Neural Network Approximation. Low rank, Sparsity, and Quantization Oct. 2017
|
|
|
- Percival Paul
- 5 years ago
- Views:
Transcription
1 Neural Network Approximation Low rank, Sparsity, and Quantization Oct. 2017

2 Motivation Faster Inference Faster Training Latency critical scenarios VR/AR, UGV/UAV Saves time and energy Higher iteration speed Saves life Smaller storage size memory footprint Lee Sedol v.s. AlphaGo 83 Watt 77 kwatt


3

4
5 Neural Network


6 Machine Learning as Optimization Supervised learning is the parameter is output, X is input y is ground truth d is the objective function Unsupervised learning some oracle function r: low rank, sparse, K

7 Machine Learning as Optimization Regularized supervised learning Probabilistic interpretation d measures conditional probability r measures prior probability Probability approach is more constrained than the optimization-approach due to normalization problem Not easy to represent uniform distribution over [0, \infty]
8 Gradient descent Can be solved by an ODE: Discretizing with step length descent with learning rate Derive Convergence proof we get gradient

 #param")
9 Linear Regression x is input, \hat{y} is prediction, y is ground truth. W with dimension (m,n) #param = m n, #OPs = m n
10 Fully-connected In general, will use nonlinearity to increase model capacity. Make sense if f is identity? I.e. f(x) = x? Sometimes, if W_2 is m by r and W_1 is r by n, then W_2 W_1 is a matrix of rank r, which is different from a m by n matrix. Deep learning!
11 Neural Network Cost d+r Activations/ Feature maps/ Neurons X y
12 Gradient descent Can be solved by an ODE: Discretizing with step length descent with learning rate Derive Convergence proof we get gradient
13 Backpropagation
14 Neural Network Training Cost d+r y Activations/ Feature maps/ Neurons Gradients X
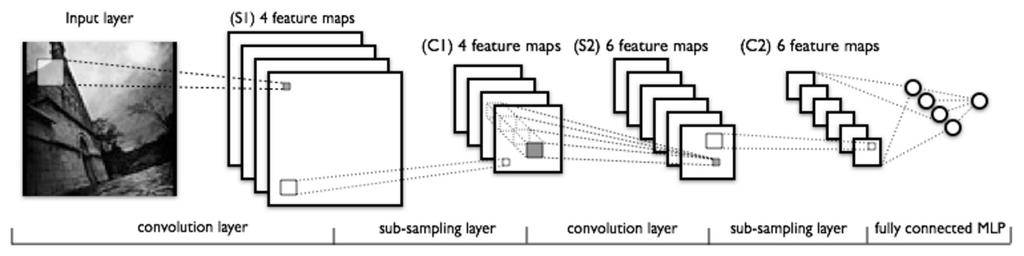
15 CNN: Alexnet-like



16 Method 2: Convolution as matrix product Convolution feature map <N, C, H, W > weights <K, C, H, W> Height Convolution as FC Kernel stride determines how much overlap under proper padding, can extract patchs feature map <N H W, C H W> weights <C H W, K> Width
17 Importance of Convolutions and FC Neupack: inspect_model.py NeuPeak: npk-model-manip XXX info Most storage size Feature map size Most Computation
18 The Matrix View of Neural Network Weights of FullyConnected and Convolutions layers take up most computation and storage size are representable as matrices Approximating the matrices approximates the network The approximation error accumulates.
19 Low rank Approximation
20 Singular Value Decomposition Matrix deocomposition view A = U S V^T Rows of U, V are orthogonal. S is diagonal. u, s, v^t = np.linalg.svd(x, full_matrices=0,compute_uv=1) The diagonals are non-negative and are in descending order. U^T U = I, but U U^T is not full rank Compact SVD
21 Truncated SVD Assume diagonals of S are in descending order Always achievable Just ignore the blue segments.

22
23 Matrix factorization => Convolution factorization Factorization into HxW followed by 1x1 feature map (N H W, C H W) first conv weights (C H W, R) feature map (N H W, R) second conv weights (R, K) feature map (N H W, K) K C K R CHW HxW HxW K R CHW C R 1x1 K
24 Approximating Convolution Weight W is a (K, C, H, W) 4-tensor can be reshaped to a (CHW, K) matrix, etc. F-norm is invariant under reshape W W_a reshape M reshape M_a approximate
25 Matrix factorization => Convolution factorization C Factorization into 1x1 followed by HxW feature map (N H W H W, C) first conv weights (C, R) feature map (N H W H W, R) = (N H W, R H W) second conv weights (R H W, K) feature map (N H W, K) Steps Reshape (CHW, K) to (C, HW, K) (C, HW, K) = (C, R) (R, HW, K) Reshape (R, HW, K) to (RHW, K) C HxW K 1x1 R HxW K
26 Horizontal-Vertical Decomposition Approximating with Separable Filters Original Convolution Factorization into Hx1 followed by 1xW feature map (N H W, C H W) weights (C H W, K) feature map (N H W W, C H) first conv weights (C H, R) feature map (N H W W, R) = (N H W, R W) second conv weights (R W, K) feature map (N H W, K) Steps Reshape (CHW, K) to (CH, WK) (CH, WK) = (CH, R) (R, WK) Reshape (R, WK) to (RW, K) C C Hx1 HxW K R 1xW K
27 Factorizing N-D convolution Original Convolution let dimension be N feature map (N D _1 D _2 D _Z, C D_1 D_2 D_N) weights (C D_1 D_2 D_N, K) C C HxWxZ K Hx1x1 R1 1xWx1 R2 Factorization into N number of D_i x1 R_0 = C, R_Z = K feature map (N D _1 D _2 D _Z, C D_1 D_2 D_N) weights (R_0 D_1, R_1) feature map (N D _1 D _2 D _Z, R_1 D_2 D_N) weights (R_1 D_2, R_2)... 1x1xZ Z
28 SVD + Kronecker Product
29 Kronecker Conv (C H W, K) Reshape as (C_1 C_2 H W, K_1 K_2) Steps Feature map is (N C H W ) Extract patches and reshape (N H W C_2, C_1 H) apply (C_1 H, K_1 R) Feature map is (N K_1 R H W C_2) Extract patches and reshape (N K_1 H W, R C_2 W) apply (R C_2 W, K_2) For rank efficiency, should have R C_2 \approx C_1
30 Exploiting Local Structures with the Kronecker Layer in Convolutional Networks 1512


