CS 570: Machine Learning Seminar. Fall 2016
|
|
|
- Spencer Atkins
- 5 years ago
- Views:
Transcription
1 CS 570: Machine Learning Seminar Fall 2016
2 Class Information Class web page: Class mailing list: My office hours: T,Th, 2-3pm or by appointment (FAB ) Machine Learning mailing list:
3 Class Description Course is 1-credit graduate seminar for students who have already taken a course in Artificial Intelligence or Machine Learning. Purpose of the course: Each term: Deep dive into one recent area of ML. Not a general ML course. Students will read and discuss recent papers in the Machine Learning literature. Each student will be responsible for presenting 1 or 2 papers during the term. Course will be offered each term, and students may take it multiple times. CS MS students who take this course for three terms may count it as one of the courses for the "Artificial Intelligence and Machine Learning" masters track requirement.
4 Course Topics Previous topics (under 510 number): Winter 2015: Graphical Models Spring 2015: Reinforcement Learning Fall 2015: Neural Network Approaches to Natural Language Processing Winter 2015: Analogy, Metaphor and Common Sense Reasoning Spring 2016: AI and Creativity: AI in Art, Music, and Literature This term s topic: Deep Reinforcement Learning
5 Course work 1-2 papers will be assigned per week for everyone in the class to read. Each week 1 or 2 students will be assigned as discussion leaders for the week's papers. I will hand out a question list with each paper assignment. You need to complete it and turn it in on the day we cover the paper. (Just to make sure you read the paper). Expected homework load: ~3-4 hours per week on average
6 Grading Class attendance and participation You may miss up to one class if necessary with no penalty Weekly questions - You can skip at most one week of this with no penalty Discussion leader presentation
7 Class Introductions
8 How to present a paper Start early Use slides Plan for 30 minutes or so Explain any unfamiliar terminology in the paper (do additional background reading if necessary) Don t go through the paper exhaustively; just talk about most important parts Include graphs / images on your slides Outside information is encouraged (demos, short videos, explanations) Present 1 3 discussion questions for class. If you don t understand something in the paper, let the class help out Don t overload slides with text
9 Discussion Leader Schedule
10 Review of Reinforcement Learning
11 Robby the Robot can learn via reinforcement learning Sensors: N,S,E,W,C(urrent) Ac;ons: Move N Move S Move E Move W Move random Stay put Try to pick up can policy = strategy Rewards/Penal;es (points): Picks up can: 10 Tries to pick up can on empty site: -1 Crashes into wall: -5
12 Supervised / Unsupervised / Reinforcement Learning Supervised: Each example has a label. Goal is to predict labels of unseen examples Unsupervised: No labels. Goal is to cluster examples into unlabeled classes. Reinforcement: No labels. Sparse, time-delayed rewards. Goal is to learn a policy : mapping from states to actions. Hard problem in reinforcement learning: credit-assignment
13 Formalization Reinforcement learning is typically formalized as a Markov decision process (MDP): Agent L only knows current state and actions available from that state. Agent L can: perceive a set S of distinct states of an environment perform a set A of actions. Components of Markov Decision Process (MDP): Possible set S of states (state space) Possible set A of actions (action space) State transition function (unknown to learner L) δ : S A S δ(s t,a t ) = s t+1 Reward function (unknown to learner L) r : S A R r(s t,a t ) = r t
14 Formalization Reinforcement learning is typically formalized as a Markov decision process (MDP): Agent L only knows current state and actions available from that state. Agent L can: perceive a set S of distinct states of an environment perform a set A of actions. Components of Markov Decision Process (MDP): Possible set S of states (state space) Possible set A of actions (action space) State transition function (unknown to learner L) δ : S A S δ(s t,a t ) = s t+1 Reward function (unknown to learner L) Note: Both δ and r can be deterministic or probabilistic. In the Robby the Robot example, they are both deterministic r : S A R r(s t,a t ) = r t
15 Goal is for agent L to learn policy π, π : S maximizes cumulative reward A, such that π
16 Example: Cumula;ve value of a policy Sensors: N,S,E,W,C(urrent) Ac;ons: Move N Move S Move E Move W Move random Stay put Try to pick up can Policy A: Always move east, picking up cans as you go Policy B: Move up and down the columns of the grid, picking up cans as you go Rewards/Penal;es (points): Picks up can: 10 Tries to pick up can on empty site: -1 Crashes into wall: -5
17 Value function: Formal definition of cumulative value with discounted rewards Let V π (s t ) denote the cumulative value of π starting from initial state s t : V π (s t ) = r t +γ r t +1 +γ 2 r t = γ i r t +i i=0 where 0 γ 1 is a discounting constant that determines the relative value of delayed versus immediate rewards. V π (s t ) is called the value function for policy π. It gives the expected value of starting in state s t and following policy π forever.
