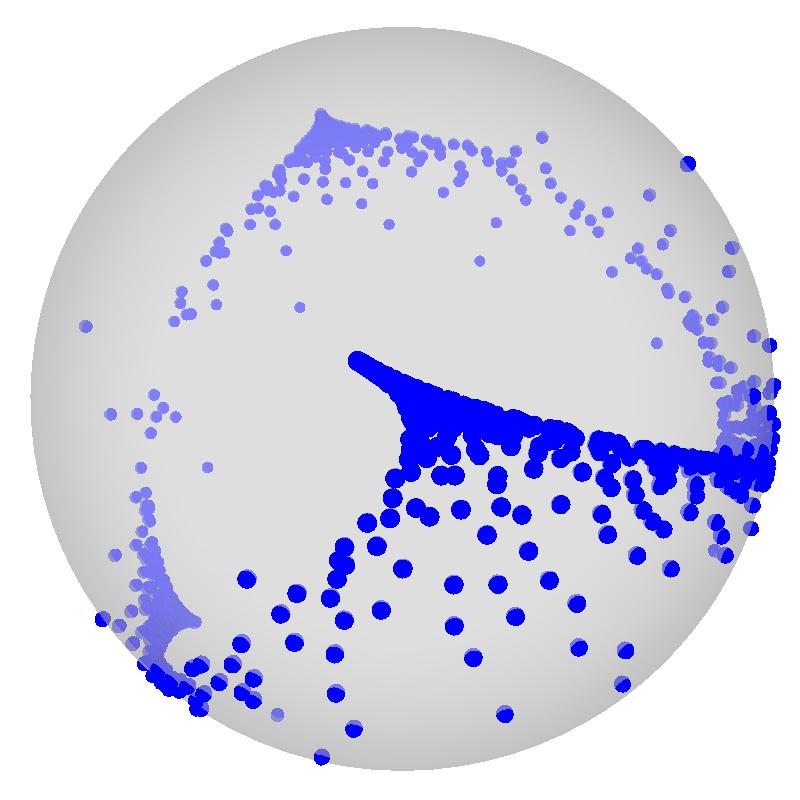
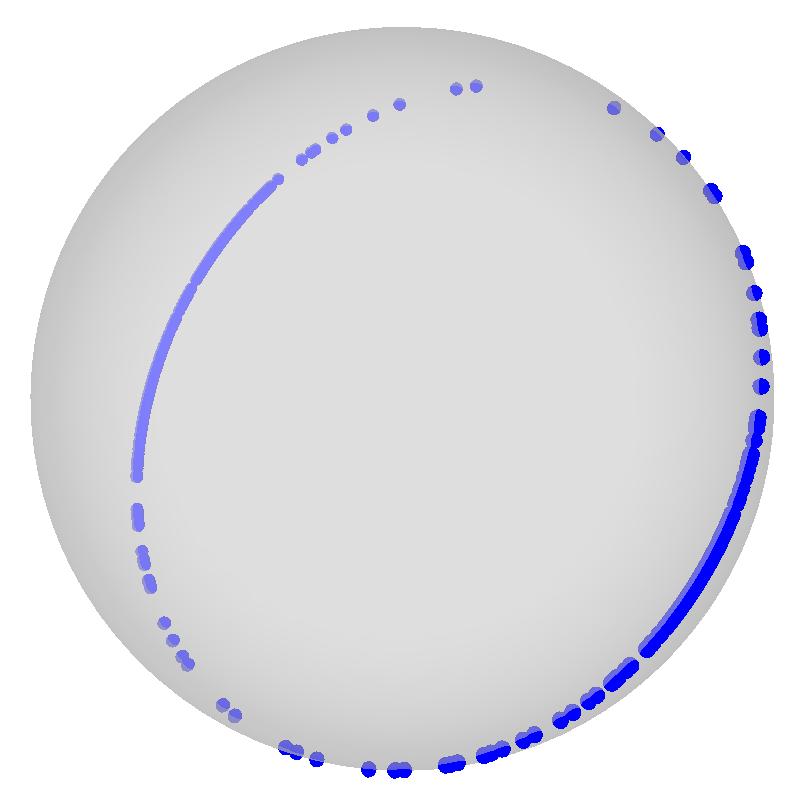
32 Examples of Normalized Embeddings t = 50 t = 5000 t =
")

33 Shape Matching (1) t = 200, t = t = 90, t = 1005


34 Shape Matching (2)


35 Shape Matching (3)
36 Sparse Shape Matching Shape/graph matching is equivalent to matching the embedded representations [Mateus et al. 2008] Here we use the projection of the embeddings on a unit hyper-sphere of dimension K and we apply rigid matching. How to select t and t, i.e., the scales associated with the two shapes to be matched? How to implement a robust matching method?
