Pattern Classification
|
|
|
- Lucinda Miller
- 5 years ago
- Views:
Transcription
1 Pattern Classfcaton All materals n these sldes ere taken from Pattern Classfcaton (nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wley & Sons, 000 th the permsson of the authors and the publsher
2 Chapter 5: Lnear Dscrmnant Functons (Sectons ) Introducton Lnear Dscrmnant Functons and Decsons Surfaces Generalzed Lnear Dscrmnant Functons
3 Introducton In Ch.3, the underlyng probablty denstes ere knon (or gven) The tranng sample as used to estmate the parameters of these probablty denstes (ML, MAP estmatons) In ths chapter, e only kno the proper forms for the dscrmnant functons Use the samples to estmate the values of the parameters of the classfer Goal Determnng the dscrmnant functons.(no knoledge of the underlyng prob.dst. s reqd.) Dscrmnant functons: Lnear n or functons of They may not be optmal, but they are very smple to use Fndng a lnear dscrmnant functon Mnmzng a crteron functon. Sample crteron fnc. Sample rsk, tranng error (small tranng error small test error)
4 Lnear dscrmnant functons 3 and decsons surfaces Lnear dscrmnant functon g() = T 0 () here s the eght vector and 0 the bas A to-category classfer th a dscrmnant functon of the form () uses the follong rule: Decde ω f g() > 0 and ω f g() < 0 Decde ω f t > - 0 and ω otherse If g() = 0 s assgned to ether class

5 4
6 5 The equaton g() = 0 defnes the decson surface that separates ponts assgned to the category ω from ponts assgned to the category ω When g() s lnear, the decson surface s a hyperplane Algebrac measure of the dstance from to the hyperplane (nterestng result!)
7 6
8 = p r. (snce s colnear th - p and = ) 7 sn ce g() = 0 and g( ) therefore r = n partcular d(0, H) = t. = 0 In concluson, a lnear dscrmnant functon dvdes the feature space by a hyperplane decson surface The orentaton of the surface s determned by the normal vector and the locaton of the surface s determned by the bas
9 The mult-category case 8 We defne c lnear dscrmnant functons g 0 t ( ) = =,...,c and assgn to ω f g () > g j () j ; n case of tes, the classfcaton s undefned In ths case, the classfer s a lnear machne A lnear machne dvdes the feature space nto c decson regons, th g () beng the largest dscrmnant f s n the regon R For a to contguous regons R and R j ; the boundary that separates them s a porton of hyperplane H j defned by: g () = g j () ( j ) t ( 0 j0 ) = 0 j s normal to H j and d(,h j ) = g g j j
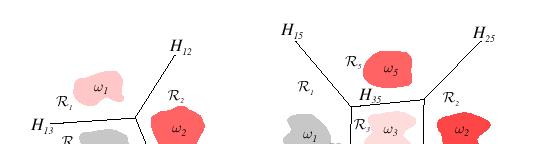
10 9
11 It s easy to sho that the decson regons for a lnear machne are conve, ths restrcton lmts the fleblty and accuracy of the classfer 0
12 Lnear Dscrmnant Functons
13 Non-lnear Dscrmnant Fncs
14 3 Hgher Dmensonal Space Constructed Feature Constructed Feature Fnd functon Φ() to map to a dfferent space
15 Generalzed Lnear Dscrmnant Functons Decson boundares hch separate beteen classes may not alays be lnear The complety of the boundares may sometmes request the use of hghly non-lnear surfaces A popular approach to generalze the concept of lnear decson functons s to consder a generalzed decson functon as: 4 g() = f () f () N f N () N here f (), N are scalar functons of the pattern R n (Eucldean Space)
16 Introducng f n () = e get: 5 g( ) = N = here = ( f ( ) =, T,..., f ( ) N, N ) T and f() = (f ( ), f ( ),..., f N ( ), f N ( )) T Ths latter representaton of g() mples that any decson functon defned by equaton () can be treated as lnear n the (N ) dmensonal space (N > n) g() mantans ts non-lnearty characterstcs n R n
17 6 The most commonly used generalzed decson functon s g() for hch f () ( N) are polynomals ( ~ T g( ) = ) f ( ) T: s the vector transpose form ~ Where s a ne eght vector, hch can be calculated from the orgnal and the orgnal lnear f (), N Quadratc decson functons for a -dmensonal feature space g( ) = here : = (,,..., 6 ) 3 T 4 and f() = 5 (, 6,,,,) T
18 For patterns R n, the most general quadratc decson functon s gven by: 7 g( ) = n j j = n n n n () = j= = The number of terms at the rght-hand sde s: l = N = n n( n ) n = ( n )( n ) Ths s the total number of eghts hch are the free parameters of the problem If for eample n = 3, the vector If for eample n = 0, the vector f() f () s 0-dmensonal s 65-dmensonal
19 In the case of polynomal decson functons of order m, a typcal f () s gven by: f ( ) here = e e,... e,..., m m m n and m s 0 or It s a polynomal th a degree beteen 0 and m. To avod repettons, e request m e,. 8 g m ( ) = n... n n = = = m m m g ( ) m m (here g 0 () = n ) s the most general polynomal decson functon of order m
20 9 Eample : Let n = 3 and m = then: Eample : Let n = and m = 3 then: ) ( g = = = = ) ( g ) ( here g ) ( g ) ( g ) ( g = = = = = = = = =
21 The commonly used quadratc decson functon can be represented as the general n- dmensonal quadratc surface: g() = T A T b c 0 here the matr A = (a j ), the vector b = (b, b,, b n ) T and c, depends on the eghts, j, of equaton () j If A s postve defnte then the decson functon s a hyperellpsod th aes n the drectons of the egenvectors of A In partcular: f A = I n (Identty), the decson functon s smply the n-dmensonal hypersphere
22 If A s negatve defnte, the decson functon descrbes a hyperhyperbolod In concluson: t s only the matr A hch determnes the shape and characterstcs of the decson functon
23 Objectve Functons J Lnear Separablty Perceptron Relaaton Procedures Convergence No lnear separablty Mn-Squared Error Msclassfed Samples All Samples
24 Lnear Separablty 3

25 -Category Lnear Case 4
26 5 Termnology Weght : a A A: Weght space Solutons: Not unque: Normalzed a = Margn a T y b

27 b > 0 Margn 6
28 Gradent Descent 7
29 Neton Descent 8
30 9
31 30
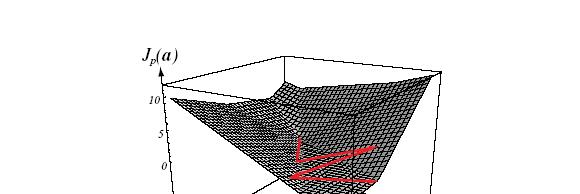
32 Perceptron 3
33 As Neural Netork 3
34 Relaaton Algorthm 33
35 34
36
37 36 Mean-Squared Error Error-Correctng Procedures Separable Samples Perceptron Relaaton procedures Nonseparable Samples Correctons n the error-correcton procedure ll NEVER converge Heurstc modfcatons Acceptable performance on nonseparable samples! MSE No guarantee that soln. s a separatng vector

38 Mn-Squared Error 37
39 38 MSE Pseudo-Inverse Drect relaton to Fscher s lnear dscrmnant If b=, MSE appromaton to the Bayes dscrmnant functon T g( ) = a y( ) b g( ) = P( ω ) P( ω )
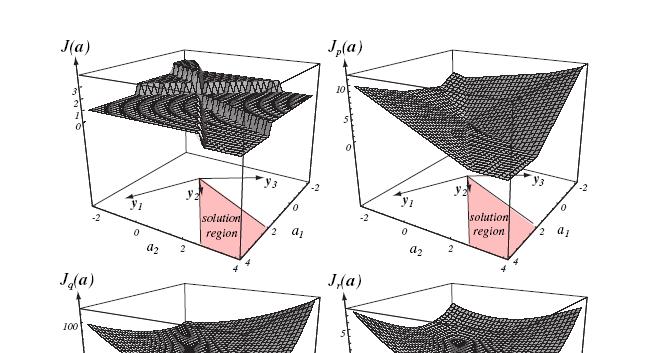
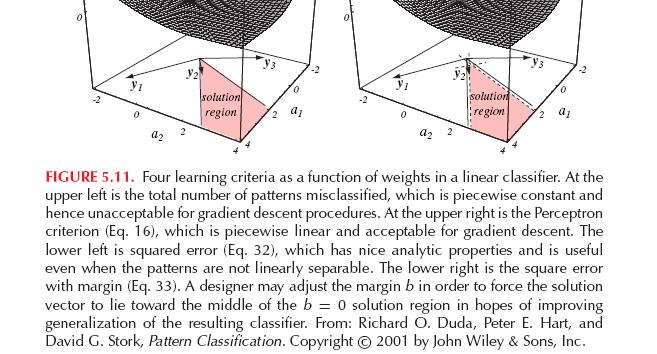
40 39
41 40 Wdro-Hoff or LMS Mnmze usng gradent descent Sngular pseudo-nverse Inverson of large matrces