18 Note that rewards received i times steps into the future are discounted exponentially ( by a factor of γ i ). If γ = 0, we only care about immediate reward. The closer γ is to 1, the more we care about future rewards relative to immediate reward.
19 Precise specification of learning task: We require that the agent learn policy π that maximizes V π (s) for all states s. We call such a policy an optimal policy, and denote it by π*: To simplify notation, let V *(s) = V π * (s)
20 What should L learn? Hard to learn π* directly, since we don t have training data of the form (s, a) Only training data availale to learner is sequence of rewards: r(s 0, a 0 ), r(s 1, a 1 ),... Most often, r(s t, a t ) = 0! So, what should the learner L learn?
21 Learn evaluation function V? One possibility: learn evaluation function V*(s). Then L would know what action to take next: L should prefer state s 1 over s 2 whenever V*(s 1 ) > V*(s 2 ) Optimal action a in state s is the one that maximizes sum of r(s,a) (immediate reward) and V* of the immediate successor state, discounted by γ: π * (s) = argmax[ r(s,a) + γv *(δ(s,a))] a
22 π * (s) = argmax[ r(s,a) + γv * (δ(s,a))] a
23 Problem with learning V* Problem: Using V* to obtain optimal policy π* requires perfect knowledge of δ and r, which we earlier said are unknown to L.
24 Alternative: Learning Q Alternative: we will estimate the following evaluation function Q: S A R, as follows: π * (s) = argmax[ r(s,a) + γv *(δ(s,a))] = argmax[ Q(s,a) ], a a where Q(s,a) = r(s,a) + γv * (δ(s,a)) Suppose learner L has a good estimate, ˆQ(s, a). Then, at each time step, L simply chooses action that maximizes ˆQ(s, a).
25 We have: How to learn Q? (In theory) [ ] π *(s) = argmax r(s, a')+γv *(δ(s, a')) a' V *(s) = max[ r(s, a')+γv *(δ(s, a')) ] a = max[ Q(s, a') ] a' because Q(s, a') = r(s, a') +γv *(δ(s, a')), by definition So, Q(s, a) = r(s, a)+γ max a' [ Q(δ(s, a), a') ] We can estimate Q via iterative approximation.
26 How to learn Q in practice? Initialize ˆQ(s, a) to small random values for all s and a Initialize s Repeat forever (or as long as you have time for): Select action a Take action a and receive reward r Observe new state s Update ˆQ(s, a) : ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) Update s s a'
27 Example Let γ =.2 Let η = 1 State: North, South, East, West, Current W = Wall E = Empty C = Can Reward: ˆQ(s, a) MoveN MoveS MoveE MoveW Move Random Stay Put Pick Up Can
28 ˆQ(s, a) State: North, South, East, West, Current W = Wall E = Empty C = Can Reward: ˆQ(s, a) Ini;alize to small random values (here, 0) for all s and a MoveN MoveS MoveE MoveW Move Random Stay Put Pick Up Can
29 Ini;alize s ˆQ(s, a) State: North, South, East, West, Current W = Wall E = Empty C = Can Reward: MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E Pick Up Can
30 Select ac;on a State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 1 ˆQ(s, a) Reward: MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E Pick Up Can
31 Perform ac;on a and receive reward r State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 1 ˆQ(s, a) Reward: 1 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E Pick Up Can
32 Observe new state s State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 1 ˆQ(s, a) Reward: 1 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E Pick Up Can
33 Update ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) State: North, South, East, West, Current a' W = Wall E = Empty C = Can Trial: 1 ˆQ(s, a) Reward: 1 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E Pick Up Can
34 Update ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) State: North, South, East, West, Current a' W = Wall E = Empty C = Can Trial: 1 ˆQ(s, a) Reward: 1 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E Pick Up Can
35 Update s s State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 1 ˆQ(s, a) Reward: MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E Pick Up Can
36 Select ac;on a State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 2 ˆQ(s, a) Reward: MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E Pick Up Can
37 Perform ac;on a and receive reward r State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 2 ˆQ(s, a) Reward: 0 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E Pick Up Can
38 Observe new state s State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 2 ˆQ(s, a) Reward: 0 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E W, E, E, E, C Pick Up Can
39 Update ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) State: North, South, East, West, Current a' W = Wall E = Empty C = Can Trial: 2 ˆQ(s, a) Reward: 0 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E W, E, E, E, C Pick Up Can
40 Update ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) State: North, South, East, West, Current a' W = Wall E = Empty C = Can Trial: 2 ˆQ(s, a) Reward: 0 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E W, E, E, E, C Pick Up Can
41 Update s s State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 2 ˆQ(s, a) Reward: 0 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E W, E, E, E, C Pick Up Can
42 Select ac;on a State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 3 ˆQ(s, a) Reward: MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E W, E, E, E, C Pick Up Can