37 Scale Selection Let C X and C X be the covariance matrices of two different embeddings X and X with respectively n and n points: det(c X ) = det(c X ) det(c X measures the volume in which the embedding X lies. Hence, we impose that the two embeddings are contained in the same volume. From this constraint we derive: t tr(l ) = t tr(l) + K log n/n
38 Robust Matching Build an association graph. Search for the largest set of mutually compatible nodes (maximal clique finding). See [Sharma and Horaud 2010] (Nordia workshop) for more details. i, i i, j i, l j, j l, l j, k k, k
Data Analysis and Manifold Learning Lecture 7: Spectral Clustering
 Data Analysis and Manifold Learning Lecture 7: Spectral Clustering Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture 7 What is spectral
Data Analysis and Manifold Learning Lecture 7: Spectral Clustering Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture 7 What is spectral
Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings
 Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline
Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline
Data Analysis and Manifold Learning Lecture 2: Properties of Symmetric Matrices and Examples
 Data Analysis and Manifold Learning Lecture 2: Properties of Symmetric Matrices and Examples Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline
Data Analysis and Manifold Learning Lecture 2: Properties of Symmetric Matrices and Examples Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline
Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis
 Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture
Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture
Spectral Processing. Misha Kazhdan
 Spectral Processing Misha Kazhdan [Taubin, 1995] A Signal Processing Approach to Fair Surface Design [Desbrun, et al., 1999] Implicit Fairing of Arbitrary Meshes [Vallet and Levy, 2008] Spectral Geometry
Spectral Processing Misha Kazhdan [Taubin, 1995] A Signal Processing Approach to Fair Surface Design [Desbrun, et al., 1999] Implicit Fairing of Arbitrary Meshes [Vallet and Levy, 2008] Spectral Geometry
LECTURE NOTE #11 PROF. ALAN YUILLE
 LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
Justin Solomon MIT, Spring 2017
 Justin Solomon MIT, Spring 2017 http://pngimg.com/upload/hammer_png3886.png You can learn a lot about a shape by hitting it (lightly) with a hammer! What can you learn about its shape from vibration frequencies
Justin Solomon MIT, Spring 2017 http://pngimg.com/upload/hammer_png3886.png You can learn a lot about a shape by hitting it (lightly) with a hammer! What can you learn about its shape from vibration frequencies
Lecture 13. Principal Component Analysis. Brett Bernstein. April 25, CDS at NYU. Brett Bernstein (CDS at NYU) Lecture 13 April 25, / 26
 Lecture 13 April 25, / 26") Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Heat Kernel Signature: A Concise Signature Based on Heat Diffusion. Leo Guibas, Jian Sun, Maks Ovsjanikov
 Heat Kernel Signature: A Concise Signature Based on Heat Diffusion i Leo Guibas, Jian Sun, Maks Ovsjanikov This talk is based on: Jian Sun, Maks Ovsjanikov, Leonidas Guibas 1 A Concise and Provably Informative
Heat Kernel Signature: A Concise Signature Based on Heat Diffusion i Leo Guibas, Jian Sun, Maks Ovsjanikov This talk is based on: Jian Sun, Maks Ovsjanikov, Leonidas Guibas 1 A Concise and Provably Informative
An Introduction to Spectral Graph Theory
 An Introduction to Spectral Graph Theory Mackenzie Wheeler Supervisor: Dr. Gary MacGillivray University of Victoria WheelerM@uvic.ca Outline Outline 1. How many walks are there from vertices v i to v j
An Introduction to Spectral Graph Theory Mackenzie Wheeler Supervisor: Dr. Gary MacGillivray University of Victoria WheelerM@uvic.ca Outline Outline 1. How many walks are there from vertices v i to v j
Linear algebra and applications to graphs Part 1
 Linear algebra and applications to graphs Part 1 Written up by Mikhail Belkin and Moon Duchin Instructor: Laszlo Babai June 17, 2001 1 Basic Linear Algebra Exercise 1.1 Let V and W be linear subspaces
Linear algebra and applications to graphs Part 1 Written up by Mikhail Belkin and Moon Duchin Instructor: Laszlo Babai June 17, 2001 1 Basic Linear Algebra Exercise 1.1 Let V and W be linear subspaces
Spectral Algorithms I. Slides based on Spectral Mesh Processing Siggraph 2010 course
 Spectral Algorithms I Slides based on Spectral Mesh Processing Siggraph 2010 course Why Spectral? A different way to look at functions on a domain Why Spectral? Better representations lead to simpler solutions
Spectral Algorithms I Slides based on Spectral Mesh Processing Siggraph 2010 course Why Spectral? A different way to look at functions on a domain Why Spectral? Better representations lead to simpler solutions
IFT LAPLACIAN APPLICATIONS. Mikhail Bessmeltsev
 IFT 6112 09 LAPLACIAN APPLICATIONS http://www-labs.iro.umontreal.ca/~bmpix/teaching/6112/2018/ Mikhail Bessmeltsev Rough Intuition http://pngimg.com/upload/hammer_png3886.png You can learn a lot about
IFT 6112 09 LAPLACIAN APPLICATIONS http://www-labs.iro.umontreal.ca/~bmpix/teaching/6112/2018/ Mikhail Bessmeltsev Rough Intuition http://pngimg.com/upload/hammer_png3886.png You can learn a lot about
Lecture 10: Dimension Reduction Techniques
 Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA
, Factor Analysis, Mixtures of PPCA") Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inria.fr http://perception.inrialpes.fr/
Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inria.fr http://perception.inrialpes.fr/
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA
 Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
8.1 Concentration inequality for Gaussian random matrix (cont d)
") MGMT 69: Topics in High-dimensional Data Analysis Falll 26 Lecture 8: Spectral clustering and Laplacian matrices Lecturer: Jiaming Xu Scribe: Hyun-Ju Oh and Taotao He, October 4, 26 Outline Concentration
MGMT 69: Topics in High-dimensional Data Analysis Falll 26 Lecture 8: Spectral clustering and Laplacian matrices Lecturer: Jiaming Xu Scribe: Hyun-Ju Oh and Taotao He, October 4, 26 Outline Concentration
Spectral Algorithms II
 Spectral Algorithms II Applications Slides based on Spectral Mesh Processing Siggraph 2010 course Applications Shape retrieval Parameterization i 1D 2D Quad meshing Shape Retrieval 3D Repository Query
Spectral Algorithms II Applications Slides based on Spectral Mesh Processing Siggraph 2010 course Applications Shape retrieval Parameterization i 1D 2D Quad meshing Shape Retrieval 3D Repository Query
Beyond Scalar Affinities for Network Analysis or Vector Diffusion Maps and the Connection Laplacian
 Beyond Scalar Affinities for Network Analysis or Vector Diffusion Maps and the Connection Laplacian Amit Singer Princeton University Department of Mathematics and Program in Applied and Computational Mathematics
Beyond Scalar Affinities for Network Analysis or Vector Diffusion Maps and the Connection Laplacian Amit Singer Princeton University Department of Mathematics and Program in Applied and Computational Mathematics
Unsupervised dimensionality reduction
 Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
MATH 423 Linear Algebra II Lecture 33: Diagonalization of normal operators.