42 4 Ho Kashyap Procedure If tranng samples are lnearly separable, Yaˆ = bˆ here bˆ > 0 Gradent descent rt both a and b
43 4 Support Vector Machnes Map to a hgher dmensonal space
44 43 Support Vector Machne (SVM) Decson surface s a hyperplane n feature space In summary Map the data to a predetermned very hgh-dmensonal space va a kernel functon Fnd the hyperplane that mamzes the margn beteen the to classes If data are not separable fnd the hyperplane that mamzes the margn and mnmzes the (a eghted average of the) msclassfcatons
45 44 Separatng Hyperplanes? X
46 45 Idea: Mamze Margn Select the separatng hyperplane that mamzes the margn! Margn Wdth Margn Wdth
47 46 Support Vectors Support Vectors Margn Wdth 46
48 47 Constraned Optmzaton The dth of the margn s: k r r r b = k Optmzaton problem: r r b = k k k r r b = 0 k ma s. t. ( b) k, of class ( b) k, of class
49 Constraned Quadratc Optmzaton 48 If class corresponds to and class corresponds to -, e can rerte as ( b), th y = ( b ), th y = y ( b), So the problem becomes: ma s. t. y ( b), or mn s. t. y ( b),
50 49 Comparson: SVM vs NN SVMs Kernel maps to a very-hgh dmensonal space Search space has a unque mnmum Tranng s etremely effcent Classfcaton etremely effcent Kernel and cost the to parameters to select Very good accuracy n typcal domans Etremely robust Neural Netorks Hdden Layers map to loer dmensonal spaces Search space has multple local mnma Tranng s epensve Classfcaton etremely effcent Requres number of hdden unts and layers Very good accuracy n typcal domans
51 50 General Summary Perceptron and relaaton procedures Do not converge on nonseparable data. MSE Works regardless of separablty, but no guarantee of separaton thout error. Ho-Kashyap Provdes a separatng vector or th the evdence of nonseparablty. (No bound on the number of steps reqd.)
Kernel Methods and SVMs Extension
 Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
Support Vector Machines CS434
 Support Vector Machnes CS434 Lnear Separators Many lnear separators exst that perfectly classfy all tranng examples Whch of the lnear separators s the best? Intuton of Margn Consder ponts A, B, and C We
Support Vector Machnes CS434 Lnear Separators Many lnear separators exst that perfectly classfy all tranng examples Whch of the lnear separators s the best? Intuton of Margn Consder ponts A, B, and C We
Image classification. Given the bag-of-features representations of images from different classes, how do we learn a model for distinguishing i them?
 Image classfcaton Gven te bag-of-features representatons of mages from dfferent classes ow do we learn a model for dstngusng tem? Classfers Learn a decson rule assgnng bag-offeatures representatons of
Image classfcaton Gven te bag-of-features representatons of mages from dfferent classes ow do we learn a model for dstngusng tem? Classfers Learn a decson rule assgnng bag-offeatures representatons of
CS 3710: Visual Recognition Classification and Detection. Adriana Kovashka Department of Computer Science January 13, 2015
 CS 3710: Vsual Recognton Classfcaton and Detecton Adrana Kovashka Department of Computer Scence January 13, 2015 Plan for Today Vsual recognton bascs part 2: Classfcaton and detecton Adrana s research
CS 3710: Vsual Recognton Classfcaton and Detecton Adrana Kovashka Department of Computer Scence January 13, 2015 Plan for Today Vsual recognton bascs part 2: Classfcaton and detecton Adrana s research
P R. Lecture 4. Theory and Applications of Pattern Recognition. Dept. of Electrical and Computer Engineering /
 Theory and Applcatons of Pattern Recognton 003, Rob Polkar, Rowan Unversty, Glassboro, NJ Lecture 4 Bayes Classfcaton Rule Dept. of Electrcal and Computer Engneerng 0909.40.0 / 0909.504.04 Theory & Applcatons
Theory and Applcatons of Pattern Recognton 003, Rob Polkar, Rowan Unversty, Glassboro, NJ Lecture 4 Bayes Classfcaton Rule Dept. of Electrcal and Computer Engneerng 0909.40.0 / 0909.504.04 Theory & Applcatons
Multilayer Perceptron (MLP)
") Multlayer Perceptron (MLP) Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr 1 / 20 Outlne
Multlayer Perceptron (MLP) Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr 1 / 20 Outlne
Linear Classification, SVMs and Nearest Neighbors
 1 CSE 473 Lecture 25 (Chapter 18) Lnear Classfcaton, SVMs and Nearest Neghbors CSE AI faculty + Chrs Bshop, Dan Klen, Stuart Russell, Andrew Moore Motvaton: Face Detecton How do we buld a classfer to dstngush
1 CSE 473 Lecture 25 (Chapter 18) Lnear Classfcaton, SVMs and Nearest Neghbors CSE AI faculty + Chrs Bshop, Dan Klen, Stuart Russell, Andrew Moore Motvaton: Face Detecton How do we buld a classfer to dstngush
Lecture 12: Classification
 Lecture : Classfcaton g Dscrmnant functons g The optmal Bayes classfer g Quadratc classfers g Eucldean and Mahalanobs metrcs g K Nearest Neghbor Classfers Intellgent Sensor Systems Rcardo Guterrez-Osuna
Lecture : Classfcaton g Dscrmnant functons g The optmal Bayes classfer g Quadratc classfers g Eucldean and Mahalanobs metrcs g K Nearest Neghbor Classfers Intellgent Sensor Systems Rcardo Guterrez-Osuna
Pattern Classification
 attern Classfcaton All materals n these sldes were taken from attern Classfcaton nd ed by R. O. Duda,. E. Hart and D. G. Stork, John Wley & Sons, 000 wth the ermsson of the authors and the ublsher Chater
attern Classfcaton All materals n these sldes were taken from attern Classfcaton nd ed by R. O. Duda,. E. Hart and D. G. Stork, John Wley & Sons, 000 wth the ermsson of the authors and the ublsher Chater
Support Vector Machines. Vibhav Gogate The University of Texas at dallas
 Support Vector Machnes Vbhav Gogate he Unversty of exas at dallas What We have Learned So Far? 1. Decson rees. Naïve Bayes 3. Lnear Regresson 4. Logstc Regresson 5. Perceptron 6. Neural networks 7. K-Nearest
Support Vector Machnes Vbhav Gogate he Unversty of exas at dallas What We have Learned So Far? 1. Decson rees. Naïve Bayes 3. Lnear Regresson 4. Logstc Regresson 5. Perceptron 6. Neural networks 7. K-Nearest
Intro to Visual Recognition
 CS 2770: Computer Vson Intro to Vsual Recognton Prof. Adrana Kovashka Unversty of Pttsburgh February 13, 2018 Plan for today What s recognton? a.k.a. classfcaton, categorzaton Support vector machnes Separable
CS 2770: Computer Vson Intro to Vsual Recognton Prof. Adrana Kovashka Unversty of Pttsburgh February 13, 2018 Plan for today What s recognton? a.k.a. classfcaton, categorzaton Support vector machnes Separable