31 Shared Group Convolution is a Kronecker Layer AlexNet partitioned a conv Conv/FC Shared Group Conv/FC

32 CP-decomposition and Xception Xception: Deep Learning with Depthwise Separable Convolutions 1610 CP-decomposition with Tensor Power Method forconvolutional Neural Networks Compression 1701 MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 1704 They submitted the paper to CVPR about the same time as Xception.
33 Matrix Joint Diagonalization = CP HxW CP C K HxW T C S K MJD T TT1 1 1 S SS123
34 CP-decomposition with Tensor Power Method for Convolutional Neural Networks Compression 1701 Convolution Xception Channel-wise

35 Tensor Train Decomposition
36 Tensor Train Decomposition: just a few SVD s
37 Tensor Train Decomposition on FC

38 Graph Summary of SVD variants Matrix Product State

39 CNN layers as Multilinear Maps
40 Sparse Approximation
41 Distribution of Weights Universal across convolutions and FC Concentration of values near 0 Large values cannot be dropped

42 Sparsity of NN: statistics

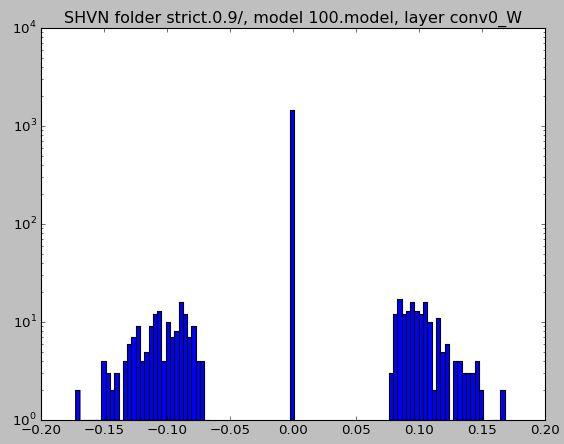
43 Sparsity of NN: statistics
44 Weight Pruning: from DeepCompression Network Train Extract Mask M W => M o W Train... The model has been trained with exccessive #epoch.
45 Sparse Matrix at Runtime Sparse Matrix = Discrete Mask + Continuous values Mask cannot be learnt the normal way The values have well-defined gradients The matrix value look up need go through a LUT CSR format A: NNZ values IA: accumulated #NNZ of rows JA: the column in the row
46 Burden of Sparseness Lost of regularity of memory access and computation Need special hardware for efficient access May need high zero ratio to match dense matrix Matrices will less than 70% zero values, better to treat as dense matrices.

47 Convolution layers are harder to compress than FC

48 Dynamic Generation of Code CVPR 15: Sparse Convolutional Neural Networks Relies on compiler for register allocation scheduling Good on CPU
49 Channel Pruning Learning the Number of Neurons in Deep Networks 1611 Channel Pruning for Accelerating Very Deep Neural Networks 1707 Also exploits low-rankness of features
50 Sparse Communication for Distributed Gradient Descent 1704
51 Quantization

52 Precursor: Ising model & Boltzmann machine Ising model used to model magnetics 1D has trivial analytic solution 2D exhibits phase-transition 2D Ising model can be used for denoising when the mean signal is reliable Inference also requires optimization
53 Neural Network Training Cost d+r Quantized Activations/ Feature maps/ Neurons y Quantized Gradients Quantized X
54 Backpropagation There will be no gradient flow if we quantize somewhere!
55 Differentiable Quantization Bengio 13: Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation REINFORCE algorithm Decompose binary stochastic neuron into stochastic and differentiable part Injection of additive/multiplicative noise Straight-through estimator Gradient vanishes after quantization.
")
56 Quantization also at Train time Neural Network can adapt to the constraints imposed by quantization Exploits Straight-through estimator (Hinton, Coursera lecture, 2012) Example
57 Bit Neural Network Matthieu Courbariaux et al. BinaryConnect: Training Deep Neural Networks with binary weights during propagations. Itay Hubara et al. Binarized Neural Networks Matthieu Courbariaux et al. Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to +1 or Rastegari et al. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks Zhou et al. DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients Hubara et al. Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations
58 Binarizing AlexNet Theoretical

59 Scaled binarization Sol: = Varaince of rows of W o B
60 XNOR-Net
61 Binary weights network Filter repetition 3x3 binary kernel has only 256 patterns modulo sign. 3x1 binary kernel only has only 4 patterns modulo sign. Not easily exploitable as we are applying CHW as filter

62 Binarizing AlexNet Theoretical
63 Scaled binarization is no longer exact and not found to be useful The solution below is quite bad, like when Y = [-4, 1]
64 Quantization of Activations XNOR-net adopted STE method in their open-source our code Input ReLU Input Capped ReLU Quantization
65 DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients Uniform stochastic quantization of gradients Simplified scaled binarization: only scalar 6 bit for ImageNet, 4 bit for SVHN Forward and backward multiplies the bit matrices from different sides. Using scalar binarization allows using bit operations Floating-point-free inference even when with BN Future work BN requires FP computation during training Require FP weights for accumulating gradients


66 SVHN A B CD A has two times as many channels as B. B has two times as many channels as C....
67 Quantization Methods Deterministic Quantization Stochastic Quantizaiton Injection of noise realizes the sampling.