 MATH 423 Linear Algebra II Lecture 33: Diagonalization of normal operators. Adjoint operator and adjoint matrix Given a linear operator L on an inner product space V, the adjoint of L is a transformation
MATH 423 Linear Algebra II Lecture 33: Diagonalization of normal operators. Adjoint operator and adjoint matrix Given a linear operator L on an inner product space V, the adjoint of L is a transformation
Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering
 Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering Shuyang Ling Courant Institute of Mathematical Sciences, NYU Aug 13, 2018 Joint
Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering Shuyang Ling Courant Institute of Mathematical Sciences, NYU Aug 13, 2018 Joint
Data dependent operators for the spatial-spectral fusion problem
 Data dependent operators for the spatial-spectral fusion problem Wien, December 3, 2012 Joint work with: University of Maryland: J. J. Benedetto, J. A. Dobrosotskaya, T. Doster, K. W. Duke, M. Ehler, A.
Data dependent operators for the spatial-spectral fusion problem Wien, December 3, 2012 Joint work with: University of Maryland: J. J. Benedetto, J. A. Dobrosotskaya, T. Doster, K. W. Duke, M. Ehler, A.
Spectral clustering. Two ideal clusters, with two points each. Spectral clustering algorithms
 A simple example Two ideal clusters, with two points each Spectral clustering Lecture 2 Spectral clustering algorithms 4 2 3 A = Ideally permuted Ideal affinities 2 Indicator vectors Each cluster has an
A simple example Two ideal clusters, with two points each Spectral clustering Lecture 2 Spectral clustering algorithms 4 2 3 A = Ideally permuted Ideal affinities 2 Indicator vectors Each cluster has an
Functional Maps ( ) Dr. Emanuele Rodolà Room , Informatik IX
 Dr. Emanuele Rodolà Room , Informatik IX") Functional Maps (12.06.2014) Dr. Emanuele Rodolà rodola@in.tum.de Room 02.09.058, Informatik IX Seminar «LP relaxation for elastic shape matching» Fabian Stark Wednesday, June 18th 14:00 Room 02.09.023
Functional Maps (12.06.2014) Dr. Emanuele Rodolà rodola@in.tum.de Room 02.09.058, Informatik IX Seminar «LP relaxation for elastic shape matching» Fabian Stark Wednesday, June 18th 14:00 Room 02.09.023
Fundamentals of Matrices
 Maschinelles Lernen II Fundamentals of Matrices Christoph Sawade/Niels Landwehr/Blaine Nelson Tobias Scheffer Matrix Examples Recap: Data Linear Model: f i x = w i T x Let X = x x n be the data matrix
Maschinelles Lernen II Fundamentals of Matrices Christoph Sawade/Niels Landwehr/Blaine Nelson Tobias Scheffer Matrix Examples Recap: Data Linear Model: f i x = w i T x Let X = x x n be the data matrix
1 Matrix notation and preliminaries from spectral graph theory
 Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
Non-linear Dimensionality Reduction
 Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Data-dependent representations: Laplacian Eigenmaps
 Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
U.C. Berkeley CS294: Spectral Methods and Expanders Handout 11 Luca Trevisan February 29, 2016
 U.C. Berkeley CS294: Spectral Methods and Expanders Handout Luca Trevisan February 29, 206 Lecture : ARV In which we introduce semi-definite programming and a semi-definite programming relaxation of sparsest
U.C. Berkeley CS294: Spectral Methods and Expanders Handout Luca Trevisan February 29, 206 Lecture : ARV In which we introduce semi-definite programming and a semi-definite programming relaxation of sparsest
Networks and Their Spectra
 Networks and Their Spectra Victor Amelkin University of California, Santa Barbara Department of Computer Science victor@cs.ucsb.edu December 4, 2017 1 / 18 Introduction Networks (= graphs) are everywhere.
Networks and Their Spectra Victor Amelkin University of California, Santa Barbara Department of Computer Science victor@cs.ucsb.edu December 4, 2017 1 / 18 Introduction Networks (= graphs) are everywhere.
