Natural Language Processing with Deep Learning CS224N/Ling284
|
|
|
- John Waters
- 5 years ago
- Views:
Transcription

1 Natural Language Processing with Deep Learning CS224N/Ling284 Christopher Manning Lecture 3: Word Window Classification, Neural Networks, and Matrix Calculus
2 1. Course plan: coming up Week 2: We learn neural net fundamentals We concentrate on understanding (deep, multi-layer) neural networks and how they can be trained (learned from data) using backpropagation (the judicious application of matrix calculus) We ll look at an NLP classifier that adds context by taking in windows around a word and classifies the center word (not just representing it across all windows)! Week 3: We learn some natural language processing We learn about putting syntactic structure (dependency parses) over sentence (this is HW3!) We develop the notion of the probability of a sentence (a probabilistic language model) and why it is really useful 2
3 Homeworks HW1 was due a couple of minutes ago! We hope you ve submitted it already! Try not to burn your late days on this easy first assignment! HW2 is now out Written part: gradient derivations for word2vec (OMG calculus) Programming part: word2vec implementation in NumPy (Not an IPython notebook) You should start looking at it early! Today s lecture will be helpful and Thursday will contain some more info. Website has lecture notes to give more detail 3



4 A note on your experience! Terrible class Don t take it Instructors don t care Too much work Best class at Stanford Changed my life Obvious that instructors care Learned a ton Hard but worth it This is a hard, advanced, graduate level class I and all the TAs really care about your success in this class Give Feedback. Work to address holes in your knowledge Come to office hours/help sessions 4
5 Office Hours / Help sessions Come to office hours/help sessions! Come to discuss final project ideas as well as the homeworks Try to come early, often and off-cycle Help sessions: daily, at various times, see calendar Coming up: Wed 12-2:30pm, Thu 6:30 9:00pm Gates Basement B21 (and B30) bring your student ID No ID? Try Piazza or tailgating hoping to get a phone in room Attending in person: Just show up! Our friendly course staff will be on hand to assist you SCPD/remote access: Use queuestatus Chris s office hours: Mon 1 3pm. Come along next Monday? 5
6 Lecture Plan Lecture 3: Word Window Classification, Neural Nets, and Calculus 1. Course information update (5 mins) 2. Classification review/introduction (10 mins) 3. Neural networks introduction (15 mins) 4. Named Entity Recognition (5 mins) 5. Binary true vs. corrupted word window classification (15 mins) 6. Matrix calculus introduction (20 mins) This will be a tough week for some! à Read tutorial materials given in syllabus Visit office hours 6
7 2. Classification setup and notation Generally we have a training dataset consisting of samples {x i,y i } N i=1 x i are inputs, e.g. words (indices or vectors!), sentences, documents, etc. Dimension d y i are labels (one of C classes) we try to predict, for example: classes: sentiment, named entities, buy/sell decision other words later: multi-word sequences 7
8 Classification intuition Training data: {x i,y i } N i=1 Simple illustration case: Fixed 2D word vectors to classify Using softmax/logistic regression Linear decision boundary Visualizations with ConvNetJS by Karpathy! Traditional ML/Stats approach: assume x i are fixed, train (i.e., set) softmax/logistic regression weights! R $ & to determine a decision boundary (hyperplane) as in the picture Method: For each x, predict: 8
9 Details of the softmax classifier We can tease apart the prediction function into two steps: 1. Take the y th row of W and multiply that row with x: Compute all f c for c = 1,, C 2. Apply softmax function to get normalized probability: = softmax(* + ) 9
10 Training with softmax and cross-entropy loss For each training example (x,y), our objective is to maximize the probability of the correct class y Or we can minimize the negative log probability of that class: 10
11 Background: What is cross entropy loss/error? Concept of cross entropy is from information theory Let the true probability distribution be p Let our computed model probability be q The cross entropy is: Assuming a ground truth (or true or gold or target) probability distribution that is 1 at the right class and 0 everywhere else: p = [0,,0,1,0, 0] then: Because of one-hot p, the only term left is the negative log probability of the true class 11
12 Classification over a full dataset Cross entropy loss function over full dataset {x i,y i } N i=1 Instead of We will write f in matrix notation: 12
13 Traditional ML optimization For general machine learning! usually only consists of columns of W: So we only update the decision boundary via Visualizations with ConvNetJS by Karpathy 13
14 3. Neural Network Classifiers Softmax ( logistic regression) alone not very powerful Softmax gives only linear decision boundaries This can be quite limiting à Unhelpful when a problem is complex Wouldn t it be cool to get these correct? 14