68 Quantization of Weights, Activations and Gradients A half #channel 2-bit AlexNet (same bit complexity as XNOR-net)

69 Quantization Error measured by Cosine Similarity Wb_sn is n-bit quantizaiton of real W x is Gaussian R. V. clipped by tanh Saturates
70
71

72 Effective Quantization Methods for Recurrent Neural Networks 2016 Our FP baseline is worse than that of Hubara.

73 Training Bit Fully Convolutional Network for Fast Semantic Segmentation 2016

74
75 FPGA is made up of many LUT's


76
77 TernGrad: Ternary Gradients to ReduceCommunication in Distributed Deep Learning 1705 Weights and activations not quantized.
78 More References Xiangyu Zhang, Jianhua Zou, Kaiming He, Jian Sun: Accelerating Very Deep Convolutional Networks for Classification and Detection. IEEE Trans. Pattern Anal. Mach. Intell. 38(10): (2016) ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices Aggregated Residual Transformations for Deep Neural Networks Convolutional neural networks with low-rank regularization

79 Backup after this slide Slide also available at my home page:

80
81 Low-rankness of Activations Accelerating Very Deep Convolutional Networks for Classification and Detection
TYPES OF MODEL COMPRESSION. Soham Saha, MS by Research in CSE, CVIT, IIIT Hyderabad
 TYPES OF MODEL COMPRESSION Soham Saha, MS by Research in CSE, CVIT, IIIT Hyderabad 1. Pruning 2. Quantization 3. Architectural Modifications PRUNING WHY PRUNING? Deep Neural Networks have redundant parameters.
TYPES OF MODEL COMPRESSION Soham Saha, MS by Research in CSE, CVIT, IIIT Hyderabad 1. Pruning 2. Quantization 3. Architectural Modifications PRUNING WHY PRUNING? Deep Neural Networks have redundant parameters.
Towards Accurate Binary Convolutional Neural Network
 Paper: #261 Poster: Pacific Ballroom #101 Towards Accurate Binary Convolutional Neural Network Xiaofan Lin, Cong Zhao and Wei Pan* firstname.lastname@dji.com Photos and videos are either original work
Paper: #261 Poster: Pacific Ballroom #101 Towards Accurate Binary Convolutional Neural Network Xiaofan Lin, Cong Zhao and Wei Pan* firstname.lastname@dji.com Photos and videos are either original work
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
TENSOR LAYERS FOR COMPRESSION OF DEEP LEARNING NETWORKS. Cris Cecka Senior Research Scientist, NVIDIA GTC 2018
 TENSOR LAYERS FOR COMPRESSION OF DEEP LEARNING NETWORKS Cris Cecka Senior Research Scientist, NVIDIA GTC 2018 Tensors Computations and the GPU AGENDA Tensor Networks and Decompositions Tensor Layers in
TENSOR LAYERS FOR COMPRESSION OF DEEP LEARNING NETWORKS Cris Cecka Senior Research Scientist, NVIDIA GTC 2018 Tensors Computations and the GPU AGENDA Tensor Networks and Decompositions Tensor Layers in
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Binary Deep Learning. Presented by Roey Nagar and Kostya Berestizshevsky
 Binary Deep Learning Presented by Roey Nagar and Kostya Berestizshevsky Deep Learning Seminar, School of Electrical Engineering, Tel Aviv University January 22 nd 2017 Lecture Outline Motivation and existing
Binary Deep Learning Presented by Roey Nagar and Kostya Berestizshevsky Deep Learning Seminar, School of Electrical Engineering, Tel Aviv University January 22 nd 2017 Lecture Outline Motivation and existing
Quantisation. Efficient implementation of convolutional neural networks. Philip Leong. Computer Engineering Lab The University of Sydney
 1/51 Quantisation Efficient implementation of convolutional neural networks Philip Leong Computer Engineering Lab The University of Sydney July 2018 / PAPAA Workshop Australia 2/51 3/51 Outline 1 Introduction
1/51 Quantisation Efficient implementation of convolutional neural networks Philip Leong Computer Engineering Lab The University of Sydney July 2018 / PAPAA Workshop Australia 2/51 3/51 Outline 1 Introduction
Convolutional Neural Network Architecture
 Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Convolutional Neural Network Architecture Zhisheng Zhong Feburary 2nd, 2018 Zhisheng Zhong Convolutional Neural Network Architecture Feburary 2nd, 2018 1 / 55 Outline 1 Introduction of Convolution Motivation
Sajid Anwar, Kyuyeon Hwang and Wonyong Sung
 Sajid Anwar, Kyuyeon Hwang and Wonyong Sung Department of Electrical and Computer Engineering Seoul National University Seoul, 08826 Korea Email: sajid@dsp.snu.ac.kr, khwang@dsp.snu.ac.kr, wysung@snu.ac.kr
Sajid Anwar, Kyuyeon Hwang and Wonyong Sung Department of Electrical and Computer Engineering Seoul National University Seoul, 08826 Korea Email: sajid@dsp.snu.ac.kr, khwang@dsp.snu.ac.kr, wysung@snu.ac.kr
Channel Pruning and Other Methods for Compressing CNN
 Channel Pruning and Other Methods for Compressing CNN Yihui He Xi an Jiaotong Univ. October 12, 2017 Yihui He (Xi an Jiaotong Univ.) Channel Pruning and Other Methods for Compressing CNN October 12, 2017
Channel Pruning and Other Methods for Compressing CNN Yihui He Xi an Jiaotong Univ. October 12, 2017 Yihui He (Xi an Jiaotong Univ.) Channel Pruning and Other Methods for Compressing CNN October 12, 2017
arxiv: v1 [cs.ne] 20 Apr 2018
![arxiv: v1 [cs.ne] 20 Apr 2018](/thumbs/86/94149502.jpg "arxiv: v1 [cs.ne] 20 Apr 2018") arxiv:1804.07802v1 [cs.ne] 20 Apr 2018 Value-aware Quantization for Training and Inference of Neural Networks Eunhyeok Park 1, Sungjoo Yoo 1, Peter Vajda 2 1 Department of Computer Science and Engineering
arxiv:1804.07802v1 [cs.ne] 20 Apr 2018 Value-aware Quantization for Training and Inference of Neural Networks Eunhyeok Park 1, Sungjoo Yoo 1, Peter Vajda 2 1 Department of Computer Science and Engineering
