Statistical Machine Learning Methods for Bioinformatics III. Neural Network & Deep Learning Theory
|
|
|
- Prudence Carson
- 6 years ago
- Views:
Transcription
1 Statstcal Machne Learnng Methods for Bonformatcs III. Neural Network & Deep Learnng Theory Janln Cheng, PhD Department of Computer Scence Unversty of Mssour 2016 Free for Academc Use. Janln Cheng & orgnal sources of some materals.
2 Classfcaton Problem Legs weght sze. Feature m Input Output Category / Label Mammal Bug Queston: How to automatcally predct output gven nput? Idea: Learn from known examples and generalze to unknown ones.
3 Data Drven Machne Learnng Approach Data wth Labels Splt Tranng Data Tranng Model: Map Input to Output Predcton New Data Test Data Test Input: words of news Output: poltcs, sports, entertanment, Tranng: Buld a model (classfer) Test: Test the model Key dea: Learn from known data and Generalze to unseen data
4 Outlne Introducton Lnear regresson Lnear Dscrmnant functon (classfcaton) One layer neural network / perceptron Mult-layer network Recurrent neural network Prevent overfttng Speedup learnng Deep learnng
5 Machne Learnng Supervsed learnng (tranng wth labeled data), un-supervsed learnng (clusterng un-labeled data), and sem-supervsed learnng (use both labeled and unlabeled data) Supervsed learnng: classfcaton and regresson Classfcaton: output s dscrete value Regresson: output s real value
6 Learnng Example: Recognze Handwrtng Classfcaton: recognze each number Clusterng: cluster the same numbers together Regresson: predct the ndex of Dow-Jones
7 Neural Network Neural Network can do both supervsed learnng and un-supervsed learnng Neural Network can do both regresson and classfcaton Neural Network has both statstcal and artfcal ntellgence roots
8 Roots of Neural Network Artfcal ntellgence root (neuron scence) Statstcal root (lnear regresson, generalzed lnear regresson, dscrmnant analyss. Ths s our focus.)
 Synapse: control release chemcal transmtters.")
9 A Typcal Cortcal Neuron Dentrtc tree neurons Juncton between neurons Collect chemcal sgnals Axon: generate Potentals (Fre/not Fre) Synapse: control release chemcal transmtters.
10 A Neural Model weght Input Actvaton Actvaton functon Adapted from
11 Statstcs Root: Lnear Regresson Example Fsh length vs. weght? X: nput or predctor Y: output or response Goal: learn a lnear functon E[y x] = wx + b. Adapted from A. Moore, 2003
12 Lnear Regresson Defnton of a lnear model: y = wx + b + nose. nose ~ N (0, σ 2 ), assume σ s a constant. y ~ N(wx + b, σ 2 ) Estmate expected value of y gven x (E[y x] = wx +b). Gven a set of data (x 1, y 1 ), (x 2, y 2 ),, (x n, y n ), to fnd the optmal parameters w and b.
13 Objectve Functon Least square error: Maxmum Lkelhood: Mnmzng square error s equvalent to maxmzng lkelhood = N b w x y P 1 ),, ( = N b wx y 1 2 ) (
14 = N b w x y P 1 ),, ( ) ( σ πσ b wx y N e = = N b w x y P 1 )),, ( log( Maxmze Lkelhood Mnmze negatve log-lkelhood: ) 2 ) ( ) 2 log( ( ) 2 1 log( ) ( σ πσ πσ σ b wx y e N b wx y N = = = ) 2 ) ( ) 2 (log( σ πσ b wx y N + = = = = Note: σ s a constant.
15 1-Varable Lnear Regresson = N b wx y 1 2 ) ( 0 ) 2( ) )*( 2( = + + = = = = N N bx wx x y x b wx y W E 0 ) 2( 1) )*( 2( 1 1 = + + = = = = N N b wx y b wx y b E Mnmze E = Error w N wx y b N = = 1 ) ( = = = N N N xx x N x y y x w 1 2 1
16 Multvarate Lnear Regresson How about multple predctors: (x 1, x 2,, x d ). y = w 0 + w 1 x 1 + w 2 x w d x d + ε For multple data ponts, each data pont s represented as (y, x ), x conssts of d predctors (x 1, x 2,, x d ). y = w 0 + w 1 x 1 + w 2 x w d x d + ε
17 A Motvatng Example Each day you get lunch at the cafetera. Your det conssts of fsh, chps, and beer. You get several portons of each The casher only tells you the total prce of the meal After several days, you should be able to fgure out the prce of each porton. Each meal prce gves a lnear constrant on the prces of the portons: prce = x w + x w + fsh fsh chps chps x beer w beer G. Hnton, 2006
18 Matrx Representaton n data ponts, d dmenson + ε = d nd n d d n w w w x x x x x x y y y n*1 n*(d+1) (d+1)*1 Y = XW + ε Matrx Representaton:
19 Multvarate Lnear Regresson Goal: mnmze square error = (Y-XW) T (Y- XW) = Y T Y -2X T WY + W T X T XW Dervatve: -2X T Y + 2X T XW = 0 W = (X T X) -1 X T Y Thus, we can solve lnear regresson usng matrx nverson, transpose, and multplcaton.
20 Dffculty and Generalzaton Numercal computaton ssue. (a lot data ponts. Matrx nverson s mpossble.) Sngular matrx (determnant s zero) : no nverson How to handle non-lnear data? Turns out neural network and ts teratve learnng algorthm can address ths problem.
21 Graphcal Representaton: One Layer Neural Network for Regresson Output Unt f o Target: y Actvaton functon f s used to convert a to output. Here t s a lnear functon. o = a. w 0 w 1 w d a =Σw x Actvaton Input Unt 1 x 1 x d
22 Gradent Descent Algorthm For a data x = (x 1,x 2, x d ), error E = (y o) 2 = (y w 0 x 0 - w 1 x w d x d ) 2 Partal dervatve: Error Mnma E o E w = = 2( y o) = 2( y o)( x ) = 2( y o) x w w Update rule: E < 0 w w E > 0 w ( t+ 1) ( t) w = w + η( y o) x Famous Delta Rule
23 Algorthm of One-Layer Regresson Neural Network Intalze weghts w (small random numbers) Repeat Present a data pont x = (x 1,x 2,,x d ) to the network and compute output o. f y > o, add ηx to w. f y < o, add -ηx to w. Untl Σ(y k -o k ) 2 s zero or below a threshold or reaches the predefned number of teratons. Comments: onlne learnng: update weght for every x. batch learnng: update weght every batch of x (.e. Σηx ).
24 Graphcal Representaton: One Layer Neural Network for Regresson Output O Target: y Output Unt out O = f(σw x ), f s actvaton functon. a =Σw x Actvaton w 0 w 1 w d Input Unt 1 x 1 x d
25 What about Hyperbolc Tanh Functon for Output Unt Can we use actvaton functon other than lnear functon? For nstance, f we want to lmt the output to be n [-1, +1], we can use hyperbolc Tanh functon: e e x x e + e x x The only thng to change s to use the new gradent.
26 Two-Category Classfcaton Two classes: C 1 and C 2. Input feature vector: x. Defne a dscrmnant functon y(x) such that x s assgned to C 1 f y(x) > 0 and to class C 2 f y(x) < 0. Lnear dscrmnant functon: y(x) = w T x + w 0 = w T x, where x = (1, x). w: weght vector, w 0 : bas.
27 A Lnear Decson Boundary n 2-D Input Space x2 w: orentaton of decson boundary w 0 : defnes the poston of the plan n terms of ts perpendcular dstance from the orgn. w y(x) = w T x = 0 x1 y(x) = w T x + w 0 = 0 l = w T x / w = w 0 / w
28 Graphcal Representaton: Perceptron, One- Layer Classfcaton Neural Network Actvaton / Transfer functon out y=g(w T x) w T x > 0: +1, class 1 w T x < 0: -1, class 2 (threshold functon) Actvaton w T x = Σw x w 0 w 1 w d Input Unt 1 x 1 x d
29 Perceptron Crteron Mnmze classfcaton error Input data (vector): x 1, x 2,, x N and correspondng target value t 1, t 2,, t N. Goal: for all x n C 1 (t = 1), w T x > 0, for all x n C 2 (t = -1), w T x < 0. Or for all x: w T xt > 0. Error: E perc (w) = T n n w x t. M s the set of n x M msclassfed data ponts.
30 Gradent Descent Error Mnma E > 0 w E < 0 w W For each msclassfed data pont, adjust weght as follows: w = w - E w η = w + η x n t n
31 Perceptron Algorthm Intalze weght w Repeat For each data pont (x n, t n ) Classfy each data pont usng current w. If w T x n t n > 0 (correct), do nothng If w T x n t n < 0 (wrong), w new = w + ηx n t n w = w new Untl w s not changed (all the data wll be separated correctly, f data s lnearly separable) or error s below a threshold. Rosenblatt, 1962
32 Perceptron Convergence Theorem For any data set whch s lnearly separable, the algorthm s guaranteed to fnd a soluton n a fnte number of steps (Rosenblatt, 1962; Block 1962; Nlsson, 1965; Mnsky and Papert 1969; Duda and Hart, 1973; Hand, 1981; Arbb, 1987; Hertz et al., 1991)
33 Perceptron Demo v=vgwemzhplsa
34 Mult-Class Lnear Dscrmnant Functon c classes. Use one dscrmnant functon y k (x) = w kt x + w k0 for each class C k. A new data pont x s assgned to class C k f y k (x) > y j (x) for all j k.
35 One-Layer Mult-Class Perceptron y 1 y c w c0 w 10 w 11 w 1d w c1 w cd x 0 = 1 x 1 x d How to learn t?
36 Mut-Threshold Perceptron Algorthm Intalze weght w Repeat Present data pont x to the network, f classfcaton s correct, do nothng. f x s wrongly classfed to C nstead of true class C j, adjust weghts connected to C and C j as follows. Add ηx k to w k. Add ηx k to w jk Untl msclassfcaton s zero or below a threshold. Note: may also Add ηx k to w lk for any l, y l > y j.
37 Lmtaton of the Perceptron Can t not separate non-lnear data completely. Or can t not ft non-lnear data well. Two drectons to attack the problem: (1) extend to mult-layer neural network (2) map data nto hgh dmenson (SVM approach)
38 Exclusve OR Problem C1 C2 (0,1) (1,1) C2 C1 (0,0) (1,0) Perceptron (or one-layer neural network) can not learn a functon to separate the two classes perfectly.
39 Logstc Regresson Estmate posteror dstrbuton: P(C 1 x) Dose response estmaton: n boassay, the relaton between dose level and death rate P(death x). We can not use 0/1 hard classfcaton. We can not use unconstraned lnear regresson because P(death x) must be n [0,1]?
40 1 x 1 x d Logstc Regresson and One Layer Neural Network Wth Sgmod P( death x) = (Sgmod functon) 1 1+ e wx Functon e z y Target: t (0 or 1) Actvaton Functon: sgmod Actvaton z = Σw x
41 How to Adjust Weghts? Mnmze error E=(t-y) 2. For smplcty, we derve the formula for one data pont. For multple data ponts, just add the gradents together. x y y y t w z z y y E w E ) (1 ) ( 2 = = Notce: ) (1 ) 1 1 (1 1 1 ) 1 1 ( y y e e z e z y z z z = + + = + =
42 Error Functon and Learnng Least Square Maxmum lkelhood: output y s the probablty of beng n C 1 (t=1). 1- y s the probablty of beng n C 2. So what s probablty of P(t x) = y t (1-y) 1-t. Maxmum lkelhood s equvalent to mnmze negatve log lkelhood: E = -log P(t x) = -tlogy - (1-t)log(1-y). (cross / relatve entropy)
43 How to Adjust Weghts? Mnmze error E= -tlogy - (1-t)log(1-y). For smplcty, we derve the formula for one data pont. For multple data ponts, just add the gradents together. x t y x y y y y t y w z z y y E w E ) ( ) (1 ) (1 = = = ) ( ) ( 1 1 y y t y y t y t y t y t y E = = = t t x y t w w ) ( 1) ( + = + η Update rule:
44 Mult-Class Logstc Regresson Transfer (or actvaton) functon s normalzed exponentals (or soft max) y 1 w c0 y c e a y = c a e j j= 1 Actvaton Functon The mage cannot be dsplayed. Your computer may not have enough memory to open the mage, or the mage may have been corrupted. Restart your computer, and then open the fle agan. If the red x stll appears, you may have to delete the mage and then nsert t agan. w 10 w 11 w 1d w c1 w 1d Actvaton to Node O x 0 x 1 x d How to learn ths network? Once agan, gradent descent.
45 Questons? Is logstc regresson a lnear regresson? Can logstc regresson handle non-lnearly separable data? How to ntroduce non-lnearty?
46 Support Vector Machne Approach x 2 Map data pont nto hgh dmenson, e.g. addng some non-lnear features. C1 C2 How about we augument feature nto three dmenson (x 1, x 2, x 12 +x 22 ). x 1 x 12 +x 2 2 = 10 All data ponts n class C2 have a larger value for the thrd feature Than data ponts n C1. Now data s lnearly separable.
47 Neural Network Approach Mult-Layer Perceptrons In addton to nput nodes and output nodes, some hdden nodes between nput / output nodes are ntroduced. Use hdden unts to learn nternal features to represent data. Hdden nodes can learn nternal representaton of data that are not explct n the nput features. Transfer functon of hdden unts are non-lnear functon
48 Mult-Layer Perceptron Connectons go from lower layer to hgher layer. (usually from nput layer to hdden layer, to output layer) Connecton between nput/hdden nodes, nput/output nodes, hdden/hdden nodes, hdden/output nodes are arbtrary as long as there s no loop (must be feedforward). However, for smplcty, we usually only allow connecton from nput nodes to hdden nodes and from hdden nodes to output nodes. The connectons wth a layer are dsallowed.
