Gaussian Mixture Model
|
|
|
- Jeffry Hunt
- 5 years ago
- Views:
Transcription
1 Case Study : Document Retrieval MAP EM, Latent Dirichlet Allocation, Gibbs Sampling Machine Learning/Statistics for Big Data CSE599C/STAT59, University of Washington Emily Fox 0 Emily Fox February 5 th, 0 Gaussian Mixture Model Most commonly used mixture model Observations: x,...,x N Parameters: = {, } =[,..., K ] = { } = {µ, } z i Lielihood: p(x i ) = X x i p(x i ) Ex. z i = country of origin, x i = height of i th person th mixture component = distribution of heights in country K Emily Fox 0 N
2 Motivates EM Algorithm Initial guess: ˆ (0) Estimate at iteration t: ˆ (t) E-Step Compute U(, ˆ (t) )=E[log p(y ) x, ˆ (t) ] M-Step Compute ˆ (t+) = arg max U(, ˆ (t) ) Emily Fox 0 MAP Estimation Bayesian approach: Place prior p( ) on parameters Infer posterior p( x) Many, many, many motivations and implications For the sae of this class, simplest motivation is to thin of this as ain to regularization ˆ MAP = arg max log p( x) Saw importance of regularization in logistic regression (ML estimate can overfit data and lead to poor generalization) Emily Fox 0 4
 ) What must be computed in E-Step remains unchanged because this term")
 = arg max U(, ˆ (t) ) Emily Fox 0 5 MAP EM Example")
 tion π π (,0,0) (0,0,) (0,,0) π π (/,/,/) (/4,/4,/) (/,/,0) π π π")
3 EM Algorithm MAP Case Re-derive EM algorithm for p( x) Add log p( ) to U(, ˆ (t) ) What must be computed in E-Step remains unchanged because this term does not depend on y. M-Step becomes: ˆ (t+) = arg max U(, ˆ (t) ) Emily Fox 0 5 MAP EM Example MoG For mixture of Gaussians, conjugate priors are: Dir(,..., K ) tion π π (,0,0) (0,0,) (0,,0) π π (/,/,/) (/4,/4,/) (/,/,0) π π π Dir(,, ) π Dir(4, 4, 4) π π π π π Dir(4, 9, 7) π Dir(0., 0., 0.) Emily Fox 0 6
4 MAP EM Example MoG For mixture of Gaussians, conjugate priors are: Dir(,..., K ) p( ) = Q (P ) Y ( ) Dirichlet posterior Assume we condition on observations Count occurrences of Then, z i = p(, z,...,z N ) / z i Conjugacy: This posterior has same form as prior Emily Fox 0 7 MAP EM Example MoG For mixture of Gaussians, conjugate priors are: Dir(,..., K ) {µ, } NIW(m 0,apple 0, 0,S 0 ) Results in following M-Step: ˆµ = r x + apple 0 m 0 r + apple 0 ˆ = r + N + P K ˆ = S 0 + r S + apple 0r apple 0 +r ( x m 0 )( x m 0 ) r + d + Emily Fox 0 8 4
5 Posterior Computations MAP EM focuses on point estimation: ˆ MAP = arg max p( x) What if we want a full characterization of the posterior? Maintain a measure of uncertainty Estimators other than posterior mode (different loss functions) Predictive distributions for future observations Often no closed-form characterization (e.g., mixture models) Alternatives: Monte Carlo based estimates using samples from posterior Variational approximations to posterior (more next time) Emily Fox 0 9 Gibb Sampling Want draws: Construct Marov chain whose steady state distribution is Simplest case: Emily Fox 0 0 5
6 Example Mixture of Gaussians Recall model Observations: Cluster indicators: Parameters: Generative model: x,...,x N z,...,z N = {, } Dir(,..., K ) {µ, } F ( ) =[,..., K ] = { } = {µ, } z i x i z i N(x i ; µ z i, z i) Want to draw posterior samples of model parameters p(, x,...,x N ) p(, x,...,x N ) Emily Fox 0 Auxiliary Variable Samplers Augment variables of interest with variables to allow closed-form for sampling, just lie in EM z In both cases, simply looing at subchain converges to draws from marginal distribution ( ) { (t) } Emily Fox 0 6
7 Example Mixture of Gaussians Dir(,..., K ) z i {µ, } F( ) x i z i N(x i ; µ z i, z i) Try auxiliary variable sampler Introduce cluster indicators into sampler z i x i N K Emily Fox 0 Example Clustering Results I log p(x π, θ) = 59.7 log p(x π, θ) = log p(x π, θ) = log p(x π, θ) = log p(x π, θ) = log p(x π, θ) = Figure courtesy of Eri Sudderth Figure.8. Learning a mixture of K = 4 Gaussians using the Gibbs sampler of Alg... Columns show the current parameters after T= (top), T=0 (middle), and T=50 (bottom) iterations from two random initializations. Each plot is labeled Emily by the current Fox 0 data log lielihood. 4 7
8 Collapsed Gibbs Samplers Marginalize a set of latent variables or parameters Sometimes marginalized variables are nuisance parameters Other times what gets marginalized are the variables Mae post-facto inferences on variables of interest based on sampled variables Can improve efficiency if marginalized variables are high-dim Reduced dimension of search space But, often introduces dependences! Emily Fox 0 5 Example Collapsed MoG Sampling Dir(,..., K ) z i {µ, } F( ) x i z i N(x i ; µ z i, z i) Collapsed sampler z i x i N K Emily Fox 0 6 8
9 Example Collapsed MoG Sampling Dir(,..., K ) z i {µ, } F( ) x i z i N(x i ; µ z i, z i) Derivation z i x i N K Important facts: p(z :N ) = Q (P ) ( ) Q (n + ) ( P n + ) (m + ) (m) = m Emily Fox 0 7 Example Clustering Results II log p(x π, θ) = log p(x π, θ) = log p(x π, θ) = 97.8 log p(x π, θ) = 449. log p(x π, θ) = 96.5 log p(x π, θ) = Figure courtesy of Eri Sudderth Figure.9. Learning a mixture of K = 4 Gaussians using the Rao Blacwellized Gibbs sampler of Alg... Columns show the current parameters after T= (top), T=0 (middle), and T=50 (bottom) iterations from two random initializations. Each Emily plot isfox labeled 0 by the current data log lielihood. 8 9
 of the integers {,..., N }.. Set z = z (t ). For each i {τ (),.")

