Deep Learning. Boyang Albert Li, Jie Jay Tan
|
|
|
- Loraine Stevens
- 5 years ago
- Views:
Transcription
1 Deep Learnng Boyang Albert L, Je Jay Tan
2 An Unrelated Vdeo A bcycle controller learned usng NEAT (Stanley)
3 What do you mean, deep? Shallow Hdden Markov models ANNs wth one hdden layer Manually selected and desgned features Deep Stacked Restrcted Boltzmann Machnes ANNs wth multple hdden layers Learnng complex features
4 Algorthms of Deep Learnng Recurrent Neural Networks Stacked Autoencoders (.e. deep neural networks) Stacked Restrcted Boltzmann Machnes (.e. deep belef networks) Convoluted Deep Belef Networks a growng lst
5 But What s Wrong wth Shallow? Needs more nodes / computng unts and weghts [Bengo, Y., et al. (2007). Greedy layerwse tranng of deep networks] Boolean functons (such as the functon that computes the multplcaton of two numbers from ther d-bt representaton) expressble by Olog layers of combnatoral logc wth O elements n each layer O2 elements when expressed wth only 2 layers Relance on manually selected features Automatcally learnng the features Dsentanglng nteractng factors, creatng nvarant features (wll come back to that)
6 Dsentanglng factors

 The Age of Insght: The Quest to Understand the")
7 Is the bran deep, too? Erc R. Kandel. (2012) The Age of Insght: The Quest to Understand the Unconscous n Art, Mnd and Bran from Venna 1900 to the Present
8 A general algorthm for the bran? One part of the bran can learn the functon of another part If the vsual nput s sent to the audtory cortex of a newborn ferret, the "audtory" cells learn to do vson. (Sharma, Angelucc, and Sur. Nature 2000) People blnded at a young age can hear better, possbly because ther bran can stll adapt. (Gougoux et al. Nature 2004) Dfferent regons of the bran look smlar
9 Feature Learnng vs. Deep Neural Network pxels
10 Feature Learnng vs. Deep Neural Network pxels edges
11 Feature Learnng vs. Deep Neural Network pxels edges object parts




12 Feature Learnng vs. Deep Neural Network pxels edges object parts object models
13 Artfcal Neural Networks y h W ( x) x y Input Layer Hdden Layer Output Layer
14 Backpropagaton Mnmze Gradent computaton: 1 J ( w) hw ( x ) y 2 2 h w x y ) w 2 (2) (2) 11 w11 J ( ) w 1 ( ( ) a y (3) ( ) (3) ( ) a y a w (3) (2) 11 ( a y ) f ' a 4 j1 (3) (2) 1 f( w a ) w (2) (2) j1 1 (2) 11 2 h ( ) w x x
15 Backpropagaton J ( ) w 1 ( ( ) 2 h w x y ) w 2 (1) (1) 11 w11 (3) ( a y ) (3) ( a y ) a w (3) (1) 11 4 j1 a ( a ) ' (2) (3) 1 y f (1) w11 f( w a ) w (2) (2) j1 1 (1) 11 h ( ) w x x
16 More than one hdden layer? I thought of that, too. Ddn t work! Lack of data and computatonal power Weghts ntalzaton Poor local mnma Dffuson of gradent Overfttng A mult-layer model s too powerful / complex
17 Dffuson of Gradent s l 1 () l () l ( l1 ) ( l) ( wj j ) f ' j1 J ( w) l l a w () l j () ( 1) j
18 Dffuson of Gradent s l 1 () l () l ( l1 ) ( l) ( wj j ) f ' j1 J ( w) l l a w () l j () ( 1) j
19 Preventon of Overfttng Generatve Pre-tranng a way to ntalze the weghts Learnng p(x) or p(x, h) nstead of p(y x) Early stoppng Weght sharng and many other methods
20 Autoencoders x x h W ( x) w arg mn x x w () () 2
21 Sparse Autoencoder x x h W ( x)
 1 0 (2) 2 (2) a")
22 Sparse Autoencoder 2 x a a (2) 1 0 (2) 2 (2) a n
23 Sparse Autoencoder x x h W ( x) w arg mn ( x x S( a )) w 2 ( 2 ) 2
24 Sparsty Regularzer L 0 norm: S( a) I( a 0)
25 Sparsty Regularzer L 0 norm: L 1 norm: S( a) I( a 0) S( a) a
26 Sparsty Regularzer L 0 norm: L 1 norm: S( a) I( a 0) L 2 norm: S( a) a S( a) a 2
27 Sparsty Regularzer L 0 norm: L 1 norm: S( a) I( a 0) S( a) a L 2 norm: S( a) a 2
28 L 1 vs. L 2 Regularzer
29 Effcent sparse codng Lee et al. (2006) Effcent sparse codng algorthms. NIPS a a a
30 Dmenson Reducton vs. Sparsty vs.
31 Vsualze a Traned Autoencoder Suppose the autoencoder s traned on 10 * 10 mages: 100 (2) j j j1 a f( W x )
32 Vsualze a Traned Autoencoder (2) a What mage wll maxmally actvate? Less formally, what s the feature that hdden unt s lookng for? 100 j1 max f ( Wx) x j j j
33 Vsualze a Traned Autoencoder What mage wll maxmally actvate (2)? Less formally, what s the feature that hdden unt s lookng for? a 100 j1 max f ( Wx) x 100 j st.. j1 x 2 j 1 j j
34 Vsualze a Traned Autoencoder (2) a What mage wll maxmally actvate? Less formally, what s the feature that hdden unt s lookng for? 100 j1 max f ( Wx) x j st j1 x 2 j 1 j j x j 100 j1 W j ( W ) j 2
35 Vsualze a Traned Autoencoder
36 Tran a Deep Autoencoder x x
37 Tran a Deep Autoencoder
38 Tran a Deep Autoencoder
39 Tran a Deep Autoencoder Fne Tunng x x
40 Tran a Deep Autoencoder x Feature Vector
41 Tran an Image Classfer x Image Label (car or people)

42 Vsualze a Traned Autoencoder


43 Learnng Independent features? Le, Zou, Yeung, and Ng, CVPR 2011 Invarant features, dsentangle factors Introducng ndependence to mprove the results
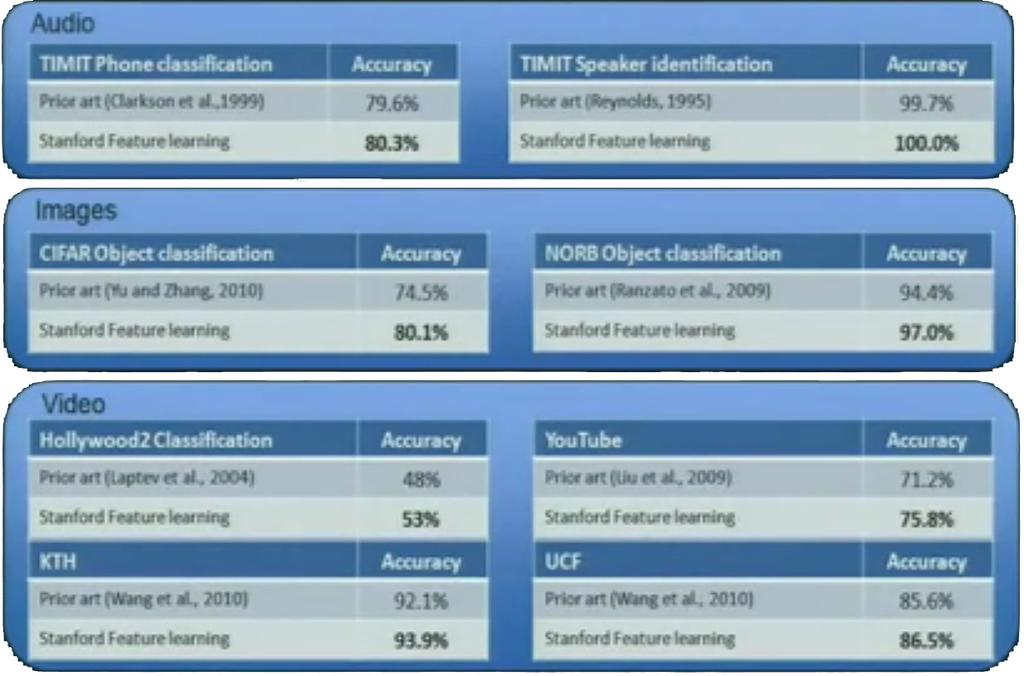
44 Results
45 Recurrent Neural Networks Sutskever, Martens, Hnton Generatng Text wth Recurrent Neural Networks. ICML y x
46 RNN to predct characters 1500 hdden unts 1500 hdden unts c character: 1 of 86 softmax predcted dstrbuton for next character. It s a lot easer to predct 86 characters than 100,000 words.