Nonlinear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Markov Chains, Random Walks on Graphs, and the Laplacian
 Markov Chains, Random Walks on Graphs, and the Laplacian CMPSCI 791BB: Advanced ML Sridhar Mahadevan Random Walks! There is significant interest in the problem of random walks! Markov chain analysis! Computer
Markov Chains, Random Walks on Graphs, and the Laplacian CMPSCI 791BB: Advanced ML Sridhar Mahadevan Random Walks! There is significant interest in the problem of random walks! Markov chain analysis! Computer
The Nyström Extension and Spectral Methods in Learning
 Introduction Main Results Simulation Studies Summary The Nyström Extension and Spectral Methods in Learning New bounds and algorithms for high-dimensional data sets Patrick J. Wolfe (joint work with Mohamed-Ali
Introduction Main Results Simulation Studies Summary The Nyström Extension and Spectral Methods in Learning New bounds and algorithms for high-dimensional data sets Patrick J. Wolfe (joint work with Mohamed-Ali
Kernels of Directed Graph Laplacians. J. S. Caughman and J.J.P. Veerman
 Kernels of Directed Graph Laplacians J. S. Caughman and J.J.P. Veerman Department of Mathematics and Statistics Portland State University PO Box 751, Portland, OR 97207. caughman@pdx.edu, veerman@pdx.edu
Kernels of Directed Graph Laplacians J. S. Caughman and J.J.P. Veerman Department of Mathematics and Statistics Portland State University PO Box 751, Portland, OR 97207. caughman@pdx.edu, veerman@pdx.edu
Spectral Generative Models for Graphs
 Spectral Generative Models for Graphs David White and Richard C. Wilson Department of Computer Science University of York Heslington, York, UK wilson@cs.york.ac.uk Abstract Generative models are well known
Spectral Generative Models for Graphs David White and Richard C. Wilson Department of Computer Science University of York Heslington, York, UK wilson@cs.york.ac.uk Abstract Generative models are well known
Principal Component Analysis
 Principal Component Analysis Laurenz Wiskott Institute for Theoretical Biology Humboldt-University Berlin Invalidenstraße 43 D-10115 Berlin, Germany 11 March 2004 1 Intuition Problem Statement Experimental
Principal Component Analysis Laurenz Wiskott Institute for Theoretical Biology Humboldt-University Berlin Invalidenstraße 43 D-10115 Berlin, Germany 11 March 2004 1 Intuition Problem Statement Experimental
Notes on Linear Algebra and Matrix Theory
 Massimo Franceschet featuring Enrico Bozzo Scalar product The scalar product (a.k.a. dot product or inner product) of two real vectors x = (x 1,..., x n ) and y = (y 1,..., y n ) is not a vector but a
Massimo Franceschet featuring Enrico Bozzo Scalar product The scalar product (a.k.a. dot product or inner product) of two real vectors x = (x 1,..., x n ) and y = (y 1,..., y n ) is not a vector but a
A New Spectral Technique Using Normalized Adjacency Matrices for Graph Matching 1
 CHAPTER-3 A New Spectral Technique Using Normalized Adjacency Matrices for Graph Matching Graph matching problem has found many applications in areas as diverse as chemical structure analysis, pattern
CHAPTER-3 A New Spectral Technique Using Normalized Adjacency Matrices for Graph Matching Graph matching problem has found many applications in areas as diverse as chemical structure analysis, pattern
Convex Optimization of Graph Laplacian Eigenvalues
 Convex Optimization of Graph Laplacian Eigenvalues Stephen Boyd Abstract. We consider the problem of choosing the edge weights of an undirected graph so as to maximize or minimize some function of the
Convex Optimization of Graph Laplacian Eigenvalues Stephen Boyd Abstract. We consider the problem of choosing the edge weights of an undirected graph so as to maximize or minimize some function of the
Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis
 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis Alvina Goh Vision Reading Group 13 October 2005 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal
Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis Alvina Goh Vision Reading Group 13 October 2005 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal
Average mixing of continuous quantum walks
 Average mixing of continuous quantum walks Juergen Kritschgau Department of Mathematics Iowa State University Ames, IA 50011 jkritsch@iastate.edu April 7, 2017 Juergen Kritschgau (ISU) 2 of 17 This is
Average mixing of continuous quantum walks Juergen Kritschgau Department of Mathematics Iowa State University Ames, IA 50011 jkritsch@iastate.edu April 7, 2017 Juergen Kritschgau (ISU) 2 of 17 This is
Robust Laplacian Eigenmaps Using Global Information
 Manifold Learning and its Applications: Papers from the AAAI Fall Symposium (FS-9-) Robust Laplacian Eigenmaps Using Global Information Shounak Roychowdhury ECE University of Texas at Austin, Austin, TX
Manifold Learning and its Applications: Papers from the AAAI Fall Symposium (FS-9-) Robust Laplacian Eigenmaps Using Global Information Shounak Roychowdhury ECE University of Texas at Austin, Austin, TX
Linear Algebra in Actuarial Science: Slides to the lecture
 Linear Algebra in Actuarial Science: Slides to the lecture Fall Semester 2010/2011 Linear Algebra is a Tool-Box Linear Equation Systems Discretization of differential equations: solving linear equations
Linear Algebra in Actuarial Science: Slides to the lecture Fall Semester 2010/2011 Linear Algebra is a Tool-Box Linear Equation Systems Discretization of differential equations: solving linear equations
Spectral Graph Theory
 Spectral Graph Theory Aaron Mishtal April 27, 2016 1 / 36 Outline Overview Linear Algebra Primer History Theory Applications Open Problems Homework Problems References 2 / 36 Outline Overview Linear Algebra