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep Learning. Convolutional Neural Network (CNNs) Ali Ghodsi. October 30, Slides are partially based on Book in preparation, Deep Learning
 Ali Ghodsi. October 30, Slides are partially based on Book in preparation, Deep Learning") Convolutional Neural Network (CNNs) University of Waterloo October 30, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Convolutional Networks Convolutional
Convolutional Neural Network (CNNs) University of Waterloo October 30, 2015 Slides are partially based on Book in preparation, by Bengio, Goodfellow, and Aaron Courville, 2015 Convolutional Networks Convolutional
Value-aware Quantization for Training and Inference of Neural Networks
 Value-aware Quantization for Training and Inference of Neural Networks Eunhyeok Park 1, Sungjoo Yoo 1, and Peter Vajda 2 1 Department of Computer Science and Engineering Seoul National University {eunhyeok.park,sungjoo.yoo}@gmail.com
Value-aware Quantization for Training and Inference of Neural Networks Eunhyeok Park 1, Sungjoo Yoo 1, and Peter Vajda 2 1 Department of Computer Science and Engineering Seoul National University {eunhyeok.park,sungjoo.yoo}@gmail.com
σ(x) = clip( x m + α 2, 0, α) = min(max( x m + α 2, 0), α) (1)
 = clip( x m + α 2, 0, α) = min(max( x m + α 2, 0), α) (1)") TRUE GRADIENT-BASED TRAINING OF DEEP BINARY ACTIVATED NEURAL NETWORKS VIA CONTINUOUS BINARIZATION Charbel Sakr, Jungwook Choi, Zhuo Wang, Kailash Gopalakrishnan, Naresh Shanbhag Dept. of Electrical and
TRUE GRADIENT-BASED TRAINING OF DEEP BINARY ACTIVATED NEURAL NETWORKS VIA CONTINUOUS BINARIZATION Charbel Sakr, Jungwook Choi, Zhuo Wang, Kailash Gopalakrishnan, Naresh Shanbhag Dept. of Electrical and
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Rethinking Binary Neural Network for Accurate Image Classification and Semantic Segmentation
 Rethinking nary Neural Network for Accurate Image Classification and Semantic Segmentation Bohan Zhuang 1, Chunhua Shen 1, Mingkui Tan 2, Lingqiao Liu 1, and Ian Reid 1 1 The University of Adelaide, Australia;
Rethinking nary Neural Network for Accurate Image Classification and Semantic Segmentation Bohan Zhuang 1, Chunhua Shen 1, Mingkui Tan 2, Lingqiao Liu 1, and Ian Reid 1 1 The University of Adelaide, Australia;
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Deep Learning & Artificial Intelligence WS 2018/2019
 Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Deep Learning & Artificial Intelligence WS 2018/2019 Linear Regression Model Model Error Function: Squared Error Has no special meaning except it makes gradients look nicer Prediction Ground truth / target
Compressing deep neural networks
 From Data to Decisions - M.Sc. Data Science Compressing deep neural networks Challenges and theoretical foundations Presenter: Simone Scardapane University of Exeter, UK Table of contents Introduction
From Data to Decisions - M.Sc. Data Science Compressing deep neural networks Challenges and theoretical foundations Presenter: Simone Scardapane University of Exeter, UK Table of contents Introduction
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Differentiable Fine-grained Quantization for Deep Neural Network Compression
 Differentiable Fine-grained Quantization for Deep Neural Network Compression Hsin-Pai Cheng hc218@duke.edu Yuanjun Huang University of Science and Technology of China Anhui, China yjhuang@mail.ustc.edu.cn
Differentiable Fine-grained Quantization for Deep Neural Network Compression Hsin-Pai Cheng hc218@duke.edu Yuanjun Huang University of Science and Technology of China Anhui, China yjhuang@mail.ustc.edu.cn
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Lecture 7 Convolutional Neural Networks
 Lecture 7 Convolutional Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 17, 2017 We saw before: ŷ x 1 x 2 x 3 x 4 A series of matrix multiplications:
Lecture 7 Convolutional Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 17, 2017 We saw before: ŷ x 1 x 2 x 3 x 4 A series of matrix multiplications:
PRUNING CONVOLUTIONAL NEURAL NETWORKS. Pavlo Molchanov Stephen Tyree Tero Karras Timo Aila Jan Kautz
 PRUNING CONVOLUTIONAL NEURAL NETWORKS Pavlo Molchanov Stephen Tyree Tero Karras Timo Aila Jan Kautz 2017 WHY WE CAN PRUNE CNNS? 2 WHY WE CAN PRUNE CNNS? Optimization failures : Some neurons are "dead":
PRUNING CONVOLUTIONAL NEURAL NETWORKS Pavlo Molchanov Stephen Tyree Tero Karras Timo Aila Jan Kautz 2017 WHY WE CAN PRUNE CNNS? 2 WHY WE CAN PRUNE CNNS? Optimization failures : Some neurons are "dead":
Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations
 Journal of Machine Learning Research 18 (2018) 1-30 Submitted 9/16; Revised 4/17; Published 4/18 Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations Itay Hubara*
Journal of Machine Learning Research 18 (2018) 1-30 Submitted 9/16; Revised 4/17; Published 4/18 Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations Itay Hubara*
Introduction to Convolutional Neural Networks 2018 / 02 / 23
 Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Introduction to Convolutional Neural Networks 2018 / 02 / 23 Buzzword: CNN Convolutional neural networks (CNN, ConvNet) is a class of deep, feed-forward (not recurrent) artificial neural networks that
Efficient DNN Neuron Pruning by Minimizing Layer-wise Nonlinear Reconstruction Error
 Efficient DNN Neuron Pruning by Minimizing Layer-wise Nonlinear Reconstruction Error Chunhui Jiang, Guiying Li, Chao Qian, Ke Tang Anhui Province Key Lab of Big Data Analysis and Application, University
Efficient DNN Neuron Pruning by Minimizing Layer-wise Nonlinear Reconstruction Error Chunhui Jiang, Guiying Li, Chao Qian, Ke Tang Anhui Province Key Lab of Big Data Analysis and Application, University