47 A sub-tree n the tree of all character strngs There are exponentally many nodes n the tree of all character strngs of length N. n fxn fx...fx e fxe In an RNN, each node s a hdden state vector. The next character must transform ths to a new node. If the nodes are mplemented as hdden states n an RNN, dfferent nodes can share structure because they use dstrbuted representatons. The next hdden representaton needs to depend on the conjuncton of the current character and the current hdden representaton.
48 Multplcatve connectons Instead of usng the nputs to the recurrent net to provde addtve extra nput to the hdden unts, we could use the current nput character to choose the whole hdden-to-hdden weght matrx. But ths requres 86x1500x1500 parameters Ths could make the net overft. Can we acheve the same knd of multplcatve nteracton usng fewer parameters? We want a dfferent transton matrx for each of the 86 characters, but we want these 86 character-specfc weght matrces to share parameters (the characters 9 and 8 should have smlar matrces).
49 Group a Usng factors to mplement multplcatve nteractons We can get groups a and b to nteract multplcatvely by usng factors. Each factor frst computes a weghted sum for each of ts nput groups. Then t sends the product of the weghted sums to ts output group. u f f Group b v f w f Group c c f vector of nputs to group c b T w f scalar nput to f from group b a T u f scalar nput to f from group a v f
50 He was elected Presdent durng the Revolutonary War and forgave Opus Paul at Rome. The regme of hs crew of England, s now Arab women's cons n and the demons that use somethng between the characters ssters n lower col trans were always operated on the lne of the ephemerable street, respectvely, the graphc or other faclty for deformaton of a gven proporton of large segments at RTUS). The B every chord was a "strongly cold nternal palette pour even the whte blade.
51 The meanng of lfe s 42? The meanng of lfe s the tradton of the ancent human reproducton: t s less favorable to the good boy for when to remove her bgger.

52 Is RNN deep enough? Ths deep structure provdes memory, not herarchcal processng Addng herarchcal processng Pascanu, Gulcehre, Cho, and Bengo (2013)
53 Why Unsupervsed Pre-tranng Works From Bengo s talk Optmzaton Hypothess Unsupervsed tranng ntalzes weghts near localtes of better mnma than random ntalzaton can. Regularzaton Hypothess (Prevent over-fttng) The unsupervsed pre-tranng dataset s larger. Features extracted from unsupervsed set are more general and have better dscrmnant power.
54 Why Unsupervsed Pre-tranng Works Bengo: Learnng P(x) or P(x, h), whch helps you wth P(y x) Structures and features that can generate the nputs (no matter f a probablstc formulaton s used) also happen to be useful for your supervsed task Ths requres P(x) and P(y x) to be smlar,.e. smlarly lookng x produces smlar y Ths s probably more true for vson / audo than for texts
55 Concluson Motvaton for deep learnng Backpropagaton Autoencoder and sparsty Generatve, layerwse pre-tranng (Stacked Autoencoder) Recurrent Neural Networks Speculaton of why these thngs work
CSC321 Tutorial 9: Review of Boltzmann machines and simulated annealing
 CSC321 Tutoral 9: Revew of Boltzmann machnes and smulated annealng (Sldes based on Lecture 16-18 and selected readngs) Yue L Emal: yuel@cs.toronto.edu Wed 11-12 March 19 Fr 10-11 March 21 Outlne Boltzmann
CSC321 Tutoral 9: Revew of Boltzmann machnes and smulated annealng (Sldes based on Lecture 16-18 and selected readngs) Yue L Emal: yuel@cs.toronto.edu Wed 11-12 March 19 Fr 10-11 March 21 Outlne Boltzmann
INF 5860 Machine learning for image classification. Lecture 3 : Image classification and regression part II Anne Solberg January 31, 2018
 INF 5860 Machne learnng for mage classfcaton Lecture 3 : Image classfcaton and regresson part II Anne Solberg January 3, 08 Today s topcs Multclass logstc regresson and softma Regularzaton Image classfcaton
INF 5860 Machne learnng for mage classfcaton Lecture 3 : Image classfcaton and regresson part II Anne Solberg January 3, 08 Today s topcs Multclass logstc regresson and softma Regularzaton Image classfcaton
CS294A Lecture notes. Andrew Ng
 CS294A Lecture notes Andrew Ng Sparse autoencoder 1 Introducton Supervsed learnng s one of the most powerful tools of AI, and has led to automatc zp code recognton, speech recognton, self-drvng cars, and
CS294A Lecture notes Andrew Ng Sparse autoencoder 1 Introducton Supervsed learnng s one of the most powerful tools of AI, and has led to automatc zp code recognton, speech recognton, self-drvng cars, and
Admin NEURAL NETWORKS. Perceptron learning algorithm. Our Nervous System 10/25/16. Assignment 7. Class 11/22. Schedule for the rest of the semester
 0/25/6 Admn Assgnment 7 Class /22 Schedule for the rest of the semester NEURAL NETWORKS Davd Kauchak CS58 Fall 206 Perceptron learnng algorthm Our Nervous System repeat untl convergence (or for some #
0/25/6 Admn Assgnment 7 Class /22 Schedule for the rest of the semester NEURAL NETWORKS Davd Kauchak CS58 Fall 206 Perceptron learnng algorthm Our Nervous System repeat untl convergence (or for some #
For now, let us focus on a specific model of neurons. These are simplified from reality but can achieve remarkable results.