f (xi )δ(zi, ) Zi = (N i + α/k)f (xi ) Zi Comparing Collapsed vs.")
 Update cached sufficient statistics to reflect the assignment of xi to cluster zi.. Set z (t) = z.")


 450 500 550 450 500 550 Standard Gibbs Sampler Rao Blacwellized Sampler 600 0 0 0 0 Standard Gibbs Sampler Rao Blacwellized")
 Gibbs samplers for a mixture of K = 4 two dimensional Gaussians.")
10 94 CHAPTER. NONPARAMETRIC AND GRAPHICAL MODELS Given previous cluster assignments z (t ), sequentially sample new assignments as follows:. Sample a random permutation τ ( ) of the integers {,..., N }.. Set z = z (t ). For each i {τ (),..., τ (N )}, sequentially resample zi as follows: (a) For each of the K clusters, determine the predictive lielihood f (xi ) = p(xi {xj zj =, j "= i}, λ) This lielihood can be computed from cached sufficient statistics via Prop...4. (b) Sample a new cluster assignment zi from the following multinomial distribution: K K!! i zi (N + α/k)f (xi )δ(zi, ) Zi = (N i + α/k)f (xi ) Zi Comparing Collapsed vs. Regular = = N i is the number of other observations assigned to cluster (see eq. (.6)). (c) Update cached sufficient statistics to reflect the assignment of xi to cluster zi.. Set z (t) = z. Optionally, mixture parameters may be sampled via steps of Alg... Algorithm.. Rao Blacwellized Gibbs sampler for a K component exponential family mixture model, as defined in Fig..9. Each iteration sequentially resamples the cluster assignments for all N observations x = {xi }N i= in a different random order. Mixture parameters are integrated out of the sampling recursion using cached sufficient statistics of the parameters assigned to each cluster log p(x π, θ) log p(x π, θ) Log Lielihood vs. Gibbs Iteration (multiple chains) Standard Gibbs Sampler Rao Blacwellized Sampler Standard Gibbs Sampler Rao Blacwellized Sampler Iteration Iteration Figure.0. Comparison of standard (Alg.., dar blue) and Rao Blacwellized (Alg.., light red) Gibbs samplers for a mixture of K = 4 two dimensional Gaussians. We compare data log lielihoods at each of 000 iterations for the single N = 00 point dataset of Figs..8 and.9. Left: Log lielihood sequences for 0 different random initializations of each algorithm. Right: From 00 different random initializations, we show the median (solid), 0.5 and 0.75 quantiles (thic dashed), and 0.05 and 0.95 quantiles (thin dashed) of the resulting log lielihood sequences. The Rao Blacwellized sampler has superior typical performance, but occasionally remains trapped in local optima for many iterations. optima for many iterations (see right columns of Figs..8 and.9). These results Figure courtesy suggest that while Rao Blacwellization can usefully accelerate mixing, convergence Eri Sudderth diagnostics are still important. Emily Fox 0 of 9 Tas : Cluster Documents n Previously: Cluster documents based on topic Emily Fox 0 0 0



11 A Generative Model Documents: x,...,x D Associated topics: z,...,z D Parameters: = {, } Generative model: z d N d D K Emily Fox 0 Tas : Cluster Documents Now: Document may belong to multiple clusters EDUCATION FINANCE TECHNOLOGY Emily Fox 0
 Emily")
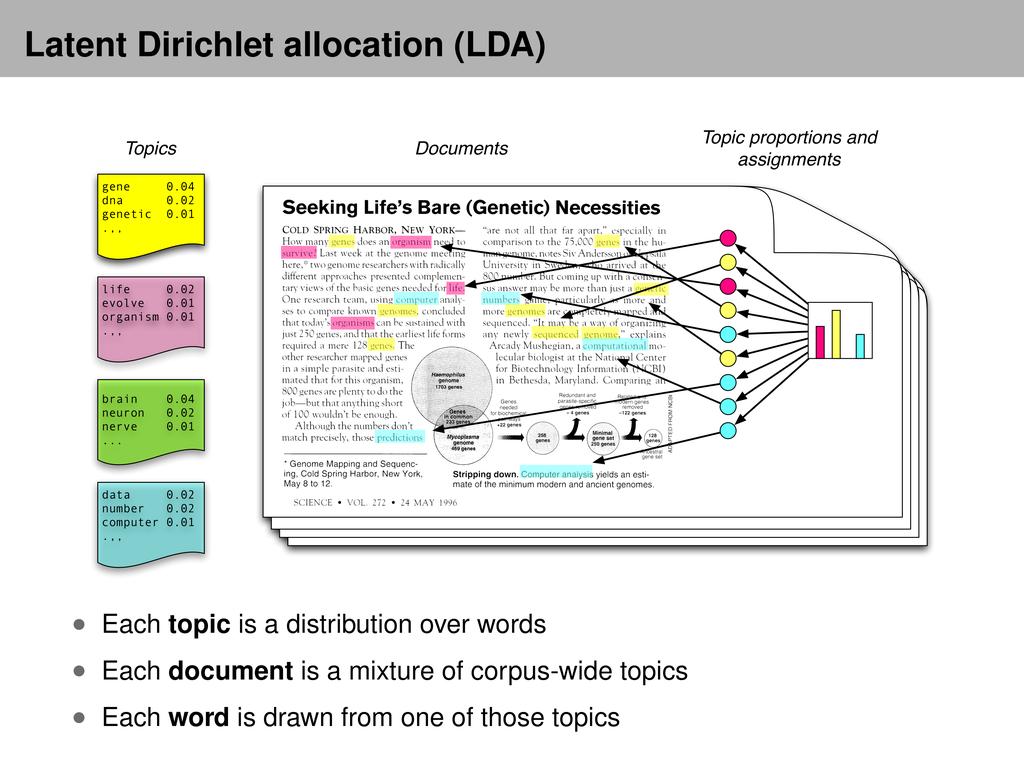
12 Latent Dirichlet Allocation (LDA) Emily Fox 0 Latent Dirichlet Allocation (LDA) Emily Fox 0 4
13 Latent Dirichlet Allocation (LDA) Latent Dirichlet allocation (LDA) Topics Topic proportions and assignments Documents But we only observe the documents; the other structure is hidden. We compute the posterior Emily Fox 0 p.topics, proportions, assignments j documents/ 5 Example Inference Topic Weights n Data: The OCR ed collection of Science from K documents Example inference Probability Model: 00-topic LDA model 0.0 n M words 0K unique terms (stop words and rare words removed) Topics Emily Fox 0 6
14 Example Inference Topic Words human evolution disease computer genome evolutionary host models dna species bacteria information genetic organisms diseases data genes life resistance computers sequence origin bacterial system gene biology new networ molecular groups strains systems sequencing phylogenetic control model map living infectious parallel information diversity malaria methods genetics group parasite networs mapping new parasites software project two united new sequences common tuberculosis simulations Emily Fox 0 7 LDA Generative Model Observations: w,...,w d N d d Associated topics: z,...,z d N d d Parameters: = {{ d }, { }} Generative model: Emily Fox 0 8 4
15 LDA Generative Model d z d i K N d D KY DY p( ) = p( ) p( d ) = d=! YN d p(zi d d )p(wi d zi d, ) i= Emily Fox 0 9 Collapsed LDA Sampling Marginalize parameters Document-specific topic weights Corpus-wide topic-specific word distributions Sample topic indicators for each word Derivation: d zi d wi d N d D K p(z:n d d ) = (P Q Q ) (n d + ) ( ) ( P nd + ) p(z ) = DY p(z:n d d ) d= p({wi d zi d = }, )= Q (P ) ( ) KY p(w z, )= p({wi d zi d = }, ) = Q (v + ) ( P v + ) Emily Fox 0 0 5