Support Vector Machines
 CS 2750: Machne Learnng Support Vector Machnes Prof. Adrana Kovashka Unversty of Pttsburgh February 17, 2016 Announcement Homework 2 deadlne s now 2/29 We ll have covered everythng you need today or at
CS 2750: Machne Learnng Support Vector Machnes Prof. Adrana Kovashka Unversty of Pttsburgh February 17, 2016 Announcement Homework 2 deadlne s now 2/29 We ll have covered everythng you need today or at
Which Separator? Spring 1
 Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Support Vector Machines
 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
INF 5860 Machine learning for image classification. Lecture 3 : Image classification and regression part II Anne Solberg January 31, 2018
 INF 5860 Machne learnng for mage classfcaton Lecture 3 : Image classfcaton and regresson part II Anne Solberg January 3, 08 Today s topcs Multclass logstc regresson and softma Regularzaton Image classfcaton
INF 5860 Machne learnng for mage classfcaton Lecture 3 : Image classfcaton and regresson part II Anne Solberg January 3, 08 Today s topcs Multclass logstc regresson and softma Regularzaton Image classfcaton
Evaluation of classifiers MLPs
 Lecture Evaluaton of classfers MLPs Mlos Hausrecht mlos@cs.ptt.edu 539 Sennott Square Evaluaton For any data set e use to test the model e can buld a confuson matrx: Counts of examples th: class label
Lecture Evaluaton of classfers MLPs Mlos Hausrecht mlos@cs.ptt.edu 539 Sennott Square Evaluaton For any data set e use to test the model e can buld a confuson matrx: Counts of examples th: class label
Support Vector Machines
 /14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
/14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
Multigradient for Neural Networks for Equalizers 1
 Multgradent for Neural Netorks for Equalzers 1 Chulhee ee, Jnook Go and Heeyoung Km Department of Electrcal and Electronc Engneerng Yonse Unversty 134 Shnchon-Dong, Seodaemun-Ku, Seoul 1-749, Korea ABSTRACT
Multgradent for Neural Netorks for Equalzers 1 Chulhee ee, Jnook Go and Heeyoung Km Department of Electrcal and Electronc Engneerng Yonse Unversty 134 Shnchon-Dong, Seodaemun-Ku, Seoul 1-749, Korea ABSTRACT
MIMA Group. Chapter 2 Bayesian Decision Theory. School of Computer Science and Technology, Shandong University. Xin-Shun SDU
 Group M D L M Chapter Bayesan Decson heory Xn-Shun Xu @ SDU School of Computer Scence and echnology, Shandong Unversty Bayesan Decson heory Bayesan decson theory s a statstcal approach to data mnng/pattern
Group M D L M Chapter Bayesan Decson heory Xn-Shun Xu @ SDU School of Computer Scence and echnology, Shandong Unversty Bayesan Decson heory Bayesan decson theory s a statstcal approach to data mnng/pattern
Kernels in Support Vector Machines. Based on lectures of Martin Law, University of Michigan
 Kernels n Support Vector Machnes Based on lectures of Martn Law, Unversty of Mchgan Non Lnear separable problems AND OR NOT() The XOR problem cannot be solved wth a perceptron. XOR Per Lug Martell - Systems
Kernels n Support Vector Machnes Based on lectures of Martn Law, Unversty of Mchgan Non Lnear separable problems AND OR NOT() The XOR problem cannot be solved wth a perceptron. XOR Per Lug Martell - Systems
Linear discriminants. Nuno Vasconcelos ECE Department, UCSD
 Lnear dscrmnants Nuno Vasconcelos ECE Department UCSD Classfcaton a classfcaton problem as to tpes of varables e.g. X - vector of observatons features n te orld Y - state class of te orld X R 2 fever blood
Lnear dscrmnants Nuno Vasconcelos ECE Department UCSD Classfcaton a classfcaton problem as to tpes of varables e.g. X - vector of observatons features n te orld Y - state class of te orld X R 2 fever blood
Lecture 10 Support Vector Machines. Oct
 Lecture 10 Support Vector Machnes Oct - 20-2008 Lnear Separators Whch of the lnear separators s optmal? Concept of Margn Recall that n Perceptron, we learned that the convergence rate of the Perceptron
Lecture 10 Support Vector Machnes Oct - 20-2008 Lnear Separators Whch of the lnear separators s optmal? Concept of Margn Recall that n Perceptron, we learned that the convergence rate of the Perceptron
A Tutorial on Data Reduction. Linear Discriminant Analysis (LDA) Shireen Elhabian and Aly A. Farag. University of Louisville, CVIP Lab September 2009
 Shireen Elhabian and Aly A. Farag. University of Louisville, CVIP Lab September 2009") A utoral on Data Reducton Lnear Dscrmnant Analss (LDA) hreen Elhaban and Al A Farag Unverst of Lousvlle, CVIP Lab eptember 009 Outlne LDA objectve Recall PCA No LDA LDA o Classes Counter eample LDA C Classes
A utoral on Data Reducton Lnear Dscrmnant Analss (LDA) hreen Elhaban and Al A Farag Unverst of Lousvlle, CVIP Lab eptember 009 Outlne LDA objectve Recall PCA No LDA LDA o Classes Counter eample LDA C Classes
The Gaussian classifier. Nuno Vasconcelos ECE Department, UCSD
 he Gaussan classfer Nuno Vasconcelos ECE Department, UCSD Bayesan decson theory recall that we have state of the world X observatons g decson functon L[g,y] loss of predctng y wth g Bayes decson rule s
he Gaussan classfer Nuno Vasconcelos ECE Department, UCSD Bayesan decson theory recall that we have state of the world X observatons g decson functon L[g,y] loss of predctng y wth g Bayes decson rule s
Natural Language Processing and Information Retrieval
 Natural Language Processng and Informaton Retreval Support Vector Machnes Alessandro Moschtt Department of nformaton and communcaton technology Unversty of Trento Emal: moschtt@ds.untn.t Summary Support
Natural Language Processng and Informaton Retreval Support Vector Machnes Alessandro Moschtt Department of nformaton and communcaton technology Unversty of Trento Emal: moschtt@ds.untn.t Summary Support
U.C. Berkeley CS294: Beyond Worst-Case Analysis Luca Trevisan September 5, 2017
 U.C. Berkeley CS94: Beyond Worst-Case Analyss Handout 4s Luca Trevsan September 5, 07 Summary of Lecture 4 In whch we ntroduce semdefnte programmng and apply t to Max Cut. Semdefnte Programmng Recall that
U.C. Berkeley CS94: Beyond Worst-Case Analyss Handout 4s Luca Trevsan September 5, 07 Summary of Lecture 4 In whch we ntroduce semdefnte programmng and apply t to Max Cut. Semdefnte Programmng Recall that
Feature Selection: Part 1
 CSE 546: Machne Learnng Lecture 5 Feature Selecton: Part 1 Instructor: Sham Kakade 1 Regresson n the hgh dmensonal settng How do we learn when the number of features d s greater than the sample sze n?