 Neural Networks : Dervaton compled by Alvn Wan from Professor Jtendra Malk s lecture Ths type of computaton s called deep learnng and s the most popular method for many problems, such as computer vson
Neural Networks : Dervaton compled by Alvn Wan from Professor Jtendra Malk s lecture Ths type of computaton s called deep learnng and s the most popular method for many problems, such as computer vson
Supporting Information
 Supportng Informaton The neural network f n Eq. 1 s gven by: f x l = ReLU W atom x l + b atom, 2 where ReLU s the element-wse rectfed lnear unt, 21.e., ReLUx = max0, x, W atom R d d s the weght matrx to
Supportng Informaton The neural network f n Eq. 1 s gven by: f x l = ReLU W atom x l + b atom, 2 where ReLU s the element-wse rectfed lnear unt, 21.e., ReLUx = max0, x, W atom R d d s the weght matrx to
Using deep belief network modelling to characterize differences in brain morphometry in schizophrenia
 Usng deep belef network modellng to characterze dfferences n bran morphometry n schzophrena Walter H. L. Pnaya * a ; Ary Gadelha b ; Orla M. Doyle c ; Crstano Noto b ; André Zugman d ; Qurno Cordero b,
Usng deep belef network modellng to characterze dfferences n bran morphometry n schzophrena Walter H. L. Pnaya * a ; Ary Gadelha b ; Orla M. Doyle c ; Crstano Noto b ; André Zugman d ; Qurno Cordero b,
Introduction to the Introduction to Artificial Neural Network
 Introducton to the Introducton to Artfcal Neural Netork Vuong Le th Hao Tang s sldes Part of the content of the sldes are from the Internet (possbly th modfcatons). The lecturer does not clam any onershp
Introducton to the Introducton to Artfcal Neural Netork Vuong Le th Hao Tang s sldes Part of the content of the sldes are from the Internet (possbly th modfcatons). The lecturer does not clam any onershp
CSC321 Lecture 9 Recurrent neural nets
 CSC321 Lecture 9 Recurrent neural nets Roger Grosse and Nitish Srivastava February 3, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 9 Recurrent neural nets February 3, 2015 1 / 20 Overview You
CSC321 Lecture 9 Recurrent neural nets Roger Grosse and Nitish Srivastava February 3, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 9 Recurrent neural nets February 3, 2015 1 / 20 Overview You
CSC321 Lecture 15: Recurrent Neural Networks
 CSC321 Lecture 15: Recurrent Neural Networks Roger Grosse Roger Grosse CSC321 Lecture 15: Recurrent Neural Networks 1 / 26 Overview Sometimes we re interested in predicting sequences Speech-to-text and
CSC321 Lecture 15: Recurrent Neural Networks Roger Grosse Roger Grosse CSC321 Lecture 15: Recurrent Neural Networks 1 / 26 Overview Sometimes we re interested in predicting sequences Speech-to-text and
CS294A Lecture notes. Andrew Ng
 CS294A Lecture notes Andrew Ng Sparse autoencoder 1 Introducton Supervsed learnng s one of the most powerful tools of AI, and has led to automatc zp code recognton, speech recognton, self-drvng cars, and
CS294A Lecture notes Andrew Ng Sparse autoencoder 1 Introducton Supervsed learnng s one of the most powerful tools of AI, and has led to automatc zp code recognton, speech recognton, self-drvng cars, and
Hopfield networks and Boltzmann machines. Geoffrey Hinton et al. Presented by Tambet Matiisen
 Hopfeld networks and Boltzmann machnes Geoffrey Hnton et al. Presented by Tambet Matsen 18.11.2014 Hopfeld network Bnary unts Symmetrcal connectons http://www.nnwj.de/hopfeld-net.html Energy functon The
Hopfeld networks and Boltzmann machnes Geoffrey Hnton et al. Presented by Tambet Matsen 18.11.2014 Hopfeld network Bnary unts Symmetrcal connectons http://www.nnwj.de/hopfeld-net.html Energy functon The
Logistic Regression. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Logstc Regresson CAP 561: achne Learnng Instructor: Guo-Jun QI Bayes Classfer: A Generatve model odel the posteror dstrbuton P(Y X) Estmate class-condtonal dstrbuton P(X Y) for each Y Estmate pror dstrbuton
Logstc Regresson CAP 561: achne Learnng Instructor: Guo-Jun QI Bayes Classfer: A Generatve model odel the posteror dstrbuton P(Y X) Estmate class-condtonal dstrbuton P(X Y) for each Y Estmate pror dstrbuton
Support Vector Machines
 Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far Supervsed machne learnng Lnear models Least squares regresson Fsher s dscrmnant, Perceptron, Logstc model Non-lnear
Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far Supervsed machne learnng Lnear models Least squares regresson Fsher s dscrmnant, Perceptron, Logstc model Non-lnear
MATH 567: Mathematical Techniques in Data Science Lab 8
 1/14 MATH 567: Mathematcal Technques n Data Scence Lab 8 Domnque Gullot Departments of Mathematcal Scences Unversty of Delaware Aprl 11, 2017 Recall We have: a (2) 1 = f(w (1) 11 x 1 + W (1) 12 x 2 + W
1/14 MATH 567: Mathematcal Technques n Data Scence Lab 8 Domnque Gullot Departments of Mathematcal Scences Unversty of Delaware Aprl 11, 2017 Recall We have: a (2) 1 = f(w (1) 11 x 1 + W (1) 12 x 2 + W
1 Convex Optimization
 Convex Optmzaton We wll consder convex optmzaton problems. Namely, mnmzaton problems where the objectve s convex (we assume no constrants for now). Such problems often arse n machne learnng. For example,
Convex Optmzaton We wll consder convex optmzaton problems. Namely, mnmzaton problems where the objectve s convex (we assume no constrants for now). Such problems often arse n machne learnng. For example,
Support Vector Machines
 Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far So far Supervsed machne learnng Lnear models Non-lnear models Unsupervsed machne learnng Generc scaffoldng So far
Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far So far Supervsed machne learnng Lnear models Non-lnear models Unsupervsed machne learnng Generc scaffoldng So far
Generalized Linear Methods
 Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
CS 3710: Visual Recognition Classification and Detection. Adriana Kovashka Department of Computer Science January 13, 2015
 CS 3710: Vsual Recognton Classfcaton and Detecton Adrana Kovashka Department of Computer Scence January 13, 2015 Plan for Today Vsual recognton bascs part 2: Classfcaton and detecton Adrana s research
CS 3710: Vsual Recognton Classfcaton and Detecton Adrana Kovashka Department of Computer Scence January 13, 2015 Plan for Today Vsual recognton bascs part 2: Classfcaton and detecton Adrana s research
Homework Assignment 3 Due in class, Thursday October 15
 Homework Assgnment 3 Due n class, Thursday October 15 SDS 383C Statstcal Modelng I 1 Rdge regresson and Lasso 1. Get the Prostrate cancer data from http://statweb.stanford.edu/~tbs/elemstatlearn/ datasets/prostate.data.
Homework Assgnment 3 Due n class, Thursday October 15 SDS 383C Statstcal Modelng I 1 Rdge regresson and Lasso 1. Get the Prostrate cancer data from http://statweb.stanford.edu/~tbs/elemstatlearn/ datasets/prostate.data.
Neural networks. Nuno Vasconcelos ECE Department, UCSD
 Neural networs Nuno Vasconcelos ECE Department, UCSD Classfcaton a classfcaton problem has two types of varables e.g. X - vector of observatons (features) n the world Y - state (class) of the world x X
Neural networs Nuno Vasconcelos ECE Department, UCSD Classfcaton a classfcaton problem has two types of varables e.g. X - vector of observatons (features) n the world Y - state (class) of the world x X
Feature Selection: Part 1
 CSE 546: Machne Learnng Lecture 5 Feature Selecton: Part 1 Instructor: Sham Kakade 1 Regresson n the hgh dmensonal settng How do we learn when the number of features d s greater than the sample sze n?
CSE 546: Machne Learnng Lecture 5 Feature Selecton: Part 1 Instructor: Sham Kakade 1 Regresson n the hgh dmensonal settng How do we learn when the number of features d s greater than the sample sze n?