15 Neural Nets for the Win! Neural networks can learn much more complex functions and nonlinear decision boundaries! In original space 15
16 Classification difference with word vectors Commonly in NLP deep learning: We learn both W and word vectors x We learn both conventional parameters and representations The word vectors re-represent one-hot vectors move them around in an intermediate layer vector space for easy classification with a (linear) softmax classifier via layer x = Le Very large number of parameters! 16
17 Neural computation 17
18 An artificial neuron Neural networks come with their own terminological baggage But if you understand how softmax models work, then you can easily understand the operation of a neuron! 18
19 A neuron can be a binary logistic regression unit f = nonlinear activation fct. (e.g. sigmoid), w = weights, b = bias, h = hidden, x = inputs h w,b (x) = f (w T x + b) 1 f (z) = 1+ e z b: We can have an always on feature, which gives a class prior, or separate it out, as a bias term 19 w, b are the parameters of this neuron i.e., this logistic regression model
20 A neural network = running several logistic regressions at the same time If we feed a vector of inputs through a bunch of logistic regression functions, then we get a vector of outputs But we don t have to decide ahead of time what variables these logistic regressions are trying to predict! 20
21 A neural network = running several logistic regressions at the same time which we can feed into another logistic regression function It is the loss function that will direct what the intermediate hidden variables should be, so as to do a good job at predicting the targets for the next layer, etc. 21
22 A neural network = running several logistic regressions at the same time Before we know it, we have a multilayer neural network. 22
23 Matrix notation for a layer We have a 1 = f (W 11 x 1 +W 12 x 2 +W 13 x 3 + b 1 ) a 2 = f (W 21 x 1 +W 22 x 2 +W 23 x 3 + b 2 ) In matrix notation Activation f is applied element-wise: f ([z 1, z 2, z 3 ]) = [ f (z 1 ), f (z 2 ), f (z 3 )] 23 etc. z = Wx + b a = f (z) W 12 b 3 a 1 a 2 a 3
24 Non-linearities (aka f ): Why they re needed Example: function approximation, e.g., regression or classification Without non-linearities, deep neural networks can t do anything more than a linear transform Extra layers could just be compiled down into a single linear transform: W 1 W 2 x = Wx With more layers, they can approximate more complex functions! 24
25 4. Named Entity Recognition (NER) The task: find and classify names in text, for example: The European Commission said [ORG] on said Thursday on Thursday it disagreed it with German disagreed advice. with German [MISC] advice. Only France and [LOC] Britain and Britain backed [LOC] Fischler backed 's proposal Fischler. [PER] 's proposal. What we have to be extremely careful of is how other countries What we have are to going be extremely to take Germany careful 's of lead, is how Welsh other National countries Farmers are going ' Union to take ( NFU Germany ) chairman 's lead, John Welsh Lloyd Jones said National BBC Farmers radio '. Union [ORG] ( NFU [ORG] ) chairman John Lloyd Jones [PER] said on BBC [ORG] radio. Possible purposes: Tracking mentions of particular entities in documents For question answering, answers are usually named entities A lot of wanted information is really associations between named entities The same techniques can be extended to other slot-filling classifications Often followed by Named Entity Linking/Canonicalization into Knowledge Base 25