CSE 546: Machne Learnng Lecture 5 Feature Selecton: Part 1 Instructor: Sham Kakade 1 Regresson n the hgh dmensonal settng How do we learn when the number of features d s greater than the sample sze n?
10-701/ Machine Learning, Fall 2005 Homework 3
 10-701/15-781 Machne Learnng, Fall 2005 Homework 3 Out: 10/20/05 Due: begnnng of the class 11/01/05 Instructons Contact questons-10701@autonlaborg for queston Problem 1 Regresson and Cross-valdaton [40
10-701/15-781 Machne Learnng, Fall 2005 Homework 3 Out: 10/20/05 Due: begnnng of the class 11/01/05 Instructons Contact questons-10701@autonlaborg for queston Problem 1 Regresson and Cross-valdaton [40
Support Vector Machines
 Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far So far Supervsed machne learnng Lnear models Non-lnear models Unsupervsed machne learnng Generc scaffoldng So far
Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far So far Supervsed machne learnng Lnear models Non-lnear models Unsupervsed machne learnng Generc scaffoldng So far
Support Vector Machines
 Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far Supervsed machne learnng Lnear models Least squares regresson Fsher s dscrmnant, Perceptron, Logstc model Non-lnear
Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far Supervsed machne learnng Lnear models Least squares regresson Fsher s dscrmnant, Perceptron, Logstc model Non-lnear
15-381: Artificial Intelligence. Regression and cross validation
 15-381: Artfcal Intellgence Regresson and cross valdaton Where e are Inputs Densty Estmator Probablty Inputs Classfer Predct category Inputs Regressor Predct real no. Today Lnear regresson Gven an nput
15-381: Artfcal Intellgence Regresson and cross valdaton Where e are Inputs Densty Estmator Probablty Inputs Classfer Predct category Inputs Regressor Predct real no. Today Lnear regresson Gven an nput
18-660: Numerical Methods for Engineering Design and Optimization
 8-66: Numercal Methods for Engneerng Desgn and Optmzaton n L Department of EE arnege Mellon Unversty Pttsburgh, PA 53 Slde Overve lassfcaton Support vector machne Regularzaton Slde lassfcaton Predct categorcal
8-66: Numercal Methods for Engneerng Desgn and Optmzaton n L Department of EE arnege Mellon Unversty Pttsburgh, PA 53 Slde Overve lassfcaton Support vector machne Regularzaton Slde lassfcaton Predct categorcal
Why Bayesian? 3. Bayes and Normal Models. State of nature: class. Decision rule. Rev. Thomas Bayes ( ) Bayes Theorem (yes, the famous one)
 Bayes Theorem (yes, the famous one)") Why Bayesan? 3. Bayes and Normal Models Alex M. Martnez alex@ece.osu.edu Handouts Handoutsfor forece ECE874 874Sp Sp007 If all our research (n PR was to dsappear and you could only save one theory, whch
Why Bayesan? 3. Bayes and Normal Models Alex M. Martnez alex@ece.osu.edu Handouts Handoutsfor forece ECE874 874Sp Sp007 If all our research (n PR was to dsappear and you could only save one theory, whch
Logistic Regression Maximum Likelihood Estimation
 Harvard-MIT Dvson of Health Scences and Technology HST.951J: Medcal Decson Support, Fall 2005 Instructors: Professor Lucla Ohno-Machado and Professor Staal Vnterbo 6.873/HST.951 Medcal Decson Support Fall
Harvard-MIT Dvson of Health Scences and Technology HST.951J: Medcal Decson Support, Fall 2005 Instructors: Professor Lucla Ohno-Machado and Professor Staal Vnterbo 6.873/HST.951 Medcal Decson Support Fall
Kristin P. Bennett. Rensselaer Polytechnic Institute
 Support Vector Machnes and Other Kernel Methods Krstn P. Bennett Mathematcal Scences Department Rensselaer Polytechnc Insttute Support Vector Machnes (SVM) A methodology for nference based on Statstcal
Support Vector Machnes and Other Kernel Methods Krstn P. Bennett Mathematcal Scences Department Rensselaer Polytechnc Insttute Support Vector Machnes (SVM) A methodology for nference based on Statstcal
The Gaussian classifier. Nuno Vasconcelos ECE Department, UCSD
 he Gaussan classfer Nuno Vasconcelos ECE Department, UCSD Bayesan decson theory recall that e have state of the orld X observatons decson functon L[,y] loss of predctn y th Bayes decson rule s the rule
he Gaussan classfer Nuno Vasconcelos ECE Department, UCSD Bayesan decson theory recall that e have state of the orld X observatons decson functon L[,y] loss of predctn y th Bayes decson rule s the rule
Maximal Margin Classifier
 CS81B/Stat41B: Advanced Topcs n Learnng & Decson Makng Mamal Margn Classfer Lecturer: Mchael Jordan Scrbes: Jana van Greunen Corrected verson - /1/004 1 References/Recommended Readng 1.1 Webstes www.kernel-machnes.org
CS81B/Stat41B: Advanced Topcs n Learnng & Decson Makng Mamal Margn Classfer Lecturer: Mchael Jordan Scrbes: Jana van Greunen Corrected verson - /1/004 1 References/Recommended Readng 1.1 Webstes www.kernel-machnes.org
Neural networks. Nuno Vasconcelos ECE Department, UCSD
 Neural networs Nuno Vasconcelos ECE Department, UCSD Classfcaton a classfcaton problem has two types of varables e.g. X - vector of observatons (features) n the world Y - state (class) of the world x X
Neural networs Nuno Vasconcelos ECE Department, UCSD Classfcaton a classfcaton problem has two types of varables e.g. X - vector of observatons (features) n the world Y - state (class) of the world x X
Support Vector Machines CS434
 Support Vector Machnes CS434 Lnear Separators Many lnear separators exst that perfectly classfy all tranng examples Whch of the lnear separators s the best? + + + + + + + + + Intuton of Margn Consder ponts
Support Vector Machnes CS434 Lnear Separators Many lnear separators exst that perfectly classfy all tranng examples Whch of the lnear separators s the best? + + + + + + + + + Intuton of Margn Consder ponts
Discriminative classifier: Logistic Regression. CS534-Machine Learning
 Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng 2 Logstc Regresson Gven tranng set D stc regresson learns the condtonal dstrbuton We ll assume onl to classes and a parametrc form for here s
Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng 2 Logstc Regresson Gven tranng set D stc regresson learns the condtonal dstrbuton We ll assume onl to classes and a parametrc form for here s
Introduction to the Introduction to Artificial Neural Network
 Introducton to the Introducton to Artfcal Neural Netork Vuong Le th Hao Tang s sldes Part of the content of the sldes are from the Internet (possbly th modfcatons). The lecturer does not clam any onershp