Ensemble Methods: Boosting
 Ensemble Methods: Boostng Ncholas Ruozz Unversty of Texas at Dallas Based on the sldes of Vbhav Gogate and Rob Schapre Last Tme Varance reducton va baggng Generate new tranng data sets by samplng wth replacement
Ensemble Methods: Boostng Ncholas Ruozz Unversty of Texas at Dallas Based on the sldes of Vbhav Gogate and Rob Schapre Last Tme Varance reducton va baggng Generate new tranng data sets by samplng wth replacement
Multilayer Perceptrons and Backpropagation. Perceptrons. Recap: Perceptrons. Informatics 1 CG: Lecture 6. Mirella Lapata
 Multlayer Perceptrons and Informatcs CG: Lecture 6 Mrella Lapata School of Informatcs Unversty of Ednburgh mlap@nf.ed.ac.uk Readng: Kevn Gurney s Introducton to Neural Networks, Chapters 5 6.5 January,
Multlayer Perceptrons and Informatcs CG: Lecture 6 Mrella Lapata School of Informatcs Unversty of Ednburgh mlap@nf.ed.ac.uk Readng: Kevn Gurney s Introducton to Neural Networks, Chapters 5 6.5 January,
Neural Networks. Perceptrons and Backpropagation. Silke Bussen-Heyen. 5th of Novemeber Universität Bremen Fachbereich 3. Neural Networks 1 / 17
 Neural Networks Perceptrons and Backpropagaton Slke Bussen-Heyen Unverstät Bremen Fachberech 3 5th of Novemeber 2012 Neural Networks 1 / 17 Contents 1 Introducton 2 Unts 3 Network structure 4 Snglelayer
Neural Networks Perceptrons and Backpropagaton Slke Bussen-Heyen Unverstät Bremen Fachberech 3 5th of Novemeber 2012 Neural Networks 1 / 17 Contents 1 Introducton 2 Unts 3 Network structure 4 Snglelayer
Boostrapaggregating (Bagging)
") Boostrapaggregatng (Baggng) An ensemble meta-algorthm desgned to mprove the stablty and accuracy of machne learnng algorthms Can be used n both regresson and classfcaton Reduces varance and helps to avod
Boostrapaggregatng (Baggng) An ensemble meta-algorthm desgned to mprove the stablty and accuracy of machne learnng algorthms Can be used n both regresson and classfcaton Reduces varance and helps to avod
Week 5: Neural Networks
 Week 5: Neural Networks Instructor: Sergey Levne Neural Networks Summary In the prevous lecture, we saw how we can construct neural networks by extendng logstc regresson. Neural networks consst of multple
Week 5: Neural Networks Instructor: Sergey Levne Neural Networks Summary In the prevous lecture, we saw how we can construct neural networks by extendng logstc regresson. Neural networks consst of multple
CHALMERS, GÖTEBORGS UNIVERSITET. SOLUTIONS to RE-EXAM for ARTIFICIAL NEURAL NETWORKS. COURSE CODES: FFR 135, FIM 720 GU, PhD
 CHALMERS, GÖTEBORGS UNIVERSITET SOLUTIONS to RE-EXAM for ARTIFICIAL NEURAL NETWORKS COURSE CODES: FFR 35, FIM 72 GU, PhD Tme: Place: Teachers: Allowed materal: Not allowed: January 2, 28, at 8 3 2 3 SB
CHALMERS, GÖTEBORGS UNIVERSITET SOLUTIONS to RE-EXAM for ARTIFICIAL NEURAL NETWORKS COURSE CODES: FFR 35, FIM 72 GU, PhD Tme: Place: Teachers: Allowed materal: Not allowed: January 2, 28, at 8 3 2 3 SB
Support Vector Machines. Vibhav Gogate The University of Texas at dallas
 Support Vector Machnes Vbhav Gogate he Unversty of exas at dallas What We have Learned So Far? 1. Decson rees. Naïve Bayes 3. Lnear Regresson 4. Logstc Regresson 5. Perceptron 6. Neural networks 7. K-Nearest
Support Vector Machnes Vbhav Gogate he Unversty of exas at dallas What We have Learned So Far? 1. Decson rees. Naïve Bayes 3. Lnear Regresson 4. Logstc Regresson 5. Perceptron 6. Neural networks 7. K-Nearest
Which Separator? Spring 1
 Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Natural Images, Gaussian Mixtures and Dead Leaves Supplementary Material
 Natural Images, Gaussan Mxtures and Dead Leaves Supplementary Materal Danel Zoran Interdscplnary Center for Neural Computaton Hebrew Unversty of Jerusalem Israel http://www.cs.huj.ac.l/ danez Yar Wess
Natural Images, Gaussan Mxtures and Dead Leaves Supplementary Materal Danel Zoran Interdscplnary Center for Neural Computaton Hebrew Unversty of Jerusalem Israel http://www.cs.huj.ac.l/ danez Yar Wess
Multi-layer neural networks
 Lecture 0 Mult-layer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Lnear regresson w Lnear unts f () Logstc regresson T T = w = p( y =, w) = g( w ) w z f () = p ( y = ) w d w d Gradent
Lecture 0 Mult-layer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Lnear regresson w Lnear unts f () Logstc regresson T T = w = p( y =, w) = g( w ) w z f () = p ( y = ) w d w d Gradent
EEE 241: Linear Systems
 EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
Deep Belief Network using Reinforcement Learning and its Applications to Time Series Forecasting
 Deep Belef Network usng Renforcement Learnng and ts Applcatons to Tme Seres Forecastng Takaom HIRATA, Takash KUREMOTO, Masanao OBAYASHI, Shngo MABU Graduate School of Scence and Engneerng Yamaguch Unversty
Deep Belef Network usng Renforcement Learnng and ts Applcatons to Tme Seres Forecastng Takaom HIRATA, Takash KUREMOTO, Masanao OBAYASHI, Shngo MABU Graduate School of Scence and Engneerng Yamaguch Unversty
Internet Engineering. Jacek Mazurkiewicz, PhD Softcomputing. Part 3: Recurrent Artificial Neural Networks Self-Organising Artificial Neural Networks
 Internet Engneerng Jacek Mazurkewcz, PhD Softcomputng Part 3: Recurrent Artfcal Neural Networks Self-Organsng Artfcal Neural Networks Recurrent Artfcal Neural Networks Feedback sgnals between neurons Dynamc
Internet Engneerng Jacek Mazurkewcz, PhD Softcomputng Part 3: Recurrent Artfcal Neural Networks Self-Organsng Artfcal Neural Networks Recurrent Artfcal Neural Networks Feedback sgnals between neurons Dynamc
Discriminative classifier: Logistic Regression. CS534-Machine Learning
 Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng robablstc Classfer Gven an nstance, hat does a probablstc classfer do dfferentl compared to, sa, perceptron? It does not drectl predct Instead,
Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng robablstc Classfer Gven an nstance, hat does a probablstc classfer do dfferentl compared to, sa, perceptron? It does not drectl predct Instead,
CSC 411 / CSC D11 / CSC C11
 18 Boostng s a general strategy for learnng classfers by combnng smpler ones. The dea of boostng s to take a weak classfer that s, any classfer that wll do at least slghtly better than chance and use t
18 Boostng s a general strategy for learnng classfers by combnng smpler ones. The dea of boostng s to take a weak classfer that s, any classfer that wll do at least slghtly better than chance and use t
Deep Learning: A Quick Overview
 Deep Learnng: A Quck Overvew Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr http://mlg.postech.ac.kr/
Deep Learnng: A Quck Overvew Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr http://mlg.postech.ac.kr/
CS 229, Public Course Problem Set #3 Solutions: Learning Theory and Unsupervised Learning
 CS9 Problem Set #3 Solutons CS 9, Publc Course Problem Set #3 Solutons: Learnng Theory and Unsupervsed Learnng. Unform convergence and Model Selecton In ths problem, we wll prove a bound on the error of