16 Collapsed LDA Sampling Marginalize parameters Document-specific topic weights d zi d K Corpus-wide topic-specific word distributions Sample topic indicators for each word Algorithm: wi d N d D Emily Fox 0 Sample Document Etruscan trade maret Emily Fox 0 6
17 Randomly Assign Topics z d i Etruscan trade maret Emily Fox 0 Randomly Assign Topics z d i Etruscan trade maret Etruscan trade maret Etruscan trade maret Etruscan Etruscan trade trade maret maret Etruscan Etruscan trade trade maret maret Etruscan Etruscan trade Etruscan trade trade maret maret maret Etruscan Etruscan trade Etruscan trade trade maret maret maret Etruscan Etruscan trade Etruscan trade trade maret maret maret Etruscan Etruscan trade Etruscan trade trade maret maret maret Etruscan Etruscan Etruscan trade trade trade maret maret maret trade Etruscan Etruscan trade ship trade trade maret maret maret Etruscan Etruscan trade trade maret maret ship Etruscan trade ship trade maret maret Etruscan trade maret Italy ship trade maret Emily Fox 0 4 7
18 Maintain Global Statistics z d i Etruscan trade maret Total counts from all docs Etruscan 0 5 maret trade Emily Fox 0 5 Resample Assignments z d i Etruscan trade maret Etruscan 0 5 maret trade Emily Fox 0 6 8
19 What is the conditional distribution for this topic? z d i? Etruscan trade maret Emily Fox 0 7 What is the conditional distribution for this topic? Part I: How much does this document lie each topic? z d i? Etruscan trade maret Topic Topic Topic Emily Fox 0 8 9
20 What is the conditional distribution for this topic? Part I: How much does this document lie each topic? Part II: How much does each topic lie this word? z d i? Etruscan trade maret Topic Topic Topic trade 0 7 Emily Fox 0 9 What is the conditional distribution for this topic? Part I: How much does this document lie each topic? Part II: How much does each topic lie this word? z d i? Etruscan trade maret Topic Topic Topic Emily Fox
21 What is the conditional distribution for this topic? Part I: How much does this document lie each topic? Part II: How much does each topic lie this word? z d i? Etruscan trade maret Topic Topic Topic n d + P K j= nd j + j vtrade P + V j= v j + Emily Fox 0 4 j Sample a New Topic Indicator z d i? Etruscan trade maret Topic Topic Topic Emily Fox 0 4
22 Update Counts z d i? Etruscan trade maret Etruscan 0 5 maret trade Emily Fox 0 4 Geometrically z d i Etruscan trade maret Topic Topic Topic Emily Fox 0 44
23 Issues with Generic LDA Sampling Slow mixing rates à Need many iterations Each iteration cycles through sampling topic assignments for all words in all documents Modern approaches: Large-scale LDA. For example, Mimno, David, Matthew D. Hoffman and David M. Blei. "Sparse stochastic inference for latent Dirichlet allocation." International Conference on Machine Learning, 0. Distributed LDA. For example, Ahmed, Amr, et al. "Scalable inference in latent variable models." Proceedings of the fifth ACM international conference on Web search and data mining (0): - Next time: Variational methods instead of sampling Emily Fox 0 45 Acnowledgements Thans to Dave Blei, David Mimno, and Jordan Boyd-Graber for some material in this lecture relating to LDA Emily Fox 0 46
Collapsed Gibbs and Variational Methods for LDA. Example Collapsed MoG Sampling
 Case Stuy : Document Retrieval Collapse Gibbs an Variational Methos for LDA Machine Learning/Statistics for Big Data CSE599C/STAT59, University of Washington Emily Fox 0 Emily Fox February 7 th, 0 Example
Case Stuy : Document Retrieval Collapse Gibbs an Variational Methos for LDA Machine Learning/Statistics for Big Data CSE599C/STAT59, University of Washington Emily Fox 0 Emily Fox February 7 th, 0 Example
LDA Collapsed Gibbs Sampler, VariaNonal Inference. Task 3: Mixed Membership Models. Case Study 5: Mixed Membership Modeling
 Case Stuy 5: Mixe Membership Moeling LDA Collapse Gibbs Sampler, VariaNonal Inference Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox May 8 th, 05 Emily Fox 05 Task : Mixe
Case Stuy 5: Mixe Membership Moeling LDA Collapse Gibbs Sampler, VariaNonal Inference Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox May 8 th, 05 Emily Fox 05 Task : Mixe
Outline. Binomial, Multinomial, Normal, Beta, Dirichlet. Posterior mean, MAP, credible interval, posterior distribution
 Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Text mining and natural language analysis. Jefrey Lijffijt
 Text mining and natural language analysis Jefrey Lijffijt PART I: Introduction to Text Mining Why text mining The amount of text published on paper, on the web, and even within companies is inconceivably
Text mining and natural language analysis Jefrey Lijffijt PART I: Introduction to Text Mining Why text mining The amount of text published on paper, on the web, and even within companies is inconceivably