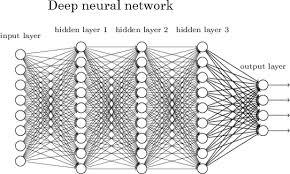
49 Mult-Layer Perceptron Two-layer neural network (one hdden and one output) wth non-lnear actvaton functon s a unversal functon approxmator (see Bald and Brunak 2001 or Bshop 96 for the proof),.e. t can approxmate any numerc functon wth arbtrary precson gven a set of approprate weghts and hdden unts. In early days, people usually used two-layer (or three-layer f you count the nput as one layer) neural network. Increasng the number of layers was occasonally helpful. Later expanded nto deep learnng wth many layers!!!
50 Two-Layer Neural Network y 1 y k y c w kj z 1 z j z M Output Actvaton functon: f (lnear,sgmod, softmax) Actvaton of unt a k : M j= 0 w kj z j Z 0 =1 Actvaton functon: g (lnear, tanh, sgmod) Actvaton of unt a j : d w 11 w 1 w j = 0 w j x 1 x 0 x 1 x x d y k = f ( M w g( d kj j= 0 = 0 w j x ))
51 Adjust Weghts by Tranng How to adjust weghts? Adjust weghts usng known examples (tranng data) (x 1,x 2,x 3,,x d,t). Try to adjust weghts so that the dfference between the output of the neural network y and t (target) becomes smaller and smaller. Goal s to mnmze Error (dfference) as we dd for one layer neural network
52 Adjust Weghts usng Gradent Descent (Back-Propagaton) Known: Data: (x 1,x 2,x 3,,x n ) target t. Unknown weghts w: w 11, w 12,.. Error Mnma Randomly ntalze weghts Repeat for each example, compute output y calculate error E = (y-t) 2 E compute the dervatve of E over w: dw= w w new = w prev η * dw Untl error doesn t decrease or max num of teratons Note: η s learnng rate or step sze. W
53 Insghts We know how to compute the dervatve of one layer neural network? How to change weghts between nput layer and hdden layer? Should we compute the dervatve of each w separately or we can reuse ntermedate results? We wll have an effcent back-propagaton algorthm. We wll derve learnng for one data example. For multple examples, we can smply add the dervatves from them for a weght parameter together.
54 Neural Network Learnng: Two Processes Forward propagaton: present an example (data) nto neural network. Compute actvaton nto unts and output from unts. Backward propagaton: propagate error back from output layer to the nput layer and compute dervatves (or gradents).
55 Forward Propagaton w 11 y 1 y k y c w kj z 1 z j z M w 1 w j Output Actvaton functon: f (lnear,sgmod, softmax) Actvaton of unt a k : M j= 1 d = 1 w kj z j z j Actvaton functon: g (lnear, tanh, sgmod) Actvaton of unt a j : y k w j x x 1 x x d Tme complexty? O(dM + MC) = O(W)
56 Backward Propagaton = M j w kj z j 1 = d w j x 1 = = C k y k t k E 1 2 ) ( 2 1 y 1 y c x 1 x x d y k z 1 z j z M w j w 11 w 1 w kj f a k : g a j : Tme complexty? O(CM+Md) = O(W) k k k t y y E = k k k k k k k k a f t y a y y E a E = δ = = ) '( ) ( j k kj k k kj z w a a E w E = δ = j C k j kj k c k j j j k k k k j a g w a z z a a y y E a E δ = δ = = = = 1 1 ) '( j j j j x wj a a E w E = δ = If no back-propagaton, tme complexty s: (MdC+CM)
57 Example 2 ) ( 2 1 t y E = ( t) y a y y E a E k k = = = δ j j z w E δ = = M w j x 1 x 1 x x d y z 1 z j z M w j w 11 w 1 w j f lnear functon a k : g s sgmod: a j : ) (1 ) ( ) ( ' j j j j j j z z w t y a g w = = δ δ j j j j j x z w z t y x w E ) (1 ) ( = = δ
58 Algorthm Intalze weghts w Repeat For each data pont x, do the followng: Forward propagaton: compute outputs and actvatons Backward propagaton: compute errors for each output unts and hdden unts. Compute gradent for each weght. Update weght w = w - η ( E / w) Untl a number of teratons or errors drops below a threshold.
59 Implementaton Issue What should we store? An nput vector x of d dmensons A M*d matrx {w j } for weghts between nput and hdden unts An actvaton vector of M dmensons for hdden unts An output vector of M dmensons for hdden unts A C*M matrx {w kj } for weghts between hdden and output unts An actvaton vector of C dmensons for output unts An output vector of C dmensons for output unts An error vector of C dmensons for output unts An error vector of M dmensons for hdden unts
60 Recurrent Network y 1 y k y c w kj z 1 z j z M w w 11 w 1 w j Forward: At tme 1: present X1, 0 At tme 2: present X2, y1 x 1 x x d Backward: Tme t: back-propagate Tme t-1: back-propagate wth Output errors and errors from prevous step
61 Recurrent Neural Network 1. Recurrent network s essentally a seres of feed-forward neural networks sharng the same weghts 2. Recurrent network s good for tme seres data and sequence data such as bologcal sequences and stock seres
62 Overfttng The tranng data contans nformaton about the regulartes n the mappng from nput to output. But t also contans nose The target values may be unrelable. There s samplng error. There wll be accdental regulartes just because of the partcular tranng cases that were chosen. When we ft the model, t cannot tell whch regulartes are real and whch are caused by samplng error. So t fts both knds of regularty. If the model s very flexble t can model the samplng error really well. Ths s a dsaster. G. Hnton, 2006
63 Example of Overfttng and Good Fttng Overfttng Good fttng Overfttng functon can not generalze well to unseen data.
64 Preventng Overfttng Use a model that has the rght capacty: enough to model the true regulartes not enough to also model the spurous regulartes (assumng they are weaker). Standard ways to lmt the capacty of a neural net: Lmt the number of hdden unts. Lmt the sze of the weghts. Stop the learnng before t has tme to overft. G. Hnton, 2006
65 Lmtng the Sze of the Weghts Weght-decay nvolves addng an extra term to the cost functon that penalzes the squared weghts. C Keeps weghts small unless they have bg error dervatves. when C = C w C w E = + E w = λ 2 0, w w 2 + λw = 1 E λ w w G. Hnton, 2006
66 The Effect of Weght-Decay It prevents the network from usng weghts that t does not need. Ths can often mprove generalzaton a lot. It helps to stop t from fttng the samplng error. It makes a smoother model n whch the output changes more slowly as the nput changes. If the network has two very smlar nputs t prefers to put half the weght on each rather than all the weght on one. w/2 w/2 w 0 G. Hnton, 2006
67 Decdng How Much to Restrct the Capacty How do we decde whch lmt to use and how strong to make the lmt? If we use the test data we get an unfar predcton of the error rate we would get on new test data. Suppose we compared a set of models that gave random results, the best one on a partcular dataset would do better than chance. But t wont do better than chance on another test set. So use a separate valdaton set to do model selecton. G. Hnton, 2006
68 Usng a Valdaton Set Dvde the total dataset nto three subsets: Tranng data s used for learnng the parameters of the model. Valdaton data s not used of learnng but s used for decdng what type of model and what amount of regularzaton works best. Test data s used to get a fnal, unbased estmate of how well the network works. We expect ths estmate to be worse than on the valdaton data. We could then re-dvde the total dataset to get another unbased estmate of the true error rate. G. Hnton, 2006
69 Preventng Overfttng by Early Stoppng If we have lots of data and a bg model, ts very expensve to keep re-tranng t wth dfferent amounts of weght decay. It s much cheaper to start wth very small weghts and let them grow untl the performance on the valdaton set starts gettng worse (but don t get fooled by nose!) The capacty of the model s lmted because the weghts have not had tme to grow bg. G. Hnton, 2006
70 Why Early Stoppng Works When the weghts are very small, every hdden unt s n ts lnear range. So a net wth a large layer of hdden unts s lnear. It has no more capacty than a lnear net n whch the nputs are drectly connected to the outputs! As the weghts grow, the hdden unts start usng ther non-lnear ranges so the capacty grows. outputs nputs G. Hnton, 2006
71 Combnng Networks When the amount of tranng data s lmted, we need to avod overfttng. Averagng the predctons of many dfferent networks s a good way to do ths. It works best f the networks are as dfferent as possble. Combnng networks reduces varance If the data s really a mxture of several dfferent regmes t s helpful to dentfy these regmes and use a separate, smple model for each regme. We want to use the desred outputs to help cluster cases nto regmes. Just clusterng the nputs s not as effcent. G. Hnton, 2006
72 How the Combned Predctor Compares wth the Indvdual Predctors On any one test case, some ndvdual predctors wll be better than the combned predctor. But dfferent ndvduals wll be better on dfferent cases. If the ndvdual predctors dsagree a lot, the combned predctor s typcally better than all of the ndvdual predctors when we average over test cases. So how do we make the ndvdual predctors dsagree? (wthout makng them much worse ndvdually). G. Hnton, 2006
73 Ways to Make Predctors Dffer Rely on the learnng algorthm gettng stuck n a dfferent local optmum on each run. A dubous hack unworthy of a true computer scentst (but defntely worth a try). Use lots of dfferent knds of models: Dfferent archtectures Dfferent learnng algorthms. Use dfferent tranng data for each model: Baggng: Resample (wth replacement) from the tranng set: a,b,c,d,e -> a c c d d Boostng: Ft models one at a tme. Re-weght each tranng case by how badly t s predcted by the models already ftted. Ths makes effcent use of computer tme because t does not bother to back-ft models that were ftted earler. G. Hnton, 2006
74 How to Speedup Learnng? The Error Surface for a Lnear Neuron The error surface les n a space wth a horzontal axs for each weght and one vertcal axs for the error. It s a quadratc bowl..e. the heght can be expressed as a functon of the weghts wthout usng powers hgher than 2. Quadratcs have constant curvature (because the second dervatve must be a constant) Vertcal cross-sectons are parabolas. G. Hnton, 2006 Horzontal cross-sectons are ellpses. E w1 w w2
75 Convergence Speed The drecton of steepest descent does not pont at the mnmum unless the ellpse s a crcle. The gradent s bg n the drecton n whch we only want to travel a small dstance. The gradent s small n the drecton n whch we want to travel a large dstance. Δw = E ε w Ths equaton s sck. G. Hnton, 2006
76 How the Learnng Goes Wrong If the learnng rate s bg, t sloshes to and fro across the ravne. If the rate s too bg, ths oscllaton dverges. How can we move quckly n drectons wth small gradents wthout gettng dvergent oscllatons n drectons wth bg gradents? E w G. Hnton, 2006
77 Fve Ways to Speed up Learnng Use an adaptve global learnng rate Increase the rate slowly f ts not dvergng Decrease the rate quckly f t starts dvergng Use separate adaptve learnng rate on each connecton Adjust usng consstency of gradent on that weght axs Use momentum Instead of usng the gradent to change the poston of the weght partcle, use t to change the velocty. Use a stochastc estmate of the gradent from a few cases Ths works very well on large, redundant datasets. G. Hnton, 2006
78 The Momentum Method Imagne a ball on the error surface wth velocty v. It starts off by followng the gradent, but once t has velocty, t no longer does steepest descent. It damps oscllatons by combnng gradents wth opposte sgns. It bulds up speed n drectons wth a gentle but consstent gradent. Δw(t) = v(t) = α Δw(t 1) ε E w (t) G. Hnton, 2006
79 How to Intalze weghts? Saturated Use small random numbers. For nstance small numbers between [-0.2, 0.2]. Some numbers are postve and some are negatve. Why are the ntal weghts should be small? 1 1+ e wx
80 Neural Network Software Weka (Java): ml/weka/ NNClass and NNRank (C++): J. Cheng, Z. Wang, G. Pollastr. A Neural Network Approach to Ordnal Regresson. IJCNN, 2008
 are a")