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Frequency-Domain Dynamic Pruning for Convolutional Neural Networks
 Frequency-Domain Dynamic Pruning for Convolutional Neural Networks Zhenhua Liu 1, Jizheng Xu 2, Xiulian Peng 2, Ruiqin Xiong 1 1 Institute of Digital Media, School of Electronic Engineering and Computer
Frequency-Domain Dynamic Pruning for Convolutional Neural Networks Zhenhua Liu 1, Jizheng Xu 2, Xiulian Peng 2, Ruiqin Xiong 1 1 Institute of Digital Media, School of Electronic Engineering and Computer
Multiscale methods for neural image processing. Sohil Shah, Pallabi Ghosh, Larry S. Davis and Tom Goldstein Hao Li, Soham De, Zheng Xu, Hanan Samet
 Multiscale methods for neural image processing Sohil Shah, Pallabi Ghosh, Larry S. Davis and Tom Goldstein Hao Li, Soham De, Zheng Xu, Hanan Samet A TALK IN TWO ACTS Part I: Stacked U-nets The globalization
Multiscale methods for neural image processing Sohil Shah, Pallabi Ghosh, Larry S. Davis and Tom Goldstein Hao Li, Soham De, Zheng Xu, Hanan Samet A TALK IN TWO ACTS Part I: Stacked U-nets The globalization
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Νεςπο-Ασαυήρ Υπολογιστική Neuro-Fuzzy Computing
 Νεςπο-Ασαυήρ Υπολογιστική Neuro-Fuzzy Computing ΗΥ418 Διδάσκων Δημήτριος Κατσαρός @ Τμ. ΗΜΜΥ Πανεπιστήμιο Θεσσαλίαρ Διάλεξη 21η BackProp for CNNs: Do I need to understand it? Why do we have to write the
Νεςπο-Ασαυήρ Υπολογιστική Neuro-Fuzzy Computing ΗΥ418 Διδάσκων Δημήτριος Κατσαρός @ Τμ. ΗΜΜΥ Πανεπιστήμιο Θεσσαλίαρ Διάλεξη 21η BackProp for CNNs: Do I need to understand it? Why do we have to write the
Normalization Techniques in Training of Deep Neural Networks
 Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
Normalization Techniques in Training of Deep Neural Networks Lei Huang ( 黄雷 ) State Key Laboratory of Software Development Environment, Beihang University Mail:huanglei@nlsde.buaa.edu.cn August 17 th,
RegML 2018 Class 8 Deep learning
 RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Handwritten Indic Character Recognition using Capsule Networks
 Handwritten Indic Character Recognition using Capsule Networks Bodhisatwa Mandal,Suvam Dubey, Swarnendu Ghosh, RiteshSarkhel, Nibaran Das Dept. of CSE, Jadavpur University, Kolkata, 700032, WB, India.
Handwritten Indic Character Recognition using Capsule Networks Bodhisatwa Mandal,Suvam Dubey, Swarnendu Ghosh, RiteshSarkhel, Nibaran Das Dept. of CSE, Jadavpur University, Kolkata, 700032, WB, India.
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Tunable Floating-Point for Energy Efficient Accelerators
 Tunable Floating-Point for Energy Efficient Accelerators Alberto Nannarelli DTU Compute, Technical University of Denmark 25 th IEEE Symposium on Computer Arithmetic A. Nannarelli (DTU Compute) Tunable
Tunable Floating-Point for Energy Efficient Accelerators Alberto Nannarelli DTU Compute, Technical University of Denmark 25 th IEEE Symposium on Computer Arithmetic A. Nannarelli (DTU Compute) Tunable
Convolutional Neural Networks II. Slides from Dr. Vlad Morariu
 Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
Convolutional Neural Networks II Slides from Dr. Vlad Morariu 1 Optimization Example of optimization progress while training a neural network. (Loss over mini-batches goes down over time.) 2 Learning rate
On the Complexity of Neural-Network-Learned Functions
 On the Complexity of Neural-Network-Learned Functions Caren Marzban 1, Raju Viswanathan 2 1 Applied Physics Lab, and Dept of Statistics, University of Washington, Seattle, WA 98195 2 Cyberon LLC, 3073
On the Complexity of Neural-Network-Learned Functions Caren Marzban 1, Raju Viswanathan 2 1 Applied Physics Lab, and Dept of Statistics, University of Washington, Seattle, WA 98195 2 Cyberon LLC, 3073
Scalable Methods for 8-bit Training of Neural Networks
 Scalable Methods for 8-bit Training of Neural Networks Ron Banner 1, Itay Hubara 2, Elad Hoffer 2, Daniel Soudry 2 {itayhubara, elad.hoffer, daniel.soudry}@gmail.com {ron.banner}@intel.com (1) Intel -
Scalable Methods for 8-bit Training of Neural Networks Ron Banner 1, Itay Hubara 2, Elad Hoffer 2, Daniel Soudry 2 {itayhubara, elad.hoffer, daniel.soudry}@gmail.com {ron.banner}@intel.com (1) Intel -
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Quantization of Fully Convolutional Networks for Accurate Biomedical Image Segmentation
 Quantization of Fully Convolutional Networks for Accurate Biomedical Image Segmentation Xiaowei Xu 1,, Qing Lu 1, Yu Hu, Lin Yang 1, Sharon Hu 1, Danny Chen 1, Yiyu Shi 1 1 Univerity of Notre Dame Huazhong
Quantization of Fully Convolutional Networks for Accurate Biomedical Image Segmentation Xiaowei Xu 1,, Qing Lu 1, Yu Hu, Lin Yang 1, Sharon Hu 1, Danny Chen 1, Yiyu Shi 1 1 Univerity of Notre Dame Huazhong
Learning Deep Architectures for AI. Part II - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Layer 1. Layer L. difference between the two precisions (B A and B W ) is chosen to balance the sum in (1), as follows: B A B W = round log 2 (2)
 is chosen to balance the sum in (1), as follows: B A B W = round log 2 (2)") AN ANALYTICAL METHOD TO DETERMINE MINIMUM PER-LAYER PRECISION OF DEEP NEURAL NETWORKS Charbel Sakr Naresh Shanbhag Dept. of Electrical Computer Engineering, University of Illinois at Urbana Champaign ABSTRACT
AN ANALYTICAL METHOD TO DETERMINE MINIMUM PER-LAYER PRECISION OF DEEP NEURAL NETWORKS Charbel Sakr Naresh Shanbhag Dept. of Electrical Computer Engineering, University of Illinois at Urbana Champaign ABSTRACT
arxiv: v2 [cs.cv] 6 Dec 2018