26 Named Entity Recognition on word sequences We predict entities by classifying words in context and then extracting entities as word subsequences Foreign ORG B-ORG Ministry ORG I-ORG spokesman O } } Shen PER B-PER Guofang PER I-PER told O O } Reuters ORG B-ORG that O O : :! BIO encoding O

27 Why might NER be hard? Hard to work out boundaries of entity Is the first entity First National Bank or National Bank Hard to know if something is an entity Is there a school called Future School or is it a future school? Hard to know class of unknown/novel entity: 27 What class is Zig Ziglar? (A person.) Entity class is ambiguous and depends on context Charles Schwab is PER not ORG here!!
28 5. Binary word window classification In general, classifying single words is rarely done Interesting problems like ambiguity arise in context! Example: auto-antonyms: "To sanction" can mean "to permit" or "to punish "To seed" can mean "to place seeds" or "to remove seeds" Example: resolving linking of ambiguous named entities: Paris à Paris, France vs. Paris Hilton vs. Paris, Texas Hathaway à Berkshire Hathaway vs. Anne Hathaway 28
29 Window classification Idea: classify a word in its context window of neighboring words. For example, Named Entity Classification of a word in context: Person, Location, Organization, None A simple way to classify a word in context might be to average the word vectors in a window and to classify the average vector Problem: that would lose position information 29
30 Window classification: Softmax Train softmax classifier to classify a center word by taking concatenation of word vectors surrounding it in a window Example: Classify Paris in the context of this sentence with window length 2: museums in Paris are amazing. X window = [ x museums x in x Paris x are x amazing ] T Resulting vector x window = x R 5d, a column vector! 30
31 Simplest window classifier: Softmax With x = x window we can use the same softmax classifier as before predicted model output probability With cross entropy error as before: same How do you update the word vectors? Short answer: Just take derivatives like last week and optimize 31
32 Binary classification with unnormalized scores Method used by Collobert & Weston (2008, 2011) Just recently won ICML 2018 Test of time award For our previous example: X window = [ x museums x in x Paris x are x amazing ] Assume we want to classify whether the center word is a Location Similar to word2vec, we will go over all positions in a corpus. But this time, it will be supervised and only some positions should get a high score. E.g., the positions that have an actual NER Location in their center are true positions and get a high score 32
33 Binary classification for NER Location Example: Not all museums in Paris are amazing. Here: one true window, the one with Paris in its center and all other windows are corrupt in terms of not having a named entity location in their center. museums in Paris are amazing Corrupt windows are easy to find and there are many: Any window whose center word isn t specifically labeled as NER location in our corpus Not all museums in Paris 33

 34 x window = [ x museums x in x Paris x are x")
34 Neural Network Feed-forward Computation Use neural activation a simply to give an unnormalized score We compute a window s score with a 3-layer neural net: s = score("museums in Paris are amazing ) 34 x window = [ x museums x in x Paris x are x amazing ]
35 Main intuition for extra layer The middle layer learns non-linear interactions between the input word vectors. X window = [ x museums x in x Paris x are x amazing ] Example: only if museums is first vector should it matter that in is in the second position 35
36 The max-margin loss Idea for training objective: Make true window s score larger and corrupt window s score lower (until they re good enough) s = score(museums in Paris are amazing) s c = score(not all museums in Paris) Minimize This is not differentiable but it is continuous we can use SGD. 36 Each option is continuous
37 Max-margin loss Objective for a single window: Each window with an NER location at its center should have a score +1 higher than any window without a location at its center xxx ß 1 à ooo For full objective function: Sample several corrupt windows per true one. Sum over all training windows. Similar to negative sampling in word2vec 37
38 Simple net for score x = [ x museums x in x Paris x are x amazing ] 38
39 Remember: Stochastic Gradient Descent Update equation: ' = step size or learning rate How do we compute " #(%)? By hand (this lecture) Algorithmically: the backpropagation algorithm (next lecture) 39
40 Computing Gradients by Hand Review of multivariable derivatives Matrix calculus: Fully vectorized gradients Much faster and more useful than non-vectorized gradients But doing a non-vectorized gradient can be good practice; watch last week s lecture for an example Lecture notes cover this material in more detail 40
41 Gradients Given a function with 1 output and 1 input! " = " $ It s gradient (slope) is its derivative %& %' = 3") 41