Spectral Graph Theory Aaron Mishtal April 27, 2016 1 / 36 Outline Overview Linear Algebra Primer History Theory Applications Open Problems Homework Problems References 2 / 36 Outline Overview Linear Algebra
Properties of Matrices and Operations on Matrices
 Properties of Matrices and Operations on Matrices A common data structure for statistical analysis is a rectangular array or matris. Rows represent individual observational units, or just observations,
Properties of Matrices and Operations on Matrices A common data structure for statistical analysis is a rectangular array or matris. Rows represent individual observational units, or just observations,
Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking p. 1/31
 Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking Dengyong Zhou zhou@tuebingen.mpg.de Dept. Schölkopf, Max Planck Institute for Biological Cybernetics, Germany Learning from
Learning from Labeled and Unlabeled Data: Semi-supervised Learning and Ranking Dengyong Zhou zhou@tuebingen.mpg.de Dept. Schölkopf, Max Planck Institute for Biological Cybernetics, Germany Learning from
Lecture: Local Spectral Methods (3 of 4) 20 An optimization perspective on local spectral methods
 20 An optimization perspective on local spectral methods") Stat260/CS294: Spectral Graph Methods Lecture 20-04/07/205 Lecture: Local Spectral Methods (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Stat260/CS294: Spectral Graph Methods Lecture 20-04/07/205 Lecture: Local Spectral Methods (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Spectral Clustering. Zitao Liu
 Spectral Clustering Zitao Liu Agenda Brief Clustering Review Similarity Graph Graph Laplacian Spectral Clustering Algorithm Graph Cut Point of View Random Walk Point of View Perturbation Theory Point of
Spectral Clustering Zitao Liu Agenda Brief Clustering Review Similarity Graph Graph Laplacian Spectral Clustering Algorithm Graph Cut Point of View Random Walk Point of View Perturbation Theory Point of
CS 468, Spring 2013 Differential Geometry for Computer Science Justin Solomon and Adrian Butscher
 CS 468, Spring 2013 Differential Geometry for Computer Science Justin Solomon and Adrian Butscher http://graphics.stanford.edu/projects/lgl/papers/nbwyg-oaicsm-11/nbwyg-oaicsm-11.pdf Need to understand
CS 468, Spring 2013 Differential Geometry for Computer Science Justin Solomon and Adrian Butscher http://graphics.stanford.edu/projects/lgl/papers/nbwyg-oaicsm-11/nbwyg-oaicsm-11.pdf Need to understand
Statistical Pattern Recognition
 Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Lecture 2: Linear Algebra Review
 EE 227A: Convex Optimization and Applications January 19 Lecture 2: Linear Algebra Review Lecturer: Mert Pilanci Reading assignment: Appendix C of BV. Sections 2-6 of the web textbook 1 2.1 Vectors 2.1.1
EE 227A: Convex Optimization and Applications January 19 Lecture 2: Linear Algebra Review Lecturer: Mert Pilanci Reading assignment: Appendix C of BV. Sections 2-6 of the web textbook 1 2.1 Vectors 2.1.1
Markov Chains and Spectral Clustering
 Markov Chains and Spectral Clustering Ning Liu 1,2 and William J. Stewart 1,3 1 Department of Computer Science North Carolina State University, Raleigh, NC 27695-8206, USA. 2 nliu@ncsu.edu, 3 billy@ncsu.edu
Markov Chains and Spectral Clustering Ning Liu 1,2 and William J. Stewart 1,3 1 Department of Computer Science North Carolina State University, Raleigh, NC 27695-8206, USA. 2 nliu@ncsu.edu, 3 billy@ncsu.edu
Diffusion and random walks on graphs
 Diffusion and random walks on graphs Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural
Diffusion and random walks on graphs Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural
Unsupervised Learning Techniques Class 07, 1 March 2006 Andrea Caponnetto
 Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
DEN: Linear algebra numerical view (GEM: Gauss elimination method for reducing a full rank matrix to upper-triangular
 form) Given: matrix C = (c i,j ) n,m i,j=1 ODE and num math: Linear algebra (N) [lectures] c phabala 2016 DEN: Linear algebra numerical view (GEM: Gauss elimination method for reducing a full rank matrix
form) Given: matrix C = (c i,j ) n,m i,j=1 ODE and num math: Linear algebra (N) [lectures] c phabala 2016 DEN: Linear algebra numerical view (GEM: Gauss elimination method for reducing a full rank matrix
Eigenvalue comparisons in graph theory
 Eigenvalue comparisons in graph theory Gregory T. Quenell July 1994 1 Introduction A standard technique for estimating the eigenvalues of the Laplacian on a compact Riemannian manifold M with bounded curvature
Eigenvalue comparisons in graph theory Gregory T. Quenell July 1994 1 Introduction A standard technique for estimating the eigenvalues of the Laplacian on a compact Riemannian manifold M with bounded curvature
Graph Isomorphisms and Automorphisms via Spectral Signatures
 JOURNAL OF L A T E X CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 1 Graph Isomorphisms and Automorphisms via Spectral Signatures Dan Raviv, Ron Kimmel Fellow, IEEE, and Alfred M. Bruckstein Abstract An isomorphism
JOURNAL OF L A T E X CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 1 Graph Isomorphisms and Automorphisms via Spectral Signatures Dan Raviv, Ron Kimmel Fellow, IEEE, and Alfred M. Bruckstein Abstract An isomorphism
Lecture 02 Linear Algebra Basics
 Introduction to Computational Data Analysis CX4240, 2019 Spring Lecture 02 Linear Algebra Basics Chao Zhang College of Computing Georgia Tech These slides are based on slides from Le Song and Andres Mendez-Vazquez.