81 NNClass Demo Abalone data: Abalone (from Spansh Abulón) are a group of shellfsh (mollusks) n the famly Halotdae and the Halots genus. They are marne snals multcom_toolbox/tools.html
82 Problem of Neural Network Vanshng gradents Cannot use unlabeled data Hard to understand the relatonshp between nput and output Cannot generate data



83

84

85


86

87

88

89


90 Deep Learnng Revoluton 2012: Is deep learnng a revoluton n artfcal ntellgence? Accomplshments Apple s Sr vrtual personal assstant Google s Street Vew & Self-Drvng Car Google/Facebook/Tweeter/Yahoo Deep Learnng Acquston Hnton s Hand Wrtng Recognton CASP10 proten contact map predcton
91
92

93
94
95
96
97
98
99
100
101

102 A model for a dstrbu0on over bnary vectors Probablty of a vector, v, under the model s defned va an energy hdden layer w j c j h v b vsble layer

103
104 Instead of a;emp0ng to sample from jont dstrbu0on p(v,h) (.e. p ), sample from p 1 (v,h). Hnton, Neural Computa-on(2002) Faster and lower varance n sample.
105 Par0als of E(v, h) easy to calculate. j j t = 0 t = 1 Hnton, Neural Computa-on(2002)
")
106 Gradent of the lkelhood wth respect to w j the dfference between nterac0on of v and h j at 0me 0 and at 0me 1. Hdden Layer j j Vsble Layer t = 0 t = 1 Hnton, Neural Computa-on(2002)
107 Gradent of the lkelhood wth respect to w j the dfference between nterac0on of v and h j at 0me 0 and at 0me 1. Hdden Layer j j Vsble Layer t = 0 t = 1 Hnton, Neural Computa-on(2002)
108 Gradent of the lkelhood wth respect to w j the dfference between nterac0on of v and h j at 0me 0 and at 0me 1. Hdden Layer j j Vsble Layer t = 0 t = 1 Δw,j = <v p j0 > - <p 1 p j1 > Hnton, Neural Computa-on(2002)
109 ɛ s the learnng rate, η s the weght cost, and υ the momentum. Gradent Smaller Weghts Avod Local Mnma
110



111 Face or not? Lnes, crcles, squares Image pxels Bran Learnng
112 Objectve of Unsupervsed Learnng: Fnd w,j to maxmze the lkelhood p(v) of vsble data Iteratve Gradent Descent Approach: Adjust w,j to ncrease the lkelhood accordng to gradent
113
114




115 ~350 nodes ~500 nodes ~500 nodes w,j ~400 nput nodes A Vector of ~400 Features (numbers between 0 and 1)
116 [0,1] 1. Weghts are learned layer by layer va unsupervsed learnng. 2. Fnal layer s learned as a supervsed neural network. 3. All weghts are fne- tuned usng supervsed back propaga0on. Hnton and Salakhutdnov, Scence, 2006
117 [0,1] 1. Weghts are learned layer by layer va unsupervsed learnng. 2. Fnal layer s learned as a supervsed neural network. 3. All weghts are fne- tuned usng supervsed back propaga0on. Hnton and Salakhutdnov, Scence, 2006

118 Speed up tranng by CUDAMat and GPUs Tran DNs wth over 1M parameters n about an hour LSDEKIINVDF [0,1] KPSEERVREII
119
120
121
122

123 Demo:
124
125
126
127 Varous Deep Learnng Archtectures Deep belef network Deep neural networks Deep autoencoder Deep convoluton networks Deep resdual network Deep recurrent network

128 Deep Belef Network
129
130 Deep AutoEncoder

131 Deep Convoluton Neural Network


132 Deep Recurrent Neural Network

133 An Example


134 Deep Resdual Network the rectfer s an actvaton functon defned as A unt employng the rectfer s also called a rectfed lnear unt (ReLU)