![arxiv: v2 [cs.cv] 6 Dec 2018](/thumbs/94/121809033.jpg "arxiv: v2 [cs.cv] 6 Dec 2018") HAQ: Hardware-Aware Automated Quantization Kuan Wang, Zhijian Liu, Yujun Lin, Ji Lin, and Song Han {kuanwang, zhijian, yujunlin, jilin, songhan}@mit.edu Massachusetts Institute of Technology arxiv:1811.0888v
HAQ: Hardware-Aware Automated Quantization Kuan Wang, Zhijian Liu, Yujun Lin, Ji Lin, and Song Han {kuanwang, zhijian, yujunlin, jilin, songhan}@mit.edu Massachusetts Institute of Technology arxiv:1811.0888v
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY,
 WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY, WITH IMPLICATIONS FOR TRAINING Sanjeev Arora, Yingyu Liang & Tengyu Ma Department of Computer Science Princeton University Princeton, NJ 08540, USA {arora,yingyul,tengyu}@cs.princeton.edu
WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY, WITH IMPLICATIONS FOR TRAINING Sanjeev Arora, Yingyu Liang & Tengyu Ma Department of Computer Science Princeton University Princeton, NJ 08540, USA {arora,yingyul,tengyu}@cs.princeton.edu
Feature Design. Feature Design. Feature Design. & Deep Learning
 Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
arxiv: v1 [cs.cv] 25 May 2018
![arxiv: v1 [cs.cv] 25 May 2018](/thumbs/87/96367766.jpg "arxiv: v1 [cs.cv] 25 May 2018") Heterogeneous Bitwidth Binarization in Convolutional Neural Networks arxiv:1805.10368v1 [cs.cv] 25 May 2018 Josh Fromm Department of Electrical Engineering University of Washington Seattle, WA 98195 jwfromm@uw.edu
Heterogeneous Bitwidth Binarization in Convolutional Neural Networks arxiv:1805.10368v1 [cs.cv] 25 May 2018 Josh Fromm Department of Electrical Engineering University of Washington Seattle, WA 98195 jwfromm@uw.edu
Deep Learning with Low Precision by Half-wave Gaussian Quantization
 Deep Learning with Low Precision by Half-wave Gaussian Quantization Zhaowei Cai UC San Diego zwcai@ucsd.edu Xiaodong He Microsoft Research Redmond xiaohe@microsoft.com Jian Sun Megvii Inc. sunjian@megvii.com
Deep Learning with Low Precision by Half-wave Gaussian Quantization Zhaowei Cai UC San Diego zwcai@ucsd.edu Xiaodong He Microsoft Research Redmond xiaohe@microsoft.com Jian Sun Megvii Inc. sunjian@megvii.com
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks. Microsoft Research
 LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks Dongqing Zhang, Jiaolong Yang, Dongqiangzi Ye, and Gang Hua Microsoft Research zdqzeros@gmail.com jiaoyan@microsoft.com
LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks Dongqing Zhang, Jiaolong Yang, Dongqiangzi Ye, and Gang Hua Microsoft Research zdqzeros@gmail.com jiaoyan@microsoft.com
Machine Learning Techniques
 Machine Learning Techniques ( 機器學習技法 ) Lecture 13: Deep Learning Hsuan-Tien Lin ( 林軒田 ) htlin@csie.ntu.edu.tw Department of Computer Science & Information Engineering National Taiwan University ( 國立台灣大學資訊工程系
Machine Learning Techniques ( 機器學習技法 ) Lecture 13: Deep Learning Hsuan-Tien Lin ( 林軒田 ) htlin@csie.ntu.edu.tw Department of Computer Science & Information Engineering National Taiwan University ( 國立台灣大學資訊工程系
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Deep Residual. Variations
 Deep Residual Network and Its Variations Diyu Yang (Originally prepared by Kaiming He from Microsoft Research) Advantages of Depth Degradation Problem Possible Causes? Vanishing/Exploding Gradients. Overfitting
Deep Residual Network and Its Variations Diyu Yang (Originally prepared by Kaiming He from Microsoft Research) Advantages of Depth Degradation Problem Possible Causes? Vanishing/Exploding Gradients. Overfitting
Bayesian Networks (Part I)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part I) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part I) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
arxiv: v2 [cs.cv] 19 Sep 2017
![arxiv: v2 [cs.cv] 19 Sep 2017](/thumbs/92/108885854.jpg "arxiv: v2 [cs.cv] 19 Sep 2017") Learning Convolutional Networks for Content-weighted Image Compression arxiv:1703.10553v2 [cs.cv] 19 Sep 2017 Mu Li Hong Kong Polytechnic University csmuli@comp.polyu.edu.hk Shuhang Gu Hong Kong Polytechnic
Learning Convolutional Networks for Content-weighted Image Compression arxiv:1703.10553v2 [cs.cv] 19 Sep 2017 Mu Li Hong Kong Polytechnic University csmuli@comp.polyu.edu.hk Shuhang Gu Hong Kong Polytechnic
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Asaf Bar Zvi Adi Hayat. Semantic Segmentation
 Asaf Bar Zvi Adi Hayat Semantic Segmentation Today s Topics Fully Convolutional Networks (FCN) (CVPR 2015) Conditional Random Fields as Recurrent Neural Networks (ICCV 2015) Gaussian Conditional random
Asaf Bar Zvi Adi Hayat Semantic Segmentation Today s Topics Fully Convolutional Networks (FCN) (CVPR 2015) Conditional Random Fields as Recurrent Neural Networks (ICCV 2015) Gaussian Conditional random
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
arxiv: v2 [cs.cv] 20 Aug 2018
![arxiv: v2 [cs.cv] 20 Aug 2018](/thumbs/83/88559350.jpg "arxiv: v2 [cs.cv] 20 Aug 2018") Joint Training of Low-Precision Neural Network with Quantization Interval Parameters arxiv:1808.05779v2 [cs.cv] 20 Aug 2018 Sangil Jung sang-il.jung Youngjun Kwak yjk.kwak Changyong Son cyson Jae-Joon
Joint Training of Low-Precision Neural Network with Quantization Interval Parameters arxiv:1808.05779v2 [cs.cv] 20 Aug 2018 Sangil Jung sang-il.jung Youngjun Kwak yjk.kwak Changyong Son cyson Jae-Joon
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding
 Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Stochastic Layer-Wise Precision in Deep Neural Networks
 Stochastic Layer-Wise Precision in Deep Neural Networks Griffin Lacey NVIDIA Graham W. Taylor University of Guelph Vector Institute for Artificial Intelligence Canadian Institute for Advanced Research