Introduction to Computational Data Analysis CX4240, 2019 Spring Lecture 02 Linear Algebra Basics Chao Zhang College of Computing Georgia Tech These slides are based on slides from Le Song and Andres Mendez-Vazquez.
Analysis of Spectral Kernel Design based Semi-supervised Learning
 Analysis of Spectral Kernel Design based Semi-supervised Learning Tong Zhang IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Rie Kubota Ando IBM T. J. Watson Research Center Yorktown Heights,
Analysis of Spectral Kernel Design based Semi-supervised Learning Tong Zhang IBM T. J. Watson Research Center Yorktown Heights, NY 10598 Rie Kubota Ando IBM T. J. Watson Research Center Yorktown Heights,
1 Matrix notation and preliminaries from spectral graph theory
 Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
Multivariate Statistical Analysis
 Multivariate Statistical Analysis Fall 2011 C. L. Williams, Ph.D. Lecture 4 for Applied Multivariate Analysis Outline 1 Eigen values and eigen vectors Characteristic equation Some properties of eigendecompositions
Multivariate Statistical Analysis Fall 2011 C. L. Williams, Ph.D. Lecture 4 for Applied Multivariate Analysis Outline 1 Eigen values and eigen vectors Characteristic equation Some properties of eigendecompositions
Linear Algebra & Geometry why is linear algebra useful in computer vision?
 Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
Matrix Mathematics. Theory, Facts, and Formulas with Application to Linear Systems Theory. Dennis S. Bernstein
 Matrix Mathematics Theory, Facts, and Formulas with Application to Linear Systems Theory Dennis S. Bernstein PRINCETON UNIVERSITY PRESS PRINCETON AND OXFORD Contents Special Symbols xv Conventions, Notation,
Matrix Mathematics Theory, Facts, and Formulas with Application to Linear Systems Theory Dennis S. Bernstein PRINCETON UNIVERSITY PRESS PRINCETON AND OXFORD Contents Special Symbols xv Conventions, Notation,
Critical Groups for Cayley Graphs of Bent Functions
 Critical Groups for Cayley Graphs of Bent Functions Thomas F. Gruebl Adviser: David Joyner December 9, 2015 1 Introduction This paper will study the critical group of bent functions in the p-ary case.
Critical Groups for Cayley Graphs of Bent Functions Thomas F. Gruebl Adviser: David Joyner December 9, 2015 1 Introduction This paper will study the critical group of bent functions in the p-ary case.
APPENDIX A. Background Mathematics. A.1 Linear Algebra. Vector algebra. Let x denote the n-dimensional column vector with components x 1 x 2.
 APPENDIX A Background Mathematics A. Linear Algebra A.. Vector algebra Let x denote the n-dimensional column vector with components 0 x x 2 B C @. A x n Definition 6 (scalar product). The scalar product
APPENDIX A Background Mathematics A. Linear Algebra A.. Vector algebra Let x denote the n-dimensional column vector with components 0 x x 2 B C @. A x n Definition 6 (scalar product). The scalar product
Lecture 13: Spectral Graph Theory
 CSE 521: Design and Analysis of Algorithms I Winter 2017 Lecture 13: Spectral Graph Theory Lecturer: Shayan Oveis Gharan 11/14/18 Disclaimer: These notes have not been subjected to the usual scrutiny reserved
CSE 521: Design and Analysis of Algorithms I Winter 2017 Lecture 13: Spectral Graph Theory Lecturer: Shayan Oveis Gharan 11/14/18 Disclaimer: These notes have not been subjected to the usual scrutiny reserved
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
An Algorithmist s Toolkit September 10, Lecture 1
 18.409 An Algorithmist s Toolkit September 10, 2009 Lecture 1 Lecturer: Jonathan Kelner Scribe: Jesse Geneson (2009) 1 Overview The class s goals, requirements, and policies were introduced, and topics
18.409 An Algorithmist s Toolkit September 10, 2009 Lecture 1 Lecturer: Jonathan Kelner Scribe: Jesse Geneson (2009) 1 Overview The class s goals, requirements, and policies were introduced, and topics
Numerical Methods I Singular Value Decomposition
 Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi
 presented by Hassan A. Kingravi") Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Lecture 1: From Data to Graphs, Weighted Graphs and Graph Laplacian
 Lecture 1: From Data to Graphs, Weighted Graphs and Graph Laplacian Radu Balan February 5, 2018 Datasets diversity: Social Networks: Set of individuals ( agents, actors ) interacting with each other (e.g.,
Lecture 1: From Data to Graphs, Weighted Graphs and Graph Laplacian Radu Balan February 5, 2018 Datasets diversity: Social Networks: Set of individuals ( agents, actors ) interacting with each other (e.g.,
AN ASYMPTOTIC BEHAVIOR OF QR DECOMPOSITION
 Unspecified Journal Volume 00, Number 0, Pages 000 000 S????-????(XX)0000-0 AN ASYMPTOTIC BEHAVIOR OF QR DECOMPOSITION HUAJUN HUANG AND TIN-YAU TAM Abstract. The m-th root of the diagonal of the upper
Unspecified Journal Volume 00, Number 0, Pages 000 000 S????-????(XX)0000-0 AN ASYMPTOTIC BEHAVIOR OF QR DECOMPOSITION HUAJUN HUANG AND TIN-YAU TAM Abstract. The m-th root of the diagonal of the upper
Quantum Computing Lecture 2. Review of Linear Algebra
 Quantum Computing Lecture 2 Review of Linear Algebra Maris Ozols Linear algebra States of a quantum system form a vector space and their transformations are described by linear operators Vector spaces
Quantum Computing Lecture 2 Review of Linear Algebra Maris Ozols Linear algebra States of a quantum system form a vector space and their transformations are described by linear operators Vector spaces
Linear Algebra & Geometry why is linear algebra useful in computer vision?
 Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
Machine Learning for Data Science (CS4786) Lecture 11
 Lecture 11") Machine Learning for Data Science (CS4786) Lecture 11 Spectral clustering Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016sp/ ANNOUNCEMENT 1 Assignment P1 the Diagnostic assignment 1 will
Machine Learning for Data Science (CS4786) Lecture 11 Spectral clustering Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016sp/ ANNOUNCEMENT 1 Assignment P1 the Diagnostic assignment 1 will
Lecture 24: Element-wise Sampling of Graphs and Linear Equation Solving. 22 Element-wise Sampling of Graphs and Linear Equation Solving
 Stat260/CS294: Randomized Algorithms for Matrices and Data Lecture 24-12/02/2013 Lecture 24: Element-wise Sampling of Graphs and Linear Equation Solving Lecturer: Michael Mahoney Scribe: Michael Mahoney
Stat260/CS294: Randomized Algorithms for Matrices and Data Lecture 24-12/02/2013 Lecture 24: Element-wise Sampling of Graphs and Linear Equation Solving Lecturer: Michael Mahoney Scribe: Michael Mahoney
Statistics for Applications. Chapter 9: Principal Component Analysis (PCA) 1/16
 1/16") Statistics for Applications Chapter 9: Principal Component Analysis (PCA) 1/16 Multivariate statistics and review of linear algebra (1) Let X be a d-dimensional random vector and X 1,..., X n be n independent
Statistics for Applications Chapter 9: Principal Component Analysis (PCA) 1/16 Multivariate statistics and review of linear algebra (1) Let X be a d-dimensional random vector and X 1,..., X n be n independent
Unsupervised Learning: Dimensionality Reduction
 Unsupervised Learning: Dimensionality Reduction CMPSCI 689 Fall 2015 Sridhar Mahadevan Lecture 3 Outline In this lecture, we set about to solve the problem posed in the previous lecture Given a dataset,
Unsupervised Learning: Dimensionality Reduction CMPSCI 689 Fall 2015 Sridhar Mahadevan Lecture 3 Outline In this lecture, we set about to solve the problem posed in the previous lecture Given a dataset,
Graph Partitioning Using Random Walks
 Graph Partitioning Using Random Walks A Convex Optimization Perspective Lorenzo Orecchia Computer Science Why Spectral Algorithms for Graph Problems in practice? Simple to implement Can exploit very efficient
Graph Partitioning Using Random Walks A Convex Optimization Perspective Lorenzo Orecchia Computer Science Why Spectral Algorithms for Graph Problems in practice? Simple to implement Can exploit very efficient
CSE 554 Lecture 7: Alignment
 CSE 554 Lecture 7: Alignment Fall 2012 CSE554 Alignment Slide 1 Review Fairing (smoothing) Relocating vertices to achieve a smoother appearance Method: centroid averaging Simplification Reducing vertex
CSE 554 Lecture 7: Alignment Fall 2012 CSE554 Alignment Slide 1 Review Fairing (smoothing) Relocating vertices to achieve a smoother appearance Method: centroid averaging Simplification Reducing vertex
2. Matrix Algebra and Random Vectors
 2. Matrix Algebra and Random Vectors 2.1 Introduction Multivariate data can be conveniently display as array of numbers. In general, a rectangular array of numbers with, for instance, n rows and p columns
2. Matrix Algebra and Random Vectors 2.1 Introduction Multivariate data can be conveniently display as array of numbers. In general, a rectangular array of numbers with, for instance, n rows and p columns
Maximizing the numerical radii of matrices by permuting their entries
 Maximizing the numerical radii of matrices by permuting their entries Wai-Shun Cheung and Chi-Kwong Li Dedicated to Professor Pei Yuan Wu. Abstract Let A be an n n complex matrix such that every row and
Maximizing the numerical radii of matrices by permuting their entries Wai-Shun Cheung and Chi-Kwong Li Dedicated to Professor Pei Yuan Wu. Abstract Let A be an n n complex matrix such that every row and
CSE 291. Assignment Spectral clustering versus k-means. Out: Wed May 23 Due: Wed Jun 13
 CSE 291. Assignment 3 Out: Wed May 23 Due: Wed Jun 13 3.1 Spectral clustering versus k-means Download the rings data set for this problem from the course web site. The data is stored in MATLAB format as
CSE 291. Assignment 3 Out: Wed May 23 Due: Wed Jun 13 3.1 Spectral clustering versus k-means Download the rings data set for this problem from the course web site. The data is stored in MATLAB format as
A Statistical Look at Spectral Graph Analysis. Deep Mukhopadhyay
 A Statistical Look at Spectral Graph Analysis Deep Mukhopadhyay Department of Statistics, Temple University Office: Speakman 335 deep@temple.edu http://sites.temple.edu/deepstat/ Graph Signal Processing
A Statistical Look at Spectral Graph Analysis Deep Mukhopadhyay Department of Statistics, Temple University Office: Speakman 335 deep@temple.edu http://sites.temple.edu/deepstat/ Graph Signal Processing
Graph fundamentals. Matrices associated with a graph
 Graph fundamentals Matrices associated with a graph Drawing a picture of a graph is one way to represent it. Another type of representation is via a matrix. Let G be a graph with V (G) ={v 1,v,...,v n
Graph fundamentals Matrices associated with a graph Drawing a picture of a graph is one way to represent it. Another type of representation is via a matrix. Let G be a graph with V (G) ={v 1,v,...,v n
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