 Testng: multply all the unts wth")
135 Prevent from over-fttng Prevent unts from coadaptng Tranng: remove randomly selected unts accordng to a rate (0.5) Testng: multply all the unts wth dropout rate
136 Deep Learnng Tools Pylearn2 Theano Caffe Torch Cuda-convnet Deeplearnng4j October 25, 2016 Data Mnng: Concepts and Technques 136
 communcated between them.")
137 Googles s TensorFlow TensorFlow s an open source software lbrary for numercal computaton usng data flow graphs. Nodes n the graph represent mathematcal operatons, whle the graph edges represent the multdmensonal data arrays (tensors) communcated between them. The flexble archtecture allows you to deploy computaton to one or more CPUs or GPUs n a desktop, server, or moble devce wth a sngle API. TensorFlow was orgnally developed by researchers and engneers workng on the Google Bran Team wthn Google's Machne Intellgence research organzaton for the purposes of conductng machne learnng and deep neural networks research, but the system s general enough to be applcable n a wde varety of other domans as well.
138 Acknowledgements Geoffery Hnton s sldes Jesse Eckholt s sldes Images.google.com
Multilayer Perceptron (MLP)
") Multlayer Perceptron (MLP) Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr 1 / 20 Outlne
Multlayer Perceptron (MLP) Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr 1 / 20 Outlne
For now, let us focus on a specific model of neurons. These are simplified from reality but can achieve remarkable results.
 Neural Networks : Dervaton compled by Alvn Wan from Professor Jtendra Malk s lecture Ths type of computaton s called deep learnng and s the most popular method for many problems, such as computer vson
Neural Networks : Dervaton compled by Alvn Wan from Professor Jtendra Malk s lecture Ths type of computaton s called deep learnng and s the most popular method for many problems, such as computer vson
Admin NEURAL NETWORKS. Perceptron learning algorithm. Our Nervous System 10/25/16. Assignment 7. Class 11/22. Schedule for the rest of the semester
 0/25/6 Admn Assgnment 7 Class /22 Schedule for the rest of the semester NEURAL NETWORKS Davd Kauchak CS58 Fall 206 Perceptron learnng algorthm Our Nervous System repeat untl convergence (or for some #
0/25/6 Admn Assgnment 7 Class /22 Schedule for the rest of the semester NEURAL NETWORKS Davd Kauchak CS58 Fall 206 Perceptron learnng algorthm Our Nervous System repeat untl convergence (or for some #
Support Vector Machines. Vibhav Gogate The University of Texas at dallas
 Support Vector Machnes Vbhav Gogate he Unversty of exas at dallas What We have Learned So Far? 1. Decson rees. Naïve Bayes 3. Lnear Regresson 4. Logstc Regresson 5. Perceptron 6. Neural networks 7. K-Nearest
Support Vector Machnes Vbhav Gogate he Unversty of exas at dallas What We have Learned So Far? 1. Decson rees. Naïve Bayes 3. Lnear Regresson 4. Logstc Regresson 5. Perceptron 6. Neural networks 7. K-Nearest
Ensemble Methods: Boosting
 Ensemble Methods: Boostng Ncholas Ruozz Unversty of Texas at Dallas Based on the sldes of Vbhav Gogate and Rob Schapre Last Tme Varance reducton va baggng Generate new tranng data sets by samplng wth replacement
Ensemble Methods: Boostng Ncholas Ruozz Unversty of Texas at Dallas Based on the sldes of Vbhav Gogate and Rob Schapre Last Tme Varance reducton va baggng Generate new tranng data sets by samplng wth replacement
EEE 241: Linear Systems
 EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
Kernel Methods and SVMs Extension
 Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
10-701/ Machine Learning, Fall 2005 Homework 3
 10-701/15-781 Machne Learnng, Fall 2005 Homework 3 Out: 10/20/05 Due: begnnng of the class 11/01/05 Instructons Contact questons-10701@autonlaborg for queston Problem 1 Regresson and Cross-valdaton [40
10-701/15-781 Machne Learnng, Fall 2005 Homework 3 Out: 10/20/05 Due: begnnng of the class 11/01/05 Instructons Contact questons-10701@autonlaborg for queston Problem 1 Regresson and Cross-valdaton [40
Generalized Linear Methods
 Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
Multilayer Perceptrons and Backpropagation. Perceptrons. Recap: Perceptrons. Informatics 1 CG: Lecture 6. Mirella Lapata
 Multlayer Perceptrons and Informatcs CG: Lecture 6 Mrella Lapata School of Informatcs Unversty of Ednburgh mlap@nf.ed.ac.uk Readng: Kevn Gurney s Introducton to Neural Networks, Chapters 5 6.5 January,
Multlayer Perceptrons and Informatcs CG: Lecture 6 Mrella Lapata School of Informatcs Unversty of Ednburgh mlap@nf.ed.ac.uk Readng: Kevn Gurney s Introducton to Neural Networks, Chapters 5 6.5 January,
Boostrapaggregating (Bagging)
") Boostrapaggregatng (Baggng) An ensemble meta-algorthm desgned to mprove the stablty and accuracy of machne learnng algorthms Can be used n both regresson and classfcaton Reduces varance and helps to avod
Boostrapaggregatng (Baggng) An ensemble meta-algorthm desgned to mprove the stablty and accuracy of machne learnng algorthms Can be used n both regresson and classfcaton Reduces varance and helps to avod
Lecture Notes on Linear Regression
 Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
Pattern Classification
 Pattern Classfcaton All materals n these sldes ere taken from Pattern Classfcaton (nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wley & Sons, 000 th the permsson of the authors and the publsher
Pattern Classfcaton All materals n these sldes ere taken from Pattern Classfcaton (nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wley & Sons, 000 th the permsson of the authors and the publsher
Logistic Regression. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Logstc Regresson CAP 561: achne Learnng Instructor: Guo-Jun QI Bayes Classfer: A Generatve model odel the posteror dstrbuton P(Y X) Estmate class-condtonal dstrbuton P(X Y) for each Y Estmate pror dstrbuton
Logstc Regresson CAP 561: achne Learnng Instructor: Guo-Jun QI Bayes Classfer: A Generatve model odel the posteror dstrbuton P(Y X) Estmate class-condtonal dstrbuton P(X Y) for each Y Estmate pror dstrbuton
Introduction to the Introduction to Artificial Neural Network
 Introducton to the Introducton to Artfcal Neural Netork Vuong Le th Hao Tang s sldes Part of the content of the sldes are from the Internet (possbly th modfcatons). The lecturer does not clam any onershp
Introducton to the Introducton to Artfcal Neural Netork Vuong Le th Hao Tang s sldes Part of the content of the sldes are from the Internet (possbly th modfcatons). The lecturer does not clam any onershp
Hopfield networks and Boltzmann machines. Geoffrey Hinton et al. Presented by Tambet Matiisen
 Hopfeld networks and Boltzmann machnes Geoffrey Hnton et al. Presented by Tambet Matsen 18.11.2014 Hopfeld network Bnary unts Symmetrcal connectons http://www.nnwj.de/hopfeld-net.html Energy functon The
Hopfeld networks and Boltzmann machnes Geoffrey Hnton et al. Presented by Tambet Matsen 18.11.2014 Hopfeld network Bnary unts Symmetrcal connectons http://www.nnwj.de/hopfeld-net.html Energy functon The
1 Convex Optimization
 Convex Optmzaton We wll consder convex optmzaton problems. Namely, mnmzaton problems where the objectve s convex (we assume no constrants for now). Such problems often arse n machne learnng. For example,
Convex Optmzaton We wll consder convex optmzaton problems. Namely, mnmzaton problems where the objectve s convex (we assume no constrants for now). Such problems often arse n machne learnng. For example,
MLE and Bayesian Estimation. Jie Tang Department of Computer Science & Technology Tsinghua University 2012
 MLE and Bayesan Estmaton Je Tang Department of Computer Scence & Technology Tsnghua Unversty 01 1 Lnear Regresson? As the frst step, we need to decde how we re gong to represent the functon f. One example:
MLE and Bayesan Estmaton Je Tang Department of Computer Scence & Technology Tsnghua Unversty 01 1 Lnear Regresson? As the frst step, we need to decde how we re gong to represent the functon f. One example:
Multilayer neural networks
 Lecture Multlayer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Mdterm exam Mdterm Monday, March 2, 205 In-class (75 mnutes) closed book materal covered by February 25, 205 Multlayer
Lecture Multlayer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Mdterm exam Mdterm Monday, March 2, 205 In-class (75 mnutes) closed book materal covered by February 25, 205 Multlayer
CSC321 Tutorial 9: Review of Boltzmann machines and simulated annealing
 CSC321 Tutoral 9: Revew of Boltzmann machnes and smulated annealng (Sldes based on Lecture 16-18 and selected readngs) Yue L Emal: yuel@cs.toronto.edu Wed 11-12 March 19 Fr 10-11 March 21 Outlne Boltzmann
CSC321 Tutoral 9: Revew of Boltzmann machnes and smulated annealng (Sldes based on Lecture 16-18 and selected readngs) Yue L Emal: yuel@cs.toronto.edu Wed 11-12 March 19 Fr 10-11 March 21 Outlne Boltzmann
Multi-layer neural networks
 Lecture 0 Mult-layer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Lnear regresson w Lnear unts f () Logstc regresson T T = w = p( y =, w) = g( w ) w z f () = p ( y = ) w d w d Gradent