Stochastic Layer-Wise Precision in Deep Neural Networks Griffin Lacey NVIDIA Graham W. Taylor University of Guelph Vector Institute for Artificial Intelligence Canadian Institute for Advanced Research
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)
: Multimodal Learning with Vision, Language and Sound. Lecture 3: Introduction to Deep Learning (continued)") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 3: Introduction to Deep Learning (continued) Course Logistics - Update on course registrations - 6 seats left now -
Deep Learning (CNNs)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
arxiv: v2 [cs.cv] 17 Nov 2017
![arxiv: v2 [cs.cv] 17 Nov 2017](/thumbs/83/87313009.jpg "arxiv: v2 [cs.cv] 17 Nov 2017") Towards Effective Low-bitwidth Convolutional Neural Networks Bohan Zhuang, Chunhua Shen, Mingkui Tan, Lingqiao Liu, Ian Reid arxiv:1711.00205v2 [cs.cv] 17 Nov 2017 Abstract This paper tackles the problem
Towards Effective Low-bitwidth Convolutional Neural Networks Bohan Zhuang, Chunhua Shen, Mingkui Tan, Lingqiao Liu, Ian Reid arxiv:1711.00205v2 [cs.cv] 17 Nov 2017 Abstract This paper tackles the problem
Binary Convolutional Neural Network on RRAM
 Binary Convolutional Neural Network on RRAM Tianqi Tang, Lixue Xia, Boxun Li, Yu Wang, Huazhong Yang Dept. of E.E, Tsinghua National Laboratory for Information Science and Technology (TNList) Tsinghua
Binary Convolutional Neural Network on RRAM Tianqi Tang, Lixue Xia, Boxun Li, Yu Wang, Huazhong Yang Dept. of E.E, Tsinghua National Laboratory for Information Science and Technology (TNList) Tsinghua
Training Neural Networks Practical Issues
 Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
Training Neural Networks Practical Issues M. Soleymani Sharif University of Technology Fall 2017 Most slides have been adapted from Fei Fei Li and colleagues lectures, cs231n, Stanford 2017, and some from
TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter Generalization and Regularization
 TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter 2019 Generalization and Regularization 1 Chomsky vs. Kolmogorov and Hinton Noam Chomsky: Natural language grammar cannot be learned by
TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter 2019 Generalization and Regularization 1 Chomsky vs. Kolmogorov and Hinton Noam Chomsky: Natural language grammar cannot be learned by
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Accelerating Convolutional Neural Networks by Group-wise 2D-filter Pruning
 Accelerating Convolutional Neural Networks by Group-wise D-filter Pruning Niange Yu Department of Computer Sicence and Technology Tsinghua University Beijing 0008, China yng@mails.tsinghua.edu.cn Shi Qiu
Accelerating Convolutional Neural Networks by Group-wise D-filter Pruning Niange Yu Department of Computer Sicence and Technology Tsinghua University Beijing 0008, China yng@mails.tsinghua.edu.cn Shi Qiu
Failures of Gradient-Based Deep Learning
 Failures of Gradient-Based Deep Learning Shai Shalev-Shwartz, Shaked Shammah, Ohad Shamir The Hebrew University and Mobileye Representation Learning Workshop Simons Institute, Berkeley, 2017 Shai Shalev-Shwartz
Failures of Gradient-Based Deep Learning Shai Shalev-Shwartz, Shaked Shammah, Ohad Shamir The Hebrew University and Mobileye Representation Learning Workshop Simons Institute, Berkeley, 2017 Shai Shalev-Shwartz
Dictionary Learning Using Tensor Methods
 Dictionary Learning Using Tensor Methods Anima Anandkumar U.C. Irvine Joint work with Rong Ge, Majid Janzamin and Furong Huang. Feature learning as cornerstone of ML ML Practice Feature learning as cornerstone
Dictionary Learning Using Tensor Methods Anima Anandkumar U.C. Irvine Joint work with Rong Ge, Majid Janzamin and Furong Huang. Feature learning as cornerstone of ML ML Practice Feature learning as cornerstone
Global Optimality in Matrix and Tensor Factorization, Deep Learning & Beyond
 Global Optimality in Matrix and Tensor Factorization, Deep Learning & Beyond Ben Haeffele and René Vidal Center for Imaging Science Mathematical Institute for Data Science Johns Hopkins University This
Global Optimality in Matrix and Tensor Factorization, Deep Learning & Beyond Ben Haeffele and René Vidal Center for Imaging Science Mathematical Institute for Data Science Johns Hopkins University This
arxiv: v1 [cs.cv] 6 Dec 2018
![arxiv: v1 [cs.cv] 6 Dec 2018](/thumbs/91/106873333.jpg "arxiv: v1 [cs.cv] 6 Dec 2018") Trained Rank Pruning for Efficient Deep Neural Networks Yuhui Xu 1, Yuxi Li 1, Shuai Zhang 2, Wei Wen 3, Botao Wang 2, Yingyong Qi 2, Yiran Chen 3, Weiyao Lin 1 and Hongkai Xiong 1 arxiv:1812.02402v1 [cs.cv]
Trained Rank Pruning for Efficient Deep Neural Networks Yuhui Xu 1, Yuxi Li 1, Shuai Zhang 2, Wei Wen 3, Botao Wang 2, Yingyong Qi 2, Yiran Chen 3, Weiyao Lin 1 and Hongkai Xiong 1 arxiv:1812.02402v1 [cs.cv]
Linear Methods for Regression. Lijun Zhang
 Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
A Deep Convolutional Neural Network Based on Nested Residue Number System
 A Deep Convolutional Neural Network Based on Nested Residue Number System Hiroki Nakahara Tsutomu Sasao Ehime University, Japan Meiji University, Japan Outline Background Deep convolutional neural network
A Deep Convolutional Neural Network Based on Nested Residue Number System Hiroki Nakahara Tsutomu Sasao Ehime University, Japan Meiji University, Japan Outline Background Deep convolutional neural network
Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation
 Computational Graphs, Learning Algorithms, Initialisation") Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation Steve Renals Machine Learning Practical MLP Lecture 5 16 October 2018 MLP Lecture 5 / 16 October 2018 Deep Neural Networks
Deep Neural Networks (3) Computational Graphs, Learning Algorithms, Initialisation Steve Renals Machine Learning Practical MLP Lecture 5 16 October 2018 MLP Lecture 5 / 16 October 2018 Deep Neural Networks
Introduction to Deep Learning CMPT 733. Steven Bergner
 Introduction to Deep Learning CMPT 733 Steven Bergner Overview Renaissance of artificial neural networks Representation learning vs feature engineering Background Linear Algebra, Optimization Regularization
Introduction to Deep Learning CMPT 733 Steven Bergner Overview Renaissance of artificial neural networks Representation learning vs feature engineering Background Linear Algebra, Optimization Regularization
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Learning Long Term Dependencies with Gradient Descent is Difficult
 Learning Long Term Dependencies with Gradient Descent is Difficult IEEE Trans. on Neural Networks 1994 Yoshua Bengio, Patrice Simard, Paolo Frasconi Presented by: Matt Grimes, Ayse Naz Erkan Recurrent
Learning Long Term Dependencies with Gradient Descent is Difficult IEEE Trans. on Neural Networks 1994 Yoshua Bengio, Patrice Simard, Paolo Frasconi Presented by: Matt Grimes, Ayse Naz Erkan Recurrent
Statistical Machine Learning
 Statistical Machine Learning Lecture 9 Numerical optimization and deep learning Niklas Wahlström Division of Systems and Control Department of Information Technology Uppsala University niklas.wahlstrom@it.uu.se
Statistical Machine Learning Lecture 9 Numerical optimization and deep learning Niklas Wahlström Division of Systems and Control Department of Information Technology Uppsala University niklas.wahlstrom@it.uu.se
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Weighted-Entropy-based Quantization for Deep Neural Networks
 Weighted-Entropy-based Quantization for Deep Neural Networks Eunhyeok Park, Junwhan Ahn, and Sungjoo Yoo canusglow@gmail.com, junwhan@snu.ac.kr, sungjoo.yoo@gmail.com Seoul National University Computing
Weighted-Entropy-based Quantization for Deep Neural Networks Eunhyeok Park, Junwhan Ahn, and Sungjoo Yoo canusglow@gmail.com, junwhan@snu.ac.kr, sungjoo.yoo@gmail.com Seoul National University Computing
ARestricted Boltzmann machine (RBM) [1] is a probabilistic
![ARestricted Boltzmann machine (RBM) [1] is a probabilistic](/thumbs/90/102816372.jpg "ARestricted Boltzmann machine (RBM) [1] is a probabilistic") 1 Matrix Product Operator Restricted Boltzmann Machines Cong Chen, Kim Batselier, Ching-Yun Ko, and Ngai Wong chencong@eee.hku.hk, k.batselier@tudelft.nl, cyko@eee.hku.hk, nwong@eee.hku.hk arxiv:1811.04608v1
1 Matrix Product Operator Restricted Boltzmann Machines Cong Chen, Kim Batselier, Ching-Yun Ko, and Ngai Wong chencong@eee.hku.hk, k.batselier@tudelft.nl, cyko@eee.hku.hk, nwong@eee.hku.hk arxiv:1811.04608v1
Quantization of Fully Convolutional Networks for Accurate Biomedical Image Segmentation
 Quantization of Fully Convolutional Networks for Accurate Biomedical Image Segmentation Xiaowei Xu 1,2, Qing Lu 2, Lin Yang 2, Sharon Hu 2, Danny Chen 2, Yu Hu 1, Yiyu Shi 2 1 Huazhong University of Science
Quantization of Fully Convolutional Networks for Accurate Biomedical Image Segmentation Xiaowei Xu 1,2, Qing Lu 2, Lin Yang 2, Sharon Hu 2, Danny Chen 2, Yu Hu 1, Yiyu Shi 2 1 Huazhong University of Science
Deep Learning Architectures and Algorithms
 Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
Deep Learning Architectures and Algorithms In-Jung Kim 2016. 12. 2. Agenda Introduction to Deep Learning RBM and Auto-Encoders Convolutional Neural Networks Recurrent Neural Networks Reinforcement Learning
Introduction to Deep Learning
 Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Introduction to Deep Learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Feedforward networks for function
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
EE-559 Deep learning 9. Autoencoders and generative models
 EE-559 Deep learning 9. Autoencoders and generative models François Fleuret https://fleuret.org/dlc/ [version of: May 1, 2018] ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE Embeddings and generative models
EE-559 Deep learning 9. Autoencoders and generative models François Fleuret https://fleuret.org/dlc/ [version of: May 1, 2018] ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE Embeddings and generative models
arxiv: v3 [cs.lg] 2 Jun 2016
![arxiv: v3 [cs.lg] 2 Jun 2016](/thumbs/74/70915650.jpg "arxiv: v3 [cs.lg] 2 Jun 2016") Darryl D. Lin Qualcomm Research, San Diego, CA 922, USA Sachin S. Talathi Qualcomm Research, San Diego, CA 922, USA DARRYL.DLIN@GMAIL.COM TALATHI@GMAIL.COM arxiv:5.06393v3 [cs.lg] 2 Jun 206 V. Sreekanth
Darryl D. Lin Qualcomm Research, San Diego, CA 922, USA Sachin S. Talathi Qualcomm Research, San Diego, CA 922, USA DARRYL.DLIN@GMAIL.COM TALATHI@GMAIL.COM arxiv:5.06393v3 [cs.lg] 2 Jun 206 V. Sreekanth
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
arxiv: v1 [cs.cv] 11 Sep 2018
![arxiv: v1 [cs.cv] 11 Sep 2018](/thumbs/90/104370041.jpg "arxiv: v1 [cs.cv] 11 Sep 2018") Discovering Low-Precision Networks Close to Full-Precision Networks for Efficient Embedded Inference Jeffrey L. McKinstry jlmckins@us.ibm.com Steven K. Esser sesser@us.ibm.com Rathinakumar Appuswamy rappusw@us.ibm.com
Discovering Low-Precision Networks Close to Full-Precision Networks for Efficient Embedded Inference Jeffrey L. McKinstry jlmckins@us.ibm.com Steven K. Esser sesser@us.ibm.com Rathinakumar Appuswamy rappusw@us.ibm.com