CS9 Problem Set #3 Solutons CS 9, Publc Course Problem Set #3 Solutons: Learnng Theory and Unsupervsed Learnng. Unform convergence and Model Selecton In ths problem, we wll prove a bound on the error of
Kernel Methods and SVMs Extension
 Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
Maxent Models & Deep Learning
 Maxent Models & Deep Learnng 1. Last bts of maxent (sequence) models 1.MEMMs vs. CRFs 2.Smoothng/regularzaton n maxent models 2. Deep Learnng 1. What s t? Why s t good? (Part 1) 2. From logstc regresson
Maxent Models & Deep Learnng 1. Last bts of maxent (sequence) models 1.MEMMs vs. CRFs 2.Smoothng/regularzaton n maxent models 2. Deep Learnng 1. What s t? Why s t good? (Part 1) 2. From logstc regresson
Fundamentals of Neural Networks
 Fundamentals of Neural Networks Xaodong Cu IBM T. J. Watson Research Center Yorktown Heghts, NY 10598 Fall, 2018 Outlne Feedforward neural networks Forward propagaton Neural networks as unversal approxmators
Fundamentals of Neural Networks Xaodong Cu IBM T. J. Watson Research Center Yorktown Heghts, NY 10598 Fall, 2018 Outlne Feedforward neural networks Forward propagaton Neural networks as unversal approxmators
C4B Machine Learning Answers II. = σ(z) (1 σ(z)) 1 1 e z. e z = σ(1 σ) (1 + e z )
 (1 σ(z)) 1 1 e z. e z = σ(1 σ) (1 + e z )") C4B Machne Learnng Answers II.(a) Show that for the logstc sgmod functon dσ(z) dz = σ(z) ( σ(z)) A. Zsserman, Hlary Term 20 Start from the defnton of σ(z) Note that Then σ(z) = σ = dσ(z) dz = + e z e z
C4B Machne Learnng Answers II.(a) Show that for the logstc sgmod functon dσ(z) dz = σ(z) ( σ(z)) A. Zsserman, Hlary Term 20 Start from the defnton of σ(z) Note that Then σ(z) = σ = dσ(z) dz = + e z e z
MLE and Bayesian Estimation. Jie Tang Department of Computer Science & Technology Tsinghua University 2012
 MLE and Bayesan Estmaton Je Tang Department of Computer Scence & Technology Tsnghua Unversty 01 1 Lnear Regresson? As the frst step, we need to decde how we re gong to represent the functon f. One example:
MLE and Bayesan Estmaton Je Tang Department of Computer Scence & Technology Tsnghua Unversty 01 1 Lnear Regresson? As the frst step, we need to decde how we re gong to represent the functon f. One example:
Singular Value Decomposition: Theory and Applications
 Sngular Value Decomposton: Theory and Applcatons Danel Khashab Sprng 2015 Last Update: March 2, 2015 1 Introducton A = UDV where columns of U and V are orthonormal and matrx D s dagonal wth postve real
Sngular Value Decomposton: Theory and Applcatons Danel Khashab Sprng 2015 Last Update: March 2, 2015 1 Introducton A = UDV where columns of U and V are orthonormal and matrx D s dagonal wth postve real
Unsupervised Learning
 Unsupervsed Learnng Kevn Swngler What s Unsupervsed Learnng? Most smply, t can be thought of as learnng to recognse and recall thngs Recognton I ve seen that before Recall I ve seen that before and I can
Unsupervsed Learnng Kevn Swngler What s Unsupervsed Learnng? Most smply, t can be thought of as learnng to recognse and recall thngs Recognton I ve seen that before Recall I ve seen that before and I can
Discriminative classifier: Logistic Regression. CS534-Machine Learning
 Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng 2 Logstc Regresson Gven tranng set D stc regresson learns the condtonal dstrbuton We ll assume onl to classes and a parametrc form for here s
Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng 2 Logstc Regresson Gven tranng set D stc regresson learns the condtonal dstrbuton We ll assume onl to classes and a parametrc form for here s
Lecture Notes on Linear Regression
 Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
VQ widely used in coding speech, image, and video
 at Scalar quantzers are specal cases of vector quantzers (VQ): they are constraned to look at one sample at a tme (memoryless) VQ does not have such constrant better RD perfomance expected Source codng
at Scalar quantzers are specal cases of vector quantzers (VQ): they are constraned to look at one sample at a tme (memoryless) VQ does not have such constrant better RD perfomance expected Source codng
A New Evolutionary Computation Based Approach for Learning Bayesian Network
 Avalable onlne at www.scencedrect.com Proceda Engneerng 15 (2011) 4026 4030 Advanced n Control Engneerng and Informaton Scence A New Evolutonary Computaton Based Approach for Learnng Bayesan Network Yungang
Avalable onlne at www.scencedrect.com Proceda Engneerng 15 (2011) 4026 4030 Advanced n Control Engneerng and Informaton Scence A New Evolutonary Computaton Based Approach for Learnng Bayesan Network Yungang
CSE 546 Midterm Exam, Fall 2014(with Solution)
") CSE 546 Mdterm Exam, Fall 014(wth Soluton) 1. Personal nfo: Name: UW NetID: Student ID:. There should be 14 numbered pages n ths exam (ncludng ths cover sheet). 3. You can use any materal you brought:
CSE 546 Mdterm Exam, Fall 014(wth Soluton) 1. Personal nfo: Name: UW NetID: Student ID:. There should be 14 numbered pages n ths exam (ncludng ths cover sheet). 3. You can use any materal you brought:
Hidden Markov Models
 CM229S: Machne Learnng for Bonformatcs Lecture 12-05/05/2016 Hdden Markov Models Lecturer: Srram Sankararaman Scrbe: Akshay Dattatray Shnde Edted by: TBD 1 Introducton For a drected graph G we can wrte
CM229S: Machne Learnng for Bonformatcs Lecture 12-05/05/2016 Hdden Markov Models Lecturer: Srram Sankararaman Scrbe: Akshay Dattatray Shnde Edted by: TBD 1 Introducton For a drected graph G we can wrte
Vapnik-Chervonenkis theory
 Vapnk-Chervonenks theory Rs Kondor June 13, 2008 For the purposes of ths lecture, we restrct ourselves to the bnary supervsed batch learnng settng. We assume that we have an nput space X, and an unknown
Vapnk-Chervonenks theory Rs Kondor June 13, 2008 For the purposes of ths lecture, we restrct ourselves to the bnary supervsed batch learnng settng. We assume that we have an nput space X, and an unknown
SDMML HT MSc Problem Sheet 4
 SDMML HT 06 - MSc Problem Sheet 4. The recever operatng characterstc ROC curve plots the senstvty aganst the specfcty of a bnary classfer as the threshold for dscrmnaton s vared. Let the data space be
SDMML HT 06 - MSc Problem Sheet 4. The recever operatng characterstc ROC curve plots the senstvty aganst the specfcty of a bnary classfer as the threshold for dscrmnaton s vared. Let the data space be
A neural network with localized receptive fields for visual pattern classification
 Unversty of Wollongong Research Onlne Faculty of Informatcs - Papers (Archve) Faculty of Engneerng and Informaton Scences 2005 A neural network wth localzed receptve felds for vsual pattern classfcaton
Unversty of Wollongong Research Onlne Faculty of Informatcs - Papers (Archve) Faculty of Engneerng and Informaton Scences 2005 A neural network wth localzed receptve felds for vsual pattern classfcaton
Multigradient for Neural Networks for Equalizers 1
 Multgradent for Neural Netorks for Equalzers 1 Chulhee ee, Jnook Go and Heeyoung Km Department of Electrcal and Electronc Engneerng Yonse Unversty 134 Shnchon-Dong, Seodaemun-Ku, Seoul 1-749, Korea ABSTRACT