42 Gradients Given a function with 1 output and n inputs It s gradient is a vector of partial derivatives with respect to each input 42


43 Jacobian Matrix: Generalization of the Gradient Given a function with m outputs and n inputs It s Jacobian is an m x n matrix of partial derivatives 43


44 Chain Rule For one-variable functions: multiply derivatives For multiple variables at once: multiply Jacobians 44
45 Example Jacobian: Elementwise activation Function 45
46 Example Jacobian: Elementwise activation Function Function has n outputs and n inputs n by n Jacobian 46
47 Example Jacobian: Elementwise activation Function 47
48 Example Jacobian: Elementwise activation Function 48

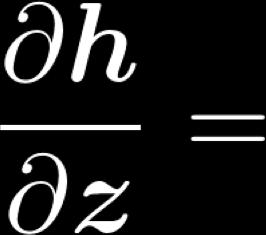
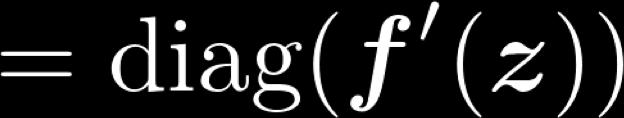
49 Example Jacobian: Elementwise activation Function 49
50 Other Jacobians Compute these at home for practice! Check your answers with the lecture notes 50
51 Other Jacobians Compute these at home for practice! Check your answers with the lecture notes 51
52 Other Jacobians Compute these at home for practice! Check your answers with the lecture notes 52
53 Other Jacobians Compute these at home for practice! Check your answers with the lecture notes 53
54 Back to our Neural Net! 54 x = [ x museums x in x Paris x are x amazing ]


55 Back to our Neural Net! Let s find In practice we care about the gradient of the loss, but we will compute the gradient of the score for simplicity 55 x = [ x museums x in x Paris x are x amazing ]

56 1. Break up equations into simple pieces 56
57 2. Apply the chain rule 57
58 2. Apply the chain rule 58
59 2. Apply the chain rule 59
60 2. Apply the chain rule 60
61 3. Write out the Jacobians Useful Jacobians from previous slide 61
62 3. Write out the Jacobians Useful Jacobians from previous slide 62
63 3. Write out the Jacobians Useful Jacobians from previous slide 63
64 3. Write out the Jacobians Useful Jacobians from previous slide 64
65 3. Write out the Jacobians Useful Jacobians from previous slide 65

66 Re-using Computation Suppose we now want to compute Using the chain rule again: 66


67 Re-using Computation Suppose we now want to compute Using the chain rule again: The same! Let s avoid duplicated computation 67


68 Re-using Computation Suppose we now want to compute Using the chain rule again: 68! is local error signal

69 Derivative with respect to Matrix: Output shape What does look like? 1 output, nm inputs: 1 by nm Jacobian? Inconvenient to do 69

70 Derivative with respect to Matrix What does look like? 1 output, nm inputs: 1 by nm Jacobian? Inconvenient to do Instead follow convention: shape of the gradient is shape of parameters So is n by m: 70


71 Derivative with respect to Matrix Remember is going to be in our answer The other term should be because It turns out! is local error signal at " # is local input signal 71