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
Clustering K-means. Machine Learning CSE546. Sham Kakade University of Washington. November 15, Review: PCA Start: unsupervised learning
 Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Topic Modelling and Latent Dirichlet Allocation
 Topic Modelling and Latent Dirichlet Allocation Stephen Clark (with thanks to Mark Gales for some of the slides) Lent 2013 Machine Learning for Language Processing: Lecture 7 MPhil in Advanced Computer
Topic Modelling and Latent Dirichlet Allocation Stephen Clark (with thanks to Mark Gales for some of the slides) Lent 2013 Machine Learning for Language Processing: Lecture 7 MPhil in Advanced Computer
Sparse Stochastic Inference for Latent Dirichlet Allocation
 Sparse Stochastic Inference for Latent Dirichlet Allocation David Mimno 1, Matthew D. Hoffman 2, David M. Blei 1 1 Dept. of Computer Science, Princeton U. 2 Dept. of Statistics, Columbia U. Presentation
Sparse Stochastic Inference for Latent Dirichlet Allocation David Mimno 1, Matthew D. Hoffman 2, David M. Blei 1 1 Dept. of Computer Science, Princeton U. 2 Dept. of Statistics, Columbia U. Presentation
Latent Dirichlet Allocation (LDA)
") Latent Dirichlet Allocation (LDA) D. Blei, A. Ng, and M. Jordan. Journal of Machine Learning Research, 3:993-1022, January 2003. Following slides borrowed ant then heavily modified from: Jonathan Huang
Latent Dirichlet Allocation (LDA) D. Blei, A. Ng, and M. Jordan. Journal of Machine Learning Research, 3:993-1022, January 2003. Following slides borrowed ant then heavily modified from: Jonathan Huang
Topic Models. Charles Elkan November 20, 2008
 Topic Models Charles Elan elan@cs.ucsd.edu November 20, 2008 Suppose that we have a collection of documents, and we want to find an organization for these, i.e. we want to do unsupervised learning. One
Topic Models Charles Elan elan@cs.ucsd.edu November 20, 2008 Suppose that we have a collection of documents, and we want to find an organization for these, i.e. we want to do unsupervised learning. One
Introduction To Machine Learning
 Introduction To Machine Learning David Sontag New York University Lecture 21, April 14, 2016 David Sontag (NYU) Introduction To Machine Learning Lecture 21, April 14, 2016 1 / 14 Expectation maximization
Introduction To Machine Learning David Sontag New York University Lecture 21, April 14, 2016 David Sontag (NYU) Introduction To Machine Learning Lecture 21, April 14, 2016 1 / 14 Expectation maximization
Study Notes on the Latent Dirichlet Allocation
 Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
Bayesian Learning and Inference in Recurrent Switching Linear Dynamical Systems
 Bayesian Learning and Inference in Recurrent Switching Linear Dynamical Systems Scott W. Linderman Matthew J. Johnson Andrew C. Miller Columbia University Harvard and Google Brain Harvard University Ryan
Bayesian Learning and Inference in Recurrent Switching Linear Dynamical Systems Scott W. Linderman Matthew J. Johnson Andrew C. Miller Columbia University Harvard and Google Brain Harvard University Ryan
Text Mining for Economics and Finance Latent Dirichlet Allocation
 Text Mining for Economics and Finance Latent Dirichlet Allocation Stephen Hansen Text Mining Lecture 5 1 / 45 Introduction Recall we are interested in mixed-membership modeling, but that the plsi model
Text Mining for Economics and Finance Latent Dirichlet Allocation Stephen Hansen Text Mining Lecture 5 1 / 45 Introduction Recall we are interested in mixed-membership modeling, but that the plsi model
27 : Distributed Monte Carlo Markov Chain. 1 Recap of MCMC and Naive Parallel Gibbs Sampling
 10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
10-708: Probabilistic Graphical Models 10-708, Spring 2014 27 : Distributed Monte Carlo Markov Chain Lecturer: Eric P. Xing Scribes: Pengtao Xie, Khoa Luu In this scribe, we are going to review the Parallel
An Introduction to Expectation-Maximization
 An Introduction to Expectation-Maximization Dahua Lin Abstract This notes reviews the basics about the Expectation-Maximization EM) algorithm, a popular approach to perform model estimation of the generative
An Introduction to Expectation-Maximization Dahua Lin Abstract This notes reviews the basics about the Expectation-Maximization EM) algorithm, a popular approach to perform model estimation of the generative
Computer Vision Group Prof. Daniel Cremers. 10a. Markov Chain Monte Carlo
 Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Mixture Models and Expectation-Maximization
 Mixture Models and Expectation-Maximiation David M. Blei March 9, 2012 EM for mixtures of multinomials The graphical model for a mixture of multinomials π d x dn N D θ k K How should we fit the parameters?