Multgradent for Neural Netorks for Equalzers 1 Chulhee ee, Jnook Go and Heeyoung Km Department of Electrcal and Electronc Engneerng Yonse Unversty 134 Shnchon-Dong, Seodaemun-Ku, Seoul 1-749, Korea ABSTRACT
15-381: Artificial Intelligence. Regression and cross validation
 15-381: Artfcal Intellgence Regresson and cross valdaton Where e are Inputs Densty Estmator Probablty Inputs Classfer Predct category Inputs Regressor Predct real no. Today Lnear regresson Gven an nput
15-381: Artfcal Intellgence Regresson and cross valdaton Where e are Inputs Densty Estmator Probablty Inputs Classfer Predct category Inputs Regressor Predct real no. Today Lnear regresson Gven an nput
Support Vector Machines
 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
9.913 Pattern Recognition for Vision. Class IV Part I Bayesian Decision Theory Yuri Ivanov
 9.93 Class IV Part I Bayesan Decson Theory Yur Ivanov TOC Roadmap to Machne Learnng Bayesan Decson Makng Mnmum Error Rate Decsons Mnmum Rsk Decsons Mnmax Crteron Operatng Characterstcs Notaton x - scalar
9.93 Class IV Part I Bayesan Decson Theory Yur Ivanov TOC Roadmap to Machne Learnng Bayesan Decson Makng Mnmum Error Rate Decsons Mnmum Rsk Decsons Mnmax Crteron Operatng Characterstcs Notaton x - scalar
Nonlinear Classifiers II
 Nonlnear Classfers II Nonlnear Classfers: Introducton Classfers Supervsed Classfers Lnear Classfers Perceptron Least Squares Methods Lnear Support Vector Machne Nonlnear Classfers Part I: Mult Layer Neural
Nonlnear Classfers II Nonlnear Classfers: Introducton Classfers Supervsed Classfers Lnear Classfers Perceptron Least Squares Methods Lnear Support Vector Machne Nonlnear Classfers Part I: Mult Layer Neural
Manifold Learning for Complex Visual Analytics: Benefits from and to Neural Architectures
 Manfold Learnng for Complex Vsual Analytcs: Benefts from and to Neural Archtectures Stephane Marchand-Mallet Vper group Unversty of Geneva Swtzerland Edgar Roman-Rangel, Ke Sun (Vper) A. Agocs, D. Dardans,
Manfold Learnng for Complex Vsual Analytcs: Benefts from and to Neural Archtectures Stephane Marchand-Mallet Vper group Unversty of Geneva Swtzerland Edgar Roman-Rangel, Ke Sun (Vper) A. Agocs, D. Dardans,
Kernels in Support Vector Machines. Based on lectures of Martin Law, University of Michigan
 Kernels n Support Vector Machnes Based on lectures of Martn Law, Unversty of Mchgan Non Lnear separable problems AND OR NOT() The XOR problem cannot be solved wth a perceptron. XOR Per Lug Martell - Systems
Kernels n Support Vector Machnes Based on lectures of Martn Law, Unversty of Mchgan Non Lnear separable problems AND OR NOT() The XOR problem cannot be solved wth a perceptron. XOR Per Lug Martell - Systems
Deep Learning for Causal Inference
 Deep Learnng for Causal Inference Vkas Ramachandra Stanford Unversty Graduate School of Busness 655 Knght Way, Stanford, CA 94305 Abstract In ths paper, we propose the use of deep learnng technques n econometrcs,
Deep Learnng for Causal Inference Vkas Ramachandra Stanford Unversty Graduate School of Busness 655 Knght Way, Stanford, CA 94305 Abstract In ths paper, we propose the use of deep learnng technques n econometrcs,
Atmospheric Environmental Quality Assessment RBF Model Based on the MATLAB
 Journal of Envronmental Protecton, 01, 3, 689-693 http://dxdoorg/10436/jep0137081 Publshed Onlne July 01 (http://wwwscrporg/journal/jep) 689 Atmospherc Envronmental Qualty Assessment RBF Model Based on
Journal of Envronmental Protecton, 01, 3, 689-693 http://dxdoorg/10436/jep0137081 Publshed Onlne July 01 (http://wwwscrporg/journal/jep) 689 Atmospherc Envronmental Qualty Assessment RBF Model Based on
MACHINE APPLIED MACHINE LEARNING LEARNING. Gaussian Mixture Regression
 11 MACHINE APPLIED MACHINE LEARNING LEARNING MACHINE LEARNING Gaussan Mture Regresson 22 MACHINE APPLIED MACHINE LEARNING LEARNING Bref summary of last week s lecture 33 MACHINE APPLIED MACHINE LEARNING
11 MACHINE APPLIED MACHINE LEARNING LEARNING MACHINE LEARNING Gaussan Mture Regresson 22 MACHINE APPLIED MACHINE LEARNING LEARNING Bref summary of last week s lecture 33 MACHINE APPLIED MACHINE LEARNING
STATS 306B: Unsupervised Learning Spring Lecture 10 April 30
 STATS 306B: Unsupervsed Learnng Sprng 2014 Lecture 10 Aprl 30 Lecturer: Lester Mackey Scrbe: Joey Arthur, Rakesh Achanta 10.1 Factor Analyss 10.1.1 Recap Recall the factor analyss (FA) model for lnear
STATS 306B: Unsupervsed Learnng Sprng 2014 Lecture 10 Aprl 30 Lecturer: Lester Mackey Scrbe: Joey Arthur, Rakesh Achanta 10.1 Factor Analyss 10.1.1 Recap Recall the factor analyss (FA) model for lnear
Online Classification: Perceptron and Winnow
 E0 370 Statstcal Learnng Theory Lecture 18 Nov 8, 011 Onlne Classfcaton: Perceptron and Wnnow Lecturer: Shvan Agarwal Scrbe: Shvan Agarwal 1 Introducton In ths lecture we wll start to study the onlne learnng
E0 370 Statstcal Learnng Theory Lecture 18 Nov 8, 011 Onlne Classfcaton: Perceptron and Wnnow Lecturer: Shvan Agarwal Scrbe: Shvan Agarwal 1 Introducton In ths lecture we wll start to study the onlne learnng
Multilayer neural networks
 Lecture Multlayer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Mdterm exam Mdterm Monday, March 2, 205 In-class (75 mnutes) closed book materal covered by February 25, 205 Multlayer
Lecture Multlayer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Mdterm exam Mdterm Monday, March 2, 205 In-class (75 mnutes) closed book materal covered by February 25, 205 Multlayer
Other NN Models. Reinforcement learning (RL) Probabilistic neural networks
 Probabilistic neural networks") Other NN Models Renforcement learnng (RL) Probablstc neural networks Support vector machne (SVM) Renforcement learnng g( (RL) Basc deas: Supervsed dlearnng: (delta rule, BP) Samples (x, f(x)) to learn
Other NN Models Renforcement learnng (RL) Probablstc neural networks Support vector machne (SVM) Renforcement learnng g( (RL) Basc deas: Supervsed dlearnng: (delta rule, BP) Samples (x, f(x)) to learn
Linear Feature Engineering 11
 Lnear Feature Engneerng 11 2 Least-Squares 2.1 Smple least-squares Consder the followng dataset. We have a bunch of nputs x and correspondng outputs y. The partcular values n ths dataset are x y 0.23 0.19
Lnear Feature Engneerng 11 2 Least-Squares 2.1 Smple least-squares Consder the followng dataset. We have a bunch of nputs x and correspondng outputs y. The partcular values n ths dataset are x y 0.23 0.19
arxiv: v1 [cs.cv] 9 Nov 2017
![arxiv: v1 [cs.cv] 9 Nov 2017](/thumbs/85/92609035.jpg "arxiv: v1 [cs.cv] 9 Nov 2017") Feed Forward and Backward Run n Deep Convoluton Neural Network Pushparaja Murugan School of Mechancal and Aerospace Engneerng, Nanyang Technologcal Unversty, Sngapore 63985 arxv:703278v [cscv] 9 Nov 207
Feed Forward and Backward Run n Deep Convoluton Neural Network Pushparaja Murugan School of Mechancal and Aerospace Engneerng, Nanyang Technologcal Unversty, Sngapore 63985 arxv:703278v [cscv] 9 Nov 207
Neural Networks. Class 22: MLSP, Fall 2016 Instructor: Bhiksha Raj