72 Why the Transposes? Hacky answer: this makes the dimensions work out! Useful trick for checking your work! Full explanation in the lecture notes 72 Each input goes to each output you get outer product
= h 1 h 2 =f(z 2 ) W 23 73")
73 Why the Transposes? f(z 1 )= h 1 h 2 =f(z 2 ) W x 1 x 2 x 3 +1
 and the shape")
74 What shape should derivatives be? is a row vector But convention says our gradient should be a column vector because is a column vector Disagreement between Jacobian form (which makes the chain rule easy) and the shape convention (which makes implementing SGD easy) We expect answers to follow the shape convention But Jacobian form is useful for computing the answers 74

75 What shape should derivatives be? Two options: 1. Use Jacobian form as much as possible, reshape to follow the convention at the end: What we just did. But at the end transpose to make the derivative a column vector, resulting in 2. Always follow the convention Look at dimensions to figure out when to transpose and/or reorder terms. 75
76 Next time: Backpropagation Backpropagation Computing gradients algorithmically and efficiently Converting what we just did by hand into an algorithm Used by deep learning software frameworks (TensorFlow, PyTorch, Chainer, etc.) 76
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Natural Language Processing with Deep Learning. CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher Classifica6on setup and nota6on Generally
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher Classifica6on setup and nota6on Generally
Natural Language Processing with Deep Learning. CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher Overview Today: Classifica(on background Upda(ng
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher Overview Today: Classifica(on background Upda(ng
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop
 Different descriptions and viewpoints of backprop") Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop Project Tips Announcement: Hint for PSet1: Understand
Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop Project Tips Announcement: Hint for PSet1: Understand
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Machine Learning Basics
 Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Deep Learning for NLP Part 2
 Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
ML4NLP Multiclass Classification
 ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
Regularization Introduction to Machine Learning. Matt Gormley Lecture 10 Feb. 19, 2018
 1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Statistical NLP for the Web
 Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Natural Language Processing with Deep Learning CS224N/Ling284. Christopher Manning Lecture 1: Introduction and Word Vectors
 Natural Language Processing with Deep Learning CS224N/Ling284 Christopher Manning Lecture 1: Introduction and Word Vectors Lecture Plan Lecture 1: Introduction and Word Vectors 1. The course (10 mins)
Natural Language Processing with Deep Learning CS224N/Ling284 Christopher Manning Lecture 1: Introduction and Word Vectors Lecture Plan Lecture 1: Introduction and Word Vectors 1. The course (10 mins)
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Neural Networks in Structured Prediction. November 17, 2015
 Neural Networks in Structured Prediction November 17, 2015 HWs and Paper Last homework is going to be posted soon Neural net NER tagging model This is a new structured model Paper - Thursday after Thanksgiving
Neural Networks in Structured Prediction November 17, 2015 HWs and Paper Last homework is going to be posted soon Neural net NER tagging model This is a new structured model Paper - Thursday after Thanksgiving
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Machine Learning (CSE 446): Neural Networks
: Neural Networks") Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
Classification with Perceptrons. Reading:
 Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT. Slides credit: Graham Neubig
 Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Slides credit: Graham Neubig Outline Perceptron: recap and limitations Neural networks Multi-layer perceptron Forward propagation
Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Slides credit: Graham Neubig Outline Perceptron: recap and limitations Neural networks Multi-layer perceptron Forward propagation
Loss Functions and Optimization. Lecture 3-1
 Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative Assignment 1 is released: http://cs231n.github.io/assignments2017/assignment1/ Due Thursday April 20, 11:59pm on Canvas (Extending
Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative Assignment 1 is released: http://cs231n.github.io/assignments2017/assignment1/ Due Thursday April 20, 11:59pm on Canvas (Extending