43 Perform ac;on a and receive reward r State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 3 ˆQ(s, a) Reward: 10 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, C, W, E W, E, E, E, C Pick Up Can
44 Observe new state s State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 3 ˆQ(s, a) Reward: 10 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
45 Update ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) State: North, South, East, West, Current a' W = Wall E = Empty C = Can Trial: 3 ˆQ(s, a) Reward: 10 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
46 Update ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) State: North, South, East, West, Current a' W = Wall E = Empty C = Can Trial: 3 ˆQ(s, a) Reward: 10 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
47 Update s s State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: 3 ˆQ(s, a) Reward: 10 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
48 Skipping ahead... State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: m ˆQ(s, a) Reward: MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
49 Skipping ahead... Select ac;on a State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: m ˆQ(s, a) Reward: MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
50 Skipping ahead... Perform ac;on a and receive reward r State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: m ˆQ(s, a) Reward: 10 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
51 Skipping ahead... Observe new state s State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: m ˆQ(s, a) Reward: 10 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
52 Skipping ahead... Update ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) State: North, South, East, West, Current a' W = Wall E = Empty C = Can Trial: m ˆQ(s, a) Reward: 10 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
53 Skipping ahead... Update ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) State: North, South, East, West, Current a' W = Wall E = Empty C = Can Trial: m ˆQ(s, a) Reward: 10 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
54 Now on a new environment... Select ac;on a State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: n ˆQ(s, a) Reward: MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
55 Now on a new environment... Perform ac;on a and receive reward r State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: n ˆQ(s, a) Reward: 0 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
56 Now on a new environment... Observe new state s State: North, South, East, West, Current W = Wall E = Empty C = Can Trial: n ˆQ(s, a) Reward: 0 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
57 Now on a new environment... Update ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) State: North, South, East, West, Current a' W = Wall E = Empty C = Can Trial: n ˆQ(s, a) Reward: 0 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
58 Now on a new environment... Update ˆQ(s, a) ˆQ(s, a)+η( r +γ max ˆQ(s', a') ˆQ(s, a) ) State: North, South, East, West, Current a' W = Wall E = Empty C = Can Trial: n ˆQ(s, a) Reward: 0 MoveN MoveS MoveE MoveW Move Random Stay Put W, E, E, E, E W, E, C, W, E W, E, E, E, C Pick Up Can
59 How to choose actions?
60 How to choose actions? Naïve strategy: at each time step, choose action that maximizes ˆQ(s, a)
61 How to choose actions? Naïve strategy: at each time step, choose action that maximizes ˆQ(s, a) This exploits current ˆQ(s, but doesn t further explore the state-action space (in case a)ˆq(s, a) is way off)
62 How to choose actions? Naïve strategy: at each time step, choose action that maximizes ˆQ(s, a) This exploits current ˆQ(s, but doesn t further explore the state-action space (in case a)ˆq(s, a) is way off) Common approach in Q learning: P(a i s) = e ˆQ(s,a i )/T e ˆQ(s,a i )/T j, T > 0
63 Another common approach: epsilon-greedy: With probability epsilon, choose random action; otherwise choose action with highest ˆQ(s, a) value
64 This balances exploitation and exploration in a tunable way: high T: more exploration (more random) low T: more exploitation (more deterministic) Can start with high T, and decrease it as improves
65 Representation of ˆQ(s, a) ˆQ(s, a) Note that in all of the above discussion, was assumed to be a look-up table, with a distinct table entry for each distinct (s,a) pair. ˆQ(s, a) More commonly, is represented as a function (e.g., as a neural network), and the function is estimated (e.g., through back-propagation). Input: Representation of state s and action a Output: ˆQ(s, a) value To speed things up, if number of possible actions is small: Input: Representation of state s Output: ˆQ(s, a) value for each possible action a
66 Q-Learning Algorithm for Neural Networks Given observed transition < s, a, r, s > : 1. Do feedforward pass for the current state s to get predicted Q-values for all possible actions. 2. Do feedforward pass for next state s and calculate maximum over network outputs: max ˆQ(s', a') a' ˆQ(s', a') Let a* denote the action with maximum. ˆQ(s', a') 3. Set a* output node s target to r +γ max. Set target for other actions a' output nodes to predicted Q-value from step 1 (so error is zero). 4. Update weights using backpropagation.