Lecture 0 Mult-layer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Lnear regresson w Lnear unts f () Logstc regresson T T = w = p( y =, w) = g( w ) w z f () = p ( y = ) w d w d Gradent
CSE 546 Midterm Exam, Fall 2014(with Solution)
") CSE 546 Mdterm Exam, Fall 014(wth Soluton) 1. Personal nfo: Name: UW NetID: Student ID:. There should be 14 numbered pages n ths exam (ncludng ths cover sheet). 3. You can use any materal you brought:
CSE 546 Mdterm Exam, Fall 014(wth Soluton) 1. Personal nfo: Name: UW NetID: Student ID:. There should be 14 numbered pages n ths exam (ncludng ths cover sheet). 3. You can use any materal you brought:
MATH 567: Mathematical Techniques in Data Science Lab 8
 1/14 MATH 567: Mathematcal Technques n Data Scence Lab 8 Domnque Gullot Departments of Mathematcal Scences Unversty of Delaware Aprl 11, 2017 Recall We have: a (2) 1 = f(w (1) 11 x 1 + W (1) 12 x 2 + W
1/14 MATH 567: Mathematcal Technques n Data Scence Lab 8 Domnque Gullot Departments of Mathematcal Scences Unversty of Delaware Aprl 11, 2017 Recall We have: a (2) 1 = f(w (1) 11 x 1 + W (1) 12 x 2 + W
CIS526: Machine Learning Lecture 3 (Sept 16, 2003) Linear Regression. Preparation help: Xiaoying Huang. x 1 θ 1 output... θ M x M
 Linear Regression. Preparation help: Xiaoying Huang. x 1 θ 1 output... θ M x M") CIS56: achne Learnng Lecture 3 (Sept 6, 003) Preparaton help: Xaoyng Huang Lnear Regresson Lnear regresson can be represented by a functonal form: f(; θ) = θ 0 0 +θ + + θ = θ = 0 ote: 0 s a dummy attrbute
CIS56: achne Learnng Lecture 3 (Sept 6, 003) Preparaton help: Xaoyng Huang Lnear Regresson Lnear regresson can be represented by a functonal form: f(; θ) = θ 0 0 +θ + + θ = θ = 0 ote: 0 s a dummy attrbute
Evaluation of classifiers MLPs
 Lecture Evaluaton of classfers MLPs Mlos Hausrecht mlos@cs.ptt.edu 539 Sennott Square Evaluaton For any data set e use to test the model e can buld a confuson matrx: Counts of examples th: class label
Lecture Evaluaton of classfers MLPs Mlos Hausrecht mlos@cs.ptt.edu 539 Sennott Square Evaluaton For any data set e use to test the model e can buld a confuson matrx: Counts of examples th: class label
Neural networks. Nuno Vasconcelos ECE Department, UCSD
 Neural networs Nuno Vasconcelos ECE Department, UCSD Classfcaton a classfcaton problem has two types of varables e.g. X - vector of observatons (features) n the world Y - state (class) of the world x X
Neural networs Nuno Vasconcelos ECE Department, UCSD Classfcaton a classfcaton problem has two types of varables e.g. X - vector of observatons (features) n the world Y - state (class) of the world x X
Linear Feature Engineering 11
 Lnear Feature Engneerng 11 2 Least-Squares 2.1 Smple least-squares Consder the followng dataset. We have a bunch of nputs x and correspondng outputs y. The partcular values n ths dataset are x y 0.23 0.19
Lnear Feature Engneerng 11 2 Least-Squares 2.1 Smple least-squares Consder the followng dataset. We have a bunch of nputs x and correspondng outputs y. The partcular values n ths dataset are x y 0.23 0.19
Week 5: Neural Networks
 Week 5: Neural Networks Instructor: Sergey Levne Neural Networks Summary In the prevous lecture, we saw how we can construct neural networks by extendng logstc regresson. Neural networks consst of multple
Week 5: Neural Networks Instructor: Sergey Levne Neural Networks Summary In the prevous lecture, we saw how we can construct neural networks by extendng logstc regresson. Neural networks consst of multple
Feature Selection: Part 1
 CSE 546: Machne Learnng Lecture 5 Feature Selecton: Part 1 Instructor: Sham Kakade 1 Regresson n the hgh dmensonal settng How do we learn when the number of features d s greater than the sample sze n?
CSE 546: Machne Learnng Lecture 5 Feature Selecton: Part 1 Instructor: Sham Kakade 1 Regresson n the hgh dmensonal settng How do we learn when the number of features d s greater than the sample sze n?
CSC 411 / CSC D11 / CSC C11
 18 Boostng s a general strategy for learnng classfers by combnng smpler ones. The dea of boostng s to take a weak classfer that s, any classfer that wll do at least slghtly better than chance and use t
18 Boostng s a general strategy for learnng classfers by combnng smpler ones. The dea of boostng s to take a weak classfer that s, any classfer that wll do at least slghtly better than chance and use t
Supporting Information
 Supportng Informaton The neural network f n Eq. 1 s gven by: f x l = ReLU W atom x l + b atom, 2 where ReLU s the element-wse rectfed lnear unt, 21.e., ReLUx = max0, x, W atom R d d s the weght matrx to
Supportng Informaton The neural network f n Eq. 1 s gven by: f x l = ReLU W atom x l + b atom, 2 where ReLU s the element-wse rectfed lnear unt, 21.e., ReLUx = max0, x, W atom R d d s the weght matrx to
INF 5860 Machine learning for image classification. Lecture 3 : Image classification and regression part II Anne Solberg January 31, 2018
 INF 5860 Machne learnng for mage classfcaton Lecture 3 : Image classfcaton and regresson part II Anne Solberg January 3, 08 Today s topcs Multclass logstc regresson and softma Regularzaton Image classfcaton
INF 5860 Machne learnng for mage classfcaton Lecture 3 : Image classfcaton and regresson part II Anne Solberg January 3, 08 Today s topcs Multclass logstc regresson and softma Regularzaton Image classfcaton
We present the algorithm first, then derive it later. Assume access to a dataset {(x i, y i )} n i=1, where x i R d and y i { 1, 1}.
} n i=1, where x i R d and y i { 1, 1}.") CS 189 Introducton to Machne Learnng Sprng 2018 Note 26 1 Boostng We have seen that n the case of random forests, combnng many mperfect models can produce a snglodel that works very well. Ths s the dea
CS 189 Introducton to Machne Learnng Sprng 2018 Note 26 1 Boostng We have seen that n the case of random forests, combnng many mperfect models can produce a snglodel that works very well. Ths s the dea
Support Vector Machines
 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
Linear Approximation with Regularization and Moving Least Squares
 Lnear Approxmaton wth Regularzaton and Movng Least Squares Igor Grešovn May 007 Revson 4.6 (Revson : March 004). 5 4 3 0.5 3 3.5 4 Contents: Lnear Fttng...4. Weghted Least Squares n Functon Approxmaton...
Lnear Approxmaton wth Regularzaton and Movng Least Squares Igor Grešovn May 007 Revson 4.6 (Revson : March 004). 5 4 3 0.5 3 3.5 4 Contents: Lnear Fttng...4. Weghted Least Squares n Functon Approxmaton...
Kristin P. Bennett. Rensselaer Polytechnic Institute
 Support Vector Machnes and Other Kernel Methods Krstn P. Bennett Mathematcal Scences Department Rensselaer Polytechnc Insttute Support Vector Machnes (SVM) A methodology for nference based on Statstcal
Support Vector Machnes and Other Kernel Methods Krstn P. Bennett Mathematcal Scences Department Rensselaer Polytechnc Insttute Support Vector Machnes (SVM) A methodology for nference based on Statstcal
Finite Mixture Models and Expectation Maximization. Most slides are from: Dr. Mario Figueiredo, Dr. Anil Jain and Dr. Rong Jin
 Fnte Mxture Models and Expectaton Maxmzaton Most sldes are from: Dr. Maro Fgueredo, Dr. Anl Jan and Dr. Rong Jn Recall: The Supervsed Learnng Problem Gven a set of n samples X {(x, y )},,,n Chapter 3 of
Fnte Mxture Models and Expectaton Maxmzaton Most sldes are from: Dr. Maro Fgueredo, Dr. Anl Jan and Dr. Rong Jn Recall: The Supervsed Learnng Problem Gven a set of n samples X {(x, y )},,,n Chapter 3 of
Lecture 12: Classification
 Lecture : Classfcaton g Dscrmnant functons g The optmal Bayes classfer g Quadratc classfers g Eucldean and Mahalanobs metrcs g K Nearest Neghbor Classfers Intellgent Sensor Systems Rcardo Guterrez-Osuna
Lecture : Classfcaton g Dscrmnant functons g The optmal Bayes classfer g Quadratc classfers g Eucldean and Mahalanobs metrcs g K Nearest Neghbor Classfers Intellgent Sensor Systems Rcardo Guterrez-Osuna
Classification as a Regression Problem
 Target varable y C C, C,, ; Classfcaton as a Regresson Problem { }, 3 L C K To treat classfcaton as a regresson problem we should transform the target y nto numercal values; The choce of numercal class
Target varable y C C, C,, ; Classfcaton as a Regresson Problem { }, 3 L C K To treat classfcaton as a regresson problem we should transform the target y nto numercal values; The choce of numercal class
C4B Machine Learning Answers II. = σ(z) (1 σ(z)) 1 1 e z. e z = σ(1 σ) (1 + e z )
 (1 σ(z)) 1 1 e z. e z = σ(1 σ) (1 + e z )") C4B Machne Learnng Answers II.(a) Show that for the logstc sgmod functon dσ(z) dz = σ(z) ( σ(z)) A. Zsserman, Hlary Term 20 Start from the defnton of σ(z) Note that Then σ(z) = σ = dσ(z) dz = + e z e z
C4B Machne Learnng Answers II.(a) Show that for the logstc sgmod functon dσ(z) dz = σ(z) ( σ(z)) A. Zsserman, Hlary Term 20 Start from the defnton of σ(z) Note that Then σ(z) = σ = dσ(z) dz = + e z e z
Which Separator? Spring 1
 Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
SDMML HT MSc Problem Sheet 4