Loss Functions and Optimization. Lecture 3-1
 Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative: Live Questions We ll use Zoom to take questions from remote students live-streaming the lecture Check Piazza for instructions and
Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative: Live Questions We ll use Zoom to take questions from remote students live-streaming the lecture Check Piazza for instructions and
Natural Language Processing
 Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Lecture 2: Linear regression
 Lecture 2: Linear regression Roger Grosse 1 Introduction Let s ump right in and look at our first machine learning algorithm, linear regression. In regression, we are interested in predicting a scalar-valued
Lecture 2: Linear regression Roger Grosse 1 Introduction Let s ump right in and look at our first machine learning algorithm, linear regression. In regression, we are interested in predicting a scalar-valued
Lecture 4: Training a Classifier
 Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Semantics with Dense Vectors. Reference: D. Jurafsky and J. Martin, Speech and Language Processing
 Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
CENG 793. On Machine Learning and Optimization. Sinan Kalkan
 CENG 793 On Machine Learning and Optimization Sinan Kalkan 2 Now Introduction to ML Problem definition Classes of approaches K-NN Support Vector Machines Softmax classification / logistic regression Parzen
CENG 793 On Machine Learning and Optimization Sinan Kalkan 2 Now Introduction to ML Problem definition Classes of approaches K-NN Support Vector Machines Softmax classification / logistic regression Parzen
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
CSC321 Lecture 2: Linear Regression
 CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
Backpropagation and Neural Networks part 1. Lecture 4-1
 Lecture 4: Backpropagation and Neural Networks part 1 Lecture 4-1 Administrative A1 is due Jan 20 (Wednesday). ~150 hours left Warning: Jan 18 (Monday) is Holiday (no class/office hours) Also note: Lectures
Lecture 4: Backpropagation and Neural Networks part 1 Lecture 4-1 Administrative A1 is due Jan 20 (Wednesday). ~150 hours left Warning: Jan 18 (Monday) is Holiday (no class/office hours) Also note: Lectures
CSC321 Lecture 5 Learning in a Single Neuron
 CSC321 Lecture 5 Learning in a Single Neuron Roger Grosse and Nitish Srivastava January 21, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 5 Learning in a Single Neuron January 21, 2015 1 / 14
CSC321 Lecture 5 Learning in a Single Neuron Roger Grosse and Nitish Srivastava January 21, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 5 Learning in a Single Neuron January 21, 2015 1 / 14
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Artificial Neural Networks
 Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
word2vec Parameter Learning Explained
 word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
Lecture 35: Optimization and Neural Nets
 Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
CSC321 Lecture 6: Backpropagation
 CSC321 Lecture 6: Backpropagation Roger Grosse Roger Grosse CSC321 Lecture 6: Backpropagation 1 / 21 Overview We ve seen that multilayer neural networks are powerful. But how can we actually learn them?
CSC321 Lecture 6: Backpropagation Roger Grosse Roger Grosse CSC321 Lecture 6: Backpropagation 1 / 21 Overview We ve seen that multilayer neural networks are powerful. But how can we actually learn them?
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
17 Neural Networks NEURAL NETWORKS. x XOR 1. x Jonathan Richard Shewchuk
 94 Jonathan Richard Shewchuk 7 Neural Networks NEURAL NETWORKS Can do both classification & regression. [They tie together several ideas from the course: perceptrons, logistic regression, ensembles of
94 Jonathan Richard Shewchuk 7 Neural Networks NEURAL NETWORKS Can do both classification & regression. [They tie together several ideas from the course: perceptrons, logistic regression, ensembles of
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam
 CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Welcome to the Machine Learning Practical Deep Neural Networks. MLP Lecture 1 / 18 September 2018 Single Layer Networks (1) 1
 1") Welcome to the Machine Learning Practical Deep Neural Networks MLP Lecture 1 / 18 September 2018 Single Layer Networks (1) 1 Introduction to MLP; Single Layer Networks (1) Steve Renals Machine Learning
Welcome to the Machine Learning Practical Deep Neural Networks MLP Lecture 1 / 18 September 2018 Single Layer Networks (1) 1 Introduction to MLP; Single Layer Networks (1) Steve Renals Machine Learning