67 Example: Learning to play backgammon Rules of backgammon
68 Complexity of Backgammon Over possible states. At each ply, 21 dice combinations, with average of about 20 legal moves per dice combination. Result is branching ratio of several hundred per ply. Chess has branching ratio of about per ply. Brute-force look-ahead search is not practical!
69 Neurogammon (G. Tesauro, 1989) Used supervised learning approach: multilayer NN trained by back-propagation on data base of recorded expert games. Input: raw board information (number of pieces at each location), and a few hand-crafted features that encoded important expert concepts. Neurogammon achieved strong intermediate level of play. Won backgammon championship at 1989 International Computer Olympiad. But not close to beating best human players.
70 TD-Gammon (G. Tesauro, 1994) Program had two main parts: Move Generator: Program that generates all legal moves from current board configuration. Predictor network: multi-layer NN that predicts Q(s,a): probability of winning the game from the current board configuration. Predictor network scores all legal moves. Highest scoring move is chosen. Rewards: Zero for all time steps except those on which game is won or lost.
71
72 Input: 198 units 24 positions, 8 input units for each position (192 input units) First 4 input units of each group of 8 represent # white pieces at that position, Second 4 represent # black units at that position Two inputs represent who is moving (white or black) Two inputs represent pieces on the bar Two inputs represent number of pieces borne off by each player.
73 50 hidden units 1 output unit (activation represents probability that white will win from given board configuration)
74 Program plays against itself. On each turn: Use network to evaluate all possible moves from current board configuration. Choose the move with the highest (lowest as black) evaluation. This produces a new board configuration. If this is end of game, run back-propagation, with target output activation of 1 or 0 depending on whether white won or lost. Else evaluate new board configuration with neural network. Calculate difference between current evaluation and previous evaluation. Run back-propagation, using the current evaluation as desired output, and the board position previous to the current move as the input.
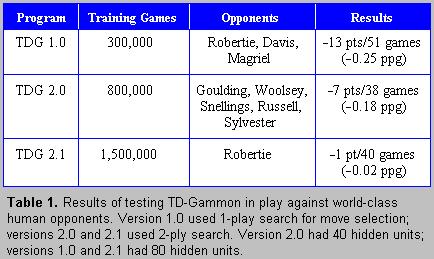

75
76 From Sutton & Barto, Reinforcement Learning: An Introduction: After playing about 300,000 games against itself, TD-Gammon 0.0 as described above learned to play approximately as well as the best previous backgammon computer programs. TD-Gammon 3.0 appears to be at, or very near, the playing strength of the best human players in the world. It may already be the world champion. These programs have already changed the way the best human players play the game. For example, TD-Gammon learned to play certain opening positions differently than was the convention among the best human players. Based on TD-Gammon's success and further analysis, the best human players now play these positions as TD-Gammon does (Tesauro, 1995).