Mixture Models and Expectation-Maximiation David M. Blei March 9, 2012 EM for mixtures of multinomials The graphical model for a mixture of multinomials π d x dn N D θ k K How should we fit the parameters?
Two Useful Bounds for Variational Inference
 Two Useful Bounds for Variational Inference John Paisley Department of Computer Science Princeton University, Princeton, NJ jpaisley@princeton.edu Abstract We review and derive two lower bounds on the
Two Useful Bounds for Variational Inference John Paisley Department of Computer Science Princeton University, Princeton, NJ jpaisley@princeton.edu Abstract We review and derive two lower bounds on the
Advanced Machine Learning
 Advanced Machine Learning Nonparametric Bayesian Models --Learning/Reasoning in Open Possible Worlds Eric Xing Lecture 7, August 4, 2009 Reading: Eric Xing Eric Xing @ CMU, 2006-2009 Clustering Eric Xing
Advanced Machine Learning Nonparametric Bayesian Models --Learning/Reasoning in Open Possible Worlds Eric Xing Lecture 7, August 4, 2009 Reading: Eric Xing Eric Xing @ CMU, 2006-2009 Clustering Eric Xing
Contents. Part I: Fundamentals of Bayesian Inference 1
 Contents Preface xiii Part I: Fundamentals of Bayesian Inference 1 1 Probability and inference 3 1.1 The three steps of Bayesian data analysis 3 1.2 General notation for statistical inference 4 1.3 Bayesian
Contents Preface xiii Part I: Fundamentals of Bayesian Inference 1 1 Probability and inference 3 1.1 The three steps of Bayesian data analysis 3 1.2 General notation for statistical inference 4 1.3 Bayesian
Latent Dirichlet Allocation (LDA)
") Latent Dirichlet Allocation (LDA) A review of topic modeling and customer interactions application 3/11/2015 1 Agenda Agenda Items 1 What is topic modeling? Intro Text Mining & Pre-Processing Natural Language
Latent Dirichlet Allocation (LDA) A review of topic modeling and customer interactions application 3/11/2015 1 Agenda Agenda Items 1 What is topic modeling? Intro Text Mining & Pre-Processing Natural Language
MCMC and Gibbs Sampling. Kayhan Batmanghelich
 MCMC and Gibbs Sampling Kayhan Batmanghelich 1 Approaches to inference l Exact inference algorithms l l l The elimination algorithm Message-passing algorithm (sum-product, belief propagation) The junction
MCMC and Gibbs Sampling Kayhan Batmanghelich 1 Approaches to inference l Exact inference algorithms l l l The elimination algorithm Message-passing algorithm (sum-product, belief propagation) The junction
Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine
 Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine Nitish Srivastava nitish@cs.toronto.edu Ruslan Salahutdinov rsalahu@cs.toronto.edu Geoffrey Hinton hinton@cs.toronto.edu
Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine Nitish Srivastava nitish@cs.toronto.edu Ruslan Salahutdinov rsalahu@cs.toronto.edu Geoffrey Hinton hinton@cs.toronto.edu
But if z is conditioned on, we need to model it:
 Partially Unobserved Variables Lecture 8: Unsupervised Learning & EM Algorithm Sam Roweis October 28, 2003 Certain variables q in our models may be unobserved, either at training time or at test time or
Partially Unobserved Variables Lecture 8: Unsupervised Learning & EM Algorithm Sam Roweis October 28, 2003 Certain variables q in our models may be unobserved, either at training time or at test time or
Latent Dirichlet Allocation Introduction/Overview
 Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Latent Dirichlet Allocation Introduction/Overview David Meyer 03.10.2016 David Meyer http://www.1-4-5.net/~dmm/ml/lda_intro.pdf 03.10.2016 Agenda What is Topic Modeling? Parametric vs. Non-Parametric Models
Lecture 10. Announcement. Mixture Models II. Topics of This Lecture. This Lecture: Advanced Machine Learning. Recap: GMMs as Latent Variable Models
 Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Applying LDA topic model to a corpus of Italian Supreme Court decisions
 Applying LDA topic model to a corpus of Italian Supreme Court decisions Paolo Fantini Statistical Service of the Ministry of Justice - Italy CESS Conference - Rome - November 25, 2014 Our goal finding
Applying LDA topic model to a corpus of Italian Supreme Court decisions Paolo Fantini Statistical Service of the Ministry of Justice - Italy CESS Conference - Rome - November 25, 2014 Our goal finding
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Review: Probabilistic Matrix Factorization. Probabilistic Matrix Factorization (PMF)
") Case Study 4: Collaborative Filtering Review: Probabilistic Matrix Factorization Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 2 th, 214 Emily Fox 214 1 Probabilistic
Case Study 4: Collaborative Filtering Review: Probabilistic Matrix Factorization Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 2 th, 214 Emily Fox 214 1 Probabilistic
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Lecturer: David Blei Lecture #3 Scribes: Jordan Boyd-Graber and Francisco Pereira October 1, 2007
 COS 597C: Bayesian Nonparametrics Lecturer: David Blei Lecture # Scribes: Jordan Boyd-Graber and Francisco Pereira October, 7 Gibbs Sampling with a DP First, let s recapitulate the model that we re using.