 SDMML HT 06 - MSc Problem Sheet 4. The recever operatng characterstc ROC curve plots the senstvty aganst the specfcty of a bnary classfer as the threshold for dscrmnaton s vared. Let the data space be
SDMML HT 06 - MSc Problem Sheet 4. The recever operatng characterstc ROC curve plots the senstvty aganst the specfcty of a bnary classfer as the threshold for dscrmnaton s vared. Let the data space be
Support Vector Machines
 /14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
/14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
Lecture 23: Artificial neural networks
 Lecture 23: Artfcal neural networks Broad feld that has developed over the past 20 to 30 years Confluence of statstcal mechancs, appled math, bology and computers Orgnal motvaton: mathematcal modelng of
Lecture 23: Artfcal neural networks Broad feld that has developed over the past 20 to 30 years Confluence of statstcal mechancs, appled math, bology and computers Orgnal motvaton: mathematcal modelng of
CS 3710: Visual Recognition Classification and Detection. Adriana Kovashka Department of Computer Science January 13, 2015
 CS 3710: Vsual Recognton Classfcaton and Detecton Adrana Kovashka Department of Computer Scence January 13, 2015 Plan for Today Vsual recognton bascs part 2: Classfcaton and detecton Adrana s research
CS 3710: Vsual Recognton Classfcaton and Detecton Adrana Kovashka Department of Computer Scence January 13, 2015 Plan for Today Vsual recognton bascs part 2: Classfcaton and detecton Adrana s research
Negative Binomial Regression
 STATGRAPHICS Rev. 9/16/2013 Negatve Bnomal Regresson Summary... 1 Data Input... 3 Statstcal Model... 3 Analyss Summary... 4 Analyss Optons... 7 Plot of Ftted Model... 8 Observed Versus Predcted... 10 Predctons...
STATGRAPHICS Rev. 9/16/2013 Negatve Bnomal Regresson Summary... 1 Data Input... 3 Statstcal Model... 3 Analyss Summary... 4 Analyss Optons... 7 Plot of Ftted Model... 8 Observed Versus Predcted... 10 Predctons...
Natural Language Processing and Information Retrieval
 Natural Language Processng and Informaton Retreval Support Vector Machnes Alessandro Moschtt Department of nformaton and communcaton technology Unversty of Trento Emal: moschtt@ds.untn.t Summary Support
Natural Language Processng and Informaton Retreval Support Vector Machnes Alessandro Moschtt Department of nformaton and communcaton technology Unversty of Trento Emal: moschtt@ds.untn.t Summary Support
Statistics MINITAB - Lab 2
 Statstcs 20080 MINITAB - Lab 2 1. Smple Lnear Regresson In smple lnear regresson we attempt to model a lnear relatonshp between two varables wth a straght lne and make statstcal nferences concernng that
Statstcs 20080 MINITAB - Lab 2 1. Smple Lnear Regresson In smple lnear regresson we attempt to model a lnear relatonshp between two varables wth a straght lne and make statstcal nferences concernng that
Support Vector Machines
 Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far Supervsed machne learnng Lnear models Least squares regresson Fsher s dscrmnant, Perceptron, Logstc model Non-lnear
Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far Supervsed machne learnng Lnear models Least squares regresson Fsher s dscrmnant, Perceptron, Logstc model Non-lnear
15-381: Artificial Intelligence. Regression and cross validation
 15-381: Artfcal Intellgence Regresson and cross valdaton Where e are Inputs Densty Estmator Probablty Inputs Classfer Predct category Inputs Regressor Predct real no. Today Lnear regresson Gven an nput
15-381: Artfcal Intellgence Regresson and cross valdaton Where e are Inputs Densty Estmator Probablty Inputs Classfer Predct category Inputs Regressor Predct real no. Today Lnear regresson Gven an nput
Neural Networks. Perceptrons and Backpropagation. Silke Bussen-Heyen. 5th of Novemeber Universität Bremen Fachbereich 3. Neural Networks 1 / 17
 Neural Networks Perceptrons and Backpropagaton Slke Bussen-Heyen Unverstät Bremen Fachberech 3 5th of Novemeber 2012 Neural Networks 1 / 17 Contents 1 Introducton 2 Unts 3 Network structure 4 Snglelayer
Neural Networks Perceptrons and Backpropagaton Slke Bussen-Heyen Unverstät Bremen Fachberech 3 5th of Novemeber 2012 Neural Networks 1 / 17 Contents 1 Introducton 2 Unts 3 Network structure 4 Snglelayer
Kernels in Support Vector Machines. Based on lectures of Martin Law, University of Michigan
 Kernels n Support Vector Machnes Based on lectures of Martn Law, Unversty of Mchgan Non Lnear separable problems AND OR NOT() The XOR problem cannot be solved wth a perceptron. XOR Per Lug Martell - Systems
Kernels n Support Vector Machnes Based on lectures of Martn Law, Unversty of Mchgan Non Lnear separable problems AND OR NOT() The XOR problem cannot be solved wth a perceptron. XOR Per Lug Martell - Systems
Lecture 10 Support Vector Machines II
 Lecture 10 Support Vector Machnes II 22 February 2016 Taylor B. Arnold Yale Statstcs STAT 365/665 1/28 Notes: Problem 3 s posted and due ths upcomng Frday There was an early bug n the fake-test data; fxed
Lecture 10 Support Vector Machnes II 22 February 2016 Taylor B. Arnold Yale Statstcs STAT 365/665 1/28 Notes: Problem 3 s posted and due ths upcomng Frday There was an early bug n the fake-test data; fxed
2E Pattern Recognition Solutions to Introduction to Pattern Recognition, Chapter 2: Bayesian pattern classification
 E395 - Pattern Recognton Solutons to Introducton to Pattern Recognton, Chapter : Bayesan pattern classfcaton Preface Ths document s a soluton manual for selected exercses from Introducton to Pattern Recognton
E395 - Pattern Recognton Solutons to Introducton to Pattern Recognton, Chapter : Bayesan pattern classfcaton Preface Ths document s a soluton manual for selected exercses from Introducton to Pattern Recognton
Support Vector Machines
 Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far So far Supervsed machne learnng Lnear models Non-lnear models Unsupervsed machne learnng Generc scaffoldng So far
Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far So far Supervsed machne learnng Lnear models Non-lnear models Unsupervsed machne learnng Generc scaffoldng So far
Structure and Drive Paul A. Jensen Copyright July 20, 2003
 Structure and Drve Paul A. Jensen Copyrght July 20, 2003 A system s made up of several operatons wth flow passng between them. The structure of the system descrbes the flow paths from nputs to outputs.
Structure and Drve Paul A. Jensen Copyrght July 20, 2003 A system s made up of several operatons wth flow passng between them. The structure of the system descrbes the flow paths from nputs to outputs.
Fundamentals of Neural Networks
 Fundamentals of Neural Networks Xaodong Cu IBM T. J. Watson Research Center Yorktown Heghts, NY 10598 Fall, 2018 Outlne Feedforward neural networks Forward propagaton Neural networks as unversal approxmators
Fundamentals of Neural Networks Xaodong Cu IBM T. J. Watson Research Center Yorktown Heghts, NY 10598 Fall, 2018 Outlne Feedforward neural networks Forward propagaton Neural networks as unversal approxmators
Linear Classification, SVMs and Nearest Neighbors
 1 CSE 473 Lecture 25 (Chapter 18) Lnear Classfcaton, SVMs and Nearest Neghbors CSE AI faculty + Chrs Bshop, Dan Klen, Stuart Russell, Andrew Moore Motvaton: Face Detecton How do we buld a classfer to dstngush
1 CSE 473 Lecture 25 (Chapter 18) Lnear Classfcaton, SVMs and Nearest Neghbors CSE AI faculty + Chrs Bshop, Dan Klen, Stuart Russell, Andrew Moore Motvaton: Face Detecton How do we buld a classfer to dstngush
Internet Engineering. Jacek Mazurkiewicz, PhD Softcomputing. Part 3: Recurrent Artificial Neural Networks Self-Organising Artificial Neural Networks
 Internet Engneerng Jacek Mazurkewcz, PhD Softcomputng Part 3: Recurrent Artfcal Neural Networks Self-Organsng Artfcal Neural Networks Recurrent Artfcal Neural Networks Feedback sgnals between neurons Dynamc
Internet Engneerng Jacek Mazurkewcz, PhD Softcomputng Part 3: Recurrent Artfcal Neural Networks Self-Organsng Artfcal Neural Networks Recurrent Artfcal Neural Networks Feedback sgnals between neurons Dynamc
Chapter 11: Simple Linear Regression and Correlation
 Chapter 11: Smple Lnear Regresson and Correlaton 11-1 Emprcal Models 11-2 Smple Lnear Regresson 11-3 Propertes of the Least Squares Estmators 11-4 Hypothess Test n Smple Lnear Regresson 11-4.1 Use of t-tests
Chapter 11: Smple Lnear Regresson and Correlaton 11-1 Emprcal Models 11-2 Smple Lnear Regresson 11-3 Propertes of the Least Squares Estmators 11-4 Hypothess Test n Smple Lnear Regresson 11-4.1 Use of t-tests
VQ widely used in coding speech, image, and video
 at Scalar quantzers are specal cases of vector quantzers (VQ): they are constraned to look at one sample at a tme (memoryless) VQ does not have such constrant better RD perfomance expected Source codng
at Scalar quantzers are specal cases of vector quantzers (VQ): they are constraned to look at one sample at a tme (memoryless) VQ does not have such constrant better RD perfomance expected Source codng
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mnng Massve Datasets Jure Leskovec, Stanford Unversty http://cs246.stanford.edu 2/19/18 Jure Leskovec, Stanford CS246: Mnng Massve Datasets, http://cs246.stanford.edu 2 Hgh dm. data Graph data Infnte