77 Convolutional Neural Networks
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Machine Learning. Machine Learning: Jordan Boyd-Graber University of Maryland REINFORCEMENT LEARNING. Slides adapted from Tom Mitchell and Peter Abeel
 Machine Learning Machine Learning: Jordan Boyd-Graber University of Maryland REINFORCEMENT LEARNING Slides adapted from Tom Mitchell and Peter Abeel Machine Learning: Jordan Boyd-Graber UMD Machine Learning
Machine Learning Machine Learning: Jordan Boyd-Graber University of Maryland REINFORCEMENT LEARNING Slides adapted from Tom Mitchell and Peter Abeel Machine Learning: Jordan Boyd-Graber UMD Machine Learning
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
Lecture 25: Learning 4. Victor R. Lesser. CMPSCI 683 Fall 2010
 Lecture 25: Learning 4 Victor R. Lesser CMPSCI 683 Fall 2010 Final Exam Information Final EXAM on Th 12/16 at 4:00pm in Lederle Grad Res Ctr Rm A301 2 Hours but obviously you can leave early! Open Book
Lecture 25: Learning 4 Victor R. Lesser CMPSCI 683 Fall 2010 Final Exam Information Final EXAM on Th 12/16 at 4:00pm in Lederle Grad Res Ctr Rm A301 2 Hours but obviously you can leave early! Open Book
Lecture 23: Reinforcement Learning
 Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Machine Learning I Reinforcement Learning
 Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Reinforcement Learning
 Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Reinforcement Learning. George Konidaris
 Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
6 Reinforcement Learning
 6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
Reinforcement Learning II
 Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Deep Reinforcement Learning. STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017
 Deep Reinforcement Learning STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017 Outline Introduction to Reinforcement Learning AlphaGo (Deep RL for Computer Go)
Deep Reinforcement Learning STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017 Outline Introduction to Reinforcement Learning AlphaGo (Deep RL for Computer Go)
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Reinforcement Learning Instructor: Fabrice Popineau [These slides adapted from Stuart Russell, Dan Klein and Pieter Abbeel @ai.berkeley.edu] Reinforcement Learning Double
CS 188: Artificial Intelligence Reinforcement Learning Instructor: Fabrice Popineau [These slides adapted from Stuart Russell, Dan Klein and Pieter Abbeel @ai.berkeley.edu] Reinforcement Learning Double
ARTIFICIAL INTELLIGENCE. Reinforcement learning
 INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Q-learning. Tambet Matiisen
 Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Introduction to Reinforcement Learning
 CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
Reinforcement Learning: An Introduction
 Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning. Hanna Kurniawati
 COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
CS230: Lecture 9 Deep Reinforcement Learning
 CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CMU Lecture 12: Reinforcement Learning. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
CS 598 Statistical Reinforcement Learning. Nan Jiang
 CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Q-learning Tutorial. CSC411 Geoffrey Roeder. Slides Adapted from lecture: Rich Zemel, Raquel Urtasun, Sanja Fidler, Nitish Srivastava
 Q-learning Tutorial CSC411 Geoffrey Roeder Slides Adapted from lecture: Rich Zemel, Raquel Urtasun, Sanja Fidler, Nitish Srivastava Tutorial Agenda Refresh RL terminology through Tic Tac Toe Deterministic
Q-learning Tutorial CSC411 Geoffrey Roeder Slides Adapted from lecture: Rich Zemel, Raquel Urtasun, Sanja Fidler, Nitish Srivastava Tutorial Agenda Refresh RL terminology through Tic Tac Toe Deterministic
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
CS 4100 // artificial intelligence. Recap/midterm review!
 CS 4100 // artificial intelligence instructor: byron wallace Recap/midterm review! Attribution: many of these slides are modified versions of those distributed with the UC Berkeley CS188 materials Thanks
CS 4100 // artificial intelligence instructor: byron wallace Recap/midterm review! Attribution: many of these slides are modified versions of those distributed with the UC Berkeley CS188 materials Thanks
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning
 Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Markov Decision Processes (and a small amount of reinforcement learning)
") Markov Decision Processes (and a small amount of reinforcement learning) Slides adapted from: Brian Williams, MIT Manuela Veloso, Andrew Moore, Reid Simmons, & Tom Mitchell, CMU Nicholas Roy 16.4/13 Session
Markov Decision Processes (and a small amount of reinforcement learning) Slides adapted from: Brian Williams, MIT Manuela Veloso, Andrew Moore, Reid Simmons, & Tom Mitchell, CMU Nicholas Roy 16.4/13 Session
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]
![Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]](/thumbs/94/119187228.jpg "Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]") Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
CS188: Artificial Intelligence, Fall 2009 Written 2: MDPs, RL, and Probability
 CS188: Artificial Intelligence, Fall 2009 Written 2: MDPs, RL, and Probability Due: Thursday 10/15 in 283 Soda Drop Box by 11:59pm (no slip days) Policy: Can be solved in groups (acknowledge collaborators)
CS188: Artificial Intelligence, Fall 2009 Written 2: MDPs, RL, and Probability Due: Thursday 10/15 in 283 Soda Drop Box by 11:59pm (no slip days) Policy: Can be solved in groups (acknowledge collaborators)
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
CSL302/612 Artificial Intelligence End-Semester Exam 120 Minutes
 CSL302/612 Artificial Intelligence End-Semester Exam 120 Minutes Name: Roll Number: Please read the following instructions carefully Ø Calculators are allowed. However, laptops or mobile phones are not
CSL302/612 Artificial Intelligence End-Semester Exam 120 Minutes Name: Roll Number: Please read the following instructions carefully Ø Calculators are allowed. However, laptops or mobile phones are not
Prof. Dr. Ann Nowé. Artificial Intelligence Lab ai.vub.ac.be
 REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
Temporal Difference Learning & Policy Iteration
 Temporal Difference Learning & Policy Iteration Advanced Topics in Reinforcement Learning Seminar WS 15/16 ±0 ±0 +1 by Tobias Joppen 03.11.2015 Fachbereich Informatik Knowledge Engineering Group Prof.