COS 597C: Bayesian Nonparametrics Lecturer: David Blei Lecture # Scribes: Jordan Boyd-Graber and Francisco Pereira October, 7 Gibbs Sampling with a DP First, let s recapitulate the model that we re using.
Gibbs Sampling. Héctor Corrada Bravo. University of Maryland, College Park, USA CMSC 644:
 Gibbs Sampling Héctor Corrada Bravo University of Maryland, College Park, USA CMSC 644: 2019 03 27 Latent semantic analysis Documents as mixtures of topics (Hoffman 1999) 1 / 60 Latent semantic analysis
Gibbs Sampling Héctor Corrada Bravo University of Maryland, College Park, USA CMSC 644: 2019 03 27 Latent semantic analysis Documents as mixtures of topics (Hoffman 1999) 1 / 60 Latent semantic analysis
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
CPSC 540: Machine Learning
 CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
CPSC 540: Machine Learning MCMC and Non-Parametric Bayes Mark Schmidt University of British Columbia Winter 2016 Admin I went through project proposals: Some of you got a message on Piazza. No news is
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Bayesian Modeling of Conditional Distributions
 Bayesian Modeling of Conditional Distributions John Geweke University of Iowa Indiana University Department of Economics February 27, 2007 Outline Motivation Model description Methods of inference Earnings
Bayesian Modeling of Conditional Distributions John Geweke University of Iowa Indiana University Department of Economics February 27, 2007 Outline Motivation Model description Methods of inference Earnings
Bayesian Approach 2. CSC412 Probabilistic Learning & Reasoning
 CSC412 Probabilistic Learning & Reasoning Lecture 12: Bayesian Parameter Estimation February 27, 2006 Sam Roweis Bayesian Approach 2 The Bayesian programme (after Rev. Thomas Bayes) treats all unnown quantities
CSC412 Probabilistic Learning & Reasoning Lecture 12: Bayesian Parameter Estimation February 27, 2006 Sam Roweis Bayesian Approach 2 The Bayesian programme (after Rev. Thomas Bayes) treats all unnown quantities
Variables which are always unobserved are called latent variables or sometimes hidden variables. e.g. given y,x fit the model p(y x) = z p(y x,z)p(z)
 = z p(y x,z)p(z)") CSC2515 Machine Learning Sam Roweis Lecture 8: Unsupervised Learning & EM Algorithm October 31, 2006 Partially Unobserved Variables 2 Certain variables q in our models may be unobserved, either at training
CSC2515 Machine Learning Sam Roweis Lecture 8: Unsupervised Learning & EM Algorithm October 31, 2006 Partially Unobserved Variables 2 Certain variables q in our models may be unobserved, either at training
16 : Approximate Inference: Markov Chain Monte Carlo
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
10-708: Probabilistic Graphical Models 10-708, Spring 2017 16 : Approximate Inference: Markov Chain Monte Carlo Lecturer: Eric P. Xing Scribes: Yuan Yang, Chao-Ming Yen 1 Introduction As the target distribution
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Topic Models. Brandon Malone. February 20, Latent Dirichlet Allocation Success Stories Wrap-up
 Much of this material is adapted from Blei 2003. Many of the images were taken from the Internet February 20, 2014 Suppose we have a large number of books. Each is about several unknown topics. How can
Much of this material is adapted from Blei 2003. Many of the images were taken from the Internet February 20, 2014 Suppose we have a large number of books. Each is about several unknown topics. How can
MCMC: Markov Chain Monte Carlo
 I529: Machine Learning in Bioinformatics (Spring 2013) MCMC: Markov Chain Monte Carlo Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2013 Contents Review of Markov
I529: Machine Learning in Bioinformatics (Spring 2013) MCMC: Markov Chain Monte Carlo Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2013 Contents Review of Markov
Latent Dirichlet Allocation
 Latent Dirichlet Allocation 1 Directed Graphical Models William W. Cohen Machine Learning 10-601 2 DGMs: The Burglar Alarm example Node ~ random variable Burglar Earthquake Arcs define form of probability
Latent Dirichlet Allocation 1 Directed Graphical Models William W. Cohen Machine Learning 10-601 2 DGMs: The Burglar Alarm example Node ~ random variable Burglar Earthquake Arcs define form of probability
Latent Variable Models and EM algorithm
 Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Introduction to Bayesian inference
 Introduction to Bayesian inference Thomas Alexander Brouwer University of Cambridge tab43@cam.ac.uk 17 November 2015 Probabilistic models Describe how data was generated using probability distributions
Introduction to Bayesian inference Thomas Alexander Brouwer University of Cambridge tab43@cam.ac.uk 17 November 2015 Probabilistic models Describe how data was generated using probability distributions
Bayesian Nonparametric Models
 Bayesian Nonparametric Models David M. Blei Columbia University December 15, 2015 Introduction We have been looking at models that posit latent structure in high dimensional data. We use the posterior
Bayesian Nonparametric Models David M. Blei Columbia University December 15, 2015 Introduction We have been looking at models that posit latent structure in high dimensional data. We use the posterior
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Lecture 4: Probabilistic Learning
 DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
Evaluation Methods for Topic Models
 University of Massachusetts Amherst wallach@cs.umass.edu April 13, 2009 Joint work with Iain Murray, Ruslan Salakhutdinov and David Mimno Statistical Topic Models Useful for analyzing large, unstructured
University of Massachusetts Amherst wallach@cs.umass.edu April 13, 2009 Joint work with Iain Murray, Ruslan Salakhutdinov and David Mimno Statistical Topic Models Useful for analyzing large, unstructured
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Lecture 8: Bayesian Estimation of Parameters in State Space Models