Introducton to the Introducton to Artfcal Neural Netork Vuong Le th Hao Tang s sldes Part of the content of the sldes are from the Internet (possbly th modfcatons). The lecturer does not clam any onershp
Lecture 10 Support Vector Machines II
 Lecture 10 Support Vector Machnes II 22 February 2016 Taylor B. Arnold Yale Statstcs STAT 365/665 1/28 Notes: Problem 3 s posted and due ths upcomng Frday There was an early bug n the fake-test data; fxed
Lecture 10 Support Vector Machnes II 22 February 2016 Taylor B. Arnold Yale Statstcs STAT 365/665 1/28 Notes: Problem 3 s posted and due ths upcomng Frday There was an early bug n the fake-test data; fxed
CSE 252C: Computer Vision III
 CSE 252C: Computer Vson III Lecturer: Serge Belonge Scrbe: Catherne Wah LECTURE 15 Kernel Machnes 15.1. Kernels We wll study two methods based on a specal knd of functon k(x, y) called a kernel: Kernel
CSE 252C: Computer Vson III Lecturer: Serge Belonge Scrbe: Catherne Wah LECTURE 15 Kernel Machnes 15.1. Kernels We wll study two methods based on a specal knd of functon k(x, y) called a kernel: Kernel
Classification learning II
 Lecture 8 Classfcaton learnng II Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square Logstc regresson model Defnes a lnear decson boundar Dscrmnant functons: g g g g here g z / e z f, g g - s a logstc functon
Lecture 8 Classfcaton learnng II Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square Logstc regresson model Defnes a lnear decson boundar Dscrmnant functons: g g g g here g z / e z f, g g - s a logstc functon
Norms, Condition Numbers, Eigenvalues and Eigenvectors
 Norms, Condton Numbers, Egenvalues and Egenvectors 1 Norms A norm s a measure of the sze of a matrx or a vector For vectors the common norms are: N a 2 = ( x 2 1/2 the Eucldean Norm (1a b 1 = =1 N x (1b
Norms, Condton Numbers, Egenvalues and Egenvectors 1 Norms A norm s a measure of the sze of a matrx or a vector For vectors the common norms are: N a 2 = ( x 2 1/2 the Eucldean Norm (1a b 1 = =1 N x (1b
APPENDIX A Some Linear Algebra
 APPENDIX A Some Lnear Algebra The collecton of m, n matrces A.1 Matrces a 1,1,..., a 1,n A = a m,1,..., a m,n wth real elements a,j s denoted by R m,n. If n = 1 then A s called a column vector. Smlarly,
APPENDIX A Some Lnear Algebra The collecton of m, n matrces A.1 Matrces a 1,1,..., a 1,n A = a m,1,..., a m,n wth real elements a,j s denoted by R m,n. If n = 1 then A s called a column vector. Smlarly,
Chapter 6 Support vector machine. Séparateurs à vaste marge
 Chapter 6 Support vector machne Séparateurs à vaste marge Méthode de classfcaton bnare par apprentssage Introdute par Vladmr Vapnk en 1995 Repose sur l exstence d un classfcateur lnéare Apprentssage supervsé
Chapter 6 Support vector machne Séparateurs à vaste marge Méthode de classfcaton bnare par apprentssage Introdute par Vladmr Vapnk en 1995 Repose sur l exstence d un classfcateur lnéare Apprentssage supervsé
Discriminative classifier: Logistic Regression. CS534-Machine Learning
 Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng robablstc Classfer Gven an nstance, hat does a probablstc classfer do dfferentl compared to, sa, perceptron? It does not drectl predct Instead,
Dscrmnatve classfer: Logstc Regresson CS534-Machne Learnng robablstc Classfer Gven an nstance, hat does a probablstc classfer do dfferentl compared to, sa, perceptron? It does not drectl predct Instead,
Recap: the SVM problem
 Machne Learnng 0-70/5-78 78 Fall 0 Advanced topcs n Ma-Margn Margn Learnng Erc Xng Lecture 0 Noveber 0 Erc Xng @ CMU 006-00 Recap: the SVM proble We solve the follong constraned opt proble: a s.t. J 0
Machne Learnng 0-70/5-78 78 Fall 0 Advanced topcs n Ma-Margn Margn Learnng Erc Xng Lecture 0 Noveber 0 Erc Xng @ CMU 006-00 Recap: the SVM proble We solve the follong constraned opt proble: a s.t. J 0
Lecture 3: Dual problems and Kernels
 Lecture 3: Dual problems and Kernels C4B Machne Learnng Hlary 211 A. Zsserman Prmal and dual forms Lnear separablty revsted Feature mappng Kernels for SVMs Kernel trck requrements radal bass functons SVM
Lecture 3: Dual problems and Kernels C4B Machne Learnng Hlary 211 A. Zsserman Prmal and dual forms Lnear separablty revsted Feature mappng Kernels for SVMs Kernel trck requrements radal bass functons SVM
Statistical pattern recognition
 Statstcal pattern recognton Bayes theorem Problem: decdng f a patent has a partcular condton based on a partcular test However, the test s mperfect Someone wth the condton may go undetected (false negatve
Statstcal pattern recognton Bayes theorem Problem: decdng f a patent has a partcular condton based on a partcular test However, the test s mperfect Someone wth the condton may go undetected (false negatve
A Bayes Algorithm for the Multitask Pattern Recognition Problem Direct Approach
 A Bayes Algorthm for the Multtask Pattern Recognton Problem Drect Approach Edward Puchala Wroclaw Unversty of Technology, Char of Systems and Computer etworks, Wybrzeze Wyspanskego 7, 50-370 Wroclaw, Poland
A Bayes Algorthm for the Multtask Pattern Recognton Problem Drect Approach Edward Puchala Wroclaw Unversty of Technology, Char of Systems and Computer etworks, Wybrzeze Wyspanskego 7, 50-370 Wroclaw, Poland
C4B Machine Learning Answers II. = σ(z) (1 σ(z)) 1 1 e z. e z = σ(1 σ) (1 + e z )
 (1 σ(z)) 1 1 e z. e z = σ(1 σ) (1 + e z )") C4B Machne Learnng Answers II.(a) Show that for the logstc sgmod functon dσ(z) dz = σ(z) ( σ(z)) A. Zsserman, Hlary Term 20 Start from the defnton of σ(z) Note that Then σ(z) = σ = dσ(z) dz = + e z e z
C4B Machne Learnng Answers II.(a) Show that for the logstc sgmod functon dσ(z) dz = σ(z) ( σ(z)) A. Zsserman, Hlary Term 20 Start from the defnton of σ(z) Note that Then σ(z) = σ = dσ(z) dz = + e z e z
Lecture Notes on Linear Regression
 Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
EEE 241: Linear Systems
 EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
Linear Approximation with Regularization and Moving Least Squares
 Lnear Approxmaton wth Regularzaton and Movng Least Squares Igor Grešovn May 007 Revson 4.6 (Revson : March 004). 5 4 3 0.5 3 3.5 4 Contents: Lnear Fttng...4. Weghted Least Squares n Functon Approxmaton...
Lnear Approxmaton wth Regularzaton and Movng Least Squares Igor Grešovn May 007 Revson 4.6 (Revson : March 004). 5 4 3 0.5 3 3.5 4 Contents: Lnear Fttng...4. Weghted Least Squares n Functon Approxmaton...