Temporal Difference Learning & Policy Iteration Advanced Topics in Reinforcement Learning Seminar WS 15/16 ±0 ±0 +1 by Tobias Joppen 03.11.2015 Fachbereich Informatik Knowledge Engineering Group Prof.
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Reinforcement Learning
 Reinforcement Learning 1 Reinforcement Learning Mainly based on Reinforcement Learning An Introduction by Richard Sutton and Andrew Barto Slides are mainly based on the course material provided by the
Reinforcement Learning 1 Reinforcement Learning Mainly based on Reinforcement Learning An Introduction by Richard Sutton and Andrew Barto Slides are mainly based on the course material provided by the
Final. Introduction to Artificial Intelligence. CS 188 Spring You have approximately 2 hours and 50 minutes.
 CS 188 Spring 2014 Introduction to Artificial Intelligence Final You have approximately 2 hours and 50 minutes. The exam is closed book, closed notes except your two-page crib sheet. Mark your answers
CS 188 Spring 2014 Introduction to Artificial Intelligence Final You have approximately 2 hours and 50 minutes. The exam is closed book, closed notes except your two-page crib sheet. Mark your answers
15-780: ReinforcementLearning
 15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
CS 188 Introduction to Fall 2007 Artificial Intelligence Midterm
 NAME: SID#: Login: Sec: 1 CS 188 Introduction to Fall 2007 Artificial Intelligence Midterm You have 80 minutes. The exam is closed book, closed notes except a one-page crib sheet, basic calculators only.
NAME: SID#: Login: Sec: 1 CS 188 Introduction to Fall 2007 Artificial Intelligence Midterm You have 80 minutes. The exam is closed book, closed notes except a one-page crib sheet, basic calculators only.
Decision Theory: Markov Decision Processes
 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan
 COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
The exam is closed book, closed calculator, and closed notes except your one-page crib sheet.
 CS 188 Fall 2015 Introduction to Artificial Intelligence Final You have approximately 2 hours and 50 minutes. The exam is closed book, closed calculator, and closed notes except your one-page crib sheet.
CS 188 Fall 2015 Introduction to Artificial Intelligence Final You have approximately 2 hours and 50 minutes. The exam is closed book, closed calculator, and closed notes except your one-page crib sheet.
Reinforcement learning an introduction
 Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning
 CS7/CS7 Fall 005 Supervised Learning: Training examples: (x,y) Direct feedback y for each input x Sequence of decisions with eventual feedback No teacher that critiques individual actions Learn to act
CS7/CS7 Fall 005 Supervised Learning: Training examples: (x,y) Direct feedback y for each input x Sequence of decisions with eventual feedback No teacher that critiques individual actions Learn to act
Reinforcement Learning
 Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Today s Outline. Recap: MDPs. Bellman Equations. Q-Value Iteration. Bellman Backup 5/7/2012. CSE 473: Artificial Intelligence Reinforcement Learning
 CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CS 287: Advanced Robotics Fall Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study
 CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Assignment #1 Roll-out: nice example paper: X.
CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Assignment #1 Roll-out: nice example paper: X.