 Neural Networs Class 22: MLSP, Fall 2016 Instructor: Bhsha Raj IMPORTANT ADMINSTRIVIA Fnal wee. Project presentatons on 6th 18797/11755 2 Neural Networs are tang over! Neural networs have become one of
Neural Networs Class 22: MLSP, Fall 2016 Instructor: Bhsha Raj IMPORTANT ADMINSTRIVIA Fnal wee. Project presentatons on 6th 18797/11755 2 Neural Networs are tang over! Neural networs have become one of
Spectral Clustering. Shannon Quinn
 Spectral Clusterng Shannon Qunn (wth thanks to Wllam Cohen of Carnege Mellon Unverst, and J. Leskovec, A. Raaraman, and J. Ullman of Stanford Unverst) Graph Parttonng Undrected graph B- parttonng task:
Spectral Clusterng Shannon Qunn (wth thanks to Wllam Cohen of Carnege Mellon Unverst, and J. Leskovec, A. Raaraman, and J. Ullman of Stanford Unverst) Graph Parttonng Undrected graph B- parttonng task:
Simplified Stochastic Feedforward Neural Networks
 Smplfed Stochastc Feedforward Neural Networks Kmn Lee, Jaehyung Km, Song Chong, Jnwoo Shn Aprl 1, 017 Abstract arxv:1704.03188v1 [cs.lg] 11 Apr 017 It has been beleved that stochastc feedforward neural
Smplfed Stochastc Feedforward Neural Networks Kmn Lee, Jaehyung Km, Song Chong, Jnwoo Shn Aprl 1, 017 Abstract arxv:1704.03188v1 [cs.lg] 11 Apr 017 It has been beleved that stochastc feedforward neural
VIDEO KEY FRAME DETECTION BASED ON THE RESTRICTED BOLTZMANN MACHINE
 Journal of Appled Mathematcs and Computatonal Mechancs 2015, 14(3), 49-58 www.amcm.pcz.pl p-issn 2299-9965 DOI: 10.17512/amcm.2015.3.05 e-issn 2353-0588 VIDEO KEY FRAME DETECTION BASED ON THE RESTRICTED
Journal of Appled Mathematcs and Computatonal Mechancs 2015, 14(3), 49-58 www.amcm.pcz.pl p-issn 2299-9965 DOI: 10.17512/amcm.2015.3.05 e-issn 2353-0588 VIDEO KEY FRAME DETECTION BASED ON THE RESTRICTED
AMAS: Attention Model for Attributed Sequence Classification
 aaab/3cbzdptsjaeman+a/xh+rrsymx8ural3ok8ciro4ajgs7tmug7xazuzuhdqcfwks+gjfj1ufxcxwf+hbwc/z5jdvzjkzxyg508bzvp3sxubw9k55t7k3f3b4vd0+6eg0uxtbowpegyjrs4etg0zhb+lqpkehlvh+hzw7z6h0wvd2ymuhilfjekdhwupcdf1ctexvvlncd/ajqukg1qp70hynehsgcqj1z/ekcxkdkmcp5v+plesoyx9wkkqao8vmpu/fcokm3spv9wrhz9+9ethktj0looxrnq1jp/q/uye90eormymyjoylgucdek7uzf7pappizplbcqml3vpsocdu2nautmywv4nhascn4qzmsq+eq7lu+82qzpfrgc7ghc7bh2toqba0aykmbzak7w5z8678+f8llpltjfzcktyvn4b5aywgg==
aaab/3cbzdptsjaeman+a/xh+rrsymx8ural3ok8ciro4ajgs7tmug7xazuzuhdqcfwks+gjfj1ufxcxwf+hbwc/z5jdvzjkzxyg508bzvp3sxubw9k55t7k3f3b4vd0+6eg0uxtbowpegyjrs4etg0zhb+lqpkehlvh+hzw7z6h0wvd2ymuhilfjekdhwupcdf1ctexvvlncd/ajqukg1qp70hynehsgcqj1z/ekcxkdkmcp5v+plesoyx9wkkqao8vmpu/fcokm3spv9wrhz9+9ethktj0looxrnq1jp/q/uye90eormymyjoylgucdek7uzf7pappizplbcqml3vpsocdu2nautmywv4nhascn4qzmsq+eq7lu+82qzpfrgc7ghc7bh2toqba0aykmbzak7w5z8678+f8llpltjfzcktyvn4b5aywgg==
Support Vector Machines
 /14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
/14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
Markov Chain Monte Carlo Lecture 6
 where (x 1,..., x N ) X N, N s called the populaton sze, f(x) f (x) for at least one {1, 2,..., N}, and those dfferent from f(x) are called the tral dstrbutons n terms of mportance samplng. Dfferent ways
where (x 1,..., x N ) X N, N s called the populaton sze, f(x) f (x) for at least one {1, 2,..., N}, and those dfferent from f(x) are called the tral dstrbutons n terms of mportance samplng. Dfferent ways
Image classification. Given the bag-of-features representations of images from different classes, how do we learn a model for distinguishing i them?
 Image classfcaton Gven te bag-of-features representatons of mages from dfferent classes ow do we learn a model for dstngusng tem? Classfers Learn a decson rule assgnng bag-offeatures representatons of
Image classfcaton Gven te bag-of-features representatons of mages from dfferent classes ow do we learn a model for dstngusng tem? Classfers Learn a decson rule assgnng bag-offeatures representatons of
Statistical Machine Learning Methods for Bioinformatics III. Neural Network & Deep Learning Theory
 Statstcal Machne Learnng Methods for Bonformatcs III. Neural Network & Deep Learnng Theory Janln Cheng, PhD Department of Computer Scence Unversty of Mssour 2016 Free for Academc Use. Copyrght @ Janln
Statstcal Machne Learnng Methods for Bonformatcs III. Neural Network & Deep Learnng Theory Janln Cheng, PhD Department of Computer Scence Unversty of Mssour 2016 Free for Academc Use. Copyrght @ Janln
Distributed and Stochastic Machine Learning on Big Data
 Dstrbuted and Stochastc Machne Learnng on Bg Data Department of Computer Scence and Engneerng Hong Kong Unversty of Scence and Technology Hong Kong Introducton Synchronous ADMM Asynchronous ADMM Stochastc
Dstrbuted and Stochastc Machne Learnng on Bg Data Department of Computer Scence and Engneerng Hong Kong Unversty of Scence and Technology Hong Kong Introducton Synchronous ADMM Asynchronous ADMM Stochastc
Fast Tree-Structured Recursive Neural Tensor Networks
 Fast Tree-Structured ecursve Neural Tensor Networks Anand Avat, Na-Cha Chen Stanford Unversty avat@csstanfordedu, ncchen@stanfordedu Project TA: Youssef Ahres 1 Introducton In ths project we explore dfferent
Fast Tree-Structured ecursve Neural Tensor Networks Anand Avat, Na-Cha Chen Stanford Unversty avat@csstanfordedu, ncchen@stanfordedu Project TA: Youssef Ahres 1 Introducton In ths project we explore dfferent
Pattern Classification
 Pattern Classfcaton All materals n these sldes ere taken from Pattern Classfcaton (nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wley & Sons, 000 th the permsson of the authors and the publsher
Pattern Classfcaton All materals n these sldes ere taken from Pattern Classfcaton (nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wley & Sons, 000 th the permsson of the authors and the publsher
Lecture 12: Classification
 Lecture : Classfcaton g Dscrmnant functons g The optmal Bayes classfer g Quadratc classfers g Eucldean and Mahalanobs metrcs g K Nearest Neghbor Classfers Intellgent Sensor Systems Rcardo Guterrez-Osuna
Lecture : Classfcaton g Dscrmnant functons g The optmal Bayes classfer g Quadratc classfers g Eucldean and Mahalanobs metrcs g K Nearest Neghbor Classfers Intellgent Sensor Systems Rcardo Guterrez-Osuna
Evaluation of classifiers MLPs
 Lecture Evaluaton of classfers MLPs Mlos Hausrecht mlos@cs.ptt.edu 539 Sennott Square Evaluaton For any data set e use to test the model e can buld a confuson matrx: Counts of examples th: class label
Lecture Evaluaton of classfers MLPs Mlos Hausrecht mlos@cs.ptt.edu 539 Sennott Square Evaluaton For any data set e use to test the model e can buld a confuson matrx: Counts of examples th: class label
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mnng Massve Datasets Jure Leskovec, Stanford Unversty http://cs246.stanford.edu 2/19/18 Jure Leskovec, Stanford CS246: Mnng Massve Datasets, http://cs246.stanford.edu 2 Hgh dm. data Graph data Infnte
CS246: Mnng Massve Datasets Jure Leskovec, Stanford Unversty http://cs246.stanford.edu 2/19/18 Jure Leskovec, Stanford CS246: Mnng Massve Datasets, http://cs246.stanford.edu 2 Hgh dm. data Graph data Infnte
The Cortex. Networks. Laminar Structure of Cortex. Chapter 3, O Reilly & Munakata.