Mean Field / Variational Approximations
 Mean Feld / Varatonal Appromatons resented by Jose Nuñez 0/24/05 Outlne Introducton Mean Feld Appromaton Structured Mean Feld Weghted Mean Feld Varatonal Methods Introducton roblem: We have dstrbuton but
Mean Feld / Varatonal Appromatons resented by Jose Nuñez 0/24/05 Outlne Introducton Mean Feld Appromaton Structured Mean Feld Weghted Mean Feld Varatonal Methods Introducton roblem: We have dstrbuton but
Chapter Newton s Method
 Chapter 9. Newton s Method After readng ths chapter, you should be able to:. Understand how Newton s method s dfferent from the Golden Secton Search method. Understand how Newton s method works 3. Solve
Chapter 9. Newton s Method After readng ths chapter, you should be able to:. Understand how Newton s method s dfferent from the Golden Secton Search method. Understand how Newton s method works 3. Solve
Regularized Discriminant Analysis for Face Recognition
 1 Regularzed Dscrmnant Analyss for Face Recognton Itz Pma, Mayer Aladem Department of Electrcal and Computer Engneerng, Ben-Guron Unversty of the Negev P.O.Box 653, Beer-Sheva, 845, Israel. Abstract Ths
1 Regularzed Dscrmnant Analyss for Face Recognton Itz Pma, Mayer Aladem Department of Electrcal and Computer Engneerng, Ben-Guron Unversty of the Negev P.O.Box 653, Beer-Sheva, 845, Israel. Abstract Ths
Vector Norms. Chapter 7 Iterative Techniques in Matrix Algebra. Cauchy-Bunyakovsky-Schwarz Inequality for Sums. Distances. Convergence.
 Vector Norms Chapter 7 Iteratve Technques n Matrx Algebra Per-Olof Persson persson@berkeley.edu Department of Mathematcs Unversty of Calforna, Berkeley Math 128B Numercal Analyss Defnton A vector norm
Vector Norms Chapter 7 Iteratve Technques n Matrx Algebra Per-Olof Persson persson@berkeley.edu Department of Mathematcs Unversty of Calforna, Berkeley Math 128B Numercal Analyss Defnton A vector norm
Logistic Regression. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Logstc Regresson CAP 561: achne Learnng Instructor: Guo-Jun QI Bayes Classfer: A Generatve model odel the posteror dstrbuton P(Y X) Estmate class-condtonal dstrbuton P(X Y) for each Y Estmate pror dstrbuton
Logstc Regresson CAP 561: achne Learnng Instructor: Guo-Jun QI Bayes Classfer: A Generatve model odel the posteror dstrbuton P(Y X) Estmate class-condtonal dstrbuton P(X Y) for each Y Estmate pror dstrbuton
Nonlinear Classifiers II
 Nonlnear Classfers II Nonlnear Classfers: Introducton Classfers Supervsed Classfers Lnear Classfers Perceptron Least Squares Methods Lnear Support Vector Machne Nonlnear Classfers Part I: Mult Layer Neural
Nonlnear Classfers II Nonlnear Classfers: Introducton Classfers Supervsed Classfers Lnear Classfers Perceptron Least Squares Methods Lnear Support Vector Machne Nonlnear Classfers Part I: Mult Layer Neural
CIS526: Machine Learning Lecture 3 (Sept 16, 2003) Linear Regression. Preparation help: Xiaoying Huang. x 1 θ 1 output... θ M x M
 Linear Regression. Preparation help: Xiaoying Huang. x 1 θ 1 output... θ M x M") CIS56: achne Learnng Lecture 3 (Sept 6, 003) Preparaton help: Xaoyng Huang Lnear Regresson Lnear regresson can be represented by a functonal form: f(; θ) = θ 0 0 +θ + + θ = θ = 0 ote: 0 s a dummy attrbute
CIS56: achne Learnng Lecture 3 (Sept 6, 003) Preparaton help: Xaoyng Huang Lnear Regresson Lnear regresson can be represented by a functonal form: f(; θ) = θ 0 0 +θ + + θ = θ = 0 ote: 0 s a dummy attrbute
Multilayer Perceptrons and Backpropagation. Perceptrons. Recap: Perceptrons. Informatics 1 CG: Lecture 6. Mirella Lapata
 Multlayer Perceptrons and Informatcs CG: Lecture 6 Mrella Lapata School of Informatcs Unversty of Ednburgh mlap@nf.ed.ac.uk Readng: Kevn Gurney s Introducton to Neural Networks, Chapters 5 6.5 January,
Multlayer Perceptrons and Informatcs CG: Lecture 6 Mrella Lapata School of Informatcs Unversty of Ednburgh mlap@nf.ed.ac.uk Readng: Kevn Gurney s Introducton to Neural Networks, Chapters 5 6.5 January,
Advanced Introduction to Machine Learning
 Advanced Introducton to Machne Learnng 10715, Fall 2014 The Kernel Trck, Reproducng Kernel Hlbert Space, and the Representer Theorem Erc Xng Lecture 6, September 24, 2014 Readng: Erc Xng @ CMU, 2014 1
Advanced Introducton to Machne Learnng 10715, Fall 2014 The Kernel Trck, Reproducng Kernel Hlbert Space, and the Representer Theorem Erc Xng Lecture 6, September 24, 2014 Readng: Erc Xng @ CMU, 2014 1
Inner Product. Euclidean Space. Orthonormal Basis. Orthogonal
 Inner Product Defnton 1 () A Eucldean space s a fnte-dmensonal vector space over the reals R, wth an nner product,. Defnton 2 (Inner Product) An nner product, on a real vector space X s a symmetrc, blnear,
Inner Product Defnton 1 () A Eucldean space s a fnte-dmensonal vector space over the reals R, wth an nner product,. Defnton 2 (Inner Product) An nner product, on a real vector space X s a symmetrc, blnear,
Generalized Linear Methods
 Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
Multilayer neural networks
 Lecture Multlayer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Mdterm exam Mdterm Monday, March 2, 205 In-class (75 mnutes) closed book materal covered by February 25, 205 Multlayer
Lecture Multlayer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Mdterm exam Mdterm Monday, March 2, 205 In-class (75 mnutes) closed book materal covered by February 25, 205 Multlayer
Video Data Analysis. Video Data Analysis, B-IT
 Lecture Vdeo Data Analyss Deformable Snakes Segmentaton Neural networks Lecture plan:. Segmentaton by morphologcal watershed. Deformable snakes 3. Segmentaton va classfcaton of patterns 4. Concept of a
Lecture Vdeo Data Analyss Deformable Snakes Segmentaton Neural networks Lecture plan:. Segmentaton by morphologcal watershed. Deformable snakes 3. Segmentaton va classfcaton of patterns 4. Concept of a
Fisher Linear Discriminant Analysis
 Fsher Lnear Dscrmnant Analyss Max Wellng Department of Computer Scence Unversty of Toronto 10 Kng s College Road Toronto, M5S 3G5 Canada wellng@cs.toronto.edu Abstract Ths s a note to explan Fsher lnear
Fsher Lnear Dscrmnant Analyss Max Wellng Department of Computer Scence Unversty of Toronto 10 Kng s College Road Toronto, M5S 3G5 Canada wellng@cs.toronto.edu Abstract Ths s a note to explan Fsher lnear
Neural Networks & Learning
 Neural Netorks & Learnng. Introducton The basc prelmnares nvolved n the Artfcal Neural Netorks (ANN) are descrbed n secton. An Artfcal Neural Netorks (ANN) s an nformaton-processng paradgm that nspred