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
Reinforcement Learning and Control
 CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
Approximate Q-Learning. Dan Weld / University of Washington
 Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
An Introduction to Reinforcement Learning
 1 / 58 An Introduction to Reinforcement Learning Lecture 01: Introduction Dr. Johannes A. Stork School of Computer Science and Communication KTH Royal Institute of Technology January 19, 2017 2 / 58 ../fig/reward-00.jpg
1 / 58 An Introduction to Reinforcement Learning Lecture 01: Introduction Dr. Johannes A. Stork School of Computer Science and Communication KTH Royal Institute of Technology January 19, 2017 2 / 58 ../fig/reward-00.jpg
INF 5860 Machine learning for image classification. Lecture 14: Reinforcement learning May 9, 2018
 Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13. Decision Making. Abdeslam Boularias. Wednesday, December 7, 2016
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Machine Learning. Reinforcement learning. Hamid Beigy. Sharif University of Technology. Fall 1396
 Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
15-780: Graduate Artificial Intelligence. Reinforcement learning (RL)
") 15-780: Graduate Artificial Intelligence Reinforcement learning (RL) From MDPs to RL We still use the same Markov model with rewards and actions But there are a few differences: 1. We do not assume we
15-780: Graduate Artificial Intelligence Reinforcement learning (RL) From MDPs to RL We still use the same Markov model with rewards and actions But there are a few differences: 1. We do not assume we
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Using first-order logic, formalize the following knowledge:
 Probabilistic Artificial Intelligence Final Exam Feb 2, 2016 Time limit: 120 minutes Number of pages: 19 Total points: 100 You can use the back of the pages if you run out of space. Collaboration on the
Probabilistic Artificial Intelligence Final Exam Feb 2, 2016 Time limit: 120 minutes Number of pages: 19 Total points: 100 You can use the back of the pages if you run out of space. Collaboration on the
1. (3 pts) In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max P (s s, a)u(s )
 In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max P (s s, a)u(s )") 3 MDP (12 points) 1. (3 pts) In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max P (s s, a)u(s ) a s where R(s) is the reward associated with being in state s. Suppose
3 MDP (12 points) 1. (3 pts) In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max P (s s, a)u(s ) a s where R(s) is the reward associated with being in state s. Suppose
Reinforcement Learning
 Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Final Exam December 12, 2017
 Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
CS188: Artificial Intelligence, Fall 2009 Written 2: MDPs, RL, and Probability
 CS188: Artificial Intelligence, Fall 2009 Written 2: MDPs, RL, and Probability Due: Thursday 10/15 in 283 Soda Drop Box by 11:59pm (no slip days) Policy: Can be solved in groups (acknowledge collaborators)
CS188: Artificial Intelligence, Fall 2009 Written 2: MDPs, RL, and Probability Due: Thursday 10/15 in 283 Soda Drop Box by 11:59pm (no slip days) Policy: Can be solved in groups (acknowledge collaborators)
Learning Tetris. 1 Tetris. February 3, 2009
 Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Deep Reinforcement Learning
 Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 50 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 50 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Reinforcement Learning. Spring 2018 Defining MDPs, Planning
 Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Lecture 12: Probability 3/2/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Announcements P3 due on Monday (3/7) at 4:59pm W3 going out
CS 188: Artificial Intelligence Spring 2011 Lecture 12: Probability 3/2/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Announcements P3 due on Monday (3/7) at 4:59pm W3 going out
1 Introduction 2. 4 Q-Learning The Q-value The Temporal Difference The whole Q-Learning process... 5
 Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
CS221 Practice Midterm
 CS221 Practice Midterm Autumn 2012 1 ther Midterms The following pages are excerpts from similar classes midterms. The content is similar to what we ve been covering this quarter, so that it should be
CS221 Practice Midterm Autumn 2012 1 ther Midterms The following pages are excerpts from similar classes midterms. The content is similar to what we ve been covering this quarter, so that it should be
A Gentle Introduction to Reinforcement Learning
 A Gentle Introduction to Reinforcement Learning Alexander Jung 2018 1 Introduction and Motivation Consider the cleaning robot Rumba which has to clean the office room B329. In order to keep things simple,
A Gentle Introduction to Reinforcement Learning Alexander Jung 2018 1 Introduction and Motivation Consider the cleaning robot Rumba which has to clean the office room B329. In order to keep things simple,
Some AI Planning Problems
 Course Logistics CS533: Intelligent Agents and Decision Making M, W, F: 1:00 1:50 Instructor: Alan Fern (KEC2071) Office hours: by appointment (see me after class or send email) Emailing me: include CS533
Course Logistics CS533: Intelligent Agents and Decision Making M, W, F: 1:00 1:50 Instructor: Alan Fern (KEC2071) Office hours: by appointment (see me after class or send email) Emailing me: include CS533
Internet Monetization
 Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
Final Exam December 12, 2017
 Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Introduction to Artificial Intelligence CSE 473, Autumn 2017 Dieter Fox Final Exam December 12, 2017 Directions This exam has 7 problems with 111 points shown in the table below, and you have 110 minutes
Reinforcement Learning
 Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
, and rewards and transition matrices as shown below:
 CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CS 7180: Behavioral Modeling and Decisionmaking
 CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
CSEP 521 Applied Algorithms. Richard Anderson Winter 2013 Lecture 1
 CSEP 521 Applied Algorithms Richard Anderson Winter 2013 Lecture 1 CSEP 521 Course Introduction CSEP 521, Applied Algorithms Monday s, 6:30-9:20 pm CSE 305 and Microsoft Building 99 Instructor Richard
CSEP 521 Applied Algorithms Richard Anderson Winter 2013 Lecture 1 CSEP 521 Course Introduction CSEP 521, Applied Algorithms Monday s, 6:30-9:20 pm CSE 305 and Microsoft Building 99 Instructor Richard
Administration. CSCI567 Machine Learning (Fall 2018) Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.
 Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.") Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search II Instructor: Anca Dragan University of California, Berkeley [These slides adapted from Dan Klein and Pieter Abbeel] Minimax Example 3 12 8 2 4 6 14
CS 188: Artificial Intelligence Adversarial Search II Instructor: Anca Dragan University of California, Berkeley [These slides adapted from Dan Klein and Pieter Abbeel] Minimax Example 3 12 8 2 4 6 14
Short Course: Multiagent Systems. Multiagent Systems. Lecture 1: Basics Agents Environments. Reinforcement Learning. This course is about:
 Short Course: Multiagent Systems Lecture 1: Basics Agents Environments Reinforcement Learning Multiagent Systems This course is about: Agents: Sensing, reasoning, acting Multiagent Systems: Distributed
Short Course: Multiagent Systems Lecture 1: Basics Agents Environments Reinforcement Learning Multiagent Systems This course is about: Agents: Sensing, reasoning, acting Multiagent Systems: Distributed
Final Exam, Spring 2006
 070 Final Exam, Spring 2006. Write your name and your email address below. Name: Andrew account: 2. There should be 22 numbered pages in this exam (including this cover sheet). 3. You may use any and all
070 Final Exam, Spring 2006. Write your name and your email address below. Name: Andrew account: 2. There should be 22 numbered pages in this exam (including this cover sheet). 3. You may use any and all
Reinforcement Learning. Introduction
 Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
RL 3: Reinforcement Learning
 RL 3: Reinforcement Learning Q-Learning Michael Herrmann University of Edinburgh, School of Informatics 20/01/2015 Last time: Multi-Armed Bandits (10 Points to remember) MAB applications do exist (e.g.
RL 3: Reinforcement Learning Q-Learning Michael Herrmann University of Edinburgh, School of Informatics 20/01/2015 Last time: Multi-Armed Bandits (10 Points to remember) MAB applications do exist (e.g.
1. (3 pts) In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max a
 In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max a") 3 MDP (2 points). (3 pts) In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max a s P (s s, a)u(s ) where R(s) is the reward associated with being in state s. Suppose now
3 MDP (2 points). (3 pts) In MDPs, the values of states are related by the Bellman equation: U(s) = R(s) + γ max a s P (s s, a)u(s ) where R(s) is the reward associated with being in state s. Suppose now
Overview Example (TD-Gammon) Admission Why approximate RL is hard TD() Fitted value iteration (collocation) Example (k-nn for hill-car)
 Admission Why approximate RL is hard TD() Fitted value iteration (collocation) Example (k-nn for hill-car)") Function Approximation in Reinforcement Learning Gordon Geo ggordon@cs.cmu.edu November 5, 999 Overview Example (TD-Gammon) Admission Why approximate RL is hard TD() Fitted value iteration (collocation)
Function Approximation in Reinforcement Learning Gordon Geo ggordon@cs.cmu.edu November 5, 999 Overview Example (TD-Gammon) Admission Why approximate RL is hard TD() Fitted value iteration (collocation)
Course basics. CSE 190: Reinforcement Learning: An Introduction. Last Time. Course goals. The website for the class is linked off my homepage.
 Course basics CSE 190: Reinforcement Learning: An Introduction The website for the class is linked off my homepage. Grades will be based on programming assignments, homeworks, and class participation.
Course basics CSE 190: Reinforcement Learning: An Introduction The website for the class is linked off my homepage. Grades will be based on programming assignments, homeworks, and class participation.
Reinforcement Learning (1)
") Reinforcement Learning 1 Reinforcement Learning (1) Machine Learning 64-360, Part II Norman Hendrich University of Hamburg, Dept. of Informatics Vogt-Kölln-Str. 30, D-22527 Hamburg hendrich@informatik.uni-hamburg.de
Reinforcement Learning 1 Reinforcement Learning (1) Machine Learning 64-360, Part II Norman Hendrich University of Hamburg, Dept. of Informatics Vogt-Kölln-Str. 30, D-22527 Hamburg hendrich@informatik.uni-hamburg.de
Natural Language Processing. Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu
 Natural Language Processing Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu Projects Project descriptions due today! Last class Sequence to sequence models Attention Pointer networks Today Weak
Natural Language Processing Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu Projects Project descriptions due today! Last class Sequence to sequence models Attention Pointer networks Today Weak