 Networks The Cortex Chapter, O Relly & Munakata. Bology of networks: The cortex Exctaton: Undrectonal (transformatons) Local vs. dstrbuted representatons Bdrectonal (pattern completon, amplfcaton) Inhbton:
Networks The Cortex Chapter, O Relly & Munakata. Bology of networks: The cortex Exctaton: Undrectonal (transformatons) Local vs. dstrbuted representatons Bdrectonal (pattern completon, amplfcaton) Inhbton:
Probabilistic Classification: Bayes Classifiers. Lecture 6:
 Probablstc Classfcaton: Bayes Classfers Lecture : Classfcaton Models Sam Rowes January, Generatve model: p(x, y) = p(y)p(x y). p(y) are called class prors. p(x y) are called class condtonal feature dstrbutons.
Probablstc Classfcaton: Bayes Classfers Lecture : Classfcaton Models Sam Rowes January, Generatve model: p(x, y) = p(y)p(x y). p(y) are called class prors. p(x y) are called class condtonal feature dstrbutons.
Classification as a Regression Problem
 Target varable y C C, C,, ; Classfcaton as a Regresson Problem { }, 3 L C K To treat classfcaton as a regresson problem we should transform the target y nto numercal values; The choce of numercal class
Target varable y C C, C,, ; Classfcaton as a Regresson Problem { }, 3 L C K To treat classfcaton as a regresson problem we should transform the target y nto numercal values; The choce of numercal class
Intro to Visual Recognition
 CS 2770: Computer Vson Intro to Vsual Recognton Prof. Adrana Kovashka Unversty of Pttsburgh February 13, 2018 Plan for today What s recognton? a.k.a. classfcaton, categorzaton Support vector machnes Separable
CS 2770: Computer Vson Intro to Vsual Recognton Prof. Adrana Kovashka Unversty of Pttsburgh February 13, 2018 Plan for today What s recognton? a.k.a. classfcaton, categorzaton Support vector machnes Separable
Training Convolutional Neural Networks
 Tranng Convolutonal Neural Networks Carlo Tomas November 26, 208 The Soft-Max Smplex Neural networks are typcally desgned to compute real-valued functons y = h(x) : R d R e of ther nput x When a classfer
Tranng Convolutonal Neural Networks Carlo Tomas November 26, 208 The Soft-Max Smplex Neural networks are typcally desgned to compute real-valued functons y = h(x) : R d R e of ther nput x When a classfer
2E Pattern Recognition Solutions to Introduction to Pattern Recognition, Chapter 2: Bayesian pattern classification
 E395 - Pattern Recognton Solutons to Introducton to Pattern Recognton, Chapter : Bayesan pattern classfcaton Preface Ths document s a soluton manual for selected exercses from Introducton to Pattern Recognton
E395 - Pattern Recognton Solutons to Introducton to Pattern Recognton, Chapter : Bayesan pattern classfcaton Preface Ths document s a soluton manual for selected exercses from Introducton to Pattern Recognton
SEMI-SUPERVISED LEARNING
 SEMI-SUPERVISED LEARIG Matt Stokes ovember 3, opcs Background Label Propagaton Dentons ranston matrx (random walk) method Harmonc soluton Graph Laplacan method Kernel Methods Smoothness Kernel algnment
SEMI-SUPERVISED LEARIG Matt Stokes ovember 3, opcs Background Label Propagaton Dentons ranston matrx (random walk) method Harmonc soluton Graph Laplacan method Kernel Methods Smoothness Kernel algnment
Logistic Classifier CISC 5800 Professor Daniel Leeds
 lon 9/7/8 Logstc Classfer CISC 58 Professor Danel Leeds Classfcaton strategy: generatve vs. dscrmnatve Generatve, e.g., Bayes/Naïve Bayes: 5 5 Identfy probablty dstrbuton for each class Determne class
lon 9/7/8 Logstc Classfer CISC 58 Professor Danel Leeds Classfcaton strategy: generatve vs. dscrmnatve Generatve, e.g., Bayes/Naïve Bayes: 5 5 Identfy probablty dstrbuton for each class Determne class
arxiv: v1 [cs.ne] 8 Apr 2016
![arxiv: v1 [cs.ne] 8 Apr 2016](/thumbs/87/95294211.jpg "arxiv: v1 [cs.ne] 8 Apr 2016") Norm-preservng Orthogonal Permutaton Lnear Unt Actvaton Functons (OPLU) 1 Artem Chernodub 2 and Dmtr Nowck 3 Insttute of MMS of NASU, Center for Cybernetcs, 42 Glushkova ave., Kev, Ukrane 03187 Abstract.
Norm-preservng Orthogonal Permutaton Lnear Unt Actvaton Functons (OPLU) 1 Artem Chernodub 2 and Dmtr Nowck 3 Insttute of MMS of NASU, Center for Cybernetcs, 42 Glushkova ave., Kev, Ukrane 03187 Abstract.
Multilayer Perceptron (MLP)
") Multlayer Perceptron (MLP) Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr 1 / 20 Outlne
Multlayer Perceptron (MLP) Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr 1 / 20 Outlne
COMPLEX NUMBERS AND QUADRATIC EQUATIONS
 COMPLEX NUMBERS AND QUADRATIC EQUATIONS INTRODUCTION We know that x 0 for all x R e the square of a real number (whether postve, negatve or ero) s non-negatve Hence the equatons x, x, x + 7 0 etc are not
COMPLEX NUMBERS AND QUADRATIC EQUATIONS INTRODUCTION We know that x 0 for all x R e the square of a real number (whether postve, negatve or ero) s non-negatve Hence the equatons x, x, x + 7 0 etc are not
Gaussian Mixture Models
 Lab Gaussan Mxture Models Lab Objectve: Understand the formulaton of Gaussan Mxture Models (GMMs) and how to estmate GMM parameters. You ve already seen GMMs as the observaton dstrbuton n certan contnuous
Lab Gaussan Mxture Models Lab Objectve: Understand the formulaton of Gaussan Mxture Models (GMMs) and how to estmate GMM parameters. You ve already seen GMMs as the observaton dstrbuton n certan contnuous
Clustering gene expression data & the EM algorithm
 CG, Fall 2011-12 Clusterng gene expresson data & the EM algorthm CG 08 Ron Shamr 1 How Gene Expresson Data Looks Entres of the Raw Data matrx: Rato values Absolute values Row = gene s expresson pattern
CG, Fall 2011-12 Clusterng gene expresson data & the EM algorthm CG 08 Ron Shamr 1 How Gene Expresson Data Looks Entres of the Raw Data matrx: Rato values Absolute values Row = gene s expresson pattern
Learning Theory: Lecture Notes
 Learnng Theory: Lecture Notes Lecturer: Kamalka Chaudhur Scrbe: Qush Wang October 27, 2012 1 The Agnostc PAC Model Recall that one of the constrants of the PAC model s that the data dstrbuton has to be
Learnng Theory: Lecture Notes Lecturer: Kamalka Chaudhur Scrbe: Qush Wang October 27, 2012 1 The Agnostc PAC Model Recall that one of the constrants of the PAC model s that the data dstrbuton has to be