Neural Netorks & Learnng. Introducton The basc prelmnares nvolved n the Artfcal Neural Netorks (ANN) are descrbed n secton. An Artfcal Neural Netorks (ANN) s an nformaton-processng paradgm that nspred
Radial-Basis Function Networks
 Radal-Bass uncton Networs v.0 March 00 Mchel Verleysen Radal-Bass uncton Networs - Radal-Bass uncton Networs p Orgn: Cover s theorem p Interpolaton problem p Regularzaton theory p Generalzed RBN p Unversal
Radal-Bass uncton Networs v.0 March 00 Mchel Verleysen Radal-Bass uncton Networs - Radal-Bass uncton Networs p Orgn: Cover s theorem p Interpolaton problem p Regularzaton theory p Generalzed RBN p Unversal
Generative classification models
 CS 675 Intro to Machne Learnng Lecture Generatve classfcaton models Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square Data: D { d, d,.., dn} d, Classfcaton represents a dscrete class value Goal: learn
CS 675 Intro to Machne Learnng Lecture Generatve classfcaton models Mlos Hauskrecht mlos@cs.ptt.edu 539 Sennott Square Data: D { d, d,.., dn} d, Classfcaton represents a dscrete class value Goal: learn
1 Convex Optimization
 Convex Optmzaton We wll consder convex optmzaton problems. Namely, mnmzaton problems where the objectve s convex (we assume no constrants for now). Such problems often arse n machne learnng. For example,
Convex Optmzaton We wll consder convex optmzaton problems. Namely, mnmzaton problems where the objectve s convex (we assume no constrants for now). Such problems often arse n machne learnng. For example,
COMPLEX NUMBERS AND QUADRATIC EQUATIONS
 COMPLEX NUMBERS AND QUADRATIC EQUATIONS INTRODUCTION We know that x 0 for all x R e the square of a real number (whether postve, negatve or ero) s non-negatve Hence the equatons x, x, x + 7 0 etc are not
COMPLEX NUMBERS AND QUADRATIC EQUATIONS INTRODUCTION We know that x 0 for all x R e the square of a real number (whether postve, negatve or ero) s non-negatve Hence the equatons x, x, x + 7 0 etc are not
2E Pattern Recognition Solutions to Introduction to Pattern Recognition, Chapter 2: Bayesian pattern classification
 E395 - Pattern Recognton Solutons to Introducton to Pattern Recognton, Chapter : Bayesan pattern classfcaton Preface Ths document s a soluton manual for selected exercses from Introducton to Pattern Recognton
E395 - Pattern Recognton Solutons to Introducton to Pattern Recognton, Chapter : Bayesan pattern classfcaton Preface Ths document s a soluton manual for selected exercses from Introducton to Pattern Recognton
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 89 Fall 206 Introducton to Machne Learnng Fnal Do not open the exam before you are nstructed to do so The exam s closed book, closed notes except your one-page cheat sheet Usage of electronc devces
CS 89 Fall 206 Introducton to Machne Learnng Fnal Do not open the exam before you are nstructed to do so The exam s closed book, closed notes except your one-page cheat sheet Usage of electronc devces
Statistical Foundations of Pattern Recognition
 Statstcal Foundatons of Pattern Recognton Learnng Objectves Bayes Theorem Decson-mang Confdence factors Dscrmnants The connecton to neural nets Statstcal Foundatons of Pattern Recognton NDE measurement
Statstcal Foundatons of Pattern Recognton Learnng Objectves Bayes Theorem Decson-mang Confdence factors Dscrmnants The connecton to neural nets Statstcal Foundatons of Pattern Recognton NDE measurement
VQ widely used in coding speech, image, and video
 at Scalar quantzers are specal cases of vector quantzers (VQ): they are constraned to look at one sample at a tme (memoryless) VQ does not have such constrant better RD perfomance expected Source codng
at Scalar quantzers are specal cases of vector quantzers (VQ): they are constraned to look at one sample at a tme (memoryless) VQ does not have such constrant better RD perfomance expected Source codng
Classification as a Regression Problem
 Target varable y C C, C,, ; Classfcaton as a Regresson Problem { }, 3 L C K To treat classfcaton as a regresson problem we should transform the target y nto numercal values; The choce of numercal class
Target varable y C C, C,, ; Classfcaton as a Regresson Problem { }, 3 L C K To treat classfcaton as a regresson problem we should transform the target y nto numercal values; The choce of numercal class
CS4495/6495 Introduction to Computer Vision. 3C-L3 Calibrating cameras
 CS4495/6495 Introducton to Computer Vson 3C-L3 Calbratng cameras Fnally (last tme): Camera parameters Projecton equaton the cumulatve effect of all parameters: M (3x4) f s x ' 1 0 0 0 c R 0 I T 3 3 3 x1
CS4495/6495 Introducton to Computer Vson 3C-L3 Calbratng cameras Fnally (last tme): Camera parameters Projecton equaton the cumulatve effect of all parameters: M (3x4) f s x ' 1 0 0 0 c R 0 I T 3 3 3 x1
Supporting Information
 Supportng Informaton The neural network f n Eq. 1 s gven by: f x l = ReLU W atom x l + b atom, 2 where ReLU s the element-wse rectfed lnear unt, 21.e., ReLUx = max0, x, W atom R d d s the weght matrx to
Supportng Informaton The neural network f n Eq. 1 s gven by: f x l = ReLU W atom x l + b atom, 2 where ReLU s the element-wse rectfed lnear unt, 21.e., ReLUx = max0, x, W atom R d d s the weght matrx to
Singular Value Decomposition: Theory and Applications
 Sngular Value Decomposton: Theory and Applcatons Danel Khashab Sprng 2015 Last Update: March 2, 2015 1 Introducton A = UDV where columns of U and V are orthonormal and matrx D s dagonal wth postve real
Sngular Value Decomposton: Theory and Applcatons Danel Khashab Sprng 2015 Last Update: March 2, 2015 1 Introducton A = UDV where columns of U and V are orthonormal and matrx D s dagonal wth postve real
INF 4300 Digital Image Analysis REPETITION
 INF 4300 Dgtal Image Analyss REPEIION Classfcaton PCA and Fsher s lnear dscrmnant Morphology Segmentaton Anne Solberg 406 INF 4300 Back to classfcaton error for thresholdng - Background - Foreground P
INF 4300 Dgtal Image Analyss REPEIION Classfcaton PCA and Fsher s lnear dscrmnant Morphology Segmentaton Anne Solberg 406 INF 4300 Back to classfcaton error for thresholdng - Background - Foreground P
Math1110 (Spring 2009) Prelim 3 - Solutions
 Prelim 3 - Solutions") Math 1110 (Sprng 2009) Solutons to Prelm 3 (04/21/2009) 1 Queston 1. (16 ponts) Short answer. Math1110 (Sprng 2009) Prelm 3 - Solutons x a 1 (a) (4 ponts) Please evaluate lm, where a and b are postve numbers.
Math 1110 (Sprng 2009) Solutons to Prelm 3 (04/21/2009) 1 Queston 1. (16 ponts) Short answer. Math1110 (Sprng 2009) Prelm 3 - Solutons x a 1 (a) (4 ponts) Please evaluate lm, where a and b are postve numbers.