CS246: Mnng Massve Datasets Jure Leskovec, Stanford Unversty http://cs246.stanford.edu 2/19/18 Jure Leskovec, Stanford CS246: Mnng Massve Datasets, http://cs246.stanford.edu 2 Hgh dm. data Graph data Infnte
Module 3 LOSSY IMAGE COMPRESSION SYSTEMS. Version 2 ECE IIT, Kharagpur
 Module 3 LOSSY IMAGE COMPRESSION SYSTEMS Verson ECE IIT, Kharagpur Lesson 6 Theory of Quantzaton Verson ECE IIT, Kharagpur Instructonal Objectves At the end of ths lesson, the students should be able to:
Module 3 LOSSY IMAGE COMPRESSION SYSTEMS Verson ECE IIT, Kharagpur Lesson 6 Theory of Quantzaton Verson ECE IIT, Kharagpur Instructonal Objectves At the end of ths lesson, the students should be able to:
Homework Assignment 3 Due in class, Thursday October 15
 Homework Assgnment 3 Due n class, Thursday October 15 SDS 383C Statstcal Modelng I 1 Rdge regresson and Lasso 1. Get the Prostrate cancer data from http://statweb.stanford.edu/~tbs/elemstatlearn/ datasets/prostate.data.
Homework Assgnment 3 Due n class, Thursday October 15 SDS 383C Statstcal Modelng I 1 Rdge regresson and Lasso 1. Get the Prostrate cancer data from http://statweb.stanford.edu/~tbs/elemstatlearn/ datasets/prostate.data.
Intro to Visual Recognition
 CS 2770: Computer Vson Intro to Vsual Recognton Prof. Adrana Kovashka Unversty of Pttsburgh February 13, 2018 Plan for today What s recognton? a.k.a. classfcaton, categorzaton Support vector machnes Separable
CS 2770: Computer Vson Intro to Vsual Recognton Prof. Adrana Kovashka Unversty of Pttsburgh February 13, 2018 Plan for today What s recognton? a.k.a. classfcaton, categorzaton Support vector machnes Separable
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 89 Fall 206 Introducton to Machne Learnng Fnal Do not open the exam before you are nstructed to do so The exam s closed book, closed notes except your one-page cheat sheet Usage of electronc devces
CS 89 Fall 206 Introducton to Machne Learnng Fnal Do not open the exam before you are nstructed to do so The exam s closed book, closed notes except your one-page cheat sheet Usage of electronc devces
Tracking with Kalman Filter
 Trackng wth Kalman Flter Scott T. Acton Vrgna Image and Vdeo Analyss (VIVA), Charles L. Brown Department of Electrcal and Computer Engneerng Department of Bomedcal Engneerng Unversty of Vrgna, Charlottesvlle,
Trackng wth Kalman Flter Scott T. Acton Vrgna Image and Vdeo Analyss (VIVA), Charles L. Brown Department of Electrcal and Computer Engneerng Department of Bomedcal Engneerng Unversty of Vrgna, Charlottesvlle,
Nonlinear Classifiers II
 Nonlnear Classfers II Nonlnear Classfers: Introducton Classfers Supervsed Classfers Lnear Classfers Perceptron Least Squares Methods Lnear Support Vector Machne Nonlnear Classfers Part I: Mult Layer Neural
Nonlnear Classfers II Nonlnear Classfers: Introducton Classfers Supervsed Classfers Lnear Classfers Perceptron Least Squares Methods Lnear Support Vector Machne Nonlnear Classfers Part I: Mult Layer Neural
Space of ML Problems. CSE 473: Artificial Intelligence. Parameter Estimation and Bayesian Networks. Learning Topics
 /7/7 CSE 73: Artfcal Intellgence Bayesan - Learnng Deter Fox Sldes adapted from Dan Weld, Jack Breese, Dan Klen, Daphne Koller, Stuart Russell, Andrew Moore & Luke Zettlemoyer What s Beng Learned? Space
/7/7 CSE 73: Artfcal Intellgence Bayesan - Learnng Deter Fox Sldes adapted from Dan Weld, Jack Breese, Dan Klen, Daphne Koller, Stuart Russell, Andrew Moore & Luke Zettlemoyer What s Beng Learned? Space
18-660: Numerical Methods for Engineering Design and Optimization
 8-66: Numercal Methods for Engneerng Desgn and Optmzaton n L Department of EE arnege Mellon Unversty Pttsburgh, PA 53 Slde Overve lassfcaton Support vector machne Regularzaton Slde lassfcaton Predct categorcal
8-66: Numercal Methods for Engneerng Desgn and Optmzaton n L Department of EE arnege Mellon Unversty Pttsburgh, PA 53 Slde Overve lassfcaton Support vector machne Regularzaton Slde lassfcaton Predct categorcal
CHALMERS, GÖTEBORGS UNIVERSITET. SOLUTIONS to RE-EXAM for ARTIFICIAL NEURAL NETWORKS. COURSE CODES: FFR 135, FIM 720 GU, PhD
 CHALMERS, GÖTEBORGS UNIVERSITET SOLUTIONS to RE-EXAM for ARTIFICIAL NEURAL NETWORKS COURSE CODES: FFR 35, FIM 72 GU, PhD Tme: Place: Teachers: Allowed materal: Not allowed: January 2, 28, at 8 3 2 3 SB
CHALMERS, GÖTEBORGS UNIVERSITET SOLUTIONS to RE-EXAM for ARTIFICIAL NEURAL NETWORKS COURSE CODES: FFR 35, FIM 72 GU, PhD Tme: Place: Teachers: Allowed materal: Not allowed: January 2, 28, at 8 3 2 3 SB
Chapter 9: Statistical Inference and the Relationship between Two Variables
 Chapter 9: Statstcal Inference and the Relatonshp between Two Varables Key Words The Regresson Model The Sample Regresson Equaton The Pearson Correlaton Coeffcent Learnng Outcomes After studyng ths chapter,
Chapter 9: Statstcal Inference and the Relatonshp between Two Varables Key Words The Regresson Model The Sample Regresson Equaton The Pearson Correlaton Coeffcent Learnng Outcomes After studyng ths chapter,
Logistic Classifier CISC 5800 Professor Daniel Leeds
 lon 9/7/8 Logstc Classfer CISC 58 Professor Danel Leeds Classfcaton strategy: generatve vs. dscrmnatve Generatve, e.g., Bayes/Naïve Bayes: 5 5 Identfy probablty dstrbuton for each class Determne class
lon 9/7/8 Logstc Classfer CISC 58 Professor Danel Leeds Classfcaton strategy: generatve vs. dscrmnatve Generatve, e.g., Bayes/Naïve Bayes: 5 5 Identfy probablty dstrbuton for each class Determne class
Online Classification: Perceptron and Winnow
 E0 370 Statstcal Learnng Theory Lecture 18 Nov 8, 011 Onlne Classfcaton: Perceptron and Wnnow Lecturer: Shvan Agarwal Scrbe: Shvan Agarwal 1 Introducton In ths lecture we wll start to study the onlne learnng
E0 370 Statstcal Learnng Theory Lecture 18 Nov 8, 011 Onlne Classfcaton: Perceptron and Wnnow Lecturer: Shvan Agarwal Scrbe: Shvan Agarwal 1 Introducton In ths lecture we wll start to study the onlne learnng
NUMERICAL DIFFERENTIATION
 NUMERICAL DIFFERENTIATION 1 Introducton Dfferentaton s a method to compute the rate at whch a dependent output y changes wth respect to the change n the ndependent nput x. Ths rate of change s called the
NUMERICAL DIFFERENTIATION 1 Introducton Dfferentaton s a method to compute the rate at whch a dependent output y changes wth respect to the change n the ndependent nput x. Ths rate of change s called the
Semi-supervised Classification with Active Query Selection
 Sem-supervsed Classfcaton wth Actve Query Selecton Jao Wang and Swe Luo School of Computer and Informaton Technology, Beng Jaotong Unversty, Beng 00044, Chna Wangjao088@63.com Abstract. Labeled samples
Sem-supervsed Classfcaton wth Actve Query Selecton Jao Wang and Swe Luo School of Computer and Informaton Technology, Beng Jaotong Unversty, Beng 00044, Chna Wangjao088@63.com Abstract. Labeled samples
P R. Lecture 4. Theory and Applications of Pattern Recognition. Dept. of Electrical and Computer Engineering /
 Theory and Applcatons of Pattern Recognton 003, Rob Polkar, Rowan Unversty, Glassboro, NJ Lecture 4 Bayes Classfcaton Rule Dept. of Electrcal and Computer Engneerng 0909.40.0 / 0909.504.04 Theory & Applcatons
Theory and Applcatons of Pattern Recognton 003, Rob Polkar, Rowan Unversty, Glassboro, NJ Lecture 4 Bayes Classfcaton Rule Dept. of Electrcal and Computer Engneerng 0909.40.0 / 0909.504.04 Theory & Applcatons
Neural Networks. Class 22: MLSP, Fall 2016 Instructor: Bhiksha Raj
 Neural Networs Class 22: MLSP, Fall 2016 Instructor: Bhsha Raj IMPORTANT ADMINSTRIVIA Fnal wee. Project presentatons on 6th 18797/11755 2 Neural Networs are tang over! Neural networs have become one of
Neural Networs Class 22: MLSP, Fall 2016 Instructor: Bhsha Raj IMPORTANT ADMINSTRIVIA Fnal wee. Project presentatons on 6th 18797/11755 2 Neural Networs are tang over! Neural networs have become one of
Maximum Likelihood Estimation (MLE)
") Maxmum Lkelhood Estmaton (MLE) Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 01 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
Maxmum Lkelhood Estmaton (MLE) Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 01 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
Image classification. Given the bag-of-features representations of images from different classes, how do we learn a model for distinguishing i them?
 Image classfcaton Gven te bag-of-features representatons of mages from dfferent classes ow do we learn a model for dstngusng tem? Classfers Learn a decson rule assgnng bag-offeatures representatons of
Image classfcaton Gven te bag-of-features representatons of mages from dfferent classes ow do we learn a model for dstngusng tem? Classfers Learn a decson rule assgnng bag-offeatures representatons of
Chapter 6 Support vector machine. Séparateurs à vaste marge
 Chapter 6 Support vector machne Séparateurs à vaste marge Méthode de classfcaton bnare par apprentssage Introdute par Vladmr Vapnk en 1995 Repose sur l exstence d un classfcateur lnéare Apprentssage supervsé