Lecture 4: Training a Classifier
 Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Machine Learning and Computational Statistics, Spring 2017 Homework 2: Lasso Regression
 Machine Learning and Computational Statistics, Spring 2017 Homework 2: Lasso Regression Due: Monday, February 13, 2017, at 10pm (Submit via Gradescope) Instructions: Your answers to the questions below,
Machine Learning and Computational Statistics, Spring 2017 Homework 2: Lasso Regression Due: Monday, February 13, 2017, at 10pm (Submit via Gradescope) Instructions: Your answers to the questions below,
CPSC 340: Machine Learning and Data Mining. Stochastic Gradient Fall 2017
 CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Natural Language Processing
 Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining Linear Classifiers: predictions Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due Friday of next
CPSC 340: Machine Learning and Data Mining Linear Classifiers: predictions Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due Friday of next
Stat 406: Algorithms for classification and prediction. Lecture 1: Introduction. Kevin Murphy. Mon 7 January,
 1 Stat 406: Algorithms for classification and prediction Lecture 1: Introduction Kevin Murphy Mon 7 January, 2008 1 1 Slides last updated on January 7, 2008 Outline 2 Administrivia Some basic definitions.
1 Stat 406: Algorithms for classification and prediction Lecture 1: Introduction Kevin Murphy Mon 7 January, 2008 1 1 Slides last updated on January 7, 2008 Outline 2 Administrivia Some basic definitions.
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Natural Language Processing with Deep Learning CS224N/Ling284. Richard Socher Lecture 2: Word Vectors
 Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Vote. Vote on timing for night section: Option 1 (what we have now) Option 2. Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9
 Option 2. Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9") Vote Vote on timing for night section: Option 1 (what we have now) Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9 Option 2 Lecture, 6:10-7 10 minute break Lecture, 7:10-8 10 minute break Tutorial,
Vote Vote on timing for night section: Option 1 (what we have now) Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9 Option 2 Lecture, 6:10-7 10 minute break Lecture, 7:10-8 10 minute break Tutorial,
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 6: Backpropagation
 Lecture 6: Backpropagation Roger Grosse 1 Introduction So far, we ve seen how to train shallow models, where the predictions are computed as a linear function of the inputs. We ve also observed that deeper
Lecture 6: Backpropagation Roger Grosse 1 Introduction So far, we ve seen how to train shallow models, where the predictions are computed as a linear function of the inputs. We ve also observed that deeper
Deep Learning (CNNs)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 9 Sep. 26, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 9 Sep. 26, 2018 1 Reminders Homework 3:
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 9 Sep. 26, 2018 1 Reminders Homework 3:
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CPSC 340: Machine Learning and Data Mining. Regularization Fall 2017
 CPSC 340: Machine Learning and Data Mining Regularization Fall 2017 Assignment 2 Admin 2 late days to hand in tonight, answers posted tomorrow morning. Extra office hours Thursday at 4pm (ICICS 246). Midterm
CPSC 340: Machine Learning and Data Mining Regularization Fall 2017 Assignment 2 Admin 2 late days to hand in tonight, answers posted tomorrow morning. Extra office hours Thursday at 4pm (ICICS 246). Midterm
CS 570: Machine Learning Seminar. Fall 2016
 CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
Do not tear exam apart!
 6.036: Final Exam: Fall 2017 Do not tear exam apart! This is a closed book exam. Calculators not permitted. Useful formulas on page 1. The problems are not necessarily in any order of di culty. Record
6.036: Final Exam: Fall 2017 Do not tear exam apart! This is a closed book exam. Calculators not permitted. Useful formulas on page 1. The problems are not necessarily in any order of di culty. Record
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Applied Machine Learning Lecture 5: Linear classifiers, continued. Richard Johansson
 Applied Machine Learning Lecture 5: Linear classifiers, continued Richard Johansson overview preliminaries logistic regression training a logistic regression classifier side note: multiclass linear classifiers
Applied Machine Learning Lecture 5: Linear classifiers, continued Richard Johansson overview preliminaries logistic regression training a logistic regression classifier side note: multiclass linear classifiers