 in State Space Models March 30, 2016 Contents 1 Bayesian estimation of parameters in state space models 2 Computational methods for parameter estimation 3 Practical parameter estimation in state space
in State Space Models March 30, 2016 Contents 1 Bayesian estimation of parameters in state space models 2 Computational methods for parameter estimation 3 Practical parameter estimation in state space
Machine Learning Lecture Notes
 Machine Learning Lecture Notes Predrag Radivojac January 25, 205 Basic Principles of Parameter Estimation In probabilistic modeling, we are typically presented with a set of observations and the objective
Machine Learning Lecture Notes Predrag Radivojac January 25, 205 Basic Principles of Parameter Estimation In probabilistic modeling, we are typically presented with a set of observations and the objective
Bayesian Nonparametrics: Dirichlet Process
 Bayesian Nonparametrics: Dirichlet Process Yee Whye Teh Gatsby Computational Neuroscience Unit, UCL http://www.gatsby.ucl.ac.uk/~ywteh/teaching/npbayes2012 Dirichlet Process Cornerstone of modern Bayesian
Bayesian Nonparametrics: Dirichlet Process Yee Whye Teh Gatsby Computational Neuroscience Unit, UCL http://www.gatsby.ucl.ac.uk/~ywteh/teaching/npbayes2012 Dirichlet Process Cornerstone of modern Bayesian
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Learning Sequence Motif Models Using Expectation Maximization (EM) and Gibbs Sampling
 and Gibbs Sampling") Learning Sequence Motif Models Using Expectation Maximization (EM) and Gibbs Sampling BMI/CS 776 www.biostat.wisc.edu/bmi776/ Spring 009 Mark Craven craven@biostat.wisc.edu Sequence Motifs what is a sequence
Learning Sequence Motif Models Using Expectation Maximization (EM) and Gibbs Sampling BMI/CS 776 www.biostat.wisc.edu/bmi776/ Spring 009 Mark Craven craven@biostat.wisc.edu Sequence Motifs what is a sequence
Document and Topic Models: plsa and LDA
 Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
CS Lecture 18. Topic Models and LDA
 CS 6347 Lecture 18 Topic Models and LDA (some slides by David Blei) Generative vs. Discriminative Models Recall that, in Bayesian networks, there could be many different, but equivalent models of the same
CS 6347 Lecture 18 Topic Models and LDA (some slides by David Blei) Generative vs. Discriminative Models Recall that, in Bayesian networks, there could be many different, but equivalent models of the same
Variational Inference (11/04/13)
") STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
AN INTRODUCTION TO TOPIC MODELS
 AN INTRODUCTION TO TOPIC MODELS Michael Paul December 4, 2013 600.465 Natural Language Processing Johns Hopkins University Prof. Jason Eisner Making sense of text Suppose you want to learn something about
AN INTRODUCTION TO TOPIC MODELS Michael Paul December 4, 2013 600.465 Natural Language Processing Johns Hopkins University Prof. Jason Eisner Making sense of text Suppose you want to learn something about
Topic Models. Advanced Machine Learning for NLP Jordan Boyd-Graber OVERVIEW. Advanced Machine Learning for NLP Boyd-Graber Topic Models 1 of 1
 Topic Models Advanced Machine Learning for NLP Jordan Boyd-Graber OVERVIEW Advanced Machine Learning for NLP Boyd-Graber Topic Models 1 of 1 Low-Dimensional Space for Documents Last time: embedding space
Topic Models Advanced Machine Learning for NLP Jordan Boyd-Graber OVERVIEW Advanced Machine Learning for NLP Boyd-Graber Topic Models 1 of 1 Low-Dimensional Space for Documents Last time: embedding space
CS242: Probabilistic Graphical Models Lecture 4A: MAP Estimation & Graph Structure Learning
 CS242: Probabilistic Graphical Models Lecture 4A: MAP Estimation & Graph Structure Learning Professor Erik Sudderth Brown University Computer Science October 4, 2016 Some figures and materials courtesy
CS242: Probabilistic Graphical Models Lecture 4A: MAP Estimation & Graph Structure Learning Professor Erik Sudderth Brown University Computer Science October 4, 2016 Some figures and materials courtesy
The Expectation-Maximization Algorithm
 1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
Unsupervised Learning
 2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
arxiv: v1 [stat.ml] 8 Jan 2012
![arxiv: v1 [stat.ml] 8 Jan 2012](/thumbs/72/67364198.jpg "arxiv: v1 [stat.ml] 8 Jan 2012") A Split-Merge MCMC Algorithm for the Hierarchical Dirichlet Process Chong Wang David M. Blei arxiv:1201.1657v1 [stat.ml] 8 Jan 2012 Received: date / Accepted: date Abstract The hierarchical Dirichlet process
A Split-Merge MCMC Algorithm for the Hierarchical Dirichlet Process Chong Wang David M. Blei arxiv:1201.1657v1 [stat.ml] 8 Jan 2012 Received: date / Accepted: date Abstract The hierarchical Dirichlet process
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA Contents in latter part Linear Dynamical Systems What is different from HMM? Kalman filter Its strength and limitation Particle Filter
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA Contents in latter part Linear Dynamical Systems What is different from HMM? Kalman filter Its strength and limitation Particle Filter
Probabilistic Time Series Classification
 Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Mixed-membership Models (and an introduction to variational inference)
") Mixed-membership Models (and an introduction to variational inference) David M. Blei Columbia University November 24, 2015 Introduction We studied mixture models in detail, models that partition data into
Mixed-membership Models (and an introduction to variational inference) David M. Blei Columbia University November 24, 2015 Introduction We studied mixture models in detail, models that partition data into
Multivariate Normal Models
 Case Study 3: fmri Prediction Graphical LASSO Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox February 26 th, 2013 Emily Fox 2013 1 Multivariate Normal Models
Case Study 3: fmri Prediction Graphical LASSO Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox February 26 th, 2013 Emily Fox 2013 1 Multivariate Normal Models
Classification: Logistic Regression from Data