OPTIMISATION. Introduction Single Variable Unconstrained Optimisation Multivariable Unconstrained Optimisation Linear Programming
 OPTIMIATION Introducton ngle Varable Unconstraned Optmsaton Multvarable Unconstraned Optmsaton Lnear Programmng Chapter Optmsaton /. Introducton In an engneerng analss, sometmes etremtes, ether mnmum or
OPTIMIATION Introducton ngle Varable Unconstraned Optmsaton Multvarable Unconstraned Optmsaton Lnear Programmng Chapter Optmsaton /. Introducton In an engneerng analss, sometmes etremtes, ether mnmum or
CHALMERS, GÖTEBORGS UNIVERSITET. SOLUTIONS to RE-EXAM for ARTIFICIAL NEURAL NETWORKS. COURSE CODES: FFR 135, FIM 720 GU, PhD
 CHALMERS, GÖTEBORGS UNIVERSITET SOLUTIONS to RE-EXAM for ARTIFICIAL NEURAL NETWORKS COURSE CODES: FFR 35, FIM 72 GU, PhD Tme: Place: Teachers: Allowed materal: Not allowed: January 2, 28, at 8 3 2 3 SB
CHALMERS, GÖTEBORGS UNIVERSITET SOLUTIONS to RE-EXAM for ARTIFICIAL NEURAL NETWORKS COURSE CODES: FFR 35, FIM 72 GU, PhD Tme: Place: Teachers: Allowed materal: Not allowed: January 2, 28, at 8 3 2 3 SB
Department of Computer Science Artificial Intelligence Research Laboratory. Iowa State University MACHINE LEARNING
 MACHINE LEANING Vasant Honavar Bonformatcs and Computatonal Bology rogram Center for Computatonal Intellgence, Learnng, & Dscovery Iowa State Unversty honavar@cs.astate.edu www.cs.astate.edu/~honavar/
MACHINE LEANING Vasant Honavar Bonformatcs and Computatonal Bology rogram Center for Computatonal Intellgence, Learnng, & Dscovery Iowa State Unversty honavar@cs.astate.edu www.cs.astate.edu/~honavar/
Composite Hypotheses testing
 Composte ypotheses testng In many hypothess testng problems there are many possble dstrbutons that can occur under each of the hypotheses. The output of the source s a set of parameters (ponts n a parameter
Composte ypotheses testng In many hypothess testng problems there are many possble dstrbutons that can occur under each of the hypotheses. The output of the source s a set of parameters (ponts n a parameter
Dynamic Programming. Preview. Dynamic Programming. Dynamic Programming. Dynamic Programming (Example: Fibonacci Sequence)
") /24/27 Prevew Fbonacc Sequence Longest Common Subsequence Dynamc programmng s a method for solvng complex problems by breakng them down nto smpler sub-problems. It s applcable to problems exhbtng the propertes
/24/27 Prevew Fbonacc Sequence Longest Common Subsequence Dynamc programmng s a method for solvng complex problems by breakng them down nto smpler sub-problems. It s applcable to problems exhbtng the propertes
Interconnect Modeling
 Interconnect Modelng Modelng of Interconnects Interconnect R, C and computaton Interconnect models umped RC model Dstrbuted crcut models Hgher-order waveform n dstrbuted RC trees Accuracy and fdelty Prepared
Interconnect Modelng Modelng of Interconnects Interconnect R, C and computaton Interconnect models umped RC model Dstrbuted crcut models Hgher-order waveform n dstrbuted RC trees Accuracy and fdelty Prepared
n α j x j = 0 j=1 has a nontrivial solution. Here A is the n k matrix whose jth column is the vector for all t j=0
 MODULE 2 Topcs: Lnear ndependence, bass and dmenson We have seen that f n a set of vectors one vector s a lnear combnaton of the remanng vectors n the set then the span of the set s unchanged f that vector
MODULE 2 Topcs: Lnear ndependence, bass and dmenson We have seen that f n a set of vectors one vector s a lnear combnaton of the remanng vectors n the set then the span of the set s unchanged f that vector
Parameter estimation class 5
 Parameter estmaton class 5 Multple Ve Geometr Comp 9-89 Marc Pollefes Content Background: Projectve geometr (D, 3D), Parameter estmaton, Algortm evaluaton. Sngle Ve: Camera model, Calbraton, Sngle Ve Geometr.
Parameter estmaton class 5 Multple Ve Geometr Comp 9-89 Marc Pollefes Content Background: Projectve geometr (D, 3D), Parameter estmaton, Algortm evaluaton. Sngle Ve: Camera model, Calbraton, Sngle Ve Geometr.
1 GSW Iterative Techniques for y = Ax
 1 for y = A I m gong to cheat here. here are a lot of teratve technques that can be used to solve the general case of a set of smultaneous equatons (wrtten n the matr form as y = A), but ths chapter sn
1 for y = A I m gong to cheat here. here are a lot of teratve technques that can be used to solve the general case of a set of smultaneous equatons (wrtten n the matr form as y = A), but ths chapter sn
MACHINE APPLIED MACHINE LEARNING LEARNING. Gaussian Mixture Regression
 11 MACHINE APPLIED MACHINE LEARNING LEARNING MACHINE LEARNING Gaussan Mture Regresson 22 MACHINE APPLIED MACHINE LEARNING LEARNING Bref summary of last week s lecture 33 MACHINE APPLIED MACHINE LEARNING
11 MACHINE APPLIED MACHINE LEARNING LEARNING MACHINE LEARNING Gaussan Mture Regresson 22 MACHINE APPLIED MACHINE LEARNING LEARNING Bref summary of last week s lecture 33 MACHINE APPLIED MACHINE LEARNING
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mnng Massve Datasets Jure Leskovec, Stanford Unversty http://cs246.stanford.edu 2/19/18 Jure Leskovec, Stanford CS246: Mnng Massve Datasets, http://cs246.stanford.edu 2 Hgh dm. data Graph data Infnte
CS246: Mnng Massve Datasets Jure Leskovec, Stanford Unversty http://cs246.stanford.edu 2/19/18 Jure Leskovec, Stanford CS246: Mnng Massve Datasets, http://cs246.stanford.edu 2 Hgh dm. data Graph data Infnte
Radar Trackers. Study Guide. All chapters, problems, examples and page numbers refer to Applied Optimal Estimation, A. Gelb, Ed.
 Radar rackers Study Gude All chapters, problems, examples and page numbers refer to Appled Optmal Estmaton, A. Gelb, Ed. Chapter Example.0- Problem Statement wo sensors Each has a sngle nose measurement
Radar rackers Study Gude All chapters, problems, examples and page numbers refer to Appled Optmal Estmaton, A. Gelb, Ed. Chapter Example.0- Problem Statement wo sensors Each has a sngle nose measurement
Multi-layer neural networks
 Lecture 0 Mult-layer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Lnear regresson w Lnear unts f () Logstc regresson T T = w = p( y =, w) = g( w ) w z f () = p ( y = ) w d w d Gradent
Lecture 0 Mult-layer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Lnear regresson w Lnear unts f () Logstc regresson T T = w = p( y =, w) = g( w ) w z f () = p ( y = ) w d w d Gradent
Maximum Likelihood Estimation (MLE)
") Maxmum Lkelhood Estmaton (MLE) Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 01 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
Maxmum Lkelhood Estmaton (MLE) Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 01 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
The Geometry of Logit and Probit
 The Geometry of Logt and Probt Ths short note s meant as a supplement to Chapters and 3 of Spatal Models of Parlamentary Votng and the notaton and reference to fgures n the text below s to those two chapters.
The Geometry of Logt and Probt Ths short note s meant as a supplement to Chapters and 3 of Spatal Models of Parlamentary Votng and the notaton and reference to fgures n the text below s to those two chapters.