Chapter 6 Support vector machne Séparateurs à vaste marge Méthode de classfcaton bnare par apprentssage Introdute par Vladmr Vapnk en 1995 Repose sur l exstence d un classfcateur lnéare Apprentssage supervsé
Midterm Examination. Regression and Forecasting Models
 IOMS Department Regresson and Forecastng Models Professor Wllam Greene Phone: 22.998.0876 Offce: KMC 7-90 Home page: people.stern.nyu.edu/wgreene Emal: wgreene@stern.nyu.edu Course web page: people.stern.nyu.edu/wgreene/regresson/outlne.htm
IOMS Department Regresson and Forecastng Models Professor Wllam Greene Phone: 22.998.0876 Offce: KMC 7-90 Home page: people.stern.nyu.edu/wgreene Emal: wgreene@stern.nyu.edu Course web page: people.stern.nyu.edu/wgreene/regresson/outlne.htm
ADVANCED MACHINE LEARNING ADVANCED MACHINE LEARNING
 1 ADVANCED ACHINE LEARNING ADVANCED ACHINE LEARNING Non-lnear regresson technques 2 ADVANCED ACHINE LEARNING Regresson: Prncple N ap N-dm. nput x to a contnuous output y. Learn a functon of the type: N
1 ADVANCED ACHINE LEARNING ADVANCED ACHINE LEARNING Non-lnear regresson technques 2 ADVANCED ACHINE LEARNING Regresson: Prncple N ap N-dm. nput x to a contnuous output y. Learn a functon of the type: N
CSci 6974 and ECSE 6966 Math. Tech. for Vision, Graphics and Robotics Lecture 21, April 17, 2006 Estimating A Plane Homography
 CSc 6974 and ECSE 6966 Math. Tech. for Vson, Graphcs and Robotcs Lecture 21, Aprl 17, 2006 Estmatng A Plane Homography Overvew We contnue wth a dscusson of the major ssues, usng estmaton of plane projectve
CSc 6974 and ECSE 6966 Math. Tech. for Vson, Graphcs and Robotcs Lecture 21, Aprl 17, 2006 Estmatng A Plane Homography Overvew We contnue wth a dscusson of the major ssues, usng estmaton of plane projectve
Errors for Linear Systems
 Errors for Lnear Systems When we solve a lnear system Ax b we often do not know A and b exactly, but have only approxmatons  and ˆb avalable. Then the best thng we can do s to solve ˆx ˆb exactly whch
Errors for Lnear Systems When we solve a lnear system Ax b we often do not know A and b exactly, but have only approxmatons  and ˆb avalable. Then the best thng we can do s to solve ˆx ˆb exactly whch
Support Vector Machines
 CS 2750: Machne Learnng Support Vector Machnes Prof. Adrana Kovashka Unversty of Pttsburgh February 17, 2016 Announcement Homework 2 deadlne s now 2/29 We ll have covered everythng you need today or at
CS 2750: Machne Learnng Support Vector Machnes Prof. Adrana Kovashka Unversty of Pttsburgh February 17, 2016 Announcement Homework 2 deadlne s now 2/29 We ll have covered everythng you need today or at
Outline and Reading. Dynamic Programming. Dynamic Programming revealed. Computing Fibonacci. The General Dynamic Programming Technique
 Outlne and Readng Dynamc Programmng The General Technque ( 5.3.2) -1 Knapsac Problem ( 5.3.3) Matrx Chan-Product ( 5.3.1) Dynamc Programmng verson 1.4 1 Dynamc Programmng verson 1.4 2 Dynamc Programmng
Outlne and Readng Dynamc Programmng The General Technque ( 5.3.2) -1 Knapsac Problem ( 5.3.3) Matrx Chan-Product ( 5.3.1) Dynamc Programmng verson 1.4 1 Dynamc Programmng verson 1.4 2 Dynamc Programmng
IV. Performance Optimization
 IV. Performance Optmzaton A. Steepest descent algorthm defnton how to set up bounds on learnng rate mnmzaton n a lne (varyng learnng rate) momentum learnng examples B. Newton s method defnton Gauss-Newton
IV. Performance Optmzaton A. Steepest descent algorthm defnton how to set up bounds on learnng rate mnmzaton n a lne (varyng learnng rate) momentum learnng examples B. Newton s method defnton Gauss-Newton
17 Support Vector Machines
 17 We now dscuss an nfluental and effectve classfcaton algorthm called (SVMs). In addton to ther successes n many classfcaton problems, SVMs are responsble for ntroducng and/or popularzng several mportant
17 We now dscuss an nfluental and effectve classfcaton algorthm called (SVMs). In addton to ther successes n many classfcaton problems, SVMs are responsble for ntroducng and/or popularzng several mportant
Evaluation for sets of classes
 Evaluaton for Tet Categorzaton Classfcaton accuracy: usual n ML, the proporton of correct decsons, Not approprate f the populaton rate of the class s low Precson, Recall and F 1 Better measures 21 Evaluaton
Evaluaton for Tet Categorzaton Classfcaton accuracy: usual n ML, the proporton of correct decsons, Not approprate f the populaton rate of the class s low Precson, Recall and F 1 Better measures 21 Evaluaton
Laboratory 3: Method of Least Squares
 Laboratory 3: Method of Least Squares Introducton Consder the graph of expermental data n Fgure 1. In ths experment x s the ndependent varable and y the dependent varable. Clearly they are correlated wth
Laboratory 3: Method of Least Squares Introducton Consder the graph of expermental data n Fgure 1. In ths experment x s the ndependent varable and y the dependent varable. Clearly they are correlated wth
Regression Analysis. Regression Analysis
 Regresson Analyss Smple Regresson Multvarate Regresson Stepwse Regresson Replcaton and Predcton Error 1 Regresson Analyss In general, we "ft" a model by mnmzng a metrc that represents the error. n mn (y
Regresson Analyss Smple Regresson Multvarate Regresson Stepwse Regresson Replcaton and Predcton Error 1 Regresson Analyss In general, we "ft" a model by mnmzng a metrc that represents the error. n mn (y
Comparison of Regression Lines
 STATGRAPHICS Rev. 9/13/2013 Comparson of Regresson Lnes Summary... 1 Data Input... 3 Analyss Summary... 4 Plot of Ftted Model... 6 Condtonal Sums of Squares... 6 Analyss Optons... 7 Forecasts... 8 Confdence
STATGRAPHICS Rev. 9/13/2013 Comparson of Regresson Lnes Summary... 1 Data Input... 3 Analyss Summary... 4 Plot of Ftted Model... 6 Condtonal Sums of Squares... 6 Analyss Optons... 7 Forecasts... 8 Confdence
Hidden Markov Models & The Multivariate Gaussian (10/26/04)
") CS281A/Stat241A: Statstcal Learnng Theory Hdden Markov Models & The Multvarate Gaussan (10/26/04) Lecturer: Mchael I. Jordan Scrbes: Jonathan W. Hu 1 Hdden Markov Models As a bref revew, hdden Markov models
CS281A/Stat241A: Statstcal Learnng Theory Hdden Markov Models & The Multvarate Gaussan (10/26/04) Lecturer: Mchael I. Jordan Scrbes: Jonathan W. Hu 1 Hdden Markov Models As a bref revew, hdden Markov models
Laboratory 1c: Method of Least Squares
 Lab 1c, Least Squares Laboratory 1c: Method of Least Squares Introducton Consder the graph of expermental data n Fgure 1. In ths experment x s the ndependent varable and y the dependent varable. Clearly
Lab 1c, Least Squares Laboratory 1c: Method of Least Squares Introducton Consder the graph of expermental data n Fgure 1. In ths experment x s the ndependent varable and y the dependent varable. Clearly
Relevance Vector Machines Explained
 October 19, 2010 Relevance Vector Machnes Explaned Trstan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introducton Ths document has been wrtten n an attempt to make Tppng s [1] Relevance Vector Machnes
October 19, 2010 Relevance Vector Machnes Explaned Trstan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introducton Ths document has been wrtten n an attempt to make Tppng s [1] Relevance Vector Machnes
Support Vector Machines CS434
 Support Vector Machnes CS434 Lnear Separators Many lnear separators exst that perfectly classfy all tranng examples Whch of the lnear separators s the best? Intuton of Margn Consder ponts A, B, and C We
Support Vector Machnes CS434 Lnear Separators Many lnear separators exst that perfectly classfy all tranng examples Whch of the lnear separators s the best? Intuton of Margn Consder ponts A, B, and C We
Department of Quantitative Methods & Information Systems. Time Series and Their Components QMIS 320. Chapter 6
 Department of Quanttatve Methods & Informaton Systems Tme Seres and Ther Components QMIS 30 Chapter 6 Fall 00 Dr. Mohammad Zanal These sldes were modfed from ther orgnal source for educatonal purpose only.
Department of Quanttatve Methods & Informaton Systems Tme Seres and Ther Components QMIS 30 Chapter 6 Fall 00 Dr. Mohammad Zanal These sldes were modfed from ther orgnal source for educatonal purpose only.
COS 511: Theoretical Machine Learning. Lecturer: Rob Schapire Lecture #16 Scribe: Yannan Wang April 3, 2014
 COS 511: Theoretcal Machne Learnng Lecturer: Rob Schapre Lecture #16 Scrbe: Yannan Wang Aprl 3, 014 1 Introducton The goal of our onlne learnng scenaro from last class s C comparng wth best expert and
COS 511: Theoretcal Machne Learnng Lecturer: Rob Schapre Lecture #16 Scrbe: Yannan Wang Aprl 3, 014 1 Introducton The goal of our onlne learnng scenaro from last class s C comparng wth best expert and
Statistical pattern recognition
 Statstcal pattern recognton Bayes theorem Problem: decdng f a patent has a partcular condton based on a partcular test However, the test s mperfect Someone wth the condton may go undetected (false negatve
Statstcal pattern recognton Bayes theorem Problem: decdng f a patent has a partcular condton based on a partcular test However, the test s mperfect Someone wth the condton may go undetected (false negatve