 Classification: Logistic Regression from Data Machine Learning: Jordan Boyd-Graber University of Colorado Boulder LECTURE 3 Slides adapted from Emily Fox Machine Learning: Jordan Boyd-Graber Boulder Classification:
Classification: Logistic Regression from Data Machine Learning: Jordan Boyd-Graber University of Colorado Boulder LECTURE 3 Slides adapted from Emily Fox Machine Learning: Jordan Boyd-Graber Boulder Classification:
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Topic Models and Applications to Short Documents
 Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Statistical Machine Learning Lecture 8: Markov Chain Monte Carlo Sampling
 1 / 27 Statistical Machine Learning Lecture 8: Markov Chain Monte Carlo Sampling Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 27 Monte Carlo Integration The big question : Evaluate E p(z) [f(z)]
1 / 27 Statistical Machine Learning Lecture 8: Markov Chain Monte Carlo Sampling Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 27 Monte Carlo Integration The big question : Evaluate E p(z) [f(z)]
CS Lecture 18. Expectation Maximization
 CS 6347 Lecture 18 Expectation Maximization Unobserved Variables Latent or hidden variables in the model are never observed We may or may not be interested in their values, but their existence is crucial
CS 6347 Lecture 18 Expectation Maximization Unobserved Variables Latent or hidden variables in the model are never observed We may or may not be interested in their values, but their existence is crucial
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Sequential Monte Carlo and Particle Filtering. Frank Wood Gatsby, November 2007
 Sequential Monte Carlo and Particle Filtering Frank Wood Gatsby, November 2007 Importance Sampling Recall: Let s say that we want to compute some expectation (integral) E p [f] = p(x)f(x)dx and we remember
Sequential Monte Carlo and Particle Filtering Frank Wood Gatsby, November 2007 Importance Sampling Recall: Let s say that we want to compute some expectation (integral) E p [f] = p(x)f(x)dx and we remember
10-701/15-781, Machine Learning: Homework 4
 10-701/15-781, Machine Learning: Homewor 4 Aarti Singh Carnegie Mellon University ˆ The assignment is due at 10:30 am beginning of class on Mon, Nov 15, 2010. ˆ Separate you answers into five parts, one
10-701/15-781, Machine Learning: Homewor 4 Aarti Singh Carnegie Mellon University ˆ The assignment is due at 10:30 am beginning of class on Mon, Nov 15, 2010. ˆ Separate you answers into five parts, one
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Probabilistic Graphical Models for Image Analysis - Lecture 4
 Probabilistic Graphical Models for Image Analysis - Lecture 4 Stefan Bauer 12 October 2018 Max Planck ETH Center for Learning Systems Overview 1. Repetition 2. α-divergence 3. Variational Inference 4.
Probabilistic Graphical Models for Image Analysis - Lecture 4 Stefan Bauer 12 October 2018 Max Planck ETH Center for Learning Systems Overview 1. Repetition 2. α-divergence 3. Variational Inference 4.
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
MH I. Metropolis-Hastings (MH) algorithm is the most popular method of getting dependent samples from a probability distribution
 algorithm is the most popular method of getting dependent samples from a probability distribution") MH I Metropolis-Hastings (MH) algorithm is the most popular method of getting dependent samples from a probability distribution a lot of Bayesian mehods rely on the use of MH algorithm and it s famous
MH I Metropolis-Hastings (MH) algorithm is the most popular method of getting dependent samples from a probability distribution a lot of Bayesian mehods rely on the use of MH algorithm and it s famous
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Content-based Recommendation
 Content-based Recommendation Suthee Chaidaroon June 13, 2016 Contents 1 Introduction 1 1.1 Matrix Factorization......................... 2 2 slda 2 2.1 Model................................. 3 3 flda 3
Content-based Recommendation Suthee Chaidaroon June 13, 2016 Contents 1 Introduction 1 1.1 Matrix Factorization......................... 2 2 slda 2 2.1 Model................................. 3 3 flda 3
Pattern Recognition and Machine Learning. Bishop Chapter 11: Sampling Methods
 Pattern Recognition and Machine Learning Chapter 11: Sampling Methods Elise Arnaud Jakob Verbeek May 22, 2008 Outline of the chapter 11.1 Basic Sampling Algorithms 11.2 Markov Chain Monte Carlo 11.3 Gibbs
Pattern Recognition and Machine Learning Chapter 11: Sampling Methods Elise Arnaud Jakob Verbeek May 22, 2008 Outline of the chapter 11.1 Basic Sampling Algorithms 11.2 Markov Chain Monte Carlo 11.3 Gibbs
Note for plsa and LDA-Version 1.1
 Note for plsa and LDA-Version 1.1 Wayne Xin Zhao March 2, 2011 1 Disclaimer In this part of PLSA, I refer to [4, 5, 1]. In LDA part, I refer to [3, 2]. Due to the limit of my English ability, in some place,
Note for plsa and LDA-Version 1.1 Wayne Xin Zhao March 2, 2011 1 Disclaimer In this part of PLSA, I refer to [4, 5, 1]. In LDA part, I refer to [3, 2]. Due to the limit of my English ability, in some place,
Distance dependent Chinese restaurant processes
 David M. Blei Department of Computer Science, Princeton University 35 Olden St., Princeton, NJ 08540 Peter Frazier Department of Operations Research and Information Engineering, Cornell University 232
David M. Blei Department of Computer Science, Princeton University 35 Olden St., Princeton, NJ 08540 Peter Frazier Department of Operations Research and Information Engineering, Cornell University 232
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Graphical Models for Query-driven Analysis of Multimodal Data
 Graphical Models for Query-driven Analysis of Multimodal Data John Fisher Sensing, Learning, & Inference Group Computer Science & Artificial Intelligence Laboratory Massachusetts Institute of Technology
Graphical Models for Query-driven Analysis of Multimodal Data John Fisher Sensing, Learning, & Inference Group Computer Science & Artificial Intelligence Laboratory Massachusetts Institute of Technology