1 Last time: least-squares problems
 MATH Linear algebra (Fall 07) Lecture Last time: least-squares problems Definition. If A is an m n matrix and b R m, then a least-squares solution to the linear system Ax = b is a vector x R n such that
MATH Linear algebra (Fall 07) Lecture Last time: least-squares problems Definition. If A is an m n matrix and b R m, then a least-squares solution to the linear system Ax = b is a vector x R n such that
Eigenvalues and Eigenvectors
 /88 Chia-Ping Chen Department of Computer Science and Engineering National Sun Yat-sen University Linear Algebra Eigenvalue Problem /88 Eigenvalue Equation By definition, the eigenvalue equation for matrix
/88 Chia-Ping Chen Department of Computer Science and Engineering National Sun Yat-sen University Linear Algebra Eigenvalue Problem /88 Eigenvalue Equation By definition, the eigenvalue equation for matrix
Kernel methods for comparing distributions, measuring dependence
 Kernel methods for comparing distributions, measuring dependence Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Principal component analysis Given a set of M centered observations
Kernel methods for comparing distributions, measuring dependence Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Principal component analysis Given a set of M centered observations
Machine Learning - MT Clustering
 Machine Learning - MT 2016 15. Clustering Varun Kanade University of Oxford November 28, 2016 Announcements No new practical this week All practicals must be signed off in sessions this week Firm Deadline:
Machine Learning - MT 2016 15. Clustering Varun Kanade University of Oxford November 28, 2016 Announcements No new practical this week All practicals must be signed off in sessions this week Firm Deadline:
Lecture 1: Graphs, Adjacency Matrices, Graph Laplacian
 Lecture 1: Graphs, Adjacency Matrices, Graph Laplacian Radu Balan January 31, 2017 G = (V, E) An undirected graph G is given by two pieces of information: a set of vertices V and a set of edges E, G =
Lecture 1: Graphs, Adjacency Matrices, Graph Laplacian Radu Balan January 31, 2017 G = (V, E) An undirected graph G is given by two pieces of information: a set of vertices V and a set of edges E, G =
Spectral Graph Theory and its Applications. Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale Unviersity
 Spectral Graph Theory and its Applications Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale Unviersity Outline Adjacency matrix and Laplacian Intuition, spectral graph drawing
Spectral Graph Theory and its Applications Daniel A. Spielman Dept. of Computer Science Program in Applied Mathematics Yale Unviersity Outline Adjacency matrix and Laplacian Intuition, spectral graph drawing
On the inverse matrix of the Laplacian and all ones matrix
 On the inverse matrix of the Laplacian and all ones matrix Sho Suda (Joint work with Michio Seto and Tetsuji Taniguchi) International Christian University JSPS Research Fellow PD November 21, 2012 Sho
On the inverse matrix of the Laplacian and all ones matrix Sho Suda (Joint work with Michio Seto and Tetsuji Taniguchi) International Christian University JSPS Research Fellow PD November 21, 2012 Sho
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 23 1 / 27 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 23 1 / 27 Overview
Learning from Sensor Data: Set II. Behnaam Aazhang J.S. Abercombie Professor Electrical and Computer Engineering Rice University
 Learning from Sensor Data: Set II Behnaam Aazhang J.S. Abercombie Professor Electrical and Computer Engineering Rice University 1 6. Data Representation The approach for learning from data Probabilistic
Learning from Sensor Data: Set II Behnaam Aazhang J.S. Abercombie Professor Electrical and Computer Engineering Rice University 1 6. Data Representation The approach for learning from data Probabilistic
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec Stanford University Jure Leskovec, Stanford University http://cs224w.stanford.edu Task: Find coalitions in signed networks Incentives: European
CS224W: Social and Information Network Analysis Jure Leskovec Stanford University Jure Leskovec, Stanford University http://cs224w.stanford.edu Task: Find coalitions in signed networks Incentives: European
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Handout to Wu Characteristic Harvard math table talk Oliver Knill, 3/8/2016
 Handout to Wu Characteristic Harvard math table talk Oliver Knill, 3/8/2016 Definitions Let G = (V, E) be a finite simple graph with vertex set V and edge set E. The f-vector v(g) = (v 0 (G), v 1 (G),...,
Handout to Wu Characteristic Harvard math table talk Oliver Knill, 3/8/2016 Definitions Let G = (V, E) be a finite simple graph with vertex set V and edge set E. The f-vector v(g) = (v 0 (G), v 1 (G),...,
Contribution from: Springer Verlag Berlin Heidelberg 2005 ISBN
 Contribution from: Mathematical Physics Studies Vol. 7 Perspectives in Analysis Essays in Honor of Lennart Carleson s 75th Birthday Michael Benedicks, Peter W. Jones, Stanislav Smirnov (Eds.) Springer
Contribution from: Mathematical Physics Studies Vol. 7 Perspectives in Analysis Essays in Honor of Lennart Carleson s 75th Birthday Michael Benedicks, Peter W. Jones, Stanislav Smirnov (Eds.) Springer